Google Lost Two Antitrust Cases, But Stock Rose 65% – Here’s Why via @sejournal, @MattGSouthern
In January, Alphabet passed Apple in market capitalization to become the second most valuable company in the world. Alphabet was worth $3.885 trillion. Apple sat at $3.846 trillion. Only Nvidia, at $4.595 trillion, was ahead.
That alone would be news. But the context makes it something else entirely. Courts had found that Google violated antitrust law in both general search services and general search text advertising. The Department of Justice asked judges to break the company apart, sell off Chrome, divest the Android operating system, and force the sale of its ad exchange. In the search case, the court rejected those proposed divestitures. In the ad-tech case, the government is still asking the judge to order a sale of Google’s ad exchange, and remedies are pending.
In this article, I’ll walk through every active Google antitrust thread, what courts have ordered, what’s still pending, and what the timelines mean. The gap between Google’s legal exposure and its market performance tells a story that matters for everyone working in search.
How We Got Here
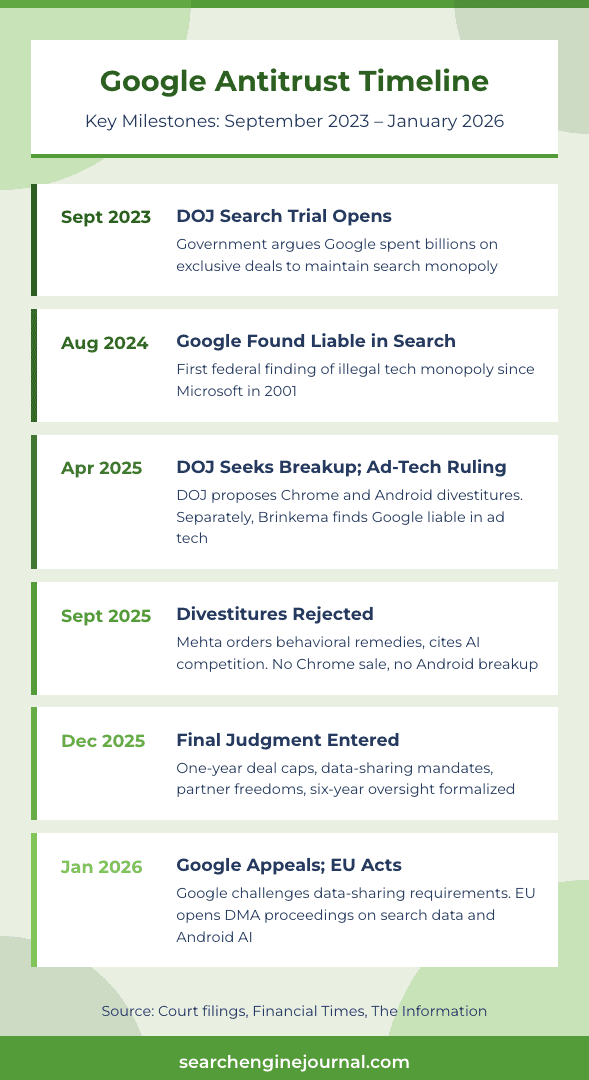
When the DOJ’s search monopoly trial opened in 2023, the government argued that Google spent billions on exclusive deals with Apple, Samsung, and browser makers to lock in its position as the default search engine. The case centered on whether those deals maintained a monopoly or reflected a better product.
In 2024, Judge Amit Mehta ruled that Google had maintained an illegal monopoly in general search services. It was the first time a federal court found a tech company had maintained an illegal monopoly since the Microsoft case in 2001.
Then came the remedies phase, where the real fight began. The DOJ wanted dramatic structural changes. Prosecutors laid out four options, including forcing Google to sell Chrome and potentially divesting Android. That was the peak fear moment for investors. It was also the point at which the case stopped being abstract legal theory and started having direct implications for how search distribution works.
What happened next surprised the industry.
The Search Case: Where It Stands
On Sept. 2, 2025, Judge Mehta issued his remedies opinion. He declined to order any divestitures. No Chrome sale. No Android breakup. No forced separation of search from the broader Alphabet structure.
His reasoning centered on AI. Mehta wrote that generative AI had changed the course of the case. He pointed to the competitive threat that AI chatbots posed to Google’s search business and concluded that the market was too dynamic for the kind of structural remedy the DOJ wanted.
Instead, Mehta ordered behavioral remedies. The final judgment, entered on Dec. 5, 2025, limits how Google can structure search distribution deals. Agreements are capped at one year and cannot be used to lock partners into defaults across multiple access points. The judgment includes provisions that require partners to have more flexibility to surface rival search options and, in some cases, third-party generative AI products.
The order also sets out data-licensing obligations for qualified rivals, including access to a portion of Google’s web index and certain user-side data. An oversight process oversees how the implementation is carried out and ensures everything stays in line during the remedy period.
Google filed its Notice of Appeal on Jan. 16, 2026. The company is specifically challenging the data-sharing requirements and the technical committee oversight. The DOJ had until Feb. 3, 2026, to decide whether to file a cross-appeal seeking stronger remedies than what Mehta ordered.
The search case landed in a unique place. Google keeps Chrome and Android. The default search deals that delivered Google the majority of mobile search activity get restructured with shorter terms and fewer restrictions on partners.
Data-sharing could enable competitors to build better search products, but the timeline for that playing out is years, not months.
The Ad-Tech Case: What’s Coming
The second federal case against Google involves digital advertising technology. This one operates on a different track with a different judge and a different set of remedies at stake.
In April 2025, Judge Leonie Brinkema ruled that Google had willfully monopolized parts of the digital ad market. Where the search case focused on consumer-facing search defaults, this case targeted Google’s ad server, ad exchange (AdX), and the connections between them.
The DOJ’s post-trial brief requested the divestiture of Google’s Ad Manager suite, including the AdX exchange. That would mean separating the tool publishers use to sell ads from the marketplace where those ads get bought and sold.
During closing arguments in November, Brinkema expressed skepticism. She noted that a potential buyer for the ad exchange hadn’t been identified and called the divestiture proposal “fairly abstract.” The court, she said, needed to be “far more down to earth and concrete.”
Brinkema said she plans to issue a decision early in 2026. That ruling could arrive at any point in Q1.
The practical stakes here are different from the search case. The search remedies affect how people find Google. The ad-tech remedies affect how publishers make money through Google.
Any forced separation of AdX would directly change the monetization stack that millions of websites rely on. Even if Brinkema follows the same pattern as Mehta and declines structural remedies, the behavioral changes she orders could reshape how programmatic advertising flows through Google’s systems.
The Epic/Play Store Settlement Question
In late January 2026, Judge James Donato held a hearing in San Francisco on a proposed settlement between Google and Epic Games. The case, which centered on Google’s Play Store practices, appeared headed for resolution. But Donato threw the terms into question.
Donato described the settlement as overly favorable to the two companies and questioned whether it came at the expense of the broader class of developers affected by Google’s Play Store policies.
The settlement terms include Epic spending $800 million over six years on Google services, plus a marketing and exploratory partnership. Reports described the partnership as involving Epic’s technology, including Unreal Engine, alongside marketing and other commercial terms.
This case matters because it touches a different part of Google’s ecosystem. The search and ad-tech cases are about how Google dominates web search and digital advertising. The Play Store case is about how Google controls app distribution on Android. Together, these cases cover the three main ways Google generates revenue and the three main ways practitioners interact with Google’s platforms.
The EU Front
European regulators are pursuing their own path, and in some areas, they’re moving faster than U.S. courts.
In September 2025, the European Commission fined Google €2.95 billion for abusing its dominance in ad tech. Google said it would appeal the decision.
Reports from December indicate the EU is preparing a non-compliance fine against Google related to Play Store anti-steering rules. That fine is expected as early as Q1 2026, which would put it on roughly the same timeline as Brinkema’s ad-tech ruling in the U.S.
But the most consequential EU action may be the newest one. On January 26, the Commission opened specification proceedings under the Digital Markets Act focused on online search data sharing and interoperability for Android AI features. The process is framed around access for rivals, including AI developers and search competitors, and is expected to conclude within six months.
That goes beyond what the U.S. search case requires. Mehta’s order mandates data-sharing with search competitors. The EU proceedings ask whether Google must open access to a broader set of rivals, including those building AI-powered products that don’t fit neatly into the traditional search category.
For those watching how AI search develops, this EU proceeding could have bigger long-term implications than anything in the U.S. cases. The question of whether Google’s search index data feeds into competing AI products affects the entire ecosystem of AI-generated answers, citations, and traffic referrals.
![]()
Why The Stock Rose Anyway
Google’s stock rose 65% in 2025, CNBC reported, which made it the best performer among the big tech stocks. Apple, by comparison, rose 8.6%. The gap between Google’s legal losses and its market gains points to a pattern that has repeated at every stage of these cases.
When we covered the original verdict in October 2024 and looked at what it could mean for SEO, the range of possible outcomes was wide. Chrome divestiture, Android breakup, elimination of default deals, forced data sharing, and structural separation of search from advertising all sat on the table.
What investors watched play out was a narrowing of that range at every step. Google offered to loosen its search engine deals in December 2024, signaling that behavioral concessions were coming. The DOJ pushed for breakups. The court landed closer to Google’s position than the government’s.
A Financial Times analysis from January 2026 placed Google’s outcome in a broader context. Across multiple Big Tech antitrust cases, judges have shown reluctance to order structural remedies. Meta won outright in November when Judge James Boasberg ruled the company doesn’t hold an illegal monopoly. In the Google ad-tech case, Brinkema expressed discomfort with divestiture. Former DOJ antitrust chief Jonathan Kanter, who helped bring these cases, acknowledged to the FT that the rulings showed the U.S. was too slow to act.
The pattern across cases is consistent. Courts are willing to find that tech companies violated antitrust law. They’re reluctant to order the kind of structural changes that would break the companies apart. And they’re citing AI competition as a central reason for that restraint.
For Google specifically, the combination of light remedies, a strong AI narrative (signs that Google had caught up to OpenAI reinforced investor confidence, according to a Fortune report), and continued dominance in search revenue removed the threat that investors feared most. The breakup scenario didn’t happen, and the stock reflected that.

What This Means For Search Professionals
The antitrust cases resolved in a way that preserves Google’s structure while introducing new requirements around data access and distribution agreements. The impact will unfold over years, not weeks. Here’s what to track.
Search distribution could diversify gradually. The one-year cap on distribution agreements and the restrictions on tying defaults across access points give Apple and Samsung more room to offer users alternatives or to negotiate different terms. Whether they will is a separate question.
Apple’s search-default deal with Google has been widely reported to be worth tens of billions annually. Without that kind of long-term lock-in, Apple has financial incentive to build or license an alternative.
Data-sharing mandates could create new competitors. The judgment requires Google to license a portion of its web index and certain user-side data to qualified rivals, with an oversight process governing the details. The scope matters enormously. Providing limited index access is different from sharing the ranking signals and full index depth that would let a competitor build a viable alternative. Google is appealing this requirement, which tells you where the company sees the real threat.
The ad-tech ruling will directly affect publisher revenue. Brinkema’s decision, expected in early 2026, determines whether Google must separate the tools publishers use to sell ads from the exchange where those ads trade. Even if she orders behavioral remedies instead of a full divestiture, changes to how Google’s ad stack operates will ripple through programmatic advertising. Publishers using Google Ad Manager should pay close attention to the timeline.
The EU’s DMA proceedings open a different front. The January proceedings cover online search data sharing and Android AI interoperability, framed around access for rivals, including AI developers. The outcome would affect how AI search products source their information and, by extension, how content gets cited in AI-generated answers.
Looking Ahead
The next 12 months will determine whether the antitrust cases produce real changes to search markets or settle into a compliance exercise that preserves the status quo.
Key dates and events to watch include Brinkema’s ad-tech remedies ruling, expected in Q1 2026. The DOJ’s decision on whether to cross-appeal Mehta’s rejection of stronger search remedies was due by early February.
Google’s search case appeal will move through the D.C. Circuit, likely taking a year or more. The EU’s DMA specification proceedings on search data sharing and Android AI interoperability are expected to conclude within six months. And the Epic/Play Store settlement faces scrutiny after Judge Donato’s criticism.
Meanwhile, the Amazon and Apple antitrust cases are pending, with trials expected in 2027. Those cases will test whether courts continue the pattern of finding violations but declining breakups, or whether the legal environment changes.
In Summary
Google was found to have maintained illegal monopolies in two separate markets. It’s appealing one case and awaiting remedies in another. Regulators on two continents are pressing forward, and yet the company just became the second most valuable in the world.
Whether the courts ultimately deliver continuity or disruption will play out over the years ahead. Either way, what gets decided in these cases shapes the infrastructure that every search professional works within.

More Resources:
Featured Image: Collagery/Shutterstock