In the late 2000s, “mobile-first” emerged as a design discipline. The argument was a single sentence: don’t design for the big screen and squeeze it down. Start with the small screen, the harder constraint, the one that forces you to figure out what actually matters. If it works on a phone, it works everywhere.
Google leaned in early. By February 2010, Eric Schmidt was telling Mobile World Congress that Google’s strategy was “Mobile First in everything.” In April 2015, the Mobilegeddon update penalized non-mobile-friendly websites at scale. In October 2016, StatCounter reported mobile traffic surpassing desktop globally for the first time. A month later, Google announced mobile-first indexing. By October 2023, that migration was complete.
The web is now standing at the same kind of inflection point. Except the harder constraint isn’t a small screen. It’s no screen at all. It’s a machine.
The approach I use, Machine-First Architecture, is a full-stack methodology covering the entire arc of how machines now interact with a brand. It runs from how an organization is identified and resolved across the web, to how a website’s pages expose their data, to how content is consumed and cited, to how an autonomous agent completes a transaction on the website itself. Four pillars, in a specific order: Identity, Structure, Content, Interaction. The order matters. Each pillar depends on the one before it.
This is a website architecture discipline, not a content optimization playbook. Content is just one of four pillars. Most existing AI-search guidance, including frameworks I deeply respect, sits inside that single pillar. Machine-First Architecture extends upstream to organizational identity and downstream to autonomous agent action because that is where the actual work now is.
Last month, I outlined five layers the technical SEO audit needs to add for AI search. That piece described what to check on a website that already exists. Machine-First Architecture is the build framework the audit assumes: the architectural sequence you follow before any audit, on a website you are designing or rebuilding from the ground up. The audit catches gaps. The architecture prevents them. Reading the two together is the point: the build sequence here, the audit checklist there.
The whole journey has to be covered, and that is the part that matters most. The agentic journey is end-to-end: a machine has to identify your brand, parse your website’s structure, evaluate your content, and complete an action on your website. If any one of those steps fails, the whole chain fails. Excellent content cannot save a website with broken identity, because the machine never resolves the right entity to attribute the content to. Strong identity does nothing if the website’s structure hides the data behind JavaScript a crawler will not run. And both of those are wasted if an agent arrives ready to transact and finds a checkout flow it cannot navigate without a human.
It is important to note that machine-first does not mean human-last. Designing for the most constrained consumer (a machine that cannot interpret visual layouts, guess at meaning, or recover from ambiguity) creates a foundation that serves all visitors more effectively. Mobile-first didn’t make desktop worse. It made desktop better by prioritizing what really matters. Machine-first does the same thing for human consumers.
This is the reference version of the framework. What each pillar covers, what to build, what fails when it is missing, and what real protocol infrastructure now backs each one.
Pillar 1: Identity. Can Machines Unambiguously Identify Who You Are?
Identity must come first because AI systems cannot evaluate, recommend, or transact with a brand they cannot confidently resolve.
Google’s Knowledge Graph holds tens of billions of entities and well over a trillion facts about them, with E-E-A-T credibility signals applied at the person-entity level. AI systems consolidate brand identity by reading multiple external platforms in parallel and reconciling what they find. When your website says “AI consultancy,” your LinkedIn says “digital agency,” and your Google Business Profile says “IT services,” models either average those signals into something vague or lose confidence in the entity altogether.
Canonical Definition
A canonical definition is a single, structured, machine-readable document that defines what an organization is in fields rather than paragraphs. Think of it as your brand’s API documentation. Every bio, directory listing, schema block, and social profile description should trace back to this one canonical source.
Entity Relationships
When an AI system answers “who are the leading consultants in this space,” the model traverses connections between entities: founders, clients, industry categories, technologies, publications. The machine-first approach means actively defining and publishing those relationships as structured data, rather than leaving them implicit in blog posts.
Ecosystem Mapping
Map every platform where your brand exists or should exist. Industry directories, review platforms, podcast directories, GitHub profiles, marketplace listings, data aggregators. Each platform exposes data to machines differently. Optimize each platform’s specific structured data format rather than copy-pasting the same bio across all of them.
Version Control
Treat your canonical definition as a versioned document. When identity changes, propagate that change across every platform in your ecosystem map. Machines synthesize identity continuously, and staleness in any one source can degrade the overall picture.
Research by The Digital Bloom from December 2025 found that brands mentioned on four or more platforms are 2.8 times more likely to appear in ChatGPT responses. The architectural condition that makes that compounding effect work, in my experience, is that the platforms tell the same story, which is what the Identity pillar is built to enforce.
A note on scope. This pillar is about the identity of the brand the AI system is trying to recognize. It is not about the cryptographic identity of the AI agent accessing the website. Both matter, but they are different problems.
Output of this pillar:
- A structured identity document serving as the single source of truth.
- A map of every platform in your digital ecosystem.
- A process for keeping all platforms aligned over time.
Pillar 2: Structure. Can Machines Extract Your Information?
Structure inverts the traditional web design process. Define the data model first, then wrap the design around the data.
Most websites are designed to look good to humans, with critical information locked inside visual layouts, JavaScript interactions, and design patterns that machines cannot parse. When an AI agent lands on a product page, it needs to extract the price, specifications, and availability programmatically. Structure is what makes that extraction work.
Structure overlaps with classical technical SEO and modern front-end engineering, but it is neither. Technical SEO has historically focused on what a single rendered page exposes to one crawler. Front-end engineering has focused on how that page is delivered and made interactive for human eyes. Structure, as a pillar of Machine-First Architecture, is upstream of both. It asks what data each page type exists to expose, before either the technical SEO audit or the front-end build begins. The audit checks whether the data is reachable. The architecture decides what data is there to be reached.
Data Models Before Page Designs
Before wireframing a page, define the discrete, extractable pieces of information that page must contain. The question changes from “what should this page look like?” to “what data does this page need to expose?” The page design wraps around the data model, instead of forcing the data model to conform to the design. This is the inversion that distinguishes architecture from audit. An audit can tell you whether your product page exposes price, availability, and specifications. Only the architecture step decides those are the four facts the page exists to express in the first place.
Information Hierarchy For Machines
Machine information hierarchy is structural, not visual. Machines read heading level, schema markup, semantic HTML, and position on the page, not font size, color, or visual weight. Architecturally, this means deciding what goes in the first content block of every page type before deciding how the page looks.
Relationship Architecture
This is where Machine-First Architecture diverges most sharply from how websites are traditionally built. The conventional process designs and ships pages one at a time, with the relationships between them inferred later from navigation menus and internal links. That is backward. Machines need to understand how pages relate to each other before they understand any single page: product taxonomies, service hierarchies, content-to-offering mappings, parent-child structures. Declare those connections explicitly through internal linking patterns, breadcrumb structures, and schema that names the hierarchical relationships directly. The test: Could a machine, starting from your homepage, construct a complete and accurate map of everything you offer by following structured, declared relationships? Not by guessing from menu labels. By traversing connections you have explicitly published.
One more decision belongs in this pillar: rendering. Critical data has to be present in the initial HTML response, before any client-side JavaScript runs. Build a JavaScript-heavy website where prices, specifications, and availability load after the page renders, and that data is locked away from every crawler that doesn’t execute JavaScript. Retrofitting a client-rendered SPA into something that serves data in static HTML is a very expensive failure mode. I broke down which AI crawlers render JavaScript and which ones don’t in “The Technical SEO Audit Needs A New Layer” if you want the specifics.
Output of this pillar:
- A data model for every key page type, defining exactly what machine-readable information each page contains.
- A relationship architecture connecting all pages.
- A rendering strategy ensuring critical data is accessible regardless of how the page is processed.
Do not start designing pages until this work is done. The rendered page is one possible output of the data model. AI search results, voice answers, agent tool calls, and chat citations are other outputs the same data model has to serve. If the design comes first, the data model is whatever the design happened to support, which is rarely what every machine consumer needs.
Pillar 3: Content. Will Machines Rely On What You Are Saying?
Content is the pillar most existing AI-search research already targets. Kevin Indig‘s Growth Memo, Duane Forrester‘s Substack, Ramon Eijkemans’ utility-writing framework, and the ongoing work coming out of SEO Week and the BrightonSEO research community have produced rigorous data on how AI systems evaluate content. I lean on their work in this pillar more than I do in the others, and so should you.
The discipline of writing for AI extraction (answer-first writing, content extractability, citable specificity, content position) is something I get into in detail in “The Technical SEO Audit Needs A New Layer,” and the practitioners I named go deeper still. What Machine-First Architecture adds to that discipline is three architectural decisions that determine whether any of the writing-side work can succeed at all. They are: how authorship is structurally established, how time is signaled, and how the page is composed as modular knowledge units rather than a monolithic narrative.
Authorship And Attribution
AI systems evaluate authorship against the broader knowledge graph when deciding whether to cite a source. Machine-first content makes authorship explicit and structured: who wrote this, what their credentials are, where else they have published. Connected to the knowledge graph through schema markup, with sameAs links to verified profiles, with the author entity itself defined in the canonical identity document established by the Identity Pillar. This is where Identity and Content compose: the author entity referenced here is the same entity defined upstream. Authorship buried in a footer bio is invisible to that compounding effect.
Temporal Signaling
AI systems weigh recency heavily. A 2024 guide loses ground to a 2026 article on the same topic, regardless of objective quality. The distinction runs deeper than ranking. As Duane Forrester wrote, pre-cutoff and post-cutoff content occupy different systems inside the same model. Pre-cutoff content is presented confidently and without attribution. Post-cutoff content arrives with hedging language and citations. The architectural move is this: declare when specific claims were true, what data they are based on, and what has changed since original publication, at a granularity finer than the page’s publication date. AI systems can then evaluate the freshness of individual claims rather than treating the whole page as one timestamp.
Knowledge Modularity
Retrieval systems extract specific claims, answers, and data points. They do not consume content as continuous narrative. Long documents have a well-documented middle-section problem: Language models attend most strongly to the beginning and end of a document and lose fidelity in the middle. Self-contained sections are how content survives that effect. The architectural move is to design content as collections of modular knowledge units rather than monolithic articles. Each section has its own clear scope, its own question, its own supporting evidence. The page tells a complete story where each component functions independently when extracted. This is a composition decision made at the architecture level, not a writing decision made at the draft step.
Output of this pillar: a content framework where:
- Authorship is structurally connected to your identity layer.
- Time is declared at claim granularity.
- The page is composed as modular knowledge units that function independently when retrieved.
Pillar 4: Interaction. Can Machines Act On Your Website Autonomously?
Interaction is the pillar where most existing AI-search frameworks stop. Visibility and citation work covers the first half of the journey: The machine finds and reads you. Accessibility work covers a different problem entirely: a human user with assistive technology making decisions in real time. The pillar that nobody else is finishing is the part where an autonomous agent has to do something on the website on behalf of a real person, with real money, with no human in the loop at the moment of action.
Leaving this last step unfinished is the costliest gap in the journey. An agent that can find your website, parse it, and decide it is the right answer will still abandon if it cannot complete the action it came to perform. That failure will be silent. You never see it in your analytics or your error log, the customer never tells you their agent gave up, and the next agent visit goes to a competitor whose interaction layer works. The full agentic journey is identification through completion, and the framework only delivers compounding value if every pillar holds.
The distinction from accessibility is important. Accessibility assumes a human is still in control: A screen reader translates the page for a person who makes decisions, interprets ambiguity, and recovers from errors. Machine interaction has no human in the loop at the point of action. The agent decides, acts, and verifies on its own.
Most of the eye-catching numbers in trade press right now (393% year-over-year jumps in AI-referred traffic, conversion lifts of 42%, peaks above 1,000% in the December holiday window) measure human traffic that came from AI-powered browsers and AI search results, not autonomous agent activity on the website. A person used ChatGPT or Atlas or Comet to find your website, then clicked through and shopped themselves. That is a real and growing share of website traffic, but it is the visibility-and-citation half of the journey, not the interaction half.
However, the logical next step for that same traffic is the machine also doing the action. The user who today asks ChatGPT to recommend a product and then clicks through to buy it will, increasingly, ask ChatGPT to buy it. The user who today asks Comet to compare hotels and then completes the booking themselves will, increasingly, hand the booking off to the agent. Each step delegates more of the journey to the machine. The Interaction pillar is the layer that has to be ready before that delegation becomes the default. That layer is currently developing, but moving very fast.
Every major AI vendor running the citation layer is also building the agent layer at the same pace, often faster. The companies that decide whether to cite your website are the same companies that decide where their agents try to act.
- OpenAI runs ChatGPT alongside the Atlas browser, with built-in agent mode (formerly the standalone Operator product, integrated into ChatGPT in mid-2025).
- Google folded Project Mariner into Gemini Agent and Chrome’s auto-browse capability in May 2026, and operates the Google-Agent fetcher for AI systems acting on user queries.
- Anthropic pairs Claude with computer-use capability and the Claude-User crawler.
- Perplexity has both its answer engine and the Comet browser.
- Microsoft built Copilot Mode and Agent Mode into Edge for multi-step automation.
Treating AI as a pure distribution channel (optimizing for citation, stopping at “be visible in the answer”) is the most dangerous position in this discipline. It assumes the journey ends at the citation, which the vendors building the system have already publicly committed it does not. The citation and agent layers are rolling out on overlapping timelines from the same companies. The website architecture has to be ready for both.
The protocol stack supporting agent-side interaction has crystallized over the last twelve months.
- Model Context Protocol (MCP): agent-to-tool communication. An inaugural project of the Agentic AI Foundation under the Linux Foundation.
- A2A: agent-to-agent coordination. A separate Linux Foundation project.
- WebMCP: agent-to-website interaction. A W3C Community Group draft.
- Agentic Commerce Protocol (ACP): agent-initiated commerce. Co-developed by OpenAI and Stripe and launched inside ChatGPT in 2025. OpenAI scaled native in-ChatGPT checkout back in early 2026 after low adoption, and ACP now powers purchases through merchant apps integrated into ChatGPT rather than native checkout. The protocol continues, the deployment model is still being figured out.
- Universal Commerce Protocol (UCP): agent-to-merchant commerce. Developed by Google with Shopify, Etsy, Wayfair, Target, and Walmart, and endorsed by 20+ partners across retail, payments, and processors (Stripe, Visa, Mastercard, American Express, Best Buy, Macy’s, The Home Depot, Zalando, and more). Announced at NRF in January 2026. Shopify’s implementation includes UCP-compliant MCP servers covering storefront browsing, customer account access, and developer tooling so agents can browse, compare, and place orders without screen-scraping.
- Visa’s Trusted Agent Protocol: cryptographic identity for agent-initiated transactions. In production.
Autonomous agent transactions are not the dominant share of website traffic today, but the infrastructure is in place, the first flows are live, and the websites that wait until traffic forces the issue will be the ones rebuilding under pressure rather than designing into it. Interaction is the build-now-for-the-near-future pillar.
Discoverability Of Actions
A human can tell that a button is clickable through visual design. An AI agent has no such intuition. It needs a programmatic action manifest: Structured declarations of what actions are available on each page, what inputs those actions require, and what outcomes they produce. Schema.org actions provide one path; WebMCP provides another. Every page must answer “what can a machine do here?” as clearly as it answers “what can a human see here?”
Predictable Outcomes
Every action must return a machine-readable response confirming what happened, what changed, and what the next available actions are. An agent adding an item to a cart needs structured state confirmation: The item was added, the cart now contains three items, the total is this amount, the next available action is checkout or continued browsing. Design the state communication layer before the visual feedback layer.
Workflow Continuity
A human navigating a multi-step checkout maintains context mentally. An agent needs that context exposed as structured data: current step, prior decisions, remaining steps, required inputs, and the ability to revise without losing progress.
Error Recovery
Treat errors as structured branching points, not dead ends. When an agent encounters an out-of-stock item, “sorry, something went wrong” is useless. The error response must include structured data: The item is unavailable in size M, available sizes are S, L, and XL, a similar product is available in size M. Every error needs to be a decision point the agent can navigate without human intervention.
Trust And Verification
Humans rely on visual trust signals: padlock icons, brand recognition, professional design. Agents acting on behalf of humans with real money need machine-verifiable trust data: structured, verifiable transaction terms covering pricing, return policies, merchant verification, and guarantees that can be evaluated programmatically before committing. Visa’s Trusted Agent Protocol adds cryptographic proof-of-identity to agent-initiated transactions. The Agentic Commerce Protocol provides the merchant-side payment specification that agent checkouts run on.
Agent Policies And Permissions
When agents visit your website, you need a way to communicate what they are allowed to do. Browse only, or transact? Compare prices? Identify themselves? Rate limits? Standards work here is moving fast and not yet settled. New drafts are published every few weeks across IETF, W3C, and vendor working groups. The architectural need stays the same regardless of which draft wins: a programmatic way to declare what agents can do on your website, before they try to do it.
Output of this pillar: a functional map of every key action on the website, designed as:
- Machine-navigable pathways with predictable outcomes.
- Structured error recovery.
- Verifiable trust signals.
- Explicit agent policies.
The human visual experience is an enhancement layer on top of this.
The Four Pillars Are Sequential, Not Parallel
Build order matters. Identity first, Structure second, Content third, Interaction last.
You cannot have machine-readable Content without resolved Identity. The authorship principle (who wrote this, what their credentials are, what entities they connect to) depends on the canonical definition that Identity establishes.
You cannot expose Interaction without underlying Structure. An agent cannot complete a checkout flow on a page where the data model was never defined. The action manifest the agent reads is built on the same structural foundation that exposes price, specifications, and availability.
You cannot fix Interaction by patching it on at the end. Websites that try this end up with disconnected JavaScript widgets that simulate machine-readability without actually delivering it. Agents detect the gap, abandon the task, and leave no trace in your analytics.
Build Identity first. Layer Structure on top of it. Build Content into the Structure. Add Interaction as the operational layer once the first three are in place. Each pillar makes the next one possible.
Where To Start: One Action Per Pillar
A practical architecture move per pillar. None of these are audit checks. They are decisions you make before any audit becomes useful.
Identity. Write your canonical definition as fields, not paragraphs. What you do, who you do it for, where you operate, what makes you credible, who the key people are, what entities you connect to. Make this the source of truth that every bio, schema block, and platform listing derives from. Then Google your business name and compare what comes back against that definition. Every platform that tells a different story is a leak in your identity that the canonical document needs to resolve.
Structure. Pick your three most important page types: homepage, primary product or service, primary content. For each, list the discrete facts the page exists to expose, in priority order, before any consideration of layout or design. If you cannot list those facts, the page is being designed before the data model exists, which is the inversion you should aim to prevent.
Content. Pick the three pages most likely to be cited by AI systems. For each, establish two architectural connections: the author entity, schema-linked to the canonical identity document established by the Identity Pillar, and granular temporal signaling on specific claims, declaring when each was true and what data underlies it. The audit will catch whether the content reads well. The architecture decides whether the content is structurally connected to your identity and dated at the claim level.
Interaction. Try to complete a core action on your website (buying something, booking something, submitting a form) using only a screen reader. If you cannot get through the flow, neither can an agent. And agents do not have the patience to figure it out. They move on to a competitor.
Where Machine-First Architecture Fits Among SEO, GEO, And Accessibility
Machine-First Architecture is deliberately broader in scope than the existing AI-search guidance most practitioners are working with. Most frameworks in this space focus on a single slice of the journey: visibility, citation, content optimization, retrieval mechanics. Those are real disciplines, and they are necessary work. Machine-First Architecture is built one altitude above them: the architectural methodology that determines whether any of those tactics can land at all, plus the autonomous-interaction layer the others do not address.
Look at the scope mapping. SEO has historically covered Structure, plus parts of Identity through schema. Generative Engine Optimization covers Content, plus parts of Structure for retrieval. Accessibility covers parts of Structure and parts of Interaction, but only for human-assisted access. Both organizational Identity and autonomous-agent Interaction sit outside the primary scope of every existing discipline. Machine-First Architecture is what sits at the union.
The framework’s scope is bounded by what AI vendors and standards bodies are actively building toward consuming, not by speculation about what future AI might want. Identity protocols are landing, with Knowledge Graph consolidation already in production and verifiable-identity standards moving through W3C. Structural data extraction is mature, with all major AI crawlers parsing JSON-LD and semantic HTML. Content evaluation has documented retrieval mechanisms across position-based citation, authorship cross-referencing, and recency weighting. Interaction protocols are crystallizing as I write this. The four pillars don’t describe what to build for an imagined future. They describe what to build for the demand surface that already exists, plus a near-future surface that is already being shipped.
Duane Forrester’s The Machine Layer is the canonical guide for the visibility-and-trust side of the journey. Read it. Machine-First Architecture is what you build under that, wrapping the same content discipline inside the full architectural span, with Identity at one end and Interaction at the other.
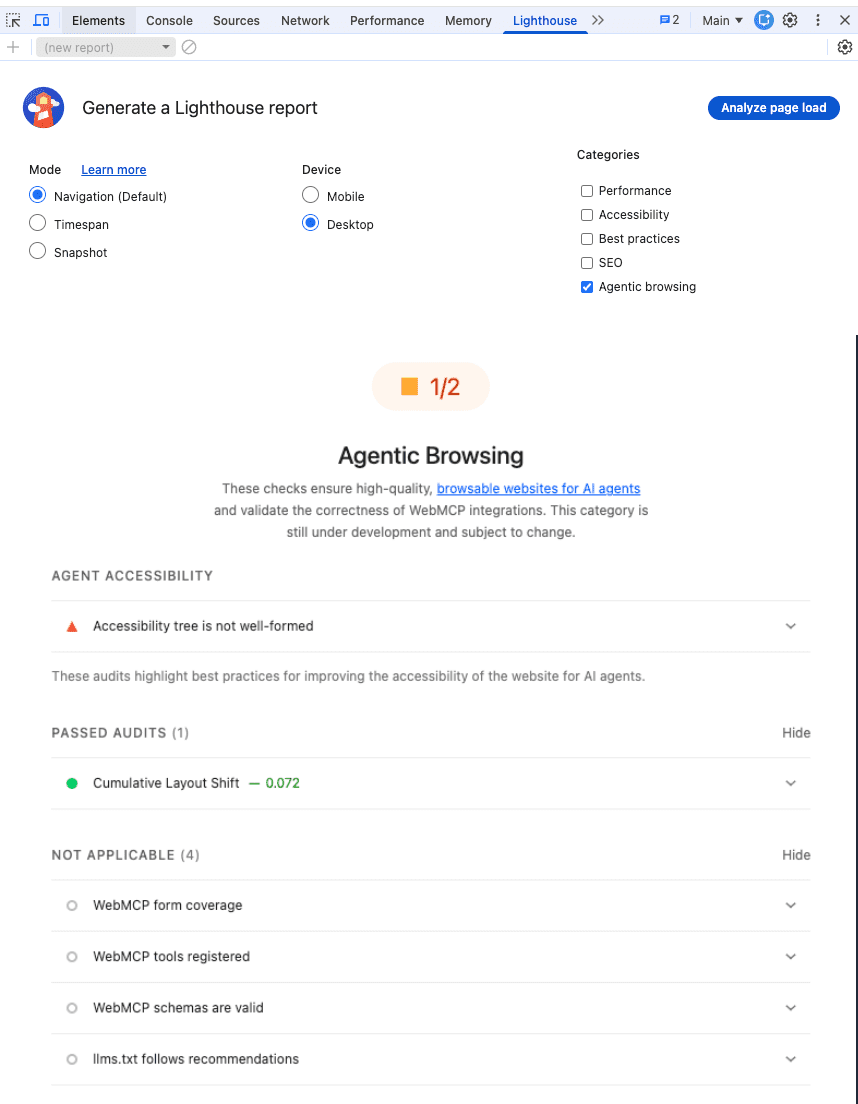
The piece on the technical SEO audit I linked in the opening is the audit you run once the architecture is in place. The accessibility tree work I covered earlier is the rendering surface where most agentic browsers actually read your website, which is where the Structure Pillar’s information hierarchy ultimately gets evaluated.
Mobile-first took years to fully play out, but the actual transition (the point where websites that ignored it started losing) happened in months. Once Google began penalizing non-mobile-friendly websites in 2015, the window for ignoring it closed.
Machine-first is following the same curve, compressed.
More Resources:
Featured Image: Olga S L/Shutterstock