Ahrefs analyzed 146 million search results to determine which query types trigger AI Overviews. The research tracked AIO appearance across 86 keyword characteristics.
Here’s a concise look at the patterns and how they may affect your strategy.
What The Analysis Found
AI Overviews appear on 20.5% of all keywords. Specific query types show notable variance, with some categories hitting 60% trigger rates while others stay below 2%.
Patterns Observed Across Query Types
Single-word queries activate AIOs only 9.5% of the time, whereas queries with seven or more words trigger them 46.4%. This correlation indicates that Google primarily uses AIOs for complex informational searches rather than simple lookups.
The question format also shows a similar trend: question-based queries result in AIOs 57.9% of the time, while non-question queries have a much lower rate of 15.5%.
The most significant distinctions are seen based on intent. Informational queries make up 99.9% of all AIO appearances, while navigational queries trigger AIOs just 0.09%. Commercial queries account for 4.3%, and transactional queries for 2.1%.
Patterns Observed Across Industry Categories
Science queries have an AIO rate of 43.6%, while health queries are at 43.0%, and pets & animals reach 36.8%. People & society questions result in AIOs 35.3% of the time.
In contrast, commerce categories exhibit opposite trends. Shopping queries are associated with AIOs only 3.2% of the time, the lowest in the dataset. Real estate remains at 5.8%, sports at 14.8%, and news at 15.1%.
YMYL queries display unexpectedly high trigger rates. Medical YMYL searches trigger AI Overviews 44.1% of the time, financial YMYL hits 22.9%, and safety YMYL reaches 31.0%.
These findings contradict Google’s focus on expert content for topics that could impact health, financial security, or safety.
Queries With Low Presence Of AI Overviews
6.3% of “very newsy” keywords trigger AI Overviews, while 20.7% of non-news queries display AIOs.
The pattern indicates that Google deliberately limits AIOs for time-sensitive content where accuracy and freshness are essential.
Local searches demonstrate a similar trend, with only 7.9% of local queries showing AI Overviews compared to 22.8% for non-local queries.
NSFW content consistently avoids AIOs across categories: adult queries trigger AIOs 1.5% of the time, gambling 1.4%, and violence 7.7%. Drug-related queries have the highest NSFW trigger rate at 12.6%, yet this remains well below the baseline.
Brand vs. Non-Brand
Branded keywords show slight differences compared to non-branded ones. Non-branded queries trigger AIOs 24.9% of the time, whereas branded queries do so 13.1% of the time.
The data indicates that AIOs occur 1.9 times more frequently for generic searches than for brand-specific lookups.
No Correlation With CPC
CPC shows no meaningful correlation with AIO appearance. Keyword cost-per-click values don’t affect trigger rates across any price range tested, with rates hovering between 12.4% and 27.6% regardless of commercial value.
Why This Matters
Publishers focused on informational content encounter the greatest AIO exposure. Question-based and how-to guides align closely with Google’s trigger criteria, putting educational content publishers at the highest risk of traffic loss.
Medical content has the highest category-specific AIO rate, despite concerns about AI accuracy in health advice.
Ecommerce and news publishers are relatively less affected by AIOs. The low trigger rates for shopping and news queries indicate these sectors experience less AI-driven traffic disruption compared to informational sites.
Looking Ahead
Using this data, publishers can review their current keyword portfolios to identify AIO exposure patterns. The most reliable indicators are query intent and length, with industry category and question format also playing significant roles.
AIO exposure varies considerably across different industry categories, with differences exceeding 40 percentage points between the highest and lowest. Content strategies need to consider this variation at the category level instead of assuming consistent baseline risk across all topics.
This post was sponsored by TAC Marketing. The opinions expressed in this article are the sponsor’s own.
After years of trying to understand the black box that is Google search, SEO professionals have a seemingly even more opaque challenge these days – how to earn AI citations.
While at first glance inclusion in AI answers seems even more of a mystery than traditional SEO, there is good news. Once you know how to look for them, the AI engines do provide clues to what they consider valuable content.
This article will give you a step-by-step guide to discovering the content that AI engines value and provide a blueprint for optimizing your website for AI citations.
Take A Systematic Approach To AI Engine Optimization
The key to building an effective AI search optimization strategy begins with understanding the behavior of AI crawlers. By analyzing how these bots interact with your site, you can identify what content resonates with AI systems and develop a data-driven approach to optimization.
While Google remains dominant, AI-powered search engines like ChatGPT, Perplexity, and Claude are increasingly becoming go-to resources for users seeking quick, authoritative answers. These platforms don’t just generate responses from thin air – they rely on crawled web content to train their models and provide real-time information.
This presents both an opportunity and a challenge. The opportunity lies in positioning your content to be discovered and referenced by these AI systems. The challenge is understanding how to optimize for algorithms that operate differently from traditional search engines.
The Answer Is A Systematic Approach
Discover what content AI engines value based on their crawler behavior.
Traditional log file analysis.
SEO Bulk Admin AI Crawler monitoring.
Reverse engineer prompting.
Content analysis.
Technical analysis.
Building the blueprint.
What Are AI Crawlers & How To Use Them To Your Advantage
AI crawlers are automated bots deployed by AI companies to systematically browse and ingest web content. Unlike traditional search engine crawlers that primarily focus on ranking signals, AI crawlers gather content to train language models and populate knowledge bases.
Major AI crawlers include:
GPTBot (OpenAI’s ChatGPT).
PerplexityBot (Perplexity AI).
ClaudeBot (Anthropic’s Claude).
Googlebot crawlers (Google AI).
These crawlers impact your content strategy in two critical ways:
Training data collection.
Real-time information retrieval.
Training Data Collection
AI models are trained on vast datasets of web content. Pages that are crawled frequently may have a higher representation in training data, potentially increasing the likelihood of your content being referenced in AI responses.
Real-Time Information Retrieval
Some AI systems crawl websites in real-time to provide current information in their responses. This means fresh, crawlable content can directly influence AI-generated answers.
When ChatGPT responds to a query, for instance, it’s synthesizing information gathered by its underlying AI crawlers. Similarly, Perplexity AI, known for its ability to cite sources, actively crawls and processes web content to provide its answers. Claude also relies on extensive data collection to generate its intelligent responses.
The presence and activity of these AI crawlers on your site directly impact your visibility within these new AI ecosystems. They determine whether your content is considered a source, if it’s used to answer user questions, and ultimately, if you gain attribution or traffic from AI-driven search experiences.
Understanding which pages AI crawlers visit most frequently gives you insight into what content AI systems find valuable. This data becomes the foundation for optimizing your entire content strategy.
How To Track AI Crawler Activity: Find & Use Log File Analysis
The Easy Way: We use SEO Bulk Admin to analyze server log files for us.
However, there’s a manual way to do it, as well.
Server log analysis remains the standard for understanding crawler behavior. Your server logs contain detailed records of every bot visit, including AI crawlers that may not appear in traditional analytics platforms, which focus on user visits.
Essential Tools For Log File Analysis
Several enterprise-level tools can help you parse and analyze log files:
Screaming Frog Log File Analyser: Excellent for technical SEOs comfortable with data manipulation.
Botify: Enterprise solution with robust crawler analysis features.
Semrush: Offers log file analysis within its broader SEO suite.
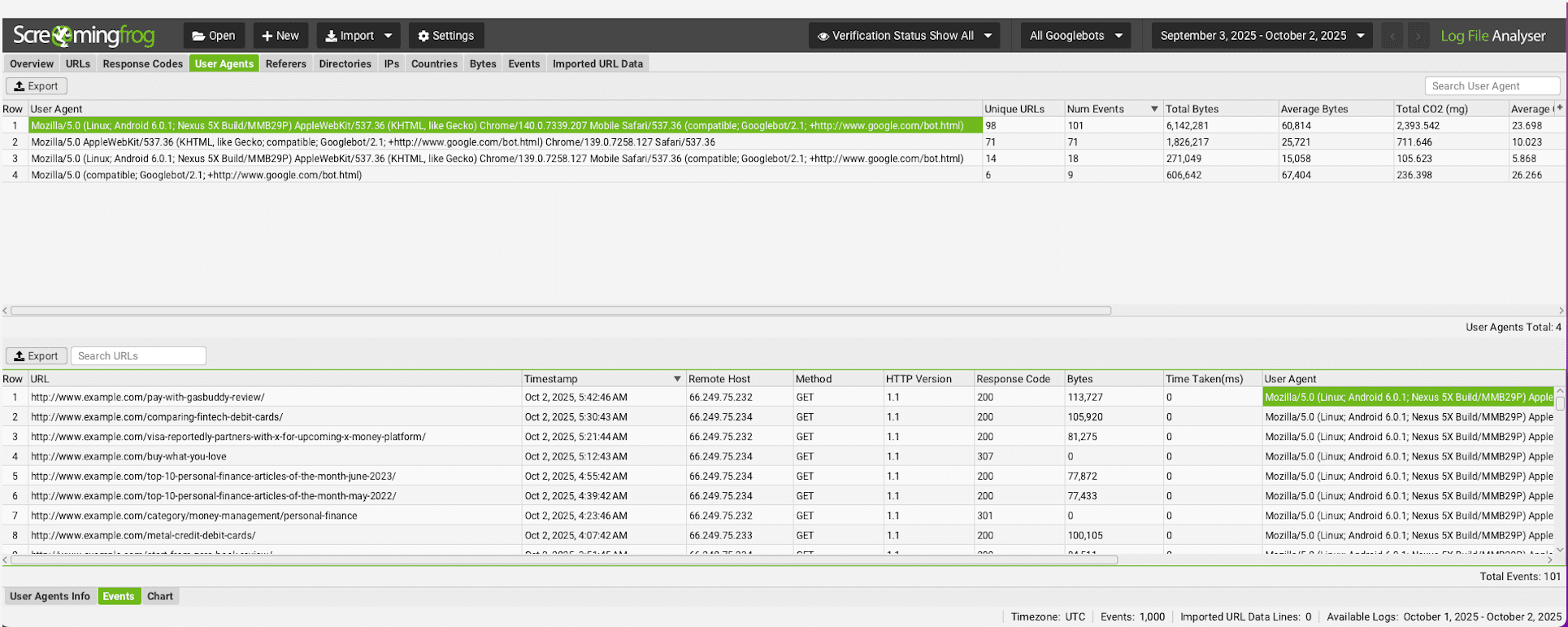
Screenshot from Screaming Frog Log File Analyser, October 2025
The Complexity Challenge With Log File Analysis
The most granular way to understand which bots are visiting your site, what they’re accessing, and how frequently, is through server log file analysis.
Your web server automatically records every request made to your site, including those from crawlers. By parsing these logs, you can identify specific user-agents associated with AI crawlers.
Here’s how you can approach it:
Access Your Server Logs: Typically, these are found in your hosting control panel or directly on your server via SSH/FTP (e.g., Apache access logs, Nginx access logs).
Identify AI User-Agents: You’ll need to know the specific user-agent strings used by AI crawlers. While these can change, common ones include:
OpenAI (for ChatGPT, e.g., `ChatGPT-User` or variations)
Perplexity AI (e.g., `PerplexityBot`)
Anthropic (for Claude, though often less distinct or may use a general cloud provider UAs)
Other LLM-related bots (e.g., “GoogleBot” and `Google-Extended` for Google’s AI initiatives, potentially `Vercelbot` or other cloud infrastructure bots that LLMs might use for data fetching).
Parse and Analyze: This is where the previously mentioned log analyzer tools come into play. Upload your raw log files into the analyzer and start filtering the results to identify AI crawler and search bot activity. Alternatively, for those with technical expertise, Python scripts or tools like Splunk or Elasticsearch can be configured to parse logs, identify specific user-agents, and visualize the data.
While log file analysis provides the most comprehensive data, it comes with significant barriers for many SEOs:
Technical Depth: Requires server access, understanding of log formats, and data parsing skills.
Resource Intensive: Large sites generate massive log files that can be challenging to process.
Time Investment: Setting up proper analysis workflows takes considerable upfront effort.
Parsing Challenges: Distinguishing between different AI crawlers requires detailed user-agent knowledge.
For teams without dedicated technical resources, these barriers can make log file analysis impractical despite its value.
An Easier Way To Monitor AI Visits: SEO Bulk Admin
While log file analysis provides granular detail, its complexity can be a significant barrier for all but the most highly technical users. Fortunately, tools like SEO Bulk Admin can offer a streamlined alternative.
The SEO Bulk Admin WordPress plugin automatically tracks and reports AI crawler activity without requiring server log access or complex setup procedures. The tool provides:
Automated Detection: Recognizes major AI crawlers, including GPTBot, PerplexityBot, and ClaudeBot, without manual configuration.
User-Friendly Dashboard: Presents crawler data in an intuitive interface accessible to SEOs at all technical levels.
Real-Time Monitoring: Tracks AI bot visits as they happen, providing immediate insights into crawler behavior.
Page-Level Analysis: Shows which specific pages AI crawlers visit most frequently, enabling targeted optimization efforts.
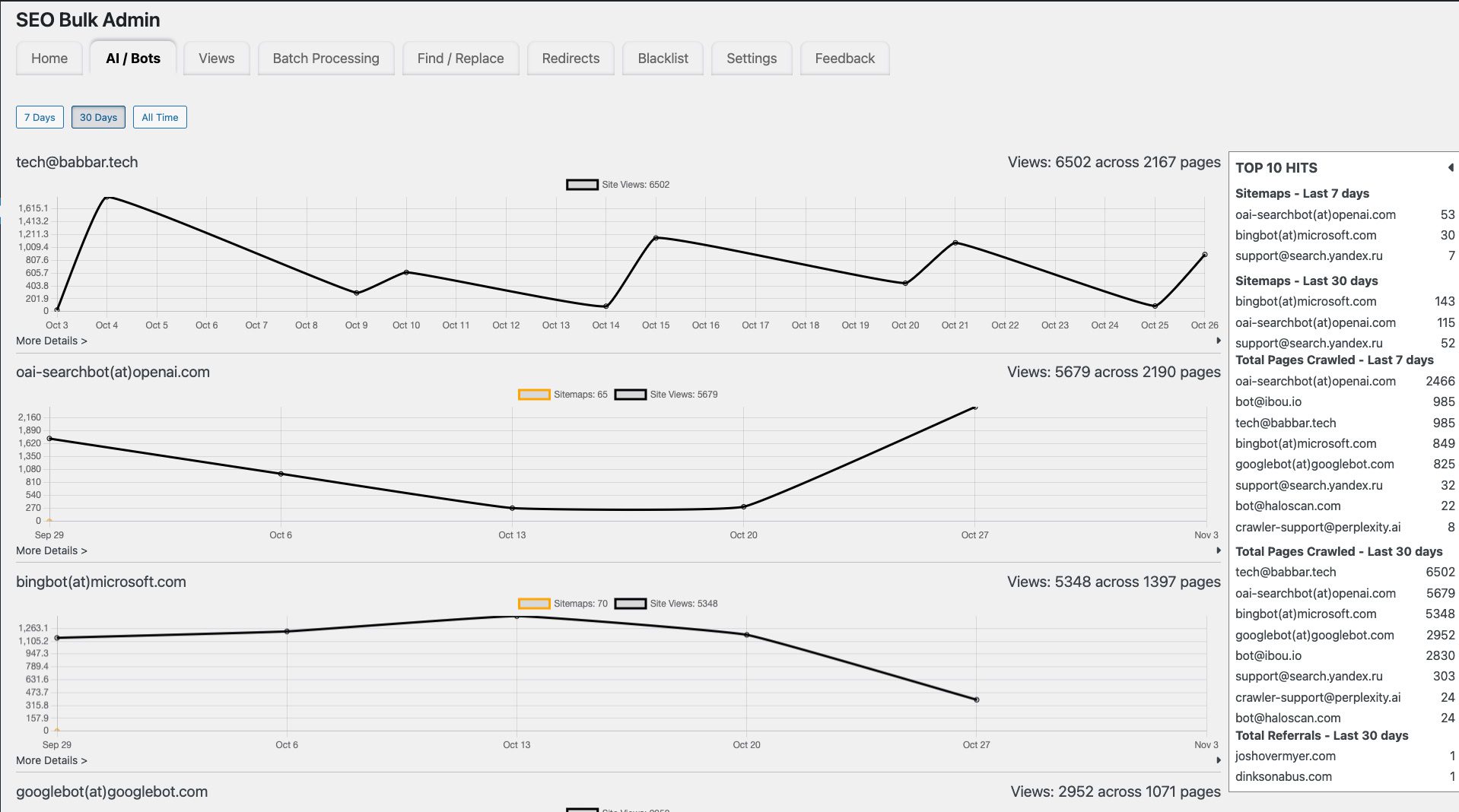
Screenshot of SEO Bulk Admin AI/Bots Activity, October 2025
This gives SEOs instant visibility into which pages are being accessed by AI engines – without needing to parse server logs or write scripts.
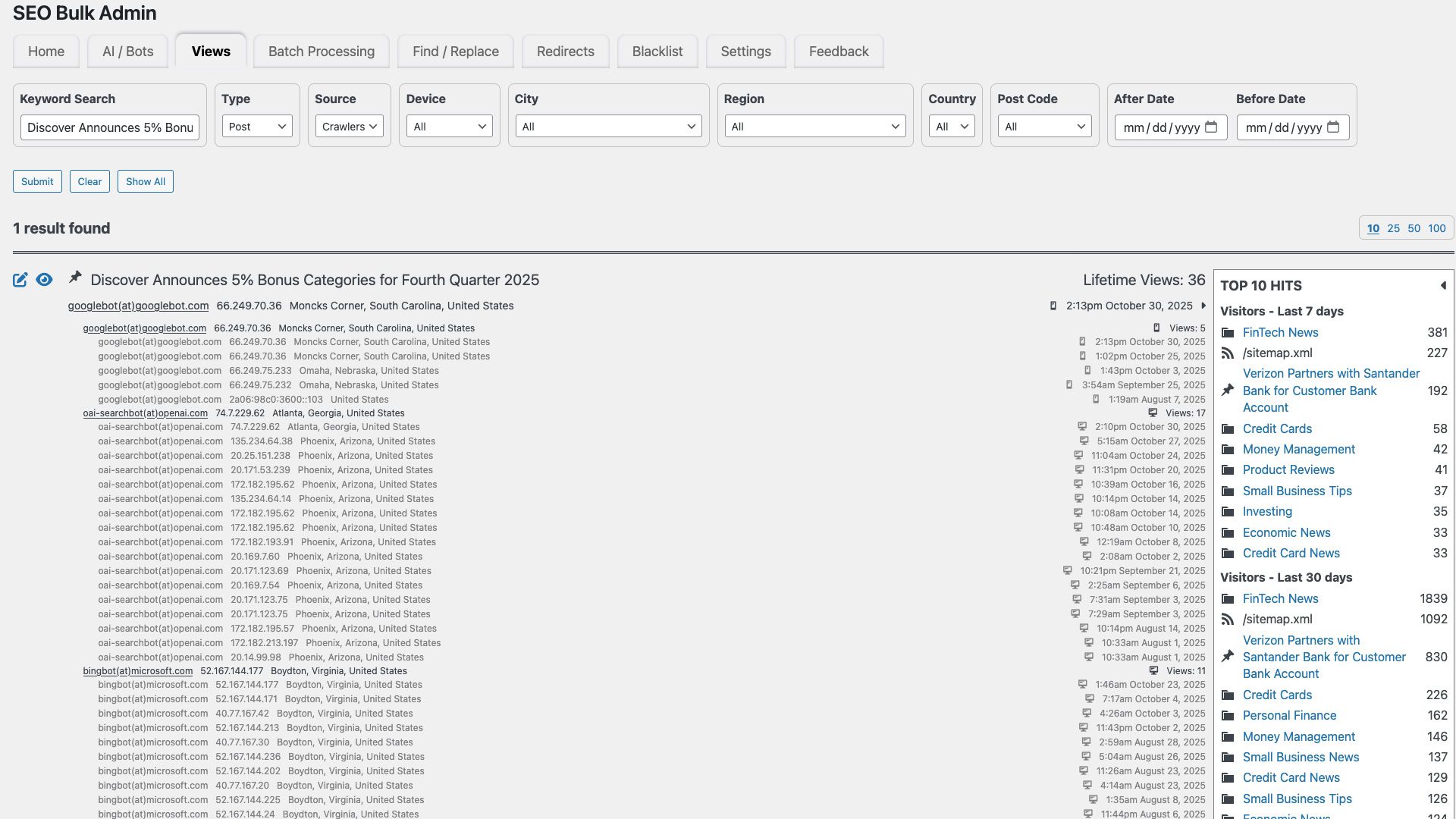
Screenshot of SEO Bulk Admin Page Level Crawler Activity, October 2025
Using AI Crawler Data To Improve Content Strategy
Once you’re tracking AI crawler activity, the real optimization work begins. AI crawler data reveals patterns that can transform your content strategy from guesswork into data-driven decision-making.
Here’s how to harness those insights:
1. Identify AI-Favored Content
High-frequency pages: Look for pages that AI crawlers visit most frequently. These are the pieces of content that these bots are consistently accessing, likely because they find them relevant, authoritative, or frequently updated on topics their users inquire about.
Specific content types: Are your “how-to” guides, definition pages, research summaries, or FAQ sections getting disproportionate AI crawler attention? This can reveal the type of information AI models are most hungry for.
2. Spot LLM-Favored Content Patterns
Structured data relevance: Are the highly-crawled pages also rich in structured data (Schema markup)? It’s an open debate, but some speculate that AI models often leverage structured data to extract information more efficiently and accurately.
Clarity and conciseness: AI models excel at processing clear, unambiguous language. Content that performs well with AI crawlers often features direct answers, brief paragraphs, and strong topic segmentation.
Authority and citations: Content that AI models deem reliable may be heavily cited or backed by credible sources. Track if your more authoritative pages are also attracting more AI bot visits.
3. Create A Blueprint From High-Performing Content
Reverse engineer success: For your top AI-crawled content, document its characteristics.
Keywords/Entities: Specific terms and entities frequently mentioned.
Structured data implementation: What schema types are used?
Internal linking patterns: How is this content connected to other relevant pages?
Upgrade underperformers: Apply these successful attributes to content that currently receives less AI crawler attention.
Refine content structure: Break down dense paragraphs, add more headings, and use bullet points for lists.
Inject structured data: Implement relevant Schema markup (e.g., `Q&A`, `HowTo`, `Article`, `FactCheck`) on pages lacking it.
Enhance clarity: Rewrite sections to achieve conciseness and directness, focusing on clearly answering potential user questions.
Expand Authority: Add references, link to authoritative sources, or update content with the latest insights.
Improve Internal Linking: Ensure that relevant underperforming pages are linked from your AI-favored content and vice versa, signaling topical clusters.
This short video walks you through the process of discovering what pages are crawled most often by AI crawlers and how to use that information to start your optimization strategy.
Here is the prompt used in the video:
You are an expert in AI-driven SEO and search engine crawling behavior analysis.
TASK: Analyze and explain why the URL [https://fioney.com/paying-taxes-with-a-credit-card-pros-cons-and-considerations/] was crawled 5 times in the last 30 days by the oai-searchbot(at)openai.com crawler, while [https://fioney.com/discover-bank-review/] was only crawled twice.
GOALS:
– Diagnose technical SEO factors that could increase crawl frequency (e.g., internal linking, freshness signals, sitemap priority, structured data, etc.)
– Compare content-level signals such as topical authority, link magnet potential, or alignment with LLM citation needs
– Evaluate how each page performs as a potential citation source (e.g., specificity, factual utility, unique insights)
– Identify which ranking and visibility signals may influence crawl prioritization by AI indexing engines like OpenAI’s
CONSTRAINTS:
– Do not guess user behavior; focus on algorithmic and content signals only
– Use bullet points or comparison table format
– No generic SEO advice; tailor output specifically to the URLs provided
– Consider recent LLM citation trends and helpful content system priorities
FORMAT:
– Part 1: Technical SEO comparison
– Part 2: Content-level comparison for AI citation worthiness
– Part 3: Actionable insights to increase crawl rate and citation potential for the less-visited URL
Output only the analysis, no commentary or summary.
By taking this data-driven approach, you move beyond guesswork and build an AI content strategy grounded in actual machine behavior on your site.
This iterative process of tracking, analyzing, and optimizing will ensure your content remains a valuable and discoverable resource for the evolving AI search landscape.
Final Thoughts On AI Optimization
Tracking and analyzing AI crawler behavior is no longer optional for SEOs seeking to remain competitive in the AI-driven search era.
By using log file analysis tools – or simplifying the process with SEO Bulk Admin – you can build a data-driven strategy that ensures your content is favored by AI engines.
Take a proactive approach by identifying trends in AI crawler activity, optimizing high-performing content, and applying best practices to underperforming pages.
With AI at the forefront of search evolution, it’s time to adapt and capitalize on new traffic opportunities from conversational search engines.
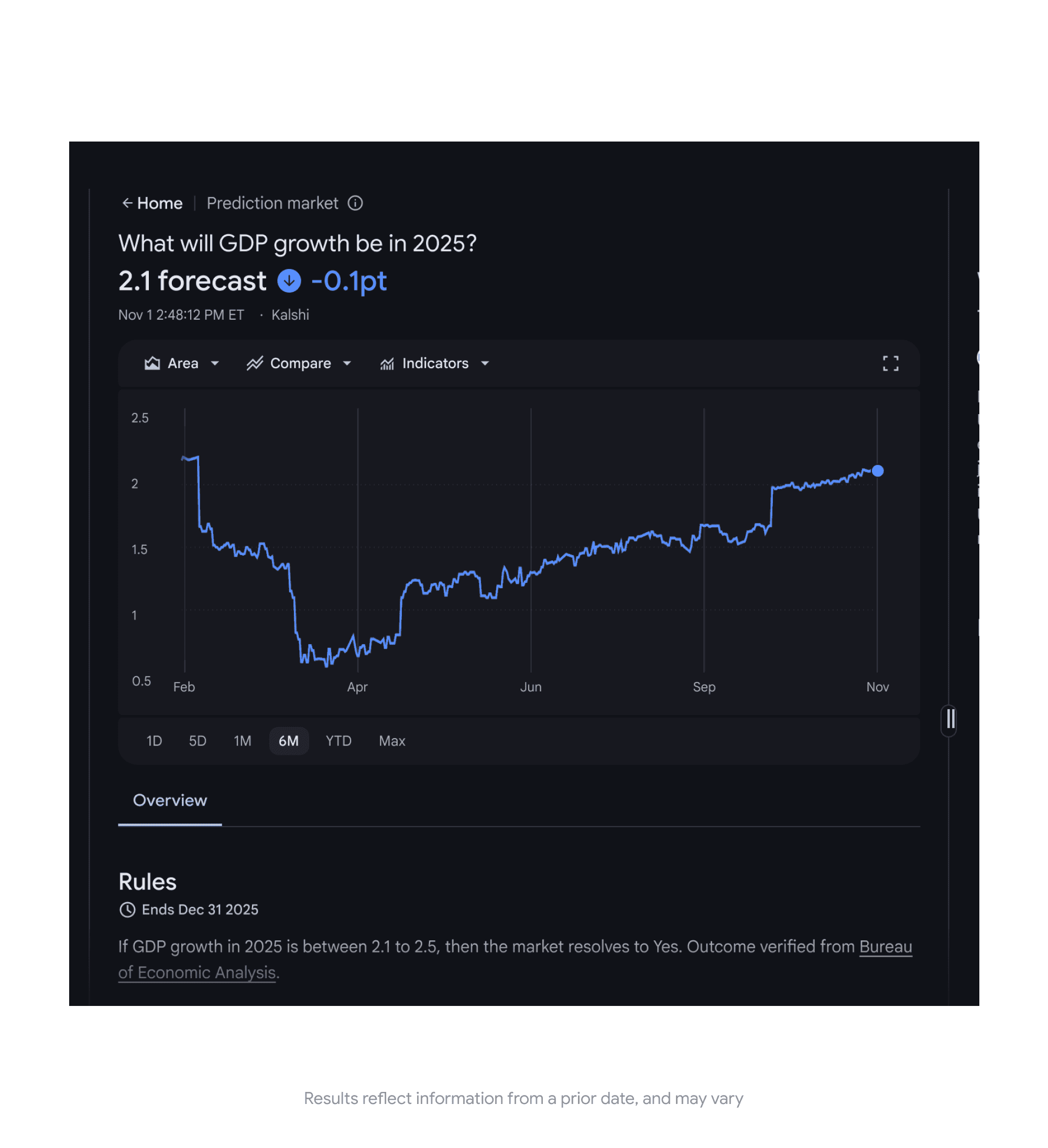
Google Finance is rolling out Deep Search capabilities, prediction markets data, and enhanced earnings tracking features across its AI-powered platform.
The updates expand Google Finance beyond basic market data into multi-step research workflows and crowd-sourced probability forecasting. Google announced the changes today, with features rolling out over the coming weeks, starting with Labs users.
Deep Search For Financial Research
Deep Search handles complex financial queries by issuing up to hundreds of simultaneous searches and synthesizing information across multiple sources.
You can ask detailed questions and select the Deep Search option. Gemini models then generate fully cited comprehensive responses within minutes, displaying the research plan during generation.
Image Credit: Google
Robert Dunnette, Director of Product Management for Google Search, wrote:
“From there, our advanced Gemini models will get to work, issuing up to hundreds of simultaneous searches and reasoning across disparate pieces of information to produce a fully cited, comprehensive response in just a few minutes.”
Deep Search offers higher usage limits for Google AI Pro and AI Ultra subscribers. Users can access it through the Google Finance experiment in Labs.
Prediction Markets Integration
Google Finance is adding support for prediction markets data from Kalshi and Polymarket, with availability rolling out over the coming weeks, starting with Labs users.
You can query future market events directly from the search box to see current probabilities and historical trends.
An example query includes “What will GDP growth be for 2025?”
The feature rolls out this week to Labs users first.
Enhanced Earnings Tracking
Google launched earnings tracking features that provide live audio streams, real-time transcripts, and AI-generated insights during corporate earnings calls.
The Earnings tab shows scheduled calls, streams live audio during calls, and maintains transcripts for later reference. AI-powered insights under “At a glance” update before, during, and after calls with information from news reports and analyst reactions.
You can compare financial data against historical results, view performance versus expectations, and access earnings documents and SEC forms.
India Expansion
Google Finance begins rolling out in India this week with support for English and Hindi.
The India launch initially offers the core Google Finance experience. Deep Search, prediction markets, and earnings features launch first in the U.S. and will expand internationally over time.
Why This Matters
Deep Search reduces the time needed to gather financial data from multiple sources, potentially resulting in fewer webpage visits.
Prediction markets offer crowd-sourced probability estimates that complement analyst forecasts. Live earnings tracking integrates call audio, transcripts, and analyst reactions into a single interface during reporting season.
Looking Ahead
Deep Search and prediction markets roll out over the coming weeks, with Labs users getting early access. Google AI Pro and AI Ultra subscribers receive higher usage limits for Deep Search queries.
The India expansion marks Google Finance’s first international launch beyond the U.S. Access the beta at google.com/finance/beta while signed into a Google account.
Featured Image: Juan Alejandro Bernal/Shutterstock
Across the industry, the systems powering discovery are diverging. Traditional search runs on algorithms designed to crawl, index, and rank the web. AI-driven systems like Perplexity, Gemini, and ChatGPT interpret it through models that retrieve, reason, and respond. That quiet shift (from ranking pages to reasoning with content) is what’s breaking the optimization stack apart.
What we’ve built over the last 20 years still matters: clean architecture, internal linking, crawlable content, structured data. That’s the foundation. But the layers above it are now forming their own gravity. Retrieval engines, reasoning models, and AI answer systems are interpreting information differently, each through its own set of learned weights and contextual rules.
Think of it like moving from high school to university. You don’t skip ahead. You build on what you’ve already learned. The fundamentals (crawlability, schema, speed) still count. They just don’t get you the whole grade anymore. The next level of visibility happens higher up the stack, where AI systems decide what to retrieve, how to reason about it, and whether to include you in their final response. That’s where the real shift is happening.
Traditional search isn’t falling off a cliff, but if you’re only optimizing for blue links, you’re missing where discovery is expanding. We’re in a hybrid era now, where old signals and new systems overlap. Visibility isn’t just about being found; it’s about being understood by the models that decide what gets surfaced.
This is the start of the next chapter in optimization, and it’s not really a revolution. It’s more of a progression. The web we built for humans is being reinterpreted for machines, and that means the work is changing. Slowly, but unmistakably.
Image Credit: Duane Forrester
Algorithms Vs. Models: Why This Shift Matters
Traditional search was built on algorithms, sets of rules, linear systems that move step by step through logic or math until they reach a defined answer. You can think of them like a formula: Start at A, process through B, solve for X. Each input follows a predictable path, and if you run the same inputs again, you’ll get the same result. That’s how PageRank, crawl scheduling, and ranking formulas worked. Deterministic and measurable.
AI-driven discovery runs on models, which operate very differently. A model isn’t executing one equation; it’s balancing thousands or millions of weights across a multi-dimensional space. Each weight reflects the strength of a learned relationship between pieces of data. When a model “answers” something, it isn’t solving a single equation; it’s navigating a spatial landscape of probabilities to find the most likely outcome.
You can think of algorithms as linear problem-solving (moving from start to finish along a fixed path) while models perform spatial problem-solving, exploring many paths simultaneously. That’s why models don’t always produce identical results on repeated runs. Their reasoning is probabilistic, not deterministic.
The trade-offs are real:
Algorithms are transparent, explainable, and reproducible, but rigid.
Models are flexible, adaptive, and creative, but opaque and prone to drift.
An algorithm decides what to rank. A model decides what to mean.
It’s also important to note that models are built on layers of algorithms, but once trained, their behavior becomes emergent. They infer rather than execute. That’s the fundamental leap and why optimization itself now spans multiple systems.
Algorithms governed a single ranking system. Models now govern multiple interpretation systems (retrieval, reasoning, and response), each trained differently, each deciding relevance in its own way.
So, when someone says, “the AI changed its algorithm,” they’re missing the real story. It didn’t tweak a formula. It evolved its internal understanding of the world.
Layer One: Crawl And Index, Still The Gatekeeper
You’re still in high school, and doing the work well still matters. The foundations of crawlability and indexing haven’t gone away. They’re the prerequisites for everything that comes next.
According to Google, search happens in three stages: crawling, indexing, and serving. If a page isn’t reachable or indexable, it never even enters the system.
That means your URL structure, internal links, robots.txt, site speed, and structured data still count. One SEO guide defines it this way: “Crawlability is when search bots discover web pages. Indexing is when search engines analyze and store the information collected during the crawling process.”
Get these mechanics right and you’re eligible for visibility, but eligibility isn’t the same as discovery at scale. The rest of the stack is where differentiation happens.
If you treat the fundamentals as optional or skip them for shiny AI-optimization tactics, you’re building on sand. The university of AI Discovery still expects you to have the high school diploma. Audit your site’s crawl access, index status, and canonical signals. Confirm that bots can reach your pages, that no-index traps aren’t blocking important content, and that your structured data is readable.
Only once the base layer is solid should you lean into the next phases of vector retrieval, reasoning, and response-level optimization. Otherwise, you’re optimizing blind.
Layer Two: Vector And Retrieval, Where Meaning Lives
Now you’ve graduated high school and you’re entering university. The rules are different. You’re no longer optimizing just for keywords or links. You’re optimizing for meaning, context, and machine-readable embeddings.
Vector search underpins this layer. It uses numeric representations of content so retrieval models can match items by semantic similarity, not just keyword overlap. Microsoft’s overview of vector search describes it as “a way to search using the meaning of data instead of exact terms.”
Modern retrieval research from Anthropic shows that by combining contextual embeddings and contextual BM25, the top-20-chunk retrieval failure rate dropped by approximately 49% (5.7 % → 2.9 %) when compared to traditional methods.
For SEOs, this means treating content as data chunks. Break long-form content into modular, well-defined segments with clear context and intent. Each chunk should represent one coherent idea or answerable entity. Structure your content so retrieval systems can embed and compare it efficiently.
Retrieval isn’t about being on page one anymore; it’s about being in the candidate set for reasoning. The modern stack relies on hybrid retrieval (BM25 + embeddings + reciprocal rank fusion), so your goal is to ensure the model can connect your chunks across both text relevance and meaning proximity.
You’re now building for discovery across retrieval systems, not just crawlers.
Layer Three: Reasoning, Where Authority Is Assigned
At university, you’re not memorizing facts anymore; you’re interpreting them. At this layer, retrieval has already happened, and a reasoning model decides what to do with what it found.
Reasoning models assess coherence, validity, relevance, and trust. Authority here means the machine can reason with your content and treat it as evidence. It’s not enough to have a page; you need a page a model can validate, cite, and incorporate.
That means verifiable claims, clean metadata, clear attribution, and consistent citations. You’re designing for machine trust. The model isn’t just reading your English; it’s reading your structure, your cross-references, your schema, and your consistency as proof signals.
Optimization at this layer is still developing, but the direction is clear. Get ahead by asking: How will a reasoning engine verify me? What signals am I sending to affirm I’m reliable?
Layer Four: Response, Where Visibility Becomes Attribution
Now you’re in senior year. What you’re judged on isn’t just what you know; it’s what you’re credited for. The response layer is where a model builds an answer and decides which sources to name, cite, or paraphrase.
In traditional SEO, you aimed to appear in results. In this layer, you aim to be the source of the answer. But you might not get the visible click. Your content may power an AI’s response without being cited.
Visibility now means inclusion in answer sets, not just ranking position. Influence means participation in the reasoning chain.
To win here, design your content for machine attribution. Use schema types that align with entities, reinforce author identity, and provide explicit citations. Data-rich, evidence-backed content gives models context they can reference and reuse.
You’re moving from rank me to use me. The shift: from page position to answer participation.
Layer Five: Reinforcement, The Feedback Loop That Teaches The Stack
University doesn’t stop at exams. You keep producing work, getting feedback, improving. The AI stack behaves the same way: Each layer feeds the next. Retrieval systems learn from user selections. Reasoning models update through reinforcement learning from human feedback (RLHF). Response systems evolve based on engagement and satisfaction signals.
In SEO terms, this is the new off-page optimization. Metrics like how often a chunk is retrieved, included in an answer, or upvoted inside an assistant feed back into visibility. That’s behavioral reinforcement.
Optimize for that loop. Make your content reusable, designed for engagement, and structured for recontextualization. The models learn from what performs. If you’re passive, you’ll vanish.
The Strategic Reframe
You’re not just optimizing a website anymore; you’re optimizing a stack. And you’re in a hybrid moment. The old system still works; the new one is growing. You don’t abandon one for the other. You build for both.
Here’s your checklist:
Ensure crawl access, index status, and site health.
Modularize content and optimize for retrieval.
Structure for reasoning: schema, attribution, trust.
Design for response: participation, reuse, modularity.
Think of this as your syllabus for the advanced course. You’ve done the high school work. Now you’re preparing for the university level. You might not know the full curriculum yet, but you know the discipline matters.
Forget the headlines declaring SEO over. It’s not ending, it’s advancing. The smart ones won’t panic; they’ll prepare. Visibility is changing shape, and you’re in the group defining what comes next.
OpenAI’s CEO Sam Altman sat for an interview where he explained that his vision for the future of ChatGPT is as a trusted assistant that’s user-aligned, saying that booking hotels is not going to be the way to monetize “the world’s smartest model.” He pointed to Google as an example of what he doesn’t want ChatGPT to become: a service that accepts advertising dollars to place the worst choice above the best choice. He then followed up to express openness to advertising.
User-Aligned Monetization Model
Altman contrasted OpenAI’s revenue approach with the ad-driven incentives of Google. He explained that Google’s Search and advertising ecosystem depends on Google’s search results “doing badly for the user,” because ranking decisions are partly tied to maximizing advertising income.
The interviewer related that he and his wife took a trip to Europe and booked multiple hotels with help from ChatGPT and ate at restaurants that ChatGPT helped him find and at no point did any kind of kickback or advertising fee go back to OpenAI, leading him to tell his wife that ChatGPT “didn’t get a dime from this… this just seems wrong….” because he was getting so much value from ChatGPT and ChatGPT wasn’t getting anything back.
Altman answered that users trust ChatGPT and that’s why so many people pay for it.
He explained:
“I think if ChatGPT finds you the… To zoom out even before the answer, one of the unusual things we noticed a while ago, and this was when it was a worst problem, ChatGPT would consistently be reported as a user’s most trusted technology product from a big tech company. We don’t really think of ourselves as a big tech company, but I guess we are now. That’s very odd on the surface, because AI is the thing that hallucinates, AI is the thing with all the errors, and that was much more of a problem. And there’s a question of why.
Ads on a Google search are dependent on Google doing badly. If it was giving you the best answer, there’d be no reason ever to buy an ad above it. So you’re like, that thing’s not quite aligned with me.
ChatGPT, maybe it gives you the best answer, maybe it doesn’t, but you’re paying it, or hopefully are paying it, and it’s at least trying to give you the best answer. And that has led to people having a deep and pretty trusting relationship with ChatGPT. You ask ChatGPT for the best hotel, not Google or something else.”
Altman’s response used the interviewer’s experience as an example of a paradigm change in user trust in technology. He contrasted ChatGPT’s model, where users directly pay for answers, with Google’s ad-based model that profits from imperfect results. His point is that ChatGPT’s business model aligns more closely with users’ interests, earning a sense of trust and reliability rather than making their users feel exploited by an advertising system. This is why users perceive ChatGPT as more trustworthy, even though ChatGPT is known to hallucinate.
Altman Is Open To Transaction Fees
Altman was strongly against accepting advertising money in exchange for showing a hotel above what ChatGPT would naturally show. He said that he would be open to accepting a transaction fee should a user book that hotel through ChatGPT because that has no influence on what ChatGPT recommends, thus preserving a user’s trust.
He shared how this would work:
“If ChatGPT were accepting payment to put a worse hotel above a better hotel, that’s probably catastrophic for your relationship with ChatGPT. On the other hand, if ChatGPT shows you it’s best hotel, whatever that is, and then if you book it with one click, takes the same cut that it would take from any other hotel, and there’s nothing that influenced it, but there’s some sort of transaction fee, I think that’s probably okay. And with our recent commerce thing, that’s the spirit of what we’re trying to do. We’ll do that for travel at some point.”
I think a takeaway here is that Altman believes the advertising model that the Internet has been built on over the past thirty-plus years can subvert user trust and lead to a poor user experience. He feels that a transaction fee model is less likely to impact the quality of the service that users are paying for and that it will maintain the feeling of trust that people have in ChatGPT.
But later on in the interview, as you’ll see, Altman surprises the interviewer with his comment about the possibility of advertisements on ChatGPT.
How OpenAI Will Monetize Itself
When pressed about how OpenAI will monetize itself, Altman responded that he expects the future of commerce will have lower margins and that he doesn’t expect to fully fund OpenAI by booking hotels but by doing exceptional things like curing diseases.
Altman explained his vision:
“So one thing I believe in general related to this is that margins are going to go dramatically down on most goods and services, including things like hotel bookings. I’m happy about that. I think there’s like a lot of taxes that just suck for the economy and getting those down should be great all around. But I think that most companies like OpenAI will make more money at a lower margin.
…I think the way to monetize the world’s smartest model is certainly not hotel booking. …I want to discover new science and figure out a way to monetize that. You can only do with the smartest model.
There is a question of, should, many people have asked, should OpenAI do ChatGPT at all? Why don’t you just go build AGI? Why don’t you go discover a cure for every disease, nuclear fusion, cheap rockets, the whole thing, and just license that technology? And it is not an unfair question because I believe that is the stuff that we will do that will be most important and make the most money eventually.
…Maybe some people will only ever book hotels and not do anything else, but a lot of people will figure out they can do more and more stuff and create new companies and ideas and art and whatever.
So maybe ChatGPT and hotel booking and whatever else is not the best way we can make money. In fact, I’m certain it’s not. I do think it’s a very important thing to do for the world, and I’m happy for OpenAI to do some things that are not the economic maxing thing.”
Advertisements May Be Coming To ChatGPT
At around the 18 minute mark the interviewer asked Altman about advertising on OpenAI and Altman acknowledged that there may be a form of advertising but was vague about what that would look like.
He explained:
“Again, there’s a kind of ad that I think would be really bad, like the one we talked about.
There are kinds of ads that I think would be very good or pretty good to do. I expect it’s something we’ll try at some point. I do not think it is our biggest revenue opportunity.”
The interviewer asked:
“What will the ad look like on the page?”
Altman responded:
“I have no idea. You asked like a question about productivity earlier. I’m really good about not doing the things I don’t want to do.”
Takeaway
Sam Altman suggests an interesting way forward on how to monetize Internet users. His way is based on trust and finding a way to monetize that doesn’t betray that trust.
Watch the interview starting at about the 16 minute mark:
AI has made it effortless to produce content, but not to stand out in SERPs.
Across nearly every industry, brands are using generative AI tools like ChatGPT, Perplexity, Claude, and more to scale content production, only to discover that, to search engines, everything sounds the same.
But this guide will help you build E-E-A-T-friendly & AI-Overview-worthy content that boosts your AI Overview visibility, while giving you more control over your rankings.
Why Does All AI-Generated Content Sound The Same?
Most generative AI models write from the same training data, producing statistically “average” answers to predictable prompts.
The result is fluent, on-topic copy that is seen as interchangeable from one brand to the next.
To most readers, it may feel novel.
To search engines, your AI content may look redundant.
Algorithms can now detect when pages express the same ideas with minor wording differences. Those pages compete for the same meaning, and only one tends to win.
The challenge for SEOs isn’t writing faster, it’s writing differently.
That starts with understanding why search engines can tell the difference even when humans can’t.
How Do Search Engines & Answer Engines See My Content?
Search engines no longer evaluate content by surface keywords.
They map meaning.
Modern ranking systems translate your content into embeddings.
When two pages share nearly identical embeddings, the algorithm treats them as duplicates of meaning, similar to duplicate content.
That’s why AI-generated content blends together. The vocabulary may change, but the structure and message remain the same.
What Do Answer Engines Look For On Web Pages?
Beyond words, engines analyze the entire ecosystem of a page:
These structural cues help determine whether content is contextually distinct or just another derivative variant.
To stand out, SEOs have to shape the context that guides the model before it writes.
That’s where the Inspiration Stage comes in.
How To Teach AI To Write Like Your Brand, Not The Internet
Before you generate another article, feed the AI your brand’s DNA.
Language models can complete sentences, but can’t represent your brand, structure, or positioning unless you teach them.
Advanced teams solve this through context engineering, defining who the AI is writing for and how that content should behave in search.
The Inspiration Stage should combine three elements that together create brand-unique outputs.
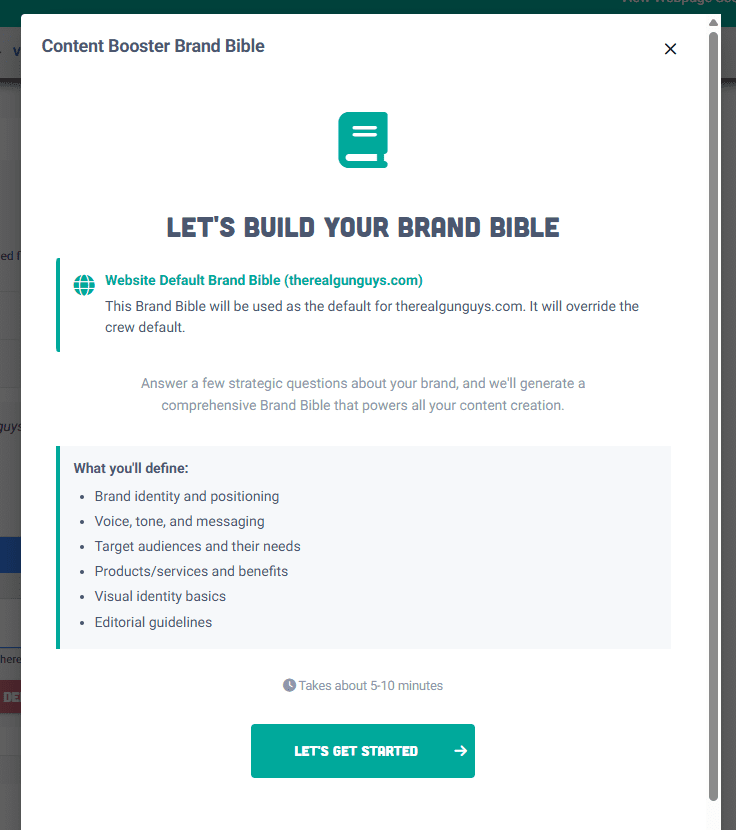
Step 1 – Create A Brand Bible: Define Who You Are
The first step is identity.
A Brand Bible translates your company’s tone, values, and vocabulary into structured guidance the AI can reference. It tells the model how to express authority, empathy, or playfulness. And just as important, what NOT to say.
Without it, every post sounds like a tech press release.
With it, you get language that feels recognizably yours, even when produced at scale.
“The Brand Bible isn’t decoration: it’s a defensive wall against generic AI sameness.”
A great example: Market Brew’s Brand Bible Wizard
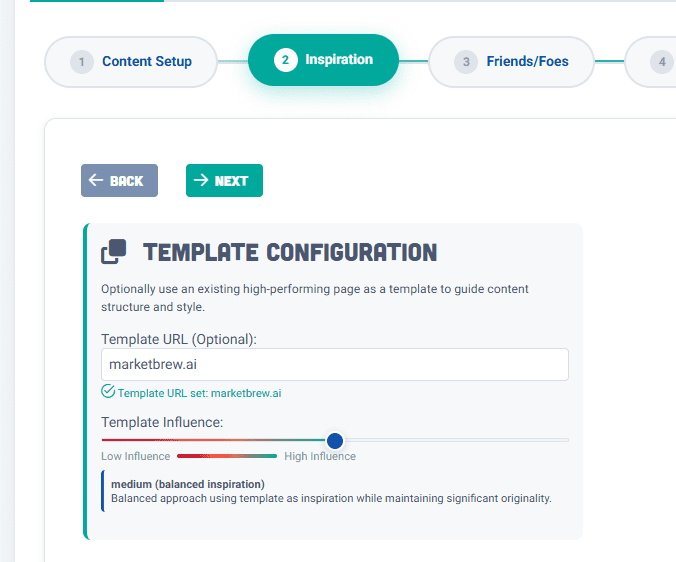
Step 2 – Create A Template URL: Structure How You Write
Great writing still needs great scaffolding.
By supplying a Template URL, a page whose structure already performs well, you give the model a layout to emulate: heading hierarchy, schema markup, internal link positions, and content rhythm.
Adding a Template Influence parameter can help the AI decide how closely to follow that structure. Lower settings would encourage creative variation; higher settings would preserve proven formatting for consistency across hundreds of pages.
Templates essentially become repeatable frameworks for ranking success.
An example of how to apply a template URL
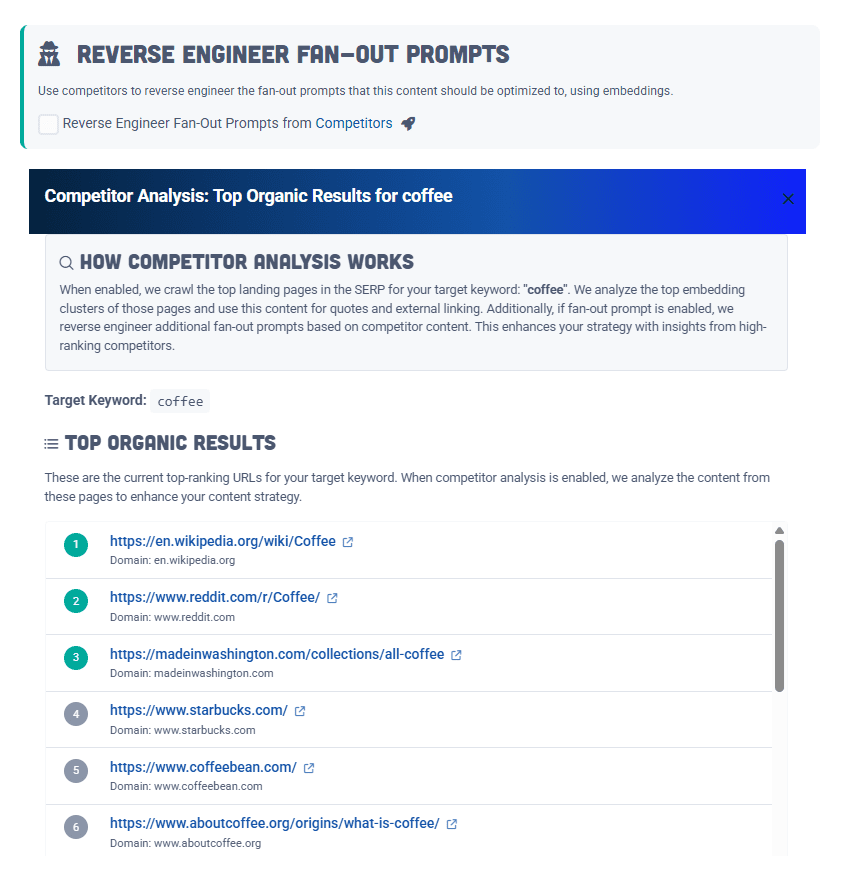
Step 3 – Reverse-Engineer Your Competitor Fan-Out Prompts: Know the Landscape
Context also means competition. When you are creating AI content, it needs to be optimized for a series of keywords and prompts.
Fan-out prompts are a concept that maps the broader semantic territory around a keyword or topic. These are a network of related questions, entities, and themes that appear across the SERP.
In addition, fan-out prompts should be reverse-engineered from top competitors in that SERP.
Feeding this intelligence into the AI ensures your content strategically expands its coverage; something that the LLM search engines are hungry for.
“It’s not copying competitors, it’s reverse-engineering the structure of authority.”
Together, these three inputs create a contextual blueprint that transforms AI from a text generator into a brand and industry-aware author.
Market Brew’s implementation of reverse engineering fan-out prompts
How To Incorporate Human-Touch Into AI Content
If your AI tool spits out finished drafts with no checkpoints, you’ve lost control of what high-quality content is.
That’s a problem for teams who need to verify accuracy, tone, or compliance.
Breaking generation into transparent stages solves this.
Incorporate checkpoints where humans can review, edit, or re-queue the content at each stage:
Research.
Outline.
Draft.
Refinement.
Metrics for readability, link balance, and brand tone become visible in real time.
This “human-in-the-loop” design keeps creative control where it belongs.
Instead of replacing editors, AI becomes their analytical assistant: showing how each change affects the structure beneath the words.
“The best AI systems don’t replace editors, they give them x-ray vision into every step of the process.”
How To Build Content The Way Search Engines Read It
Modern SEO focuses on predictive quality signals: indicators that content is likely to perform before it ever ranks.
These include:
Semantic alignment: how closely the page’s embeddings match target intent clusters.
Brand consistency and clarity: tone and terminology that match the brand bible without losing readability.
Tracking these signals during creation turns optimization into a real-time discipline.
Teams can refine strategy based on measurable structure, not just traffic graphs weeks later.
That’s the essence of predictive SEO: understanding success before the SERP reflects it.
The Easy Way To Create High-Visibility Content For Modern SERPs
Top SEO teams are already using the Content Booster approach.
Market Brew’s Content Booster is one such example.
It embeds AI writing directly within a search engine simulation, using the same mechanics that evaluate pages to guide creation.
Writers begin by loading their Brand Bible, selecting a Template URL, and enabling reverse-engineered fan-out prompts.
Next, the internal and external linking strategy is defined, which uses a search engine model’s link scoring system, plus its entity-based text classifier as a guide to place the most valuable links possible.
This is bolstered by a “friends/foes” section that allows writers to define quoting / linking opportunities to friendly sites, and “foe” sites where external linking should be avoided.
The Content Booster then produces and evaluates a 7-stage content pipeline, each driven by thousands of AI agents.
Stage
Function
What You Get
0. Brand Bible
Upload your brand assets and site; Market Brew learns your tone, voice, and banned terms.
Every piece written in your unique brand style.
1. Opportunity & Strategy
Define your target keyword or prompt, tone, audience, and linking strategy.
A strategic blueprint tied to real search intent.
2. Brief & Structure
Creates an SEO-optimized outline using semantic clusters and entity graphs.
Perfectly structured brief ready for generation.
3. Draft Generation
AI produces content constrained by embeddings and brand parameters.
A first draft aligned with ranking behavior, not just text patterns.
4. Optimization & Alignment
Uses cosine similarity and Market Brew’s ranking model to score each section.
Data-driven tuning for maximum topical alignment.
5. Internal Linking & Entity Enrichment
Adds schema markup, entity tags, and smart internal links.
Optimized crawl flow and contextual authority.
6. Quality & Compliance
Checks grammar, plagiarism, accessibility, and brand voice.
Ready-to-publish content that meets editorial and SEO standards.
Editors can inspect or refine content at any stage, ensuring human direction without losing automation.
Instead of waiting months to measure results, teams see predictive metrics: like fan-out coverage, audience/persona compliance, semantic similarity, link distribution, embedding clusters and more. The moment a draft is generated.
This isn’t about outsourcing creativity.
It’s about giving SEO professionals the same visibility and control that search engineers already have.
Your Next Steps
If you teach your AI to think like your best strategist, sameness stops being a problem.
Every brand now has access to the same linguistic engine; the only differentiator is context.
The future of SEO belongs to those who blend human creativity with algorithmic understanding, who teach their models to think like search engines while sounding unmistakably human.
By anchoring AI in brand, structure, and competition, and by measuring predictive quality instead of reactive outcomes, SEOs can finally close the gap between what we publish and what algorithms reward.
“The era of AI sameness is already here. The brands that thrive will be the ones that teach their AI to sound human and think like a search engine.”
A simplified explanation of how Google ranks content is that it is based on understanding search queries and web pages, plus a number of external ranking signals. With AI Mode, that’s just the starting point for ranking websites. Even keywords are starting to go away, replaced by increasingly complex queries and even images. How do you optimize for that? The following are steps that can be taken to help answer that question.
Latent Questions Are A Profound Change To SEO
The word “latent” means something that exists but cannot be seen. When a user issues a complex query the LLM must not only understand the query but also map out follow-up questions that a user might ask as part of an information journey about the topic. Those questions that comprise the follow-up questions are latent questions. Virtually every query contains latent questions.
Google’s Information Gain Patent
The issue of latent queries poses a new problem for SEO: How do you optimize for questions that are unknown? Optimizing for AI search means optimizing for the entire range of questions that are related to the initial or head query.
But even the concept of a head query is going away because users are now asking complex queries which demand complex answers. This is precisely why it may be useful for AI SEO purposes to optimize not just for one query but for the immediate information needs of the user.
How does Google understand the information need that’s hidden within a user’s query? The answer is found in Google’s Information Gain Patent. That patent is about ranking a web page that is relevant for a query then afterward ranking other web pages that have different but related content.
Identify The Latent (Hidden) Questions
One way to look at AI search results is to break them down into the questions that the AI answers are satisfying, to identify the hidden query fan-out questions.
For example, if you ask Google’s AI Mode how to make pizza dough the AI Mode will generate a pizza dough recipe. The answer is synthesized from multiple queries.
There is a way to extract the hidden (latent) questions by using a Reverse Question Answering Prompt, which I’ll show below.
Here is an example of an initial query and the additional query fan-out questions that are involved:
Initial Query: How to make pizza dough?
Query Fan-Out Questions:
What ingredients are needed to make pizza dough?
How much pizza dough does this recipe make?
What indicates that the yeast is active?
How long should the dough be kneaded by hand?
How long should the dough be kneaded with a mixer?
How long should the dough rise during the first proofing?
How can you develop more complex flavor in the dough?
What should the oven temperature be for baking the pizza?
How long should the pizza bake?
Actual AI Mode Question And Answers
Here are some of the hidden query fan-out questions accompanied by the answers that Google’s AI Mode generated.
Question: What ingredients are needed to make pizza dough? Answer: “1 and 1/3 cups warm water (around 105-110°F or 40-43°C); 1 tablespoon granulated sugar (or honey); 1 packet active dry or instant yeast (2 1/4 teaspoons); 3 1/2 to 4 cups all-purpose or bread flour, plus more for dusting; 2 tablespoons extra-virgin olive oil, plus more for greasing; 1 teaspoon salt.”
Question: How much pizza dough does this recipe make? Answer: “This recipe makes enough dough for two 10-12 inch pizzas.”
Question: What indicates that the yeast is active? Answer: “Cover and let it sit for about 5-10 minutes, until the mixture is foamy and bubbly. This indicates the yeast is active.”
Screenshot Of The Actual AI Mode Answer
Reverse Question Answering Prompt
You can use the Reverse Question Answering Prompt to identify the underlying questions in any AI Mode answer. You can even use a similar but more precise prompt to analyze your own content to identify what questions the document answers. It’s a good way to check if your content does or does not answer the questions you want it to answer.
Prompt To Extract Questions From AI Mode
Here is the prompt to use to extract the hidden questions within an AI Mode answer:
Analyze the document and extract a list of questions that are directly and completely answered by full sentences in the text. Only include questions if the document contains a full sentence or sentences that clearly answers it. Do not include any questions that are answered only partially, implicitly, or by inference.
For each question, ensure that it is a clear and concise restatement of the exact information present. This is a reverse question generation task: only use the content already present in the document.
For each question, also include the exact sentences from the document that answer it. Only generate questions that have a complete, direct answer in the form of a full sentence or sentences in the document.
Reverse Question Answering Analysis For Web Content
The previously described prompt can be used to extract the questions that are answered by your own or a competitor’s content. But it will not differentiate between the core search queries the document is relevant for and other questions that are ancillary to the main topic.
To do a Reverse Question Answering analysis with your own content, try this more precise variant of the prompt:
Analyze the document and extract a list of questions that are core to the document’s central topic and are directly and completely answered by full sentences in the text.
Only include questions if the document contains a full sentence or contiguous sentences that clearly answers it. Do not include any questions that are answered only partially, implicitly, or by inference. Crucially, exclude any questions about supporting anecdotes, personal asides, or general background information that is not the main subject of the document.
For each question, ensure that it is a clear and concise restatement of the exact information present. This is a reverse question generation task: only use the content already present in the document.
For each question, also include the exact sentences from the document that answer it. Only generate questions that have a complete, direct answer in the form of a full sentence or sentences in the document.
The above prompt is meant to emulate how an LLM or information retrieval system might extract the core questions that a web document answers, while ignoring the parts of the document that aren’t central to its informational purpose, such as tangential commentary that do not directly contribute to the document’s main topic or purpose.
Cultivate Being Mentioned On Other Sites
Something that is becoming increasingly apparent is that AI search tends to rank companies whose websites are recommended by other sites. Research by Ahrefs found a strong correlation between sites that appear in AI Overviews and branded mentions.
According to Ahrefs:
“So we looked at these factors that correlate with the amount of times a brand appears in AI overviews, tested tons of different things, and by far the strongest correlation, very, very strong correlation, almost 0.67, was branded web mentions.
So if your brand is mentioned in a ton of different places on the web, that correlates very highly with your brand being mentioned in lots of AI conversations as well.”
This finding strongly suggests that visibility in AI search may depend less on backlinks and more on how often a brand is discussed across the web. AI models seem to learn which brands are recommended by how often those sites are mentioned across other sites, including sites like Reddit.
Post-Keyword Ranking Era
We are in a post-keyword ranking era. Google’s organic search was already using AI and a core topicality system to better understand queries and the topic that web pages were about. The big difference now is that Google’s AI Mode has enabled users to search with long and complex conversational queries that aren’t necessarily answered by web pages that are focused on being relevant to keywords instead of to what people are actually looking for.
Write About Topics
Writing about topics seems like a straightforward approach but what it means depends on the context of the topic.
What “topic writing” proposes is that instead of writing about the keyword Blue Widget, the writer must write about the topic of Blue Widget.
The old way of SEO was to think about Blue Widget and all the associated Blue Widget keyword phrases:
Associated keyword phrases
How to make blue widgets
Cheap blue widgets
Best blue widgets
Images And Videos
The up to date way to write is to think in terms of answers and helpfulness. For example, do the images on a travel site communicate what a destination is about? Will a reader linger on the photo? On a product site, do the images communicate useful information that will help a consumer determine if something will fit and what it might look like on them?
Images and videos, if they’re helpful and answer questions, could become increasingly important as users begin to search with images and increasingly expect to see more videos in the search results, both short and longform videos.
New agentic capabilities are launching in AI Mode: you can now get help booking event tickets or beauty & wellness appointments. This is available to all users opted into Labs in the U.S., with higher limits for Google AI Pro & Ultra subscribers.
AI Mode now performs multi-site searches for three booking categories and returns real-time options with a curated list of time slots or ticket prices.
Here’s what U.S. users see when visiting the landing page in Search Labs:
Screenshot from: labs.google.com/search/experiment/43, November 2025.
Screenshot from: labs.google.com/search/experiment/43, November 2025.
Restaurant Reservations
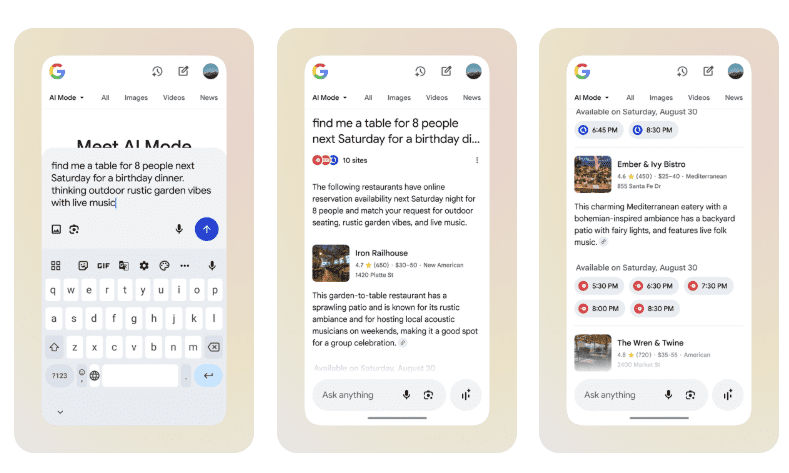
You can ask for party size, time, neighborhood, or cuisine.
Google’s example:
“find me a dinner reservation for 3 people this Friday after 6pm around Logan Square. craving ramen or bibimbap.”
Results include available times with links to book.
Event Tickets
Google AI Pro and Ultra subscribers can search for concert and event tickets with price and seating preferences, for example:
“find me 2 cheap tickets for the Shaboozey concert coming up. prefer standing floor tickets.”
Wellness Appointments
Also for Pro and Ultra subscribers, AI Mode can surface real-time availability from local service booking platforms and link you to complete the appointment.
How It Works
AI Mode searches across multiple websites to surface real-time availability, then presents a curated list. It links you directly to the provider’s booking page to finalize the reservation or purchase.
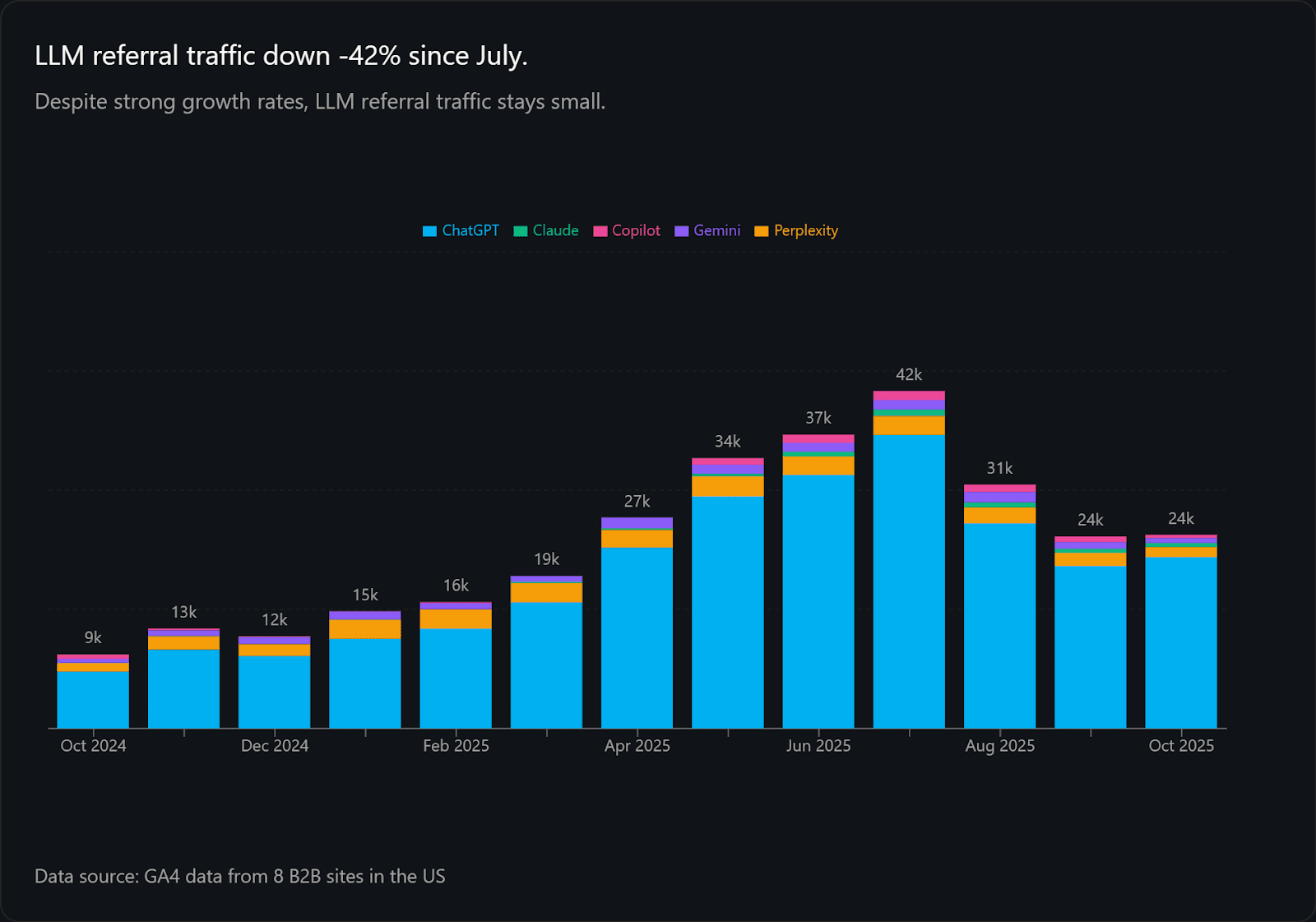
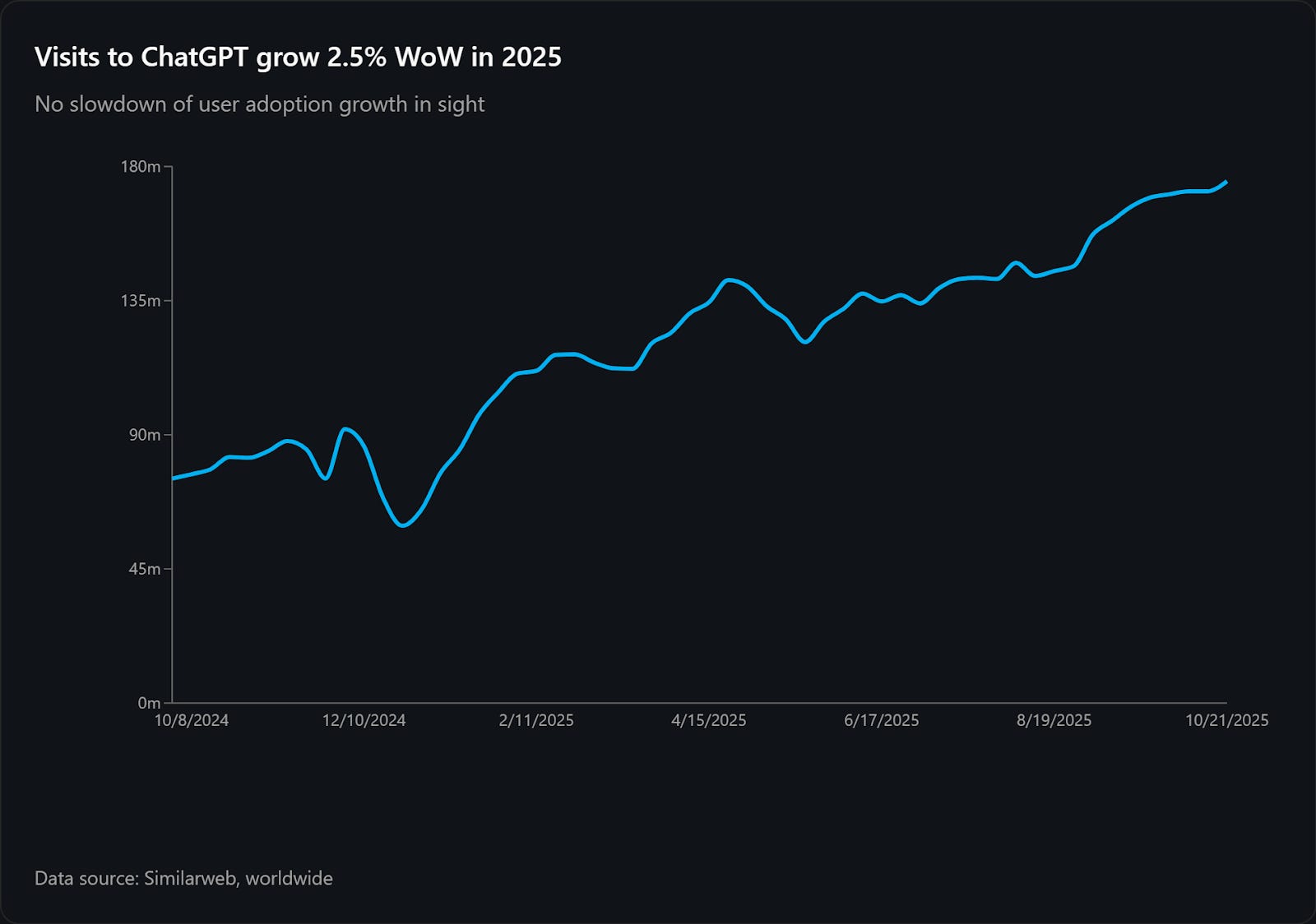
In December 2024, I analyzed six B2B sites and found LLM referral traffic was growing at such a fast rate it would make up 50% of organic traffic in three years.
Today, I’m finding the monthly growth rate of LLM traffic dropped from 25.1% in 2024 to 10.4% in November 2025.
Even from January to July 2025, the average growth rate was lower (19.2%) than my projection. That’s fast, but not enough to reach 50% organic traffic in three years.
LLM contribution to organic traffic grew from 0.14% in 2024 to 1.10% in 2025, which is more than I projected (0.79%).
In August, several factors influenced LLM referral traffic:
Seasonality: Siege Media documented that B2B sites lost LLM traffic in August due to vacation season.
Router: ChatGPT 5, which launched on August 7, has a router that picks the model. The router favors non-reasoning models, which show fewer citations and send less traffic out.
Concentration: Josh from Profound found a higher concentration of referrals to Reddit and Wikipedia starting late July.
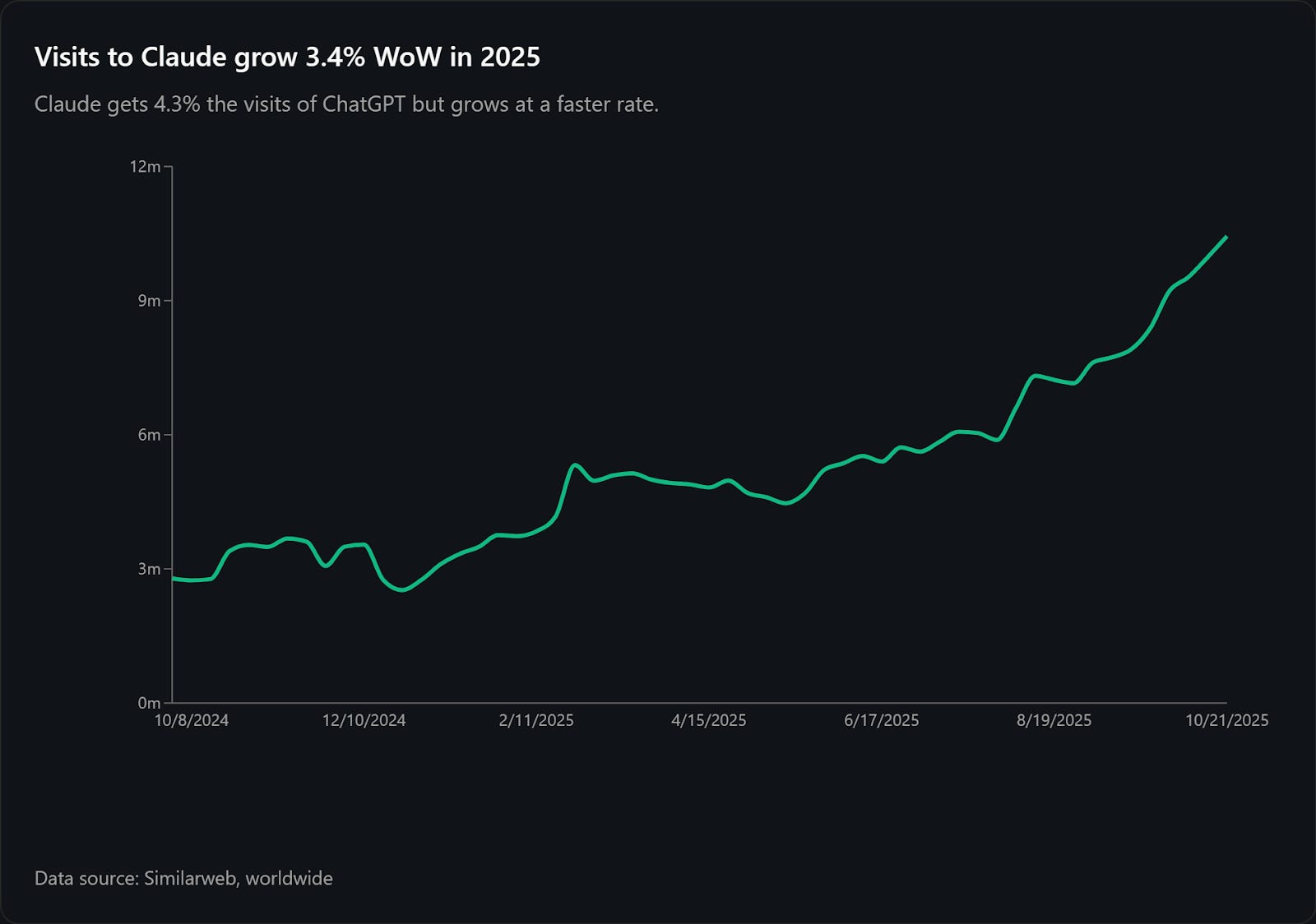
Business seasonality has a lower impact because neither ChatGPT (consumer focus) nor Claude (business focus) sees a decrease in site visits.
Image Credit: Kevin Indig
Image Credit: Kevin Indig
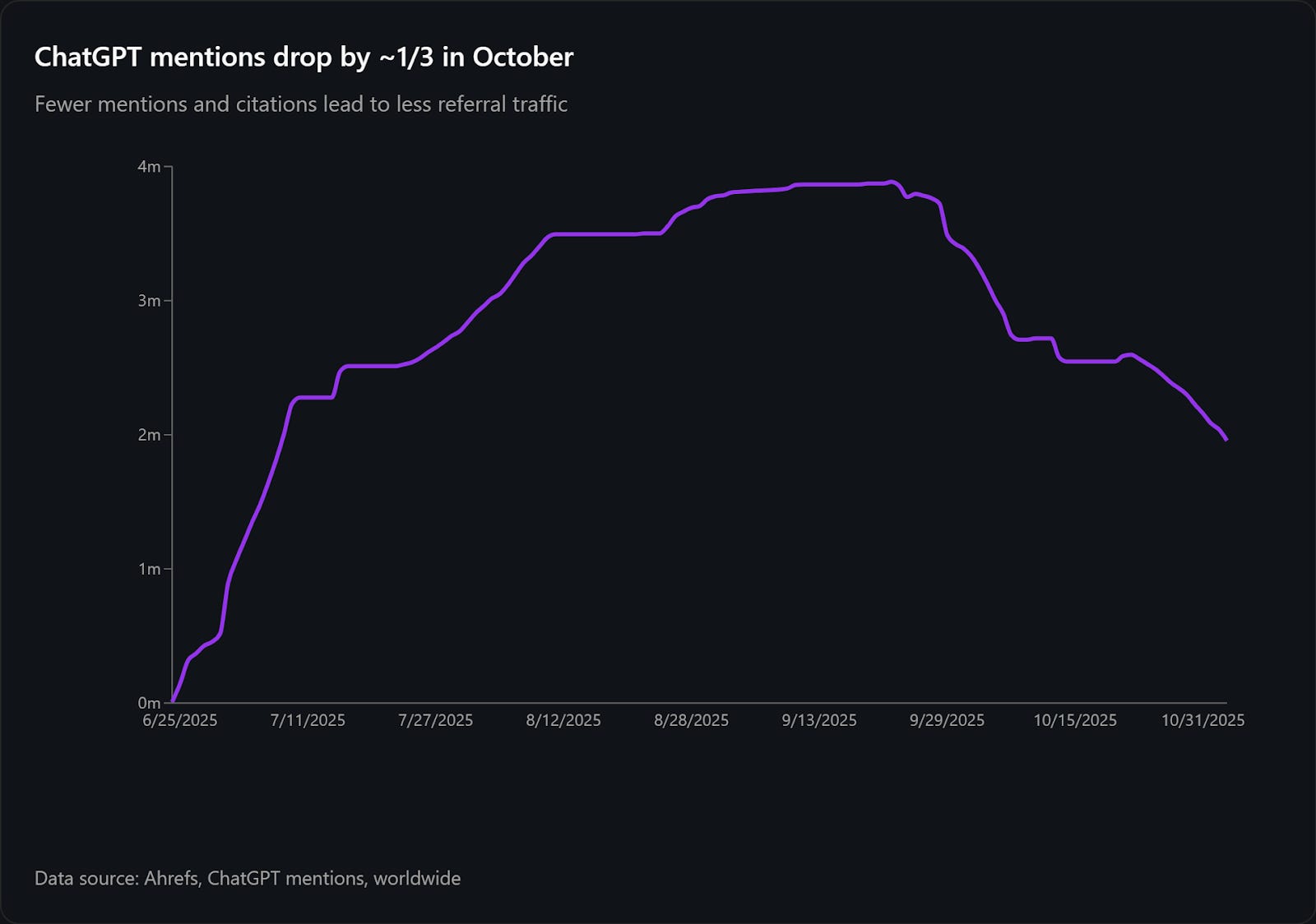
ChatGPT mentions, however, dropped by one-third in October and continue dropping in November.
Image Credit: Kevin Indig
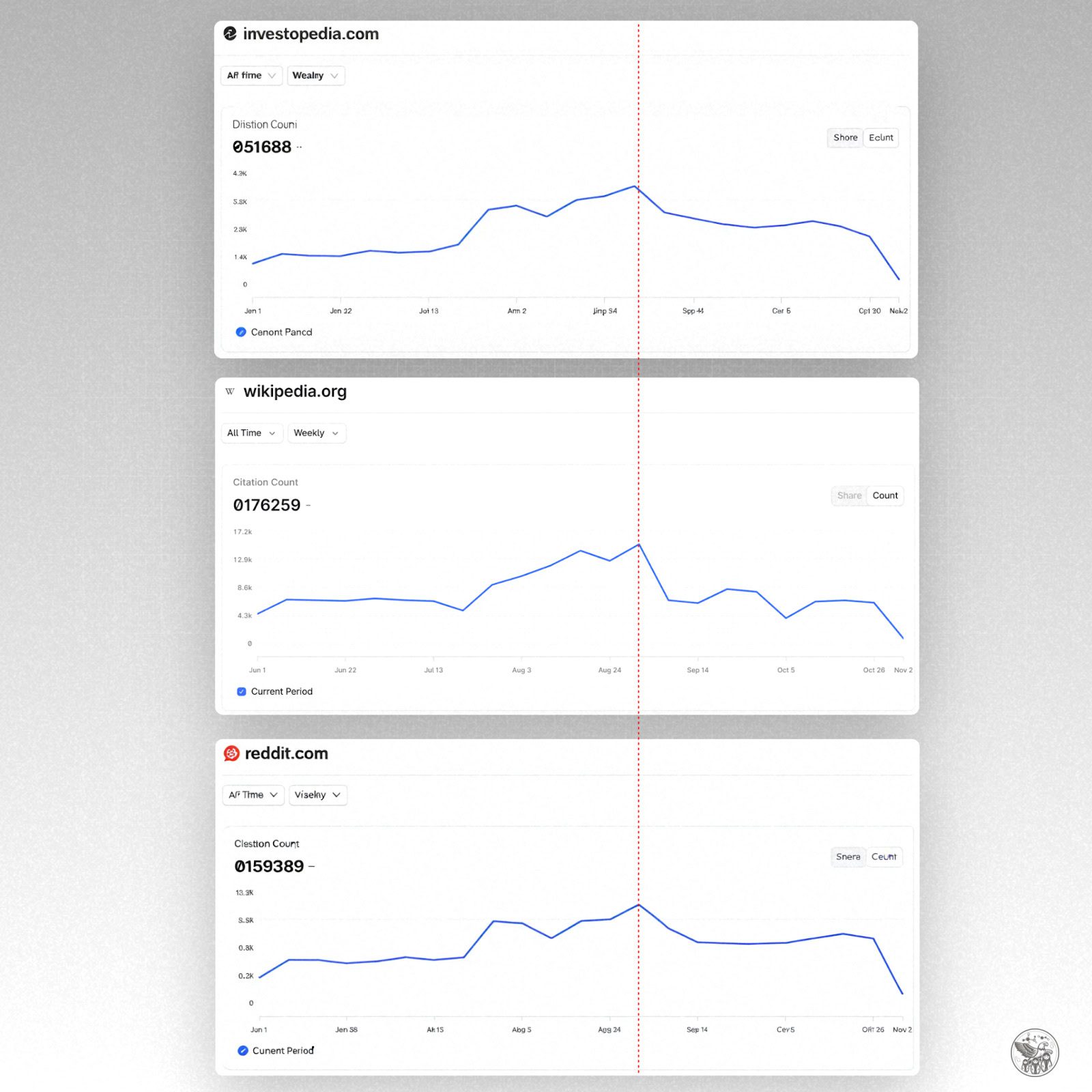
Citations for large domains like Reddit or Wikipedia follow suit (based on Profound data).
Major sites see citation declines in September (Image Credit: Kevin Indig)
Conclusion: LLM visits are up, which removes seasonality as dominant cause. The driver of lower referral traffic is ChatGPT, showing fewer citations due to the model router.
Visibility Is The Real Price
Traffic was never the right way to value LLMs because LLMs make clicks redundant:
The AI Mode study I published last month validates that clicks only occurred for shopping-related tasks (zero-click share = ~100%).
Pew Research has found that only 1% of users click links in AI Overviews.
Focusing on traffic leads to disappointing results. ChatGPT is more like TikTok than Google Search. The currency of the AI world is visibility.
The good news: LLMs grow the pie. Semrush found people don’t use Google less often because they also use ChatGPT. If LLMs are additive to Google Search, the visibility surface grows even though clicks per source shrink. You have more places to be seen, fewer clicks per place.
But our success metrics need to change. Referral traffic neither works for ChatGPT nor Google, as AI Overviews and AI mode swallow more clicks. Instead, we need to adopt visibility-first.
Default To Zero LLM Traffic
Track LLM and organic search seasonality for your vertical to measure the total pie of citations and make sense of drops/spikes.
Monitor total citation and mention count to answer the question, “Are we growing because the market grows?” Lower citations/mentions means fewer chances to influence purchase decisions.
Prioritize brand mentions over citations in LLMs. Mentions without links drive familiarity and influence purchase decisions.
Stop expecting (meaningful) LLM referral traffic. Budget for visibility.
Invest resources where LLMs go to train: UGC and third-party reviews like Reddit, YouTube, review sites, community forums.
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Featured Image: Paulo Bobita/Search Engine Journal