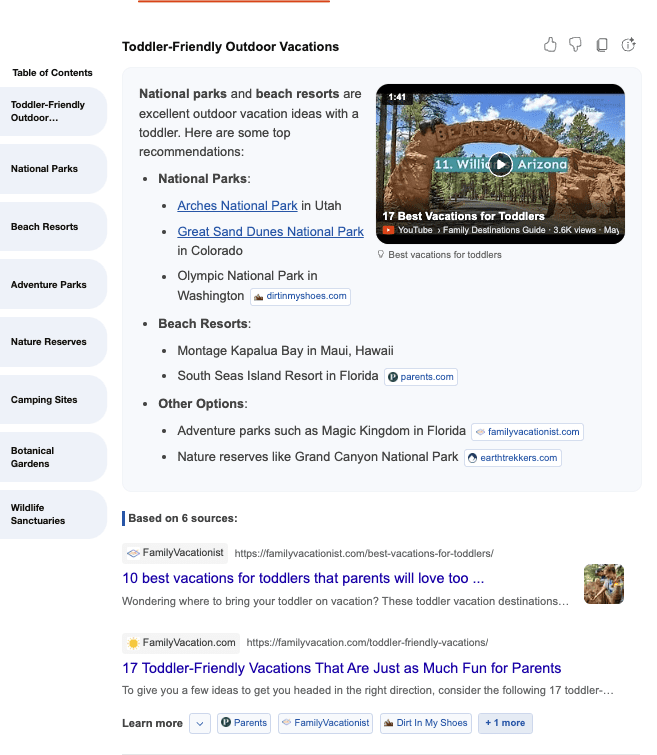
SEO Reinvented: Responding To Algorithm Shifts via @sejournal, @pageonepower
A lot has been said about the remarkable opportunities of Generative AI (GenAI), and some of us have also been extremely vocal about the risks associated with using this transformative technology.
The rise of GenAI presents significant challenges to the quality of information, public discourse, and the general open web. GenAI’s power to predict and personalize content can be easily misused to manipulate what we see and engage with.
Generative AI search engines are contributing to the overall noise, and rather than helping people find the truth and forge unbiased opinions, they tend (at least in their present implementation) to promote efficiency over accuracy, as highlighted by a recent study by Jigsaw, a unit inside Google.
Despite the hype surrounding SEO alligator parties and content goblins, our generation of marketers and SEO professionals has spent years working towards a more positive web environment.
We’ve shifted the marketing focus from manipulating audiences to empowering them with knowledge, ultimately aiding stakeholders in making informed decisions.
Creating an ontology for SEO is a community-led effort that aligns perfectly with our ongoing mission to shape, improve, and provide directions that truly advance human-GenAI interaction while preserving content creators and the Web as a shared resource for knowledge and prosperity.
Traditional SEO practices in the early 2010s focused heavily on keyword optimization. This included tactics like keyword stuffing, link schemes, and creating low-quality content primarily intended for search engines.
Since then, SEO has shifted towards a more user-centric approach. The Hummingbird update (2013) marked Google’s transition towards semantic search, which aims to understand the context and intent behind search queries rather than just the keywords.
This evolution has led SEO pros to focus more on topic clusters and entities than individual keywords, improving content’s ability to answer multiple user queries.
Entities are distinct items like people, places, or things that search engines recognize and understand as individual concepts.
By building content that clearly defines and relates to these entities, organizations can enhance their visibility across various platforms, not just traditional web searches.
This approach ties into the broader concept of entity-based SEO, which ensures that the entity associated with a business is well-defined across the web.
Fast-forward to today, static content that aims to rank well in search engines is constantly transformed and enriched by semantic data.
This involves structuring information so that it is understandable not only by humans but also by machines.
This transition is crucial for powering Knowledge Graphs and AI-generated responses like those offered by Google’s AIO or Bing Copilot, which provide users with direct answers and links to relevant websites.
As we move forward, the importance of aligning content with semantic search and entity understanding is growing.
Businesses are encouraged to structure their content in ways that are easily understood and indexed by search engines, thus improving visibility across multiple digital surfaces, such as voice and visual searches.
The use of AI and automation in these processes is increasing, enabling more dynamic interactions with content and personalized user experiences.
Whether we like it or not, AI will help us compare options faster, run deep searches effortlessly, and make transactions without passing through a website.
The future of SEO is promising. The SEO service market size is expected to grow from $75.13 billion in 2023 to $88.91 billion in 2024 – a staggering CAGR of 18.3% (according to The Business Research Company) – as it adapts to incorporate reliable AI and semantic technologies.
These innovations support the creation of more dynamic and responsive web environments that adeptly cater to user needs and behaviors.
However, the journey hasn’t been without challenges, especially in large enterprise settings. Implementing AI solutions that are both explainable and strategically aligned with organizational goals has been a complex task.
Building effective AI involves aggregating relevant data and transforming it into actionable knowledge.
This differentiates an organization from competitors using similar language models or development patterns, such as conversational agents or retrieval-augmented generation copilots and enhances its unique value proposition.
Imagine an ontology as a giant instruction manual for describing specific concepts. In the world of SEO, we deal with a lot of jargon, right? Topicality, backlinks, E-E-A-T, structured data – it can get confusing!
An ontology for SEO is a giant agreement on what all those terms mean. It’s like a shared dictionary, but even better. This dictionary doesn’t just define each word. It also shows how they all connect and work together. So, “queries” might be linked to “search intent” and “web pages,” explaining how they all play a role in a successful SEO strategy.
Imagine it as untangling a big knot of SEO practices and terms and turning them into a clear, organized map – that’s the power of ontology!
While Schema.org is a fantastic example of a linked vocabulary, it focuses on defining specific attributes of a web page, like content type or author. It excels at helping search engines understand our content. But what about how we craft links between web pages?
What about the query a web page is most often searched for? These are crucial elements in our day-to-day work, and an ontology can be a shared framework for them as well. Think of it as a playground where everyone is welcome to contribute on GitHub similar to how the Schema.org vocabulary evolves.
The idea of an ontology for SEO is to augment Schema.org with an extension similar to what GS1 did by creating its vocabulary. So, is it a database? A collaboration framework or what? It is all of these things together. SEO ontology operates like a collaborative knowledge base.
It acts as a central hub where everyone can contribute their expertise to define key SEO concepts and how they interrelate. By establishing a shared understanding of these concepts, the SEO community plays a crucial role in shaping the future of human-centered AI experiences.
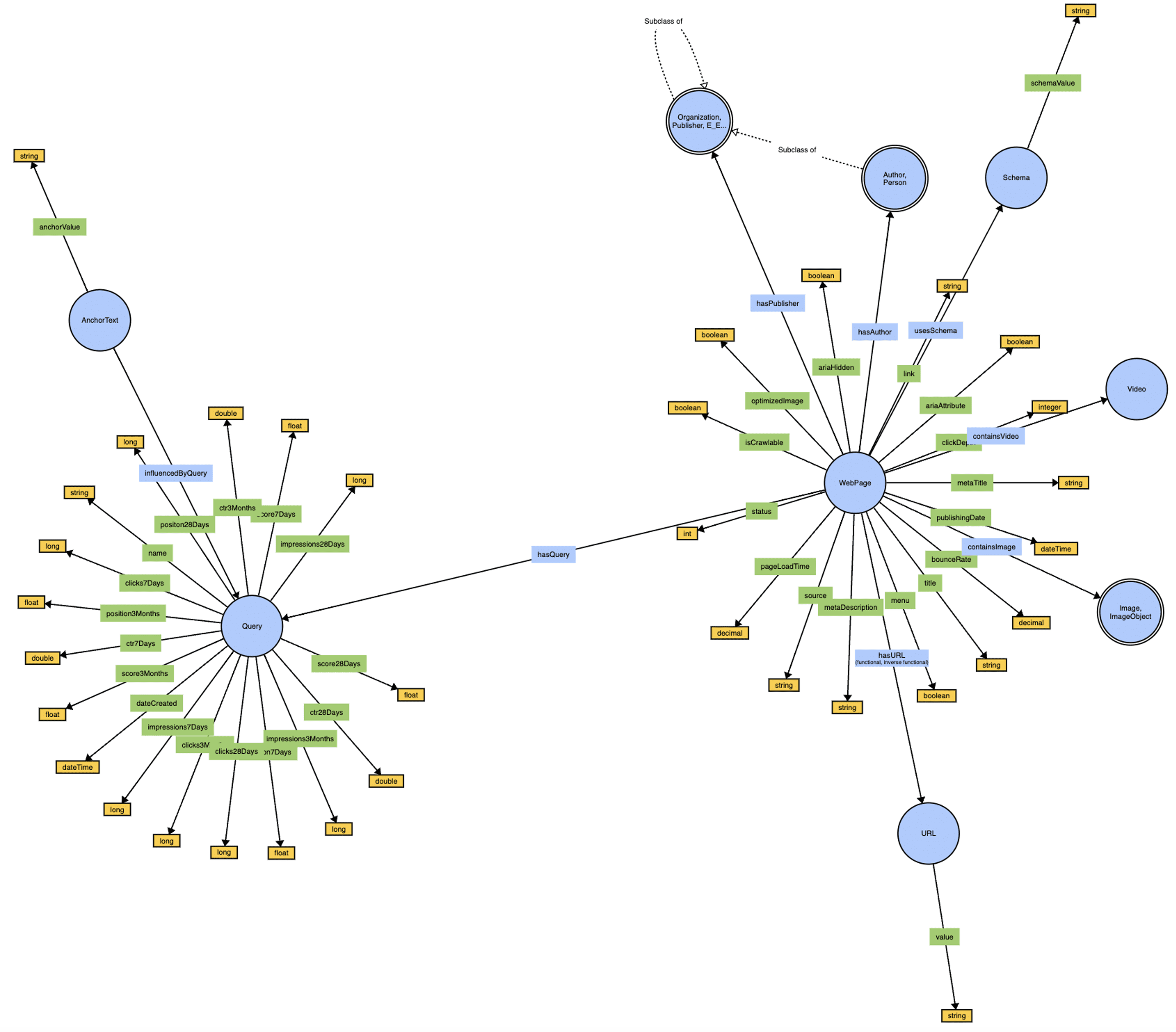
Screenshot from WebVowl, August 2024SEOntology – a snapshot (see an interactive visualization here).
The Data Interoperability Challenge In The SEO Industry
Let’s start small and review the benefits of a shared ontology with a practical example (here is a slide taken from Emilija Gjorgjevska’s presentation at this year’s ZagrebSEOSummit)
 Image from Emilija Gjorgjevska’s, ZagrebSEOSummit, August 2024
Image from Emilija Gjorgjevska’s, ZagrebSEOSummit, August 2024Imagine your colleague Valentina uses a Chrome extension to export data from Google Search Console (GSC) into Google Sheets. The data includes columns like “ID,” “Query,” and “Impressions” (as shown on the left). But Valentina collaborates with Jan, who’s building a business layer using the same GSC data. Here’s the problem: Jan uses a different naming convention (“UID,” “Name,” “Impressionen,” and “Klicks”).
Now, scale this scenario up. Imagine working with n different data partners, tools, and team members, all using various languages. The effort to constantly translate and reconcile these different naming conventions becomes a major obstacle to effective data collaboration.
Significant value gets lost in just trying to make everything work together. This is where an SEO ontology comes in. It is a common language, providing a shared name for the same concept across different tools, partners, and languages.
By eliminating the need for constant translation and reconciliation, an SEO ontology streamlines data collaboration and unlocks the true value of your data.
The Genesis Of SEOntology
In the last year, we have witnessed the proliferation of AI Agents and the wide adoption of Retrieval Augmented Generation (RAG) in all its different forms (Modular, Graph RAG, and so on).
RAG represents an important leap forward in AI technology, addressing a key limitation of traditional large language models (LLMs) by letting them access external knowledge.
Traditionally, LLMs are like libraries with one book – limited by their training data. RAG unlocks a vast network of resources, allowing LLMs to provide more comprehensive and accurate responses.
RAGs improve factual accuracy, and context understanding, potentially reducing bias. While promising, RAG faces challenges in data security, accuracy, scalability, and integration, especially in the enterprise sector.
For successful implementation, RAG requires high-quality, structured data that can be easily accessed and scaled.
We’ve been among the first to experiment with AI Agents and RAG powered by the Knowledge Graph in the context of content creation and SEO automation.
 Screenshot from Agent WordLift, August 2023
Screenshot from Agent WordLift, August 2023Knowledge Graphs (KGs) Are Indeed Gaining Momentum In RAG Development
Microsoft’s GraphRAG and solutions like LlamaIndex demonstrate this. Baseline RAG struggles to connect information across disparate sources, hindering tasks requiring a holistic understanding of large datasets.
KG-powered RAG approaches like the one offered by LlamaIndex in conjunction with WordLift address this by creating a knowledge graph from website data and using it alongside the LLM to improve response accuracy, particularly for complex questions.
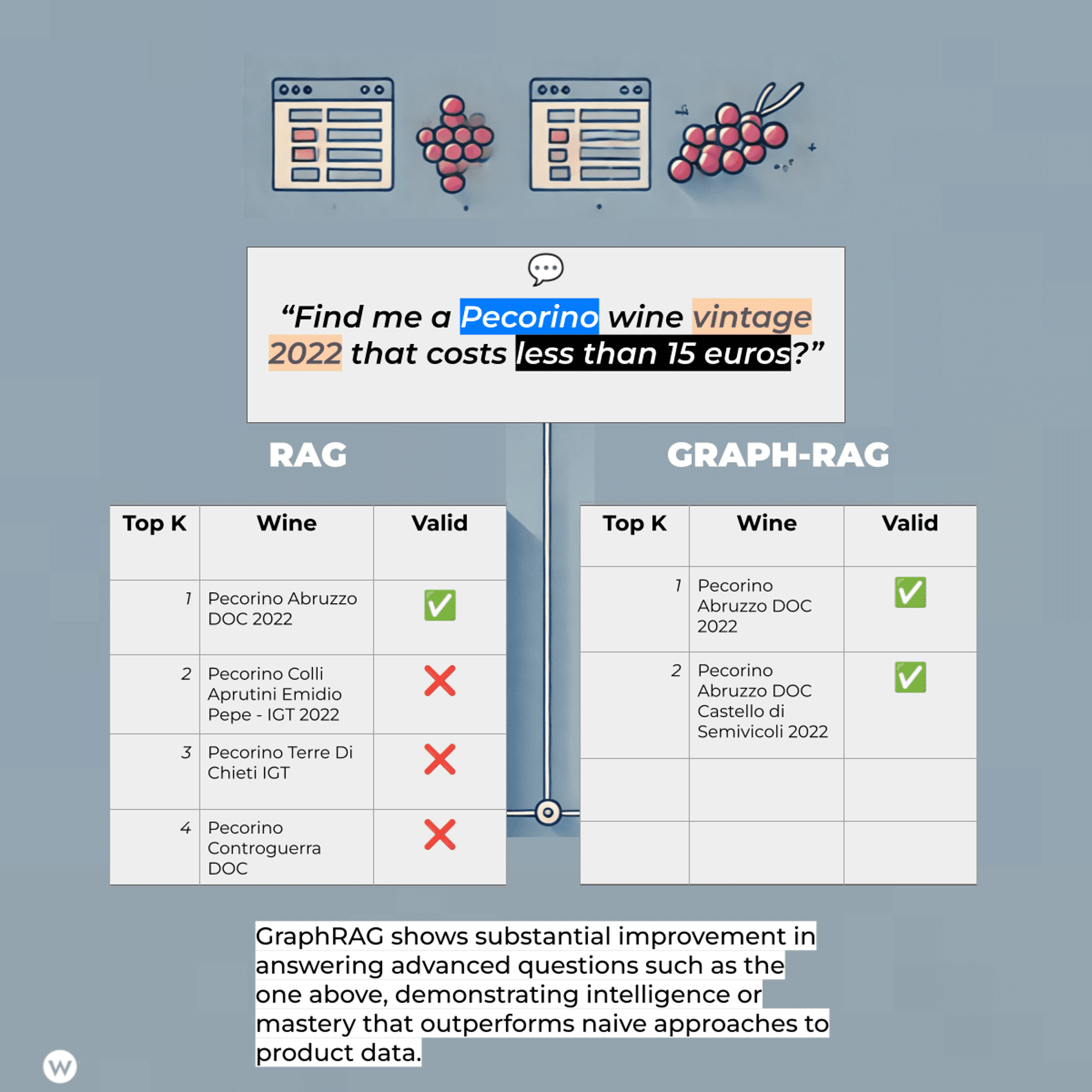 Image from author, August 2024
Image from author, August 2024We have tested workflows with clients in different verticals for over a year.
From keyword research for large editorial teams to the generation of question and answers for ecommerce websites, from content bucketing to drafting the outline of a newsletter or revamping existing articles, we’ve been testing different strategies and learned a few things along the way:
1. RAG Is Overhyped
It is simply one of many development patterns that achieve a goal of higher complexity. A RAG (or Graph RAG) is meant to help you save time finding an answer. It’s brilliant but doesn’t solve any marketing tasks a team must handle daily. You need to focus on the data and the data model.
While there are good RAGs and bad RAGs, the key differentiation is often represented by the “R” part of the equation: the Retrieval. Primarily, the retrieval differentiates a fancy demo from a real-world application, and behind a good RAG, there is always good data. Data, though, is not just any type of data (or graph data).
It is built around a coherent data model that makes sense for your use case. If you build a search engine for wines, you need to get the best dataset and model the data around the features a user will rely on when looking for information.
So, data is important, but the data model is even more important. If you are building an AI Agent that has to do things in your marketing ecosystem, you must model the data accordingly. You want to represent the essence of web pages and content assets.
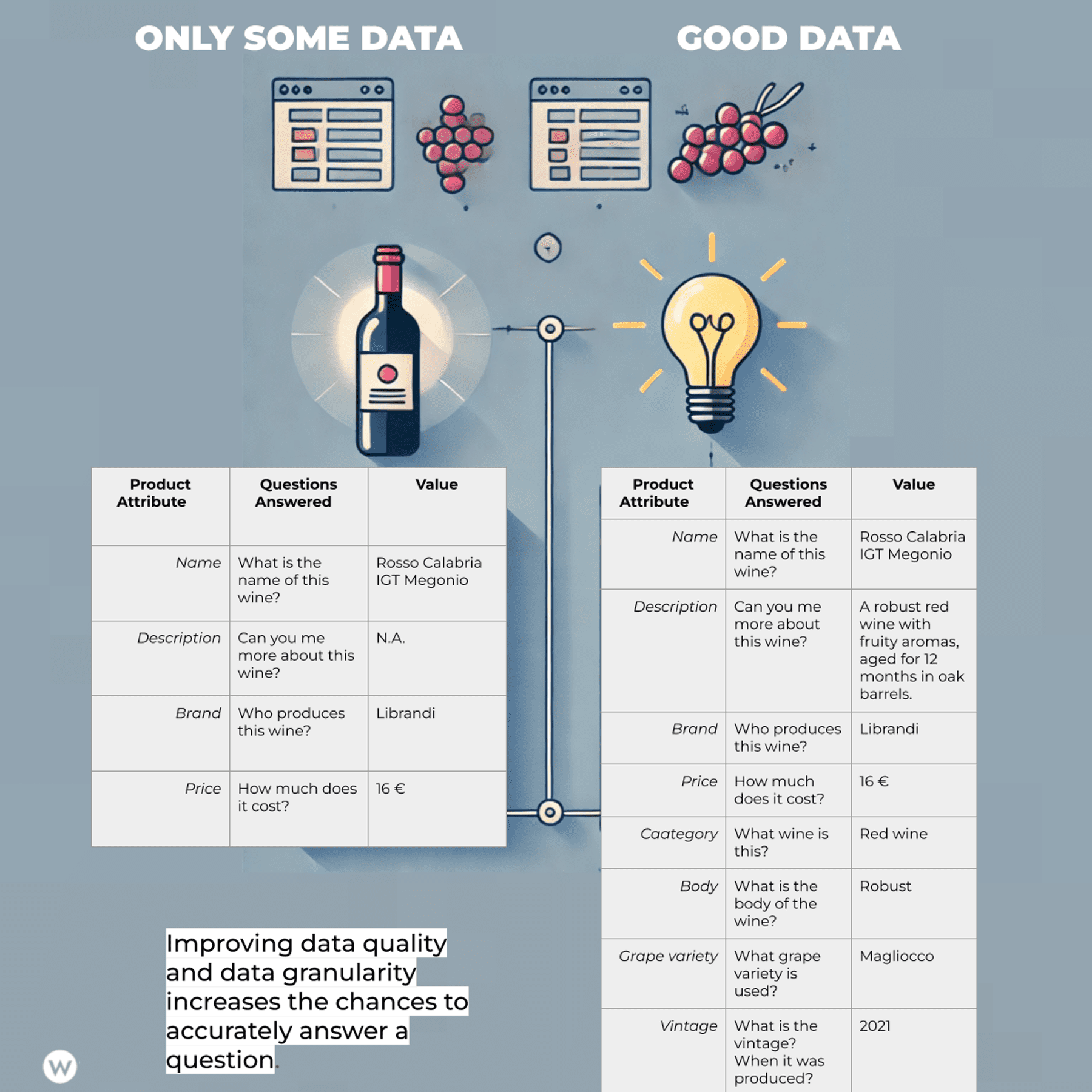 Image from author, August 2024
Image from author, August 20242. Not Everyone Is Great At Prompting
Expressing a task in written form is hard. Prompt engineering is going at full speed towards automation (here is my article on going from prompting to prompt programming for SEO) as only a few experts can write the prompt that brings us to the expected outcome.
This poses several challenges for the design of the user experience of autonomous agents. Jakon Nielsen has been very vocal about the negative impact of prompting on the usability of AI applications:
“One major usability downside is that users must be highly articulate to write the required prose text for the prompts.”
Even in rich Western countries, statistics provided by Nielsen tell us that only 10% of the population can fully utilize AI!
| Simple Prompt Using Chain-of-Thought (CoT) | More Sophisticated Prompt Combining Graph-of-Thought (GoT) and Chain-of-Knowledge (CoK) |
| “Explain step-by-step how to calculate the area of a circle with a radius of 5 units.” | “Using the Graph-of-Thought (GoT) and Chain-of-Knowledge (CoK) techniques, provide a comprehensive explanation of how to calculate the area of a circle with a radius of 5 units. Your response should: Start with a GoT diagram that visually represents the key concepts and their relationships, including: Circle Radius Area Pi (π) Formula for circle area Follow the GoT diagram with a CoK breakdown that: a) Defines each concept in the diagram b) Explains the relationships between these concepts c) Provides the historical context for the development of the circle area formula Present a step-by-step calculation process, including: a) Stating the formula for the area of a circle b) Explaining the role of each component in the formula c) Showing the substitution of values d) Performing the calculation e) Rounding the result to an appropriate number of decimal places Conclude with practical applications of this calculation in real-world scenarios. Throughout your explanation, ensure that each step logically follows the previous one, creating a clear chain of reasoning from basic concepts to the final result.” This improved prompt incorporates GoT by requesting a visual representation of the concepts and their relationships. It also employs CoK by asking for definitions, historical context, and connections between ideas. The step-by-step breakdown and real-world applications further enhance the depth and practicality of the explanation.” |
3. You Shall Build Workflows To Guide The User
The lesson learned is that we must build detailed standard operating procedures (SOP) and written protocols that outline the steps and processes to ensure consistency, quality, and efficiency in executing particular optimization tasks.
We can see empirical evidence of the rise of prompt libraries like the one offered to users of Anthropic models or the incredible success of projects like AIPRM.
In reality, we learned that what creates business value is a series of ci steps that help the user translate the context he/she is navigating in into a consistent task definition.
We can start to envision marketing tasks like conducting keyword research as a Standard Operating Procedure that can guide the user across multiple steps (here is how we intend the SOP for keyword discovery using Agent WordLift)
4. The Great Shift To Just-in-Time UX
In traditional UX design, information is pre-determined and can be organized in hierarchies, taxonomies, and pre-defined UI patterns. As AI becomes the interface to the complex world of information, we’re witnessing a paradigm shift.
UI topologies tend to disappear, and the interaction between humans and AI remains predominantly dialogic. Just-in-time assisted workflows can help the user contextualize and improve a workflow.
- You need to think in terms of business value creation, focus on the user’s interactive journey, and facilitate the interaction by creating a UX on the fly. Taxonomies remain a strategic asset, but they operate behind the scenes as the user is teleported from one task to another, as recently brilliantly described by Yannis Paniaras from Microsoft.
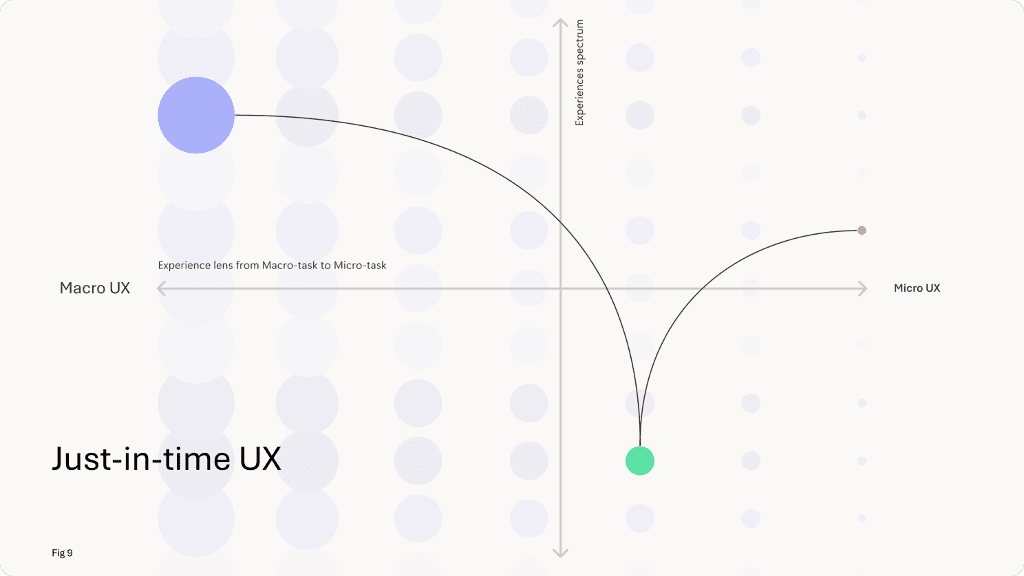 Image from “The Shift to Just-In-Time UX: How AI is Reshaping User Experiences” by Yannis Paniaras, August 2024
Image from “The Shift to Just-In-Time UX: How AI is Reshaping User Experiences” by Yannis Paniaras, August 20245. From Agents To RAG (And GraphRAG) To Reporting
Because the user needs a business impact and RAG is only part of the solution, the focus quickly shifts from more generic questions and answering user patterns to advanced multi-step workflows.
The biggest issue, though, is what outcome the user needs. If we increase the complexity to capture the highest business goals, it is not enough to, let’s say, “query your data” or “chat with your website.”
A client wants a report, for example, of what is the thematic consistency of content within the entire website (this is a concept that we recently discovered as SiteRadus in Google’s massive data leak), the overview of the seasonal trends across hundreds of paid campaigns, or the ultimate review of the optimization opportunities related to the optimization of Google Merchant Feed.
You must understand how the business operates and what deliverables you will pay for. What concrete actions could boost the business? What questions need to be answered?
This is the start of creating a tremendous AI-assisted reporting tool.
How Can A Knowledge Graph (KG) Be Coupled With An Ontology For AI Alignment, Long-term Memory, And Content Validation?
The three guiding principles behind SEOntology:
- Making SEO data interoperable to facilitate the creation of knowledge graphs while reducing unneeded crawls and vendor locked-in;
- Infusing SEO know-how into AI agents using a domain-specific language.
- Collaboratively sharing knowledge and tactics to improve findability and prevent misuse of Generative AI.
When you deal with at least two data sources in your SEO automation task, you will already see the advantage of using SEOntology.
SEOntology As “The USB-C Of SEO/Crawling Data”
Standardizing data about content assets, products, user search behavior, and SEO insights is strategic. The goal is to have a “shared representation” of the Web as a communication channel.
Let’s take a step backward. How does a Search Engine represent a web page? This is our starting point here. Can we standardize how a crawler would represent data extracted from a website? What are the advantages of adopting standards?
Practical Use Cases
Integration With Botify And Dynamic Internal Linking
Over the past few months, we’ve been working closely with the Botify team to create something exciting: a Knowledge Graph powered by Botify’s crawl data and enhanced by SEOntology. This collaboration is opening up new possibilities for SEO automation and optimization.
Leveraging Existing Data With SEOntology
Here’s the cool part: If you’re already using Botify, we can tap into that goldmine of data you’ve collected. No need for additional crawls or extra work on your part. We use the Botify Query Language (BQL) to extract and transform the needed data using SEOntology.
Think of SEOntology as a universal translator for SEO data. It takes the complex information from Botify and turns it into a format that’s not just machine-readable but machine-understandable. This allows us to create a rich, interconnected Knowledge Graph filled with valuable SEO insights.
What This Means for You
Once we have this Knowledge Graph, we can do some pretty amazing things:
- Automated Structured Data: We can automatically generate structured data markup for your product listing pages (PLPs). This helps search engines better understand your content, potentially improving your visibility in search results.
- Dynamic Internal Linking: This is where things get really interesting. We use the data in the Knowledge Graph to create smart, dynamic internal links across your site. Let me break down how this works and why it’s so powerful.
In the diagram below, we can also see how data from Botify can be blended with data from Google Search Console.
While in most implementations, Botify already imports this data into its crawl projects, when this is not the case, we can trigger a new API request and import clicks, impressions, and positions from GSC into the graph.
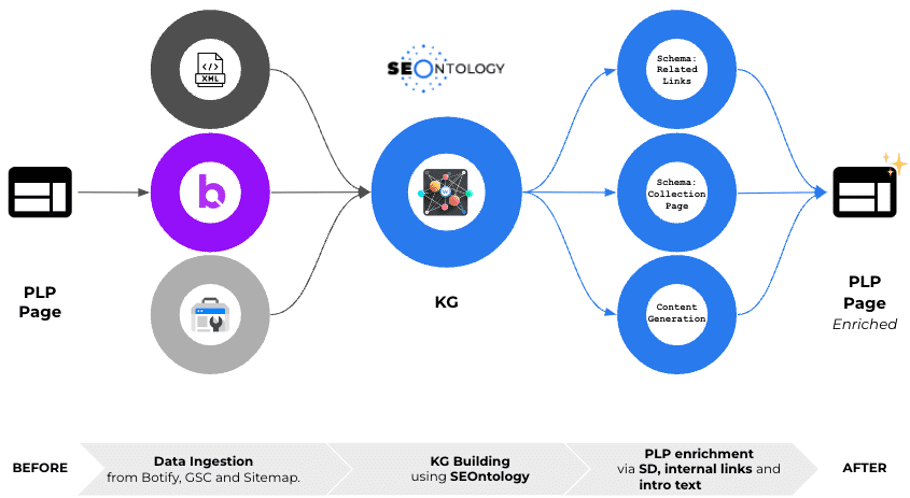
Collaboration With Advertools For Data Interoperability
Similarly, we collaborated with the brilliant Elias Dabbas, creator of Advertools — a favorite Python library among marketers – to automate a wide range of marketing tasks.
Our joint efforts aim to enhance data interoperability, allowing for seamless integration and data exchange across different platforms and tools.
In the first Notebook, available in the SEOntology GitHub repository, Elias showcases how we can effortlessly construct attributes for the WebPage class, including title, meta description, images, and links. This foundation enables us to easily model complex elements, such as internal linking strategies. See here the structure:
- Internal_Links
-
- anchorTextContent
- NoFollow
- Link
We can also add a flag if the page is already using schema markup:
- usesSchema
Formalizing What We Learned From The Analysis Of The Leaked Google Search Documents
While we want to be extremely conscious in deriving tactics or small schemes from Google’s massive leak, and we are well aware that Google will quickly prevent any potential misuse of such information, there is a great level of information that, based on what we learned, can be used to improve how we represent web content and organize marketing data.
Despite these constraints, the leak offers valuable insights into improving web content representation and marketing data organization. To democratize access to these insights, I’ve developed a Google Leak Reporting tool designed to make this information readily available to SEO pros and digital marketers.
For instance, understanding Google’s classification system and its segmentation of websites into various taxonomies has been particularly enlightening. These taxonomies – such as ‘verticals4’, ‘geo’, and ‘products_services’ – play a crucial role in search ranking and relevance, each with unique attributes that influence how websites and content are perceived and ranked in search results.
By leveraging SEOntology, we can adopt some of these attributes to enhance website representation.
Now, pause for a second and imagine transforming the complex SEO data you manage daily through tools like Moz, Ahrefs, Screaming Frog, Semrush, and many others into an interactive graph. Now, envision an Autonomous AI Agent, such as Agent WordLift, at your side.
This agent employs neuro-symbolic AI, a cutting-edge approach that combines neural learning capabilities with symbolic reasoning, to automate SEO tasks like creating and updating internal links. This streamlines your workflow and introduces a level of precision and efficiency previously unattainable.
SEOntology serves as the backbone for this vision, providing a structured framework that enables the seamless exchange and reuse of SEO data across different platforms and tools. By standardizing how SEO data is represented and interconnected, SEOntology ensures that valuable insights derived from one tool can be easily applied and leveraged by others. For instance, data on keyword performance from SEMrush could inform content optimization strategies in WordLift, all within a unified, interoperable environment. This not only maximizes the utility of existing data but also accelerates the automation and optimization processes that are crucial for effective marketing.
Infusing SEO Know-How Into AI Agents
As we develop a new agentic approach to SEO and digital marketing, SEOntology serves as our domain-specific language (DSL) for encoding SEO skills into AI agents. Let’s look at a practical example of how this works.
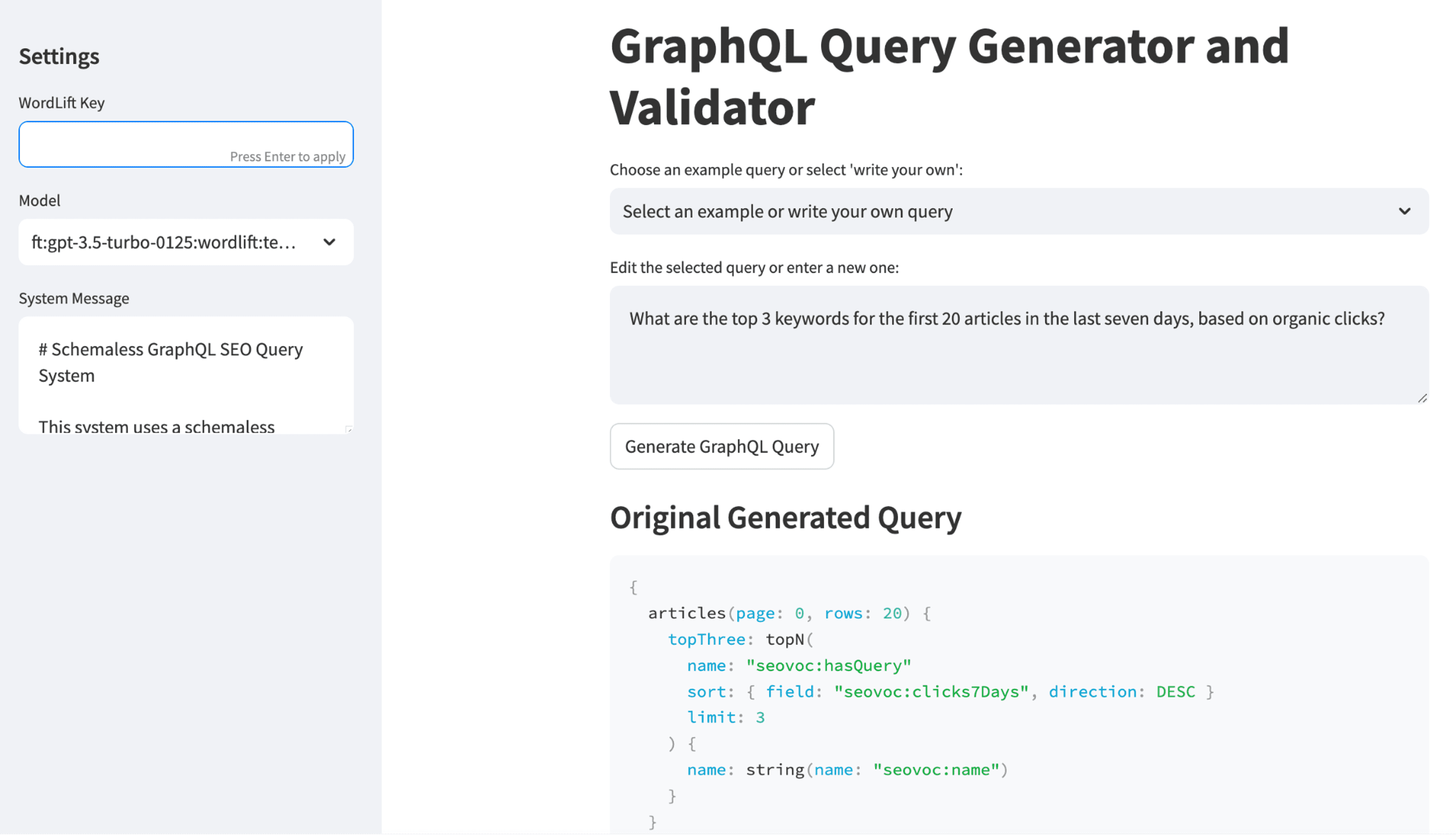 Screenshot from WordLift, August 2024
Screenshot from WordLift, August 2024We’ve developed a system that makes AI agents aware of a website’s organic search performance, enabling a new kind of interaction between SEO professionals and AI. Here’s how the prototype works:
System Components
- Knowledge Graph: Stores Google Search Console (GSC) data, encoded with SEOntology.
- LLM: Translates natural language queries into GraphQL and analyzes data.
- AI Agent: Provides insights based on the analyzed data.
Human-Agent Interaction
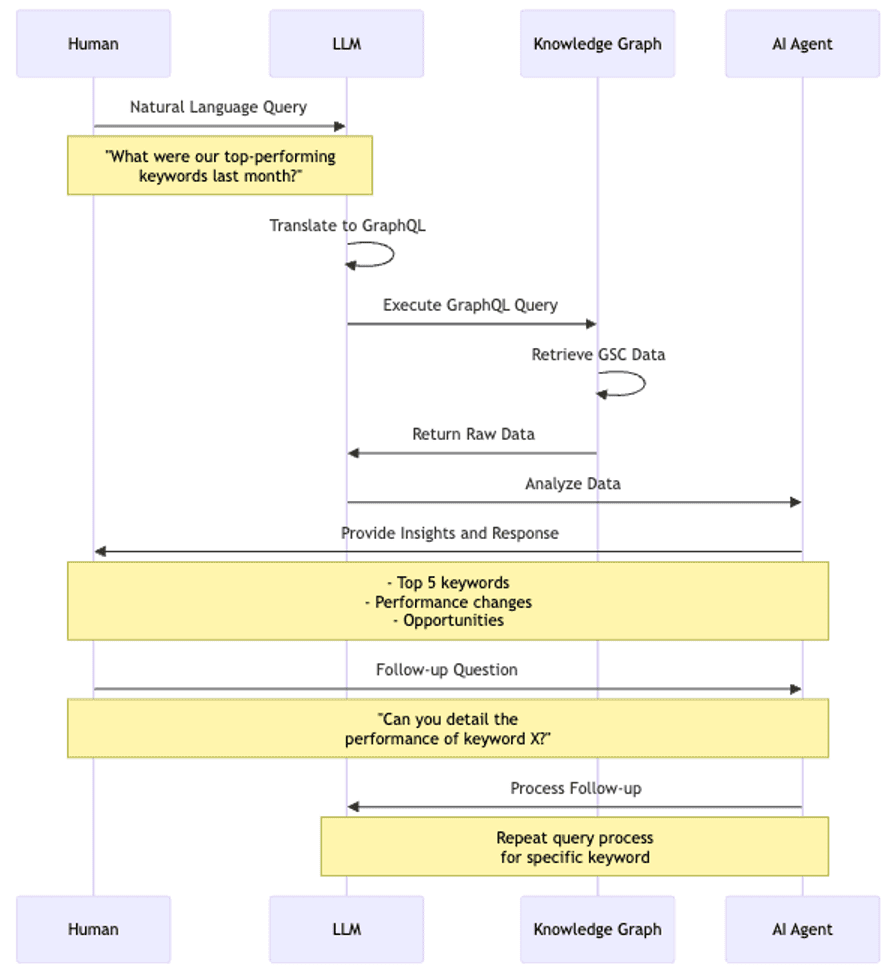 Image from author, August 2024
Image from author, August 2024The diagram illustrates the flow of a typical interaction. Here’s what makes this approach powerful:
- Natural Language Interface: SEO professionals can ask questions in plain language without constructing complex queries.
- Contextual Understanding: The LLM understands SEO concepts, allowing for more nuanced queries and responses.
- Insightful Analysis: The AI agent doesn’t just retrieve data; it provides actionable insights, such as:
- Identifying top-performing keywords.
- Highlighting significant performance changes.
- Suggesting optimization opportunities.
- Interactive Exploration: Users can ask follow-up questions, enabling a dynamic exploration of SEO performance.
By encoding SEO knowledge through SEOntology and integrating performance data, we’re creating AI agents that can provide context-aware, nuanced assistance in SEO tasks. This approach bridges the gap between raw data and actionable insights, making advanced SEO analysis more accessible to professionals at all levels.
This example illustrates how an ontology like SEOntology can empower us to build agentic SEO tools that automate complex tasks while maintaining human oversight and ensuring quality outcomes. It’s a glimpse into the future of SEO, where AI augments human expertise rather than replacing it.
Human-In-The-Loop (HTIL) And Collaborative Knowledge Sharing
Let’s be crystal clear: While AI is revolutionizing SEO and Search, humans are the beating heart of our industry. As we dive deeper into the world of SEOntology and AI-assisted workflows, it’s crucial to understand that Human-in-the-Loop (HITL) isn’t just a fancy add-on—it’s the foundation of everything we’re building.
The essence of creating SEOntology is to transfer our collective SEO expertise to machines while ensuring we, as humans, remain firmly in the driver’s seat. It’s not about handing over the keys to AI; it’s about teaching it to be the ultimate co-pilot in our SEO journey.
Human-Led AI: The Irreplaceable Human Element
SEOntology is more than a technical framework – it’s a catalyst for collaborative knowledge sharing that emphasizes human potential in SEO. Our commitment extends beyond code and algorithms to nurturing skills and expanding the capabilities of new-gen marketers and SEO pros.
Why? Because AI’s true power in SEO is unlocked by human insight, diverse perspectives, and real-world experience. After years of working with AI workflows, I’ve realized that agentive SEO is fundamentally human-centric. We’re not replacing expertise; we’re amplifying it.
We deliver more efficient and trustworthy results by blending cutting-edge tech with human creativity, intuition, and ethical judgment. This approach builds trust with clients within our industry and across the web.
Here’s where humans remain irreplaceable:
- Understanding Business Needs: AI can crunch numbers but can’t replace the nuanced understanding of business objectives that seasoned SEO professionals bring. We need experts who can translate client goals into actionable SEO strategies.
- Identifying Client Constraints: Every business is unique, with its limitations and opportunities. It takes human insight to navigate these constraints and develop tailored SEO approaches that work within real-world parameters.
- Developing Cutting-Edge Algorithms: The algorithms powering our AI tools don’t materialize out of thin air. We need brilliant minds to develop state-of-the-art algorithms, learn from human input, and continually improve.
- Engineering Robust Systems: Behind every smooth-running AI tool is a team of software engineers who ensure our systems are fast, secure, and reliable. This human expertise keeps our AI assistants running like well-oiled machines.
- Passion for a Better Web: At the heart of SEO is a commitment to making the web a better place. We need people who share Tim Berners’s—Lee’s vision—people who are passionate about developing the web of data and improving the digital ecosystem for everyone.
- Community Alignment and Resilience: We need to unite to analyze the behavior of search giants and develop resilient strategies. It’s about solving our problems innovatively as individuals and as a collective force. This is what I always loved about the SEO industry!
Extending The Reach Of SEOntology
As we continue to develop SEOntology, we’re not operating in isolation. Instead, we’re building upon and extending existing standards, particularly Schema.org, and following the successful model of the GS1 Web Vocabulary.
SEOntology As An Extension Of Schema.org
Schema.org has become the de facto standard for structured data on the web, providing a shared vocabulary that webmasters can use to markup their pages.
However, while Schema.org covers a broad range of concepts, it doesn’t delve deeply into SEO-specific elements. This is where SEOntology comes in.
An extension of Schema.org, like SEOntology, is essentially a complementary vocabulary that adds new types, properties, and relationships to the core Schema.org vocabulary.
This allows us to maintain compatibility with existing Schema.org implementations while introducing SEO-specific concepts not covered in the core vocabulary.
Learning From GS1 Web Vocabulary
The GS1 Web Vocabulary offers a great model for creating a successful extension that interacts seamlessly with Schema.org. GS1, a global organization that develops and maintains supply chain standards, created its Web Vocabulary to extend Schema.org for e-commerce and product information use cases.
The GS1 Web Vocabulary demonstrates, even recently, how industry-specific extensions can influence and interact with schema markup:
- Real-world impact: The https://schema.org/Certification property, now officially embraced by Google, originated from GS1’s https://www.gs1.org/voc/CertificationDetails. This showcases how extensions can drive the evolution of Schema.org and search engine capabilities.
We want to follow a similar approach to extend Schema.org and become the standard vocabulary for SEO-related applications, potentially influencing future search engine capabilities, AI-driven workflows, and SEO practices.
Much like GS1 defined their namespace (gs1:) while referencing schema terms, we have defined our namespace (seovoc:) and are integrating the classes within the Schema.org hierarchy when possible.
The Future Of SEOntology
SEOntology is more than just a theoretical framework; it’s a practical tool designed to empower SEO professionals and tool makers in an increasingly AI-driven ecosystem.
Here’s how you can engage with and benefit from SEOntology.
If you’re developing SEO tools:
- Data Interoperability: Implement SEOntology to export and import data in a standardized format. This ensures your tools can easily interact with other SEOntology-compliant systems.
- AI-Ready Data: By structuring your data according to SEOntology, you’re making it more accessible for AI-driven automations and analyses.
If you’re an SEO professional:
- Contribute to Development: Just like with Schema.org, you can contribute to SEOntology’s evolution. Visit its GitHub repository to:
- Raise issues for new concepts or properties you think should be included.
- Propose changes to existing definitions.
- Participate in discussions about the future direction of SEOntology.
- Implement in Your Work: Start using SEOntology concepts in your structured data.
In Open Source We Trust
SEOntology is an open-source effort, following in the footsteps of successful projects like Schema.org and other shared linked vocabularies.
All discussions and decisions will be public, ensuring the community has a say in SEOntology’s direction. As we gain traction, we’ll establish a committee to steer its development and share regular updates.
Conclusion And Future Work
The future of marketing is human-led, not AI-replaced. SEOntology isn’t just another buzzword – it’s a step towards this future. SEO is strategic for the development of agentive marketing practices.
SEO is no longer about rankings; it’s about creating intelligent, adaptive content and fruitful dialogues with our stakeholders across various channels. Standardizing SEO data and practices is strategic to build a sustainable future and to invest in responsible AI.
Are you ready to join this revolution?
There are three guiding principles behind the work of SEOntology that we need to make clear to the reader:
- As AI needs semantic data, we need to make SEO data interoperable, facilitating the creation of knowledge graphs for everyone. SEOntology is the USB-C of SEO/crawling data. Standardizing data about content assets and products and how people find content, products, and information in general is important. This is the first objective. Here, we have two practical use cases. We have a connector for WordLift that gets crawl data from the Botify crawler and helps you jump-start a KG that uses SEOntology as a data model. We are also working with Advertools, an open-source crawler and SEO tool, to make data interoperable with SEOntology;
- As we progress with the development of a new agentic way of doing SEO and digital marketing, we want to infuse the know-how of SEO using SEOntology, a domain-specific language to infuse the SEO mindset to SEO agents (or multi-agent systems like Agent WordLift). In this context, the skill required to create dynamic internal links is encoded as nodes in a knowledge graph, and opportunities become triggers to activate workflows.
- We expect to work with human-in-the-loop HITL, meaning that the ontology will become a way to collaboratively share knowledge and tactics that help improve findability and prevent the misuse of Generative AI that is polluting the Web today.
Project Overview
This work on SEOntology is the product of collaboration. I extend my sincere thanks to the WordLift team, especially CTO David Riccitelli. I also appreciate our clients for their dedication to innovation in SEO through knowledge graphs. Special thanks to Milos Jovanovik and Emilia Gjorgjevska for their critical expertise. Lastly, I’m grateful to the SEO community and the SEJ editorial team for their support in sharing this work.
More resources:
Featured Image: tech_BG/Shutterstock