New research from OpenAI and Harvard finds that “Seeking Information” messages now account for 24% of ChatGPT conversations, up from 14% a year earlier.
This is an NBER working paper (not peer-reviewed), based on consumer ChatGPT plans only, and the study used privacy-preserving methods where no human read user messages.
The working paper analyzes a representative sample of about 1.1 million conversations from May 2024 through June 2025.
By July, ChatGPT reached more than 700 million weekly active users, sending roughly 2.5 billion messages per day, or about 18 billion per week.
What People Use ChatGPT For
The three dominant topics are Practical Guidance, Seeking Information, and Writing, which together account for about 77% of usage.
Practical Guidance remains around 29%. Writing declined from 36% to 24% over the past year. Seeking Information grew from 14% to 24%.
The authors write that Seeking Information “appears to be a very close substitute for web search.”
Asking vs. Doing
The paper classifies intent as Asking, Doing, or Expressing.
About 49% of messages are Asking, 40% are Doing, and 11% are Expressing.
Asking messages “are consistently rated as having higher quality” than the other categories, based on an automated classifier and user feedback.
Work vs. Personal Use
Non-work usage rose from 53% in June 2024 to 73% in June 2025.
At work, Writing is the top use case, representing about 40% of work-related messages. Education is a major use: 10% of all messages involve tutoring or teaching.
Coding And Companionship
Only 4.2% of messages are about computer programming, and 1.9% concern relationships or personal reflection.
Who’s Using It
The study documents rapid global adoption.
Early gender gaps have narrowed, with the share of users having typically feminine names rising from 37% in January 2024 to 52% in July 2025.
Growth in the lowest-income countries has been more than four times that of the highest-income countries.
Why This Matters
If a quarter of conversations are information-seeking, some queries that would have gone to search may go toward conversational tools.
Consider responding to this shift with content that answers questions, while adding expertise that a chatbot can’t replicate. Writing and editing account for a large share of work-related use, which aligns with how teams are already folding AI into content workflows.
Looking Ahead
ChatGPT is becoming a major destination for finding information online.
In addition to the shift toward finding info, it’s worth highlighting that 70% of ChatGPT use is personal, not professional. This means consumer habits are changing broadly.
As this technology grows, it’ll be vital to track how your audience uses AI tools and adjust your content strategy to meet them where they are.
When I last wrote about Google AI Mode, my focus was on the big differentiators: conversational prompts, memory-driven personalization, and the crucial pivot from keywords to context.
As we see with the Q2 ad platform financial results below, this shift is rapidly reshaping performance advertising. While AI Mode means Google has to rethink how it makes money, it forces us advertisers to rethink something even more fundamental: our entire strategy.
In the article about AI Mode, I laid out how prompts are different from keywords, why “synthetic keywords” are really just a temporary band-aid, and how fewer clicks might just challenge the age-old cost-per-click (CPC) revenue model.
This follow-up is about what these changes truly mean for us as advertisers, and why holding onto that keyword-era mindset could cost us our competitive edge.
The Great Rewiring Of Search
The biggest shift since we first got keyword-targeted online advertising is now in full swing. People aren’t searching with those relatively concise keywords anymore, the ones we optimized for how Google used to weigh certain words in a query.
Large language models (LLMs) have pretty much removed the shackles from the search bar. Now, users can fire off prompts with hundreds of words, and add even more context.
Think about the 400,000 token context window of GPT-5, which is like tens of thousands of words. Thankfully, most people don’t need that much space to explain what they want, but they are speaking in full sentences now, stutters and all.
Google’s internal ads in AI Mode document shares that early testers of AI Mode are asking queries that are two to three times as long as traditional searches on Google.
And thanks to LLMs’ multi-modal capabilities, users are searching with images (Google reports 20 billion Lens searches per month), drawing sketches, and even sending video. They’re finding what they need in entirely new ways.
Increasingly, users aren’t just looking for a list of what might be relevant. They expect a guided answer from the AI, one that summarizes options based on their personal preferences. People are asking AI to help them decide, not just to find.
And that fundamental change in user behavior is now reshaping the very platforms where these searches happen, starting with Google.
The Impact On Google As The Main Ads Platform
All of this definitely poses a threat to Google’s primary revenue stream. But as I mentioned in a LinkedIn post, the traffic didn’t vanish; it just moved.
Users didn’t ditch Google; they simply stopped using it the way they did when keywords were king. Plus, we’re seeing new players emerge, and search itself has fragmented:
This creates a fresh challenge for us advertisers: How do we design campaigns that actually perform when intent originates in these wildly new ways?
What Q2 Earnings Reports Told Us About AI In Search
The Q2 earnings calls were packed with GenAI details. Some of the most jaw-dropping figures involved the expected infrastructure investments.
Microsoft announced plans to spend an eye-watering $30 billion on capital expenditures in the coming quarter, and Alphabet estimated an $85 billion budget for the next year. I guess we’ll all be clicking a lot of ads to help pay for that. So, where will those ads come from when keywords are slowly being replaced by prompts?
Google shared some numbers to illustrate the scale of this shift. AI Overviews already reach 2 billion users a month. AI Mode itself is up to 100 million. The real question is, how is AI actually enabling better ads, and thus improving monetization?
Google reports:
Over 90 Performance Max improvements in the past year drove 10%+ more conversions and value.
Google’s AI Max for Search campaigns show a 27% lift in conversions or value over exact or phrase matches.
Microsoft Ads tells a similar story. In Q2 2025, it reported:
Users were 53% more likely to convert within 30 minutes.
So, what’s an advertiser to do with all this?
What Advertisers Should Do
As shared recently in a conversation with Kasim Aslam, these ecosystems are becoming intent originators. That old “search bar” is now a conversation, a screenshot, or even a voice command.
If your campaigns are still relying on waiting for someone to type a query, you’re showing up to the party late. Smart advertisers don’t just respond to intent; they predict it and position for it.
But how? Well, take a look at the Google products that are driving results for advertisers: They’re the newest AI-first offerings. Performance Max, for example, is keywordless advertising driven by feeds, creative, and audiences.
It blends elements of Dynamic Search Ads (DSAs), automatically created assets, and super broad keywords. This allows your ads to show up no matter how people search, even if they’re using those sprawling, multi-part prompts.
Sure, advertisers can still use today’s best practices, like reviewing search term reports and automatically created assets, then adding negatives or exclusions for the irrelevant ones. But let’s be honest, that’s a short-term, old-model approach.
As AI gains memory and contextual understanding, ads will be shown based on scenarios and user intent that isn’t even explicitly expressed.
Relying solely on negatives won’t cut it. The future demands that advertisers focus on getting involved earlier in the decision-making process and making sure the AI has all the right information to advocate for their brand.
Keywords Aren’t The Lever They Once Were
In the AI Mode era, prompts aren’t just simple queries; they’re rich, multi-turn conversations packed with context.
As I outlined in my last article, these interactions can pull in past sessions, images, and deeply personal preferences. No keyword list in the world can capture that level of nuance.
Tinuiti’s Q2 benchmark report shows Performance Max accounts for 59% of Shopping ad spend and delivers 18% higher click-through rates. This is a clear illustration that the platform is taking control of targeting.
And when structured feeds plus dynamic creative drive a 27% lift in conversions according to Google data, it’s because the creative itself is doing the targeting.
Those journeys happen out of sight, which is the biggest threat to advertisers whose strategies aren’t evolving.
The Real Danger: Invisible Decisions
One of my key takeaways from the AI Mode discussion was the risk of “zero-click” journeys. If the assistant delivers what a user needs inside the conversation, your brand might never get a visit.
According to Adobe Analytics, AI-powered referrals to U.S. retail sites grew 1,200% between July 2024 and February 2025. Traffic from these sources now doubles every 60 days.
These users:
Visit 12% more pages per session.
Bounce 23% less often.
Spend 45% more time browsing (especially in travel and finance verticals).
Even more importantly, 53% of users say they plan to rely on AI tools for shopping going forward.
In short, users are starting their journeys before they reach a traditional search engine, and they’re more engaged when they do. And winning in this environment means rethinking our levers for influence.
Why This Is An Opportunity, Not A Death Sentence
As I argued before, platforms aren’t killing keyword advertising; they’re evolving it. The advertisers winning now are leaning into the new levers:
Signals Over Keywords
Use customer relationship management (CRM) data to build high-intent audience lists.
Layer first-party data into automated campaign types through conversion value adjustments, audiences, or budget settings.
Optimize your product feed with rich attributes so AI has more to work with and knows exactly which products to recommend.
Ensure feed hygiene so LLMs have the most current data about your offers.
Enhance your website with more data for the LLMs to work with, like data tables, and schema.
Creative As Targeting
Build modular ad assets that AI can assemble dynamically: multiple headlines, descriptions, and images tailored to different audiences.
Test variations that align with different stages of the buying journey so you’re likely to show in more contextual scenarios across the entire consumer journey, not only at the end.
Measurement Beyond Clicks
Frequently evaluate the new metrics in Google Ads for AI Max and Performance Max. Changes are rolling out frequently, enabling smarter optimizations.
Track feed impression share by enabling these extra columns in Google Ads.
Monitor how often your products are surfaced in AI-driven recommendations, as with the recently updated AI Max report for “search terms and landing pages from AI Max.”
Focus your measurement on how well users are able to complete tasks, not just clicks.
The future isn’t about bidding on a query. It’s about supplying the AI with the best “raw ingredients” so you win the recommendation at the exact moment of decision.
That mindset shift is the real competitive advantage in the AI-first era.
The Bottom Line
My previous AI Mode post was about the mechanics of the shift. This one is about the mindset change required to survive it.
Keywords aren’t vanishing, but their role is shrinking fast. In an AI-driven, context-first search landscape, the brands that thrive will stop obsessing over what the user types and start shaping what the AI recommends.
If you can win that moment, you won’t just get found. You’ll get chosen.
Google’s Gemini app now accepts audio file uploads, answering what the company acknowledges was its most requested feature.
For marketers and content teams, it means you can push recordings straight into Gemini for analysis, summaries, and repurposed content without jumping between tools.
Josh Woodward, VP at Google Labs and Gemini, announced the change on X:
“You can now upload any file to @GeminiApp. Including the #1 request: audio files are now supported!”
What’s New
Gemini can now ingest audio files in the same multi-file workflow you already use for documents and images.
You can attach up to 10 files per prompt, and files inside ZIP archives are supported, which helps when you want to upload raw tracks or several interview takes together.
Limits
Free plan: total audio length up to 10 minutes per prompt; up to 5 prompts per day.
AI Pro and AI Ultra: total audio length up to 3 hours per prompt.
Per prompt: up to 10 files across supported formats. Details are listed in Google’s Help Center.
Why This Matters
If your team works with podcasts, webinars, interviews, or customer calls, this closes a gap that often forced a separate transcription step.
You can upload a full interview and turn it into show notes, pull quotes, or a working draft in one place. It also helps meeting-heavy teams: a recorded strategy session can become action items and a brief without exporting to another tool first.
For agencies and networks, batching multiple episodes or takes into one prompt reduces friction in weekly workflows.
The practical win is fewer handoffs: source audio goes in, and the outlines, summaries, and excerpts you need come out. Inside the same system you already use for text prompting.
Quick Tip
Upload your audio together with any supporting context in the same prompt. That gives Gemini the grounding it needs to produce cleaner summaries and more accurate excerpts.
If you’re testing on the free tier, plan around the 10-minute ceiling; longer content is best on AI Pro or Ultra.
Looking Ahead
Google’s limits pages do change, so keep an eye on total length, file-count rules, and any new guardrails that affect longer recordings or larger teams. Also watch for deeper Workspace tie-ins (for example, easier handoffs from Meet recordings) that would streamline getting audio into Gemini without manual uploads.
Anthropic agreed to a proposed $1.5 billion settlement in Bartz v. Anthropic over claims it downloaded pirated books to help train Claude.
If approved, plaintiffs’ counsel says it would be the largest U.S. copyright recovery to date. A preliminary approval hearing is set for today.
In June, Judge William Alsup held that training on lawfully obtained books can qualify as fair use, while copying and storing millions of pirated books is infringement. That order set the stage for settlement talks.
Settlement Details
The deal would pay about $3,000 per eligible title, with an estimated class size of roughly 500,000 books. Plaintiffs allege Anthropic pulled at least 7 million copies from piracy sites Library Genesis and Pirate Library Mirror.
“As best as we can tell, it’s the largest copyright recovery ever.”
How Payouts Would Work
According to the Authors Guild’s summary, the fund is paid in four tranches after court approvals: $300M soon after preliminary approval, $300M after final approval, then $450M at 12 months and 450M at 24 months, with interest accruing in escrow.
A final “Works List” is due October 10, which will drive a searchable database for claimants.
The Guild notes the agreement requires destruction of pirated copies and resolves only past conduct.
Why This Matters
If you rely on AI tools in content workflows, provenance now matters more. Expect more licensing deals and clearer disclosures from vendors about training data sources.
For publishers and creators, the per-work payout sets a reference point that may strengthen negotiating leverage in future licensing talks.
Looking Ahead
The judge will consider preliminary approval today. If granted, the notice process begins this fall and payments to rightsholders would follow final approval and claims processing, funded on the installment schedule above.
Google has published exact usage limits for Gemini Apps across the free tier and paid Google AI plans, replacing earlier vague language with concrete numbers marketers can plan around.
The Help Center update covers daily caps for prompts, images, Deep Research, video generation, and context windows, and notes that you’ll see in-product notices when you’re close to a limit.
What’s New
Until recently, Google’s documentation used general phrasing about “limited access” without specifying amounts.
The Help Center page now lists per-tier allowances for Gemini 2.5 Pro prompts, image generation, Deep Research, and more. It also clarifies that practical caps can vary with prompt complexity, file sizes, and conversation length, and that limits may change over time.
Google’s Help Center states:
“Gemini Apps has usage limits designed to ensure an optimal experience for everyone… we may at times have to cap the number of prompts, conversations, and generated assets that you can have within a specific timeframe.”
Free vs. Paid Tiers
On the free experience, you can use Gemini 2.5 Pro for up to five prompts per day.
The page lists general access to 2.5 Flash and includes:
100 images per day
20 Audio Overviews per day
Five Deep Research reports per month using 2.5 Flash).
Because overall app limits still apply, actual throughput depends on how long and complex your prompts are and how many files you attach.
Google AI Pro increases ceilings to:
100 prompts per day on Gemini 2.5 Pro
1,000 images per day
20 Deep Research reports per day (using 2.5 Pro).
Google AI Ultra raises those to
500 prompts per day
200 Deep Research reports per day
Includes Deep Think with 10 prompts per day at a 192,000-token context window for more complex reasoning tasks.
Context Windows and Advanced Features
Context windows differ by tier. The free tier lists a 32,000-token context size, while Pro and Ultra show 1 million tokens, which is helpful when you need longer conversations or to process large documents in one go.
Ultra’s Deep Think is separate from the 1M context and is capped at 192k tokens for its 10 daily prompts.
Video generation is currently in preview with model-specific limits. Pro shows up to three videos per day with Veo 3 Fast (preview), while Ultra lists up to five videos per day with Veo 3 (preview).
Google indicates some features receive priority or early access on paid plans.
Availability and Requirements
The Gemini app in Google AI Pro and Ultra is available in 150+ countries and territories for users 18 or older.
Upgrades are tied to select Google One paid plans for personal accounts, which consolidate billing with other premium Google services.
Why This Matters
Clear ceilings make it easier to scope deliverables and budgets.
If you produce a steady stream of social or ad creative, the image caps and prompt totals are practical planning inputs.
Teams doing competitive analysis or longer-form research can evaluate whether the free tier’s five Deep Research reports per month cover occasional needs or if Pro’s daily allotment, Ultra’s higher limit, and Deep Think are a better fit for heavier workloads.
The documentation also emphasizes that caps can vary with usage patterns, so it’s worth watching the in-app limit warnings on busy days.
Looking Ahead
Google notes that limits may evolve. If your workflows depend on specific daily counts or large context windows, it’s sensible to review the Help Center page periodically and adjust plans as features move from preview to general availability.
New research examining 16 million URLs aligns with Google’s predictions that hallucinated links will become an issue across AI platforms.
An Ahrefs study shows that AI assistants send users to broken web pages nearly three times more often than Google Search.
The data arrives six months after Google’s John Mueller raised awareness about this issue.
ChatGPT Leads In URL Hallucination Rates
ChatGPT creates the most fake URLs among all AI assistants tested. The study found that 1% of URLs people clicked led to 404 pages. Google’s rate is just 0.15%.
The problem gets worse when looking at all URLs ChatGPT mentions, not just clicked ones. Here, 2.38% lead to error pages. Compare this to Google’s top search results, where only 0.84% are broken links.
Claude came in second with 0.58% broken links for clicked URLs. Copilot had 0.34%, Perplexity 0.31%, and Gemini 0.21%. Mistral had the best rate at 0.12%, but it also sends the least traffic to websites.
Why Does This Happen?
The research found two main reasons why AI creates fake links.
First, some URLs used to exist but don’t anymore. When AI relies on old information instead of searching the web in real-time, it might suggest pages that have been deleted or moved.
Second, AI sometimes invents URLs that sound right but never existed.
Ryan Law from Ahrefs shared examples from their own site. AI assistants created fake URLs like “/blog/internal-links/” and “/blog/newsletter/” because these sound like pages Ahrefs might have. But they don’t actually exist.
Limited Impact on Overall Traffic
The problem may seem significant, but most websites won’t notice much impact. AI assistants only bring in about 0.25% of website traffic. Google, by comparison, drives 39.35% of traffic.
This means fake URLs affect a tiny portion of an already small traffic source. Still, the issue might grow as more people use AI for research and information.
The study also found that 74% of new web pages contain AI-generated content. When this content includes fake links, web crawlers might index them, spreading the problem further.
Mueller’s Prediction Proves Accurate
These findings match what Google’s John Mueller predicted in March. He forecasted a “slight uptick of these hallucinated links being clicked” over the next 6-12 months.
Mueller suggested focusing on better 404 pages rather than chasing accidental traffic.
His advice to collect data before making big changes looks smart now, given the small traffic impact Ahrefs found.
Mueller also predicted the problem would fade as AI services improve how they handle URLs. Time will tell if he’s right about this, too.
Looking Forward
For now, most websites should focus on two things. Create helpful 404 pages for users who hit broken links. Then, set up redirects only for fake URLs that get meaningful traffic.
This allows you to handle the problem without overreacting to what remains a minor issue for most sites.
Ask a question in ChatGPT, Perplexity, Gemini, or Copilot, and the answer appears in seconds. It feels effortless. But under the hood, there’s no magic. There’s a fight happening.
This is the part of the pipeline where your content is in a knife fight with every other candidate. Every passage in the index wants to be the one the model selects.
For SEOs, this is a new battleground. Traditional SEO was about ranking on a page of results. Now, the contest happens inside an answer selection system. And if you want visibility, you need to understand how that system works.
Image Credit: Duane Forrester
The Answer Selection Stage
This isn’t crawling, indexing, or embedding in a vector database. That part is done before the query ever happens. Answer selection kicks in after a user asks a question. The system already has content chunked, embedded, and stored. What it needs to do is find candidate passages, score them, and decide which ones to pass into the model for generation.
Every modern AI search pipeline uses the same three stages (across four steps): retrieval, re-ranking, and clarity checks. Each stage matters. Each carries weight. And while every platform has its own recipe (the weighting assigned at each step/stage), the research gives us enough visibility to sketch a realistic starting point. To basically build our own model to at least partially replicate what’s going on.
The Builder’s Baseline
If you were building your own LLM-based search system, you’d have to tell it how much each stage counts. That means assigning normalized weights that sum to one.
A defensible, research-informed starting stack might look like this:
Lexical retrieval (keywords, BM25): 0.4.
Semantic retrieval (embeddings, meaning): 0.4.
Re-ranking (cross-encoder scoring): 0.15.
Clarity and structural boosts: 0.05.
Every major AI system has its own proprietary blend, but they’re all essentially brewing from the same core ingredients. What I’m showing you here is the average starting point for an enterprise search system, not exactly what ChatGPT, Perplexity, Claude, Copilot, or Gemini operate with. We’ll never know those weights.
Hybrid defaults across the industry back this up. Weaviate’s hybrid search alpha parameter defaults to 0.5, an equal balance between keyword matching and embeddings. Pinecone teaches the same default in its hybrid overview.
Re-ranking gets 0.15 because it only applies to the short list. Yet its impact is proven: “Passage Re-Ranking with BERT” showed major accuracy gains when BERT was layered on BM25 retrieval.
Clarity gets 0.05. It’s small, but real. A passage that leads with the answer, is dense with facts, and can be lifted whole, is more likely to win. That matches the findings from my own piece on semantic overlap vs. density.
At first glance, this might sound like “just SEO with different math.” It isn’t. Traditional SEO has always been guesswork inside a black box. We never really had access to the algorithms in a format that was close to their production versions. With LLM systems, we finally have something search never really gave us: access to all the research they’re built on. The dense retrieval papers, the hybrid fusion methods, the re-ranking models, they’re all public. That doesn’t mean we know exactly how ChatGPT or Gemini dials their knobs, or tunes their weights, but it does mean we can sketch a model of how they likely work much more easily.
From Weights To Visibility
So, what does this mean if you’re not building the machine but competing inside it?
Overlap gets you into the room, density makes you credible, lexical keeps you from being filtered out, and clarity makes you the winner.
That’s the logic of the answer selection stack.
Lexical retrieval is still 40% of the fight. If your content doesn’t contain the words people actually use, you don’t even enter the pool.
Semantic retrieval is another 40%. This is where embeddings capture meaning. A paragraph that ties related concepts together maps better than one that is thin and isolated. This is how your content gets picked up when users phrase queries in ways you didn’t anticipate.
Re-ranking is 15%. It’s where clarity and structure matter most. Passages that look like direct answers rise. Passages that bury the conclusion drop.
Clarity and structure are the tie-breaker. 5% might not sound like much, but in close fights, it decides who wins.
Two Examples
Zapier’s Help Content
Zapier’s documentation is famously clean and answer-first. A query like “How to connect Google Sheets to Slack” returns a ChatGPT answer that begins with the exact steps outlined because the content from Zapier provides the exact data needed. When you click through a ChatGPT resource link, the page you land on is not a blog post; it’s probably not even a help article. It’s the actual page that lets you accomplish the task you asked for.
Lexical? Strong. The words “Google Sheets” and “Slack” are right there.
Semantic? Strong. The passage clusters related terms like “integration,” “workflow,” and “trigger.”
Re-ranking? Strong. The steps lead with the answer.
Clarity? Very strong. Scannable, answer-first formatting.
In a 0.4 / 0.4 / 0.15 / 0.05 system, Zapier’s chunk scores across all dials. This is why their content often shows up in AI answers.
A Marketing Blog Post
Contrast that with a typical long marketing blog post about “team productivity hacks.” The post mentions Slack, Google Sheets, and integrations, but only after 700 words of story.
Lexical? Present, but buried.
Semantic? Decent, but scattered.
Re-ranking? Weak. The answer to “How do I connect Sheets to Slack?” is hidden in a paragraph halfway down.
Clarity? Weak. No liftable answer-first chunk.
Even though the content technically covers the topic, it struggles in this weighting model. The Zapier passage wins because it aligns with how the answer selection layer actually works.
Traditional search still guides the user to read, evaluate, and decide if the page they land on answers their need. AI answers are different. They don’t ask you to parse results. They map your intent directly to the task or answer and move you straight into “get it done” mode. You ask, “How to connect Google Sheets to Slack,” and you end up with a list of steps or a link to the page where the work is completed. You don’t really get a blog post explaining how someone did this during their lunch break, and it only took five minutes.
Volatility Across Platforms
There’s another major difference from traditional SEO. Search engines, despite algorithm changes, converged over time. Ask Google and Bing the same question, and you’ll often see similar results.
LLM platforms don’t converge, or at least, aren’t so far. Ask the same question in Perplexity, Gemini, and ChatGPT, and you’ll often get three different answers. That volatility reflects how each system weights its dials. Gemini may emphasize citations. Perplexity may reward breadth of retrieval. ChatGPT may compress aggressively for conversational style. And we have data that shows that between a traditional engine, and an LLM-powered answer platform, there is a wide gulf between answers. Brightedge’s data (62% disagreement on brand recommendations) and ProFound’s data (…AI modules and answer engines differ dramatically from search engines, with just 8 – 12% overlap in results) showcase this clearly.
For SEOs, this means optimization isn’t one-size-fits-all anymore. Your content might perform well in one system and poorly in another. That fragmentation is new, and you’ll need to find ways to address it as consumer behavior around using these platforms for answers shifts.
Why This Matters
In the old model, hundreds of ranking factors blurred together into a consensus “best effort.” In the new model, it’s like you’re dealing with four big dials, and every platform tunes them differently. In fairness, the complexity behind those dials is still pretty vast.
Ignore lexical overlap, and you lose part of that 40% of the vote. Write semantically thin content, and you can lose another 40. Ramble or bury your answer, and you won’t win re-ranking. Pad with fluff and you miss the clarity boost.
The knife fight doesn’t happen on a SERP anymore. It happens inside the answer selection pipeline. And it’s highly unlikely those dials are static. You can bet they move in relation to many other factors, including each other’s relative positioning.
The Next Layer: Verification
Today, answer selection is the last gate before generation. But the next stage is already in view: verification.
Research shows how models can critique themselves and raise factuality. Self-RAG demonstrates retrieval, generation, and critique loops. SelfCheckGPT runs consistency checks across multiple generations. OpenAI is reported to be building a Universal Verifier for GPT-5. And, I wrote about this whole topic in a recent Substack article.
When verification layers mature, retrievability will only get you into the room. Verification will decide if you stay there.
Closing
This really isn’t regular SEO in disguise. It’s a shift. We can now more clearly see the gears turning because more of the research is public. We also see volatility because each platform spins those gears differently.
For SEOs, I think the takeaway is clear. Keep lexical overlap strong. Build semantic density into clusters. Lead with the answer. Make passages concise and liftable. And I do understand how much that sounds like traditional SEO guidance. I also understand how the platforms using the information differ so much from regular search engines. Those differences matter.
This is how you survive the knife fight inside AI. And soon, how you pass the verifier’s test once you’re there.
New research from BrightEdge shows that Google AI Overviews, AI Mode, and ChatGPT recommend different brands nearly 62% of the time. BrightEdge concludes that each AI search platform is interpreting the data in different ways, suggesting different ways of thinking about each AI platform.
Methodology And Results
BrightEdge’s analysis was conducted with its AI Catalyst tool, using tens of thousands of the same queries across ChatGPT, Google AI Overviews (AIO), and Google AI Mode. The research documented a 61.9% overall disagreement rate, with only 33.5% of queries showing the exact same brands in all three AI platforms.
Google AI Overviews averaged 6.02 brand mentions per query, compared to ChatGPT’s 2.37. Commercial intent search queries containing phrases like “buy,” “where,” or “deals” generated brand mentions 65% of the time across all platforms, suggesting that these kinds of high-intent keyword phrases continue to be reliable for ecommerce, just like in traditional search engines. Understandably, e-commerce and finance verticals achieved 40% or more brand-mention coverage across all three AI platforms.
Three Platforms Diverge
Not all was agreement between the three AI platforms in the study. Many identical queries led to very different brand recommendations depending on the AI platform.
BrightEdge shares that:
ChatGPT cites trusted brands even when it’s not grounding on search data, indicating that it’s relying on LLM training data.
Google AI Overviews cites brands 2.5 times more than ChatGPT.
Google AI Mode cites brands less often than both ChatGPT and AIO.
The research indicates that ChatGPT favors trusted brands, Google AIO emphasizes breadth of coverage with more brand mentions per query, and Google AI Mode selectively recommends brands.
Next we untangle why these patterns exist.
Differences Exist
BrightEdge asserts that this split across the three platforms is not random. I agree that there are differences, but I disagree that “authority” has anything to do with it and offer an alternate explanation later on.
These are the conclusions that they draw from the data:
“The Brand Authority Play: ChatGPT’s reliance on training data means established brands with strong historical presence can capture mentions without needing fresh citations. This creates an “authority dividend” that many brands don’t realize they’re already earning—or could be earning with the right positioning.
The Volume Opportunity: Google AI Overview’s hunger for brand mentions means there are 6+ available slots per relevant query, with clear citation paths showing exactly how to earn visibility. While competitors focus on traditional SEO, innovative brands are reverse-engineering these citation networks.
The Quality Threshold: Google AI Mode’s selectivity means fewer brands make the cut, but those that do benefit from heavy citation backing that reinforces their authority across the web.”
Not Authority – It’s About Training Data
BrightEdge refers to “authority signals” within ChatGPT’s underlying LLM. My opinion differs in regard to an LLM’s generated output, not retrieval-augmented responses that pull in live citations. I don’t think there are any signals in the sense of ranking-related signals. In my opinion, the LLM is simply reaching for the entity (brand) related to a topic.
What looks like “authority” to someone with their SEO glasses on is more likely about frequency, prominence, and contextual embedding strength.
Frequency: How often the brand appears in the training data.
Prominence: How central the brand is in those contexts (headline vs. footnote).
Contextual Embedding Strength: How tightly the brand is associated with certain topics based on the model’s training data.
If a brand appears widely in appropriate contexts within the training data, then, in my opinion, it is more likely to be generated as a brand mention by the LLM, because this reflects patterns in the training data and not authority.
That said, I agree with BrightEdge that being authoritative is important, and that quality shouldn’t be minimized.
Patterns Emerge
The research data suggests that there are unique patterns across all three platforms that can behave as brand citation triggers. One pattern all three share is that keyword phrases with a high commercial intent generate brand mentions in nearly two-thirds of cases. Industries like e-commerce and finance achieve higher brand coverage, which, in my opinion, reflects the ability of all three platforms to accurately understand the strong commercial intents for keywords inherent to those two verticals.
A little sunshine in a partly cloudy publishing environment is the finding that comparison queries for “best” products generate 43% brand citations across all three AI platforms, again reflecting the ability of those platforms to understand user query contexts.
Citation Network Effect
BrightEdge has an interesting insight about creating presence in all three platforms that it calls a citation network effect. BrightEdge asserts that earning citations in one platform could influence visibility in the others.
They share:
“A well-crafted piece… could: Earn authority mentions on ChatGPT through brand recognition
Generate 6+ competitive mentions on Google AI Overview through comprehensive coverage
Secure selective, heavily-cited placement on Google AI Mode through third-party validation
The citation network effect means that earning mentions on one platform often creates the validation needed for another. “
Optimizing For Traditional Search Remains
Nevertheless, I agree with BrightEdge that there’s a strategic opportunity in creating content that works across all three environments, and I would make it explicit that SEO, optimizing for traditional search, is the keystone upon which the entire strategy is crafted.
Traditional SEO is still the way to build visibility in AI search. BrightEdge’s data indicates that this is directly effective for AIO and has a more indirect effect for AI Mode and ChatGPT.
ChatGPT can cite brand names directly from training data and from live data. It also cites brands directly from the LLM, which suggests that generating strong brand visibility tied to specific products and services may be helpful, as that is what eventually makes it into the AI training data.
BrightEdge’s conclusion about the data leans heavily into the idea that AI is creating opportunities for businesses that build brand awareness in the topics they want to be surfaced in. They share:
“We’re witnessing the emergence of AI-native brand discovery. With this fundamental shift, brand visibility is determined not by search rankings but by AI recommendation algorithms with distinct personalities and preferences.
The brands winning this transition aren’t necessarily the ones with the biggest SEO budgets or the most content. They’re the ones recognizing that AI disagreement creates more paths to visibility, not fewer.
As AI becomes the primary discovery mechanism across industries, understanding these platform-specific triggers isn’t optional—it’s the difference between capturing comprehensive brand visibility and watching competitors claim the opportunities you didn’t know existed.
The 62% disagreement gap isn’t breaking the system. It’s creating one—and smart brands are already learning to work it.”
A post on LinkedIn called attention to Perplexity’s content discovery feed called Discover, which generates content on trending news topics. It praised the feed as a positive example of programmatic SEO, although some said that its days in Google’s search results are numbered. Everyone in that discussion believes those pages are one thing. In fact, they are something else entirely.
Context: Perplexity Discover
Perplexity publishes a Discover feed of trending topics. The page is like a portal to the news of the day, featuring short summaries and links to web pages containing the full summary plus links to the original news reporting.
SEOs have noticed that some of those pages are ranking in Google Search, spurring a viral discussion on LinkedIn.
Perplexity Discover And Programmatic SEO
Programmatic SEO is the use of automation to optimize web content and could also apply to scaled content creation. It can be tricky to pull off well and can result in a poor outcome if not.
A LinkedIn post calling attention to the Perplexity AI-generated Discover feed cited it as an example of programmatic SEO “on steroids.”
They wrote:
“For every trending news topic, it automatically creates a public webpage.
These pages are now showing up in Google Search results.
When clicked, users land on a summary + can ask follow-up questions in the chatbot.
…This is such a good Programmatic SEO tactic put on steroids!”
One of the comments in that discussion hailed the Perplexity pages as an example of good programmatic SEO:
“This is a very bold move by Perplexity. Programmatic SEO at scale, backed by trending topics, is a smart way to capture attention and traffic. The key challenge will be sustainability – Google may see this as thin content or adjust algorithms against it. Still, it shows how AI + SEO is evolving faster than expected.”
Another person agreed:
“SEO has been part of their growth strategy since last year, and it works for them quite well”
The rest of the comments praised Perplexity’s SEO as “bold” and “clever” as well as providing “genuine user value.”
But there were also some that predicted that “Google won’t allow this trend…” and that “Google will nerf it in a few weeks…”
The overall sentiment of Perplexity’s implementation of programmatic SEO was positive.
Except that there is no SEO.
Perplexity Discover Is Not Programmatic SEO
Contrary to what was said in the LinkedIn discussion, Perplexity is not engaging in “programmatic SEO,” nor are they trying to rank in Google.
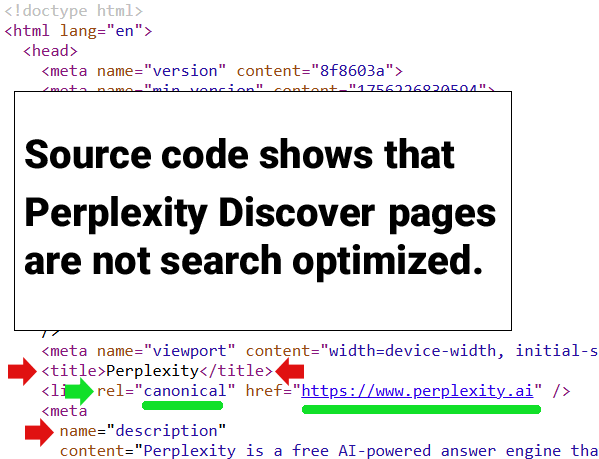
A peek at the source code of any of the Discover pages shows that the title elements and the meta descriptions are not optimized to rank in search engines.
Screenshot Of A Perplexity Discover Web Page
Every single page created by Perplexity appears to have the exact same title and meta description elements:
Perplexity
Every page contains the same canonical tag:
https://www.perplexity.ai” />
It’s clear that Perplexity’s Discover pages are not optimized for Google Search and that the pages are not created for search engines.
The pages are created for humans.
Given how the Discover pages are not optimized, it’s not a surprise that:
Every page I tested failed to rank in Google Search.
It’s clear that Perplexity is engaged in programmatic SEO.
Perplexity’s Discover pages are not created to rank in Google Search.
Perplexity’s Discover pages are created specifically for humans.
If any pages rank in Google, that’s entirely an accident and not by design.
What Is Perplexity Actually Doing?
Perplexity’s Discover pages are examples of something bigger than SEO. They are web pages created for the benefit of users. The fact that no SEO is applied shows that Perplexity is focused on making the Discover pages destinations that users turn to in order to keep in touch with the events of the day.
Perplexity Discover is a user-first web destination created with zero SEO, likely because the goals are more ambitious than depending on Google for traffic.
The Surprising SEO Insight?
It may well be that a good starting point for creating a website and forming a strategy for promoting it lies outside the SEO sandbox. In my experience, I’ve had success creating and promoting outside the standard SEO framework, because SEO strategies are inherently limited: they have one goal, ranking, and miss out on activities that create popularity.
SEO limits how you can promote a site with arbitrary rules such as:
Don’t obtain links from sites that nofollow their links.
Don’t get links from sites that have low popularity.
Offline promotion doesn’t help your site rank.
And here’s the thing: promoting a site with strategies focused on building brand name recognition with an audience tends to create the kinds of user behavior signals that we know Google is looking for.