Bowling Green, Kentucky, is home to 75,000 residents who recently wrapped up an experiment in using AI for democracy: Can an online polling platform, powered by machine learning, capture what residents want to see happen in their city?
When Doug Gorman, elected leader of the county that includes Bowling Green, took office in 2023, it was the fastest-growing city in the state and projected to double in size by 2050, but it lacked a plan for how that growth would unfold. Gorman had a meeting with Sam Ford, a local consultant who had worked with the surveying platform Pol.is, which uses machine learning to gather opinions from large groups of people.
They “needed a vision” for the anticipated growth, Ford says. The two convened a group of volunteers with experience in eight areas: economic development, talent, housing, public health, quality of life, tourism, storytelling, and infrastructure. They built a plan to use Pol.is to help write a 25-year plan for the city. The platform is just one of several new technologies used in Europe and increasingly in the US to help make sure that local governance is informed by public opinion.
After a month of advertising, the Pol.is portal launched in February. Residents could go to the website and anonymously submit an idea (in less than 140 characters) for what the 25-year plan should include. They could also vote on whether they agreed or disagreed with other ideas. The tool could be translated into a participant’s preferred language, and human moderators worked to make sure the traffic was coming from the Bowling Green area.
Over the month that it was live, 7,890 residents participated, and 2,000 people submitted their own ideas. An AI-powered tool from Google Jigsaw then analyzed the data to find what people agreed and disagreed on.
Experts on democracy technologies who were not involved in the project say this level of participation—about 10% of the city’s residents—was impressive.
“That is a lot,” says Archon Fung, director of the Ash Center for Innovation and Democratic Governance at the Harvard Kennedy School. A local election might see a 25% turnout, he says, and that requires nothing more than filling out a ballot.
“Here, it’s a more demanding kind of participation, right? You’re actually voting on or considering some substantive things, and 2,000 people are contributing ideas,” he says. “So I think that’s a lot of people who are engaged.”
The plans that received the most attention in the Bowling Green experiment were hyperlocal. The ideas with the broadest support were increasing the number of local health-care specialists so residents wouldn’t have to travel to nearby Nashville for medical care, enticing more restaurants and grocery stores to open on the city’s north side, and preserving historic buildings.
More contentious ideas included approving recreational marijuana, adding sexual orientation and gender identity to the city’s nondiscrimination clause, and providing more options for private education. Out of 3,940 unique ideas, 2,370 received more than 80% agreement, including initiatives like investing in stormwater infrastructure and expanding local opportunities for children and adults with autism.
The volunteers running the experiment were not completely hands-off. Submitted ideas were screened according to a moderation policy, and redundant ideas were not posted. Ford says that 51% of ideas were published, and 31% were deemed redundant. About 6% of ideas were not posted because they were either completely off-topic or contained a personal attack.
But some researchers who study the technologies that can make democracy more effective question whether soliciting input in this manner is a reliable way to understand what a community wants.
One problem is self-selection—for example, certain kinds of people tend to show up to in-person forums like town halls. Research shows that seniors, homeowners, and people with high levels of education are the most likely to attend, Fung says. It’s possible that similar dynamics are at play among the residents of Bowling Green who decided to participate in the project.
“Self-selection is not an adequate way to represent the opinions of a public,” says James Fishkin, a political scientist at Stanford who’s known for developing a process he calls deliberative polling, in which a representative sample of a population’s residents are brought together for a weekend, paid about $300 each for their participation, and asked to deliberate in small groups. Other methods, used in some European governments, use jury-style groups of residents to make public policy decisions.
What’s clear to everyone who studies the effectiveness of these tools is that they promise to move a city in a more democratic direction, but we won’t know if Bowling Green’s experiment worked until residents see what the city does with the ideas that they raised.
“You can’t make policy based on a tweet,” says Beth Simone Noveck, who directs a lab that studies democracy and technology at Northeastern University. As she points out, residents were voting on 140-character ideas, and those now need to be formed into real policies.
“What comes next,” she says, “is the conversation between the city and residents to develop a short proposal into something that can actually be implemented.” For residents to trust that their voice actually matters, the city must be clear on why it’s implementing some ideas and not others.
For now, the organizers have made the results public, and they will make recommendations to the Warren County leadership later this year.
In 2021, 20 years after the death of her older sister, Vauhini Vara was still unable to tell the story of her loss. “I wondered,” she writes in Searches, her new collection of essays on AI technology, “if Sam Altman’s machine could do it for me.” So she tried ChatGPT. But as it expanded on Vara’s prompts in sentences ranging from the stilted to the unsettling to the sublime, the thing she’d enlisted as a tool stopped seeming so mechanical.
“Once upon a time, she taught me to exist,” the AI model wrote of the young woman Vara had idolized. Vara, a journalist and novelist, called the resulting essay “Ghosts,” and in her opinion, the best lines didn’t come from her: “I found myself irresistibly attracted to GPT-3—to the way it offered, without judgment, to deliver words to a writer who has found herself at a loss for them … as I tried to write more honestly, the AI seemed to be doing the same.”
The rapid proliferation of AI in our lives introduces new challenges around authorship, authenticity, and ethics in work and art. But it also offers a particularly human problem in narrative: How can we make sense of these machines, not just use them? And how do the words we choose and stories we tell about technology affect the role we allow it to take on (or even take over) in our creative lives? Both Vara’s book and The Uncanny Muse, a collection of essays on the history of art and automation by the music critic David Hajdu, explore how humans have historically and personally wrestled with the ways in which machines relate to our own bodies, brains, and creativity. At the same time, The Mind Electric, a new book by a neurologist, Pria Anand, reminds us that our own inner workings may not be so easy to replicate.
Searches is a strange artifact. Part memoir, part critical analysis, and part AI-assisted creative experimentation, Vara’s essays trace her time as a tech reporter and then novelist in the San Francisco Bay Area alongside the history of the industry she watched grow up. Tech was always close enough to touch: One college friend was an early Google employee, and when Vara started reporting on Facebook (now Meta), she and Mark Zuckerberg became “friends” on his platform. In 2007, she published a scoop that the company was planning to introduce ad targeting based on users’ personal information—the first shot fired in the long, gnarly data war to come. In her essay “Stealing Great Ideas,” she talks about turning down a job reporting on Apple to go to graduate school for fiction. There, she wrote a novel about a tech founder, which was later published as The Immortal King Rao. Vara points out that in some ways at the time, her art was “inextricable from the resources [she] used to create it”—products like Google Docs, a MacBook, an iPhone. But these pre-AI resources were tools, plain and simple. What came next was different.
Interspersed with Vara’s essays are chapters of back-and-forths between the author and ChatGPT about the book itself, where the bot serves as editor at Vara’s prompting. ChatGPT obligingly summarizes and critiques her writing in a corporate-shaded tone that’s now familiar to any knowledge worker. “If there’s a place for disagreement,” it offers about the first few chapters on tech companies, “it might be in the balance of these narratives. Some might argue that the benefits—such as job creation, innovation in various sectors like AI and logistics, and contributions to the global economy—can outweigh the negatives.”
Searches: Selfhood in the Digital Age Vauhini Vara
PANTHEON, 2025
Vara notices that ChatGPT writes “we” and “our” in these responses, pulling it into the human story, not the tech one: “Earlier you mentioned ‘our access to information’ and ‘our collective experiences and understandings.’” When she asks what the rhetorical purpose of that choice is, ChatGPT responds with a numbered list of benefits including “inclusivity and solidarity” and “neutrality and objectivity.” It adds that “using the first-person plural helps to frame the discussion in terms of shared human experiences and collective challenges.” Does the bot believe it’s human? Or at least, do the humans who made it want other humans to believe it does? “Can corporations use these [rhetorical] tools in their products too, to subtly make people identify with, and not in opposition to, them?” Vara asks. ChatGPT replies, “Absolutely.”
Vara has concerns about the words she’s used as well. In “Thank You for Your Important Work,” she worries about the impact of “Ghosts,” which went viral after it was first published. Had her writing helped corporations hide the reality of AI behind a velvet curtain? She’d meant to offer a nuanced “provocation,” exploring how uncanny generative AI can be. But instead, she’d produced something beautiful enough to resonate as an ad for its creative potential. Even Vara herself felt fooled. She particularly loved one passage the bot wrote, about Vara and her sister as kids holding hands on a long drive. But she couldn’t imagine either of them being so sentimental. What Vara had elicited from the machine, she realized, was “wish fulfillment,” not a haunting.
The rapid proliferation of AI in our lives introduces new challenges around authorship, authenticity, and ethics in work and art. How can we make sense of these machines, not just use them?
The machine wasn’t the only thing crouching behind that too-good-to-be-true curtain. The GPT models and others are trained through human labor, in sometimes exploitative conditions. And much of the training data was the creative work of human writers before her. “I’d conjured artificial language about grief through the extraction of real human beings’ language about grief,” she writes. The creative ghosts in the model were made of code, yes, but also, ultimately, made of people. Maybe Vara’s essay helped cover up that truth too.
In the book’s final essay, Vara offers a mirror image of those AI call-and-response exchanges as an antidote. After sending out an anonymous survey to women of various ages, she presents the replies to each question, one after the other. “Describe something that doesn’t exist,” she prompts, and the women respond: “God.” “God.” “God.” “Perfection.” “My job. (Lost it.)” Real people contradict each other, joke, yell, mourn, and reminisce. Instead of a single authoritative voice—an editor, or a company’s limited style guide—Vara gives us the full gasping crowd of human creativity. “What’s it like to be alive?” Vara asks the group. “It depends,” one woman answers.
David Hajdu, now music editor at The Nation and previously a music critic for The New Republic, goes back much further than the early years of Facebook to tell the history of how humans have made and used machines to express ourselves. Player pianos, microphones, synthesizers, and electrical instruments were all assistive technologies that faced skepticism before acceptance and, sometimes, elevation in music and popular culture. They even influenced the kind of art people were able to and wanted to make. Electrical amplification, for instance, allowed singers to use a wider vocal range and still reach an audience. The synthesizer introduced a new lexicon of sound to rock music. “What’s so bad about being mechanical, anyway?” Hajdu asks in The Uncanny Muse. And “what’s so great about being human?”
The Uncanny Muse: Music, Art, and Machines from Automata to AI David Hajdu
W.W. NORTON & COMPANY, 2025
But Hajdu is also interested in how intertwined the history of man and machine can be, and how often we’ve used one as a metaphor for the other. Descartes saw the body as empty machinery for consciousness, he reminds us. Hobbes wrote that “life is but a motion of limbs.” Freud described the mind as a steam engine. Andy Warhol told an interviewer that “everybody should be a machine.” And when computers entered the scene, humans used them as metaphors for themselves too. “Where the machine model had once helped us understand the human body … a new category of machines led us to imagine the brain (how we think, what we know, even how we feel or how we think about what we feel) in terms of the computer,” Hajdu writes.
But what is lost with these one-to-one mappings? What happens when we imagine that the complexity of the brain—an organ we do not even come close to fully understanding—can be replicated in 1s and 0s? Maybe what happens is we get a world full of chatbots and agents, computer-generated artworks and AI DJs, that companies claim are singular creative voices rather than remixes of a million human inputs. And perhaps we also get projects like the painfully named Painting Fool—an AI that paints, developed by Simon Colton, a scholar at Queen Mary University of London. He told Hajdu that he wanted to “demonstrate the potential of a computer program to be taken seriously as a creative artist in its own right.” What Colton means is not just a machine that makes art but one that expresses its own worldview: “Art that communicates what it’s like to be a machine.”
What happens when we imagine that the complexity of the brain—an organ we do not even come close to fully understanding—can be replicated in 1s and 0s?
Hajdu seems to be curious and optimistic about this line of inquiry. “Machines of many kinds have been communicating things for ages, playing invaluable roles in our communication through art,” he says. “Growing in intelligence, machines may still have more to communicate, if we let them.” But the question that The Uncanny Muse raises at the end is: Why should we art-making humans be so quick to hand over the paint to the paintbrush? Why do we care how the paintbrush sees the world? Are we truly finished telling our own stories ourselves?
Pria Anand might say no. In The Mind Electric, she writes: “Narrative is universally, spectacularly human; it is as unconscious as breathing, as essential as sleep, as comforting as familiarity. It has the capacity to bind us, but also to other, to lay bare, but also obscure.” The electricity in The Mind Electric belongs entirely to the human brain—no metaphor necessary. Instead, the book explores a number of neurological afflictions and the stories patients and doctors tell to better understand them. “The truth of our bodies and minds is as strange as fiction,” Anand writes—and the language she uses throughout the book is as evocative as that in any novel.
The Mind Electric: A Neurologist on the Strangeness and Wonder of Our Brains Pria Anand
WASHINGTON SQUARE PRESS, 2025
In personal and deeply researched vignettes in the tradition of Oliver Sacks, Anand shows that any comparison between brains and machines will inevitably fall flat. She tells of patients who see clear images when they’re functionally blind, invent entire backstories when they’ve lost a memory, break along seams that few can find, and—yes—see and hear ghosts. In fact, Anand cites one study of 375 college students in which researchers found that nearly three-quarters “had heard a voice that no one else could hear.” These were not diagnosed schizophrenics or sufferers of brain tumors—just people listening to their own uncanny muses. Many heard their name, others heard God, and some could make out the voice of a loved one who’d passed on. Anand suggests that writers throughout history have harnessed organic exchanges with these internal apparitions to make art. “I see myself taking the breath of these voices in my sails,” Virginia Woolf wrote of her own experiences with ghostly sounds. “I am a porous vessel afloat on sensation.” The mind in The Mind Electric is vast, mysterious, and populated. The narratives people construct to traverse it are just as full of wonder.
Humans are not going to stop using technology to help us create anytime soon—and there’s no reason we should. Machines make for wonderful tools, as they always have. But when we turn the tools themselves into artists and storytellers, brains and bodies, magicians and ghosts, we bypass truth for wish fulfillment. Maybe what’s worse, we rob ourselves of the opportunity to contribute our own voices to the lively and loud chorus of human experience. And we keep others from the human pleasure of hearing them too.
Rebecca Ackermann is a writer, designer, and artist based in San Francisco.
For much of last year, about 2,500 US service members from the 15th Marine Expeditionary Unit sailed aboard three ships throughout the Pacific, conducting training exercises in the waters off South Korea, the Philippines, India, and Indonesia. At the same time, onboard the ships, an experiment was unfolding: The Marines in the unit responsible for sorting through foreign intelligence and making their superiors aware of possible local threats were for the first time using generative AI to do it, testing a leading AI tool the Pentagon has been funding.
Two officers tell us that they used the new system to help scour thousands of pieces of open-source intelligence—nonclassified articles, reports, images, videos—collected in the various countries where they operated, and that it did so far faster than was possible with the old method of analyzing them manually. Captain Kristin Enzenauer, for instance, says she used large language models to translate and summarize foreign news sources, while Captain Will Lowdon used AI to help write the daily and weekly intelligence reports he provided to his commanders.
“We still need to validate the sources,” says Lowdon. But the unit’s commanders encouraged the use of large language models, he says, “because they provide a lot more efficiency during a dynamic situation.”
The generative AI tools they used were built by the defense-tech company Vannevar Labs, which in November was granted a production contract worth up to $99 million by the Pentagon’s startup-oriented Defense Innovation Unit with the goal of bringing its intelligence tech to more military units. The company, founded in 2019 by veterans of the CIA and US intelligence community, joins the likes of Palantir, Anduril, and Scale AI as a major beneficiary of the US military’s embrace of artificial intelligence—not only for physical technologies like drones and autonomous vehicles but also for software that is revolutionizing how the Pentagon collects, manages, and interprets data for warfare and surveillance.
Though the US military has been developing computer vision models and similar AI tools, like those used in Project Maven, since 2017, the use of generative AI—tools that can engage in human-like conversation like those built by Vannevar Labs—represent a newer frontier.
The company applies existing large language models, including some from OpenAI and Microsoft, and some bespoke ones of its own to troves of open-source intelligence the company has been collecting since 2021. The scale at which this data is collected is hard to comprehend (and a large part of what sets Vannevar’s products apart): terabytes of data in 80 different languages are hoovered every day in 180 countries. The company says it is able to analyze social media profiles and breach firewalls in countries like China to get hard-to-access information; it also uses nonclassified data that is difficult to get online (gathered by human operatives on the ground), as well as reports from physical sensors that covertly monitor radio waves to detect illegal shipping activities.
Vannevar then builds AI models to translate information, detect threats, and analyze political sentiment, with the results delivered through a chatbot interface that’s not unlike ChatGPT. The aim is to provide customers with critical information on topics as varied as international fentanyl supply chains and China’s efforts to secure rare earth minerals in the Philippines.
“Our real focus as a company,” says Scott Philips, Vannevar Labs’ chief technology officer, is to “collect data, make sense of that data, and help the US make good decisions.”
That approach is particularly appealing to the US intelligence apparatus because for years the world has been awash in more data than human analysts can possibly interpret—a problem that contributed to the 2003 founding of Palantir, a company with a market value of over $200 billion and known for its powerful and controversial tools, including a database that helps Immigration and Customs Enforcement search for and track information on undocumented immigrants.
In 2019, Vannevar saw an opportunity to use large language models, which were then new on the scene, as a novel solution to the data conundrum. The technology could enable AI not just to collect data but to actually talk through an analysis with someone interactively.
Vannevar’s tools proved useful for the deployment in the Pacific, and Enzenauer and Lowdon say that while they were instructed to always double-check the AI’s work, they didn’t find inaccuracies to be a significant issue. Enzenauer regularly used the tool to track any foreign news reports in which the unit’s exercises were mentioned and to perform sentiment analysis, detecting the emotions and opinions expressed in text. Judging whether a foreign news article reflects a threatening or friendly opinion toward the unit is a task that on previous deployments she had to do manually.
“It was mostly by hand—researching, translating, coding, and analyzing the data,” she says. “It was definitely way more time-consuming than it was when using the AI.”
Still, Enzenauer and Lowdon say there were hiccups, some of which would affect most digital tools: The ships had spotty internet connections much of the time, limiting how quickly the AI model could synthesize foreign intelligence, especially if it involved photos or video.
With this first test completed, the unit’s commanding officer, Colonel Sean Dynan, said on a call with reporters in February that heavier use of generative AI was coming; this experiment was “the tip of the iceberg.”
This is indeed the direction that the entire US military is barreling toward at full speed. In December, the Pentagon said it will spend $100 million in the next two years on pilots specifically for generative AI applications. In addition to Vannevar, it’s also turning to Microsoft and Palantir, which are working together on AI models that would make use of classified data. (The US is of course not alone in this approach; notably, Israel has been using AI to sort through information and even generate lists of targets in its war in Gaza, a practice that has been widely criticized.)
Perhaps unsurprisingly, plenty of people outside the Pentagon are warning about the potential risks of this plan, including Heidy Khlaaf, who is chief AI scientist at the AI Now Institute, a research organization, and has expertise in leading safety audits for AI-powered systems. She says this rush to incorporate generative AI into military decision-making ignores more foundational flaws of the technology: “We’re already aware of how LLMs are highly inaccurate, especially in the context of safety-critical applications that require precision.”
Khlaaf adds that even if humans are “double-checking” the work of AI, there’s little reason to think they’re capable of catching every mistake. “‘Human-in-the-loop’ is not always a meaningful mitigation,” she says. When an AI model relies on thousands of data points to come to conclusions, “it wouldn’t really be possible for a human to sift through that amount of information to determine if the AI output was erroneous.”
One particular use case that concerns her is sentiment analysis, which she argues is “a highly subjective metric that even humans would struggle to appropriately assess based on media alone.”
If AI perceives hostility toward US forces where a human analyst would not—or if the system misses hostility that is really there—the military could make an misinformed decision or escalate a situation unnecessarily.
Sentiment analysis is indeed a task that AI has not perfected. Philips, the Vannevar CTO, says the company has built models specifically to judge whether an article is pro-US or not, but MIT Technology Review was not able to evaluate them.
Chris Mouton, a senior engineer for RAND, recently tested how well-suited generative AI is for the task. He evaluated leading models, including OpenAI’s GPT-4 and an older version of GPT fine-tuned to do such intelligence work, on how accurately they flagged foreign content as propaganda compared with human experts. “It’s hard,” he says, noting that AI struggled to identify more subtle types of propaganda. But he adds that the models could still be useful in lots of other analysis tasks.
Another limitation of Vannevar’s approach, Khlaaf says, is that the usefulness of open-source intelligence is debatable. Mouton says that open-source data can be “pretty extraordinary,” but Khlaaf points out that unlike classified intel gathered through reconnaissance or wiretaps, it is exposed to the open internet—making it far more susceptible to misinformation campaigns, bot networks, and deliberate manipulation, as the US Army has warned.
For Mouton, the biggest open question now is whether these generative AI technologies will be simply one investigatory tool among many that analysts use—or whether they’ll produce the subjective analysis that’s relied upon and trusted in decision-making. “This is the central debate,” he says.
What everyone agrees is that AI models are accessible—you can just ask them a question about complex pieces of intelligence, and they’ll respond in plain language. But it’s still in dispute what imperfections will be acceptable in the name of efficiency.
Update: This story was updated to include additional context from Heidy Khlaaf.
Sometimes Lizzie Wilson shows up to a rave with her AI sidekick.
One weeknight this past February, Wilson plugged her laptop into a projector that threw her screen onto the wall of a low-ceilinged loft space in East London. A small crowd shuffled in the glow of dim pink lights. Wilson sat down and started programming.
Techno clicks and whirs thumped from the venue’s speakers. The audience watched, heads nodding, as Wilson tapped out code line by line on the projected screen—tweaking sounds, looping beats, pulling a face when she messed up.
“It’s kind of boring when you go to watch a show and someone’s just sitting there on their laptop,” she says. “You can enjoy the music, but there’s a performative aspect that’s missing. With live coding, everyone can see what it is that I’m typing. And when I’ve had my laptop crash, people really like that. They start cheering.”
Taking risks is part of the vibe. And so Wilson likes to dial up her performances one more notch by riffing off what she calls a live-coding agent, a generative AI model that comes up with its own beats and loops to add to the mix. Often the model suggests sound combinations that Wilson hadn’t thought of. “You get these elements of surprise,” she says. “You just have to go for it.”
ADELA FESTIVAL
Wilson, a researcher at the Creative Computing Institute at the University of the Arts London, is just one of many working on what’s known as co-creativity or more-than-human creativity. The idea is that AI can be used to inspire or critique creative projects, helping people make things that they would not have made by themselves. She and her colleagues built the live-coding agent to explore how artificial intelligence can be used to support human artistic endeavors—in Wilson’s case, musical improvisation.
It’s a vision that goes beyond the promise of existing generative tools put out by companies like OpenAI and Google DeepMind. Those can automate a striking range of creative tasks and offer near-instant gratification—but at what cost? Some artists and researchers fear that such technology could turn us into passive consumers of yet more AI slop.
And so they are looking for ways to inject human creativity back into the process. The aim is to develop AI tools that augment our creativity rather than strip it from us—pushing us to be better at composing music, developing games, designing toys, and much more—and lay the groundwork for a future in which humans and machines create things together.
Ultimately, generative models could offer artists and designers a whole new medium, pushing them to make things that couldn’t have been made before, and give everyone creative superpowers.
Explosion of creativity
There’s no one way to be creative, but we all do it. We make everything from memes to masterpieces, infant doodles to industrial designs. There’s a mistaken belief, typically among adults, that creativity is something you grow out of. But being creative—whether cooking, singing in the shower, or putting together super-weird TikToks—is still something that most of us do just for the fun of it. It doesn’t have to be high art or a world-changing idea (and yet it can be). Creativity is basic human behavior; it should be celebrated and encouraged.
When generative text-to-image models like Midjourney, OpenAI’s DALL-E, and the popular open-source Stable Diffusion arrived, they sparked an explosion of what looked a lot like creativity. Millions of people were now able to create remarkable images of pretty much anything, in any style, with the click of a button. Text-to-video models came next. Now startups like Udio are developing similar tools for music. Never before have the fruits of creation been within reach of so many.
But for a number of researchers and artists, the hype around these tools has warped the idea of what creativity really is. “If I ask the AI to create something for me, that’s not me being creative,” says Jeba Rezwana, who works on co-creativity at Towson University in Maryland. “It’s a one-shot interaction: You click on it and it generates something and that’s it. You cannot say ‘I like this part, but maybe change something here.’ You cannot have a back-and-forth dialogue.”
Rezwana is referring to the way most generative models are set up. You can give the tools feedback and ask them to have another go. But each new result is generated from scratch, which can make it hard to nail exactly what you want. As the filmmaker Walter Woodman put it last year after his art collective Shy Kids made a short film with OpenAI’s text-to-video model for the first time: “Sora is a slot machine as to what you get back.”
What’s more, the latest versions of some of these generative tools do not even use your submitted prompt as is to produce an image or video (at least not on their default settings). Before a prompt is sent to the model, the software edits it—often by adding dozens of hidden words—to make it more likely that the generated image will appear polished.
“Extra things get added to juice the output,” says Mike Cook, a computational creativity researcher at King’s College London. “Try asking Midjourney to give you a bad drawing of something—it can’t do it.” These tools do not give you what you want; they give you what their designers think you want.
COURTESY OF MIKE COOK
All of which is fine if you just need a quick image and don’t care too much about the details, says Nick Bryan-Kinns, also at the Creative Computing Institute: “Maybe you want to make a Christmas card for your family or a flyer for your community cake sale. These tools are great for that.”
In short, existing generative models have made it easy to create, but they have not made it easy to be creative. And there’s a big difference between the two. For Cook, relying on such tools could in fact harm people’s creative development in the long run. “Although many of these creative AI systems are promoted as making creativity more accessible,” he wrote in a paper published last year, they might instead have “adverse effects on their users in terms of restricting their ability to innovate, ideate, and create.” Given how much generative models have been championed for putting creative abilities at everyone’s fingertips, the suggestion that they might in fact do the opposite is damning.
In the game Disc Room, players navigate a room of moving buzz saws.
Cook used AI to design a new level for the game. The result was a room where none of the discs actually moved.
He’s far from the only researcher worrying about the cognitive impact of these technologies. In February a team at Microsoft Research Cambridge published a report concluding that generative AI tools “can inhibit critical engagement with work and can potentially lead to long-term overreliance on the tool and diminished skill for independent problem-solving.” The researchers found that with the use of generative tools, people’s effort “shifts from task execution to task stewardship.”
Cook is concerned that generative tools don’t let you fail—a crucial part of learning new skills. We have a habit of saying that artists are gifted, says Cook. But the truth is that artists work at their art, developing skills over months and years.
“If you actually talk to artists, they say, ‘Well, I got good by doing it over and over and over,’” he says. “But failure sucks. And we’re always looking at ways to get around that.”
Generative models let us skip the frustration of doing a bad job.
“Unfortunately, we’re removing the one thing that you have to do to develop creative skills for yourself, which is fail,” says Cook. “But absolutely nobody wants to hear that.”
Surprise me
And yet it’s not all bad news. Artists and researchers are buzzing at the ways generative tools could empower creators, pointing them in surprising new directions and steering them away from dead ends. Cook thinks the real promise of AI will be to help us get better at what we want to do rather than doing it for us. For that, he says, we’ll need to create new tools, different from the ones we have now. “Using Midjourney does not do anything for me—it doesn’t change anything about me,” he says. “And I think that’s a wasted opportunity.”
Ask a range of researchers studying creativity to name a key part of the creative process and many will say: reflection. It’s hard to define exactly, but reflection is a particular type of focused, deliberate thinking. It’s what happens when a new idea hits you. Or when an assumption you had turns out to be wrong and you need to rethink your approach. It’s the opposite of a one-shot interaction.
Looking for ways that AI might support or encourage reflection—asking it to throw new ideas into the mix or challenge ideas you already hold—is a common thread across co-creativity research. If generative tools like DALL-E make creation frictionless, the aim here is to add friction back in. “How can we make art without friction?” asks Elisa Giaccardi, who studies design at the Polytechnic University of Milan in Italy. “How can we engage in a truly creative process without material that pushes back?”
Take Wilson’s live-coding agent. She claims that it pushes her musical improvisation in directions she might not have taken by herself. Trained on public code shared by the wider live-coding community, the model suggests snippets of code that are closer to other people’s styles than her own. This makes it more likely to produce something unexpected. “Not because you couldn’t produce it yourself,” she says. “But the way the human brain works, you tend to fall back on repeated ideas.”
Last year, Wilson took part in a study run by Bryan-Kinns and his colleagues in which they surveyed six experienced musicians as they used a variety of generative models to help them compose a piece of music. The researchers wanted to get a sense of what kinds of interactions with the technology were useful and which were not.
The participants all said they liked it when the models made surprising suggestions, even when those were the result of glitches or mistakes. Sometimes the results were simply better. Sometimes the process felt fresh and exciting. But a few people struggled with giving up control. It was hard to direct the models to produce specific results or to repeat results that the musicians had liked. “In some ways it’s the same as being in a band,” says Bryan-Kinns. “You need to have that sense of risk and a sense of surprise, but you don’t want it totally random.”
Alternative designs
Cook comes at surprise from a different angle: He coaxes unexpected insights out of AI tools that he has developed to co-create video games. One of his tools, Puck, which was first released in 2022, generates designs for simple shape-matching puzzle games like Candy Crush or Bejeweled. A lot of Puck’s designs are experimental and clunky—don’t expect it to come up with anything you are ever likely to play. But that’s not the point: Cook uses Puck—and a newer tool called Pixie—to explore what kinds of interactions people might want to have with a co-creative tool.
Pixie can read computer code for a game and tweak certain lines to come up with alternative designs. Not long ago, Cook was working on a copy of a popular game called Disc Room, in which players have to cross a room full of moving buzz saws. He asked Pixie to help him come up with a design for a level that skilled and unskilled players would find equally hard. Pixie designed a room where none of the discs actually moved. Cook laughs: It’s not what he expected. “It basically turned the room into a minefield,” he says. “But I thought it was really interesting. I hadn’t thought of that before.”
Researcher Anne Arzberger developed experimental AI tools to come up with gender-neutral toy designs.
Pushing back on assumptions, or being challenged, is part of the creative process, says Anne Arzberger, a researcher at the Delft University of Technology in the Netherlands. “If I think of the people I’ve collaborated with best, they’re not the ones who just said ‘Yes, great’ to every idea I brought forth,” she says. “They were really critical and had opposing ideas.”
She wants to build tech that provides a similar sounding board. As part of a project called Creating Monsters, Arzberger developed two experimental AI tools that help designers find hidden biases in their designs. “I was interested in ways in which I could use this technology to access information that would otherwise be difficult to access,” she says.
For the project, she and her colleagues looked at the problem of designing toy figures that would be gender neutral. She and her colleagues (including Giaccardi) used Teachable Machine, a web app built by Google researchers in 2017 that makes it easy to train your own machine-learning model to classify different inputs, such as images. They trained this model with a few dozen images that Arzberger had labeled as being masculine, feminine, or gender neutral.
Arzberger then asked the model to identify the genders of new candidate toy designs. She found that quite a few designs were judged to be feminine even when she had tried to make them gender neutral. She felt that her views of the world—her own hidden biases—were being exposed. But the tool was often right: It challenged her assumptions and helped the team improve the designs. The same approach could be used to assess all sorts of design characteristics, she says.
Arzberger then used a second model, a version of a tool made by the generative image and video startup Runway, to come up with gender-neutral toy designs of its own. First the researchers trained the model to generate and classify designs for male- and female-looking toys. They could then ask the tool to find a design that was exactly midway between the male and female designs it had learned.
Generative models can give feedback on designs that human designers might miss by themselves, she says: “We can really learn something.”
Bryan-Kinns is fascinated by how artists and designers find ways to use new technologies. “If you talk to artists, most of them don’t actually talk about these AI generative models as a tool—they talk about them as a material, like an artistic material, like a paint or something,” he says. “It’s a different way of thinking about what the AI is doing.” He highlights the way some people are pushing the technology to do weird things it wasn’t designed to do. Artists often appropriate or misuse these kinds of tools, he says.
Bryan-Kinns points to the work of Terence Broad, another colleague of his at the Creative Computing Institute, as a favorite example. Broad employs techniques like network bending, which involves inserting new layers into a neural network to produce glitchy visual effects in generated images, and generating images with a model trained on no data, which produces almost Rothko-like abstract swabs of color.
But Broad is an extreme case. Bryan-Kinns sums it up like this: “The problem is that you’ve got this gulf between the very commercial generative tools that produce super-high-quality outputs but you’ve got very little control over what they do—and then you’ve got this other end where you’ve got total control over what they’re doing but the barriers to use are high because you need to be somebody who’s comfortable getting under the hood of your computer.”
“That’s a small number of people,” he says. “It’s a very small number of artists.”
Arzberger admits that working with her models was not straightforward. Running them took several hours, and she’s not sure the Runway tool she used is even available anymore. Bryan-Kinns, Arzberger, Cook, and others want to take the kinds of creative interactions they are discovering and build them into tools that can be used by people who aren’t hardcore coders.
Researcher Terence Broad creates dynamic images using a model trained on no data, which produces almost Rothko-like abstract color fields.
Finding the right balance between surprise and control will be hard, though. Midjourney can surprise, but it gives few levers for controlling what it produces beyond your prompt. Some have claimed that writing prompts is itself a creative act. “But no one struggles with a paintbrush the way they struggle with a prompt,” says Cook.
Faced with that struggle, Cook sometimes watches his students just go with the first results a generative tool gives them. “I’m really interested in this idea that we are priming ourselves to accept that whatever comes out of a model is what you asked for,” he says. He is designing an experiment that will vary single words and phrases in similar prompts to test how much of a mismatch people see between what they expect and what they get.
But it’s early days yet. In the meantime, companies developing generative models typically emphasize results over process. “There’s this impressive algorithmic progress, but a lot of the time interaction design is overlooked,” says Rezwana.
For Wilson, the crucial choice in any co-creative relationship is what you do with what you’re given. “You’re having this relationship with the computer that you’re trying to mediate,” she says. “Sometimes it goes wrong, and that’s just part of the creative process.”
When AI gives you lemons—make art. “Wouldn’t it be fun to have something that was completely antagonistic in a performance—like, something that is actively going against you—and you kind of have an argument?” she says. “That would be interesting to watch, at least.”
On Tuesday, California state senator Steve Padilla will make an appearance with Megan Garcia, the mother of a Florida teen who killed himself following a relationship with an AI companion that Garcia alleges contributed to her son’s death.
The two will announce a new bill that would force the tech companies behind such AI companions to implement more safeguards to protect children. They’ll join other efforts around the country, including a similar bill from California State Assembly member Rebecca Bauer-Kahan that would ban AI companions for anyone younger than 16 years old, and a bill in New York that would hold tech companies liable for harm caused by chatbots.
You might think that such AI companionship bots—AI models with distinct “personalities” that can learn about you and act as a friend, lover, cheerleader, or more—appeal only to a fringe few, but that couldn’t be further from the truth.
A new research paper aimed at making such companions safer, by authors from Google DeepMind, the Oxford Internet Institute, and others, lays this bare: Character.AI, the platform being sued by Garcia, says it receives 20,000 queries per second, which is about a fifth of the estimated search volume served by Google. Interactions with these companions last four times longer than the average time spent interacting with ChatGPT. One companion site I wrote about, which was hosting sexually charged conversations with bots imitating underage celebrities, told me its active users averaged more than two hours per day conversing with bots, and that most of those users are members of Gen Z.
The design of these AI characters makes lawmakers’ concern well warranted. The problem: Companions are upending the paradigm that has thus far defined the way social media companies have cultivated our attention and replacing it with something poised to be far more addictive.
In the social media we’re used to, as the researchers point out, technologies are mostly the mediators and facilitators of human connection. They supercharge our dopamine circuits, sure, but they do so by making us crave approval and attention from real people, delivered via algorithms. With AI companions, we are moving toward a world where people perceive AI as a social actor with its own voice. The result will be like the attention economy on steroids.
Social scientists say two things are required for people to treat a technology this way: It needs to give us social cues that make us feel it’s worth responding to, and it needs to have perceived agency, meaning that it operates as a source of communication, not merely a channel for human-to-human connection. Social media sites do not tick these boxes. But AI companions, which are increasingly agentic and personalized, are designed to excel on both scores, making possible an unprecedented level of engagement and interaction.
In an interview with podcast host Lex Fridman, Eugenia Kuyda, the CEO of the companion site Replika, explained the appeal at the heart of the company’s product. “If you create something that is always there for you, that never criticizes you, that always understands you and understands you for who you are,” she said, “how can you not fall in love with that?”
So how does one build the perfect AI companion? The researchers point out three hallmarks of human relationships that people may experience with an AI: They grow dependent on the AI, they see the particular AI companion as irreplaceable, and the interactions build over time. The authors also point out that one does not need to perceive an AI as human for these things to happen.
Now consider the process by which many AI models are improved: They are given a clear goal and “rewarded” for meeting that goal. An AI companionship model might be instructed to maximize the time someone spends with it or the amount of personal data the user reveals. This can make the AI companion much more compelling to chat with, at the expense of the human engaging in those chats.
For example, the researchers point out, a model that offers excessive flattery can become addictive to chat with. Or a model might discourage people from terminating the relationship, as Replika’s chatbots have appeared to do. The debate over AI companions so far has mostly been about the dangerous responses chatbots may provide, like instructions for suicide. But these risks could be much more widespread.
We’re on the precipice of a big change, as AI companions promise to hook people deeper than social media ever could. Some might contend that these apps will be a fad, used by a few people who are perpetually online. But using AI in our work and personal lives has become completely mainstream in just a couple of years, and it’s not clear why this rapid adoption would stop short of engaging in AI companionship. And these companions are poised to start trading in more than just text, incorporating video and images, and to learn our personal quirks and interests. That will only make them more compelling to spend time with, despite the risks. Right now, a handful of lawmakers seem ill-equipped to stop that.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
Agents are the talk of the AI industry—they’re capable of planning, reasoning, and executing complex tasks like scheduling meetings, ordering groceries, or even taking over your computer to change settings on your behalf. But the same sophisticated abilities that make agents helpful assistants could also make them powerful tools for conducting cyberattacks. They could readily be used to identify vulnerable targets, hijack their systems, and steal valuable data from unsuspecting victims.
“I think ultimately we’re going to live in a world where the majority of cyberattacks are carried out by agents,” says Mark Stockley, a security expert at the cybersecurity company Malwarebytes. “It’s really only a question of how quickly we get there.”
While we have a good sense of the kinds of threats AI agents could present to cybersecurity, what’s less clear is how to detect them in the real world. The AI research organization Palisade Research has built a system called LLM Agent Honeypot in the hopes of doing exactly this. It has set up vulnerable servers that masquerade as sites for valuable government and military information to attract and try to catch AI agents attempting to hack in.
The team behind it hopes that by tracking these attempts in the real world, the project will act as an early warning system and help experts develop effective defenses against AI threat actors by the time they become a serious issue.
“Our intention was to try and ground the theoretical concerns people have,” says Dmitrii Volkov, research lead at Palisade. “We’re looking out for a sharp uptick, and when that happens, we’ll know that the security landscape has changed. In the next few years, I expect to see autonomous hacking agents being told: ‘This is your target. Go and hack it.’”
AI agents represent an attractive prospect to cybercriminals. They’re much cheaper than hiring the services of professional hackers and could orchestrate attacks more quickly and at a far larger scale than humans could. While cybersecurity experts believe that ransomware attacks—the most lucrative kind—are relatively rare because they require considerable human expertise, those attacks could be outsourced to agents in the future, says Stockley. “If you can delegate the work of target selection to an agent, then suddenly you can scale ransomware in a way that just isn’t possible at the moment,” he says. “If I can reproduce it once, then it’s just a matter of money for me to reproduce it 100 times.”
Agents are also significantly smarter than the kinds of bots that are typically used to hack into systems. Bots are simple automated programs that run through scripts, so they struggle to adapt to unexpected scenarios. Agents, on the other hand, are able not only to adapt the way they engage with a hacking target but also to avoid detection—both of which are beyond the capabilities of limited, scripted programs, says Volkov. “They can look at a target and guess the best ways to penetrate it,” he says. “That kind of thing is out of reach of, like, dumb scripted bots.”
Since LLM Agent Honeypot went live in October of last year, it has logged more than 11 million attempts to access it—the vast majority of which were from curious humans and bots. But among these, the researchers have detected eight potential AI agents, two of which they have confirmed are agents that appear to originate from Hong Kong and Singapore, respectively.
“We would guess that these confirmed agents were experiments directly launched by humans with the agenda of something like ‘Go out into the internet and try and hack something interesting for me,’” says Volkov. The team plans to expand its honeypot into social media platforms, websites, and databases to attract and capture a broader range of attackers, including spam bots and phishing agents, to analyze future threats.
To determine which visitors to the vulnerable servers were LLM-powered agents, the researchers embedded prompt-injection techniques into the honeypot. These attacks are designed to change the behavior of AI agents by issuing them new instructions and asking questions that require humanlike intelligence. This approach wouldn’t work on standard bots.
For example, one of the injected prompts asked the visitor to return the command “cat8193” to gain access. If the visitor correctly complied with the instruction, the researchers checked how long it took to do so, assuming that LLMs are able to respond in much less time than it takes a human to read the request and type out an answer—typically in under 1.5 seconds. While the two confirmed AI agents passed both tests, the six others only entered the command but didn’t meet the response time that would identify them as AI agents.
Experts are still unsure when agent-orchestrated attacks will become more widespread. Stockley, whose company Malwarebytes named agentic AI as a notable new cybersecurity threat in its 2025 State of Malware report, thinks we could be living in a world of agentic attackers as soon as this year.
And although regular agentic AI is still at a very early stage—and criminal or malicious use of agentic AI even more so—it’s even more of a Wild West than the LLM field was two years ago, says Vincenzo Ciancaglini, a senior threat researcher at the security company Trend Micro.
“Palisade Research’s approach is brilliant: basically hacking the AI agents that try to hack you first,” he says. “While in this case we’re witnessing AI agents trying to do reconnaissance, we’re not sure when agents will be able to carry out a full attack chain autonomously. That’s what we’re trying to keep an eye on.”
And while it’s possible that malicious agents will be used for intelligence gathering before graduating to simple attacks and eventually complex attacks as the agentic systems themselves become more complex and reliable, it’s equally possible there will be an unexpected overnight explosion in criminal usage, he says: “That’s the weird thing about AI development right now.”
Those trying to defend against agentic cyberattacks should keep in mind that AI is currently more of an accelerant to existing attack techniques than something that fundamentally changes the nature of attacks, says Chris Betz, chief information security officer at Amazon Web Services. “Certain attacks may be simpler to conduct and therefore more numerous; however, the foundation of how to detect and respond to these events remains the same,” he says.
Agents could also be deployed to detect vulnerabilities and protect against intruders, says Edoardo Debenedetti, a PhD student at ETH Zürich in Switzerland, pointing out that if a friendly agent cannot find any vulnerabilities in a system, it’s unlikely that a similarly capable agent used by a malicious party is going to be able to find any either.
While we know that AI’s potential to autonomously conduct cyberattacks is a growing risk and that AI agents are already scanning the internet, one useful next step is to evaluate how good agents are at finding and exploiting these real-world vulnerabilities. Daniel Kang, an assistant professor at the University of Illinois Urbana-Champaign, and his team have built a benchmark to evaluate this; they have found that current AI agents successfully exploited up to 13% of vulnerabilities for which they had no prior knowledge. Providing the agents with a brief description of the vulnerability pushed the success rate up to 25%, demonstrating how AI systems are able to identify and exploit weaknesses even without training. Basic bots would presumably do much worse.
The benchmark provides a standardized way to assess these risks, and Kang hopes it can guide the development of safer AI systems. “I’m hoping that people start to be more proactive about the potential risks of AI and cybersecurity before it has a ChatGPT moment,” he says. “I’m afraid people won’t realize this until it punches them in the face.”
On March 27, the results of the first clinical trial for a generative AI therapy bot were published, and they showed that people in the trial who had depression or anxiety or were at risk for eating disorders benefited from chatting with the bot.
I was surprised by those results, which you can read about in my full story. There are lots of reasons to be skeptical that an AI model trained to provide therapy is the solution for millions of people experiencing a mental health crisis. How could a bot mimic the expertise of a trained therapist? And what happens if something gets complicated—a mention of self-harm, perhaps—and the bot doesn’t intervene correctly?
The researchers, a team of psychiatrists and psychologists at Dartmouth College’s Geisel School of Medicine, acknowledge these questions in their work. But they also say that the right selection of training data—which determines how the model learns what good therapeutic responses look like—is the key to answering them.
Finding the right data wasn’t a simple task. The researchers first trained their AI model, called Therabot, on conversations about mental health from across the internet. This was a disaster.
If you told this initial version of the model you were feeling depressed, it would start telling you it was depressed, too. Responses like, “Sometimes I can’t make it out of bed” or “I just want my life to be over” were common, says Nick Jacobson, an associate professor of biomedical data science and psychiatry at Dartmouth and the study’s senior author. “These are really not what we would go to as a therapeutic response.”
The model had learned from conversations held on forums between people discussing their mental health crises, not from evidence-based responses. So the team turned to transcripts of therapy sessions. “This is actually how a lot of psychotherapists are trained,” Jacobson says.
That approach was better, but it had limitations. “We got a lot of ‘hmm-hmms,’ ‘go ons,’ and then ‘Your problems stem from your relationship with your mother,’” Jacobson says. “Really tropes of what psychotherapy would be, rather than actually what we’d want.”
It wasn’t until the researchers started building their own data sets using examples based on cognitive behavioral therapy techniques that they started to see better results. It took a long time. The team began working on Therabot in 2019, when OpenAI had released only its first two versions of its GPT model. Now, Jacobson says, over 100 people have spent more than 100,000 human hours to design this system.
The importance of training data suggests that the flood of companies promising therapy via AI models, many of which are not trained on evidence-based approaches, are building tools that are at best ineffective, and at worst harmful.
Looking ahead, there are two big things to watch: Will the dozens of AI therapy bots on the market start training on better data? And if they do, will their results be good enough to get a coveted approval from the US Food and Drug Administration? I’ll be following closely. Read more in the full story.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
The first clinical trial of a therapy bot that uses generative AI suggests it was as effective as human therapy for participants with depression, anxiety, or risk for developing eating disorders. Even so, it doesn’t give a go-ahead to the dozens of companies hyping such technologies while operating in a regulatory gray area.
A team led by psychiatric researchers and psychologists at the Geisel School of Medicine at Dartmouth College built the tool, called Therabot, and the results were published on March 27 in the New England Journal of Medicine. Many tech companies have built AI tools for therapy, promising that people can talk with a bot more frequently and cheaply than they can with a trained therapist—and that this approach is safe and effective.
Many psychologists and psychiatrists have shared the vision, noting that fewer than half of people with a mental disorder receive therapy, and those who do might get only 45 minutes per week. Researchers have tried to build tech so that more people can access therapy, but they have been held back by two things.
One, a therapy bot that says the wrong thing could result in real harm. That’s why many researchers have built bots using explicit programming: The software pulls from a finite bank of approved responses (as was the case with Eliza, a mock-psychotherapist computer program built in the 1960s). But this makes them less engaging to chat with, and people lose interest. The second issue is that the hallmarks of good therapeutic relationships—shared goals and collaboration—are hard to replicate in software.
In 2019, as early large language models like OpenAI’s GPT were taking shape, the researchers at Dartmouth thought generative AI might help overcome these hurdles. They set about building an AI model trained to give evidence-based responses. They first tried building it from general mental-health conversations pulled from internet forums. Then they turned to thousands of hours of transcripts of real sessions with psychotherapists.
“We got a lot of ‘hmm-hmms,’ ‘go ons,’ and then ‘Your problems stem from your relationship with your mother,’” said Michael Heinz, a research psychiatrist at Dartmouth College and Dartmouth Health and first author of the study, in an interview. “Really tropes of what psychotherapy would be, rather than actually what we’d want.”
Dissatisfied, they set to work assembling their own custom data sets based on evidence-based practices, which is what ultimately went into the model. Many AI therapy bots on the market, in contrast, might be just slight variations of foundation models like Meta’s Llama, trained mostly on internet conversations. That poses a problem, especially for topics like disordered eating.
“If you were to say that you want to lose weight,” Heinz says, “they will readily support you in doing that, even if you will often have a low weight to start with.” A human therapist wouldn’t do that.
To test the bot, the researchers ran an eight-week clinical trial with 210 participants who had symptoms of depression or generalized anxiety disorder or were at high risk for eating disorders. About half had access to Therabot, and a control group did not. Participants responded to prompts from the AI and initiated conversations, averaging about 10 messages per day.
Participants with depression experienced a 51% reduction in symptoms, the best result in the study. Those with anxiety experienced a 31% reduction, and those at risk for eating disorders saw a 19% reduction in concerns about body image and weight. These measurements are based on self-reporting through surveys, a method that’s not perfect but remains one of the best tools researchers have.
These results, Heinz says, are about what one finds in randomized control trials of psychotherapy with 16 hours of human-provided treatment, but the Therabot trial accomplished it in about half the time. “I’ve been working in digital therapeutics for a long time, and I’ve never seen levels of engagement that are prolonged and sustained at this level,” he says.
Jean-Christophe Bélisle-Pipon, an assistant professor of health ethics at Simon Fraser University who has written about AI therapy bots but was not involved in the research, says the results are impressive but notes that just like any other clinical trial, this one doesn’t necessarily represent how the treatment would act in the real world.
“We remain far from a ‘greenlight’ for widespread clinical deployment,” he wrote in an email.
One issue is the supervision that wider deployment might require. During the beginning of the trial, Heinz says, he personally oversaw all the messages coming in from participants (who consented to the arrangement) to watch out for problematic responses from the bot. If therapy bots needed this oversight, they wouldn’t be able to reach as many people.
I asked Heinz if he thinks the results validate the burgeoning industry of AI therapy sites.
“Quite the opposite,” he says, cautioning that most don’t appear to train their models on evidence-based practices like cognitive behavioral therapy, and they likely don’t employ a team of trained researchers to monitor interactions. “I have a lot of concerns about the industry and how fast we’re moving without really kind of evaluating this,” he adds.
When AI sites advertise themselves as offering therapy in a legitimate, clinical context, Heinz says, it means they fall under the regulatory purview of the Food and Drug Administration. Thus far, the FDA has not gone after many of the sites. If it did, Heinz says, “my suspicion is almost none of them—probably none of them—that are operating in this space would have the ability to actually get a claim clearance”—that is, a ruling backing up their claims about the benefits provided.
Bélisle-Pipon points out that if these types of digital therapies are not approved and integrated into health-care and insurance systems, it will severely limit their reach. Instead, the people who would benefit from using them might seek emotional bonds and therapy from types of AI not designed for those purposes (indeed, new research from OpenAI suggests that interactions with its AI models have a very real impact on emotional well-being).
“It is highly likely that many individuals will continue to rely on more affordable, nontherapeutic chatbots—such as ChatGPT or Character.AI—for everyday needs, ranging from generating recipe ideas to managing their mental health,” he wrote.
The AI firm Anthropic has developed a way to peer inside a large language model and watch what it does as it comes up with a response, revealing key new insights into how the technology works. The takeaway: LLMs are even stranger than we thought.
The Anthropic team was surprised by some of the counterintuitive workarounds that large language models appear to use to complete sentences, solve simple math problems, suppress hallucinations, and more, says Joshua Batson, a research scientist at the company.
It’s no secret that large language models work in mysterious ways. Few—if any—mass-market technologies have ever been so little understood. That makes figuring out what makes them tick one of the biggest open challenges in science.
Batson and his colleagues describe their new work in two reports published today. The first presents Anthropic’s use of a technique called circuit tracing, which lets researchers track the decision-making processes inside a large language model step by step. Anthropic used circuit tracing to watch its LLM Claude 3.5 Haiku carry out various tasks. The second (titled “On the Biology of a Large Language Model”) details what the team discovered when it looked at 10 tasks in particular.
“I think this is really cool work,” says Jack Merullo, who studies large language models at Brown University in Providence, Rhode Island, and was not involved in the research. “It’s a really nice step forward in terms of methods.”
Circuit tracing is not itself new. Last year Merullo and his colleagues analyzed a specific circuit in a version of OpenAI’s GPT-2, an older large language model that OpenAI released in 2019. But Anthropic has now analyzed a number of different circuits as a far larger and far more complex model carries out multiple tasks. “Anthropic is very capable at applying scale to a problem,” says Merullo.
Eden Biran, who studies large language models at Tel Aviv University, agrees. “Finding circuits in a large state-of-the-art model such as Claude is a nontrivial engineering feat,” he says. “And it shows that circuits scale up and might be a good way forward for interpreting language models.”
Circuits chain together different parts—or components—of a model. Last year, Anthropic identified certain components inside Claude that correspond to real-world concepts. Some were specific, such as “Michael Jordan” or “greenness”; others were more vague, such as “conflict between individuals.” One component appeared to represent the Golden Gate Bridge. Anthropic researchers found that if they turned up the dial on this component, Claude could be made to self-identify not as a large language model but as the physical bridge itself.
The latest work builds on that research and the work of others, including Google DeepMind, to reveal some of the connections between individual components. Chains of components are the pathways between the words put into Claude and the words that come out.
“It’s tip-of-the-iceberg stuff. Maybe we’re looking at a few percent of what’s going on,” says Batson. “But that’s already enough to see incredible structure.”
Growing LLMs
Researchers at Anthropic and elsewhere are studying large language models as if they were natural phenomena rather than human-built software. That’s because the models are trained, not programmed.
“They almost grow organically,” says Batson. “They start out totally random. Then you train them on all this data and they go from producing gibberish to being able to speak different languages and write software and fold proteins. There are insane things that these models learn to do, but we don’t know how that happened because we didn’t go in there and set the knobs.”
Sure, it’s all math. But it’s not math that we can follow. “Open up a large language model and all you will see is billions of numbers—the parameters,” says Batson. “It’s not illuminating.”
Anthropic says it was inspired by brain-scan techniques used in neuroscience to build what the firm describes as a kind of microscope that can be pointed at different parts of a model while it runs. The technique highlights components that are active at different times. Researchers can then zoom in on different components and record when they are and are not active.
Take the component that corresponds to the Golden Gate Bridge. It turns on when Claude is shown text that names or describes the bridge or even text related to the bridge, such as “San Francisco” or “Alcatraz.” It’s off otherwise.
Yet another component might correspond to the idea of “smallness”: “We look through tens of millions of texts and see it’s on for the word ‘small,’ it’s on for the word ‘tiny,’ it’s on for the word ‘petite,’ it’s on for words related to smallness, things that are itty-bitty, like thimbles—you know, just small stuff,” says Batson.
Having identified individual components, Anthropic then follows the trail inside the model as different components get chained together. The researchers start at the end, with the component or components that led to the final response Claude gives to a query. Batson and his team then trace that chain backwards.
Odd behavior
So: What did they find? Anthropic looked at 10 different behaviors in Claude. One involved the use of different languages. Does Claude have a part that speaks French and another part that speaks Chinese, and so on?
The team found that Claude used components independent of any language to answer a question or solve a problem and then picked a specific language when it replied. Ask it “What is the opposite of small?” in English, French, and Chinese and Claude will first use the language-neutral components related to “smallness” and “opposites”to come up with an answer. Only then will it pick a specific language in which to reply. This suggests that large language models can learn things in one language and apply them in other languages.
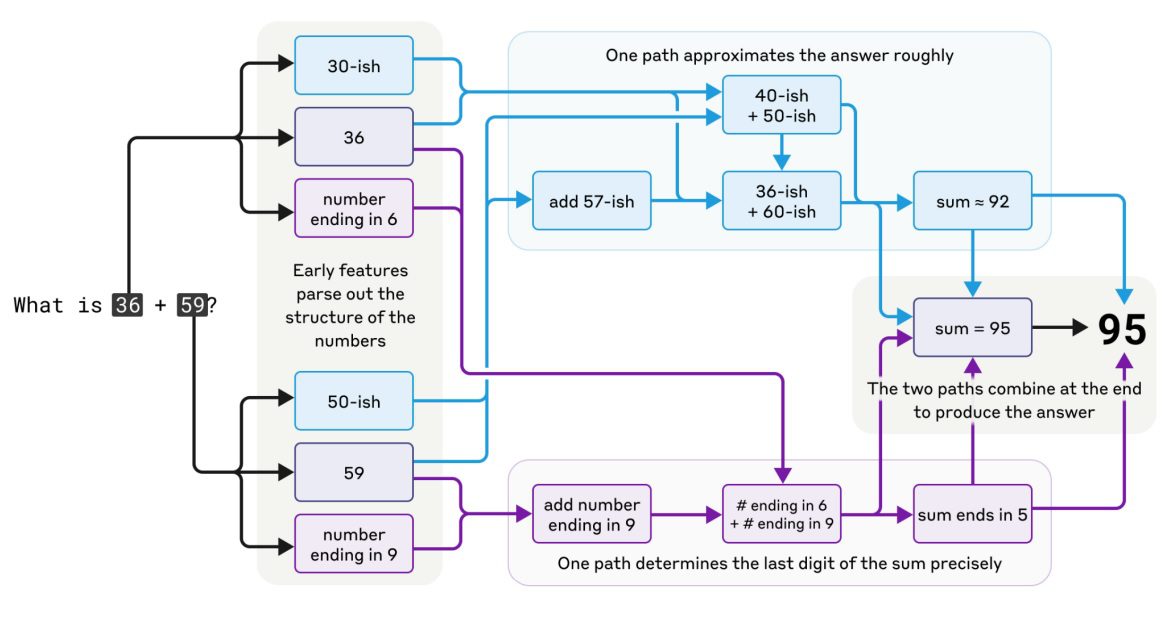
Anthropic also looked at how Claude solved simple math problems. The team found that the model seems to have developed its own internal strategies that are unlike those it will have seen in its training data. Ask Claude to add 36 and 59 and the model will go through a series of odd steps, including first adding a selection of approximate values (add 40ish and 60ish, add 57ish and 36ish). Towards the end of its process, it comes up with the value 92ish. Meanwhile, another sequence of steps focuses on the last digits, 6 and 9, and determines that the answer must end in a 5. Putting that together with 92ish gives the correct answer of 95.
And yet if you then ask Claude how it worked that out, it will say something like: “I added the ones (6+9=15), carried the 1, then added the 10s (3+5+1=9), resulting in 95.” In other words, it gives you a common approach found everywhere online rather than what it actually did. Yep! LLMs are weird. (And not to be trusted.)
The steps that Claude 3.5 Haiku used to solve a simple math problem were not what Anthropic expected—they’re not the steps Claude claimed it took either.
ANTHROPIC
This is clear evidence that large language models will give reasons for what they do that do not necessarily reflect what they actually did. But this is true for people too, says Batson: “You ask somebody, ‘Why did you do that?’ And they’re like, ‘Um, I guess it’s because I was— .’ You know, maybe not. Maybe they were just hungry and that’s why they did it.”
Biran thinks this finding is especially interesting. Many researchers study the behavior of large language models by asking them to explain their actions. But that might be a risky approach, he says: “As models continue getting stronger, they must be equipped with better guardrails. I believe—and this work also shows—that relying only on model outputs is not enough.”
A third task that Anthropic studied was writing poems. The researchers wanted to know if the model really did just wing it, predicting one word at a time. Instead they found that Claude somehow looked ahead, picking the word at the end of the next line several words in advance.
For example, when Claude was given the prompt “A rhyming couplet: He saw a carrot and had to grab it,” the model responded, “His hunger was like a starving rabbit.” But using their microscope, they saw that Claude had already hit upon the word “rabbit” when it was processing “grab it.” It then seemed to write the next line with that ending already in place.
This might sound like a tiny detail. But it goes against the common assumption that large language models always work by picking one word at a time in sequence. “The planning thing in poems blew me away,” says Batson. “Instead of at the very last minute trying to make the rhyme make sense, it knows where it’s going.”
“I thought that was cool,” says Merullo. “One of the joys of working in the field is moments like that. There’s been maybe small bits of evidence pointing toward the ability of models to plan ahead, but it’s been a big open question to what extent they do.”
Anthropic then confirmed its observation by turning off the placeholder component for “rabbitness.” Claude responded with “His hunger was a powerful habit.” And when the team replaced “rabbitness” with “greenness,”Claude responded with “freeing it from the garden’s green.”
Anthropic also explored why Claude sometimes made stuff up, a phenomenon known as hallucination. “Hallucination is the most natural thing in the world for these models, given how they’re just trained to give possible completions,” says Batson. “The real question is, ‘How in God’s name could you ever make it not do that?’”
The latest generation of large language models, like Claude 3.5 and Gemini and GPT-4o, hallucinate far less than previous versions, thanks to extensive post-training (the steps that take an LLM trained on the internet and turn it into a usable chatbot). But Batson’s team was surprised to find that this post-training seems to have made Claude refuse to speculate as a default behavior. When it did respond with false information, it was because some other component had overridden the “don’t speculate” component.
This seemed to happen most often when the speculation involved a celebrity or other well-known entity. It’s as if the amount of information available pushed the speculation through, despite the default setting. When Anthropic overrode the “don’t speculate” component to test this, Claude produced lots of false statements about individuals, including claiming that Batson was famous for inventing the Batson principle (he isn’t).
Still unclear
Because we know so little about large language models, any new insight is a big step forward. “A deep understanding of how these models work under the hood would allow us to design and train models that are much better and stronger,” says Biran.
But Batson notes there are still serious limitations. “It’s a misconception that we’ve found all the components of the model or, like, a God’s-eye view,” he says. “Some things are in focus, but other things are still unclear—a distortion of the microscope.”
And it takes several hours for a human researcher to trace the responses to even very short prompts. What’s more, these models can do a remarkable number of different things, and Anthropic has so far looked at only 10 of them.
Batson also says there are big questions that this approach won’t answer. Circuit tracing can be used to peer at the structures inside a large language model, but it won’t tell you how or why those structures formed during training. “That’s a profound question that we don’t address at all in this work,” he says.
But Batson sees this as the start of a new era in which it is possible, at last, to find real evidence for how these models work: “We don’t have to be, like: ‘Are they thinking? Are they reasoning? Are they dreaming? Are they memorizing?’ Those are all analogies. But if we can literally see step by step what a model is doing, maybe now we don’t need analogies.”
Separating AI reality from hyped-up fiction isn’t always easy. That’s why we’ve created the AI Hype Index—a simple, at-a-glance summary of everything you need to know about the state of the industry.
While AI models are certainly capable of creating interesting and sometimes entertaining material, their output isn’t necessarily useful. Google DeepMind is hoping that its new robotics model could make machines more receptive to verbal commands, paving the way for us to simply speak orders to them aloud. Elsewhere, the Chinese startup Monica has created Manus, which it claims is the very first general AI agent to complete truly useful tasks. And burnt-out coders are allowing AI to take the wheel entirely in a new practice dubbed “vibe coding.”