This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
We did the math on AI’s energy footprint. Here’s the story you haven’t heard.
It’s well documented that AI is a power-hungry technology. But there has been far less reporting on the extent of that hunger, how much its appetite is set to grow in the coming years, where that power will come from, and who will pay for it.
For the past six months, MIT Technology Review’s team of reporters and editors have worked to answer those questions. The result is an unprecedented look at the state of AI’s energy and resource usage, where it is now, where it is headed in the years to come, and why we have to get it right.
At the centerpiece of this package is an entirely novel line of reporting into the demands of inference—the way human beings interact with AI when we make text queries or ask AI to come up with new images or create videos. Experts say inference is set to eclipse the already massive amount of energy required to train new AI models. Here’s everything we found out.
Here’s what you can expect from the rest of the package, including:
+ We went out into the world to see the effects of this energy hunger—from the deserts of Nevada, where data centers in an industrial park the size of Detroit demand ever more water to keep their processors cool and running.
+ But it’s not all doom and gloom. Check out the reasons to be optimistic, and examine why future AI systems could be far less energy intensive than today’s.
AI can do a better job of persuading people than we do
The news: Millions of people argue with each other online every day, but remarkably few of them change someone’s mind. New research suggests that large language models (LLMs) might do a better job, especially when they’re given the ability to adapt their arguments using personal information about individuals. The finding suggests that AI could become a powerful tool for persuading people, for better or worse.
The big picture: The findings are the latest in a growing body of research demonstrating LLMs’ powers of persuasion. The authors warn they show how AI tools can craft sophisticated, persuasive arguments if they have even minimal information about the humans they’re interacting with. Read the full story.
—Rhiannon Williams
How AI is introducing errors into courtrooms
It’s been quite a couple weeks for stories about AI in the courtroom. You might have heard about the deceased victim of a road rage incident whose family created an AI avatar of him to show as an impact statement (possibly the first time this has been done in the US).
But there’s a bigger, far more consequential controversy brewing, legal experts say. AI hallucinations are cropping up more and more in legal filings. And it’s starting to infuriate judges. Just consider these three cases, each of which gives a glimpse into what we can expect to see more of as lawyers embrace AI. Read the full story.
—James O’Donnell
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Donald Trump has signed the Take It Down Act into US law It criminalizes the distribution of non-consensual intimate images, including deepfakes. (The Verge) + Tech platforms will be forced to remove such material within 48 hours of being notified. (CNN) + It’s only the sixth bill he’s signed into law during his second term. (NBC News)
2 There’s now a buyer for 23andMe Pharma firm Regeneron has swooped in and offered to help it keep operating. (WSJ $) + The worth of your genetic data? $17. (404 Media) + Regeneron promised to prioritize security and ethical use of that data. (TechCrunch)
3 Microsoft is adding Elon Musk’s AI models to its cloud platform Err, is that a good idea? (Bloomberg $) + Musk wants to sell Grok to other businesses. (The Information $)
4 Autonomous cars trained to react like humans cause fewer road injuries A study found they were more cautious around cyclists, pedestrians and motorcyclists. (FT $) + Waymo is expanding its robotaxi operations out of San Francisco. (Reuters) + How Wayve’s driverless cars will meet one of their biggest challenges yet. (MIT Technology Review)
5 Hurricane season is on its way DOGE cuts means we’re less prepared. (The Atlantic $) + COP30 may be in crisis before it’s even begun. (New Scientist $)
6 Telegram handed over data from more than 20,000 users In the first three months of 2025 alone. (404 Media)
7 GM has stopped exporting cars to China Trump’s tariffs have put an end to its export plans. (NYT $)
8 Blended meats are on the rise Plants account for up to 70% of these new meats—and consumers love them. (WP $) + Alternative meat could help the climate. Will anyone eat it? (MIT Technology Review)
9 SAG-AFTRA isn’t happy about Fornite’s AI-voiced Darth Vader It’s slapped Fortnite’s creators with an unfair labor practice charge. (Ars Technica) + How Meta and AI companies recruited striking actors to train AI. (MIT Technology Review)
10 This AI model can swiftly build Lego structures Thanks to nothing more than a prompt. (Fast Company $)
Quote of the day
“Platforms have no incentive or requirement to make sure what comes through the system is non-consensual intimate imagery.”
—Becca Branum, deputy director of the Center for Democracy and Technology, says the new Take It Down Act could fuel censorship, Wired reports.
One more thing
Are friends electric?
Thankfully, the difference between humans and machines in the real world is easy to discern, at least for now. While machines tend to excel at things adults find difficult—playing world-champion-level chess, say, or multiplying really big numbers—they find it hard to accomplish stuff a five-year-old can do with ease, such as catching a ball or walking around a room without bumping into things.
This fundamental tension—what is hard for humans is easy for machines, and what’s hard for machines is easy for humans—is at the heart of three new books delving into our complex and often fraught relationship with robots, AI, and automation. They force us to reimagine the nature of everything from friendship and love to work, health care, and home life. Read the full story.
—Bryan Gardiner
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ Congratulations to William Goodge, who ran across Australia in just 35 days! + A British horticulturist has created a garden at this year’s Chelsea Flower Show just for dogs. + The Netherlands just loves a sidewalk garden. + Did you know the T Rex is a north American hero? Me neither
Google’s AI Overviews answers queries directly on search result pages. The feature often eliminates the need to visit external sites, although it includes links to some for deeper research.
Google provides no comprehensive reports of links in Overviews, leaving little official insight for publishers. Third-party tools offer that data, but at prices many merchants cannot afford.
We’re left with Search Console to reveal links to a site in Overviews indirectly. Here’s how.
Search Console ‘Positions’
Search Console’s “Performance” tab lists a site’s URLs in organic search results. Every section (“element”) of search results (e.g., “People also ask,” image packs, AI Overviews) counts as one single position.
A Google Search results page is composed of many search result elements. The “position” metric is an attempt to show approximately where on the page a given link was seen, relative to other results on the page…
Each element in Search results occupies a single position, whether it contains a single link or many different links or child elements.
For example, a URL in an image block at the top of results will show in position 1 in the Performance section for that query. A competitor’s URL in that same image section for the same query would also show as position 1.
Search Console shows the topmost position of a URL in search results. A URL simultaneously in a top image pack and the fourth organic search listing would show as position 1.
AI Overviews are one of those elements. Thus all links in a single AI Overview for a given query will show in Search Console as position 1. Google’s John Mueller confirmed this with the caveat, “I don’t know if AIO is always shown first.”
Hence identifying your URLs in AI Overviews starts with those in the top position.
Step 1: Create a filter
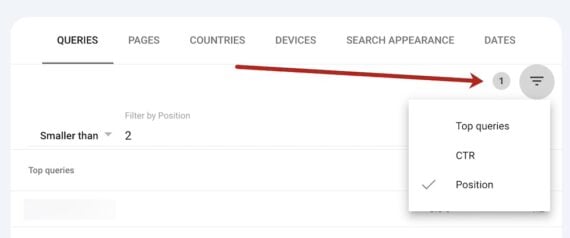
In Search Console’s “Performance” tab, scroll down to “Queries” and create a filter to see where your site ranks number 1:
Click the “filter” icon to the top-right of your query list.
Select “Position.”
In the filter settings, select “Smaller than” and type “2.”
Click “Done.”
Your report is now filtered for search queries where your site ranks below 2. This will include average positions — e.g., if your site appears in AI Overviews on mobile but not desktop, the average position is slightly higher than 1.
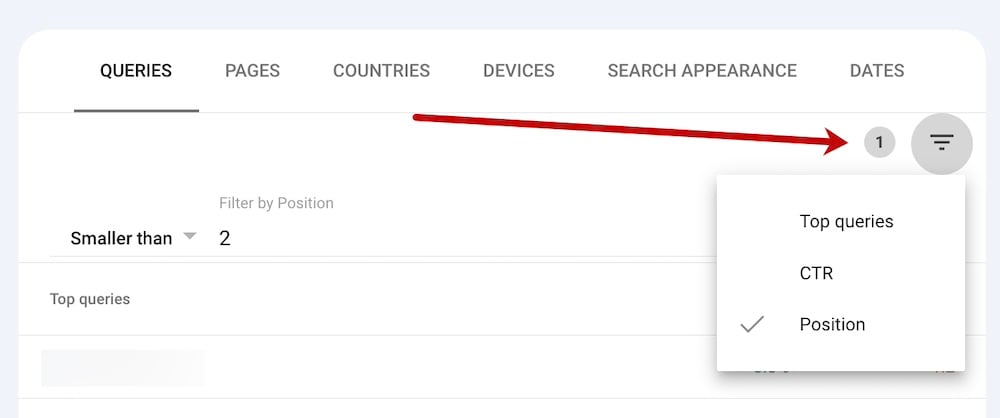
In Search Console, filter “Queries” by “Smaller than 2.” Click image to enlarge.
Step 2: Sort results by clicks
Click-throughs in AI Overviews are much lower than traditional organic listings. Sorting the above report by “CTR” will isolate queries with low clicks, making them good candidates for AI Overviews.
To sort the report, click the “CTR” header twice.
Clicking any query in this list will also show when an AI Overview likely began citing your URL: when the average position increased, and the CTR dropped.
Sort the report by click-through rate to see when the average position increased and the CTR dropped. Click image to enlarge.
This exercise does not provide total site performance in AI Overviews, but it’s the only free method I know. It helps evaluate the impact of AI Overviews on your site’s visibility in search results and identify URLs better optimized for AI-driven answers.
Google has announced updates to its Gemini AI platform at Google I/O, introducing features that could transform how search and marketing professionals analyze data and interact with digital tools.
The new capabilities focus on enhanced reasoning, improved interface interactions, and more efficient workflows.
Gemini 2.5 Models Get Performance Upgrades
Google highlights that Gemini 2.5 Pro leads the WebDev Arena leaderboard with an ELO score of 1420. It ranks first in all categories on the LMArena leaderboard, which measures human preferences for AI models.
The model features a one-million-token context window for processing large content inputs, effectively supporting both long text analysis and video understanding.
Meanwhile, Gemini 2.5 Flash has been updated to enhance performance in reasoning, multimodality, code, and long context processing.
Google reports it now utilizes 20-30% fewer tokens than previous versions. The updated Flash model is currently available in the Gemini app and will be generally available for production in Google AI Studio and Vertex AI in early June.
Gemini Live: New Camera and Screen Sharing Capabilities
The expanded Gemini Live feature is a significant addition to the Gemini ecosystem, now available on Android and iOS devices.
Google reports that Gemini Live conversations are, on average, five times longer than text-based interactions.
Camera and screen sharing capabilities, allowing users to point their phones at objects for real-time visual help.
Integration with Google Maps, Calendar, Tasks, and Keep (coming in the next few weeks).
The ability to create calendar events directly from conversations.
These features enable marketers to demonstrate products, troubleshoot issues, and plan campaigns through natural conversations with AI assistance.
Deep Think: Enhanced Reasoning for Complex Problems
The experimental “Deep Think” mode for Gemini 2.5 Pro uses research techniques that enable the model to consider multiple solutions before responding.
Google is making Deep Think available to trusted testers through the Gemini API to gather feedback prior to a wider release.
New Developer Tools for Marketing Applications
Several enhancements to the developer experience include:
Thought Summaries: Both 2.5 Pro and Flash will now provide structured summaries of their reasoning process in the Gemini API and Vertex AI.
Thinking Budgets: This feature is expanding to 2.5 Pro, enabling developers to manage token usage for thinking prior to responses, which impacts costs and performance.
MCP Support: The introduction of native support for the Model Context Protocol in the Gemini API allows for integration with open-source tools.
Here are examples of what thought summaries and thinking budgets look like in the Gemini interface:
Image Credit: Google
Image Credit: Google
Gemini in Chrome & New Subscription Plans
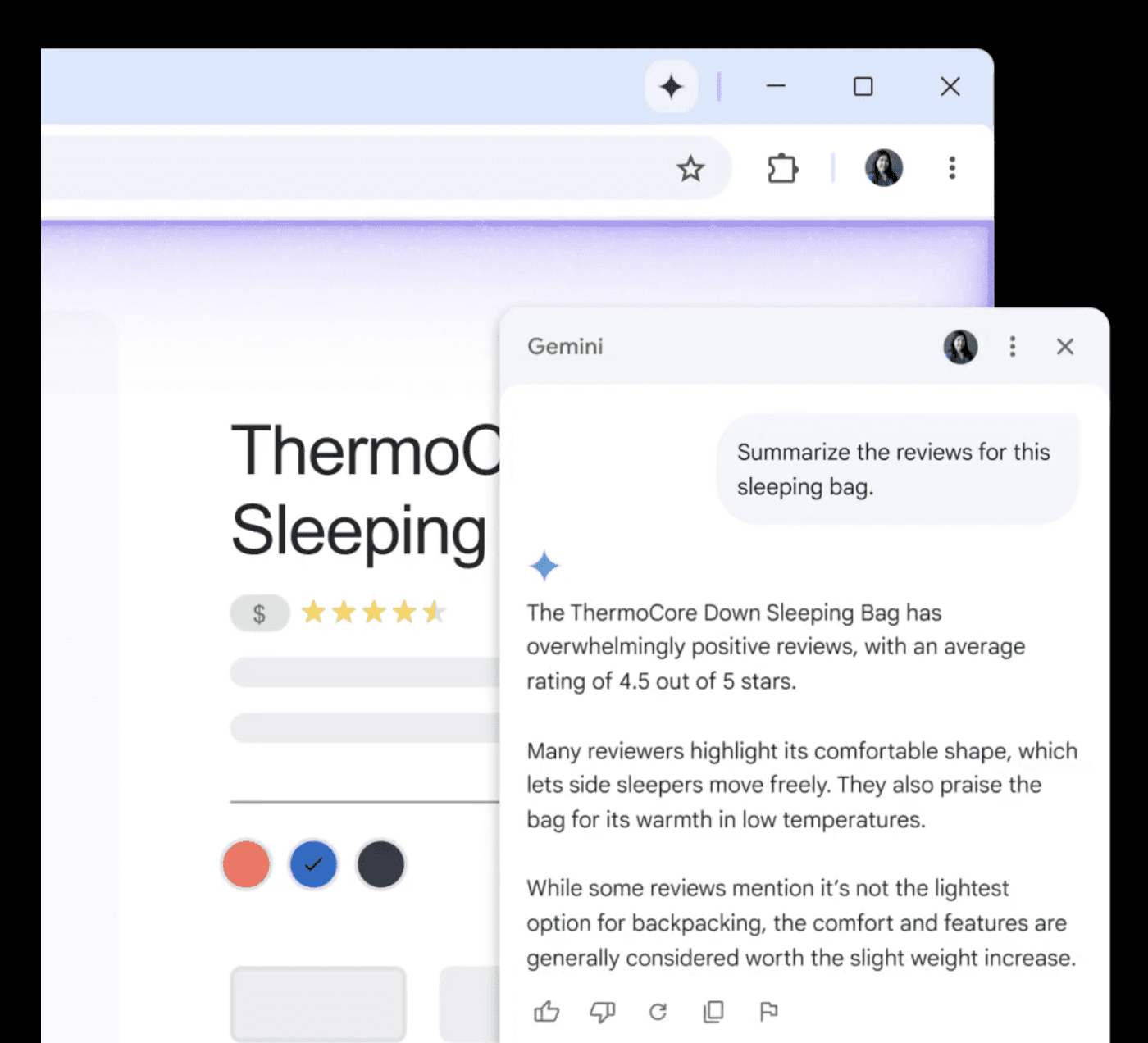
Gemini is being integrated into Chrome, rolling out to Google AI subscribers in the U.S. This feature allows users to ask questions about content while browsing websites.
You can see an example of this capability in the image below:
Image Credit: Google
Google also announced two subscription plans: Google AI Pro and Google AI Ultra.
The Ultra plan costs $249.99/month (with 50% off the first three months for new users) and provides access to Google’s advanced models with higher usage limits and early access to experimental AI features.
Looking Ahead
These updates to Gemini signify notable advancements in AI that marketers can integrate into their analytical workflows.
As these features roll out in the coming months, SEO and marketing teams can assess how these tools fit with their current strategies and technical requirements.
The incorporation of AI into Chrome and the upgraded conversational abilities indicate ongoing evolution in how consumers engage with digital content, a trend that search and marketing professionals must monitor closely.
At its annual I/O developer conference, Google announced upgrades to its AI-powered Search tools, making features like AI Mode and AI Overviews available to more people.
These updates, which Search Engine Journal received an advanced look at during a preview event, show Google’s commitment to creating interactive search experiences.
Here’s what’s changing and what it means for digital marketers.
AI Overviews: Improved Accuracy, Global Reach
AI Overviews, launched last year, are now available in over 200 countries and more than 40 languages.
Google reports that this feature is transforming how people utilize Search, with a 10% increase in search activity for queries displaying AI Overviews in major markets like the U.S. and India.
At the news preview, Liz Reid, Google’s VP and Head of Search, addressed concerns regarding AI accuracy.
She acknowledged that there have been “edge cases” where AI Overviews provided incorrect or even harmful information. Reid explained that these issues were taken seriously, corrections were made, and continuous AI training has led to improved results over time.
Expect Google to continue enhancing how AI ensures accuracy and reliability.
AI Mode: Now Available to More Users
AI Mode is now rolling out to all users in the U.S. without the need to sign up for Search Labs.
Previously, only testers could try AI Mode. Now, anyone in the U.S. will see a new tab for AI Mode in Search and in the Google app search bar.
How AI Mode Works
AI Mode uses a “query fan-out” system that breaks big questions into smaller parts and runs many searches at once.
Users can also ask follow-up questions and get links to helpful sites within the search results.
Google is using AI Mode and AI Overviews as testing grounds for new features, like the improved Gemini 2.5 AI model. User feedback will help shape what becomes part of the main Search experience.
New Tools: Deep Search, Live Visual Search, and AI-Powered Agents
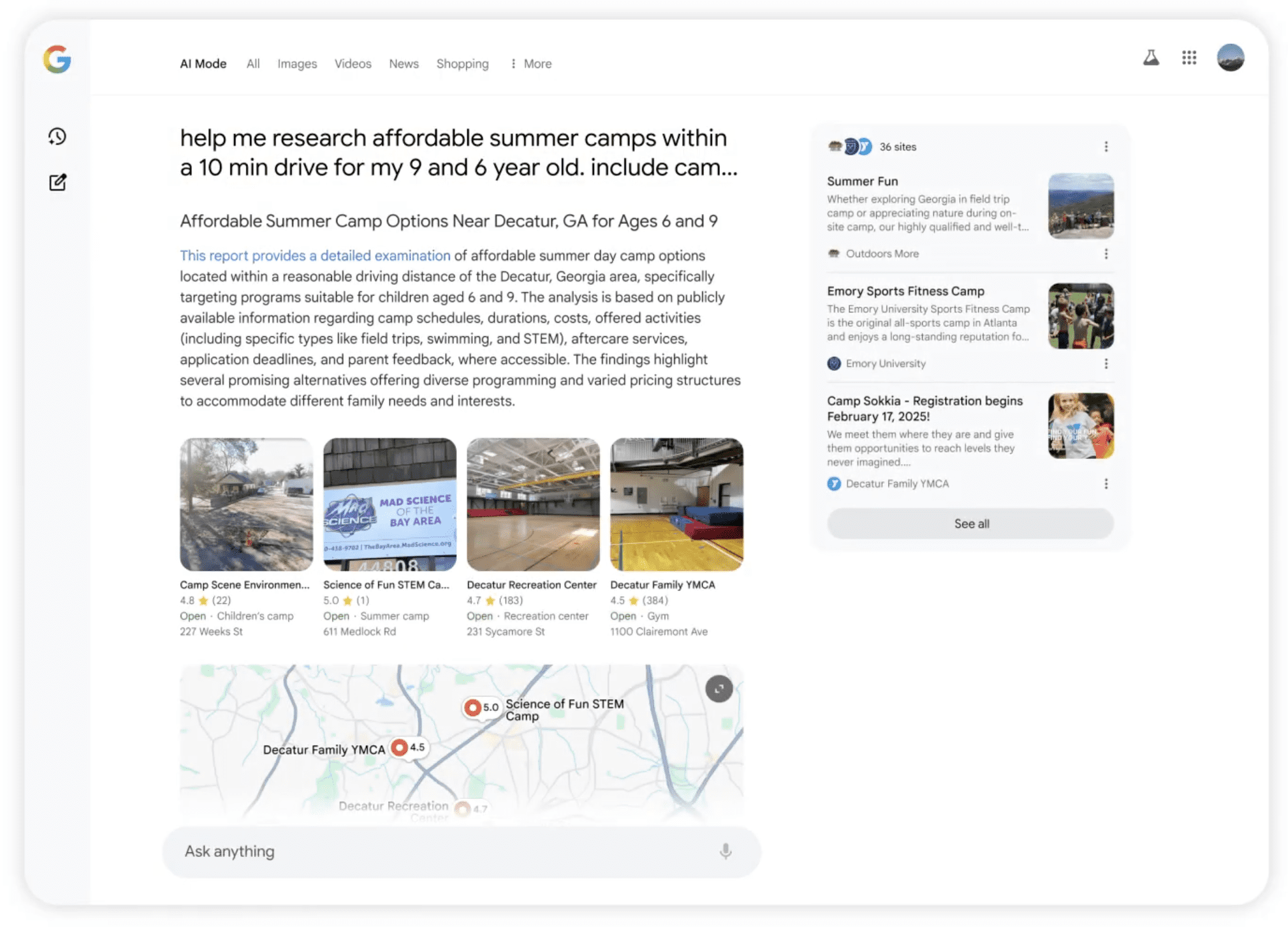
Deep Search: Research Made Easy
Deep Search in AI Mode helps users dig deeper. It can run hundreds of searches at once and build expert-level, fully-cited reports in minutes.
Image Credit: Google
Image Credit: Google
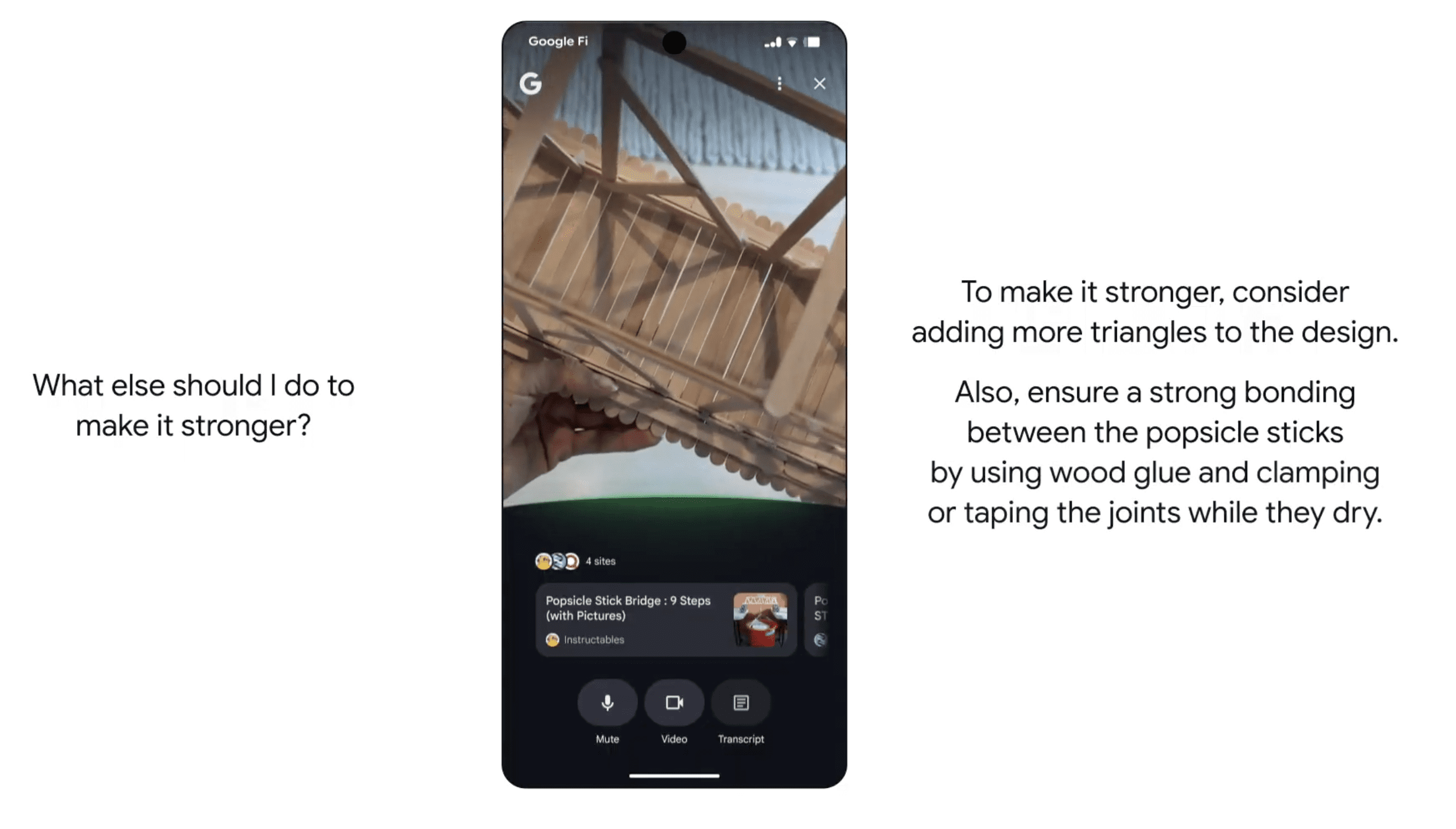
Live Visual Search With Project Astra
Google is updating how users can search visually. With Search Live, you can use your phone’s camera to talk with Search about what you see.
For example, point your camera at something, ask a question, and get quick answers and links. This feature can boost local searches, visual shopping, and on-the-go learning.
Image Credit: Google
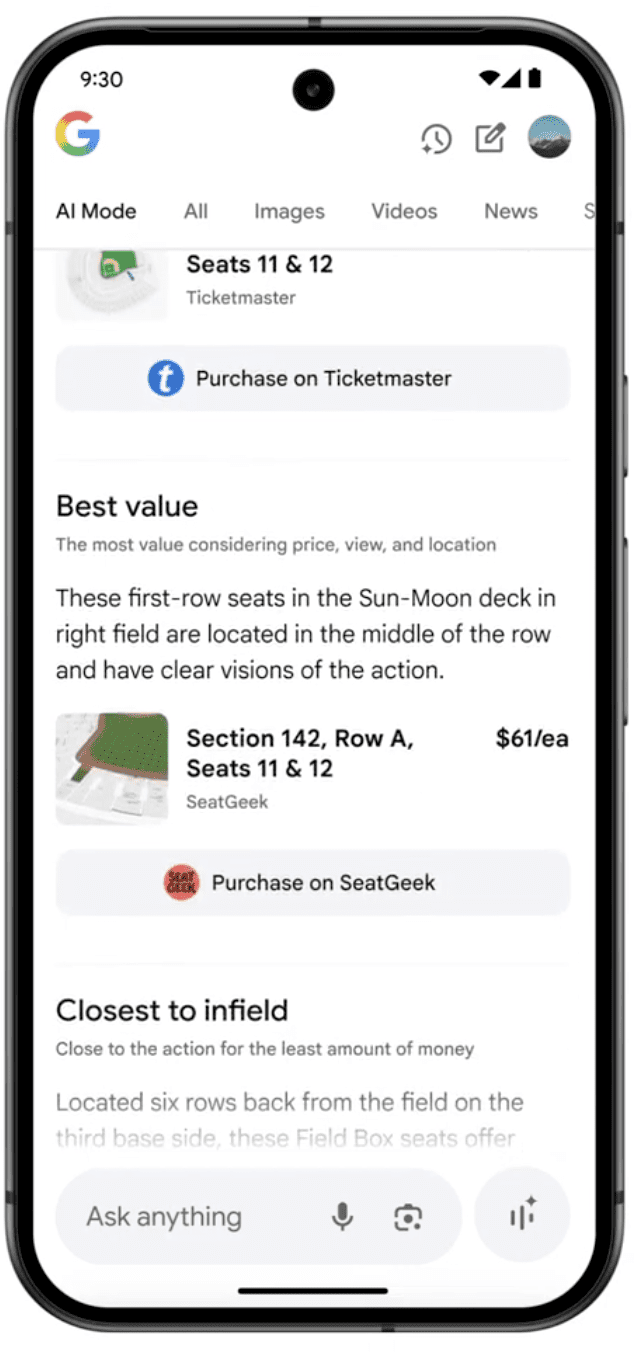
AI Agents: Getting Tasks Done for You
Google is adding agentic features, which are AI tools capable of managing multi-step tasks.
Initially, AI Mode will assist users in purchasing event tickets, reserving restaurant tables, and scheduling appointments. The AI evaluates hundreds of options and completes forms, but users always finalize the purchase.
Partners such as Ticketmaster, StubHub, Resy, and Vagaro are already onboard.
Image Credit: Google
Image Credit: Google
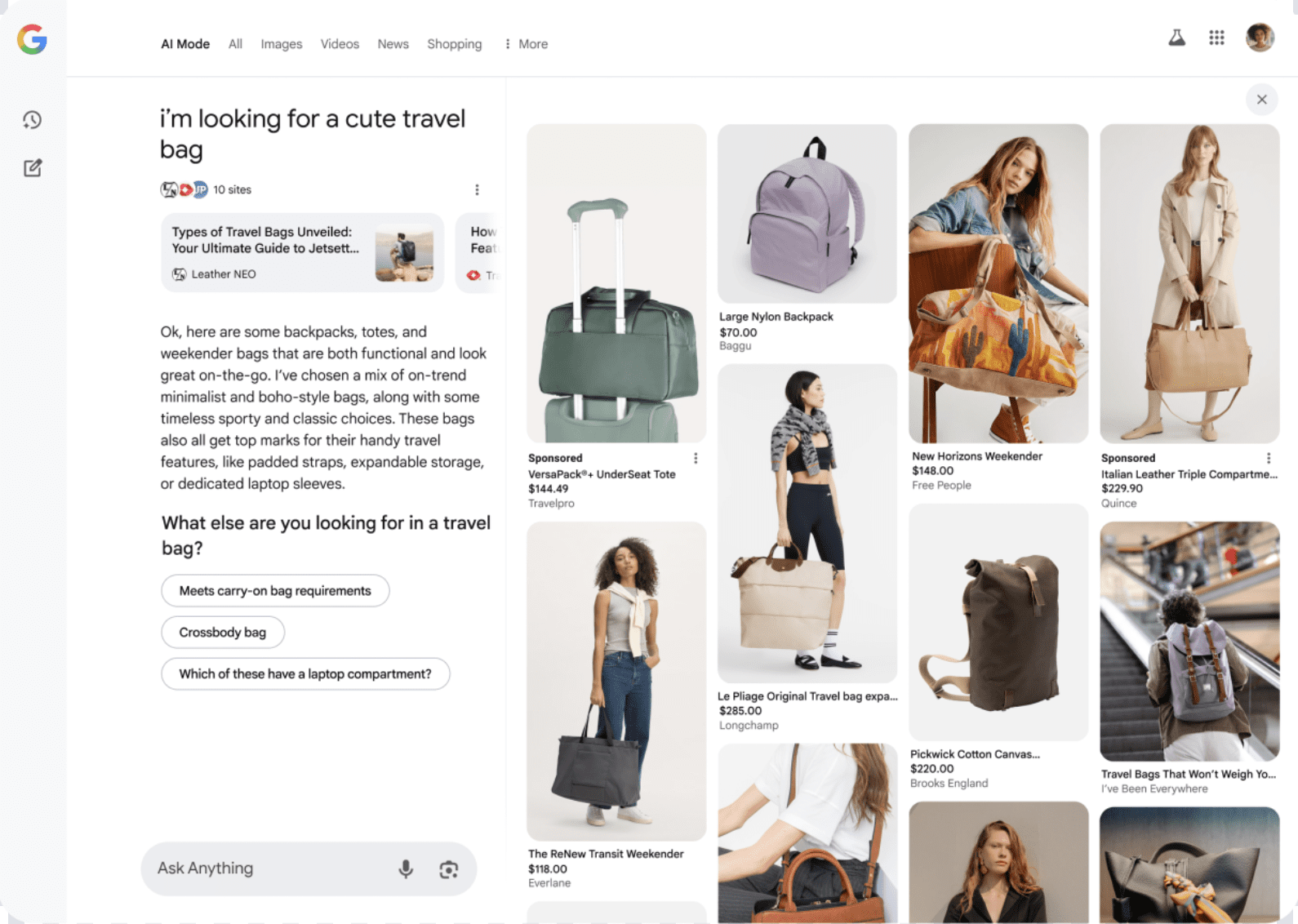
Smarter Shopping: Try On Clothes and Buy With Confidence
AI Mode is enhancing the shopping experience. The new tools use Gemini and Google’s Shopping Graph and include:
Personalized Visuals: Product panels show items based on your style and needs.
Virtual Try-On: Upload a photo to see how clothing looks on you, powered by Google’s fashion AI.
Agentic Checkout: Track prices, get sale alerts, and let Google’s AI buy for you via Google Pay when the price drops.
Custom Charts: For sports and finance, AI Mode can build charts and graphs using live data.
Image Credit: Google
Personalization and Privacy Controls
Soon, AI Mode will offer more personalized results by using your past searches and, if you opt in, data from other Google apps like Gmail.
For example, if you’re planning a trip, AI Mode can suggest restaurants or events based on your bookings and interests. Google says you’ll always know when your personal info is used and can manage your privacy settings anytime.
Google’s View: Search Use Cases Are Growing
CEO Sundar Pichai addressed how AI is reshaping search during the preview event.
He described the current transformation as “far from a zero sum moment,” noting that the use cases for Search are “dramatically expanding.”
Pichai highlighted increasing user excitement and conveyed optimism, stating that “all of this will keep getting better” as AI capabilities mature.
Looking Ahead
Google’s latest announcements signal a continued push toward AI as the core of the search experience.
With AI Mode rolling out in the U.S. and global expansion of AI Overviews, marketers should proactively adapt their strategies to meet the evolving expectations of both users and Google’s algorithms.
This week’s ask an SEO question comes from Jubi in Kerala:
“We changed our on-page content recently as keyword positions were nil. After updating the content, the keywords started appearing, but after four weeks the keywords went back to nil. Why is this so, any suggestions? [Page provided]”
Great to meet you, Jubi, and thank you for the question.
I reviewed your page, and although it is written for the user and in a conversational tone with keywords incorporated throughout, the site, overall, is likely the problem.
SEO is more than words on a page. It is also:
How your brand is represented by third parties.
The code of the site.
User and spider experience defined both topically and structurally.
The overall quality of the experience for the user, the spiders, and the algorithms.
Consumers not needing to do more searches as the solutions are provided by your website, or you give them the resources to implement with trusted third parties (backlinks) when you do not offer the product, service, or solution.
Changing the wording on a page can and does help, but it relies on the rest of the website, too.
I looked at your website for about five minutes, and multiple things popped out. After plugging it into an SEO tool that shows the history of the site, I have some starting points for you to help your site rank, and hopefully, this can help with your client work, too.
Focus On Your Target Audience And Region
First and foremost, your website is in U.S. English, and the language declarations are also in U.S. English. Your target audience is Kerala, India, and you offer digital marketing services in Kerala for local companies.
With a Google Search, I went to see if American English is the common language. Instead, it is Malayalam.
If both English and Malayalam are used, create both versions on your website. More importantly, see how people search in your area.
This is important for both you as a vendor and your local SEO and marketing clients.
I’ve done this in Scandinavia, where TV commercials in Sweden are in English (or were back then), so product searches and types were done in English more than in Swedish.
By having both languages available in content and PPC campaigns, conversions and revenue both scaled vs. only having the Swedish versions when I started working with this brand.
If they are not searching in English as a primary language, use the language they search in as the primary and make English the backup.
Next, look at your schema. You have a local business, which is great, but there are other ways you can define the area you serve and what you do.
Service schema can show you have a service, and you can nest an area served in because you’re a local business with a specific region you service.
Clean Up Hacked Code
Your website was hacked, and the hackers filled it with tons and tons of low-value content to try and rank for brands and brand products.
These pages are all 404, which is great, but they’re still being found. 410 them and make sure you block the parameter in robots.txt correctly. It looks like you’re missing an “*” on it.
You may also want to format a full robots.txt vs. using your software’s default with the one disallow line.
Undo The Over-Optimization
The website follows almost every bad practice with over-optimization, including things that are more for an end user rather than ranking a page.
Your meta descriptions on multiple pages are just keywords with commas in between vs. a sentence or two that tells the person what they’ll find if they click through.
I wasn’t sure if I was seeing it correctly, so I did a site:yourdomain search on Google and saw the descriptions were, in fact, just keywords with commas.
There are a couple of hundred backlinks, but they’re all directories and spammy websites. Think about your local media and trade organizations in India. How can you get featured there instead?
Is there a local chamber of commerce, small business, or local business group you can work with?
What can you share about market trends that will get you on the local news or news and business sites to link to your resources? These are the backlinks that will help you.
Redo Your Blog
The blog has some topically relevant content, but the content is thin, and your guides that are supposed to answer questions start with sales pitches instead.
Sales pitches do not belong in the first paragraph or even the first five paragraphs of a blog post or guide ever.
People are there to learn. If they like what they learned, you have earned their trust. If the topic is relevant to a product or service you offer, that is when you do the sales pitch.
I clicked on two posts, and after the sales pitch, you share concepts, which is good, but there are no examples that the user can use.
The pages are missing supporting graphics and images to demonstrate concepts, information about the person who created the content, and ways to implement the solution.
One of the posts talks about slow webpage speed. Instead of giving a way to fix it or a starting point, the content just defines what it is. The person has to do another search, which means it is a bad experience.
Add in a couple of starting points like removing excess files (give a couple of types), using server-side rendering with how this helps and an example, plugins or tools for compressing images that don’t need to be in high-resolution, etc.
Now the person has action items, and you have an opportunity to link to detailed guides off of keywords (internal links) naturally to your pages that teach this.
This adds a ton of value to the user and gives them a reason to come back to you or even hire you to do the work for them.
On multiple posts, the writer stuffs internal links off of keyword phrases that are not naturally occurring. These are in the sales pitches, the opening, and the closing of each post.
In theory, this may not be bad for SEO, but it is not helpful for the user and may send low-quality page experience signals to Google if users are bouncing.
From my experience, your content is less likely to get sourced or linked to if it is a sales pitch vs. sharing a solution, but that is just what I’ve experienced.
Instead of starting with a sales pitch or having sales pitches in every post, build an email or SMS list and use remarketing to bring them back.
If you start with a sales pitch and no actual solution, they’ll likely bounce as the page is low-quality.
Final Thoughts
Your service pages overall are not bad. It is the rest of the website.
It needs to be recoded and focused on your target audience, the over-optimizations should be undone, and your agency needs to become the go-to digital marketing agency in your region. Most importantly, the code and content need to be cleaned up.
You offer these services, but prospective clients seeing these bad practices may be turned off and cost you business.
Also, don’t forget to create a Google Business Profile; you don’t currently have one even though you have a physical location, have active clients, and offer services.
I hope this helps, and thank you for asking a really good question.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
Microsoft Bing published an announcement stating that the IndexNow search crawling technology is a powerful way for ecommerce companies to surface the latest and most accurate shopping-related information in AI Search and search engine shopping features.
Generative Search Requires Timely Shopping Information
Ecommerce sites typically depend on merchant feeds, search engine crawling and updates to Schema.org structured data to communicate what’s for sale, new products, retired products, changes to prices, availability and other important features. Each of those methods can be a point of failure due to slow crawling by search engines and inconsistent updating which can delay the correct information from surfacing in AI search and shopping features.
IndexNow solves that problem. Content platforms like Wix, Duda, Shopify and WooCommerce support IndexNow, a Microsoft technology that enables speeding indexing of new or updated content. Pairing IndexNow with Schema.org assures fast indexing so that the correct information surfaces in AI Search and shopping features.
IndexNow recommends the following Schema.org Product Type properties:
“title (name in JSON-LD)
description
price (list/retail price)
link (product landing page URL)
image link (image in JSON-LD)
shipping (especially important for Germany and Austria)
id (a unique identifier for the product)
brand
gtin
mpn
datePublished
dateModified
Optional fields to further enhance context and classification:
category (helps group products for search and shopping platforms)
seller (recommended for marketplaces or resellers)
In 2019, Karen Hao, a senior reporter with MIT Technology Review, pitched me on writing a story about a then little-known company, OpenAI. It was her biggest assignment to date. Hao’s feat of reporting took a series of twists and turns over the coming months, eventually revealing how OpenAI’s ambition had taken it far afield from its original mission. The finished story was a prescient look at a company at a tipping point—or already past it. And OpenAI was not happy with the result. Hao’s new book, Empire of AI: Dreams and Nightmares in Sam Altman’s OpenAI, is an in-depth exploration of the company that kick-started the AI arms race, and what that race means for all of us. This excerpt is the origin story of that reporting. — Niall Firth, executive editor, MIT Technology Review
I arrived at OpenAI’s offices on August 7, 2019. Greg Brockman, then thirty‑one, OpenAI’s chief technology officer and soon‑to‑be company president, came down the staircase to greet me. He shook my hand with a tentative smile. “We’ve never given someone so much access before,” he said.
At the time, few people beyond the insular world of AI research knew about OpenAI. But as a reporter at MIT Technology Review covering the ever‑expanding boundaries of artificial intelligence, I had been following its movements closely.
Until that year, OpenAI had been something of a stepchild in AI research. It had an outlandish premise that AGI could be attained within a decade, when most non‑OpenAI experts doubted it could be attained at all. To much of the field, it had an obscene amount of funding despite little direction and spent too much of the money on marketing what other researchers frequently snubbed as unoriginal research. It was, for some, also an object of envy. As a nonprofit, it had said that it had no intention to chase commercialization. It was a rare intellectual playground without strings attached, a haven for fringe ideas.
But in the six months leading up to my visit, the rapid slew of changes at OpenAI signaled a major shift in its trajectory. First was its confusing decision to withhold GPT‑2 and brag about it. Then its announcement that Sam Altman, who had mysteriously departed his influential perch at YC, would step in as OpenAI’s CEO with the creation of its new “capped‑profit” structure. I had already made my arrangements to visit the office when it subsequently revealed its deal with Microsoft, which gave the tech giant priority for commercializing OpenAI’s technologies and locked it into exclusively using Azure, Microsoft’s cloud‑computing platform.
Each new announcement garnered fresh controversy, intense speculation, and growing attention, beginning to reach beyond the confines of the tech industry. As my colleagues and I covered the company’s progression, it was hard to grasp the full weight of what was happening. What was clear was that OpenAI was beginning to exert meaningful sway over AI research and the way policymakers were learning to understand the technology. The lab’s decision to revamp itself into a partially for‑profit business would have ripple effects across its spheres of influence in industry and government.
So late one night, with the urging of my editor, I dashed off an email to Jack Clark, OpenAI’s policy director, whom I had spoken with before: I would be in town for two weeks, and it felt like the right moment in OpenAI’s history. Could I interest them in a profile? Clark passed me on to the communications head, who came back with an answer. OpenAI was indeed ready to reintroduce itself to the public. I would have three days to interview leadership and embed inside the company.
Brockman and I settled into a glass meeting room with the company’s chief scientist, Ilya Sutskever. Sitting side by side at a long conference table, they each played their part. Brockman, the coder and doer, leaned forward, a little on edge, ready to make a good impression; Sutskever, the researcher and philosopher, settled back into his chair, relaxed and aloof.
I opened my laptop and scrolled through my questions. OpenAI’s mission is to ensure beneficial AGI, I began. Why spend billions of dollars on this problem and not something else?
Brockman nodded vigorously. He was used to defending OpenAI’s position. “The reason that we care so much about AGI and that we think it’s important to build is because we think it can help solve complex problems that are just out of reach of humans,” he said.
He offered two examples that had become dogma among AGI believers. Climate change. “It’s a super‑complex problem. How are you even supposed to solve it?” And medicine. “Look at how important health care is in the US as a political issue these days. How do we actually get better treatment for people at lower cost?”
On the latter, he began to recount the story of a friend who had a rare disorder and had recently gone through the exhausting rigmarole of bouncing between different specialists to figure out his problem. AGI would bring together all of these specialties. People like his friend would no longer spend so much energy and frustration on getting an answer.
Why did we need AGI to do that instead of AI? I asked.
This was an important distinction. The term AGI, once relegated to an unpopular section of the technology dictionary, had only recently begun to gain more mainstream usage—in large part because of OpenAI.
And as OpenAI defined it, AGI referred to a theoretical pinnacle of AI research: a piece of software that had just as much sophistication, agility, and creativity as the human mind to match or exceed its performance on most (economically valuable) tasks. The operative word was theoretical. Since the beginning of earnest research into AI several decades earlier, debates had raged about whether silicon chips encoding everything in their binary ones and zeros could ever simulate brains and the other biological processes that give rise to what we consider intelligence. There had yet to be definitive evidence that this was possible, which didn’t even touch on the normative discussion of whether people should develop it.
AI, on the other hand, was the term du jour for both the version of the technology currently available and the version that researchers could reasonably attain in the near future through refining existing capabilities. Those capabilities—rooted in powerful pattern matching known as machine learning—had already demonstrated exciting applications in climate change mitigation and health care.
Sutskever chimed in. When it comes to solving complex global challenges, “fundamentally the bottleneck is that you have a large number of humans and they don’t communicate as fast, they don’t work as fast, they have a lot of incentive problems.” AGI would be different, he said. “Imagine it’s a large computer network of intelligent computers—they’re all doing their medical diagnostics; they all communicate results between them extremely fast.”
This seemed to me like another way of saying that the goal of AGI was to replace humans. Is that what Sutskever meant? I asked Brockman a few hours later, once it was just the two of us.
“No,” Brockman replied quickly. “This is one thing that’s really important. What is the purpose of technology? Why is it here? Why do we build it? We’ve been building technologies for thousands of years now, right? We do it because they serve people. AGI is not going to be different—not the way that we envision it, not the way we want to build it, not the way we think it should play out.”
That said, he acknowledged a few minutes later, technology had always destroyed some jobs and created others. OpenAI’s challenge would be to build AGI that gave everyone “economic freedom” while allowing them to continue to “live meaningful lives” in that new reality. If it succeeded, it would decouple the need to work from survival.
“I actually think that’s a very beautiful thing,” he said.
In our meeting with Sutskever, Brockman reminded me of the bigger picture. “What we view our role as is not actually being a determiner of whether AGI gets built,” he said. This was a favorite argument in Silicon Valley—the inevitability card. If we don’t do it, somebody else will. “The trajectory is already there,” he emphasized, “but the thing we can influence is the initial conditions under which it’s born.
“What is OpenAI?” he continued. “What is our purpose? What are we really trying to do? Our mission is to ensure that AGI benefits all of humanity. And the way we want to do that is: Build AGI and distribute its economic benefits.”
His tone was matter‑of‑fact and final, as if he’d put my questions to rest. And yet we had somehow just arrived back to exactly where we’d started.
Our conversation continued on in circles until we ran out the clock after forty‑five minutes. I tried with little success to get more concrete details on what exactly they were trying to build—which by nature, they explained, they couldn’t know—and why, then, if they couldn’t know, they were so confident it would be beneficial. At one point, I tried a different approach, asking them instead to give examples of the downsides of the technology. This was a pillar of OpenAI’s founding mythology: The lab had to build good AGI before someone else built a bad one.
Brockman attempted an answer: deepfakes. “It’s not clear the world is better through its applications,” he said.
I offered my own example: Speaking of climate change, what about the environmental impact of AI itself? A recent study from the University of Massachusetts Amherst had placed alarming numbers on the huge and growing carbon emissions of training larger and larger AI models.
That was “undeniable,” Sutskever said, but the payoff was worth it because AGI would, “among other things, counteract the environmental cost specifically.” He stopped short of offering examples.
“It is unquestioningly very highly desirable that data centers be as green as possible,” he added.
“No question,” Brockman quipped.
“Data centers are the biggest consumer of energy, of electricity,” Sutskever continued, seeming intent now on proving that he was aware of and cared about this issue.
“It’s 2 percent globally,” I offered.
“Isn’t Bitcoin like 1 percent?” Brockman said.
“Wow!” Sutskever said, in a sudden burst of emotion that felt, at this point, forty minutes into the conversation, somewhat performative.
Sutskever would later sit down with New York Times reporter Cade Metz for his book Genius Makers, which recounts a narrative history of AI development, and say without a hint of satire, “I think that it’s fairly likely that it will not take too long of a time for the entire surface of the Earth to become covered with data centers and power stations.” There would be “a tsunami of computing . . . almost like a natural phenomenon.” AGI—and thus the data centers needed to support them—would be “too useful to not exist.”
I tried again to press for more details. “What you’re saying is OpenAI is making a huge gamble that you will successfully reach beneficial AGI to counteract global warming before the act of doing so might exacerbate it.”
“I wouldn’t go too far down that rabbit hole,” Brockman hastily cut in. “The way we think about it is the following: We’re on a ramp of AI progress. This is bigger than OpenAI, right? It’s the field. And I think society is actually getting benefit from it.”
“The day we announced the deal,” he said, referring to Microsoft’s new $1 billion investment, “Microsoft’s market cap went up by $10 billion. People believe there is a positive ROI even just on short‑term technology.”
OpenAI’s strategy was thus quite simple, he explained: to keep up with that progress. “That’s the standard we should really hold ourselves to. We should continue to make that progress. That’s how we know we’re on track.”
Later that day, Brockman reiterated that the central challenge of working at OpenAI was that no one really knew what AGI would look like. But as researchers and engineers, their task was to keep pushing forward, to unearth the shape of the technology step by step.
He spoke like Michelangelo, as though AGI already existed within the marble he was carving. All he had to do was chip away until it revealed itself.
There had been a change of plans. I had been scheduled to eat lunch with employees in the cafeteria, but something now required me to be outside the office. Brockman would be my chaperone. We headed two dozen steps across the street to an open‑air café that had become a favorite haunt for employees.
This would become a recurring theme throughout my visit: floors I couldn’t see, meetings I couldn’t attend, researchers stealing furtive glances at the communications head every few sentences to check that they hadn’t violated some disclosure policy. I would later learn that after my visit, Jack Clark would issue an unusually stern warning to employees on Slack not to speak with me beyond sanctioned conversations. The security guard would receive a photo of me with instructions to be on the lookout if I appeared unapproved on the premises. It was odd behavior in general, made odder by OpenAI’s commitment to transparency. What, I began to wonder, were they hiding, if everything was supposed to be beneficial research eventually made available to the public?
At lunch and through the following days, I probed deeper into why Brockman had cofounded OpenAI. He was a teen when he first grew obsessed with the idea that it could be possible to re‑create human intelligence. It was a famous paper from British mathematician Alan Turing that sparked his fascination. The name of its first section, “The Imitation Game,” which inspired the title of the 2014 Hollywood dramatization of Turing’s life, begins with the opening provocation, “Can machines think?” The paper goes on to define what would become known as the Turing test: a measure of the progression of machine intelligence based on whether a machine can talk to a human without giving away that it is a machine. It was a classic origin story among people working in AI. Enchanted, Brockman coded up a Turing test game and put it online, garnering some 1,500 hits. It made him feel amazing. “I just realized that was the kind of thing I wanted to pursue,” he said.
In 2015, as AI saw great leaps of advancement, Brockman says that he realized it was time to return to his original ambition and joined OpenAI as a cofounder. He wrote down in his notes that he would do anything to bring AGI to fruition, even if it meant being a janitor. When he got married four years later, he held a civil ceremony at OpenAI’s office in front of a custom flower wall emblazoned with the shape of the lab’s hexagonal logo. Sutskever officiated. The robotic hand they used for research stood in the aisle bearing the rings, like a sentinel from a post-apocalyptic future.
“Fundamentally, I want to work on AGI for the rest of my life,” Brockman told me.
What motivated him? I asked Brockman.
What are the chances that a transformative technology could arrive in your lifetime? he countered.
He was confident that he—and the team he assembled—was uniquely positioned to usher in that transformation. “What I’m really drawn to are problems that will not play out in the same way if I don’t participate,” he said.
Brockman did not in fact just want to be a janitor. He wanted to lead AGI. And he bristled with the anxious energy of someone who wanted history‑defining recognition. He wanted people to one day tell his story with the same mixture of awe and admiration that he used to recount the ones of the great innovators who came before him.
A year before we spoke, he had told a group of young tech entrepreneurs at an exclusive retreat in Lake Tahoe with a twinge of self‑pity that chief technology officers were never known. Name a famous CTO, he challenged the crowd. They struggled to do so. He had proved his point.
In 2022, he became OpenAI’s president.
During our conversations, Brockman insisted to me that none of OpenAI’s structural changes signaled a shift in its core mission. In fact, the capped profit and the new crop of funders enhanced it. “We managed to get these mission‑aligned investors who are willing to prioritize mission over returns. That’s a crazy thing,” he said.
OpenAI now had the long‑term resources it needed to scale its models and stay ahead of the competition. This was imperative, Brockman stressed. Failing to do so was the real threat that could undermine OpenAI’s mission. If the lab fell behind, it had no hope of bending the arc of history toward its vision of beneficial AGI. Only later would I realize the full implications of this assertion. It was this fundamental assumption—the need to be first or perish—that set in motion all of OpenAI’s actions and their far‑reaching consequences. It put a ticking clock on each of OpenAI’s research advancements, based not on the timescale of careful deliberation but on the relentless pace required to cross the finish line before anyone else. It justified OpenAI’s consumption of an unfathomable amount of resources: both compute, regardless of its impact on the environment; and data, the amassing of which couldn’t be slowed by getting consent or abiding by regulations.
Brockman pointed once again to the $10 billion jump in Microsoft’s market cap. “What that really reflects is AI is delivering real value to the real world today,” he said. That value was currently being concentrated in an already wealthy corporation, he acknowledged, which was why OpenAI had the second part of its mission: to redistribute the benefits of AGI to everyone.
Was there a historical example of a technology’s benefits that had been successfully distributed? I asked.
“Well, I actually think that—it’s actually interesting to look even at the internet as an example,” he said, fumbling a bit before settling on his answer. “There’s problems, too, right?” he said as a caveat. “Anytime you have something super transformative, it’s not going to be easy to figure out how to maximize positive, minimize negative.
“Fire is another example,” he added. “It’s also got some real drawbacks to it. So we have to figure out how to keep it under control and have shared standards.
“Cars are a good example,” he followed. “Lots of people have cars, benefit a lot of people. They have some drawbacks to them as well. They have some externalities that are not necessarily good for the world,” he finished hesitantly.
“I guess I just view—the thing we want for AGI is not that different from the positive sides of the internet, positive sides of cars, positive sides of fire. The implementation is very different, though, because it’s a very different type of technology.”
His eyes lit up with a new idea. “Just look at utilities. Power companies, electric companies are very centralized entities that provide low‑cost, high‑quality things that meaningfully improve people’s lives.”
It was a nice analogy. But Brockman seemed once again unclear about how OpenAI would turn itself into a utility. Perhaps through distributing universal basic income, he wondered aloud, perhaps through something else.
He returned to the one thing he knew for certain. OpenAI was committed to redistributing AGI’s benefits and giving everyone economic freedom. “We actually really mean that,” he said.
“The way that we think about it is: Technology so far has been something that does rise all the boats, but it has this real concentrating effect,” he said. “AGI could be more extreme. What if all value gets locked up in one place? That is the trajectory we’re on as a society. And we’ve never seen that extreme of it. I don’t think that’s a good world. That’s not a world that I want to sign up for. That’s not a world that I want to help build.”
In February 2020, I published my profile for MIT Technology Review, drawing on my observations from my time in the office, nearly three dozen interviews, and a handful of internal documents. “There is a misalignment between what the company publicly espouses and how it operates behind closed doors,” I wrote. “Over time, it has allowed a fierce competitiveness and mounting pressure for ever more funding to erode its founding ideals of transparency, openness, and collaboration.”
Hours later, Elon Musk replied to the story with three tweets in rapid succession:
“OpenAI should be more open imo”
“I have no control & only very limited insight into OpenAI. Confidence in Dario for safety is not high,” he said, referring to Dario Amodei, the director of research.
“All orgs developing advanced AI should be regulated, including Tesla”
Afterward, Altman sent OpenAI employees an email.
“I wanted to share some thoughts about the Tech Review article,” he wrote. “While definitely not catastrophic, it was clearly bad.”
It was “a fair criticism,” he said that the piece had identified a disconnect between the perception of OpenAI and its reality. This could be smoothed over not with changes to its internal practices but some tuning of OpenAI’s public messaging. “It’s good, not bad, that we have figured out how to be flexible and adapt,” he said, including restructuring the organization and heightening confidentiality, “in order to achieve our mission as we learn more.” OpenAI should ignore my article for now and, in a few weeks’ time, start underscoring its continued commitment to its original principles under the new transformation. “This may also be a good opportunity to talk about the API as a strategy for openness and benefit sharing,” he added, referring to an application programming interface for delivering OpenAI’s models.
“The most serious issue of all, to me,” he continued, “is that someone leaked our internal documents.” They had already opened an investigation and would keep the company updated. He would also suggest that Amodei and Musk meet to work out Musk’s criticism, which was “mild relative to other things he’s said” but still “a bad thing to do.” For the avoidance of any doubt, Amodei’s work and AI safety were critical to the mission, he wrote. “I think we should at some point in the future find a way to publicly defend our team (but not give the press the public fight they’d love right now).”
OpenAI wouldn’t speak to me again for three years.
In a 2019 speech at Georgetown University, Mark Zuckerberg famously declared that he didn’t want Facebook to be an “arbiter of truth.” And yet, in the years since, his company, Meta, has used several methods to moderate content and identify misleading posts across its social media apps, which include Facebook, Instagram, and Threads. These methods have included automatic filters that identify illegal and malicious content, and third-party factcheckers who manually research the validity of claims made in certain posts.
Zuckerberg explained that while Meta has put a lot of effort into building “complex systems to moderate content,” over the years, these systems have made many mistakes, with the result being “too much censorship.” The company therefore announced that it would be ending its third-party factchecker program in the US, replacing it with a system called Community Notes, which relies on users to flag false or misleading content and provide context about it.
While Community Notes has the potential to be extremely effective, the difficult job of content moderation benefits from a mix of different approaches. As a professor of natural language processing at MBZUAI, I’ve spent most of my career researching disinformation, propaganda, and fake news online. So, one of the first questions I asked myself was: will replacing human factcheckers with crowdsourced Community Notes have negative impacts on users?
Wisdom of crowds
Community Notes got its start on Twitter as Birdwatch. It’s a crowdsourced feature where users who participate in the program can add context and clarification to what they deem false or misleading tweets. The notes are hidden until community evaluation reaches a consensus—meaning, people who hold different perspectives and political views agree that a post is misleading. An algorithm determines when the threshold for consensus is reached, and then the note becomes publicly visible beneath the tweet in question, providing additional context to help users make informed judgments about its content.
Community Notes seems to work rather well. A team of researchers from University of Illinois Urbana-Champaign and University of Rochester found that X’s Community Notes program can reduce the spread of misinformation, leading to post retractions by authors. Facebook is largely adopting the same approach that is used on X today.
Having studied and written about content moderation for years, it’s great to see another major social media company implementing crowdsourcing for content moderation. If it works for Meta, it could be a true game-changer for the more than 3 billion people who use the company’s products every day.
That said, content moderation is a complex problem. There is no one silver bullet that will work in all situations. The challenge can only be addressed by employing a variety of tools that include human factcheckers, crowdsourcing, and algorithmic filtering. Each of these is best suited to different kinds of content, and can and must work in concert.
Spam and LLM safety
There are precedents for addressing similar problems. Decades ago, spam email was a much bigger problem than it is today. In large part, we’ve defeated spam through crowdsourcing. Email providers introduced reporting features, where users can flag suspicious emails. The more widely distributed a particular spam message is, the more likely it will be caught, as it’s reported by more people.
Another useful comparison is how large language models (LLMs) approach harmful content. For the most dangerous queries—related to weapons or violence, for example—many LLMs simply refuse to answer. Other times, these systems may add a disclaimer to their outputs, such as when they are asked to provide medical, legal, or financial advice. This tiered approach is one that my colleagues and I at the MBZUAI explored in a recent study where we propose a hierarchy of ways LLMs can respond to different kinds of potentially harmful queries. Similarly, social media platforms can benefit from different approaches to content moderation.
Automatic filters can be used to identify the most dangerous information, preventing users from seeing and sharing it. These automated systems are fast, but they can only be used for certain kinds of content because they aren’t capable of the nuance required for most content moderation.
Crowdsourced approaches like Community Notes can flag potentially harmful content by relying on the knowledge of users. They are slower than automated systems but faster than professional factcheckers.
Professional factcheckers take the most time to do their work, but the analyses they provide are deeper compared to Community Notes, which are limited to 500 characters. Factcheckers typically work as a team and benefit from shared knowledge. They are often trained to analyze the logical structure of arguments, identifying rhetorical techniques frequently employed in mis- and disinformation campaigns. But the work of professional factcheckers can’t scale in the same way Community Notes can. That’s why these three methods are most effective when they are used together.
Indeed, Community Notes have been found to amplify the work done by factcheckers so it reaches more users. Another study found that Community Notes and factchecking complement each other, as they focus on different types of accounts, with Community Notes tending to analyze posts from large accounts that have high “social influence.” When Community Notes and factcheckers do converge on the same posts, their assessments are similar, however. Another study found that crowdsourced content moderation itself benefits from the findings of professional factcheckers.
A path forward
At its heart, content moderation is extremely difficult because it is about how we determine truth—and there is much we don’t know. Even scientific consensus, built over years by entire disciplines, can change over time.
That said, platforms shouldn’t retreat from the difficult task of moderating content altogether—or become overly dependent on any single solution. They must continuously experiment, learn from their failures, and refine their strategies. As it’s been said, the difference between people who succeed and people who fail is that successful people have failed more times than others have even tried.
This content was produced by the Mohamed bin Zayed University of Artificial Intelligence. It was not written by MIT Technology Review’s editorial staff.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Inside the story that enraged OpenAI
—Niall Firth, executive editor, MIT Technology Review
In 2019, Karen Hao, a senior reporter with MIT Technology Review, pitched me a story about a then little-known company, OpenAI. It was her biggest assignment to date. Hao’s feat of reporting took a series of twists and turns over the coming months, eventually revealing how OpenAI’s ambition had taken it far afield from its original mission.
At first glance, the Bathhouse spa in Brooklyn looks not so different from other high-end spas. What sets it apart is out of sight: a closet full of cryptocurrency-mining computers that not only generate bitcoins but also heat the spa’s pools, marble hammams, and showers.
When cofounder Jason Goodman opened Bathhouse’s first location in Williamsburg in 2019, he used conventional pool heaters. But after diving deep into the world of bitcoin, he realized he could fit cryptocurrency mining seamlessly into his business. Read the full story.
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Nvidia wants to build an AI supercomputer in Taiwan As Trump’s tariffs upend existing supply chains. (WSJ $) + Jensen Huang has denied that Nvidia’s chips are being diverted into China. (Bloomberg $)
2 xAI’s Grok dabbled in Holocaust denial The chatbot said it was “skeptical” about points that historians agree are facts. (Rolling Stone $) + It blamed the comments on a programming error. (The Guardian)
3 Apple is planning to overhaul Siri entirely To make it an assistant fit for the AI age. (Bloomberg $)
4 Dentists are worried by RFK Jr’s fluoride ban Particularly in rural America. (Ars Technica) + Florida has become the second state to ban fluoride in public water. (NBC News)
5 Fewer people want to work in America’s factories That’s a problem when Trump is so hell-bent on kickstarting the manufacturing industry. (WSJ $) + Sweeping tariffs could threaten the US manufacturing rebound. (MIT Technology Review)
6 Meet the crypto investors hoping to bend the President’s ear They’re treating Trump’s meme coin dinner as an opportunity to push their agendas. (WP $) + Many of them are offloading their coins, too. (Wired $) + Crypto bigwigs are targets for criminals. (WSJ $) + Bodyguards and other forms of security are becoming de rigueur. (Bloomberg $)
7 How the US reversed the overdose epidemic Naloxone is a major factor. (Vox) + How the federal government is tracking changes in the supply of street drugs. (MIT Technology Review)
8 Chatbots really love the heads of the companies that made them And are not so fond of the leaders of its rivals. (FT $) + What if we could just ask AI to be less biased? (MIT Technology Review)
9 Technology is a double-edged sword What connects us can simultaneously outrage us. (The Atlantic $)
10 Meet the people hooked on watching nature live streams They find checking in with animals puts their own troubles in perspective. (The Guardian)
Quote of the day
“People are just scared. They don’t know where they fit in this new world.”
—Angela Jiang, who is working on a startup exploring the impact of AI on the labor market, tells the Wall Street Journal about the woes of tech job seekers trying to land new jobs in the current economy.
One more thing
How the Rubin Observatory will help us understand dark matter and dark energy
We can put a good figure on how much we know about the universe: 5%. That’s how much of what’s floating about in the cosmos is ordinary matter—planets and stars and galaxies and the dust and gas between them. The other 95% is dark matter and dark energy, two mysterious entities aptly named for our inability to shed light on their true nature.
Previous work has begun pulling apart these dueling forces, but dark matter and dark energy remain shrouded in a blanket of questions—critically, what exactly are they?
Enter the Vera C. Rubin Observatory, one of our 10 breakthrough technologies for 2025. Boasting the largest digital camera ever created, Rubin is expected to study the cosmos in the highest resolution yet once it begins observations later this year. And with a better window on the cosmic battle between dark matter and dark energy, Rubin might narrow down existing theories on what they are made of. Here’s a look at how.
—Jenna Ahart
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ Archaeologists in Canada are facing a mighty challenge—to solve how thousands of dinosaurs died in what’s now a forest in Alberta. + Before Brian Johnson joined AC/DC, he sang on this very distinctive hoover (vacuum cleaner) ad. + Wealthy Londoners are adding spas to their gardens, because why not. + I must eat the crystal breakfast!
Millions of people argue with each other online every day, but remarkably few of them change someone’s mind. New research suggests that large language models (LLMs) might do a better job. The finding suggests that AI could become a powerful tool for persuading people, for better or worse.
A multi-university team of researchers found that OpenAI’s GPT-4 was significantly more persuasive than humans when it was given the ability to adapt its arguments using personal information about whoever it was debating.
Their findings are the latest in a growing body of research demonstrating LLMs’ powers of persuasion. The authors warn they show how AI tools can craft sophisticated, persuasive arguments if they have even minimal information about the humans they’re interacting with. The research has been published in the journal Nature Human Behavior.
“Policymakers and online platforms should seriously consider the threat of coordinated AI-based disinformation campaigns, as we have clearly reached the technological level where it is possible to create a network of LLM-based automated accounts able to strategically nudge public opinion in one direction,” says Riccardo Gallotti, an interdisciplinary physicist at Fondazione Bruno Kessler in Italy, who worked on the project.
“These bots could be used to disseminate disinformation, and this kind of diffused influence would be very hard to debunk in real time,” he says.
The researchers recruited 900 people based in the US and got them to provide personal information like their gender, age, ethnicity, education level, employment status, and political affiliation.
Participants were then matched with either another human opponent or GPT-4 and instructed to debate one of 30 randomly assigned topics—such as whether the US should ban fossil fuels, or whether students should have to wear school uniforms—for 10 minutes. Each participant was told to argue either in favor of or against the topic, and in some cases they were provided with personal information about their opponent, so they could better tailor their argument. At the end, participants said how much they agreed with the proposition and whether they thought they were arguing with a human or an AI.
Overall, the researchers found that GPT-4 either equaled or exceeded humans’ persuasive abilities on every topic. When it had information about its opponents, the AI was deemed to be 64% more persuasive than humans without access to the personalized data—meaning that GPT-4 was able to leverage the personal data about its opponent much more effectively than its human counterparts. When humans had access to the personal information, they were found to be slightly less persuasive than humans without the same access.
The authors noticed that when participants thought they were debating against AI, they were more likely to agree with it. The reasons behind this aren’t clear, the researchers say, highlighting the need for further research into how humans react to AI.
“We are not yet in a position to determine whether the observed change in agreement is driven by participants’ beliefs about their opponent being a bot (since I believe it is a bot, I am not losing to anyone if I change ideas here), or whether those beliefs are themselves a consequence of the opinion change (since I lost, it should be against a bot),” says Gallotti. “This causal direction is an interesting open question to explore.”
Although the experiment doesn’t reflect how humans debate online, the research suggests that LLMs could also prove an effective way to not only disseminate but also counter mass disinformation campaigns, Gallotti says. For example, they could generate personalized counter-narratives to educate people who may be vulnerable to deception in online conversations. “However, more research is urgently needed to explore effective strategies for mitigating these threats,” he says.
While we know a lot about how humans react to each other, we know very little about the psychology behind how people interact with AI models, says Alexis Palmer, a fellow at Dartmouth College who has studied how LLMs can argue about politics but did not work on the research.
“In the context of having a conversation with someone about something you disagree on, is there something innately human that matters to that interaction? Or is it that if an AI can perfectly mimic that speech, you’ll get the exact same outcome?” she says. “I think that is the overall big question of AI.”