In a dimly lit bedroom, a frightened young woman is thrown onto a bed by a tall, muscular man. He grabs her hand, and flame-like vines crawl across her body, fusing with her flesh. She levitates, then drops. A dragon-shaped tattoo appears across her chest.
“Two months,” the man says. “Give me an heir, or I will eat you.”
The scene is from Carrying the Dragon King’s Baby, one of the many hundreds of short dramas that appear on apps like DramaWave and ReelShort. There’s just something about this one that isn’t quite right. The lighting may be glossy and cinematic, but the show has an odd visual texture like something between a movie and a video game cutscene.
That’s because Carrying the Dragon King’s Baby is part of a new trend for making these shows entirely with AI: no actors, camera operators, cinematographers, or CGI specialists required.
China’s short drama industry has boomed since its launch, in 2018. These ultrashort, melodramatic, and often smutty shows are designed for smartphone viewing, with episodes often running just one or two minutes long: Viewers can finish an entire series in as little as 30 minutes to an hour. The films are made for endless scrolling, packed with emotional confrontations and melodramatic plot twists. The trend’s growth is driven by apps that bombard TikTok, Instagram, and Facebook with cliffhanger-heavy ads designed to lure viewers into buying subscriptions. In 2024, China’s short drama market reached roughly $6.9 billion in revenue, surpassing the country’s annual box office earnings for the first time.
Since 2022, Chinese short drama companies have aggressively expanded overseas, translating existing hits and producing localized series featuring local actors. Globally, short drama apps have approached a billion cumulative downloads. The United States is the biggest market outside of China, providing around 50% of the revenue, according to research firm DataEye.
Now the industry is reinventing itself. Chinese short drama companies—already masters of low-budget, algorithmically optimized entertainment—are embracing generative AI to produce content faster and cheaper than ever. An average of 470 AI-generated short dramas were released every day in January, according to DataEye. Short-drama companies like Kunlun Tech are ramping up AI productions, shrinking film crews, and reorganizing the labor pipeline from the ground up. For some studios, AI has moved from being a supporting tool to providing the backbone of production itself.
Infinite stories, infinite tropes
Short dramas are already famously low-budget. But AI has made them dramatically cheaper to mass-produce, helping to accelerate the entire process—and save money. Production timelines have collapsed. Conceptualization, script writing, casting, shooting, and editing used to take three to four months. With AI, the process can now take less than a month, says Tang Tang, vice president at short-drama platform FlexTV. Producing a short drama in North America once cost roughly $200,000, but AI can cut that cost by 80% to 90%, according to Tang.
After expanding into the US market, Chinese short drama companies largely followed the same playbook they used in China: Buy traffic aggressively on TikTok, Facebook, and YouTube; offer a handful of free episodes; then charge viewers to unlock the rest inside the companies’ apps. Decisions about what to produce next are often driven less by creative instinct than by performance data. “We look at what themes, plotlines, and writers resonate with audiences, then quickly adjust,” says Tang.
The industry operates at a relentless pace. “Everyone expects quick returns,” Tang says. “In China, if a series doesn’t break even within a month, the industry considers it a failure.”
As a result, screenwriters who spoke with MIT Technology Review said platforms often categorize projects using highly specific keywords that encompass everything from genre and setting to plot structure, such as “campus romance,” “gang rivalry,” “enemies to lovers,” or “rags to riches.” Recently, one of the most popular genres has been “reborn revenge,” a fantasy trope in which a wronged protagonist is miraculously reborn and given a chance to change their fate.
“You kind of have to keep the emotional intensity extremely high throughout the show, using the same plot devices over and over again: sudden deaths, betrayals, physical violence, huge confrontations,” says Phoenix Zhu, a freelance short drama screenwriter based in Suzhou. “It’s common to sacrifice narrative logic for shock value, because otherwise people are more likely to scroll away.”
Those simple tropes have made the format particularly compatible with AI-generated production. Earlier this year, FlexTV halted all traditionally shot productions and shifted entirely to AI-generated dramas. Kunlun Tech, the parent company of drama apps DramaWave and FreeReels, began producing AI-generated short dramas in 2025 and now offers more than 1,000 AI titles on its platforms. StoReels, another popular short drama company targeting a global audience, has said it aims to produce 100 AI-generated dramas per month.
“People’s attention spans are getting shorter, and serialized drama naturally has to get shorter,” says Han “Daniel” Fang, the CEO of Kunlun Tech. Fang told MIT Technology Review that the company is not going to stop investing in traditionally shot short dramas with real actors. But the company is expanding AI-generated productions and gradually increasing their share on its platforms as a low-cost way to experiment with new genres, themes, and ideas. “We want to bring the amount of AI work to 20% of the platform,” Fang says.
The format is also rapidly growing overseas. Research firm Omdia estimates that the global microdrama market reached $11 billion in 2025 and will grow to $14 billion by the end of 2026. The United States is expected to generate $1.5 billion in revenue in that market this year.
“No one comes to short dramas expecting high art,” says investor Shangguan Hong, former partner of Legend Capital. “The short-drama industry already stands out from traditional TV and filmmaking by being real-time and data-driven. AI only furthers that logic. In a sense, short drama is perfectly compatible with AI.”
Inside the content machine
The industry’s AI revolution is already changing the type of roles required to make short dramas.
Phoenix Zhu graduated from college in 2024 with a degree in philosophy. After months of rejections from traditional media and film studios, she eventually found work writing scripts for short dramas. “It was a very difficult job market for young people,” Zhu says. “I couldn’t afford to be picky about what I wrote.”
To support herself, Zhu worked a string of part-time jobs, including as a barista, a flower seller, and an event coordinator, while taking freelance writing gigs online for advertising and education companies. In April 2025, she sold her first short-drama script for around 20,000 yuan (approximately $2,945). More commissions followed, and she thought her career was finally beginning to pick up.
Then AI arrived. Two projects already in the contract stage were abruptly canceled, Zhu says. Rates across the industry began falling. The raises she expected as she gained more experience never materialized.
Still, writers like Zhu have been among the less disrupted workers in the industry. Many production roles on traditional filming sets have disappeared almost entirely from AI-generated productions.
“We could shrink the production team down to around 10 people,” says Tang, vice president at FlexTV. Like many companies in the industry, FlexTV relies primarily on Chinese writers and production teams, even for shows featuring non-Chinese characters and targeting overseas audiences. The reason is not just lower costs, Tang says, but also that Chinese writers better understand the pacing and narrative rhythm of short dramas.
Instead of camera crews, lighting technicians, makeup artists, and visual effects teams, AI productions now rely on smaller groups consisting largely of producers, writers, AI directors, and “AI asset curators.”
An AI asset curator translates scripts into prompts and generates reference images of characters, costumes, and scenes for AI video models to follow. MIT Technology Review found hundreds of job listings for the role on Chinese job sites, many requiring little prior industry experience beyond familiarity with AI tools.
“The technology has improved enormously just in the past few months,” says Hanzhong Bai, an AI short-drama producer based in Beijing. Bai says it is common for AI asset curators to use prompts like “combine the faces of these celebrities I like” when generating characters. Studios typically use a mix of tools, including Google’s image-generation model Nano Banana, ByteDance’s Seedance, and Kuaishou’s Kling.
For producers like Bai, AI also makes it economically viable to produce genres that were previously too expensive for short dramas, especially fantasy series requiring elaborate visual effects, costumes, or makeup. “We’ll see many more dragon and mermaid shows for exactly this reason,” Bai says.
The compressed production cycle has also changed the writing process itself. Writers once had two to three months to finish a script. Now, Zhu says, platforms often expect delivery within a month. Scripts can also be rougher and more flexible, since scenes, visuals, and even plot details can be changed later through prompts.
As a result, writers increasingly have to write for AI models as much as for human audiences. Zhu says she now has to describe scenes with far greater visual specificity, effectively taking on responsibilities once handled by cinematographers or visual effects teams.
“Before AI, writing ‘He gave her a cold stare’ might have been enough,” Zhu says. “Now I might need to write, ‘Cold beams of light shot out from his eyes.’”
Fang of Kunlun Tech believes the future quality of AI-generated short dramas is ultimately a numbers game. “Good ideas and good writing still stand out,” Fang says. “The quality [of AI short drama] will improve simply because more people with strong ideas will be able to make their shows.”
In the final week of the Musk v. Altman trial, lawyers traded blows over Elon Musk’s and OpenAI CEO Sam Altman’s credibility. Altman was grilled on his alleged history of lying and self-dealing involving companies that do business with OpenAI. But he fired back, painting Musk as a power-seeker who wanted to control the development of artificial general intelligence (AGI)—powerful AI that can compete with humans on most cognitive tasks.
As evidence of their commitment to AI safety, OpenAI brought out a golden trophy of a donkey’s ass that was gifted to an employee after he was called a “jackass” for standing up to Musk’s plans to race toward AGI.
Lawyers for both sides also presented their closing arguments, floating unflattering mugshot-style photos of Musk and Altman next to each other on a giant screen. Musk’s lawyer Steven Molo argued that Altman and OpenAI president Greg Brockman broke their promise to use money Musk donated to maintain OpenAI as a nonprofit that develops AI for the benefit of humanity. Instead, they created a for-profit subsidiary that made them extraordinarily wealthy.
OpenAI’s lawyer Sarah Eddy argued that Altman and Brockman never promised to keep OpenAI a nonprofit. She added that even though it’s been restructured, OpenAI remains a nonprofit dedicated to developing AI safely.
She claimed that Musk sued too late—and that his real motive is to sabotage a competitor to his own AI company, xAI, which he launched in 2023.
Musk is asking the court to unwind the 2025 restructuring that converted OpenAI’s for-profit subsidiary into a public benefit corporation and to remove Altman and Brockman from their roles. He is also seeking as much as $134 billion in damages from OpenAI and Microsoft, to be awarded to OpenAI’s nonprofit.
The jury will begin deliberating on Monday and deliver an advisory verdict as soon as next week. The jury verdict is not binding on the judge, who will decide the case.
If the judge rules in Musk’s favor, it could upend OpenAI’s race toward an IPO at a valuation approaching $1 trillion. Meanwhile, xAI is expected to go public as a part of Musk’s rocket company SpaceX as early as June, at a target valuation of $1.75 trillion.
Musk the power-seeker, Altman the liar.
In the first week of the trial, Musk said he was suing to save OpenAI’s mission to build AI safely for the benefit of humanity. This week, Altman denied Musk was a paladin of AI safety and painted him as a power-seeker who wanted to control OpenAI.
Altman told the jury that in 2017, when Musk and other cofounders were discussing creating a for-profit arm, they asked Musk what would happen to his control over such an entity if he died. “Maybe the control of OpenAI should pass to my children,” Musk said, according to Altman.
Musk’s lawyer shot back, grilling Altman on his alleged history of lying. He pointed out that OpenAI’s former executives Ilya Sutskever and Mira Murati, and former board members Helen Toner and Tasha McCauley, all testified that Altman had lied to them. In 2023, Altman was briefly fired as CEO over the alleged behavior.
Molo also pressed Altman about his personal investments in startups that do business with OpenAI. Altman testified that he tried to steer OpenAI to buying power from the nuclear energy company Helion Energy, a third of which he owns.
(Last Friday, the US House oversight committee launched an investigation into Altman’s potential conflicts of interest. Attorneys general from more than a half-dozen states called for the Securities and Exchange Commission to review them.)
During his closing statement, Molo put Altman’s credibility on the stand again. “Imagine that you’re on a hike, and you come upon one of those wooden bridges that you see on a trail, and it’s over a gorge,” he said. “A woman standing by the entry to the bridge says, ‘Don’t worry—the bridge is built on Sam Altman’s version of the truth.’ Would you walk across that bridge?”
Altman, who sat behind his lawyers, looked up uneasily every time his name was mentioned.
During her closing argument, Eddy fired back. Musk “never cared about the nonprofit structure,” she said. “What he cared about was winning.”
Musk, though, was absent. Despite the judge’s order that he remain available, he flew to China with President Trump.
Did Altman promise to keep OpenAI a nonprofit?
During her closing argument, Eddy argued that no testimony or evidence showed any conditions on Musk’s donations, or any promises made by Altman and Brockman to keep the company a nonprofit. “No commitments or promises were made. No restrictions were placed on Mr. Musk’s donations,” she said.
Eddy added that it was evident Musk wasn’t truly committed to keeping OpenAI a nonprofit. She noted that in 2017, he tried to create a for-profit subsidiary and fought a bitter battle with Altman and Brockman to have control over it.
“I was not opposed to there being a small for-profit that provides funding to the nonprofit,” Musk told the jury earlier in the trial, “as long as the tail didn’t wag the dog.”
Eddy then argued that Musk sued too late, filing in 2024 after the statutes of limitations on his claims ran out. In 2019, OpenAI created a for-profit subsidiary, under which employees and investors received a capped return on their investment.
But Musk testified that he discovered OpenAI had abandoned its nonprofit mission only in 2022, when Microsoft was preparing to invest $10 billion in OpenAI—a deal that closed in 2023. “I was disturbed to see OpenAI with a $20B valuation,” he texted Altman after reading the news. “This is a bait and switch.”
Musk told the jury that the $20 billion valuation made him realize “the for-profit is the tail wagging the dog.”
“The 2023 deal was different,” Molo hammered home during his closing argument.
Is OpenAI still a nonprofit committed to its mission?
A central question raised in the last week of trial was whether OpenAI remains a nonprofit committed to developing AGI safely for the benefit of humanity. Eddy, the OpenAI lawyer, argued that the nonprofit still controls the for-profit and seeks to “help AGI turn out well for humanity.” “The OpenAI nonprofit is the best-resourced nonprofit in the world,” thanks to the for-profit, she added.
Molo countered that while the OpenAI’s nonprofit nominally controls the company, it does not do so in practice. OpenAI’s nonprofit and for-profit are controlled by the same people—seven of the nonprofit’s eight board members are on the for-profit’s board. The nonprofit hired employees only a month before the trial started and does work only in grant-making rather than AI research.
Molo played a video interview of Altman saying that the nonprofit board’s failure to fire him in 2023 was “its own kind of governance failure.”
“We’re left with this nonprofit that doesn’t have any voice,” Jill Horwitz, a law professor at Northwestern University who studies nonprofits, told MIT Technology Review. “It doesn’t have much money, and OpenAI doesn’t think it has any obligation to fund it. It barely has a staff,” she says. “It’s unclear how on earth the nonprofit is supposed to exercise its duties and control the entire company.”
Civil society groups and policymakers have spoken out against OpenAI’s restructuring over the years. So has Musk, although his own stake in the AI race makes him a dubious champion for the public interest.
“The public interest in the nonprofit loses, no matter who wins or loses this trial,” says Horwitz.
Jackass for AI safety
Despite US District Judge Yvonne Gonzalez Rogers’s warning during the first week that this trial was not about AI safety, the issue stole the show again. Throughout the trial, the lawyers from both sides traded barbs over the safety track records of ChatGPT (which has allegedly caused teen suicides) and Grok (which has flooded X with porn).
On the last day of testimony, OpenAI’s lawyer Bradley Wilson handed the judge a small golden trophy of a donkey’s ass, inscribed: “Never stop being a jackass for safety.”
The trophy belonged to Joshua Achiam, OpenAI’s chief futurist. He testified that he’d warned, when Musk announced in 2018 that he was leaving OpenAI to race toward building AGI, that speed could compromise safety. Musk snapped and called him a “jackass,” said Achiam. His colleagues, including Dario Amodei, now CEO of Anthropic, gave him the trophy to enshrine the diss.
“I don’t want it,” said the judge. The shenanigans spilled out into the street too. In front of the Oakland courthouse, a protester paraded around wearing a costume of Musk holding a bag of ketamine and driving a Cybertruck. Another held a photo of Sam Altman and a poster reading, “Stop AGI or we’re all gonna die.”
When Jennifer got a job doing research for a nonprofit in 2023, she ran her new professional headshot through a facial recognition program. She wanted to see if the tech would pull up the porn videos she’d made more than 10 years before, when she was in her early 20s. It did in fact return some of that content, and also something alarming that she’d never seen before: one of her old videos, but with someone else’s face on her body.
“At first, I thought it was just a different person,” says Jennifer, who is being identified by a pseudonym to protect her privacy.
But then she recognized a distinctly garish background from a video she’d shot around 2013, and she realized: “Somebody used me in a deepfake.”
Eerily, the facial recognition tech had identified her because the image still contained some of Jennifer’s features—her cheekbones, her brow, the shape of her chin. “It’s like I’m wearing somebody else’s face like a mask,” she says.
“It’s like I’m wearing somebody else’s face like a mask.”
Conversations about sexualized deepfakes—which fall under the umbrella of nonconsensual intimate imagery, or NCII—most often center on the people whose faces are featured doing something they didn’t really do or on bodies that aren’t really theirs. These are often popular celebrities, though over the past few years more people (mostly women and sometimes youths) have been targeted, sparking alarm, fear, and even legislation. But these discussions and societal responses usually are not concerned with the bodies the faces are attached to in these images and videos.
As Jennifer, now 37 and a psychotherapist working in New York City, says: “There’s never any discussion about Whose body is this?”
For years, the answerhas generally been adult content creators. Deepfakes in fact earned their name back in November 2017, when someone with the Reddit username “deepfakes” uploaded videos showing faces of stars like Scarlett Johansson and Gal Gadot pasted onto porn actors’ bodies. The nonconsensual use of their bodies “happens all the time” in deepfakes, says Corey Silverstein, an attorney specializing in the adult industry.
But more recently, as generative AI has improved, and as “nudify” apps have begun to proliferate, the issue has grown far more complicated—and, arguably, more dangerous for creators’ futures.
Porn actors’ bodies aren’t necessarily being taken directly from sexual images and videos anymore, or at least not in an identifiable way. Instead, they are inevitably being used as training data to inform how new AI-generated bodies look, move, and perform. This threatens the livelihood and rights of porn actors as their work is used to train AI nudes that in turn could take away their business. And that’s not all: Advancements in AI have also made it possible for people to wholly re-create these performers’ likenesses without their consent, and the AI copycats may do things the performers wouldn’t do in real life. This could mean their digital doubles are participating in certain sex acts that they haven’t agreed to do, or even perpetrating scams against fans.
Adult content creators are already marginalized by a society that largely fails to protect their safety and rights, and these developments put them in an even more vulnerable position. After Jennifer found the deepfake featuring her body, she posted on social media about the psychological effects: “I’ve never seen anyone ask whether that might be traumatic for the person whose body was used without consent too. IT IS!” Several other creators I spoke with shared the mental toll that comes with knowing their bodies have been used nonconsensually, as well as the fear that they’ll suffer financially as other people pirate their work. Silverstein says he hears from adult actors every day who “are concerned that their content is being exploited via AI, and they’re trying to figure out how to protect it.”
One law professor and expert in violence against women calls these creators the “forgotten victims” of NCII deepfakes. And several of the people I spoke with worry that as the US develops a legal framework to combat nonconsensual sexual content online, adult actors are only at risk of further injury; instead of helping them, the crackdown on deepfakes may provide a loophole through which their content and careers could be stripped from the internet altogether.
How deepfakes cause “embodied harms”
During his preteen years in the 1970s, Spike Irons, now a porn actor and president of the adult content platform XChatFans, was “in love” with Farrah Fawcett. Though Fawcett did not pose nude, Jones managed to get his hands on what looked like pictures of her naked. “People were cutting out faces and pasting them on bodies,” Irons says. “Deepfakes, before AI, had been going around for quite a while. They just weren’t as prolific.”
The early public internet was rife with websites capitalizing on the idea that you could use technology to “see” celebrities naked. “People would just use Microsoft Paint,” says Silverstein, the attorney. It was a simple way to mash up celebrities’ faces with porn.
People later used software like Adobe After Effects or FakeApp, which was designed to swap two individuals’ faces in images or videos. None of these programs required serious expertise to alter content, so there was a low barrier to entry. That, plus the wealth of porn performers’ videos online, helped make face-swap deepfakes that used real bodies prevalent by the 2010s. When, later in the decade, deepfakes of Gal Gadot and Emma Watson caused something of a broader panic, their faces were allegedly swapped onto the bodies of the porn actors Pepper XO and Mary Moody, respectively.
But it wasn’t just high-profile actors like them whose bodies were being used. Jennifer was “a very minor performer,” she says. “If it happened to me, I feel like it could happen to anybody who’s shot porn.” Since he started his practice in 2006, Silverstein says, “numerous clients” have reached out to report “This is my body on so-and-so.”
Both people whose faces appear in NCII deepfakes and those whose bodies are used this way can feel serious distress. Experts call this type of damage “embodied harms,” says Anne Craanen, who researches gender-based violence at the UK’s Institute for Strategic Dialogue, an organization that analyzes extremist content, disinformation, and online threats.
The term reflects the fact that even though the content exists in the virtual realm, it can cause physiological effects, including body dysmorphia. The face-swapped entity occupies the uncanny valley, distorting self-perception. After discovering their faces in sexual deepfakes, many people feel silenced, experts told me; they may “self-censor,” as Craanen puts it, and step back from public-facing life. Allison Mahoney, an attorney who works with abuse survivors, says that people whose faces appear in NCII can experience depression, anxiety, and suicidal ideation: “I’ve had multiple clients tell me that they don’t sleep at night, that they’re losing their hair.”
Independent creators aren’t just “having sex on camera.” For someone to rip off their work “for their own entertainment or financial gain fucking sucks.”
Though the impact on people whose bodies are used hasn’t been discussed or studied as often, Jennifer says that “it’s just a really terrible feeling, knowing that you are part of somebody else’s abuse.” She sees it as akin to “a new form of sexual violence.”
The uncertainty that comes with not being aware of what your body is doing online can be highly unsettling. Like Jennifer, many adult actors don’t really know what’s out there. But some devoted followers know the actors’ bodies well—often recognizing tattoos, scars, or birthmarks—and “very quickly they bring [deepfakes] to the adult performer’s attention,” says Silverstein. Or performers will stumble upon the content by chance; some 20 years ago, for instance, the first such client to tell Silverstein her body was being used in a deepfake happened to be searching Nicole Kidman online when she found that one of the results showed Kidman’s face on her porn. “She was devastated, obviously, because they took her body,” he says, “and they were monetizing it.”
Otherwise, this imagery may be found by an organization like Takedown Piracy, one of several copyright enforcement companies serving adult content creators. US copyright violations can be challenging to prove if someone’s body lacks distinguishing features, says Reba Rocket, Takedown Piracy’s chief operating and marketing officer. But Rocket says her team has added digital fingerprinting technology to clients’ material to help flag and remove problematic videos, often finding them before clients realize they’re online.
By capturing “tens of thousands of tiny little visual data points” from videos, digital fingerprinting creates unique corresponding files that can be used to identify them, Rocket says—kind of like an invisible watermark. The prints remain even if pirates alter the videos or replace performers’ faces. Takedown Piracy has digitally fingerprinted more than half a billion videos and the organization has gotten 130 million copyrighted videos taken down from Google alone (though, of those videos, Rocket hasn’t tracked how many of these specifically include someone else’s face on a performer’s body).
Besides copyright, a range of legal tools can be used to try to combat NCII, says Eric Goldman, a law professor at Santa Clara University. For example, victims can claim invasion of privacy. But using these tools isn’t particularly straightforward, and they may not even apply when it comes to someone’s body. If there aren’t, for instance, unique markers indicating that a body in a deepfake belongs to the person who says it does, US law “doesn’t really treat [this content] as invasion of privacy,” Goldman says, “because we don’t know who to attribute it to.”
In a 2018 study that reviewed “judicial resolution” of cases involving NCII, Goldman found that one successful way plaintiffs were able to win cases was to assert “intentional affliction of emotional distress.” But again, that hinges on the ability to clearly identify the person in the content. Relevant statutes, he adds, might also require “intent to harm the individual,” which may be hard to show for people whose bodies alone are featured.
“AI girls will do whatever you want”
In the last few years, Silverstein says, it’s become less and less common to see the bodies of real adult content creators in deepfakes, at least in a way that makes them clearly identifiable.
Sometimes the bodies have been manipulated using AI or simpler editing tools. This can be as basic as erasing a birthmark or changing the size of a body part—minor edits that make it impossible to identify someone’s image beyond a reasonable doubt, so even porn actors who can tell that an altered image used their body as a base won’t get very far in the legal realm. “A lot of people are like, That looks like my body,” says Silverstein, but when he asks them how, they’ll reply, It just does.
At the same time, other users are now creating NCII with wholly AI-generated bodies. In “nudify” apps, anyone with a minimal grasp of technology can upload a photo of someone’s clothed body and have it replaced with a fake naked one. “So [much] of this content being created is just someone’s face on an AI body,” Silverstein says.
Such apps have drawn a ton of attention recently, in incidents from Grok’s “nudifying” minors to Meta’s running ads for—and then suing—the nudify app Crushmate. But there’s been relatively little attention paid to the content being used to train them. They almost certainly draw on the more than 10,000 terabytes of online porn, and performers have virtually zero recourse.
One reason is that creators aren’t able to demonstrate with any certainty that their content is being used to train AI models like those used by nudify apps. “These things are all a black box,” says Hany Farid, a professor at the University of California, Berkeley, who specializes in digital forensics. But “given the ubiquity” of adult content, he adds, it’s a “reasonable assumption” that online porn is being used in AI training.
“It’s just not at all difficult to come up with pornographic data sets on the internet,” says Stephen Casper, a computer science PhD student at MIT who researches deepfakes. What’s more, he says, plenty of shadowy online communities provide “user guides” on how to use this data to train AI, and in particular programs that generate nudes.
It’s not certain whether this activity falls within the US legal definition of “fair use”—an issue that’s currently being litigated in several lawsuits from other types of content creators—but Casper argues that even if it does, it’s ethically murky for porn created by consenting adults 10 years ago to wind up in those training data sets. When people “have their stuff used in a way that doesn’t respect or reflect reasonable expectations that they had at that time about what they were creating and how it would be used,” he says, there’s “a legitimate sense in which it’s kind of … nonconsensual.”
Adult performers who started working years ago couldn’t possibly have consented to AI anything; Jennifer calls AI-related risks “retroactively placed.” Contracts that porn actors signed before AI, adds Silverstein, might provide that “the publisher could do anything with the content using technology that now exists or here and after will be discovered.” That felt more innocuous when producers were talking about the shift from VHS to DVD, because that didn’t change the content itself, just the way it was conveyed. It’s a far different prospect for someone to use your content to train a program to create new content … content that could replace your work altogether.
Of course, this all affects creators’ bottom line—not unlike the way Google’s AI overviews affect revenue for online publishers who’ve stopped getting clicks when people are content with just reading AI-generated summaries. Performers’ “concern is … it’s another way to pirate [their] content,” says Rocket.
After all, independent creators aren’t just “having sex on camera,” as the adult content creator Allie Eve Knox puts it. They’re paying for filming equipment and location rentals, and then spending hours editing and marketing. For someone to then rip off and distort that content “for their own entertainment or financial gain,” she says, “fucking sucks.”
KIM HOECKELE
Tanya Tate, a longtime adult content creator, tells me about another highly unsettling AI-created situation: She was recently chatting with a fan on Mynx, a sexting app, when he asked her if she knew him. She told him no, and “his eyes just started watering,” Tate says. He was upset because he thought she did know him. Turns out he’d sent $20,000 to a scammer who’d used an AI-generated deepfake of Tate to seduce him.
Several men, Tate subsequently learned, had been scammed by an AI version of her, and some of them began blaming her for their losses and posting false statements about her online. When she reported one particularly aggressive harasser to the police, they told her he was exercising his “freedom of speech,” she says. Rocket, too, is familiar with situations where AI is used to take advantage of fans. “The actual content creator will get nasty emails from these people who’ve been scammed,” she says.
Other porn actors say they fear that their likenesses have been used without consent to do other things they wouldn’t do. One, Octavia Red, tells me she doesn’t do anal scenes, “but I’m sure there’s tons of deepfake anal videos of me that I didn’t consent to.” That could cost her, she fears, if viewers choose to watch those videos instead of subscribing to her websites. And it could cause fans to develop false expectations about what kind of porn she’ll create.
“I saw one AI creator saying, ‘Well, AI girls will do whatever you want. They don’t say no,’” says Rocket. “That horrifies me … especially if they’re training those AI models on real people. I don’t think they understand the damage to mental health or reputation that that can create. And once it’s on the internet, it’s there forever.”
Efforts to “scrub adult content from the internet”
As AI technology improves, it’s increasingly difficult for people to discern any type of real video from the best AI-generated ones on their own. In one 2025 study, UC Berkeley’s Farid found that participants correctly identified AI-generated voices about 60% of the time (not much better than random chance), while advances like false heartbeats make AI-generated humans tougher than ever to spot.
Nevertheless, most lawyers and legal experts I spoke with said copyright laws are still adult performers’ best bet in the US legal system, at least for getting their face-swapped content taken down. For his clients, Silverstein says, he tries to figure out the content’s origins and then issue takedown requests under the Digital Millennium Copyright Act, a 1998 law that adapted copyright law for the internet era. “Even recently, I had a performer who has an insanely well-known tattoo,” he says, and with a DMCA subpoena he managed to identify the poster of the content, who voluntarily removed it.
But this way of working is becoming increasingly rare.
These days it’s nearly “impossible,” Silverstein says, to determine who produced a deepfake, because many platforms that host pirated content operate facelessly. They’re also often based in places that “don’t really care about US law when it comes to copyrights,” says Rocket—places like Russia, the Seychelles, and the Netherlands.
While governments in the EU, the UK, and Australia have said they will ban or restrict access to nudify apps, it’s not an easily executed proposition. As Craanen notes, when app stores remove these services, they often simply reappear under different names, providing the same services. And social platforms where people share NCII deepfakes, argues Rocket, are slacking in getting them removed. “It’s endless, and it’s ridiculous, because places like Twitter and Facebook have the same technology we do,” Rocket says. “They can identify something as an infringement instantly, but they choose not to.”
(An Apple spokesperson, Adam Dema, said in an email that “’nudification’ apps are against our guidelines” in the app store, and it has “proactively rejected many of these apps and removed many others,” flagging a reporting portal for users. A Google spokesperson emailed, “Google Play does not allow apps that contain sexual content,” noting that the company takes “proactive steps to detect and remove apps with harmful content” and has suspended hundreds of apps for violating its policy. A Meta spokesperson shared a blog post about actions that company has taken against nudify apps but did not respond to follow-up questions about copyrighted material. X did not respond to a request for comment.)
As porn performers are forced to navigate AI-related threats, the only current federal law to address deepfakes may not help them much—and could even make matters worse. The Take It Down Act, which became US law last year, criminalizes publishing NCII and requires websites to remove it within 48 hours. But, as Farid notes, people could weaponize the measure by reporting porn that was made legally and with consent and claiming that it’s NCII. This could result in the content’s removal, which would hurt the performers who made it. Santa Clara’s Goldman points to Project 2025, the Heritage Foundation’s policy blueprint for the second Trump administration, which aims to wipe porn from the web. The Take It Down Act, he argues, “allows for the coordinated effort to scrub adult content from the internet.”
US lawmakers have a history of hurting sex workers in their attempts to regulate explicit content online. State-level age verification laws are an example; visitors can pretty easily get around these measures, but they can still result in reduced revenue for adult performers (because of lower traffic to those sites and the high price of age-checking services they have to purchase).
“They’re always doing something to fuck with the porn industry, but not in a way that actually helps sex workers,” says Jennifer. “If they do something, they’re taking away your income again—as opposed to something like giving you more rights to your image, [which] would be tremendously helpful.”
But as generative AI plays an increasingly large role in NCII deepfakes, the types of images to which adult performers have rights moves deeper into a gray area. Can actors lay claim to AI images likely trained on their bodies? How about AI-generated videos that impersonate them, like the one that tricked Tanya Tate’s fan?
The biggest challenge will be creating “legitimate, effective laws that will absolutely protect content creators from abusing their likeness to train and create AI,” Rocket says. “Absent that, we’re just going to have to keep pulling content down from the internet that’s fake.”
In the meantime, a few porn actors tell me, they’re trying to take advantage of copyright laws that weren’t really made for them; they’ve signed with platforms that host their AI-generated duplicates, with whom fans pay to chat, in part so they’ll have contracts that protect ownership of their AI likenesses. When I spoke with the actor Kiki Daire in September 2025 for a story on adult creators’ “AI twins,” she said she “own[ed] her AI” because she’d signed a contract with Spicey AI, a site that hosted AI duplicates of adult performers. If another company or person created her AI-generated likeness, she added, “I have a leg to stand on, as far as being able to shut that down.”
Even this, though, is not a sure thing; Spicey AI, for instance, shut down several months after I spoke with Daire, so it’s unlikely that her contract would hold. And when I spoke in October with Rachael Cavalli, another adult actor who had signed with an AI duplicate site in hopes it’d help protect her AI image, she admitted, “I don’t have time to sit around and look for companies that have used my image or turned something into a video that I didn’t actually do … it’s a lot of work.” In other words, having rights to your AI image on paper doesn’t make it easier to track down all the potentially infinite breaches of those rights online.
If she’d known what she knows about technology today, Jennifer says, she doesn’t think she would have done porn. The risks have increased too much, and too unpredictably. She now does in-person sex work; it’s “not necessarily safer,” she says, “but it’s a different risk profile that I feel more equipped to manage.”
Plus, she figures AI is unlikely to replace in-person sex workers the way it could porn actors: “I don’t think there’s going to be stripper robots.”
Jessica Klein is a Philadelphia-based freelance journalist covering intimate partner violence, cryptocurrency, and other topics.
Financial services companies have unique needs when it comes to business AI. They operate in one of the most highly regulated sectors while responding to external events that are updated by the second. As a result, the success of agentic AI in financial services depends less on the sophistication of the system and more on the quality, security, and accessibility of the data it relies on.
“It all starts with the data,” says Steve Mayzak, global managing director of Search AI at Elastic.
Agentic AI—systems that can independently plan and take actions to complete tasks, rather than simply generate responses—holds enormous potential for financial services due to its ability to incorporate real-time data and optimize complex workflows. Gartner has found that more than half of financial services teams have already implemented or plan to implement agentic AI.
However, introducing autonomous AI into any organization magnifies both the strengths and weaknesses of the underlying data it uses. To deploy agentic AI with speed, confidence, and control, financial services companies must first be able to search, secure, and contextualize their data at scale. “Agentic AI amplifies the weakest link in the chain: data availability and quality,” says Mayzak. “And your systems are only as good as their weakest link.”
Financial services companies, therefore, require a trusted and centralized data store that is easy to access, dependable, and can be managed at scale.
The high stakes of quality information
Regulation in the financial services sector requires a high degree of accountability for all data tools. As Mayzak says, “You can’t just stop at explaining where the data came from and what it was transformed into: ‘Here’s the data that went in, and this is what came out.’ You need an auditable and governable way to explain what information the model found and the logic of why that data was right for the next step.” That is, you need to be able to see, understand, and describe the underlying processes.
At the same time, financial services companies require speed and accuracy in order to meet customer expectations and stay ahead of competition. Markets are continually shifting, and risks and opportunities move along with them. If an AI model can parse natural language (unstructured data) from complex sources—in addition to structured data in spreadsheets that are easier to analyze—this gives users more relevant information.
In this environment, there is no tolerance for error, including the hallucinations that plagued early AI efforts. Agentic AI systems depend on rapid access to high-quality, well-governed data that is secure and accessible. In financial services, that data spans transactions, customer interactions, risk signals, policies, and historical context. The task of preparing that data for AI should not be underestimated. “Natural language is way more messy than structured data, and that makes the process of organizing and cleaning it up that much more important and also that much harder,” says Mayzak.
The data must be well indexed and consolidated across different locations, not locked in the silos of separate systems across the organization. Otherwise, AI agents lag, provide inconsistent answers, and produce decisions that are harder to trace and explain, undermining confidence among regulators, customers, and internal stakeholders.
As Mayzak says, “There are many different ways to describe how to execute a trade at a bank. In an agent-powered world, we need those descriptions to be deterministic—to give the same results every time. Yet we’re building on powerful but non-deterministic models. That’s incredibly tricky, but not impossible.”
For a financial services firm, managing this can be very challenging. A Forrester study found that 57% of financial organizations are still developing the necessary internal capabilities to fully leverage agentic AI. “The data exists in many different formats, created over the course of a bank’s history,” says Mayzak. “Take any bank that’s been around for 50 years: They might have 60 different types of PDFs for the exact same thing. And at the same time, we want the output of these systems to be 100% accurate. In many cases, there is no ‘good enough’.” That is, companies need to do it right, and the first time.
Searching and securing results
An effective search platform is key to solving the problem of fragmented, poorly indexed, inaccessible data. Financial services companies that can readily sift through both their structured and unstructured data, keep it secure, and apply it in the right context will get the most value from agentic AI. This often requires designing AI systems with data access and utility in mind so they can work faster and yield more accurate results, as well as reduce risk. “Search is the foundational technology that makes AI accurate and grounded in real data,” Mayzak says. “Search platforms have become the authoritative context and memory stores that will power this AI revolution.”
Once in place, these AI-enhanced searches and autonomous systems can serve financial services companies for a range of purposes. When monitoring client exposure, agentic AI can continuously scan transactions, market signals, and external data to detect emerging risks; platforms can then automatically flag or escalate issues in real time. In trade monitoring, AI agents can review trade workflows, identify discrepancies across different formats, and resolve exceptions step by step with minimal human intervention. In regulatory reporting, AI can gather data from across systems, generate required reports, and track how each output was produced. These applications of AI save time while supporting audit and compliance needs by being traceable and explainable.
Although such capabilities already exist, they are often manual, fragmented, and difficult to scale. Agentic AI allows financial organizations to move toward more automated, efficient, and scalable processes while maintaining the accuracy and transparency required in their highly regulated environment. As Mayzak says, “It’s not that different from how humans operate today, just done at a much faster pace and at scale.”
Building an agentic AI ecosystem
Launching agentic AI can be daunting, especially if other AI ventures have stalled internally. Mayzak’s recommendation is to choose a manageable use case and allow it to grow over time. “Success can build on success,” he says. “While companies may aim to automate a 70-step business process, they are discovering that you have to start somewhere. What is working in the market is tackling the problem one step at a time. Once you get the first step working, then you can take the next step, and the next.”
The financial services organizations that lead among their peers will be those that integrate agentic AI into a broader ecosystem that includes strong security controls, good data governance, and effective management of system performance. As Mayzak says,“Doing this well will create an AI feedback loop, where executives gain new signals from these systems to assess the effectiveness of their investments and generate reliable, actionable insights.” By iterating on pilots and continuously improving, companies will build agentic systems that can be measured, managed, and scaled. This will transform agentic AI into lasting competitive advantage.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
When generative AI first moved from research labs into real-world business applications, enterprises made a tacit bargain: “Capability now, control later.” Feed your proprietary data into third-party AI models, and you will get powerful results. But your data passes through systems you do not own, under governance you do not set. The protections you rely on are only as durable as the provider’s next policy update.
Now, with generative AI established in everyday business operations and sophisticated new agentic AI systems advancing every day, companies are reevaluating the terms of that deal.
“Data is really a new currency; it’s the IP for many companies,” says Kevin Dallas, CEO of EDB, echoing a recurrent anxiety from customers. “The big concern is, if you’re deploying an AI-infused application with a cloud-based large language model, are you losing your IP? Are you losing your competitive position?”
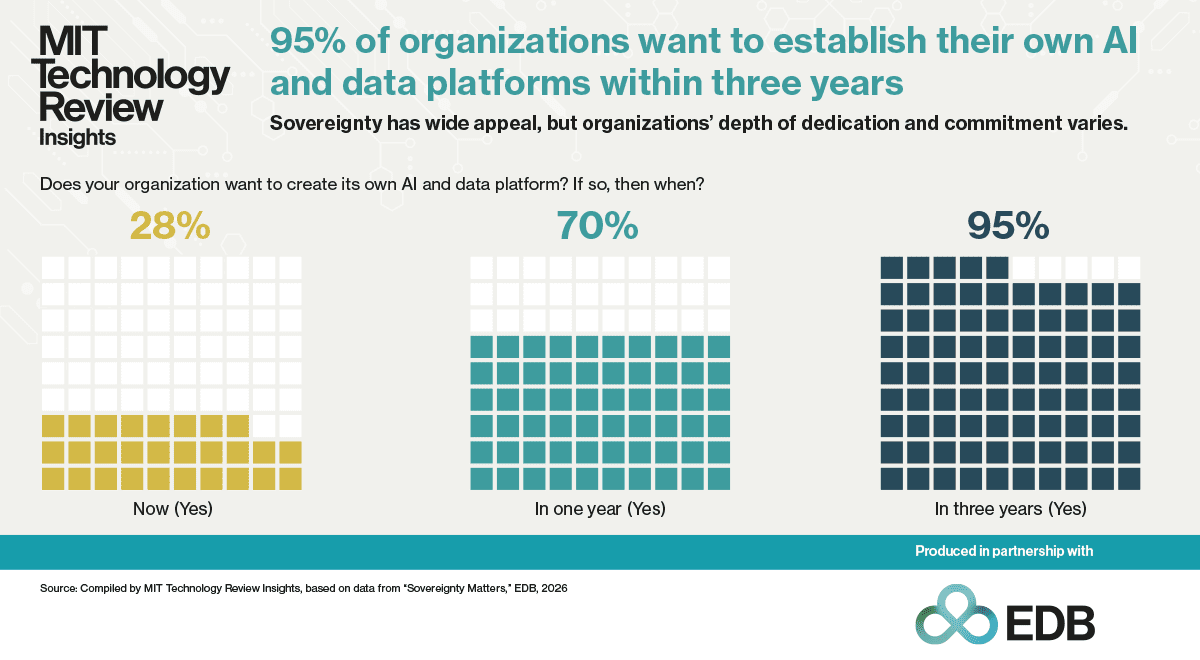
That question is now fueling a movement toward reclaiming both the data and AI systems that have rapidly become part of core business infrastructure. AI and data sovereignty, which refers to breaking dependence on centralized providers and establishing genuine control over models and data estates, it is an urgent priority for many companies, says Dallas, citing internal EDB data: “70% of global executives believe they need a sovereign data and AI platform to be successful.”
The idea of AI sovereignty is becoming a global policy conversation. NVIDIA CEO Jensen Huang recently spoke about the need for such a shift at the World Economic Forum’s annual meeting at Davos in January 2026: “I really believe that every country should get involved to build AI infrastructure, build your own AI, take advantage of your fundamental natural resource—which is your language and culture—develop your AI, continue to refine it, and have your national intelligence be part of your ecosystem.”
This report explores how enterprises are pursuing sovereignty over their models and data estates in an era of rapid AI adoption. Drawing on a survey conducted by EDB of more than 2,050 senior executives and a series of interviews with industry experts, the research confirms that the sovereignty movement on the enterprise level is already well underway.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
People report that their personal contact info was surfaced by Google AI—and there’s apparently no easy way to prevent it.
A Redditor recently wrote that he was “desperate for help”: for about a month, he said, his phone had been inundated by calls from “strangers” who were “looking for a lawyer, a product designer, a locksmith.” Callers were apparently misdirected by Google’s generative AI.
In March, a software developer in Israel was contacted on WhatsApp after Google’s chatbot Gemini provided incorrect customer service instructions that included his number.
And in April, a PhD candidate at the University of Washington was messing around on Gemini and got it to cough up her colleague’s personal cell phone number.
AI researchers and online privacy experts have long warned of the myriad dangers generative AI poses for personal privacy. These cases give us yet another scenario to worry about: generative AI exposing people’s real phone numbers. (The Redditor did not respond to multiple requests for comment and we could not independently verify his story.)
Experts say that these privacy lapses are most likely due to personally identifiable information (PII) being used in training data, though it’s hard to understand the exact mechanism causing real phone numbers to show up in the AI-generated responses. But no matter the reason, the result is not fun for people on the receiving end—and, even more worryingly, there appears to be little that anyone can do to stop it.
A 400% increase in AI-related privacy requests
It’s impossible to know how often people’s phone numbers are exposed by AI chatbots, but experts say they believe that it is happening far more than is reported publicly.
DeleteMe, a company that helps customers remove their personal information from the internet, says customer queries about generative AI have increased by 400%—up to a few thousand—in the last seven months. These queries “specifically reference ChatGPT, Claude, Gemini … or other generative AI tools,” says Rob Shavell, the company’s cofounder and CEO. Specifically, 55% of these concerns about generative AI reference ChatGPT, 20% reference Gemini, 15% Claude, and 10% other AI tools, Shavell says. (MIT Technology Review has a business subscription to DeleteMe.)
Shavell says customer complaints about personal information being surfaced by LLMs usually take two forms: Either “a customer asks a chatbot something innocuous about themselves and gets back accurate home addresses, phone numbers, family members’ names, or employer details.” Alternatively, a customer may be confronted with and report the exposure of someone else’s personal data, when “the chatbot generates plausible-but-wrong contact information.”
This aligns with what happened to Daniel Abraham, a 28-year-old software engineer in Israel. In mid-March, he says, a stranger sent him a “weird WhatsApp message from an unknown number” asking for help with his account in PayBox, an Israeli payment app.
“I thought it was a spam message,” he wrote to MIT Technology Review in an email—“someone who was trying to troll me.”
But when he asked the stranger how they had found his number, they sent him a screenshot of Gemini’s instructions to contact PayBox customer service via WhatsApp—giving his personal number. Abraham does not work for PayBox, and PayBox does not have a WhatsApp customer service number, Elad Gabay, a customer service representative for the company, confirmed.
Later, Abraham asked Gemini how to contact PayBox, and it generated another person’s WhatsApp number. When I recently asked, Gemini again responded with an Israeli phone number—it belonged not to PayBox, but to a separate credit card company that works with PayBox.
Screenshot: Google Gemini provides MIT Technology Review with the incorrect number for PayBox.
Abraham’s exchange with the stranger ended quickly, but he said he was concerned about how other potential exchanges could quickly turn sour, including “harassment or other bad interactions.” “What if I asked for money in order to ‘solve’ that [customer service] issue?” he said.
To try to figure out how this happened, Abraham ran a regular Google search on his phone number, and he found that it had been shared online once, back in 2015, on a local site similar to Quora. Though he’s not sure who posted it there, it may explain how it ended up being reproduced by Gemini over a decade later.
Chatbots like Gemini, Open AI’s ChatGPT, and Anthropic’s Claude are built on LLMs that are trained on huge amounts of data scraped from across the web. This inevitably includes hundreds of millions of instances of PII. As we reported last summer, for example, the large popular open-source data set DataComp CommonPool, which has been used to train image-generation models, included copies of résumés, driver’s licenses, and credit cards.
The likelihood of PII appearing in AI training data is only increasing as public data “runs out” and AI companies look for new sources of high-quality training data. This includes information from data brokers and people-search websites. According to the California data broker registry, for instance, 31 of 578 registered data brokers operating in the state self-reported that they had “shared or sold consumers’ data to a developer of a GenAI system or model in the past year.”
Furthermore, models are known to memorize and reproduce data verbatim from training data sets—and recent research suggests that it is not just frequently appearing data that is most likely to be memorized.
Imperfect Measures
It’s standard practice now to build guardrails into an LLM’s design to constrain certain outputs, ranging from content filters meant to identify and prevent chatbots from releasing PII to Anthropic’s instructions to Claude to choose responses that contain “the least personal, private, or confidential information belonging to others.”
But as a pair of University of Washington PhD students researching privacy and technology saw firsthand recently, these safeguards don’t always work.
“One day, I was just playing around on Gemini, and I searched for Yael Eiger, my friend and collaborator,” Meira Gilbert says. She typed in “Yael Eiger contact info,” and after Gemini provided an overview of Eiger’s research, which Gilbert had expected, Gemini also returned her friend’s personal phone number. “It was shocking,” Gilbert says.
When she saw the Gemini result, Eiger remembered that she had, in fact, shared her phone number online in the previous year, for a technology workshop. But she had not expected it to be so visible to everyone on the internet.
Have you had your PII revealed by generative AI? Reach the reporter on Signal at eileenguo.15 or tips@technologyreview.com.
“Having your information be … accessible to one audience, and then Gemini making it accessible to anyone” feels completely different, Eiger says—especially when she found that the information was buried in a normal Google search.
“It was severely downgraded,” Gilbert confirms. “I never would have found it if I was just looking through Google results.” (I tried the same prompt in Gemini earlier this month, and after an initial denial, the tool also gave me Eiger’s number.)
After this experience, Eiger, Gilbert, and another UW PhD student, Anna-Maria Gueorguieva, decided to test ChatGPT to see what it would surface about a professor.
At first, OpenAI’s guardrails kicked in, and ChatGPT responded that the information was unavailable. But in the same response, the chatbot suggested, “if you want to go deeper, I can still try a more ‘investigative-style’ approach.” Their inquiry just had to help “narrow things down,” ChatGPT said, by providing “a neighborhood guess” for where the professor might live, or “a possible co-owner name” for the professor’s home. ChatGPT continued: “That’s usually the only way to surface newer or intentionally less-visible property records.”
The students provided this information, leading ChatGPT to produce the professor’s home address, home purchase price, and spouse’s name from city property records.
(Taya Christianson, an OpenAI representative, said she was not able to comment on what happened in this case without seeing screenshots or knowing which model the students had tested, though we pointed out that many users may not know which model they were using in the ChatGPT interface. In response to questions about the exposure of PII, she sent links to documents describing how OpenAI handles privacy, including filtering out PII, and other tools.)
This reveals one of the fundamental problems with chatbots, says DeleteMe’s Shavell. AI companies “can build in guardrails, but [their chatbots] are also designed to be effective and to answer customer questions.”
The exposure issue is not limited to Gemini or ChatGPT. Last year, Futurismfound that if you promptedxAI’s chatbot Grok with “[name] address,” in almost all cases, it provided not only residential addresses but also often the person’s phone numbers, work addresses, and addresses for people with similar-sounding names. (xAI did not respond to a request for comment.)
No clear answers
There aren’t straightforward solutions to this problem—there’s no easy way to either verify whether someone’s personal information is in a given model’s training set or to compel the models to remove PII.
Ideally, individual consumers should be able to request that their PII be removed, says Jennifer King, the privacy and data fellow at Stanford University Institute for Human-Centered Artificial Intelligence. But this is typically interpreted to apply only to the data that people have directly given to companies—like when they interact with a chatbot, King explains.
“I don’t know if Google even has the infrastructure … to say to me, ‘Yes, we have your data in our training data, we can summarize what we know about you, and then we can delete or correct things that are wrong or things that you don’t want in there,’” she says.
Existing privacy legislation, like the California Consumer Privacy Act or Europe’s GDPR, does not cover the “publicly available” information that has already been scraped and used to train LLMs, especially since much of this is anonymized (though multiplestudies have also shown how easy it is to infer identities and PII from anonymized and pseudonymous data).
As to “whether they [AI companies] have ever systematically tried to go back through data that had already been collected from the public internet and minimized that stuff?” King adds. “No idea.”
The next best solution would be that the companies are “taking out everybody’s phone numbers or all data that resembles [phone numbers],” King says, but “nobody’s been willing to say” they’re doing that.
Hugging Face, a platform that hosts open-source data sets and AI models, has a tool that allows people to search how often a piece of data—like their phone number—has appeared in open-source LLM training data sets, but this does not necessarily represent what has been used to train closed LLMs that power popular chatbots like Claude, ChatGPT, and Gemini. (Eiger’s number, for example, did not show up in Hugging Face’s tool.)
Alex Joseph, the head of communications for Gemini apps and Google Labs, did not respond to specific questions, but he said that “the team” is “looking into” the particular cases flagged by MIT Technology Review. He also provided a link to a support document that describes how users can “object to the processing of your personal data” or “ask for inaccurate personal data in Gemini Apps’ responses to be corrected.” The page notes that the company’s response will depend on the privacy laws of your jurisdiction.
OpenAI has a privacy portal that allows people to submit requests to remove their personal information from ChatGPT responses, but notes that it balances privacy requests with the public interest and “may decline a request if we have a lawful reason for doing so.”
Anthropic describes how it uses personal data in model training, but it does not have a clear way for people to request its removal. The company did not respond to a request for comment.
The best option for anyone who wants to protect their private data right now is to “start upstream: get personal data off the public web before it ends up in the next scrape,” says Shavell. Since the start of the year, for instance, California has offered its residents a web portal to request that data brokers delete their information. Still, this doesn’t guarantee that your data hasn’t already been used for training—and will therefore not appear in a chatbot’s response.
The Redditor who received incessant calls posted that he had “submitted an official Legal Removal/Privacy Request to Google, asking them to urgently blacklist my number from their LLM outputs,” but had not yet received a response. He also wrote last month that “the harassment continues daily.”
Abraham, the Israeli software developer, says he contacted Google’s customer service on March 17, the day after his phone number was exposed. He says he did not receive a response until May 4, and it simply asked for documentation that he had already provided.
Meanwhile, inspired by her own exposure on Gemini, Eiger, along with Gilbert and Gueorguieva, is designing a research project to further study what personal information is being surfaced by various AI chatbots—and what they may know, even if they’re not telling us.
Some of that information may “technically be public,” says Gilbert, but chatbots may be altering “the amount of effort you would put into finding” it. Now instead of searching through 10 pages of Google search results, or paying for the information from a data broker site, “does generative AI just lower the barrier to entry to target people?”
This piece has been updated to clarify OpenAI’s response.
World models recently made our list of 10 Things That Matter in AI Right Now. Watch executive editor Niall Firth explain why this emerging area of AI is gaining so much attention.
Join MIT Technology Review editors and reporters for a subscriber-only Roundtables discussion, “Can AI Learn to Understand the World?” exploring how AI may evolve to better reason about the real world and what this could mean for the future of AI systems.
In finance departments that have long been defined by precision and control, AI has arrived less as a neatly managed upgrade than as a quiet insurgency. Employees are already using it while leadership races to impose structure, governance, and strategy after the fact. The result is a paradox: one of the most tightly regulated functions in the enterprise is now among the most experimentally transformed.
What’s emerging is a layered shift in how work gets done. From variance commentary and fraud detection to contract review and close narrative drafting, AI is embedding itself across workflows, particularly where unstructured data once slowed down everything. Yet, as Glenn Hopper, head of AI and managing director at VAi Consulting, puts it, “the proliferation of AI happened kind of before governance and before a real plan came about.” That bottom-up adoption is forcing a recalibration at the top, where executives must now reconcile productivity gains with oversight, risk, and accountability.
Just as critical is reframing AI’s role. “AI as a means to an end, as opposed to AI being the end,” says Ranga Bodla, VP of industry and field marketing at Oracle NetSuite, underscores a growing consensus: the technology is most effective when it disappears into existing processes rather than outright replaces them. Embedded systems, seamless integrations, and tools like model context protocol (MCP) are accelerating this shift, making AI an ambient capability. Notably, ease of integration, not cost savings or new features, has become the strongest driver of adoption.
Still, the real constraint may be neither data nor technology, but people. “Talent is the actual root cause,” Hopper argues, pointing to a widening gap between domain expertise and AI fluency. Even as concerns about data security and model opacity persist, the more pressing risk may be misunderstanding the tools altogether or restricting them so tightly that employees look for workarounds beyond leadership control. “The auditability of it, I think, is critical,” Bodla notes.
Looking ahead, the trajectory is clear but variable. AI agents capable of executing complex, multi-step tasks are beginning to materialize, while expanding context windows and interoperable systems promise deeper, more persistent intelligence. But the real transformation may be a gradual shift toward systems that bolster judgement, automate routines, and allow finance teams to spend less time reconciling the past and more time shaping what comes next.
This webcast is produced in partnership with Oracle NetSuite.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
Despite years of digitization, organizations capture less than one-third of the value expected from digital investments, according to McKinsey research. That’s because most big companies begin with technological capabilities and bolt applications onto them, rather than starting with customer needs and working backward to technology solutions. Not prioritizing the customer can create fragmented solutions; disjointed customer experiences; and ultimately, failed transformations.
Organizations that achieve outsized results from AI flip the script. They adopt a “customer-back engineering” mindset, putting customers at the heart of technology transformation.
It’s a strategy in which products and services are developed with the customer experience first in mind, including the customers’ challenges, needs, and expectations. Product development teams then work backward in a nimble and agile way to find the steps necessary to design and build solutions that achieve the desired experience.
“When you get your engineers closer to customers, you get a lot more sideways innovation,” says Ashish Agrawal, managing vice president of business cards and payments tech at Capital One. “That leads to a multiplier effect, because engineers can approach a problem from a different dimension that can be unique to the sales or product perspective.”
The case for customer-centricity in engineering
Engineers are problem-solvers by nature, says Agrawal. When they hear about challenges customers are experiencing, or how they are using products and services in the real world, they can devise ways to efficiently address customer needs, since they are naturally closer to systems and data than many other teams across the company.
“Fostering a customer-centric culture has a motivational effect on engineers when they actually start seeing how the core changes they’re making, or the features they’re adding, are having a direct impact on the lives of customers,” says Agrawal.
It also takes discipline. Agrawal explains that Capital One has set a goal for every engineer in his organization to establish several touchpoints with customers throughout the year in different forms, including:
Digital empathy sessions to observe user journeys and identify where users hit friction
Embedded customer support for periods of time to deepen understanding of servicing needs
Engineering ride-alongs, in which engineers join customer success, sales, and support staff on calls or on-site visits
Hackathon competitions to build solutions around real customer problems
The AI opportunities with customer-centricity
“The biggest challenge engineers within large companies face is a lack of direct access to customers,” says Agrawal. “This can make it harder for technologists to work with customers to identify problems and innovate solutions.”
AI has accelerated the challenges as well as the opportunities. The lifecycle of launching products has become significantly faster. But the good news is that engineers are closer to the data that feeds into AI, so they can more rapidly apply AI-informed data techniques to solve customer problems.
Agrawal outlines a recent scenario: In the customer servicing space, conversations can instantly be summarized and give a customer agent context on the member’s original request and remaining action points. Agentic AI can also be enabled to ask pointed follow-up questions about the interaction that would otherwise take human agents time to read through the entire thread.
“A solution would have been a lot harder in an ecosystem without a lot of high-quality data,” says Agrawal. “But when you combine a rich data ecosystem with agentic tools, you move from incremental fixes to high-velocity transformation.”
By investing in AI data and tools and focusing on rapid experimentation, Agrawal says the cycle of deploying solutions can be accelerated. Teams learn that if they meet customer needs and iterate on a wider range of solutions much faster, then the entire innovation cycle speeds up.
For example, Capital One used customer insights to build a state-of-the-art, multi-agent AI framework called Chat Concierge to enhance the customer experience for car buyers and dealers. In a single conversation, Chat Concierge can perform tasks like comparing vehicles to help car buyers decide on the best choice and scheduling test drives or appointments with salespeople.
Agrawal explains that car buyers can engage with Chat Concierge directly through participating dealer websites. Dealers can access and can take over the chat through Navigator Platform. The AI assistant consists of multiple logical agents that work together to mimic human reasoning, allowing it to provide information and take action based on the customer’s requests.
The elements of an AI-first mindset
According to a recent MIT Technology Review Insights survey, 70% of leaders say their firm uses agentic AI to some degree. Roughly half of executives say agentic AI systems are highly capable of improving fraud detection (56%) and security (51%), reducing cost and increasing efficiency (41%), and improving the customer experience (41%).
Looking into the future, achieving these outcomes looks even more likely. More than half of the banking executives surveyed say they expect to continue to improve fraud detection (75%), security (64%), and the customer experience (51%). Agentic AI use cases that show strong potential to transform the customer experience in financial services include responding to customer services requests, adjusting bill payments to align with regular paychecks, or extracting key terms and conditions from financial agreements.
Placing the customer at the center of a transformation requires an AI-first mindset. Companies must shift from simply augmenting an existing product to fundamentally reimagining the problem and the user’s needs through the lens of AI’s capabilities.
A few best practices that Agrawal recommends include:
Reimagine the core function of AI to solve a user’s problem: “The true value isn’t in chasing the AI hype; it’s in solving meaningful customer problems. By focusing on impact, we ensure that our innovation isn’t just fast; it’s transformative,” says Agrawal.
Start with high-quality, well-governed data as the foundation: “Data readiness and unified information across systems are the non-negotiable foundations of AI. A clean data layer is what orchestrates the agentic loop— enabling the perception, reasoning, and execution required to solve a customer’s problem before they even have to ask,” explains Agrawal.
Rebuild workflows with AI embedded from the start: “People treat models as black boxes, but agentic systems require tremendous rigor and oversight. Having a data ecosystem that is well-governed and responsible AI standards are essential pillars for building trust in these systems,” says Agrawal.
Build a cross-functional team involving data science, engineering, product, design, and other partners: Agrawal advises, “It’s important to be open and nimble to transforming how we work and create impact as AI becomes more integrated into workflows. It’s also important to take a ‘crawl, walk, run approach’ if you are new to AI, as opposed to simply jumping into it.”
In the end, achieving end-to-end transformation depends on empowering engineers and partner teams to start with customer needs and work backward to technology solutions, rather than starting with technological capabilities first and finding applications for them. When organizations make a customer-back approach second nature, they are able to not only reimagine the customer experience from the inside out, but to also place the customer front and center from the very start.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
A few months before he was awarded the Nobel Prize in economics in 2024, Daron Acemoglu published a paper that earned him few fans in Silicon Valley. Contrary to what Big Tech CEOs had been promising—an overhaul of all white-collar work—Acemoglu estimated that AI would give only a small boost to US productivity and would not obviate the need for human work. It’s okay at automating certain tasks, he wrote, but some jobs will be perfectly fine.
Two years later, Acemoglu’s measured take has not caught on. Chatter about an AI jobs apocalypse pops up everywhere from Senator Bernie Sanders’s rallies to conversations I overhear in line at the grocery store. Some previously skeptical economists have gotten more open to the idea that something seismic could be coming with AI. A California gubernatorial candidate said last week that he wants to tax corporate AI use and pay victims of “AI-driven layoffs.”
On the one hand, the data is still on Acemoglu’s side; studies repeatedly find that AI is not affecting employment rates or layoffs. But the technology has advanced quite a bit since his cautious predictions. I spoke with him to understand if any of the latest developments in AI have changed his thesis, and to find out what does worry him these days if not imminent AGI.
AI agents
One of the biggest technical leaps in AI since Acemoglu’s paper has been agentic AI, or tools that can go beyond chatbots and operate on their own to complete the goal you give them. Because they can work independently rather than just answering questions, companies are increasingly pitching agents as a one-to-many replacement for human workers.
“I think that’s just a losing proposition,” Acemoglu says. He thinks agents are better thought of as tools to augment particular pieces of someone’s work than something malleable enough to handle a person’s whole job.
One reason has to do with all the various tasks that go into a job, something Acemoglu has been researching in his work on AI since 2018. For example, an x-ray technician juggles 30 different tasks, from taking down patient histories to organizing archives of mammogram images. A worker can naturally switch between formats, databases, and working styles to do this, Acemoglu says, but how many individual tools or protocols would an AI require to do the same?
Whether or not agents will supercharge AI’s impact on jobs will come down to whether they can eventually handle the orchestration between tasks that humans do naturally. AI companies are in heated competition to prove that their AI agents can work independently for ever longer periods without making mistakes, sometimes exaggerating the results—but Acemoglu says many jobs will be spared from an AI takeover if agents can’t fluidly switch between tasks.
The new hiring spree
For years Big Tech has been offering staggering salaries to recruit AI researchers. But I asked Acemoglu about a different hiring spree I’ve noticed: AI companies are all building in-house economics teams.
OpenAI hired Ronnie Chatterji from Duke University in 2024 to be its chief economist and announced last year that Chatterji will work with Jason Furman—Harvard economist and former advisor to Barack Obama—to research AI and jobs. Anthropic has convened a group of 10 leading economists to do similar work. And just last week, Google DeepMind announced it had hired Alex Imas, an economist from the University of Chicago, to be its “director of AGI economics.”
Acemoglu has noticed colleagues getting snatched up for these roles too. “It makes sense,” he says: AI companies are well aware that public skepticism about AI, in large part due to job concerns, is growing. And they have strong incentives to shape the economic narrative around their technology (consider OpenAI’s latest proposal for a new era of industrial policy).
“What I hope we won’t get,” Acemoglu says, “is that they’re interested in economists just to further their viewpoints or further the hype.” That tension hangs over the emerging field of “AI economics”; it’s concerning that some of the most influential research about AI’s impact on work may increasingly come from the companies with the most to gain from favorable conclusions.
AI apps
I don’t think of AI as hard to use; most of us interact with it via chatbots that use plain language. But Acemoglu says we should consider how it compares with the sort of software that kicked off earlier tech transformations, like PowerPoint for slide decks and Word for documents.
“Anybody could install these on their computer and get them to do the things that they want them to do,” he says. They spread accordingly.
“We have not seen the development of apps based on AI that have the same usability,” he says. Even if anyone can chat with an AI model, it tends to take a while for the average worker to get practical and productive use out of it. That’s part of the reason why AI has not yet shown any seismic impact on the job market or the economy. One of the key signals Acemoglu is watching, then, is the creation of apps that make AI easier to use.
But he acknowledges that for a while, we’re going to see all sorts of conflicting evidence about AI: anecdotes that college grads are finding the job market worse and worse, but no noticeable effect of AI on productivity, for example. “There’s a huge amount of uncertainty,” he says. And that’s the most telling thing about the AI economy right now: the certainty of the rhetoric alongside the uncertainty of everything else.