Separating AI reality from hyped-up fiction isn’t always easy. That’s why we’ve created the AI Hype Index—a simple, at-a-glance summary of everything you need to know about the state of the industry.
Millions of us use chatbots every day, even though we don’t really know how they work or how using them affects us. In a bid to address this, the FTC recently launched an inquiry into how chatbots affect children and teenagers. Elsewhere, OpenAI has started to shed more light on what people are actually using ChatGPT for, and why it thinks its LLMs are so prone to making stuff up.
There’s still plenty we don’t know—but that isn’t stopping governments from forging ahead with AI projects. In the US, RFK Jr. is pushing his staffers to use ChatGPT, while Albania is using a chatbot for public contract procurement. Proceed with caution.
Some AI chatbots rely on flawed research from retracted scientific papers to answer questions, according to recent studies. The findings, confirmed by MIT Technology Review, raise questions about how reliable AI tools are at evaluating scientific research and could complicate efforts by countries and industries seeking to invest in AI tools for scientists.
AI search tools and chatbots are already known to fabricate links and references. But answers based on the material from actual papers can mislead as well if those papers have been retracted. The chatbot is “using a real paper, real material, to tell you something,” says Weikuan Gu, a medical researcher at the University of Tennessee in Memphis and an author of one of the recent studies. But, he says, if people only look at the content of the answer and do not click through to the paper and see that it’s been retracted, that’s really a problem.
Gu and his team asked OpenAI’s ChatGPT, running on the GPT-4o model, questions based on information from 21 retracted papers about medical imaging. The chatbot’s answers referenced retracted papers in five cases but advised caution in only three. While it cited non-retracted papers for other questions, the authors note that it may not have recognized the retraction status of the articles. In a study from August, a different group of researchers used ChatGPT-4o mini to evaluate the quality of 217 retracted and low-quality papers from different scientific fields; they found that none of the chatbot’s responses mentioned retractions or other concerns. (No similar studies have been released on GPT-5, which came out in August.)
The public uses AI chatbots to ask for medical advice and diagnose health conditions. Students and scientists increasingly usescience-focused AI tools to review existing scientific literature and summarize papers. That kind of usage is likely to increase. The US National Science Foundation, for instance, invested $75 million in building AI models for science research this August.
“If [a tool is] facing the general public, then using retraction as a kind of quality indicator is very important,” says Yuanxi Fu, an information science researcher at the University of Illinois Urbana-Champaign. There’s “kind of an agreement that retracted papers have been struck off the record of science,” she says, “and the people who are outside of science—they should be warned that these are retracted papers.” OpenAI did not provide a response to a request for comment about the paper results.
The problem is not limited to ChatGPT. In June,MIT Technology Review tested AI tools specifically advertised for research work, such as Elicit, Ai2 ScholarQA (now part of the Allen Institute for Artificial Intelligence’s Asta tool), Perplexity, and Consensus, using questions based on the 21 retracted papers in Gu’s study. Elicit referenced five of the retracted papers in its answers, while Ai2 ScholarQA referenced 17, Perplexity 11, and Consensus 18—all without noting the retractions.
Some companies have since made moves to correct the issue. “Until recently, we didn’t have great retraction data in our search engine,” says Christian Salem, cofounder of Consensus. His company has now started using retraction data from a combination of sources, including publishers and data aggregators, independent web crawling, and Retraction Watch, which manually curates and maintains a database of retractions. In a test of the same papers in August, Consensus cited only five retracted papers.
Elicit told MIT Technology Review that it removes retracted papers flagged by the scholarly research catalogue OpenAlex from its database and is “still working on aggregating sources of retractions.” Ai2 told us that its tool does not automatically detect or remove retracted papers currently. Perplexity said that it “[does] not ever claim to be 100% accurate.”
However, relying on retraction databases may not be enough. Ivan Oransky, the cofounder of Retraction Watch, is careful not to describe it as a comprehensive database, saying that creating one would require more resources than anyone has: “The reason it’s resource intensive is because someone has to do it all by hand if you want it to be accurate.”
Further complicating the matter is that publishers don’t share a uniform approach to retraction notices. “Where things are retracted, they can be marked as such in very different ways,” says Caitlin Bakker from University of Regina, Canada, an expert in research and discovery tools. “Correction,” “expression of concern,” “erratum,” and “retracted” are among some labels publishers may add to research papers—and these labels can be added for many reasons, including concerns about the content, methodology, and data or the presence of conflicts of interest.
Some researchers distribute their papers on preprint servers, paper repositories, and other websites, causing copies to be scattered around the web. Moreover, the data used to train AI models may not be up to date. If a paper is retracted after the model’s training cutoff date, its responses might not instantaneously reflect what’s going on, says Fu. Most academic search engines don’t do a real-time check against retraction data, so you are at the mercy of how accurate their corpus is, says Aaron Tay, a librarian at Singapore Management University.
Oransky and other experts advocate making more context available for models to use when creating a response. This could mean publishing information that already exists, like peer reviews commissioned by journals and critiques from the review site PubPeer, alongside the published paper.
Many publishers, such as Nature and the BMJ, publish retraction notices as separate articles linked to the paper, outside paywalls. Fu says companies need to effectively make use of such information, as well as any news articles in a model’s training data that mention a paper’s retraction.
The users and creators of AI tools need to do their due diligence. “We are at the very, very early stages, and essentially you have to be skeptical,” says Tay.
Ananya is a freelance science and technology journalist based in Bengaluru, India.
Imagine this: You’ve been feeling unwell, so you call up your doctor’s office to make an appointment. To your surprise, they schedule you in for the next day. At the appointment, you aren’t rushed through describing your health concerns; instead, you have a full half hour to share your symptoms and worries and the exhaustive details of your health history with someone who listens attentively and asks thoughtful follow-up questions. You leave with a diagnosis, a treatment plan, and the sense that, for once, you’ve been able to discuss your health with the care that it merits.
The catch? You might not have spoken to a doctor, or other licensed medical practitioner, at all.
This is the new reality for patients at a small number of clinics in Southern California that are run by the medical startup Akido Labs. These patients—some of whom are on Medicaid—can access specialist appointments on short notice, a privilege typically only afforded to the wealthy few who patronize concierge clinics.
The key difference is that Akido patients spend relatively little time, or even no time at all, with their doctors. Instead, they see a medical assistant, who can lend a sympathetic ear but has limited clinical training. The job of formulating diagnoses and concocting a treatment plan is done by a proprietary, LLM-based system called ScopeAI that transcribes and analyzes the dialogue between patient and assistant. A doctor then approves, or corrects, the AI system’s recommendations.
“Our focus is really on what we can do to pull the doctor out of the visit,” says Jared Goodner, Akido’s CTO.
According to Prashant Samant, Akido’s CEO, this approach allows doctors to see four to five times as many patients as they could previously. There’s good reason to want doctors to be much more productive. Americans are getting older and sicker, and many struggle to access adequate health care. The pending 15% reduction in federal funding for Medicaid will only make the situation worse.
But experts aren’t convinced that displacing so much of the cognitive work of medicine onto AI is the right way to remedy the doctor shortage. There’s a big gap in expertise between doctors and AI-enhanced medical assistants, says Emma Pierson, a computer scientist at UC Berkeley. Jumping such a gap may introduce risks. “I am broadly excited about the potential of AI to expand access to medical expertise,” she says. “It’s just not obvious to me that this particular way is the way to do it.”
AI is already everywhere in medicine. Computer vision tools identify cancers during preventive scans, automated research systems allow doctors to quickly sort through the medical literature, and LLM-powered medical scribes can take appointment notes on a clinician’s behalf. But these systems are designed to support doctors as they go about their typical medical routines.
What distinguishes ScopeAI, Goodner says, is its ability to independently complete the cognitive tasks that constitute a medical visit, from eliciting a patient’s medical history to coming up with a list of potential diagnoses to identifying the most likely diagnosis and proposing appropriate next steps.
Under the hood, ScopeAI is a set of large language models, each of which can perform a specific step in the visit—from generating appropriate follow-up questions based on what a patient has said to to populating a list of likely conditions. For the most part, these LLMs are fine-tuned versions of Meta’s open-access Llama models, though Goodner says that the system also makes use of Anthropic’s Claude models.
During the appointment, assistants read off questions from the ScopeAI interface, and ScopeAI produces new questions as it analyzes what the patient says. For the doctors who will review its outputs later, ScopeAI produces a concise note that includes a summary of the patient’s visit, the most likely diagnosis, two or three alternative diagnoses, and recommended next steps, such as referrals or prescriptions. It also lists a justification for each diagnosis and recommendation.
ScopeAI is currently being used in cardiology, endocrinology, and primary care clinics and by Akido’s street medicine team, which serves the Los Angeles homeless population. That team—which is led by Steven Hochman, a doctor who specializes in addiction medicine—meets patients out in the community to help them access medical care, including treatment for substance use disorders.
Previously, in order to prescribe a drug to treat an opioid addiction, Hochman would have to meet the patient in person; now, caseworkers armed with ScopeAI can interview patients on their own, and Hochman can approve or reject the system’s recommendations later. “It allows me to be in 10 places at once,” he says.
Since they started using ScopeAI, the team has been able to get patients access to medications to help treat their substance use within 24 hours—something that Hochman calls “unheard of.”
This arrangement is only possible because homeless patients typically get their health insurance from Medicaid, the public insurance system for low-income Americans. While Medicaid allows doctors to approve ScopeAI prescriptions and treatment plans asynchronously, both for street medicine and clinic visits, many other insurance providers require that doctors speak directly with patients before approving those recommendations. Pierson says that discrepancy raises concerns. “You worry about that exacerbating health disparities,” she says.
Samant is aware of the appearance of inequity, and he says the discrepancy isn’t intentional—it’s just a feature of how the insurance plans currently work. He also notes that being seen quickly by an AI-enhanced medical assistant may be better than dealing with long wait times and limited provider availability, which is the status quo for Medicaid patients. And all Akido patients can opt for traditional doctor’s appointments, if they are willing to wait for them, he says.
Part of the challenge of deploying a tool like ScopeAI is navigating a regulatory and insurance landscape that wasn’t designed for AI systems that can independently direct medical appointments. Glenn Cohen, a professor at Harvard Law School, says that any AI system that effectively acts as a “doctor in a box” would likely need to be approved by the FDA and could run afoul of medical licensure laws, which dictate that only doctors and other licensed professionals can practice medicine.
The California Medical Practice Act says that AI can’t replace a doctor’s responsibility to diagnose and treat a patient, but doctors are allowed to use AI in their work, and they don’t need to see patients in-person or in real-time before diagnosing them. Neither the FDA nor the Medical Board of California were able to say whether or not ScopeAI was on solid legal footing based only on a written description of the system.
But Samant is confident that Akido is in compliance, as ScopeAI was intentionally designed to fall short of being a “doctor in a box.” Because the system requires a human doctor to review and approve of all of its diagnostic and treatment recommendations, he says, it doesn’t require FDA approval.
At the clinic, this delicate balance between AI and doctor decision making happens entirely behind the scenes. Patients don’t ever see the ScopeAI interface directly—instead, they speak with a medical assistant who asks questions in the way that a doctor might in a typical appointment. That arrangement might make patients feel more comfortable. But Zeke Emanuel, a professor of medical ethics and health policy at the University of Pennsylvania who served in the Obama and Biden administrations, worries that this comfort could be obscuring from patients the extent to which an algorithm is influencing their care.
Pierson agrees. “That certainly isn’t really what was traditionally meant by the human touch in medicine,” she says.
DeAndre Siringoringo, a medical assistant who works at Akido’s cardiology office in Rancho Cucamonga, says that while he tells the patients he works with that an AI system will be listening to the appointment in order to gather information for their doctor, he doesn’t inform them about the specifics of how ScopeAI works, including the fact that it makes diagnostic recommendations to doctors.
Because all ScopeAI recommendations are reviewed by a doctor, that might not seem like such a big deal—it’s the doctor who makes the final diagnosis, not the AI. But it’s been widely documented that doctors using AI systems tend to go along with the system’s recommendations more often than they should, a phenomenon known as automation bias.
At this point, it’s impossible to know whether automation bias is affecting doctors’ decisions at Akido clinics, though Pierson says it’s a risk—especially when doctors aren’t physically present for appointments. “I worry that it might predispose you to sort of nodding along in a way that you might not if you were actually in the room watching this happen,” she says.
An Akido spokesperson says that automation bias is a valid concern for any AI tool that assists a doctor’s decision-making and that the company has made efforts to mitigate that bias. “We designed ScopeAI specifically to reduce bias by proactively countering blind spots that can influence medical decisions, which historically lean heavily on physician intuition and personal experience,” she says. “We also train physicians explicitly on how to use ScopeAI thoughtfully, so they retain accountability and avoid over-reliance.”
Akido evaluates ScopeAI’s performance by testing it on historical data and monitoring how often doctors correct its recommendations; those corrections are also used to further train the underlying models. Before deploying ScopeAI in a given specialty, Akido ensures that when tested on historical data sets, the system includes the correct diagnosis in its top three recommendations at least 92% of the time.
But Akido hasn’t undertaken more rigorous testing, such as studies that compare ScopeAI appointments with traditional in-person or telehealth appointments, in order to determine whether the system improves—or at least maintains—patient outcomes. Such a study could help indicate whether automation bias is a meaningful concern.
“Making medical care cheaper and more accessible is a laudable goal,” Pierson says. “But I just think it’s important to conduct strong evaluations comparing to that baseline.”
As long as there has been AI, there have been people sounding alarms about what it might do to us: rogue superintelligence, mass unemployment, or environmental ruin from data center sprawl. But this week showed that another threat entirely—that of kids forming unhealthy bonds with AI—is the one pulling AI safety out of the academic fringe and into regulators’ crosshairs.
This has been bubbling for a while. Two high-profile lawsuits filed in the last year, against Character.AI and OpenAI, allege that companion-like behavior in their models contributed to the suicides of two teenagers. A study by US nonprofit Common Sense Media, published in July, found that 72% of teenagers have used AI for companionship. Stories in reputable outlets about “AI psychosis” have highlighted how endless conversations with chatbots can lead people down delusional spirals.
It’s hard to overstate the impact of these stories. To the public, they are proof that AI is not merely imperfect, but a technology that’s more harmful than helpful. If you doubted that this outrage would be taken seriously by regulators and companies, three things happened this week that might change your mind.
A California law passes the legislature
On Thursday, the California state legislature passed a first-of-its-kind bill. It would require AI companies to include reminders for users they know to be minors that responses are AI generated. Companies would also need to have a protocol for addressing suicide and self-harm and provide annual reports on instances of suicidal ideation in users’ conversations with their chatbots. It was led by Democratic state senator Steve Padilla, passed with heavy bipartisan support, and now awaits Governor Gavin Newsom’s signature.
There are reasons to be skeptical of the bill’s impact. It doesn’t specify efforts companies should take to identify which users are minors, and lots of AI companies already include referrals to crisis providers when someone is talking about suicide. (In the case of Adam Raine, one of the teenagers whose survivors are suing, his conversations with ChatGPT before his death included this type of information, but the chatbot allegedly went on to give advice related to suicide anyway.)
Still, it is undoubtedly the most significant of the efforts to rein in companion-like behaviors in AI models, which are in the works in other states too. If the bill becomes law, it would strike a blow to the position OpenAI has taken, which is that “America leads best with clear, nationwide rules, not a patchwork of state or local regulations,” as the company’s chief global affairs officer, Chris Lehane, wrote on LinkedIn last week.
The Federal Trade Commission takes aim
The very same day, the Federal Trade Commission announced an inquiry into seven companies, seeking information about how they develop companion-like characters, monetize engagement, measure and test the impact of their chatbots, and more. The companies are Google, Instagram, Meta, OpenAI, Snap, X, and Character Technologies, the maker of Character.AI.
The White House now wields immense, and potentially illegal, political influence over the agency. In March, President Trump fired its lone Democratic commissioner, Rebecca Slaughter. In July, a federal judge ruled that firing illegal, but last week the US Supreme Court temporarily permitted the firing.
“Protecting kids online is a top priority for the Trump-Vance FTC, and so is fostering innovation in critical sectors of our economy,” said FTC chairman Andrew Ferguson in a press release about the inquiry.
Right now, it’s just that—an inquiry—but the process might (depending on how public the FTC makes its findings) reveal the inner workings of how the companies build their AI companions to keep users coming back again and again.
Sam Altman on suicide cases
Also on the same day (a busy day for AI news), Tucker Carlson published an hour-long interview with OpenAI’s CEO, Sam Altman. It covers a lot of ground—Altman’s battle with Elon Musk, OpenAI’s military customers, conspiracy theories about the death of a former employee—but it also includes the most candid comments Altman’s made so far about the cases of suicide following conversations with AI.
Altman talked about “the tension between user freedom and privacy and protecting vulnerable users” in cases like these. But then he offered up something I hadn’t heard before.
“I think it’d be very reasonable for us to say that in cases of young people talking about suicide seriously, where we cannot get in touch with parents, we do call the authorities,” he said. “That would be a change.”
So where does all this go next? For now, it’s clear that—at least in the case of children harmed by AI companionship—companies’ familiar playbook won’t hold. They can no longer deflect responsibility by leaning on privacy, personalization, or “user choice.” Pressure to take a harder line is mounting from state laws, regulators, and an outraged public.
But what will that look like? Politically, the left and right are now paying attention to AI’s harm to children, but their solutions differ. On the right, the proposed solution aligns with the wave of internet age-verification laws that have now been passed in over 20 states. These are meant to shield kids from adult content while defending “family values.” On the left, it’s the revival of stalled ambitions to hold Big Tech accountable through antitrust and consumer-protection powers.
Consensus on the problem is easier than agreement on the cure. As it stands, it looks likely we’ll end up with exactly the patchwork of state and local regulations that OpenAI (and plenty of others) have lobbied against.
For now, it’s down to companies to decide where to draw the lines. They’re having to decide things like: Should chatbots cut off conversations when users spiral toward self-harm, or would that leave some people worse off? Should they be licensed and regulated like therapists, or treated as entertainment products with warnings? The uncertainty stems from a basic contradiction: Companies have built chatbots to act like caring humans, but they’ve postponed developing the standards and accountability we demand of real caregivers. The clock is now running out.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
Sure, the clips you see in demo reels are cherry-picked to showcase a company’s models at the top of their game. But with the technology in the hands of more users than ever before—Sora and Veo 3 are available in the ChatGPT and Gemini apps for paying subscribers—even the most casual filmmaker can now knock out something remarkable.
The downside is that creators are competing with AI slop, and social media feeds are filling up with faked news footage. Video generation also uses up a huge amount of energy, many times more than text or image generation.
With AI-generated videos everywhere, let’s take a moment to talk about the tech that makes them work.
How do you generate a video?
Let’s assume you’re a casual user. There are now a range of high-end tools that allow pro video makers to insert video generation models into their workflows. But most people will use this technology in an app or via a website. You know the drill: “Hey, Gemini, make me a video of a unicorn eating spaghetti. Now make its horn take off like a rocket.” What you get back will be hit or miss, and you’ll typically need to ask the model to take another pass or 10 before you get more or less what you wanted.
So what’s going on under the hood? Why is it hit or miss—and why does it take so much energy? The latest wave of video generation models are what’s known as latent diffusion transformers. Yes, that’s quite a mouthful. Let’s unpack each part in turn, starting with diffusion.
What’s a diffusion model?
Imagine taking an image and adding a random spattering of pixels to it. Take that pixel-spattered image and spatter it again and then again. Do that enough times and you will have turned the initial image into a random mess of pixels, like static on an old TV set.
A diffusion model is a neural network trained to reverse that process, turning random static into images. During training, it gets shown millions of images in various stages of pixelation. It learns how those images change each time new pixels are thrown at them and, thus, how to undo those changes.
The upshot is that when you ask a diffusion model to generate an image, it will start off with a random mess of pixels and step by step turn that mess into an image that is more or less similar to images in its training set.
But you don’t want any image—you want the image you specified, typically with a text prompt. And so the diffusion model is paired with a second model—such as a large language model (LLM) trained to match images with text descriptions—that guides each step of the cleanup process, pushing the diffusion model toward images that the large language model considers a good match to the prompt.
An aside: This LLM isn’t pulling the links between text and images out of thin air. Most text-to-image and text-to-video models today are trained on large data sets that contain billions of pairings of text and images or text and video scraped from the internet (a practice many creators are very unhappy about). This means that what you get from such models is a distillation of the world as it’s represented online, distorted by prejudice (and pornography).
It’s easiest to imagine diffusion models working with images. But the technique can be used with many kinds of data, including audio and video. To generate movie clips, a diffusion model must clean up sequences of images—the consecutive frames of a video—instead of just one image.
What’s a latent diffusion model?
All this takes a huge amount of compute (read: energy). That’s why most diffusion models used for video generation use a technique called latent diffusion. Instead of processing raw data—the millions of pixels in each video frame—the model works in what’s known as a latent space, in which the video frames (and text prompt) are compressed into a mathematical code that captures just the essential features of the data and throws out the rest.
A similar thing happens whenever you stream a video over the internet: A video is sent from a server to your screen in a compressed format to make it get to you faster, and when it arrives, your computer or TV will convert it back into a watchable video.
And so the final step is to decompress what the latent diffusion process has come up with. Once the compressed frames of random static have been turned into the compressed frames of a video that the LLM guide considers a good match for the user’s prompt, the compressed video gets converted into something you can watch.
With latent diffusion, the diffusion process works more or less the way it would for an image. The difference is that the pixelated video frames are now mathematical encodings of those frames rather than the frames themselves. This makes latent diffusion far more efficient than a typical diffusion model. (Even so, video generation still uses more energy than image or text generation. There’s just an eye-popping amount of computation involved.)
What’s a latent diffusion transformer?
Still with me? There’s one more piece to the puzzle—and that’s how to make sure the diffusion process produces a sequence of frames that are consistent, maintaining objects and lighting and so on from one frame to the next. OpenAI did this with Sora by combining its diffusion model with another kind of model called a transformer. This has now become standard in generative video.
Transformers are great at processing long sequences of data, like words. That has made them the special sauce inside large language models such as OpenAI’s GPT-5 and Google DeepMind’s Gemini, which can generate long sequences of words that make sense, maintaining consistency across many dozens of sentences.
But videos are not made of words. Instead, videos get cut into chunks that can be treated as if they were. The approach that OpenAI came up with was to dice videos up across both space and time. “It’s like if you were to have a stack of all the video frames and you cut little cubes from it,” says Tim Brooks, a lead researcher on Sora.
A selection of videos generated with Veo 3 and Midjourney. The clips have been enhanced in postproduction with Topaz, an AI video-editing tool. Credit: VaigueMan
Using transformers alongside diffusion models brings several advantages. Because they are designed to process sequences of data, transformers also help the diffusion model maintain consistency across frames as it generates them. This makes it possible to produce videos in which objects don’t pop in and out of existence, for example.
And because the videos are diced up, their size and orientation do not matter. This means that the latest wave of video generation models can be trained on a wide range of example videos, from short vertical clips shot with a phone to wide-screen cinematic films. The greater variety of training data has made video generation far better than it was just two years ago. It also means that video generation models can now be asked to produce videos in a variety of formats.
What about the audio?
A big advance with Veo 3 is that it generates video with audio, from lip-synched dialogue to sound effects to background noise. That’s a first for video generation models. As Google DeepMind CEO Demis Hassabis put it at this year’s Google I/O: “We’re emerging from the silent era of video generation.”
The challenge was to find a way to line up video and audio data so that the diffusion process would work on both at the same time. Google DeepMind’s breakthrough was a new way to compress audio and video into a single piece of data inside the diffusion model. When Veo 3 generates a video, its diffusion model produces audio and video together in a lockstep process, ensuring that the sound and images are synched.
You said that diffusion models can generate different kinds of data. Is this how LLMs work too?
No—or at least not yet. Diffusion models are most often used to generate images, video, and audio. Large language models—which generate text (including computer code)—are built using transformers. But the lines are blurring. We’ve seen how transformers are now being combined with diffusion models to generate videos. And this summer Google DeepMind revealed that it was building an experimental large language model that used a diffusion model instead of a transformer to generate text.
Here’s where things start to get confusing: Though video generation (which uses diffusion models) consumes a lot of energy, diffusion models themselves are in fact more efficient than transformers. Thus, by using a diffusion model instead of a transformer to generate text, Google DeepMind’s new LLM could be a lot more efficient than existing LLMs. Expect to see more from diffusion models in the near future!
Generative AI has the potential to transform the finance function. By taking on some of the more mundane tasks that can occupy a lot of time, generative AI tools can help free up capacity for more high-value strategic work. For chief financial officers, this could mean spending more time and energy on proactively advising the business on financial strategy as organizations around the world continue to weather ongoing geopolitical and financial uncertainty.
CFOs can use large language models (LLMs) and generative AI tools to support everyday tasks like generating quarterly reports, communicating with investors, and formulating strategic summaries, says Andrew W. Lo, Charles E. and Susan T. Harris professor and director of the Laboratory for Financial Engineering at the MIT Sloan School of Management. “LLMs can’t replace the CFO by any means, but they can take a lot of the drudgery out of the role by providing first drafts of documents that summarize key issues and outline strategic priorities.”
Generative AI is also showing promise in functions like treasury, with use cases including cash, revenue, and liquidity forecasting and management, as well as automating contracts and investment analysis. However, challenges still remain for generative AI to contribute to forecasting due to the mathematical limitations of LLMs. Regardless, Deloitte’s analysis of its 2024 State of Generative AI in the Enterprise survey found that one-fifth (19%) of finance organizations have already adopted generative AI in the finance function.
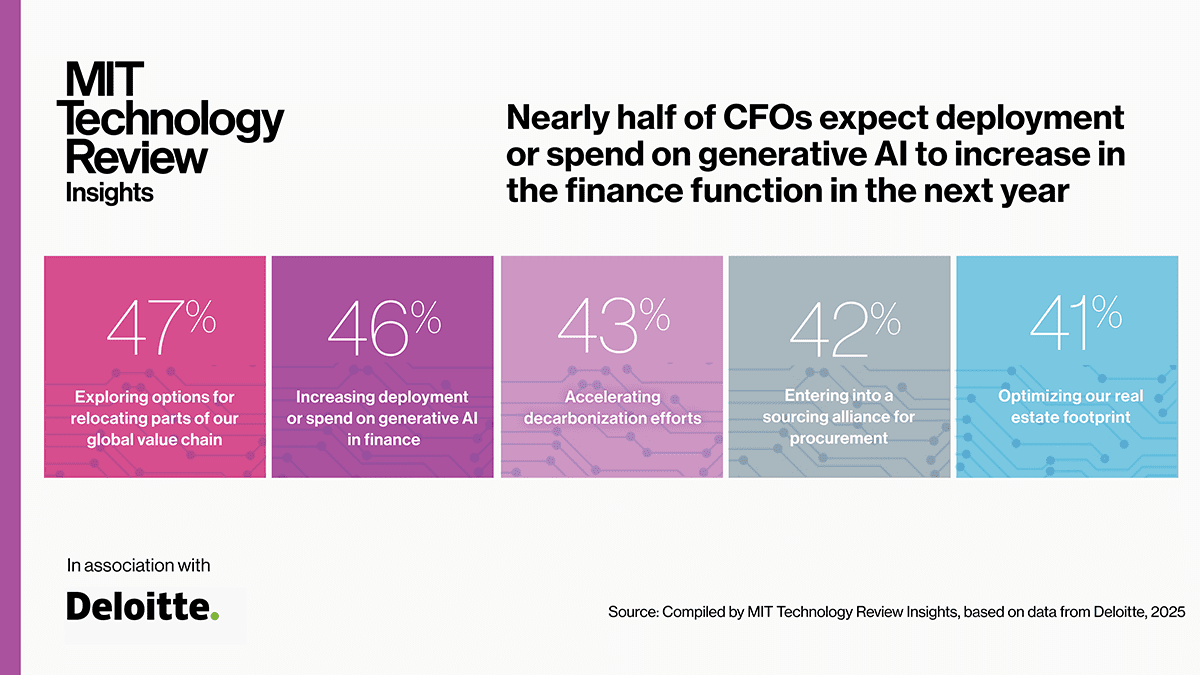
Despite return on generative AI investments in finance functions being 8 points below expectations so far for surveyed organizations (see Figure 1), some finance departments appear to be moving ahead with investments. Deloitte’s fourth-quarter 2024 North American CFO Signals survey found that 46% of CFOs who responded expect deployment or spend on generative AI in finance to increase in the next 12 months (see Figure 2). Respondents cite the technology’s potential to help control costs through self-service and automation and free up workers for higher-level, higher-productivity tasks as some of the top benefits of the technology.
“Companies have used AI on the customer-facing side of the house for a long time, but in finance, employees are still creating documents and presentations and emailing them around,” says Robyn Peters, principal in finance transformation at Deloitte Consulting LLP. “Largely, the human-centric experience that customers expect from brands in retail, transportation, and hospitality haven’t been pulled through to the finance organization. And there’s no reason we cannot do that—and, in fact, AI makes it a lot easier to do.”
If CFOs think they can just sit by for the next five years and watch how AI evolves, they may lose out to more nimble competitors that are actively experimenting in the space. Future finance professionals are growing up using generative AI tools too. CFOs should consider reimagining what it looks like to be a successful finance professional, in collaboration with AI.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
In Silicon Valley’s imagined future, AI models are so empathetic that we’ll use them as therapists. They’ll provide mental-health care for millions, unimpeded by the pesky requirements for human counselors, like the need for graduate degrees, malpractice insurance, and sleep. Down here on Earth, something very different has been happening.
Last week, we published a story about people finding out that their therapists were secretly using ChatGPT during sessions. In some cases it wasn’t subtle; one therapist accidentally shared his screen during a virtual appointment, allowing the patient to see his own private thoughts being typed into ChatGPT in real time. The model then suggested responses that his therapist parroted.
It’s my favorite AI story as of late, probably because it captures so well the chaos that can unfold when people actually use AI the way tech companies have all but told them to.
As the writer of the story, Laurie Clarke, points out, it’s not a total pipe dream that AI could be therapeutically useful. Early this year, I wrote about the first clinical trial of an AI bot built specifically for therapy. The results were promising! But the secretive use by therapists of AI models that are not vetted for mental health is something very different. I had a conversation with Clarke to hear more about what she found.
I have to say, I was really fascinated that people called out their therapists after finding out they were covertly using AI. How did you interpret the reactions of these therapists? Were they trying to hide it?
In all the cases mentioned in the piece, the therapist hadn’t provided prior disclosure of how they were using AI to their patients. So whether or not they were explicitly trying to conceal it, that’s how it ended up looking when it was discovered. I think for this reason, one of my main takeaways from writing the piece was that therapists should absolutely disclose when they’re going to use AI and how (if they plan to use it). If they don’t, it raises all these really uncomfortable questions for patients when it’s uncovered and risks irrevocably damaging the trust that’s been built.
In the examples you’ve come across, are therapists turning to AI simply as a time-saver? Or do they think AI models can genuinely give them a new perspective on what’s bothering someone?
Some see AI as a potential time-saver. I heard from a few therapists that notes are the bane of their lives. So I think there is some interest in AI-powered tools that can support this. Most I spoke to were very skeptical about using AI for advice on how to treat a patient. They said it would be better to consult supervisors or colleagues, or case studies in the literature. They were also understandably very wary of inputting sensitive data into these tools.
There is some evidence AI can deliver more standardized, “manualized” therapies like CBT [cognitive behavioral therapy] reasonably effectively. So it’s possible it could be more useful for that. But that is AI specifically designed for that purpose, not general-purpose tools like ChatGPT.
What happens if this goes awry? What attention is this getting from ethics groups and lawmakers?
At present, professional bodies like the American Counseling Association advise against using AI tools to diagnose patients. There could also be more stringent regulations preventing this in future. Nevada and Illinois, for example, have recently passed laws prohibiting the use of AI in therapeutic decision-making. More states could follow.
OpenAI’s Sam Altman said last month that “a lot of people effectively use ChatGPT as a sort of therapist,” and that to him, that’s a good thing. Do you think tech companies are overpromising on AI’s ability to help us?
I think that tech companies are subtly encouraging this use of AI because clearly it’s a route through which some people are forming an attachment to their products. I think the main issue is that what people are getting from these tools isn’t really “therapy” by any stretch. Good therapy goes far beyond being soothing and validating everything someone says. I’ve never in my life looked forward to a (real, in-person) therapy session. They’re often highly uncomfortable, and even distressing. But that’s part of the point. The therapist should be challenging you and drawing you out and seeking to understand you. ChatGPT doesn’t do any of these things.
Earlier this year, when my colleague Casey Crownhart and I spent six months researching the climate and energy burden of AI, we came to see one number in particular as our white whale: how much energy the leading AI models, like ChatGPT or Gemini, use up when generating a single response.
This fundamental number remained elusive even as the scramble to power AI escalated to the White House and the Pentagon, and as projections showed that in three years AI could use as much electricity as 22% of all US households.
The problem with finding that number, as we explain in our piece published in May, was that AI companies are the only ones who have it. We pestered Google, OpenAI, and Microsoft, but each company refused to provide its figure. Researchers we spoke to who study AI’s impact on energy grids compared it to trying to measure the fuel efficiency of a car without ever being able to drive it, making guesses based on rumors of its engine size and what it sounds like going down the highway.
This story is a part of MIT Technology Review’s series “Power Hungry: AI and our energy future,” on the energy demands and carbon costs of the artificial-intelligence revolution.
But then this summer, after we published, a strange thing started to happen. In June, OpenAI’s Sam Altman wrote that an average ChatGPT query uses 0.34 watt-hours of energy. In July, the French AI startup Mistral didn’t publish a number directly but released an estimate of the emissions generated. In August, Google revealed that answering a question to Gemini uses about 0.24 watt-hours of energy. The figures from Google and OpenAI were similar to what Casey and I estimated for medium-size AI models.
So with this newfound transparency, is our job complete? Did we finally harpoon our white whale, and if so, what happens next for people studying the climate impact of AI? I reached out to some of our old sources, and some new ones, to find out.
The numbers are vague and chat-only
The first thing they told me is that there’s a lot missing from the figures tech companies published this summer.
OpenAI’s number, for example, did not appear in a detailed technical paper but rather in a blog post by Altman that leaves lots of unanswered questions, such as which model he was referring to, how the energy use was measured, and how much it varies. Google’s figure, as Crownhart points out, refers to the median amount of energy per query, which doesn’t give us a sense of the more energy-demanding Gemini responses, like when it uses a reasoning model to “think” through a hard problem or generates a really long response.
The numbers also refer only to interactions with chatbots, not the other ways that people are becoming increasingly reliant on generative AI.
“As video and image becomes more prominent and used by more and more people, we need the numbers from different modalities and how they measure up,” says Sasha Luccioni, AI and climate lead at the AI platform Hugging Face.
This is also important because the figures for asking a question to a chatbot are, as expected, undoubtedly small—the same amount of electricity used by a microwave in just seconds. That’s part of the reason AI and climate researchers don’t suggest that any one individual’s AI use creates a significant climate burden.
A full accounting of AI’s energy demands—one that goes beyond what’s used to answer an individual query to help us understand its full net impact on the climate—would require application-specific information on how all this AI is being used. Ketan Joshi, an analyst for climate and energy groups, acknowledges that researchers don’t usually get such specific information from other industries but says it might be justified in this case.
“The rate of data center growth is inarguably unusual,” Joshi says. “Companies should be subject to significantly more scrutiny.”
We have questions about energy efficiency
Companies making billion-dollar investments into AI have struggled to square this growth in energy demand with their sustainability goals. In May, Microsoft said that its emissions have soared by over 23% since 2020, owing largely to AI, while the company has promised to be carbon negative by 2030. “It has become clear that our journey towards being carbon negative is a marathon, not a sprint,” Microsoft wrote.
Tech companies often justify this emissions burden by arguing that soon enough, AI itself will unlock efficiencies that will make it a net positive for the climate. Perhaps the right AI system, the thinking goes, could design more efficient heating and cooling systems for a building, or help discover the minerals required for electric-vehicle batteries.
But there are no signs that AI has been usefully used to do these things yet. Companies have shared anecdotes about using AI to find methane emission hot spots, for example, but they haven’t been transparent enough to help us know if these successes outweigh the surges in electricity demand and emissions that Big Tech has produced in the AI boom. In the meantime, more data centers are planned, and AI’s energy demand continues to rise and rise.
The ‘bubble’ question
One of the big unknowns in the AI energy equation is whether society will ever adopt AI at the levels that figure into tech companies’ plans. OpenAI has said that ChatGPT receives 2.5 billion prompts per day. It’s possible that this number, and the equivalent numbers for other AI companies, will continue to soar in the coming years. Projections released last year by the Lawrence Berkeley National Laboratory suggest that if they do, AI alone could consume as much electricity annually as 22% of all US households by 2028.
But this summer also saw signs of a slowdown that undercut the industry’s optimism. OpenAI’s launch of GPT-5 was largely considered a flop, even by the company itself, and that flop led critics to wonder if AI may be hitting a wall. When a group at MIT found that 95% of businesses are seeing no return on their massive AI investments, stocks floundered. The expansion of AI-specific data centers might be an investment that’s hard to recoup, especially as revenues for AI companies remain elusive.
One of the biggest unknowns about AI’s future energy burden isn’t how much a single query consumes, or any other figure that can be disclosed. It’s whether demand will ever reach the scale companies are building for or whether the technology will collapse under its own hype. The answer will determine whether today’s buildout becomes a lasting shift in our energy system or a short-lived spike.
When Yichao Ji—also known as “Peak”—appeared in a launch video for Manus in March, he didn’t expect it to go viral. Speaking in fluent English, the 32-year-old introduced the AI agent built by Chinese startup Butterfly Effect, where he serves as chief scientist.
The video was not an elaborate production—it was directed by cofounder Zhang Tao and filmed in a corner of their Beijing office. But something about Ji’s delivery, and the vision behind the product, cut through the noise. The product, then still an early preview available only through invite codes, spread across the Chinese internet to the world in a matter of days. Within a week of its debut, Manus had attracted a waiting list of around 2 million people.
At first sight, Manus works like most chatbots: Users can ask it questions in a chat window. However, besides providing answers, it can also carry out tasks (for example, finding an apartment that meets specified criteria within a certain budget). It does this by breaking tasks down into steps, then using a cloud-based virtual machine equipped with a browser and other tools to execute them—perusing websites, filling in forms, and so on.
Ji is the technical core of the team. Now based in Singapore, he leads product and infrastructure development as the company pushes forward with its global expansion.
Despite his relative youth, Ji has over a decade of experience building products that merge technical complexity with real-world usability. That earned him credibility among both engineers and investors—and put him at the forefront of a rising class of Chinese technologists with AI products and global ambitions.
Serial builder
The son of a professor and an IT professional, Ji moved to Boulder, Colorado, at age four for his father’s visiting scholar post, returning to Beijing in second grade.
His fluent English set him apart early on, but it was an elementary school robotics team that sparked his interest in programming. By high school, he was running the computer club, teaching himself how to build operating systems, and drawing inspiration from Bill Gates, Linux, and open-source culture. He describes himself as a lifelong Apple devotee, and it was Apple’s launch of the App Store in 2008 that ignited his passion for development.
In 2010, as a high school sophomore, Ji created the Mammoth browser, a customizable third-party iPhone browser. It quickly became the most-downloaded third-party browser developed by an individual in China and earned him the Macworld Asia Grand Prize in 2011. International tech site AppAdvice called it a product that “redefined the way you browse the internet.” At age 20, he was on the cover of Forbes magazine and made its “30 Under 30” list.
During his teenage years, Ji developed several other iOS apps, including a budgeting tool designed for Hasbro’s Monopoly game, which sold well—until it attracted a legal notice for using the trademarked name. But Ji wasn’t put off a career in tech by that early brush with a multinational legal team. If anything, he says, it sharpened his instincts for both product and risk.
In 2012, Ji launched his own company, Peak Labs, and later led the development of Magi, a search engine. The tool extracted information from across the web to answer queries—conceptually similar to today’s AI-powered search, but powered by a custom language model.
Magi was briefly popular, drawing millions of users in its first month, but consumer adoption didn’t stick. It did, however, attract enterprise interest, and Ji adapted it for B2B use, before selling it in 2022.
AI acumen
Manus would become his next act—and a more ambitious one. His cofounders, Zhang Tao and Xiao Hong, complement Ji’s technical core with product know-how, storytelling, and organizational savvy. Both Xiao and Ji are serial entrepreneurs who have been backed by venture capital firm ZhenFund multiple times. Together, they represent the kind of long-term collaboration and international ambition that increasingly defines China’s next wave of entrepreneurs.
JULIANA TAN
People who have worked with Ji describe him as a clear thinker, a fast talker, and a tireless, deeply committed builder who thinks in systems, products, and user flows. He represents a new generation of Chinese technologists: equally at home coding or in pitch meetings, fluent in both building and branding. He’s also a product of open-source culture, and remains an active contributor whose projects regularly garner attention—and GitHub stars—across developer communities.
With new funding led by US venture capital firm Benchmark, Ji and his team are taking Manus to the wider world, relocating operations outside of China, to Singapore, and actively targeting consumers around the world. The product is built on US-based infrastructure, drawing on technologies like Claude Sonnet, Microsoft Azure, and open-source tools such as Browser Use. It’s a distinctly global setup: an AI agent developed by a Chinese team, powered by Western platforms, and designed for international users. That isn’t incidental; it reflects the more fluid nature of AI entrepreneurship today, where talent, infrastructure, and ambition move across borders just as quickly as the technology itself.
For Ji, the goal isn’t just building a global company—it’s building a legacy. “I hope Manus is the last product I’ll ever build,” Ji says. “Because if I ever have another wild idea—(I’ll just) leave it to Manus!”
Earlier this summer, I walked through the glassy lobby of a fancy office in London, into an elevator, and then along a corridor into a clean, carpeted room. Natural light flooded in through its windows, and a large pair of umbrella-like lighting rigs made the room even brighter. I tried not to squint as I took my place in front of a tripod equipped with a large camera and a laptop displaying an autocue. I took a deep breath and started to read out the script.
I’m not a newsreader or an actor auditioning for a movie—I was visiting the AI company Synthesia to give it what it needed to create a hyperrealistic AI-generated avatar of me. The company’s avatars are a decent barometer of just how dizzying progress has been in AI over the past few years, so I was curious just how accurately its latest AI model, introduced last month, could replicate me.
When Synthesia launched in 2017, its primary purpose was to match AI versions of real human faces—for example, the former footballer David Beckham—with dubbed voices speaking in different languages. A few years later, in 2020, it started giving the companies that signed up for its services the opportunity to make professional-level presentation videos starring either AI versions of staff members or consenting actors. But the technology wasn’t perfect. The avatars’ body movements could be jerky and unnatural, their accents sometimes slipped, and the emotions indicated by their voices didn’t always match their facial expressions.
Now Synthesia’s avatars have been updated with more natural mannerisms and movements, as well as expressive voices that better preserve the speaker’s accent—making them appear more humanlike than ever before. For Synthesia’s corporate clients, these avatars will make for slicker presenters of financial results, internal communications, or staff training videos.
I found the video demonstrating my avatar as unnerving as it is technically impressive. It’s slick enough to pass as a high-definition recording of a chirpy corporate speech, and if you didn’t know me, you’d probably think that’s exactly what it was. This demonstration shows how much harder it’s becoming to distinguish the artificial from the real. And before long, these avatars will even be able to talk back to us. But how much better can they get? And what might interacting with AI clones do to us?
The creation process
When my former colleague Melissa visited Synthesia’s London studio to create an avatar of herself last year, she had to go through a long process of calibrating the system, reading out a script in different emotional states, and mouthing the sounds needed to help her avatar form vowels and consonants. As I stand in the brightly lit room 15 months later, I’m relieved to hear that the creation process has been significantly streamlined. Josh Baker-Mendoza, Synthesia’s technical supervisor, encourages me to gesture and move my hands as I would during natural conversation, while simultaneously warning me not to move too much. I duly repeat an overly glowing script that’s designed to encourage me to speak emotively and enthusiastically. The result is a bit as if if Steve Jobs had been resurrected as a blond British woman with a low, monotonous voice.
It also has the unfortunate effect of making me sound like an employee of Synthesia.“I am so thrilled to be with you today to show off what we’ve been working on. We are on the edge of innovation, and the possibilities are endless,” I parrot eagerly, trying to sound lively rather than manic. “So get ready to be part of something that will make you go, ‘Wow!’ This opportunity isn’t just big—it’s monumental.”
Just an hour later, the team has all the footage it needs. A couple of weeks later I receive two avatars of myself: one powered by the previous Express-1 model and the other made with the latest Express-2 technology. The latter, Synthesia claims, makes its synthetic humans more lifelike and true to the people they’re modeled on, complete with more expressive hand gestures, facial movements, and speech. You can see the results for yourself below.
COURTESY SYNTHESIA
Last year, Melissa found that her Express-1-powered avatar failed to match her transatlantic accent. Its range of emotions was also limited—when she asked her avatar to read a script angrily, it sounded more whiny than furious. In the months since, Synthesia has improved Express-1, but the version of my avatar made with the same technology blinks furiously and still struggles to synchronize body movements with speech.
By way of contrast, I’m struck by just how much my new Express-2 avatar looks like me: Its facial features mirror my own perfectly. Its voice is spookily accurate too, and although it gesticulates more than I do, its hand movements generally marry up with what I’m saying.
But the tiny telltale signs of AI generation are still there if you know where to look. The palms of my hands are bright pink and as smooth as putty. Strands of hair hang stiffly around my shoulders instead of moving with me. Its eyes stare glassily ahead, rarely blinking. And although the voice is unmistakably mine, there’s something slightly off about my digital clone’s intonations and speech patterns. “This is great!” my avatar randomly declares, before slipping back into a saner register.
Anna Eiserbeck, a postdoctoral psychology researcher at the Humboldt University of Berlin who has studied how humans react to perceived deepfake faces, says she isn’t sure she’d have been able to identify my avatar as a deepfake at first glance.
But she would eventually have noticed something amiss. It’s not just the small details that give it away—my oddly static earring, the way my body sometimes moves in small, abrupt jerks. It’s something that runs much deeper, she explains.
“Something seemed a bit empty. I know there’s no actual emotion behind it— it’s not a conscious being. It does not feel anything,” she says. Watching the video gave her “this kind of uncanny feeling.”
My digital clone, and Eiserbeck’s reaction to it, make me wonder how realistic these avatars really need to be.
I realize that part of the reason I feel disconcerted by my avatar is that it behaves in a way I rarely have to. Its oddly upbeat register is completely at odds with how I normally speak; I’m a die-hard cynical Brit who finds it difficult to inject enthusiasm into my voice even when I’m genuinely thrilled or excited. It’s just the way I am. Plus, watching the videos on a loop makes me question if I really do wave my hands about that way, or move my mouth in such a weird manner. If you thought being confronted with your own face on a Zoom call was humbling, wait until you’re staring at a whole avatar of yourself.
When Facebook was first taking off in the UK almost 20 years ago, my friends and I thought illicitly logging into each other’s accounts and posting the most outrageous or rage-inducing status updates imaginable was the height of comedy. I wonder if the equivalent will soon be getting someone else’s avatar to say something truly embarrassing: expressing support for a disgraced politician or (in my case) admitting to liking Ed Sheeran’s music.
Express-2 remodels every person it’s presented with into a polished professional speaker with the body language of a hyperactive hype man. And while this makes perfect sense for a company focused on making glossy business videos, watching my avatar doesn’t feel like watching me at all. It feels like something else entirely.
How it works
The real technical challenge these days has less to do with creating avatars that match our appearance than with getting them to replicate our behavior, says Björn Schuller, a professor of artificial intelligence at Imperial College London. “There’s a lot to consider to get right; you have to have the right micro gesture, the right intonation, the sound of voice and the right word,” he says. “I don’t want an AI [avatar] to frown at the wrong moment—that could send an entirely different message.”
To achieve an improved level of realism, Synthesia developed a number of new audio and video AI models. The team created a voice cloning model to preserve the human speaker’s accent, intonation, and expressiveness—unlike other voice models, which can flatten speakers’ distinctive accents into generically American-sounding voices.
When a user uploads a script to Express-1, its system analyzes the words to infer the correct tone to use. That information is then fed into a diffusion model, which renders the avatar’s facial expressions and movements to match the speech.
Alongside the voice model, Express-2 uses three other models to create and animate the avatars. The first generates an avatar’s gestures to accompany the speech fed into it by the Express-Voice model. A second evaluates how closely the input audio aligns with the multiple versions of the corresponding generated motion before selecting the best one. Then a final model renders the avatar with that chosen motion.
This third rendering model is significantly more powerful than its Express-1 predecessor. Whereas the previous model had a few hundred million parameters, Express-2’s rendering model’s parameters number in the billions. This means it takes less time to create the avatar, says Youssef Alami Mejjati, Synthesia’s head of research and development:
“With Express-1, it needed to first see someone expressing emotions to be able to render them. Now, because we’ve trained it on much more diverse data and much larger data sets, with much more compute, it just learns these associations automatically without needing to see them.”
Narrowing the uncanny valley
Although humanlike AI-generated avatars have been around for years, the recent boom in generative AI is making it increasingly easier and more affordable to create lifelike synthetic humans—and they’re already being put to work. Synthesia isn’t alone: AI avatar companies like Yuzu Labs, Creatify, Arcdads, and Vidyard give businesses the tools to quickly generate and edit videos starring either AI actors or artificial versions of members of staff, promising cost-effective ways to make compelling ads that audiences connect with. Similarly, AI-generated clones of livestreamers have exploded in popularity across China in recent years, partly because they can sell products 24/7 without getting tired or needing to be paid.
For now at least, Synthesia is “laser focused” on the corporate sphere. But it’s not ruling out expanding into new sectors such as entertainment or education, says Peter Hill, the company’s chief technical officer. In an apparent step toward this, Synthesia recently partnered with Google to integrate Google’s powerful new generative video model Veo 3 into its platform, allowing users to directly generate and embed clips into Synthesia’s videos. It suggests that in the future, these hyperrealistic artificial humans could take up starring roles in detailed universes with ever-changeable backdrops.
At present this could, for example, involve using Veo 3 to generate a video of meat-processing machinery, with a Synthesia avatar next to the machines talking about how to use them safely. But future versions of Synthesia’s technology could result in educational videos customizable to an individual’s level of knowledge, says Alex Voica, head of corporate affairs and policy at Synthesia. For example, a video about the evolution of life on Earth could be tweaked for someone with a biology degree or someone with high-school-level knowledge. “It’s going to be such a much more engaging and personalized way of delivering content that I’m really excited about,” he says.
The next frontier, according to Synthesia, will be avatars that can talk back, “understanding” conversations with users and responding in real time Think ChatGPT, but with a lifelike digital human attached.
Synthesia has already added an interactive element by letting users click through on-screen questions during quizzes presented by its avatars. But it’s also exploring making them truly interactive: Future users could ask their avatar to pause and expand on a point, or ask it a question. “We really want to make the best learning experience, and that means through video that’s entertaining but also personalized and interactive,” says Alami Mejjati. “This, for me, is the missing part in online learning experiences today. And I know we’re very close to solving that.”
We already know that humans can—and do—form deep emotional bonds with AI systems, even with basic text-based chatbots. Combining agentic technology—which is already capable of navigating the web, coding, and playing video games unsupervised—with a realistic human face could usher in a whole new kind of AI addiction, says Pat Pataranutaporn, an assistant professor at the MIT Media Lab.
“If you make the system too realistic, people might start forming certain kinds of relationships with these characters,” he says. “We’ve seen many cases where AI companions have influenced dangerous behavior even when they are basically texting. If an avatar had a talking head, it would be even more addictive.”
Schuller agrees that avatars in the near future will be perfectly optimized to adjust their projected levels of emotion and charisma so that their human audiences will stay engaged for as long as possible. “It will be very hard [for humans] to compete with charismatic AI of the future; it’s always present, always has an ear for you, and is always understanding,” he says. “Al will change that human-to-human connection.”
As I pause and replay my Express-2 avatar, I imagine holding conversations with it—this uncanny, permanently upbeat, perpetually available product of pixels and algorithms that looks like me and sounds like me, but fundamentally isn’t me. Virtual Rhiannon has never laughed until she’s cried, or fallen in love, or run a marathon, or watched the sun set in another country.
But, I concede, she could deliver a damned good presentation about why Ed Sheeran is the greatest musician ever to come out of the UK. And only my closest friends and family would know that it’s not the real me.