The research assessed free/consumer versions of ChatGPT, Copilot, Gemini, and Perplexity, answering news questions in 14 languages across 22 public-service media organizations in 18 countries.
The EBU said in announcing the findings:
“AI’s systemic distortion of news is consistent across languages and territories.”
What The Study Found
In total, 2,709 core responses were evaluated, with qualitative examples also drawn from custom questions.
Overall, 45% of responses contained at least one significant issue, and 81% had some issue. Sourcing was the most common problem area, affecting 31% of responses at a significant level.
How Each Assistant Performed
Performance varied by platform. Google Gemini showed the most issues: 76% of its responses contained significant problems, driven by 72% with sourcing issues.
The other assistants were at or below 37% for major issues overall and below 25% for sourcing issues.
Examples Of Errors
Accuracy problems included outdated or incorrect information.
For instance, several assistants identified Pope Francis as the current Pope in late May, despite his death in April, and Gemini incorrectly characterized changes to laws on disposable vapes.
Methodology Notes
Participants generated responses between May 24 and June 10, using a shared set of 30 core questions plus optional local questions.
The study focused on the free/consumer versions of each assistant to reflect typical usage.
Many organizations had technical blocks that normally restrict assistant access to their content. Those blocks were removed for the response-generation period and reinstated afterward.
Why This Matters
When using AI assistants for research or content planning, these findings reinforce the need to verify claims against original sources.
As a publication, this could impact how your content is represented in AI answers. The high rate of errors increases the risk of misattributed or unsupported statements appearing in summaries that cite your content.
Looking Ahead
The EBU and BBC published a News Integrity in AI Assistants Toolkit alongside the report, offering guidance for technology companies, media organizations, and researchers.
Reuters reports the EBU’s view that growing reliance on assistants for news could undermine public trust.
As EBU Media Director Jean Philip De Tender put it:
“When people don’t know what to trust, they end up trusting nothing at all, and that can deter democratic participation.”
Brave disclosed security vulnerabilities in AI browsers that could allow malicious websites to hijack AI assistants and access sensitive user accounts.
The issues affect Perplexity Comet, Fellou, and potentially other AI browsers that can take actions on behalf of users.
The vulnerabilities stem from indirect prompt injection attacks where websites embed hidden instructions that AI browsers process as legitimate user commands. Brave published the findings after reporting the issues to affected companies.
What Brave Found
Perplexity Comet Vulnerability
Comet’s screenshot feature can be exploited by embedding nearly invisible text in webpages.
When users take screenshots to ask questions, the AI extracts hidden text using what appears to be OCR and processes it as commands rather than untrusted content.
Brave notes Comet isn’t open-source, so this behavior is inferred and can’t be verified from source code.
The hidden instructions use faint colors that humans can barely see but AI systems extract and execute. This lets attackers issue commands to the AI assistant without the user’s knowledge.
Fellou Navigation Vulnerability
Fellou browser sends webpage content to its AI system when users navigate to a site.
Asking the AI assistant to visit a webpage causes the browser to pass the page’s visible content to the AI in a way that lets the webpage text override user intent.
This means visiting a malicious site could trigger unintended AI actions without requiring explicit user interaction with the AI assistant.
Access To Sensitive Accounts
The vulnerabilities become dangerous because AI assistants operate with user authentication privileges.
A hijacked AI browser can access banking sites, email providers, work systems, and cloud storage where users remain logged in.
Brave notes that even summarizing a Reddit post could result in attackers stealing money or private data if the post contains hidden malicious instructions.
Industry Context
Brave describes indirect prompt injection as a systemic challenge facing AI browsers rather than an isolated issue.
The problem revolves around AI systems failing to distinguish between trusted user input and untrusted webpage content when constructing prompts.
Brave is withholding details of one additional vulnerability found in another browser until next week.
Why This Matters
Brave argues that traditional web security models break when AI agents act on behalf of users.
Natural language instructions on any webpage can trigger cross-domain actions reaching banks, healthcare providers, corporate systems, and email hosts.
Same-origin policy protections become irrelevant because AI assistants execute with full user privileges across all authenticated sites.
The disclosure arrives the same day OpenAI launched ChatGPT Atlas with agent mode capabilities, highlighting the tension between AI browser functionality and security.
People using AI browsers with agent features face a tradeoff between automation capabilities and exposure to these systemic vulnerabilities.
Looking Ahead
Brave’s research continues with additional findings scheduled for disclosure next week.
The company indicated it’s exploring longer-term solutions to address the trust boundary problems in agentic browsing.
OpenAI released ChatGPT Atlas today, describing it as “the browser with ChatGPT built in.”
OpenAI announced the launch in a blog post and livestream featuring CEO Sam Altman and team members including Ben Goodger, who previously helped develop Google Chrome and Mozilla Firefox.
Atlas is available now on macOS worldwide for Free, Plus, Pro, and Go users. Windows, iOS, and Android versions are coming soon.
What Does ChatGPT Atlas Do?
Unified New Tab Experience
Opening a new tab creates a starting point where you can ask questions or enter URLs. Results appear with tabs to switch between links, images, videos, and news where available.
OpenAI describes this as showing faster, more useful results in one place. The tab-based navigation keeps ChatGPT answers and traditional search results within the same view.
ChatGPT Sidebar
A ChatGPT sidebar appears in any browser window to summarize content, compare products, or analyze data from the page you’re viewing.
The sidebar provides assistance without leaving the current page.
Cursor
Cursor chat lets you highlight text in emails, calendar invites, or documents and get ChatGPT help with one click.
The feature can rewrite selected text inline without opening a separate chat window.
Agent Mode
Agent mode can open tabs and click through websites to complete tasks with user approval. OpenAI says it can research products, book appointments, or organize tasks inside your browser.
The company describes it as an early experience that may make mistakes on complex workflows, but is rapidly improving reliability and task success rates.
Browser Memories
Browser memories let ChatGPT remember context from sites you visit and bring back relevant details when needed. The feature can continue product research or build to-do lists from recent activity.
Browser memories are optional. You can view all memories in settings, archive ones no longer relevant, and clear browsing history to delete them.
A site-level toggle in the address bar controls which pages ChatGPT can see.
Privacy Controls
Users control what ChatGPT can see and remember. You can clear specific pages, clear entire browsing history, or open an incognito window to temporarily log out of ChatGPT.
By default, OpenAI doesn’t use browsing content to train models. You can opt in by enabling “include web browsing” in data controls settings.
OpenAI added safeguards for agent mode. It cannot run code in the browser, download files, install extensions, or access other apps on your computer or file system. It pauses to ensure you’re watching when taking actions on sensitive sites like financial institutions.
The company acknowledges agents remain susceptible to hidden malicious instructions in webpages or emails that could override intended behavior. OpenAI ran thousands of hours of red-teaming and designed safeguards to adapt to novel attacks, but notes the safeguards won’t stop every attack.
Why This Matters
Atlas blurs the line between browser and search engine by putting ChatGPT responses alongside traditional search results in the same view. This changes the browsing model from ‘visit search engine, then navigate to sites’ to ‘ask questions and browse simultaneously.’
This matters because it’s another major platform where AI-generated answers appear before organic links.
The agent mode also introduces a new variable: AI systems that can navigate sites, fill forms, and complete purchases on behalf of users without traditional click-through patterns.
The privacy controls around site visibility and browser memories create a permission layer that hasn’t existed in traditional browsers. Sites you block from ChatGPT’s view won’t contribute to AI responses or memories, which could affect how your content gets discovered and referenced.
Looking Ahead
OpenAI is rolling out Atlas for macOS starting today. First-run setup imports bookmarks, saved passwords, and browsing history from your current browser.
Windows, iOS, and Android versions are scheduled to launch in the coming months without specific release dates.
The roadmap includes multi-profile support, improved developer tools, and guidance for websites to add ARIA tags to help the agent work better with their content.
The Wikimedia Foundation (WMF) reported a decline in human pageviews on Wikipedia compared with the same months last year.
Marshall Miller, Senior Director of Product, Core Experiences at Wikimedia Foundation, wrote that the organization believes the decline reflects changes in how people access information, particularly through AI search and social platforms.
What Changed In The Data
Wikimedia observed unusually high traffic around May. The traffic appeared human but investigation revealed bots designed to evade detection.
WMF updated its bot detection systems and applied the new logic to reclassify traffic from March through August.
Miller noted the revised data shows “a decrease of roughly 8% as compared to the same months in 2024.”
WMF cautions that comparisons require careful interpretation because bot detection rules changed over time.
The Role Of AI Search
Miller attributed the decline to generative AI and social platforms reshaping information discovery.
He wrote that search engines are “providing answers directly to searchers, often based on Wikipedia content.”
This creates a scenario where Wikipedia serves as source material for AI-powered search features without generating traffic to the site itself.
Wikipedia’s Role In AI Systems
The traffic decline comes as AI systems increasingly depend on Wikipedia as source material.
Research from Profound analyzing 680 million AI citations finds that within ChatGPT’s top 10 most-cited sources, Wikipedia accounts for 47.9% of the top-10 share. For Google AI Overviews, Wikipedia’s top-10 share is 5.7%, with Reddit 21.0% and YouTube 18.8%.
WMF also reported a 50% surge in bandwidth from AI bots since January 2024. These bots scrape content primarily for training computer vision models.
Wikipedia launched Wikimedia Enterprise in 2021, offering commercial, SLA-backed data access for high-volume reusers, including search and AI companies.
Why This Matters
If Wikipedia loses traffic while serving as ChatGPT’s most-cited source, the model that sustains content creation is breaking. You can produce authoritative content that AI systems depend on and still see referral traffic decline.
The incentive structure assumes publishers benefit from creating material that powers AI answers, but Wikipedia’s data shows that assumption doesn’t hold.
Track how AI features affect your traffic and whether being cited translates to meaningful engagement.
Looking Ahead
WMF says it will continue updating bot detection systems and monitoring how generative AI and social media shape information access.
Wikipedia remains a core dataset for modern search and AI systems, even when users don’t visit the site directly. Publishers should expect similar dynamics as AI search features expand across platforms.
GEO/AEO is criticized by SEOs who claim that it’s just SEO at best and unsupported lies at worst. Are SEOs right, or are they just defending their turf? Bing recently published a guide to AI search visibility that provides a perfect opportunity to test whether optimization for AI answers recommendations is distinct from traditional SEO practices.
Chunking Content
Some AEO/GEO optimizers are saying that it’s important to write content in chunks because that’s how AI and LLMs break up a pages of content, into chunks of content. Bing’s guide to answer engine optimization, written by Krishna Madhavan, Principal Product Manager at Bing, echoes the concept of chunking.
Bing’s Madhavan writes:
“AI assistants don’t read a page top to bottom like a person would. They break content into smaller, usable pieces — a process called parsing. These modular pieces are what get ranked and assembled into answers.”
The thing that some SEOs tend to forget is that chunking content is not new. It’s been around for at least five years. Google introduced their passage ranking algorithm back in 2020. The passages algorithm breaks up a web page into sections to understand how the page and a section of it is relevant to a search query.
“Passage ranking is an AI system we use to identify individual sections or “passages” of a web page to better understand how relevant a page is to a search.”
“Very specific searches can be the hardest to get right, since sometimes the single sentence that answers your question might be buried deep in a web page. We’ve recently made a breakthrough in ranking and are now able to better understand the relevancy of specific passages. By understanding passages in addition to the relevancy of the overall page, we can find that needle-in-a-haystack information you’re looking for. This technology will improve 7 percent of search queries across all languages as we roll it out globally.”
As far as chunking is concerned, any SEO who has optimized content for Google’s Featured Snippets can attest to the importance of creating passages that directly answer questions. It’s been a fundamental part of SEO since at least 2014, when Google introduced Featured Snippets.
Titles, Descriptions, and H1s
The Bing guide to ranking in AI also states that descriptions, headings, and titles are important signals to AI systems.
I don’t think I need to belabor the point that descriptions, headings, and titles are fundamental elements of SEO. So again, there is nothing her to differentiate AEO/GEO from SEO.
Lists and Tables
Bing recommends bulleted lists and tables as a way to easily communicate complex information to users and search engines. This approach to organizing data is similar to an advanced SEO method called disambiguation. Disambiguation is about making the meaning and purpose of a web page as clear as possible, to make it less ambiguous.
Making a page less ambiguous can incorporate semantic HTML to clearly delineate which part of a web page is the main content (MC in the parlance of Google’s third-party quality rater guidelines) and which part of the web page is just advertisements, navigation, a sidebar, or the footer.
Another form of disambiguation is through the proper use of HTML elements like ordered lists (OL) and the use of tables to communicate tabular data such as product comparisons or a schedule of dates and times for an event.
The use of HTML elements (like H, OL, and UL) give structure to on-page information, which is why it’s called structured information. Structured information and structured data are two different things. Structured information is on the page and is seen in the browser and by crawlers. Structured data is meta data that only a bot will see.
There are studies that structured information helps AI Agents make sense of a web page, so I have to concede that structured information is something that is particularly helpful to AI Agents in a unique way.
Question And Answer Pairs
Bing recommends Q&A’s, which are question and answer pairs that an AI can use directly. Bing’s Madhavan writes:
“Direct questions with clear answers mirror the way people search. Assistants can often lift these pairs word for word into AI-generated responses.”
This is a mix of passage ranking and the SEO practice of writing for featured snippets, where you pose a question and give the answer. It’s a risky approach to create an entire page of questions and answers but if it feels useful and helpful then it may be worth doing.
Something to keep in mind is that Google’s systems consider content lacking in unique insight on the same level of spam. Google also considers content created specifically for search engines as low quality as well.
Anyone considering writing questions and answers on a web page for the purpose of AI SEO should first consider the whether it’s useful for people and think deeply about the quality of the question and answer pairs. Otherwise it’s just a page of rote made for search engine content.
Be Precise With Semantic Clarity
Bing also recommends semantic clarity. This is also important for SEO. Madhavan writes:
“Write for intent, not just keywords. Use phrasing that directly answers the questions users ask.
Avoid vague language. Terms like innovative or eco mean little without specifics. Instead, anchor claims in measurable facts.
Add context. A product page should say “42 dB dishwasher designed for open-concept kitchens” instead of just “quiet dishwasher.”
Use synonyms and related terms. This reinforces meaning and helps AI connect concepts (quiet, noise level, sound rating).”
They also advise to not use abstract words like “next-gen” or “cutting edge” because it doesn’t really say anything. This is a big, big issue with AI-generated content because it tends to use abstract words that can completely be removed and not change the meaning of the sentence or paragraph.
Lastly, they advise to not use decorative symbols, which is good a tip. Decorative symbols like the arrow → symbol don’t really communicate anything semantically.
All of this advice is good. It’s good for SEO, good for AI, and like all the other AI SEO practices, there is nothing about it that is specific to AI.
Bing Acknowledges Traditional SEO
The funny thing about Bing’s guide to ranking better for AI is that it explicitly acknowledges that traditional SEO is what matters.
Bing’s Madhavan writes:
“Whether you call it GEO, AIO, or SEO, one thing hasn’t changed: visibility is everything. In today’s world of AI search, it’s not just about being found, it’s about being selected. And that starts with content.
…traditional SEO fundamentals still matter.”
AI Search Optimization = SEO
Google and Bing have incorporated AI into traditional search for about a decade. AI Search ranking is not new. So it should not be surprising that SEO best practices align with ranking for AI answers. The same considerations also parallel with considerations about users and how they interact with content.
Many SEOs are still stuck in the decades-old keyword optimization paradigm and maybe for them these methods of disambiguation and precision are new to them. So perhaps it’s a good thing that the broader SEO industry catches up with many of these concepts for optimizing content and to recognize that there is no AEO/GEO, it’s still just SEO.
Search has never stood still. Every few years, a new layer gets added to how people find and evaluate information. Generative AI systems like ChatGPT, Copilot Search, and Perplexity haven’t replaced Google or Bing. They’ve added a new surface where discovery happens earlier, and where your visibility may never show up in analytics.
Call it Generative Engine Optimization, call it AI visibility work, or just call it the next evolution of SEO. Whatever the label, the work is already happening. SEO practitioners are already tracking citations, analyzing which content gets pulled into AI responses, and adapting strategies as these platforms evolve weekly.
This work doesn’t replace SEO, rather it builds on top of it. Think of it as the “answer layer” above the traditional search layer. You still need structured content, clean markup, and good backlinks, among the other usual aspects of SEO. That’s the foundation assistants learn from. The difference is that assistants now re-present that information to users directly inside conversations, sidebars, and app interfaces.
If your work stops at traditional rankings, you’ll miss the visibility forming in this new layer. Tracking when and how assistants mention, cite, and act on your content is how you start measuring that visibility.
Your brand can appear in multiple generative answers without you knowing. These citations don’t show up in any analytics tool until someone actually clicks.
Image Credi: Duane Forrester
Perplexity explains that every answer it gives includes numbered citations linking to the original sources. OpenAI’s ChatGPT Search rollout confirms that answers now include links to relevant sites and supporting sources. Microsoft’s Copilot Search does the same, pulling from multiple sources and citing them inside a summarized response. And Google’s own documentation for AI overviews makes it clear that eligible content can be surfaced inside generative results.
Each of these systems now has its own idea of what a “citation” looks like. None of them report it back to you in analytics.
That’s the gap. Your brand can appear in multiple generative answers without you knowing. These are the modern zero-click impressions that don’t register in Search Console. If we want to understand brand visibility today, we need to measure mentions, impressions, and actions inside these systems.
But there’s yet another layer of complexity here: content licensing deals. OpenAI has struck partnerships with publishers including the Associated Press, Axel Springer, and others, which may influence citation preferences in ways we can’t directly observe. Understanding the competitive landscape, not just what you’re doing, but who else is being cited and why, becomes essential strategic intelligence in this environment.
In traditional SEO, impressions and clicks tell you how often you appeared and how often someone acted. Inside assistants, we get a similar dynamic, but without official reporting.
Mentions are when your domain, name, or brand is referenced in a generative answer.
Impressions are when that mention appears in front of a user, even if they don’t click.
Actions are when someone clicks, expands, or copies the reference to your content.
These are not replacements for your SEO metrics. They’re early indicators that your content is trusted enough to power assistant answers.
If you read last week’s piece, where I discussed how 2026 is going to be an inflection year for SEOs, you’ll remember the adoption curve. During 2026, assistants are projected to reach around 1 billion daily active users, embedding themselves into phones, browsers, and productivity tools. But that doesn’t mean they’re replacing search. It means discovery is happening before the click. Measuring assistant mentions is about seeing those first interactions before the analytics data ever arrives.
Let’s be clear. Traditional search is still the main driver of traffic. Google handles over 3.5 billion searches per day. In May 2025, Perplexity processed 780 million queries in a full month. That’s roughly what Google handles in about five hours.
The data is unambiguous. AI assistants are a small, fast-growing complement, not a replacement (yet).
But if your content already shows up in Google, it’s also being indexed and processed by the systems that train and quote inside these assistants. That means your optimization work already supports both surfaces. You’re not starting over. You’re expanding what you measure.
Ranking is an output-aligned process. The system already knows what it’s trying to show and chooses the best available page to match that intent. Retrieval, on the other hand, is pre-answer-aligned. The system is still assembling the information that will become the answer and that difference can change everything.
When you optimize for ranking, you’re trying to win a slot among visible competitors. When you optimize for retrieval, you’re trying to be included in the model’s working set before the answer even exists. You’re not fighting for position as much as you’re fighting for participation.
That’s why clarity, attribution, and structure matter so much more in this environment. Assistants pull only what they can quote cleanly, verify confidently, and synthesize quickly.
When an assistant cites your site, it’s doing so because your content met three conditions:
It answered the question directly, without filler.
It was machine-readable and easy to quote or summarize.
It carried provenance signals the model trusted: clear authorship, timestamps, and linked references.
Those aren’t new ideas. They’re the same best practices SEOs have worked with for years, just tested earlier in the decision chain. You used to optimize for the visible result. Now you’re optimizing for the material that builds the result.
One critical reality to understand: citation behavior is highly volatile. Content cited today for a specific query may not appear tomorrow for that same query. Assistant responses can shift based on model updates, competing content entering the index, or weighting adjustments happening behind the scenes. This instability means you’re tracking trends and patterns, not guarantees (not that ranking was guaranteed, but they are typically more stable). Set expectations accordingly.
Not all content has equal citation potential, and understanding this helps you allocate resources wisely. Assistants excel at informational queries (”how does X work?” or “what are the benefits of Y?”). They’re less relevant for transactional queries like “buy shoes online” or navigational queries like “Facebook login.”
If your content serves primarily transactional or branded navigational intent, assistant visibility may matter less than traditional search rankings. Focus your measurement efforts where assistant behavior actually impacts your audience and where you can realistically influence outcomes.
The simplest way to start is manual testing.
Run prompts that align with your brand or product, such as:
“What is the best guide on [topic]?”
“Who explains [concept] most clearly?”
“Which companies provide tools for [task]?”
Use the same query across ChatGPT Search, Perplexity, and Copilot Search. Document when your brand or URL appears in their citations or answers.
Log the results. Record the assistant used, the prompt, the date, and the citation link if available. Take screenshots. You’re not building a scientific study here; you’re building a visibility baseline.
Once you’ve got a handful of examples, start running the same queries weekly or monthly to track change over time.
You can even automate part of this. Some platforms now offer API access for programmatic querying, though costs and rate limits apply. Tools like n8n or Zapier can capture assistant outputs and push them to a Google Sheet. Each row becomes a record of when and where you were cited. (To be fair, it’s more complicated than 2 short sentences make it sound, but it’s doable by most folks, if they’re willing to learn some new things.)
This is how you can create your first “ai-citation baseline“ report if you’re willing to just stay manual in your approach.
But don’t stop at tracking yourself. Competitive citation analysis is equally important. Who else appears for your key queries? What content formats do they use? What structural patterns do their cited pages share? Are they using specific schema markup or content organization that assistants favor? This intelligence reveals what assistants currently value and where gaps exist in the coverage landscape.
We don’t have official impression data yet, but we can infer visibility.
Look at the types of queries where you appear in assistants. Are they broad, informational, or niche?
Use Google Trends to gauge search interest for those same queries. The higher the volume, the more likely users are seeing AI answers for them.
Track assistant responses for consistency. If you appear across multiple assistants for similar prompts, you can reasonably assume high impression potential.
Impressions here don’t mean analytics views. They mean assistant-level exposure: your content seen in an answer window, even if the user never visits your site.
Actions are the most difficult layer to observe, but not because assistant ecosystems hide all referrer data. The tracking reality is more nuanced than that.
Most AI assistants (Perplexity, Copilot, Gemini, and paid ChatGPT users) do send referrer data that appears in Google Analytics 4 as perplexity.ai / referral or chatgpt.com / referral. You can see these sources in your standard GA4 Traffic Acquisition reports. (useful article)
The real challenges are:
Free-tier users don’t send referrers. Free ChatGPT traffic arrives as “Direct” in your analytics, making it impossible to distinguish from bookmark visits, typed URLs, or other referrer-less traffic sources. (useful article)
No query visibility. Even when you see the referrer source, you don’t know what question the user asked the AI that led them to your site. Traditional search gives you some query data through Search Console. AI assistants don’t provide this.
Volume is still small but growing. AI referral traffic typically represents 0.5% to 3% of total website traffic as of 2025, making patterns harder to spot in the noise of your overall analytics. (useful article)
Here’s how to improve tracking and build a clearer picture of AI-driven actions:
Set up dedicated AI traffic tracking in GA4. Create a custom exploration or channel group using regex filters to isolate all AI referral sources in one view. Use a pattern like the excellent example in this Orbit Media article to capture traffic from major platforms ( ^https://(www.meta.ai|www.perplexity.ai|chat.openai.com|claude.ai|gemini.google.com|chatgpt.com|copilot.microsoft.com)(/.*)?$ ). This separates AI referrals from generic referral traffic and makes trends visible.
Add identifiable UTM parameters when you control link placement. In content you share to AI platforms, in citations you can influence, or in public-facing URLs. Even platforms that send referrer data can benefit from UTM tagging for additional attribution clarity. (useful article)
Monitor “Direct” traffic patterns. Unexplained spikes in direct traffic, especially to specific landing pages that assistants commonly cite, may indicate free-tier AI users clicking through without referrer data. (useful article)
Track which landing pages receive AI traffic. In your AI traffic exploration, add “Landing page + query string” as a dimension to see which specific pages assistants are citing. This reveals what content AI systems find valuable enough to reference.
Watch for copy-paste patterns in social media, forums, or support tickets that match your content language exactly. That’s a proxy for text copied from an assistant summary and shared elsewhere.
Each of these tactics helps you build a more complete picture of AI-driven actions, even without perfect attribution. The key is recognizing that some AI traffic is visible (paid tiers, most platforms), some is hidden (free ChatGPT), and your job is to capture as much signal as possible from both.
Machine-Validated Authority (MVA) isn’t visible to us as it’s an internal trust signal used by AI systems to decide which sources to quote. What we can measure are the breadcrumbs that correlate with it:
Frequency of citation
Presence across multiple assistants
Stability of the citation source (consistent URLs, canonical versions, structured markup)
When you see repeat citations or multi-assistant consistency, you’re seeing a proxy for MVA. That consistency is what tells you the systems are beginning to recognize your content as reliable.
Perplexity reports almost 10 billion queries a year across its user base. That’s meaningful visibility potential even if it’s small compared to search.
Microsoft’s Copilot Search is embedded in Windows, Edge, and Microsoft 365. That means millions of daily users see summarized, cited answers without leaving their workflow.
Google’s rollout of AI Overviews adds yet another surface where your content can appear, even when no one clicks through. Their own documentation describes how structured data helps make content eligible for inclusion.
Each of these reinforces a simple truth: SEO still matters, but it now extends beyond your own site.
Start small. A basic spreadsheet is enough.
Columns:
Date.
Assistant (ChatGPT Search, Perplexity, Copilot).
Prompt used.
Citation found (yes/no).
URL cited.
Competitor citations observed.
Notes on phrasing or ranking position.
Add screenshots and links to the full answers for evidence. Over time, you’ll start to see which content themes or formats surface most often.
If you want to automate, set up a workflow in n8n that runs a controlled set of prompts weekly and logs outputs to your sheet. Even partial automation will save time and let you focus on interpretation, not collection. Use this sheet and its data to augment what you can track in sources like GA4.
Before investing heavily in assistant monitoring, consider resource allocation carefully. If assistants represent less than 1% of your traffic and you’re a small team, extensive tracking may be premature optimization. Focus on high-value queries where assistant visibility could materially impact brand perception or capture early-stage research traffic that traditional search might miss.
Manual quarterly audits may suffice until the channel grows to meaningful scale. This is about building baseline understanding now so you’re prepared when adoption accelerates, not about obsessive daily tracking of negligible traffic sources.
Executives understand and prefer dashboards, not debates about visibility layers, so show them real-world examples. Put screenshots of your brand cited inside ChatGPT or Copilot next to your Search Console data. Explain that this is not a new algorithm update but a new front end for existing content. It’s up to you to help them understand this critical difference.
Frame it as additive reach. You’re showing leadership that the company’s expertise is now visible in new interfaces before clicks happen. That reframing keeps support for SEO strong and positions you as the one tracking the next wave.
It’s worth noting that citation practices exist within a shifting legal landscape. Publishers and content creators have raised concerns about copyright and fair use as AI systems train on and reproduce web content. Some platforms have responded with licensing agreements, while legal challenges continue to work through courts.
This environment may influence how aggressively platforms cite sources, which sources they prioritize, and how they balance attribution with user experience. The frameworks we build today should remain flexible as these dynamics evolve and as the industry establishes clearer norms around content usage and attribution.
AI assistant visibility is not yet a major traffic source. It’s a small but growing signal of trust.
By measuring mentions and citations now, you build an early-warning system. You’ll see when your content starts appearing in assistants long before any of your analytics tools do. This means that when 2026 arrives and assistants become a daily habit, you won’t be reacting to the curve. You’ll already have data on how your brand performs inside these new systems.
If you extend the concept here of “data” to a more meta level, you could say it’s already telling us that the growth is starting, it’s explosive, and it’s about to have an impact in consumer’s behaviors. So now is the moment to take that knowledge and focus it on the more day-to-day work you do and start to plan for how those changes impact that daily work.
Traditional SEO remains your base layer. Generative visibility sits above it. Machine-Validated Authority lives inside the systems. Watching mentions, impressions, and actions is how we start making what’s in the shadows measurable.
We used to measure rankings because that’s what we could see. Today, we can measure retrieval for the same reason. This is just the next evolution of evidence-based SEO. Ultimately, you can’t fix what you can’t see. We cannot see how trust is assigned inside the system, but we can see the outputs of each system.
The assistants aren’t replacing search (yet). They’re simply showing you how visibility behaves when the click disappears. If you can measure where you appear in those layers now, you’ll know when the slope starts to change and you’ll already be ahead of it.
Google Search Advocate John Mueller provided detailed technical SEO feedback to a developer on Reddit who vibe coded a website in two days and launched it on Product Hunt.
The developer posted in r/vibecoding that they built a Bento Grid Generator for personal use, published it on Product Hunt, and received over 90 upvotes within two hours.
Mueller responded with specific technical issues affecting the site’s search visibility.
Mueller wrote:
“I love seeing vibe-coded sites, it’s cool to see new folks make useful & self-contained things for the web, I hope it works for you.
This is just a handful of the things I noticed here. I’ve seen similar things across many vibe-coded sites, so perhaps this is useful for others too.”
Mueller’s Technical Feedback
Mueller identified multiple issues with the site.
The homepage stores key content in a llms.txt JavaScript file. Mueller noted that Google doesn’t use this file, and he’s not aware of other search engines using it either.
Mueller wrote:
“Generally speaking, your homepage should have everything that people and bots need to understand what your site is about, what the value of your service / app / site is.”
He recommended adding a popup-welcome-div in HTML that includes the information to make it immediately available to bots.
For meta tags, Mueller said the site only needs title and description tags. The keywords, author, and robots meta tags provide no SEO benefit.
The site includes hreflang tags despite having just one language version. Mueller said these aren’t necessary for single-language sites.
Mueller flagged the JSON-LD structured data as ineffective, noting:
“Check out Google’s ‘Structured data markup that Google Search supports’ for the types supported by Google. I don’t think anyone else supports your structured data.”
He called the hidden h1 and h2 tags “cheap & useless.” Mueller suggested using a visible, dismissable banner in the HTML instead.
The robots.txt file contains unnecessary directives. Mueller recommended skipping the sitemap if it’s just one page.
Mueller suggested adding the domain to Search Console and making it easier for visitors to understand what the app or site does.
Setting Expectations
Mueller closed his feedback with realistic expectations about the impact of technical SEO fixes.
He said:
“Will you automatically get tons of traffic from just doing these things? No, definitely not. However, it makes it easier for search engines to understand your site, so that they could be sending you traffic from search.”
He noted that implementing these changes now sets you up for success later.
Mueller added:
“Doing these things sets you up well, so that you can focus more on the content & functionality, without needing to rework everything later on.”
The Vibe Coding Trade-Off
This exchange highlights a tension with vibe coding and search visibility.
The developer built a functional product that generated immediate user engagement. The site works, looks polished, and achieved success on Product Hunt within hours.
None of the flagged issues affects user experience. But every implementation choice Mueller criticized shares the same characteristic. It works for visitors while providing nothing to search engines.
Sites built for rapid launch can achieve product success without search visibility. But the technical debt adds up.
The fixes aren’t too challenging, but they require addressing issues that seemed fine when the goal was to ship fast rather than rank well.
When conversational AIs like ChatGPT, Perplexity, or Google AI Mode generate snippets or answer summaries, they’re not writing from scratch, they’re picking, compressing, and reassembling what webpages offer. If your content isn’t SEO-friendly and indexable, it won’t make it into generative search at all. Search, as we know it, is now a function of artificial intelligence.
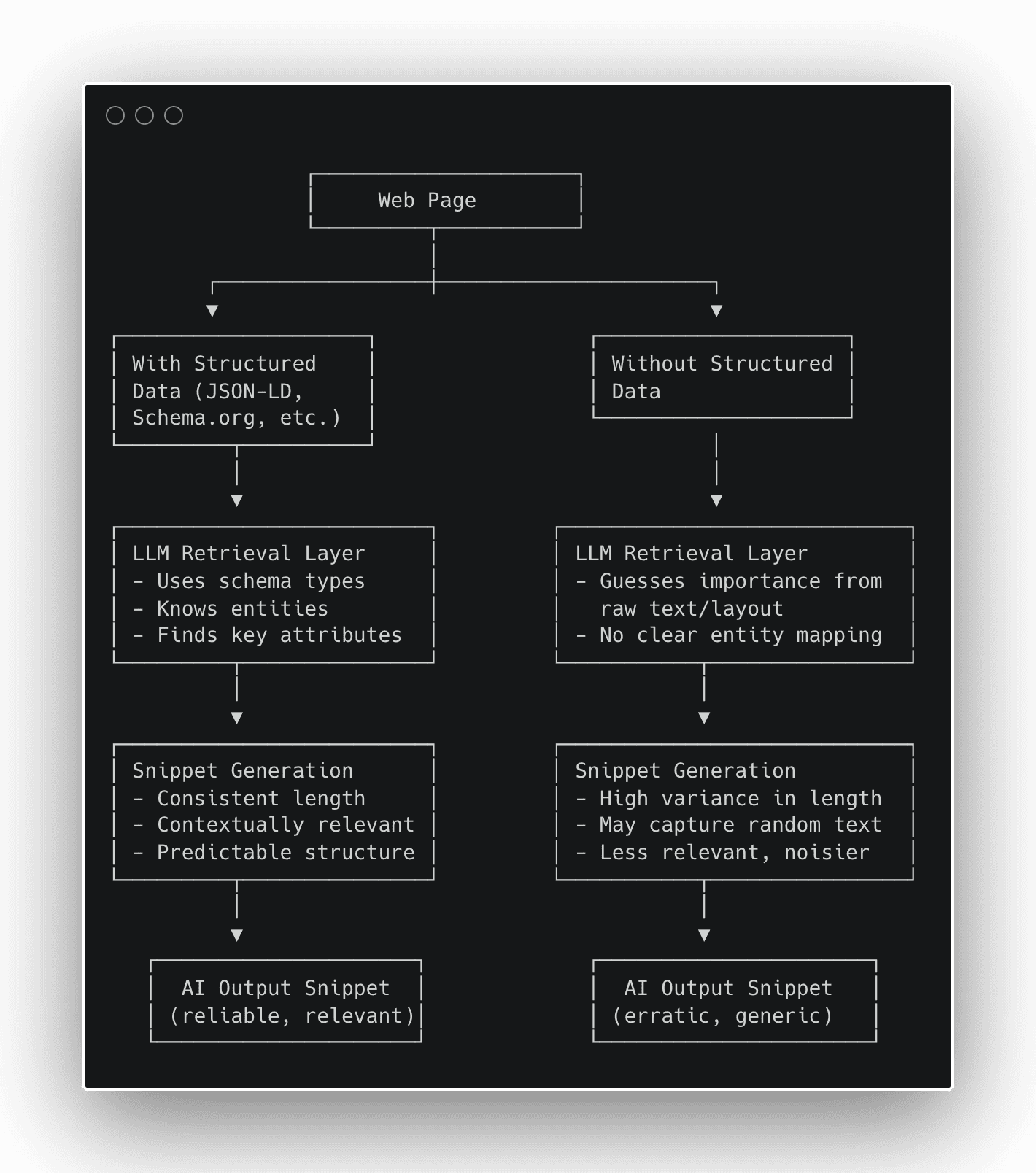
But what if your page doesn’t “offer” itself in a machine-readable form? That’s where structured data comes in, not just as an SEO gig, but as a scaffold for AI to reliably pick the “right facts.” There has been some confusion in our community, and in this article, I will:
walk through controlled experiments on 97 webpages showing how structured data improves snippet consistency and contextual relevance,
map those results into our semantic framework.
Many have asked me in recent months if LLMs use structured data, and I’ve been repeating over and over that an LLM doesn’t use structured data as it has no direct access to the world wide web. An LLM uses tools to search the web and fetch webpages. Its tools – in most cases – greatly benefit from indexing structured data.
Image by author, October 2025
In our early results, structured data increases snippet consistency and improves contextual relevance in GPT-5. It also hints at extending the effective wordlim envelope – this is a hidden GPT-5 directive that decides how many words your content gets in a response. Imagine it as a quota on your AI visibility that gets expanded when content is richer and better-typed. You can read more about this concept, which I first outlined on LinkedIn.
Why This Matters Now
Wordlim constraints: AI stacks operate with strict token/character budgets. Ambiguity wastes budget; typed facts conserve it.
Disambiguation & grounding: Schema.org reduces the model’s search space (“this is a Recipe/Product/Article”), making selection safer.
Knowledge graphs (KG): Schema often feeds KGs that AI systems consult when sourcing facts. This is the bridge from web pages to agent reasoning.
My personal thesis is that we want to treat structured data as the instruction layer for AI. It doesn’t “rank for you,” it stabilizes what AI can say about you.
Experiment Design (97 URLs)
While the sample size was small, I wanted to see how ChatGPT’s retrieval layer actually works when used from its own interface, not through the API. To do this, I asked GPT-5 to search and open a batch of URLs from different types of websites and return the raw responses.
You can prompt GPT-5 (or any AI system) to show the verbatim output of its internal tools using a simple meta-prompt. After collecting both the search and fetch responses for each URL, I ran an Agent WordLift workflow [disclaimer, our AI SEO Agent] to analyze every page, checking whether it included structured data and, if so, identifying the specific schema types detected.
These two steps produced a dataset of 97 URLs, annotated with key fields:
has_sd → True/False flag for structured data presence.
schema_classes → the detected type (e.g., Recipe, Product, Article).
search_raw → the “search-style” snippet, representing what the AI search tool showed.
open_raw → a fetcher summary, or structural skim of the page by GPT-5.
Using a “LLM-as-a-Judge” approach powered by Gemini 2.5 Pro, I then analyzed the dataset to extract three main metrics:
Consistency: distribution of search_raw snippet lengths (box plot).
Contextual relevance: keyword and field coverage in open_raw by page type (Recipe, E-comm, Article).
Quality score: a conservative 0–1 index combining keyword presence, basic NER cues (for e-commerce), and schema echoes in the search output.
The Hidden Quota: Unpacking “wordlim”
While running these tests, I noticed another subtle pattern, one that might explain why structured data leads to more consistent and complete snippets. Inside GPT-5’s retrieval pipeline, there’s an internal directive informally known as wordlim: a dynamic quota determining how much text from a single webpage can make it into a generated answer.
At first glance, it acts like a word limit, but it’s adaptive. The richer and better-typed a page’s content, the more room it earns in the model’s synthesis window.
From my ongoing observations:
Unstructured content (e.g., a standard blog post) tends to get about ~200 words.
Structured content (e.g., product markup, feeds) extends to ~500 words.
Dense, authoritative sources (APIs, research papers) can reach 1,000+ words.
This isn’t arbitrary. The limit helps AI systems:
Encourage synthesis across sources rather than copy-pasting.
Avoid copyright issues.
Keep answers concise and readable.
Yet it also introduces a new SEO frontier: your structured data effectively raises your visibility quota. If your data isn’t structured, you’re capped at the minimum; if it is, you grant AI more trust and more space to feature your brand.
While the dataset isn’t yet large enough to be statistically significant across every vertical, the early patterns are already clear – and actionable.
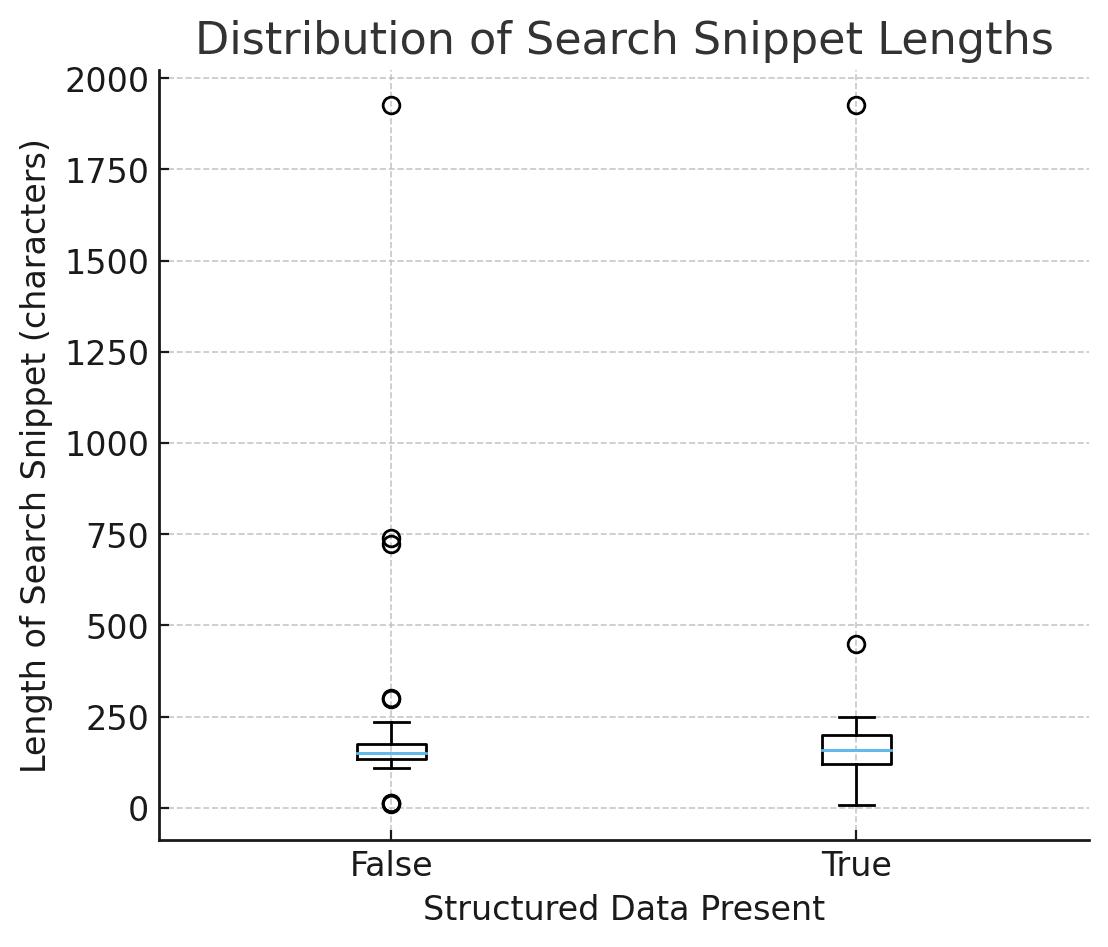
Figure 1 – How Structured Data Affects AI Snippet Generation (Image by author, October 2025)
Results
Figure 2 – Distribution of Search Snippet Lengths (Image by author, October 2025)
1) Consistency: Snippets Are More Predictable With Schema
In the box plot of search snippet lengths (with vs. without structured data):
Medians are similar → schema doesn’t make snippets longer/shorter on average.
Spread (IQR and whiskers) is tighter when has_sd = True → less erratic output, more predictable summaries.
Interpretation: Structured data doesn’t inflate length; it reduces uncertainty. Models default to typed, safe facts instead of guessing from arbitrary HTML.
2) Contextual Relevance: Schema Guides Extraction
Recipes: With Recipe schema, fetch summaries are far likelier to include ingredients and steps. Clear, measurable lift.
Ecommerce: The search tool often echoes JSON‑LD fields (e.g., aggregateRating, offer, brand) evidence that schema is read and surfaced. Fetch summaries skew to exact product names over generic terms like “price,” but the identity anchoring is stronger with schema.
Articles: Small but present gains (author/date/headline more likely to appear).
3) Quality Score (All Pages)
Averaging the 0–1 score across all pages:
No schema → ~0.00
With schema → positive uplift, driven mostly by recipes and some articles.
Even where means look similar, variance collapses with schema. In an AI world constrained by wordlim and retrieval overhead, low variance is a competitive advantage.
Beyond Consistency: Richer Data Extends The Wordlim Envelope (Early Signal)
While the dataset isn’t yet large enough for significance tests, we observed this emerging pattern: Pages with richer, multi‑entity structured data tend to yield slightly longer, denser snippets before truncation.
Hypothesis: Typed, interlinked facts (e.g., Product + Offer + Brand + AggregateRating, or Article + author + datePublished) help models prioritize and compress higher‑value information – effectively extending the usable token budget for that page. Pages without schema more often get prematurely truncated, likely due to uncertainty about relevance.
Next step: We’ll measure the relationship between semantic richness (count of distinct Schema.org entities/attributes) and effective snippet length. If confirmed, structured data not only stabilizes snippets – it increases informational throughput under constant word limits.
Lexical Graph: chunked copy (care instructions, size guides, FAQs) linked back to entities.
Why it works: The entity layer gives AI a safe scaffold; the lexical layer provides reusable, quotable evidence. Together they drive precision under thewordlim constraints.
Here’s how we’re translating these findings into a repeatable SEO playbook for brands working under AI discovery constraints.
Unify entity + lexical Keep specs, FAQs, and policy text chunked and entity‑linked.
Harden snippet surface Facts must be consistent across visible HTML and JSON‑LD; keep critical facts above the fold and stable.
Instrument Track variance, not just averages. Benchmark keyword/field coverage inside machine summaries by template.
Conclusion
Structured data doesn’t change the average size of AI snippets; it changes their certainty. It stabilizes summaries and shapes what they include. In GPT-5, especially under aggressive wordlim conditions, that reliability translates into higher‑quality answers, fewer hallucinations, and greater brand visibility in AI-generated results.
For SEOs and product teams, the takeaway is clear: treat structured data as core infrastructure. If your templates still lack solid HTML semantics, don’t jump straight to JSON-LD: fix the foundations first. Start by cleaning up your markup, then layer structured data on top to build semantic accuracy and long-term discoverability. In AI search, semantics is the new surface area.
When it comes to LLM visibility, not all brands are created equal. For some, it matters far more than others.
LLMs give different answers to the same question. Trackers combat this by simulating prompts repeatedly to get an average visibility/citation score.
While simulating the same prompts isn’t perfect, secondary benefits like sentiment analysis are not SEO-specific issues. Which right now is a good thing.
Unless a visibility tracker offers enough scale at a reasonable price, I would be wary. But if the traffic converts well and you need to know more, get tracking.
(Image Credit: Harry Clarkson-Bennett)
A small caveat to start. This really depends on how your business makes money and whether LLMs are a fundamental part of your audience journey. You need to understand how people use LLMs and what it means for your business.
Brands that sell physical products have a different journey from publishers that sell opinion or SaaS companies that rely more deeply on comparison queries than anyone else.
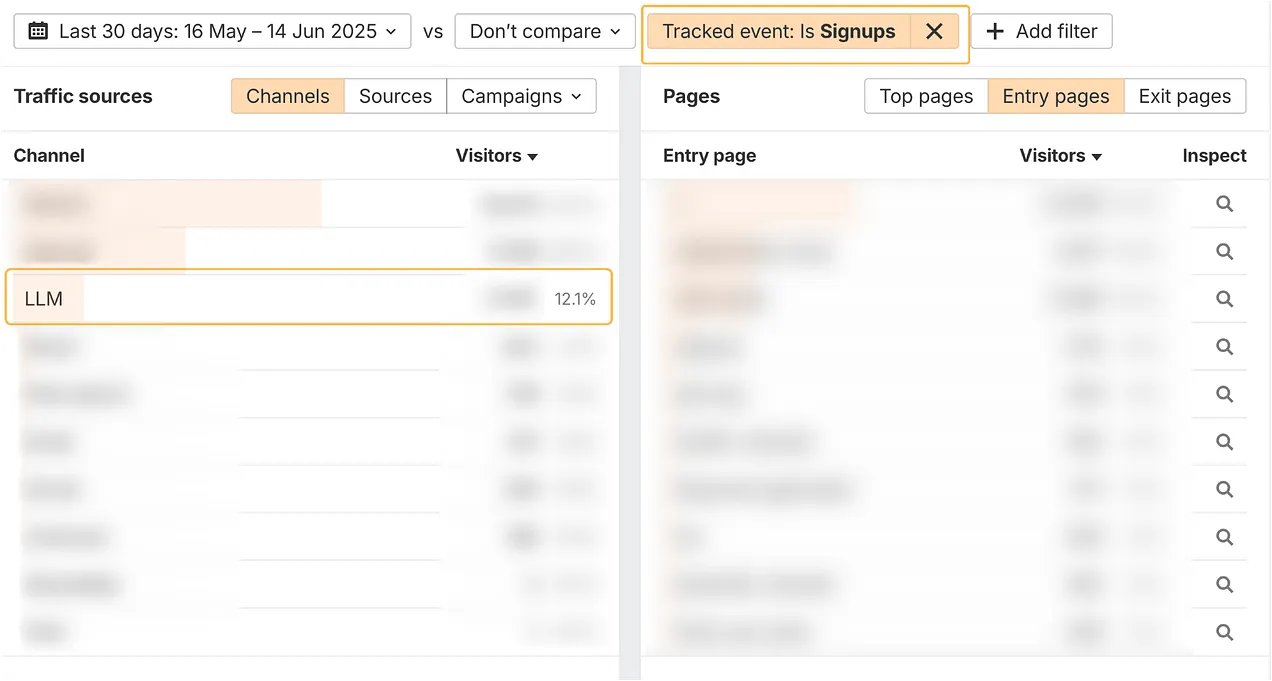
For example, Ahrefs made public some of its conversion rate data from LLMs. 12.1% of their signups came from LLMs from just 0.5% of their total traffic. Which is huge.
AI search visitors convert 23x better than traditional organic search visitors for Ahrefs. (Image Credit: Harry Clarkson-Bennett)
But for us, LLM traffic converts significantly worse. It is a fraction of a fraction.
Honestly, I think LLM visibility trackers at this scale are a bit here today and gone tomorrow. If you can afford one, great. If not, don’t sweat it. Take it all with a pinch of salt. AI search is just a part of most journeys, and tracking the same prompts day in, day out has obvious flaws.
They’re just aggregating what someone said about you on Reddit while they’re taking a shit in 2016.
What Do They Do?
Trackers like Profound and Brand Radar are designed to show you how your brand is framed and recommended in AI answers. Over time, you can measure yours and your competitors’ visibility in the platforms.
Image Credit: Harry Clarkson-Bennett
But LLM visibility is smoke and mirrors.
Ask a question, get an answer. Ask the same question, to the same machine, from the same computer, and get a different answer. A different answer with different citations and businesses.
It has to be like this, or else we’d never use the boring ones.
To combat the inherent variance determined by their temperature setting, LLM trackers simulate prompts repeatedly throughout the day. In doing so, you get an average visibility and citation score alongside some other genuinely useful add-ons like your sentiment score and some competitor benchmarking.
“Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.”
Simulate a prompt 100 times. If your content was used in 70 of the responses and you were cited seven times, you would have a 70% visibility score and a 7% citation score.
Trust me, that’s much better than it sounds… These engines do not want to send you traffic.
In Brian Balfour’s excellent words, they have identified the moat and the gates are open. They will soon shut. As they shut, monetization will be hard and fast. The likelihood of any referral traffic, unless it’s monetized, is low.
Like every tech company ever.
If you aren’t flush with cash, I’d say most businesses just do not need to invest in them right now. They’re a nice-to-have rather than a necessity for most of us.
How Do They Work?
As far as I can tell, there are two primary models.
Pay for a tool that tracks specific synthetic prompts that you add yourself.
Purchase an enterprise-like tool that tracks more of the market at scale.
Some tools, like Profound, offer both. The cheaper model (the price point is not for most businesses) lets you track synthetic prompts under topics and/or tags. The enterprise model gives you a significantly larger scale.
Whereas tools like Ahrefs Brand Radar provide a broader view of the entire market. As the prompts are all synthetic, there are some fairly large holes. But I prefer broad visibility.
This makes for a far more useful version of these tools IMO and goes some way to answering the synthetic elephant in the room. And it helps you understand the role LLMs play in the user journey. Which is far more valuable.
The Problem
Does doing good SEO improve your chances of improving your LLM visibility?
Certainly looks like it…
GPT-5 no longer needs to train on more information. It is as well-versed as its overlords now want to pay for. It’s bored of ravaging the internet’s detritus and reaches out to a search index using RAG to verify a response. A response, it does not quite have the appropriate level of confidence to answer effectively.
But I’m sure we will need to modify it somewhat if your primary goal is to increase LLM visibility. Increase expenditure on TOFU and digital PR campaigns being a notable point.
Image Credit: Harry Clarkson-Bennett
Right now, LLMs have an obvious spam problem. One I don’t expect they’ll be willing to invest in solving anytime soon. The AI bubble and gross valuation of these companies will dictate how they drive revenue. And quickly.
It sure as hell won’t be sorting out their spam problem. When you have a $300 billion contract to pay and revenues of $12 billion, you need some more money. Quickly.
So anyone who pays for best page link inclusions or adds hidden and footer text to their websites will benefit in the short-term. But most of us should still build things actual, breathing, snoring people.
With the new iterations of LLM trackers calling search instead of formulating an answer for prompts based on learned ‘knowledge’, it becomes even harder to create an ‘LLM optimization strategy.’
As a news site, I know that most prompts we would vaguely show up in would trigger the web index. So I just don’t quite see the value. It’s very SEO-led.
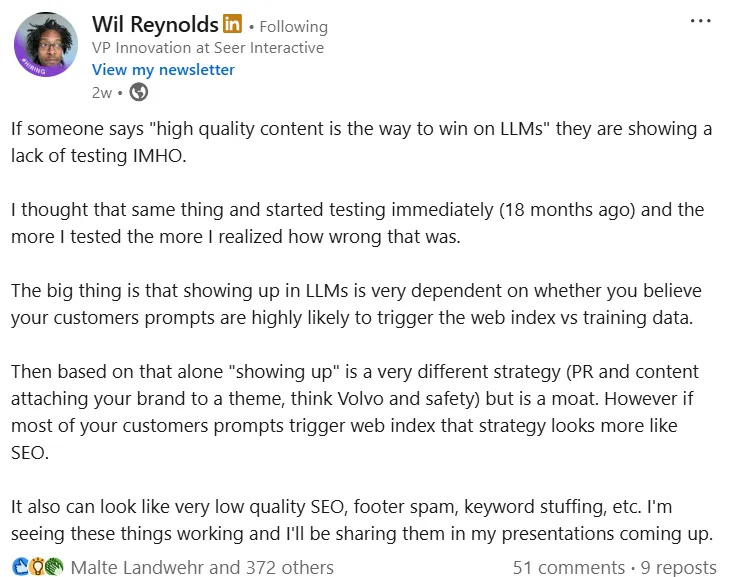
If you don’t believe me, Will Reynolds is an inarguably better source of information (Image Credit: Harry Clarkson-Bennett)
How You Can Add Value With Sentiment Analysis
I found almost zero value to be had from tracking prompts in LLMs at a purely answer level. So, let’s forget all that for a second and use them for something else. Let’s start with some sentiment analysis.
These trackers give us access to:
A wider online sentiment score.
Review sources LLMs called upon (at a prompt level).
Sentiment scores by topics.
Prompts and links to on and off-site information sources.
You can identify where some of these issues start. Which, to be fair, is basically Trustpilot and Reddit.
I won’t go through everything, but a couple of quick examples:
LLMs may be referencing some not-so-recently defunct podcasts and newsletters as “reasons to subscribe.”
Your cancellation process may be cited as the most serious issues for most customers.
Unless you have explicitly stated that these podcasts and newsletters have finished, it’s all fair game. You need to tighten up your product marketing and communications strategy.
For people first. Then for LLMs.
These are not SEO specific projects. We’re moving into an era where solely SEO projects will be difficult to get pushed through. A fantastic way of getting buy-in is to highlight projects with benefits outside of search.
Highlighting serious business issues – poor reviews, inaccurate, out-of-date information et al. – can help get C-suite attention and support for some key brand reputation projects.
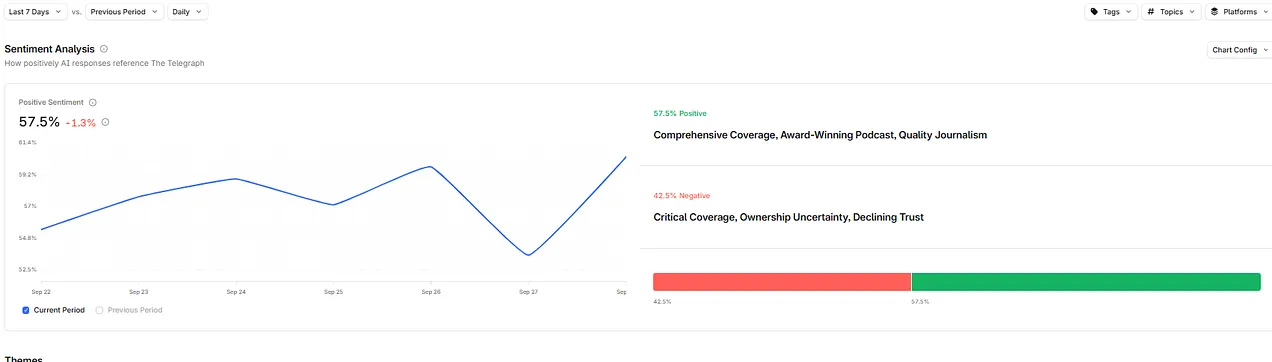
Profound’s sentiment analysis tab (Image Credit: Harry Clarkson-Bennett)
Here it is broken down by topic. You can see individual prompts and responses to each topic (Image Credit: Harry Clarkson-Bennett)
To me, this has nothing to do with LLMs. Or what our audience might ask an ill-informed answer engine. They are just the vessel.
It is about solving problems. Problems that drive real value to your business. In your case, this could be about increasing the LTV of a customer. Increasing their retention rate, reducing churn, and increasing the chance of a conversion by providing an improved experience.
If you’ve worked in SEO for long enough, someone will have floated the idea of improving your online sentiment and reviews past you.
“But will this improve our SEO?”
Said Jeff, a beleaguered business owner.
Who knows, Jeff. It really depends on what is holding you back compared to your competition. And like it or not, search is not very investible right now.
But that doesn’t matter in this instance. This isn’t a search-first project. It’s an audience-first project. It encompasses everyone. From customer service to SEO and editorial. It’s just the right thing to do for the business.
A quick hark back to the Google Leak shows you just how many review and sentiment-focused metrics may affect how you rank.
There are nine alone that mention review or sentiment in the title
There are nine alone that mention review or sentiment in the title (Image Credit: Harry Clarkson-Bennett)
This isn’t because Google knows better than people. It’s because they have stored how we feel about pages and brands in relation to queries and used that as a feedback loop. Google trusts brands because we do.
Most of us have never had to worry about reviews and sentiment. But this is a great time to fix any issues you may have under the guise of AEO, GEO, SEO, or whatever you want to call it.
So keeping tabs on your reputation and identifying potentially serious issues is never a bad thing.
Could I Just Build My Own?
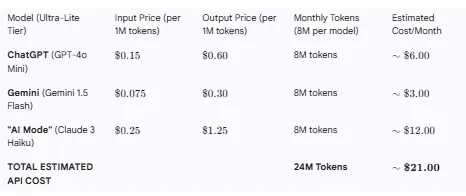
Yep. For starters, you’d need an estimation of monthly LLM API costs based on the number of monthly tokens required. Let’s use Profound’s lower-end pricing tier as an estimate and our old friend Gemini to figure out some estimated costs.
Based on this, here’s a (hopefully) accurate cost estimate per model from our robot pal.
Image Credit: Harry Clarkson-Bennett
Right then. You now need some back-end functionality, data storage, and some front-end visualization. I’ll tot up as we go.
$21 per month
Back-End
A Scheduler/Runner like Render VPS to execute 800 API calls per day.
A data orchestrater. Essentially, some Python code to parse raw JSON and extract relevant citation and visibility data.
$10 per month
Data Storage
A database, like Supabase (which you can integrate directly through Lovable), to store raw responses and structured metrics.
Data storage (which should be included as part of your database).
$15 per month
Front-End Visualization
A web dashboard to create interactive, shareable dashboards. I unironically love Lovable. It’s easy to connect directly to databases. I have also used Streamlit previously. Lovable looks far sleeker but has its own challenges.
You may also need a visualization library to help generate time series charts and graphs. Some dashboards have this built in.
$50 per month
$96 all in. I think the likelihood is it’s closer to $50 than $100. No scrimping. At the higher end of budgets for tools I use (Lovable) and some estimates from Gemini, we’re talking about a tool that will cost under $100 a month to run and function very well.
This isn’t a complicated project or setup. It is, IMO, an excellent project to learn the vibe coding ropes. Which I will say is not all sunshine and rainbows.
So, Should I Buy One?
If you can afford it, I would get one. For at least a month or two. Review your online sentiment. See what people really say about you online. Identify some low lift wins around product marketing and review/reputation management, and review how your competitors fare.
This might be the most important part of LLM visibility. Set up a tracking dashboard via Google Analytics (or whatever dreadful analytics provider you use) and see a) how much traffic you get and b) whether it’s valuable.
The more valuable it is, the more value there will be in tracking your LLM visibility.
You could also make one. The joy of making one is a) you can learn a new skill and b) you can make other things for the same cost.
Google’s VP of Product, Robby Stein, recently answered the question of what people should think about in terms of AEO/GEO. He provided a multi-part answer that began with how Google’s AI creates answers and ended with guidance on what creators should consider.
Foundations Of Google AI Search
The question asked was about AEO/GEO, which was characterized by the podcast host as the evolution of SEO. Google’s Robby Stein’s answer suggested thinking about the context of AI answers.
This is the question that was asked:
“What’s your take on this whole rise of AEO, GEO, which is kind of this evolution of SEO?
I’m guessing your answer is going to be just create awesome stuff and don’t worry about it, but you know, there’s a whole skill of getting to show up in these answers. Thoughts on what people should be thinking about here?”
Stein began his answer describing the foundations of how Google’s AI search works:
“Sure. I mean, I can give you a little bit of under the hood, like how this stuff works, because I do think that helps people understand what to do.
When our AI constructs a response, it’s actually trying to, it does something called query fan-out, where the model uses Google search as a tool to do other querying.
So maybe you’re asking about specific shoes. It’ll add and append all of these other queries, like maybe dozens of queries, and start searching basically in the background. And it’ll make requests to our data kind of backend. So if it needs real-time information, it’ll go do that.
And so at the end of the day, actually something’s searching. It’s not a person, but there’s searches happening.”
Robby Stein shows that Google’s AI still relies on conventional search engine retrieval, it’s just scaled and automated. The system performs dozens of background searches and evaluates the same quality signals that guide ordinary search rankings.
That means that “answer engine optimization” is basically the same as SEO because the underlying indexing, ranking and quality factors inherent to traditional SEO principles still apply to queries that the AI itself issues as part of the query fan-out process.
For SEOs, the insight is that visibility in AI answers depends less on gaming a new algorithm and more on producing content that satisfies intent so thoroughly that Google’s automated searches treat it as the best possible answer. As you’ll see later in this article, originality also plays a role.
Role Of Traditional Search Signals
An interesting part of this discussion is centered on the kinds of quality signals that Google describes in its Quality Raters Guidelines. Stein talks about originality of the content, for example.
Here’s what he said:
“And then each search is paired with content. So if for a given search, your webpage is designed to be extremely helpful.
And then you can look up Google’s human rater guidelines and read… what makes great information? This is something Google has studied more than anyone.
And it’s like:
Do you satisfy the user intent of what they’re trying to get?
Do you have sources?
Do you cite your information?
Is it original or is it repeating things that have been repeated 500 times?
And there’s these best practices that I think still do largely apply because it’s going to ultimately come down to an AI is doing research and finding information.
And a lot of the core signals, is this a good piece of information for the question, they’re still valid. They’re still extremely valid and extremely useful. And that will produce a response where you’re more likely to show up in those experiences now.”
Although Stein is describing AI Search results, his answer shows that Google’s AI Search still values the same underlying quality factors found in traditional search. Originality, source citations, and satisfying intent remain the foundation of what makes information “good” in Google’s view. AI has changed the interface of search and encouraged more complex queries, but the ranking factors continue to be the same recognizable signals related to expertise and authoritativeness.
More On How Google’s AI Search Works
The podcast host, Lenny, followed up with another question about how Google’s AI Search might follow a different approach from a strictly chatbot approach.
He asked:
“It’s interesting your point about how it goes in searches. When you use it, it’s like searching a thousand pages or something like that. Is that a just a different core mechanic to how other popular chatbots work because the others don’t go search a bunch of websites as you’re asking.”
Stein answered with more details about how AI search works, going beyond query fan-out, identifying factors it uses to surface what they feel to be the best answers. For example, he mentions parametric memory. Parametric memory is the knowledge that an AI has as part of its training. It’s essentially the knowledge stored within the model and not fetched from external sources.
Stein explained:
“Yeah, this is something that we’ve done uniquely for our AI. It obviously has the ability to use parametric memory and thinking and reasoning and all the things a model does.
But one of the things that makes it unique for designing it specifically for informational tasks, like we want it to be the best at informational needs. That’s what Google’s all about.
And so how does it find information?
How does it know if information is right?
How does it check its work?
These are all things that we built into the model. And so there is a unique access to Google. Obviously, it’s part of Google search.
So it’s Google search signals, everything from spam, like what’s content that could be spam and we don’t want to probably use in a response, all the way to, this is the most authoritative, helpful piece of information.
We’re going link to it and we’re going to explain, hey, according to this website, check out that information and you’re going to probably go see that yourself.
So that’s how we’ve thought about designing this.”
Stein’s explanation makes it clear that Google’s AI Search is not designed to mimic the conversational style of general chatbots but to reinforce the company’s core goal of delivering trustworthy information that’s authoritative and helpful.
Google’s AI Search does this by relying on signals from Google Search, such as spam detection and helpfulness, the system grounds its AI-generated answers in the same evaluation and ranking framework inherent in regular search ranking.
This approach positions AI Search as less a standalone version of search and more like an extension of Google’s information-retrieval infrastructure, where reasoning and ranking work together to surface factually accurate answers.
Advice For Creators
Stein at one point acknowledges that creators want to know what to do for AI Search. He essentially gives the advice to think about the questions people are asking. In the old days that meant thinking about what keywords searchers are using. He explains that’s no longer the case because people are using long conversational queries now.
He explained:
“I think the only thing I would give advice to would be, think about what people are using AI for.
I mentioned this as an expansionary moment, …that people are asking a lot more questions now, particularly around things like advice or how to, or more complex needs versus maybe more simple things.
And so if I were a creator, I would be thinking, what kind of content is someone using AI for? And then how could my content be the best for that given set of needs now? And I think that’s a really tangible way of thinking about it.”
Stein’s advice doesn’t add anything new but it does reframe the basics of SEO for the AI Search era. Instead of optimizing for isolated keywords, creators should consider anticipating the fuller intent and informational journey inherent in conversational questions. That means structuring content to directly satisfy complex informational needs, especially “how to” or advice-driven queries that users increasingly pose to AI systems rather than traditional keyword search.
Takeaways
AI Is Search Still Built on Traditional SEO Signals Google’s AI Search relies on the same core ranking principles as traditional search—intent satisfaction, originality, and citation of sources.
How Query Fan-Out Works AI Search issues dozens of background searches per query, using Google Search as a tool to fetch real-time data and evaluate quality signals.
Integration of Parametric Memory and Search Signals The model blends stored knowledge (parametric memory) with live Google Search data, combining reasoning with ranking systems to ensure factual accuracy.
Google’s AI Search Is Like An Extension of Traditional Search AI Search isn’t a chatbot; it’s a search-based reasoning system that reinforces Google’s informational trust model rather than replacing it.
Guidance for Creators in the AI Search Era Optimizing for AI means understanding user intent behind long, conversational queries—focusing on advice- and how-to-style content that directly satisfies complex informational needs.
Google’s AI Search builds on the same foundations that have long defined traditional search, using retrieval, ranking, and quality signals to surface information that demonstrates originality and trustworthiness. By combining live search signals with the model’s own stored knowledge, Google has created a system that explains information and cites the websites that provided it. For creators, this means that success now depends on producing content that fully addresses the complex, conversational questions people bring to AI systems.
Watch the podcast segment starting at about the 15:30 minute mark: