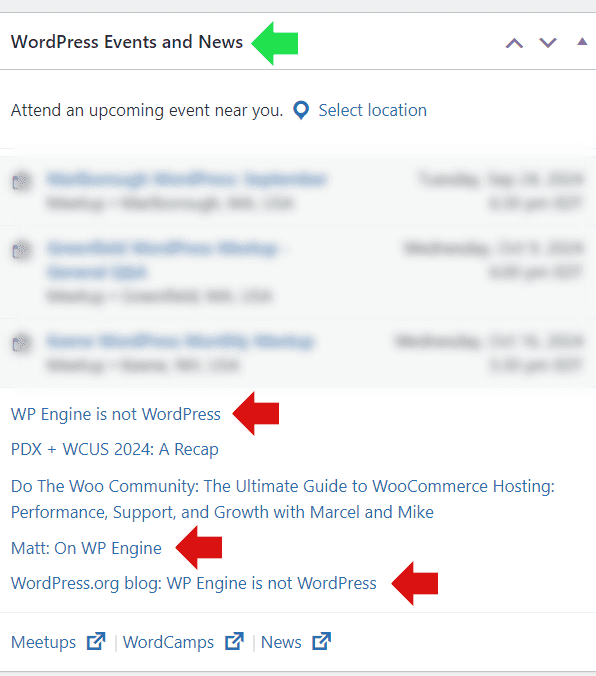
The WordPress Foundation applied to trademark ‘Managed WordPress’ and ‘Hosted WordPress’ for software and hosting services. If approved, this would limit commercial use of these terms by web hosts and even plugins without prior permission.
Trademark Applications Filed By WordPress
The trademark applications for the two hosting related phrases are dated July 12, 2024 and lists the WordPress Foundation as the applicant of the trademarks on the phrases “Managed WordPress” and “Hosted WordPress”.
The WordPress Foundation is the non-profit organization that’s behind the open-source WordPress content management system.
The applications cover the use of the phrases in web hosting, servers for web hosting, downloadable software platforms for web hosting, cloud hosting services, SaaS services, software for managing website content (including downloadable software), web development software, downloadable software for design and managing websites, and plugin software.
Why WordPress Filed Trademarks
The trademark application is filed on an “Intent to Use” basis, which means that they say they’re going to use it.
The trademark applications both inform:
“The applicant has a bona fide intention, and is entitled, to use the mark in commerce on or in connection with the identified goods/services.”
Who Wants To Own The Trademarks?
The trademark application was filed by the WordPress Foundation, a non-profit entity that is separate from the for-profit Automattic. Yet it was Automattic that was demanding money in exchange for a license to use certain WordPress related phrase.
How can Automattic make claims for trademarks that are claimed by WordPress Foundation, a separate legal entity? The answer to the question may be that the WordPress Foundation has an agreement with Automattic for commercial use and enforcing their trademarks.
“During calls on September 17th and 19th, for instance, Automattic CFO Mark Davies told a WP Engine board member that Automattic would “go to war” if WP Engine did not agree to pay its competitor Automattic a significant percentage of its gross revenues – tens of millions of dollars in fact – on an ongoing basis. Mr. Davies suggested the payment ostensibly would be for a “license” to use certain trademarks like WordPress, even though WP Engine needs no such license.
WP Engine’s uses of those marks to describe its services – as all companies in this space do – are fair uses under settled trademark law and consistent with WordPress’ own guidelines.”
The back and forth between WordPress, Matt Mullenweg and WP Engine omits this little detail but it suggests that Automattic is licensed to enforce trademarks on behalf of the WordPress Foundation.
Implications Of Trademark Filing
The trademark application could have an impact on web hosts that use the phrases “Managed WordPress” and “Hosted WordPress” because the WordPress Foundation would be able to enforce their ownership of the phrase or ask for licensing fees.
The WordPress Foundation’s role in this trademark application is to assert legal control over the terms “Managed WordPress” and “Hosted WordPress” so as to control what entities are able to use those phrases.
If the trademark application passes examination then there is supposed to be a period of time where third parties can file objections to the trademark application.
Google removed their documentation for the cache: search operator because it no longer works. The Internet Archive’s Wayback Machine shows the documentation was live as of September 17, 2024. The URL now redirects to a changelog notice announcing its removal.
It was announced on March 2024 by Google SearchLiaison via X (formerly Twitter) that the cache: search operator was removed.
“Hey, catching up. Yes, it’s been removed. I know, it’s sad. I’m sad too. It’s one of our oldest features. But it was meant for helping people access pages when way back, you often couldn’t depend on a page loading. These days, things have greatly improved. So, it was decided to retire it.
Personally, I hope that maybe we’ll add links to @internetarchive from where we had the cache link before, within About This Result. It’s such an amazing resource. For the information literacy goal of About The Result, I think it would also be a nice fit — allowing people to easily see how a page changed over time. No promises. We have to talk to them, see how it all might go — involves people well beyond me. But I think it would be nice all around.”
“We know that many people, including those in the research community, value being able to see previous versions of webpages when available. That’s why we’ve added links to the Internet Archive’s Wayback Machine to our ‘About this page’ feature.”
“Removing the cache: search operator documentation What: Removed the cache: search operator documentation.
Why: The cache: search operator no longer works in Google Search.”
The disappearance of the documentation is a reminder that Google Search is continually changing which means that anyone involved with publishing and search should keep that expectation in mind, particularly for SEO.
WP Engine issued a cease and desist letter to Matt Mullenweg, demanding he stop making ‘false, misleading, and disparaging statements’ and cease using his position at WordPress.org to benefit his for-profit company, Automattic. The letter refutes Mullenweg’s public accusations and outlines his demands for tens of millions of dollars to avoid taking a ‘nuclear approach’ against WP Engine.
A screenshot of a text message by Mullenweg states:
If you’re saying “next week” that’s saying “no”, so I will proceed with the scorched earth nuclear approach to WPE
Thank you for the clarity, it gives me time to work on things and hone my message.
WP Engine Cease And Desist
Matt Mullenweg, co-founder of WordPress and CEO of the for-profit Automattic, posted on Reddit and in a Slack channel that WordPress had initiated litigation against WordPress and himself. It was later revealed that WP Engine had in fact filed a Cease and Desist request (C&D).
The C&D document, sent to the Automattic Chief Legal Officer, documents what it says are false factual statements, outlines a timeline of events, and rebuts Mullenweg’s allegations, accusations and statements.
WP Engine makes four key demands:
Cease Making False Factual Statements Regarding WP Engine.
Cease Interfering with WP Engine’s Contractual Relationships With its Employees.
Cease Interfering with WP Engine’s Contractual Relationships With its Customers
Preserve All Potentially Relevant Documents and Data.
Mullenweg Accused Of Serious Misconduct
Automattic is accused of “serious misconduct” toward WP Engine, laying out its version of events including that Mullenweg threatened to take a “scorched earth nuclear approach” against WP Engine if it refused to agree to give Automattic tens of millions of dollars in cash by 4:30 PM.
When the deadline for an agreement was not met, the legal document states that Mullenweg publicly made disparaging remarks against WP Engine in front of a live audience, on YouTube and on blog posts on the non-profit WordPress.org website.
In fact, Mullenweg’s posts were linked from the admin panel of every WordPress site around the world, millions of websites.
Screenshot Of A WordPress Admin Panel
Accused Of Abusing His Privileged Position Of Power
WP Engine’s C&D accuses Mullenweg of abusing his unique position as both the CEO of a competitor (Automattic, Inc.) and as a director at the non-profit WordPress.org which produces the open source WordPress content management system.
The document states:
“Mr. Mullenweg’s statements also reflect a clear abuse of his conflicting roles as both (1) the Director of the non-profit WordPress Foundation, and (2) the CEO of at least two for-profit businesses that compete with WP Engine.
…Mr. Mullenweg’s covert demand that WP Engine hand over tens of millions to his for-profit company Automattic, while publicly masquerading as an altruistic protector of the WordPress community, is disgraceful.”
List Of Disparaging Remarks Against WP Engine
WP Engine’s C&D documents all the remarks Mullenweg made:
Encouragement of WordPress users to switch away from WP Engine
Suggesting that WP Engine is retaliatory towards its employees
Accusing WP Engine of misusing the trademarks
Accusing WP Engine investors of not caring about open source
Suggesting that WP Engine may be retaliatory against own employees
WP Engine’s C&D rebuts every allegation by Mullenweg, addressing each instance point by point.
Among the rebuttals:
Rebuttal Of Accusation That WP Engine Contributes Little
“Even considering Mr. Mullenweg’s incorrect statement that contribution is only based on hours worked and contributors to Five for the Future, Mr. Mullenweg falsely stated that WP Engine is failing on this metric. In reality, WP Engine is ranked 30 out of 189 in hours contributed and 16 out of 189 in contributors, significantly outpacing multiple other contributors relative to our revenue.”
Rebuttal Of Trademark Misuse
“WP Engine’s use of “WP” is explicitly permitted by WordPress Foundation’s trademark policy:
‘The abbreviation ‘WP’ is not covered by the WordPress trademarks and you are free to use it in any way you see fit.’
Moreover, WP Engine’s use of the WordPress mark is entirely compliant with governing trademark law. For more than a decade, WP Engine has fairly used that term to describe its services, as other members of the WordPress ecosystem do.”
Speculation Of WP Engine Retaliation
“Is not just false and wholly unsubstantiated – it is also absurd.”
What’s Next?
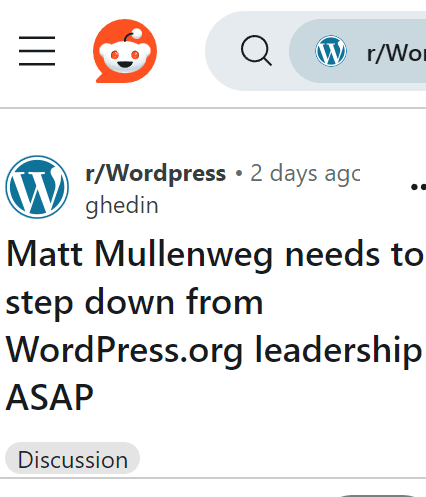
The next move appears to be up to Mullenweg. Many member’s of the WordPress community have already expressed surprise about what Mullenweg did and some on Reddit are calling for Mullenweg to step down.
Matt Mullenweg, co-founder of WordPress and CEO of Automattic announced on Reddit that WP Engine initiated legal action against WordPress, Automattic, and Mullenweg himself. Mullenweg wrote that WordPress is countersuing.
WP Engine is a leading managed WordPress host provider that Mullenweg alleges is violating the WordPress trademark.
Mullenweg’s comments came in a Reddit thread titled “Matt Mullenweg needs to step down from WordPress.org leadership ASAP” in which he explained his side of the issue with WP Engine.
He wrote that he discussed the situation with the WP Engine employees attending the WordCamp WordPress conference last Friday in which he mentioned possibly banning WP Engine and that he was trying to resolve his issue with the company up until his closing Q&A which he decided turned into a speech against WP Engine.
Mullenweg described visiting the WP Engine booth at WordCamp and offering to print the employees new attendee badges in the even that WP Engine is banned.
His description:
“That *if* we had to take down the WP Engine booth and ban WP Engine that evening, my colleague Chloé could print them all new personal badges if they still wanted to attend the conference personally, as they are community members, not just their company.”
Mullenweg insisted that he tried to resolve the conflict:
“The entire day I was in discussions with Heather Brunner and Lee Wittlinger trying to de-escalate and resolve their trademark violations and bad behavior in the WordPress community. I returned to the booth around 4:30 PM to say that I had finally gotten a message back from Lee and Heather and was optimistic we could reach a solution so the booth would not be taken down that evening.
I wanted to resolve everything before my presentation on Friday afternoon, where I was either going to do normal Q&A as planned or present the case for what WP Engine has done wrong. Heather and Lee responded to my text messages, but refused to get on a call or reach any sort of verbal understanding with me, and so I delivered the presentation. I was calling both backstage literally minutes before I got on, trying to avoid this entire scenario.
WP Engine has now filed formal legal action against WordPress.org, myself, Automattic, and we are doing the same against them, so I may not be able to comment on this too much in the future.”
Reactions To Mullenweg’s Post
As if this moment there has been no public announcement by WP Engine. Some Redditors in that discussion were incredulous that Mullenweg put a deadline of that afternoon to finalize a solution with WP Engine.
One Redditor posted:
“What could possibly be resolved in a few hours at a conference? Were they to change their name and cut a fat check that day?”
Mullenweg responded:
“They have been stringing things along for years, it appears their main strategy is just to delay resolution while they continue their bad behavior, printing cash.”
This is a developing story, more will be added as it becomes known.
Just in time for the holiday advertising surge, Reddit announced new AI and automation features to its Ads Manager.
In their announcement last week, Reddit unveiled three distinct features to help advertisers unlock new opportunities for growth.
These new features aim to especially help SMBs or any advertiser looking to get started in Reddit Ads.
Read on to discover the new features available now in the Reddit Ads Manager.
Reddit Ads Inspiration Library
The first new feature Reddit launched to its Ads Manager is the new inspiration library.
It uses AI and automation to create a collection of top-performing Reddit ad creative that is received well by its communities.
For each ad, the library uses an AI model to determine and show what Reddit creative best practices were used to achieve peak performance.
Some of the benefits for advertisers include:
Quickly identify top-performing ad copies
Find top-performing ads relevant to your industry or campaign objective
See the top three best practices used and identified in order to integrate into your campaigns.
The New AI Copywriter
In efforts to make Reddit campaign creation and launch easier for marketers, Reddit’s next new feature helps with a time-consuming task: ad copy.
Currently in beta, Reddit announced its AI copywriter tool in Ads Manager.
It uses AI to generate ad copy specific to Reddit best practices and campaign inputs like target audience and product background.
If you’ve never created a Reddit ad before and want to test it out, this tool can help create a resonating message that’s unique to the Reddit communities you’re targeting instead of trying to write every ad from scratch.
The New Image Auto-Cropper
The last feature announced by Reddit is aimed to streamline campaign creation workflow even further with the auto-cropper tool.
When importing images into campaigns, Reddit’s auto-cropper tool will automatically crop to fit Reddit’s recommended display ratios.
As with any AI tool, always be sure to double-check images to ensure nothing important is cropped out in order to provide the best experience possible to users.
Why Advertisers Should Care
Advertisers of all sizes can benefit from these updates to the Reddit Ads Manager – but especially small businesses or brands just getting started with Reddit.
In a time where marketers are positioned to do more with less, any AI tool to help streamline workflow and optimization can help scale success faster.
It’s also worth exploring if you think your target audience is on Reddit or part of a Reddit community.
You may be surprised that Reddit has over 73 million daily active visitors – so don’t discount an opportunity to reach your target customer in a new atmosphere.
Google’s John Mueller answered a question on Reddit about image alt text and SEO, offering a comprehensive explanation of why alt text is important and why using AI for automatically creating alt text may be inadequate.
Alt Text
The person asking the question wanted to know whether alt text was still relevant for search optimization. In order to understand the role of alt text for SEO it’s useful to learn the technical reason for why alt text exists.
Alt is short for alternate or alternative content. Alt, in the context of the question, is an HTML attribute of the image element. The purpose of “alt” is to provide alternate information about an image that can help a site visitor who might not be able to see the image and if the information is useful to them within the context of the web page.
Web page content is commonly considered to be text but images are also content when they have an “informative value” that helps a site visitor understand the web page topic.
“Choosing appropriate text alternatives: Imagine that you’re reading the web page aloud over the phone to someone who needs to understand the page. This should help you decide what (if any) information or function the images have. If they appear to have no informative value and aren’t links or buttons, it’s probably safe to treat them as decorative.”
Complex images like graphs and illustrations may require a two-part alternate text, with the alt text providing a concise description of what the image is about and the surrounding text offering a longer more comprehensive description of the content of the image (another way is to link to the longer description).
Question About Alt Text And SEO
The person asking the question understands that Google is using complex algorithms to “view” the image and understand them and basically wants to know if the use of alt text is therefore redundant (repetitive) and superfluous (extra information that’s not necessary).
This is the question asked:
“Image alt text in the era of computer vision
Are images alt texts still relevant for SEO with all the computer vision and images recognition advancement? Is there any info of Google or other search engines using machine learning models to crawl images rather than relying on the user provided alt texts?”
Context Is Key In SEO
The assumption made by the person asking the question is reasonable and the question is valid. The information they may be missing is the context in which Google uses AI to “view” images and read the text that’s inside of them. Google’s documentation shows that the context for that kind of AI vision is in Google Lens, Google Translate, and other search surfaces but Google’s documentation doesn’t specifically mention the use of AI vision capabilities in the regular Google search results ((hat tip to @schachin for pointing me to that documentation!).
John Mueller’s answer adds the context that’s missing. He explains that the text content that’s around the image helps to give context to the image and what it means. Simply using AI vision to understand the image doesn’t provide insight into what that image means in the context of the web page.
Here’s Mueller’s answer:
“For image search, there’s the context that comes from the page + image combination that matters.
A photo of a beach might be a relaxing poster, it might be the beach from a hotel, it could be the site of a chemical spill. Just knowing that the image is of a beach doesn’t really give sufficient background information to be able to show it in image search appropriately. A lot of it does come from the page, and the alt-text is unique in that it’s what directly connects the image to the page with context.
Unless your site is a photo agency, traffic for “photo of a beach” isn’t going to be that useful – but for a hotel, having “hotel with beach in X” can be relevant. Again, a lot of that can come from the rest of the page, but the alt attribute value is a unique opportunity to give context. (And with that … if you use AI to create alt texts based on the image file, and get “photo of a beach” as the alt text for that image, you’re not getting the most out of the alt text, both for users & search engines.)”
That’s a great description of why alt text is important for SEO. Alt text shows how the image is directly related to the content of the web page.
Why AI Fails For Alt Text
Mueller also points up a shortcoming in the use of AI for scaling alt text in that in general an AI describes the image but fails to label it within the context of the content. Using alt text to communicate an informative description in the context of the text context is the right way to do it as described by the W3C and for SEO in general and for accessibility reasons.
At the “Made on YouTube” event, which was held at Pier 57 on Sept. 18, 2024, CEO Neal Mohan, product executives, and top creators introduced nine new features and tools aimed at helping creators express their creativity, build communities, and grow their businesses.
Here is a quick overview of the announcements:
Veo for Dream Screen: Dream Screen, which allows creators to generate backgrounds in YouTube Shorts, will soon be enhanced with Google’s DeepMind technology, bringing more realistic backgrounds and standalone video clips.
Inspiration Tab: The upgraded Inspiration tab in YouTube Studio helps creators turn curated suggestions into full projects, with AI refining ideas, titles, and thumbnails to fit their style.
Communities: A new feature that allows creators to create spaces on their channel pages where both they and their fans can post art, share ideas, and engage with each other.
Community Hub: This new space in the YouTube Studio app helps creators engage more effectively with their audiences, with AI-powered suggestions for replies to comments.
Auto Dubbing: Soon to be available to more creators, auto dubbing will allow creators to add audio tracks in different languages, making their content more accessible globally.
Hype: A new way for viewers to support smaller creators by “hyping” their videos to help them appear on a weekly leaderboard, which increases visibility and audience reach.
YouTube Shopping: YouTube’s shopping program is expanding to creators in Indonesia, Thailand, and Vietnam, following its success in the U.S. and South Korea.
Gifts Powered by Jewels: This feature allows viewers to engage with live streams on vertical video formats, giving creators another way to earn revenue.
Big Screen Experience: Creators will soon be able to structure their content into seasons and episodes, improving the TV viewing experience. Additionally, autoplay features for channel pages will help engage viewers from the start.
For more details, you can read about the “Made On YouTube” event here and watch the New YouTube Features — Explained! video below.
In the video, YouTube’s Chief Product Officer, Johanna Voolich, says, “On YouTube, success isn’t one-size-fits-all.” It is as distinctive as the video platform’s talented creators and artists.
Whether it is about expressing yourself, building a community, or achieving financial independence, YouTube aims to provide lasting opportunities for creators to chart their own path to success.
Dream Screen With Google DeepMind’s Veo
The most eye-catching announcement at this week’s “Made on YouTube” event was Google DeepMind’s Veo.
Screenshot from blog.google, September 2024
Last year, YouTube launched Dream Screen, which allows creators to generate limitless backgrounds for YouTube Shorts.
While millions of creators are already using Dream Screen, YouTube announced its plans to integrate Google DeepMind’s advanced video-generating model, Veo, into YouTube Shorts later this year.
With Veo, creators will be able to produce even more immersive backgrounds.
For example, BookTubers could immerse themselves in the world of the classic novel, The Secret Garden, or a fashion designer could instantly bring creative and playful design ideas to life to present to their audience.
This means creators will soon be able to generate standalone six-second video clips for their YouTube Shorts using Veo.
For instance, if you are reviewing your footage and sense that something is needed to bring it all together, you can easily create a single clip that seamlessly integrates with the content you have already filmed.
These creations will include a SynthID watermark, along with a label that clearly informs viewers they were generated using AI.
Inspiration Tab Also Gets A Makeover
YouTube also unveiled an Inspiration Tab makeover.
Screenshot from blog.google, September 2024
As 20.4 million YouTube creators worldwide already know all too well, generating fresh ideas can be tough.
So, the Inspiration Tab in YouTube Studio is getting a makeover, creating a brainstorming buddy that is powered by generative AI.
It will assist in generating suggestions that you can develop into complete projects, including video ideas, titles, thumbnails, and outlines that align with your style.
Next year, YouTube will roll out a new shortcut that will take you directly to the Inspiration Tab from any source of inspiration, such as your top comments, other videos, or even your own content library.
Four New Features To Build Stronger Connections
YouTube understands that the bond between creators and their loyal fans is special. So, they introduced four new tools to build even stronger connections:
1. Communities
Creators can think of this feature as their own space on their channel to discuss videos, share fan art, and connect with others.
Communities are live on select channels, with wider access planned for early 2025.
2. Hype
A new feature to spotlight emerging creators. Fans can “hype” a video, boosting its chances of being discovered.
Hype has already been tested in Brazil, Türkiye, and Taiwan, and will soon roll out to other countries.
3. Auto Dubbing
YouTube’s automatic dubbing tool allows creators to generate translated audio tracks, making content accessible in multiple languages.
Soon, it will support even more languages, and they are testing a feature that will replicate tone and ambiance for a more natural listening experience.
4. Comments Tab
YouTube is reimagining the Comments tab in the YouTube Studio app, turning it into a “Community” hub for deeper engagement.
Responding to comments can be overwhelming for creators, so YouTube is introducing AI-powered suggestions to help creators craft responses faster, along with tools like community spotlights and audience metrics.
Three New Ways To Support The Creator Economy
YouTube’s creative ecosystem contributed more than $35 billion to the U.S. GDP in 2022, which supported over 390,000 full-time equivalent jobs in the country, according to a report by Oxford Economics.
“Today, YouTube is the only platform that shares revenue with creators at scale, across multiple formats. Our YouTube Partner Program pays out more than any other creator monetization platform, and we’ve paid $70 billion to creators, artists, and media companies over the last three years,” notes Voolich.
YouTube has also unveiled three new features to reinforce their support for the Creator Economy:
1. Jewels And Gifts
YouTube launched digital items designed to boost real-time fan interaction and provide a new way for creators to earn.
Initially, this will roll out in the U.S. for vertical livestreams, making it simpler for viewers to engage, show excitement, and participate actively, enhancing the live experience.
2. YouTube Shopping Expansion
YouTube Shopping now has over 250,000 creators! The affiliate program is available in the U.S. and South Korea, and YouTube is expanding to Indonesia through a partnership with Shopee.
Soon, YouTube will bring the program to Thailand and Vietnam, allowing more creators to promote products and grow their businesses globally.
3. Access To Living Rooms
Creators are increasingly creating content specifically for the big screen, with TV revenue growing over 30% year over year.
To support this, YouTube introduced features like organizing content into seasons and episodes, making it easier for viewers to follow their favorite shows.
Additionally, YouTube enhances the TV experience with immersive content from creators’ channels, better subscription management, and easier access to links in descriptions.
The Biggest Splash For YouTube Since Brandcast
The annual YouTube event did not fail to deliver. By unveiling nine new features at Made on YouTube 2024, the platform made its biggest splash since Brandcast back in May.
What does this mean for YouTube?
Creators are central to YouTube’s success. They are the ones who bring their ideas, stories, and visions to the platform. And they are uploading more than 500 hours of content to YouTube every minute.
What does this mean for brands and their agencies?
Well, creators have turned YouTube into the second-most visited website in the world, after Google Search.
As of September 2024, YouTube had more than 2.5 billion monthly users, who collectively watch more than 1 billion hours of videos every day. And YouTube Shorts is now averaging over 70 billion daily views from billions of monthly logged-in users.
So, brands and their agencies can reach potential customers while they’re searching, browsing, or watching YouTube videos.
At Brandcast back in May, YouTube unveiled new ad offerings, touted creator influence, and shared strong viewership metrics. At Made on YouTube this week, it announced a lot of new products and updated features that aim to give creators the opportunity to build engaging communities, drive sustainable businesses, and express creativity on their platform.
And as any fan of the movie Ghostbusters (1984) can tell you, that makes this “the biggest interdimensional cross rip since the Tunguska Blast of 1909.”
More resources:
Featured Image: YouTube CEO Neal Mohan speaks onstage at Made on YouTube at Pier 57 on September 18, 2024 in New York City. (Photo by Dave Kotinsky/Getty Images for Made on YouTube 2024)
SEO for Paws launched earlier this year, with the previous first event attracting 300 attendees to watch five hours of non-stop live streaming.
To continue the good work it does, the next event will be held on Sept. 25, 2024.
The charity event is a live-streamed fundraiser and features a stellar speaker list that includes some of the industry’s best SEO professionals and personalities, including Aleyda Solis and John Mueller.
SEO for Paws is the passion of Anton Shulke, an expert at organizing live stream events, to help a charity close to his heart.
When the war broke out in Ukraine, Anton was living in Kyiv. Even though Anton managed to escape the city, he has tirelessly continued his support for his favorite charity, which aids the many pets that were left behind in Kyiv after the war broke out.
At the previous event, Anton raised an impressive $6,000 that has gone directly to support four shelters and over 300 cats and dogs.
The network of tiny animal shelters operates entirely on donations as they do not receive government funding or support from large charities.
Shulke shares:
“Before the war, I tried to help those small cats and dogs shelters, but just a bit.
We are talking about super small shelters, 30-100 animals, they are in private flats. Sometimes in tiny flats, like one-bedroom or even studio flats. And the owner lives there; often, it is family.”
The war made their situation even more dire, with increased animal abandonment and limited resources.
Though facing personal hardships, Shulke has remained dedicated to Ukraine’s small, donation-dependent pet shelters and vulnerable animals.
Anton is well-known for his love of cats. Dynia, who traveled across Europe with Anton’s family after escaping Kyiv, is a regular feature on his social media channels.
Image from Anton Shulke, September 2024
King Arthur Survived, Thanks To SEO For Paws
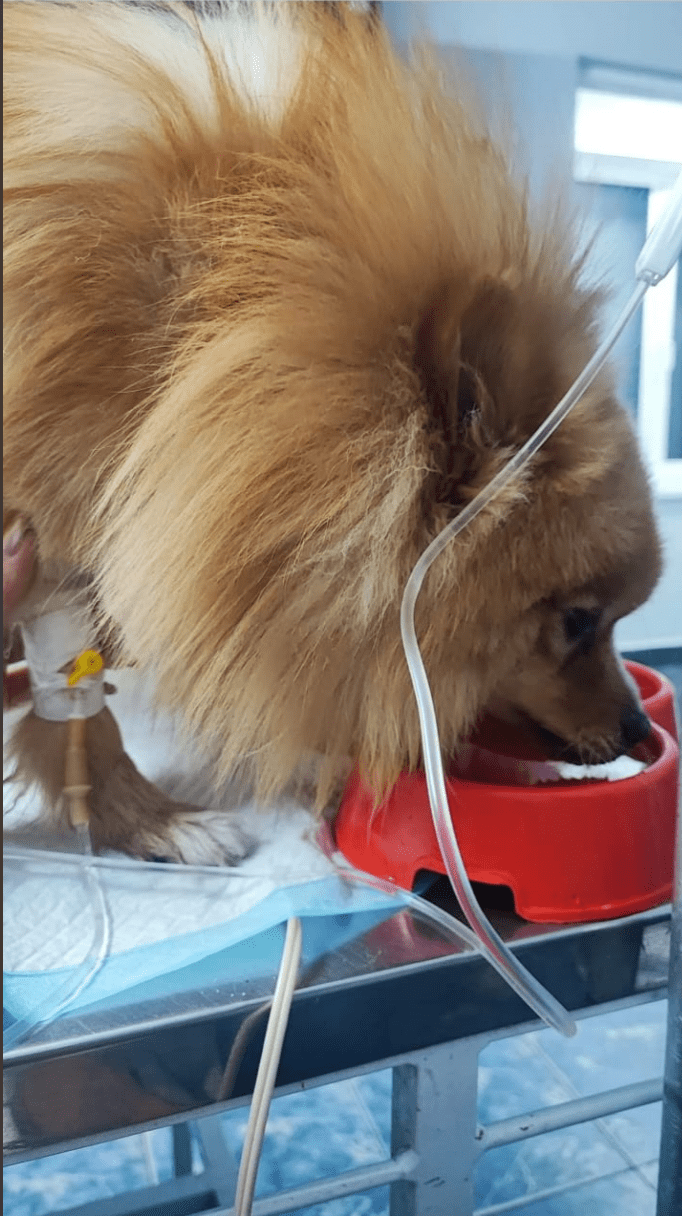
One of the animals that has benefited from the generous support of the SEO community is a small Pomeranian dog who was found frozen to the ground and covered in snow.
A kind passer-by spotted what looked like a fur hat between parked cars and took him to a clinic.
Image from Anton Shulke, September 2024
The little dog was seriously ill and, even with treatment, had only 30% of survival. Just to cover his first night, the treatment costs were $800. After posting on Facebook asking for help, funds were raised.
The lady who found the dog took him home. Even though he had escaped near death in a war zone, he had to spend the night hiding in the shower to avoid the annoyance of her resident cats!
After surviving the first night, the woman’s children named the dog King Arthur, deciding that such a beautiful and proud name would surely give him the strength to recover fully.
King Arthur continued his treatment for a month, with regular tests and follow-up care. And each time the funds fell short, the woman’s neighbors and Anton stepped in to help.
Without the generous support of Anton’s Buy Me a Coffee and SEO for Paws fundraising, King Arthur might not have survived.
Image from Anton Shulke, September 2024
SEO For Paws – Cat Lovers, Dog Lovers, And SEO
The upcoming “SEO for Paws” livestream aims to continue fundraising efforts. The event, which runs from 11:45 a.m. to 3:00 p.m. ET, will offer actionable SEO and digital marketing advice from experts while raising money for the animal shelters.
Headline speakers who have donated their time to support his cause include Aleyda Solis, John Mueller, Sarah Presch, Gianluca Fiorelli, Gerry White, Bibi Raven, and Garrett French, among others.
Attendance is free, but participants are encouraged to donate.
Event Highlights
Date and Time: Sept. 25, 2024, from 11:45 a.m. to 3:00 p.m. ET (3:45 p.m. to 7:00 p.m. GMT).
Access: Free registration with the option to join live, participate in Q&A sessions, and a recording will be made available on YouTube.
Speakers: The live stream will feature 13 SEO and digital marketing experts, who will share actionable insights and a headline from Googler John Mueller, who will tell stories and anecdotes about the sometimes wonderfully weird world of search, SEO, and the web.
The event page states:
“Get ready to relive the magic of the SEO for Paws 2024 charity live stream, a truly pawsitive event that brought the SEO community together to support Ukrainian animal shelters in need. Join us on September 25, 2024, for a day filled with inspiring talks, valuable networking opportunities, and a chance to make a real difference!”
How To Make A Difference
The “SEO for Paws” live stream is an opportunity to make a meaningful difference while listening to excellent speakers.
All money raised is donated to help cats and dogs in Ukraine.
Matt Mullenweg, co-founder of WordPress.org content management system and CEO of Automattic, ended a successful WordCamp USA conference with a poorly received keynote that sharply criticized a prominent managed WordPress web host. The overwhelming response was negative toward his statements and a subsequent blog post that continued his combative remarks.
The response on social media to his speech and blog post was so immense that at one point “WordPress” was the number one trending topic on X (formerly Twitter).
This article doesn’t take sides, it’s only reporting what was said and the general response to it.
What Happened
WordPress is built on the idea of a worldwide community working together to create an open source system for publishing ideas. It is responsible for the creation of perhaps millions of jobs, enabled countless ecommerce companies to sell online and created multiple markets and services that would not otherwise exist, all of it built on the idea of community.
WordCamp is the physical manifestation of the WordPress community, a conference organized by volunteers that enables WordPress users at every level to meet and exchange ideas. It’s ordinarily an uplifting and inspirational event which is why nobody was prepared for the bombshell that would close the week of events beginning on September 17th and ending on the 20th.
It’s not that there weren’t hints. Matt Mullenweg published a blog post on the first day of the conference that begins on a cheerful note then becomes progressively darker.
He begins by praising the community that powers WordPress and is responsible for WordCamp:
“If you ever have a chance to visit a WordCamp, I recommend it. It’s an amazing group of people brought together by this crazy idea that by working together regardless of our differences or where we came from or what school we went to we can be united by a simple yet groundbreaking idea: that software can give you more Freedom.”
Mullenweg then criticized Meta as “disingenuously” claiming to participate in the open source movement and then praised companies that give back to the open source WordPress community as part of the Five for the Future program (in which companies are encouraged to put 5% back into growing the WordPress platform).
He then openly criticized WP Engine for not contributing enough.
The amounts that companies are giving back to WordPress is the ax that Mullenweg was swinging in his conference closing keynote on Friday, specifically calling out WP Engine by name.
Ending A Conference On A Low Note
Mullenweg stated that there are some companies that use up resources without giving back, following up by pointing a finger at WP Engine for only sponsoring 40 hours per week of work toward improving the WordPress core.
He said:
“And there are those that treat open source simply as a resource to extract from its natural surroundings, like oil from the grounds, a finite resource, something to be extracted and used.
…a lot of this information that I’m sharing with you all has come from WP engine employees who’ve reached out to me and and talked to me about all this. So thank you all for being brave and for sharing this information that you think your company is doing something wrong.
WP Engine has good people, some of whom are listed on that page, but the company is controlled by Silver Lake, a private equity firm with 102 billion in assets under management. Silver Lake doesn’t give a dang about your open source ideals, it just wants return on capital.”
Matt Mullenweg then took the step of encouraging the WordPress community to find a different web host. He didn’t directly name WP Engine or call for a boycott, but the meaning of his words were not lost on the audience, given that he just accused WP Engine of not giving “a dang about …open source ideals.”
He said:
“So it’s at this point that I ask everyone in the WordPress community to go vote with your wallet. Who are you giving your money to? Someone who is going to nourish the ecosystem or someone is going to frack every bit of value out of it until it withers?”
Followed a minute later with:
“Think about that next time it comes up to renew your hosting or domain. Weigh your dollars towards companies that give back more…
Those of us who are makers who curate the source need to be wary of those who take our curations and squeeze out the juice. They’re grifters who will hop on to the next fad.”
Mullenweg said that he tried to speak with them beforehand but couldn’t get through.
Shocked Audience Sides With WP Engine
Near the end of his keynote, Mullenweg commented about a potential ban on WP Engine at future WordCamps was met with a surprising silence from the audience, with only a few applauding.
“No one I spoke with at #wcus sympathized with @photomatt’s take on @wpengine’s contributions to WP.
One thing is clear: if you want to encourage more contributions to WP don’t light contributors on fire on stage. There’s more to the story between A8C and Silver Lake than we know”
“I didn’t know how to feel after the public shaming of WP Engine by Matt today. I tried to see both sides….and I felt upset at WP Engine & at Matt at the same time.
After seeing what transpired the hours since on X, I believe it was wrong to call out WP Engine and believe this did more harm. “
“I work very closely with @WPEngine in my day job. They’ve got some fantastic people over there, and are doing many different things to further WordPress in many different ways.
And I will continue to work with them happily.”
Mullenweg Doubles Down
Mullenweg’s keynote wasn’t the end of his negative criticism. On Saturday he published an article on the official WordPress.org blog that amplified the remarks from his keynote that also generated a largely negative response on social media, with some on X and Facebook even calling for him to step down.
Mullenweg wrote:
“I spoke yesterday at WordCamp about how Lee Wittlinger at Silver Lake, a private equity firm with $102B assets under management, can hollow out an open source community. Today, I would like to offer a specific, technical example of how they break the trust and sanctity of our software’s promise to users to save themselves money so they can extract more profits from you.”
The rest of the blog post gets worse.
Backlash Overwhelmingly Against Mullenweg
One of the cleverest responses is published on WPHercules website which is word for word copy of Mullenweg’s article but with the words WP Engine replaced with WordPress.com (the managed WordPress hosting service), titled WordPress.com Is Not WordPress.org
WordPress agency owner Kevin Geary wrote in a blog response:
“This wasn’t my first WordCamp, but I legitimately felt bad for first-timers. Imagine an awesome and uplifting week ending like the Payback scene in The Sum of All Fears… A little awkward.
…Matt has presumably attempted diplomacy multiple times in different ways over the years as he passed that collection plate around, but without great success when it comes to WP Engine.
The question now becomes, is public ridicule and shame a valid approach? And should this ridicule and shame get delivered in the closing talk at a WordCamp?”
A WordPress community member tweeted that the post “ridiculous and completely unnecessary” and that WP apparently stands for “We’re petty.”
A negative tweet that is representative of the general mood:
“It’s been concerning for a few years now – at least for me. I don’t think a CEO should attack people/corps based on personal opinions, no matter if right or wrong. Not good for the WordPress ecosystem tbh. Agree?”
Another member of the WordPress community tweeted:
“When I go to an event or trade show, I do not assume the organizers support or endorse every vendor.
I also don’t expect them to criticize any vendor publicly at the event.”
“There’s been talk of the “existential” threat to WordPress’ standing for a number of years. Now it’s crystal clear that Matt is that existential threat.”
Targeting Of WP Engine Perceived As Unfair
This article isn’t taking sides, it’s only reporting what was said and how the WordPress community responded.
Some background information for those who may not be aware is that WP Engine is a managed web host that voluntarily contributes to the development of WordPress core, supports WordCamp and develops free plugins enjoyed by millions of WordPress publishers such as Advanced Custom Fields, LocalWP, WPGraphQL, Better Search Replace, and WP Migrate Lite.
The backlash on social media is firmly against Matt Mullenweg, including in the private Facebook group Dynamic WordPress (registration required) where a discussion generated over 100 posts. One member of the group who attended WordCamp remarked on the shocked faces of WordCamp attendees and more than one person wrote “Matt needs to go!” as others sympathized with WP Engine.
Watch Mullenweg’s keynote at the 7:08:25 minute mark ( 7 hour, 8 minute, 25 seconds):
Google has launched a major revamp of its Crawler documentation, shrinking the main overview page and splitting content into three new, more focused pages. Although the changelog downplays the changes there is an entirely new section and basically a rewrite of the entire crawler overview page. The additional pages allows Google to increase the information density of all the crawler pages and improves topical coverage.
What Changed?
Google’s documentation changelog notes two changes but there is actually a lot more.
Here are some of the changes:
Added an updated user agent string for the GoogleProducer crawler
Added content encoding information
Added a new section about technical properties
The technical properties section contains entirely new information that didn’t previously exist. There are no changes to the crawler behavior, but by creating three topically specific pages Google is able to add more information to the crawler overview page while simultaneously making it smaller.
This is the new information about content encoding (compression):
“Google’s crawlers and fetchers support the following content encodings (compressions): gzip, deflate, and Brotli (br). The content encodings supported by each Google user agent is advertised in the Accept-Encoding header of each request they make. For example, Accept-Encoding: gzip, deflate, br.”
There is additional information about crawling over HTTP/1.1 and HTTP/2, plus a statement about their goal being to crawl as many pages as possible without impacting the website server.
What Is The Goal Of The Revamp?
The change to the documentation was due to the fact that the overview page had become large. Additional crawler information would make the overview page even larger. A decision was made to break the page into three subtopics so that the specific crawler content could continue to grow and making room for more general information on the overviews page. Spinning off subtopics into their own pages is a brilliant solution to the problem of how best to serve users.
This is how the documentation changelog explains the change:
“The documentation grew very long which limited our ability to extend the content about our crawlers and user-triggered fetchers.
…Reorganized the documentation for Google’s crawlers and user-triggered fetchers. We also added explicit notes about what product each crawler affects, and added a robots.txt snippet for each crawler to demonstrate how to use the user agent tokens. There were no meaningful changes to the content otherwise.”
The changelog downplays the changes by describing them as a reorganization because the crawler overview is substantially rewritten, in addition to the creation of three brand new pages.
While the content remains substantially the same, the division of it into sub-topics makes it easier for Google to add more content to the new pages without continuing to grow the original page. The original page, called Overview of Google crawlers and fetchers (user agents), is now truly an overview with more granular content moved to standalone pages.
Google published three new pages:
Common crawlers
Special-case crawlers
User-triggered fetchers
1. Common Crawlers
As it says on the title, these are common crawlers, some of which are associated with GoogleBot, including the Google-InspectionTool, which uses the GoogleBot user agent. All of the bots listed on this page obey the robots.txt rules.
These are the documented Google crawlers:
Googlebot
Googlebot Image
Googlebot Video
Googlebot News
Google StoreBot
Google-InspectionTool
GoogleOther
GoogleOther-Image
GoogleOther-Video
Google-CloudVertexBot
Google-Extended
3. Special-Case Crawlers
These are crawlers that are associated with specific products and are crawled by agreement with users of those products and operate from IP addresses that are distinct from the GoogleBot crawler IP addresses.
List of Special-Case Crawlers:
AdSense User Agent for Robots.txt: Mediapartners-Google
AdsBot User Agent for Robots.txt: AdsBot-Google
AdsBot Mobile Web User Agent for Robots.txt: AdsBot-Google-Mobile
APIs-Google User Agent for Robots.txt: APIs-Google
Google-Safety User Agent for Robots.txt: Google-Safety
3. User-Triggered Fetchers
The User-triggered Fetchers page covers bots that are activated by user request, explained like this:
“User-triggered fetchers are initiated by users to perform a fetching function within a Google product. For example, Google Site Verifier acts on a user’s request, or a site hosted on Google Cloud (GCP) has a feature that allows the site’s users to retrieve an external RSS feed. Because the fetch was requested by a user, these fetchers generally ignore robots.txt rules. The general technical properties of Google’s crawlers also apply to the user-triggered fetchers.”
The documentation covers the following bots:
Feedfetcher
Google Publisher Center
Google Read Aloud
Google Site Verifier
Takeaway:
Google’s crawler overview page became overly comprehensive and possibly less useful because people don’t always need a comprehensive page, they’re just interested in specific information. The overview page is less specific but also easier to understand. It now serves as an entry point where users can drill down to more specific subtopics related to the three kinds of crawlers.
This change offers insights into how to freshen up a page that might be underperforming because it has become too comprehensive. Breaking out a comprehensive page into standalone pages allows the subtopics to address specific users needs and possibly make them more useful should they rank in the search results.
I would not say that the change reflects anything in Google’s algorithm, it only reflects how Google updated their documentation to make it more useful and set it up for adding even more information.