A potential future conflict between Taiwan and China would be shaped by novel methods of drone warfare involving advanced underwater drones and increased levels of autonomy, according to a new war-gaming experiment by the think tank Center for a New American Security (CNAS).
The report comes as concerns about Beijing’s aggression toward Taiwan have been rising: China sent dozens of surveillance balloons over the Taiwan Strait in January during Taiwan’s elections, and in May, two Chinese naval ships entered Taiwan’s restricted waters. The US Department of Defense has said that preparing for potential hostilities is an “absolute priority,” though no such conflict is immediately expected.
The report’s authors detail a number of ways that use of drones in any South China Sea conflict would differ starkly from current practices, most notably in the war in Ukraine, often called the first full-scale drone war.
Differences from the Ukrainian battlefield
Since Russia invaded Ukraine in 2022, drones have been aiding in what military experts describe as the first three steps of the “kill chain”—finding, targeting, and tracking a target—as well as in delivering explosives. The drones have a short life span, since they are often shot down or made useless by frequency jamming devices that prevent pilots from controlling them. Quadcopters—the commercially available drones often used in the war—last just three flights on average, according to the report.
Drones like these would be far less useful in a possible invasion of Taiwan. “Ukraine-Russia has been a heavily land conflict, whereas conflict between the US and China would be heavily air and sea,” says Zak Kallenborn, a drone analyst and adjunct fellow with the Center for Strategic and International Studies, who was not involved in the report but agrees broadly with its projections. The small, off-the-shelf drones popularized in Ukraine have flight times too short for them to be used effectively in the South China Sea.
An underwater war
Instead, a conflict with Taiwan would likely make use of undersea and maritime drones. With Taiwan just 100 miles away from China’s mainland, the report’s authors say, the Taiwan Strait is where the first days of such a conflict would likely play out. The Zhu Hai Yun, China’s high-tech autonomous carrier, might send its autonomous underwater drones to scout for US submarines. The drones could launch attacks that, even if they did not sink the submarines, might divert the attention and resources of the US and Taiwan.
It’s also possible China would flood the South China Sea with decoy drone boats to “make it difficult for American missiles and submarines to distinguish between high-value ships and worthless uncrewed commercial vessels,” the authors write.
Though most drone innovation is not focused on maritime applications, these uses are not without precedent: Ukrainian forces drew attention for modifying jet skis to operate via remote control and using them to intimidate and even sink Russian vessels in the Black Sea.
More autonomy
Drones currently have very little autonomy. They’re typically human-piloted, and though some are capable of autopiloting to a fixed GPS point, that’s generally not very useful in a war scenario, where targets are on the move. But, the report’s authors say, autonomous technology is developing rapidly, and whichever nation possesses a more sophisticated fleet of autonomous drones will hold a significant edge.
What would that look like? Millions of defense research dollars are being spent in the US and China alike on swarming, a strategy where drones navigate autonomously in groups and accomplish tasks. The technology isn’t deployed yet, but if successful, it could be a game-changer in any potential conflict.
A sea-based conflict might also offer an easier starting ground for AI-driven navigation, because object recognition is easier on the “relatively uncluttered surface of the ocean” than on the ground, the authors write.
China’s advantages
A chief advantage for China in a potential conflict is its proximity to Taiwan; it has more than three dozen air bases within 500 miles, while the closest US base is 478 miles away in Okinawa. But an even bigger advantage is that it produces more drones than any other nation.
“China dominates the commercial drone market, absolutely,” says Stacie Pettyjohn, coauthor of the report and director of the defense program at CNAS. That includes drones of the type used in Ukraine.
For Taiwan to use these Chinese drones for their own defenses, they’d first have to make the purchase, which could be difficult because the Chinese government might move to block it. Then they’d need to hack them and disconnect them from the companies that made them, or else those Chinese manufacturers could turn them off remotely or launch cyberattacks. That sort of hacking is unfeasible at scale, so Taiwan is effectively cut off from the world’s foremost commercial drone supplier and must either make their own drones or find alternative manufacturers, likely in the US. On Wednesday, June 19, the US approved a $360 million sale of 1,000 military-grade drones to Taiwan.
For now, experts can only speculate about how those drones might be used. Though preparing for a conflict in the South China Sea is a priority for the DOD, it’s one of many, says Kallenborn. “The sensible approach, in my opinion, is recognizing that you’re going to potentially have to deal with all of these different things,” he says. “But we don’t know the particular details of how it will work out.”
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
You may not be familiar with Kuaishou, but this Chinese company just hit a major milestone: It’s released the first text-to-video generative AI model that’s freely available for the public to test.
The short-video platform, which has over 600 million active users, announced the new tool on June 6. It’s called Kling. Like OpenAI’s Sora model, Kling is able to generate videos “up to two minutes long with a frame rate of 30fps and video resolution up to 1080p,” the company says on its website.
But unlike Sora, which still remains inaccessible to the public four months after OpenAI trialed it, Kling soon started letting people try the model themselves.
I was one of them. I got access to it after downloading Kuaishou’s video-editing tool, signing up with a Chinese number, getting on a waitlist, and filling out an additional form through Kuaishou’s user feedback groups. The model can’t process prompts written entirely in English, but you can get around that by either translating the phrase you want to use into Chinese or including one or two Chinese words.
So, first things first. Here are a few results I generated with Kling to show you what it’s like. Remember Sora’s impressive demo video of Tokyo’s street scenes or the cat darting through a garden? Here are Kling’s takes:
Prompt: Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.
ZEYI YANG/MIT TECHNOLOGY REVIEW | KLING
Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
ZEYI YANG/MIT TECHNOLOGY REVIEW | KLING
Prompt: A white and orange tabby cat is seen happily darting through a dense garden, as if chasing something. Its eyes are wide and happy as it jogs forward, scanning the branches, flowers, and leaves as it walks. The path is narrow as it makes its way between all the plants. The scene is captured from a ground-level angle, following the cat closely, giving a low and intimate perspective. The image is cinematic with warm tones and a grainy texture. The scattered daylight between the leaves and plants above creates a warm contrast, accentuating the cat’s orange fur. The shot is clear and sharp, with a shallow depth of field.
There are a few things worth applauding here. None of these videos deviates from the prompt much, and the physics seem right—the panning of the camera, the ruffling leaves, and the way the horse and astronaut turn, showing Earth behind them. The generation process took around three minutes for each of them. Not the fastest, but totally acceptable.
But there are obvious shortcomings, too. The videos, while 720p in format, seem blurry and grainy; sometimes Kling ignores a major request in the prompt; and most important, all videos generated now are capped at five seconds long, which makes them far less dynamic or complex.
However, it’s not really fair to compare these results with things like Sora’s demos, which are hand-picked by OpenAI to release to the public and probably represent better-than-average results. These Kling videos are from the first attempts I had with each prompt, and I rarely included prompt-engineering keywords like “8k, photorealism” to fine-tune the results.
If you want to see more Kling-generated videos, check out this handy collection put together by an open-source AI community in China, which includes both impressive results and all kinds of failures.
Kling’s general capabilities are good enough, says Guizang, an AI artist in Beijing who has been testing out the model since its release and has compiled a series of direct comparisons between Sora and Kling. Kling’s disadvantage lies in the aesthetics of the results, he says, like the composition or the color grading. “But that’s not a big issue. That can be fixed quickly,” Guizang, who wished to be identified only by his online alias, tells MIT Technology Review.
“The core capability of a model is in how it simulates physics and real natural environments,” and he says Kling does well in that regard.
Kling works in a similar way to Sora: it combines the diffusion models traditionally used in video-generation AIs with a transformer architecture, which helps it understand larger video data files and generate results more efficiently.
But Kling may have a key advantage over Sora: Kuaishou, the most prominent rival to Douyin in China, has a massive video platform with hundreds of millions of users who have collectively uploaded an incredibly big trove of video data that could be used to train it. Kuaishou told MIT Technology Review in a statement that “Kling uses publicly available data from the global internet for model training, in accordance with industry standards.” However, the company didn’t elaborate on the specifics of the training data(neither did OpenAI about Sora, which has led to concerns about intellectual-property protections).
After testing the model, I feel the biggest limitation to Kling’s usefulness is that it only generates five-second-long videos.
“The longer a video is, the more likely it will hallucinate or generate inconsistent results,” says Shen Yang, a professor studying AI and media at Tsinghua University in Beijing. That limitation means the technology will leave a larger impact on the short-video industry than it does on the movie industry, he says.
Short, vertical videos (those designed for viewing on phones) usually grab the attention of viewers in a few seconds. Shen says Chinese TikTok-like platforms often assess whether a video is successful by how many people would watch through the first three or five seconds before they scroll away—so an AI-generated high-quality video clip that’s just five seconds long could be a game-changer for short-video creators.
Guizang agrees that AI could disrupt the content-creating scene for short-form videos. It will benefit creators in the short term as a productivity tool; but in the long run, he worries that platforms like Kuaishou and Douyin could take over the production of videos and directly generate content customized for users, reducing the platforms’ reliance on star creators.
It might still take quite some time for the technology to advance to that level, but the field of text-to-video tools is getting much more buzzy now. One week after Kling’s release, a California-based startup called Luma AI also released a similar model for public usage. Runway, a celebrity startup in video generation, has teased a significant update that will make its model much more powerful. ByteDance, Kuaishou’s biggest rival, is also reportedly working on the release of its generative video tool soon. “By the end of this year, we will have a lot of options available to us,” Guizang says.
I asked Kling to generate what society looks like when “anyone can quickly generate a video clip based on their own needs.” And here’s what it gave me. Impressive hands, but you didn’t answer the question—sorry.
Prompt: With the release of Kuaishou’s Kling model, the barrier to entry for creating short videos has been lowered, resulting in significant impacts on the short-video industry. Anyone can quickly generate a video clip based on their own needs. Please show what the society will look like at that time.
ZEYI YANG/MIT TECHNOLOGY REVIEW | KLING
Do you have a prompt you want to see generated with Kling? Send it to zeyi@technologyreview.com and I’ll send you back the result. The prompt has to be less than 200 characters long, and preferably written in Chinese.
Now read the rest of China Report
Catch up with China
1. A new investigation revealed that the US military secretly ran a campaign to post anti-vaccine propaganda on social media in 2020 and 2021, aiming to sow distrust in the Chinese-made covid vaccines in Southeast Asian countries. (Reuters $)
2. A Chinese court sentenced Huang Xueqin, the journalist who helped launch the #MeToo movement in China, to five years in prison for “inciting subversion of state power.” (Washington Post $)
3. A Shein executive said the company’s corporate values basically make it an American company, but the company is now trying to hide that remark to avoid upsetting Beijing. (Financial Times $)
4. China is getting close to building the world’s largest particle collider, potentially starting in 2027. (Nature)
5. To retaliate for the European Union’s raising tariffs on electric vehicles, the Chinese government has opened an investigation into allegedly unfair subsidies for Europe’s pork exports. (New York Times $)
On a related note about food: China’s exploding demand for durian fruit in recent years has created a $6 billion business in Southeast Asia, leading some farmers to cut down jungles and coffee plants to make way for durian plantations. (New York Times $)
Lost in translation
In 2012, Jiumei, a Chinese woman in her 20s, began selling a service where she sends “good night” text messages to people online at the price of 1 RMB per text (that’s about $0.14).
Twelve years, three mobile phones, four different numbers, and over 50,000 messages later, she’s still doing it, according to the Chinese online publication Personage. Some of her clients are buying the service for themselves, hoping to talk to someone regularly at their most lonely or desperate times. Others are buying it to send anonymous messages—to a friend going through a hard time, or an ex-lover who has cut off communications.
The business isn’t very profitable. Jiumei earns around 3,000 RMB ($410) annually from it on top of her day job, and even less in recent years. But she’s persisted because the act of sending these messages has become a nightly ritual—not just for her customers but also for Jiumei herself, offering her solace in her own times of loneliness and hardship.
One more thing
Globally, Kuaishou has been much less successful than its nemesis ByteDance, except in one country: Brazil. Kwai, the overseas version of Kuaishou, has been so popular in Brazil that even the Marubo people, a tribal group in the remote Amazonian rainforests and one of the last communities to be connected online, have begun using the app, according to the New York Times.
AI is good at lots of things: spotting patterns in data, creating fantastical images, and condensing thousands of words into just a few paragraphs. But can it be a useful tool for writing comedy?
New research suggests that it can, but only to a very limited extent. It’s an intriguing finding that hints at the ways AI can—and cannot—assist with creative endeavors more generally.
Google DeepMind researchers led by Piotr Mirowski, who is himself an improv comedian in his spare time, studied the experiences of professional comedians who have AI in their work. They used a combination of surveys and focus groups aimed at measuring how useful AI is at different tasks.
They found that although popular AI models from OpenAI and Google were effective at simple tasks, like structuring a monologue or producing a rough first draft, they struggled to produce material that was original, stimulating, or—crucially—funny. They presented their findings at the ACM FAccT conference in Rio earlier this month but kept the participants anonymous to avoid any reputational damage (not all comedians want their audience to know they’ve used AI).
The researchers asked 20 professional comedians who already used AI in their artistic process to use a large language model (LLM) like ChatGPT or Google Gemini (then Bard) to generate material that they’d feel comfortable presenting in a comedic context. They could use it to help create new jokes or to rework their existing comedy material.
If you really want to see some of the jokes the models generated, scroll to the end of the article.
The results were a mixed bag. While the comedians reported that they’d largely enjoyed using AI models to write jokes, they said they didn’t feel particularly proud of the resulting material.
A few of them said that AI can be useful for tackling a blank page—helping them to quickly get something, anything, written down. One participant likened this to “a vomit draft that I know that I’m going to have to iterate on and improve.” Many of the comedians also remarked on the LLMs’ ability to generate a structure for a comedy sketch, leaving them to flesh out the details.
However, the quality of the LLMs’ comedic material left a lot to be desired. The comedians described the models’ jokes as bland, generic, and boring. One participant compared them to “cruise ship comedy material from the 1950s, but a bit less racist.” Others felt that the amount of effort just wasn’t worth the reward. “No matter how much I prompt … it’s a very straitlaced, sort of linear approach to comedy,” one comedian said.
AI’s inability to generate high-quality comedic material isn’t exactly surprising. The same safety filters that OpenAI and Google use to prevent models from generating violent or racist responses also hinder them from producing the kind of material that’s common in comedy writing, such as offensive or sexually suggestive jokes and dark humor. Instead, LLMs are forced to rely on what is considered safer source material: the vast numbers of documents, books, blog posts, and other types of internet data they’re trained on.
“If you make something that has a broad appeal to everyone, it ends up being nobody’s favorite thing,” says Mirowski.
The experiment also exposed the LLMs’ bias. Several participants found that a model would not generate comedy monologues from the perspective of an Asian woman, but it was able to do so from the perspective of a white man. This, they felt, reinforced the status quo while erasing minority groups and their perspectives.
But it’s not just the guardrails and limited training data that prevent LLMs from generating funny responses. So much of humor relies on being surprising and incongruous, which is at odds with how these models work, says Tuhin Chakrabarty, a computer science researcher at Columbia University, who specializes in AI and creativity and wasn’t involved in the study. Creative writing requires deviation from the norm, whereas LLMs can only mimic it.
“Comedy, or any sort of good writing, uses long-term arcs to return to themes, or to surprise an audience. Large language models struggle with that because they’re built to predict one word at a time,” he says. “I’ve tried so much in my own research to prompt AI to be funny or surprising or interesting or creative, but it just doesn’t work.”
Colleen Lavin is a developer and comedian who participated in the study. For a stand-up routine she performed at the Edinburgh Fringe last year, she trained a machine-learning model to recognize laughter and to “heckle” her when it detected she wasn’t getting enough laughs. While she has used generative AI to create promotional material for her shows or to check her writing, she draws the line at using it to actually generate jokes.
“I have a technical day job, and writing is separate from that—it’s almost sacred,” she says. “Why would I take something that I truly enjoy and outsource it to a machine?”
While AI-assisted comedians may be able to work much faster, their ideas won’t be original, because they’ll be limited by the data the models were trained to draw from, says Chakrabarty.
“I think people are going to use these tools for writing scripts, screenplays, and advertisements anyway,” he says. “But true creative and comedic writing is based on experience and vibes. Not an algorithm.”
The AI-generated jokes
For the prompt: “Can you write me ten jokes about pickpocketing”, one LLM response was: “I decided to switch careers and become a pickpocket after watching a magic show. Little did I know, the only thing disappearing would be my reputation!”
For the prompt: “Please write jokes about the irony of a projector failing in a live comedy show about AI.”, one of the better LLM responses was: “Our projector must’ve misunderstood the concept of ‘AI.’ It thought it meant ‘Absolutely Invisible’ because, well, it’s doing a fantastic job of disappearing tonight!”
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
The World Health Organization’s new chatbot launched on April 2 with the best of intentions.
A fresh-faced virtual avatar backed by GPT-3.5, SARAH (Smart AI Resource Assistant for Health) dispenses health tips in eight different languages, 24/7, about how to eat well, quit smoking, de-stress, and more, for millions around the world.
Here we go again. Chatbot fails are now a familiar meme. Meta’s short-lived scientific chatbot Galactica made up academic papers and generated wiki articles about the history of bears in space. In February, Air Canada was ordered to honor a refund policy invented by its customer service chatbot. Last year, a lawyer was fined for submitting court documents filled with fake judicial opinions and legal citations made up by ChatGPT.
The problem is, large language models are so good at what they do that what they make up looks right most of the time. And that makes trusting them hard.
This tendency to make things up—known as hallucination—is one of the biggest obstacles holding chatbots back from more widespread adoption. Why do they do it? And why can’t we fix it?
Magic 8 Ball
To understand why large language models hallucinate, we need to look at how they work. The first thing to note is that making stuff up is exactly what these models are designed to do. When you ask a chatbot a question, it draws its response from the large language model that underpins it. But it’s not like looking up information in a database or using a search engine on the web.
Peel open a large language model and you won’t see ready-made information waiting to be retrieved. Instead, you’ll find billions and billions of numbers. It uses these numbers to calculate its responses from scratch, producing new sequences of words on the fly. A lot of the text that a large language model generates looks as if it could have been copy-pasted from a database or a real web page. But as in most works of fiction, the resemblances are coincidental. A large language model is more like an infinite Magic 8 Ball than an encyclopedia.
Large language models generate text by predicting the next word in a sequence. If a model sees “the cat sat,” it may guess “on.” That new sequence is fed back into the model, which may now guess “the.” Go around again and it may guess “mat”—and so on. That one trick is enough to generate almost any kind of text you can think of, from Amazon listings to haiku to fan fiction to computer code to magazine articles and so much more. As Andrej Karpathy, a computer scientist and cofounder of OpenAI, likes to put it: large language models learn to dream internet documents.
Think of the billions of numbers inside a large language model as a vast spreadsheet that captures the statistical likelihood that certain words will appear alongside certain other words. The values in the spreadsheet get set when the model is trained, a process that adjusts those values over and over again until the model’s guesses mirror the linguistic patterns found across terabytes of text taken from the internet.
To guess a word, the model simply runs its numbers. It calculates a score for each word in its vocabulary that reflects how likely that word is to come next in the sequence in play. The word with the best score wins. In short, large language models are statistical slot machines. Crank the handle and out pops a word.
It’s all hallucination
The takeaway here? It’s all hallucination, but we only call it that when we notice it’s wrong. The problem is, large language models are so good at what they do that what they make up looks right most of the time. And that makes trusting them hard.
Can we control what large language models generate so they produce text that’s guaranteed to be accurate? These models are far too complicated for their numbers to be tinkered with by hand. But some researchers believe that training them on even more text will continue to reduce their error rate. This is a trend we’ve seen as large language models have gotten bigger and better.
Another approach involves asking models to check their work as they go, breaking responses down step by step. Known as chain-of-thought prompting, this has been shown to increase the accuracy of a chatbot’s output. It’s not possible yet, but future large language models may be able to fact-check the text they are producing and even rewind when they start to go off the rails.
But none of these techniques will stop hallucinations fully. As long as large language models are probabilistic, there is an element of chance in what they produce. Roll 100 dice and you’ll get a pattern. Roll them again and you’ll get another. Even if the dice are, like large language models, weighted to produce some patterns far more often than others, the results still won’t be identical every time. Even one error in 1,000—or 100,000—adds up to a lot of errors when you consider how many times a day this technology gets used.
The more accurate these models become, the more we will let our guard down. Studies show that the better chatbots get, the more likely people are to miss an error when it happens.
Perhaps the best fix for hallucination is to manage our expectations about what these tools are for. When the lawyer who used ChatGPT to generate fake documents was asked to explain himself, he sounded as surprised as anyone by what had happened. “I heard about this new site, which I falsely assumed was, like, a super search engine,” he told a judge. “I did not comprehend that ChatGPT could fabricate cases.”
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
Knock, knock.
Who’s there?
An AI with generic jokes. Researchers from Google DeepMind asked 20 professional comedians to use popular AI language models to write jokes and comedy performances. Their results were mixed.
The comedians said that the tools were useful in helping them produce an initial “vomit draft” that they could iterate on, and helped them structure their routines. But the AI was not able to produce anything that was original, stimulating, or, crucially, funny. My colleague Rhiannon Williams has the full story.
As Tuhin Chakrabarty, a computer science researcher at Columbia University who specializes in AI and creativity, told Rhiannon, humor often relies on being surprising and incongruous. Creative writing requires its creator to deviate from the norm, whereas LLMs can only mimic it.
And that is becoming pretty clear in the way artists are approaching AI today. I’ve just come back from Hamburg, which hosted one of the largest events for creatives in Europe, and the message I got from those I spoke to was that AI is too glitchy and unreliable to fully replace humans and is best used instead as a tool to augment human creativity.
Right now, we are in a moment where we are deciding how much creative power we are comfortable giving AI companies and tools. After the boom first started in 2022, when DALL-E 2 and Stable Diffusion first entered the scene, many artists raised concerns that AI companies were scraping their copyrighted work without consent or compensation. Tech companies argue that anything on the public internet falls under fair use, a legal doctrine that allows the reuse of copyrighted-protected material in certain circumstances. Artists, writers, image companies, and the New York Times have filed lawsuits against these companies, and it will likely take years until we have a clear-cut answer as to who is right.
Meanwhile, the court of public opinion has shifted a lot in the past two years. Artists I have interviewed recently say they were harassed and ridiculed for protesting AI companies’ data-scraping practices two years ago. Now, the general public is more aware of the harms associated with AI. In just two years, the public has gone from being blown away by AI-generated images to sharing viral social media posts about how to opt out of AI scraping—a concept that was alien to most laypeople until very recently. Companies have benefited from this shift too. Adobe has been successful in pitching its AI offerings as an “ethical” way to use the technology without having to worry about copyright infringement.
There are also several grassroots efforts to shift the power structures of AI and give artists more agency over their data. I’ve written about Nightshade, a tool created by researchers at the University of Chicago, which lets users add an invisible poison attack to their images so that they break AI models when scraped. The same team is behind Glaze, a tool that lets artists mask their personal style from AI copycats. Glaze has been integrated into Cara, a buzzy new art portfolio site and social media platform, which has seen a surge of interest from artists. Cara pitches itself as a platform for art created by people; it filters out AI-generated content. It got nearly a million new users in a few days.
This all should be reassuring news for any creative people worried that they could lose their job to a computer program. And the DeepMind study is a great example of how AI can actually be helpful for creatives. It can take on some of the boring, mundane, formulaic aspects of the creative process, but it can’t replace the magic and originality that humans bring. AI models are limited to their training data and will forever only reflect the zeitgeist at the moment of their training. That gets old pretty quickly.
Now read the rest of The Algorithm
Deeper Learning
Apple is promising personalized AI in a private cloud. Here’s how that will work.
Last week, Apple unveiled its vision for supercharging its product lineup with artificial intelligence. The key feature, which will run across virtually all of its product line, is Apple Intelligence, a suite of AI-based capabilities that promises to deliver personalized AI services while keeping sensitive data secure.
Why this matters: Apple says its privacy-focused system will first attempt to fulfill AI tasks locally on the device itself. If any data is exchanged with cloud services, it will be encrypted and then deleted afterward. It’s a pitch that offers an implicit contrast with the likes of Alphabet, Amazon, or Meta, which collect and store enormous amounts of personal data. Read more from James O’Donnell here.
Bits and Bytes
How to opt out of Meta’s AI training If you post or interact with chatbots on Facebook, Instagram, Threads, or WhatsApp, Meta can use your data to train its generative AI models. Even if you don’t use any of Meta’s platforms, it can still scrape data such as photos of you if someone else posts them. Here’s our quick guide on how to opt out. (MIT Technology Review)
Microsoft’s Satya Nadella is building an AI empire Nadella is going all in on AI. His $13 billion investment in OpenAI was just the beginning. Microsoft has become an “the world’s most aggressive amasser of AI talent, tools, and technology” and has started building an in-house OpenAI competitor. (The Wall Street Journal)
OpenAI has hired an army of lobbyists As countries around the world mull AI legislation, OpenAI is on a lobbyist hiring spree to protect its interests. The AI company has expanded its global affairs team from three lobbyists at the start of 2023 to 35 and intends to have up to 50 by the end of this year. (Financial Times)
UK rolls out Amazon-powered emotion recognition AI cameras on trains People traveling through some of the UK’s biggest train stations have likely had their faces scanned by Amazon software without their knowledge during an AI trial. London stations such as Euston and Waterloo have tested CCTV cameras with AI to reduce crime and detect people’s emotions. Emotion recognition technology is extremely controversial. Experts say it is unreliable and simply does not work. (Wired)
Clearview AI used your face. Now you may get a stake in the company. The facial recognition company, which has been under fire for scraping images of people’s faces from the web and social media without their permission, has agreed to an unusual settlement in a class action against it. Instead of paying cash, it is offering a 23% stake in the company for Americans whose faces are in its data sets. (The New York Times)
Elephants call each other by their names This is so cool! Researchers used AI to analyze the calls of two herds of African savanna elephants in Kenya. They found that elephants use specific vocalizations for each individual and recognize when they are being addressed by other elephants. (The Guardian)
Meta has created a system that can embed hidden signals, known as watermarks, in AI-generated audio clips, which could help in detecting AI-generated content online.
The tool, called AudioSeal, is the first that can pinpoint which bits of audio in, for example, a full hourlong podcast might have been generated by AI. It could help to tackle the growing problem of misinformation and scams using voice cloning tools, says Hady Elsahar, a research scientist at Meta. Malicious actors have used generative AI to create audio deepfakes of President Joe Biden, and scammers have used deepfakes to blackmail their victims. Watermarks could in theory help social media companies detect and remove unwanted content.
However, there are some big caveats. Meta says it has no plans yet to apply the watermarks to AI-generated audio created using its tools. Audio watermarks are not yet adopted widely, and there is no single agreed industry standard for them. And watermarks for AI-generated content tend to be easy to tamper with—for example, by removing or forging them.
Fast detection, and the ability to pinpoint which elements of an audio file are AI-generated, will be critical to making the system useful, says Elsahar. He says the team achieved between 90% and 100% accuracy in detecting the watermarks, much better results than in previous attempts at watermarking audio.
AudioSeal is available on GitHub for free. Anyone can download it and use it to add watermarks to AI-generated audio clips. It could eventually be overlaid on top of AI audio generation models, so that it is automatically applied to any speech generated using them. The researchers who created it will present their work at the International Conference on Machine Learning in Vienna, Austria, in July.
AudioSeal is created using two neural networks. One generates watermarking signals that can be embedded into audio tracks. These signals are imperceptible to the human ear but can be detected quickly using the other neural network. Currently, if you want to try to spot AI-generated audio in a longer clip, you have to comb through the entire thing in second-long chunks to see if any of them contain a watermark. This is a slow and laborious process, and not practical on social media platforms with millions of minutes of speech.
AudioSeal works differently: by embedding a watermark throughout each section of the entire audio track. This allows the watermark to be “localized,” which means it can still be detected even if the audio is cropped or edited.
Ben Zhao, a computer science professor at the University of Chicago, says this ability, and the near-perfect detection accuracy, makes AudioSeal better than any previous audio watermarking system he’s come across.
“It’s meaningful to explore research improving the state of the art in watermarking, especially across mediums like speech that are often harder to mark and detect than visual content,” says Claire Leibowicz, head of AI and media integrity at the nonprofit Partnership on AI.
But there are some major flaws that need to be overcome before these sorts of audio watermarks can be adopted en masse. Meta’s researchers tested different attacks to remove the watermarks and found that the more information is disclosed about the watermarking algorithm, the more vulnerable it is. The system also requires people to voluntarily add the watermark to their audio files.
This places some fundamental limitations on the tool, says Zhao. “Where the attacker has some access to the [watermark] detector, it’s pretty fragile,” he says. And this means only Meta will be able to verify whether audio content is AI-generated or not.
Leibowicz says she remains unconvinced that watermarks will actually further public trust in the information they’re seeing or hearing, despite their popularity as a solution in the tech sector. That’s partly because they are themselves so open to abuse.
“I’m skeptical that any watermark will be robust to adversarial stripping and forgery,” she adds.
MIT Technology Review’s How To series helps you get things done.
If you post or interact with chatbots on Facebook, Instagram, Threads, or WhatsApp, Meta can use your data to train its generative AI models beginning June 26, according to its recently updated privacy policy. Even if you don’t use any of Meta’s platforms, it can still scrape data such as photos of you if someone else posts them.
Internet data scraping is one of the biggest fights in AI right now. Tech companies argue that anything on the public internet is fair game, but they are facing a barrage of lawsuits over their data practices and copyright. It will likely take years until clear rules are in place.
In the meantime, they are running out of training data to build even bigger, more powerful models, and to Meta, your posts are a gold mine.
If you’re uncomfortable with having Meta use your personal information and intellectual property to train its AI models in perpetuity, consider opting out. Although Meta does not guarantee it will allow this, it does say it will “review objection requests in accordance with relevant data protection laws.”
What that means for US users
Users in the US or other countries without national data privacy laws don’t have any foolproof ways to prevent Meta from using their data to train AI, which has likely already been used for such purposes. Meta does not have an opt-out feature for people living in these places.
A spokesperson for Meta says it does not use the content of people’s private messages to each other to train AI. However, public social media posts are seen as fair game and can be hoovered up into AI training data sets by anyone. Users who don’t want that can set their account settings to private to minimize the risk.
The company has built in-platform tools that allow people to delete their personal information from chats with Meta AI, the spokesperson says.
How users in Europe and the UK can opt out
Users in the European Union and the UK, which are protected by strict data protection regimes, have the right to object to their data being scraped, so they can opt out more easily.
If you have a Facebook account:
1. Log in to your account. You can access the new privacy policy by following this link. At the very top of the page, you should see a box that says “Learn more about your right to object.” Click on that link, or here.
Alternatively, you can click on your account icon at the top right-hand corner. Select “Settings and privacy” and then “Privacy center.” On the left-hand side you will see a drop-down menu labeled “How Meta uses information for generative AI models and features.” Click on that, and scroll down. Then click on “Right to object.”
2. Fill in the form with your information. The form requires you to explain how Meta’s data processing affects you. I was successful in my request by simply stating that I wished to exercise my right under data protection law to object to my personal data being processed. You will likely have to confirm your email address.
3. You should soon receive both an email and a notification on your Facebook account confirming if your request has been successful. I received mine a minute after submitting the request.
If you have an Instagram account:
1. Log in to your account. Go to your profile page, and click on the three lines at the top-right corner. Click on “Settings and privacy.”
2. Scroll down to the “More info and support” section, and click “About.” Then click on “Privacy policy.” At the very top of the page, you should see a box that says “Learn more about your right to object.” Click on that link, or here.
At its Worldwide Developer Conference on Monday, Apple for the first time unveiled its vision for supercharging its product lineup with artificial intelligence. The key feature, which will run across virtually all of its product line, is Apple Intelligence, a suite of AI-based capabilities that promises to deliver personalized AI services while keeping sensitive data secure. It represents Apple’s largest leap forward in using our private data to help AI do tasks for us. To make the case it can do this without sacrificing privacy, the company says it has built a new way to handle sensitive data in the cloud.
Apple says its privacy-focused system will first attempt to fulfill AI tasks locally on the device itself. If any data is exchanged with cloud services, it will be encrypted and then deleted afterward. The company also says the process, which it calls Private Cloud Compute, will be subject to verification by independent security researchers.
The pitch offers an implicit contrast with the likes of Alphabet, Amazon, or Meta, which collect and store enormous amounts of personal data. Apple says any personal data passed on to the cloud will be used only for the AI task at hand and will not be retained or accessible to the company, even for debugging or quality control, after the model completes the request.
Simply put, Apple is saying people can trust it to analyze incredibly sensitive data—photos, messages, and emails that contain intimate details of our lives—and deliver automated services based on what it finds there, without actually storing the data online or making any of it vulnerable.
It showed a few examples of how this will work in upcoming versions of iOS. Instead of scrolling through your messages for that podcast your friend sent you, for example, you could simply ask Siri to find and play it for you. Craig Federighi, Apple’s senior vice president of software engineering, walked through another scenario: an email comes in pushing back a work meeting, but his daughter is appearing in a play that night. His phone can now find the PDF with information about the performance, predict the local traffic, and let him know if he’ll make it on time. These capabilities will extend beyond apps made by Apple, allowing developers to tap into Apple’s AI too.
Because the company profits more from hardware and services than from ads, Apple has less incentive than some other companies to collect personal online data, allowing it to position the iPhone as the most private device. Even so, Apple has previously found itself in the crosshairs of privacy advocates. Security flaws led to leaks of explicit photos from iCloud in 2014. In 2019, contractors were found to be listening to intimate Siri recordings for quality control. Disputes about how Apple handles data requests from law enforcement are ongoing.
The first line of defense against privacy breaches, according to Apple, is to avoid cloud computing for AI tasks whenever possible. “The cornerstone of the personal intelligence system is on-device processing,” Federighi says, meaning that many of the AI models will run on iPhones and Macs rather than in the cloud. “It’s aware of your personal data without collecting your personal data.”
That presents some technical obstacles. Two years into the AI boom, pinging models for even simple tasks still requires enormous amounts of computing power. Accomplishing that with the chips used in phones and laptops is difficult, which is why only the smallest of Google’s AI models can be run on the company’s phones, and everything else is done via the cloud. Apple says its ability to handle AI computations on-device is due to years of research into chip design, leading to the M1 chips it began rolling out in 2020.
Yet even Apple’s most advanced chips can’t handle the full spectrum of tasks the company promises to carry out with AI. If you ask Siri to do something complicated, it may need to pass that request, along with your data, to models that are available only on Apple’s servers. This step, security experts say, introduces a host of vulnerabilities that may expose your information to outside bad actors, or at least to Apple itself.
“I always warn people that as soon as your data goes off your device, it becomes much more vulnerable,” says Albert Fox Cahn, executive director of the Surveillance Technology Oversight Project and practitioner in residence at NYU Law School’s Information Law Institute.
Apple claims to have mitigated this risk with its new Private Cloud Computer system. “For the first time ever, Private Cloud Compute extends the industry-leading security and privacy of Apple devices into the cloud,” Apple security experts wrote in their announcement, stating that personal data “isn’t accessible to anyone other than the user—not even to Apple.” How does it work?
Historically, Apple has encouraged people to opt in to end-to-end encryption (the same type of technology used in messaging apps like Signal) to secure sensitive iCloud data. But that doesn’t work for AI. Unlike messaging apps, where a company like WhatsApp does not need to see the contents of your messages in order to deliver them to your friends, Apple’s AI models need unencrypted access to the underlying data to generate responses. This is where Apple’s privacy process kicks in. First, Apple says, data will be used only for the task at hand. Second, this process will be verified by independent researchers.
Needless to say, the architecture of this system is complicated, but you can imagine it as an encryption protocol. If your phone determines it needs the help of a larger AI model, it will package a request containing the prompt it’s using and the specific model, and then put a lock on that request. Only the specific AI model to be used will have the proper key.
When asked by MIT Technology Review whether users will be notified when a certain request is sent to cloud-based AI models instead of being handled on-device, an Apple spokesperson said there will be transparency to users but that further details aren’t available.
Dawn Song, co-Director of UC Berkeley Center on Responsible Decentralized Intelligence and an expert in private computing, says Apple’s new developments are encouraging. “The list of goals that they announced is well thought out,” she says. “Of course there will be some challenges in meeting those goals.”
Cahn says that to judge from what Apple has disclosed so far, the system seems much more privacy-protective than other AI products out there today. That said, the common refrain in his space is “Trust but verify.” In other words, we won’t know how secure these systems keep our data until independent researchers can verify its claims, as Apple promises they will, and the company responds to their findings.
“Opening yourself up to independent review by researchers is a great step,” he says. “But that doesn’t determine how you’re going to respond when researchers tell you things you don’t want to hear.” Apple did not respond to questions from MIT Technology Review about how the company will evaluate feedback from researchers.
The privacy-AI bargain
Apple is not the only company betting that many of us will grant AI models mostly unfettered access to our private data if it means they could automate tedious tasks. OpenAI’s Sam Altman described his dream AI tool to MIT Technology Review as one “that knows absolutely everything about my whole life, every email, every conversation I’ve ever had.” At its own developer conference in May, Google announced Project Astra, an ambitious project to build a “universal AI agent that is helpful in everyday life.”
It’s a bargain that will force many of us to consider for the first time what role, if any, we want AI models to play in how we interact with our data and devices. When ChatGPT first came on the scene, that wasn’t a question we needed to ask. It was simply a text generator that could write us a birthday card or a poem, and the questions it raised—like where its training data came from or what biases it perpetuated—didn’t feel quite as personal.
Now, less than two years later, Big Tech is making billion-dollar bets that we trust the safety of these systems enough to fork over our private information. It’s not yet clear if we know enough to make that call, or how able we are to opt out even if we’d like to. “I do worry that we’re going to see this AI arms race pushing ever more of our data into other people’s hands,” Cahn says.
Apple will soon release beta versions of its Apple Intelligence features, starting this fall with the iPhone 15 and the new macOS Sequoia, which can be run on Macs and iPads with M1 chips or newer. Says Apple CEO Tim Cook, “We think Apple intelligence is going to be indispensable.”
The rise of generative AI, coupled with the rapid adoption and democratization of AI across industries this decade, has emphasized the singular importance of data. Managing data effectively has become critical to this era of business—making data practitioners, including data engineers, analytics engineers, and ML engineers, key figures in the data and AI revolution.
Organizations that fail to use their own data will fall behind competitors that do and miss out on opportunities to uncover new value for themselves and their customers. As the quantity and complexity of data grows, so do its challenges, forcing organizations to adopt new data tools and infrastructure which, in turn, change the roles and mandate of the technology workforce.
Data practitioners are among those whose roles are experiencing the most significant change, as organizations expand their responsibilities. Rather than working in a siloed data team, data engineers are now developing platforms and tools whose design improves data visibility and transparency for employees across the organization, including analytics engineers, data scientists, data analysts, machine learning engineers, and business stakeholders.
This report explores, through a series of interviews with expert data practitioners, key shifts in data engineering, the evolving skill set required of data practitioners, options for data infrastructure and tooling to support AI, and data challenges and opportunities emerging in parallel with generative AI. The report’s key findings include the following:
The foundational importance of data is creating new demands on data practitioners. As the rise of AI demonstrates the business importance of data more clearly than ever, data practitioners are encountering new data challenges, increasing data complexity, evolving team structures, and emerging tools and technologies—as well as establishing newfound organizational importance.
Data practitioners are getting closer to the business, and the business closer to the data. The pressure to create value from data has led executives to invest more substantially in data-related functions. Data practitioners are being asked to expand their knowledge of the business, engage more deeply with business units, and support the use of data in the organization, while functional teams are finding they require their own internal data expertise to leverage their data.
The data and AI strategy has become a key part of the business strategy. Business leaders need to invest in their data and AI strategy—including making important decisions about the data team’s organizational structure, data platform and architecture, and data governance—because every business’s key differentiator will increasingly be its data.
Data practitioners will shape how generative AI is deployed in the enterprise. The key considerations for generative AI deployment—producing high-quality results, preventing bias and hallucinations, establishing governance, designing data workflows, ensuring regulatory compliance—are the province of data practitioners, giving them outsize influence on how this powerful technology will be put to work.
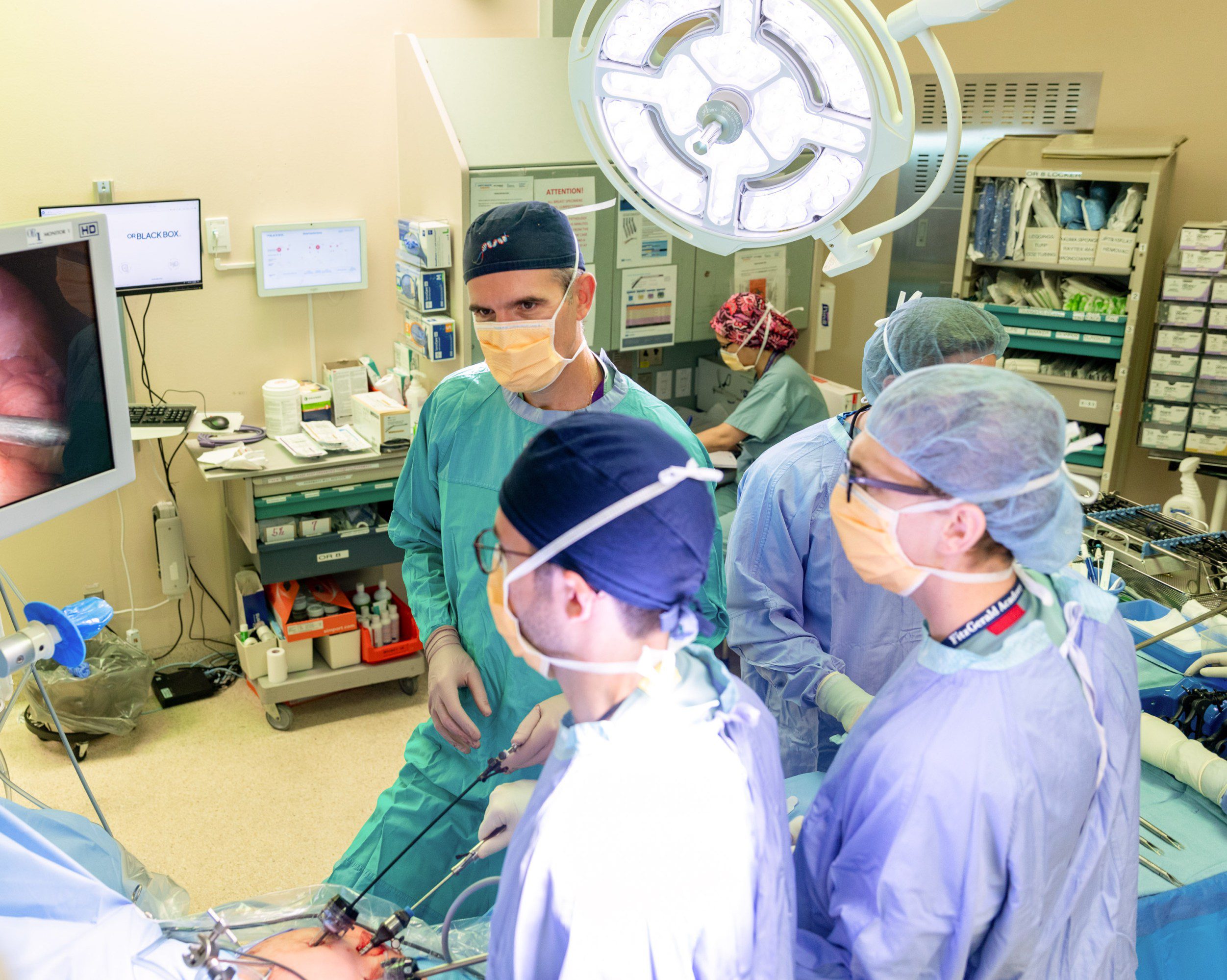
The first time Teodor Grantcharov sat down to watch himself perform surgery, he wanted to throw the VHS tape out the window.
“My perception was that my performance was spectacular,” Grantcharov says, and then pauses—“until the moment I saw the video.” Reflecting on this operation from 25 years ago, he remembers the roughness of his dissection, the wrong instruments used, the inefficiencies that transformed a 30-minute operation into a 90-minute one. “I didn’t want anyone to see it.”
This reaction wasn’t exactly unique. The operating room has long been defined by its hush-hush nature—what happens in the OR stays in the OR—because surgeons are notoriously bad at acknowledging their own mistakes. Grantcharov jokes that when you ask “Who are the top three surgeons in the world?” a typical surgeon “always has a challenge identifying who the other two are.”
But after the initial humiliation over watching himself work, Grantcharov started to see the value in recording his operations. “There are so many small details that normally take years and years of practice to realize—that some surgeons never get to that point,” he says. “Suddenly, I could see all these insights and opportunities overnight.”
There was a big problem, though: it was the ’90s, and spending hours playing back grainy VHS recordings wasn’t a realistic quality improvement strategy. It would have been nearly impossible to determine how often his relatively mundane slipups happened at scale—not to mention more serious medical errors like those that kill some 22,000 Americans each year. Many of these errors happen on the operating table, from leaving surgical sponges inside patients’ bodies to performing the wrong procedure altogether.
While the patient safety movement has pushed for uniform checklists and other manual fail-safes to prevent such mistakes, Grantcharov believes that “as long as the only barrier between success and failure is a human, there will be errors.” Improving safety and surgical efficiency became something of a personal obsession. He wanted to make it challenging to make mistakes, and he thought developing the right system to create and analyze recordings could be the key.
It’s taken many years, but Grantcharov, now a professor of surgery at Stanford, believes he’s finally developed the technology to make this dream possible: the operating room equivalent of an airplane’s black box. It records everything in the OR via panoramic cameras, microphones, and anesthesia monitors before using artificial intelligence to help surgeons make sense of the data.
Grantcharov’s company, Surgical Safety Technologies, is not the only one deploying AI to analyze surgeries. Many medical device companies are already in the space—including Medtronic with its Touch Surgery platform, Johnson & Johnson with C-SATS, and Intuitive Surgical with Case Insights.
But most of these are focused solely on what’s happening inside patients’ bodies, capturing intraoperative video alone. Grantcharov wants to capture the OR as a whole, from the number of times the door is opened to how many non-case-related conversations occur during an operation. “People have simplified surgery to technical skills only,” he says. “You need to study the OR environment holistically.”
Teodor Grantcharov in a procedure that is being recorded by Surgical Safety Technologies’ AI-powered black-box system.
COURTESY OF SURGICAL SAFETY TECHNOLOGIES
Success, however, isn’t as simple as just having the right technology. The idea of recording everything presents a slew of tricky questions around privacy and could raise the threat of disciplinary action and legal exposure. Because of these concerns, some surgeons have refused to operate when the black boxes are in place, and some of the systems have even been sabotaged. Aside from those problems, some hospitals don’t know what to do with all this new data or how to avoid drowning in a deluge of statistics.
Grantcharov nevertheless predicts that his system can do for the OR what black boxes did for aviation. In 1970, the industry was plagued by 6.5 fatal accidents for every million flights; today, that’s down to less than 0.5. “The aviation industry made the transition from reactive to proactive thanks to data,” he says—“from safe to ultra-safe.”
Grantcharov’s black boxes are now deployed at almost 40 institutions in the US, Canada, and Western Europe, from Mount Sinai to Duke to the Mayo Clinic. But are hospitals on the cusp of a new era of safety—or creating an environment of confusion and paranoia?
Shaking off the secrecy
The operating room is probably the most measured place in the hospital but also one of the most poorly captured. From team performance to instrument handling, there is “crazy big data that we’re not even recording,” says Alexander Langerman, an ethicist and head and neck surgeon at Vanderbilt University Medical Center. “Instead, we have post hoc recollection by a surgeon.”
Indeed, when things go wrong, surgeons are supposed to review the case at the hospital’s weekly morbidity and mortality conferences, but these errors are notoriously underreported. And even when surgeons enter the required notes into patients’ electronic medical records, “it’s undoubtedly—and I mean this in the least malicious way possible—dictated toward their best interests,” says Langerman. “It makes them look good.”
The operating room wasn’t always so secretive.
In the 19th century, operations often took place in large amphitheaters—they were public spectacles with a general price of admission. “Every seat even of the top gallery was occupied,” recounted the abdominal surgeon Lawson Tait about an operation in the 1860s. “There were probably seven or eight hundred spectators.”
However, around the 1900s, operating rooms became increasingly smaller and less accessible to the public—and its germs. “Immediately, there was a feeling that something was missing, that the public surveillance was missing. You couldn’t know what happened in the smaller rooms,” says Thomas Schlich, a historian of medicine at McGill University.
And it was nearly impossible to go back. In the 1910s a Boston surgeon, Ernest Codman, suggested a form of surveillance known as the end-result system, documenting every operation (including failures, problems, and errors) and tracking patient outcomes. Massachusetts General Hospital didn’t accept it, says Schlich, and Codman resigned in frustration.
Students watch a surgery performed at the former Philadelphia General Hospital around the turn of the century.
PUBLIC DOMAIN VIA WIKIPEDIA
Such opacity was part of a larger shift toward medicine’s professionalization in the 20th century, characterized by technological advancements, the decline of generalists, and the bureaucratization of health-care institutions. All of this put distance between patients and their physicians. Around the same time, and particularly from the 1960s onward, the medical field began to see a rise in malpractice lawsuits—at least partially driven by patients trying to find answers when things went wrong.
This battle over transparency could theoretically be addressed by surgical recordings. But Grantcharov realized very quickly that the only way to get surgeons to use the black box was to make them feel protected. To that end, he has designed the system to record the action but hide the identity of both patients and staff, even deleting all recordings within 30 days. His idea is that no individual should be punished for making a mistake. “We want to know what happened, and how we can build a system that makes it difficult for this to happen,” Grantcharov says. Errors don’t occur because “the surgeon wakes up in the morning and thinks, ‘I’m gonna make some catastrophic event happen,’” he adds. “This is a system issue.”
AI that sees everything
Grantcharov’s OR black box is not actually a box at all, but a tablet, one or two ceiling microphones, and up to four wall-mounted dome cameras that can reportedly analyze more than half a million data points per day per OR. “In three days, we go through the entire Netflix catalogue in terms of video processing,” he says.
The black-box platform utilizes a handful of computer vision models and ultimately spits out a series of short video clips and a dashboard of statistics—like how much blood was lost, which instruments were used, and how many auditory disruptions occurred. The system also identifies and breaks out key segments of the procedure (dissection, resection, and closure) so that instead of having to watch a whole three- or four-hour recording, surgeons can jump to the part of the operation where, for instance, there was major bleeding or a surgical stapler misfired.
Critically, each person in the recording is rendered anonymous; an algorithm distorts people’s voices and blurs out their faces, transforming them into shadowy, noir-like figures. “For something like this, privacy and confidentiality are critical,” says Grantcharov, who claims the anonymization process is irreversible. “Even though you know what happened, you can’t really use it against an individual.”
Another AI model works to evaluate performance. For now, this is done primarily by measuring compliance with the surgical safety checklist—a questionnaire that is supposed to be verbally ticked off during every type of surgical operation. (This checklist has long been associated with reductions in both surgical infections and overall mortality.) Grantcharov’s team is currently working to train more complex algorithms to detect errors during laparoscopic surgery, such as using excessive instrument force, holding the instruments in the wrong way, or failing to maintain a clear view of the surgical area. However, assessing these performance metrics has proved more difficult than measuring checklist compliance. “There are some things that are quantifiable, and some things require judgment,” Grantcharov says.
Each model has taken up to six months to train, through a labor-intensive process relying on a team of 12 analysts in Toronto, where the company was started. While many general AI models can be trained by a gig worker who labels everyday items (like, say, chairs), the surgical models need data annotated by people who know what they’re seeing—either surgeons, in specialized cases, or other labelers who have been properly trained. They have reviewed hundreds, sometimes thousands, of hours of OR videos and manually noted which liquid is blood, for instance, or which tool is a scalpel. Over time, the model can “learn” to identify bleeding or particular instruments on its own, says Peter Grantcharov, Surgical Safety Technologies’ vice president of engineering, who is Teodor Grantcharov’s son.
For the upcoming laparoscopic surgery model, surgeon annotators have also started to label whether certain maneuvers were correct or mistaken, as defined by the Generic Error Rating Tool—a standardized way to measure technical errors.
While most algorithms operate near perfectly on their own, Peter Grantcharov explains that the OR black box is still not fully autonomous. For example, it’s difficult to capture audio through ceiling mikes and thus get a reliable transcript to document whether every element of the surgical safety checklist was completed; he estimates that this algorithm has a 15% error rate. So before the output from each procedure is finalized, one of the Toronto analysts manually verifies adherence to the questionnaire. “It will require a human in the loop,” Peter Grantcharov says, but he gauges that the AI model has made the process of confirming checklist compliance 80% to 90% more efficient. He also emphasizes that the models are constantly being improved.
In all, the OR black box can cost about $100,000 to install, and analytics expenses run $25,000 annually, according to Janet Donovan, an OR nurse who shared with MIT Technology Review an estimate given to staff at Brigham and Women’s Faulkner Hospital in Massachusetts. (Peter Grantcharov declined to comment on these numbers, writing in an email: “We don’t share specific pricing; however, we can say that it’s based on the product mix and the total number of rooms, with inherent volume-based discounting built into our pricing models.”)
“Big brother is watching”
Long Island Jewish Medical Center in New York, part of the Northwell Health system, was the first hospital to pilot OR black boxes, back in February 2019. The rollout was far from seamless, though not necessarily because of the tech.
“In the colorectal room, the cameras were sabotaged,” recalls Northwell’s chair of urology, Louis Kavoussi—they were turned around and deliberately unplugged. In his own OR, the staff fell silent while working, worried they’d say the wrong thing. “Unless you’re taking a golf or tennis lesson, you don’t want someone staring there watching everything you do,” says Kavoussi, who has since joined the scientific advisory board for Surgical Safety Technologies.
Grantcharov’s promises about not using the system to punish individuals have offered little comfort to some OR staff. When two black boxes were installed at Faulkner Hospital in November 2023, they threw the department of surgery into crisis. “Everybody was pretty freaked out about it,” says one surgical tech who asked not to be identified by name since she wasn’t authorized to speak publicly. “We were being watched, and we felt like if we did something wrong, our jobs were going to be on the line.”
It wasn’t that she was doing anything illegal or spewing hate speech; she just wanted to joke with her friends, complain about the boss, and be herself without the fear of administrators peeking over her shoulder. “You’re very aware that you’re being watched; it’s not subtle at all,” she says. The early days were particularly challenging, with surgeons refusing to work in the black-box-equipped rooms and OR staff boycotting those operations: “It was definitely a fight every morning.”
“In the colorectal room, the cameras were sabotaged,” recalls Louis Kavoussi. “Unless you’re taking a golf or tennis lesson, you don’t want someone staring there watching everything you do.”
At some level, the identity protections are only half measures. Before 30-day-old recordings are automatically deleted, Grantcharov acknowledges, hospital administrators can still see the OR number, the time of operation, and the patient’s medical record number, so even if OR personnel are technically de-identified, they aren’t truly anonymous. The result is a sense that “Big Brother is watching,” says Christopher Mantyh, vice chair of clinical operations at Duke University Hospital, which has black boxes in seven ORs. He will draw on aggregate data to talk generally about quality improvement at departmental meetings, but when specific issues arise, like breaks in sterility or a cluster of infections, he will look to the recordings and “go to the surgeons directly.”
In many ways, that’s what worries Donovan, the Faulkner Hospital nurse. She’s not convinced the hospital will protect staff members’ identities and is worried that these recordings will be used against them—whether through internal disciplinary actions or in a patient’s malpractice suit. In February 2023, she and almost 60 others sent a letter to the hospital’s chief of surgery objecting to the black box. She’s since filed a grievance with the state, with arbitration proceedings scheduled for October.
The legal concerns in particular loom large because, already, over 75% of surgeons report having been sued at least once, according to a 2021 survey by Medscape, an online resource hub for health-care professionals. To the layperson, any surgical video “looks like a horror show,” says Vanderbilt’s Langerman. “Some plaintiff’s attorney is going to get ahold of this, and then some jury is going to see a whole bunch of blood, and then they’re not going to know what they’re seeing.” That prospect turns every recording into a potential legal battle.
From a purely logistical perspective, however, the 30-day deletion policy will likely insulate these recordings from malpractice lawsuits, according to Teneille Brown, a law professor at the University of Utah. She notes that within that time frame, it would be nearly impossible for a patient to find legal representation, go through the requisite conflict-of-interest checks, and then file a discovery request for the black-box data. While deleting data to bypass the judicial system could provoke criticism, Brown sees the wisdom of Surgical Safety Technologies’ approach. “If I were their lawyer, I would tell them to just have a policy of deleting it because then they’re deleting the good and the bad,” she says. “What it does is orient the focus to say, ‘This is not about a public-facing audience. The audience for these videos is completely internal.’”
A data deluge
When it comes to improving quality, there are “the problem-first people, and then there are the data-first people,” says Justin Dimick, chair of the department of surgery at the University of Michigan. The latter, he says, push “massive data collection” without first identifying “a question of ‘What am I trying to fix?’” He says that’s why he currently has no plans to use the OR black boxes in his hospital.
Mount Sinai’s chief of general surgery, Celia Divino, echoes this sentiment, emphasizing that too much data can be paralyzing. “How do you interpret it? What do you do with it?” she asks. “This is always a disease.”
At Northwell, even Kavoussi admits that five years of data from OR black boxes hasn’t been used to change much, if anything. He says that hospital leadership is finally beginning to think about how to use the recordings, but a hard question remains: OR black boxes can collect boatloads of data, but what does it matter if nobody knows what to do with it?
Grantcharov acknowledges that the information can be overwhelming. “In the early days, we let the hospitals figure out how to use the data,” he says. “That led to a big variation in how the data was operationalized. Some hospitals did amazing things; others underutilized it.” Now the company has a dedicated “customer success” team to help hospitals make sense of the data, and it offers a consulting-type service to work through surgical errors. But ultimately, even the most practical insights are meaningless without buy-in from hospital leadership, Grantcharov suggests.
Getting that buy-in has proved difficult in some centers, at least partly because there haven’t yet been any large, peer-reviewed studies showing how OR black boxes actually help to reduce patient complications and save lives. “If there’s some evidence that a comprehensive data collection system—like a black box—is useful, then we’ll do it,” says Dimick. “But I haven’t seen that evidence yet.”
A screenshot of the analytics produced by the black box.
COURTESY OF SURGICAL SAFETY TECHNOLOGIES
The best hard data thus far is from a 2022 study published in the Annals of Surgery, in which Grantcharov and his team used OR black boxes to show that the surgical checklist had not been followed in a fifth of operations, likely contributing to excess infections. He also says that an upcoming study, scheduled to be published this fall, will show that the OR black box led to an improvement in checklist compliance and reduced ICU stays, reoperations, hospital readmissions, and mortality.
On a smaller scale, Grantcharov insists that he has built a steady stream of evidence showing the power of his platform. For example, he says, it’s revealed that auditory disruptions—doors opening, machine alarms and personal pagers going off—happen every minute in gynecology ORs, that a median 20 intraoperative errors are made in each laparoscopic surgery case, and that surgeons are great at situational awareness and leadership while nurses excel at task management.
Meanwhile, some hospitals have reported small improvements based on black-box data. Duke’s Mantyh says he’s used the data to check how often antibiotics are given on time. Duke and other hospitals also report turning to this data to help decrease the amount of time ORs sit empty between cases. By flagging when “idle” times are unexpectedly long and having the Toronto analysts review recordings to explain why, they’ve turned up issues ranging from inefficient communication to excessive time spent bringing in new equipment.
That can make a bigger difference than one might think, explains Ra’gan Laventon, clinical director of perioperative services at Texas’s Memorial Hermann Sugar Land Hospital: “We have multiple patients who are depending on us to get to their care today. And so the more time that’s added in some of these operational efficiencies, the more impactful it is to the patient.”
The real world
At Northwell, where some of the cameras were initially sabotaged, it took a couple of weeks for Kavoussi’s urology team to get used to the black boxes, and about six months for his colorectal colleagues. Much of the solution came down to one-on-one conversations in which Kavoussi explained how the data was automatically de-identified and deleted.
During his operations, Kavoussi would also try to defuse the tension, telling the OR black box “Good morning, Toronto,” or jokingly asking, “How’s the weather up there?” In the end, “since nothing bad has happened, it has become part of the normal flow,” he says.
The reality is that no surgeon wants to be an average operator, “but statistically, we’re mostly average surgeons, and that’s okay,” says Vanderbilt’s Langerman. “I’d hate to be a below-average surgeon, but if I was, I’d really want to know about it.” Like athletes watching game film to prepare for their next match, surgeons might one day review their recordings, assessing their mistakes and thinking about the best ways to avoid them—but only if they feel safe enough to do so.
“Until we know where the guardrails are around this, there’s such a risk—an uncertain risk—that no one’s gonna let anyone turn on the camera,” Langerman says. “We live in a real world, not a perfect world.”
Simar Bajaj is an award-winning science journalist and 2024 Marshall Scholar. He has previously written for the Washington Post, Time magazine, the Guardian, NPR, and the Atlantic, as well as the New England Journal of Medicine, Nature Medicine, and The Lancet. He won Science Story of the Year from the Foreign Press Association in 2022 and the top prize for excellence in science communications from the National Academies of Science, Engineering, and Medicine in 2023. Follow him on X at @SimarSBajaj.