As SEO professionals, reports are a key part of our communication toolbox.
We spend time running workshops and writing summaries of work and project plans. These are all part of our process for gaining buy-in and showing value from the work we’re doing.
Our reports are just as important.
Where We Go Wrong
The problem that we sometimes run into as SEO professionals is not thinking about the report as a communication tool. We take shortcuts, expecting the data to speak for itself. We don’t worry enough about how it can be taken out of context.
If done right, SEO reports will continue to reinforce the messaging we’ve been giving through our training, proposals, and pitches.
When done wrong, SEO reports cause confusion, sometimes panic, and, overall, a sinking sense of distrust from our stakeholders.
What Is The Report For?
When creating reports, we must identify what the report should show.
If we are reporting on the outcome of a specific project, then we need to consider the original hypothesis.
What were we aiming for in that project? What were the promised milestones and the measures of success? They all need to be included – even the metrics that don’t look so good.
Is this a regular report, like a monthly update on performance? If so, we need to consider all the areas of SEO that we are directly affecting, as well as areas outside of our control that can help explain any increases or decreases in performance. There is a need to give the context in which our SEO work operates.
This should form the starting point from which we choose the report metrics.
Aspects Of A Good SEO Report
A good SEO report will help communicate insight and the next steps. It should have sufficient detail to help the reader make decisions.
Include Relevant Data
Reports should include data that is relevant to the topic being reviewed.
They should not overwhelm a reader with unnecessary information.
Keep Them Brief
Reports should be brief enough that pertinent data and insight are easy to find.
Brevity might be the difference between a report being read and being ignored.
Keep the data being reported succinct. Sometimes, a chart will better illustrate the data than a table.
Remember The Audience
Reports should be tailored to the needs of the recipient. It may be the report is being produced for another SEO professional, or the managing director of the company.
These two audiences may need very different data to help explain the progress of SEO activity.
The needs of the report’s reader to make a decision and identify the next steps must be considered. A fellow SEO may need the details of which pages are returning a 404 server error, but the managing director likely won’t.
Make Them Easy To Understand
They should not include unexplained jargon or expect readers to infer meaning from statistics.
Write reports with the recipient’s knowledge in mind. Liberal use of jargon for someone not in the industry might put them off reading a report.
Conversely, jargon and acronyms will be fine for someone who knows SEO and can help to keep reports brief.
Keep Them Impartial
SEO reports are a form of internal marketing. They can be used to highlight all of the good SEO work that’s been carried out.
Reports should be honest and unbiased, however. They shouldn’t gloss over negatives.
Decreases in performance over time can highlight critical issues. These shouldn’t be omitted from the report because they don’t look good. They are a perfect way of backing up your expert recommendations for the next steps.
Provide Insight
Data alone is likely to be unhelpful to most.
Reports shouldn’t just be figures. Insight and conclusion must be drawn, too.
This means that, as an SEO expert, we should be able to add value to the report by analyzing the data. Our conclusions can be presented as actions or suggestions for a way forward.
Reporting On Metrics Correctly
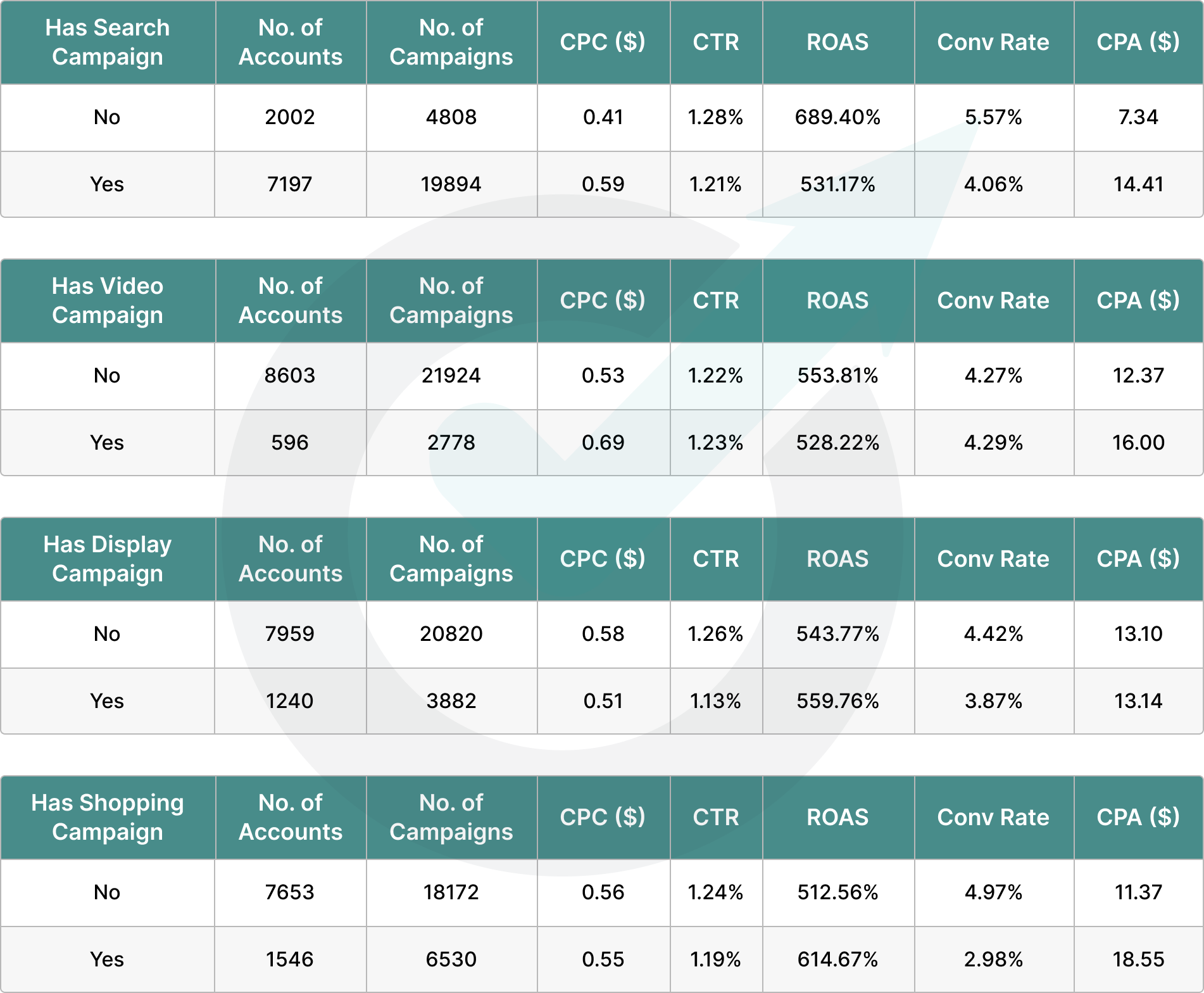
Metrics used incorrectly can lead to poor conclusions being made. An example of this is the “site-wide bounce rate.”
A bounce is typically measured as a visit to a website that only led to one page being viewed and no other interactions occurring.
Bounce rate is the percentage of all visits to the site that ended up as a bounce.
The bounce rate of a page can be useful, but only really if it is being compared with something else.
For instance, if changes have been made to a page’s layout and bounce rate increases, it could point to there being a problem with visitors navigating with the new layout.
However, reporting on bounce rate of a page without looking deeper at other metrics can be misleading.
For instance, if the changes to the page were designed to help visitors find information more easily, then the increase in bounce rate could be an indicator of the new design’s success.
The difference in bounce rate cannot be used in isolation as a measure of success.
Similarly, reporting on the average bounce rate across the entire website is usually misleading.
Some pages on the website might have a high bounce rate but be perfectly fine. For others, it indicates a problem. For example:
- A contact page might see a lot of visitors bounce as they find a phone number and leave the site to call it.
- A homepage or product page with a high bounce rate is usually a sign that the page is not meeting the needs of users, however.
Reports should look to draw conclusions from a range of metrics.
Metrics Need Context
Few metrics can be used in isolation and still enable accurate insight to be drawn.
For example, think of crawling and indexing data.
A report on the number of URLs that are being crawled by Googlebot sounds like a fair metric to demonstrate the technical health of the website.
Though what does it show, really?
An increase in URLs crawled could indicate that Googlebot is finding more of your site’s pages that it previously couldn’t. If you have been working on creating new sections of your site, this may be a positive trend.
However, if you dig deeper and discover that the URLs Googlebot has been crawling are the result of spam attacks on your site, this is actually a big problem.
In isolation, the volume of crawled pages doesn’t give any real context on the technical SEO of the site. There needs to be more context in order to draw reliable conclusions.
Over-Reliance On Metrics
There are other metrics that are relied on a little too much in SEO reports – measures of the authority of a page or domain, for instance.
These third-party metrics do well in guessing the ranking potential of a page in the eyes of search engines, but they are never going to be 100% accurate.
They can help to show if a site is improving over time, but only against the calculations of that reporting tool.
These sorts of metrics can be useful for SEO professionals to use as a rough gauge of the success of an authority-building project. However, they can cause problems when reported to managers, clients, and stakeholders.
If they are not properly informed of what these scores mean, it is easy for them to hold on to them as the goal for SEO. They are not.
Well-converting organic traffic is the goal. The two metrics will not always correlate.
Which Metrics Matter?
The metrics that should be used together to illustrate SEO performance depend on the purpose of the report. It also depends on what the recipient needs to know.
Some clients or managers may be used to receiving reports with certain metrics in them. It may be that the SEO reports feed into their own reporting, and as such, they expect to see certain metrics.
It is a good idea to find out from the report recipient if there is anything in particular they would like to know.
The report should always link back to the brand’s business and marketing goals. The metrics used in the report should communicate if the goals are being met.
For instance, if a pet store’s marketing goal is to increase sales of “non-slip pet bowls,” then metrics to include in the SEO report could be:
- Overall traffic to the pages in the www.example.com/pet-accessories/bowls/non-slip folder.
- Organic traffic to those pages.
- Overall and organic conversions on these pages.
- Overall and organic sales on these pages.
- Bounce rate of each of these pages.
- Traffic volume landing on these pages from the organic SERPs.
Over time, this report will help identify if SEO is contributing to the goal of increasing sales of non-slip pet bowls.
Organic Performance Reports
These are reports designed to give a picture of a website’s ongoing SEO performance. They give top-level insight into the source and behavior of organic traffic over time.
They should include data that indicates if the business, marketing, and SEO goals are being met.
An SEO performance report should look at the organic search channel, both on its own and in relation to other channels.
By doing this, we can see the impact of other channels on the success of SEO. We can also identify any trends or patterns.
These reports should allow the reader to identify the impact of recent SEO activity on organic traffic.
Metrics To Include
Some good metrics to report on for organic performance reports include:
Overall Visits
The number of visits to the website gives something to compare the organic search visits to.
We can tell if organic traffic is decreasing whereas overall traffic is increasing or if organic traffic is growing despite an overall drop in traffic.
It is possible to use overall traffic visit data to discern if there is seasonality in the website’s popularity.
Traffic Visits By Channel
The number of visits coming from each marketing channel helps you identify if there is any impact from other channels on SEO performance.
For instance, new PPC ads going online could mean the cannibalization of organic search traffic.
All Traffic And Organic Traffic Goal Completions
Have visitors completed the goals in the website’s analytics software?
Comparing organic and other traffic goal completions will again help identify if the organic traffic is completing above or below-average goal completions compared to other channels.
This could help determine if SEO activity has as much of a positive effect as hoped.
Page Level Traffic
If there are certain pages that have been worked on recently, such as new content or keyword optimization, include organic traffic metrics for them. This means going granular in your reporting.
Report on organic traffic over time, conversions on the pages (if appropriate), and actions carried out from that page. This can show if recent work has been successful in increasing organic traffic to those pages or not.
Organic Landing Page Sessions
These are the pages that visitors arrived at from the organic SERPs. They identify which pages are bringing the most organic traffic to the website.
From here, pages that have not been optimized but show potential to drive traffic can be identified.
Revenue Generated
If you can directly link the work you are carrying out to the revenue it generates, this is likely the most important metric you can include.
At the end of the day, this is what your boss and your boss’s boss likely care about. Is SEO making more money for the company?
Keyword Ranking Reports
A note on keyword rankings reports: Consider what they show before including them.
An overall report of “your site is ranking for X keywords” doesn’t give any helpful insight or fuel for a way forward.
- Which keywords?
- Are those keywords driving traffic to the site?
- Are they worth optimizing for further?
Metrics To Include
Keyword ranking reports should demonstrate growth or decline in rankings for specific keywords the site is being optimized for.
Ideally, data should be pulled from first-party tools like Google Search Console to give as accurate an indication of ranking as possible.
Rather than focusing on individual keywords, you may want to look at trends. That is, is your site growing in visibility for terms that convert?
For example, demonstrating that the website has moved from ranking in first position for 10 terms to ranking in first position for 20 terms does not demonstrate how that might impact revenue.
In the age of generative engine optimization, brand is becoming more important.
Perhaps including a section on brand searches and how they are utilized to navigate straight to products would be beneficial.
Taking my pet store example, I might not only want to see how my website would rank for “helens pet store” but also for “helens pet store cat bowls” and “helens pet store dog beds.”
This helps you analyze how your brand is growing in reputation for your products and services. These searches show that visitors are so confident they want to buy from you that they want to navigate straight to your site.
Technical Performance Reports
Good SEO performance requires a website that can be crawled and indexed easily by search engines.
This means that regular audits need to be carried out to identify anything that might prevent the correct pages from appearing in the SERPs.
Reports are slightly different from audits in that a technical audit will look at a lot of different factors and investigate them.
A thorough technical audit can be vast. It needs to diagnose issues and methods of improving the site’s performance.
Depending on the audience of a technical report, it may need to selectively highlight the issues. It should also show the success of previous SEO work.
The key to knowing which metrics to include in a technical report is understanding what’s happened on the site so far.
If work has been carried out to fix an issue, include metrics that indicate the success of that fix.
For instance, if there has been a problem with a spider trap on the site that has been remedied, then report on crawl metrics and log files.
This might not be necessary for every technical report, but it can be useful in this instance.
If the site has problems with loading slowly, then metrics about load speed will be crucial for the technical report.
A good way to convey the metrics in a technical SEO report is by including prioritization of actions.
If the metrics show that there are some urgent issues, mark them as such. If there are issues that can wait or be fixed over time, highlight them.
Technical SEO can feel overwhelming for people who aren’t experts in it.
Breaking down the issues into priorities can make your reports more accessible and actionable.
Metrics To Include
There are certain metrics that may be useful to include as part of a technical performance report:
Server Response Codes
It can be prudent to keep track over time of the number and percentage of pages returning a non-200 response code.
An audit of the site should determine exactly which pages are not returning a 200 response code.
This information may not be useful to the recipient of the technical performance report, so it may be better to include it as an appendix or not at all.
If the volume of non-200 response codes reduces over time, this can be a good indicator that technical issues on the site are being fixed.
If it goes up, then it can be summarized that further work needs to be carried out.
Page Load Speed Times
It can be helpful to report on an average of page load speed times across the site. This can indicate if the site’s load speed is improving or not.
Perhaps, what is even more useful to report on is the average load speed of the top five fastest and five slowest pages. This can help to show if there are certain templates that are very quick, as well as the pages that might need further improvement.
Any Data That Shows A Need To Act
This is really important to include. If an error on a site will prevent it from being indexed, then this needs to be highlighted in the report.
This might be different from report to report.
Metrics could be crawl data, site downtime, broken schema markup, etc. Also, consider including these metrics in subsequent reports to show how the fixes have impacted performance.
A Word Of Warning
In my experience, technical SEO metrics can be received in one of two ways: either the metrics are not considered relatable to the stakeholder’s role, and therefore, they gloss over their importance, or they focus on them as an area of SEO they can understand.
For example, Core Web Vitals. We know that Core Web Vitals are not that critical for rankings. However, I have experienced many developers focusing only on Core Web Vitals as a measure of how well-tuned the website is from an organic search perspective.
Why? In my opinion, because SEO pros have started reporting on them more, and they are an easy technical SEO element for stakeholders to understand and influence.
They make sense, are easily measured, and can be optimized for.
Unfortunately, as a result of this, they are sometimes given undue importance. We direct engineers to spend entire sprints trying to raise the Core Web Vitals scores by tiny amounts, believing every little one counts.
When reporting on technical SEO, consider how you communicate the value of the metrics you are reporting on. Are these critical website health metrics? Or are they “nice to know”?
Make sure you give the full context of the metrics within your report.
Link Building Reports
A link building campaign can yield benefits for a website beyond boosting its authority with the search engines.
If done well, links should also drive traffic to the website. It is important to capture this information on link building reports, too, as it is a good measure of success.
Metrics To Include
- URLs Of Links Gained: Which links have been gained in the reporting period?
- Links Gained Through Link Building Activity: Of the links gained, which ones can be directly attributed to outreach efforts?
- Links Driving Traffic: Of the links gained during the period, which ones have resulted in referral traffic, and what is the volume of visits?
- Percentage Of Valuable Vs. Less Valuable Links: Of the links gained in the period, which ones are perhaps marked as “nofollow” or are on syndicated and canonicalized pages?
You may be tempted to include a page or domain strength score in these reports. If that helps to communicate the effectiveness of an outreach campaign, that’s understandable.
Remember, however, that links from highly relevant websites will still benefit your site, even if they do not have high authority.
Don’t let your outreach efforts be discarded because the links gained don’t score high with these metrics.
Conclusion
The best way to construct a report on SEO is to consider it a story. First, who is the audience? Make sure you are writing your report in a level of language they will understand.
Create a narrative. What do you want these metrics to say? Do you include all the twists and turns, and are you being honest about the metrics you comment on?
Make sure you bring the report to a conclusion. If there is action to be taken from it, what is that action? Highlight and reiterate anything you want stakeholders to remember as a key takeaway from the report.
Finally, seek reviews on your reports. Ask your stakeholders to give you feedback on the report.
Determine if it meets their needs or if additional context or data is needed. Essentially, this report is for them. If they aren’t getting value from it, then you are doing your SEO work a disservice.
More resources:
Featured Image: Mer_Studio/Shutterstock