
Clean Up XML Sitemaps with Search Console
An XML sitemap helps Google crawl a site, understand its structure, and discover more pages.
For years Google has asserted XML sitemaps in Search Console don’t directly help rankings, but in my experience a sitemap often provides a boost in organic traffic, especially for new sites and those with thousands of pages or more.
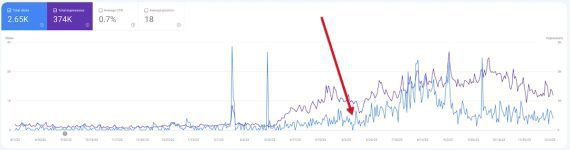
The screenshot below from Search Console is for traffic to a new hobby site that submitted a sitemap in late May 2023. Organic search traffic improved in early June and then declined a couple of months later, but not to the previous level.

Organic search traffic to a new hobby site quickly improved after submitting a sitemap and then declined, but not to the previous level. Click image to enlarge.
Presumably Google values sitemaps, or it wouldn’t include them in Seach Console. But they’re helpful only when properly formatted and error-free. I’ve seen many sitemaps containing broken URLs or pages with noindex tags or blocked from crawling.
A sitemap should be a clear path for Google to navigate the site and include only URLs intended to drive traffic.
To verify, submit the sitemap to Search Console and allow a few weeks for Google to crawl your site. Then return to Search Console and navigate to Indexing > Sitemaps. Click “See page indexing” beneath the three dots beside the sitemap URL.
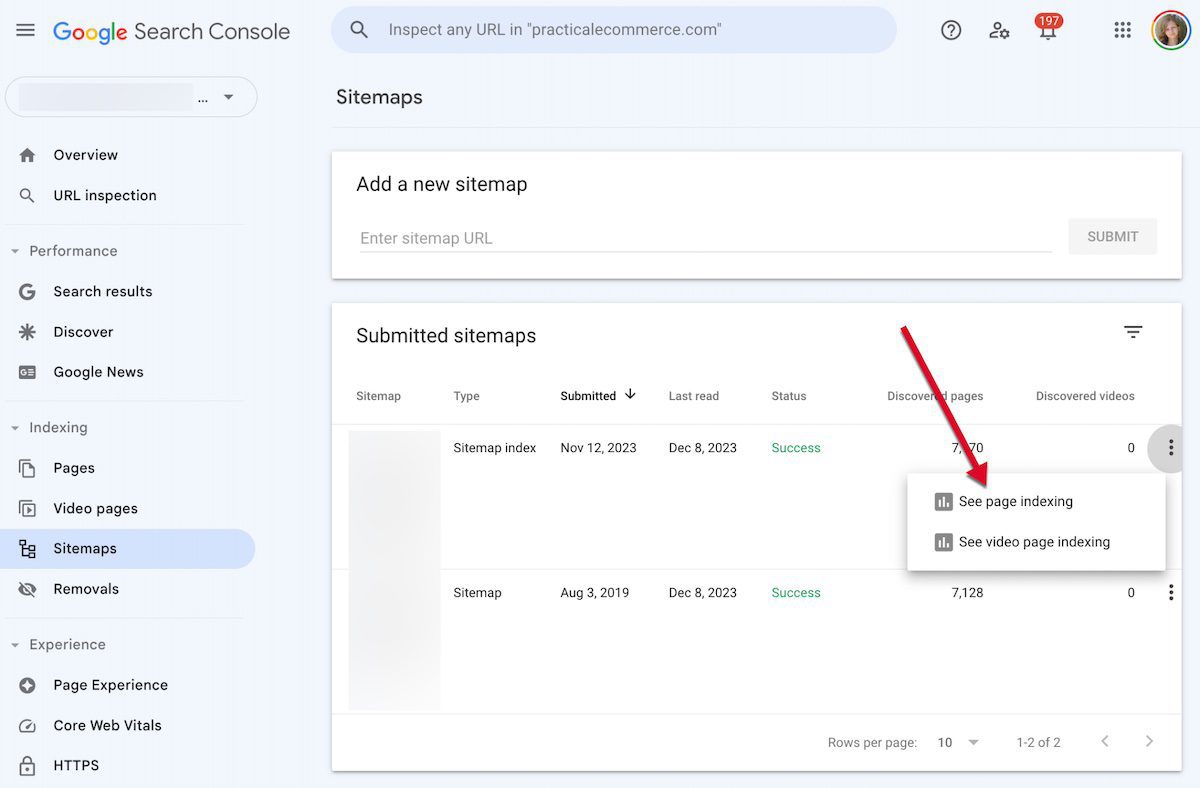
To verify a sitemap, navigate in Search Console to Indexing > Sitemaps. Click “See page indexing” beneath the three dots beside the sitemap URL. Click image to enlarge.
In the report, look for reasons for not indexing, such as:
- Nonexistent (404) pages.
- Pages with redirects.
- Pages with noindex tags.
- Pages with conflicting canonical tags.
- Duplicate pages, wherein indexed the version is not in the sitemap.
Remove all those URLs from the sitemap or fix the errors.
Google ignores priority and changefreq sitemap attributes. There’s no way to instruct Google which pages are important, although including only indexable pages in a sitemap is a good first step.
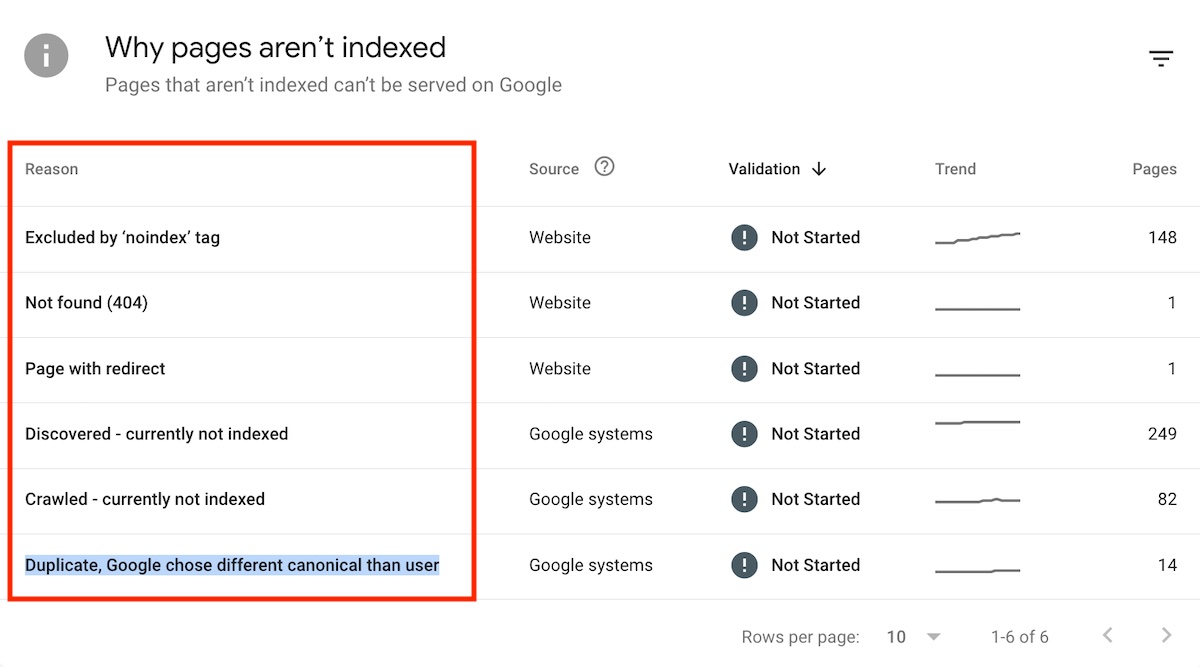
Search Console’s “See page indexing” report lists reasons “Why pages aren’t indexed.” Click image to enlarge.
Video Pages
Using sitemaps, Search Console can identify pages with videos, although in my testing the primary sitemap page showed, incorrectly, only zeros in the “Discovered videos” column, presumably due to a bug.
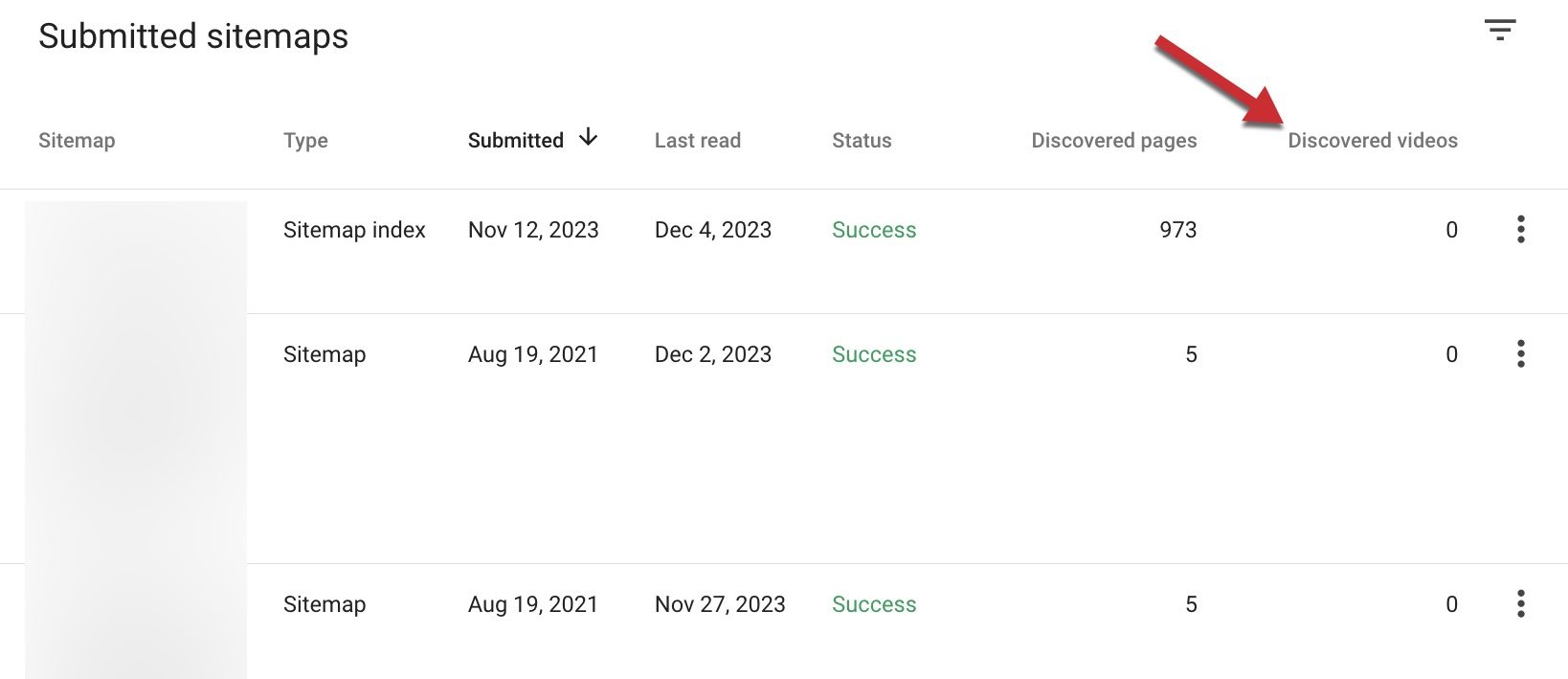
Search Console’s primary sitemap page lists zeros under the “Discovered videos,” likely due to a bug. Click image to enlarge.
Ignore the zeroes and check the “See video page indexation” report listing the URLs from that sitemap with indexed videos or errors.
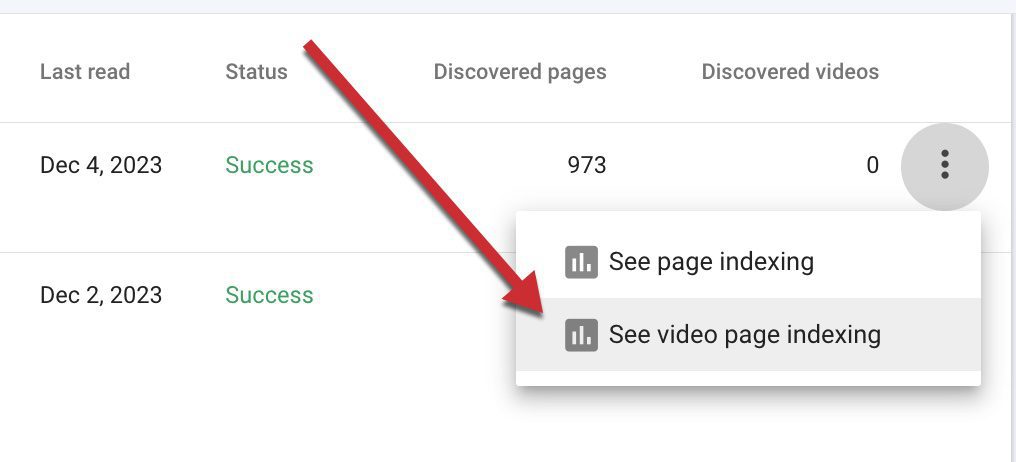
The “See video page indexation” report lists the URLs with indexed videos or errors. Click image to enlarge.
Better Crawls
Cleaning up sitemaps ensures smooth crawls from Googlebot and thus elevated indexing. Error-free sitemaps are especially important for sites with thousands (or millions) of URLs or many under the “Discovered but not crawled” and “Crawled but not yet indexed” categories.