OpenAI acquired a technology from Rockset that will enable the creation of new products, real-time data analysis, and recommendation systems, possibly signaling a new phase for OpenAI that could change the face of search marketing in the near future.
What Is Rockset And Why It’s Important
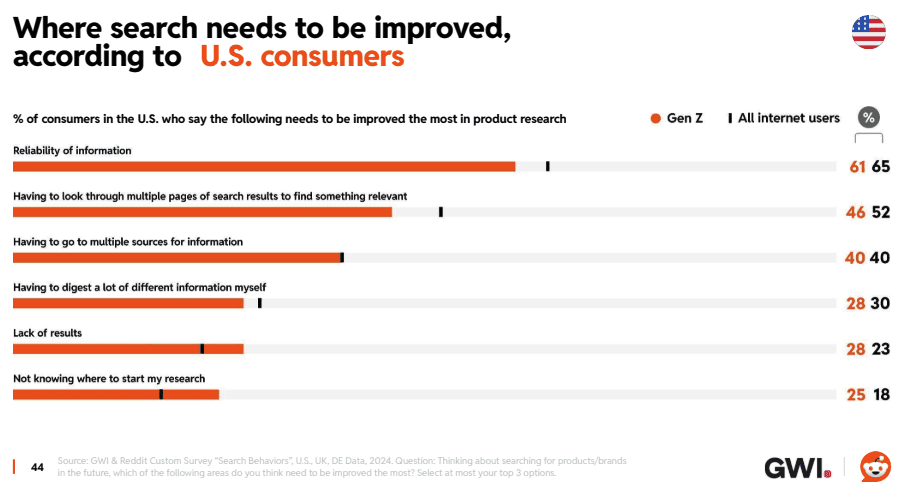
Rockset describes its technology as a Hybrid Search, a type of multi-faceted approach to search (integrating vector search, text search and metadata filtering) to retrieve documents that can augment the generation process in RAG systems. RAG is a technique that combines search with generative AI that is intended to create more factually accurate and contextually relevant results. It’s a technology that plays a role in BING’s AI search and Google’s AI Overviews.
Rockset’s research paper about the Rockset Hybrid Search Architecture notes:
“All vector search is becoming hybrid search as it drives the most relevant, real-time application experiences. Hybrid search involves incorporating vector search and text
search as well as metadata filtering, all in a single query. Hybrid search is used in search, recommendations and retrieval augmented generation (RAG) applications.
…Rockset is designed and optimized to ingest data in real time, index different data types and run retrieval and ranking algorithms.”
What makes Rockset’s hybrid search important is that it allows the indexing and use of multiple data types (vectors, text, geospatial data about objects & events), including real-time data use. That powerful flexibility allows the technology to interact with different kinds of data that can be used for in-house and consumer-facing applications related to contextually relevant product recommendations, customer segmentation and analysis for targeted marketing campaigns, personalization, personalized content aggregation, location-based recommendations (restaurants, services, etc.) and in applications that increase user engagement (Rockset lists numerous case studies of how their technology is used).
OpenAI’s announcement explained:
“AI has the opportunity to transform how people and organizations leverage their own data. That’s why we’ve acquired Rockset, a leading real-time analytics database that provides world-class data indexing and querying capabilities.
Rockset enables users, developers, and enterprises to better leverage their own data and access real-time information as they use AI products and build more intelligent applications.
…Rockset’s infrastructure empowers companies to transform their data into actionable intelligence. We’re excited to bring these benefits to our customers…”
OpenAI’s announcement also explains that they intend to integrate Rockset’s technology into their own retrieval infrastructure.
At this point we know the transformative quality of hybrid search and the possibilities but OpenAI is at this point only offering general ideas of how this will translate into APIs and products that companies and individuals can create and use.
The official announcement of the acquisition from Rockset, penned by one of the cofounders, offered these clues:
“We are thrilled to join the OpenAI team and bring our technology and expertise to building safe and beneficial AGI.
…Advanced retrieval infrastructure like Rockset will make AI apps more powerful and useful. With this acquisition, what we’ve developed over the years will help make AI accessible to all in a safe and beneficial way.
Rockset will become part of OpenAI and power the retrieval infrastructure backing OpenAI’s product suite. We’ll be helping OpenAI solve the hard database problems that AI apps face at massive scale.”
What Exactly Does The Acquisition Mean?
Duane Forrester, formerly of Bing Search and Yext (LinkedIn profile), shared his thoughts:
“Sam Altman has stated openly a couple times that they’re not chasing Google. I get the impression he’s not really keen on being seen as a search engine. More like they want to redefine the meaning of the phrase “search engine”. Reinvent the category and outpace Google that way. And Rockset could be a useful piece in that approach.
Add in Apple is about to make “ChatGPT” a mainstream thing with consumers when they launch the updated Siri this Fall, and we could very easily see query starts migrate away from traditional search engine boxes. Started with TikTok/social, now moving to ai-assistants.”
Another approach, which could impact SEO, is that OpenAI could create a product based on an API that can be used by companies to power in-house and consumer facing applications. With that approach, OpenAI provides the infrastructure (like they currently do with ChatGPT and foundation models) and let the world innovate all over the place with OpenAI at the center (as it currently does) as the infrastructure.
I asked Duane about that scenario and he agreed but also remained open to an even wider range of possibilities:
“Absolutely, a definite possibility. As I’ve been approaching this topic, I’ve had to go up a level. Or conceptually switch my thinking. Search is, at its heart, information retrieval. So if I go down the IR path, how could one reinvent “search” with today’s systems and structures that redefine how information retrieval happens?
This is also – it should be noted- a description for the next-gen advanced site search. They could literally take over site search across a wide range of mid-to-enterprise level companies. It’s easily as advanced as the currently most advanced site-search systems. Likely more advanced if they launch it. So ultimately, this could herald a change to consumer search (IR) and site-search-based systems.
Expanding from that, apps, as they allude to. So I can see their direction here.”
Deedy Das of Menlo Ventures (Poshmark, Roku, Uber) speculated on Twitter about how this acquisition may transform OpenAI:
“This is speculation but I imagine Rockset will power all their enterprise search offerings to compete with Glean and / or a consumer search offering to compete with Perplexity / Google. Permissioning capabilities of Rockset make me think more the former than latter”
Others on Twitter offered their take on how this will affect the future of AI:
“I doubt OpenAI will jump into the enterprise search fray. It’s just far too challenging and something that Microsoft and Google are best positioned to go after.
This is a play to accelerate agentic behaviors and make deep experts within the enterprise. You might argue it’s the same thing an enterprise search but taking an agent first approach is much more inline with the OpenAI mission.”
A Consequential Development For OpenAI And Beyond
The acquisition of Rockset may prove to be the foundation of one of the most consequential changes to how businesses use and deploy AI, which in turn, like many other technological developments, could also have an effect on the business of digital marketing.
Read how Rockset customers power recommendation systems, real-time personalization, real-time analytics, and other applications:
Featured Case Studies
Read the official Rockset announcement:
OpenAI Acquires Rockset
Read the official OpenAI announcement:
OpenAI acquires Rockset
Enhancing our retrieval infrastructure to make AI more helpful
Read the original Rockset research paper:
Rockset Hybrid Search Architecture (PDF)
Featured Image by Shutterstock/Iconic Bestiary