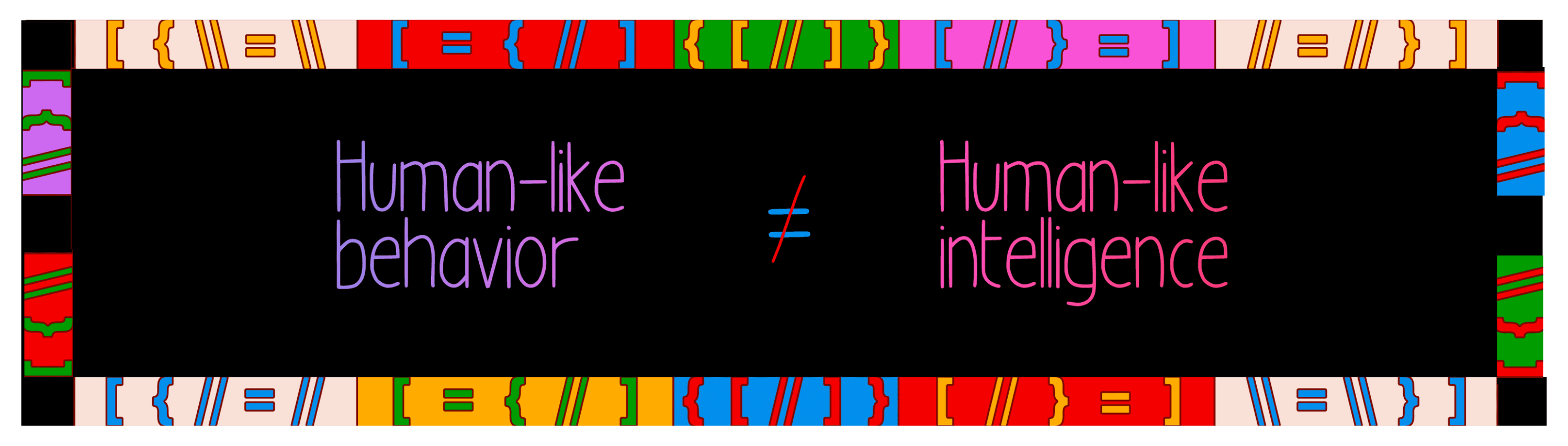Google updated their documentation to reflect that it added eight new languages to its translated results feature, broadening the reach of publishers to an increasingly global scale, with automatic translations to a site visitor’s native language.
Google Translated Results
Translated Results is a Google Search feature that will automatically translate the title link and meta description into the local language of a user, making a website published in one language available to a searcher in another language. If the searcher clicks on the link of a translated result the web page itself will also be automatically translated.
According to Google’s documentation for this feature:
“Google doesn’t host any translated pages. Opening a page through a translated result is no different than opening the original search result through Google Translate or using Chrome in-browser translation. This means that JavaScript on the page is usually supported, as well as embedded images and other page features.”
This feature benefits publishers because it makes their website available to a larger audience.
Search Feature Available In More Languages
Google’s documentation for this feature was updated to reflect that it is now available in eight more languages.
Users who speak the following languages will now have automatic access to a broader range of websites.
List Of Added Languages
Arabic
Gujarati
Korean
Persian
Thai
Turkish
Urdu
Vietnamese
Why Did It Take So Long?
It seems odd that Google didn’t already translate results into so many major languages like Turkish, Arabic or Korean. So I asked international SEO expert Christopher Shin (LinkedIn profile) about why it might have taken so long for Google to do this in the Korean language.
Christopher shared:
Google was always facing difficulties in the South Korean market as a search engine, and that has to do mainly with Naver and Kakao, formerly known as Daum.
But the whole paradigm shift to Google began when more and more students that went abroad to where Google is the dominant search engine came back to South Korea. When more and more students, travelers abroad etc., returned to Korea, they started to realize the strengths and weaknesses of the local search portals and the information capabilities these local portals provided. Laterally, more and more businesses in South Korea like Samsung, Hyundai etc., started to also shift marketing and sales to global markets, so the importance of Google as a tool for companies was also becoming more important with the domestic population.
Naver is still the dominant search portal, but not to retrieve answers to specific queries, rather for the purpose of shopping, reviews etc.
So I believe that market prioritization may be a big part as to the delayed introduction of Translated Google Search Results. And in terms of numbers, Korea is smaller with only roughly 52M nationwide and continues to decline due to poor birth rates.
Another big factor as I see it, has to do with the complexity of the Korean language which would make it more challenging to build out a translation tool that only replicates a simple English version. We use the modern Korean Hangeul but also the country uses Hanja, which are words from the Chinese origin. I used to have my team use Google Translate until all of them complained that Naver’s Papago does a better job, but with the introduction of ChatGPT, the competitiveness offered by Google was slim.”
Takeaway
It’s not an understatement to say that 2024 has not been a good year for publishers, from the introduction of AI Overviews to the 2024 Core Algorithm Update, and missing image thumbnails on recipe blogger sites, there hasn’t been much good news coming out of Google. But this news is different because it creates the opportunity for publisher content to be shown in even more languages than ever.
This excerpt is from The Digital Marketing Success Plan, the new book from SEJ VIP Contributor Corey Morris.
In what is the most distracted and disrupted era in digital marketing–especially SEO–history, we’re testing and trying things out faster than ever. While change is coming at us fast, it is critically important to still have a documented, actionable, and accountable plan for your digital marketing efforts.
In his new book, Corey Morris, details a five-step START Planning process to help brands arrive at their own digital marketing success plans to ensure ROI and business outcomes are at the heart of every effort while allowing plenty of room and agility for the rapid changes we’re experiencing in digital and search marketing.
Search Engine Journal has an exclusive feature of the first step in the START Planning process–”S for Strategy”–unpacking the four steps in this first and most critical phase.
Chapter 3: S For Strategy
The Strategy Phase is the most comprehensive part of the START planning process. The subsequent phases are all dependent on the work done and defined in this phase.
Strategy works through profiling, auditing, research, and goal setting. Knowing what marketing has been done in the past, where things stand currently, and—most importantly—where you want to go is critical at this juncture and overall for any digital marketing success plan.
The strategy phase has four steps, the first of which is profile. This could be considered a simple step, as we’re just gathering information and definitions.
However, it could also be misinterpreted, and it is challenging because it requires an expert to ask the right questions. That includes detailing the team involved in the effort and defining the product (services) we must sell, the brand, and the target audiences.
In short, we’re putting the details on the table about who we are, our resources, and our capabilities. We are identifying what we’re selling, what value it has, how we deliver it, and the pricing model. We also must know what our brand is in terms of positioning, differentiation, and equity that it holds.
And, as important as anything, we must know who our target audience personas are, their customer behaviors, and the funnels or journeys they take to buy.
Anyone can ramble off some demographics or targets. But, as companies grow, having a mutually agreed understanding of what the business sells, who it sells to, and the money it costs to do so is extremely hard.
I say all of this in hopes that you don’t get stuck here on some of the hard details, and also knowing that if it is easy, you might want to challenge some things and see if you can go deeper and ensure that you truly have the agreement and buy-in that you seem to.
The second step in the strategy phase is audit. We need to know what we’ve done in the past and are currently doing so we have a full picture of what has worked, what hasn’t, and why. Audits are important at this juncture, and this step might be one of the most time-consuming in the entire digital marketing success plan development journey.
As you obtain or create documentation of historical activities, you’ll need access to all the past and present networks and platforms. Then, you can deep dive into audits, including technical paid search, technical SEO, content SEO, web systems, email marketing systems, and more, based on what has been done in the past and what is available for you at this juncture.
The third step in the strategy phase is research. So far, the focus has been on who we are and what we’ve done leading up to where we currently stand with our efforts. This phase is where we get perspectives beyond our own data and understanding.
This is where we seek out internal perspectives from marketing, sales, ops, product, and other relevant teams and stakeholders—as well as from our customers or clients. Additionally, we’re doing external research to learn new insights or validate what we think when it comes to competitors, target audiences, and what the future opportunity forecasts or models out for us.
The final step in strategy is goals. With a thorough picture of who we are, where we stand, and what opportunities are out there for us, we can workshop to arrive at a realistic set of goals. Maybe we came into the process with our own goals, or maybe at this point, we’re starting from scratch.
Regardless, this step is critical to the rest of the process and arriving at a plan that can drive success. This is where we look at business goals and how marketing can affect them and ensure we set proper expectations before we move the strategy from ideas to action.
“WE HAVE A PROBLEM” Premium Roofing Manufacturer Story
A high-end roofing manufacturing company came to us with a unique problem. Marcy, their marketing manager, had a lot of past success with SEO, their website and email marketing, and extensive campaigns driving traffic to their websites for homeowners and contractors alike–fueling their sales operations.
Marcy had gone through several different agencies over the past few years. She had varying experiences with them, had a great one for a while, and then had a couple that didn’t value or know as much about SEO. She didn’t realize that, at the time, it was a line item to some of those agencies. It was getting done, and rankings and traffic were fine. Nothing was sticking out of the ordinary.
One day, Marcy noticed a problem in Google Analytics. Traffic is starting to drop overall. She dives in and, as she is very familiar with the reports and channels and diagnoses this as an SEO problem within a minute. SEO traffic is dropping, but she can’t tell why.
The agency says everything looks good on their end. Marcy can’t find any errors on the site. However, there’s this mysterious drop where she can see they’re not where they used to be in the Google rankings. Subsequent drops in traffic, conversions, and form submissions going through to their sales team validate it.
She remembered her work with me a few years prior at a different agency and reached out. She thought of me as someone she could trust to fix any SEO problem, which I take as high praise. I was at a conference in Silicon Valley, getting ready to take the stage to speak about SEO troubleshooting.
And so that was the ironic part of it to me. I gave my speech and immediately after had a longer conversation with Marcy over the phone. I could dive in and see the same things she saw, and I knew that we needed to do a full audit very quickly and understand what was going on.
I brought the rest of my team back home into the challenge. Within two days, we had diagnosed two very acute issues that were hidden and that most people wouldn’t see. We wouldn’t have found them unless we had gone through our analysis auditing process to get that deep.
We presented those findings to Marcy and her CEO, who both knew how big of a negative impact this would have on their business if they didn’t get this corrected.
We presented three options. One was to fix the issues technically within their current site. Still, being forward-thinking and ROI-driven, we didn’t want just to offer to patch the holes and wait for the next problem to come. So, we presented two other plans. They included a midrange plan and a long-range plan to build a new website and not only fix the issues but also strategically amplify some other things.
They opted to invest in the new website, and that turned into an ongoing relationship with us to monitor and amplify their SEO and take it to new heights, not just reclaiming what they had lost but making new ground. And I’m excited that we saw that all the way through. It played out exactly as we had projected and was validated by growth for them.
The company eventually sold for a record amount and won awards from our peers for that work. The moral of the story is not just to accept the status quo but to realize that not all professionals who have SEO in their title have an equal set of skills. Auditing is an important tool in getting to the root cause, not just for fixing an immediate problem but even more critically for long-term success.
“WE HAVE TO GET THIS RIGHT” Continuing Care Retirement Community Story
Jamaal found us through Google. He was the director of admissions and marketing for a high-end retirement facility that serves as a continuing care community. They had everything: independent living, dining in chef-inspired restaurants, activities, a pub, and anything that active senior living would want through the continuum of care, including assisted living and skilled nursing.
They have an excellent reputation in their city and are well known; however, that’s with the community at large. They needed help to reach their target audience, who could be potential residents or adult child influencers in their lives—the next generation down.
When something happens, and it’s time to look for this type of living situation, the people at that important step are less aware and less prepared for the conversations they must have with their loved ones in a critical phase of life. These people were supposed to be moving into research and action toward admission.
Also, while it was a wealthy, high-end property, it was nonprofit, very benevolent, and gave back so much. The margins were tight, and there wasn’t a large marketing budget, but they knew they needed to do something.
Jamaal’s challenge when he came to us was, “I know you can do everything. I know I probably need all the things under the digital marketing umbrella. I even need a new website, but I don’t have the budget.”
We said, “That’s not a problem. We start small with many of our clients and find the areas where we can have the greatest ROI and impact. Then, we build from there and create budgets, opening up dollars for investment in other opportunities.”
So, we came into the situation, and we analyzed their audience. They had a wealth of data. They knew their business inside and out, and it was fantastic for us to see that. Still, they needed help understanding digital marketing and couldn’t connect the dots.
They had talked to three or four other providers who gave them high-ticket products or service offerings and didn’t want to work with them to find the right solution or where they should get the most bang for their buck.
We returned to them and recommended, “You should start with SEO.”
Jamaal laughed because he said that was the opposite recommendation that several of the other agencies had made. They had said, “No, you should start with $100,000 a month in Google Ads.”
I said, “You should start on SEO at a fraction of that,” even though we knew the challenges were there with being unable to build a new website. We’d have to navigate their antiquated website and optimize what they had.
We knew that telling the story, getting the content right, and even optimizing a lousy website would get us further along in the long-term journey of driving new leads to the website. We knew we only needed a handful of people to find the site to understand what they did at the right moment, get the right story, and come through the doors and experience this wonderful place.
After building momentum, one lead at a time, we could start talking about a new website, activate additional marketing channels, and layer in aspects of the digital marketing success plan to see success in the long term.
Ultimately, they grew as a business and their marketing investment grew respectively. Eventually, they were acquired by a large hospital system, where everyone could flourish and get the mission and the word out.
The moral of the story is it’s always better to do something rather than nothing.
But if you’re on a limited budget, understand that the obvious answers or the expensive ones aren’t necessarily the best ones. Be willing to dig into the data, do the hard work, and see the opportunity to create new budgets.
By seeing small successes, one at a time, you can build toward bigger things.
To learn more about why digital marketing planning is so important, Corey’s START Planning process, and how to implement which he details in the full book (including more real stories and “how to” sections for each phase of the process), download the book now on Amazon.
For a limited time through July 17, the Kindle version is only 99 cents.
You can also find out more information and free resources at https://thedmsp.com
MIT Technology Review‘s How To series helps you get things done.
Planning a vacation should, in theory, be fun. But drawing up a list of activities for a trip can also be time consuming and stressful, particularly if you don’t know where to begin.
Luckily, tech companies have been competing to create tools that can help you to do just that. Travel has become one of the most popular use cases for AI that Google, Microsoft, and OpenAI like to point to in demos, and firms like Tripadvisor, Expedia, and Booking.com have started to launch AI-powered vacation-planning products too. While AI agents that can manage the entire process of planning and booking your vacation are still some way off, the current generation of AI tools are still pretty handy at helping you with various tasks, like creating itineraries or brushing up on your language skills.
AI models are prone to making stuff up, which means you should always double-check their suggestions yourself. But they can still be a really useful resource. Read on for some ideas on how AI tools can help make planning your time away that little bit easier—leaving you with more time to enjoy yourself.
Narrow down potential locations for your break
First things first: You have to choose where to travel to. The beauty of large language models (LLMs) like ChatGPT is that they’re trained on vast swathes of the internet, meaning they can digest information that would take a human hours to research and quickly condense it into simple paragraphs.
This makes them great tools to help draw you up a list of places you’d be interested in going. The more specific you can be in your prompt, the better—for example, telling the chatbot you’d like suggestions for destinations with warm climates, child-friendly beaches, and busy nightlife (such as Mexico, Thailand, Ibiza, and Australia) will return more relevant countries than vague prompts.
However, given AI models’ propensity for making things up—known as hallucinating—it’s worth checking that its information on proposed locations and potential activities is actually accurate.
How to use it: Fire up your LLM of choice—ChatGPT, Gemini, or Copilot are just some of the available models—and ask it to suggest locations for a holiday. Include important details like the temperatures, locations, length of trip, and activities you’re interested in. This could look something like: “Suggest a list of locations for two people going on a two-week vacation. The locations should be hot throughout July and August, based in a city but with easy access to a beach.”
Pick places to visit while you’re there
Once you’re on your vacation, you can use tools like ChatGPT or Google’s Gemini to draw up itineraries for day trips. For example, you could use a prompt like “Give me an itinerary for a day driving from Florence around the countryside in Chianti. Include some medieval villages and a winery, and finish with dinner at a restaurant with a good view.” As always with LLMs, the more specific you can be, the better. And to be on the safe side, you ought to cross-reference the final itinerary against Google Maps to check that the order of the suggestions makes sense.
Beyond LLMs, there are also tailored tools available that can help you to work out the kinds of conditions you might encounter, including weather and traffic. If you’re planning a city break, you might want to check out Immersive View, a feature for Google Maps that Google launched last year. It uses AI and computer vision to create a 3D model depicting how a certain location in a supported city will look at a specific time of day up to four days in the future. Because it’s able to draw from weather forecasts and traffic data, it could help you predict whether a rooftop bar will still be bathed in sunshine tomorrow evening, or if you’d be better off picking a different route for a drive at the weekend.
How to use it: Check to see if your city is on this list. Then open up Google Maps, navigate to an area you’re interested in, and select Immersive View. You’ll be presented with an interactive map with the option to change the date and time of day you’d like to check.
Checking flights and accommodations
Once you’ve decided where to go, booking flights and a place to stay is the next thing to tackle. Many travel booking sites have integrated AI chatbots into their websites, the vast majority of which are powered by ChatGPT. But unless you’re particularly wedded to using a specific site, it could be worth looking at the bigger picture.
Looking up flights on multiple browser tabs can be cumbersome, but Google’s Gemini has a solution. The model integrates with Google Flights and Google Hotels, pulling in real-time information from Google’s partner companies in a way that makes it easy to compare times and, crucially, prices.
This is a quick and easy way to search for flights and accommodations within your personal budget. For example, I instructed Gemini to show me flights for a round trip from London to Paris for under £200. It’s a great starting point to get a rough idea of how much you’re likely to spend, and how long it’ll take you to get there.
How to use it: Once you’ve opened up Gemini (you may need to sign in to a Google account to do this), open up Settings and go to Extensions to check that Google Flights & Hotels is enabled. Then return to the Gemini main page and enter your query, specifying where you’re flying from and to, the length of your stay, and any cost requirements you may wish to share.
If you’re a spreadsheet fan, you can ask Gemini to export the plan to Sheets, which you can then share with friends and family.
Practice your language skills
You’ve probably heard that the best way to get better at another language is to practice speaking it. However, tutors can be expensive, and you may not know anyone else who speaks the tongue you’re trying to brush up on.
Back in September last year, OpenAI updated ChatGPT to allow users to speak to it. You can try it out for yourself using the ChatGPT app for Android or iOS. I opened up the voice chat option and read it some basic phrases in French that it successfully translated into English (“Do you speak English?” “Can you help me?” and “Where is the museum?”) in spite of my poor pronunciation. It was also good at offering up alternative phrases when I asked it for less formal examples, such as swapping bonjour (hello) for salut, which translates as “hi.” And it allowed me to hold basic conversations with the disembodied AI voice.
How to use it: Download the ChatGPT app and press the headphone icon to the right of the search bar. This will trigger a voice conversation with the AI model.
Translate on the go
Google has integrated its powerful translation technology into camera software, allowing you to simply point your phone camera toward an unfamiliar phrase and see it translated into English. This is particularly useful for deciphering menus, road signs, and shop names while you’re out and about.
How to use it: Download the Google Translate app and select Camera.
Write online reviews (and social media captions)
Positive reviews are a great way for small businesses to set themselves apart from their competition on the internet. But writing them can be time consuming, so why not get AI to help you out?
How to use it: Telling a chatbot like Gemini, Copilot, or ChatGPT what you enjoyed about a particular restaurant, guided tour, or destination can take some of the hard work out of writing a quick summary. The more specific you can be, the better. Prompt the model with something like: “Write a positive review for the Old Tavern in Mykonos, Greece, that mentions its delicious calamari.” While you’re unlikely to want to copy and paste the chatbot’s response in its entirety, it can help you with the structure and phrasing of your own review.
Similarly, if you’re someone who struggles to come up with captions for Instagram posts about your travels, asking the same LLMs to help you can be a good way to get over writer’s block.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
I’m getting married later this summer and am feverishly planning a honeymoon together with my fiancé. It has been at times overwhelming trying to research and decide between what seem like millions of options while juggling busy work schedules and wedding planning.
Thankfully, my colleague Rhiannon Williams has just published a piece about how to use AI to plan your vacation. You can read her story here. The timing could not be better! I decided to put her tips to the test and use AI to plan my honeymoon itinerary.
I asked ChatGPT to suggest a travel plan over three weeks in Japan and the Philippines, our dream destinations. I told the chatbot that in Tokyo I wanted to see art and design and eat good food, and in the Philippines I wanted to go somewhere laid-back and outdoorsy that is not very touristy. I also asked ChatGPT to be specific in its suggestions for hotels and activities to book.
The results were pretty good, and they aligned with the research I had already done. I was delighted to see the AI propose we visit Siargao Island in the Philippines, which is known for its surfing. We were planning on going there anyway, but I haven’t had a chance to do much research on what there is to do. ChatGPT came up with some divine-looking day trips involving a stingless-jellyfish sanctuary, cave pools, and other adventures.
The AI produced a decent first draft of the trip itinerary. I reckon this saved me a lot of time doing research on planned destinations I didn’t know much about, such as Siargao.
But … when I asked about places I did know more about, such as Tokyo, I wasn’t that impressed. ChatGPT suggested I visit Shibuya Crossing and eat at a sushi restaurant, which, like, c’mon, are some of the most obvious things for tourists to do there. However, I am willing to consider that the problem might have been me and my prompting. Because I found that the more specific I made my prompts, the better the results were.
But here’s the thing. Language models work by predicting the next likely word in a sentence. These AI systems don’t have an understanding of what it is like to experience these things, or how long they take. For example, ChatGPT suggested spending one whole day taking photos at a scenic spot. That would get boring pretty quickly. The AI systems of today lack the kind of last-mile reasoning and planning skills that would help me with logistics and budgeting. It also suggested accommodations that were way out of our price range.
But this whole process might become much smoother as we build the next generation of AI agents.
Agents are AI algorithms and models that can complete complex tasks in the real world. The idea is that one day they could execute a vast range of tasks, much like a human assistant. Agents are the new hot thing in AI, and I just published an explainer looking at what they are and how they work. You can read it here.
In the future, an AI agent could not only suggest things to do and places to stay on my honeymoon; it would also go a step further than ChatGPT and book flights for me. It would remember my preferences and budget for hotels and only propose accommodation that matched my criteria. It might also remember what I liked to do on past trips, and suggest very specific things to do tailored to those tastes. It might even request bookings for restaurants on my behalf.
Unfortunately for my honeymoon, today’s AI systems lack the kind of reasoning, planning, and memory needed. It’s still early days for these systems, and there are a lot of unsolved research questions. But who knows—maybe for our 10th anniversary trip?
Now read the rest of The Algorithm
Deeper Learning
A way to let robots learn by listening will make them more useful
Most AI-powered robots today use cameras to understand their surroundings and learn new tasks, but it’s becoming easier to train robots with sound too, helping them adapt to tasks and environments where visibility is limited.
Sound on: Researchers at Stanford University tested how much more successful a robot can be if it’s capable of “listening.” They chose four tasks: flipping a bagel in a pan, erasing a whiteboard, putting two Velcro strips together, and pouring dice out of a cup. In each task, sounds provided clues that cameras or tactile sensors struggle with, like knowing if the eraser is properly contacting the whiteboard or whether the cup contains dice. When using vision alone in the last test, the robot could tell 27% of the time whether there were dice in the cup, but that rose to 94% when sound was included. Read more from James O’Donnell.
Bits and Bytes
AI lie detectors are better than humans at spotting lies Researchers at the University of Würzburg in Germany found that an AI system was significantly better at spotting fabricated statements than humans. Humans usually only get it right around half the time, but the AI could spot if a statement was true or false in 67% of cases. However, lie detection is a controversial and unreliable technology, and it’s debatable whether we should even be using it in the first place. (MIT Technology Review)
A hacker stole secrets from OpenAI A hacker managed to access OpenAI’s internal messaging systems and steal information about its AI technology. The company believes the hacker was a private individual, but the incident raised fears among OpenAI employees that China could steal the company’s technology too. (The New York Times)
AI has vastly increased Google’s emissions over the past five years Google said its greenhouse-gas emissions totaled 14.3 million metric tons of carbon dioxide equivalent throughout 2023. This is 48% higher than in 2019, the company said. This is mostly due to Google’s enormous push toward AI, which will likely make it harder to hit its goal of eliminating carbon emissions by 2030. This is an utterly depressing example of how our societies prioritize profit over the climate emergency we are in. (Bloomberg)
Why a $14 billion startup is hiring PhDs to train AI systems from their living rooms An interesting read about the shift happening in AI and data work. Scale AI has previously hired low-paid data workers in countries such as India and the Philippines to annotate data that is used to train AI. But the massive boom in language models has prompted Scale to hire highly skilled contractors in the US with the necessary expertise to help train those models. This highlights just how important data work really is to AI. (The Information)
A new “ethical” AI music generator can’t write a halfway decent song Copyright is one of the thorniest problems facing AI today. Just last week I wrote about how AI companies are being forced to cough up for high-quality training data to build powerful AI. This story illustrates why this matters. This story is about an “ethical” AI music generator, which only used a limited data set of licensed music. But without high-quality data, it is not able to generate anything even close to decent. (Wired)
Internet nastiness, name-calling, and other not-so-petty, world-altering disagreements
AI is sexy, AI is cool. AI is entrenching inequality, upending the job market, and wrecking education. AI is a theme-park ride, AI is a magic trick. AI is our final invention, AI is a moral obligation. AI is the buzzword of the decade, AI is marketing jargon from 1955. AI is humanlike, AI is alien. AI is super-smart and as dumb as dirt. The AI boom will boost the economy, the AI bubble is about to burst. AI will increase abundance and empower humanity to maximally flourish in the universe. AI will kill us all.
What the hell is everybody talking about?
Artificial intelligence is the hottest technology of our time. But what is it? It sounds like a stupid question, but it’s one that’s never been more urgent. Here’s the short answer: AI is a catchall term for a set of technologies that make computers do things that are thought to require intelligence when done by people. Think of recognizing faces, understanding speech, driving cars, writing sentences, answering questions, creating pictures. But even that definition contains multitudes.
And that right there is the problem. What does it mean for machines to understand speech or write a sentence? What kinds of tasks could we ask such machines to do? And how much should we trust the machines to do them?
As this technology moves from prototype to product faster and faster, these have become questions for all of us. But (spoilers!) I don’t have the answers. I can’t even tell you what AI is. The people making it don’t know what AI is either. Not really. “These are the kinds of questions that are important enough that everyone feels like they can have an opinion,” says Chris Olah, chief scientist at the San Francisco–based AI lab Anthropic. “I also think you can argue about this as much as you want and there’s no evidence that’s going to contradict you right now.”
But if you’re willing to buckle up and come for a ride, I can tell you why nobody really knows, why everybody seems to disagree, and why you’re right to care about it.
Let’s start with an offhand joke.
Back in 2022, partway through the first episode of Mystery AI Hype Theater 3000, a party-pooping podcast in which the irascible cohosts Alex Hanna and Emily Bender have a lot of fun sticking “the sharpest needles’’ into some of Silicon Valley’s most inflated sacred cows, they make a ridiculous suggestion. They’re hate-reading aloud from a 12,500-word Medium post by a Google VP of engineering, Blaise Agüera y Arcas, titled “Can machines learn how to behave?” Agüera y Arcas makes a case that AI can understand concepts in a way that’s somehow analogous to the way humans understand concepts—concepts such as moral values. In short, perhaps machines can be taught to behave.
COURTESY IMAGE
Hanna and Bender are having none of it. They decide to replace the term “AI’’ with “mathy math”—you know, just lots and lots of math.
The irreverent phrase is meant to collapse what they see as bombast and anthropomorphism in the sentences being quoted. Pretty soon Hanna, a sociologist and director of research at the Distributed AI Research Institute, and Bender, a computational linguist at the University of Washington (and internet-famous critic of tech industry hype), open a gulf between what Agüera y Arcas wants to say and how they choose to hear it.
“How should AIs, their creators, and their users be held morally accountable?” asks Agüera y Arcas.
How should mathy math be held morally accountable? asks Bender.
“There’s a category error here,” she says. Hanna and Bender don’t just reject what Agüera y Arcas says; they claim it makes no sense. “Can we please stop it with the ‘an AI’ or ‘the AIs’ as if they are, like, individuals in the world?” Bender says.
Alex Hanna
BRITTANY HOSEA-SMALL
It might sound as if they’re talking about different things, but they’re not. Both sides are talking about large language models, the technology behind the current AI boom. It’s just that the way we talk about AI is more polarized than ever. In May, OpenAI CEO Sam Altman teased the latest update to GPT-4, his company’s flagship model, by tweeting, “Feels like magic to me.”
There’s a lot of road between math and magic.
Emily Bender
COURTESY PHOTO
AI has acolytes, with a faith-like belief in the technology’s current power and inevitable future improvement. Artificial general intelligence is in sight, they say; superintelligence is coming behind it. And it has heretics, who pooh-pooh such claims as mystical mumbo-jumbo.
The buzzy popular narrative is shaped by a pantheon of big-name players, from Big Tech marketers in chief like Sundar Pichai and Satya Nadella to edgelords of industry like Elon Musk and Altman to celebrity computer scientists like Geoffrey Hinton. Sometimes these boosters and doomers are one and the same, telling us that the technology is so good it’s bad.
As AI hype has ballooned, a vocal anti-hype lobby has risen in opposition, ready to smack down its ambitious, often wild claims. Pulling in this direction are a raft of researchers, including Hanna and Bender, and also outspoken industry critics like influential computer scientist and former Googler Timnit Gebru and NYU cognitive scientist Gary Marcus. All have a chorus of followers bickering in their replies.
In short, AI has come to mean all things to all people, splitting the field into fandoms. It can feel as if different camps are talking past one another, not always in good faith.
Maybe you find all this silly or tiresome. But given the power and complexity of these technologies—which are already used to determine how much we pay for insurance, how we look up information, how we do our jobs, etc. etc. etc.—it’s about time we at least agreed on what it is we’re even talking about.
Yet in all the conversations I’ve had with people at the cutting edge of this technology, no one has given a straight answer about exactly what it is they’re building. (A quick side note: This piece focuses on the AI debate in the US and Europe, largely because many of the best-funded, most cutting-edge AI labs are there. But of course there’s important research happening elsewhere, too, in countries with their own varying perspectives on AI, particularly China.) Partly, it’s the pace of development. But the science is also wide open. Today’s large language models can do amazing things. The field just can’t find common ground on what’s really going on under the hood.
These models are trained to complete sentences. They appear to be able to do a lot more—from solving high school math problems to writing computer code to passing law exams to composing poems. When a person does these things, we take it as a sign of intelligence. What about when a computer does it? Is the appearance of intelligence enough?
These questions go to the heart of what we mean by “artificial intelligence,” a term people have actually been arguing about for decades. But the discourse around AI has become more acrimonious with the rise of large language models that can mimic the way we talk and write with thrilling/chilling (delete as applicable) realism.
We have built machines with humanlike behavior but haven’t shrugged off the habit of imagining a humanlike mind behind them. This leads to over-egged evaluations of what AI can do; it hardens gut reactions into dogmatic positions, and it plays into the wider culture wars between techno-optimists and techno-skeptics.
Add to this stew of uncertainty a truckload of cultural baggage, from the science fiction that I’d bet many in the industry were raised on, to far more malign ideologies that influence the way we think about the future. Given this heady mix, arguments about AI are no longer simply academic (and perhaps never were). AI inflames people’s passions and makes grownups call each other names.
“It’s not in an intellectually healthy place right now,” Marcus says of the debate. For years Marcus has pointed out the flaws and limitations of deep learning, the tech that launched AI into the mainstream, powering everything from LLMs to image recognition to self-driving cars. His 2001 book The Algebraic Mind argued that neural networks, the foundation on which deep learning is built, are incapable of reasoning by themselves. (We’ll skip over it for now, but I’ll come back to it later and we’ll see just how much a word like “reasoning” matters in a sentence like this.)
Marcus says that he has tried to engage Hinton—who last year went public with existential fears about the technology he helped invent—in a proper debate about how good large language models really are. “He just won’t do it,” says Marcus. “He calls me a twit.” (Having talked to Hinton about Marcus in the past, I can confirm that. “ChatGPT clearly understands neural networks better than he does,” Hinton told me last year.) Marcus also drew ire when he wrote an essay titled “Deep learning is hitting a wall.” Altman responded to it with a tweet: “Give me the confidence of a mediocre deep learning skeptic.”
At the same time, banging his drum has made Marcus a one-man brand and earned him an invitation to sit next to Altman and give testimony last year before the US Senate’s AI oversight committee.
And that’s why all these fights matter more than your average internet nastiness. Sure, there are big egos and vast sums of money at stake. But more than that, these disputes matter when industry leaders and opinionated scientists are summoned by heads of state and lawmakers to explain what this technology is and what it can do (and how scared we should be). They matter when this technology is being built into software we use every day, from search engines to word-processing apps to assistants on your phone. AI is not going away. But if we don’t know what we’re being sold, who’s the dupe?
“It is hard to think of another technology in history about which such a debate could be had—a debate about whether it is everywhere, or nowhere at all,” Stephen Cave and Kanta Dihal write in Imagining AI, a 2023 collection of essays about how different cultural beliefs shape people’s views of artificial intelligence. “That it can be held about AI is a testament to its mythic quality.”
Above all else, AI is an idea—an ideal—shaped by worldviews and sci-fi tropes as much as by math and computer science. Figuring out what we are talking about when we talk about AI will clarify many things. We won’t agree on them, but common ground on what AI is would be a great place to start talking about what AI should be.
What is everyone really fighting about, anyway?
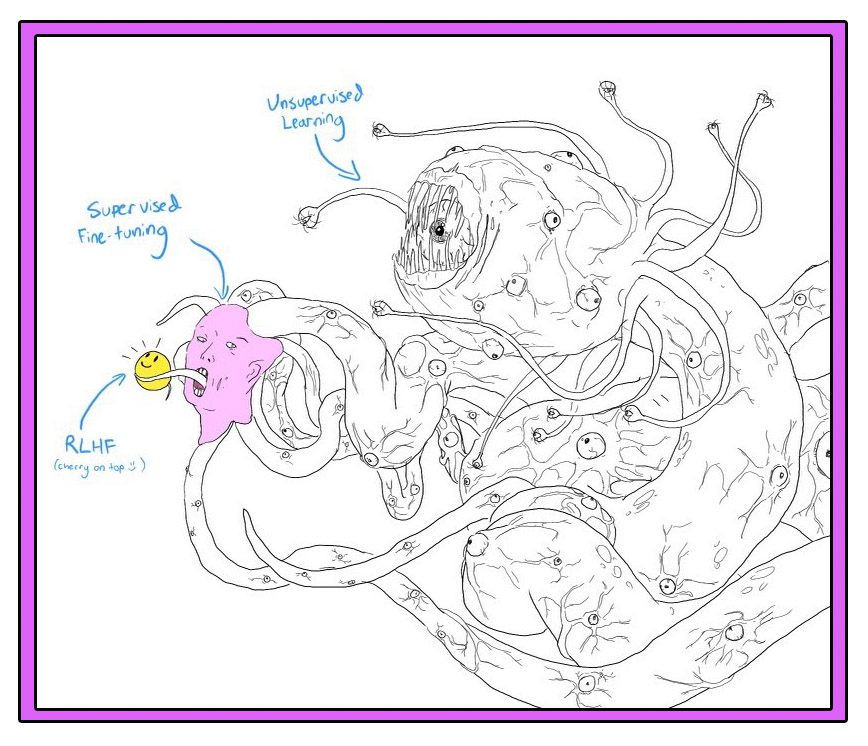
In late 2022, soon after OpenAI released ChatGPT, a new meme started circulating online that captured the weirdness of this technology better than anything else. In most versions, a Lovecraftian monster called the Shoggoth, all tentacles and eyeballs, holds up a bland smiley-face emoji as if to disguise its true nature. ChatGPT presents as humanlike and accessible in its conversational wordplay, but behind that façade lie unfathomable complexities—and horrors. (“It was a terrible, indescribable thing vaster than any subway train—a shapeless congeries of protoplasmic bubbles,” H.P. Lovecraft wrote of the Shoggoth in his 1936 novella At the Mountains of Madness.)
@ANTHRUPAD VIA KNOWYOURMEME.COM
For years one of the best-knowntouchstones for AI in pop culture was The Terminator, says Dihal. But by putting ChatGPT online for free, OpenAI gave millions of people firsthand experience of something different. “AI has always been a sort of really vague concept that can expand endlessly to encompass all kinds of ideas,” she says. But ChatGPT made those ideas tangible: “Suddenly, everybody has a concrete thing to refer to.” What is AI? For millions of people the answer was now: ChatGPT.
The AI industry is selling that smiley face hard. Consider how TheDaily Show recently skewered the hype, as expressed by industry leaders. Silicon Valley’s VC in chief, Marc Andreessen: “This has the potential to make life much better … I think it’s honestly a layup.” Altman: “I hate to sound like a utopic tech bro here, but the increase in quality of life that AI can deliver is extraordinary.” Pichai: “AI is the most profound technology that humanity is working on. More profound than fire.”
Jon Stewart: “Yeah, suck a dick, fire!”
But as the meme points out, ChatGPT is a friendly mask. Behind it is a monster called GPT-4, a large language model built from a vast neural network that has ingested more words than most of us could read in a thousand lifetimes. During training, which can last months and cost tens of millions of dollars, such models are given the task of filling in blanks in sentences taken from millions of books and a significant fraction of the internet. They do this task over and over again. In a sense, they are trained to be supercharged autocomplete machines. The result is a model that has turned much of the world’s written information into a statistical representation of which words are most likely to follow other words, captured across billions and billions of numerical values.
It’s math—a hell of a lot of math. Nobody disputes that. But is it just that, or does this complex math encode algorithms capable of something akin to human reasoning or the formation of concepts?
Many of the people who answer yes to that question believe we’re close to unlocking something called artificial general intelligence, or AGI, a hypothetical future technology that can do a wide range of tasks as well as humans can. A few of them have even set their sights on what they call superintelligence, sci-fi technology that can do things far better than humans. This cohort believes AGI will drastically change the world—but to what end? That’s yet another point of tension. It could fix all the world’s problems—or bring about its doom.
kinda mad how the so called godfathers of AI managed to convince seemingly smart people within AI field & many regulators to buy into the absurd idea that a sophisticated curve fitting (to a dataset) machine can have the urge to exterminate humans
Today AGI appears in the mission statements of the world’s top AI labs. But the term was invented in 2007 as a niche attempt to inject some pizzazz into a field that was then best known for applications that read handwriting on bank deposit slips or recommended your next book to buy. The idea was to reclaim the original vision of an artificial intelligence that could do humanlike things (more on that soon).
It was really an aspiration more than anything else, Google DeepMind cofounder Shane Legg, who coined the term, told me last year: “I didn’t have an especially clear definition.”
AGI became the most controversial idea in AI. Some talked it up as the next big thing: AGI was AI but, you know, much better. Others claimed the term was so vague that it was meaningless.
“AGI used to be a dirty word,” Ilya Sutskever told me, before he resigned as chief scientist at OpenAI.
But large language models, and ChatGPT in particular, changed everything. AGI went from dirty word to marketing dream.
Which brings us to what I think is one of the most illustrative disputes of the moment—one that sets up the sides of the argument and the stakes in play.
Seeing magic in the machine
A few months before the public launch of OpenAI’s large language model GPT-4 in March 2023, the company shared a prerelease version with Microsoft, which wanted to use the new model to revamp its search engine Bing.
At the time, Sebastian Bubeck was studying the limitations of LLMs and was somewhat skeptical of their abilities. In particular, Bubeck—the vice president of generative AI research at Microsoft Research in Redmond, Washington—had been trying and failing to get the technology to solve middle school math problems. Things like: x – y = 0; what are x and y? “My belief was that reasoning was a bottleneck, an obstacle,” he says. “I thought that you would have to do something really fundamentally different to get over that obstacle.”
Then he got his hands on GPT-4. The first thing he did was try those math problems. “The model nailed it,” he says. “Sitting here in 2024, of course GPT-4 can solve linear equations. But back then, this was crazy. GPT-3 cannot do that.”
But Bubeck’s real road-to-Damascus moment came when he pushed it to do something new.
The thing about middle school math problems is that they are all over the internet, and GPT-4 may simply have memorized them. “How do you study a model that may have seen everything that human beings have written?” asks Bubeck. His answer was to test GPT-4 on a range of problems that he and his colleagues believed to be novel.
Playing around with Ronen Eldan, a mathematician at Microsoft Research, Bubeck asked GPT-4 to give, in verse, a mathematical proof that there are an infinite number of primes.
Here’s a snippet of GPT-4’s response: “If we take the smallest number in S that is not in P / And call it p, we can add it to our set, don’t you see? / But this process can be repeated indefinitely. / Thus, our set P must also be infinite, you’ll agree.”
Cute, right? But Bubeck and Eldan thought it was much more than that. “We were in this office,” says Bubeck, waving at the room behind him via Zoom. “Both of us fell from our chairs. We couldn’t believe what we were seeing. It was just so creative and so, like, you know, different.”
The Microsoft team also got GPT-4 to generate the code to add a horn to a cartoon picture of a unicorn drawn in Latex, a word processing program. Bubeck thinks this shows that the model could read the existing Latex code, understand what it depicted, and identify where the horn should go.
“There are many examples, but a few of them are smoking guns of reasoning,” he says—reasoning being a crucial building block of human intelligence.
BUBECK ET AL
Bubeck, Eldan, and a team of other Microsoft researchers described their findings in a paper that they called “Sparks of artificial general intelligence”: “We believe that GPT-4’s intelligence signals a true paradigm shift in the field of computer science and beyond.” When Bubeck shared the paper online, he tweeted: “time to face it, the sparks of #AGI have been ignited.”
The Sparks paper quickly became infamous—and a touchstone for AI boosters. Agüera y Arcas and Peter Norvig, a former director of research at Google and coauthor of Artificial Intelligence: A Modern Approach, perhaps the most popular AI textbook in the world, cowrote an article called “Artificial General Intelligence Is Already Here.” Published in Noema, a magazine backed by an LA think tank called the Berggruen Institute, their argument uses the Sparks paper as a jumping-off point: “Artificial General Intelligence (AGI) means many different things to different people, but the most important parts of it have already been achieved by the current generation of advanced AI large language models,” they wrote. “Decades from now, they will be recognized as the first true examples of AGI.”
Since then, the hype has continued to balloon. Leopold Aschenbrenner, who at the time was a researcher at OpenAI focusing on superintelligence, told me last year: “AI progress in the last few years has been just extraordinarily rapid. We’ve been crushing all the benchmarks, and that progress is continuing unabated. But it won’t stop there. We’re going to have superhuman models, models that are much smarter than us.” (He was fired from OpenAI in April because, he claims, he raised security concerns about the tech he was building and “ruffled some feathers.” He has since set up a Silicon Valley investment fund.)
In June, Aschenbrenner put out a 165-page manifesto arguing that AI will outpace college graduates by “2025/2026” and that “we will have superintelligence, in the true sense of the word” by the end of the decade. But others in the industry scoff at such claims. When Aschenbrenner tweeted a chart to show how fast he thought AI would continue to improve given how fast it had improved in last few years, the tech investor Christian Keil replied that by the same logic, his baby son, who had doubled in size since he was born, would weigh 7.5 trillion tons by the time he was 10.
It’s no surprise that “sparks of AGI” has also become a byword for over-the-top buzz. “I think they got carried away,” says Marcus, speaking about the Microsoft team. “They got excited, like ‘Hey, we found something! This is amazing!’ They didn’t vet it with the scientific community.” Bender refers to the Sparks paper as a “fan fiction novella.”
Not only was it provocative to claim that GPT-4’s behavior showed signs of AGI, but Microsoft, which uses GPT-4 in its own products, has a clear interest in promoting the capabilities of the technology. “This document is marketing fluff masquerading as research,” one tech COO posted on LinkedIn.
Some also felt the paper’s methodology was flawed. Its evidence is hard to verify because it comes from interactions with a version of GPT-4 that was not made available outside OpenAI and Microsoft. The public version has guardrails that restrict the model’s capabilities, admits Bubeck. This made it impossible for other researchers to re-create his experiments.
One group tried to re-create the unicorn example with a coding language called Processing, which GPT-4 can also use to generate images. They found that the public version of GPT-4 could produce a passable unicorn but not flip or rotate that image by 90 degrees. It may seem like a small difference, but such things really matter when you’re claiming that the ability to draw a unicorn is a sign of AGI.
The key thing about the examples in the Sparks paper, including the unicorn, is that Bubeck and his colleagues believe they are genuine examples of creative reasoning. This means the team had to be certain that examples of these tasks, or ones very like them, were not included anywhere in the vast data sets that OpenAI amassed to train its model. Otherwise, the results could be interpreted instead as instances where GPT-4 reproduced patterns it had already seen.
JUN IONEDA
Bubeck insists that they set the model only tasks that would not be found on the internet. Drawing a cartoon unicorn in Latex was surely one such task. But the internet is a big place. Other researchers soon pointed out that there are indeed online forums dedicated to drawing animals in Latex. “Just fyi we knew about this,” Bubeck replied on X. “Every single query of the Sparks paper was thoroughly looked for on the internet.”
(This didn’t stop the name-calling: “I’m asking you to stop being a charlatan,” Ben Recht, a computer scientist at the University of California, Berkeley, tweeted back before accusing Bubeck of “being caught flat-out lying.”)
Bubeck insists the work was done in good faith, but he and his coauthors admit in the paper itself that their approach was not rigorous—notebook observations rather than foolproof experiments.
Still, he has no regrets: “The paper has been out for more than a year and I have yet to see anyone give me a convincing argument that the unicorn, for example, is not a real example of reasoning.”
That’s not to say he can give me a straight answer to the big question—though his response reveals what kind of answer he’d like to give. “What is AI?” Bubeck repeats back to me. “I want to be clear with you. The question can be simple, but the answer can be complex.”
“There are many simple questions out there to which we still don’t know the answer. And some of those simple questions are the most profound ones,” he says. “I’m putting this on the same footing as, you know, What is the origin of life? What is the origin of the universe? Where did we come from? Big, big questions like this.”
Seeing only math in the machine
Before Bender became one of the chief antagonists of AI’s boosters, she made her mark on the AI world as a coauthor on two influential papers. (Both peer-reviewed, she likes to point out—unlike the Sparks paper and many of the others that get much of the attention.) The first, written with Alexander Koller, a fellow computational linguist at Saarland University in Germany, and published in 2020, was called “Climbing towards NLU” (NLU is natural-language understanding).
“The start of all this for me was arguing with other people in computational linguistics whether or not language models understand anything,” she says. (Understanding, like reasoning, is typically taken to be a basic ingredient of human intelligence.)
Bender and Koller argue that a model trained exclusively on text will only ever learn the form of a language, not its meaning. Meaning, they argue, consists of two parts: the words (which could be marks or sounds) plus the reason those words were uttered. People use language for many reasons, such as sharing information, telling jokes, flirting, warning somebody to back off, and so on. Stripped of that context, the text used to train LLMs like GPT-4 lets them mimic the patterns of language well enough for many sentences generated by the LLM to look exactly like sentences written by a human. But there’s no meaning behind them, no spark. It’s a remarkable statistical trick, but completely mindless.
They illustrate their point with a thought experiment. Imagine two English-speaking people stranded on neighboring deserted islands. There is an underwater cable that lets them send text messages to each other. Now imagine that an octopus, which knows nothing about English but is a whiz at statistical pattern matching, wraps its suckers around the cable and starts listening in to the messages. The octopus gets really good at guessing what words follow other words. So good that when it breaks the cable and starts replying to messages from one of the islanders, she believes that she is still chatting with her neighbor. (In case you missed it, the octopus in this story is a chatbot.)
The person talking to the octopus would stay fooled for a reasonable amount of time, but could that last? Does the octopus understand what comes down the wire?
JUN IONEDA
Imagine that the islander now says she has built a coconut catapult and asks the octopus to build one too and tell her what it thinks. The octopus cannot do this. Without knowing what the words in the messages refer to in the world, it cannot follow the islander’s instructions. Perhaps it guesses a reply: “Okay, cool idea!” The islander will probably take this to mean that the person she is speaking to understands her message. But if so, she is seeing meaning where there is none. Finally, imagine that the islander gets attacked by a bear and sends calls for help down the line. What is the octopus to do with these words?
Bender and Koller believe that this is how large language models learn and why they are limited. “The thought experiment shows why this path is not going to lead us to a machine that understands anything,” says Bender. “The deal with the octopus is that we have given it its training data, the conversations between those two people, and that’s it. But then here’s something that comes out of the blue and it won’t be able to deal with it because it hasn’t understood.”
The other paper Bender is known for, “On the Dangers of Stochastic Parrots,” highlights a series of harms that she and her coauthors believe the companies making large language models are ignoring. These include the huge computational costs of making the models and their environmental impact; the racist, sexist, and other abusive language the models entrench; and the dangers of building a system that could fool people by “haphazardly stitching together sequences of linguistic forms … according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.”
Google senior management wasn’t happy with the paper, and the resulting conflict led two of Bender’s coauthors, Timnit Gebru and Margaret Mitchell, to be forced out of the company, where they had led the AI Ethics team. It also made “stochastic parrot” a popular put-down for large language models—and landed Bender right in the middle of the name-calling merry-go-round.
The bottom line for Bender and for many like-minded researchers is that the field has been taken in by smoke and mirrors: “I think that they are led to imagine autonomous thinking entities that can make decisions for themselves and ultimately be the kind of thing that could actually be accountable for those decisions.”
Always the linguist, Bender is now at the point where she won’t even use the term AI “without scare quotes,” she tells me. Ultimately, for her, it’s a Big Tech buzzword that distracts from the many associated harms. “I’ve got skin in the game now,” she says. “I care about these issues, and the hype is getting in the way.”
Extraordinary evidence?
Agüera y Arcas calls people like Bender “AI denialists”—the implication being that they won’t ever accept what he takes for granted. Bender’s position is that extraordinary claims require extraordinary evidence, which we do not have.
But there are people looking for it, and until they find something clear-cut—sparks or stochastic parrots or something in between—they’d prefer to sit out the fight. Call this the wait-and-see camp.
As Ellie Pavlick, who studies neural networks at Brown University, tells me: “It’s offensive to some people to suggest that human intelligence could be re-created through these kinds of mechanisms.”
She adds, “People have strong-held beliefs about this issue—it almost feels religious. On the other hand, there’s people who have a little bit of a God complex. So it’s also offensive to them to suggest that they just can’t do it.”
Pavlick is ultimately agnostic. She’s a scientist, she insists, and will follow wherever the science leads. She rolls her eyes at the wilder claims, but she believes there’s something exciting going on. “That’s where I would disagree with Bender and Koller,” she tells me. “I think there’s actually some sparks—maybe not of AGI, but like, there’s some things in there that we didn’t expect to find.”
Ellie Pavlick
COURTESY PHOTO
The problem is finding agreement on what those exciting things are and why they’re exciting. With so much hype, it’s easy to be cynical.
Researchers like Bubeck seem a lot more cool-headed when you hear them out. He thinks the infighting misses the nuance in his work. “I don’t see any problem in holding simultaneous views,” he says. “There is stochastic parroting; there is reasoning—it’s a spectrum. It’s very complex. We don’t have all the answers.”
“We need a completely new vocabulary to describe what’s going on,” he says. “One reason why people push back when I talk about reasoning in large language models is because it’s not the same reasoning as in human beings. But I think there is no way we can not call it reasoning. It is reasoning.”
Anthropic’s Olah plays it safe when pushed on what we’re seeing in LLMs, though his company, one of the hottest AI labs in the world right now, built Claude 3, an LLM that has received just as much hyperbolic praise as GPT-4 (if not more) since its release earlier this year.
“I feel like a lot of these conversations about the capabilities of these models are very tribal,” he says. “People have preexisting opinions, and it’s not very informed by evidence on any side. Then it just becomes kind of vibes-based, and I think vibes-based arguments on the internet tend to go in a bad direction.”
Olah tells me he has hunches of his own. “My subjective impression is that these things are tracking pretty sophisticated ideas,” he says. “We don’t have a comprehensive story of how very large models work, but I think it’s hard to reconcile what we’re seeing with the extreme ‘stochastic parrots’ picture.”
That’s as far as he’ll go: “I don’t want to go too much beyond what can be really strongly inferred from the evidence that we have.”
Last month, Anthropic released results from a study in which researchers gave Claude 3 the neural network equivalent of an MRI. By monitoring which bits of the model turned on and off as they ran it, they identified specific patterns of neurons that activated when the model was shown specific inputs.
Anthropic also reported patterns that it says correlate with inputs that attempt to describe or show abstract concepts. “We see features related to deception and honesty, to sycophancy, to security vulnerabilities, to bias,” says Olah. “We find features related to power seeking and manipulation and betrayal.”
These results give one of the clearest looks yet at what’s inside a large language model. It’s a tantalizing glimpse at what look like elusive humanlike traits. But what does it really tell us? As Olah admits, they do not know what the model does with these patterns. “It’s a relatively limited picture, and the analysis is pretty hard,” he says.
Even if Olah won’t spell out exactly what he thinks goes on inside a large language model like Claude 3, it’s clear why the question matters to him. Anthropic is known for its work on AI safety—making sure that powerful future models will behave in ways we want them to and not in ways we don’t (known as “alignment” in industry jargon). Figuring out how today’s models work is not only a necessary first step if you want to control future ones; it also tells you how much you need to worry about doomer scenarios in the first place. “If you don’t think that models are going to be very capable,” says Olah, “then they’re probably not going to be very dangerous.”
Why we all can’t get along
In a 2014 interview with the BBC that looked back on her career, the influential cognitive scientist Margaret Boden, now 87, was asked if she thought there were any limits that would prevent computers (or “tin cans,” as she called them) from doing what humans can do.
“I certainly don’t think there’s anything in principle,” she said. “Because to deny that is to say that [human thinking] happens by magic, and I don’t believe that it happens by magic.”
Margaret Boden
ALAMY
But, she cautioned, powerful computers won’t be enough to get us there: the AI field will also need “powerful ideas”—new theories of how thinking happens, new algorithms that might reproduce it. “But these things are very, very difficult and I see no reason to assume that we will one of these days be able to answer all of those questions. Maybe we will; maybe we won’t.”
Boden was reflecting on the early days of the current boom, but this will-we-or-won’t-we teetering speaks to decades in which she and her peers grappled with the same hard questions that researchers struggle with today. AI began as an ambitious aspiration 70-odd years ago and we are still disagreeing about what is and isn’t achievable, and how we’ll even know if we have achieved it. Most—if not all—of these disputes come down to this: We don’t have a good grasp on what intelligence is or how to recognize it. The field is full of hunches, but no one can say for sure.
We’ve been stuck on this point ever since people started taking the idea of AI seriously. Or even before that, when the stories we consumed started planting the idea of humanlike machines deep in our collective imagination. The long history of these disputes means that today’s fights often reinforce rifts that have been around since the beginning, making it even more difficult for people to find common ground.
To understand how we got here, we need to understand where we’ve been. So let’s dive into AI’s origin story—one that also played up the hype in a bid for cash.
A brief history of AI spin
The computer scientist John McCarthy is credited with coming up with the term “artificial intelligence” in 1955 when writing a funding application for a summer research program at Dartmouth College in New Hampshire.
The plan was for McCarthy and a small group of fellow researchers, a who’s-who of postwar US mathematicians and computer scientists—or “John McCarthy and the boys,” as Harry Law, a researcher who studies the history of AI at the University of Cambridge and ethics and policy at Google DeepMind, puts it—to get together for two months (not a typo) and make some serious headway on this new research challenge they’d set themselves.
From left to right, Oliver Selfridge, Nathaniel Rochester, Ray Solomonoff, Marvin Minsky, Peter Milner, John McCarthy, and Claude Shannon sitting on the lawn at the 1956 Dartmouth conference.
COURTESY OF THE MINSKY FAMILY
“The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it,” McCarthy and his coauthors wrote. “An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves.”
That list of things they wanted to make machines do—what Bender calls “the starry-eyed dream”—hasn’t changed much. Using language, forming concepts, and solving problems are defining goals for AI today. The hubris hasn’t changed much either: “We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer,” they wrote. That summer, of course, has stretched to seven decades. And the extent to which these problems are in fact now solved is something that people still shout about on the internet.
But what’s often left out of this canonical history is that artificial intelligence almost wasn’t called “artificial intelligence” at all.
John McCarthy
COURTESY PHOTO
More than one of McCarthy’s colleagues hated the term he had come up with. “The word ‘artificial’ makes you think there’s something kind of phony about this,” Arthur Samuel, a Dartmouth participant and creator of the first checkers-playing computer, is quoted as saying in historian Pamela McCorduck’s 2004 book Machines Who Think. The mathematician Claude Shannon, a coauthor of the Dartmouth proposal who is sometimes billed as “the father of the information age,” preferred the term “automata studies.” Herbert Simon and Allen Newell, two other AI pioneers, continued to call their own work “complex information processing” for years afterwards.
In fact, “artificial intelligence” was just one of several labels that might have captured the hodgepodge of ideas that the Dartmouth group was drawing on. The historian Jonnie Penn has identified possible alternatives that were in play at the time, including “engineering psychology,” “applied epistemology,” “neural cybernetics,” “non-numerical computing,” “neuraldynamics,” “advanced automatic programming,” and “hypothetical automata.” This list of names reveals how diverse the inspiration for their new field was, pulling from biology, neuroscience, statistics, and more. Marvin Minsky, another Dartmouth participant, has described AI as a “suitcase word” because it can hold so many divergent interpretations.
But McCarthy wanted a name that captured the ambitious scope of his vision. Calling this new field “artificial intelligence” grabbed people’s attention—and money. Don’t forget: AI is sexy, AI is cool.
In addition to terminology, the Dartmouth proposal codified a split between rival approaches to artificial intelligence that has divided the field ever since—a divide Law calls the “core tension in AI.”
McCarthy and his colleagues wanted to describe in computer code “every aspect of learning or any other feature of intelligence” so that machines could mimic them. In other words, if they could just figure out how thinking worked—the rules of reasoning—and write down the recipe, they could program computers to follow it. This laid the foundation of what came to be known as rule-based or symbolic AI (sometimes referred to now as GOFAI, “good old-fashioned AI”). But coming up with hard-coded rules that captured the processes of problem-solving for actual, nontrivial problems proved too hard.
The other path favored neural networks, computer programs that would try to learn those rules by themselves in the form of statistical patterns. The Dartmouth proposal mentions it almost as an aside (referring variously to “neuron nets” and “nerve nets”). Though the idea seemed less promising at first, some researchers nevertheless continued to work on versions of neural networks alongside symbolic AI. But it would take decades—plus vast amounts of computing power and much of the data on the internet—before they really took off. Fast-forward to today and this approach underpins the entire AI boom.
The big takeaway here is that, just like today’s researchers, AI’s innovators fought about foundational concepts and got caught up in their own promotional spin. Even team GOFAI was plagued by squabbles. Aaron Sloman, a philosopher and fellow AI pioneer now in his late 80s, recalls how “old friends” Minsky and McCarthy “disagreed strongly” when he got to know them in the ’70s: “Minsky thought McCarthy’s claims about logic could not work, and McCarthy thought Minsky’s mechanisms could not do what could be done using logic. I got on well with both of them, but I was saying, ‘Neither of you have got it right.’” (Sloman still thinks no one can account for the way human reasoning uses intuition as much as logic, but that’s yet another tangent!)
Marvin Minsky
MIT MUSEUM
As the fortunes of the technology waxed and waned, the term “AI” went in and out of fashion. In the early ’70s, both research tracks were effectively put on ice after the UK government published a report arguing that the AI dream had gone nowhere and wasn’t worth funding. All that hype, effectively, had led to nothing. Research projects were shuttered, and computer scientists scrubbed the words “artificial intelligence” from their grant proposals.
When I was finishing a computer science PhD in 2008, only one person in the department was working on neural networks. Bender has a similar recollection: “When I was in college, a running joke was that AI is anything that we haven’t figured out how to do with computers yet. Like, as soon as you figure out how to do it, it wasn’t magic anymore, so it wasn’t AI.”
But that magic—the grand vision laid out in the Dartmouth proposal—remained alive and, as we can now see, laid the foundations for the AGI dream.
Good and bad behavior
In 1950, five years before McCarthy started talking about artificial intelligence, Alan Turing had published a paper that asked: Can machines think? To address that question, the famous mathematician proposed a hypothetical test, which he called the imitation game. The setup imagines a human and a computer behind a screen and a second human who types questions to each. If the questioner cannot tell which answers come from the human and which come from the computer, Turing claimed, the computer may as well be said to think.
What Turing saw—unlike McCarthy’s crew—was that thinking is a really difficult thing to describe. The Turing test was a way to sidestep that problem. “He basically said: Instead of focusing on the nature of intelligence itself, I’m going to look for its manifestation in the world. I’m going to look for its shadow,” says Law.
In 1952, BBC Radio convened a panel to explore Turing’s ideas further. Turing was joined in the studio by two of his Manchester University colleagues—professor of mathematics Maxwell Newman and professor of neurosurgery Geoffrey Jefferson—and Richard Braithwaite, a philosopher of science, ethics, and religion at the University of Cambridge.
Braithwaite kicked things off: “Thinking is ordinarily regarded as so much the specialty of man, and perhaps of other higher animals, the question may seem too absurd to be discussed. But of course, it all depends on what is to be included in ‘thinking.’”
The panelists circled Turing’s question but never quite pinned it down.
When they tried to define what thinking involved, what its mechanisms were, the goalposts moved. “As soon as one can see the cause and effect working themselves out in the brain, one regards it as not being thinking but a sort of unimaginative donkey work,” said Turing.
Here was the problem: When one panelist proposed some behavior that might be taken as evidence of thought—reacting to a new idea with outrage, say—another would point out that a computer could be made to do it.
As Newman said, it would be easy enough to program a computer to print “I don’t like this new program.” But he admitted that this would be a trick.
Exactly, Jefferson said: He wanted a computer that would print “I don’t like this new program” because it didn’t like the new program. In other words, for Jefferson, behavior was not enough. It was the process leading to the behavior that mattered.
But Turing disagreed. As he had noted, uncovering a specific process—the donkey work, to use his phrase—did not pinpoint what thinking was either. So what was left?
“From this point of view, one might be tempted to define thinking as consisting of those mental processes that we don’t understand,” said Turing. “If this is right, then to make a thinking machine is to make one which does interesting things without our really understanding quite how it is done.”
It is strange to hear people grapple with these ideas for the first time. “The debate is prescient,” says Tomer Ullman, a cognitive scientist at Harvard University. “Some of the points are still alive—perhaps even more so. What they seem to be going round and round on is that the Turing test is first and foremost a behaviorist test.”
For Turing, intelligence was hard to define but easy to recognize. He proposed that the appearance of intelligence was enough—and said nothing about how that behavior should come about.
JUN IONEDA
And yet most people, when pushed, will have a gut instinct about what is and isn’t intelligent. There are dumb ways and clever ways to come across as intelligent. In 1981, Ned Block, a philosopher at New York University, showed that Turing’s proposal fell short of those gut instincts. Because it said nothing of what caused the behavior, the Turing test can be beaten through trickery (as Newman had noted in the BBC broadcast).
“Could the issue of whether a machine in fact thinks or is intelligent depend on how gullible human interrogators tend to be?” asked Block. (Or as computer scientist Mark Reidl has remarked: “The Turing test is not for AI to pass but for humans to fail.”)
Imagine, Block said, a vast look-up table in which human programmers had entered all possible answers to all possible questions. Type a question into this machine, and it would look up a matching answer in its database and send it back. Block argued that anyone using this machine would judge its behavior to be intelligent: “But actually, the machine has the intelligence of a toaster,” he wrote. “All the intelligence it exhibits is that of its programmers.”
Block concluded that whether behavior is intelligent behavior is a matter of how it is produced, not how it appears. Block’s toasters, which became known as Blockheads, are one of the strongest counterexamples to the assumptions behind Turing’s proposal.
Looking under the hood
The Turing test is not meant to be a practical metric, but its implications are deeply ingrained in the way we think about artificial intelligence today. This has become particularly relevant as LLMs have exploded in the past several years. These models get ranked by their outward behaviors, specifically how well they do on a range of tests. When OpenAI announced GPT-4, it published an impressive-looking scorecard that detailed the model’s performance on multiple high school and professional exams. Almost nobody talks about how these models get those results.
That’s because we don’t know. Today’s large language models are too complex for anybody to say exactly how their behavior is produced. Researchers outside the small handful of companies making those models don’t know what’s in their training data; none of the model makers have shared details. That makes it hard to say what is and isn’t a kind of memorization—a stochastic parroting. But even researchers on the inside, like Olah, don’t know what’s really going on when faced with a bridge-obsessed bot.
This leaves the question wide open: Yes, large language models are built on math—but are they doing something intelligent with it?
And the arguments begin again.
“Most people are trying to armchair through it,” says Brown University’s Pavlick, meaning that they are arguing about theories without looking at what’s really happening. “Some people are like, ‘I think it’s this way,’ and some people are like, ‘Well, I don’t.’ We’re kind of stuck and everyone’s unsatisfied.”
Bender thinks that this sense of mystery plays into the mythmaking. (“Magicians do not explain their tricks,” she says.) Without a proper appreciation of where the LLM’s words come from, we fall back on familiar assumptions about humans, since that is our only real point of reference. When we talk to another person, we try to make sense of what that person is trying to tell us. “That process necessarily entails imagining a life behind the words,” says Bender. That’s how language works.
JUN IONEDA
“The parlor trick of ChatGPT is so impressive that when we see these words coming out of it, we do the same thing instinctively,” she says. “It’s very good at mimicking the form of language. The problem is that we are not at all good at encountering the form of language and not imagining the rest of it.”
For some researchers, it doesn’t really matter if we can’t understand the how. Bubeck used to study large language models to try to figure out how they worked, but GPT-4 changed the way he thought about them. “It seems like these questions are not so relevant anymore,” he says. “The model is so big, so complex, that we can’t hope to open it up and understand what’s really happening.”
But Pavlick, like Olah, is trying to do just that. Her team has found that models seem to encode abstract relationships between objects, such as that between a country and its capital. Studying one large language model, Pavlick and her colleagues found that it used the same encoding to map France to Paris and Poland to Warsaw. That almost sounds smart, I tell her. “No, it’s literally a lookup table,” she says.
But what struck Pavlick was that, unlike a Blockhead, the model had learned this lookup table on its own. In other words, the LLM figured out itself that Paris is to France as Warsaw is to Poland. But what does this show? Is encoding its own lookup table instead of using a hard-coded one a sign of intelligence? Where do you draw the line?
“Basically, the problem is that behavior is the only thing we know how to measure reliably,” says Pavlick. “Anything else requires a theoretical commitment, and people don’t like having to make a theoretical commitment because it’s so loaded.”
Geoffrey Hinton
RAMSEY CARDY / COLLISION / SPORTSFILE
Not all people. A lot of influential scientists are just fine with theoretical commitment. Hinton, for example, insists that neural networks are all you need to re-create humanlike intelligence. “Deep learning is going to be able to do everything,” he told MIT Technology Review in 2020.
It’s a commitment that Hinton seems to have held onto from the start. Sloman, who recalls the two of them arguing when Hinton was a graduate student in his lab, remembers being unable to persuade him that neural networks cannot learn certain crucial abstract concepts that humans and some other animals seem to have an intuitive grasp of, such as whether something is impossible. We can just see when something’s ruled out, Sloman says. “Despite Hinton’s outstanding intelligence, he never seemed to understand that point. I don’t know why, but there are large numbers of researchers in neural networks who share that failing.”
And then there’s Marcus, whose view of neural networks is the exact opposite of Hinton’s. His case draws on what he says scientists have discovered about brains.
Brains, Marcus points out, are not blank slates that learn fully from scratch—they come ready-made with innate structures and processes that guide learning. It’s how babies can learn things that the best neural networks still can’t, he argues.
Gary Marcus
AP IMAGES
“Neural network people have this hammer, and now everything is a nail,” says Marcus. “They want to do all of it with learning, which many cognitive scientists would find unrealistic and silly. You’re not going to learn everything from scratch.”
Not that Marcus—a cognitive scientist—is any less sure of himself. “If one really looked at who’s predicted the current situation well, I think I would have to be at the top of anybody’s list,” he tells me from the back of an Uber on his way to catch a flight to a speaking gig in Europe. “I know that doesn’t sound very modest, but I do have this perspective that turns out to be very important if what you’re trying to study is artificial intelligence.”
Given his well-publicized attacks on the field, it might surprise you that Marcus still believes AGI is on the horizon. It’s just that he thinks today’s fixation on neural networks is a mistake. “We probably need a breakthrough or two or four,” he says. “You and I might not live that long, I’m sorry to say. But I think it’ll happen this century. Maybe we’ve got a shot at it.”
The power of a technicolor dream
Over Dor Skuler’s shoulder on the Zoom call from his home in Ramat Gan, Israel, a little lamp-like robot is winking on and off while we talk about it. “You can see ElliQ behind me here,” he says. Skuler’s company, Intuition Robotics, develops these devices for older people, and the design—part Amazon Alexa, part R2-D2—must make it very clear that ElliQ is a computer. If any of his customers show signs of being confused about that, Intuition Robotics takes the device back, says Skuler.
ElliQ has no face, no humanlike shape at all. Ask it about sports, and it will crack a joke about having no hand-eye coordination because it has no hands and no eyes. “For the life of me, I don’t understand why the industry is trying to fulfill the Turing test,” Skuler says. “Why is it in the best interest of humanity for us to develop technology whose goal is to dupe us?”
Instead, Skuler’s firm is betting that people can form relationships with machines that present as machines. “Just like we have the ability to build a real relationship with a dog,” he says. “Dogs provide a lot of joy for people. They provide companionship. People love their dog—but they never confuse it to be a human.”
ELLIQ
ElliQ’s users, many in their 80s and 90s, refer to the robot as an entity or a presence—sometimes a roommate. “They’re able to create a space for this in-between relationship, something between a device or a computer and something that’s alive,” says Skuler.
But no matter how hard ElliQ’s designers try to control the way people view the device, they are competing with decades of pop culture that have shaped our expectations. Why are we so fixated on AI that’s humanlike? “Because it’s hard for us to imagine something else,” says Skuler (who indeed refers to ElliQ as “she” throughout our conversation). “And because so many people in the tech industry are fans of science fiction. They try to make their dream come true.”
How many developers grew up today thinking that building a smart machine was seriously the coolest thing—if not the most important thing—that they could possibly do?
It was not long ago that OpenAI launched its new voice-controlled version of ChatGPT with a voice that sounded like Scarlett Johansson, after which many people—including Altman—flagged the connection to Spike Jonze’s 2013 movie Her.
Science fiction co-invents what AI is understood to be. As Cave and Dihal write in Imagining AI: “AI was a cultural phenomenon long before it was a technological one.”
Stories and myths about remaking humans as machines have been around for centuries. People have been dreaming of artificial humans for probably as long as they have dreamed of flight, says Dihal. She notes that Daedalus, the figure in Greek mythology famous for building a pair of wings for himself and his son, Icarus, also built what was effectively a giant bronze robot called Talos that threw rocks at passing pirates.
The word robot comes from robota, a term for “forced labor” coined by the Czech playwright Karel Čapek in his 1920 play Rossum’s Universal Robots. The “laws of robotics” outlined in Isaac Asimov’s science fiction, forbidding machines from harming humans, are inverted by movies like The Terminator, which is an iconic reference point for popular fears about real-world technology. The 2014 film Ex Machina is a dramatic riff on the Turing test. Last year’s blockbuster The Creator imagines a future world in which AI has been outlawed because it set off a nuclear bomb, an event that some doomers consider at least an outside possibility.
Cave and Dihal relate how another movie, 2014’s Transcendence, in which an AI expert played by Johnny Depp gets his mind uploaded to a computer, served a narrative pushed by ur-doomers Stephen Hawking, fellow physicist Max Tegmark, and AI researcher Stuart Russell. In an article published in the Huffington Post on the movie’s opening weekend, the trio wrote: “As the Hollywood blockbuster Transcendence debuts this weekend with … clashing visions for the future of humanity, it’s tempting to dismiss the notion of highly intelligent machines as mere science fiction. But this would be a mistake, and potentially our worst mistake ever.”
ALCON ENTERTAINMENT VIA ALAMY
Right around the same time, Tegmark founded the Future of Life Institute, with a remit to study and promote AI safety. Depp’s costar in the movie, Morgan Freeman, was on the institute’s board, and Elon Musk, who had a cameo in the film, donated $10 million in its first year. For Cave and Dihal, Transcendence is a perfect example of the multiple entanglements between popular culture, academic research, industrial production, and “the billionaire-funded fight to shape the future.”
On the London leg of his world tour last year, Altman was asked what he’d meant when he tweeted: “AI is the tech the world has always wanted.” Standing at the back of the room that day, behind an audience of hundreds, I listened to him offer his own kind of origin story: “I was, like, a very nervous kid. I read a lot of sci-fi. I spent a lot of Friday nights home, playing on the computer. But I was always really interested in AI and I thought it’d be very cool.” He went to college, got rich, and watched as neural networks became better and better. “This can be tremendously good but also could be really bad. What are we going to do about that?” he recalled thinking in 2015. “I ended up starting OpenAI.”
Why you should care that a bunch of nerds are fighting about AI
Okay, you get it: No one can agree on what AI is. But what everyone does seem to agree on is that the current debate around AI has moved far beyond the academic and the scientific. There are political and moral components in play—which doesn’t help with everyone thinking everyone else is wrong.
Untangling this is hard. It can be difficult to see what’s going on when some of those moral views take in the entire future of humanity and anchor them in a technology that nobody can quite define.
But we can’t just throw our hands up and walk away. Because no matter what this technology is, it’s coming, and unless you live under a rock, you’ll use it in one form or another. And the form that technology takes—and the problems it both solves and creates—will be shaped by the thinking and the motivations of people like the ones you just read about. In particular, by the people with the most power, the most cash, and the biggest megaphones.
Which leads me to the TESCREALists. Wait, come back! I realize it’s unfair to introduce yet another new concept so late in the game. But to understand how the people in power may mold the technologies they build, and how they explain them to the world’s regulators and lawmakers, you need to really understand their mindset.
Timnit Gebru
WIKIMEDIA
Gebru,who founded the Distributed AI Research Institute after leaving Google, and Émile Torres, a philosopher and historian at Case Western Reserve University, have traced the influence of several techno-utopian belief systems on Silicon Valley. The pair argue that to understand what’s going on with AI right now—both why companies such as Google DeepMind and OpenAI are in a race to build AGI and why doomers like Tegmark and Hinton warn of a coming catastrophe—the field must be seen through the lens of what Torres has dubbed the TESCREAL framework.
The clunky acronym (pronounced tes-cree-all) replaces an even clunkier list of labels: transhumanism, extropianism, singularitarianism, cosmism, rationalism, effective altruism, and longtermism. A lot has been written (and will be written) about each of these worldviews, so I’ll spare you here. (There are rabbit holes within rabbit holes for anyone wanting to dive deeper. Pick your forum and pack your spelunking gear.)
Émile Torres
COURTESY PHOTO
This constellation of overlapping ideologies is attractive to a certain kind of galaxy-brain mindset common in the Western tech world. Some anticipate human immortality; others predict humanity’s colonization of the stars. The common tenet is that an all-powerful technology—AGI or superintelligence, choose your team—is not only within reach but inevitable. You can see this in the do-or-die attitude that’s ubiquitous inside cutting-edge labs like OpenAI: If we don’t make AGI, someone else will.
What’s more, TESCREALists believe that AGI could not only fix the world’s problems but level up humanity. “The development and proliferation of AI—far from a risk that we should fear—is a moral obligation that we have to ourselves, to our children and to our future,” Andreessen wrote in a much-dissected manifesto last year. I have been told many times over that AGI is the way to make the world a better place—by Demis Hassabis, CEO and cofounder of Google DeepMind; by Mustafa Suleyman, CEO of the newly minted Microsoft AI and another cofounder of DeepMind; by Sutskever, Altman, and more.
But as Andreessen noted, it’s a yin-yang mindset. The flip side of techno-utopia is techno-hell. If you believe that you are building a technology so powerful that it will solve all the world’s problems, you probably also believe there’s a non-zero chance it will all go very wrong. When asked at the World Government Summit in February what keeps him up at night, Altman replied: “It’s all the sci-fi stuff.”
It’s a tension that Hinton has been talking up for the last year. It’s what companies like Anthropic claim to address. It’s what Sutskever is focusing on in his new lab, and what he wanted a special in-house team at OpenAI to focus on last year before disagreements over the way the company balanced risk and reward led most members of that team to leave.
Sure, doomerism is part of the spin. (“Claiming that you have created something that is super-intelligent is good for sales figures,” says Dihal. “It’s like, ‘Please, someone stop me from being so good and so powerful.’”) But boom or doom, exactly what (and whose) problems are these guys supposedly solving? Are we really expected to trust what they build and what they tell our leaders?
Gebru and Torres (and others) are adamant: No, we should not. They are highly critical of these ideologies and how they may influence the development of future technology, especially AI. Fundamentally, they link several of these worldviews—with their common focus on “improving” humanity—to the racist eugenics movements of the 20th century.
One danger, they argue, is that a shift of resources toward the kind of technological innovations that these ideologies demand, from building AGI to extending life spans to colonizing other planets, will ultimately benefit people who are Western and white at the cost of billions of people who aren’t. If your sight is set on fantastical futures, it’s easy to overlook the present-day costs of innovation, such as labor exploitation, the entrenchment of racist and sexist bias, and environmental damage.
“Are we trying to build a tool that’s useful to us in some way?” asks Bender, reflecting on the casualties of this race to AGI. If so, who’s it for, how do we test it, how well does it work? “But if what we’re building it for is just so that we can say that we’ve done it, that’s not a goal that I can get behind. That’s not a goal that’s worth billions of dollars.”
Bender says that seeing the connections between the TESCREAL ideologies is what made her realize there was something more to these debates. “Tangling with those people was—” she stops. “Okay, there’s more here than just academic ideas. There’s a moral code tied up in it as well.”
Of course, laid out like this without nuance, it doesn’t sound as if we—as a society, as individuals—are getting the best deal. It also all sounds rather silly. When Gebru described parts of the TESCREAL bundle in a talk last year, her audience laughed. It’s also true that few people would identify themselves as card-carrying students of these schools of thought, at least in their extremes.
But if we don’t understand how those building this tech approach it, how can we decide what deals we want to make? What apps we decide to use, what chatbots we want to give personal information to, what data centers we support in our neighborhoods, what politicians we want to vote for?
It used to be like this: There was a problem in the world, and we built something to fix it. Here, everything is backward: The goal seems to be to build a machine that can do everything, and to skip the slow, hard work that goes into figuring out what the problem is before building the solution.
And as Gebru said in that same talk, “A machine that solves all problems: if that’s not magic, what is it?”
Semantics, semantics … semantics?
When asked outright what AI is, a lot of people dodge the question. Not Suleyman. In April, the CEO of Microsoft AI stood on the TED stage and told the audience what he’d told his six-year-old nephew in response to that question. The best answer he could give, Suleyman explained, was that AI was “a new kind of digital species”—a technology so universal, so powerful, that calling it a tool no longer captured what it could do for us.
“On our current trajectory, we are heading toward the emergence of something we are all struggling to describe, and yet we cannot control what we don’t understand,” he said. “And so the metaphors, the mental models, the names—these all matter if we are to get the most out of AI whilst limiting its potential downsides.”
Language matters! I hope that’s clear from the twists and turns and tantrums we’ve been through to get to this point. But I also hope you’re asking: Whose language? And whose downsides? Suleyman is an industry leader at a technology giant that stands to make billions from its AI products. Describing the technology behind those products as a new kind of species conjures something wholly unprecedented, something with agency and capabilities that we have never seen before. That makes my spidey sense tingle. You?
I can’t tell you if there’s magic here (ironically or not). And I can’t tell you how math can realize what Bubeck and many others see in this technology (no one can yet). You’ll have to make up your own mind. But I can pull back the curtain on my own point of view.
Writing about GPT-3 back in 2020, I said that the greatest trick AI ever pulled was convincing the world it exists. I still think that: We are hardwired to see intelligence in things that behave in certain ways, whether it’s there or not. In the last few years, the tech industry has found reasons of its own to convince us that AI exists, too. This makes me skeptical of many of the claims made for this technology.
With large language models—via their smiley-face masks—we are confronted by something we’ve never had to think about before. “It’s taking this hypothetical thing and making it really concrete,” says Pavlick. “I’ve never had to think about whether a piece of language required intelligence to generate because I’ve just never dealt with language that didn’t.”
AI is many things. But I don’t think it’s humanlike. I don’t think it’s the solution to all (or even most) of our problems. It isn’t ChatGPT or Gemini or Copilot. It isn’t neural networks. It’s an idea, a vision, a kind of wish fulfillment. And ideas get shaped by other ideas, by morals, by quasi-religious convictions, by worldviews, by politics, and by gut instinct. “Artificial intelligence” is a helpful shorthand to describe a raft of different technologies. But AI is not one thing; it never has been, no matter how often the branding gets seared into the outside of the box.
“The truth is these words”—intelligence, reasoning, understanding, and more—“were defined before there was a need to be really precise about it,” says Pavlick. “I don’t really like when the question becomes ‘Does the model understand—yes or no?’ because, well, I don’t know. Words get redefined and concepts evolve all the time.”
I think that’s right. And the sooner we can all take a step back, agree on what we don’t know, and accept that none of this is yet a done deal, the sooner we can—I don’t know, I guess not all hold hands and sing kumbaya. But we can stop calling each other names.
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
There’s been so much news coming out of China’s autonomous-vehicle industry lately that it’s hard to keep track.
The government is finally allowing Tesla to bring its Full Self-Driving (FSD) feature to China. New government permits let companies test driverless cars on the road and allow cities to build smart road infrastructure that will tell these cars where to go. In short, there are a lot of changes taking place. And they all point in the same direction: There’s an immense appetite to make autonomous cars a reality soon. And the Chinese government, on both the central and local levels, has been a major force pushing for it.
So what’s happened lately?
First of all, Tesla got the approval for its FSD feature (rather misleadingly named, since it still has lots of restrictions) after it entered into a deal with the Chinese AI company Baidu to map the country.
As I reported last summer, in the absence of Tesla FSD, Chinese EV makers were already starting to offer their own driver-assistance programs to help the cars navigate in cities, but they still often look to Tesla for assurance on what technology or strategy to use. The official entry of FSD, which is reportedly set to be rolled out in China sometime later this year, will surely bring another round of competition to the country’s auto market.
Then, the government also handed out the permits that allow companies to test and experiment with driverless cars. On June 4, the Chinese Ministry of Industry and Information Technology issued nine permits for testing a more advanced version of autonomous driving technologies on the road.
The companies that got the permits include prominent EV makers like BYD and NIO, but they also had to collaborate with companies that sell services like ride-hailing, freight trucks, or public buses to test the technology. The idea seems to be to test autonomous vehicles in realistic use cases to see how the technology performs.
And most recently, on July 3, the central government announced a list of 20 cities that will pilot the building of smart, connected roads. The idea is that if a road has various kinds of sensors, cameras, and data transmitters built into it, it can communicate with self-driving vehicles in real time and help them make better decisions.
A few of the cities on the list have already commenced the work. Wuhan recently budgeted 17 billion RMB ($2.3 billion) for an infrastructure project that will involve building 15,000 smart parking spots, transforming three miles of roads, and building an industrial park for making autonomous-vehicle chips.
To be honest, I start to get numb about yet another new policy or new permit. The list of news could go on longer if I also included actions taken on the municipal level to give companies more approvals to test on the roads or to expand their services.
To China, autonomous cars represent one potential way to combine new advantages in car-making and AI and take the lead in a cutting-edge field. And while some foreign companies like Tesla are partaking in the campaign, there are lots of Chinese companies responding to the government’s call, and they’re eager to show off their technological prowess.
But I think the takeaway here is clear: The Chinese government is willing to pour its support into the autonomous-vehicle industry and is eager to come out on top while other countries take a more cautious approach.
The industry has not agreed on the best way to approach fully self-driving cars, and that’s why there are so many different forms of the technology in experiments: autopilot functions, Tesla FSD, robotaxis, smart connected roads. But it’s telling that all of them are receiving so much regulatory and policy support.
It’s possible that this could all change overnight in the event of an incident like Waymo’s accident in the US last year, but for now, it feels as if China is opening up its roads to make way for more driverless cars, and gearing up to lead the industry.
What are your takes on the endless stream of news from China about self-driving cars? Let me know by writing to zeyi@technologyreview.com.
Now read the rest of China Report
Catch up with China
1. An underground network is paying travelers to smuggle Nvidia chips into China, where its chips are in high demand because of the US export ban. (Wall Street Journal $)
2. The Chinese EV leader BYD will spend $1 billion to build a factory in Turkey. (Financial Times $)
This will probably help BYD avoid some of the tariffs that Europe has imposed on made-in-China EVs. (MIT Technology Review)
3. OpenAI’s recent decision to cut off access to its services in China won’t affect its business clients much, because they can still access ChatGPT through Microsoft’s cloud service. (The Information $)
4. Can you imagine Microsoft telling its employees to use only iPhones for work? Yep, that just happened in China as part of the effort to improve cybersecurity defenses. (Bloomberg $)
5. A Chinese academic recently revealed that the country currently has over 8.1 million data-center racks and a combined processing power of 230 exaflops—as much as 200 of the most advanced supercomputers today. And China wants to increase the total by 30% next year. (The Register)
6. Chinese factory owners are turning into TikTok comedians to find new business partners overseas. (Rest of World)
7. China is spending twice as much as the US on researching fusion energy. (Wall Street Journal $)
Lost in translation
At the 2024 World Artificial Intelligence Conference (WAIC), held last week in Shanghai, humanoid robots were the star of the show, according to the Chinese publication Huxiu. The event saw a significant increase in exhibitors and panels, driven by a surge of new AI startups. But it was the concept of “embodied AI,” which integrates deep learning with robotics, that received the most attention from the audience.
At the conference, one company presented Galbot, a humanoid robot capable of performing complex tasks like opening drawers and hanging clothes, aiming for applications in elder care and household chores. Another introduced AnyFold, which can fold a blanket. Other robots can perform gymnastics, help users lift heavy objects, or just show very nuanced facial expressions.
One more thing
Who says multimodal AI has no real uses? People have figured out that ChatGPT’s image interpretation function is surprisingly good at one task: finding the most ripe and tasty watermelon out of a bunch of them. Now I’m hopeful about AI again.
As technology goes, the internet of things (IoT) is old: internet-connected devices outnumbered people on Earth around 2008 or 2009, according to a contemporary Cisco report. Since then, IoT has grown rapidly. Researchers say that by the early 2020s, estimates of the number of devices ranged anywhere from the low tens of billions to over 50 billion.
Currently, though, IoT is seeing unusually intense new interest for a long-established technology, even one still experiencing market growth. A sure sign of this buzz is the appearance of acronyms, such as AIoT and GenAIoT, or “artificial intelligence of things” and “generative artificial intelligence of things.”
What is going on? Why now? Examining potential changes to consumer IoT could provide some answers. Specifically, the vast range of areas where the technology finds home and personal uses, from smart home controls through smart watches and other wearables to VR gaming—to name just a handful. The underlying technological changes sparking interest in this specific area mirror those in IoT as a whole.
Rapid advances converging at the edge
IoT is much more than a huge collection of “things,” such as automated sensing devices and attached actuators to take limited actions. These devices, of course, play a key role. A recent IDC report estimated that all edge devices—many of them IoT ones—account for 20% of the world’s current data generation.
IoT, however, is much more. It is a huge technological ecosystem that encompasses and empowers these devices. This ecosystem is multi-layered, although no single agreed taxonomy exists.
Most analyses will include among the strata the physical devices themselves (sensors, actuators, and other machines with which these immediately interact); the data generated by these devices; the networking and communication technology used to gather and send the generated data to, and to receive information from, other devices or central data stores; and the software applications that draw on such information and other possible inputs, often to suggest or make decisions.
The inherent value from IoT is not the data itself, but the capacity to use it in order to understand what is happening in and around the devices and, in turn, to use these insights, where necessary, to recommend that humans take action or to direct connected devices to do so.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
What is AI?
AI is sexy, AI is cool. AI is entrenching inequality, upending the job market, and wrecking education. The AI boom will boost the economy, the AI bubble is about to burst. AI will increase abundance and empower humanity to maximally flourish in the universe. AI will kill us all.
What the hell is everybody talking about?
Artificial intelligence is the hottest technology of our time. But what is it? It sounds like a stupid question, but it’s one that’s never been more urgent.
If you’re willing to buckle up and come for a ride, I can tell you why nobody really knows, why everybody seems to disagree, and why you’re right to care about it. Read the full story.
—Will Douglas Heaven
The Chinese government is all in on autonomous vehicles
There’s been so much news coming out of China’s autonomous-vehicle industry lately that it’s hard to keep track.
The government is finally allowing Tesla to bring its Full Self-Driving feature to China. New government permits let companies test driverless cars on the road and allow cities to build smart road infrastructure that will tell these cars where to go.
In short, there are a lot of changes taking place. And they all point in the same direction: The Chinese government is throwing its weight behind the autonomous-vehicle industry and is eager to come out on top while other countries take a more cautious approach. Read the full story.
—Zeyi Yang
This story is from China Report, our weekly newsletter covering tech and power in China. Sign up to receive it in your inbox every Tuesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Microsoft and Apple will no longer sit on OpenAI’s board The move comes as regulators start to pay close attention to Big Tech’s investments in AI startups. (FT $) + Microsoft claims its exit is down to OpenAI’s newfound stability. (WSJ $) + OpenAI will update its stakeholders with regular meetings, instead. (Bloomberg $)
2 The US has taken down a Russian bot farm on X The propaganda mill used AI to scale up its operations. (WP $) + Google Search results are full of Russian AI spam, too. (Wired $) + The Kremlin is rewriting Wikipedia to suit its own agenda. (Economist $)
3 Amazon claims to have met a clean energy goal seven years early Some experts aren’t convinced its calculation method is up to scratch, though. (NYT $) + Carbon capture needs to improve if we’re ever to move away from fossil fuels. (Knowable Magazine) + How electricity could clean up transportation, steel, and even fertilizer. (MIT Technology Review)
4 Rechargeable batteries come at an environmental cost They appear to be a growing source of forever chemicals. (The Verge) + The race to destroy PFAS, the forever chemicals. (MIT Technology Review)
5 What happens to your money when your startup bank folds? Plenty of customers are finding out the hard way. (NYT $)
6 Crypto fans are up in arms over Germany selling confiscated bitcoin But the state of Saxony doesn’t have a choice. (CoinDesk) + Crypto scams are alive and well. (Wired $)
7 How to prepare your home for a hurricane Stronger materials, tighter seals, and a whole lot of work. (Wired $) + The quest to build wildfire-resistant homes. (MIT Technology Review)
8 No one answers the phone anymore And it’s a bigger problem than you’d think. (Slate $)
9 Philips Hue smart lightbulbs seem to have a mind of their own Owners claim the bulbs are overriding settings to full brightness. (Insider $)
10 Gen Z uses the iPhone Notes app to generate outfits All those little digital stickers are coming in handy. (Vogue Business $)
Quote of the day
“I faced the issues of AI early, but it will happen for others. It may not be a happy ending.”
—Lee Saedol, the legendary Go player who lost to Google DeepMind’s AI program in 2016, warns an audience in Seoul about the risks the technology may pose, the New York Times reports.
The big story
This super-realistic virtual world is a driving school for AI
February 2022
Building driverless cars is a slow and expensive business. After years of effort and billions of dollars of investment, the technology is still stuck in the pilot phase.
Autonomous technology company Waabi thinks it can do better. In 2021 it revealed the controversial new shortcut to autonomous vehicles it’s betting on. The big idea? Ditch the cars.
Wasabi has built a super-realistic virtual environment called Waabi World. Instead of training an AI driver in real vehicles, it plans to do it entirely inside the simulation. But simulation alone is a bold strategy, and how far it can go depends on how realistic Waabi World really is. Read the full story.
—Will Douglas Heaven
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ If this video doesn’t fill you with joy, I don’t know what will. + Apo Whang-Od Oggay is the world’s oldest tattoo artist, and very cool. + The world’s most difficult maze holds a very interesting secret. + Netflix’s Supacell features some of the very best of Black British talent.
There are roughly 26.2 million ecommerce websites worldwide. That’s according to BuiltWith, which tracks 2,500 ecommerce technologies and attributes, such as spend, revenue, employee count, social media count, industry, location, and rank.
Per BuiltWith, the U.S. has 13.3 million ecommerce sites, the most of any nation.
–
According to Statista, ecommerce produced approximately 19% of global retail sales in 2023 and will account for about 25% by 2027.
–
In addition, Statista estimates Turkey will experience the most retail ecommerce growth worldwide between 2024 and 2029, with a compound annual rate of 11.6%. Also, with growth rates exceeding 11%, India and Brazil rank among the ecommerce markets with the fastest expansion rates in the world.
–
Moreover, according to Statista, by 2029 retail ecommerce in the United States will produce $1.88 trillion in revenue, although the projected annual growth will slow from 30.2% in 2020 to 4.7% in 2029.
An SEO asked on LinkedIn why an anonymous user on Reddit could outrank a credible website with a named author. Google’s answer gives a peek at what’s going on with search rankings and why Reddit can outrank expert articles.
Why Do Anonymous Redditors Outrank Experts?
The person asking the question wanted to know why an anonymous author on Reddit can outrank an actual author that has “credibility” such as in a brand name site like PCMag.
The person wrote:
“I was referring to how important the credibility of the writer is now. If we search for ‘best product under X amount,’ we see, let’s say, PCMag and Reddit both on the first page.
PCMag is a reliable source for that product, while Reddit has UGC and surely doesn’t guarantee authenticity. Where do you see this in terms of credibility?
In my opinion, Google must be focusing more on this, especially after the AI boom, where misinformation can be easily and massively spread.
Do you think this is an important factor in rankings anymore?”
This is their question that points out what the SEO feels is wrong with Google’s search results:
“As we can see, Reddit, popular for anonymous use, ranks much higher than many other websites.
This means that content from anonymous users is acceptable.
Can I conclude that a blog without any ‘about’ page or ‘author profile’ can also perform as well?”
Relevance And Usefulness Versus Credibility
Google’s John Mueller answered the question by pointing out that there are multiple kinds of websites, not just sites that are perceived to be credible and everyone else. The idea of credibility is one dimension of what a site can be, one quality of a website. Mueller’s answer reminded that search (and SEO) is multidimensional.
Google’s John Mueller answered:
“Both are websites, but also, they’re quite different, right? Finding the right tools for your needs, the right platforms for your audience and for your messages – it’s worth looking at more than just a simplification like that. Google aims to provide search results that are relevant & useful for users, and there’s a lot involved in that.
I feel this might fit, perhaps you have seen it before -“
Does Reddit Lack Credibility?
When it comes to recipes , in my opinion, Reddit users lack a lot of credibility in some contexts. When it comes to recipes, I’ll take the opinions of a recipe blogger or Serious Eats over what a random Redditor “thinks” a recipe should be.
The person asking the question mentioned product reviews as a topic that Reddit fails at credibility and ironically that’s actually a topic where Reddit actually shines. A person on Reddit who is sharing their hands-on experience using a brand of air fryer or mobile phone is the epitome of what Google is trying to rank for reviews because it’s the opinion of someone with days, weeks, months, years of actual experience with a product.
Saying that UGC product reviews are useful doesn’t invalidate the professional product reviews. It’s possible that both UGC and professional reviews have value, right? And I think that’s the point that John Mueller was trying to get across about not simplifying search to one ranking criteria, one dimension.
This a dimension of search that the person asking the question overlooked, the hands-on experience of the reviewer and it illustrates what Mueller means when he says that “it’s worth looking at more than just a simplification” of what’s ranking in the search results.
OTOH… Feels Like A Slap In The Face
There are many high quality sites with original photos, actual reviews and content based on real experience that are no longer ranking the search results. I know because I have seen many of these sites that in my opinion should be ranking but are not. Googlers have expressed the possibility that a future update will help more quality sites bounce back and many expert publishers are counting on that.
Nevertheless, it must be acknowledged that it must feel like a slap in the face for an expert author to see an anonymous Redditor outranking them in Google’s search results.
Multidimensional Approach To SEO
A common issue I see in how some digital marketers and bloggers debug the search engine results pages (SERPs) is that they see it through one, two, or three dimensions such as:
Keywords,
Expertise
Credibility
Links
Reviewing the SERPs to understand why Google is ranking something is a good idea. But reviewing it with just a handful of dimensions, a limited amount of “signals” can be frustrating and counterproductive.
It was only a few years ago that SEOs convinced themselves that “author signals” were a critical part of ranking and now almost everyone (finally) understands that this was all a misinterpretation of what Google and Googlers said (despite the Googlers consistently denying that authorship was a ranking signal).
The “authorship” SEO trend is an example of a one dimensional approach to SEO that overlooked the multidimensional quality of how Google ranks web pages.
There are thousands of contexts that contribute to what is ranked, like solving a problem from the user perspective, interpreting user needs, adapting to cultural and language nuances, nationwide trends, local trends, and so on. There are also ranking contexts (dimensions) that are related to Google’s Core Topicality Systems which are used to understand search queries and web pages.
Ranking web pages, from Google’s perspective, is a multidimensional problem. What that means is that reducing a search ranking problem to one dimension, like the anonymity of User Generated Content, inevitably leads to frustration. Broadening the perspective leads to better SEO.