Stop Guessing. Start Converting: The Key To Smarter Lead Generation In 2025 via @sejournal, @Juxtacognition
Marketers have always relied on data to fine-tune their strategies.
But for years, that data has been based on assumptions made from broad industry benchmarks, competitor insights, and vague trends.
The result?
Marginal conversion improvements and a constant struggle to truly connect with the audience.
Better Leads → More Sales In 2025: How To Analyze Leads To Improve Marketing Performance from CallRail shows you how to transform customer conversations into actionable insights that improve your marketing performance at every stage of the funnel.
And you can download your copy right now.
What If You Could Stop Guessing & Start Marketing With Precision?
The secret lies in the conversations your customers are already having with you.
Every call, chat, and interaction holds valuable insights and the exact words, concerns, and motivations that drive your audience to take action.
Yet, most businesses overlook this goldmine of data.
Instead, they continue to make decisions based on surface-level analytics like click-through rates, page views, and lead form submissions.
And while that strategy works, it’s only part of the story. Why?
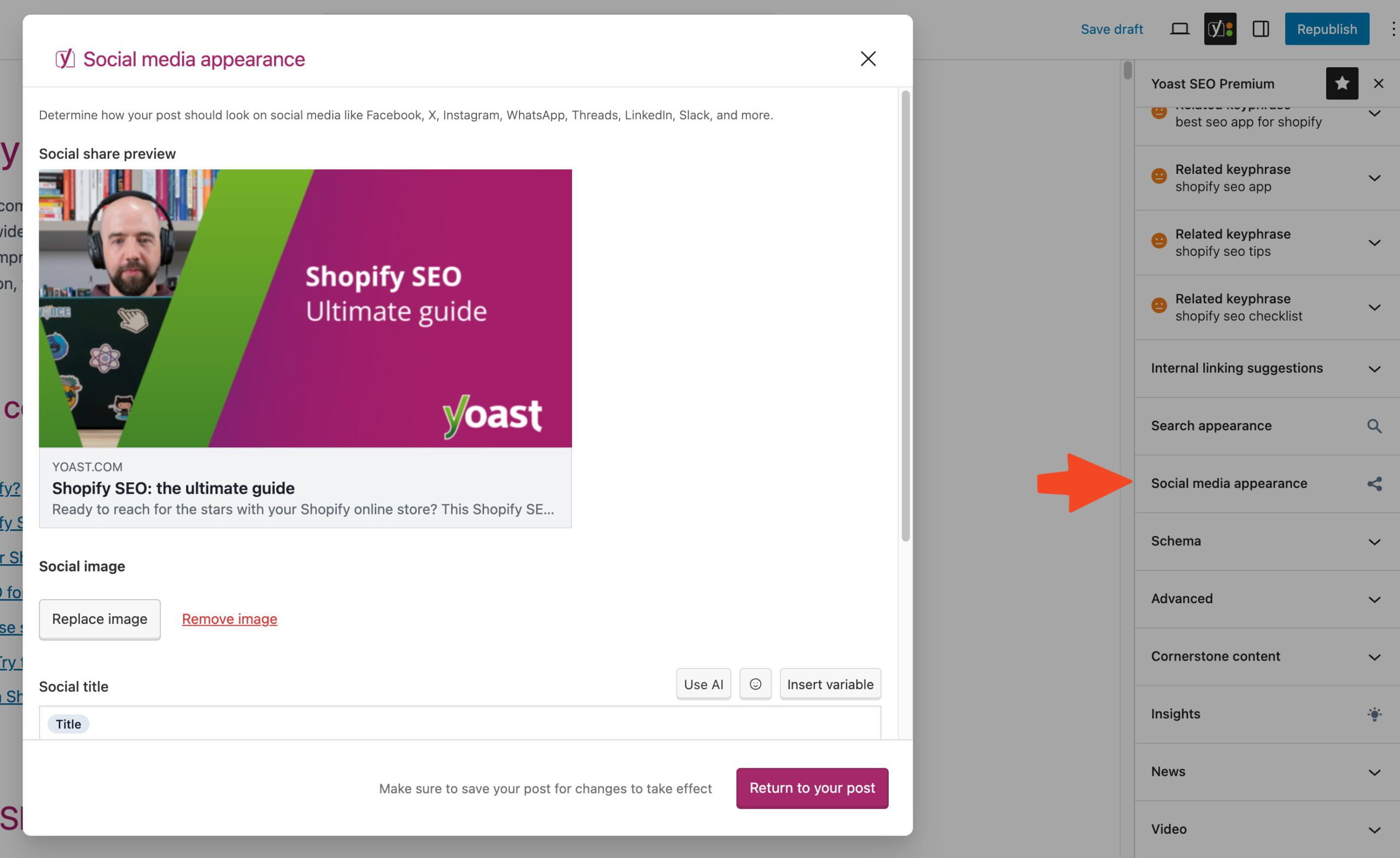
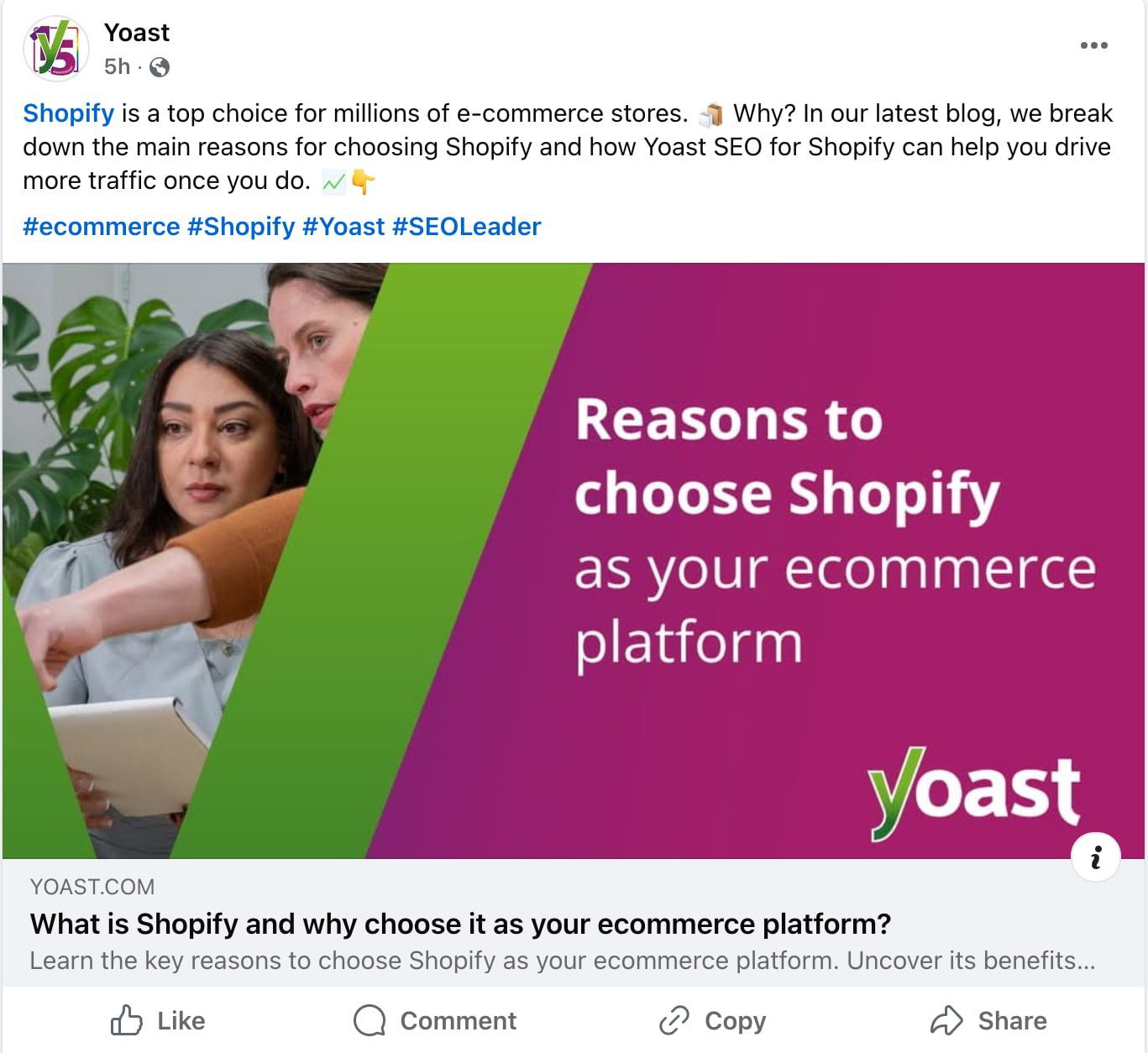
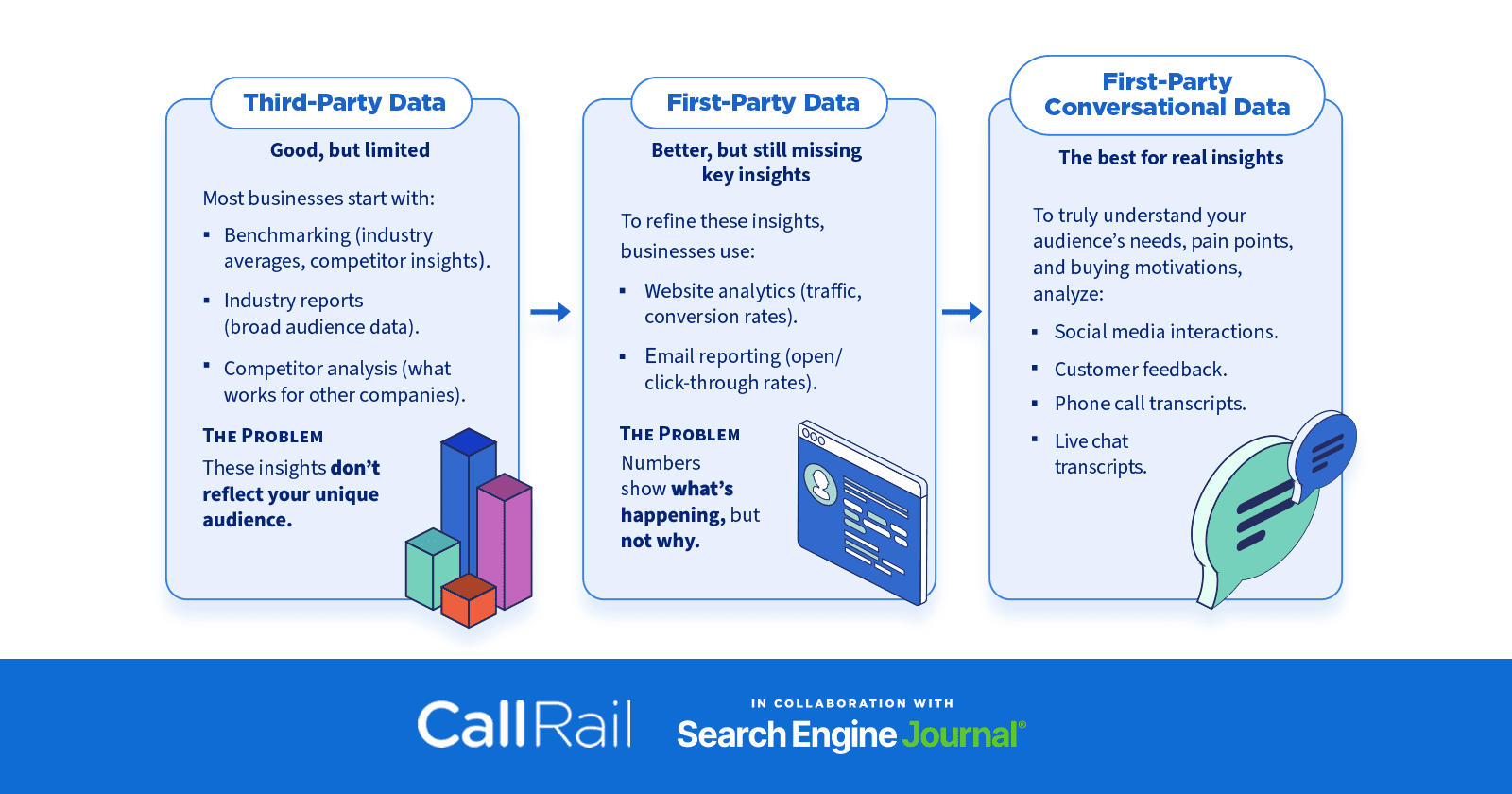 Image by Paulo Bobita/Search Engine Journal, March 2025
Image by Paulo Bobita/Search Engine Journal, March 2025While numbers show what’s happening, your customers’ conversations can tell you why a customer did or didn’t convert and what he or she was thinking.
By leveraging these conversations and other first-party conversational data, you can unlock real insights, refine your messaging, and optimize your marketing, sales, customer service, and more.
Without the guesswork.
The Power Of Listening To Your Customers
Better Leads → More Sales In 2025: How To Analyze Leads To Improve Marketing Performance shows you how to make the most of those insights by providing practical, step-by-step strategies for improving lead quality, increasing conversions, and refining your marketing approach.
You’ll learn how to craft messaging that resonates with your audience, optimize funnels to reflect actual user behavior, and uncover friction points before they impact conversions.
From improving marketing copy to boosting customer retention and increasing Customer Lifetime Value (CLV), the strategies outlined are practical and results-driven.
You’ll be able to move away from guesswork with confidence and build marketing campaigns that feel relevant, personal, and persuasive, leading to higher-quality leads and more sales.
The Future Of Marketing Is Data-Driven And Customer-Focused
Brands that win in 2025 won’t be those with the biggest ad budgets.
They’ll be the ones that listen.
When you understand your customers’ frustrations, their needs, and the exact words they use to describe their problems, you can craft campaigns that feel personal, relevant, and persuasive.
This isn’t just about getting more leads.
It’s about getting the right leads and turning them into loyal customers.
What You’ll Learn In This Ebook:
- Uncover Customer Insights: Learn how to extract powerful insights from customer conversations, sentiment analysis, and first-hand interactions.
- Improve Marketing Messaging: Use the language your audience naturally speaks to create high-converting ads, landing pages, and content.
- Optimize Your Lead Generation Funnels & Customer Journeys: Build a pipeline that reflects real customer behavior. Not assumptions.
- Reduce Friction & Increase Conversions: Identify barriers before they impact your bottom line.
- Increase CLV & Customer Lifespan: Find upsell opportunities and improve customer retention using call and chat transcript analysis.
Why This Matters
- Marketing is evolving. Customers expect brands to understand them and not just sell to them.
- Data beats guesswork. First-party conversational data gives you direct access to what your customers truly care about.
- Better insights = higher conversions. When your message aligns with customer needs, engagement and sales increase.
Want to put these insights to work for your business?
Download your free copy today and start turning customer conversations into your most powerful marketing asset.

Featured Image: Paulo Bobita/Search Engine Journal