Google’s Sundar Pichai recently said that the future of Search is agentic, but what does that really mean? A recent tweet from Google’s search product lead shows what the new kind of task-based search looks like. It’s increasingly apparent that the internet is transitioning to a model where every person has their own agent running tasks on their behalf, experiencing an increasingly personal internet.
Search Is Becoming Task-Oriented
The internet, with search as the gateway to it, is a model where websites are indexed, ranked, and served to users who basically use the exact same queries to retrieve virtually the same sets of web pages. AI is starting to break that model because users are transitioning to researching topics, where a link to a website does not provide the clear answers users are gradually becoming conditioned to ask for. The internet was built to serve websites that users could go to and read stuff and to connect with others via social media.
What’s changing is that now people can use that same search box to do things, exactly as Pichai described. For example, Google recently announced the worldwide rollout of the ability to describe the needs for a restaurant reservation, and AI agents go out and fetch the information, including booking information.
“Date nights and big group dinners just got a lot easier.
We’re thrilled to expand agentic restaurant booking in Search globally, including the UK and India!
Tell AI Mode your group size, time, and vibe—it scans multiple platforms simultaneously to find real-time, bookable spots.
No more app-switching. No more hassle. Just great food.”
That’s not search, that’s task completion. What was not stated is that restaurants will need to be able to interact with these agents, to provide information like available reservation slots, menu choices that evening, and at some point those websites will need to be able to book a reservation with the AI agent. This is not something that’s coming in the near future, it’s here right now.
“I feel like in search, with every shift, you’re able to do more with it.
…If I fast forward, a lot of what are just information seeking queries will be agentic search. You will be completing tasks, you have many threads running.”
When asked if search will still be around in ten years, Pichai answered:
“Search would be an agent manager, right, in which you’re doing a lot of things.
…And I can see search doing versions of those things, and you’re getting a bunch of stuff done.”
Everyone Has Their Own Personal Internet
Cloudflare recently published an article that says the internet was the first way for humans to interact with online content, and that cloud infrastructure was the second adaptation that emerged to serve the needs of mobile devices. The next adaptation is wild and has implications for SEO because it introduces a hyper-personalized version of the web that impacts local SEO, shopping, and information retrieval.
AI agents are currently forced to use an internet infrastructure that’s built to serve humans. That’s the part that Cloudflare says is changing. But the more profound insight is that the old way, where millions of people asked the same question and got the same indexed answer, is going away. What’s replacing it is a hyper-personal experience of the web, where every person can run their own agent.
“Unlike every application that came before them, agents are one-to-one. Each agent is a unique instance. Serving one user, running one task. Where a traditional application follows the same execution path regardless of who’s using it, an agent requires its own execution environment: one where the LLM dictates the code path, calls tools dynamically, adjusts its approach, and persists until the task is done.
Think of it as the difference between a restaurant and a personal chef. A restaurant has a menu — a fixed set of options — and a kitchen optimized to churn them out at volume. That’s most applications today. An agent is more like a personal chef who asks: what do you want to eat? They might need entirely different ingredients, utensils, or techniques each time. You can’t run a personal-chef service out of the same kitchen setup you’d use for a restaurant.”
Cloudflare’s angle is that they are providing the infrastructure to support the needs of billions of agents representing billions of humans. But that is not the part that concerns SEO. The part that concerns digital marketing is that the moment when search transforms into an “agent manager” is here, right now.
WordPress 7.0
Content management systems are rapidly adapting to this change. It’s very difficult to overstate the importance of the soon-to-be-released WordPress 7.0, as it is jam-packed with the capability to connect to AI systems that will enable the internet transition from a human-centered web to an increasingly agentic-centered web.
The current internet is built for human interaction. Agents are operating within that structure, but that’s going to change very fast. The search marketing community really needs to wrap its collective mind around this change and to really understand how content management systems fit into that picture.
What Sources Do The Agents Trust?
Search marketing professional Mike Stewart recently posted on Facebook about this change, reflecting on what it means to him.
“I let Claude take over my computer. Not metaphorically — it moved my mouse, opened apps, and completed tasks on its own. That’s when something clicked… This isn’t just AI assisting anymore. This is AI operating on your behalf.
Google’s CEO is already talking about “agentic search” — where AI doesn’t just return results, it manages the process. So the real questions become: 👉 Who controls the journey? 👉 What sources does the agent trust? 👉 Where does your business show up in that decision layer? Because you don’t get “agentic search” without the ecosystem feeding it — websites, content, businesses.
That part isn’t going away. But it is being abstracted.”
Task-Based Agentic Search
I think the part that I guess we need to wrap our heads around is that humans are still making the decision to click the “make the reservation” button, and at some point, at least at the B2B layer, making purchases will increasingly become automated.
I still have my doubts about the complete automation of shopping. It feels unnatural, but it’s easy to see that the day may rapidly be approaching when, instead of writing a shopping list, a person will just tell an AI agent to talk to the local grocery store AI agent to identify which one has the items in stock at the best price, dump it into a shopping cart, and show it to the human, who then approves it.
The big takeaway is that the web may be transitioning to the “everyone has a personal chef” model, and that’s a potentially scary level of personalization. How does an SEO optimize for that? I think that’s where WordPress 7.0 comes in, as well as any other content management systems that are agentic-web ready.
Ask ChatGPT or Claude to recommend a product in your market. If your brand does not appear, you have a problem that no amount of keyword optimization will fix.
Most SEO professionals, when faced with this, immediately think about content. More pages, more keywords, better on-page signals. But the reason your brand is absent from an AI recommendation may have nothing to do with pages or keywords. It has to do with something called relational knowledge, and a 2019 research paper that most marketers have never heard of.
The Paper Most Marketers Missed
In September 2019, Fabio Petroni and colleagues at Facebook AI Research and University College London published “Language Models as Knowledge Bases?” at EMNLP, one of the top conferences in natural language processing.
Their question was straightforward: Does a pretrained language model like BERT actually store factual knowledge in its weights? Not linguistic patterns or grammar rules, but facts about the world. Things like “Dante was born in Florence” or “iPod Touch is produced by Apple.”
To test this, they built a probe called LAMA (LAnguage Model Analysis). They took known facts, thousands of them drawn from Wikidata, ConceptNet, and SQuAD, and converted each one into a fill-in-the-blank statement. “Dante was born in ___.” Then they asked BERT to predict the missing word.
BERT, without any fine-tuning, recalled factual knowledge at a level competitive with a purpose-built knowledge base. That knowledge base had been constructed using a supervised relation extraction system with an oracle-based entity linker, meaning it had direct access to the sentences containing the answers. A language model that had simply read a lot of text performed nearly as well.
The model was not searching for answers. It had absorbed associations between entities and concepts during training, and those associations were retrievable. BERT had built an internal map of how things in the world relate to each other.
After this, the research community started taking seriously the idea that language models work as knowledge stores, not merely as pattern-matching engines.
What “Relational Knowledge” Means
Petroni tested what he and others called relational knowledge: facts expressed as a triple of subject, relation, and object. For example: (Dante, [born-in], Florence). (Kenya, [diplomatic-relations-with], Uganda). (iPod Touch, [produced-by], Apple).
What makes this interesting for brand visibility (and AIO) is that Petroni’s team discovered that the model’s ability to recall a fact depends heavily on the structural type of the relationship. They identified three types, and the accuracy differences between them were large.
1-To-1 Relations: One Subject, One Object
These are unambiguous facts. “The capital of Japan is ___.” There is one answer: Tokyo. Every time the model encountered Japan and capital in the training data, the same object appeared. The association built up cleanly over repeated exposure.
BERT got these right 74.5% of the time, which is high for a model that was never explicitly trained to answer factual questions.
N-To-1 Relations: Many Subjects, One Object
Here, many different subjects share the same object. “The official language of Mauritius is ___.” The answer is English, but English is also the answer for dozens of other countries. The model has seen the pattern (country → official language → English) many times, so it knows the shape of the answer well. But it sometimes defaults to the most statistically common object rather than the correct one for that specific subject.
Accuracy dropped to around 34%. The model knows the category but gets confused within it.
N-To-M Relations: Many Subjects, Many Objects
This is where things get messy. “Patrick Oboya plays in position ___.” A single footballer might play midfielder, forward, or winger depending on context. And many different footballers share each of those positions. The mapping is loose in both directions.
BERT’s accuracy here was only about 24%. The model typically predicts something of the correct type (it will say a position, not a city), but it cannot commit to a specific answer because the training data contains too many competing signals.
I find this super useful because it maps directly onto what happens when an AI tries to recommend a brand. Brands (without monopolies) operate in a “many-to-many” relationship. So “Recommend a [Brand] with a [feature]” is one of the hardest things for AI to “predict” with consistency. I will come back to that…
What Has Happened Since 2019
Petroni’s paper established that language models store relational knowledge. The obvious next question was: where, exactly?
In 2022, Damai Dai and colleagues at Microsoft Research published “Knowledge Neurons in Pretrained Transformers” at ACL. They introduced a method to locate specific neurons in BERT’s feed-forward layers that are responsible for expressing specific facts. When they activated these “knowledge neurons,” the model’s probability of producing the correct fact increased by an average of 31%. When they suppressed them, it dropped by 29%.
OMG! This is not a metaphor. Factual associations are encoded in identifiable neurons within the model. You can find them, and you can change them.
Later that year, Kevin Meng and colleagues at MIT published “Locating and Editing Factual Associations in GPT” at NeurIPS. This took the same ideas and applied them to GPT-style models, which is the architecture behind ChatGPT, Claude, and the AI assistants that buyers actually use when they ask for recommendations. Meng’s team found they could pinpoint the specific components inside GPT that activate when the model recalls a fact about a subject.
More importantly, they could change those facts. They could edit what the model “believes” about an entity without retraining the whole system.
That finding matters for SEOs. If the associations inside these models were fixed and permanent, there would be nothing to optimize for. But they are not fixed. They are shaped by what the model absorbed during training, and they shift when the model is retrained on new data. The web content, the technical documentation, the community discussions, the analyst reports that exist when the next training run happens will determine which brands the model associates with which topics.
So, the progress from 2019 to 2022 looks like this. Petroni showed that models store relational knowledge. Dai showed where it is stored. Meng showed it can be changed. That last point is the one that should matter most to anyone trying to influence how AI recommends brands.
What This Means For Brands In AI Search
Let me translate Petroni’s three relation types into brand positioning scenarios.
The 1-To-1 Brand: Tight Association
Think of Stripe and online payments. The association is specific and consistently reinforced across the web. Developer documentation, fintech discussions, startup advice columns, integration guides: They all connect Stripe to the same concept. When someone asks an AI, “What is the best payment processing platform for developers?” the model retrieves Stripe with high confidence, because the relational link is unambiguous.
This is Petroni’s 1-to-1 dynamic. Strong signal, no competing noise.
The N-To-1 Brand: Lost In The Category
Now consider being one of 15 cybersecurity vendors associated with “endpoint protection.” The model knows the category well. It has seen thousands of discussions about endpoint protection. But when asked to recommend a specific vendor, it defaults to whichever brand has the strongest association signal. Usually, that is the one most discussed in authoritative contexts: analyst reports, technical forums, standards documentation.
If your brand is present in the conversation but not differentiated, you are in an N-to-1 situation. The model might mention you occasionally, but it will tend to retrieve the brand with the strongest association instead.
The N-To-M Brand: Everywhere And Nowhere
This is the hardest position. A large enterprise software company operating across cloud infrastructure, consulting, databases, and hardware has associations with many topics, but each of those topics is also associated with many competitors. The associations are loose in both directions.
The result is what Petroni observed with N-to-M relations: The model produces something of the correct type but cannot commit to a specific answer. The brand appears occasionally in AI recommendations but never reliably for any specific query.
I see this pattern frequently when working with enterprise brands. They have invested heavily in content across many topics, but have not built the kind of concentrated, reinforced associations that the model needs to retrieve them with confidence for any single one.
Measuring The Gap
If you accept the premise, and the research supports it, that AI recommendations are driven by relational associations stored in the model’s weights, then the practical question is: Can you measure where your brand sits in that landscape?
AI Share of Voice is the metric most teams start with. It tells you how often your brand appears in AI-generated responses. That is useful, but it is a score without a diagnosis. Knowing your Share of Voice is 8% does not tell you why it is 8%, or which specific topics are keeping you out of the recommendations where you should appear.
Two brands can have identical Share of Voice scores for completely different structural reasons. One might be broadly associated with many topics but weakly on each. Another might be deeply associated with two topics but invisible everywhere else. These are different problems requiring different strategies.
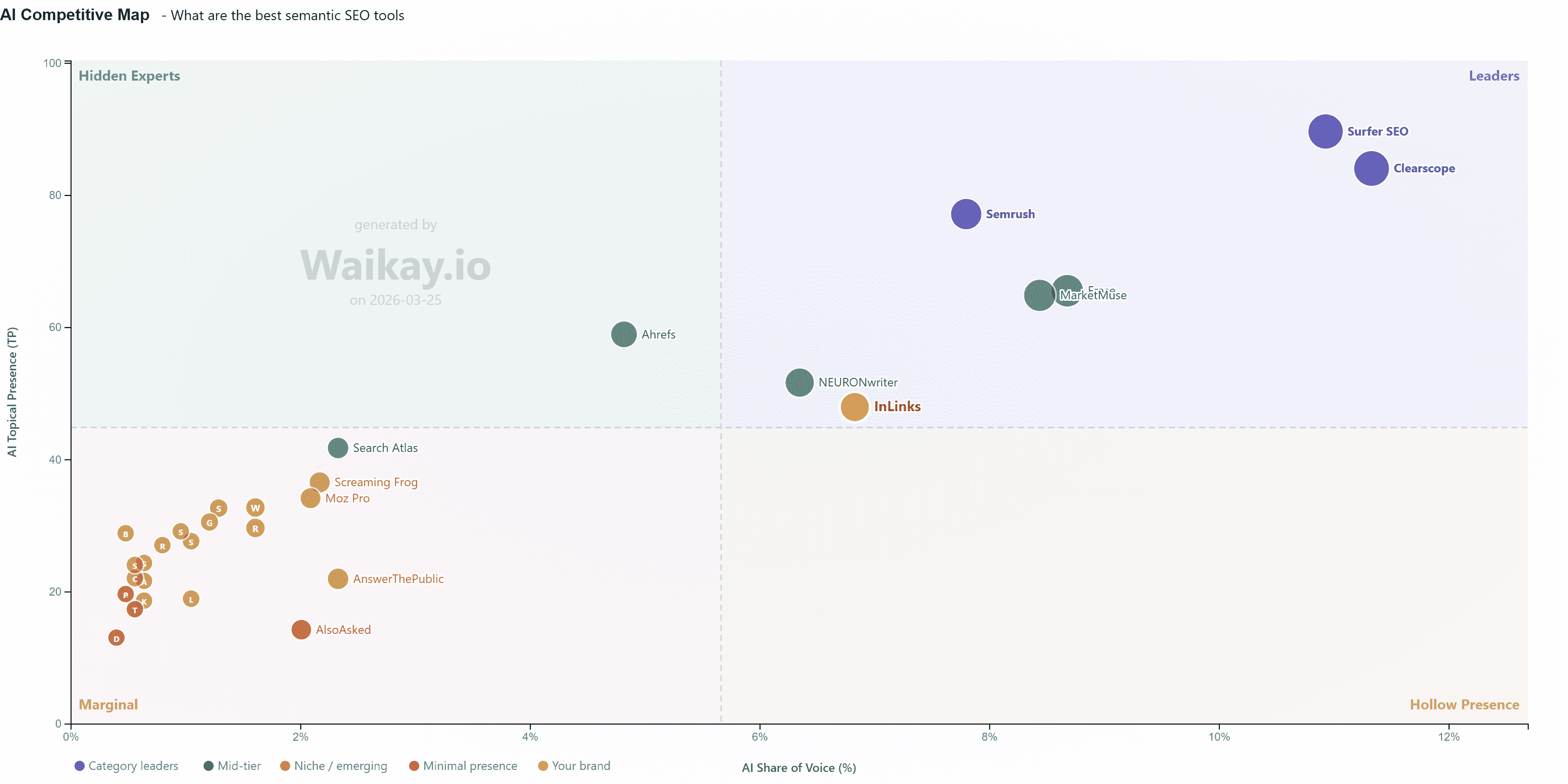
This is the gap that a metric called AI Topical Presence, developed by Waikay, is designed to address. Rather than measuring whether you appear, it measures what the AI associates you with, and what it does not. [Disclosure: I am the CEO of Waikay]
Topical Presence is as important as Share of Voice (Image from author, March 2026)
The metric captures three dimensions. Depth measures how strongly the AI connects your brand to relevant topics, weighted by importance. Breadth measures how many of the core commercial topics in your market the AI associates with your brand. Concentration measures how evenly those associations are distributed, using a Herfindahl-Hirschman Index borrowed from competition economics.
A brand with high depth but low breadth is known well for a few things but invisible for many others. A brand with wide coverage but high concentration is fragile: One model update could change its visibility significantly. The component breakdown tells you which problem you have and which lever to pull.
In the chart above, we start to see how different brands are really competing with each other in a way we have not been able to see before. For example, Inlinks is competing much more closely with a product called Neuronwriter than previously understood. Neuronwriter has less share of voice (I probably helped them by writing this article… oops!), but they have a better topical presence around the prompt, “What are the best semantic SEO tools?” So all things being equal, a bit of marketing is all they need to take Inlinks. This, of course, assumes that Inlinks stands still. It won’t. By contrast, the threat of Ahrefs is ever-present, but by being a full-service offering, they have to spread their “share of voice” across all of their product offerings. So while their topical presence is high, the brand is not the natural choice for an LLM to choose for this prompt.
This connects back to Petroni’s framework. If your brand is in a 1-to-1 position for some topics but absent from others, topical presence shows you where the gaps are. If you are in an N-to-1 or N-to-M situation, it helps you identify which associations need strengthening and which topics competitors have already built dominant positions on.
From Ranking Pages To Building Associations
For 25 years, SEO has been about ranking pages. PageRank itself was a page-level algorithm; the clue was always in the name (IYKYK … No need to correct me…). Even as Google moved towards entities and knowledge graphs, the practical work of SEO remained rooted in keywords, links, and on-page optimization.
AI visibility requires something different. The models that generate brand recommendations are retrieving associations built during training, formed from patterns of co-occurrence across many contexts. A brand that publishes 500 blog posts about “zero trust” will not build the same association strength as a brand that appears in NIST documentation, peer discussions, analyst reports, and technical integrations.
This is fantastic news for brands that do good work in their markets. Content volume alone does not create strong relational associations. The model’s training process works as a quality filter: It learns from patterns across the entire corpus, not from any single page. A brand with real expertise, discussed across many contexts by many voices, will build stronger associations than a brand that simply publishes more.
The question to ask is not “Do we have a page about this topic?” It is: “If someone read everything the AI has absorbed about this topic, would our brand come across as a credible participant in the conversation?”
That is a harder question. But the research that began with Petroni’s fill-in-the-blank tests in 2019 has given us enough understanding of the mechanism to measure it. And what you can measure, you can improve.
Every major AI platform can now browse websites autonomously. Chrome’s auto browse scrolls and clicks. ChatGPT Atlas fills forms and completes purchases. Perplexity Comet researches across tabs. But none of these agents sees your website the way a human does.
This is Part 4 in a five-part series on optimizing websites for the agentic web. Part 1 covered the evolution from SEO to AAIO. Part 2 explained how to get your content cited in AI responses. Part 3 mapped the protocols forming the infrastructure layer. This article gets technical: how AI agents actually perceive your website, and what to build for them.
The core insight is one that keeps coming up in my research: The most impactful thing you can do for AI agent compatibility is the same work web accessibility advocates have been pushing for decades. The accessibility tree, originally built for screen readers, is becoming the primary interface between AI agents and your website.
According to the 2025 Imperva Bad Bot Report (Imperva is a cybersecurity company), automated traffic surpassed human traffic for the first time in 2024, constituting 51% of all web interactions. Not all of that is agentic browsing, but the direction is clear: the non-human audience for your website is already larger than the human one, and it’s growing. Throughout this article, we draw exclusively from official documentation, peer-reviewed research, and announcements from the companies building this infrastructure.
Three Ways Agents See Your Website
When a human visits your website, they see colors, layout, images, and typography. When an AI agent visits, it sees something entirely different. Understanding what agents actually perceive is the foundation for building websites that work for them.
The major AI platforms use three distinct approaches, and the differences have direct implications for how you should structure your website.
Vision: Reading Screenshots
Anthropic’s Computer Use takes the most literal approach. Claude captures screenshots of the browser, analyzes the visual content, and decides what to click or type based on what it “sees.” It’s a continuous feedback loop: screenshot, reason, act, screenshot. The agent operates at the pixel level, identifying buttons by their visual appearance and reading text from the rendered image.
Google’s Project Mariner follows a similar pattern with what Google describes as an “observe-plan-act” loop: observe captures visual elements and underlying code structures, plan formulates action sequences, and act simulates user interactions. Mariner achieved an 83.5% success rate on the WebVoyager benchmark.
The vision approach works, but it’s computationally expensive, sensitive to layout changes, and limited by what’s visually rendered on screen.
ChatGPT Atlas uses ARIA tags, the same labels and roles that support screen readers, to interpret page structure and interactive elements.
Atlas is built on Chromium, but rather than analyzing rendered pixels, it queries the accessibility tree for elements with specific roles (“button”, “link”) and accessible names. This is the same data structure that screen readers like VoiceOver and NVDA use to help people with visual disabilities navigate the web.
Microsoft’s Playwright MCP, the official MCP server for browser automation, takes the same approach. It provides accessibility snapshots rather than screenshots, giving AI models a structured representation of the page. Microsoft deliberately chose accessibility data over visual rendering for their browser automation standard.
Hybrid: Both At Once
In practice, the most capable agents combine approaches. OpenAI’s Computer-Using Agent (CUA), which powers both Operator and Atlas, layers screenshot analysis with DOM processing and accessibility tree parsing. It prioritizes ARIA labels and roles, falling back to text content and structural selectors when accessibility data isn’t available.
Perplexity’s research confirms the same pattern. Their BrowseSafe paper, which details the safety infrastructure behind Comet’s browser agent, describes using “hybrid context management combining accessibility tree snapshots with selective vision.”
Platform
Primary Approach
Details
Anthropic Computer Use
Vision (screenshots)
Screenshot, reason, act feedback loop
Google Project Mariner
Vision + code structure
Observe-plan-act with visual and structural data
OpenAI Atlas
Accessibility tree
Explicitly uses ARIA tags and roles
OpenAI CUA
Hybrid
Screenshots + DOM + accessibility tree
Microsoft Playwright MCP
Accessibility tree
Accessibility snapshots, no screenshots
Perplexity Comet
Hybrid
Accessibility tree + selective vision
The pattern is clear. Even platforms that started with vision-first approaches are incorporating accessibility data. And the platforms optimizing for reliability and efficiency (Atlas, Playwright MCP) lead with the accessibility tree.
Your website’s accessibility tree isn’t a compliance artifact. It’s increasingly the primary interface agents use to understand and interact with your website.
Last year, before the European Accessibility Act took effect, I half-joked that it would be ironic if the thing that finally got people to care about accessibility was AI agents, not the people accessibility was designed for. That’s no longer a joke.
The Accessibility Tree Is Your Agent Interface
The accessibility tree is a simplified representation of your page’s DOM that browsers generate for assistive technologies. Where the full DOM contains every div, span, style, and script, the accessibility tree strips away the noise and exposes only what matters: interactive elements, their roles, their names, and their states.
This is why it works so well for agents. A typical page’s DOM might contain thousands of nodes. The accessibility tree reduces that to the elements a user (or agent) can actually interact with: buttons, links, form fields, headings, landmarks. For AI models that process web pages within a limited context window, that reduction is significant.
Follow WAI-ARIA best practices by adding descriptive roles, labels, and states to interactive elements like buttons, menus, and forms. This helps ChatGPT recognize what each element does and interact with your site more accurately.
And:
Making your website more accessible helps ChatGPT Agent in Atlas understand it better.
Research data backs this up. The most rigorous data on this comes from a UC Berkeley and University of Michigan study published for CHI 2026, the premier academic conference on human-computer interaction. The researchers tested Claude Sonnet 4.5 on 60 real-world web tasks under different accessibility conditions, collecting 40.4 hours of interaction data across 158,325 events. The results were striking:
Condition
Task Success Rate
Avg. Completion Time
Standard (default)
78.33%
324.87 seconds
Keyboard-only
41.67%
650.91 seconds
Magnified viewport
28.33%
1,072.20 seconds
Under standard conditions, the agent succeeded nearly 80% of the time. Restrict it to keyboard-only interaction (simulating how screen reader users navigate) and success drops to 42%, taking twice as long. Restrict the viewport (simulating magnification tools), and success drops to 28%, taking over three times as long.
The paper identifies three categories of gaps:
Perception gaps: agents can’t reliably access screen reader announcements or ARIA state changes that would tell them what happened after an action.
Cognitive gaps: agents struggle to track task state across multiple steps.
Action gaps: agents underutilize keyboard shortcuts and fail at interactions like drag-and-drop.
The implication is direct. Websites that present a rich, well-labeled accessibility tree give agents the information they need to succeed. Websites that rely on visual cues, hover states, or complex JavaScript interactions without accessible alternatives create the conditions for agent failure.
Perplexity’s search API architecture paper from September 2025 reinforces this from the content side. Their indexing system prioritizes content that is “high quality in both substance and form, with information captured in a manner that preserves the original content structure and layout.” Websites “heavy on well-structured data in list or table form” benefit from “more formulaic parsing and extraction rules.” Structure isn’t just helpful. It’s what makes reliable parsing possible.
Semantic HTML: The Agent Foundation
The accessibility tree is built from your HTML. Use semantic elements, and the browser generates a useful accessibility tree automatically. Skip them, and the tree is sparse or misleading.
This isn’t new advice. Web standards advocates have been screaming “use semantic HTML” for two decades. Not everyone listened. What’s new is that the audience has expanded. It used to be about screen readers and a relatively small percentage of users. Now it’s about every AI agent that visits your website.
Use native elements. A element automatically appears in the accessibility tree with the role “button” and its text content as the accessible name. A
does not. The agent doesn’t know it’s clickable.
Search flights
Label your forms. Every input needs an associated label. Agents read labels to understand what data a field expects.
The autocomplete attribute deserves attention. It tells agents (and browsers) exactly what type of data a field expects, using standardized values like name, email, tel, street-address, and organization. When an agent fills a form on someone’s behalf, autocomplete attributes make the difference between confident field mapping and guessing.
Establish heading hierarchy. Use h1 through h6 in logical order. Agents use headings to understand page structure and locate specific content sections. Skip levels (jumping from h1 to h4) create confusion about content relationships.
Use landmark regions. HTML5 landmark elements (
, ,
,
,
) tell agents where they are on the page. A
element is unambiguously navigation. A
requires interpretation. Clarity for the win, always.
Flight Search
Microsoft’s Playwright test agents, introduced in October 2025, generate test code that uses accessible selectors by default. When the AI generates a Playwright test, it writes:
const todoInput = page.getByRole('textbox', { name: 'What needs to be done?' });
Not CSS selectors. Not XPath. Accessible roles and names. Microsoft built its AI testing tools to find elements the same way screen readers do, because it’s more reliable.
The final slide of my Conversion Hotel keynote about optimizing websites for AI agents. (Image Credit: Slobodan Manic)
ARIA: Useful, Not Magic
OpenAI recommends ARIA (Accessible Rich Internet Applications), the W3C standard for making dynamic web content accessible. But ARIA is a supplement, not a substitute. Like protein shakes: useful on top of a real diet, counterproductive as a replacement for actual food.
If you can use a native HTML element or attribute with the semantics and behavior you require already built in, instead of re-purposing an element and adding an ARIA role, state or property to make it accessible, then do so.
The fact that the W3C had to make “don’t use ARIA” the first rule of ARIA tells you everything about how often it gets misused.
Adrian Roselli, a recognized web accessibility expert, raised an important concern in his October 2025 analysis of OpenAI’s guidance. He argues that recommending ARIA without sufficient context risks encouraging misuse. Websites that use ARIA are generally less accessible according to WebAIM’s annual survey of the top million websites, because ARIA is often applied incorrectly as a band-aid over poor HTML structure. Roselli warns that OpenAI’s guidance could incentivize practices like keyword-stuffing in aria-label attributes, the same kind of gaming that plagued meta keywords in early SEO.
The right approach is layered:
Start with semantic HTML. Use , , , , and other native elements. These work correctly by default.
Add ARIA when native HTML isn’t enough. Custom components that don’t have HTML equivalents (tab panels, tree views, disclosure widgets) need ARIA roles and states to be understandable.
Use ARIA states for dynamic content. When JavaScript changes the page, ARIA attributes communicate what happened:
Keep aria-label descriptive and honest. Use it to provide context that isn’t visible on screen, like distinguishing between multiple “Delete” buttons on the same page. Don’t stuff it with keywords.
The principle is the same one that applies to good SEO: build for the user first, optimize for the system second. Semantic HTML is building for the user. ARIA is fine-tuning for edge cases where HTML falls short.
The Rendering Question
Browser-based agents like Chrome auto browse, ChatGPT Atlas, and Perplexity Comet run on Chromium. They execute JavaScript. They can render your single-page application.
But not everything that visits your website is a full browser agent.
AI crawlers (PerplexityBot, OAI-SearchBot, ClaudeBot) index your content for retrieval and citation. Many of these crawlers do not execute client-side JavaScript. If your page is a blank
until React hydrates, these crawlers see an empty page. Your content is invisible to the AI search ecosystem.
Part 2 of this series covered the citation side: AI systems select fragments from indexed content. If your content isn’t in the initial HTML, it’s not in the index. If it’s not in the index, it doesn’t get cited. Server-side rendering isn’t just a performance optimization.
It’s a visibility requirement.
Even for full browser agents, JavaScript-heavy websites create friction. Dynamic content that loads after interactions, infinite scroll that never signals completion, and forms that reconstruct themselves after each input all create opportunities for agents to lose track of state. The A11y-CUA research attributed part of agent failure to “cognitive gaps”: agents losing track of what’s happening during complex multi-step interactions. Simpler, more predictable rendering reduces these failures.
Microsoft’s guidance from Part 2 applies here directly: “Don’t hide important answers in tabs or expandable menus: AI systems may not render hidden content, so key details can be skipped.” If information matters, put it in the visible HTML. Don’t require interaction to reveal it.
Practical rendering priorities:
Server-side render or pre-render content pages. If an AI crawler can’t see it, it doesn’t exist in the AI ecosystem.
Avoid blank-shell SPAs for content pages. Frameworks like Next.js (which powers this website), Nuxt, and Astro make SSR straightforward.
Don’t hide critical information behind interactions. Prices, specifications, availability, and key details should be in the initial HTML, not behind accordions or tabs.
Use standard links for navigation. Client-side routing that doesn’t update the URL or uses onClick handlers instead of real links breaks agent navigation.
Testing Your Agent Interface
You wouldn’t ship a website without testing it in a browser. Testing how agents perceive your website is becoming equally important.
Screen reader testing is the best proxy. If VoiceOver (macOS), NVDA (Windows), or TalkBack (Android) can navigate your website successfully, identifying buttons, reading form labels, and following the content structure, agents can likely do the same. Both audiences rely on the same accessibility tree. This isn’t a perfect proxy (agents have capabilities screen readers don’t, and vice versa), but it catches the majority of issues.
Microsoft’s Playwright MCP provides direct accessibility snapshots. If you want to see exactly what an AI agent sees, Playwright MCP generates structured accessibility snapshots of any page. These snapshots strip away visual presentation and show you the roles, names, and states that agents work with. Published as @playwright/mcp on npm, it’s the most direct way to view your website through an agent’s eyes.
The output looks something like this (simplified):
If your critical interactive elements don’t appear in the snapshot, or appear without useful names, agents will struggle with your website.
Browserbase’s Stagehand (v3, released October 2025, and humbly self-described as “the best browser automation framework”) provides another angle. It parses both DOM and accessibility trees, and its self-healing execution adapts to DOM changes in real time. It’s useful for testing whether agents can complete specific workflows on your website, like filling a form or completing a checkout.
The Lynx browser is a low-tech option worth trying. It’s a text-only browser that strips away all visual rendering, showing you roughly what a non-visual agent parses. A trick I picked up from Jes Scholz on the podcast.
A practical testing workflow:
Run VoiceOver or NVDA through your website’s key user flows. Can you complete the core tasks without vision?
Generate Playwright MCP accessibility snapshots of critical pages. Are interactive elements labeled and identifiable?
View your page source. Is the primary content in the HTML, or does it require JavaScript to render?
Load your page in Lynx or disable CSS and check if the content order and hierarchy still make sense. Agents don’t see your layout.
A Checklist For Your Development Team
If you’re sharing this article with your developers (and you should), here’s the prioritized implementation list. Ordered by impact and effort, starting with the changes that affect the most agent interactions for the least work.
High impact, low effort:
Use native HTML elements. for actions, for links, for dropdowns. Replace patterns wherever they exist.
Label every form input. Associate elements with inputs using the for attribute. Add autocomplete attributes with standard values.
Server-side render content pages. Ensure primary content is in the initial HTML response.
High impact, moderate effort:
Implement landmark regions. Wrap content in , , , and elements. Add aria-label when multiple landmarks of the same type exist on the same page.
Fix heading hierarchy. Ensure a single h1, with h2 through h6 in logical order without skipping levels.
Move critical content out of hidden containers. Prices, specifications, and key details should not require clicks or interactions to reveal.
Moderate impact, low effort:
Add ARIA states to dynamic components. Use aria-expanded, aria-controls, and aria-hidden for menus, accordions, and toggles.
Use descriptive link text. “Read the full report” instead of “Click here.” Agents use link text to understand where links lead.
Test with a screen reader. Make it part of your QA process, not a one-time audit.
Key Takeaways
AI agents perceive websites through three approaches: vision, DOM parsing, and the accessibility tree. The industry is converging on the accessibility tree as the most reliable method. OpenAI Atlas, Microsoft Playwright MCP, and Perplexity’s Comet all rely on accessibility data.
Web accessibility is no longer just about compliance. The accessibility tree is the literal interface AI agents use to understand your website. The UC Berkeley/University of Michigan study shows agent success rates drop significantly when accessibility features are constrained.
Semantic HTML is the foundation. Native elements like , , , and automatically create a useful accessibility tree. No framework required. No ARIA needed for the basics.
ARIA is a supplement, not a substitute. Use it for dynamic states and custom components. But start with semantic HTML and add ARIA only where native elements fall short. Misused ARIA makes websites less accessible, not more.
Server-side rendering is an agent visibility requirement. AI crawlers that don’t execute JavaScript can’t see content in blank-shell SPAs. If your content isn’t in the initial HTML, it doesn’t exist in the AI ecosystem.
Screen reader testing is the best proxy for agent compatibility. If VoiceOver or NVDA can navigate your website, agents probably can too. For direct inspection, Playwright MCP accessibility snapshots show exactly what agents see.
The first three parts of this series covered why the shift matters, how to get cited, and what protocols are being built. This article covered the implementation layer. The encouraging news is that these aren’t separate workstreams. Accessible, well-structured websites perform better for humans, rank better in search, get cited more often by AI, and work better for agents. It’s the same work serving four audiences.
And the work builds on itself. The semantic HTML and structured data covered here are exactly what WebMCP builds on for its declarative form approach. The accessibility tree your website exposes today becomes the foundation for the structured tool interfaces of tomorrow.
Up next in Part 5: the commerce layer. How Stripe, Shopify, and OpenAI are building the infrastructure for AI agents to complete purchases, and what it means for your checkout flow.
As SEJ’s Roger Montti reported, Pichai described a version of search where users have “many threads running” and are completing tasks rather than browsing results.
But the interview covered more than that one quote. Throughout the conversation, Pichai laid out a timeline, identified the barriers slowing adoption, described how he already uses an internal agent tool, and confirmed infrastructure constraints that limit how quickly this vision can ship.
Here’s what the rest of the interview reveals for search professionals.
How Pichai’s Language Has Escalated
The “agent manager” line didn’t come out of nowhere. Pichai’s language about search’s future has gotten more specific over the past 18 months.
In December 2024, he told an interviewer that search would “change profoundly in 2025” and that Google would be able to “tackle more complex questions than ever before.”
By October 2025, during Google’s Q3 earnings call, he was calling it an “expansionary moment for Search” and reporting that AI Mode queries had doubled quarter over quarter.
In February 2026, he reported Search revenue hit $63 billion in Q4 2025 with growth accelerating from 10% in Q1 to 17% in Q4, attributing the increase to AI features.
Now, in April, he’s putting a label on it. Not “search will change” or “search is expanding,” but “search as an agent manager” where users complete tasks.
Each time the language has moved from abstract to concrete, from prediction to description.
The 2027 Inflection Point
Collison asked Pichai when a fully agentic business process, like automated financial forecasting with no human in the loop, might happen at Google. Pichai pointed to next year.
“I definitely expect in some of these areas 2027 to be an important inflection point for certain things.”
He added that non-engineering workflows would see changes “pretty profoundly” in 2027, noting that some groups inside Google are already working this way.
“There are some groups within Google who are shifting more profoundly, and so for me a big task is how do you diffuse that to more and more groups, particularly in 2026.”
He also acknowledged that younger, AI-native companies have an advantage in adopting these workflows, while larger organizations like Google face retraining and change management challenges.
The Intelligence Overhang
One of the most useful parts of the interview wasn’t from Pichai. It was Collison’s description of what he called the “intelligence overhang,” the gap between what AI can do today and how much organizations are actually using it.
Collison identified four barriers that slow adoption even when the models are capable. The first is prompting skill. Getting good results from AI takes practice, and most people inside organizations haven’t built that skill yet.
The second is company-specific context. Even a skilled prompter needs to know which internal tools, datasets, and conventions to reference. The third is data access. An agent can’t answer “what’s the status of this deal?” if it can’t reach the CRM or if permissions block it. The fourth is role definition. Job descriptions, team structures, and approval workflows were designed for a world without AI coworkers.
Pichai agreed with this assessment and said Google faces the same challenges internally.
“Identity access controls are like real hard problems and so we are working through those things, but those are the key things which are limiting diffusion to us too.”
He described how Google’s internal agent tool, which he referred to as Antigravity, is already changing how he works as CEO. He said he queries it to get quick reads on product launches.
“Hey, we launched this thing, like what did people think about this? Tell me like the worst five things people are talking about, the best five things people are talking about, and I type that.”
That’s a concrete example of the agent manager concept in action today inside Google. Pichai is using search as a task-completion tool, not a link-returning tool. The gap between that internal experience and what’s available to external users is part of what Google is working to close.
For SEO teams and agencies, the intelligence overhang is worth thinking about on two levels. There’s the overhang in your own organization, where AI tools could be doing more than they currently are. And there’s the overhang on Google’s side, where the models are already capable of agent-style search but the product hasn’t fully shipped it yet.
What’s Gating The Timeline
Pichai confirmed that Google’s 2026 capital expenditure will land between $175 billion and $185 billion, correcting a $150 billion figure that Collison cited. That’s roughly six times the $30 billion range Google was spending before the current AI buildout.
When asked about bottlenecks, Pichai identified four constraints in order.
Wafer production capacity is the most basic limit. Memory supply is “definitely one of the most critical constraints now.” Permitting and regulatory timelines for building new data centers are a growing concern. And critical supply chain components beyond memory add additional pressure.
“There is no way that the leading memory companies are going to dramatically improve their capacity. So you have those constraints in the short term, but they get, they get more relaxed as you go out.”
He said these constraints would also drive efficiency gains, predicting that Google would make its AI systems “30x more efficient” even as it scales spending.
He also noted that he personally dedicates an hour each week to reviewing compute allocation at a granular level across teams and projects within Google.
What This Means For Search Professionals
Pichai’s description of search as an agent manager changes the question that SEO professionals need to ask about their work.
In a results-based search model, the goal is to rank. In an agent-based model, the goal is to be useful to a system that’s completing a task. Those are different problems.
Consider what agent-completed search looks like in practice. You tell search to find a plumber, check reviews, confirm availability for Saturday morning, and book an appointment. The agent doesn’t return ten blue links. It pulls from structured business data, review platforms, and booking systems to complete the job. The businesses that are chosen are those whose information is accurate, structured, and accessible to the agent. The ones with outdated hours, no booking integration, or thin review profiles don’t get surfaced.
The same pattern applies to ecommerce. A shopper says, “find me running shoes under $150 that work for flat feet and can arrive by Friday.” An agent that can complete that task needs product data, inventory availability, shipping estimates, and compatibility information. Sites that provide that data in structured, machine-readable formats become part of the agent’s toolkit. Sites that bury it inside JavaScript-rendered pages or behind login walls get skipped.
If an agent can synthesize an answer from five sources without sending the user to any of them, what’s the value of being one of those five sources? That depends entirely on whether the agent cites you, links to you, or treats your content as raw material without attribution.
This aligns with the changes we see in AI Mode. Google reported during its Q4 2025 earnings call that AI Mode queries are three times longer than traditional searches and frequently prompt follow-up questions.
The 2027 timeline matters too. If non-engineering enterprise workflows start becoming agentic next year, the businesses providing the information and services that those agents draw from will need to be structured for machine consumption, not just human browsing. Structured data, clean APIs, and accurate business information become infrastructure, not nice-to-haves.
The Measurement Gap
Pichai’s insistence that AI search is non-zero-sum deserves more scrutiny than it usually gets.
But total query growth and individual site traffic are different metrics. Google can be right that more people are searching more often while individual publishers and businesses see less referral traffic from those searches. Both things can be true at the same time.
Google hasn’t shared outbound click data from AI Mode. Until Google provides that data, Pichai’s “expansionary” claim is an assertion, not a verifiable fact. Search professionals should track their own referral traffic trends independently rather than relying on Google’s characterization of the overall market.
Looking Ahead
Pichai’s language in this interview goes further than what Google has said publicly before. Previous statements described AI search as an evolution. This one puts a clearer label on Google’s direction for Search. Search as an agent manager is a product vision.
The timeline he laid out, with 2027 as the inflection point for non-engineering agentic workflows, gives you a window. How Google monetizes agent-completed tasks, whether agents cite sources or simply use them, and what visibility even means in an agent-manager model are all open questions that will need answers before 2027 arrives.
Google I/O 2026 is scheduled for May 19-20 and will likely provide more details on how these capabilities will ship.
Here are the five most interesting things I learned.
1. Search Will Still Exist In The Future, But Much Of It Will Be Agentic
Sundar was asked if agents would replace Search. He said:
“If I fast forward, a lot of what are just information-seeking queries will be agentic in Search. You’ll be completing tasks. You’ll have many threads running.”
And also, Search will change so that we think of it like an agent manager.
“It keeps evolving. Search will be an agent manager in which you’re doing a lot of things. I think, in some ways, you know, I use Antigravity today, and you know, you have a bunch of agents doing stuff, and I can see search doing versions of those things, and you’re getting a bunch of stuff done.”
He said that people do deep research in AI Mode, and it will soon be the norm to do long-running tasks. He also said that the form factor of devices will change.
2. Google Uses Antigravity Internally
Boy, do I love Google’s IDE and agent manager, Antigravity. I have built so many things with it, including my own RSS feed reader, a screenshot and annotation tool, workflows to publish things I write in a Google Doc to my WordPress site, and a bunch of tools to do agentic things with Google Search Console and Google Analytics 4 data. While I think Claude Cowork and Claude Code are incredible, I truly do prefer using Antigravity.
It turns out that Google makes good use of Antigravity internally. Except they don’t call it Antigravity. They call it “Jet Ski.”
Sundar said that the Google DeepMind and the Google Software Engineers use it:
“I can see groups, and in particular I would say GDM and some of the SWE groups really change their workflows. They are using, we call this for some strange reason, we have a different name internally than externally of the same product, but it’s Jet Ski internally which is Antigravity. You’re living on it, you’re living in an agent manager world. You have workflows, and you’re working in this new way.”
He also uses it himself.
“I would query in Antigravity, in our internal version of Antigravity. “Hey, we launched this thing. What did people think about this? Tell me the worst five things people are talking about?” and I type that. Now that brings it back. Has my life gotten easier? Yes. In the past I would have to spend a lot more time trying to get a sense for it. Now an AI agent is helping me in that journey.”
Also, just last week, the Google Search team started using Antigravity.
“Just last week we rolled it [Antigravity] out to the Search team. We’re constantly pushing that. In a large organization, I think change management is a hard aspect of this technology diffusing, which may be easy for a small company. You can quickly switch over.”
If you want to learn how to use Antigravity, I’ve created a full guide teaching you how it works, and how I use it to not only code, but create full agentic workflows that I actually use in my day-to-day work. It’s available in the paid part of my community, The Search Bar. And next Thursday, the Search Bar Pro crew is having an event where we’re going to split into two teams, Team Claude Code and Team Antigravity, and see who can build the better SEO tool.
I know it’s a bit of a pain to try and use something new in your workflows. I thoroughly believe that those who learn how to use Antigravity today will have a big advantage as things really start to take off as AI improves.
3. Robotics Is Growing Fast
Sundar admitted that Google was previously too early to robotics. AI has become the missing ingredient for ideas conceived 10 to 15 years ago. The Gemini Robotics models have reached state-of-the-art status for spatial reasoning. Google has partnered back with Boston Dynamics and Agile and a few other companies.
Most interesting to me was the discussion on Wing for drone delivery.
“I think we are scaling up Wing where in some reasonable time period, 40 million Americans will have access to a Wing delivery service. I’m not talking years out or something like that.”
When asked if Google was going to do more to build hardware, Sundar said having first-party hardware for robotics and AI would be important.
“I think we’d keep a very open mind. My lesson from Waymo and on the AI side with TPUs, et cetera, I need to really push the curve well, particularly in areas where you have safety, regulatory, everything. You want the first hand experience of the product feedback cycle. I think having first party hardware will end up being very important.”
4. Agentic OpenClaw-Like Systems Are The Future
There’s a reason why OpenClaw (initially Clawdbot) went crazy viral a few weeks ago. I still haven’t set up an OpenClaw system because I don’t feel I know enough about security to make this system safe.
When Sundar was asked if something OpenClaw-like was coming from Google, he said he thought it was the future.
“I think you want to give users capability where you have persistent long-running tasks in a reliable, secure way. You have to think through things like identity, access, et cetera. But I think that’s the future. That’s the agentic future. And bringing that for consumers is a bit of an exciting frontier we are looking at. This is one of mine too.
I think effectively the consumer interfaces are going to have full coding models underneath, and the right harnesses and the right skills and the ability to persist and run somewhere security in the cloud, locally and in the cloud. All those primitives are coming together.
Today I feel like there’s 1% of the world, maybe not 1%, 0.1% of the world who’s living this future. They are building stuff for themselves, but bringing that to mass adoption. Yes. It is a very exciting frontier I think.”
5. AI And AI Agents Are Going To Improve Dramatically In 2027
Sundar was asked when he thought it would happen that agentic systems would be able to work fully with no human in the loop. He said twice that 2027 was likely to be a big year.
“I definitely expect in some of these areas ’27 to be an important inflection point for certain things. Even the people doing it, that is the workflow through which they would produce it. Maybe for a while you would check it in the conventional way, but you switch over, a crossover. But I expect ’27 to be a big year in which some of those shifts happen pretty profoundly.”
The interview finished with Sundar talking about what he was most excited about. He did mention that putting data centers in space was very exciting, but this last bit was super interesting.
“I literally spent time yesterday with someone who was explaining some improvement in post-training, which is one person talking through the improvement they are doing. Listening to it, I’m like, “Oh, it’s going to really show up as a nice jump.” That’s the constant power of this moment. All of that, I don’t want to be specific about the second one, but we’ll publish it one day I’m sure.”
It sounds to me like he is talking about agentic self-improvement.
We are currently learning how to have AI build and do things for us. I recall first learning to code with ChatGPT as a partner. It would give me code to paste into VS Code. Then I’d run it and paste the errors back into ChatGPT. We went back and forth until something actually worked. I felt like I was unnecessary in this process – the copying and pasting robot, and sure enough, today’s systems like Antigravity, Claude Code, and ChatGPT Codex run the code, check the errors, and fix things up without much need for human involvement.
It makes sense to me that the next step in this process is to have AI systems learn to improve their usefulness without us having to prompt them specifically. I expect that when this happens, we will see even faster progression of AI capabilities and usefulness!
More Resources:
Read Marie’s newsletter, AI News You Can Use. Subscribe now.
Welcome to the week’s Pulse: updates affect when you can start analyzing core update performance, how much you can trust your impression data, and what Google’s CEO thinks AI will do to software security.
Here’s what matters for you and your work.
March 2026 Core Update Is Complete
Google’s March 2026 core update finished rolling out on April 8. The Google Search Status Dashboard confirms the completion.
Key facts: The rollout took 12 days, starting March 27 and finishing April 8. That’s within Google’s two-week estimate and faster than the December update, which took 18 days. Google called it “a regular update” and didn’t publish a companion blog post or new guidance. This was the third confirmed update in roughly five weeks, following the February Discover core update and the March spam update.
Why This Matters
You can now run a clean before-and-after comparison in Search Console. Google recommends waiting at least one full week after completion before drawing conclusions, which means mid-April is the earliest window for reliable analysis.
A ranking drop after a core update does not mean your site violated a policy. Core updates reassess content quality across the web. Some pages move up while others move down. Roger Montti, writing for Search Engine Journal, suggested the spam-then-core sequencing may not have been a coincidence, describing it as clearing the table before recalibrating quality signals.
What SEO Professionals Are Saying
Lily Ray, VP, SEO & AI Search at Amsive, noted on X that YouTube has gained visibility since the core update began rolling out:
“Just checked a client that ranked in AI Overviews last week and now the top 4 links in AI Overviews are all YouTube.
Let me guess: the core update was another way for Google to boost YouTube, like it did with the Discover core update.”
Aleyda Solís, SEO consultant and founder of Orainti, is running a poll on LinkedIn asking how the update impacted peoples’ websites. Currently, most respondants say the impact of the update with either positve or not noticeable.
Google Fixes Search Console Bug That Inflated Impressions For Nearly A Year
Google confirmed a logging error in Search Console that over-reported impressions starting May 13, 2025. The company updated its Data Anomalies page on April 3 to acknowledge the issue.
Key facts: The bug ran for nearly 11 months before Google publicly acknowledged it. Clicks and other metrics were not affected. Google said the fix will roll out over the next several weeks, and sites may see a decrease in reported impressions during that period.
Why This Matters
If your impression numbers have looked unusually healthy since last May, this bug is likely part of the reason. The correction will change what your Performance report shows, but it will not change how your site actually performed in search. The impressions were logged incorrectly. Your actual visibility may not have changed.
Teams that reported impression-based metrics to clients or stakeholders since May were working with inflated numbers. Click data provides a cleaner signal for performance analysis while the fix rolls out. Treat May 13, 2025 as a data annotation point, similar to how you would mark an algorithm update date in your reporting.
What SEO Professionals Are Saying
Brodie Clark, independent SEO consultant, flagged the issue on March 30, four days before Google’s acknowledgment. He wrote:
“Heads-up: there is something bizarre going on with Google Search Console data right now.
Similar to the changes that came to light after the disabling of &num=100, impressions are again skyrocketing for specific surfaces on desktop.”
Clark documented impression spikes across merchant listings and Google Images filters on multiple ecommerce sites and called for the Search Console team to investigate.
Chris Long, co-founder of Nectiv, wrote on LinkedIn: “Holy moly SEOs. It turns out Google has been accidentally inflating impressions in Search Console reports for ALMOST A YEAR.” Long noted that Google did not indicate how much impressions would decrease, and that the profiles he checked appeared stable so far.
Pichai Says AI Could ‘Break Pretty Much All Software’
Google CEO Sundar Pichai said AI models are “going to break pretty much all software out there” during a podcast conversation with Stripe CEO Patrick Collison. The interview covered AI infrastructure constraints and security risks.
Key facts: Pichai framed software security as a hidden constraint on AI deployment alongside memory supply and energy. When investor Elad Gil mentioned hearing that black market zero-day prices were falling because AI was increasing the supply of discoverable vulnerabilities, Pichai said he was “not at all surprised.”
Why This Matters
The security conversation may feel distant from daily SEO work, but it connects to the infrastructure your sites run on. If AI accelerates the pace at which vulnerabilities are found and exploited, the window between a flaw existing and an attacker using it gets shorter. That puts more pressure on maintaining current patches and auditing dependencies.
Pichai’s comments were conversational, not a formal Google policy statement. But they came from someone who oversees both the company’s AI models and its threat intelligence operation. Google’s threat teams have been warning about software security risks tied to faster vulnerability discovery.
Mueller Calls Self-Described SEO Gurus ‘Clueless Imposters’
Google’s John Mueller responded to a blog post by SEO professional Preeti Gupta about how the word “guru” is misused in the SEO industry. Mueller shared his view on Bluesky.
Key facts: Mueller wrote:
“To me, when someone self-declares themselves as an SEO guru, it’s an extremely obvious sign that they’re a clueless imposter. SEO is not belief-based, nobody knows everything, and it changes over time. You have to acknowledge that you were wrong at times, learn, and practice more.”
Gupta’s original post explained that in India the word guru carries deep cultural and spiritual meaning that is trivialized when SEO practitioners use it as a self-applied label.
Why This Matters
The core of what Mueller said is that SEO changes over time and that nobody has it all figured out.
Just look at what happened this week. Core updates continue to happen without a clear explanation of what changed. A basic logging bug in Search Console went unnoticed for nearly a year. The tools and signals we rely on every day are imperfect, and treating any methodology or perspective as settled knowledge is how mistakes get made.
The speculation about where search is going has never been louder. But this week’s events were a core update finishing, a data bug getting patched, and a Google Search Advocate reminding people that nobody has all the answers.
The future Pichai describes may be coming, but it hasn’t arrived yet. Right now, the job is still reading your Search Console data, waiting for a core update to settle, and staying honest about what you do and do not know.
Mueller’s comment that SEO “is not belief-based” and “changes over time” is as good a summary of this week as any. Those who will succeed in the next version of search are probably the ones paying attention to this version first.
Top Stories Of The Week:
Here are the main links from this week’s coverage.
More Resources:
For more context, these earlier stories help fill in the background.
Google’s John Mueller responded to a question about how Google treats outbound links from a site that has a link-related penalty. His answer suggests the situation may not work in the way many assume.
An SEO asked on Bluesky whether a site that has what they described as a “link penalty” could affect the value of outbound links. The question is somewhat vague because a link penalty can mean different things.
Was the site buying or building low quality inbound links?
Was the site selling links?
Was the site involved in some kind of link building scheme?
Despite the vagueness of the question, there’s a legitimate concern underlying it, which is about whether getting links from a site that lost rankings could also transfer harmful signals to other sites.
“Hey @johnmu.com hypothetically speaking. If a site has a link penalty are the outbound links from that site devalued? Or do they have the ability to pass on poor signals.. ie bad neighbours?”
There are a number of link related algorithms that I have written about in the past. And as often happens in SEO, other SEOs will pick up on what I wrote and paraphrase it without mentioning my article. Then someone else will paraphrase that and after a couple generations of that there are some weird ideas circulating around.
Poor Signals AKA Link Cooties
If you really want to dig deep into link-related algorithms, I wrote a long and comprehensive article titled What Is Google’s Penguin Algorithm. Many of the research papers discussed in that article were never written about by anyone until I wrote about them. I strongly encourage you to read that article, but only if you’re ready to commit to a really deep dive into the topic.
Another one is about an algorithm that starts with a seed set of trusted sites, and then the further a site is from that seed set, the likelier that site is spam. That’s about link distance ranking, ranking links. Nobody had ever written about this link distance ranking patent until I wrote about it first. Over the years, other SEOs have written about it after reading my article, and though they don’t link to my article, they’re mostly paraphrasing what I wrote. You know how I can tell those SEOs copied my article? They use the phrase “link distance ranking,” a phrase that I invented. Yup! That phrase does not exist in the patent. I invented it, lol.
The other foundational article that I wrote is about Google’s Link Graph and how it plays into ranking web pages. Everything I write is easy to understand and is based on research papers and patents that I link to so that you can go and read them yourself.
The idea behind the research papers and patents is that there are ways to use the link relationships between sites to identify what a site is about, but also whether it’s in a spammy neighborhood, which means low-quality content and/or manipulated links.
The articles about Link Graphs and link distance ranking algorithms are the ones that are related to the question that was asked about outbound links passing on a negative signal. The thing about it is that those algorithms aren’t about passing a negative signal. They’re based on the intuition that good sites link to other good sites, and spammy sites tend to link to other spammy sites. There’s no outbound link cooties being passed from site to site.
So what probably happened is that one SEO copied my article, then added something to it, and fifty others did the same thing, and then the big takeaway ends up being about outbound link cooties. And that’s how we got to this point where someone’s asking Mueller if sites pass “poor signals” (link cooties) to the sites they link to.
Google May Ignore Links From Problematic Sites
Google’s John Mueller was seemingly confused about the question, but he did confirm that Google basically just ignores low quality links. In other words, there are no “link cooties” being passed from one site to another one.
Mueller responded:
“I’m not sure what you mean with ‘has a link penalty’, but in general, if our systems recognize that a site links out in a way that’s not very helpful or aligned with our policies, we may end up ignoring all links out from that site. For some sites, it’s just not worth looking for the value in links.”
Mueller’s answer suggests that Google does not necessarily treat links from problematic sites as harmful but may instead choose to ignore them entirely. This means that rather than passing value or negative signals, those links may simply be excluded from consideration.
That doesn’t mean that links aren’t used to identify spammy sites. It just means that spamminess isn’t something that is passed from one site to another.
Ignoring Links Is Not The Same As Passing Negative Signals
The distinction about ignoring links is important because it separates two different ideas that are easily conflated.
One is that a link can lose value or be discounted.
The other is that a link can actively pass negative signals.
Mueller’s explanation aligns with the idea that Google simply ignores low-quality links altogether. In that case, the links are not contributing positively, but they are also not spreading a negative signal to other sites. They’re just ignored.
And that kind of aligns with the idea of something else that I was the first to write about, the Reduced Link Graph. A link graph is basically a map of the web created from all the link relationships from one page to another page. If you drop all the links that are ignored from that link graph, all the spammy sites drop out. That’s the reduced link graph.
Mueller cited two interesting factors for ignoring links: helpfulness and the state of not being aligned with their policies. That helpfulness part is interesting, also kind of vague, but it kind of makes sense.
Takeaways:
Links from problematic low quality sites may be ignored
Links don’t pass on “poor signals”
Negative signal propagation is highly likely not a thing
Google’s systems appear to prioritize usefulness and policy alignment when evaluating links
If you write an article based on one of mine, link back to it. 🙂
A SISTRIX analysis of German search data found far more losers than winners after Google’s March core update.
The analysis revealed 134 domains experiencing confirmed visibility losses and 32 with gains. SISTRIX determined these figures by examining 1,371 domains showing significant visibility changes, then applying filters such as a 52-week Visibility Index history, 30 days of daily data, and visual confirmation of each domain’s trend.
The SISTRIX data covers the German search market specifically. Results in other markets may differ.
What The Data Shows
Online shops accounted for the largest share of losers, with 39 of 134. Losses cut across verticals, hitting fashion (cecil.de, down 30%), electronics (media-dealer.de, down 37%), gardening (123zimmerpflanzen.de, down 27%), and B2B supply retailers. Larger German brands like notebooksbilliger.de and expert.de also declined, each losing about 11%.
Seven language and education tools lost visibility together, forming the most distinct cluster among the losers. verbformen.de fell 30%, bab.la dropped 22%, and korrekturen.de, studysmarter.de, linguee.de, openthesaurus.de, and reverso.net all declined by 7% to 15%. These sites offer conjugation tables, translations, synonyms, and study tools.
SISTRIX reports that recipe and food portals have faced pressure from Featured Snippets and, more recently, AI Overviews. The March update affected several of them. kuechengoetter.de lost 29%, schlemmer-atlas.de fell 25%, and eatsmarter.de dropped 18%. chefkoch.de, Germany’s largest recipe site, remained stable.
Among user-generated content platforms, gutefrage.net (Germany’s equivalent of Quora) lost about 24% of its visibility. SISTRIX noted that the site has been declining since mid-2025, when its Visibility Index peaked at 127. It was around 62 before this update and dropped to 47. x.com also fell 25% in German search visibility.
Who Gained
The 32 winners were dominated by official websites and established brands.
audible.de was the largest gainer at 172%, jumping from a Visibility Index of about 3 to over 8. ratiopharm.de gained 12%, commerzbank.de gained 11%, and government sites like hessen.de and arbeitsagentur.de gained 5-8%.
Four German airport websites grew in parallel. Stuttgart Airport rose 22%, Cologne-Bonn 18%, Hamburg 17%, and Munich 8%. SISTRIX described the airport gains as the clearest cluster signal among winners, which may point to a broader ranking pattern rather than isolated site-level changes.
chatgpt.com gained 32% and bing.com gained 19% in German search visibility, though both started from low baselines (Visibility Index under 5). SISTRIX attributed this more to rising demand for brand search than to algorithmic preference.
Why This Matters
The German data covers a single market, and SISTRIX’s methodology captures domains with a Visibility Index above 1, so smaller sites aren’t represented in this dataset. But the patterns are worth watching.
The language tool cluster is notable. Seven sites offering similar functionality all lost visibility at the same time. SISTRIX raises the question of whether these losses reflect Google devaluing such sites or a shift in user behavior as AI tools cover similar functions.
If you’re tracking your own site’s performance after the March core update, Google recommends waiting at least one full week after the update is complete before drawing conclusions. Your baseline period should be before March 27, compared with performance after April 8.
Looking Ahead
SISTRIX plans to publish additional market analyses. Their English-language core update tracking page covers UK and US radar data but hasn’t yet published the detailed winners-and-losers breakdown for those markets.
Google hasn’t commented on what specific changes the March 2026 core update made. As with all core updates, pages can move up or down as Google’s systems reassess quality across the web.
An analysis of more than 400 websites by Zyppy founder Cyrus Shepard identifies five characteristics associated with whether a site gained or lost estimated organic traffic over the past 12 months.
Shepard classified sites by revisiting many of the same ones covered in Lily Ray’s December core update analysis, categorizing them by business model, content type, and other features, then measuring correlation with traffic changes. Traffic estimates come from third-party tools, not verified Search Console data.
Five features showed the strongest association with traffic gains, measured by Spearman correlation:
Offers a Product or Service: 70% of winning sites offered their own product or service, compared to 34% of losing sites. Service-based offerings like subscriptions and digital goods performed well alongside physical products.
Allows Task Completion: 83% of winners let users complete the task they searched for, versus 50% of losers. Sites don’t need to sell anything to score here.
Proprietary Assets: 92% of winners owned something difficult to replicate, such as unique datasets, user-generated content, or specialized software. Among losers, that figure was 57%.
Tight Topical Focus: Winners tended to cover a single narrow topic deeply. Shepard noted that a general “topical focus” classification showed no difference between winners and losers, but tightening the definition to single-topic depth revealed the pattern.
Strong Brand: 32% of winners had high branded search volume relative to their overall traffic, compared to 16% of losers. Shepard measured brand strength by examining each site’s top 20 keywords for navigational branded terms using Ahrefs data.
The effects were additive. Sites with zero features had a 13.5% win rate. Sites with all five reached 69.7%.
What Didn’t Correlate
The study also tested features Shepard expected to matter but found no correlation with traffic changes. These included first-hand experience, personal perspectives, user-generated content, community platforms, and uniqueness of information.
Shepard cautioned against misreading those findings.
He suggested these features may already be baked into Google’s algorithm from earlier updates, meaning they could still matter even if they don’t show differential results between winners and losers in this dataset.
Why This Matters
Shepard’s findings suggest that sites offering a product, completing a task, or owning harder-to-replicate assets were more likely to show estimated organic traffic gains in this dataset. The study puts specific numbers behind that pattern, though it doesn’t establish causation.
The additive pattern is the most useful finding for those evaluating their position. A site with one winning feature had a win rate (15%) roughly the same as a site with no winning features (13%). The gap only widened at three or more features.
Roger Montti’s analysis for Search Engine Journal in December identified related patterns from the other direction, noting that Google’s topical classifications have become more precise and that core updates sometimes correct over-ranking rather than penalizing sites.
Looking Ahead
The correlation values in this study are moderate (0.206–0.391), and the methodology relies on third-party traffic estimates rather than verified analytics. Correlation doesn’t establish causation.
Sites that offer products may perform better for reasons beyond Google’s ranking preferences, including higher return-visitor rates and more natural backlink profiles.
The full dataset is public, which means others can test these classifications against their own data.
The next time you ask an AI what product to buy, which agency to hire, or which software platform actually works, pay attention to where the answer comes from. Increasingly, it does not come from the vendor’s own website. It comes from a stranger’s Reddit comment written eighteen months ago, upvoted 847 times by people who tried the thing themselves.
This is not an accident. It’s architecture.
The Reddit Effect
The financial architecture behind Reddit’s presence in AI answers became public in early 2024. Google signed an initial licensing agreement with Reddit worth a reported $60 million per year, with total disclosed licensing across multiple AI companies reaching $203 million. That arrangement gave Google real-time access to Reddit’s posts and comments for training its AI models and powering AI Overviews, and the terms are now being renegotiated upward. Reddit executives have said current agreements undervalue the platform’s discussions, which now fuel everything from ChatGPT to Google’s generative answers.
Reddit’s visibility in traditional search has fluctuated over this period, with organic rankings dropping noticeably in early January 2025. But its foothold in the AI answer layer has proven more durable than its SERP position, because these are different systems pulling from the same data source. Reddit’s hold on the AI layer reflects something structural about the content itself, not just a licensing arrangement.
Why Community Signals Work For AI
To understand why community platforms have become load-bearing infrastructure for AI answers, you need to hold two ideas at once.
First, community signals enter AI systems through two distinct pathways, not one. In the parametric pathway, community content gets baked into model weights during training and becomes part of what the model knows before anyone types a query. In the retrieval pathway, community content gets pulled in real time through retrieval-augmented generation (RAG) when the model needs current, specific, or contested information. Brands absent from community platforms before a model’s training cutoff face a significantly harder problem than brands simply absent from recent crawls. They are invisible at both layers simultaneously.
Second, the quality filtering that community platforms apply, through upvotes, accepted answers, reply chains, and sustained engagement, functions as a proxy signal that training pipelines have learned to weight. OpenAI’s training data hierarchy explicitly places Reddit content with three or more upvotes at Tier 2, directly below Wikipedia and licensed publisher partners. A heavily upvoted Reddit thread is treated as more credible input than most published content on the open web, because it carries the accumulated validation of hundreds or thousands of independent human judgments.
Any system that rewards community consensus will attract people who want to manufacture it, and this one is no exception. The SEO parallel is exact: The same logic that made link spam profitable for decades is now making fake community engagement attractive to anyone who understands how AI systems weigh these signals.
The Trap Plan incident in late 2025 is the clearest recent case study. A marketing firm posted approximately 100 fake organic comments promoting a game on Reddit, then published a blog post documenting the campaign’s approach. The screenshots circulated everywhere. The post was ultimately deleted, but the reputational damage was not. A thread naming the company indexed in Google and sat in search results alongside legitimate coverage, visible to every potential customer searching the brand.
The detection infrastructure is more robust than in the early link spam era. Reddit’s automated systems flag coordinated inauthentic behavior through patterns in posting timing, account age, karma accumulation, and comment structure, and moderator communities actively watch for coordinated campaigns. The community itself maintains a strong norm against manufactured consensus, and the backlash when a campaign is exposed tends to be proportional to how authentic it claimed to be.
There is also a structural dimension that goes beyond individual campaigns. Research by Originality.ai found that 15% of Reddit posts in 2025 were likely AI-generated, up from 13% in 2024. That is not just brands gaming the system. It is a broader contamination of the community signal itself, creating a feedback loop where AI trains on Reddit content that increasingly contains AI-generated material designed to look like human consensus. The argument for building authentic community presence now, before detection systems become more aggressive about filtering synthetic signals, is a strategic one, not a moral one. Manufactured signals degrade faster than authentic ones, and the penalty when they collapse is worse than the benefit while they worked.
What Brands Should Actually Do
The practical implication is not “post more on Reddit.” It is more precise than that.
Monitor brand mentions across Reddit, Stack Overflow, Quora, and review platforms not as a reputation exercise but as entity intelligence. The narrative that forms in community discussions, the specific language, the repeated associations, the persistent objections, is the narrative AI systems are more likely to reproduce than anything on your own website. If community threads consistently describe your enterprise product as “great for small teams,” that characterization will surface in AI answers regardless of how your positioning page reads.
Ensure subject matter experts are participating in relevant communities under their real identities, contributing answers to questions they actually know well. The upvote accumulation those answers generate is a durable quality signal that persists across training cycles. One genuinely helpful response in a relevant technical subreddit or a well-supported Stack Overflow answer does more long-term structural work than ten pieces of owned content, because it carries community validation that owned content cannot provide.
Create content that community members actively want to reference. Original research, specific benchmarks, documented case studies with real numbers, these are the formats that generate organic community citations, which in turn generate the kind of third-party mentions that AI systems treat as consensus rather than marketing. A practical rule of thumb that holds in community engagement generally: 80% of participation should contribute genuine value with no promotional intent, and the 20% that mentions your product should only appear when it is the honest answer to the question being asked.
Think of community presence as a context moat with a long construction timeline. Unlike most marketing assets, authentic community reputation compounds slowly and is genuinely difficult for competitors to replicate quickly. A brand that has been a good-faith participant in its relevant communities for two years has something that cannot be acquired in a quarter.
The Review Layer
Most brands managing reviews understand that aggregate star ratings affect purchase decisions. Fewer understand that the specific review content, the language customers use, the features they praise or criticize, the comparisons they draw to competitors, is increasingly the raw material for how AI describes your brand at the moment of recommendation.
Here is where the landscape shifts in a way that most review management programs have not caught up with yet. Not all review platforms are accessible to AI retrieval systems, and the differences are significant.
A June 2025 analysis of 456,570 AI citations found that review platforms divide into three distinct categories based on crawler access policies. Platforms like Clutch and SourceForge allow full crawler access, and their content surfaces regularly in AI-generated answers. Platforms like G2 and Capterra operate with selective access that permits some retrieval. Major platforms (Yelp is an example) block AI crawlers at the robots.txt level, which means reviews written there, however numerous or positive, are structurally unavailable to AI retrieval at the point of recommendation.
The citation data reflects this directly. For Perplexity, 75% of review site citations in the software category come from G2. Clutch dominates AI citations in the agency and digital services category. The market prominence of a review platform and its accessibility to AI crawlers are different variables, and review management strategy that conflates them is directing effort toward platforms where the AI visibility signal cannot be retrieved regardless of review volume.
This is not an argument that major platform reviews are worthless. They still matter significantly for direct consumer decision-making, traditional search, and brand reputation overall. It is an argument that the AI visibility value of a review depends specifically on whether the platform permits retrieval, and that understanding has material consequences for where teams prioritize cultivating review volume when AI answer visibility is the goal.
One additional layer of complexity: robots.txt compliance among AI crawlers is not guaranteed. Analysis by Tollbit found that 13.26% of AI bot requests ignored robots.txt directives in Q2 2025, up from 3.3% in Q4 2024. The boundary between “blocked” and “accessible” is not as clean in practice as it is in policy. The implication is to treat your entire review footprint as potentially accessible to AI retrieval while being deliberate about which platforms receive active cultivation for AI visibility specifically.
The Broader Picture
Community presence has always been a trust signal. What has changed is that the systems making purchase recommendations at scale are now reading those signals directly, at the platform level, and weighting them above the content brands produce about themselves.
SEO professionals who have spent years optimizing owned content for search visibility now face a layer of visibility that operates on fundamentally different inputs. The link-building parallel is not rhetorical. Just as the profession eventually accepted that links from authoritative external sources outweigh on-page optimization in many contexts, the community signal layer is demonstrating the same dynamic for AI-generated answers. Authority comes from outside the brand’s control, which means the work of building it looks less like content production and more like sustained, authentic participation in the places where buyers actually talk.
The brands that start building authentic community presence now are constructing a signal that compounds. Genuine community reputation is difficult to manufacture at scale, genuinely difficult for competitors to replicate quickly, and structurally favored by the same AI systems that are increasingly the first stop in the purchase journey. Later entrants will find it expensive to match.
If you want to learn more about topics like these, take a look at my newest book on Amazon: The Machine Layer: How to Stay Visible and Trusted in the Age of AI Search. It’s written to help you not only understand the topics I write about here, but also to help you learn more about LLMs and consumer behavior, build ways to grow conversations within your organization, and can serve as a workbook with multiple frameworks included.
More Resources:
Featured Image: ginger_polina_bublik/Shutterstock; Paulo Bobita/Search Engine Journal