Several years ago, Suzanne Berger was visiting a manufacturing facility in Ohio, talking to workers on the shop floor, when a machinist offered a thought that could serve as her current credo.
“Technology takes a step forward—workers take a step forward too,” the employee said.
Berger, to explain, is an MIT political scientist who for decades has advocated for the revitalization of US manufacturing. She has written books and coauthored reports about the subject, visited scores of factories, helped the issue regain traction in America, and in the process earned the title of Institute Professor, MIT’s highest faculty honor.
Over time, Berger has developed a distinctive viewpoint about manufacturing, seeing it as an arena where technological advances can drive economic growth and nimble firms can thrive.
This stands in contrast to the view that manufacturing is a sunsetting part of the US economy, lagging behind knowledge work and service industries and no longer a prime source of jobs. To Berger, the sector might have suffered losses, but we should think about it differently now: Rather than being threatened by change, it can thrive on innovation.
She is keenly interested in medium-size and small manufacturers, not just huge factories, given that 98% of US manufacturers have 500 or fewer employees. And she is interested, especially, in how technology can help them. Roughly one-tenth of US manufacturers use robots, for instance, a number that clearly disappoints her.
Her focus on these smaller manufacturers is pragmatic. The US is not going to bring back textile manufacturing or steelmaking jobs anytime soon. And although the tech giants have made some concessions to domestic manufacturing, all major product lines from all tech companies are made largely overseas. Small and midsize firms may also have more opportunities to be flexible and innovative.
And in the middle of Ohio, there it was, in a simple sentence: Technology takes a step forward—workers take a step forward too.
“I think workers do recognize that,” Berger says, sitting in her MIT office, with a view of East Cambridge out the window. “People don’t want to work on technologies of the 1940s. People do want to feel they’re moving to the future, and that’s what young workers also want. They want decent pay. They want to feel they’re advancing, the company is advancing, and they are somehow part of the future. That’s what we all want in jobs.”
Now Berger is part of a new campus-wide effort to do something tangible about these issues. She is a co-director of MIT’s Initiative for New Manufacturing (INM), launched in May 2025, which aims to reinvigorate the business of making things in the US. The idea is to enhance innovation and encourage companies to tightly link their innovation and production processes. This lets them rapidly fine-tune new products and new production technologies—and create good jobs along the way.
“We want to work with firms big and small, in cities, small towns, and everywhere in between, to help them adopt new approaches for increased productivity,” MIT President Sally A. Kornbluth explained at the launch of INM. “We want to deliberately design high-quality, human-centered manufacturing jobs that bring new life to communities across the country.”
An unexpected product
Whether she is examining data, talking to visitors about manufacturing, or venturing into yet another plant to look around and ask questions, Berger’s involvement with the Initiative for New Manufacturing is just the latest chapter in a fascinating, unpredictable career.
Once upon a time—her first two decades in academia—Berger was a political scientist who didn’t study either the US or manufacturing. She was a highly regarded scholar of French and European politics, whose research focused on rural workers, other laborers, and the persistence of political polarization. After growing up in New Jersey, she attended the University of Chicago and got her PhD from Harvard, where she studied with the famed political scientist Stanley Hoffmann.
Berger joined the MIT faculty in 1968 and soon began publishing extensively. Her 1972 book, Peasants Against Politics, argued that geographical political divisions in contemporary France largely replicated those seen at the time of the French Revolution. Her other books include The French Political System (1974) and Dualism and Discontinuity in Industrial Societies (1980), the latter written with the MIT economist Michael Piore.
By the mid-1980s, Berger was a well-established, tenured professor who had never set foot in a factory. In 1986, however, she was named to MIT’s newly formed Commission on Industrial Productivity on the strength of her studies about worker politics and economic change. The commission was a multiyear study group examining broad trends in US industry: By the 1980s, after decades of postwar dominance, US manufacturing had found itself challenged by other countries, most famously by Japan in areas like automaking and consumer electronics.
Two unexpected things emerged from that group. One was a best-selling book. Made in America: Regaining the Productive Edge, coauthored by Michael Dertouzos, Richard Lester, and Robert Solow, rapidly sold 300,000 copies, a sign of how much industrial decline was weighing on Americans. Looking at eight industries, Made in America found, among other things, that US manufacturers overemphasized short-term thinking and were neglecting technology transfer—that is, they were missing chances to turn lab innovations into new products.
The other unexpected thing to materialize from the Commission on Industrial Productivity was the rest of Suzanne Berger’s career. Once she started studying manufacturing in close empirical fashion, she never really stopped.
“MIT really changed me,” Berger told MIT News in 2019, referring to her move into the study of manufacturing. “I’ve learned a lot at MIT.”
At first she started examining some of the US’s important competitors, including Hong Kong and Taiwan. She and Richard Lester co-edited the books Made by Hong Kong (1997) and Global Taiwan (2005), scrutinizing those countries’ manufacturing practices.
Over time, though, Berger has mostly turned her attention to US manufacturing. She was a core player in a five-year MIT examination of manufacturing that led her to write How We Compete (2006), a book about why and when multinational companies start outsourcing work to other firms and moving their operations overseas.
She followed that up by cochairing the MIT commission known as Production in the Innovation Economy (PIE), formed in 2010, which looked closely at US manufacturing, and coauthored the 2013 book Making in America, summarizing the ways manufacturing had started incorporating advanced technologies. Then she participated extensively in MIT’s Work of the Future study group, whose research concluded that while AI and other technologies are changing the workplace, they will not necessarily wipe out whole cohorts of employees.
“Suzanne is amazing,” says Christopher Love, the Raymond A. (1921) and Helen E. St. Laurent Professor of Chemical Engineering at MIT and another co-director of the Initiative for New Manufacturing. “She’s been in this space and thinking about these questions for decades. Always asking, ‘What does it look like to be successful in manufacturing? What are the requirements around it?’ She’s obviously had a really large role to play here on the MIT campus in any number of important studies.”
“If I have a great idea for a new drug or food product … if I have to ship it off somewhere to figure out if I can make it or not, I lose time, I lose momentum, I lose financing.”
Christopher Love
“She always asks challenging questions and really values the collaboration between engineering and social science and management,” says John Hart, head of the MIT Department of Mechanical Engineering, director of the Center for Advanced Production Technologies, and the third co-director, with Berger and Love, of the Initiative for New Manufacturing.
Moreover, Love adds, “the number of people she’s trained and mentored and brought along through the years reflects her commitment.”
For instance, Berger was the PhD advisor of Richard Locke, currently dean of the MIT Sloan School of Management. Separately, she spent nearly two decades as director of MISTI, the MIT program that sends students abroad for internships and study. Basically, Berger’s footprints are all around MIT.
And now, in her 80s, she is helping to lead the Initiative for New Manufacturing. Indeed, she came up with its name herself. The initiative raises a couple of questions. What is new in the world of US manufacturing? And what can MIT do to help it?
Home alone
To start with, the Initiative for New Manufacturing is an ongoing project designed to enhance many aspects of US manufacturing. Berger’s previous efforts ended in written summaries—which have helped shape public dialogue around manufacturing. But the new initiative was not designed with an endpoint in mind.
Since last spring, the Initiative for New Manufacturing has signed up industry partners—Amgen, Autodesk, Flex, GE Vernova, PTC, Sanofi, and Siemens—with which it may collaborate on manufacturing advances. It has also launched a 12-month certificate program, the Technologist Advanced Manufacturing Program (TechAMP), in partnership with six universities, community colleges, and technology centers. The courses, held at the partner institutions, give manufacturing employees and other students the chance to study basic manufacturing principles developed at MIT.
“We hope that the program equips manufacturing technologists to be innovators and problem-solvers in their organizations, and to effectively deploy new technologies that can improve manufacturing productivity,” says Hart, an expert in, among other things, 3D printing, an area where firms can find new manufacturing applications.
But to really grasp what MIT can do today, we need to look at how manufacturing in the US has shrunk.
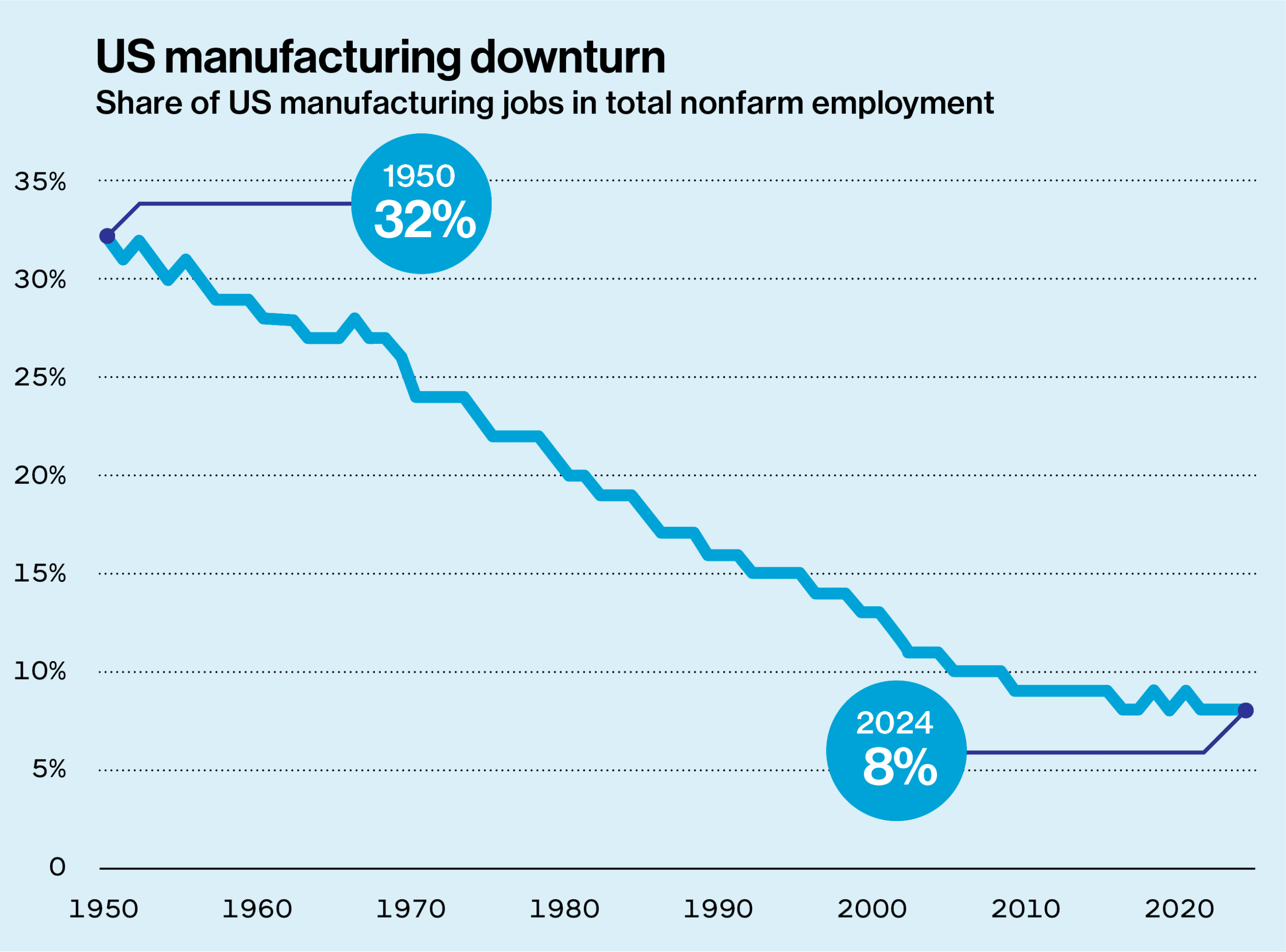
The first few decades after World War II were a golden age of American manufacturing. The country led the world in making things, and the sector accounted for about a quarter of US GDP throughout the 1950s. In recent years, that figure has hovered around 10%.
In 1959 there were 15 million manufacturing jobs in the US. By 1979, the rapidly growing country had around 20 million such jobs, even as the economy was diversifying. But the 1980s and the first decade of the 2000s saw big losses of manufacturing jobs, and there are about 12.8 million in the US today.
As even Berger will acknowledge, the situation is not going to turn around instantly.
“Manufacturing at the moment is really still in decline,” she says. “The number of workers has gone down, and investment in manufacturing has actually gone down over the last year.”
As she sees it, diminished manufacturing capacity is a problem for three big reasons: It hurts a country’s general innovation capacity, it makes it harder to respond to times of need (such as pandemics), and it’s bad for national security.
“If you look at what the defense industrial base is in the United States, it is the same industrial base we’re talking about, with old technology,” she says. That is, defense technology comes from the same firms that haven’t updated their production methods lately. “Our national security is sitting on top of a worn-out industrial base,” Berger says, adding: “It’s a very stark picture.”
However, the first point—that manufacturing more makes a country more innovative—is the most essential conclusion she has developed on this subject. Production and innovation go better together. The ability to make things stems from innovation, but our useful advances are not just abstract lab discoveries. They often get worked out while we produce stuff.
“Innovation is closely connected to production, and if we outsource and offshore all our production, we’re also offshoring and outsourcing our innovation capabilities,” Berger says. “If we go back 40 years, the whole manufacturing landscape has changed in ways that are very detrimental to the US capabilities. The great American companies of 40 years ago were all vertically integrated and did everything from basic R&D through sales.” Think of General Electric, IBM, and DuPont.
Berger continues: “There was a technological disruption in the late 1980s and early 1990s, when people discovered it was possible to separate design and production. In the past, if you were making wafers, the chip designer and the engineer who figured out how to make the chip had to be together in the same plant. Once you were able to send that all as a digital file over the internet, you could separate those things. That’s what made outsourcing and offshoring more feasible.”
Meanwhile, seeing the possibilities of offshoring, markets started punishing big firms that didn’t pare down to their “core competency.” Companies like AT&T and Xerox used to run famous research departments. That is no longer how such firms work. “DuPont closed the basic research labs that discovered nylon,” Berger notes. But back in the 1930s, DuPont was able to move that material from the lab to the market within five years, building a factory that quickly scaled up production of wildly popular nylon stockings. “The picture looked a little different,” she says.
Indeed, she says, “we had a radical change in the structure of companies. With the collapse of the vertically integrated companies, huge holes opened up in the industrial ecosystem.” Major companies that did their own research, trained workers, and manufactured in the US had spillover effects, producing the advances and the skilled, talented workers who populated the whole manufacturing ecosystem. “Once the big firms were no longer doing those activities, other companies were left home alone,” Berger says, meaning they were unable to afford research activities or generate as many advances. “All of this explains the state we see in manufacturing today. The big question is, how do we rebuild this?”
“Innovation can come from anywhere”
Over a decade ago, Christopher Love received a US Department of Defense grant to develop a small, portable system for creating biologic drugs, which are made from living organisms or their products. The idea was to see if such a device could be taken out onto the battlefield. The research was promising enough for Love to cofound a startup, Sunflower Therapeutics, that focuses on small-scale protein production for biopharmaceutical manufacturing and other medical applications. One might characterize the original project as either a piece of military equipment or a medical advance. It’s also a case study in new manufacturing.
After all, Love and his colleagues created a new method for making batches of certain types of drugs. That’s manufacturing; it’s an innovation leading directly to production, and the small size of the operation means it won’t get shipped overseas. And, as Love enjoys pointing out, his team’s innovation is hardly the first case of using living cells to make a product for nearby consumption. Your local craft brewery is actually a modestly sized manufacturer that won’t be shipping its jobs overseas either.
“The emerging generation of manufacturing has this new equilibrium between automation (machines, robots), human work, and software and data.”
John Hart
“Innovation can come from anywhere,” Love says. “What you really need is access to production. This is something Suzanne has been thinking about for a long time—that proximity. The same thing can happen in biomanufacturing. If I have a great idea for a new drug or food product or new material, if I have to ship it off somewhere to figure out if I can make it or not, I lose time, I lose momentum, I lose financing. I need that manufacturing to be super close.”
New manufacturing can come in multiple forms and, yes, can include robots and other forms of automation. The issue is complex. Robots do replace workers, in the aggregate. But if they increase productivity, firms that are early adopters of robots grow more than other firms and employ more people, as economic studies in France, Spain, and Canada have shown. The wager is that a sensible deployment of robots leads to more overall growth. Meanwhile, US firms added more than 34,000 robots in workplaces in 2024; China added nearly 300,000. Berger hopes US firms won’t be technology laggards, as that could lead to an even steeper decline in the manufacturing sector. Instead, she encourages manufacturers to use robots productively to stay ahead of the competition.
“The emerging generation of manufacturing has this new equilibrium between automation (machines, robots), human work, and software and data,” Hart says. “A lot of the interesting opportunities in manufacturing, I think, come from the combination of those capabilities to improve productivity, improve quality, and make manufacturing more flexible.”
Another form of new manufacturing may happen at firms that, like the old heavyweight corporations, see value in keeping research and development in-house. At the Initiative for New Manufacturing launch event in May, one of the speakers was JB Straubel, founder of Redwood Materials, which recycles rechargeable batteries. The company has figured out how to extract materials like cobalt, nickel, and lithium, which otherwise are typically mined. To do so, the company has had to develop a variety of new industrial processes—again, one of the keys to reviving manufacturing here.
“Whether you’re building a new machine or trying a new process … acquiring a new technology is one of the most important ways a company can innovate,” Berger says. Although she acknowledges that “innovation is risky, and everything does not succeed,” she points out that “a single focus on optimization [in firms] has not served us well.”
Manufacturing success stories
The future of US manufacturing, then, can take many forms. But Berger, when she visits factories, is consistently struck by the vintage machines often on display. She tells the story of a manufacturer she visited within the last couple of years that not only uses milling machines made during World War II but buys them up when other firms in the field discard them.
“If you have all old equipment, your productivity is going to be low, your profits are going to be low, you’ll want low-skill workers, and you’re only going to be able to pay low wages,” she says. “And each one of those features reinforces the others. It’s like a dead-end trap.”
But things don’t need to be this way, Berger believes. And in some places, she visits firms that represent manufacturing success stories.
“The idea that Americans don’t like manufacturing, that it’s dirty and difficult—I think this is totally [wrong],” she says. “Americans really do like making things with their hands, and Americans do think we ought to have manufacturing. Whenever I’ve been in a plant where it seems well run—and the owners, the managers, are proud of their workers and recognize their accomplishments, and people are respected—people seem pleased about having those jobs.”
Flash back to the exchange Berger had with that worker in Ohio, and the vision for the Initiative for New Manufacturing falls further into place: Technological change has a key role to play in creating that kind of work. Okay, US manufacturing may not be overhauled overnight. It will take an effort to change it, one midsize manufacturer after another. But getting that done seems vital for Americans in Ohio, in Massachusetts, and all over.
“We really see a moral imperative,” Berger says, “which is to be able to reach out to the whole country to try to rebuild manufacturing.”