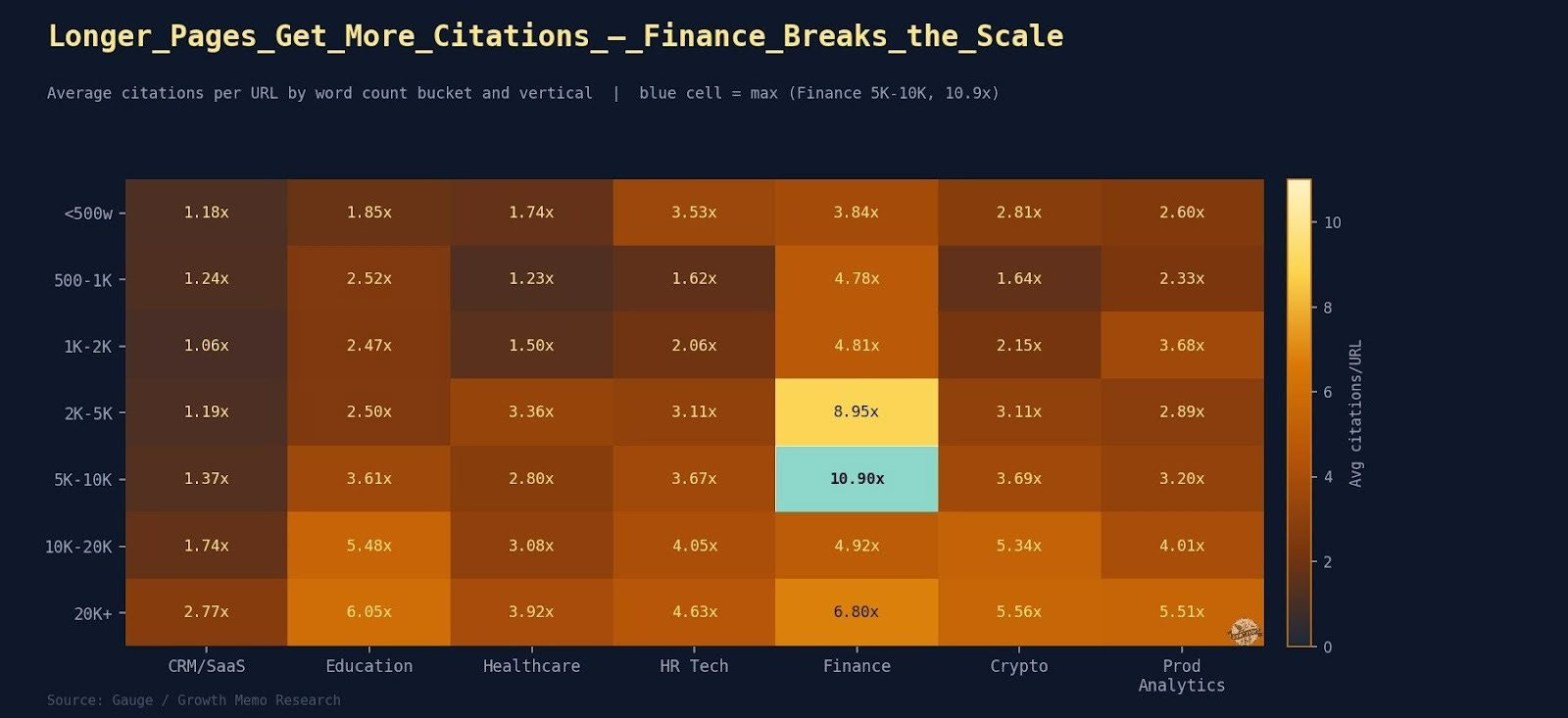
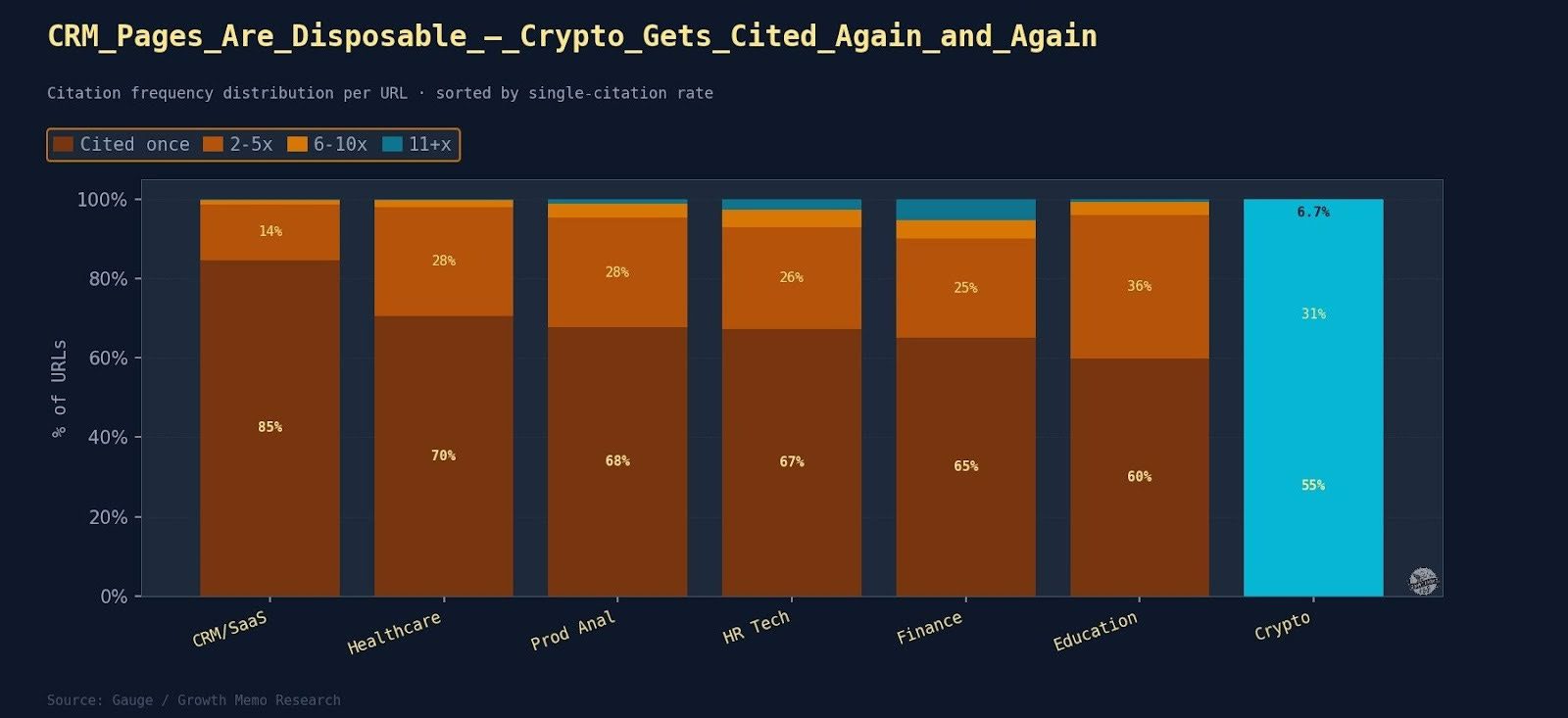
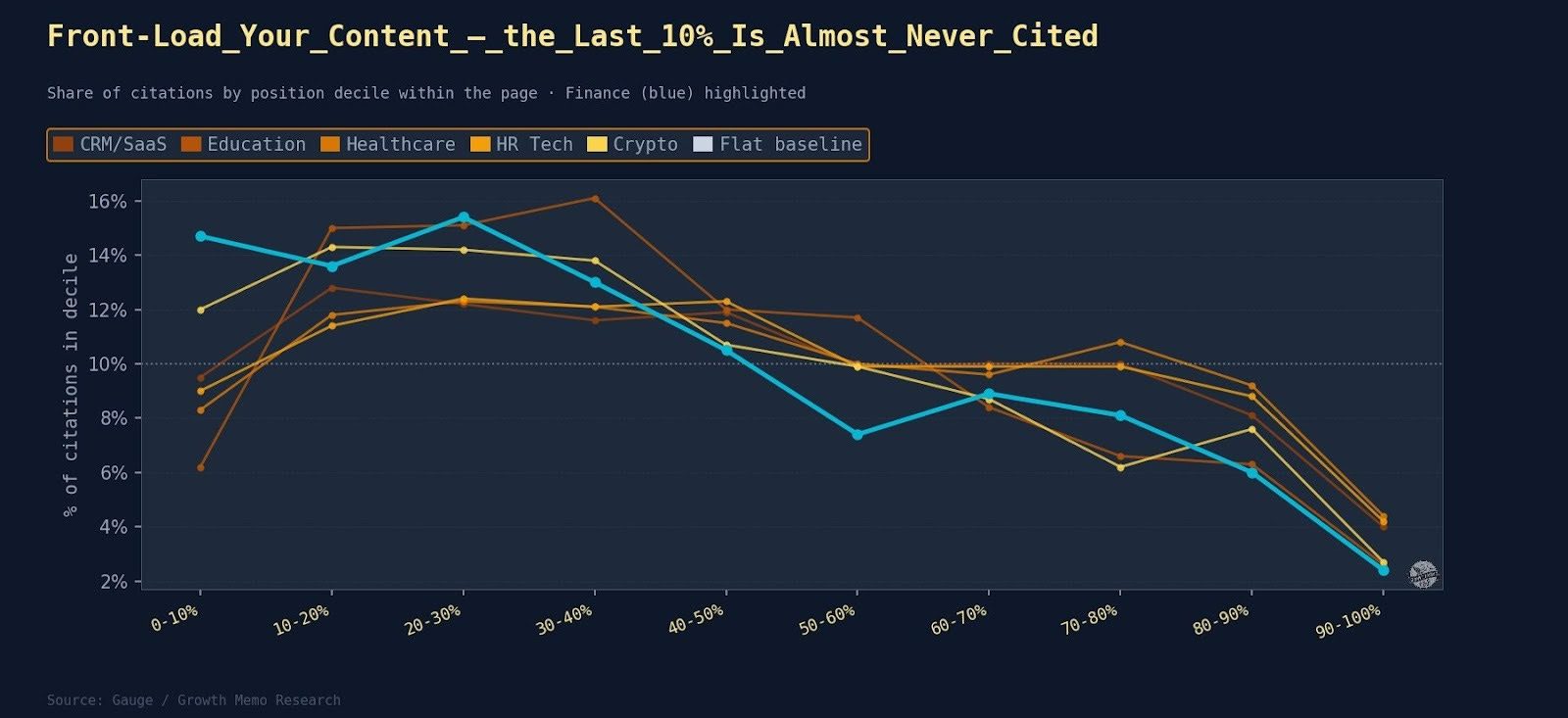
Half Your Traffic Left. The SEO Industry Sent Thoughts and Frameworks

Before AI Overviews launched in May 2024, Define Media Group’s portfolio of major U.S. publishers averaged 1.7 billion organic search clicks per quarter. Steady. Predictable. The kind of number you build a business model on and then stop thinking about, because why would you?
After the launch, traffic dropped 16% and never recovered. When Google expanded AI Overviews in May 2025, the decline accelerated. By Q4 2025, organic search traffic across that portfolio was down 42% from the pre-AIO baseline.
Nearly half the organic traffic, gone, from a portfolio large enough to be directional for the entire publishing industry.
The traffic bargain (you produce content, Google sends clicks, advertising revenue funds the next round of production) has been the economic engine of the open web for 20 years. That engine is seizing up in plain sight, and the industry’s response has been to argue about which dashboard to stare at while it happens.
New Interface, Same Delusion
The first camp did what the SEO industry always does when the ground shifts: they built new tools to measure the shaking.
Prompt tracking. LLM visibility dashboards. Share-of-answer metrics. In under 18 months, an entire vendor category materialized to sell you a number that tells you how often your brand appears in AI-generated responses. It’s Search Console for the chatbot era, and it comes with the same comforting implication: If the number goes up, you’re winning. If it goes down, buy more of the thing that makes it go up.
I’ve written about this before, and I’ll be blunt again: These tools are selling you bullshit with a confidence interval drawn on it in crayon. When a dashboard tells you your brand “appeared in 73% of relevant AI responses,” what it actually measured is: We fired some prompts at an API, got some outputs, and counted mentions. That’s not a ranking. That’s a lottery ticket.
The engineers who built these models cannot fully explain why a specific output appeared. But sure, a SaaS tool perched atop Mount Dunning-Kruger with a trend line has it all figured out.
The industry keeps buying because the alternative is admitting we’re flying blind. Questioning the data means telling the room that the “directional” charts in the client deck are noise dressed up as insight. Nobody wants to be that person. So the vendors keep selling, the dashboards keep flickering, and the number doesn’t need to correlate with revenue. It just needs to fluctuate enough to sustain a subscription.
Jono Alderson made the broader version of this argument in a recent piece, Clicks Don’t Count (and They Never Did). His point: SEO has always measured the interface rather than the forces underneath it. Rankings, traffic, visibility scores. None of these were measures of competitiveness. They were measurements of a presentation layer. We spent two decades optimizing what we could see and calling it strategy.
He’s right. And prompt tracking is the newest iteration of the same mistake. Old retrieval visibility in a trench coat, pretending to be two disciplines.
The second camp is more intellectually serious. Jono’s piece is the best version of this argument, and I agree with more of it than I’m about to make it sound like.
His framework: stop measuring the interface, start measuring competitiveness. Six structural dimensions drawn from marketing science validated for decades: experience integrity, physical availability, mental availability, distinctiveness, reputation, commercial proof. AI systems aggregate signals about brands across the web, not pages in isolation. The entities that are genuinely competitive get recommended and surfaced. Visibility is the output, not the input.
I think this is broadly correct. I also think it has a timing problem the size of a crater.
Those six dimensions operate on timescales of years. Building mental availability is a sustained brand investment. Earning reputation signals is the compound interest of consistently not being terrible. Strengthening distinctive assets requires buy-in from people who’ve never heard of Ehrenberg-Bass and aren’t going to read a blog post to find out.
The traffic collapse is happening in quarters.
Tell a publisher who just lost 42% of their search traffic to “strengthen structural competitiveness” and watch their face. It’s like telling someone whose house is flooding to invest in better drainage. You’re not wrong. You’re just not helping.
Jono knows this, to his credit. When someone in his comments asked how to operationalize the framework, his answer was honest: Redefine SEO to own those areas, or navigate the organizational politics of working with the teams that do. “Lots of organizational politics, either way.” That’s the kind of understatement that only someone who’s actually tried it would make.
What Actually Broke
The measurement debate is a sideshow. The traffic bargain wasn’t a metric. It was the economic foundation of content production on the open web.
Google needed content to crawl. Publishers needed distribution to monetize. Produce something worth indexing, Google sends traffic, you convert it into revenue, that revenue funds more content. The loop ran for 20 years. Everyone pretended it was a partnership rather than a dependency, and the pretence held because the numbers worked.
AI Overviews break the loop. Google synthesizes the answer from your content and serves it directly. The user gets what they need. Your content gets consumed on Google’s surface, with Google’s ads, generating Google’s engagement metrics. You get a citation link that roughly nobody clicks and a warm feeling about “brand visibility.”
Google’s own VP of Product for Search, Robby Stein, recently described how they had to “teach the model how to link out.” Linking to publishers wasn’t the default behavior. It had to be engineered back in. The system’s natural state is to absorb your content and answer the question. Sending traffic your way is the afterthought they bolted on, so the extraction doesn’t look like what it actually is: taking your stuff and serving it as theirs.
The breakage isn’t uniform. Define’s data shows breaking news traffic up 103% across all Google surfaces, while evergreen content dropped 40%. The Top Stories carousel has been largely shielded from AI Overview incursion. Evergreen content has not. The how-to guides, the explainers, the reference material, the content categories that built the SEO industry, are exactly the categories AI Overviews were designed to absorb and replace.
Google is selecting which content survives the transition. Time-sensitive content still drives clicks because you can’t summarize something that’s still developing. Everything else is increasingly raw material for the answer machine, and the machine doesn’t pay for raw materials.
If “competitiveness” replaces traffic as the operating metric, SEO’s scope has to change. Jono’s six dimensions are mostly owned by product, brand, and marketing. Experience integrity is product and UX. Mental availability is brand investment. Reputation is years of not cutting corners. Commercial proof is a function of whether the thing you sell is actually good. SEO teams control technical discoverability, content strategy, and site architecture. That’s one layer of the competitiveness framework, not the whole building.
So the discipline either expands into a cross-functional strategic role (good luck explaining to the CMO that SEO now owns brand strategy because the retrieval models changed) or it contracts honestly and positions itself as the technical infrastructure that makes competitiveness legible to machines. Either option beats “we’ll get you more organic traffic,” which is a promise that ages worse every quarter.
Clicks may not have been the right metric. Jono makes a persuasive case. We measured the interface and called it the system.
But clicks paid the bills. They funded editorial teams, justified content investment, and sustained the publishing ecosystem that both search engines and AI systems depend on for training data and retrieval sources. Without content to crawl, there’s nothing to index. Without content to train on, there’s nothing to synthesise. The irony is apparently lost on the company deploying AI Overviews.
Nobody’s building a transition strategy. The prompt-tracking vendors are selling the new dashboard. The strategists are selling the long view. Google won’t help. They broke the bargain, and their Discover push suggests they’d rather build a distribution surface they fully control than repair the one that shared value with publishers. The AI companies need content to exist, but haven’t worked out how to fund its production.
Everyone’s got a framework. Nobody’s got an answer.
The clicks didn’t count. But something needs to. Soon.
More Resources:
This post was originally published on The Inference.
Featured Image: Accogliente Design/Shutterstock