It raises a massive question because this is a Microsoft tool: Are the insights useless if your audience doesn’t touch the Bing ecosystem?
Microsoft Clarity Grounding Queries
When you ask Copilot a question, it translates your words into simple search terms called grounding queries to find facts on the web before it answers. You can use this data to improve your own website and content.
Finding gaps where your content does not match what the AI searches for.
Simplifying pages that the AI reads but does not link to.
Using these simple layouts to help your Google search results.
Copilot Vs. Gemini
Both Copilot and Gemini use retrieval-augmented approaches. Instead of generating answers using only pre-trained parameters, they dynamically query external search indexes to retrieve real-time data, which they then use as context to ground their final responses.
Feature
Microsoft Copilot
Google Gemini
Structure
Uses a query translator, Bing index search, and OpenAI models to write the final text.
Uses a query translator, Google Search, and Google’s Gemini models to write the final text.
Pulling Sources
Uses the Bing index and Microsoft Graph to scan web pages, emails, and Microsoft 365 files. (With permissions enabled)
Uses Google Search and Google Workspace to scan web pages, Google Drive files, and Gmail. (With permissions enabled)
Synthesising Answers
Focuses on direct answers. It uses structured lists, tables, and bullet points to show facts quickly.
Focuses on creative, conversational answers. It is built to handle text, images, and code at the same time.
Does Ranking In Bing Matter?
Yes (Correlation).
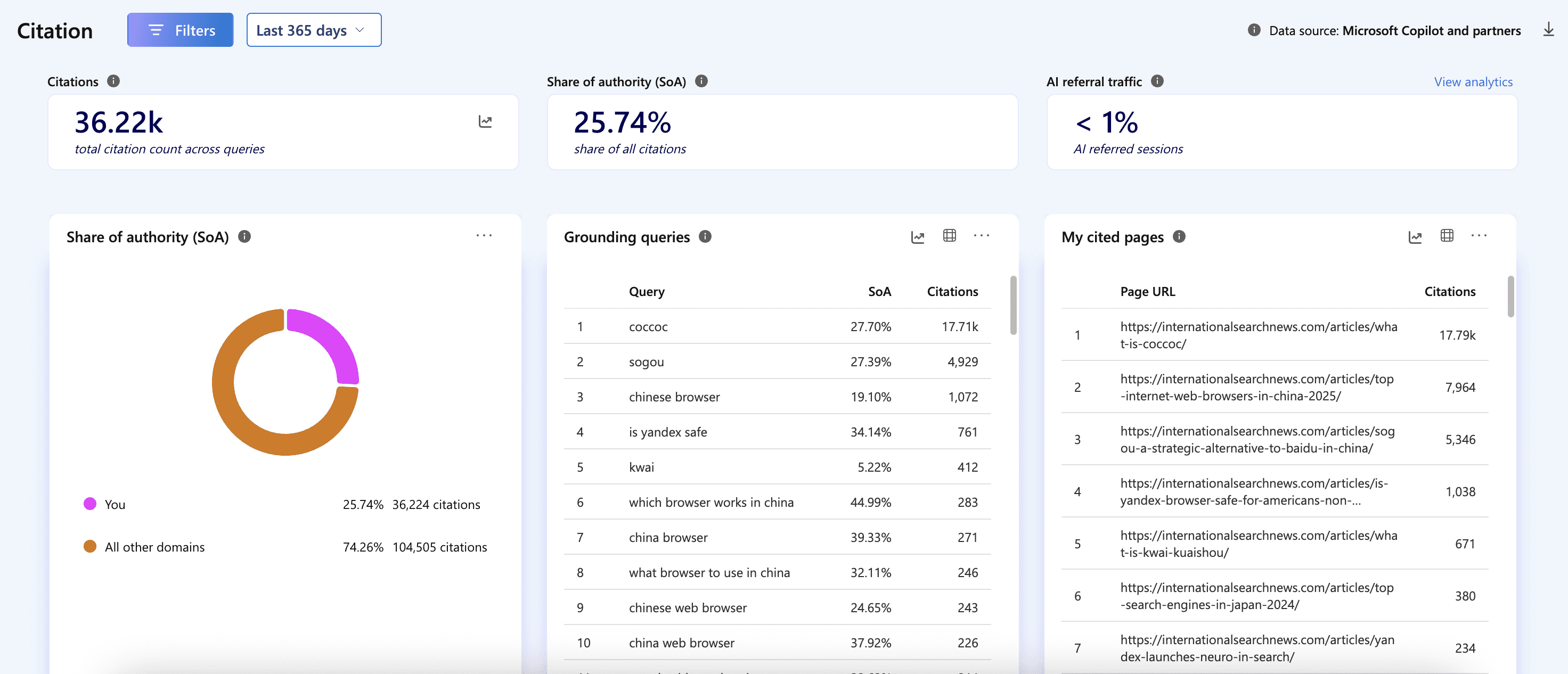
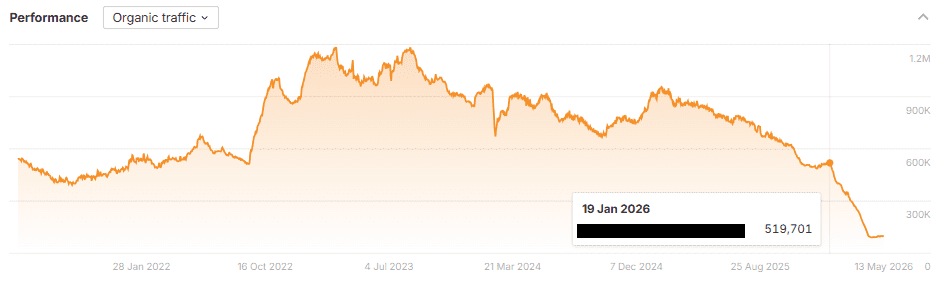
One of my websites was doing extremely well in Copilot, with over 36,000 citations across all queries. Now, Clarity doesn’t give you the prompts/queries themselves, but it does give you the Grounding queries (grounding queries and key phrases used to retrieve your site’s content).
Image from author, May 2026
My website has a history, running for years with a previous domain merged in 2019, and boasts over 1,000 articles. Given that Google barely sends traffic, and third-party SEO tools often label it as spam due to non-English backlinks (it covers search engines like Baidu, CocCoc, SwissCows, attracting an international audience), I never expected 36,000 citations.
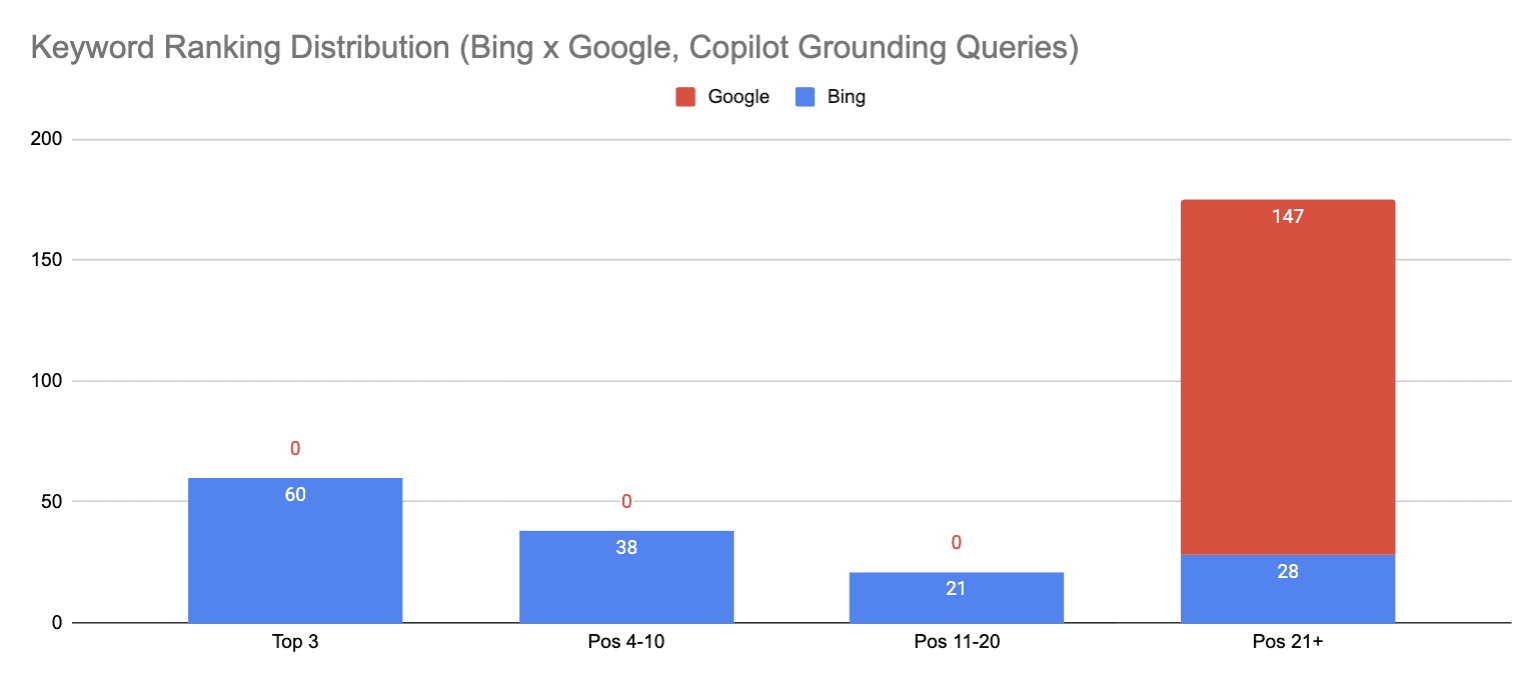
So, why the Copilot love? I took the 147 grounding queries and tracked their rank in Google and Bing.
Image from author, May 2026
Of the 147 queries, Bing ranked all but 6, with the majority in traffic-driving positions (top 20). Google didn’t rank a single one.
So, If This Is Heavily Dependent On Bing Indexing, Is Clarity’s Data Useful Outside Of The Bing/Microsoft Ecosystem?
Because this is a Microsoft tool, the backend data feeding this dashboard is primarily capturing how your site is cited across Microsoft’s AI surfaces (like Copilot and Bing generative search).
It is not giving you a direct window into how OpenAI’s ChatGPT (using its own search), Google Gemini, or Perplexity are citing your links, because those platforms do not share their internal grounding logs with Microsoft.
Even though the data collection source is skewed toward Microsoft’s AI engine, the insights themselves are highly transferable to your broader, platform-agnostic AI optimization strategies.
Can We Assume Other LLMs Retrieve Data In The Same Way?
If the Bing ecosystem flags that a specific page on your site has a high “Share of Authority” for a complex query, it means that page is structured perfectly for AI consumption (clear tables, bullet points, direct answers). Data suggests that you can replicate that formatting across your site to appeal to Google Gemini as well.
However, this can be argued against as other research suggests that the similarity between LLMs is dependent on positional biases, and some may use the SDSR method rather than RAG.
Researchers in SEO have also found that ChatGPT has started to use Google Search as a fallback, when it was initially Bing.
In Summary
If your audience doesn’t touch the Microsoft ecosystem, this dashboard won’t give you a perfect 1-to-1 reflection of your total AI traffic, but it doesn’t make the data useless.
What grounding queries reveal is how AI systems distill user intent into retrievable search terms. That process is broadly consistent across platforms, even when the underlying indexes differ. A page earning citations in Copilot is doing something right structurally with clear answers, well-scoped topics, content aligned with how AI engines translate questions into queries. The Bing dependency tells you where the data comes from. The structural patterns tell you something more transferable.
The gap data is equally instructive. Pages your site ranks for in Bing that never appear as grounding queries signal a mismatch. Either the content isn’t structured for AI retrieval, or the topic isn’t one AI engines are actively grounding answers around.
Treat Clarity’s Citations dashboard as a useful proxy or “lab environment” and window into how LLMs read, slice/chunk, and credit your website’s content. Even if Copilot isn’t your primary AI traffic source, the patterns it surfaces are worth paying attention to.
“There is now ample evidence, collected over the last few years, that AI systems are unpredictable and difficult to control.” That’s Dario Amodei in January, writing about the technology his company sells.
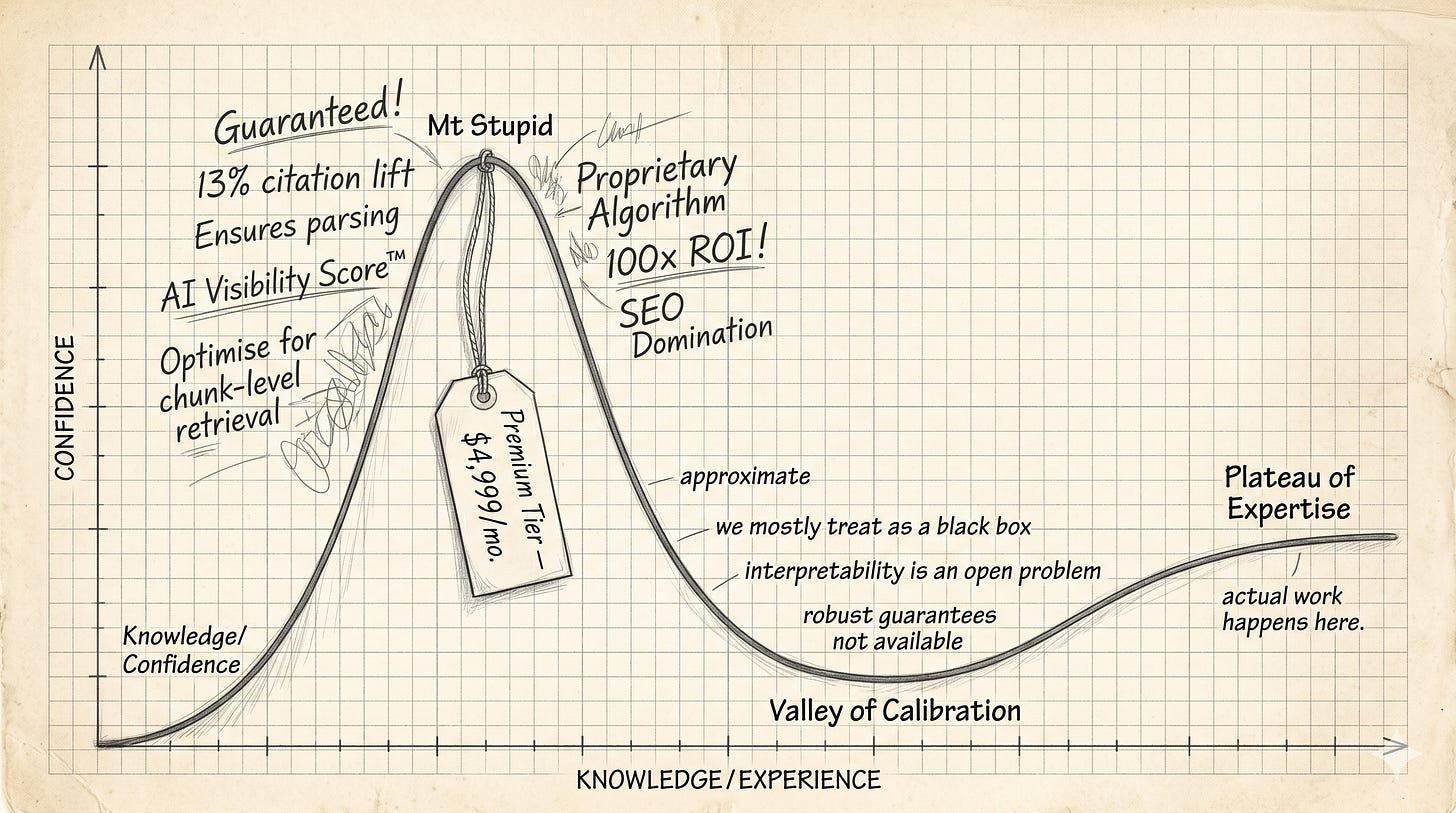
Compare with what’s on your LinkedIn timeline this week. Here’s the script: Schema markup ensures AI engines parse your content. The first sentence of every section must be the answer. Optimize for chunk-level retrieval. There’s a 13% citation lift available if you do X, a 2.8x conversion improvement if you do Y.
It’s one of the cleanest patterns going right now, and the industry has elected not to notice. The people closest to these systems are increasingly cautious about claims of control. The people furthest from it are increasingly certain they know how it works … they’ve cracked it. That gradient runs the wrong way.
“We mostly treat AI models as a black box: something goes in and a response comes out, and it’s not clear why the model gave that particular response instead of another.”
Anthropic, writing about its own model, two years ago.
Things haven’t gotten more confident since. Neel Nanda, who runs Google DeepMind’s mechanistic interpretability team, gave an interview to 80,000 Hours in September 2025 in which the headline finding was that the most ambitious version of mech interp is probably dead. He doesn’t see a realistic world where the discipline delivers “the kind of robust guarantees that some people want from interpretability.” Worth re-reading.
The person whose job is to read AI minds is publicly conceding that the project, as originally conceived, won’t get there.
At NeurIPS 2024, Ilya Sutskever, co-founder of Safe Superintelligence and formerly chief scientist at OpenAI, accepted his Test of Time award and used the platform to say something the room wasn’t expecting from him:
Sutskever’s career is essentially the scaling hypothesis with a face on it. Hearing him say the next phase produces less predictable outputs is itself an admission.
Now scroll back to your timeline. The gradient is Dunning-Kruger redrawn at an industry scale: Mt. Stupid with a pricing page, and the valley of calibration where the actual work happens.
Image Credit: Pedro Dias
What The People Selling It Actually Say
A practitioner posts a four-pillar framework for “Technical GEO.” A consultant guarantees inclusion in AI Overviews. An agency markets a 13% lift in citation likelihood, derived from data the agency itself produced about the agency’s own prescriptions. A widely shared post promises that maintaining a 300-character paragraph limit dictates how a vector database chunks your content. A vendor claims a 78% “share of model.” A senior figure in your inbox describes a 2.8x improvement in conversion from being cited in SGE.
The vocabulary is deterministic: “ensures,” “guarantees,” “dictates,” percentages precise to the decimal, frameworks confidently named. None of it sounds anything like the language the people who built these systems use when describing how the systems behave.
This is the part I keep getting stuck on. The consultants are confident about the tactics they’ve measured against themselves. Run the same playbook on a few clients, watch some metric move, call it evidence. No control groups, no pre-registered hypotheses, no measurement of what the tactic is actually claimed to change. That’s the bar a real test has to clear; everything else has been confirmation in costume. The problem is the confidence level, which is wrong by an order of magnitude regardless of whether the underlying tactic does anything. The same model that Anthropic publicly says it cannot fully account for is being optimized against by people who confidently claim to know exactly what they’re doing.
Either Anthropic has been suspiciously modest in public, or somebody else is suspiciously certain.
When Somebody Tests
On Monday, last week, Ahrefs published a study by Louise Linehan and Xibeijia Guan with a title that should ideally be impossible: We Tracked 1,885 Pages Adding Schema. AI Citations Barely Moved.
The methodology is the kind of work you would expect to be standard, if the discipline cared about standards. 1,885 pages that added JSON-LD schema between August 2025 and March 2026. 4,000 matched control pages. Citation changes measured 30 days before and 30 days after the schema was added, across Google AI Overviews, Google AI Mode, and ChatGPT. Difference-in-differences on the matched groups.
The finding: No meaningful uplift in citations on any platform. AI Overviews actually showed a small but statistically significant decline. The report notes the odds of a gap that large being chance are roughly 1 in 2,500. The schema-makes-LLMs-understand-your-content thesis, tested at scale against a controlled baseline, did not survive the test.
This is the empirical confirmation of the technical case I made a week ago in The Whole Point Was the Mess: that LLMs read unstructured language, and that schema-and-chunking prescriptions are reasoning about an architecture that doesn’t exist. From first principles, two weeks ago. From controlled measurement, last Monday.
It is worth sitting with that. The dominant prescriptive category in the entire GEO playbook has been empirically falsified under controlled conditions, by a vendor with a substantial audience, in the open. And the frameworks keep selling.
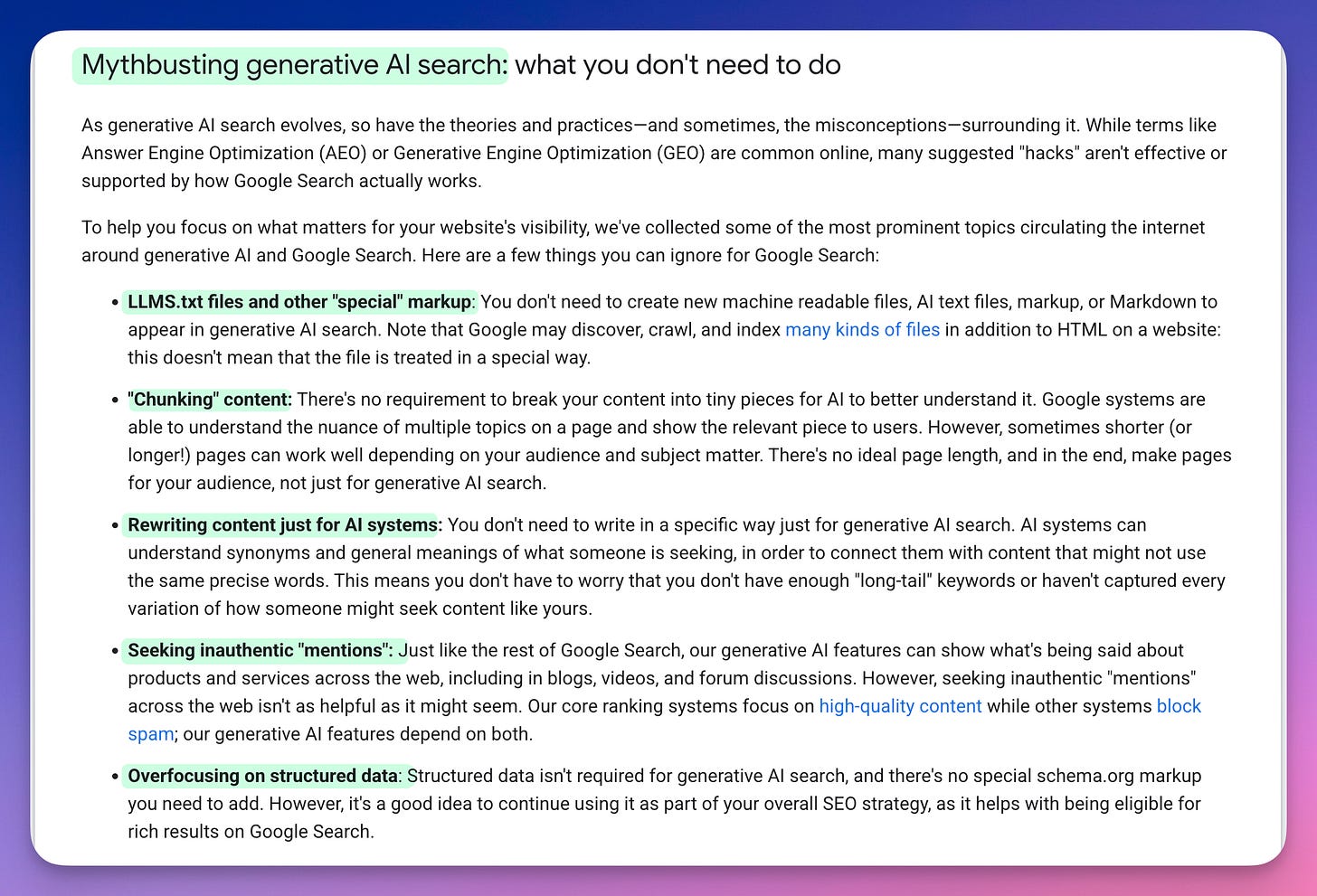
“Many suggested ‘hacks’ aren’t effective or supported by how Google Search actually works.”
Google names Answer Engine Optimization and Generative Engine Optimization by their full terms and rejects the playbook outright.
Image Credit: Pedro Dias
That is the search engine the consultants claim to be optimizing for, telling its own developer audience that the optimizations don’t work. From first principles, two weeks ago. From controlled measurement, last Monday. From Google itself, last Friday. Three independent sources of the same answer, all within a fortnight. All ignored by the people selling the opposite.
The Cost Of Asking
This is where the diagnosis stops being polite.
Confident claims compound on these platforms in a way that skeptical corrections don’t. The difference is in who pays. Posting a confident claim costs you nothing. It gets engagement, builds an audience, generates inbound, makes the slide deck look forward-looking. If it turns out to be wrong, nothing happens. By the time anyone notices, everyone’s moved on to the next acronym.
Posting the correction costs you. It picks a fight. It marks you as a contrarian, or worse, as somebody who doesn’t get it. On LinkedIn, where most of this happens, it works against your professional brand. The algorithm will not reward it. The original poster owns the comment section and can ignore your methodology question while engaging with the congratulatory replies. Your reply lives in a collapsed thread.
There’s a specific move worth naming here. Ask a GEO consultant to explain, in plain terms, what their methodology actually does, what mechanism it acts on, what would count as evidence, what would falsify it. The response escalates into jargon. “Vector-space alignment.” “T1 query optimisation.” “Chunk-level semantic retrieval.” Real terms from machine-learning research, glued into combinations that sound rigorous and resist plain-language verification. The pattern works because it can. Asking “what does that actually mean” looks naive, and observers without the specific technical knowledge can’t tell which combinations are real and which are improvised on the spot.
Read the comments on any high-engagement GEO post. Fifteen replies in, 12 are agreements or “here’s another skill to add to your list.” Two or three offer diplomatically-framed skepticisms: “I would love to see more data,” or “the list is right, but…” The author engages substantively with the philosophical objection because pushing back against “this is too technical” is easy. The methodological objection, that the prescribed skills produce confident speculation without a measurement layer underneath, gets the politest burial.
What this adds up to is gaslighting at industry scale. The people reading the technology correctly get positioned as the ones who haven’t caught up; the prescriptions that controlled tests just falsified get sold as forward-looking. GEO has worked out how to make calibration look like the deficiency.
A recent X experiment captured the dynamic outside SEO. Someone posted a Monet painting and claimed it was AI-generated, asking the replies to explain its inferiority to a real Monet. Hundreds responded, confidently cataloging the “AI tells.” Flat brushwork, soulless composition, no cohesion, no soul. They were analyzing a Monet. The frame determined what they saw.
It’s the same trick. Vocabulary substitutes for substance; framing activates confirmation bias before any examination begins; the performance of analysis becomes what’s purchased rather than the analysis itself; “this is X” arrives before anyone checks whether it is. Once the frame is set, the analysis follows.
So the people most equipped to push back, the practitioners who’ve actually tried to test things, the technical SEOs who know what schema does and doesn’t do, the ones who can spot a fabricated lift number from across the room, stay quiet.
The result, on the timelines the C-suite reads, is a one-sided market.
The cost falls on the people who buy the claim. Clients pay for schema audits the Ahrefs study just falsified. Junior practitioners build careers on methodologies that won’t survive a controlled test. And the discipline burns credibility it will need later, when traditional search displaces further, and SEOs are expected to sit in rooms with engineering teams who’ve just spent two years watching the field confidently mis-call the technology.
Knowledge advances by trying to disprove your hypothesis, not confirm it. GEO does the opposite, runs studies designed to validate what it’s already selling. If the professionals claiming this expertise won’t even try to falsify themselves, who do we expect to believe us?
The Absence Is The Data
Strip the discourse, and what remains is the absence.
A serious technical field watches a controlled test contradict its dominant prescriptions, and the prescriptions keep selling. At that point, asking whether the prescriptions are wrong stops being the interesting question. That has been answered. The harder question is what’s wrong with a field that watches and doesn’t correct.
Same with the gradient. When the people who built the systems hedge and the people optimizing for those systems guarantee, asking who’s right stops being interesting. The researches and builders are right. Nobody who has worked on inference attribution thinks otherwise. The harder question is why the field lets the guarantees travel unchallenged.
The honest answer is that the incentives don’t pull toward correction. Confidence sells in ways caution can’t. The reportable framework wins the budget; the sensible assessment loses. And hedged language doesn’t fit on a pricing page where a guarantee fits perfectly.
None of this needs villains. The market for attention rewards confidence over calibration, every time.
You can keep watching the gradient run the wrong way. Or you can read what it actually is: an industry standing on Mt. Stupid, charging for the view.
More Resources:
This post was originally published on The Inference.
This post was sponsored by WP Engine. The opinions expressed in this article are the sponsor’s own.
Why are we missing the SERP window on breaking stories we should be winning? How are smaller outlets ranking faster than us on the same news? Why is our ad stack tanking Core Web Vitals on our highest-traffic pages?
In most large newsrooms, the answer traces back to the same culprit: a fragile, patchwork legacy CMS held together with ad-hoc plugins. For SEO and growth teams, that’s a direct hit to organic search traffic and ad revenue. Below are four publishing workflow fixes that move both metrics in the same direction.
The 4 Publishing Pillars That Improve SEO & Monetization
To stop paying this tax, media organizations are moving away from treating their workflows as a collection of disparate parts. Instead, they are adopting a unified system that eliminates the friction between engineering, editorial, and growth.
A modern publishing standard addresses these marketing hurdles through four key operational pillars:
Pillar 1: Automated Governance (Built-In SEO & Tracking Integrity)
Marketing integrity relies on consistency.
In a fragmented system, SEO metadata, tracking pixels, and brand standards are often managed manually, leading to human error.
A unified approach embeds governance directly into the workflow.
By using automated checklists, organizations ensure that no article goes live until it meets defined standards, protecting the brand and ensuring every piece of content is optimized for discovery from the moment of publication.
Pillar 2: Fearless Iteration (Continuous SEO & CRO Optimization Without Risk)
High-traffic articles are a marketer’s most valuable asset. However, in a legacy stack, updating a live story to include, for instance, a Call-to-Action (CTA), is often a high-risk maneuver that could break site layouts.
A modern unified approach allows for “staged” edits, enabling teams to draft and review iterations on live content without forcing those changes live immediately. This allows for a continuous improvement cycle that protects the user experience and site uptime.
Pillar 3: Cross-Functional Collaboration (Reducing Workflow Bottlenecks Between Editorial, SEO & Engineering)
Any type of technology disruption requires a team to collaborate in real-time. The “Sticky-taped” approach often forces teams to work in separate tools, creating bottlenecks.
A modern unified standard utilizes collaborative editing, separating editorial functions into distinct areas for text, media, and metadata. This allows an SEO specialist or a growth marketer to optimize a story simultaneously with the journalist, ensuring the content is “market-ready” the instant it’s finished.
Late-breaking or real-time events, such as global geopolitical shifts or live sports, require in-the-moment storytelling to keep audiences informed, engaged, and on-site. Traditionally, “Live Blogs” relied on clunky third-party embeds that fragmented user data and slowed page loads.
A unified standard treats breaking news as a native capability, enabling rapid-fire updates that keep the audience glued to the brand’s own domain, maximizing ad impressions and subscription opportunities.
If those are things you’ve explored changing, it may be time to examine your own Fragmentation Tax, and why a new publishing standard is required to reclaim growth.
Stop Paying The Fragmentation Tax: How A Siloed CMS, Disconnected Data & Tech Debt Are Costing You Growth
The Fragmentation Tax is the hidden cost of operational inefficiency. It drains budgets, burns out teams, and stunts the ability to scale. For digital marketing and growth leads, this tax is paid in three distinct “currencies”:
1. Siloed Data & Strategic Blindness.
When your ad server, subscriber database, and content tools exist as siloed work streams, you lose the ability to see the full picture of the reader’s journey.
Without integrated attribution, marketers are forced to make strategic pivots based on vanity metrics like generic pageviews rather than true business intelligence, such as conversion funnels or long-term reader retention.
2. The Editorial Velocity Gap.
In the era of breaking news, being second is often the same as being last. If an editorial team is forced into complex, manual workflows because of a fragmented tech stack, content reaches the market too late to capture peak search volume or social trends. This friction creates a culture of caution precisely when marketing needs a culture of velocity to capture organic traffic.
3. Tech Debt vs. Innovation.
Tech debt is the future cost of rework created by choosing “quick-and-dirty” solutions. This is a silent killer of marketing budgets. Every hour an engineering team spends fixing plugin conflicts or managing security fires caused by a cobbled-together infrastructure is an hour stolen from innovation.
Conclusion: Trading Toil for Agility
Ultimately, shifting to a unified standard is about reducing inefficiencies caused by “fighting the tools.” By removing the technical toil that typically hides insights in siloed tools, media organizations can finally trade operational friction for strategic agility.
When your site’s foundation is solid and fast, editors can hit “publish” without worrying about things breaking. At the same time, marketers can test new ways to grow the audience without waiting weeks for developers to update code. This setup clears the way for everyone to move faster and focus on what actually matters: telling great stories and connecting with readers.
The era of stitching software together with “sticky tape” is over. For modern media companies to thrive amid constant digital disruption, infrastructure must be a launchpad, not a hindrance. By eliminating the Fragmentation Tax, marketing leaders can finally stop surviving and start growing.
Jason Konen is director of product management at WP Engine, a global web enablement company that empowers companies and agencies of all sizes to build, power, manage, and optimize their WordPressⓇ websites and applications with confidence.
This post was sponsored by Victorious. The opinions expressed in this article are the sponsor’s own.
A year into the shift toward AI search, the marketing industry is full of confident takes about the factors that impact AI visibility. But we’ve seen very little data to support commonly held assumptions.
We wanted to see what correlations we could find between traditional search performance and AI mentions and citations. So we built a study to see if we could uncover evidence-based recommendations from the data.
The Study Methodology: Comparing Traditional Search vs. AI Search Performance
To compare how brands perform in traditional search versus AI search, we needed a dataset that captured both signals for the same companies during the same period of time.
We built it out in four phases.
Step 1: Determine The Brand Set.
We selected a representative cross-section of 177 brands across five verticals: healthcare, SaaS, financial services, ecommerce/retail, and legal services.
Step 2: Capture The AI Visibility Signal.
For each brand, we tested vertical-specific prompts across eight AI platforms: ChatGPT, Perplexity, Gemini, Google AI Overview, Google AI Mode, Microsoft Copilot, Claude, and Meta AI. That gave us 107,011 AI responses to analyze.
For every response, we recorded two things: whether the platform named the brand (mention), and whether it linked to the brand’s domain as a source (citation).
Step 3: Pull The Organic Performance Data.
For the same 177 brands, we tracked domain-level organic performance in Semrush during the first quarter of 2026, including traffic trends and Authority Scores.
Step 4: Cross-Reference The Two Datasets.
We joined the AI visibility data with the organic data so every brand had three comparable measures: mention rate, citation rate, and Authority Score. That structure let us look at the relationship between traditional ranking signals and AI visibility, and whether those factors were more or less related across the different verticals.
Why We Tracked Mention Rate & Citations Separately
One metric doesn’t capture AI visibility, so we tracked both mention rate and citation rate as separate signals. For example, a brand can be mentioned often and cited rarely, or cited often and rarely mentioned. Tracking both separately, rather than collapsing them into a single “AI visibility” score, ended up being central to the nuances we could pull from the different verticals.
Finding 1: Most Brands Have No AI Mentions At All
Of the 177 brands in our dataset, only 18 had any AI mention rate above zero in Q1 2026. That means 89.8 percent of the brands we tested were largely absent from AI search across the eight platforms we measured. They weren’t mentioned. The brands weren’t surfaced in relation to answers, as sources, or examples.
This runs counter to a lot of the current industry chatter, which treats AI visibility as a race that’s already well underway. Our data shows a very different picture. For an overwhelming number of brands, the race hasn’t yet begun.
The fact that only 18 of the 177 brands in our research registered any AI mentions at all indicates that brands willing to take AI visibility seriously now will be competing against a small number of incumbents in their vertical, not against the entire category.
Finding 2: AI Visibility Patterns Vary By Vertical
Once we broke the data down by vertical, three distinct patterns emerged.
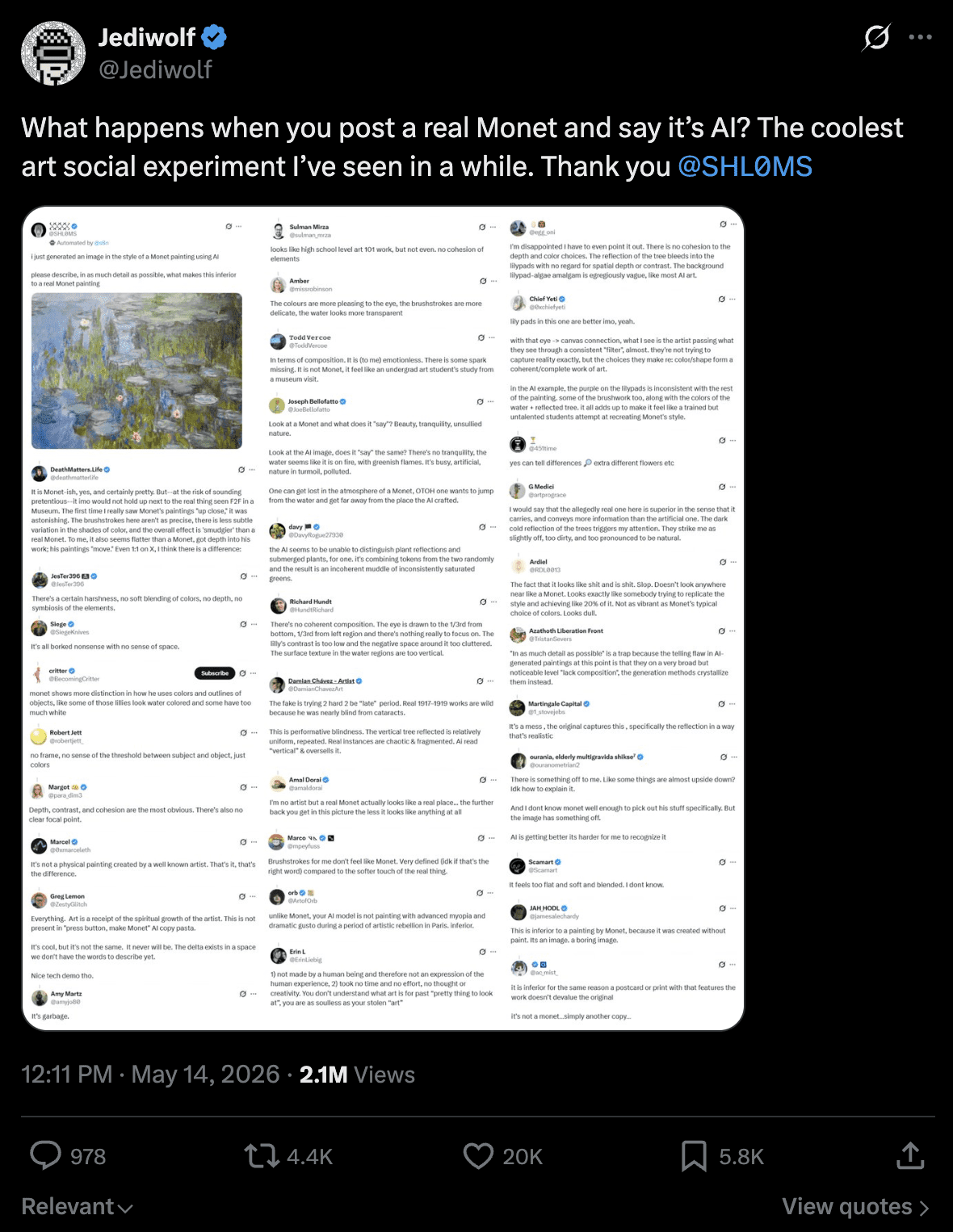
“Q1 2026 Quarterly Search Report: Mention rate vs. citation rate, by vertical: Healthcare, SaaS, and Financial Services” created by Victorious. May 2026.
Brands within these three verticals were consistently mentioned and cited, but for different reasons. Healthcare brands benefit from clear entity identifiers such as names, locations, specialties, and network affiliations, which reinforce the signals that AI platforms use to evaluate expertise and authority. SaaS brands are commonly featured on third-party platforms such as G2, Reddit, and LinkedIn, where products are discussed by users and reviewers. Financial Services benefits from strong editorial media presence on platforms like MarketWatch, Bankrate, and NerdWallet, which are common sources AI platforms turn to for financial questions.
Financial Services was also the only vertical where citation slightly exceeded mention, which suggests AI platforms trust the content slightly more than it trusts specific brands yet.
In each case, the brands that show up have something AI platforms can attach the brand identity to: structured data, third-party validation, or editorial coverage. The brands that don’t show up usually lack one or more of those.
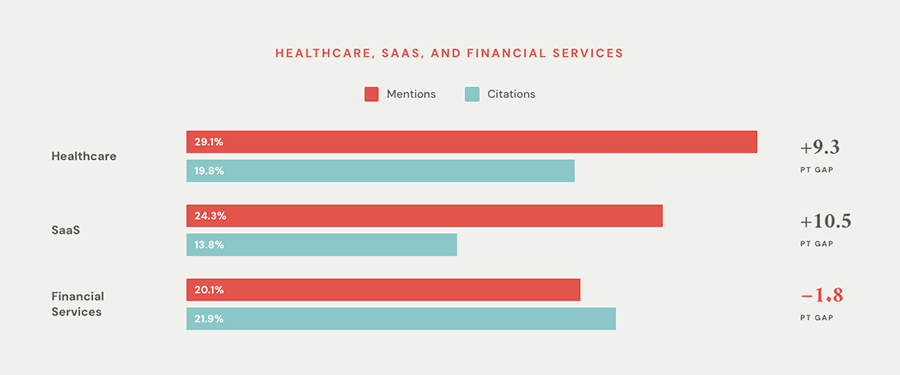
Mentioned More Than Cited: Ecommerce & Retail Brands
“Q1 2026 Quarterly Search Report: Mention rate vs. citation rate for Ecommerce/Retail” created by Victorious. May 2026.
Ecommerce posted the widest gap in our dataset. AI platforms recognize these brands but pull their source material from somewhere else, usually marketplaces, aggregators, and review sites rather than the brands’ own domains.
For these brands, recognition comes from marketplace presence and consumer familiarity. The bigger challenge for ecommerce brands is giving AI platforms content worth citing on their own domain, instead of leaving the field to Amazon, Reddit, and review aggregators.
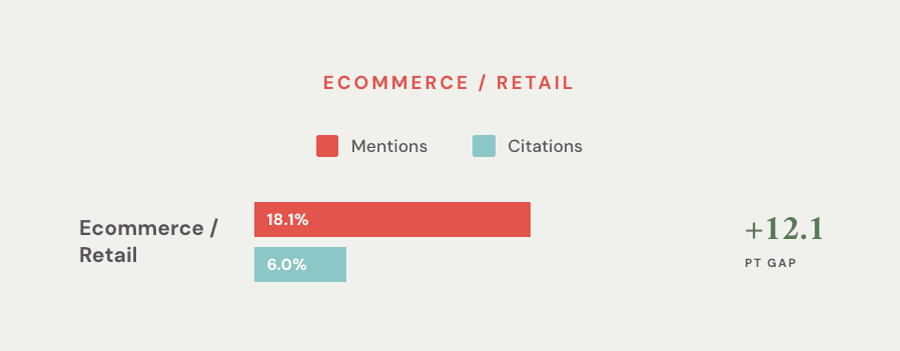
Cited But Rarely Mentioned: Legal Services
“Q1 2026 Quarterly Search Report: Mention rate vs. citation rate for Legal Services” created by Victorious. May 2026.
Legal services posted the inverse pattern as ecommerce brands. AI platforms regularly source content from legal sites, but they rarely credit the firm behind the article.
Closing that gap means building the entity signals that connect a piece of content back to a recognizable firm.
Findings 3 – 4
Each AI platform draws from a different set of sources.
Personalization may be compounding early AI visibility.
Google’s Personal Intelligence update pulls signals from a user’s Gmail and Photos into AI Mode responses, biasing results toward brands the user has already encountered. If that effect holds, brands that win a user’s first AI interaction on a topic could compound their visibility faster than later entrants. The full report walks through what we’re watching in Q2 to test this.
Key Takeaway
If you take away nothing else from this data, remember that you haven’t lost first-mover advantage. With only 18 of the 177 brands we measured earning mentions AI search, there’s still white space in your vertical waiting to be claimed.
Google upgraded AI Mode with Gemini 3.5 Flash as the new default model and redesigned the Search box with AI capabilities, the company announced at I/O. The changes also include search agents and an international expansion of Personal Intelligence.
Liz Reid, VP and Head of Search, said AI Mode has passed one billion monthly users. She said queries have more than doubled every quarter since launch and reached an all-time high last quarter.
Gemini 3.5 Flash As Default In AI Mode
Google made Gemini 3.5 Flash the new default model in AI Mode for everyone globally, starting today.
Google redesigned the Search box with AI. Reid called it the biggest upgrade to the Search box in over 25 years.
The new box expands dynamically to accommodate longer queries. It offers AI-powered suggestions beyond autocomplete and accepts multimodal inputs, including images, files, videos, and Chrome tabs. Standard search results still appear alongside AI features. The redesigned box is rolling out today in all countries and languages where AI Mode is available.
Separately, users can now ask follow-up questions directly from an AI Overview, which then flows into a conversational AI Mode session. Context carries over between the two. This is live today on desktop and mobile worldwide.
Search Agents
The company announced search agents that run in the background to monitor the web and deliver updates. The first type, information agents, will look across the web, including blogs, news sites, and social posts. They’ll also tap Google’s real-time data on finance and shopping.
Information agents will launch this summer for Google AI Pro and Ultra subscribers.
Agentic booking is also expanding to local experiences and services. Users can share criteria and get results with pricing and availability. For select categories, such as home repair and pet care, Google said users can ask it to call businesses on their behalf. These booking features will roll out to everyone in the U.S. this summer.
Google also announced new agentic shopping capabilities in Search, with details on a separate Shopping blog post.
Generative UI And Mini Apps
The Antigravity platform and Gemini 3.5 Flash coding capabilities are coming to Search. In response to a query, Search can generate custom visual tools and simulations tailored to the question.
Google said Search can also build custom dashboards or trackers that users can return to over time. Reid compared these to mini-apps for specific tasks, like tracking a health routine or managing a move.
The generative UI capabilities will be free for everyone in Search this summer. Antigravity mini apps will start rolling out for AI Pro and Ultra subscribers in the U.S. in the coming months.
Personal Intelligence Expands Internationally
Personal Intelligence in AI Mode is expanding to nearly 200 countries and territories across 98 languages. The feature no longer requires a subscription.
Users can connect Gmail and Google Photos to AI Mode, with Calendar support coming. The feature first launched for AI Pro and Ultra subscribers in January and expanded to free U.S. users in March.
Why This Matters
These updates extend the trajectory Pichai outlined in April. He called search an “agent manager” and predicted users would run long-running tasks rather than browse results. Search agents and custom mini apps move in that direction.
More query activity within Google’s AI interfaces may mean that fewer queries result in outbound clicks. Google says queries hit an all-time high, but independent measurements have consistently found that AI Overviews reduce clicks on queries where they appear.
Personal Intelligence expanding without a subscription in nearly 200 countries is the most concrete change to monitor. Personalized results at this scale could affect how Google selects which content to surface. When connected, the system can draw on a user’s email and photos alongside web results.
Looking Ahead
Gemini 3.5 Flash is now available in AI Mode. The redesigned Search box is starting to roll out. Personal Intelligence is expanding to nearly 200 countries and territories without a subscription requirement.
Several features are scheduled for this summer with different availability tiers. Information agents and Antigravity mini apps will require an AI Pro or Ultra subscription. Agentic booking will be available to everyone in the U.S. Generative UI will be free for everyone in Search.
No timeline was given for Google Calendar integration with Personal Intelligence.
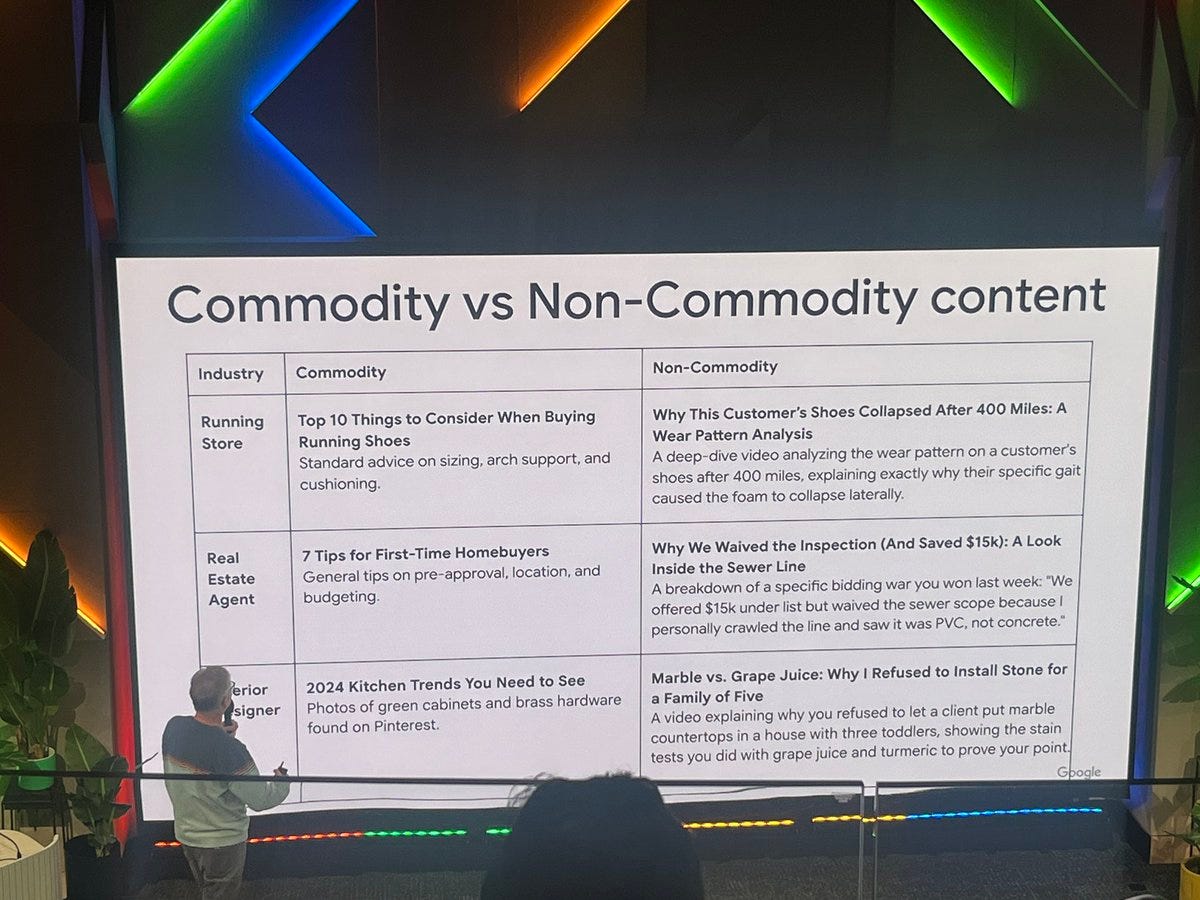
Google’s recent definition of commodity vs. non-commodity content is a bit meh. Meh if I’m being kind. Downright useless if I’m being more reasonable.
Complete and utter rubbish if I’ve had a drink.
Image Credit: Harry Clarkson-Bennett
They all read like headlines you’d see in Discover and scroll past very quickly.
Maybe in a few years, that’ll be all that’s left, and that’s what Googlers are prepping us for. Personally, I think it’s far more likely their idea of quality, interesting content is just a bit rubbish.
Marble vs. grape juice – what a stupid title. Although interesting that they specify this is a video. Don’t hate the shoe one. No idea how that will make money for anyone, however… Doesn’t matter to Google.
Anyway, here’s how I think you can create unique, interesting content that still drives actual value to your business. (Hint: It’s not about grape juice).
TL;DR
Commodity content is doomed for two reasons: It is easily summarized (because it has been done to death), and it doesn’t make (as much) money in a zero-click world.
If you are creating content just for SEO and have nothing unique to offer, stop. You are throwing money down the drain.
Be more than an SEO. Help other teams structure their workflows to generate the maximum value from all channels, with things like demand analysis.
Google calculates the uniqueness of a document using a custom “information gain” score at a query and document level.
Why Commodity Content Is Doomed
People are like water. We take the easiest possible route. One that really doesn’t include clicking to find an answer, even if said answer is riddled with BS.
“Focus on making unique, non-commodity content that visitors from Search and your own readers will find helpful and satisfying. Then you’re on the right path for success with our AI search experiences, where users are asking longer and more specific questions — as well as follow-up questions to dig even deeper.”
This means we have to focus our efforts elsewhere.
We have to focus our time and efforts on content more likely to drive legitimate value. Content that cannot easily be summarized by AI adds something of real value to the user and hasn’t already been thrashed to death by savvy SEO teams.
If you’re unsure whether to create content or not, ask yourself two questions:
Are we creating this just for SEO?
Are we adding anything unique to the existing corpus of information?
If you answered 1. Yes and 2. No, throw it straight in the bin.
You do not have the time, money, or resources anymore to spend time on content that doesn’t drive value.
Does This Mean Things Like Search Volume Are Useless?
At an individual keyword level, search volume has been declining in value for a long time. We just can’t generate the value we once could, and it isn’t coming back.
But search volume just indicates demand. If you’re savvy and use monthly data, you can help content, social, paid marketing, and editorial teams understand when users really care about a topic.
In this capacity, your job is to help teams understand when to create or update content, what that content should cover, and crucially, why it’s spiking in search at this particular time.
Five years’ worth of searches in Google for [family holidays] (Image Credit: Harry Clarkson-Bennett)
If we take searches for [family holidays] in Google Trends as an example, there is clear and obvious consistency. Searches spike every January as people plan their family holidays for the year ahead in the bleak midwinter.
So you should still get your core family holiday content ready for January. But as we shouldn’t operate in a silo, you should share this with social and travel teams so they know what time of year this type of content will generate the most value.
Planning and structure take center stage.
It is no longer about “Create x, get y.” That click-based marketing is dead.
Commodity Or Not Commodity
Loosely, this header was a Shakespearean-based to be or not to be joke, which is a. clunky and b. outside of my wheelhouse.
Image Credit: Harry Clarkson-Bennett
Now I’ve had to explain it.
I wrote about this in “How to do evergreen content in 2026 and beyond.” Which is, ironically, quite a commodity topic. But it has evolved. There’s new stuff to share. You can make commodity, non-commodity.
But you need to have a level of understanding and expertise that can really elevate a topic. That requires experience, a level of uniqueness, and a platform. Your content needs to be found, and what we have always done in search is unlikely to be anywhere near as valuable.
The Pillars Of Non-Commodity Content
Uniqueness.
E-E-A-T.
Engagement.
Structure.
Uniqueness
Uniqueness is the bedrock of everything when it comes to content that will continue to drive value. Without uniqueness, there’s no E-E-A-T. You won’t generate any shares, likes, comments, or links. Certainly not any good ones.
You can make this as fancy as you like.
If you’re lucky enough to have access to high-quality data sources like Similarweb, you can create some truly brilliant proprietary metrics that elevate your content above and beyond.
Let me give you an example.
Similarweb gives excellent engagement data at a site level. App-level too. If I was to combine these three metrics (pages per session, session duration and bounce rate) I have a composite engagement score.
Something no one else has.
If I took that engagement score and correlated it with third-party traffic data or something like branded search/backlinks, I could correlate engagement data with traffic from search over time.
This is part of our audience engagement index (coming soon!) Image Credit: Harry Clarkson-Bennett
This is what stands out. This is what audiences will read, share, and crucially, remember. It requires more effort.
And as we know from the Google Leak (this brilliant warehouse from Daniel Foley Carter is superb), effort is quite literally estimated and scored by Google. Things that are difficult to replicate are rewarded.
Unless they’re absolutely insane. Then probably the opposite.
You don’t get good at this overnight. But Google has been prepping us for this for some time. If you look at the declining youth engagement in the above graph, maybe people have, too.
Not everyone is fortunate enough to have access to Similarweb data. But that doesn’t matter. Creativity and quality research is more important (and more readily available) than ever.
There are so many quality free data sources – Google Trends (combined with Glimpse), Keyword Planner, some free plans on tools like Ahrefs or Similarweb etc. You just need to identify metrics and combine them to make something bigger and better.
Documents are identified against a topic, scored, compared and presented based on the user’s likely need (Image Credit: Harry Clarkson-Bennett)
“In some implementations, information gain scores may be determined for one or more documents by applying data indicative of the documents, such as their entire contents, salient extracted information, a semantic representation across a machine learning model to generate an information gain score.”
Patents aren’t absolute. Just because a patent is present, it doesn’t mean it is always in use. If they’re frequently cited, recently updated, and have worldwide applications, that’s usually a very good sign they have a level of importance.
This patent is all of those things (Image Credit: Harry Clarkson-Bennett)
But “ranking factors” aren’t absolute either. SERPs and topics are vastly different. It’s why we have subtopics like local SEO, YMYL, et al.
What matters for one term or topic may not matter as much, if at all, for another. It’s the nuance of the job and why trial and error is so important.
You don’t know until you know.
Consider The Four E’s
Your content needs a purpose.
Yes, it needs to convert. That is a business purpose. But it needs a purpose for people. Is it designed to entertain? Educate? As audiences turn away from news (and probably more widely, commodity content), this matters more than ever.
What we now term as commodity content was never designed to do any of the above. It was just designed to make money. Over the years, anything substandard propped up by Google just to make money has died.
This is the next cab of the rank.
E-E-A-T
E-E-A-T has taken a bit of a kicking recently. Not without reason.
The premise is sound. Not unreasonable for readers to expect the author to be, you know, a real person, who knows something and has some kind of online presence. And Google absolutely does track authorship and entities. Plenty of evidence of that.
Google has built and maintained its Knowledge Graph for decades, and entities have been the bedrock of news SEO for years. But E-E-A-T requires you to join the dots. To remove ambiguity – something we call disambiguation.
The Knowledge Graph and disambiguation in action (Image Credit: Harry Clarkson-Bennett)
Doesn’t mean doing this is incredibly valuable, but it’s foundational. Particularly in this modern-day iteration of the internet.
Remember, E-E-A-T Projects Have To Add Value
The problem with the whole – use experts, showcase expertise, prove you test everything, create video, make an effort in the industry, etc. – is now twofold:
It’s expensive.
And less valuable than ever.
Having that person build some kind of profile in the industry. A platform that their content can be shared from and that reduces reliance on search can only be a good thing.
If they’re a legitimate expert on the topic, know how to structure great content and effectively showcase expertise, then you’re onto a bloody winner.
Which is why commodity content is doomed. Because people don’t care about it, and now it doesn’t drive value.
We need to find ways to make non-commodity content truly valuable to the business. If it isn’t driving some kind of trackable value, ignore it. Move on.
Be ruthless, brave and interesting.
Content just for SEO has diminishing returns. It’s almost certainly a bad idea IF you do it the same way you have been for the last 10 years.
Engagement
I have always felt that links should be a happy byproduct of creating and sharing brilliant stuff.
Make me an offer, link sellers. I’m all ears. (Image Credit: Harry Clarkson-Bennett)
I’ve never made an effort to build links. I have just made an effort to write stuff I think is interesting, made some semi-libelous jokes, and got out there in the industry.
That is, more or less the Google definition of link building. In their world of sunshine, links are just earned by doing beautiful things. I am, in this scenario, the poster boy for white hat SEO.
The problem is, people need to make money, and links still drive rankings. So there’s a market there. And if you’re a student of the scriptures like I am, you’ll know the buying and selling of links is the oldest recorded job.
Either way, my inbox is full.
Anyway, your content has to fulfill a need. We’re moving away from straight-laced content, being able to do that for you as a publisher. Traditional ad revenue and the volume model sucks, and you sure as hell aren’t going to drive any subscriptions with what time is x or how to tie your shoes.
I really hope this is a good thing for SEOs and publishers. I want us to focus on content that really makes a difference to people’s lives. Content that makes them smile or think.
Content that makes people angry has been a big hit when it comes to numbers for a long time. But I don’t think anger is the emotion you should shoot for.
Measurement
You need to measure quality engagement, on and off-site. That means:
On-Site
No need to overcomplicate it for now.
Session duration.
Bounce rate.
Link clicks.
Pages per session.
Comments.
Read time.
Off-Site
Very much depends on the platform and the purpose, but I would focus on:
Links.
Shares.
Comments.
Saves.
Watch time.
You need to track metrics that tell you clearly whether people truly care about what you are creating. Clicks are dying, so I’d rather be measured against something a. more valuable and b. less miserable.
Create a composite metric(s) that gives you and your creators something to clearly focus on. Make their job easy by guiding their content with simple, straightforward metrics. Metrics that don’t just chase page views.
Structure
Structure’s not sexy. Let’s be honest.
But it matters. If, for some reason, you think LLMs are the zenith of society and content consumption, then you should know that models are more likely to cite or reference content from the top or bottom of the page, thanks to their inability to properly follow an argument.
Semantic markup is still the foundation of a well-ordered page (Image Credit: Harry Clarkson-Bennett)
Unless, of course, the entity and topic are repeatedly referenced throughout.
I shouldn’t have to tell you that this is a bad idea and your content will become unreadable to living, breathing people.
But maybe you don’t care about that anymore.
Proper structure really matters. People have expectations (and accessibility needs). In more traditional commodity content, they want their question answered immediately. If you satisfy that – and the intro to your article isn’t abysmal – you might generate a longer session, a click, or hell, maybe even a conversion.
Theoretically, non-commodity content accessed via search should still be intent-driven. Possibly more so if we’re to believe the more qualified users with longer tail queries theory Google espouses.
So you still need to follow a similar, highly coherent page structure:
Answer the question.
Some form of TL;DR article summary.
Argument.
Concluding thoughts.
Coherent FAQs (if applicable).
One that logically answers queries in the appropriate format – text, video, image, list, etc. – and is highly consumable.
The argument section is where LLMs tend to lose their ability to accurately and appropriately cite and reference content. Which is not at all dissimilar to people.
I am not saying you need to continually refresh and restate the entity in question. That may be construed as keyword stuffing. It needs to read well for people. But you need to be clear, concise and accurate to make consuming your content simple.
Don’t People Consume Content In Different Ways?
You’re absolutely right, my pedantic friend, they do. Broadly, I think there are four types of consumption:
Scanners: The vast majority. Too lazy or illiterate to read the whole thing, but will be satisfied from a headline, bold text, bullet points, and headers. They treat a page like a map, not a story.
Answer seekers: They find what they want and leave. But still leave satisfied.
Visual/audio consumers: A cohort that either refuses to or cannot read, but will stare at a pretty picture for 60 seconds.
Deep readers: A small cohort, but a deeply engaged one, desperate for you to get something wrong.
I suspect these groups cover more than 90% of people. There are also fact-checkers – who skip the narrative and head straight for the citations, data points, or the “About Us” section before deciding if the content is worth their time.
And community-readers, who scroll to the bottom of the article to see the community reaction before deciding whether the content is worth their time. This is (obviously) more of a social trait. Particularly from younger audiences.
Your content can and should satisfy all of these people. It must:
Answer the question.
Be highly scannable.
Broken up with clear, distinct headers.
Form a concise, easy-to-follow narrative.
Be highly scannable.
Easy to share.
Visually appealing (audio and video options available).
Cite sources and clearly explain your methodology if appropriate.
You might think it’s beneath you, but if you don’t optimize for scanners and answer-seekers, you risk losing up to c. 80% or more of your potential audience within the first few seconds.
This is why front-loading (putting the most important info at the top) and using clear hierarchies is so vital in modern writing.
Google’s Universal Commerce Protocol is the first production blueprint for what every website (ecommerce or not) will eventually need to expose to AI agents: discoverable actions, predictable outcomes, persistent sessions, and explicit agent policies.
UCP was released as infrastructure for Google Merchant Center retailers. But the more important story is the architecture underneath it. UCP is the first real implementation of what I’ve been talking about in the Interaction pillar of machine-first architecture. If you want to understand what agent-ready websites look like in practice, you need to look at UCP’s developer documentation. The architecture is the lesson, and it goes far beyond Google Shopping.
What Google Actually Built
UCP is an open standard Google unveiled in January 2026 at the National Retail Federation conference alongside Shopify, Etsy, Wayfair, Target, and Walmart, as a common language between AI surfaces (Gemini, Google AI Mode) and merchant backends. According to Google’s “Under the Hood” post on UCP, the protocol has four moving parts worth paying attention to.
A discovery endpoint at /.well-known/ucp. Agents query the /.well-known/ucp URL to learn what a merchant’s website can do, which products it sells, which actions it exposes, and which transports it supports. This manifest is the handshake between an AI agent and a merchant’s backend. Without that manifest, an agent has no knowledge of what it needs to parse or call. At best, it will try to guess.
Three REST endpoints for checkout. UCP reduces the entire transaction to three calls: Create a session, update a session, complete a session. That is it. No cart page, no address form, no confirmation screen. The checkout state lives in session responses, not in rendered HTML. Human layer of your website gets completely ignored. An interface will exist, but it will not be the one you designed.
Transport flexibility. UCP supports REST, Model Context Protocol (MCP) bindings, and A2A (Agent-to-Agent), so agents built on different stacks can talk to the same merchant backend without custom adapters. An agent running inside Gemini and an agent running on a custom MCP client can both hit the same UCP endpoints. This was a very smart move.
An open specification at ucp.dev. UCP is published as an open spec any website, AI platform, or merchant platform can implement. Google does not own the protocol or its governance. The openness matters because the architecture becomes portable to any website outside Google Merchant Center, even if Google’s onboarding path does not.
Google is building UCP for its own Shopping ecosystem first. UCP’s design is the real lesson for everyone else, and that design is a textbook implementation of the Interaction pillar of machine-first architecture. Shopping carts are abandoned by roughly 70% of humans (per Baymard Institute’s long-running checkout research). You can expect the agent abandonment rate on websites with no Interaction layer to be closer to 100%.
The Interaction pillar of machine-first architecture describes what a website must expose so an AI agent can accomplish a goal on it. Five properties: discoverable actions, predictable outcomes, workflow continuity, error recovery, and agent policies. UCP maps to each one almost perfectly.
Discoverable actions. The Interaction pillar says agents need a machine-readable index of what they are allowed to do on a page before they try to do it. UCP’s /.well-known/ucp capability manifest is exactly the machine-readable action index the Interaction pillar calls for, shipped as a production endpoint. An agent fetches the manifest, reads the list of available operations, and plans its next step. No trial and error, no DOM scraping.
Predictable outcomes. The Interaction pillar says every action should return machine-readable state (computed totals, allocated inventory, success flags), not a 200 OK with an HTML receipt. UCP session responses carry structured data at every step: pricing breakdowns, discount allocations, and explicit session state. An agent reading a UCP response knows exactly what just happened and what it owes next.
Workflow continuity. The Interaction pillar says agents need stable session references that survive across multi-step workflows, so they do not lose context mid-task. UCP sessions have persistent IDs, and PUT updates carry that ID forward. An agent can add a line item, apply a discount, adjust shipping, and complete the order across multiple calls without re-creating state.
Error recovery. The Interaction pillar says failures should return structured alternatives, not dead ends. When a UCP discount code fails, the session response explains why and surfaces alternatives the agent can try. A human might click “try again.” An agent needs a payload that tells it what to do next.
Agent policies. The Interaction pillar says websites should declare what agents are allowed to do, what requires human confirmation, and what is off-limits entirely. UCP’s capability declarations are that policy layer: A merchant signals which actions agents can invoke, under what conditions, and where human approval is required. Request signatures and tokenized payments enforce the policy at the protocol level.
Google’s /.well-known/ucp endpoint is the Interaction pillar’s “discoverability of actions” being shipped as production infrastructure. Agents query it to learn what a website can do before they attempt to do it. UCP requires three REST endpoints for checkout: session creation, updates, and completion. That is the entire Interaction pillar reduced to three API calls.
The Gap UCP Exposes For Everyone Else
UCP is Google’s answer to the agent-traffic gap inside its Shopping ecosystem. Every non-UCP website still has the gap, though not every retailer agrees on where the gap actually lives.
Breanna Fowler, Dell’s Head of Global Consumer Revenue Programs, told Digital Commerce 360 in an April 2026 interview that she has not yet noticed “anything behaviorally consistent” in the agent traffic reaching Dell.com. Her focus is search and discoverability, not agent-specific infrastructure: “If I can’t find your products easily and effortlessly, no amount of content and configurator capabilities, nobody really gives a crap about that stuff.”
Fowler is right that nothing matters if agents cannot find the product. But for an AI agent, “finding” a product does not mean typing into a search box. Finding means querying a capability manifest, reading a structured product catalog, and invoking a discoverable action. In a human-first website, findability is a UI problem. In an agent-ready website, findability is a protocol problem. UCP exists because Google decided that treating findability and checkout as protocol problems, not UI problems, is the only way agent conversions ever scale.
A Gemini agent shopping through a UCP-enabled merchant does not parse a product grid, does not guess at form fields, and does not hope nothing re-renders under it. The agent queries /.well-known/ucp, reads the capability manifest, and advances the session through UCP’s three checkout endpoints. The rest of the web (every SaaS dashboard, every B2B quote flow, every booking system, every subscription portal) has no equivalent protocol coming to rescue it.
Baymard Institute’s aggregated checkout research puts the human cart abandonment rate at 70.22% across 50 studies. The agent abandonment rate on websites without an Interaction layer is closer to 100% because humans hesitate at checkout, while agents cannot even find checkout.
What Every Website Can Learn From UCP’s Architecture
You do not need to implement UCP. You are probably not even a commerce business. UCP’s architecture still generalizes into five principles any agent-ready website should implement: a capability manifest, structured actions, machine-readable state, persistent sessions, and an explicit agent policy.
1. Publish a capability manifest. Agents need to know what your website can do before they start. That manifest might be a /.well-known/ endpoint, an llms.txt file, a WebSite schema node with potentialAction entries, or an MCP server listing available tools. The format matters less than the existence. If there is nothing for an agent to query, the agent has to guess, and guessing is how conversions die.
2. Expose actions as structured data. Schema.org has supported Actions for over a decade, including BuyAction, OrderAction, ReserveAction, SubscribeAction, and SearchAction. Almost no websites use them. UCP’s POST /sessions endpoint is effectively a BuyAction target given a stable API contract, which is what schema.org Actions have needed for a decade to actually work. Any website can do the same on its own actions: declare the action type, name the endpoint, document the payload. The how AI agents see your website post covered the Structure pillar side of this question. Schema.org Actions are the Interaction pillar side.
3. Return machine-readable state at every step. Every response to an agent should carry structured state the agent can parse: what happened, what changed, what is next. HTML confirmation pages are not machine state. A redirect to /thank-you is not machine state. JSON with named fields and explicit flags is machine state. Returning JSON state instead of HTML confirmation pages is the single biggest architectural shift from human-first design to agent-ready design.
4. Design for sessions, not pageviews. Agents do not restart when they get distracted. They come back to a workflow in progress and expect the state to still be there. Sessions with stable IDs, safe-to-retry updates, and graceful resume paths are not optional for agents; they are the base layer. Pageview analytics trained a generation of product teams to think in discrete hits. Agents think in transactions.
5. Declare your agent policy explicitly. An agent policy defines three things: what agents can do without asking a human, what requires human confirmation, and what is off-limits entirely. UCP answers these questions through capability declarations. Your website can answer them through an AGENTS.md file, a /.well-known/ policy endpoint, or structured annotations. Pick one. Publish it. Guessing a policy is how agents end up taking actions their users did not intend.
None of these principles require Google’s participation. None require UCP’s adoption. They require a decision to treat a website as an API surface for agents in addition to a screen for humans.
Citation Gets You Into The Answer. Actions Get You Into The Revenue
Most of the AXO conversation today is still about the Content pillar: how to get cited in ChatGPT answers, how to rank in Google AI Overviews, how to become the source AI surfaces quote. That work matters. Citation drives awareness, and awareness is the top of the funnel. The SEO to AAIO and Answer Engine Optimization articles covered how to win it.
UCP demonstrates the Interaction pillar, which is the other half of the agent-ready website stack that AEO and GEO do not cover. The Interaction pillar is about being transacted through by an AI agent, not quoted in its answer. The difference between a cited website and a transactable website is the Interaction pillar. Citation gets you into the AI’s answer. Discoverable actions get you into the AI’s revenue.
On the Cheeky Pint podcast, Sundar Pichai described a future where an AI user has “many threads running” at the same time, research, comparison, booking, purchase, all executing in parallel on behalf of a single human. In that model, the website that lets the agent resolve its thread fastest wins the thread. Resolution means completing an action, not loading a page. Dell has the traffic and loses the thread. A UCP-enabled merchant resolves the same thread in three API calls.
UCP is the first production artifact that gets the Interaction pillar right. UCP will not be the last. Every website that wants to participate in agent-mediated revenue will eventually need to ship its own version of the same architecture, through an open protocol, a schema.org capability layer, a WebMCP endpoint, or a custom MCP server. The spec can vary even if the principles cannot.
UCP is the working reference implementation of the Interaction pillar, built by Google and running in production inside Google Shopping today. Every other website still owes its own answer. Dell’s Breanna Fowler said discoverability is what matters. For an agent, discoverability is a protocol.
Google has finally published guidance for AI optimization. Yet “Optimizing your website for generative AI features on Google Search,” published May 15, offers nothing beyond traditional search engine optimization basics.
The guidelines apply to AI Overviews and AI Mode, but not necessarily to Gemini, Google’s standalone genAI platform, and certainly not to other models such as ChatGPT and Claude.
SEO
The guidelines start with confirming that traditional SEO remains as relevant as ever because (i) AI answers rely on search results and (ii) “fan-out” queries use actual human searches.
To Google, there’s no difference between “optimizing for AI” and “SEO,” stating:
From Google Search’s perspective, optimizing for generative AI search is optimizing for the search experience, and thus still SEO.
The guidelines list traditional SEO tactics, mainly:
Create original, helpful, people-first content with a unique point of view.
Structure content and pages for humans, not AI agents.
Use quality, helpful images and videos.
Ensure pages are crawlable by Google’s bots. (I use Search Console’s URL Inspection tool to confirm crawlability.)
Use the same semantic HTML structure for people and AI agents.
Minimize duplicate content.
Make sure content is visible with JavaScript disabled.
Emphasize user experience from multiple devices.
Ensure ecommerce product feeds are detailed and submitted to Merchant Center.
GEO Myths
Google’s guidelines address common myths for generative AI optimization, stating:
“Chunking” content (i.e., breaking it into short paragraphs for AI retrieval) is not required.
Writing in an “AI-friendly” way is not required.
“Seeking inauthentic mentions” may flag your site as spam (like traditional SEO). AI systems do evaluate brand and product mentions across the web, but, like Google, can tell real mentions from fake ones.
No “special” structured data, such as from Schema.org, is required, though it helps generate rich snippets in organic results.
Core Concepts
The guidelines emphasize two core concepts for optimizing AI on Google Search:
AI Overviews and AI Mode rely directly on organic search.
No additional tactics are required or recommended beyond traditional SEO.
Google suggests becoming familiar with the Universal Commerce Protocol, as AI agents will eventually not only search but also perform various actions on behalf of humans, such as booking a hotel or making a purchase.
Over the past few years, I’ve watched AI content creation tools rapidly gain adoption across the SEO/GEO industry. These tools offer the promise of leveraging AI to automate content creation, reduce headcount, cut costs, and scale output.
As someone who has spent the last decade helping companies recover from Google algorithm updates, my spidey senses started tingling the minute I heard the pitches for many of these tools. Even before AI was part of the conversation, Google already had a long history of reducing the visibility of automated content in its search results.
Despite recent advancements in the quality of AI outputs, I’ve remained skeptical that publishing AI-generated or AI-assisted content at scale can drive sustained performance in Google’s search results. This is especially true now, given how Google updated its ranking systems in recent years specifically to demote overly optimized, SEO-driven content.
Over the past several months, I have been monitoring more than 220 websites that were publicly identified, either by themselves or by their AI content vendors, as customers of various AI content creation, automation, and scaling platforms. These tools fully write articles, assist with writing them, or use AI automations and workflows to support content creation. Many of these tools also now focus on driving visibility, mentions, and citations in AI search responses (AEO/GEO).
I wanted to analyze what happens after the claims of big wins.
A consistent pattern emerged across the 220+ sites I’ve been monitoring, and I believe it is concerning enough to be worth writing about: it works, until it doesn’t.
Below, I will share some of the trends I am observing, plus a variety of common SEO/GEO approaches I believe may be causing declines in organic search (and consequently, AI search) visibility. As a reminder, what is dangerous for SEO can also be dangerous for AI search, largely because of RAG.
Methodology & Disclaimers
Before we dive in, it’s important to set the stage with my approach and provide some important disclaimers.
This analysis is based on third-party SEO measurement data: organic traffic estimates and organic page count time series data from Ahrefs, corroborated against the Sistrix Visibility Index data to confirm broader visibility patterns. Top-traffic URLs were identified using Ahrefs’ top-pages export. Where I describe URL patterns or percentage changes, I am quoting directly from these third-party tools as of May 2026.
The dataset covers more than 220 client domains tracked across the publicly published customer-stories pages of over a dozen AI content platforms. For many of these sites, I narrowed the analysis to a specific subfolder where the AI-assisted content had been published, either identified directly in the case study itself or inferred from a sharp increase in new pages around the time of the case study’s publication.
The analysis, conclusions, and recommendations throughout this piece reflect my own professional opinions based on more than a decade of helping companies recover from Google algorithm updates. Other SEO/GEO practitioners may disagree with my findings and approaches, and individual sites and strategies will always have their own context.
3 Important Disclaimers About This Data:
First, these are third-party estimates, not first-party analytics. They are well-validated tools in the SEO industry, but they are not perfect measurements of organic search performance.
Second, the traffic declines described here could reflect many factors, including but not limited to algorithmic adjustments by Google, on-site changes by the site operators themselves, off-site competitive dynamics, brand changes, acquisitions, seasonality, and changes to internal site architecture. I am not asserting that any AI content tool directly caused any traffic outcome described in this piece. I am describing a correlation observed across many listed sites that share similar content patterns and organic traffic trajectories.
Third, vendors and specific domains are deliberately not named here. The pattern is the story, not the specific actors. Any resemblance to a specific company, vendor, or case study is incidental to the broader pattern described.
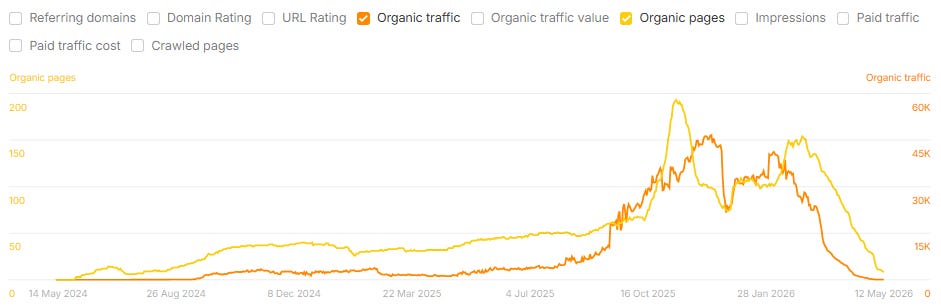
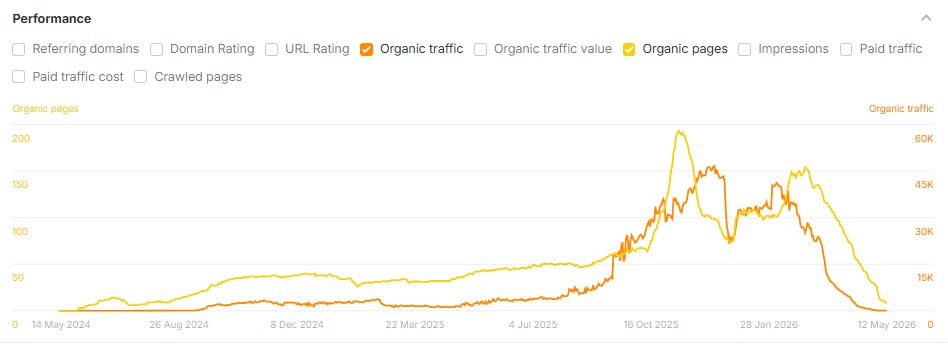
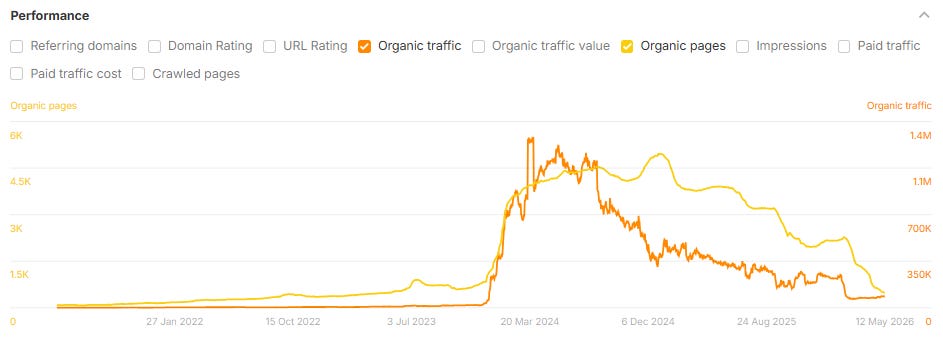
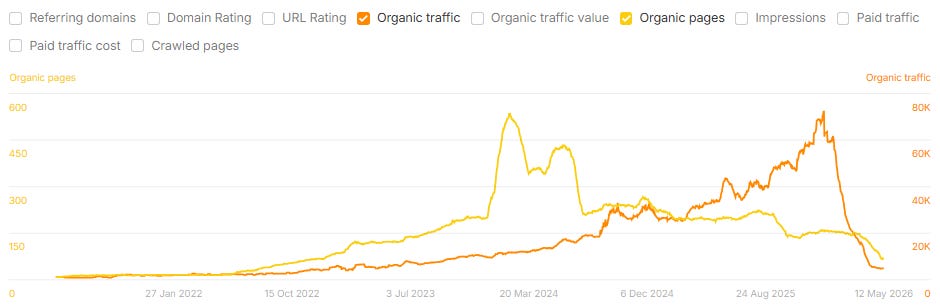
What The Data Shows: Rapid Growth Before A Steep Decline
If there is one thing the data makes clear, it is this: scaling content production with AI is not a low-risk strategy for organic search. It can produce real short-term gains in both SEO and AI search (LLMs use search engines), but across this dataset, those gains have rarely held. In many cases, the eventual loss has exceeded the initial peak.
Across the group of 220+ sites and subfolders I analyzed:
54% lost 30% or more of their peak organic traffic.
39% lost 50% or more.
22% lost 75% or more.
Within those declines, a recurring trajectory appears: a rapid growth in organic pages over six to 12 months; an organic traffic peak within roughly three to six months of the content peak; and then a steep decline in traffic that erases most of the gain (and frequently drops below the prior baseline) within the following year.
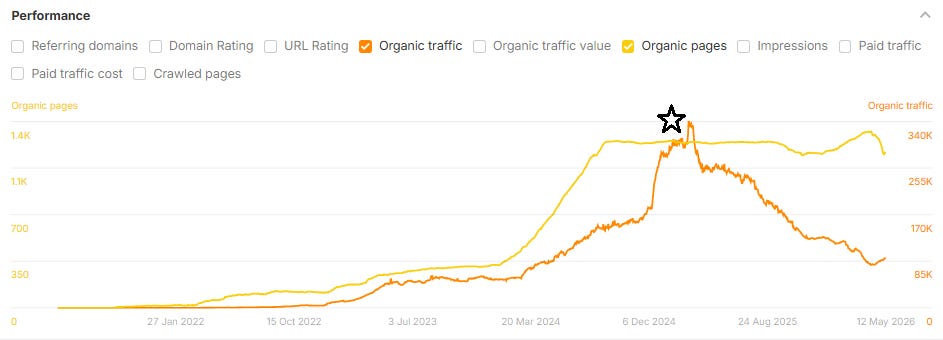
Image Credit: Lily Ray
Most of these traffic drops took place after the case studies were published (which also makes me wonder whether the case studies themselves could be contributing to the declines). In the example below, the case study was published in January 2025, indicated by the the black star below:
Image Credit: Lily Ray
I am also continuously monitoring changes to organic page growth and organic traffic to these sites and subfolders over time. Looking at the updated data, a substantial number of these brands appear to have substantially reduced their content footprints in 2025 and 2026, often removing, redirecting, or 410’ing many of the same pages featured as success stories in published case studies. This could explain the recent drop in pages (yellow line) shown in the above screenshot (and potentially, the corresponding increase in organic search traffic).
In many cases, these case studies remain published to this day, but the pages they reference do not.
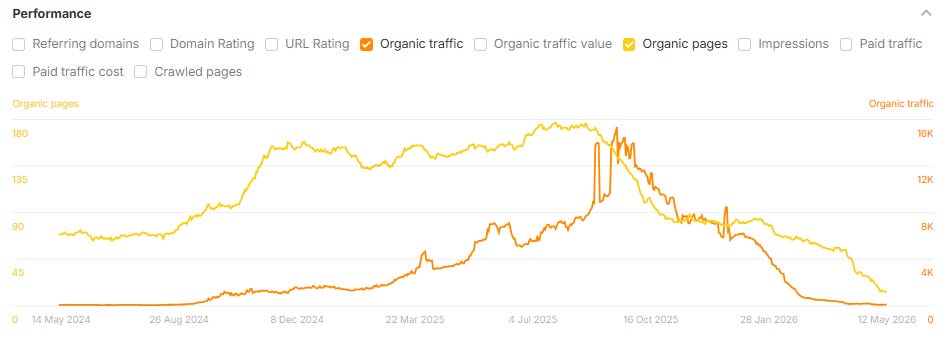
The Familiar Rank & Tank Playbook
When a site starts seeing traffic drops due to sitewide content quality issues, it’s rarely a gentle decline. As Glenn Gabe refers to it, a better label would be “Mount AI”: steep growth, followed by a similarly shaped drop-off in organic traffic, once Google’s systems have gathered enough signals to identify what is going on.
Below are several examples of case study sites that used AI to scale content creation and saw massive drops in organic traffic after their case studies were published:
Image Credit: Lily RayImage Credit: Lily RayImage Credit: Lily RayThis site’s decline started during the unconfirmed “self-promotional listicle Google update” in January 2026, which I also wrote about on my Substack (Image Credit: Lily Ray)
This pattern is consistent across industries, including cybersecurity, travel, marketing, SaaS, healthcare, B2B services, crypto, and consumer goods, and it shows up across vendors.
The shape of the line in the chart is similar to trajectories we have seen among many sites affected by Google’s algorithm updates in recent years. It is the same boom-bust cycle the SEO industry has watched repeatedly in different forms, accelerated this time by the speed at which AI tools have enabled site owners to scale content.
The SEO Industry Just Went Through This
What is hard to overstate is just how recently the SEO industry watched a near-identical cycle play out. Many SEOs and site owners are still licking their wounds from a brutal round of Google updates and new spam policies that obliterated many sites’ traffic a few years back.
In September 2023, Google launched the Helpful Content Update, the most aggressive crackdown it had done in years against content that, according to its announcement, “feels like it was created for search engines instead of people.”
Roughly six months later, in March 2024, it followed up with the longest core update in Google’s history, which Google states was designed to “reduce unhelpful, unoriginal content in search results by 45%.” Across two consecutive update cycles, Google’s stated target was the same thing: content produced at scale, regardless of whether the production method was human, AI, or a combination of both.
Alongside the March 2024 update, Google formalized a new spam policy called “Scaled Content Abuse,” explicitly naming the practice it was working to suppress: generating many pages to manipulate search rankings, regardless of authorship.
The SEO industry is still working through the collateral damage from those updates, including significant losses for many small publishers, some of whom were publishing original, human-written content but used excessive SEO frameworks that the updates likely flagged. The casualty list also included some publishers who had partnered with ad networks and other emerging tools offering AI content creation and scaling as a service.
Having spent hundreds of hours analyzing and presenting about those two major updates, I can say that the content I am seeing published with many of these new AI tools often looks and feels a lot like the exact type of content that was wiped off the map with these 2023 and 2024 Google updates.
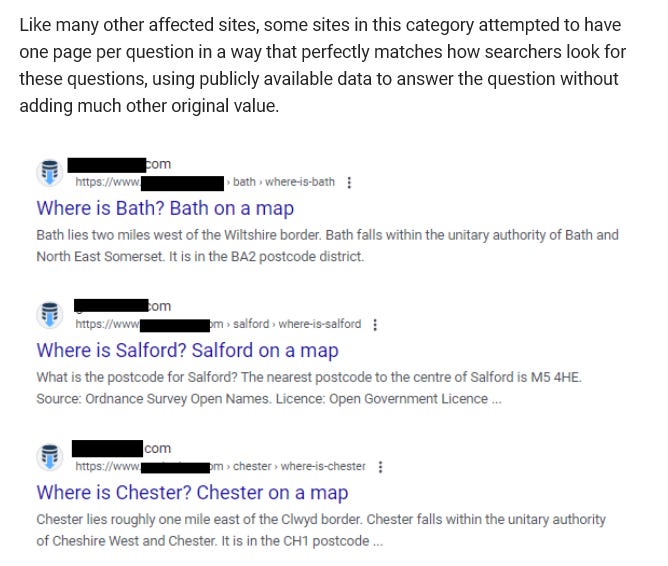
8 Recurring Content Patterns That Are Risky For SEO And AI Search
So, what types of content am I seeing published by companies using AI tools to build articles that I believe are ultimately risky for SEO? I believe the answer lies in page templates that aim to influence SEO rankings, AI search responses, and/or citations in AI search, but are highly formulaic and easily repeatable by competitors.
What starts as a genuine approach to try to build helpful content (and score a mention/citation) ends up being an easily detectable footprint by Google when enough sites are publishing similar pages, and the index becomes flooded with tens or hundreds of thousands of these similar pages, which is easier than ever to do using AI.
This is exactly what Google means when it talks about writing for search engines, not humans.
Reviewing top-traffic URLs across the declining domains, eight distinct content templates appear repeatedly. Most sites seeing declines in the analysis use some combination of at least three or four. The most aggressive ones use all eight. Typically, affected sites also have hundreds or thousands of these articles, which amplifies the problem and generally leads to steeper traffic losses.
1. Comparison Pages At Scale
Pattern: /blog/[product-A]-vs-[product-B] published at scale across most reasonable head-to-head matchups in a category. Observed across the dataset for product-vs-product pairings, framework-vs-framework pairings, and, in at least one case, concept-vs-concept pairings unrelated to the publisher’s actual business.
2. The “What Is X” Glossary
Single-term, single-question pages designed to be cited by AI engines. Pattern: /resources/what-is-[term] or /glossary/[term]. Observed across the dataset, including programmatic glossaries scaled across multiple languages from a single source template. Scaling translations with AI and without human review can also frequently lead to sitewide content quality issues.
3. The “Best [X] For [Y]” Listicle
The most familiar AI-content template, with origins in the affiliate-content era. This pattern was observed across the dataset in both broad-category and narrow-niche variants.
4. The Self-Promotional Listicle
A variant of No. 3 in which the publisher is itself a competitor in the category being ranked, and frequently lists itself as the No. 1 best among competitors. These pages generally lack real evidence that the company genuinely tested all of the competitors in the list, which is recommended by Google for review pages.
I wrote about this “listicle” page template causing SEO/GEO issues in February 2026, when I found that many companies publishing dozens, hundreds, or even thousands of self-promotional listicles saw extreme traffic drops beginning on the same day (approximately Jan. 21, 2026). This pattern was observed across multiple sites in the dataset, most aggressively in B2B services.
5. The Competitor-Vs-Alternatives Page
Pattern: /blog/[competitor-brand]-alternatives, or, in the more programmatic form, dedicated landing pages built for every named competitor in a category. This approach was observed extensively across the dataset, including one case where the majority of a site’s top traffic pages were dedicated to individual competitor brand names.
6. Programmatic Location And Language Scaling
This is one of the oldest tricks in the SEO book, and one that I’ve seen sites get in trouble for with algorithm updates for at least 10 years. The approach: Use one template multiplied across every geography or language a search engine will index, with very little unique content per local landing page.
In many cases, the company publishing these pages often does not have real brick-and-mortar locations in each of the neighborhood/city/state pages they are targeting.
This page type was observed across the dataset including state-by-state content, country-by-country service pages, and the multilingual programmatic glossaries described above.
7. The FAQ Farm
Each page answers exactly one question. Pattern: /faq/[full-question]. Designed for extraction by AI engines: a clear question in the URL, the answer in the first paragraph, bullet points in the body, schema markup at the bottom.
The problem? This approach creates a lot of low-quality content and baggage for the site when implemented at scale. Scaling FAQs was also observed extensively across the dataset, including in industries where the templated tone was a noticeable mismatch with the publisher’s brand context.
Publishing off-topic content, with no apparent connection to the publisher’s actual business, at high volumes, is one of the fastest ways to get in trouble with search engine algorithms. This was also a huge problem during the Helpful Content Update and March 2024 Core Updates, when many sites were experimenting with publishing off-topic content, like funny quotes, jokes, baby names, horoscopes, and other high-volume articles that weren’t actually topically relevant for the publisher.
This method was used across multiple sites in the dataset, including pieces on entertainment topics on a services platform, lists of names and jokes, social-media memes on B2B websites, and historical or biographical content on business-focused sites.
A large B2B company’s blog subfolder hit by the unconfirmed late-January 2026 Google update. (Image Credit: Lily Ray)
Google did not announce or confirm an update by name in January 2026, but at least 40 sites I identified saw a negative trend beginning around Jan. 20, 2026. In many cases, the impact was isolated to the company’s blog or other subfolder containing a lot of new SEO-driven content. My analysis found that some of these companies were scaling dozens, hundreds, or even thousands of these self-promoting listicles, in which they named their own company the No. 1 best when compared to competitors.
I suspect this adjustment on Google’s end was just the start of Google (and likely the LLM providers building on top of search) beginning to demote this type of content in search results, and it appears that the impact was greater than just the listicles themselves. For affected sites, the entire blog or subfolder containing these articles often also saw declines. In other cases, the impact was carried over across the full domain.
How To Use AI Content Tools Safely
I do believe there is a way to use AI content tools safely, and a way for these tools to support the creation of high-quality content. The tools themselves are not the problem, but the implementation can be. I believe these tools should be used and overseen by experienced SEO professionals who understand the landscape of content approaches that Google has grown extremely sophisticated at penalizing and demoting over the past 10+ years. The problem often stems from a “set it and forget it” approach, or when the goal is to scale as many pages as quickly as possible without human review.
Using AI content tools for research, organization, content briefs, pulling in proprietary company data and insights, and more can be invaluable for speeding up the content creation process. But when articles are simply published “for SEO/GEO” without consideration of the risks involved with search engine ranking systems, the well-intentioned content can actually backfire for both SEO and AI search.
To perform well, I recommend that any AI-assisted content should still demonstrate E-E-A-T, add original or unique information above and beyond what is offered by competing pages (information gain), and consider being transparent about the use of AI to create the content (which is recommended by Google).
The Bottom Line
If there is one takeaway from monitoring these 220+ sites over the past several months, it’s that the playbooks being sold as “AI-first SEO” or “GEO-optimized content at scale” look remarkably similar to the playbooks that got sites flattened by the Helpful Content Update and the March 2024 Core Update. The packaging is new, but the pattern is not.
Across the dataset, the brands still growing are generally the ones whose content does not match the eight templates above. Many brands that scaled into those templates are the ones now removing pages, redirecting subfolders, and taking other steps to try to mitigate recent losses in traffic.
If you’re currently evaluating an AI content vendor, or running a program in-house, here are a few practical questions I think are worth asking before publishing another page:
Does this page actually exist because a real customer or reader needs it, or because a search engine or LLM might cite it?
Could a competitor publish a near-identical version of this page tomorrow using the same prompt?
Would I be comfortable if Google, a journalist, or my own customers saw the full list of URLs in this subfolder?
Is the article inherently biased, and if so, is the page transparent with users about those biases?
Is there any first-party data, expertise, or original perspective on this page that isn’t available on the first ten results already ranking for the query?
None of this means AI content tools are unusable. They can be genuinely useful for research, briefs, internal data synthesis, and accelerating workflows where a human expert is still in the loop. The trouble starts when the goal becomes volume, or when the people closest to the content stop reviewing what is going out the door.
The SEO industry has already lived through this cycle once in the last few years. The sites that came out of it best were the ones that prioritized quality, originality, and topical focus over scale. I expect the same to be true of this cycle, and I’ll keep tracking the data as it plays out.
Do you know who your audience is and what they want?
Over the last 20 years or so, we used to rely almost purely on data to answer that question. But as cookie tracking and user signals declined and analytics shifted toward sampling (what we refer to as the “signal-loss era”), we’ve lost some of that superpower. On top of this, we’ve handed over control to hyper-personalized platforms with “black box” targeting algorithms to find our audiences, leaving us less able to truly understand what is going on. And in doing so, we have lost track of the user.
In a way, the abundance of data made us complacent: “Data-informed” became the standard, while “user-informed” strategies progressively faded.
The problem with that over-reliance on data is that it made it “okay” to forget we are fundamentally communicating with humans and creating connections. We focused on the outcome and lost the drive to know who we’re connecting with and what leads us to acquire certain users or lose some.
And while signal loss and AI targeting might be perceived as a constraint, in reality, it is actually a great opportunity to go back to basics of marketing. It means we can focus on really understanding the user as a person, and not as trace fragments of data they leave in our web analytics.
Ultimately, getting to know them means we can serve them better – and find stronger, long-lasting ways to connect.
The Opportunity: Understanding Users And How We Reach Them
Even if we still had the data we had before, would it even be enough? I don’t think so, because it assumes user behavior is limited to what we can observe. In reality, behavior is shaped by a series of small, automatic decisions that happen below the surface, often driving outcomes before any action is even initiated – let alone tracked.
On top of this, when we talk about “understanding the user,” this is often reduced to understanding their needs and a rough demographic, but that’s only part of the picture. Users are people, with unique needs and patterns of thoughts at every stage of their consideration journey.
Now more than ever, we need to truly know who we are talking to and interacting with. What makes them favor us over a competitor? What media and channels are they using so we can reach them? What emotional triggers are really relevant to them? What is important to them at every stage of the journey? Only after answering these questions can we claim to have at least scratched the surface.
I’ve said before that human decision-making is inherently imperfect, shaped by cognitive biases and heuristics that help us navigate complexity without analyzing every option in detail. And that’s the reason why knowing what they want is often not enough to get the full picture – you need to know how they make decisions too.
When we fully understand the user, we can shape our approach ahead of outcomes, inform testing and platform targeting, and even anticipate results before execution.
A Practical Alternative To Cookie-Based Strategies: The R.E.M. Framework
To make sure you can reach the right audience, even when data is scarce and tracking unreliable, you should work with three simple things to aim for: Being Relevant, Everywhere, and Memorable in your strategy, from creatives, messaging, and channel choices.
This is what I call the R.E.M. Framework.
Image by author, April 2026
1. Be Relevant (And Relatable)
Relevancy is the first gateway to attention. In a world saturated with competing stimuli, it’s one of the primary filters the brain uses to decide what deserves focus.
Think about it: You might be having a great conversation with a friend in a group full of other people talking, and pay attention only to what they say. And yet, if your name is mentioned by someone else in a conversation you are not listening to, it’s very likely that you will automatically start paying attention to that instead.
This is what is commonly referred to as “the cocktail party effect,” a great example of how stimuli that are relevant to our personal experience, context, and goals can automatically capture our attention even when we are engaged in another task – something that happens consistently on social media, for example.
Today, we often refer to attention as “marketing’s primary currency,” and for a good reason. In a market so saturated, we only have a few seconds to pique our users’ interest before they move on to the next thing. And any content that won’t result in early engagement is likely to be dropped by the algorithm, which won’t serve it to other users as deemed not a good fit for our audience.
This is known by the industry as “the three-second rule,” and might in fact even be optimistic for newer platforms where short-form video prevails, like TikTok videos and Instagram reels. Short-form videos tend to make people forget what they came to the platform for in the first place much faster than long-form videos, and it’s exceptionally easy to lose a viewer on these formats if the hook isn’t instantly strong enough.
But in order to understand how to capture interest early, we need to take a step back and understand how attention works.
As humans, we are consistently exposed to a lot of stimuli at the same time, and we don’t have the cognitive resources to process each one of them, so we select some of them for further processing while ignoring others. We do so via a process called “selective attention” that can be driven by internal motivations (“endogenous orienting”) or external drivers (“exogenous orienting”). In other words, we tend to allocate attention based on our own goals (for example, when we have a deadline and we need to focus on a deliverable) or on the perceptual features of the objects around us (for example, the sound of the phone ringing or a stand-out word in a sentence).
That means that we have two ways to engage someone’s attention: by connecting with their goals, or presenting them with something that stands out in a sea of other similar things.
We can argue that relevancy sits in between these processes and can engage them both. As a matter of fact, when we are researching something, we are already deciding to filter out all the results that seem relevant to our own goal. But it works the other way too: Something relevant to our needs, goals, and context will jump out when we are doomscrolling on socials, even when we are not engaged in a search.
So relevancy is a sort of “catch-all” for attention.
How do you make sure you are immediately relevant?
By identifying what your audience needs, and leading with the solution in the hook. Don’t waste time with obscure messaging or secondary angles that you can elaborate on once you’ve anchored attention.
Strong tests and creatives are the ones that don’t focus on the business, but focus on the user and what they are trying to solve instead. And hyper-personalized platforms make this even more layered. Make the audience see themselves in what you offer, and you’ll shorten the time it takes for them to recognize you as the right choice.
2. Be Everywhere (Your Audience Is)
But can you be relevant to everyone? Of course not. So it’s imperative you understand your audience and their motivations to capture existing demand. And beyond that, you need to be present where they can find you, with the message they’re looking for in that moment.
This is one of the main challenges, now that journeys are so scattered across different platforms and search experiences. There are so many channels people discover us by, that it’s virtually impossible to track where certain journeys even start from. We might get a user from an LLM query, or a social post, or a Google search. Most likely, it’s all of them. A consideration journey is not linear, and it’s in fact the result of a continuous loop of discovery and evaluation, something we know now as “The Messy Middle.” Even the best attribution models rarely capture this.
The “Messy Middle” from Google’s 2020 consumer behavior report. (Screenshot by author, April 2026)
So, the solution is to work cross-functionally to cast a wide net across different channels, because visibility builds trust. “Out of sight, out of mind”: Our brain forms associations that strengthen with repeated exposure, and drops whatever is not used. If you’re consistently present where your audience is, with relevant content, you create the perception that you are indeed everywhere – without actually having to be.
And that matters, because repeated exposure is part of how we cast a choice in a sea of options. We call this “availability heuristic,” a decision-making shortcut that makes us favor what comes to mind easily: what we’ve seen often, recently, or remember clearly. Think about recommending a movie. You’re far more likely to mention something you’ve just watched, or keep seeing suggested, than something from years ago.
So, while relevance gets you noticed, presence keeps you top of mind. That means that when someone is ready to act, you’re already part of the consideration set, often before they even start a search.
Of course, going omnichannel is a beast in itself. Creatives and messages in one platform won’t work on another – you still need to test and iterate – but if you do it from a customer lens, your work is much simpler, and the benefits are two-fold: You can target different moments in the journey and stay top of mind.
But how do you prioritize channels when resources are limited?
You can rely on demographic research, personas, and early discovery data to establish a rough baseline, although that only gets you so far. Mapping who they are doesn’t tell you what they do when they make a choice, and how those behaviors shift across the journey. That’s the piece you have to find out for yourself: How do they make decisions? Who do they rely on for information, and where do they go to find it? And just as importantly, where are they when they’re not actively looking, and how can you meet them there?
And this is where personas fall short. They might tell you what people need and who they are, but not how they feel when making a decision. Often, what gets labeled as a bad strategy is simply incomplete research.
To really understand your audience, you need all of this information, which brings us to the next part.
3. Be Memorable
Being memorable is the one variable that still carries the most weight – yet is the hardest one to achieve. Why? Because it relies on creating a meaningful connection with the audience. And what that connection looks like can vary a lot across different individuals.
The general playbook to produce an emotion in marketing has often relied on the assumption that we share the same set of basic reactions, something that is based on Paul Ekman’s studies isolating fear, anger, happiness, surprise, disgust, and sadness as the “six basic emotions.”
And while it is true that some of these can be shared, the reality of the human emotional experience is much more nuanced and is often modulated by personal context, expectation, cultural values, and much more.
While attention works similarly across different individuals, memorability relies on personal context, values, and experiences. Think about an ad that stayed with you. What was the reason why you remember it so well? Chances are, it is because of the way it made you feel. Another reader of this article will have chosen a completely different ad.
Some brands, messages, or creatives stay with us because they elicit an emotional reaction. They make us laugh, they trigger nostalgia, sometimes they outrage us. But they all make us feel a certain way. And even when we choose employing rules of thumb like going for what we already know (“familiarity bias”) or what our peers suggest (“social proof”), it’s often because these are choices that are validated and make us feel safe.
We often hear that people make decisions emotionally, then they justify them rationally. This idea is reflected in early theories like Damasio’s “Somatic Marker Hypothesis,” which proposes that emotional signals influence decision-making, and is supported by neurophysiological evidence showing that physiological arousal varies between liked and disliked brands, pointing to the involvement of emotional processes in brand evaluation.
Electrodermal activity to liked versus disliked brands. Disliked brands elicited significantly higher physiological arousal than liked brands, illustrating that emotional intensity can vary independently of stated preference (Walla et al., 2011).
And that’s important, because the way we feel about a brand determines not only our perceptions but it’s pervasive of the entire experience with them, including trust and willingness to engage with their messaging and offer. We remember experiences for how they made us feel; we connect with some brands and ethos, and we disconnect wildly from some. Once you gain that memorability with your audience, you have an easier time retaining it – as well as guiding them to choose you.
What does this mean for you? Get acquainted not only with what your user needs or what is most likely to catch their eye, but with their personal and cultural context, how they feel, and what their expectations and values are – because these are all aspects that influence the relationship between brand and consumer. A genuine connection will make the user bypass any intermediate evaluation, and make you stand out from competitors, looping us back to our R – the relevancy you aim for in the first step of this framework.
Takeaways
Catching attention isn’t the only metric of success in the signal loss and hyper-personalization era. You need to be everywhere, and to stay top of mind when your audience is looking for the solution you can offer. So it’s imperative you know your users, their motivations, and their emotional states to capture existing demand and connect with them, wherever they are.
Easy, right?
Not really, but here are some starting points:
Find what your audience needs by collating data that goes beyond search, and takes into account customer service logs, user interviews, and social scraping (both for your brands and your competitors), so that you can capture both the pre-purchase and post-purchase journeys. Use that data to inform your USP and messaging in your test and creatives. Make it all about them, not you.
Don’t take channels for granted, or ignore them just because they’re not useful to your immediate key performance indicators (KPIs). Visibility is often the result of compound actions and cross-functional collaboration. Map out your discoverability across different channels, content formats, and ways to consume content, so that you can target different moments in your audience’s journey. Let this be your guiding light when you pick your battles.
Get to know your audience at a granular level: What do they feel when they search? What are their values? What are their expectations? If they know us, how do they feel about us? Use those emotional drivers to understand what creatives, messaging, and format might be best to use as a gateway to create a meaningful connection.
In summary, start with finding your audience, learn how they decide and understand their underlying needs; all of this will inform your unique selling proposition (USP) and product value proposition, your messaging and creatives, as well as your distribution channels and the choice of formats.
It’s time we go beyond personas and start looking at the real people behind the screen.