OPenAI announced that it is upgrading all ChatGPT accounts to be eligible for the project sharing feature, which enables users to share a ChatGPT project with others who can then participate and make changes. The feature was previously available only to users on OpenAI’s Business, Enterprise, and Edu plans.
The new feature is available to users globally in the Free, Plus, Pro, and budget Go plans, whether accessed on the web, iOS, or Android devices.
There are limits specific to each plan according to the announcement:
Free users can collaborate on up to 5 files and with 5 collaborators
Plus and Go users can share up to 25 files with up to 10 collaborators
Pro users can share up to 40 files with up to 100 collaborators OpenAI suggested the following use cases:
“Group work: Upload notes, proposals, and contracts so collaborators can draft deliverables faster and stay in sync.
Content creation: Apply project-specific instructions to keep tone and style consistent across contributors.
Reporting: Store datasets and reports in one project, and return each week to generate updates without starting over.
Research: Keep transcripts, survey results, and market research in one place, so anyone in the project can query and build on the findings.
Project owners can choose to share a project with “Only those invited” or “Anyone with a link,” and can change visibility settings at any time including switching back to invite-only.”
Microsoft announced its Copilot Fall Release, introducing features to make AI more personal and collaborative.
New capabilities include group collaboration, long-term memory, health tools, and voice-enabled learning.
Mustafa Suleyman, head of Microsoft AI, wrote in the announcement that the release represents a shift in how AI supports users.
Suleyman wrote:
“… technology should work in service of people. Not the other way around. Ever.”
What’s New
Search Improvements
Copilot Search combines AI-generated answers with traditional results in one view, providing cited responses for faster discovery.
Microsoft also highlighted its in-house models, including MAI-Voice-1, MAI-1-Preview, and MAI-Vision-1, as groundwork for more immersive Copilot experiences.
Memory & Personalization
Copilot now includes long-term memory that tracks user preferences and information across conversations.
You can ask Copilot to remember specific details like training for a marathon or an anniversary, and the AI can recall this information in future interactions. Users can edit, update, or delete memories at any time.
Search Across Services
New connector features link Copilot to OneDrive, Outlook, Gmail, Google Drive, and Google Calendar so you can search for documents, emails, and calendar events across multiple accounts using natural language.
Microsoft notes this is rolling out gradually and may not yet be available in all regions or languages.
Edge & Windows Integration
Copilot Mode in Edge is evolving into what Microsoft calls an “AI browser.”
With user permission, Copilot can see open tabs, summarize information, and take actions like booking hotels or filling forms.
Voice-only navigation enables hands-free browsing. Journeys and Actions are currently available in the U.S. only.
Shared AI Sessions
The Groups feature turns Copilot into a collaborative workspace for up to 32 people.
You can invite friends, classmates, or teammates to shared sessions. Start a session by sending a link, and anyone with the link can join and see the same conversation in real time.
This feature is U.S. only at launch.
Health Features
Copilot for health grounds responses in credible sources like Harvard Health for medical questions.
Health features are available only in the U.S. at copilot.microsoft.com and in the Copilot iOS app.
Voice Tutoring
Learn Live provides voice-enabled Socratic tutoring for educational topics.
Interactive whiteboards help you work through concepts for test preparation, language practice, or exploring new subjects. U.S. only.
“Mico” Character
Microsoft introduced Mico, an optional visual character that reacts during voice conversations.
Separately, Copilot adds a “real talk” conversation style that challenges assumptions and adapts to user preferences.
Why This Matters
These features change how Copilot fits into your workflow.
The move from individual to collaborative sessions means teams can use AI together rather than separately synthesizing results.
Long-term memory reduces the need to repeat context, which matters for ongoing projects where Copilot needs to understand your specific situation.
Looking Ahead
Features are live in the U.S. now. Microsoft says updates are rolling out across the UK, Canada, and beyond in the next few weeks.
Some features require a Microsoft 365 Personal, Family, or Premium subscription; usage limits apply. Specific availability varies by market, device, and platform.
We’re looking for a powerhouse project manager to keep our marketing team inspired and on track.
This is a Philippines-based, fully-remote position working on U.S.-adjacent hours (8 p.m. – 4 a.m. PHT) to be my partner in crime execution on some exciting projects.
We do things a little differently here, and we’ve learned that culture fit is everything. When it’s a match, people tend to stay; nearly half our team has been with us for more than five years.
If you’re the kind of team member who has loads of experience leaning into complex projects, honest conversations, and big ideas, we’d love to meet you.
About SEJ
We help our advertisers communicate with precision and creativity in an AI-driven world. Our campaigns are built on data, empathy, and continuous experimentation. We manage multi-channel strategies across content, email, and social media, and we’re looking for someone who can keep the moving parts aligned without losing sight of the humans behind them.
We’re hiring a Senior Digital Marketing Project Manager to lead strategy execution, client relationships, and team coordination. You’ll help us build marketing systems that are smart, efficient, and grounded in trust.
Why This Role Is Different
This is an AI-first position. You already use tools like ChatGPT, Claude, or Gemini to work smarter, automate workflows, and uncover insights that move the needle. Your success here depends on seeing where AI enhances human creativity … and where it doesn’t.
We’re a team that values autonomy, initiative, and straight talk. We’d rather have one clear, respectful conversation than weeks of confusion. We care deeply about doing great work and making each other better through feedback and shared accountability.
What You’ll Do
Manage and optimize complex digital marketing campaigns from strategy to execution.
Translate business goals into clear, actionable plans for clients and internal teams.
Keep communication flowing: up, down, and across.
Identify opportunities to integrate AI tools into analytics and operations.
Support a culture of feedback, growth, and curiosity.
Who You Are
You’re organized and strategic, but not rigid. You like structure, but you also know when to improvise.
You’re skilled at managing both clients and creatives. You can lead with empathy and keep projects on schedule.
You don’t shy away from a tough conversation if it means getting to a better outcome.
You’re the kind of team member who says things like:
“Let’s make sure we’re solving the right problem.”
“I appreciate the feedback! Here’s what I’m hearing.”
“How can AI help us work smarter here?”
Why Work With Search Engine Journal?
We’re a remote-first, global team that values:
Clarity over chaos.
Progress over perfection.
Honest collaboration over hierarchy.
We’re remote, flexible, and results-focused. You’ll have real ownership, real support, and the chance to do your best work with people who actually care about doing theirs.
Before you get started, it’s important to heed this warning: There is math ahead! If doing math and learning equations makes your head swim, or makes you want to sit down and eat a whole cake, prepare yourself (or grab a cake). But if you like math, if you enjoy equations, and you really do believe that k=N (you sadist!), oh, this article is going to thrill you as we explore hybrid search in a bit more depth.
(Image Credit: Duane Forrester)
For years (decades), SEO lived inside a single feedback loop. We optimized, ranked, and tracked. Everything made sense because Google gave us the scoreboard. (I’m oversimplifying, but you get the point.)
Now, AI assistants sit above that layer. They summarize, cite, and answer questions before a click ever happens. Your content can be surfaced, paraphrased, or ignored, and none of it shows in analytics.
That doesn’t make SEO obsolete. It means a new kind of visibility now runs parallel to it. This article shows ideas of how to measure that visibility without code, special access, or a developer, and how to stay grounded in what we actually know.
Why This Matters
Search engines still drive almost all measurable traffic. Google alone handles almost 4 billion searches per day. By comparison, Perplexity’s reported total annual query volume is roughly 10 billion.
So yes, assistants are still small by comparison. But they’re shaping how information gets interpreted. You can already see it when ChatGPT Search or Perplexity answers a question and links to its sources. Those citations reveal which content blocks (chunks) and domains the models currently trust.
The challenge is that marketers have no native dashboard to show how often that happens. Google recently added AI Mode performance data into Search Console. According to Google’s documentation, AI Mode impressions, clicks, and positions are now included in the overall “Web” search type.
That inclusion matters, but it’s blended in. There’s currently no way to isolate AI Mode traffic. The data is there, just folded into the larger bucket. No percentage split. No trend line. Not yet.
Until that visibility improves, I’m suggesting we can use a proxy test to understand where assistants and search agree and where they diverge.
Two Retrieval Systems, Two Ways To Be Found
Traditional search engines use lexical retrieval, where they match words and phrases directly. The dominant algorithm, BM25, has powered solutions like Elasticsearch and similar systems for years. It’s also in use in today’s common search engines.
AI assistants rely on semantic retrieval. Instead of exact words, they map meaning through embeddings, the mathematical fingerprints of text. This lets them find conceptually related passages even when the exact words differ.
Each system makes different mistakes. Lexical retrieval misses synonyms. Semantic retrieval can connect unrelated ideas. But when combined, they produce better results.
Inside most hybrid retrieval systems, the two methods are fused using a rule called Reciprocal Rank Fusion (RRF). You don’t have to be able to run it, but understanding the concept helps you interpret what you’ll measure later.
RRF In Plain English
Hybrid retrieval merges multiple ranked lists into one balanced list. The math behind that fusion is RRF.
The formula is simple: score equals one divided by k plus rank. This is written as 1 ÷ (k + rank). If an item appears in several lists, you add those scores together.
Here, “rank” means the item’s position in that list, starting with 1 as the top. “k” is a constant that smooths the difference between top and mid-ranked items. Most systems typically use something near 60, but each may tune it differently.
It’s worth remembering that a vector model doesn’t rank results by counting word matches. It measures how close each document’s embedding is to the query’s embedding in multi-dimensional space. The system then sorts those similarity scores from highest to lowest, effectively creating a ranked list. It looks like a search engine ranking, but it’s driven by distance math, not term frequency.
(Image Credit: Duane Forrester)
Let’s make it tangible with small numbers and two ranked lists. One from BM25 (keyword relevance) and one from a vector model (semantic relevance). We’ll use k = 10 for clarity.
Document A is ranked number 1 in BM25 and number 3 in the vector list. From BM25: 1 ÷ (10 + 1) = 1 ÷ 11 = 0.0909. From the vector list: 1 ÷ (10 + 3) = 1 ÷ 13 = 0.0769. Add them together: 0.0909 + 0.0769 = 0.1678.
Document B is ranked number 2 in BM25 and number 1 in the vector list. From BM25: 1 ÷ (10 + 2) = 1 ÷ 12 = 0.0833. From the vector list: 1 ÷ (10 + 1) = 1 ÷ 11 = 0.0909. Add them: 0.0833 + 0.0909 = 0.1742.
Document C is ranked number 3 in BM25 and number 2 in the vector list. From BM25: 1 ÷ (10 + 3) = 1 ÷ 13 = 0.0769. From the vector list: 1 ÷ (10 + 2) = 1 ÷ 12 = 0.0833. Add them: 0.0769 + 0.0833 = 0.1602.
Document B wins here as it ranks high in both lists. If you raise k to 60, the differences shrink, producing a smoother, less top-heavy blend.
This example is purely illustrative. Every platform adjusts parameters differently, and no public documentation confirms which k values any engine uses. Think of it as an analogy for how multiple signals get averaged together.
Where This Math Actually Lives
You’ll never need to code it yourself as RRF is already part of modern search stacks. Here are examples of this type of system from their foundational providers. If you read through all of these, you’ll have a deeper understanding of how platforms like Perplexity do what they do:
All of them follow the same basic process: Retrieve with BM25, retrieve with vectors, score with RRF, and merge. The math above explains the concept, not the literal formula inside every product.
Observing Hybrid Retrieval In The Wild
Marketers can’t see those internal lists, but we can observe how systems behave at the surface. The trick is comparing what Google ranks with what an assistant cites, then measuring overlap, novelty, and consistency. This external math is a heuristic, a proxy for visibility. It’s not the same math the platforms calculate internally.
Step 1. Gather The Data
Pick 10 queries that matter to your business.
For each query:
Run it in Google Search and copy the top 10 organic URLs.
Run it in an assistant that shows citations, such as Perplexity or ChatGPT Search, and copy every cited URL or domain.
Now you have two lists per query: Google Top 10 and Assistant Citations.
(Be aware that not every assistant shows full citations, and not every query triggers them. Some assistants may summarize without listing sources at all. When that happens, skip that query as it simply can’t be measured this way.)
Step 2. Count Three Things
Intersection (I): how many URLs or domains appear in both lists.
Novelty (N): how many assistant citations do not appear in Google’s top 10. If the assistant has six citations and three overlap, N = 6 − 3 = 3.
Frequency (F): how often each domain appears across all 10 queries.
Step 3. Turn Counts Into Quick Metrics
For each query set:
Shared Visibility Rate (SVR) = I ÷ 10. This measures how much of Google’s top 10 also appears in the assistant’s citations.
Unique Assistant Visibility Rate (UAVR) = N ÷ total assistant citations for that query. This shows how much new material the assistant introduces.
Repeat Citation Count (RCC) = (sum of F for each domain) ÷ number of queries. This reflects how consistently a domain is cited across different answers.
Example:
Google top 10 = 10 URLs. Assistant citations = 6. Three overlap. I = 3, N = 3, F (for example.com) = 4 (appears in four assistant answers). SVR = 3 ÷ 10 = 0.30. UAVR = 3 ÷ 6 = 0.50. RCC = 4 ÷ 10 = 0.40.
You now have a numeric snapshot of how closely assistants mirror or diverge from search.
Step 4. Interpret
These scores are not industry benchmarks by any means, simply suggested starting points for you. Feel free to adjust as you feel the need:
High SVR (> 0.6) means your content aligns with both systems. Lexical and semantic relevance are in sync.
Moderate SVR (0.3 – 0.6) with high RCC suggests your pages are semantically trusted but need clearer markup or stronger linking.
Low SVR (< 0.3) with high UAVR shows assistants trust other sources. That often signals structure or clarity issues.
High RCC for competitors indicates the model repeatedly cites their domains, so it’s worth studying for schema or content design cues.
Step 5. Act
If SVR is low, improve headings, clarity, and crawlability. If RCC is low for your brand, standardize author fields, schema, and timestamps. If UAVR is high, track those new domains as they may already hold semantic trust in your niche.
(This approach won’t always work exactly as outlined. Some assistants limit the number of citations or vary them regionally. Results can differ by geography and query type. Treat it as an observational exercise, not a rigid framework.)
Why This Math Is Important
This math gives marketers a way to quantify agreement and disagreement between two retrieval systems. It’s diagnostic math, not ranking math. It doesn’t tell you why the assistant chose a source; it tells you that it did, and how consistently.
That pattern is the visible edge of the invisible hybrid logic operating behind the scenes. Think of it like watching the weather by looking at tree movement. You’re not simulating the atmosphere, just reading its effects.
On-Page Work That Helps Hybrid Retrieval
Once you see how overlap and novelty play out, the next step is tightening structure and clarity.
Write in short claim-and-evidence blocks of 200-300 words.
Use clear headings, bullets, and stable anchors so BM25 can find exact terms.
Add structured data (FAQ, HowTo, Product, TechArticle) so vectors and assistants understand context.
Keep canonical URLs stable and timestamp content updates.
Publish canonical PDF versions for high-trust topics; assistants often cite fixed, verifiable formats first.
These steps support both crawlers and LLMs as they share the language of structure.
Reporting And Executive Framing
Executives don’t care about BM25 or embeddings nearly as much as they care about visibility and trust.
Your new metrics (SVR, UAVR, and RCC) can help translate the abstract into something measurable: how much of your existing SEO presence carries into AI discovery, and where competitors are cited instead.
Pair those findings with Search Console’s AI Mode performance totals, but remember: You can’t currently separate AI Mode data from regular web clicks, so treat any AI-specific estimate as directional, not definitive. Also worth noting that there may still be regional limits on data availability.
These limits don’t make the math less useful, however. They help keep expectations realistic while giving you a concrete way to talk about AI-driven visibility with leadership.
Summing Up
The gap between search and assistants isn’t a wall. It’s more of a signal difference. Search engines rank pages after the answer is known. Assistants retrieve chunks before the answer exists.
The math in this article is an idea of how to observe that transition without developer tools. It’s not the platform’s math; it’s a marketer’s proxy that helps make the invisible visible.
In the end, the fundamentals stay the same. You still optimize for clarity, structure, and authority.
Now you can measure how that authority travels between ranking systems and retrieval systems, and do it with realistic expectations.
That visibility, counted and contextualized, is how modern SEO stays anchored in reality.
Every SEO strategy claims to drive “relevant traffic.” It is one of the industry’s most overused phrases, and one of the least examined. We celebrate growth in organic sessions and point to conversions as proof that our efforts are working.
Yet the metric we often use to prove “relevance” – last-click revenue or leads – tells us nothing about why those visits mattered, or how they contributed to the user’s journey.
If we want to mature SEO measurement, we need to redefine what relevance means and start measuring it directly, not infer it from transactional outcome.
With AI disrupting the user journey, and a lack of data and visibility from these platforms and Google’s latest Search additions (AI Mode and AI Overviews), now is the perfect time to redefine what SEO success looks like for the new, modern Search era – and for me, this starts with defining “relevant traffic.”
The Illusion Of Relevance
In most performance reports, “relevant traffic” is shorthand for “traffic that converts.”
But this definition is structurally flawed. Conversion metrics reward the final interaction, not the fit between user intent and content. They measure commercial efficiency, not contextual alignment.
A visitor could land on a blog post, spend five minutes reading, bookmark it, and return two weeks later via paid search to convert. In most attribution models, that organic session adds no measurable value to SEO. Yet that same session might have been the most relevant interaction in the entire funnel – the moment the brand aligned with the user’s need.
In Universal Analytics, we had some insights into this as we were able to view assisted conversion paths, but with Google Analytics 4, viewing conversion path reports is only available in the Advertising section.
Even when we had visibility on the conversion paths, we didn’t always consider the attribution touchpoints that Organic had on conversions with last-click attribution to other channels.
When we define relevance only through monetary endpoints, we constrain SEO to a transactional role and undervalue its strategic contribution: shaping how users discover, interpret, and trust a brand.
The Problem With Last-Click Thinking
Last-click attribution still dominates SEO reporting, even as marketers acknowledge its limitations.
It persists not because it is accurate, but because it is easy. It allows for simple narratives: “Organic drove X in revenue this month.” But simplicity comes at the cost of understanding.
User journeys are no longer linear; Search is firmly establishing itself as multimodal, which has been a shift happening over the past decade and is being further enabled by improvements in hardware, and AI.
Search is iterative, fragmented, and increasingly mediated by AI summarization and recommendation layers. A single decision may involve dozens of micro-moments, queries that refine, pivot, or explore tangents. Measuring “relevant traffic” through the lens of last-click attribution is like judging a novel by its final paragraph.
The more we compress SEO’s role into the conversion event, the more we disconnect it from how users actually experience relevance: as a sequence of signals that build familiarity, context, and trust.
What Relevance Really Measures
Actual relevance exists at the intersection of three dimensions: intent alignment, experience quality, and journey contribution.
1. Intent Alignment
Does the content match what the user sought to understand or achieve?
Are we solving the user’s actual problem, not just matching their keywords?
Relevance begins when the user’s context meets the brand’s competence.
2. Experience Quality
How well does the content facilitate progress, not just consumption?
Do users explore related content, complete micro-interactions, or return later?
Engagement depth, scroll behavior, and path continuation are not vanity metrics; they are proxies for satisfaction.
3. Journey Contribution
What role does the interaction play in the broader decision arc?
Did it inform, influence, or reassure, even if it did not close?
Assisted conversions, repeat session value, and brand recall metrics can capture this more effectively than revenue alone.
These dimensions demand a shift from output metrics (traffic, conversions) to outcome metrics (user progress, decision confidence, and informational completeness).
In other words, from “how much” to “how well.”
Measuring Relevance Beyond The Click
If we accept that relevance is not synonymous with revenue, then new measurement frameworks are needed. These might include:
Experience fit indices: Using behavioral data (scroll depth, dwell time, secondary navigation) to quantify whether users engage as expected given the intent type. Example: informational queries that lead to exploration and bookmarking score high on relevance, even if they do not convert immediately.
Query progression analysis: Tracking whether users continue refining their query after visiting your page. If they stop searching or pivot to branded terms, that is evidence of resolved intent.
Session contribution mapping: Modeling the cumulative influence of organic visits across multiple sessions and touchpoints. Tools like GA4’s data-driven attribution can be extended to show assist depth rather than last-touch value.
Experience-level segmentation: Grouping traffic by user purpose (for example, research, comparison, decision) and benchmarking engagement outcomes against expected behaviors for that intent.
These models do not replace commercial key performance indicators (KPIs); they contextualize them. They help organizations distinguish between traffic that sells and traffic that shapes future sales.
This isn’t to say that SEO activities shouldn’t be tied to commercial KPIs, but the role of SEO has evolved in the wider web ecosystem, and our understanding of value should also evolve with it.
Why This Matters Now
AI-driven search interfaces, from Google’s AI Overviews to ChatGPT and Perplexity, are forcing marketers to confront a new reality – relevance is being interpreted algorithmically.
Users are no longer exposed to 10 blue links and maybe some static SERP features, but to synthesized, conversational results. In this environment, content must not only rank; it must earn inclusion through semantic and experiential alignment.
This makes relevance an operational imperative. Brands that measure relevance effectively will understand how users perceive and progress through discovery in both traditional and AI-mediated ecosystems. Those who continue to equate relevance with conversion will misallocate resources toward transactional content at the expense of influence and visibility.
The next generation of SEO measurement should ask:
Does this content help the user make a better decision, faster? Not just, Did it make us money?
From Performance Marketing To Performance Understanding
The shift from measuring revenue to measuring relevance parallels the broader evolution of marketing itself, from performance marketing to performance understanding.
For years, the goal has been attribution: assigning value to touchpoints. But attribution without understanding is accounting, not insight.
Measuring relevance reintroduces meaning into the equation. It bridges brand and performance, showing not just what worked, but why it mattered.
This mindset reframes SEO as an experience design function, not merely a traffic acquisition channel. It also creates a more sustainable way to defend SEO investment by proving how organic experiences improve user outcomes and brand perception, not just immediate sales.
Redefining “Relevant Traffic” For The Next Era Of Search
It is time to retire the phrase “relevant traffic” as a catch-all justification for SEO success. Relevance cannot be declared; it must be demonstrated through evidence of user progress and alignment.
A modern SEO report should read less like a sales ledger and more like an experience diagnostic:
What intents did we serve best?
Which content formats drive confidence?
Where does our relevance break down?
Only then can we claim, with integrity, that our traffic is genuinely relevant.
Final Thought
Relevance is not measured at the checkout page. It is estimated that now a user feels understood.
Until we start measuring that, “relevant traffic” remains a slogan, not a strategy.
A new research paper from Google DeepMind proposes a new AI search ranking algorithm called BlockRank that works so well it puts advanced semantic search ranking within reach of individuals and organizations. The researchers conclude that it “can democratize access to powerful information discovery tools.”
In-Context Ranking (ICR)
The research paper describes the breakthrough of using In-Context Ranking (ICR), a way to rank web pages using a large language model’s contextual understanding abilities.
It prompts the model with:
Instructions for the task (for example, “rank these web pages”)
Candidate documents (the pages to rank)
And the search query.
ICR is a relatively new approach first explored by researchers from Google DeepMind and Google Research in 2024 (Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?PDF). That earlier study showed that ICR could match the performance of retrieval systems built specifically for search.
But that improvement came with a downside in that it requires escalating computing power as the number of pages to be ranked are increased.
When a large language model (LLM) compares multiple documents to decide which are most relevant to a query, it has to “pay attention” to every word in every document and how each word relates to all others. This attention process gets much slower as more documents are added because the work grows exponentially.
The new research solves that efficiency problem, which is why the research paper is called, Scalable In-context Ranking with Generative Models, because it shows how to scale In-context Ranking (ICR) with what they call BlockRank.
How BlockRank Was Developed
The researchers examined how the model actually uses attention during In-Context Retrieval and found two patterns:
Inter-document block sparsity: The researchers found that when the model reads a group of documents, it tends to focus mainly on each document separately instead of comparing them all to each other. They call this “block sparsity,” meaning there’s little direct comparison between different documents. Building on that insight, they changed how the model reads the input so that it reviews each document on its own but still compares all of them against the question being asked. This keeps the part that matters, matching the documents to the query, while skipping the unnecessary document-to-document comparisons. The result is a system that runs much faster without losing accuracy.
Query-document block relevance: When the LLM reads the query, it doesn’t treat every word in that question as equally important. Some parts of the question, like specific keywords or punctuation that signal intent, help the model decide which document deserves more attention. The researchers found that the model’s internal attention patterns, particularly how certain words in the query focus on specific documents, often align with which documents are relevant. This behavior, which they call “query-document block relevance,” became something the researchers could train the model to use more effectively.
The researchers identified these two attention patterns and then designed a new approach informed by what they learned. The first pattern, inter-document block sparsity, revealed that the model was wasting computation by comparing documents to each other when that information wasn’t useful. The second pattern, query-document block relevance, showed that certain parts of a question already point toward the right document.
Based on these insights, they redesigned how the model handles attention and how it is trained. The result is BlockRank, a more efficient form of In-Context Retrieval that cuts unnecessary comparisons and teaches the model to focus on what truly signals relevance.
Benchmarking Accuracy Of BlockRank
The researchers tested BlockRank for how well it ranks documents on three major benchmarks:
BEIR A collection of many different search and question-answering tasks used to test how well a system can find and rank relevant information across a wide range of topics.
MS MARCO A large dataset of real Bing search queries and passages, used to measure how accurately a system can rank passages that best answer a user’s question.
Natural Questions (NQ) A benchmark built from real Google search questions, designed to test whether a system can identify and rank the passages from Wikipedia that directly answer those questions.
They used a 7-billion-parameter Mistral LLM and compared BlockRank to other strong ranking models, including FIRST, RankZephyr, RankVicuna, and a fully fine-tuned Mistral baseline.
BlockRank performed as well as or better than those systems on all three benchmarks, matching the results on MS MARCO and Natural Questions and doing slightly better on BEIR.
The researchers explained the results:
“Experiments on MSMarco and NQ show BlockRank (Mistral-7B) matches or surpasses standard fine-tuning effectiveness while being significantly more efficient at inference and training. This offers a scalable and effective approach for LLM-based ICR.”
They also acknowledged that they didn’t test multiple LLMs and that these results are specific to Mistral 7B.
Is BlockRank Used By Google?
The research paper says nothing about it being used in a live environment. So it’s purely conjecture to say that it might be used. Also, it’s natural to try to identify where BlockRank fits into AI Mode or AI Overviews but the descriptions of how AI Mode’s FastSearch and RankEmbed work are vastly different from what BlockRank does. So it’s unlikely that BlockRank is related to FastSearch or RankEmbed.
Why BlockRank Is A Breakthrough
What the research paper does say is that this is a breakthrough technology that puts an advanced ranking system within reach of individuals and organizations that wouldn’t normally be able to have this kind of high quality ranking technology.
The researchers explain:
“The BlockRank methodology, by enhancing the efficiency and scalability of In-context Retrieval (ICR) in Large Language Models (LLMs), makes advanced semantic retrieval more computationally tractable and can democratize access to powerful information discovery tools. This could accelerate research, improve educational outcomes by providing more relevant information quickly, and empower individuals and organizations with better decision-making capabilities.
Furthermore, the increased efficiency directly translates to reduced energy consumption for retrieval-intensive LLM applications, contributing to more environmentally sustainable AI development and deployment.
By enabling effective ICR on potentially smaller or more optimized models, BlockRank could also broaden the reach of these technologies in resource-constrained environments.”
SEOs and publishers are free to their opinions of whether or not this could be used by Google. I don’t think there’s evidence of that but it would be interesting to ask a Googler about it.
Google appears to be in the process of making BlockRank available on GitHub, but it doesn’t appear to have any code available there yet.
This science fiction book series confronted me with existential questions like “Are we alone in the universe?” and “Do I actually like LitRPG??” (LitRPG—which stands for “literary role-playing game”—is a relatively new genre that merges the conventions of computer RPGs with those of science fiction and fantasy novels.) In the series, aliens destroy most of Earth, leaving the titular Carl and Princess Donut, his ex-girlfriend’s cat, to fight in a bloodthirsty game of survival with rules that are part reality TV and part video game dungeon crawl. I particularly recommend the audiobook, voiced by Jeff Hays, which makes the numerous characters easy to differentiate.
Journaling, offline and open-source
For years I’ve tried to find a perfect system to keep track of all my random notes and weird little rabbit holes of inspiration. None of my paper journals or paid apps have been able to top how customizable and convenient the developer-favorite notetaking app Obsidian is. Thanks to this app, I’ve been able to cancel subscription services I was using to track my reading habits, fitness goals, and journaling—and I also use it to track tasks I do for work, like drafting this article. It’s open-source and files are stored on my device, so I don’t have to worry about whether I’m sharing my private thoughts with a company that might scrape them for AI.
Bird-watching with Merlin
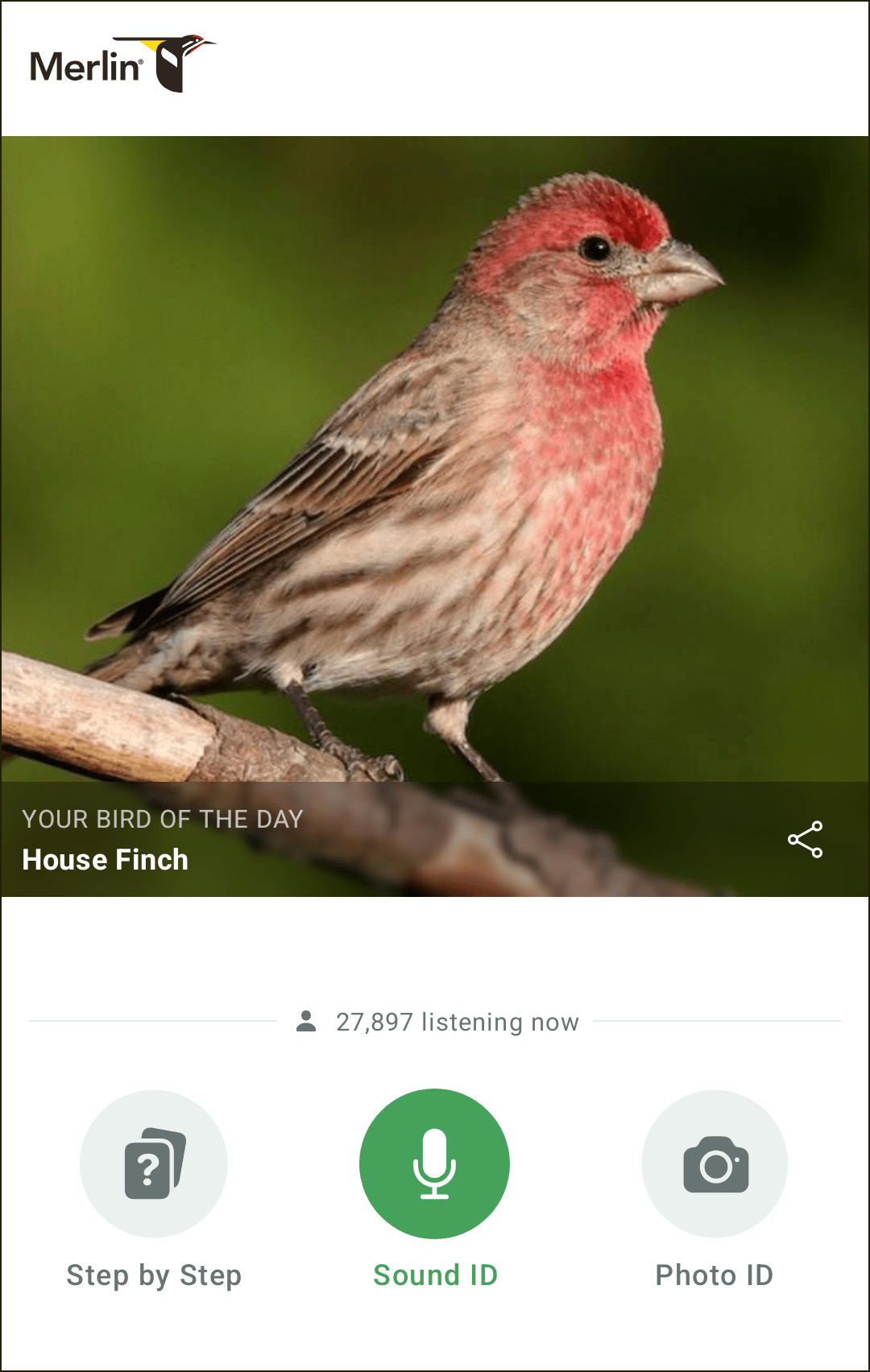
Sometimes I have to make a conscious effort to step away from my screens and get out in the world. The latest version of the birding app Merlin, from the Cornell Lab of Ornithology, helps ease the transition. I can “collect” and identify species via step-by-step questions, photos, or—my favorite—audio that I record so that the app can analyze it to indicate which birds are singing in real time. Using the audio feature, I “captured” the red-eyed vireo flitting up in the tree canopy and backlit by the sun. Fantastic for my backyard feeder or while I’m out on the trail.
It’s late Augustin Rwanda’s capital, Kigali, and people are filling a large hall at one of Africa’s biggest gatherings of minds in AI and machine learning. The room is draped in white curtains, and a giant screen blinks with videos created with generative AI. A classic East African folk song by the Tanzanian singer Saida Karoli plays loudly on the speakers.
Friends greet each other as waiters serve arrowroot crisps and sugary mocktails. A man and a woman wearing leopard skins atop their clothes sip beer and chat; many women are in handwoven Ethiopian garb with red, yellow, and green embroidery. The crowd teems with life. “The best thing about the Indaba is always the parties,” computer scientist Nyalleng Moorosi tells me. Indaba means “gathering” in Zulu, and Deep Learning Indaba, where we’re meeting, is an annual AI conference where Africans present their research and technologies they’ve built.
Moorosi is a senior researcher at the Distributed AI Research Institute and has dropped in for the occasion from the mountain kingdom of Lesotho. Dressed in her signature “Mama Africa” headwrap, she makes her way through the crowded hall.
Moments later, a cheerful set of Nigerian music begins to play over the speakers. Spontaneously, people pop up and gather around the stage, waving flags of many African nations. Moorosi laughs as she watches. “The vibe at the Indaba—the community spirit—is really strong,” she says, clapping.
Moorosi is one of the founding members of the Deep Learning Indaba, which began in 2017 from a nucleus of 300 people gathered in Johannesburg, South Africa. Since then, the event has expanded into a prestigious pan-African movement with local chapters in 50 countries.
This year, nearly 3,000 people applied to join the Indaba; about 1,300 were accepted. They hail primarily from English-speaking African countries, but this year I noticed a new influx from Chad, Cameroon, the Democratic Republic of Congo, South Sudan, and Sudan.
Moorosi tells me that the main “prize” for many attendees is to be hired by a tech company or accepted into a PhD program. Indeed, the organizations I’ve seen at the event include Microsoft Research’s AI for Good Lab, Google, the Mastercard Foundation, and the Mila–Quebec AI Institute. But she hopes to see more homegrown ventures create opportunities within Africa.
That evening, before the dinner, we’d both attended a panel on AI policy in Africa. Experts discussed AI governance and called for those developing national AI strategies to seek more community engagement. People raised their hands to ask how young Africans could access high-level discussions on AI policy, and whether Africa’s continental AI strategy was being shaped by outsiders. Later, in conversation, Moorosi told me she’d like to see more African priorities (such as African Union–backed labor protections, mineral rights, or safeguards against exploitation) reflected in such strategies.
On the last day of the Indaba, I ask Moorosi about her dreams for the future of AI in Africa. “I dream of African industries adopting African-built AI products,” she says, after a long moment. “We really need to show our work to the world.”
Abdullahi Tsanni is a science writer based in Senegal who specializes in narrative features.
Embryologists are the scientists behind the scenes of in vitro fertilization who oversee the development and selection of embryos, prepare them for transfer, and maintain the lab environment. They’ve been a critical part of IVF for decades, but their job has gotten a whole lot busier in recent years as demand for the fertility treatment skyrockets and clinics struggle to keep up. The United States is in fact facing a critical shortage of both embryologists and genetic counselors.
Klaus Wiemer, a veteran embryologist and IVF lab director, believes artificial intelligence might help by predicting embryo health in real time and unlocking new avenues for productivity in the lab.
Wiemer is the chief scientific officer and head of clinical affairs at Fairtility, a company that uses artificial intelligence to shed light on the viability of eggs and embryos before proceeding with IVF. The company’s algorithm, called CHLOE (for Cultivating Human Life through Optimal Embryos), has been trained on millions of embryo data points and outcomes and can quickly sift through a patient’s embryos to point the clinician to the ones with the highest potential for successful implantation. This, the company claims, will improve time to pregnancy and live births. While its effectiveness has been tested only retrospectively to date, CHLOE is the first and only FDA-approved AI tool for embryo assessment.
Current challenge
When a patient undergoes IVF, the goal is to make genetically normal embryos. Embryologists collect cells from each embryo and send them off for external genetic testing. The results of this biopsy can take up to two weeks, and the process can add thousands of dollars to the treatment cost. Moreover, passing the screen just means an embryo has the correct number of chromosomes. That number doesn’t necessarily reflect the overall health of the embryo.
“An embryo has one singular function, and that is to divide,” says Wiemer. “There are millions of data points concerning embryo cell division, cell division characteristics, area and size of the inner cell mass, and the number of times the trophectoderm [the layer that contributes to the future placenta] contracts.”
The AI model allows for a group of embryos to be constantly measured against the optimal characteristics at each stage of development. “What CHLOE answers is: How well did that embryo develop? And does it have all the necessary components that are needed in order to make a healthy implantation?” says Wiemer. CHLOE produces an AI score reflecting all the analysis that’s been done within an embryo.
In the near future, Wiemer says, reducing the percentage of abnormal embryos that IVF clinics transfer to patients should not require a biopsy: “Every embryology laboratory will be doing automatic assessments of embryo development.”
A changing field
Wiemer, who started his career in animal science, says the difference between animal embryology and human embryology is the extent of paperwork. “Embryologists spend 40% of their time on non-embryology skills,” he adds. “AI will allow us to declutter the embryology field so we can get back to being true scientists.” This means spending more time studying the embryos, ensuring that they are developing normally, and using all that newfound information to get better at picking which embryos to transfer.
“CHLOE is like having a virtual assistant in the lab to help with embryo selection, ensure conditions are optimal, and send out reports to patients and clinical staff,” he says. “Getting to study data and see what impacts embryo development is extremely rewarding, given that this capability was impossible a few years ago.”
Amanda Smith is a freelance journalist and writer reporting on culture, society, human interest, and technology.
At the southern tip of San Francisco Bay, surrounded by the tech giants Google, Apple, and Microsoft, sits the historic NASA Ames Research Center. Its rich history includes a grab bag of fascinating scientific research involving massive wind tunnels, experimental aircraft, supercomputing, astrobiology, and more.
Founded in 1939 as a West Coast lab for the National Advisory Committee for Aeronautics (NACA), NASA Ames was built to close the US gap with Germany in aeronautics research. Named for NACA founding member Joseph Sweetman Ames, the facility grew from a shack on Moffett Field into a sprawling compound with thousands of employees. A collection of 5,000 images from NASA Ames’s archives paints a vivid picture of bleeding-edge work at the heart of America’s technology hub.
Wind tunnels
NASA AMES RESEARCH CENTER ARCHIVES
A key motivation for the new lab was the need for huge wind tunnels to jump-start America’s aeronautical research, which was far behind Germany’s. Smaller tunnels capable of speeds up to 300 miles per hour were built first, followed by a massive 40-by-80-foot tunnel for full-scale aircraft. Powered up in March 1941, these tunnels became vital after Pearl Harbor, helping scientists rapidly develop advanced aircraft.
Today, NASA Ames operates the world’s largest pressurized wind tunnel, with subsonic and transonic chambers for testing rockets, aircraft, and wind turbines.
Pioneer and Voyager 2
NASA AMES RESEARCH CENTER ARCHIVES
From 1965 to 1992, Ames managed the Pioneer missions, which explored the moon, Venus, Jupiter, and Saturn. It also contributed to Voyager 2, launched in 1977, which journeyed past four planets before entering interstellar space in 2018. Ames’s archive preserves our first glimpses of strange new worlds seen during these pioneering missions.
Odd aircraft
NASA AMES RESEARCH CENTER ARCHIVES
The skeleton of a hulking airship hangar, obsolete even before its completion, remains on NASA Ames’s campus.
Many odd-looking experimental aircraft—such as vertical take-off and landing (VTOL) aircraft, jets, and rotorcraft—have been developed and tested at the facility over the years, and new designs continue to take shape there today.
Vintage illustrations
NASA AMES RESEARCH CENTER ARCHIVES
Awe-inspiring retro illustrations in the Ames archives depict surfaces of distant planets, NASA spacecraft descending into surreal alien landscapes, and fantastical renderings of future ring-shaped human habitats in space. The optimism and excitement of the ’70s and ’80s is evident.
Bubble suits and early VR
NASA AMES RESEARCH CENTER ARCHIVES
In the 1980s, NASA Ames researchers worked to develop next-generation space suits, such as the bulbous, hard-shelled AX-5 model. NASA Ames’s Human-Machine Interaction Group also did pioneering work in the 1980s with virtual reality and came up with some wild-looking hardware. Long before today’s AR/VR boom, Ames researchers glimpsed the technology’s potential—which was limited only by computing power.
Decades of federally funded research at Ames fueled breakthroughs in aviation, spaceflight, and supercomputing—an enduring legacy now at risk as federal grants for science face deep cuts.
A version of this story appeared on Beautiful Public Data (beautifulpublicdata.com), a newsletter by Jon Keegan that curates visually interesting data sets collected by local, state, and federal government agencies.