AI Search In 2026: Five Findings From 300 Enterprise Marketing Execs
This post was sponsored by Branch. The opinions expressed in this article are the sponsor’s own.
Is AI search actually replacing SEO, or do I need to budget for both?
How do I attribute conversions to ChatGPT vs. AI Overviews?
AI is progressing so quickly that it’s hard to keep track of the changes, let alone know how to take action.
That’s why we surveyed 300 marketing executives from large enterprises to understand how they’re responding to AI search and where their organizations stand.
The findings point to a rapidly growing technology, a majority of executives who are bullish on change, and an infrastructure that’s woefully unprepared to support the cacophony of technological changes we’re experiencing.
Finding 1: SEO Isn’t Dead & AI Search Is Additive (Not A Replacement)
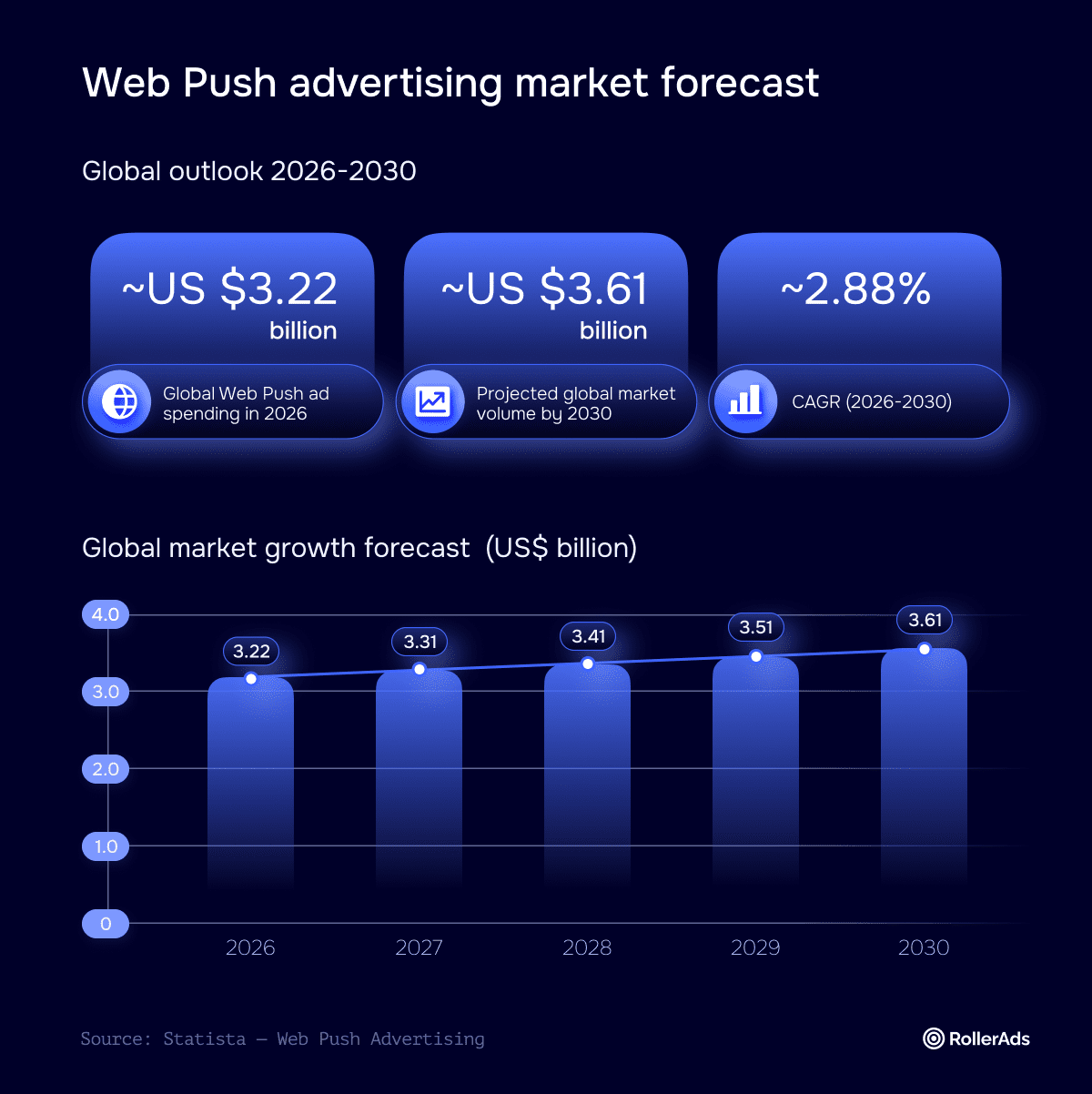
AI search is showing massive growth. From virtually zero at the beginning of 2023, it now accounts for a mean of 35% of all website traffic.
In two years, AI search has been able to leapfrog decades of growth won by other channels. Naturally, the death of traditional SEO became a popular prediction. If consumers could get contextually rich answers from a chatbot, why would they bother searching at all?
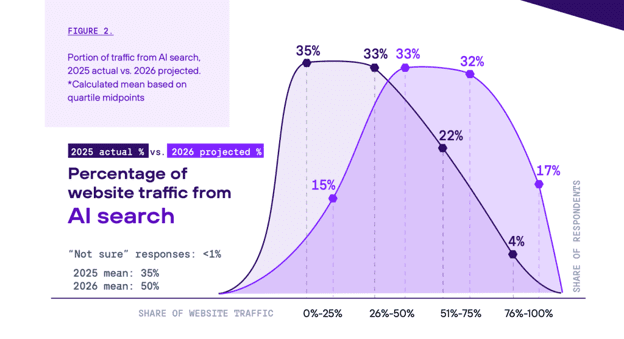
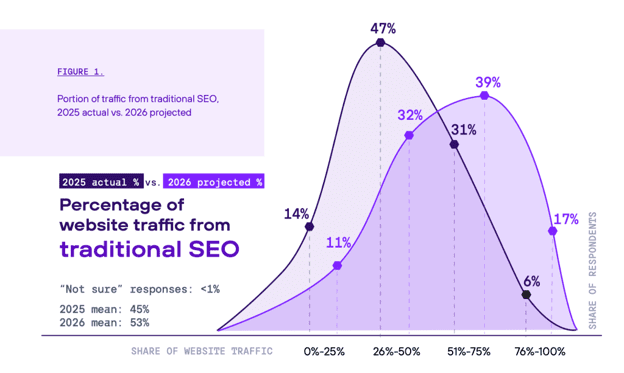
Like history, the results are more complex and subtle. The data shows that traditional SEO’s share of web traffic is growing too. Respondents predicted it will gain a full 8 points of traffic share, from 45% in 2025 to 53% in 2026.
What does this mean?
Think about your own interactions with a chatbot. You bounce ideas around, get pointed to recommended sites, then often run your own follow-up searches. Just last night I asked ChatGPT for help packing for a trip to Iceland. After getting a firm lecture on the inadequacy of my rain jacket, I headed to Google to actually find and buy one. ChatGPT was responsible for two or three website hits, Google two or three more.
AI search is adding a new mechanism to consumer discovery. Consumers can refine ideas or recommendations in chatbots and switch to search with a more refined query. It’s no surprise that after the emergence of the chatbot, Google is reporting more complex, multimodal traditional searches.
Embrace The Fact That Consumer Behavior Is (Purposefully) Occluded Between Channels
Incidentally, Google is central to the difficulty of parsing traditional SEO from AI search. It deliberately blurs the distinction between search, AI Overviews, and AI Mode, and to protect its position as the leader in search, it has every reason to. Search for a coffee maker in AI Mode, and you’ll be served a sponsored post. Click on it, and you’ll see a paid search campaign UTM tracking link. Advertisers are starting to show up in AI search results, and they don’t even know it’s happening.
ChatGPT (as of today) is only throwing a single UTM source referral with its traffic, leaving marketers knowing the traffic was sourced from ChatGPT, but nothing more. Marketers see much higher intent traffic, but have no context for the referral. To get even a glimpse up-funnel, marketers are resorting to combing through search logs to understand ChatGPT bot behavior on their websites.
You can’t fight these trends. It’s better to lean into your existing strategies while figuring out how to shift for new technologies. Google Gemini Ads are easy; if you run Search Ads, Google has likely already opted you into running them. Watch your campaign outcomes and don’t be surprised when some outliers change behavior. Google will repurpose your Search Ads to find what works in Gemini, you just need to supply the platform with the assets to iterate on the new medium.
ChatGPT is harder, but not impossible. Treat ChatGPT referral traffic as high-intent users who are likely past the initial discovery phase and well into the funnel. Don’t risk churn by forcing them along superfluous funnels.
Beware Of Conflicts Between SEO & AI Search
The technology behind SEO and AI are vastly different. Search ranks content by relevance; AI aggregates multiple signals to distill an answer. Often the same fundamentals serve both technologies: machine-readable text, standards-based schemas, clarity, and social scores all signal quality to algorithms.
But sometimes they pull in opposite directions. In search, you can create two pages to target the exact opposite intent. One page markets an automobile as “luxurious”, while another touts the same car as “affordable.” Search will target each page with a separate intent. An LLM will aggregate all pages related to that product and get confused by the conflicting signals. Are you luxurious or affordable?
To prepare for AI search, beware of situations where SEO strategies actually serve as a detriment to the new technology.
Finding 2: Marketers Are Betting Massive Dollars On AI Search, But Struggle To Measure The Results
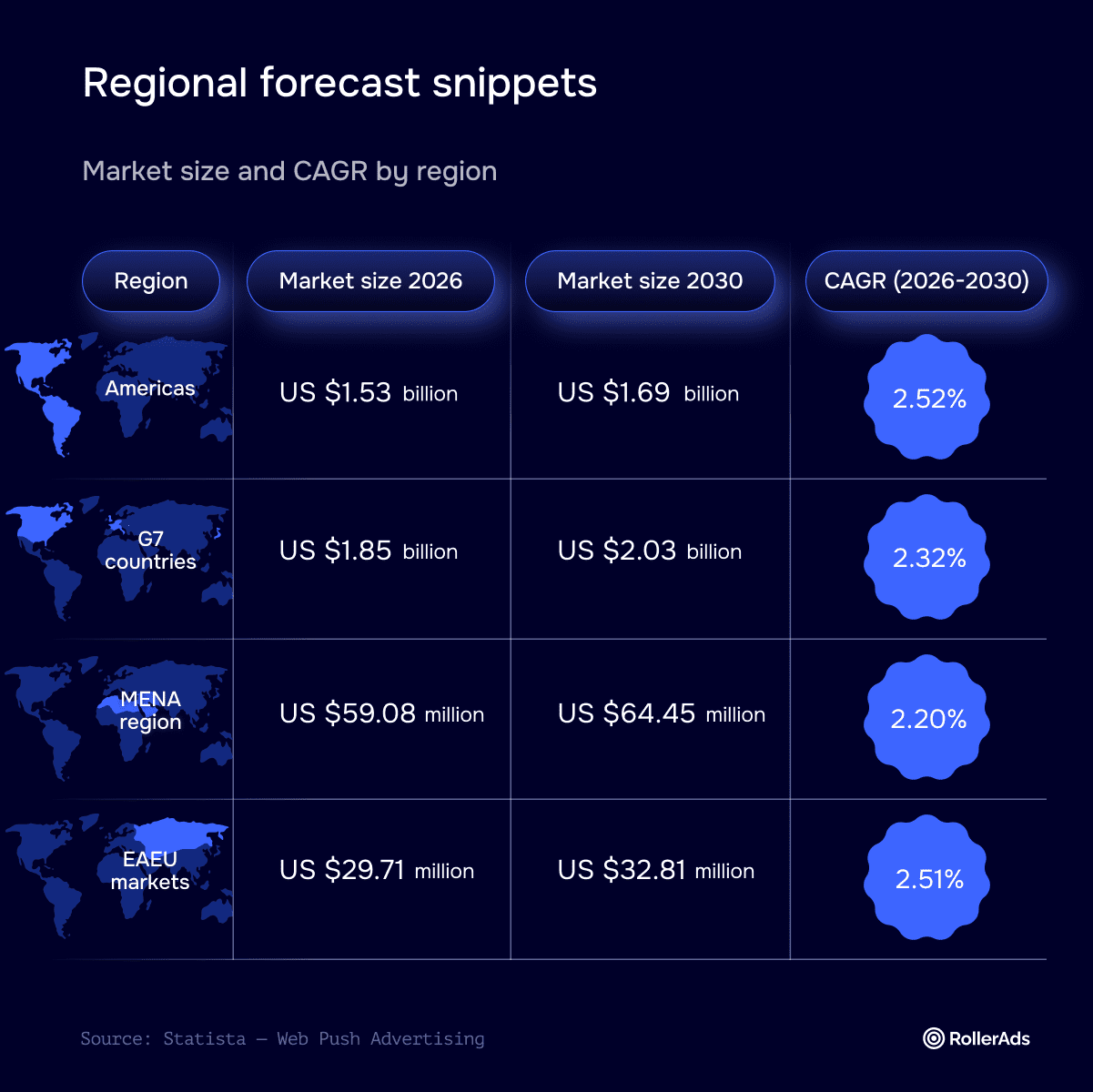
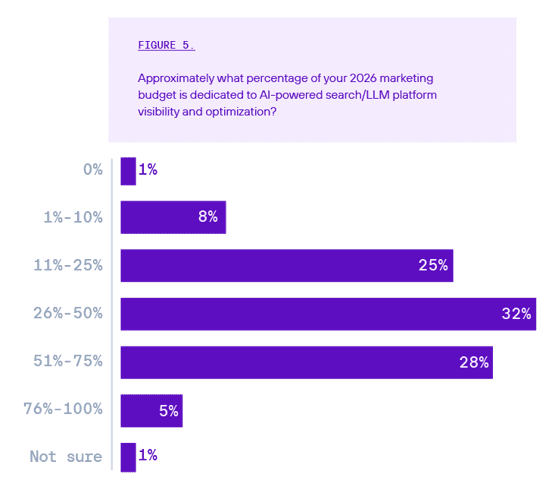
As AI search grows in share, it’s no surprise that marketers are setting aside budget. What is surprising is just how much. Sixty-five percent of enterprise executives are allocating at least 25% of their entire marketing budget to AI, and 28% are allocating over half. That’s a significant commitment for a channel where advertising models are still being built out.
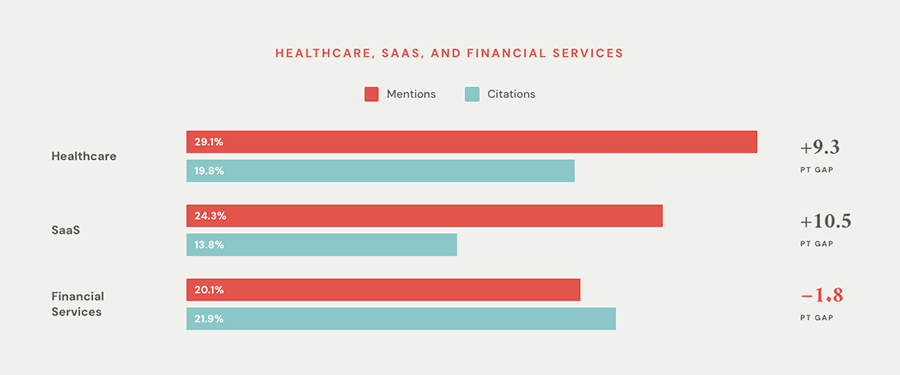
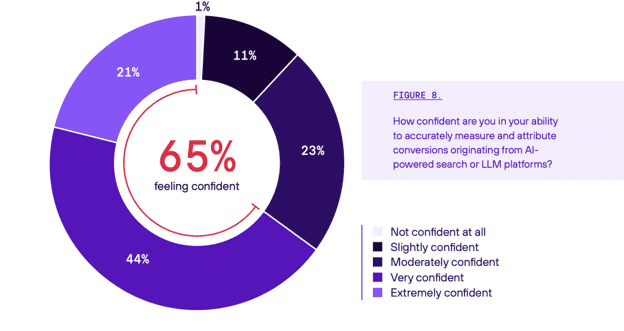
Marketers express confidence in measuring the outcomes of these budgets, but a closer look shows cracks. Two-thirds say they are very confident, and 80% say that AI attribution is clearer than traditional SEO.
But in a more detailed follow-up question, 66% also report challenges with the basics of measurement. Fewer than 1 in 5 say they face no measurement challenges at all.
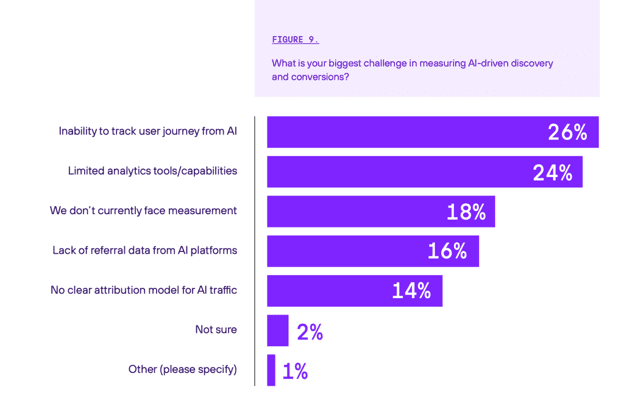
Mohammed Faizan of M&C Saatchi Performance suggests the reason is that current measurement just isn’t up to task: “Teams are confident in what they can see, and what they can see is a small, clean edge of the funnel: clear referrals from AI platforms, last-click conversions. That’s not measurement. That’s noticing the obvious. AI isn’t showing up in your attribution model; it’s hiding inside your branded search growth, your direct traffic lift, your ‘unexplained’ conversion spikes.”
This problem is about to get worse. Measuring referral traffic from ChatGPT is one thing; paying for it is another. As AI search scales into a paid channel, marketers will need attribution frameworks that don’t exist yet.
If a consumer spends a week in chatbot conversations, performing searches, and running into retargeting ads, how do you attribute that sale? The measurement gap that exists today will only widen as spend increases.
The good news is there are steps you can take now.
Embrace All Channels; Measure Whatever You Can
Advertising has become a black box. Algorithms run by the large ad platforms consume an enormous amount of data to predict and serve the most relevant ads. As digital channels multiply, the number of potential touchpoints grow and measurement gets murkier. Marketers will increasingly rely on algorithms to model and attribute spend across their channels.
To feed these models, you need data. The more, the better. Measure organic traffic, paid search, LLM referrals, and every other source you can instrument. The modeled attribution of the future will need that foundation.
Focus On End Impact, Not Platform Reporting
The more abstracted your measurement model becomes from real outcomes, the more you risk misattribution. Advertising has progressed from CPM to CPC to CPA, each shift allowing marketers to find better-performing media sources. But now multiple channels claim the same action.
The best way to avoid duplicated attribution claims isn’t to model share based on what each platform reports, it’s to model the actual sales outcome from the platform investment. OpenAI may not deserve 10% of your budget just because it claims 10% of your sales. An incrementality test could reveal it actually drives 50% of sales. True performance reporting takes the sting out of advertising on emerging technology.
Findings 3-5 Are In The Full Report
Marketers are willing to act quickly with AI: The vast majority think they’ll be executing closed-loop transactions in chatbots by the end of this year.
And so far, despite the negative press, AI is serving as a net-positive for marketers: Only 3% of respondents are seeing negative marketing performance from AI. Yet, when asked about the outlook in the future, concern outweighs their optimism.
Download the full report to see how your competitors are actually spending, measuring, and planning for AI search this year.
Image Credits
Featured Image: Image by Branch Used with permission.
In-Post Images: Images by Branch. Used with permission.