Silent. Rigid. Clumsy.
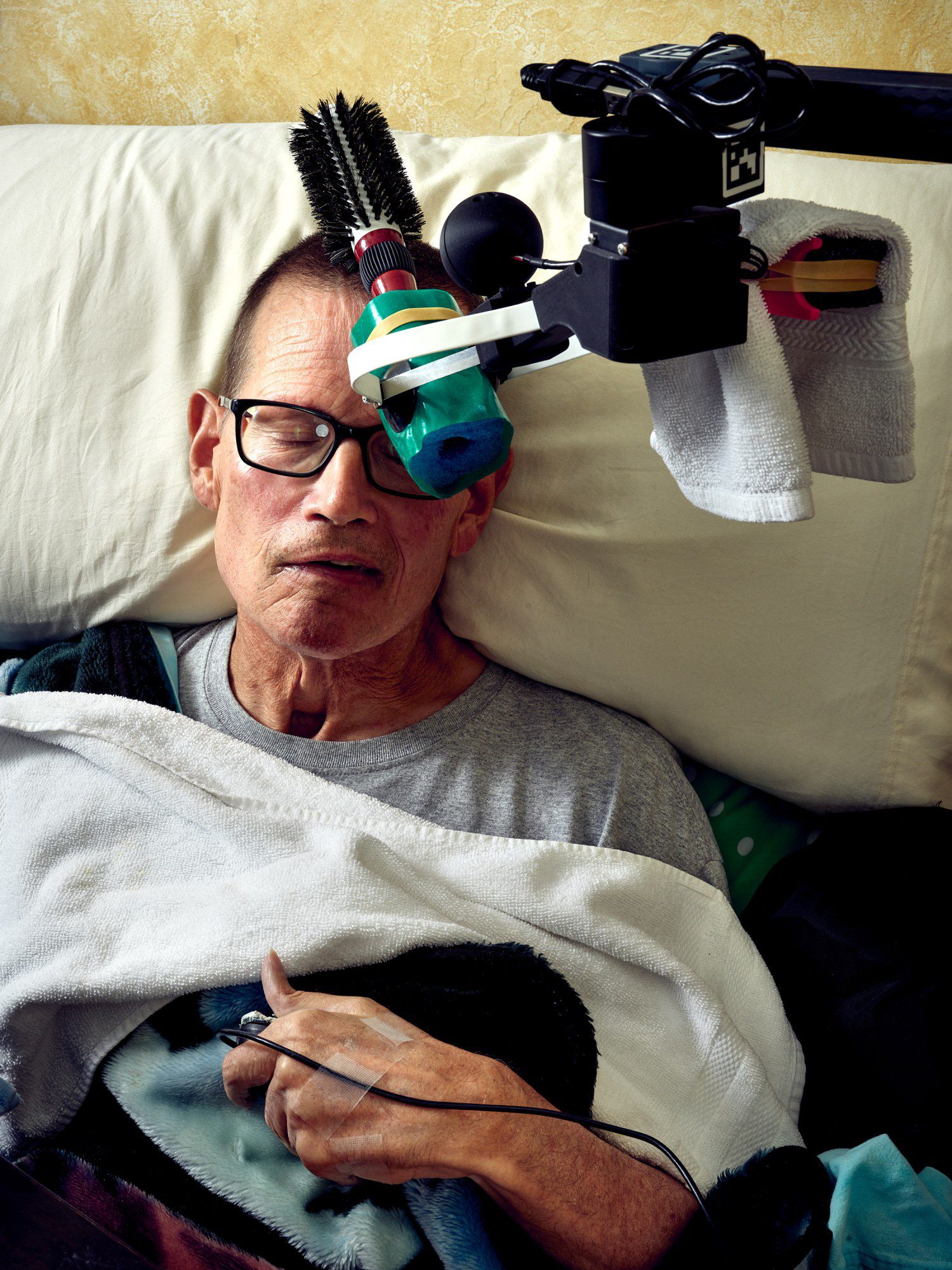
Henry and Jane Evans are used to awkward houseguests. For more than a decade, the couple, who live in Los Altos Hills, California, have hosted a slew of robots in their home.
In 2002, at age 40, Henry had a massive stroke, which left him with quadriplegia and an inability to speak. Since then, he’s learned how to communicate by moving his eyes over a letter board, but he is highly reliant on caregivers and his wife, Jane.
Henry got a glimmer of a different kind of life when he saw Charlie Kemp on CNN in 2010. Kemp, a robotics professor at Georgia Tech, was on TV talking about PR2, a robot developed by the company Willow Garage. PR2 was a massive two-armed machine on wheels that looked like a crude metal butler. Kemp was demonstrating how the robot worked, and talking about his research on how health-care robots could help people. He showed how the PR2 robot could hand some medicine to the television host.
“All of a sudden, Henry turns to me and says, ‘Why can’t that robot be an extension of my body?’ And I said, ‘Why not?’” Jane says.
There was a solid reason why not. While engineers have made great progress in getting robots to work in tightly controlled environments like labs and factories, the home has proved difficult to design for. Out in the real, messy world, furniture and floor plans differ wildly; children and pets can jump in a robot’s way; and clothes that need folding come in different shapes, colors, and sizes. Managing such unpredictable settings and varied conditions has been beyond the capabilities of even the most advanced robot prototypes.
That seems to finally be changing, in large part thanks to artificial intelligence. For decades, roboticists have more or less focused on controlling robots’ “bodies”—their arms, legs, levers, wheels, and the like—via purpose-driven software. But a new generation of scientists and inventors believes that the previously missing ingredient of AI can give robots the ability to learn new skills and adapt to new environments faster than ever before. This new approach, just maybe, can finally bring robots out of the factory and into our homes.
Progress won’t happen overnight, though, as the Evanses know far too well from their many years of using various robot prototypes.
PR2 was the first robot they brought in, and it opened entirely new skills for Henry. It would hold a beard shaver and Henry would move his face against it, allowing him to shave and scratch an itch by himself for the first time in a decade. But at 450 pounds (200 kilograms) or so and $400,000, the robot was difficult to have around. “It could easily take out a wall in your house,” Jane says. “I wasn’t a big fan.”
More recently, the Evanses have been testing out a smaller robot called Stretch, which Kemp developed through his startup Hello Robot. The first iteration launched during the pandemic with a much more reasonable price tag of around $18,000.
Stretch weighs about 50 pounds. It has a small mobile base, a stick with a camera dangling off it, and an adjustable arm featuring a gripper with suction cups at the ends. It can be controlled with a console controller. Henry controls Stretch using a laptop, with a tool that that tracks his head movements to move a cursor around. He is able to move his thumb and index finger enough to click a computer mouse. Last summer, Stretch was with the couple for more than a month, and Henry says it gave him a whole new level of autonomy. “It was practical, and I could see using it every day,” he says.
Using his laptop, he could get the robot to brush his hair and have it hold fruit kebabs for him to snack on. It also opened up Henry’s relationship with his granddaughter Teddie. Before, they barely interacted. “She didn’t hug him at all goodbye. Nothing like that,” Jane says. But “Papa Wheelie” and Teddie used Stretch to play, engaging in relay races, bowling, and magnetic fishing.
Stretch doesn’t have much in the way of smarts: it comes with some preinstalled software, such as the web interface that Henry uses to control it, and other capabilities such as AI-enabled navigation. The main benefit of Stretch is that people can plug in their own AI models and use them to do experiments. But it offers a glimpse of what a world with useful home robots could look like. Robots that can do many of the things humans do in the home—tasks such as folding laundry, cooking meals, and cleaning—have been a dream of robotics research since the inception of the field in the 1950s. For a long time, it’s been just that: “Robotics is full of dreamers,” says Kemp.
But the field is at an inflection point, says Ken Goldberg, a robotics professor at the University of California, Berkeley. Previous efforts to build a useful home robot, he says, have emphatically failed to meet the expectations set by popular culture—think the robotic maid from The Jetsons. Now things are very different. Thanks to cheap hardware like Stretch, along with efforts to collect and share data and advances in generative AI, robots are getting more competent and helpful faster than ever before. “We’re at a point where we’re very close to getting capability that is really going to be useful,” Goldberg says.
Folding laundry, cooking shrimp, wiping surfaces, unloading shopping baskets—today’s AI-powered robots are learning to do tasks that for their predecessors would have been extremely difficult.
Missing pieces
There’s a well-known observation among roboticists: What is hard for humans is easy for machines, and what is easy for humans is hard for machines. Called Moravec’s paradox, it was first articulated in the 1980s by Hans Moravec, thena roboticist at the Robotics Institute of Carnegie Mellon University. A robot can play chess or hold an object still for hours on end with no problem. Tying a shoelace, catching a ball, or having a conversation is another matter.
There are three reasons for this, says Goldberg. First, robots lack precise control and coordination. Second, their understanding of the surrounding world is limited because they are reliant on cameras and sensors to perceive it. Third, they lack an innate sense of practical physics.
“Pick up a hammer, and it will probably fall out of your gripper, unless you grab it near the heavy part. But you don’t know that if you just look at it, unless you know how hammers work,” Goldberg says.
On top of these basic considerations, there are many other technical things that need to be just right, from motors to cameras to Wi-Fi connections, and hardware can be prohibitively expensive.
Mechanically, we’ve been able to do fairly complex things for a while. In a video from 1957, two large robotic arms are dexterous enough to pinch a cigarette, place it in the mouth of a woman at a typewriter, and reapply her lipstick. But the intelligence and the spatial awareness of that robot came from the person who was operating it.
“The missing piece is: How do we get software to do [these things] automatically?” says Deepak Pathak, an assistant professor of computer science at Carnegie Mellon.
Researchers training robots have traditionally approached this problem by planning everything the robot does in excruciating detail. Robotics giant Boston Dynamics used this approach when it developed its boogying and parkouring humanoid robot Atlas. Cameras and computer vision are used to identify objects and scenes. Researchers then use that data to make models that can be used to predict with extreme precision what will happen if a robot moves a certain way. Using these models, roboticists plan the motions of their machines by writing a very specific list of actions for them to take. The engineers then test these motions in the laboratory many times and tweak them to perfection.
This approach has its limits. Robots trained like this are strictly choreographed to work in one specific setting. Take them out of the laboratory and into an unfamiliar location, and they are likely to topple over.
Compared with other fields, such as computer vision, robotics has been in the dark ages, Pathak says. But that might not be the case for much longer, because the field is seeing a big shake-up. Thanks to the AI boom, he says, the focus is now shifting from feats of physical dexterity to building “general-purpose robot brains” in the form of neural networks. Much as the human brain is adaptable and can control different aspects of the human body, these networks can be adapted to work in different robots and different scenarios. Early signs of this work show promising results.
Robots, meet AI
For a long time, robotics research was an unforgiving field, plagued by slow progress. At the Robotics Institute at Carnegie Mellon, where Pathak works, he says, “there used to be a saying that if you touch a robot, you add one year to your PhD.” Now, he says, students get exposure to many robots and see results in a matter of weeks.
What separates this new crop of robots is their software. Instead of the traditional painstaking planning and training, roboticists have started using deep learning and neural networks to create systems that learn from their environment on the go and adjust their behavior accordingly. At the same time, new, cheaper hardware, such as off-the-shelf components and robots like Stretch, is making this sort of experimentation more accessible.
Broadly speaking, there are two popular ways researchers are using AI to train robots. Pathak has been using reinforcement learning, an AI technique that allows systems to improve through trial and error, to get robots to adapt their movements in new environments. This is a technique that Boston Dynamics has also started using in its robot “dogs” called Spot.
Deepak Pathak’s team at Carnegie Mellon has used an AI technique called reinforcement learning to create a robotic dog that can do extreme parkour with minimal pre-programming.
In 2022, Pathak’s team used this method to create four-legged robot “dogs” capable of scrambling up steps and navigating tricky terrain. The robots were first trained to move around in a general way in a simulator. Then they were set loose in the real world, with a single built-in camera and computer vision software to guide them. Other similar robots rely on tightly prescribed internal maps of the world and cannot navigate beyond them.
Pathak says the team’s approach was inspired by human navigation. Humans receive information about the surrounding world from their eyes, and this helps them instinctively place one foot in front of the other to get around in an appropriate way. Humans don’t typically look down at the ground under their feet when they walk, but a few steps ahead, at a spot where they want to go. Pathak’s team trained its robots to take a similar approach to walking: each one used the camera to look ahead. The robot was then able to memorize what was in front of it for long enough to guide its leg placement. The robots learned about the world in real time, without internal maps, and adjusted their behavior accordingly. At the time, experts told MIT Technology Review the technique was a “breakthrough in robot learning and autonomy” and could allow researchers to build legged robots capable of being deployed in the wild.
Pathak’s robot dogs have since leveled up. The team’s latest algorithm allows a quadruped robot to do extreme parkour. The robot was again trained to move around in a general way in a simulation. But using reinforcement learning, it was then able to teach itself new skills on the go, such as how to jump long distances, walk on its front legs, and clamber up tall boxes twice its height. These behaviors were not something the researchers programmed. Instead, the robot learned through trial and error and visual input from its front camera. “I didn’t believe it was possible three years ago,” Pathak says.
In the other popular technique, called imitation learning, models learn to perform tasks by, for example, imitating the actions of a human teleoperating a robot or using a VR headset to collect data on a robot. It’s a technique that has gone in and out of fashion over decades but has recently become more popular with robots that do manipulation tasks, says Russ Tedrake, vice president of robotics research at the Toyota Research Institute and an MIT professor.
By pairing this technique with generative AI, researchers at the Toyota Research Institute, Columbia University, and MIT have been able to quickly teach robots to do many new tasks. They believe they have found a way to extend the technology propelling generative AI from the realm of text, images, and videos into the domain of robot movements.
The idea is to start with a human, who manually controls the robot to demonstrate behaviors such as whisking eggs or picking up plates. Using a technique called diffusion policy, the robot is then able to use the data fed into it to learn skills. The researchers have taught robots more than 200 skills, such as peeling vegetables and pouring liquids, and say they are working toward teaching 1,000 skills by the end of the year.
Many others have taken advantage of generative AI as well. Covariant, a robotics startup that spun off from OpenAI’s now-shuttered robotics research unit, has built a multimodal model called RFM-1. It can accept prompts in the form of text, image, video, robot instructions, or measurements. Generative AI allows the robot to both understand instructions and generate images or videos relating to those tasks.
The Toyota Research Institute team hopes this will one day lead to “large behavior models,” which are analogous to large language models, says Tedrake. “A lot of people think behavior cloning is going to get us to a ChatGPT moment for robotics,” he says.
In a similar demonstration, earlier this year a team at Stanford managed to use a relatively cheap off-the-shelf robot costing $32,000 to do complex manipulation tasks such as cooking shrimp and cleaning stains. It learned those new skills quickly with AI.
Called Mobile ALOHA (a loose acronym for “a low-cost open-source hardware teleoperation system”), the robot learned to cook shrimp with the help of just 20 human demonstrations and data from other tasks, such as tearing off a paper towel or piece of tape. The Stanford researchers found that AI can help robots acquire transferable skills: training on one task can improve its performance for others.
While the current generation of generative AI works with images and language, researchers at the Toyota Research Institute, Columbia University, and MIT believe the approach can extend to the domain of robot motion.
This is all laying the groundwork for robots that can be useful in homes. Human needs change over time, and teaching robots to reliably do a wide range of tasks is important, as it will help them adapt to us. That is also crucial to commercialization—first-generation home robots will come with a hefty price tag, and the robots need to have enough useful skills for regular consumers to want to invest in them.
For a long time, a lot of the robotics community was very skeptical of these kinds of approaches, says Chelsea Finn, an assistant professor of computer science and electrical engineering at Stanford University and an advisor for the Mobile ALOHA project. Finn says that nearly a decade ago, learning-based approaches were rare at robotics conferences and disparaged in the robotics community. “The [natural-language-processing] boom has been convincing more of the community that this approach is really, really powerful,” she says.
There is one catch, however. In order to imitate new behaviors, the AI models need plenty of data.
More is more
Unlike chatbots, which can be trained by using billions of data points hoovered from the internet, robots need data specifically created for robots. They need physical demonstrations of how washing machines and fridges are opened, dishes picked up, or laundry folded, says Lerrel Pinto, an assistant professor of computer science at New York University. Right now that data is very scarce, and it takes a long time for humans to collect.
Some researchers are trying to use existing videos of humans doing things to train robots, hoping the machines will be able to copy the actions without the need for physical demonstrations.
Pinto’s lab has also developed a neat, cheap data collection approach that connects robotic movements to desired actions. Researchers took a reacher-grabber stick, similar to ones used to pick up trash, and attached an iPhone to it. Human volunteers can use this system to film themselves doing household chores, mimicking the robot’s view of the end of its robotic arm. Using this stand-in for Stretch’s robotic arm and an open-source system called DOBB-E, Pinto’s team was able to get a Stretch robot to learn tasks such as pouring from a cup and opening shower curtains with just 20 minutes of iPhone data.
But for more complex tasks, robots would need even more data and more demonstrations.
The requisite scale would be hard to reach with DOBB-E, says Pinto, because you’d basically need to persuade every human on Earth to buy the reacher-grabber system, collect data, and upload it to the internet.
A new initiative kick-started by Google DeepMind, called the Open X-Embodiment Collaboration, aims to change that. Last year, the company partnered with 34 research labs and about 150 researchers to collect data from 22 different robots, including Hello Robot’s Stretch. The resulting data set, which was published in October 2023, consists of robots demonstrating 527 skills, such as picking, pushing, and moving.
Sergey Levine, a computer scientist at UC Berkeley who participated in the project, says the goal was to create a “robot internet” by collecting data from labs around the world. This would give researchers access to bigger, more scalable, and more diverse data sets. The deep-learning revolution that led to the generative AI of today started in 2012 with the rise of ImageNet, a vast online data set of images. The Open X-Embodiment Collaboration is an attempt by the robotics community to do something similar for robot data.
Early signs show that more data is leading to smarter robots. The researchers built two versions of a model for robots, called RT-X, that could be either run locally on individual labs’ computers or accessed via the web. The larger, web-accessible model was pretrained with internet data to develop a “visual common sense,” or a baseline understanding of the world, from the large language and image models.
When the researchers ran the RT-X model on many different robots, they discovered that the robots were able to learn skills 50% more successfully than in the systems each individual lab was developing.
“I don’t think anybody saw that coming,” says Vincent Vanhoucke, Google DeepMind’s head of robotics. “Suddenly there is a path to basically leveraging all these other sources of data to bring about very intelligent behaviors in robotics.”
Many roboticists think that large vision-language models, which are able to analyze image and language data, might offer robots important hints as to how the surrounding world works, Vanhoucke says. They offer semantic clues about the world and could help robots with reasoning, deducing things, and learning by interpreting images. To test this, researchers took a robot that had been trained on the larger model and asked it to point to a picture of Taylor Swift. The researchers had not shown the robot pictures of Swift, but it was still able to identify the pop star because it had a web-scale understanding of who she was even without photos of her in its data set, says Vanhoucke.
Vanhoucke says Google DeepMind is increasingly using techniques similar to those it would use for machine translation to translate from English to robotics. Last summer, Google introduced a vision-language-action model called RT-2. This model gets its general understanding of the world from online text and images it has been trained on, as well as its own interactions in the real world. It translates that data into robotic actions. Each robot has a slightly different way of translating English into action, he adds.
“We increasingly feel like a robot is essentially a chatbot that speaks robotese,” Vanhoucke says.
Baby steps
Despite the fast pace of development, robots still face many challenges before they can be released into the real world. They are still way too clumsy for regular consumers to justify spending tens of thousands of dollars on them. Robots also still lack the sort of common sense that would allow them to multitask. And they need to move from just picking things up and placing them somewhere to putting things together, says Goldberg—for example, putting a deck of cards or a board game back in its box and then into the games cupboard.
But to judge from the early results of integrating AI into robots, roboticists are not wasting their time, says Pinto.
“I feel fairly confident that we will see some semblance of a general-purpose home robot. Now, will it be accessible to the general public? I don’t think so,” he says. “But in terms of raw intelligence, we are already seeing signs right now.”
Building the next generation of robots might not just assist humans in their everyday chores or help people like Henry Evans live a more independent life. For researchers like Pinto, there is an even bigger goal in sight.
Home robotics offers one of the best benchmarks for human-level machine intelligence, he says. The fact that a human can operate intelligently in the home environment, he adds, means we know this is a level of intelligence that can be reached.
“It’s something which we can potentially solve. We just don’t know how to solve it,” he says.
For Henry and Jane Evans, a big win would be to get a robot that simply works reliably. The Stretch robot that the Evanses experimented with is still too buggy to use without researchers present to troubleshoot, and their home doesn’t always have the dependable Wi-Fi connectivity Henry needs in order to communicate with Stretch using a laptop.
Even so, Henry says, one of the greatest benefits of his experiment with robots has been independence: “All I do is lay in bed, and now I can do things for myself that involve manipulating my physical environment.”
Thanks to Stretch, for the first time in two decades, Henry was able to hold his own playing cards during a match.
“I kicked everyone’s butt several times,” he says.
“Okay, let’s not talk too big here,” Jane says, and laughs.




 “” class=”wp-image-1091775″ srcset=”https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg 3000w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=300,232 300w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=768,593 768w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=1536,1187 1536w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=2048,1582 2048w” sizes=”(max-width: 3000px) 100vw, 3000px” />
“” class=”wp-image-1091775″ srcset=”https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg 3000w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=300,232 300w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=768,593 768w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=1536,1187 1536w, https://wp.technologyreview.com/wp-content/uploads/2024/04/David_Vintiner__A7A0695.jpg?resize=2048,1582 2048w” sizes=”(max-width: 3000px) 100vw, 3000px” />