When I last wrote to you in this magazine, I told you a bit about the MIT Collaboratives, an effort to spark new ideas and modes of inquiry and help the people of MIT solve global problems. Since then, we’ve launched the first collaborative, grounding it in the human-centered fields represented by our School of Humanities, Arts, and Social Sciences (SHASS). We’re calling it the MIT Human Insight Collaborative, or MITHIC.
In broad terms, MITHIC is an endorsement of the quality of our faculty in these fields and an expression of how deeply we value the scholarly and artistic practices that expand our understanding of the things that make us human.
In a practical sense, it’s designed to help our scholars in human-centered disciplines “go big.” MITHIC will give them the resources to pursue their most innovative ideas within their discipline, create opportunities for them to collaborate with colleagues outside it, and enable them to explore fresh approaches to teaching our students.
We celebrated the launch of MITHIC with a showcase of creative excellence. MIT faculty shared research that blends the humanistic with the technological, MIT students improvised on jazz saxophone, and in a keynote conversation, the acclaimed novelist Min Jin Lee talked about her dedication to putting the human at the center of her work.
Our faculty are wonderfully energized by MITHIC, and more than 100 have already taken part in the collaborative’s “Meeting of the Minds” events, organized to connect researchers across the Institute who work on similar topics—from cybersecurity to food security, climate simulations to the bioeconomy.
There may never have been a more important time for society to make humane choices about new technologies. And I’m thrilled that at MIT we’ve created a collaborative powered by human insight to support our scholars, students, explorers, and makers in shaping a future of technology in service to humanity.
“I’m moving to Boston in three weeks!” At my high school graduation, I had just learned I’d been accepted into the Interphase EDGE program, an incredible opportunity to acclimate to life at MIT before the 2022 school year began.
I was glad to have that chance, since I faced a big change from life at home in Claremore, on the Cherokee Nation reservation in northeastern Oklahoma. I’d been away on my own only once, on a fifth-grade trip to Space Camp in Huntsville, Alabama, where I first fell in love with aerospace engineering.
It didn’t take long to find community on campus. To my surprise, out of the dozen students at a welcome event for the Indigenous community, three grad students and an undergrad were in the aero-astro department. As a prospective Course 16 major and a FIRST Robotics alum, I was excited to discover that they planned to start a new team for the First Nations Launch (FNL) rocketry competition, a NASA Artemis Student Challenge. It was the perfect opportunity to merge my technical passion with my cultural roots.
That first year, many people questioned the need for our team. “MIT already has a Rocket Team,” they’d say. But while most build teams are defined by the specific projects they work on, the product is just one aspect of the experience.
Yes, I’ve learned to design, build, launch, and safely recover a model rocket. But doing that alongside other Indigenous engineers on the team we call MIT Doya (ᏙᏯ, Cherokee for beaver) has taught me more than engineering skills. Beyond learning how to work with composites or design fins, I’ve learned how to navigate classes and connect with professors. I’ve learned about grad school. And I’ve learned how to celebrate my Indigenous identity and honor my ancestors with my work. For instance, we often hold smudging ceremonies—burning sage to purify ourselves or our rockets—at our team meetings and competitions.
Our team emphasizes universal consensus and buy-in on the technical side and pays attention to the success of each team member on a personal level. We call this gadugi (ᎦᏚᎩ) in Cherokee, or “everyone helping each other.”
I’ve also learned that embracing my culture can offer a better approach to engineering challenges. While many engineering settings foster top-down decision-making, our team tests and incorporates as many ideas as possible to engage everyone, emphasizing universal consensus and buy-in on the technical side while paying attention to the success of each team member on a personal level. We call this gadugi (ᎦᏚᎩ) in Cherokee, or “everyone helping each other.” And we find it’s led to better technical results—and a better experience for everyone on the team.
I feel incredibly fortunate to work closely with other Indigenous students on an engineering project we all deeply care about. I’ve looked up to the senior members of the team, seeing in them proof of what an Indigenous student at MIT can be and accomplish. And I’ve loved mentoring newer members, passing along what I’ve learned to help them excel.
Our launch weekends expand our community further, allowing us to work alongside inspiring Indigenous engineers from NASA’s Jet Propulsion Lab and Blue Origin. I’ve gotten to meet my heroes and seen that it’s possible to succeed as a Native American in aerospace engineering. In fact, my FNL experiences have already helped me secure an amazing internship. Last summer—exactly a decade after setting my heart on aerospace engineering at Space Camp—I returned to Huntsville as a lunar payloads intern on the Mark I Lunar Lander at Blue Origin.
Through the FNL team, I’ve significantly advanced my technical skills. As our systems and simulations lead the first year, I integrated all the components of the physical design into a cohesive computer model with accuracy in both geometry and mass distribution. From that model, I can run simulated flights while adjusting for various launch conditions and trying out different motors. A small change on the ground can yield a big change in our final altitude, which must be within a specific range—so this analysis drives the overall design.
In our first year, our challenge was to re-create the design of a kit rocket while making it lighter by fabricating all the parts ourselves, primarily using hand-laid carbon fiber and fiberglass. We finished in second place and were named Rookie Team of the Year.
For 2023–’24, our challenge was to build a rocket large enough to carry a deployable drone, leading us to build an airframe 7.5 inches in diameter. We also had to design and fabricate the drone’s chassis to meet strict specifications: It had to fit inside the rocket on the launchpad, deploy at apogee (ours was 2,136 feet), unfold from a compact stowed configuration to 16 by 16 inches, descend by parachute to 500 feet, and then release the parachute for piloted navigation to a landing pad. To meet FAA requirements, two of our team members studied for and earned Part 107 remote pilot certificates so they could operate the drone.
Since this new challenge required us to fabricate a rocket while also designing and building the drone, we broke up into two subteams to work on both in parallel. This approach required precise coordination between the subteams to ensure that everything would integrate well for the final launch. As team captain, I managed this coordination while staying involved on the technical side as systems and simulations lead and airframe lead. And as we worked our way through the project milestones from proposal through flight readiness review, we kept in mind that we needed both an operational drone and a safe flight to the right altitude to meet the challenge.
In April our team traveled to Kenosha, Wisconsin, to put our rocket to the test. We loaded the parachutes and payload, blessing it with some medicine before sending our hard work into the sky. But when I went to load our motor, the motor mount fell off in my hand. We quickly proceeded to the range safety officer, who was able to salvage our rocket and our launch with the last-minute addition of an external motor retention device. After that minor (but almost catastrophic) delay, we had a safe launch and successful recovery—and earned the Next Step Award, a $15,000 grant to represent FNL in the University Student Launch Initiative, a NASA-hosted competition open to everyone, for the 2024–’25 season.
Six weeks later, when the overall competition winners were announced, we were thrilled to learn we had won the grand prize! Along with bragging rights, we won a VIP trip to Kennedy Space Center in August and got to walk through the iconic Vehicle Assembly Building, explore the shuttle landing strip, see Polaris Dawn on the launchpad, and watch a Starlink launch from the beach in the early morning hours.
This year, I’m honored to serve as team captain again, leading an expanded team as we tackle the challenges of the new Student Launch Initiative. I’m already looking forward to May, when we’ll launch the rocket we’ll be perfecting between now and then. And to honor our Indigenous heritage and send it into the sky with good intentions, I’ll make sure we smudge before flight.
Hailey Polson ’26, an aero-astro major and a citizen of the Cherokee Nation, is captain of MIT’s First Nations Launch team.
What if construction materials could be put together, taken apart, and reused as easily as Lego bricks? That’s the vision a team of MIT engineers hopes to realize with a new kind of masonry it’s developing from recycled glass. Using a custom 3D-printing technology provided by the MIT spinoff Evenline, the team has made strong, multilayered glass bricks, each in the shape of a figure eight, that are designed to interlock and stack. The bricks can easily be taken apart for reuse in new structures.
“Glass as a structural material kind of breaks people’s brains a little bit,” says Evenline founder Michael Stern ’09, SM ’15, coauthor of a paper on the work. “We’re showing this is an opportunity to push the limits of what’s been done in architecture.”
A tube of glass is extruded in a hot 3D printer.
ETHAN TOWNSEND
Stern and Kaitlyn Becker ’09, an assistant professor of mechanical engineering and another coauthor, got the inspiration for the bricks partly from their experience as undergraduates in MIT’s Glass Lab.
“I found the material fascinating,” says Stern, who went on to design a 3D printer capable of depositing molten recycled glass. “I started thinking of how glass printing can find its place.”
“I get excited about expanding design and manufacturing spaces for challenging materials with interesting characteristics, like glass and its optical properties and recyclability,” says Becker, who began exploring those ideas as a faculty member. “As long as it’s not contaminated, you can recycle glass almost infinitely.”
For their new study, Becker, Stern, and coauthors Daniel Massimino, SM ’24, and Charlotte Folinus ’20, SM ’22, of MIT and Ethan Townsend at Evenline used a glass printer that pairs with a furnace to melt crushed glass bottles into a material that can be deposited in layered patterns. They printed prototype bricks using soda-lime glass that is typically used in a glassblowing studio. Two round pegs made of a different material, similar to the studs on a Lego brick, are incorporated into each one so they can interlock. Another material placed between the bricks prevents scratches or cracks but can be removed if a structure is to be dismantled and recycled. The prototypes’ figure-eight shape allows assembly into curved walls, though recycled bricks could also be remelted in the printer and formed into new shapes. The group is looking into whether more of the interlocking feature could be made from printed glass too.
MIT engineers demonstrate how they make strong, reconfigurable bricks out of recycled glass. The team uses custom 3D glass printing technology from MIT spinoff Evenline to create the figure-eight shaped bricks, which are designed to interlock.
The bricks’ mechanical strength was tested in a hydraulic press that squeezed them until they began to fracture. The strongest held up to pressures comparable to what concrete blocks can withstand. The researchers have used the bricks to construct a curved wall and aim to build progressively bigger, self-supporting structures.
“We’re thinking of stepping stones to buildings,” Stern says, “and want to start with something like a pavilion—a temporary structure that humans can interact with, and that you could then reconfigure into a second design. And you could imagine that these blocks could go through a lot of lives.”
With these words, solemnly intoned, members of the MIT Osiris Society began their clandestine meetings for nearly 70 years.
Created in 1903 as a “senior society” and modeled on both the fraternities of Cornell and the mythology of ancient Egypt, Osiris gave MIT’s senior leadership an opportunity to speak frankly and off the record with a group of handpicked student leaders. Its existence was acknowledged, and names of its members appeared in MIT yearbooks, but the deliberative purpose of the society remained secret for decades.
Rather than being based on inductees’ wealth or their family’s political power—common criteria for senior societies at other schools—membership was designated “for those undergraduates who have shown in their daily life an especial love and devotion to the Institute,” reads the once-secret history of Osiris that now resides in MIT’s archives.
This history was written by Edward Pennell Brooks, Class of 1917, as a speech he gave at several Osiris initiations in the early 1950s, but its factual content is attributed to Alfred Edgar Burton, MIT’s first dean of students. If the organization’s purpose were not kept secret, Burton warned, MIT’s leaders wouldn’t be able to have such frank and open discussions with the students.
“It was a very interesting organization—the word I would use is ‘private’ rather than ‘secret,’” says William J. Hecht ’61, SM ’76, who was inducted into Osiris in 1961 and went on to serve as executive vice president and chief executive of the MIT Alumni Association for 25 years. “If something controversial were to come up—a faculty gripe about something—it was a way that the administration or the faculty could air it in front of a small group (we were around a dozen) of ‘student leaders’ and be candid about what’s what.”
Osiris was started by Arthur Jeremiah Sweet, Class of 1904, who transferred to MIT after having a run-in with the fraternities at Cornell. Sweet wanted to create a society without the baggage of the Greek system, so he settled on Egyptian mythology, choosing the god credited with teaching the ancient technology of agriculture to humans. Sweet then assembled an impressive group of student leaders. “When once launched, however, there became a need of finding out what it was to do,” Brooks wrote.
Osiris members met over dinner to discuss issues pertaining to “the welfare and betterment of MIT,” but the group claimed no official power.
MIT ARCHIVES
In stepped Dean Burton, who suggested that Osiris could help President Henry Smith Pritchett better understand MIT’s student body. Pritchett certainly needed help: Shortly after he was inaugurated in 1900, the annual “cane rush” competition between freshmen and sophomores had resulted in a student death. Pritchett then angered many students with his near-successful attempt to merge MIT with Harvard.
“Pritchett grasped this as a chance, so I have been told, to reestablish good relations with leaders of undergraduate life,” the history reads.
Pritchett and Burton thus became the first honorary members of Osiris.
In years that followed, names of inductees appeared occasionally in The Tech, which referred to Osiris as one of many senior societies. Given the growing number of MIT honorary societies, it was a good cover story.
Ten MIT presidents and numerous deans and vice presidents would become honorary members of Osiris; full members included student government leaders and many editors of The Tech, most notably James Rhyne Killian ’26, who became MIT’s 10th president (see “Editor of The Tech becomes president of MIT,” MIT Alumni News, July/August 2024).
Secrecy was so paramount that even using the name Osiris was discouraged.
Burton warned in 1907 that Osiris faced three big dangers. First, “the natural tendency for the meetings to lapse into merely social gathering of congenial spirits.” Second, the possibility that the society would become well known among undergraduates, who would seek to gain membership as a student honor. Third, the way proximity to power might limit the frankness of the discussions. The solution, Burton wrote, was careful guidance of alumni and honorary members to keep Osiris focused on its mission—and to keep its purpose a secret.
Secrecy was so paramount that even using the name Osiris was discouraged. In several letters that Paul E. Gray ’54, SM ’55, ScD ’60, then dean of the School of Engineering, wrote to Osiris member Gregory Jackson ’70 in March 1971, Gray refers to Osiris by the number 270. (Gray had been inducted as an honorary member in 1965 and would become MIT’s 14th president in 1980.) The number referred to 270 Beacon Street, the address of the University Club, where many Osiris members were inducted until the club moved to 40 Trinity Place in 1926. Later, Osiris initiations moved to the Club of Odd Volumes at 77 Mt. Vernon Street, a private club for bibliophiles of which Killian was a member.
“I joined Osiris in my junior year at a meeting of the entire group at a formal dinner at the Club of Odd Volumes in Boston,” recalls Tom Burns ’62, SM ’63. “At the time, we were asked to be somewhere in Boston in a tuxedo [and] were blindfolded and driven around for a while by a senior member of the Society, ending up at the Club to be confronted by a large group of faculty and student members.” (A written description of initiations in the 1960s says that tuxedo-clad initiates typically were told to perform a stunt—such as flying paper airplanes in front of a ticket counter at Logan—while waiting to get picked up.) While two annual meetings were held at the club, Burns says faculty members typically hosted the regular dinner meetings, many in Killian’s penthouse apartment at 100 Memorial Drive. Student members were responsible for selecting the topics and leading the discussions, he says, and picked the next year’s inductees.
Of course, inviting many successive editors of the MIT student newspaper to join a society with such a secret purpose was inherently risky. Sure enough, on February 18, 1955, The Tech ran a front-page article with the headline “Student Leaders Meet With Administration and Faculty In Secret Society, Osiris.” The article was unsigned, as were all news articles at the time, but Stephen N. Cohen ’56, then editor of The Tech, appears on the Osiris membership rolls. (Tellingly, the next three editors—John A. Friedman ’57, Leland E. Holloway Jr. ’58, and Stewart Wade Wilson ’59—do not.) A week later, Eldon H. Reiley ’55, president of MIT’s Undergraduate Association, president of the Institute Committee, and a member of Osiris, published an 11-paragraph statement in The Tech saying, among other things, that “Osiris is an informal group of faculty and students who meet from time to time over dinner and discuss issues pertaining to the welfare and betterment of MIT. The group has no power in itself.”
Reiley wrote the truth: Nowhere in the archives or in interviews with surviving members is there a hint that the student members of Osiris decided anything other than the names of the next year’s recruits.
Howard Wesley Johnson was inducted as an honorary member in 1965, shortly before becoming MIT’s 12th president in 1966. Johnson clearly took his Osiris duties seriously: Its meetings were entered into his appointment book, and when he missed the initiation in 1968, he wrote “to the men of OSIRIS,” apologizing that “business in defense of M.I.T. demands that I be absent.”
Johnson’s letter hints at the forces that ultimately put an end to the organization: Osiris was a relic of the past—for example, it had no female members until 1969—and MIT was under attack in the present.
“I was added in 1969 when I was vice president of the Graduate Student Council,” recalls Marvin Sirbu Jr. ’66, ’67, SM ’68, EE ’70, ScD ’73. “I remember how remarkable it was that students and faculty/administrators met and talked informally in the way that they did at Osiris meetings.”
The names of 11 student members of Osiris appeared in the 1904 Technique beneath a drawing of an iconic statue of the Egyptian god. No explanatory text was included.
TECHNIQUE 1904
Today Howard Johnson’s presidency is remembered for his deft handling of student unrest, including three days in November 1969 when more than a thousand people protested the Institute’s relationship with the US Department of Defense. The documentary November Actions includes film from meetings of a joint committee of faculty and students that helped defuse the situation. While many of the students were members of Osiris, they were present because they were elected student leaders, not because they belonged to the secret society. But Sirbu suggests that the Osiris meetings may explain why those in the room felt so comfortable with each other.
Handwritten minutes from two meetings in the spring of 1971 reveal that topics discussed included marijuana, civility in Osiris meetings, and the possible reemergence of McCarthyism on campus. An article in The Tech reported that topics such as research policy and housing were also typical. But Osiris was in decline. That March, Gray had observed that 34 people had RSVPed “yes” for the March 16 meeting, but only 27 had shown up—and that “actives” (student members) were outnumbered by “over thirties” by about three to one.
A few weeks before Provost Jerome Wiesner became MIT’s president in July 1971, a letter signed by Killian and Johnson went out to members asking for financial donations, signaling the end of the Institute’s financial support for Osiris.
“At the end of my junior year, I was apprised by Dan Nyhart, then MIT’s dean for student affairs, that Osiris was in arrears to the Institute and needed to pay its debt,” recalls Lee Giguere ’73, who joined in 1972 with fellow Tech editor Alex Makowski ’72.
“In those days—the early 1970s—the atmosphere was pretty radical,” he says, and accessing a “private channel to the powers that be” ran counter to his understanding of his role as a reporter. Although he remembers compiling a list of new initiates, there are no records showing that those students were ever invited to join.
But the exact date of Osiris’s demise remains unclear. Burns recalls a conversation with Frederick Fassett, former dean of residence, about the subject in the early 1970s. “He merely said that it had outlived its value, partly as a result of changes experienced in the 1960s,” he says. “I never received any formal notice of its end.”
Brackish groundwater is a major potential source of drinking water in underserved areas of the world, but desalinating it affordably is a challenge. A new system developed by mechanical engineering professor Amos Winter, Jon Bessette, SM ’22, and staff engineer Shane Pratt manages to do the job entirely on solar energy, with no need for batteries or grid power.
The system is a variation of a previous design based on electrodialysis, which uses an electric field to draw out salt ions as water is pumped through a stack of ion-exchange membranes. That design incorporated both a solar array and a sensor-based control system that dialed the desalting process up and down in response to the amount of sunlight available, but it made the necessary calculations only every three minutes.
(Left to right): Jon Bessette, Shane Pratt, and Muriel McWhinnie (UROP) stand in front of the electrodialysis desalination system during an installation in July.
SHANE PRATT
“In that time, a cloud could literally come by and block the sun,” Winter says. So backup batteries were still needed.
The new system, however, updates the desalination rate three to five times per second. That means it doesn’t have to make up for any lag in solar energy, so it doesn’t require batteries for energy storage.
In a six-month trial in New Mexico, a prototype produced up to 5,000 liters per day despite large swings in weather and available sunlight—typically while harnessing more than 94% of the electrical energy generated by its solar panels. The team hopes to launch a company based on the technology soon.
Two MIT professors, an alumnus, and a former postdoc are among the winners of 2024’s Nobel Prizes.
From left: Daron Acemoglu, Simon Johnson, Victor Ambros, and Gary Ruvkun
ADAM GLANZMAN (ACEMOGLU); MICHELLE FIORENZA (JOHNSON); COURTESY OF UMASS CHAN MEDICAL SCHOOL (AMBROS); COURTESY OF THE HARVARD GAZETTE (RUVKUN)
Professors Daron Acemoglu and Simon Johnson, PhD ’89, shared the prize in economics with political scientist James Robinson of the University of Chicago, with whom they have long collaborated. Using evidence from the last 500 years, their work has empirically demonstrated that “inclusive” governments such as democracies, which extend individual rights and political liberties while upholding the rule of law, have generated greater economic activity than “extractive” political systems, where power is wielded by a small elite. Partly because economic growth depends on technological innovation, it is best sustained when countries protect property rights, giving more people the incentive to invent things.
Acemoglu, an Institute Professor, has been a member of the MIT faculty since 1993. Johnson, the Ronald A. Kurtz Professor of Entrepreneurship at MIT Sloan, was chief economist of the International Monetary Fund from 2007 to 2008.
Meanwhile, Victor Ambros ’75, PhD ’79, a professor at the University of Massachusetts Chan Medical School, and Gary Ruvkun, a professor at Harvard Medical School and Massachusetts General Hospital, shared the prize in medicine for their discovery of microRNA, a class of tiny RNA molecules that help govern gene regulation. This crucial mechanism allows cells with the same chromosomes to develop into cell types with different characteristics and functions.
The foundation for their discoveries was laid by their work on mutant forms of the roundworm C. elegans as MIT postdocs in the lab of Professor H. Robert Horvitz (who would win a Nobel in 2002). Later, working independently, they showed that a certain roundworm gene produces a very short RNA molecule that binds to messenger RNA encoding a different gene and blocks it from being translated into protein. Since then, more than 1,000 microRNA genes have been found in humans.
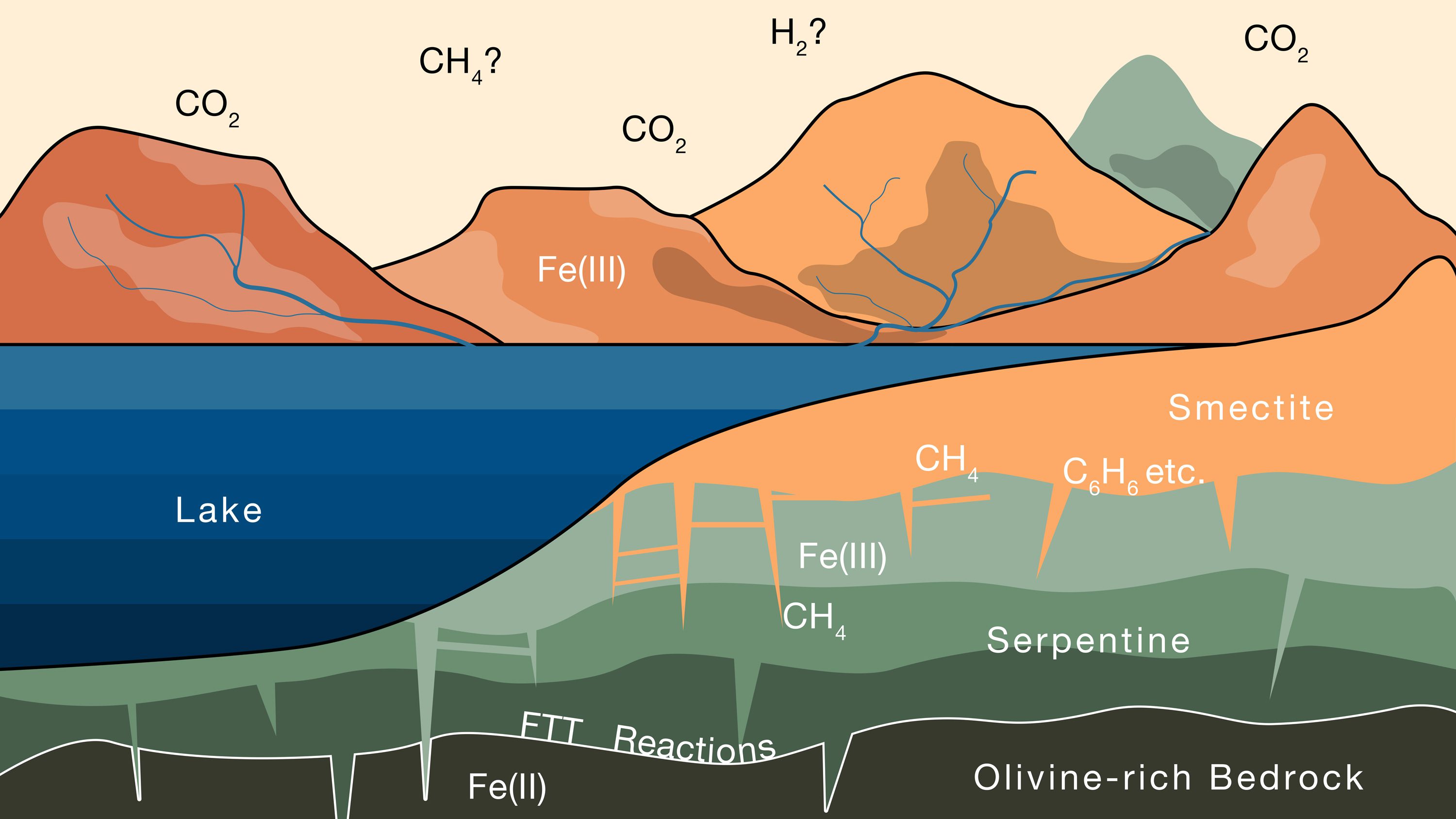
Despite increasing evidence that water flowed on Mars billions of years ago, scientists have been mystified by what happened to the thick, carbon dioxide–rich atmosphere that must have once kept that water from freezing.
Now two MIT geologists think they know. Geology professor Oliver Jagoutz and Joshua Murray, PhD ’24, propose that much of this missing atmosphere could be locked up in the planet’s clay-covered crust.
While water was present on Mars, they suggest, the liquid could have trickled through certain rock types and set off a slow chain of reactions that progressively drew carbon dioxide out of the atmosphere and converted it into methane, a form of carbon that could be stored in the clay for eons.
This schematic illustrates the progressive alteration of iron-rich rocks on Mars as the rocks interact with water containing CO2 from the atmosphere. Over several billion years, this process could have stored enough CO2 in the clay surface, in the form of methane, to explain most of the CO2 that went missing from the planet’s early atmosphere.
COURTESY OF THE RESEARCHERS
The researchers applied their knowledge of interactions between rocks and gases on Earth to how similar processes could play out on Mars. They found that the quantity of clay covering the Martian surface could hold up to 1.7 bar of CO2, which would be equivalent to around 80% of the planet’s early atmosphere. “In some ways, Mars’s missing atmosphere could be hiding in plain sight,” Murray says.
The researchers think it’s possible that this sequestered carbon could one day be recovered and converted into propellant to fuel future missions between Mars and Earth.
Every December we publish a rundown of innovative marketing campaigns for the year. We handpick campaigns from established companies that have received awards and recognition or that we encountered directly.
Here is a list of outstanding marketing campaigns for 2024. The campaigns feature collaborations, dupes, celebrity spots, mobile apps, mascots, dance routines, pop-ups, and AI-powered videos.
In a campaign to help people socialize, Heineken released The Boring Mode app. With a single swipe, The Boring Mode turns a smartphone into a boring phone, blocking other social and work apps, notifications, and even the camera for a set period. During events, including the Amsterdam Dance Event and Live Out Festival in Mexico, Heineken activated hidden messages when people held up their mobile phones to encourage them to turn their smartphones boring and keep the moment in their memory, not on their phones.
McDonald’s secretly introduced a Chicken Big Mac, a spin on the classic menu item through a dupe of an L.A. pop-up called McDonnell’s by Chain. McDonald’s also enlisted influencer Kai Cenat to stir debate on whether or not a Chicken Big Mac is a Big Mac. McDonald’s then launched the Chicken Big Mac on October 10, allowing followers to order the item and decide for themselves.
Squarespace teamed up with creative visionary Rick Rubin, co-founder of Def Jam Recordings and former co-president of Columbia Records, to build Tetragrammaton, an online world of curated materials, and a new website template, Transmission. Inspired by Rubin’s Tetragrammaton, Transmission is a minimally designed, customizable framework for anyone to share their interests, with layouts showcasing audiovisual media and members-only content.
Qatar Airways launched an AI-powered “Star in Your Own Adventure” campaign, in which viewers select from multiple scenes within a film to star in the leading roles. Through AI technology, the characters become a reflection of the viewer’s appearance, adapting to their facial features and skin tone. The immersive experience now offers holiday-centric moments, including an elf, snowman, gingerbread person, and cheerful characters, inviting participants to star in their personalized holiday-themed Qatar Airways film.
Calvin Klein has launched its winter 2024 collection campaign, starring Jeremy Allen White from “The Bear” television series. This is the third global campaign with White. While the previous two focused on White in Calvin Klein’s emblematic underwear, the new campaign features classic, understated styles, demonstrating the brand’s ability to remain relevant and give fans what they want.
Liquid Death canned water collaborated with E.l.f. Cosmetics to launch Corpse Paint. Liquid Death wants to help consumers “murder” their thirst and prefers irreverent and organic marketing over advertising. Brand collaborations allow Liquid Death to inject its spirit and provide the partner brand with an opportunity to expand and do something unexpected. The Corpse Paint collaboration captured more than 250 million social impressions. Other recent collaborations with Liquid Death include sparkling water with ice cream chain Van Leeuwen and a casket cooler with Yeti.
Mattel is celebrating Polly Pocket‘s 35th birthday by making the pocket-sized doll an Airbnb host and opening her two-story Slumber Party Fun compact, a 42-foot-tall structure in Littleton, Massachusetts. Guests experienced a retro picnic, beauty fun with Polly’s vanity, fashion try-ons with Polly’s closet, slumber party fun in Polly’s Action Park Tent, and more. Guests booked stays for September 12 to 14. Polly’s home was also opened for 21 daytime experiences for up to 12 guests each from September 16 to October 6. Guests were responsible for travel to and from Littleton, Massachusetts. The location showed the popularity of Airbnb.
Gap ran a fall 2024 campaign called “Get Loose,” which starred global pop star Troye Sivan and the dance group CDK Company. Set to Thundercat’s viral hit “Funny Thing,” the film features original choreography showcasing dancers in baggy and loose-fit denim. Sivan is known for his music videos, featuring elaborate and sometimes racy dance routines, and has a combined social following of over 39 million. As part of the campaign, Sivan created an in-store playlist on Spotify. With the Thundercat soundtrack, Gap is tapping into viral TikTok songs, celebrity ambassadors, and dance-heavy advertising to reach Gen Z consumers.
In 2023, Pop-Tarts signed a multi-year agreement to become the title sponsor of the college football Pop-Tarts Bowl game, originally commissioned as the Sunshine Classic. To celebrate the event, Pop-Tarts launched the “first edible mascot” last December. The Kansas State football team devoured a Frosted Strawberry mascot in a viral event on social media. For this year, the game’s MVP will select one of three flavors to “ascend to ‘mouth heaven.’” In the run-up to the game, consumers can guess the third flavor, purchase limited-edition Pop-Tarts Printed Fun Mascot Packs, and follow along on Instagram and TikTok.
Coca-Cola launched three short AI-generated video ads for Christmas, and the results have sparked backlash on social media and in the press. Three AI studios (Secret Level, Silverside AI, and Wild Card) produced the ads using the generative AI models Leonardo, Luma, Runway, and Kling. The ads highlight the weaknesses and limitations of current video-generation models, such as difficulties with proportionality and natural movement. While the ads are essentially derivatives of the Coca-Cola Christmas ads from 1995, the new AI-powered experiments have drawn much attention and sparked conversation, which is not necessarily bad.
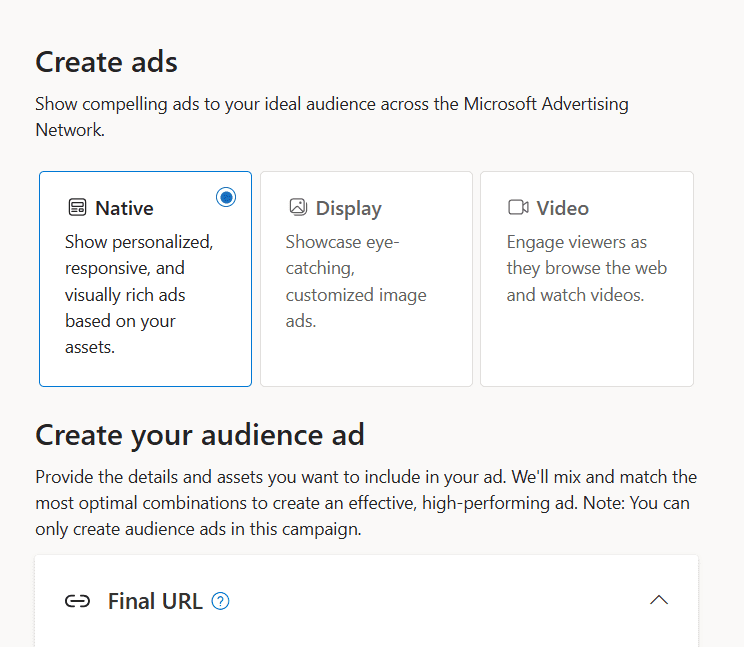
Following on the footsteps of Performance Max campaigns, Microsoft Ads launched multi-format campaigns for Audience Ads.
This new feature allows advertisers to create a single campaign that seamlessly integrates various ad formats, including native, display, and online video ads.
Upon its launch, multi-format campaigns for Audience ads are available globally and now the default selection when creating a new Audience ads campaign.
Benefits of Multi-Format Campaigns
The new campaign type comes with several advantages to advertisers, including:
More cohesive campaign management: You now only need one audience ads campaign for different ad formats across display, native, and video. Previously, you would’ve needed to set up different campaigns for each ad format.
Easier budget management: You can manage and optimize your campaign budget across the different ad formats all within one campaign.
Continued flexibility: The ability to create separate campaigns for different ad formats still exists, giving your account the flexibility it needs to optimize according to its goals.
How to Set Up A Multi-Format Campaign
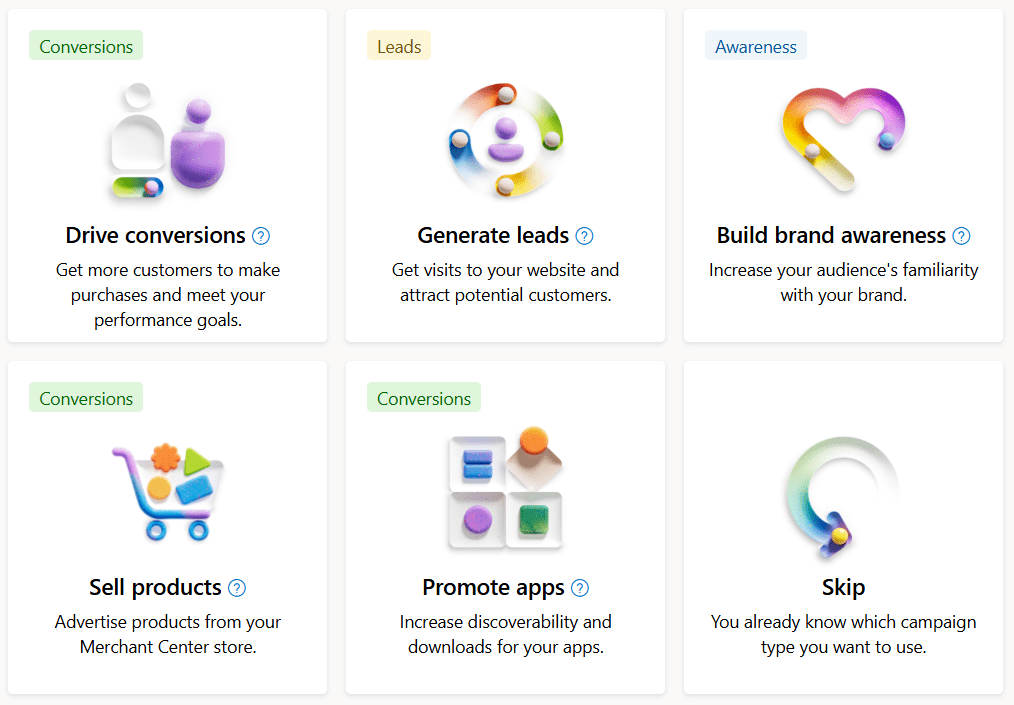
In order to use multi-format campaigns, you need to choose a campaign objective of either of the following:
Drive conversions
Generate leads
Build brand awareness
Screenshot taken by author, December 2024.
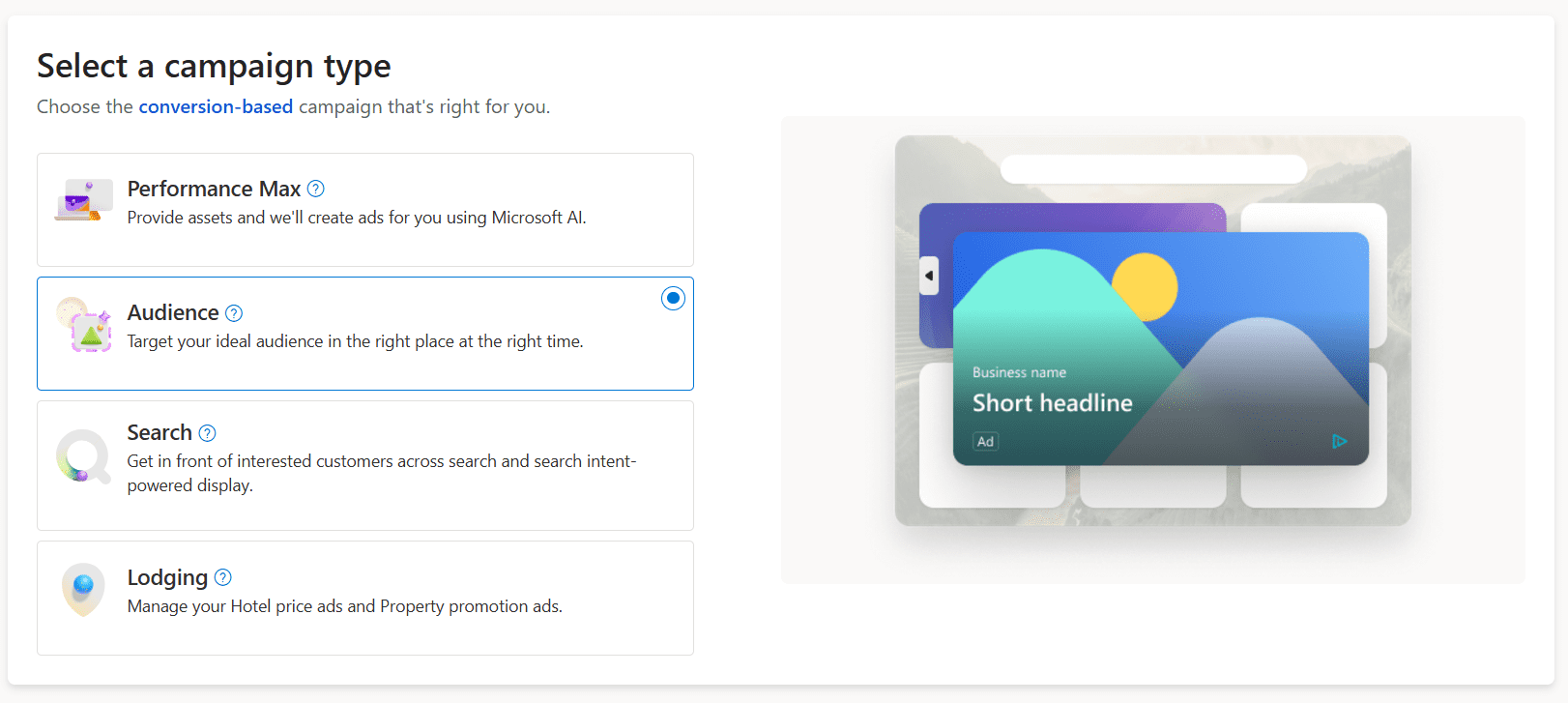
Then, you’ll choose “Audience” as the campaign type.
Screenshot taken by author, December 2024
During the campaign creation process, you can select the different types of ad formats. You can choose just one, or all three ad formats depending on your assets and your goals.
Screenshot taken by author, December 2024
After creating your first ad format, you’ll scroll down to the bottom and either select “continue” or “Save and create another ad” to create the additional ad formats within the same campaign:
Screenshot taken by author, December 2024
After creating all your ad formats, you’ll follow the remainder of the typical campaign steps, like:
Targets and locations
Budgets and bid strategies
Ad group settings
Create A More Cohesive Campaign To Drive Results
This update reflects Microsoft Ads’ commitment to evolving its platform to meet the needs of modern advertisers.
By offering a streamlined, flexible solution for combining ad formats, Microsoft makes it easier for advertisers to reach their audiences across diverse channels without the complexity of managing multiple campaigns.
It’s especially helpful for advertisers with smaller budgets that want to use Audience ads, but don’t have the budget to set up three different campaigns just to use each ad format.
For advertisers looking to maximize efficiency and deliver cohesive messaging across native, display, and video ads, multi-format campaigns provide an innovative solution.
Will you be giving multi-format campaigns a try in 2025?
If you want more quality in your pipeline, you need more quality in your marketing efforts.
That means you should focus more on your ideal customer profile (ICP) and their journey to conversion.
Reflecting on the year, I can tell you that these are some of the most impactful places to spend time and resources to support a more quality-driven pipeline.
I just saw a post in my social feed that could not have been more timely:
Content is your round-the-clock salesperson.
It can reach more people in one day that you’ll meet in a lifetime.
The content that you’re putting out there is dictating the type of lead you’re going to get from that content.
So, when you’re looking at your pipeline, what do you see?
I hear it from organizations all the time. They want leads in their pipeline who are most likely to convert (i.e., high quality).
And I also see the efforts they’re putting in, and there’s so much opportunity they’re missing.
The bottom line: If you’re looking for higher quality in your pipeline, you need higher quality in your marketing efforts.
To inject more quality into your marketing efforts, you need to build a content strategy based on what your ideal customer wants and needs to solve their pain.
So, step back and audit: What is your round-the-clock salesperson selling for your business? Is it attracting the right leads?
Quality can no longer be an afterthought for your marketing team, and the executive team needs to get on board, too.
The stuff in this article isn’t new. But sometimes, we need reminders of the foundations.
My hope is that it gives you at least one ah-ha moment to help you be more intentional – and successful – with your lead generation efforts.
How To Shift To Quality-Driving Marketing Strategies
I’ve had the pleasure of moderating half our 45 webinars this year with some great experts!
There are some resounding themes that surface across them all. The importance of quality, branding, consistency, and holistic strategies came to the top of the list.
And have you noticed all the branding articles in your LinkedIn feed, or is it just my algo? Psst … it’s because it’s important…
With leaner teams, leaner budgets, and leaner attention span (and let’s not forget all the changes in search this year), marketers just don’t have the resources to “try it and see what happens.”
There are some places you can focus your resources on that can have a big impact on the quality of leads you attract and retain.
First, you have to understand all the content touchpoints your audience needs to help nurture them into the next phase along their journey.
Think about call-to-action (CTA) to get them into your pipeline, and educate them if they’re not ready to convert yet. (This is where alignment with sales will be an essential part of this strategy planning.)
A solid strategy tells your story, delivers value throughout the customer journey, and woos your audience with a solution that fits their needs.
No more creating content that doesn’t serve your audience.
Notice what I said: Your audience needs. Put yourself in their shoes and create content that informs and shows value.
The Importance Of Intent-Driven Content To Support Journeys
Remember those leaner teams, leaner attention span? Teams don’t have time to do all the things. Plus, consumers don’t have time to focus on all the content that hits them.
So, focus your attention on places that matter.
Intent-driven content supports journeys by focusing on the content relevant to the ICPs you want to grow, helping streamline content creation.
Using the research from the ICPs and sales and marketing alignment, this is where you’ll create targeted pieces that address specific pain points or needs at that moment of the journey.
Content is tailored for each stage of the journey (awareness, consideration, decision, retention, advocacy), and showcases your value at that stage.
When coupled with your first-party data, you can create a personalized experience to make them feel seen. This helps build loyalty.
Email/CRM Automation Is The Easiest And Fastest Way To Inject Quality Content Into Customer Journeys
We all know that it costs more to attract new customers. So, start by looking at the leads you already have. Improve their experience with you.
You have gold at your fingertips. Use data you have on your leads (i.e., demographics, firmographics, engagement, behavior) to help you understand where leads are in their journey and how you can nurture them with targeted content. This also serves as the foundation for leading scoring.
Tip: Use third-party compilers to enrich missing or outdated data that would be helpful to your segmentation strategy, like accuracy, buyer intent, company size, revenue, etc.
Lead scoring is often overlooked by many sales teams. This functionality, available in CRMs, can help you easily identify where leads are in their marketing journey and how qualified they truly are.
Leads get scored based on the likelihood they will convert. For each demographic or firmographic they have that matches your core ICP, they get points.
Plus, they get additional points for each action they take on your site.
Sales and marketing need to collaborate here on what data points, actions, and behaviors get what score. The idea is that the higher the score, the more likely that the lead is a qualified lead.
Once a lead hits a certain score (determined and agreed upon by the team), the most qualified leads get pushed to your sales team to nurture and close (SQLs, sales qualified leads), and the lower scores stay with marketing for automated nurturing (MQLs, marketing qualified leads).
Using these data-based insights, give them a custom experience to show them you’re here to help and provide value.
The onboarding process is the most important part of their interaction with your brand. That first email is the first impression of how you’re going to interact with them. Let’s do a quick audit:
First, can you tell, based on how they got in your pipeline and what actions they’ve taken on your site, what stage of the journey they’re in?
Second, does that onboarding content match that stage?
Where I see most lost opportunities is when brands go for the direct sell, even if the lead is still in those awareness/consideration stages.
In those stages, they need information to educate and nurture them to conversion. A direct sales push could have them unsubscribing if you’re not providing value, making it more difficult to get them into your pipeline again.
Beyond onboarding, look at your journey stages or the segments of the audience you have.
Once you have the journey mapped, look at the content you already have that can support the journey. Fill gaps where needed.
Use one piece of content to make several (“sweat the assets”). Try different formats to help reach users with media that is more palatable for them.
And, most of all, lean on sales and customer service to help develop content you don’t have.
Automation Within Your CRM Is Powerful
If the tech gods didn’t want us to use technology, they wouldn’t have blessed us with all the toys we have.
For this article, I’m going to focus on the automation within your CRM/email platform that can help you be more efficient and effective with your resources, and enable your sales to spend their time on the most valuable leads.
Automation can be set up to tag users based on actions or behavior, which helps increase or decrease lead scores.
The key benefit of lead scores is that you can send only the most qualified leads (SQLs) to your sales team. Let marketing nurture those who aren’t ready yet.
Then, building on the segmentation and scoring above, with the right setup and triggers, you can identify their place in the journey and provide them with the right content at the right time.
Example: We have prospecting flows set up for readers who download one of our ebooks, but don’t subscribe to our newsletter.
The goal is to get users who don’t subscribe to our newsletter to do so.
These are fairly robust flows and contain multiple branches with personalized content based on website behavior, content engagement, self-identified interests, and other attributes.
We entice them with content based on interests. Below, you can see emails, delays in timing, and triggers to push them to other workflows.
Image from author, December 2024
You can use automation to provide that intent-driven content we talked about above.
Your strategy should include thinking clearly through the customer journey to current customers (think upsell, cross-sell, retention).
Automation can be used across the journey and is great for converting abandoned carts, showing personalized offers to users on your site, or getting prospects to convert into your newsletter.
There’s so much more to unpack here, but hopefully, you can envision how workflows are powered by data and segmentation and help your team spend their time in other places by nurturing leads for you.
Targeted Retargeting
There’s power in building a well-intentioned segmentation and tagging workflows.
Building on the segmentation above, you can serve targeted ads to leads or customers when they’re on their favorite social media site or just browsing the web.
If you’re running retargeting, how much personalization is going into it? Or are you going straight for the bottom of the funnel?
This is another opportunity to show you’re listening, you know them, build loyalty, and stay top-of-mind.
Join Your Marketing And Sales Teams (& Customer Service) At The Hip
I’ll say it again: If you want more quality in your pipeline, you need more quality in your marketing efforts.
You have a wealth of knowledge under your roof. How well are you leveraging it? Here’s your chance to knowledge-share in order to make more informed decisions.
In order to put your best efforts into the most impactful places, sales and marketing should collaborate on ICP development, a content strategy to attract, nurture, and retain customers, and, of course, a feedback loop on lead quality.
Marketing needs to hear the good, the bad, and the ugly of their efforts.
When you’re looking at marketing to drive quality leads more than anything, feedback on customer interactions gives them a vantage point to create/modify content that speaks more closely to their needs.
For your sales team, knowing the customer more deeply enables them to personalize efforts during their sales journey, and create more meaningful connections.
This builds trust, increases the likelihood of closing deals, and helps with greater customer satisfaction and loyalty.
Communication and feedback are really the core components here.
I could go on and on here, so let me know if a deeper post might interest you.
Actions For Sales & Marketing Alignment:
Collaborative persona development: marketing can provide data on market trends and behaviors, while the sales team contributes insights from direct customer interactions.
Regular communication between teams: Slack, standups, joint training sessions.
Collaborate on nurture sequences – a place content mismatch can break a deal.
It’s important to note that ICP knowledge and sales and marketing collaboration are the foundational blocks for success. Everything in this post hinges on this working partnership.
Holistic Marketing Campaigns For A Full, Consistent Journey
A holistic marketing strategy takes into account all stages of the journey, and that different people consume content differently across multiple channels.
This is your opportunity to test different content formats with different CTAs.
You may find that certain content formats perform better on specific channels, and optimize toward that.
To keep building on quality, maintaining brand consistency is so important here.
The more types of content and channels you put them on, the more imperative it is that you treat each as an extension of the current campaign and not a one-off.
Nothing can turn off a lead faster than an inconsistent experience. They see that as a reflection of your brand and the rest of the journey with you.
Get Real About Costs And What You’re Willing To Pay For A Lead
I said it before: “Investing in quality resources for lead generation may mean higher costs, but it can lead to higher quality leads and lower overall Customer Acquisition Costs (CAC).”
CRM access and continual feedback from sales fill a blind spot to help marketing more fully understand lead quality and where content/channels need to be tweaked.
It’s up to marketing to convey the value of the marketing and the expected return on the investment.
Sometimes, ROI is long term and not easily realized in the short term. And, not all metrics or journey stages are going to be easy to quantify.
When presenting the plan to stakeholders, take the time to go through shifts in strategy and provide the whys behind it.
Explain the importance of focusing on content to drive better leads, and tell the story. Show the numbers.
And, use examples that might help them reflect on their own buying habits to get the buy-in you’re looking for.
Which brings us to a stakeholder’s favorite marketing excuse…
Get Real About What You Can Track And What You Don’t Need To Track
Not every click or conversion holds the same weight. This will become evident when you plan your lead scoring. And it’s time we stopped treating marketing performance metrics that way, too.
Sure, it’s easy to track form fills on a gated whitepaper in the consideration phase, but it’s not as easy to track awareness efforts from an optimized blog post.
Yet, that blog post counts as a touchpoint along the journey, and needs to have budget and resources allocated to it.
This is where asking for budget and showing attribution gets tricky. With the move to quality, lead costs can be more expensive (especially at first while you’re optimizing).
Stakeholders and your CFO are asking how many of those awareness leads converted and at what cost – when, in reality, those may not be realized for months or years, depending on your sales cycle.
So, what do you track? It depends. For each stage of the journey, you will have different metrics to track across different media types.
Awareness pieces are designed to drive engagement, so it usually doesn’t make sense to push a “buy now” CTA when they’re just becoming acquainted with your brand.
Podcasts, for example, are an awareness tool. You should track downloads, listening time, reviews, and followers.
For a blog post, tracking track time on site, scroll depth, along with any engagement like social shares of blog posts.
You might not be able to directly attribute these efforts to sales, but they do aid in the sale process and, as such, need resources.
If your efforts are well-developed and backed with insightful data, these awareness pieces should help you continue nurturing leads along the way.
Be patient, but also be testing.
Adapt your thinking to evaluate lifetime value rather than needing to value each individual touchpoint.
Adapt Or Get Left Behind
There are so many more things I could have talked about. I feel remiss that I didn’t even touch on AI, but that’s a whole post we’ll save for another day.
Quick plug for AI: Let it be your sidekick, your research assistant, the Robin to your Batman. Use AI to help automate tasks that are taking up human resources. Think about where you need humans to do the work, and see what you can offload to AI. I also use AI to inspire me when I’m short on time. It can also help you analyze data or perform competitor research.
Building the strategy, journeys, and segmentation to power the personalization and automation engine will take your team time. Be tenacious and patient – don’t wait for perfection.
Know that your email is golden, and can be your biggest source of conversions, especially if segmented properly. This is your chance to have one-on-one conversations and meet prospects where they are in their journey.
A strong segmentation strategy will help with lead-scoring power automation and support a great retargeting strategy.
Now, it’s time to get real about what you’re willing to pay for a quality lead, what resources need to go into making that happen, and what makes sense to track as you forge into this new strategy.
Here’s to driving quality leads and focusing on the journey in 2025!