The Trump administration’s chainsaw approach to federal spending lives on, even as Elon Musk turns on the president. On May 28, Secretary of Defense Pete Hegseth announced he’d be gutting a key office at the Department of Defense responsible for testing and evaluating the safety of weapons and AI systems.
As part of a string of moves aimed at “reducing bloated bureaucracy and wasteful spending in favor of increased lethality,” Hegseth cut the size of the Office of the Director of Operational Test and Evaluation in half. The group was established in the 1980s—following orders from Congress—after criticisms that the Pentagon was fielding weapons and systems that didn’t perform as safely or effectively as advertised. Hegseth is reducing the agency’s staff to about 45, down from 94, and firing and replacing its director. He gave the office just seven days to implement the changes.
It is a significant overhaul of a department that in 40 years has never before been placed so squarely on the chopping block. Here’s how today’s defense tech companies, which have fostered close connections to the Trump administration, stand to gain, and why safety testing might suffer as a result.
The Operational Test and Evaluation office is “the last gate before a technology gets to the field,” says Missy Cummings, a former fighter pilot for the US Navy who is now a professor of engineering and computer science at George Mason University. Though the military can do small experiments with new systems without running it by the office, it has to test anything that gets fielded at scale.
“In a bipartisan way—up until now—everybody has seen it’s working to help reduce waste, fraud, and abuse,” she says. That’s because it provides an independent check on companies’ and contractors’ claims about how well their technology works. It also aims to expose the systems to more rigorous safety testing.
The gutting comes at a particularly pivotal time for AI and military adoption: The Pentagon is experimenting with putting AI into everything, mainstream companies like OpenAI are now more comfortable working with the military, and defense giants like Anduril are winning big contracts to launch AI systems (last Thursday, Anduril announced a whopping $2.5 billion funding round, doubling its valuation to over $30 billion).
Hegseth claims his cuts will “make testing and fielding weapons more efficient,” saving $300 million. But Cummings is concerned that they are paving a way to faster adoption while increasing the chances that new systems won’t be as safe or effective as promised. “The firings in DOTE send a clear message that all perceived obstacles for companies favored by Trump are going to be removed,” she says.
Anduril and Anthropic, which have launched AI applications for military use, did not respond to my questions about whether they pushed for or approve of the cuts. A representative for OpenAI said that the company was not involved in lobbying for the restructuring.
“The cuts make me nervous,” says Mark Cancian, a senior advisor at the Center for Strategic and International Studies who previously worked at the Pentagon in collaboration with the testing office. “It’s not that we’ll go from effective to ineffective, but you might not catch some of the problems that would surface in combat without this testing step.”
It’s hard to say precisely how the cuts will affect the office’s ability to test systems, and Cancian admits that those responsible for getting new technologies out onto the battlefield sometimes complain that it can really slow down adoption. But still, he says, the office frequently uncovers errors that weren’t previously caught.
It’s an especially important step, Cancian says, whenever the military is adopting a new type of technology like generative AI. Systems that might perform well in a lab setting almost always encounter new challenges in more realistic scenarios, and the Operational Test and Evaluation group is where that rubber meets the road.
So what to make of all this? It’s true that the military was experimenting with artificial intelligence long before the current AI boom, particularly with computer vision for drone feeds, and defense tech companies have been winning big contracts for this push across multiple presidential administrations. But this era is different. The Pentagon is announcing ambitious pilots specifically for large language models, a relatively nascent technology that by its very nature produces hallucinations and errors, and it appears eager to put much-hyped AI into everything. The key independent group dedicated to evaluating the accuracy of these new and complex systems now only has half the staff to do it. I’m not sure that’s a win for anyone.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
IBM announced detailed plans today to build an error-corrected quantum computer with significantly more computational capability than existing machines by 2028. It hopes to make the computer available to users via the cloud by 2029.
The proposed machine, named Starling, will consist of a network of modules, each of which contains a set of chips, housed within a new data center in Poughkeepsie, New York. “We’ve already started building the space,” says Jay Gambetta, vice president of IBM’s quantum initiative.
IBM claims Starling will be a leap forward in quantum computing. In particular, the company aims for it to be the first large-scale machine to implement error correction. If Starling achieves this, IBM will have solved arguably the biggest technical hurdle facing the industry today to beat competitors including Google, Amazon Web Services, and smaller startups such as Boston-based QuEra and PsiQuantum of Palo Alto, California.
IBM, along with the rest of the industry, has years of work ahead. But Gambetta thinks it has an edge because it has all the building blocks to build error correction capabilities in a large-scale machine. That means improvements in everything from algorithm development to chip packaging. “We’ve cracked the code for quantum error correction, and now we’ve moved from science to engineering,” he says.
Correcting errors in a quantum computer has been an engineering challenge, owing to the unique way the machines crunch numbers. Whereas classical computers encode information in the form of bits, or binary 1 and 0, quantum computers instead use qubits, which can represent “superpositions” of both values at once. IBM builds qubits made of tiny superconducting circuits, kept near absolute zero, in an interconnected layout on chips. Other companies have built qubits out of other materials, including neutral atoms, ions, and photons.
Quantum computers sometimes commit errors, such as when the hardware operates on one qubit but accidentally also alters a neighboring qubit that should not be involved in the computation. These errors add up over time. Without error correction, quantum computers cannot accurately perform the complex algorithms that are expected to be the source of their scientific or commercial value, such as extremely precise chemistry simulations for discovering new materials and pharmaceutical drugs.
But error correction requires significant hardware overhead. Instead of encoding a single unit of information in a single “physical” qubit, error correction algorithms encode a unit of information in a constellation of physical qubits, referred to collectively as a “logical qubit.”
Currently, quantum computing researchers are competing to develop the best error correction scheme. Google’s surface code algorithm, while effective at correcting errors, requires on the order of 100 qubits to store a single logical qubit in memory. AWS’s Ocelot quantum computer uses a more efficient error correction scheme that requires nine physical qubits per logical qubit in memory. (The overhead is higher for qubits performing computations for storing data.) IBM’s error correction algorithm, known as a low-density parity check code, will make it possible to use 12 physical qubits per logical qubit in memory, a ratio comparable to AWS’s.
One distinguishing characteristic of Starling’s design will be its anticipated ability to diagnose errors, known as decoding, in real time. Decoding involves determining whether a measured signal from the quantum computer corresponds to an error. IBM has developed a decoding algorithm that can be quickly executed by a type of conventional chip known as an FPGA. This work bolsters the “credibility” of IBM’s error correction method, says Neil Gillespie of the UK-based quantum computing startup Riverlane.
However, other error correction schemes and hardware designs aren’t out of the running yet. “It’s still not clear what the winning architecture is going to be,” says Gillespie.
IBM intends Starling to be able to perform computational tasks beyond the capability of classical computers. Starling will have 200 logical qubits, which will be constructed using the company’s chips. It should be able to perform 100 million logical operations consecutively with accuracy; existing quantum computers can do so for only a few thousand.
The system will demonstrate error correction at a much larger scale than anything done before, claims Gambetta. Previous error correction demonstrations, such as those done by Google and Amazon, involve a single logical qubit, built from a single chip. Gambetta calls them “gadget experiments,” saying “They’re small-scale.”
Still, it’s unclear whether Starling will be able to solve practical problems. Some experts think that you need a billion error-corrected logical operations to execute any useful algorithm. Starling represents “an interesting stepping-stone regime,” says Wolfgang Pfaff, a physicist at the University of Illinois Urbana-Champaign. “But it’s unlikely that this will generate economic value.” (Pfaff, who studies quantum computing hardware, has received research funding from IBM but is not involved with Starling.)
The timeline for Starling looks feasible, according to Pfaff. The design is “based in experimental and engineering reality,” he says. “They’ve come up with something that looks pretty compelling.” But building a quantum computer is hard, and it’s possible that IBM will encounter delays due to unforeseen technical complications. “This is the first time someone’s doing this,” he says of making a large-scale error-corrected quantum computer.
IBM’s road map involves first building smaller machines before Starling. This year, it plans to demonstrate that error-corrected information can be stored robustly in a chip called Loon. Next year the company will build Kookaburra, a module that can both store information and perform computations. By the end of 2027, it plans to connect two Kookaburra-type modules together into a larger quantum computer, Cockatoo. After demonstrating that successfully, the next step is to scale up and connect around 100 modules to create Starling.
This strategy, says Pfaff, reflects the industry’s recent embrace of “modularity” when scaling up quantum computers—networking multiple modules together to create a larger quantum computer rather than laying out qubits on a single chip, as researchers did in earlier designs.
IBM is also looking beyond 2029. After Starling, it plans to build another, Blue Jay. (“I like birds,” says Gambetta.) Blue Jay will contain 2000 logical qubits and is expected to be capable of a billion logical operations.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
IBM aims to build the world’s first large-scale, error-corrected quantum computer by 2028
The news: IBM announced detailed plans today to build an error-corrected quantum computer with significantly more computational capability than existing machines by 2028. It hopes to make the computer available to users via the cloud by 2029.
What is it? The proposed machine, named Starling, will consist of a network of modules, each of which contains a set of chips, housed within a new data center in Poughkeepsie, New York.
Why it matters: IBM claims Starling will be a leap forward in quantum computing. In particular, the company aims for it to be the first large-scale machine to implement error correction. If Starling achieves this, IBM will have solved arguably the biggest technical hurdle facing the industry today. Read the full story.
—Sophia Chen
The Pentagon is gutting the team that tests AI and weapons systems
The Trump administration’s chainsaw approach to federal spending lives on, even as Elon Musk turns on the president.
As part of a string of moves, Secretary of Defense Pete Hegseth has cut the size of the Office of the Director of Operational Test and Evaluation in half. The group was established in the 1980s after criticisms that the Pentagon was fielding weapons and systems that didn’t perform as safely or effectively as advertised. Hegseth is reducing the agency’s staff to about 45, down from 94, and firing and replacing its director.
It is a significant overhaul of a department that in 40 years has never before been placed so squarely on the chopping block. Here’s how defense tech companies stand to gain (and the rest of us may stand to lose).
—James O’Donnell
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Conspiracy theories are spreading about the LA protests Misleading photos and videos are circulating on social media. (NYT $) + Donald Trump has vowed to send 700 Marines to the city. (The Guardian) + Waymo has paused its service in downtown LA after its vehicles were set alight. (LA Times $)
2 RFK Jr has fired an entire CDC panel of vaccine experts The anti-vaccine advocate accused them of conflicts of interest. (Ars Technica) + He claims that their replacements will “exercise independent judgment.” (WSJ $) + RFK Jr is interested in using a toxic bleach solution to treat ailments. (Wired $) + How measuring vaccine hesitancy could help health professionals tackle it. (MIT Technology Review)
3 A new covid variant is spreading across Europe and the US While it’s considered low risk, ‘Nimbus’ appears to be more infectious. (Wired $)
4 White House security cautioned against installing Starlink internet But Elon Musk’s team ignored them and fitted the service in the complex anyway. (WP $) + Trump isn’t planning on getting rid of it, though. (Bloomberg $)
5 Developers are underwhelmed by Apple’s AI efforts Its WWDC announcements haven’t been met with much enthusiasm. (WSJ $) + The company is opening up its AI models to developers for the first time. (FT $) + Where’s the overhauled, AI-powered Siri we were promised? (TechCrunch)
6 Meta is assembling a new AI research lab Researchers will be tasked with beating its rivals to achieve superintelligence. (Bloomberg $) + There’s no doubt that Meta is feeling the heat right now. (The Information $)
7 Vulnerable minors are increasingly becoming radicalized online The sad case of Rhianan Rudd illustrates the ease of access to extremist material. (FT $)
8 Our nerves may play a central role in how cancer spreads Researchers believe they may help tumors to grow. (New Scientist $) + Why it’s so hard to use AI to diagnose cancer. (MIT Technology Review)
9 An end is in sight for the video game actors’ strike Major labels have reached a tentative deal with the SAG-AFTRA. (Variety $) + How Meta and AI companies recruited striking actors to train AI. (MIT Technology Review)
10 The UK is planning a robotaxi trial next next Many years behind other countries. (FT $)
Quote of the day
“At the end of the day, what they need to do is deliver on what they presented a year ago.”
—Bob O’Donnell, chief analyst at Technalysis Research, tells Reuters where Apple went wrong with its lacklustre WWDC announcements.
One more thing
The great AI consciousness conundrum
AI consciousness isn’t just a devilishly tricky intellectual puzzle; it’s a morally weighty problem with potentially dire consequences that philosophers, cognitive scientists, and engineers alike are currently grappling with.
Fail to identify a conscious AI, and you might unintentionally subjugate a being whose interests ought to matter. Mistake an unconscious AI for a conscious one, and you risk compromising human safety and happiness for the sake of an unthinking, unfeeling hunk of silicon and code.
Over the past few decades, a small research community has doggedly attacked the question of what consciousness is and how it works. The effort has yielded real progress. And now, with the rapid advance of AI technology, these insights could offer our only guide to the untested, morally fraught waters of artificial consciousness. Read the full story.
—Grace Huckins
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
In February and March 2025, DHL queried 24,000 consumers across 24 countries as to their online shopping habits and preferences. The survey, consisting of 70 questions, required respondents to have made at least one online purchase in the previous three months.
Most respondents shop far more than once every three months. Fifty-eight percent browse for goods and services online at least twice weekly.
–
Per the DHL study, 91% of respondents now use their smartphones to shop, utilizing not only mobile browsers but also retailer apps and voice commands.
–
Expensive and slow delivery are respondents’ top two online shopping frustrations, followed by weak product descriptions, returns expense, and insufficient product photos.
–
When asked about their top improvements to online shopping, respondents cited free and fast delivery, free returns, and better product details.
Google is offering voluntary buyouts to employees across several of its core U.S.-based teams, including Search, Ads, engineering, marketing, and research.
The offer provides eligible employees with at least 14 weeks of severance and is available through July 1, according to reporting from The Verge and The Information.
The buyouts are limited to employees in the U.S. who report into Google’s Core Systems division, and exclude staff at DeepMind, Google Cloud, YouTube, and central ad sales.
An Exit Path, Not a Layoff
While Google has conducted layoffs in other departments earlier this year, the current program is being positioned differently.
It’s entirely voluntary and framed as an opportunity for employees to step away if their goals or performance no longer align with Google’s direction.
In a memo obtained by Business Insider, Jen Fitzpatrick, the Senior Vice President of Core Systems, explained the reasoning behind the move:
“The Voluntary Exit Program may be a fit for Core Googlers who aren’t feeling excited about and aligned with Core’s mission and goals, or those who are having difficulty meeting the demands of their role.”
Fitzpatrick added:
“This isn’t about reducing the number of people in Core. We will use this opportunity to create internal mobility and fresh growth opportunities.”
While the message downplays the idea of forced exits, this move bears a resemblance to earlier reorganizations.
In January, Google began with internal reshuffling in its Platforms and Devices division, which later led to confirmed layoffs affecting Pixel, Nest, Android, and Assistant teams. Whether the current buyouts will lead to further cuts remains to be seen.
New Return-to-Office Rules
Alongside the exit program, Google is updating its hybrid work policy.
All U.S.-based Core employees who live within 50 miles of an approved return site are being asked to transfer back to an office and follow the standard three-day in-office schedule.
Fitzpatrick noted that while remote flexibility is still supported, in-person presence is viewed as critical to collaboration and innovation.
Fitzpatrick wrote:
“When it comes to connection, collaboration, and moving quickly to innovate together, there’s just no substitute for coming together in person.”
These changes are positioned as part of a cultural shift toward spending more time in the office and aligning around shared goals.
Tied to Google’s Broader AI Push
This move comes as Google deploys its AI strategy across multiple business units. Over the past year, the company has:
This shows AI is driving changes both internally and externally.
Fitzpatrick’s memo opens by framing the current moment as a “transformational” shift for Google:
“AI is reshaping everything—our products, our tools, the way we work, how we innovate, and so on.”
Looking Ahead
While Google insists this isn’t about cutting jobs, the voluntary exit program and mandatory RTO policies make a couple of things clear. Google is fine-tuning who builds its products and how they do it.
Google wants its teams engaged, in-office, and ready to build the next generation of AI-driven tools.
For marketers and SEO professionals, this restructuring could foreshadow faster product rollouts, rapidly evolving search experiences, and continued automation in advertising tools.
YouTube has announced that Posts will now appear in the Shorts feed. This change allows users to see and interact with Posts while watching short videos.
How the Feature Works
You can now see Posts while scrolling through Shorts on YouTube.
In the screenshot below, you can see that the layout keeps the same vertical aspect ratio. While scrolling, the video gets smaller, using half the screen for Posts.
Screenshot from: YouTube.com/CreatorInsider, June 2025.
You can like and comment on these Posts without stopping your video.
See more about it in YouTube’s video announcement:
Background on YouTube Posts
YouTube has had posts as part of its creator toolkit for several years. These posts let channel owners share polls, quizzes, GIFs, text updates, images, and videos.
Posts are found in a special tab on the creator’s channel. They can also show up on subscribers’ homepages or in their subscription feeds.
Potential New Exposure
This update gives creators a new way to reach their YouTube audience with posts.
Further, this gives creators a way to reach Shorts viewers without creating vertical videos.
If you only publish traditional long-form content on your channel, you can potentially get into the Shorts feed by publishing text or images.
Looking Ahead
With this update, YouTube is experimenting with combining other content types with its most popular features.
It’s possible that YouTube is making this change because it’s competing with Instagram and TikTok, which mix videos with different types of content. Combining content formats has the potential to boost user engagement and keep people on YouTube longer.
For creators, this provides an additional distribution channel with a bare minimum cost to entry. Writing a text post may now get you in the same feed as a fully produced Short.
YouTube hasn’t announced specifics for how Posts will be selected or how often they’ll appear. Creators will have to do their own testing to see how this impacts visibility.
Google’s John Mueller used a clever technique to show the publisher of an educational site how to diagnose their search performance issues, which were apparently triggered by a domain migration but were actually caused by the content.
Site With Ranking Issues
Someone posted a plea for help on the Bluesky social network to help their site recover from a site migration gone wrong. The person associated with the website attributed the de-indexing directly to the site migration because there was a direct correlation between the two events.
SEO Insight An interesting point to highlight is that the site migration preceded the de-indexing by Google but it’s not the cause. The site migration is not the cause for the de-indexing. The migration is what set a chain of events into action that led to the real cause, which as you’ll see later on is low quality content. A common error that SEOs and publishers make is to stop investigating upon discovering the most obvious reason for why something is happening. But the most obvious reason is not always the actual reason, as you’ll see further on.
Sudden Deindexing & Traffic Drop after Domain Migration (from javatpoint.com to tpointtech.com) – Need Help”
Google’s John Mueller answered their plea and suggested they do a site search on Bing with their new domain, like this:
site:tpointtech.com sexy
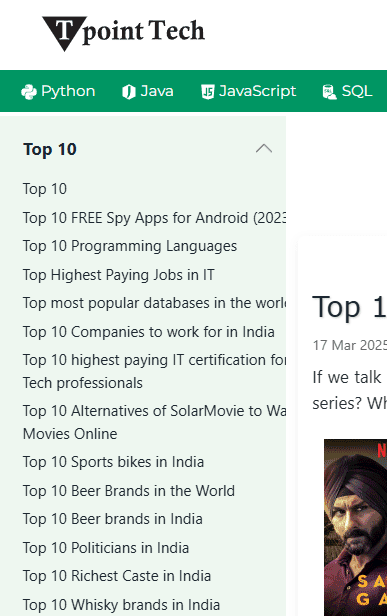
And when you do that Bing shows “top ten list” articles about various Indian celebrities.
Google’s John Mueller also suggested doing a site search for “watch online” and “top ten list” which revealed that the site is host to scores of low quality web pages that are irrelevant to their topic.
A screenshot of one of the pages shows how abundant the off-topic web pages are on that website:
Where Did Irrelevant Pages Come From?
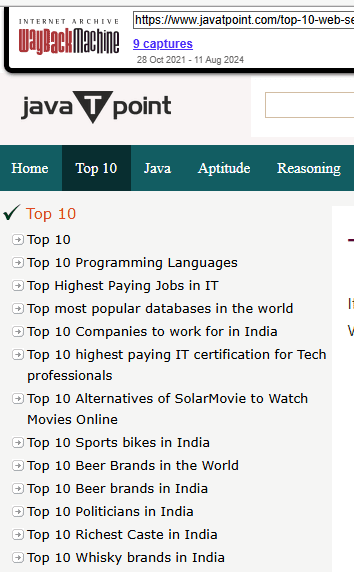
The irrelevant pages originated from the original domain, Javatpoint.com, from which they migrated. When they migrated to Tpointtech they also brought along all of that low quality irrelevant content as well.
Here’s a screenshot of the original domain, demonstrating that the off-topic content originated on the old domain:
Google’s John Mueller posted:
“One of the things I noticed is that there’s a lot of totally unrelated content on the site. Is that by design? If you go to Bing and use [site:tpointtech.com watch online], [site:tpointtech.com sexy], [site:tpointtech.com top 10] , similarly probably in your Search Console, it looks really weird.”
Takeaways
Bing Is Useful For Site Searches Google’s John Mueller showed that Bing can be useful for identifying pages that Google is not indexing which could then indicate a content problem.
SEO Insight The fact that Bing continues to index the off topic content may highlight a difference between Google and Bing. The domain migration might be showing one of the ways that Google identifies the motivation for content, whether the intent is to rank and monetize rather than create something useful to site visitors. An argument could be made that the wildly off-topic nature of the content betrays the “made-for-search-engines” motivation that Google cautions against.
Irrelevant Content A site generally has a main topic, with branching related subtopics. But in general the main topic and subtopics relate to each other in a way that makes sense for the user. Adding wildly off-topic content low quality content betrays an intent to create content for traffic, something that Google explicitly prohibits.
Past Performance Doesn’t Predict Future Performance There’s a tendency on the part of site publishers to shrug about their content quality because it seems to them that Google likes it just fine. But that doesn’t mean the content is fine, it means that it hasn’t become an issue yet. Some problems are dormant and when I see this in site reviews and generally say that this may not be a problem now but it could become a problem later so it’s best to be proactive about it now.
Given that the search performance issues occurred after the site migration but the irrelevant content was pre-existing it appears that the effects of the irrelevant content were muted by the standing the original content had. Nevertheless the irrelevant content was still an issue, it just hadn’t hatched into an issue yet. Migrating the site to a new domain forced Google to re-evaluate the entire site and that’s when the low quality content became an issue.
Content Quality Versus Content Intent It’s possible for someone to make a case that the content, although irrelevant, was high quality and shouldn’t have made a difference. What calls attention to me is that the topics appear to signal an intent to create content for ranking and monetization purposes. It’s hard to argue that the content is useful for site visitors to an educational site.
Expansion Of Content Topics Lastly there’s the issue of whether it’s a good idea to expand the range of topics that a site is relevant for. A television review site can expand to include reviews of other electronics like headphones and keyboards and it’s especially smoother if the domain name doesn’t set up the wrong expectation. That’s why domains with the product types in them are so limiting because they presume the publisher will never achieve so much success that they’ll have to expand the range of topics.
Google now supports structured data that allows businesses to show loyalty program benefits in search results.
Businesses can use two new types of structured data. One type defines the loyalty program itself, while the other illustrates the benefits members receive for specific products.
Here’s what you need to know.
Loyalty Structured Data
When businesses use this new structured data for loyalty programs, their products can display member benefits directly in Google. This allows shoppers to view the perks before clicking on any listings.
Google recognizes four specific types of loyalty benefits that can be displayed:
Loyalty Points: Points earned per purchase
Member-Only Prices: Exclusive pricing for members
Special Returns: Perks like free returns
Special Shipping: Benefits like free or expedited shipping
This is a new way to make products more visible. It may also result in higher clicks from search results.
The announcement states:
“… member benefits, such as lower prices and earning loyalty points, are a major factor considered by shoppers when buying products online.”
Details & Requirements
The new feature needs two steps.
First, add loyalty program info to your ‘Organization’ structured data.
Then, add loyalty benefits to your ‘Product’ structured data.
Bonus step: Check if your markup works using the Rich Results Test tool.
With valid markup in place, Google will be aware of your loyalty program and the perks associated with each product.
Important implementation note: Google recommends placing all loyalty program information on a single dedicated page rather than spreading it across multiple pages. This helps ensure proper crawling and indexing.
Multi-Tier Programs Now Supported
Businesses can define multiple membership tiers within a single loyalty program—think bronze, silver, and gold levels. Each tier can have different requirements for joining, such as:
This flexibility allows businesses to create sophisticated loyalty structures that match their existing programs.
Merchant Center Takes Priority
Google Shopping software engineers Irina Tuduce and Pascal Fleury say this feature is:
“… especially important if you don’t have a Merchant Center account and want the ability to provide a loyalty program for your business.”
It’s worth reiterating: If your business already uses Google Merchant Center, keep using that for loyalty programs.
In fact, if you implement both structured data markup and Merchant Center loyalty programs, Google will prioritize the Merchant Center settings. This override ensures there’s no confusion about which data source takes precedence.
Looking Ahead
The update seems aimed at helping smaller businesses compete with larger retailers, which often have complex Merchant Center setups.
Now, smaller sites can share similar information using structured data, including sophisticated multi-tier programs that were previously difficult to implement without Merchant Center.
Small and medium e-commerce sites without Merchant Center accounts should strongly consider adopting this markup.
Last week, I sent out an update on my marketplace SEO issue, and it would be a complete miss if I didn’t do the same for the topic of product-led SEO, because they’re directly related.
In this issue, you’ll get:
A thorough look at what product-led SEO is, what it isn’t, and where it’s valuable.
Three primary modalities of product-led SEO.
Three real-world current examples, with notes about why they’re working in the current search landscape.
The top watch-outs for product-led SEO programs based on modality.
And premium subscribers will get access to:
My guiding checklist for product-led SEO and
An interactive assessment landing in your inbox this week that will guide you in creating a high-level plan to refine your product-led approach. Sign up for full access so you don’t miss out.
Also, a quick thanks to Amanda Johnson, who partnered with me on this one. Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Some companies, not all, can take a hyperscalable approach to organic growth: product-led SEO.
While most sites drive SEO traffic through company-generated content (i.e., content libraries), product-led SEO allows certain sites to scale landing pages with content that comes out of the product.
In this post, I highlight five different examples and types of product-led SEO.
Guidance here has also been fully updated to reflect the recent changes in search, including the impact of AIOs, AI Mode, and LLMs, as well as how these changes affect a product-led SEO approach.
The term product-led SEO (or PLSEO for short) was first coined by Eli Schwartz in his book of the same name.
PLSEO is an organic growth strategy where your SEO practices are focused on improving the discoverability, adoption, and user experience of your product itself within search results, instead of focusing on growing organic visibility through traditional content marketing efforts.
In plain terms, the content comes from your product instead of writers.
A few examples:
TripAdvisor: millions of programmatic pages supported by reviews (UGC).
Uber Eats: millions of programmatic pages supported by restaurants (inventory).
Zillow: millions of programmatic pages supported by properties (inventory).
The key distinction from marketing-led SEO is that a product or growth team considers SEO in the development of the product itself, surfacing user-generated content or other inventory directly into (Google) Search.
Unlike company-generated content, product-led SEO leverages user interactions, integrations, or data to create content.
It’s an aggregator strategy, meaning it only works for companies that “aggregate” (think: collect and group) goods like reviews, suppliers, locations, and more.
Product-led SEO has been quite the buzz, especially amongst SaaS companies, but it often gets misunderstood.
Product-led SEO is not:
Dependent on manually crafting every landing or content page: Unlike traditional SEO approaches, where each landing page is carefully crafted by content teams, product-led SEO often uses programmatic or automated methods to generate large volumes of pages directly from product, inventory, or user data.
Solely focused on targeting queries for marketing angles: While typical SEO practices might start with creating content around keyword research or audience-based query discovery, product-led SEO begins with in-product signals (e.g., what users build or interact with) and surfaces that as content.
Relying on fixed pages: Traditional SEO often involves creating a finite set of cornerstone assets or topic clusters, expanding content from there. Product-led SEO, however, continually scales as the product (or user base) grows – each new UGC, integration, or product addition automatically adds indexable pages.
Some companies carry out a product-led SEO strategy with user-generated content (UGC), while others might use integrations or apps.
Here, I’m going to provide a look into three primary modalities of product-led SEO – and with three real-world, current examples.
UGC-driven PLSEO (like Figma, Traveladvisor, or Cameo): Community members create new assets – design files, shout-out profiles, wikis, etc. – and each submission spawns its own landing page. Over time, these pages accumulate long-tail keyword coverage without editorial teams writing each one.
Supply-driven PLSEO (like Zapier, IMDb): In this model, the product itself “supplies” data – integrations, API endpoints, or statistical datasets – that automatically translate into SEO pages.
Locale-driven PLSEO (like Doordash, Booking.com, or Zillow): As listings go live or update (a new restaurant, a hotel’s availability), a corresponding city- or neighborhood-specific page is generated. These pages capture “near me” and other local keywords.
A site might choose to employ multiple modalities, depending on its offerings, but I’ll also dive into what approach may work best based on your business type or goals.
Important note before you dive in: All marketplaces are product-led SEO plays, but not all product-led SEO plays are marketplaces. For a deep dive into marketplace SEO practices, check out Effective Marketplace SEO is more like Product Growth.
With UGC-based PLSEO, user contributions (templates, profiles, reviews) become the primary SEO fuel.
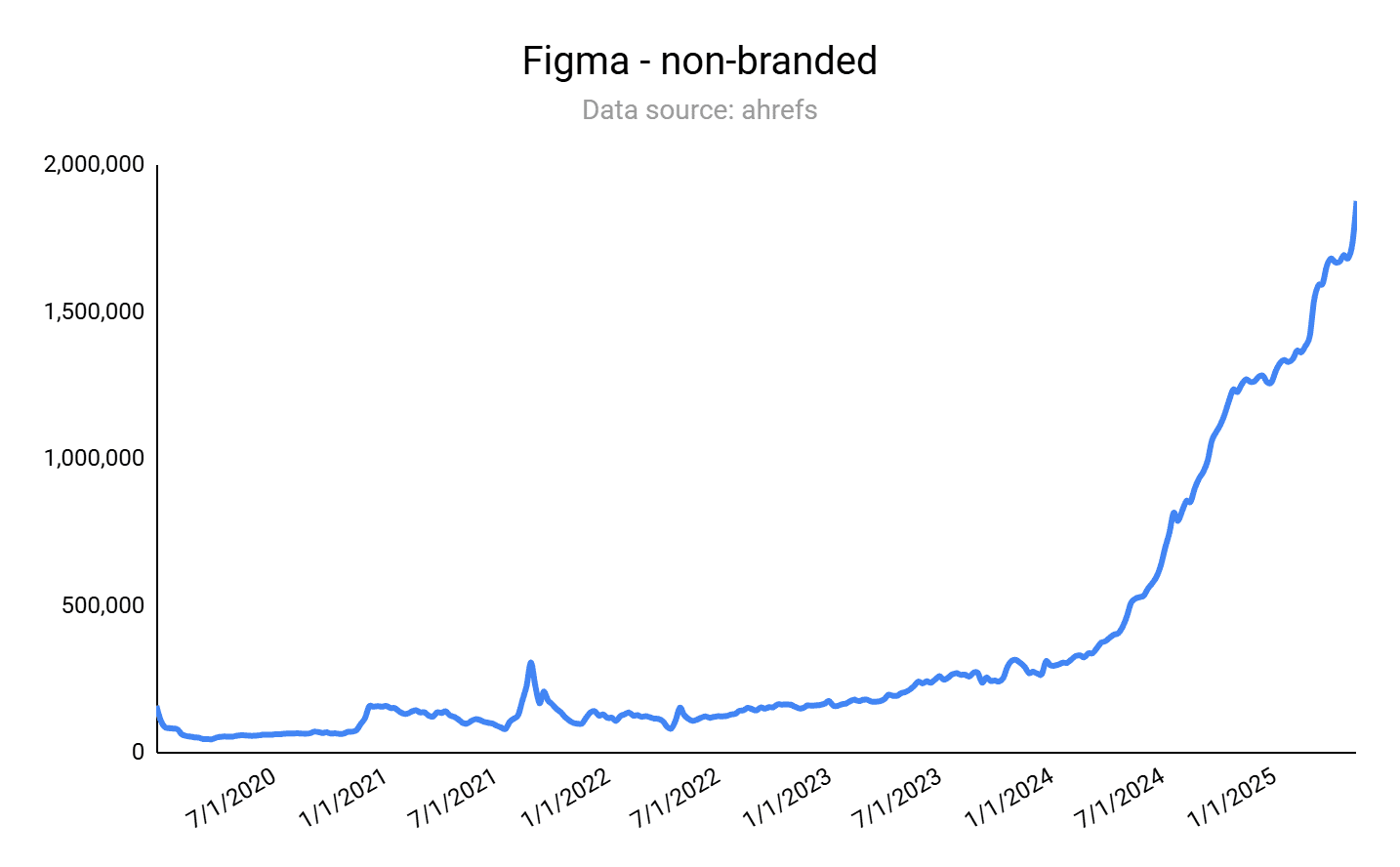
Design tool Figma is an archetypal example of an SEO aggregator that drives product-led SEO through user-generated content.
The scaling mechanism for Figma is the community, where users can upload and sell templates for all sorts of use cases, from mobile app design to GUI templates.
As you can see in the screenshot below, Figma’s organic traffic is exploding.
Image Credit: Kevin Indig
If you do a quick check of Figma in your preferred SEO tool, you’ll notice the following:
The main URL shows that, globally, Figma’s organic rankings and traffic have held or grown slightly since the intense changes across the search landscape.
The organic rankings and traffic of the /community/ and /templates/ subdirectories have either held or increased, depending on the particular country.
The number of total pages on the site has stayed about the same.
What this likely means:
For Figma, its UGC product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
This SEO approach is difficult to replicate, which creates a growth loop for Figma that is hard to compete with.
A UGC-driven approach helps overcome current search challenges. Figma has a countless number of helpful kits and templates that AI-driven search and LLMs can rely on in their sourcing and recommendations. (A quick search of “what are the best free UI kits?” in ChatGPT gave me a list of 10 recommendations, and seven were from Figma. In Google’s AI Mode, I received two to three “best of” lists that were just Figma free kits.)
Notion or Typeshare follow the same approach:
With knowledge management software Notion, users can create their own wikis and allow Google to index specific pages, or whole workspaces.
Typeshare is a social posting tool that automatically adds social content to a mini blog that users can decide to index in Search.
Top Use Cases For UGC Product-Led SEO
This type of SEO excels for sites and businesses that can continuously scale content based on what users contribute or interact with, including:
SaaS companies where users can create their own templates, designs, or workflows to share and sell.
Code snippet sharing sites or platforms.
Knowledge-sharing forums or wiki platforms (like the HubSpot Community).
Review and recommendation aggregators – marketplaces like G2 and TripAdvisor.
For supply-driven product-led SEO, remember: The product itself “supplies” data. That’s the content that produces pages for optimization.
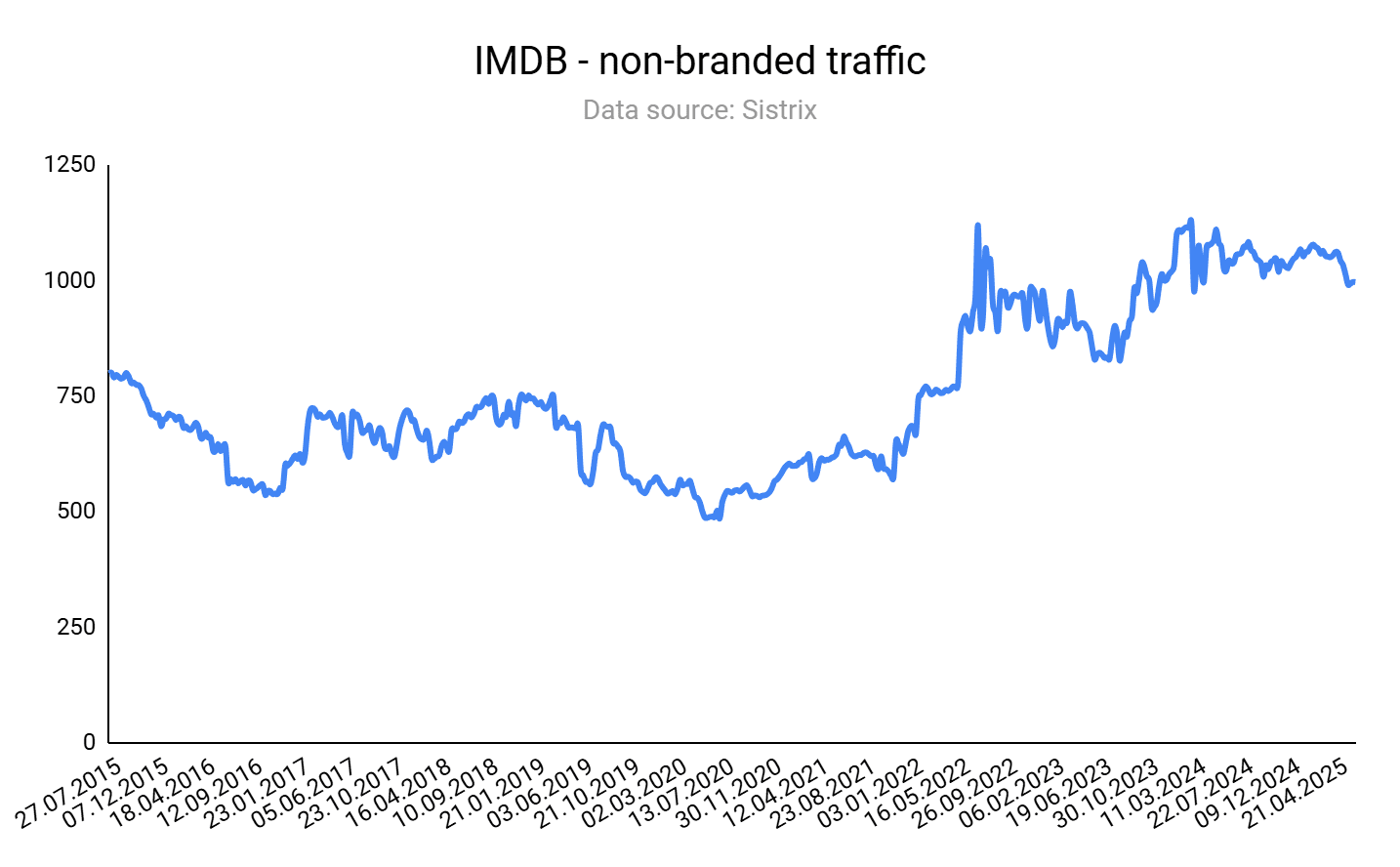
An excellent B2C example of this (and a site that you’re likely familiar with already) is IMDb.
IMDb’s massive repository of movie and TV metadata – cast lists, release dates, ratings, and filming locations – produces SEO pages that rank for film enthusiasts’ long-tail queries.
Whenever new data (e.g., “new Netflix release 2025”) is ingested via AWS Data Exchange or partner feeds, IMDb’s platform auto-generates or updates the corresponding title page, ensuring fresh content for searches like “when is [Movie Title] coming out on streaming?”
Plus, IMDb benefits from a boost with a side of UGC from user ratings and commentary.
This data-supply-driven approach turns product updates into continuous SEO signals.
Image Credit: Kevin Indig
If you do a quick check of IMDb in your preferred SEO tool, you’ll notice:
The main URL shows that, globally, IMDb organic rankings and traffic have held or grown slightly since the intense changes across the search landscape.
The organic rankings and traffic of the /boxoffice/ and /calendar/ subdirectories have either held, increased, or even skyrocketed, depending on the particular country.
The number of total pages on the site has decreased slightly in the last 12 months, by about 23%.
What this likely means:
For IMDb, its supply-driven product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
This SEO approach is difficult for other sites to replicate, which creates a growth loop for IMDb that is hard to compete with. IMDb’s global data supply is robust and hard to beat.
A supply-driven approach helps overcome current search challenges. Because IMDb is responsive to date-driven, rating-driven data changes, it provides an excellent source of updated, live information for traditional searching and LLMs to surface in conversation-based searches.
Top Use Cases For Supply-Driven Product-Led SEO
This type of PLSEO excels when you have unique, defensible datasets and a templating system to publish pages at scale, capturing long-tail and high-intent queries without manual content creation.
Examples of orgs that could benefit from this modality include:
Security and vulnerability databases that can auto-publish advisory pages for each newly discovered vulnerability (like Snyk).
Real-time pricing and compensation sites (think Glassdoor or fintech rate comparison sites).
SaaS products that collect user behavior or performance metrics (e.g., “Average page load times for Shopify stores”).
The locale-driven PLSEO modality leverages hyperlocal or geo-specific inventory – restaurants, homes, hotels – to create SEO pages for every location or zip code.
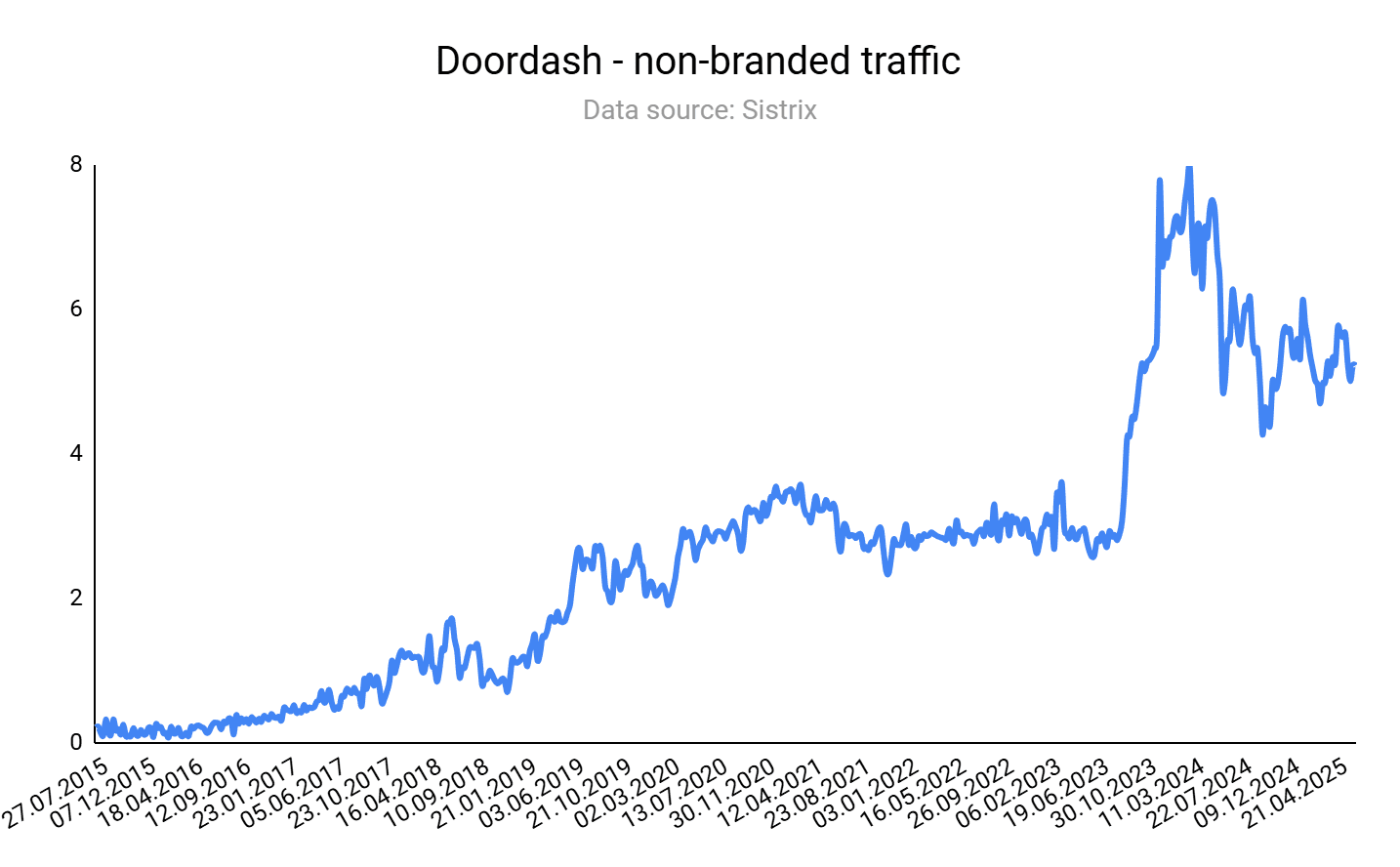
Food delivery service Doordash scales organic traffic by aggregating restaurants and types of food, similar to Uber Eats or Instacart.
Image Credit: Kevin Indig
Since food delivery has a strong local intent, near me queries are essential. Doordash addresses that with an extensive list of city pages.
The right page layout and content are key for sites that scale through product inventory.
Doordash’s city pages contain restaurants, text, and FAQ.
Restaurant pages themselves follow a similar pattern: They cover meals to order, reviews, and FAQ.
Another important factor? Internal linking. City pages link to nearby cities; restaurant pages to restaurants in the same city.
Doordash has also created pages for schools (order near a campus), hotels (order near a hotel), and zip codes to cover all possible user intentions.
Other examples of product inventory-driven sites are real estate site Zillow or coupon code site Retailmenot.
If you do a quick check of Doordash in your preferred SEO tool, you’ll notice:
The main URL shows Doordash’s organic rankings and traffic have declined significantly and then held in the U.S. market, but have grown slightly since January 2025 in some global markets.
It has reduced its total number of pages by ~30%.
What this likely means:
For Doordash, its product inventory, product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
Part of this sustained presence (despite a challenging SEO landscape) is likely due to investment in the brand, expanding globally, and reducing unimportant pages and topics to their business.
I predict that search engines and LLMs will continue to give favor to hyperlocal content, which is hard to match.
These product inventory sites that are centered on location (like Doordash, Zillow) or millions of products have the right infrastructure to do it well.
This particular approach to product-led SEO can work well for businesses that can programmatically generate search-ready pages from their product or listing inventory, including:
Food delivery & local ordering platforms.
Real estate marketplaces.
Ecommerce retailers with expansive catalogs.
Travel & accommodation aggregators.
Automotive listing portals.
While product-led SEO can drive the creation of SEO growth loops around your business – ones that are difficult for your competitors to replicate – this approach doesn’t come without some big challenges.
Keep the following in mind:
1. Sites using PLSEO approaches need to watch out for SEO hygiene, spam, and site maintenance issues.
Inventory changes (menus, listings, hours, availability) on the site can keep content fresh – an advantage for both classic SEO and potential LLM training inputs.
However, the hygiene and maintenance required to keep these pages functioning and accurate are significant. Don’t employ this practice without the proper infrastructure in place to maintain it over time.
And if you rely on UGC? It’s mission-critical to have smart QA processes and spam filters in place to ensure content quality.
2. SEO aggregators, especially marketplaces, have been significantly impacted by the rollouts of AI-based search.
PLSEO is not exempt from the impact of Google’s AIOs, AI Mode, and LLM-based search. In actuality, many aggregator marketplaces have been disproportionally affected.
One of the biggest challenges, especially for product-led UGC SEO plays, is that all your hard work may go unclicked.
Creating systems to do this kind of SEO at scale is labor-intensive.
It’s highly likely that AIOs, AI Mode, and LLMs will reference the user generated content without you earning the organic traffic for it.
However, building a strong, trusted brand through community, publication mentions, and shared links can earn more mentions in LLMs.
Because I recently reworked my in-depth guide to marketplace SEO, I’m going to save you some extra scrolling here.
If you’re interested in the best use cases and how to approach marketplace SEO from a product growth mindset, take a leap over here for some great examples and a full framework: Effective Marketplace SEO is more like Product Growth.
3. Don’t cut corners on the depth of information provided in favor of scaling.
For many sites, the key to scaling product-led SEO is deploying a programmatic approach.
But programmatic landing pages should still contain a depth of information, have strong technical SEO, and engaging content with sufficient user value.
If you don’t have these resources and practices in place, along with the proper processes to maintain pages over time, then it’s likely programmatic SEO isn’t for your org.
With the rise of AI-based search, LLMs like ChatGPT, as well as Google’s AI Overviews and AI Mode, are moving toward understanding and presenting information in more conversational and context-rich formats, which programmatic pages often lack.
Another watch-out? If these programmatic pages are highly templated with lots of elements, they’re often a lot for a human reader to take in at once. And that can lead to poor UX if not done correctly.
4. Future challenge: A web surfed by AI agents.
While it’s likely we don’t need to be worried about this today, we need to start brainstorming how to adapt our content creation for what the web could look like tomorrow.
In what ways would your product-led SEO approach need to change to adapt to AI agent traffic, while also prioritizing human UX?
If users start using queries and commands like “order my favorite dish from the Indian food restaurant I went to last month and have it delivered,” or “give me 3 for-sale listings of 2 bed, 2 bath condos in my area that I didn’t review last week,” to send an AI agent to your site, how would your PLSEO practices need to adapt?
What about PLSEO practices that surface unique integrations, templates, and workflows?
If AI agents become users of products and software themselves – and therefore also have the ability to generate their own apps, integrations, and product workflows as needed – humans, and even their AI counterparts, then skip the need for this search entirely. (Brands that solely rely on these types of searches could say goodbye to organic traffic and visibility.)
I don’t have the answers here – I’d argue no one does right now. So, no need for immediate alarm or dramatic changes.
But it’s important to start investing time and testing to consider what your brand may need to change for an AI agent future.
Adopting a product-led SEO strategy can unlock substantial growth – and growth that holds and is sustained despite the increase in AI-based search – but it’s not a one-size-fits-all solution.
When executed well, PLSEO turns your product (or product data) into an ever-expanding library of SEO assets.
Instead of relying solely on a content team to crank out new blog posts or landing pages, you leverage in-product signals – user contributions, integrations, inventory feeds – to automatically spawn indexable pages.
But before starting or reworking your product-led SEO program, you need to have the right motions in place. For this SEO approach, there are many essential moving parts – and each one is important.
Featured Image: Paulo Bobita/Search Engine Journal
“I’m reaching out for help with a puzzling issue in Google Analytics 4 (GA4). We’ve experienced a sudden and unexplained surge in traffic over a four-day period, but surprisingly, Google Search Console (GSC) doesn’t show any corresponding data.
The anomaly is specific to organic search traffic, and it’s only affecting our main page. I’d greatly appreciate any insights you can offer on what might be causing this discrepancy.”
Why GA4 And GSC Report Different Traffic Numbers
It’s a very interesting and common question about data from Google Analytics 4 and Google Search Console.
They are both Google products, so you could assume their data would be consistent. However, it isn’t, and for very good reasons.
Let’s take a look at the differences between the two.
Traffic Mediums
Google Analytics measures user interactions with a digital property. It is highly customizable and can even accept data inputs.
Google Search Console provides an overview of your website’s performance in Google Search.
This means that Google Analytics 4 is measuring traffic from all types of sources, including paid search campaigns, email newsletters, display ads, and direct visits.
Google Search Console is far narrower in scope, as it only reports on Google Search traffic.
Organic Sources
Another key difference to remember is that when reporting on organic traffic, Google Analytics will look at all sources marked as “organic search,” which includes other search engines like Bing, Naver, and Yandex.
This means that unless you instruct Google Analytics 4 to filter the organic search sources to only Google, you will see vastly different numbers between the two programs.
Clicks And Sessions
The two most comparable metrics are Google Analytics 4’s “sessions” and Google Search Console’s “clicks.” However, they are not identical metrics.
A “session” in GA4 is counted when a user either opens your app in the foreground or views a page of your website. A session, by default, lasts only 30 minutes, although this can be altered through your configuration of GA4.
A “click” in Google Search Console is counted when a user clicks on a link displayed in Google Search (across web, images, or video, and including News and Discover).
Reasons For Higher GSC Clicks Than GA4 Sessions
As you can imagine, these small but critical differences in the technical ways these two metrics are counted can have a significant impact on the end volumes reported.
There are other reasons that can impact the final numbers.
Typically, we see Google Search Console’s “clicks” being higher than Google Analytics’ organic “sessions” from Google.
Let’s assume a user clicks on an organic search listing on Google Search and arrives at the webpage it links to. What would be registered in different scenarios?
Cookies
This is a differentiating factor that is becoming more prominent as laws surrounding cookie policies change.
GA4 requires cookies to be accepted in order to track a user’s interaction with a website, whereas GSC doesn’t.
This means that a user might click on an organic search result in Google Search, which registers as a “click” in Google Search Console, arrive on the webpage, but not accept cookies. It means there would be one click registered in Google Search Console but no session registered in Google Analytics 4.
JavaScript
GA4 won’t work if JavaScript is blocked on the website, whereas GSC doesn’t rely on your site’s code to track clicks, but is based on search engine-side data. Therefore, will continue to register clicks.
If JavaScript is blocked in some way, this would again result in a click being registered on Google Search Console, but no session being registered in Google Analytics 4.
Ad Blockers
If the user is utilizing an ad blocker, it may well suppress Google Analytics 4, preventing the session from being registered.
However, since Google Search Console is not affected by ad blockers, it will still register the click.
Tracking Code
Google Analytics 4 only tracks pages that have the GA4 tracking code installed on them.
If the URL the user clicks on from Google Search results does not contain the tracking code, Google Search Console will still register the click, but Google Analytics will not register the session.
Filters And Segments
GA4 allows filtering and segments to be set up that can discount some visits or reclassify them as coming from another source or medium.
Google Search Console does not allow this. It means that if the user clicks on a URL and displays some behavior that gets it caught in a filter, then Google Analytics may not count that session, or may reclassify it as coming from a source other than Google.
In that instance, Google Search Console would register the click, but Google Analytics 4 may not register the session, or may register it as a different source or medium.
Similarly, if your GA4 account has segments set up and these are not properly managed during the reporting process, you may find that you are only reporting on a subset of your Google organic data, even if the full data has been captured correctly by Google Analytics 4.
Why GA4 Might Report More Sessions Than GSC Clicks
In your case, you’ve mentioned that you have seen a surge in organic search traffic to your main page only. Let’s look at some of the potential reasons that might be the case.
Semantics
I want to start by looking at the technicalities. You haven’t specified what metric you are using to determine “traffic” in Google Analytics 4.
For example, if you are using “page views,” then that would not be a closely comparable metric to Google Search Console “clicks,” as there can be several page views per session.
However, if you are looking at “sessions,” that is more comparable.
Also, you haven’t specified whether you have filtered down to look at just Google as the source of the organic traffic, or if you might be including other search engines as sources as well.
That would mean you are likely getting much higher sessions reported in Google Analytics, as Google Search Console only reports on Google clicks.
Tracking Issues
I would start by looking at the way tracking has been set up on your site. It could be that you have incorrectly set up cross-domain tracking, or there is something causing your tracking code to fire twice, only on the homepage.
This could be causing inflated sessions to be recorded in your Google Analytics 4 account.
Multiple Domains
The way you have set up your Google Analytics 4 properties may be quite different from your Google Search Console account.
In GA4, it’s possible to combine multiple domains under one view, whereas in GSC, you cannot.
So, for example, if you have a brand with multiple ccTLDs like example.com, example.fr, example.co.uk, then you will have these set out as separate properties in Google Search Console.
In Google Analytics 4, however, it’s possible to combine all these websites to show an overall brand’s website traffic.
It might not be obvious at first glance when looking at your homepage’s traffic, as you’ll likely only see one row with “/” as the reported URL.
When you add “hostname” as an additional column in those reports, you will be shown a breakdown of each ccTLD’s homepage, rather than a combined homepage row.
In this instance, it might be that you are viewing the Google Search Console account for one of your ccTLDs, e.g., example.com, whereas when you look at your Google Analytics 4 traffic, you may be viewing a row detailing the combined ccTLDs’ homepages’ traffic.
Length Of A Standard Session
Google Search Console tracks clicks from Google Search. It doesn’t go much beyond that initial journey from SERP to webpage. As such, it is really reporting on how users got to your webpage from an organic search.
Google Analytics 4 is looking at user behavior on your site, too. This means it will continue to track a user as they navigate around your site.
As mentioned, by default, Google Analytics 4 will only track a session for 30 minutes unless another interaction occurs.
If a user navigated to your website, landed on the homepage, and then took a phone call for an hour, they might be shown as languishing on your homepage for 30 minutes.
Then, when they come back to their computer and navigate from your homepage to another page, it will count as a second session starting.
It is most likely that in this scenario, the second session would be attributed to direct/none, but there may be cases where Google Analytics 4 is able to identify the previous referral source.
However, it is unlikely that this would cause the sudden spike in organic traffic that you have noticed on your homepage.
Bots Mimicking Google
It might well be that Google Analytics 4 is being forced to classify landing page traffic incorrectly as coming from an organic search source due to bot traffic spoofing the referral information of a search engine.
Google Search Console is better at filtering out this fake traffic due to the way it records interactions from Google Search to your website.
If there is a surge of bots visiting your homepage with this fake Google referrer, they may be incorrectly counted by Google Analytics 4 as genuine visitors from Google Search.
Misclassified UTMs
UTM tracking is often used within paid media campaigns to assign value to different campaigns more accurately.
It enables marketers to specify the medium, source, and campaign from which the traffic came if it clicked on their advert. However, mistakes happen, and quite often, UTMs are set up incorrectly, which alters the attribution of traffic irrevocably.
In this instance, if a member of your team was testing a new campaign, or perhaps using a UTM as part of an internal split test, they may have incorrectly specified “organic” as the medium instead of the correct value.
As such, when a user clicks on the advert or participates in the split test, their visit may be misattributed as organic instead of the correct source.
If your team is testing something and has used an incorrect UTM, this would explain a sudden surge in organic traffic to your homepage.
UTMs do not affect Google Search Console in this way, so the traffic that is misattributed in Google Analytics 4 would not register in Google Search Console as an organic click.
In Summary
There are a myriad of reasons why Google Analytics 4 may be reporting a different volume of homepage sessions than Google Search Console reports homepage clicks.
When using these two data sources, it’s best to recognize that they report on similar but not exactly the same metrics.
It is also wise to recognize that Google Analytics 4 can be highly customized, but improper setup may lead to data discrepancies.
It is best to use these two tools in conjunction when working on SEO to give you the widest possible view of your organic search performance.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal