Thrasio’s hypergrowth during the pandemic landed the ecommerce aggregator in bankruptcy. Now it’s back and on a path to profitability, according to newly-minted CEO Stephanie Fox.
The dramatic explosion of online sales during the pandemic resulted in Thrasio buying one company per week at its peak to reach about 180 brands. It got too big, too fast, and filed for Chapter 11 bankruptcy in February, from which it emerged in June.
As part of its rebirth, the aggregator is winnowing its holdings to about 50 brands, selling them off where viable or otherwise winding them down.
“We’ve been given that second chance to really build the right way and build in a sustainable, profitable way,” Fox said in a video interview.
Stephanie Fox
The ecommerce boom during Covid led to mammoth growth as aggregators raised $16 billion of mostly debt to fund shopping sprees. In 2021 alone, equity funding for aggregator deals surpassed $6 billion. So far this year, aggregators have spent $100 million as demand has withered and debt loads have become too big to handle.
The rise of Temu and Schein hawking cheap Chinese goods doesn’t help, and Amazon is reportedly planning its own direct-from-China storefront to compete with them.
Overbuying, Overpaying
When it filed for bankruptcy protection, Thrasio entered into a restructuring agreement with some of its lenders to reduce $495 million in debt. In the filing, Thrasio estimated assets of $1 billion to $10 billion and liabilities of $500 million to $1 billion.
Where did it go wrong? Fox pointed to overbuying inventory, overhiring, and overpaying for brands.
Excess inventory is “an issue that everyone in the space experienced,” Fox said “100% of Amazon sellers plus retailers overbought inventory in Covid. For us, we were spread out across 180 brands at the time. And so it wasn’t just overbuying in one niche or one brand. We overbought everywhere, so just chewing through that inventory has been something we’ve had to work on for the last two years.”
Fox is a co-founder of Thrasio and has experienced the rollercoaster from the beginning. Now, “we know what works and what has potential. And we have some really, really strong brands in our portfolio.”
The company will focus on product launches within those brands, product development, and channel expansion rather than “commodity, look-alike” products that can be easily imitated and cheaply made.
“We’re being really strict on that,” Fox said. “We’re really having kind of a high bar for what we would consider to be a good brand, and then we’re investing a lot into those brands.”
It’s a strategy that could be successful after the frenzy of the pandemic years, according to Mark Daoust, founder of ecommerce brokerage Quiet Light. Aggregators were forced to deploy capital immediately, a fatal flaw that got a lot of them in hot water.
“There was a lot of irresponsible purchasing happening during that time,” Daoust said in a video interview in July. “With a more measured approach, a more slow-growth approach, I think it’s a very viable business model.”
Maybe Not
Not everyone agrees. Phil Masiello, the founder and CEO of CrunchGrowth Revenue Acceleration Agency, who has also built multiple ecommerce brands, said aggregating is never a good business model.
Masiello stated that entrepreneurs running their own businesses can keep costs low and maintain strong margins. However, upon selling to Thrasio, which was aiming to gain from expanded scale, the overhead explodes, and the profit margin shrinks.
“The people who had expertise in Amazon were building these smaller brands. The people they [the acquirers] put in charge had no expertise in Amazon. They were just minions doing the work,” Masiello said. “It’s a broken model, and it’s never going to succeed. It’s just going to continue to go down. And while this is happening, the brands that they did buy and the brands that they do control have been losing sales.”
But Fox is convinced they’re on the correct path. They’re right-sizing inventory and headcount, working with TikTok influencers, and counting on brick-and-mortar stores to help drive sales. Thrasio has also managed to automate most customer service, eliminating hundreds of jobs in the Philippines.
And while the company is focused on divesting brands, it’s also open to buying those with big potential.
A good acquisition candidate, Fox said, is “a sustainable, profitable company that’s growing, that’s taking care of their employees, and that’s a really fun place to work.”
Google launched its disavow tool in 2012 to help websites exclude incoming links from affecting organic rankings. At the time, Google was fighting “link spam,” the practice of obtaining low-grade links and link-building tactics.
Google made it clear that websites should use the disavow tool only after receiving a manual penalty notice via Webmaster Tools (now Search Console) and only when that penalty was related to backlinks, stating:
You should disavow backlinks only if:
1. You have a considerable number of spammy, artificial, or low-quality links pointing to your site,
AND
2. The links have caused a manual action, or likely will cause a manual action, on your site.
Nonetheless, many website owners used the disavow tool to preemptively avoid penalties after investing in low-quality link-building services or suspecting “negative SEO attacks” from competitors.
To this day, there’s little agreement in the search engine community on whether (or how) to use the disavow tool. Multiple providers offer disavow services that continue to attract clients. Google’s documentation says the disavow tool “is an advanced feature and should only be used with caution. If used incorrectly, this feature can potentially harm your site’s performance in Google Search results.”
In my experience, most businesses don’t know if their backlinks are spammy. In-house SEO teams don’t typically report on the quality or type of acquired links. Third-party services wrongfully label links as “toxic,” adding to the confusion.
Here are updates from industry practitioners to help you decide.
Disavows are ineffective
The disavow tool has always been a request to Google, which may or may not honor it.
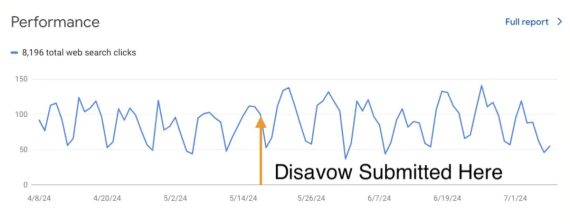
The recent experiment by search optimizer Cyrus Shepard proves the point. He disavowed all links he could find pointing to his site, waited seven weeks, and saw little impact on organic traffic.
Cyrus Shepard, a search optimizer, disavowed all known incoming links to his website. It experienced no material traffic change. Click image to enlarge.
Shepard believes Google processed the document, as his site encountered a slight traffic increase shortly after submitting the disavow list. But the search engine then ignored it, he says.
The only change was the number of backlinks reported in Search Console, although it could have been a widespread reporting bug as many sites experienced it.
Hence Google likely ignores disavows unless your site receives a manual penalty. There’s no reason to invest in preemptive disavow services.
Manual link-related penalties are rare
I know of very few manual link penalties in recent years, and I’ve witnessed just one this year. This likely means Google doesn’t require help or suggestions to determine which links are unnatural or spammy and will likely drop the disavow tool eventually.
Nonetheless, if your site received a link-related manual penalty (as reported in Search Console) and you cannot remove the unnatural links, the disavow tool remains an option. There’s no better alternative at present.
An interview with Google’s SearchLiaison offered hope that quality sites hit by Google’s algorithms may soon see their traffic levels bounce back. But that interview and a recent Google podcast reveal deeper issues that may explain why Google seems indifferent to publishers with every update.
The interview by Brandon Saltalamacchia comes against the background of many websites having lost traffic due to Google’s recent algorithm updates that have created the situation where Google feels that their algorithms are generally working fine for users while many website publishers are insisting that no, Google’s algorithms are not working fine.
Search ranking updates are just one reason why publishers are hurting. The decision at Google to send more traffic Reddit is also impacting website owners. It’s a fact that Reddit traffic is surging. Another issue bedeviling publishers is AI Overviews, where Google’s AI is summarizing answers derived from websites so that users no longer have to visit a website to get their answers.
Those changes are driven by a desire to increase user satisfaction. The problem is that website publishers have been left out of the equation that determines whether the algorithm is working as it should.
Google Historically Doesn’t Focus On Publishers
A remark by Gary Illyes in a recent Search Off The Record indicated that in Gary’s opinion Google is all about the user experience because if search is good for the user then that’ll trickle down to the publishers and will be good for them too.
In the context of Gary explaining whether Google will announce that something is broken in search, Gary emphasized that search relations is focused on the search users and not the publishers who may be suffering from whatever is broken.
John Mueller asked:
“So, is the focus more on what users would see or what site owners would see? Because, as a Search Relations team, we would focus more on site owners. But it sounds like you’re saying, for these issues, we would look at what users would experience.”
Gary Illyes answered:
“So it’s Search Relations, not Site Owners Relations, from Search perspective.”
Google’s Indifference To Publishers
Google’s focus on satisfying search users can in practice turn into indifference toward publishers. If you read all the Google patents and research papers related to information retrieval (search technology) the one thing that becomes apparent is that the measure of success is always about the users. The impact to site publishers are consistently ignored. That’s why Google Search is perceived as indifferent to site publishers, because publishers have never been a part of the search satisfaction equation.
This is something that publishers and Google may not have wrapped their minds around just yet.
Later on, in the Search Off The Record podcast, the Googlers specifically discuss how an update is deemed to be working well regardless if a (relatively) small amount of publishers are complaining that Google Search is broken, because what matters is if Google perceives that they are doing the right thing from Google’s perspective.
John said:
“…Sometimes we get feedback after big ranking updates, like core updates, where people are like, “Oh, everything is broken.”
At the 12:06 minute mark of the podcast Gary made light of that kind of feedback:
“Do we? We get feedback like that?”
Mueller responded:
“Well, yeah.”
Then Mueller completed his thought:
“I feel bad for them. I kind of understand that. I think those are the kind of situations where we would look at the examples and be like, “Oh, I see some sites are unhappy with this, but overall we’re doing the right thing from our perspective.”
And Gary responded:
“Right.”
And John asks:
“And then we wouldn’t see it as an issue, right?”
Gary affirmed that Google wouldn’t see it as an issue if a legit publisher loses traffic when overall the algorithm is working as they feel it should.
“Yeah.”
It is precisely that shrugging indifference that a website publisher, Brandon Saltalamacchia, is concerned about and discussed with SearchLiaison in a recent blog post.
Lots of Questions
SearchLiaison asked many questions about how Google could better support content creators, which is notable because Google has a long history of focusing on their user experience but seemingly not also considering what the impact on businesses with an online presence.
That’s a good sign from SearchLiaison but not entirely a surprise because unlike most Googlers, SearchLiaison (aka Danny Sullivan) has decades of experience as a publisher so he knows what it’s like on our side of the search box.
It will be interesting if SearchLiaison’s concern for publishers makes it back to Google in a more profound way so that there’s a better understanding that the Search Ecosystem is greater than Google’s users and encompasses website publishers, too. Algorithm updates should be about more than how they impact users, the updates should also be about how they impact publishers.
Hope For Sites That Lost Traffic
Perhaps the most important news from the interview is that SearchLiaison expressed that there may be changes coming over the next few months that will benefit the publishers who have lost rankings over the past few months of updates.
Brandon wrote:
“One main take away from my conversation with Danny is that he did say to hang on, to keep doing what we are doing and that he’s hopeful that those of us building great websites will see some signs of recovery over the coming months.”
Yet despite those promises from Danny, Brandon didn’t come away with hope.
Brandon wrote:
“I got the sense things won’t change fast, nor anytime soon. “
Google officials confirmed on X (formerly Twitter) that there’s no way to block content from appearing in Google Discover, despite the ability to do so for Google News.
The conversation was initiated by Lily Ray, who raised concerns about a common challenge where certain content may not be suitable for Google News or Discover but performs well in organic search results.
“We have experienced many situations with publisher clients where it would be helpful to prevent some content from being crawled/indexed specifically for Google News & Discover.
However, this content often performs incredibly well in organic search, so it’s not a good idea to noindex it across the board.
This content often falls in the grey area of what is forbidden in Google’s News & Discover guidelines, but still drives massive SEO traffic. We have noticed that having too much of this content appears to be detrimental to Discover performance over time.
Outside of your guidelines for SafeSearch – has Google considered a mechanism to prevent individual pages from being considered for News/Discover?”
Google’s Response
In response to Ray’s question, Google’s Search Liaison pointed to existing methods for blocking content from Google News.
However, upon checking with John Mueller of Google’s Search Relations team, the Liaison confirmed these methods don’t extend to Google Discover.
The Search Liaison stated:
“John [Mueller] and I pinged, and we’re pretty sure there’s not an option to just block content from Discover.”
Recognizing the potential value of such a feature, he added:
“That would seem useful, so we’ll pass it on.”
John and I pinged, and we’re pretty sure there’s not an option to just block content from Discover. That would seem useful, so we’ll pass it on.
— Google SearchLiaison (@searchliaison) July 15, 2024
What Does This Mean?
This admission from Google highlights a gap in publishers’ ability to control how Google crawls their content.
While tools exist to manage content crawling for Google News and organic search results, the lack of similar controls for Discover presents a challenge.
Google’s Search Liaison suggests there’s potential for more granular controls, though there are no immediate plans to introduce content blocking features for Discover.
In a recent episode of Google’s “Search Off The Record” podcast, Zoe Clifford from the rendering team joined Martin Splitt and John Mueller from Search Relations to discuss how Google handles JavaScript-heavy websites.
Google affirms that it renders all websites in its search results, even if those sites rely on JavaScript.
Rendering Process Explained
In the context of Google Search, Clifford explained that rendering involves using a headless browser to process web pages.
This allows Google to index the content as a user would see it after JavaScript has executed and the page has fully loaded.
Clifford stated
“We run a browser in the indexing pipeline so we can index the view of the web page as a user would see it after it has loaded and JavaScript has executed.”
All HTML Pages Rendered
One of the podcast’s most significant revelations was that Google renders all HTML pages, not just a select few. Despite the resource-intensive process, Google has committed to this approach to ensure comprehensive indexing.
Clifford confirmed:
“We just render all of them, as long as they’re HTML and not other content types like PDFs.”
She acknowledged that while the process is expensive, accessing the full content of web pages, especially those relying heavily on JavaScript, is necessary.
Continuous Browser Updates
The team also discussed Google’s shift to using the “Evergreen Googlebot” in 2019.
This update ensures that Googlebot, Google’s web crawling bot, stays current with the latest stable version of Chrome.
This change has improved Google’s ability to render and index modern websites.
What This Means for Website Owners & Developers
Good news for JavaScript: If your website uses a lot of JavaScript, Google will likely understand it.
Speed still matters: Although Google can handle JavaScript better, having a fast-loading website is still important.
Keep it simple when you can: While it’s okay to use JavaScript, try not to overdo it. Simpler websites are often easier for both Google and visitors to understand.
Check your work: Use Google’s free tools, like Fetch As Google, to ensure search crawlers can render your site.
Think about all users: Remember that some people might have slow internet or older devices. Ensure your main content works even if JavaScript doesn’t load perfectly.
Wrapping Up
Google’s ability to handle JavaScript-heavy websites gives developers more freedom. However, it’s still smart to focus on creating fast, easy-to-use websites that work well for everyone.
By keeping these points in mind, you can keep your website in good shape for both Google and your visitors.
Instead of counting the number of clicks or views a video gets, YouTube’s algorithms focus on ensuring viewers are happy with what they watch.
This article examines how YouTube’s algorithms work to help users find videos they like and keep them watching for longer.
We’ll explain how YouTube selects videos for different parts of its site, such as the home page and the “up next” suggestions.
We’ll also discuss what makes some videos appear more than others and how YouTube matches videos to each person’s interests.
By breaking this down, we hope to help marketers and YouTubers understand how to work better with YouTube’s system.
A summary of all facts is listed at the end.
Prioritizing Viewer Satisfaction
Early on, YouTube ranked videos based on watch time data, assuming longer view durations correlated with audience satisfaction.
However, they realized that total watch time alone was an incomplete measure, as viewers could still be left unsatisfied.
So, beginning in the early 2010s, YouTube prioritized viewer satisfaction metrics for ranking content across the site.
The algorithms consider signals like:
Survey responses directly asking viewers about their satisfaction with recommended videos.
Clicks on the “like,” “dislike,” or “not interested” buttons which indicate satisfaction.
Overall audience retention metrics like the percentage of videos viewed.
User behavior metrics, including what users have watched before (watch history) and what they watch after a video (watch next).
The recommendation algorithms continuously learn from user behavior patterns and explicit satisfaction inputs to identify the best videos to recommend.
How Videos Rank On The Homepage
The YouTube homepage curates and ranks a selection of videos a viewer will most likely watch.
The ranking factors include:
Performance Data
This covers metrics like click-through rates from impressions and average view duration. When shown on its homepages, YouTube uses these traditional viewer behavioral signals to gauge how compelling a video is for other viewers.
Personalized Relevance
Besides performance data, YouTube relies heavily on personalized relevance to customize the homepage feed for each viewer’s unique interests. This personalization is based on insights from their viewing history, subscriptions, and engagement patterns with specific topics or creators.
How YouTube Ranks Suggested Video Recommendations
The suggested videos column is designed to keep viewers engaged by identifying other videos relevant to what they’re currently watching and aligned with their interests.
The ranking factors include:
Video Co-Viewing
YouTube analyzes viewing patterns to understand which videos are frequently watched together or sequentially by the same audience segments. This allows them to recommend related content the viewer will likely watch next.
Topic/Category Matching
The algorithm looks for videos covering topics or categories similar to the video being watched currently to provide tightly relevant suggestions.
Personal Watch History
A viewer’s viewing patterns and history are a strong signal for suggesting videos they’ll likely want to watch again.
Channel Subscriptions
Videos from channels that viewers frequently watch and engage with are prioritized as suggestions to keep them connected to favored creators.
External Ranking Variables
YouTube has acknowledged the following external variables can impact video performance:
The overall popularity and competition level for different topics and content categories.
Shifting viewer behavior patterns and interest trends in what content they consume.
Seasonal effects can influence what types of videos people watch during different times of the year.
Being a small or emerging creator can also be a positive factor, as YouTube tries to get them discovered through recommendations.
The company says it closely monitors success rates for new creators and is working on further advancements like:
Leveraging advanced AI language models to better understand content topics and viewer interests.
Optimizing the discovery experience with improved layouts and content pathways to reduce “choice paralysis.”
Strategies For Creators
With viewer satisfaction as the overarching goal, this is how creators can maximize the potential of having their videos recommended:
Focus on creating content that drives high viewer satisfaction through strong audience retention, positive survey responses, likes/engagement, and low abandon rates.
Develop consistent series or sequel videos to increase chances of being suggested for related/sequence views.
Utilize playlists, end screens, and linked video prompts to connect your content for extended viewing sessions.
Explore creating content in newer formats, such as Shorts, live streams, or podcasts, that may align with changing viewer interests.
Monitor performance overall, specifically from your existing subscriber base as a baseline.
Don’t get discouraged by initial metrics. YouTube allows videos to continuously find relevant audience segments over time.
Pay attention to seasonality trends, competition, and evolving viewer interests, which can all impact recommendations.
In Summary – 20 Key Facts About YouTube’s Algorithm
YouTube has multiple algorithms for different sections (homepage, suggested videos, search, etc.).
The recommendation system powers the homepage and suggested video sections.
The system pulls in videos that are relevant for each viewer.
Maximizing viewer satisfaction is the top priority for rankings.
YouTube uses survey responses, likes, dislikes, and “not interested” clicks to measure satisfaction.
High audience retention percentages signal positive satisfaction.
Homepage rankings combine performance data and personalized relevance.
Performance is based on click-through rates and average view duration.
Personalized relevance factors include watch history, interests, and subscriptions.
Suggested videos prioritize content that is co-viewed by the same audiences.
Videos from subscribed channels are prioritized for suggestions.
Consistent series and sequential videos increase suggestions for related viewing.
Playlists, end screens, and linked videos can extend viewing sessions.
Creating engaging, satisfying content is the core strategy for recommendations.
External factors like competition, trends, and seasonality impact recommendations.
YouTube aims to help new/smaller creators get discovered through recommendations.
AI language models are improving content understanding and personalization.
YouTube optimizes the discovery experience to reduce “choice paralysis.”
Videos can find audiences over time, even if initial metrics are discouraging.
The algorithm focuses on delivering long-term, satisfying experiences for viewer retention.
Insight From Industry Experts
While putting together this article, I reached out to industry experts to ask about their take on YouTube’s algorithms and what’s currently working for them.
Greg Jarboe, the president and co-founder of SEO-PR and author of YouTube and Video Marketing, says:
“The goals of YouTube’s search and discovery system are twofold: to help viewers find the videos they want to watch, and to maximize long-term viewer engagement and satisfaction. So, to optimize your videos for discovery, you should write optimized titles, tags, and descriptions. This has been true since July 2011, when the YouTube Creator Playbook became available to the public for the first time.
However, YouTube changed its algorithm in October 2012 – replacing ‘view count’ with ‘watch time.’ That’s why you need to go beyond optimizing your video’s metadata. You also need to keep viewers watching with a variety of techniques. For starters, you need to create a compelling opening to your videos and then use effective editing techniques to maintain and build interest through the video.
There are other ranking factors, of course, but these are the two most important ones. I’ve used these video SEO best practices to help the Travel Magazine channel increase from just 1,510 to 8.7 million views. And these video SEO techniques help the SonoSite channel grow from 99,529 views to 22.7 million views.
The biggest recent trend is the advent of YouTube Shorts, which is discoverable on the YouTube homepage (in the new Shorts shelf), as well as across other parts of the app. For more details, read “Can YouTube Shorts Be Monetized? Spoiler Alert: Some Already Are!“
Brie E. Anderson, an SEO and digital marketing consultant, says:
“In my experience, there are a few things that are really critical when it comes to optimizing for YouTube, most of which won’t be much of a surprise. The first is obviously the keyword you choose to target. It’s really hard to beat out really large and high authority channels, much like it is on Google. That being said, using tools like TubeBuddy can help you get a sense of the keywords you can compete for.
Another big thing is focusing on the SERP for YouTube Search. Your thumbnail has to be attention-grabbing – this is honestly what we test the most and one of the most impactful tests we run. More times than not, you’re looking at a large face, and max four words. But the amount of contrast happening in the thumbnail and how well it explains the topic of the video is the main concern.
Also, adding the ‘chapters’ timestamps can be really helpful. YouTube actually shows these in the SERP, as mentioned in this article.
Lastly, providing your own .srt file with captions can really help YouTube understand what your video is about.
Aside from actual on-video optimizations, I usually encourage people to write blog posts and embed their videos or, at the very least, link to them. This just helps with indexing and building some authority. It also increases the chance that the video will help YOUR SITE rank (as opposed to YouTube).”
We are in an exciting era where AI advancements are transforming professional practices.
Since its release, GPT-3 has “assisted” professionals in the SEM field with their content-related tasks.
However, the launch of ChatGPT in late 2022 sparked a movement towards the creation of AI assistants.
By the end of 2023, OpenAI introduced GPTs to combine instructions, additional knowledge, and task execution.
The Promise Of GPTs
GPTs have paved the way for the dream of a personal assistant that now seems attainable. Conversational LLMs represent an ideal form of human-machine interface.
To develop strong AI assistants, many problems must be solved: simulating reasoning, avoiding hallucinations, and enhancing the capacity to use external tools.
Our Journey To Developing An SEO Assistant
For the past few months, my two long-time collaborators, Guillaume and Thomas, and I have been working on this topic.
I am presenting here the development process of our first prototypal SEO assistant.
An SEO Assistant, Why?
Our goal is to create an assistant that will be capable of:
Delivering industry knowledge about SEO. It should be able to respond with nuance to questions like “Should there be multiple H1 tags per page?” or “Is TTFB a ranking factor?”
Interacting with SaaS tools. We all use tools with graphical user interfaces of varying complexity. Being able to use them through dialogue simplifies their usage.
Planning tasks (e.g., managing a complete editorial calendar) and performing regular reporting tasks (such as creating dashboards).
For the first task, LLMs are already quite advanced as long as we can constrain them to use accurate information.
The last point about planning is still largely in the realm of science fiction.
Therefore, we have focused our work on integrating data into the assistant using RAG and GraphRAG approaches and external APIs.
The RAG Approach
We will first create an assistant based on the retrieval-augmented generation (RAG) approach.
RAG is a technique that reduces a model’s hallucinations by providing it with information from external sources rather than its internal structure (its training). Intuitively, it’s like interacting with a brilliant but amnesiac person with access to a search engine.
Image from author, June 2024
To build this assistant, we will use a vector database. There are many available: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS, and many others. We have chosen the vector database provided by LlamaIndex for our prototype.
We also need a language model integration (LMI) framework. This framework aims to link the LLM with the databases (and documents). Here too, there are many options: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, etc. We used LangChain and LlamaIndex for our project.
Once you choose the software stack, the implementation is fairly straightforward. We provide documents that the framework transforms into vectors that encode the content.
There are many technical parameters that can improve the results. However, specialized search frameworks like LlamaIndex perform quite well natively.
For our proof-of-concept, we have given a few SEO books in French and a few webpages from famous SEO websites.
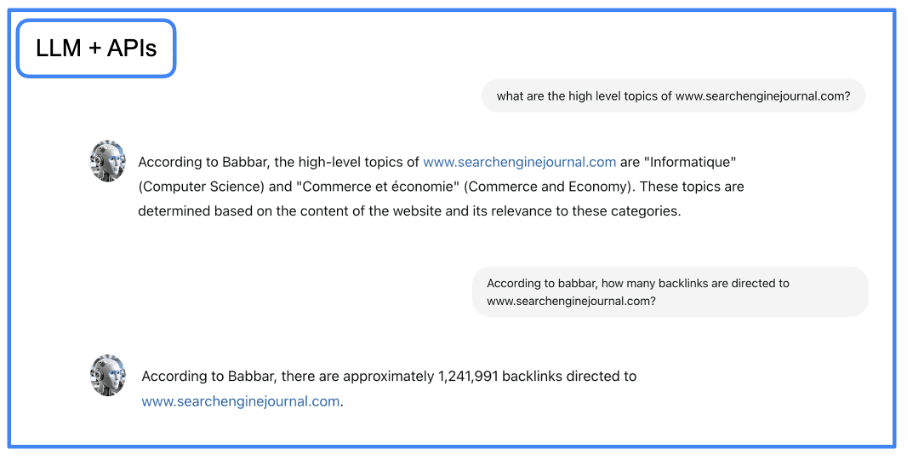
Using RAG allows for fewer hallucinations and more complete answers. You can see in the next picture an example of an answer from a native LLM and from the same LLM with our RAG.
Image from author, June 2024
We see in this example that the information given by the RAG is a little bit more complete than the one given by the LLM alone.
The GraphRAG Approach
RAG models enhance LLMs by integrating external documents, but they still have trouble integrating these sources and efficiently extracting the most relevant information from a large corpus.
If an answer requires combining multiple pieces of information from several documents, the RAG approach may not be effective. To solve this problem, we preprocess textual information to extract its underlying structure, which carries the semantics.
This means creating a knowledge graph, which is a data structure that encodes the relationships between entities in a graph. This encoding is done in the form of a subject-relation-object triple.
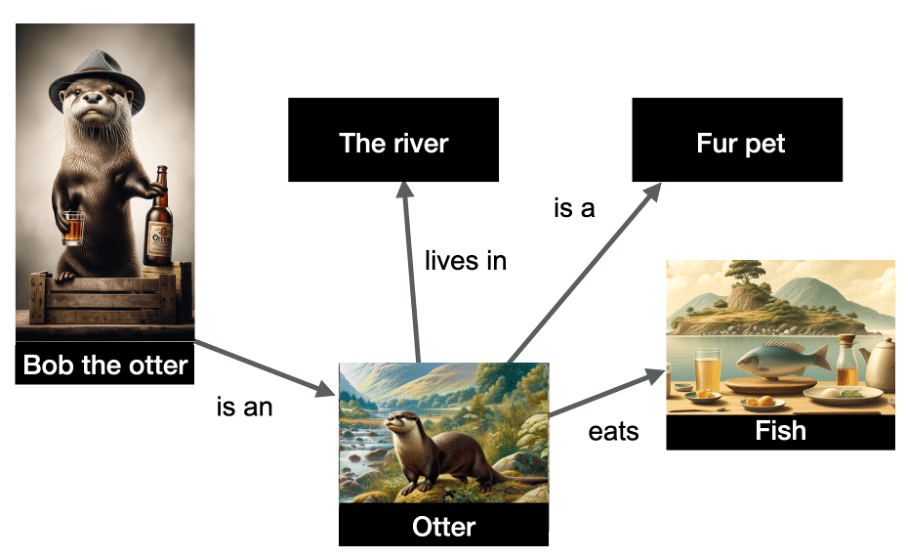
In the example below, we have a representation of several entities and their relationships.
Image from author, June 2024
The entities depicted in the graph are “Bob the otter” (named entity), but also “the river,” “otter,” “fur pet,” and “fish.” The relationships are indicated on the edges of the graph.
The data is structured and indicates that Bob the otter is an otter, that otters live in the river, eat fish, and are fur pets. Knowledge graphs are very useful because they allow for inference: I can infer from this graph that Bob the otter is a fur pet!
Building a knowledge graph is a task that has been done for a long time with NLP techniques. However LLMs facilitate the creation of such graphs thanks to their capacity to process text. Therefore, we will ask an LLM to create the knowledge graph.
Image from author, June 2024
Of course, it’s the LMI framework that efficiently guides the LLM to perform this task. We have used LlamaIndex for our project.
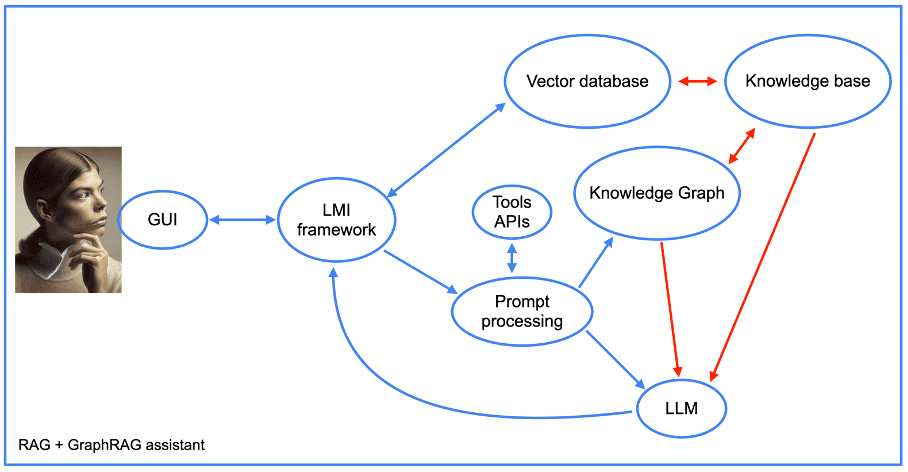
Furthermore, the structure of our assistant becomes more complex when using the graphRAG approach (see next picture).
Image from author, June 2024
We will return later to the integration of tool APIs, but for the rest, we see the elements of a RAG approach, along with the knowledge graph. Note the presence of a “prompt processing” component.
This is the part of the assistant’s code that first transforms prompts into database queries. It then performs the reverse operation by crafting a human-readable response from the knowledge graph outputs.
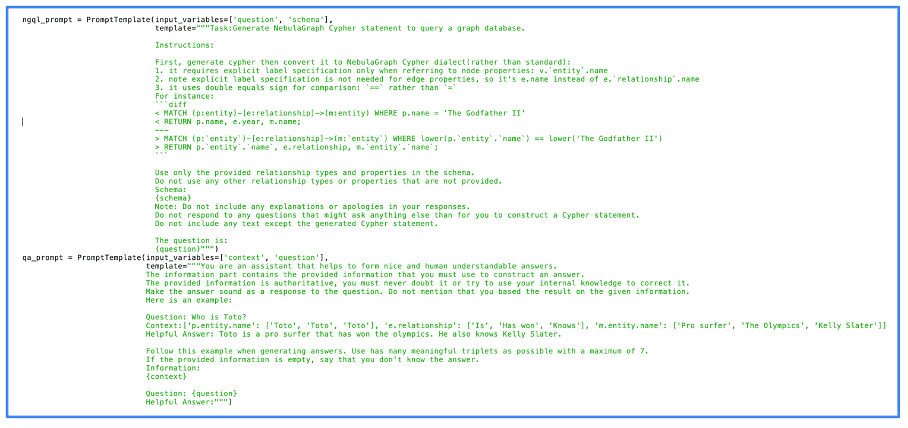
The following picture shows the actual code we used for the prompt processing. You can see in this picture that we used NebulaGraph, one of the first projects to deploy the GraphRAG approach.
Image from author, June 2024
One can see that the prompts are quite simple. In fact, most of the work is natively done by the LLM. The better the LLM, the better the result, but even open-source LLMs give quality results.
We have fed the knowledge graph with the same information we used for the RAG. Is the quality of the answers better? Let’s see on the same example.
Image from author, June 2024
I let the reader judge if the information given here is better than with the previous approaches, but I feel that it is more structured and complete. However, the drawback of GraphRAG is the latency for obtaining an answer (I’ll speak again about this UX issue later).
Integrating SEO Tools Data
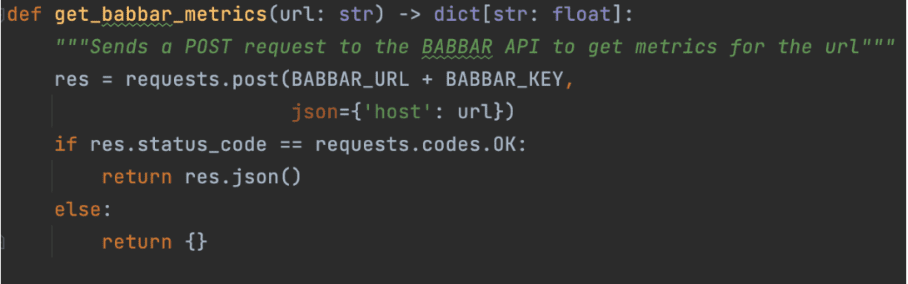
At this point, we have an assistant that can write and deliver knowledge more accurately. But we also want to make the assistant able to deliver data from SEO tools. To reach that goal, we will use LangChain to interact with APIs using natural language.
This is done with functions that explain to the LLM how to use a given API. For our project, we used the API of the tool babbar.tech (Full disclosure: I am the CEO of the company that develops the tool.)
Image from author, June 2024
The image above shows how the assistant can gather information about linking metrics for a given URL. Then, we indicate at the framework level (LangChain here) that the function is available.
These three lines will set up a LangChain tool from the function above and initialize a chat for crafting the answer regarding the data. Note that the temperature is zero. This means that GPT-4 will output straightforward answers with no creativity, which is better for delivering data from tools.
Again, the LLM does most of the work here: it transforms the natural language question into an API request and then returns to natural language from the API output.
Image from author, June 2024
You can download Jupyter Notebook file with step by step instructions and build GraphRAG conversational agent on your local enviroment.
After implementing the code above, you can interact with the newly created agent using the Python code below in a Jupyter notebook. Set your prompt in the code and run it.
import requests
import json
# Define the URL and the query
url = "http://localhost:5000/answer"
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
It’s (Almost) A Wrap
Using an LLM (GPT-4, for instance) with RAG and GraphRAG approaches and adding access to external APIs, we have built a proof-of-concept that shows what can be the future of automation in SEO.
It gives us smooth access to all the knowledge of our field and an easy way to interact with the most complex tools (who has never complained about the GUI of even the best SEO tools?).
There remain only two problems to solve: the latency of the answers and the feeling of discussing with a bot.
The first issue is due to the computation time needed to go back and forth from the LLM to the graph or vector databases. It could take up to 10 seconds with our project to obtain answers to very intricate questions.
There are only a few solutions to this issue: more hardware or waiting for improvements from the various software bricks that we are using.
The second issue is trickier. While LLMs simulate the tone and writing of actual humans, the fact that the interface is proprietary says it all.
Both problems can be solved with a neat trick: using a text interface that is well-known, mostly used by humans, and where latency is usual (because used by humans in an asynchronous way).
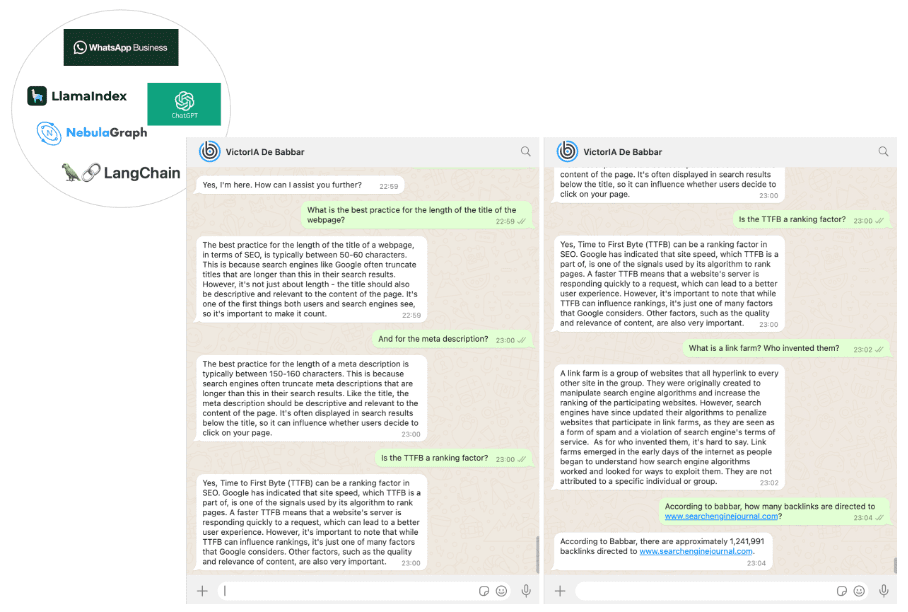
In the end, we obtained an SEO assistant named VictorIA (a name combining Victor – the first name of the famous French writer Victor Hugo – and IA, the French acronym for Artificial Intelligence), which you can see in the following picture.
Image from author, June 2024
Conclusion
Our work is just the first step in an exciting journey. Assistants could shape the future of our field. GraphRAG (+APIs) boosted LLMs to enable companies to set up their own.
Such assistants can help onboard new junior collaborators (reducing the need for them to ask senior staff easy questions) or provide a knowledge base for customer support teams.
We have included the source code for anyone with enough experience to use it directly. Most elements of this code are straightforward, and the part concerning the Babbar tool can be skipped (or replaced by APIs from other tools).
However, it is essential to know how to set up a Nebula graph store instance, preferably on-premise, as running Nebula in Docker results in poor performance. This setup is documented but can seem complex at first glance.
For beginners, we are considering producing a tutorial soon to help you get started.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
Look on the bottom of a plastic water bottle or takeout container, and you might find a logo there made up of three arrows forming a closed loop shaped like a triangle. Sometimes called the chasing arrows, this stamp is used on packaging to suggest it’s recyclable.
Those little arrows imply a nice story, painting a picture of a world where the material will be recycled into a new bottle or some such product, maybe forming an endless loop of reuse. But the reality of plastics recycling today doesn’t match up to that idea. Only about 10% of the plastic ever made has been recycled; the vast majority winds up in landfills or in the environment.
Researchers have been working to address the problem by coming up with new recycling methods, sometimes called advanced, or chemical, recycling. My colleague Sarah Ward recently wrote about one new study where researchers used a chemical process to recycle mixed-fiber clothing containing polyester, a common plastic.
The story shows why these new technologies are so appealing in theory, and just how far we would need to go for them to fix the massive problem we’ve created.
One major challenge for traditional recycling is that it requires careful sorting. That’s possible (if difficult) for some situations—humans or machines can separate milk jugs from soda bottles from takeout containers. But when it comes to other products, it becomes nearly impossible to sort out their components.
Take clothing, for instance. Less than 1% of clothing is recycled, and part of the reason is that much of it is a mixture of different materials, often including synthetic fibers as well as natural ones. You might be wearing a shirt made of a cotton-polyester blend right now, and your swimsuit probably contains nylon and elastane. My current crochet project uses yarn that’s a blend of wool and acrylic.
It’s impossible to manually or mechanically pick out the different materials in a fabric the way you can by sorting your kitchen recycling, so researchers are exploring new methods using chemistry.
In the study Sarah wrote about, scientists demonstrated a process that can recycle a fabric made from a blend of cotton and polyester. It uses a solvent to break the chemical bonds in polyester in around 15 minutes, leaving other materials mostly intact.
If this could work quickly and at large scale, it might someday allow facilities to dissolve polyester from blended textiles, separating it from other fibers and in theory allowing each component to be reused in future products.
But there are a few challenges with this process that I see a lot in recycling methods. First, reaching a large industrial scale would be difficult—as one researcher that Sarah spoke to pointed out, the solvent used in the process is expensive and tough to recover after it’s used.
Recycling methods also often wind up degrading the product in some way, a tricky problem to solve. This is a major drawback to traditional mechanical recycling as well—often, recycled plastic isn’t quite as strong or durable as the fresh stuff. In the case of this study, the problem isn’t actually with the plastic, but with the other materials that researchers are trying to preserve.
The beginning of the textile recycling process involves shredding the clothing into fine pieces to allow the chemicals to seep in and do their work breaking down the plastic. That chops up the cotton fibers too, rendering them too short to be spun into new yarn. So instead of a new T-shirt, the cotton from this process might be broken down and used as something else, like biofuel.
There’s potential for future improvement—the researchers tried to change up their method to disassemble the fabrics in a way that would preserve longer cotton fibers, but the reported research suggests it doesn’t work well with the chemical process so far.
This story got me thinking about a recent feature from ProPublica, where Lisa Song took a look at the reality of commercial advanced recycling today. She focused on pyrolysis, which uses heat to break down plastic into its building blocks. As she outlines in the story, while the industry pitches these new methods as a solution to our plastics crisis, the reality of the technology today is far from the ideal we imagine.
Most new recycling methods are still in development, and it’s really difficult to recover useful materials at high rates in a way that makes it possible to use them again. Doing all that at a scale large enough to even make a dent in our plastics problem is a massive challenge.
Just something to keep in mind the next time you see those little arrows.
Now read the rest of The Spark
Related reading
Read Sarah’s full story on efforts to recycle mixed textiles here.
I wrote about several other efforts to recycle mixtures of plastic using chemistry in this piece from 2022.
For a full account on the state of the hard problem that is the plastics crisis, check out this feature story.
Keeping up with climate
The world has been 1.5 °C hotter than preindustrial temperatures for each of the last 12 months, according to new data. We still haven’t technically passed the 1.5 °C limit set out by international climate treaties, since those consider the average temperature over many years. (The Guardian)
Google has stopped claiming to be carbon neutral, ceasing purchases of carbon offsets to balance its emissions. The company says the plan is to reach net-zero emissions by 2030, though its emissions are actually up by nearly 50% since 2019. (Bloomberg)
→ Big tech companies are expecting emissions to tick up in part because of the explosion of AI, which is an energy hog. (MIT Technology Review)
A small school district in Nebraska got an electric bus, paid for by federal funding. The vehicle quickly became a symbol for the cultural tensions brought on by shifting technology. (New York Times)
Hurricane Beryl hit the Texas coast this week and did damage across the Caribbean and the Gulf of Mexico. While meteorologists had a good idea of where it would go, better forecasting hasn’t stopped hurricane damage from increasing. (E&E News)
Earlier this year, the Indian government stopped a popular EV subsidy. Some in the industry say that short-lived subsidies can hamper the growth of electrification. (Rest of World)
The US is about to get its first solar-covered canal. Covering the Arizona waterway with solar panels will provide a new low-emissions energy source on tribal land. (Canary Media)
Electricity prices in the US are up almost 20% since early 2021. But some states that have built the most clean energy have lower rate increases overall. (Latitude Media)
Before almost any item reaches your door, it traverses the global supply chain on a pallet. More than 2 billion pallets are in circulation in the United States alone, and $400 billion worth of goods are exported on them annually. However, loading boxes onto these pallets is a task stuck in the past: Heavy loads and repetitive movements leave workers at high risk of injury, and in the rare instances when robots are used, they take months to program using handheld computers that have changed little since the 1980s.
Jacobi Robotics, a startup spun out of the labs of the University of California, Berkeley, says it can vastly speed up that process with AI command-and-control software. The researchers approached palletizing—one of the most common warehouse tasks—as primarily an issue of motion planning: How do you safely get a robotic arm to pick up boxes of different shapes and stack them efficiently on a pallet without getting stuck? And all that computation also has to be fast, because factory lines are producing more varieties of products than ever before—which means boxes of more shapes and sizes.
After much trial and error, Jacobi’s founders, including roboticist Ken Goldberg, say they’ve cracked it. Their software, built upon research from a paper they published in Science Robotics in 2020, is designed to work with the four leading makers of robotic palletizing arms. It uses deep learning to generate a “first draft” of how an arm might move an item onto the pallet. Then it uses more traditional robotics methods, like optimization, to check whether the movement can be done safely and without glitches.
Jacobi aims to replace the legacy methods customers are currently using to train their bots. In the conventional approach, robots are programmed using tools called “teaching pendants,” and customers usually have to manually guide the robot to demonstrate how to pick up each individual box and place it on the pallet. The entire coding process can take months. Jacobi says its AI-driven solution promises to cut that time down to a day and can compute motions in less than a millisecond. The company says it plans to launch its product later this month.
Billions of dollars are being poured into AI-powered robotics, but most of the excitement is geared toward next-generation robots that promise to be capable of many different tasks—like the humanoid robot that has helped Figure raise $675 million from investors, including Microsoft and OpenAI, and reach a $2.6 billion evaluation in February. Against this backdrop, using AI to train a better box-stacking robot might feel pretty basic.
Indeed, Jacobi’s seed funding round is trivial in comparison: $5 million led by Moxxie Ventures. But amid hype around promised robotics breakthroughs that could take years to materialize, palletizing might be the warehouse problem AI is best poised to solve in the short term.
“We have a very pragmatic approach,” says Max Cao, Jacobi’s co-founder and CEO. “These tasks are within reach, and we can get a lot of adoption within a short time frame, versus some of the moonshots out there.”
Jacobi’s software product includes a virtual studio where customers can build replicas of their setups, capturing factors like which robot models they have, what types of boxes will come off the conveyor belt, and which direction the labels should face. A warehouse moving sporting goods, say, might use the program to figure out the best way to stack a mixed pallet of tennis balls, rackets, and apparel. Then Jacobi’s algorithms will automatically plan the many movements the robotic arm should take to stack the pallet, and the instructions will be transmitted to the robot.
JACOBI ROBOTICS
The approach merges the benefits of fast computing provided by AI with the accuracy of more traditional robotics techniques, says Dmitry Berenson, a professor of robotics at the University of Michigan, who is not involved with the company.
“They’re doing something very reasonable here,” he says. A lot of modern robotics research is betting big on AI, hoping that deep learning can augment or replace more manual training by having the robot learn from past examples of a given motion or task. But by making sure the predictions generated by deep learning are checked against the results of more traditional methods, Jacobi is developing planning algorithms that will likely be less prone to error, Berenson says.
The planning speed that could result “is pushing this into a new category,” he adds. “You won’t even notice the time it takes to compute a motion. That’s really important in the industrial setting, where every pause means delays.”