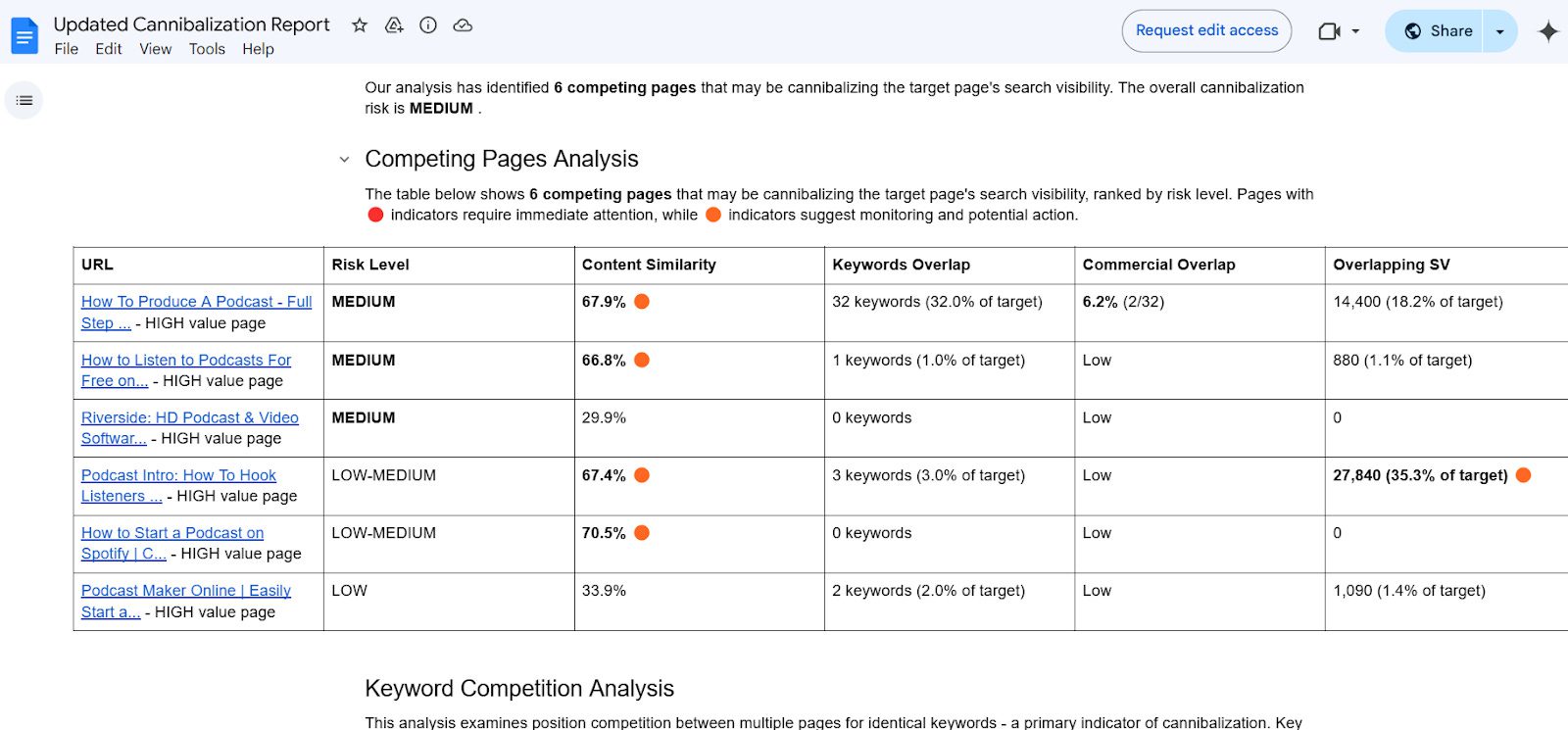
DoorDash Co-Founder: Customer Obsessed, Not Competitor Focused via @sejournal, @martinibuster

Garry Tan, President and CEO of Y Combinator, interviewed Tony Xu, co-founder of DoorDash, in a conversation that revealed useful insights on how to choose a niche, what it takes for an entrepreneur to succeed in a crowded and competitive field, and how DoorDash built long-lasting brand signals that can benefit any business in today’s digital economy.
DoorDash began with the non-scalable $10 domain (‘Palo Alto Delivery’) and PDF menus on a static HTML web page, taking orders over Google Voice and the founders were able to scale that to the nationwide success it is today by focusing on three actionable principles which allowed them to grow past their initial shortcomings and build on their strengths.
These lessons are especially important in today’s digital marketing environment where the importance of building relationships with customers has accelerated because of the advent of AI-powered search and AI assistants.
Y Combinator
Y Combinator is a Venture Capital and startup incubator responsible for dozens of the biggest digital brands like Airbnb, DoorDash, Quora, Stripe, Webflow, and Zapier to name a few. The Y Combinator video podcast interviews brings real insights directly related to digital marketing, entrepreneurship, and the daily work involved in keeping running businesses today.
Their podcast’s tag line suggests finding a place within the digital technology economy and the DoorDash experience shows how to do it.
“All the world is changing around technology and you may contribute a line of code. What will yours be?”
Three Takeaways
Tony Xu relates the beginnings of DoorDash and how it grew to become a successful company. It wasn’t a matter of getting a lot of money thrown at him and then finding success. He and his team struggled to figure out how to make the business successful. Perhaps a key to their success was that they founded the company on three ideas, creating a strong foundation upon which to build success.
Another takeaway is that a good business idea isn’t always an instant success. Success can take years to build. So be sure to give yourself a long runway measured in years not months for taking off.
The three takeaways are:
- Choose Business Niche By What Feels Meaningful
- Customer Obsession As A Strategic Philosophy
- Don’t Follow The Competition: Follow The Opportunity
Choosing Your Best Niche
Tony Xu explained that the DoorDash team started by exploring different projects that felt interesting to them and ultimately settling on the one that felt the most meaningful and exciting. The idea for DoorDash came about by observing a local macaroon shop that had to decline delivery orders because they lacked the infrastructure.
What’s interesting about DoorDash is that they’re in between two customer bases, the merchants and the end users. They opted to not conduct surveys but rather the founders immersed themselves in the merchants’ daily routines to identify the pain points for growth and expansion and to identify where DoorDash could help.
Tony Xu explains:
“Our question that we tended to ask business owners was can we follow you around for a day… we wanted to actually feel what it was like, their lived experience versus just asking a bunch of survey questions. It was toward the end of the time we spent with the store manager that she had showed us a booklet of orders she had turned down. All of them were delivery orders.”
He described that this was a common thread with business owners who had these small shops with orders they were unable to fulfill. He said they imagined the scale of what could be done, that they could have just delivered orders for this one bakery, or for all bakeries, all types of restaurants, all types of retailers. They discovered a need from a wide range of merchants but what they didn’t know at this point was if consumers cared or whether there was a driver workforce to partner for.
Customer Obsession As A Strategic Philosophy
Tony Xu shared that their early customer base was mainly young families and that ended up shaping their service through direct feedback. Another example of allowing the business to be shaped by the customer is an event that went badly and resulted in many upset customers. DoorDash settled on the customer-first approach by choosing to refund all the customers after a service meltdown during a Stanford football game, at the cost of 40% of the founder’s bank balances. Further, they stayed up overnight to bake and hand-deliver apology cookies the next morning at 5 AM before their customers awakened.
Tony shared how that experience solidified their business around customer satisfaction:
“That was an early story that ultimately, you know, became the story that translated to our internal company value of customer obsessed, not competitor focused… I think the founding team always had this desire to at least do things the right way even if we wouldn’t have made it.”
These experiences cemented the company’s core customer-centered philosophy of being “customer obsessed, not competitor focused.”
Don’t Follow The Competition: Follow the Opportunity
Conventional wisdom assumes that established players have done the research and that there are good reasons for why competitors do what they do. What Tony Xu revealed is that isn’t necessarily true. He doesn’t explain the reasons why competitors missed a golden opportunity but it’s easy to surmise that competitors build based on conventional assumptions and are unaware that demographics and user habits change which results in opportunities.
Tony shared that their competitors focused on dense urban markets because the conventional wisdom was that this was where more people it was more profitable to serve the densely populated areas. DoorDash went a different direction by focusing on suburbs because they discovered a customer need in that suburban customers had fewer nearby restaurants and it was that fact that made a delivery service more valuable. Serving families also resulted in higher average order size, easier parking, and simpler food drop-offs which in turn led to stronger performance across the board.
Takeaway:
Many smaller independent sites today fail to differentiate themselves to site visitors. They follow what their competitors do and because of that virtually all recipe sites, all mom sites all travel sites look exactly the same.
Becoming the same as your competitor is not the way to beat your competitors. That’s why the skyscraper and 10x content strategies are so lousy because they presume that being the same as the competitor “but better” is what your users want. Circling back to Tony Xu, he found success by being customer obsessed so the question is what does that mean for you and your site visitors?
Becoming customer-focused isn’t a new age feel-good thing to do, it’s a practical and proven approach to creating a successful business. It informs every choice you make from the design of the site, the service, and the content and it becomes a strength that no competitor can copy and steal from you.
Lastly, it’s satisfying and easier to focus on a topic that is meaningful. If there’s a way to build an ecosystem that might be even better as it can become a moat around the business.
Watch the Y Combinator podcast:
DoorDash CEO: Customer Obsession, Surviving Startup Death & Creating A New Market
Featured Image by Shutterstock/sockagphoto