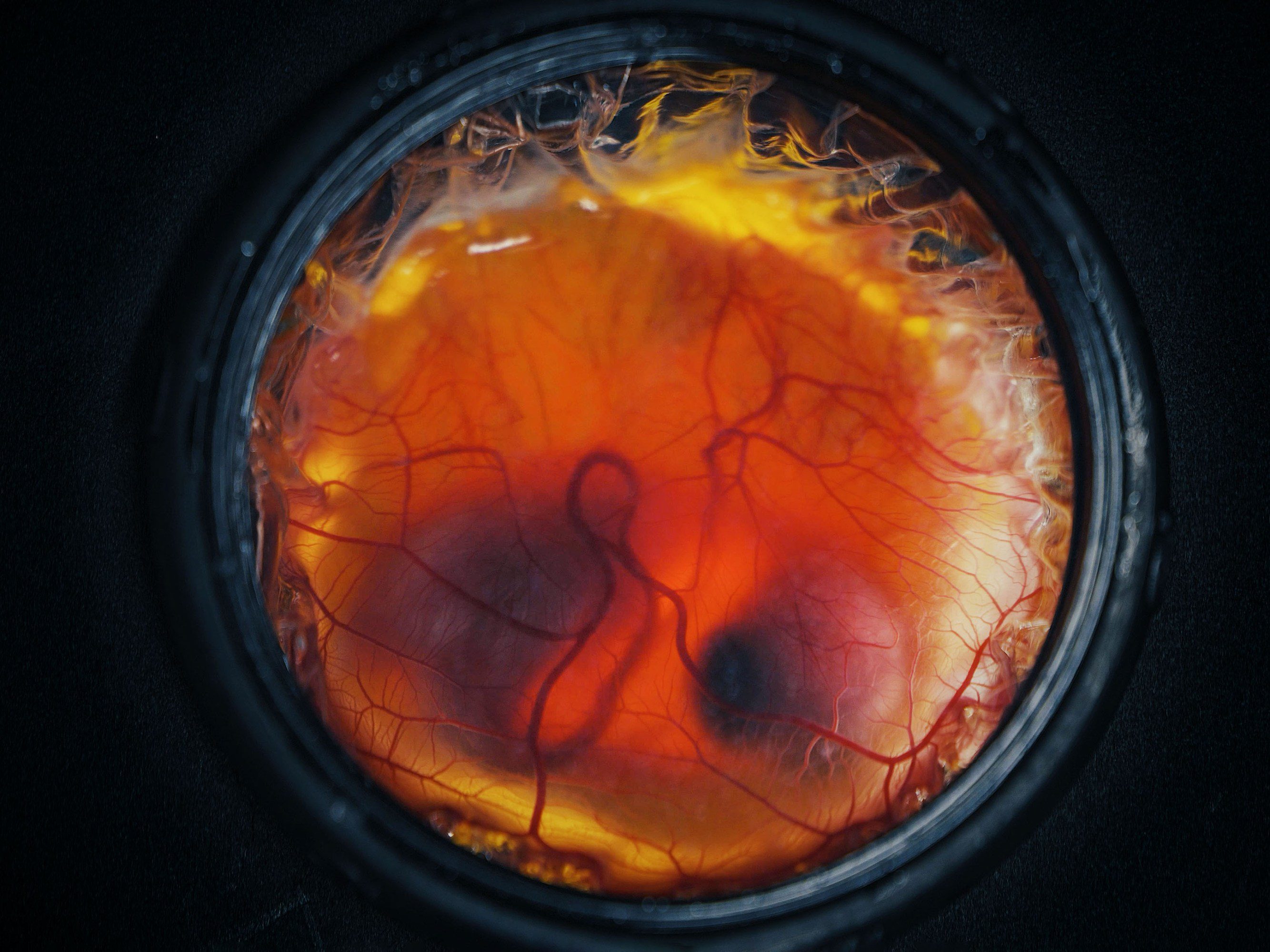
Artificial eggshell, not artificial egg: Colossal Biosciences has grown baby chicks inside 3D-printed plastic containers coated with a silicone-based membrane that mimics an eggshell’s oxygen exchange — a meaningful step, but scientists say the company is overselling it.
The moa is one target: Colossal’s goal is resurrecting the giant moa, a 12-foot flightless bird hunted to extinction — which would require genetically rewriting thousands of DNA letters and scaling up the artificial eggs to the size of a salad spinner.
Scientists are skeptical: Researchers have been growing birds in artificial containers since 1998 and say Colossal’s claims of a first-ever breakthrough are overblown — a familiar pattern for a company that last year also faced widespread rejection of its “dire wolf” resurrection claim.
The baby chicks were shifting and starting to pip—or trying to hatch. But not from an egg.
Instead, these chickens were growing inside transparent 3D-printed plastic cups at the Dallas headquarters of Colossal Biosciences.
The biotech company today claimed it has developed a “fully artificial egg” as part of its effort to resurrect extinct avian species, including birds like the dodo and the giant moa.
But “artificial eggshell” would probably be a better description for the invention. It’s an oval-shaped printed lattice, coated inside with a special silicone-based membrane that lets in oxygen, just as a real eggshell does.
To generate birds, Colossal took recently laid chicken eggs and carefully poured their contents into the artificial shells, where they continued growing. A window on top lets researchers peek inside.
“To see them all moving around in their artificial eggs was absolutely mind blowing,” says Andrew Pask, the company’s chief biology officer. “You really feel you can grow life outside of the womb.”
Colossal was founded in 2021 with plans to use gene editing and reproductive technology to restore extinct species, including the woolly mammoth. It’s since raised more than $800 million toward what it now terms the “scalable and controllable” creation of animals.
According to Pask, the egg technology could help conserve at-risk bird species. It could also play a role in a project to re-create the extinct giant moa, a flightless 12-foot-tall bird that once lived in New Zealand and laid four-liter eggs, larger than those of any living bird.
But Colossal may be able build one that’s big enough. The company provided a photograph of a prototype 3D-printed egg so large that staff have started to call it the “salad spinner.”
The moa went extinct after canoes carrying the ancestors of the Maori arrived on New Zealand’s South Island about 750 years ago. Archeological sites showcase the birds’ bones alongside stone cutting tools—clear evidence that they were hunted.
To be clear—Colossal isn’t close to re-creating the moa. Before that could happen, scientists would need to study DNA data from old moa bones and insert thousands of genetic changes into the genome of an existing bird, something that’s still technically difficult to do—with or without an artificial egg.
COLOSSAL BIOSCIENCES
Some scientists also think Colossal is taking too much credit for its artificial eggshell, which it announced in a thundering YouTube video intoning that the company has solved the “impossible question of which came first, the chicken or the egg.”
The video is pure Hollywood—it’s meant to be funny and exciting. But Colossal has a habit of antagonizing scientists by making false and exaggerated claims. Last year, for instance, the company said it had re-created the extinct dire wolf—a claim widely rejected by experts.
This time, Colossal’s fluffed-up assertion of having created the “first-ever shell-less incubation system” is what’s raising hackles among the small flock of scientists who’ve been working on the technology for years.
“Clearly an overstatement,” says Katsuya Obara, at the University of Tsukuba in Japan, who in 2024 hatched chickens from beneath transparent plastic film. “The technology here is essentially a modification of existing methods.”
In fact, Obara notes, growing birds in artificial containers goes all the way back to 1998, when another Japanese group managed to do it with quail.
What may be an advance by Colossal is the special membrane, which lets the embryo access more oxygen. Previous systems required scientists to supplement the gas—something that may not have been good for the chicks, as often some of them would fail to hatch.
The work on the artificial eggshell was carried out in Dallas by Colossal’s exogenous development team, or Exo Dev. That group is also trying to develop artificial wombs for mammals, starting with marsupials.
“We’re looking at every single facet of what’s happening during a mammalian pregnancy to unpack exactly how we then go about recapitulating that,” says Pask.
For that team, an artificial eggshell is a relatively quick and easy technical win. That’s because chickens are already an example of ex utero development. After an egg is laid, a small embryo sitting on top of the yolk starts growing, drawing nutrients from the yolk, the white, and even the shell, which provides calcium. (Colossal says it has to add ground-up calcium to the artificial eggs.)
COLOSSAL BIOSCIENCES
In order to create a moa, Colossal will have to genetically alter another type of bird, changing potentially thousands of DNA letters. But so far, chickens are the only bird species that can be genetically engineered. And that’s via a tricky process of editing stem cells that produce egg and sperm. Scientists have to add or delete DNA letters from these cells and then inject them back into an egg. The resulting bird will carry the genetic changes in its gonads—and then be able to pass them on.
Pask says Colossal’s idea is that it could modify avian stem cells enough to produce moa-like sperm or eggs. But then you might have the odd situation of a chicken laying an egg with a moa embryo inside it. “You would have chickens making moa egg and moa sperm. But it’s still a chicken egg,” he says.
Helen Sang, a professor emeritus at the Roslin Institute in the United Kingdom, says she’s not sure a moa embryo could survive on the yolk of a chicken egg, given evolutionary differences. “There are significant challenges to overcome to grow an embryo of a different species in artificial eggs,” says Sang.
Just one of those is the huge size discrepancy. The amount of yolk in a chicken egg would hardly be enough to support the much larger moa chick. Yet Pask says that is exactly where the artificial egg will come in handy.
He says it may be possible to use a fine needle to slowly “put 50 yolks together to make that yolk mass much larger.”
“The chicken egg isn’t going to be big enough to support the growth of the moa through to term, to when it would normally hatch, but that’s when you could then take that egg, put it into the artificial egg environment, and then scale it up in size,” he says.
So far, Pask says, the artificial egg is working well for chickens—almost too well. “We hatched 26 chickens and then [our CEO] asked us to put the brakes on. We have too many chickens running around.”
Optimizing the “human as a weapons system”: Anduril is building smart glasses that let soldiers order drone strikes through eye-tracking and voice commands.
Two different bets: The company is pursuing both a $159 million Army contract and a self-funded helmet-headset combo called EagleEye. The latter is something the military never asked for, but Anduril is confident the Army will eventually prefer it.
The attention problem: Soldiers already drowning in information could reject the technology if it demands more mental bandwidth than it saves. And a smart glasses system tasked with identifying threats and recommending strikes would introduce massive new risks of mistakes.
A high bar, years away: The system must survive dust, explosions, and limited connectivity. The Army won’t even put a prototype into production until 2028, if it picks one at all.
The defense-tech company Anduril has shared new details about the augmented-reality headset for the military it’s prototyping with Meta, including a vision for ordering drone strikes via eye-tracking and voice commands.
Quay Barnett, who leads the efforts as a vice president at Anduril following a career in the Army’s Special Operations Command, says his fundamental goal is to optimize “the human as a weapons system.” The vision is undoubtedly cyborg-inspired: Barnett wants drones and soldiers to see together, share information seamlessly, and make decisions as one.
Anduril actually has two such projects in the works. The first is the Army’s Soldier Born Mission Command, or SBMC, for which the company won a $159 million prototyping contract last year to work with Meta on augmented-reality glasses to attach to existing military helmets. But Anduril has also embarked on a self-funded side quest, announced in October, to design its own helmet and headset combo called EagleEye. This is something the military has not asked for, but Anduril insists it will prefer it and purchase it in the end.
So far, both systems are years away. The Army isn’t expected to move its top choice for the SBMC program into production until 2028, if it picks one at all (the previous lead for the effort, Microsoft, was set to receive a $22 billion production contract that was ultimately cancelled when the glasses didn’t prove viable). But Barnett told MIT Technology Review about where both Anduril’s prototypes are headed.
Depending on the situation, the glasses for either prototype will overlay certain information onto a soldier’s field of view. This might be as simple as a compass or as complex as an entire map of the area, information about where nearby drones are flying, or AI-driven recognition of a target like a truck.
The soldier would then speak to the interface in plain language—for example, to order an evacuation for someone who’s been injured or to plan a route taking into account which areas are off limits. A large language model—Anduril is in tests with Google’s Gemini, Meta’s Llama, and even Anthropic’s Claude, despite the company’s conflict with the Pentagon—will be used to help translate a soldier’s speech into commands the software can follow. And the engine for it all will be Anduril’s software Lattice, which incorporates data from lots of different military hardware into one picture. The Army announced in March that it would spend $20 billion to integrate Lattice with essentially its entire infrastructure.
Barnett’s team is designing the headset to carry out multi-step tasks. A soldier might send a drone to surveil an area and instruct it to come back once it’s found something that looks like an artillery unit; then the system would recommend courses of action, like sending a nearby drone to strike, that would have to be approved by the normal chain of command. Leading the system through this, if all goes to plan, might not even require speech; the soldier could instead communicate through tracked eye movements and subtle taps.
That’s the idea, anyway. It’s worked on early prototypes, Barnett says, but there aren’t yet versions ready for the Army to test at scale. The component parts began arriving in March. Because of federal military contracting rules, these parts—unlike Meta’s commercial smart glasses—required new supply chains that don’t rely on Chinese companies.
It’s a lot for soldiers already bogged down in information overload, says Jonathan Wong, a former US Marine who works as a senior policy researcher at RAND on Army efforts to buy new tech. Both smart glasses projects aim to create a clean interface that presents only the right information at the right time. But it’s a product that soldiers will reject if it costs more of their attention than it saves. “How much mental bandwidth do you have to be both aware of your surroundings and to operate this technology in a way that makes you and your whole unit better?” he says.
Wong recalls that as a platoon commander, for example, he had a radio that operated on three different channels at once. “The moment that two people were on different channels talking at the same time, I immediately couldn’t comprehend anything that either one of them was trying to tell me, and I was probably not aware of my own surroundings,” he says. “I think there are limits to what you can take in.”
Ideally, Barnett says, smart glasses can ease that information overload. Anduril’s approach is to get creative with ways the user can access necessary information quickly. Voice commands and eye tracking are a piece of that strategy. But even if it’s all technically feasible, it might take years of field testing to know if the system is actually useful for soldiers, Wong says.
Such a system would mark a major escalation in how closely soldiers rely on imperfect AI systems. While computer vision models used to identify objects have long been employed by militaries, and chatbots have recently entered decision-making during the war in Iran, these technologies have not yet made their way to most frontline soldiers. A smart glasses system tasked with identifying threats and recommending strikes would introduce massive new risks of errors.
Anduril is not the only one competing to develop smart goggles for combat. Rivet, which specializes in wearable sensors for the military, received a $195 million prototyping contract the same time, and in March the Israeli defense-tech company Elbit received its own $120 million contract. This all comes after Microsoft lost its role leading the Army’s smart glasses effort, following a Pentagon audit that found the Army wasn’t properly testing the glasses, a mistake that could have wasted $22 billion.
For both Anduril’s prototypes, the company is testing a new system for digital night vision, which uses electronic sensors and algorithms to boost low levels of light. It’s been a promised technology for decades but has tended to work too slowly for practical use and produce grainy images. Anduril says it has found improvements over previous prototypes through techniques rooted in both new generative AI and older machine learning.
Much of the other hardware for both projects is being built by Meta, including the displays and the waveguides that send visuals to the user’s eye without blocking the view. That might be a surprise to anyone who knows the backstory: In 2017, Facebook (now Meta) ousted Anduril founder Palmer Luckey following an internal conflict involving his support for Donald Trump. The two are now back in the augmented-reality business together, while Mark Zuckerberg has also adopted a friendlier posture toward the second Trump administration.
For the Army initiative, this suite of smart glasses, night vision, and sensors will be attached to the helmets and other gear soldiers already wear, with a separate battery pack. The EagleEye version will instead incorporate the tech into the helmet itself. Even if the Army doesn’t prefer EagleEye in the end, Barnett says, Anduril will attempt to sell the system to foreign militaries.
Multiple challenges must still be overcome. Unlike Meta’s Ray-Ban glasses, the prototypes have to operate in an environment full of dust, explosions, and smoke. Adding the computing power and battery life they need also means more weight for soldiers already carrying upwards of 100 pounds. Then the technology has to work in environments without ubiquitous 5G cell connections; powerful computer vision and AI models will need to run locally on the device.
For the Army to want to buy it at scale, “it’s got to work, and it’s got to be pretty seamless,” Wong says. “It’s a high bar.”
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
When Google opens its doors tomorrow for its annual developer conference, I/O, it will do so as a clear third place in the foundation model race. A year ago, at Google I/O 2025, the situation looked very different: The company was still riding high from the launch of Gemini 2.5 Pro that March, and distinguishing among the top-tier large language models often felt like a subjective splitting of hairs.
But a foundation model’s reputation these days rests largely on its coding capabilities, and for months Google’s coding tools have been outgunned by Anthropic’s Claude Code and OpenAI’s Codex. Those systems are so dramatically superior to Google’s own offerings that the company has reportedly had to allow some engineers at DeepMind, its AI division, to use Claude for their work—lest they fall farther behind.
So when I arrive at the conference in Mountain View, California tomorrow, I’ll certainly be on the lookout for any efforts Google is making to claw its way back into frontrunner position. But I’m also eager to see new developments in areas where Google shapes the cutting edge, such as AI for science. The company’s moves there might receive less attention, but they will be no less consequential.
Here are three things I’ll be paying particular attention to over the next two days.
An attempted coding comeback
Google is taking its AI coding crisis seriously. According to reporting from The Information, there’s a new AI coding team at DeepMind. And the Los Angeles Times has reported that John Jumper, who shared a 2024 Nobel Prize in chemistry with DeepMind CEO Demis Hassabis for their work on the protein structure prediction software AlphaFold, is lending his talents to the efforts. I would be surprised if we don’t see a major new coding release at I/O, perhaps in the form of an update to the company’s Antigravity agentic coding platform.
That said, we shouldn’t expect anything transformative here. Googlers have access to models and products that are substantially ahead of those released to the public, yet they were still reportedly fighting over who got access to Claude Code last month. Unless the company has made astonishing progress since then, Google probably won’t make it back to the coding frontier in the next two days.
Science and health
Coding might be Google DeepMind’s weakness, but science is its conspicuous strength. It is the only frontier AI company to have earned a Nobel Prize. And as LLMs have come to dominate the AI-for-science landscape, Google has only solidified its lead. Last year, the company released multiple scientific AI tools, including the AI co-scientist, which formulates hypotheses and research plans in response to user questions and has been described as an “oracle” by one Stanford scientist, and AlphaEvolve, a system that iteratively discovers new solutions for mathematical and computational problems. If any new scientific tools are announced at I/O, they’ll be worth noting.
I’ll also be paying close attention to any moves Google makes in health and medicine. Google is doing some of the best research out there on LLM-basedhealth tools, but OpenAI has defined the health AI conversation since the release of ChatGPT Health in January. Google has announced that it will be making its AI-powered Health Coach publicly available tomorrow, but promotional material suggests that the tool is geared more toward providing advice on topics such as fitness and diet than to addressing users’ medical concerns. Is this another area where Google has fallen behind, or is the company exercising appropriate caution in a high-stakes domain?
The drama
While Google fans congregate down in Mountain View, roughly 30 miles north in Oakland the Elon Musk v. Sam Altman trial will be wrapping up. The past few months have seen more than their fair share of AI CEO drama—before the trial, the animosity between Altman and Anthropic CEO Dario Amodei took center stage as Anthropic and OpenAI worked to negotiate deals with the US Department of Defense. But DeepMind’s Hassabis has, for the most part, steered clear of such drama. He effectively presents himself as a Nobel Prize-winning nerd, and if he has written screeds about any of his peers, they haven’t been leaked to the press or appeared in legal discovery.
That’s not to say that Google is controversy free. Last month, a group of 600 employees, many of whom work for DeepMind, sent a letter to CEO Sundar Pichai protesting an impending DoD deal. Google signed that deal the next day. Hassabis, Pichai, and all the other big names will surely do their best to skirt these and other touchy subjects while on stage, but controversies will worm their way in regardless. It will be interesting to see whether Google can maintain its veneer of neutrality.
On Monday, the jury in Musk v. Altman dealt Elon Musk a major blow—reaching a unanimous advisory verdict that he had sued OpenAI too late and, as a result, his claims are barred by the applicable statutes of limitations. US District Judge Yvonne Gonzalez Rogers immediately accepted it.
Musk announced on X that he will be appealing the decision. “The judge & jury never actually ruled on the merits of the case, just on a calendar technicality,” he wrote.
OpenAI was cofounded by Musk and a group of researchers in 2015 as a nonprofit with a mission to develop AI for the benefit of humanity, unconstrained by a need to generate financial returns. Musk donated $38 million to the company during its early days, allegedly on the basis that OpenAI CEO Sam Altman and president Greg Brockman had promised to keep the company a nonprofit committed to the mission.
Musk brought two claims against OpenAI. First, he argued that Altman and Brockman breached the charitable trust he created through his donations by breaking their promise to keep the company a nonprofit and creating a for-profit subsidiary that ballooned over the years. Second, he argued that Altman and Brockman unjustly enriched themselves at Musk’s expense. He sued OpenAI in 2024.
Musk asked the court to unwind a 2025 restructuring that converted OpenAI’s for-profit subsidiary into a public benefit corporation and to remove Altman and Brockman from their roles.
OpenAI argued that the time for Musk to sue the company had run out before he brought the case. The statute of limitations on the breach of charitable trust claim is three years, while the statute of limitations on the unjust enrichment claim is two years. This means that Musk should have discovered, or had reason to discover, Altman and Brockman’s alleged breach of charitable trust no earlier than 2021 and their alleged unjust enrichment no earlier than 2022.
While Musk argued he discovered that Altman and Brockman had broken their promise only in 2022, OpenAI claimed that Musk had reason to think this well before 2021.
Musk told the jury that he has gone through “three phases” in his beliefs about OpenAI: In phase one, he was “enthusiastically supportive” of the company. In phase two, “I started to lose confidence that they were telling me the truth,” he said. In phase three, “I’m sure they’re looting the nonprofit.”
Here’s a deeper dive into a timeline of the events as testified in the trial. You can read my dispatches from all three weeks of the trial here and here and here.
2017: Musk proposes creating a for-profit subsidiary
In 2017, two years after OpenAI was founded, Musk and the other cofounders tried to create a for-profit subsidiary to raise enough capital to build artificial general intelligence—powerful AI that can compete with humans on most cognitive tasks. They fought a bitter power battle over who would get to control the entity. Musk also proposed merging OpenAI with his electric-car company, Tesla.
During the trial, OpenAI’s lawyers pressed Musk on these discussions, suggesting that Musk knew in 2017 about Altman and Brockman’s plans to pivot the company—even participating in such plans—and had reason to sue then.
“I was not opposed to there being a small for-profit that provides funding to the nonprofit,” Musk told the jury, “as long as the tail didn’t wag the dog.”
2019: OpenAI creates a for-profit subsidiary with capped profits
In 2019, OpenAI created a for-profit subsidiary, under which employees and investors would receive a capped return on their investment. At the same time, the company secured a $1 billion investment from Microsoft. OpenAI argued that Musk again had reason to sue the company then.
But Musk testified that he didn’t think the move was violating the nonprofit’s mission. “If you’ve got a capped-profit situation, it hasn’t violated the nonprofit’s goal,” Musk told the jury earlier in the trial. “There was no basis for me to file a lawsuit at that time.”
2020: Microsoft snags an exclusive license
In 2020, when Microsoft secured an exclusive license to OpenAI’s GPT-3 model, Musk posted on X: “This does seem like the opposite of open. OpenAI is essentially captured by Microsoft.” OpenAI once again argued that Musk had reason to sue then.
But Musk testified that after reading the post, Altman reassured him that “OpenAI was staying on the mission as a nonprofit.” Musk said although he was skeptical, he still had no reason to sue the company at that point.
2022: Microsoft prepares to invest $10 billion in OpenAI
It was only in 2022, Musk testified, that he discovered OpenAI had abandoned its nonprofit mission. At that time, Microsoft was preparing to invest $10 billion in OpenAI—a deal that closed in 2023.
“I was disturbed to see OpenAI with a $20B valuation,” Musk texted Altman after reading the news. “This is a bait and switch.”
Musk told the jury this was the moment that made him realize “the for-profit is the tail wagging the dog.” He thought Microsoft would give $10 billion only if it expected “a very big financial return.” He argued that this was the point he realized “OpenAI had become, for all intents and purposes, a for-profit company with a $20 billion valuation.”
“The 2023 deal was different,” Steven Molo, one of Musk’s lawyers, hammered home during his closing argument.
The jury sides with OpenAI
It was up to the jury to decide whether the evidence supported Musk’s claim that he first realized in 2023 that OpenAI was no longer a nonprofit committed to its mission. In the verdict announced today, they found Musk did in fact have reason to think that he was being misled by Altman and Brockman before 2021. They did not address whether he was in fact misled.
Courts often decide cases on procedural grounds like statutes of limitations when they can, because it can be the cleaner way to resolve a case than to grapple with its merits.
Musk has said he will appeal the decision to the Ninth Circuit Court of Appeals, a federal appellate court that reviews decisions from district courts in California and other states.
Every year the World Health Organization publishes a global health statistics report. It features the numbers behind world health trends and, importantly, assesses whether we’re on track to reach ambitious goals set in 2015. It’s a bit like a health grade.
The 2026 report was published on Wednesday. And the results aren’t looking brilliant. While we are seeing some improvements, they are uneven, and they’re far too slow.
The targets themselves are part of the United Nations’ Sustainable Development Goals, a sprawling and ambitious plan focused on improving life around the world. The 17 goals were set to tackle poverty and climate change and to boost education, gender equality, health, and well-being, among many other quality of life issues. Those targets were meant to be met by 2030.
Perhaps they were a little too ambitious. Here are the numbers and statistics that stood out to me on this year’s world health report card.
1.3 million new cases of HIV in 2024
Before the SDGs, there were the Millennium Development Goals. One MDG target was to halt and reverse the spread of HIV—and that target was exceeded by 2015. Back then, we were considered on track to “end the AIDS epidemic by 2030.”
How depressing, then, to see that in 2024 there were an estimated 1.3 million new cases of HIV. That’s 40% lower than the figure from 2010. But it’s still 1.3 million additional people with HIV. The SDG target is to reduce HIV incidence by 90% by 2030—we’re not likely to meet it.
10.7 million new cases of TB
The picture is even bleaker for tuberculosis, which ranks 10th on the WHO’s list of top global causes of death. The goal was to reduce cases by 80% between 2015 and 2030. So far, cases have only fallen by a measly 12%. And when you break the change down by region, the Americas saw an increase of 13%
An 8.5% rise in malaria cases
And then there’s malaria, the mosquito-borne disease with a 7% fatality rate. The European region has been free of malaria since 2015, but the disease is a significant concern in many countries in the Global South, particularly in Africa. The goal was to lower rates by 90% between 2015 and 2030. In 2024, there were an estimated 282 million cases of malaria globally—representing an 8.5% increase in incidence rates.
Antimalarial drug resistance is a major challenge here—forms of the malaria virus that are resistant to drugs have been confirmed or suspected in eight countries in Africa, according to a separate WHO report. Mosquitoes that are resistant to commonly used insecticides are present in nine African countries. And climate change, which can alter mosquito habitats, may be making things worse.
42.8 million children are wasting
We’re not meeting child health targets, either. Take malnutrition, for example. As of 2024, the global prevalence of wasting in children was 6.6%—that’s a staggering 42.8 million children who are literally wasting away because of a lack of adequate food. On the other end of the spectrum, 5.5% of children are now considered overweight. Both figures were meant to be below 5% by 2030, which now seems unlikely.
Vaccination rates are dropping in the Americas
Progress in improving childhood vaccination coverage has stalled. Globally, an estimated 76% of children are getting their second dose of a measles vaccine—a figure far below the the approximately 95% needed to prevent outbreaks. The Americas currently has lower rates of vaccine coverage for three of the four “core” vaccines than it did in 2015.
This is partly due to a lack of investment, says Goodarz Danaei, an epidemiologist at the Harvard T.H. Chan School of Public Health. “But now we have a misinformation campaign going around vaccines that makes it worse,” he adds.
And of course the pandemic affected progress toward health goals in more direct ways: 7 million people died of covid-19. The WHO report estimates that, for each of these, there were an additional two “excess” deaths related to the pandemic, due to disruptions in health care, for example. That puts the total figure at 22.1 million pandemic-related deaths.
A woman dies every two minutes from “maternal causes”
Maternal mortality rates fell by about 40% between 2020 and 2023. But today’s rate equates to 712 maternal deaths every single day. That’s one every two minutes. The WHO report notes that we’d have to reduce the mortality rate by almost 15% per year in order to meet the 2030 target. This seems incredibly unlikely, particularly given the recent decimation of US funding for global aid programs, which is expected to result in thousands of additional maternal deaths.
Progress has also slowed in reducing the risk of death from noninfectious diseases like cancer, diabetes and cardiovascular disease. “Overall, neither the world nor any WHO region is currently on track to meet the 2030 SDG target,” the report states.
2.1 billion people struggle to afford health care
Despite plans to make health care more affordable, a significant chunk of the population is being pushed into poverty by health-care costs. In 2022, 2.1 billion people faced financial hardship due to health spending—and 1.6 billion of them were living in or had been pushed into poverty.
Across the board, there have been some important improvements in global health. But the achievements have not gone far enough. “The good news is that there is progress,” says Danaei. “But as always, the glass is half empty.”
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
In a dimly lit bedroom, a frightened young woman is thrown onto a bed by a tall, muscular man. He grabs her hand, and flame-like vines crawl across her body, fusing with her flesh. She levitates, then drops. A dragon-shaped tattoo appears across her chest.
“Two months,” the man says. “Give me an heir, or I will eat you.”
The scene is from Carrying the Dragon King’s Baby, one of the many hundreds of short dramas that appear on apps like DramaWave and ReelShort. There’s just something about this one that isn’t quite right. The lighting may be glossy and cinematic, but the show has an odd visual texture like something between a movie and a video game cutscene.
That’s because Carrying the Dragon King’s Baby is part of a new trend for making these shows entirely with AI: no actors, camera operators, cinematographers, or CGI specialists required.
China’s short drama industry has boomed since its launch, in 2018. These ultrashort, melodramatic, and often smutty shows are designed for smartphone viewing, with episodes often running just one or two minutes long: Viewers can finish an entire series in as little as 30 minutes to an hour. The films are made for endless scrolling, packed with emotional confrontations and melodramatic plot twists. The trend’s growth is driven by apps that bombard TikTok, Instagram, and Facebook with cliffhanger-heavy ads designed to lure viewers into buying subscriptions. In 2024, China’s short drama market reached roughly $6.9 billion in revenue, surpassing the country’s annual box office earnings for the first time.
Since 2022, Chinese short drama companies have aggressively expanded overseas, translating existing hits and producing localized series featuring local actors. Globally, short drama apps have approached a billion cumulative downloads. The United States is the biggest market outside of China, providing around 50% of the revenue, according to research firm DataEye.
Now the industry is reinventing itself. Chinese short drama companies—already masters of low-budget, algorithmically optimized entertainment—are embracing generative AI to produce content faster and cheaper than ever. An average of 470 AI-generated short dramas were released every day in January, according to DataEye. Short-drama companies like Kunlun Tech are ramping up AI productions, shrinking film crews, and reorganizing the labor pipeline from the ground up. For some studios, AI has moved from being a supporting tool to providing the backbone of production itself.
Infinite stories, infinite tropes
Short dramas are already famously low-budget. But AI has made them dramatically cheaper to mass-produce, helping to accelerate the entire process—and save money. Production timelines have collapsed. Conceptualization, script writing, casting, shooting, and editing used to take three to four months. With AI, the process can now take less than a month, says Tang Tang, vice president at short-drama platform FlexTV. Producing a short drama in North America once cost roughly $200,000, but AI can cut that cost by 80% to 90%, according to Tang.
After expanding into the US market, Chinese short drama companies largely followed the same playbook they used in China: Buy traffic aggressively on TikTok, Facebook, and YouTube; offer a handful of free episodes; then charge viewers to unlock the rest inside the companies’ apps. Decisions about what to produce next are often driven less by creative instinct than by performance data. “We look at what themes, plotlines, and writers resonate with audiences, then quickly adjust,” says Tang.
The industry operates at a relentless pace. “Everyone expects quick returns,” Tang says. “In China, if a series doesn’t break even within a month, the industry considers it a failure.”
As a result, screenwriters who spoke with MIT Technology Review said platforms often categorize projects using highly specific keywords that encompass everything from genre and setting to plot structure, such as “campus romance,” “gang rivalry,” “enemies to lovers,” or “rags to riches.” Recently, one of the most popular genres has been “reborn revenge,” a fantasy trope in which a wronged protagonist is miraculously reborn and given a chance to change their fate.
“You kind of have to keep the emotional intensity extremely high throughout the show, using the same plot devices over and over again: sudden deaths, betrayals, physical violence, huge confrontations,” says Phoenix Zhu, a freelance short drama screenwriter based in Suzhou. “It’s common to sacrifice narrative logic for shock value, because otherwise people are more likely to scroll away.”
Those simple tropes have made the format particularly compatible with AI-generated production. Earlier this year, FlexTV halted all traditionally shot productions and shifted entirely to AI-generated dramas. Kunlun Tech, the parent company of drama apps DramaWave and FreeReels, began producing AI-generated short dramas in 2025 and now offers more than 1,000 AI titles on its platforms. StoReels, another popular short drama company targeting a global audience, has said it aims to produce 100 AI-generated dramas per month.
“People’s attention spans are getting shorter, and serialized drama naturally has to get shorter,” says Han “Daniel” Fang, the CEO of Kunlun Tech. Fang told MIT Technology Review that the company is not going to stop investing in traditionally shot short dramas with real actors. But the company is expanding AI-generated productions and gradually increasing their share on its platforms as a low-cost way to experiment with new genres, themes, and ideas. “We want to bring the amount of AI work to 20% of the platform,” Fang says.
The format is also rapidly growing overseas. Research firm Omdia estimates that the global microdrama market reached $11 billion in 2025 and will grow to $14 billion by the end of 2026. The United States is expected to generate $1.5 billion in revenue in that market this year.
“No one comes to short dramas expecting high art,” says investor Shangguan Hong, former partner of Legend Capital. “The short-drama industry already stands out from traditional TV and filmmaking by being real-time and data-driven. AI only furthers that logic. In a sense, short drama is perfectly compatible with AI.”
Inside the content machine
The industry’s AI revolution is already changing the type of roles required to make short dramas.
Phoenix Zhu graduated from college in 2024 with a degree in philosophy. After months of rejections from traditional media and film studios, she eventually found work writing scripts for short dramas. “It was a very difficult job market for young people,” Zhu says. “I couldn’t afford to be picky about what I wrote.”
To support herself, Zhu worked a string of part-time jobs, including as a barista, a flower seller, and an event coordinator, while taking freelance writing gigs online for advertising and education companies. In April 2025, she sold her first short-drama script for around 20,000 yuan (approximately $2,945). More commissions followed, and she thought her career was finally beginning to pick up.
Then AI arrived. Two projects already in the contract stage were abruptly canceled, Zhu says. Rates across the industry began falling. The raises she expected as she gained more experience never materialized.
Still, writers like Zhu have been among the less disrupted workers in the industry. Many production roles on traditional filming sets have disappeared almost entirely from AI-generated productions.
“We could shrink the production team down to around 10 people,” says Tang, vice president at FlexTV. Like many companies in the industry, FlexTV relies primarily on Chinese writers and production teams, even for shows featuring non-Chinese characters and targeting overseas audiences. The reason is not just lower costs, Tang says, but also that Chinese writers better understand the pacing and narrative rhythm of short dramas.
Instead of camera crews, lighting technicians, makeup artists, and visual effects teams, AI productions now rely on smaller groups consisting largely of producers, writers, AI directors, and “AI asset curators.”
An AI asset curator translates scripts into prompts and generates reference images of characters, costumes, and scenes for AI video models to follow. MIT Technology Review found hundreds of job listings for the role on Chinese job sites, many requiring little prior industry experience beyond familiarity with AI tools.
“The technology has improved enormously just in the past few months,” says Hanzhong Bai, an AI short-drama producer based in Beijing. Bai says it is common for AI asset curators to use prompts like “combine the faces of these celebrities I like” when generating characters. Studios typically use a mix of tools, including Google’s image-generation model Nano Banana, ByteDance’s Seedance, and Kuaishou’s Kling.
For producers like Bai, AI also makes it economically viable to produce genres that were previously too expensive for short dramas, especially fantasy series requiring elaborate visual effects, costumes, or makeup. “We’ll see many more dragon and mermaid shows for exactly this reason,” Bai says.
The compressed production cycle has also changed the writing process itself. Writers once had two to three months to finish a script. Now, Zhu says, platforms often expect delivery within a month. Scripts can also be rougher and more flexible, since scenes, visuals, and even plot details can be changed later through prompts.
As a result, writers increasingly have to write for AI models as much as for human audiences. Zhu says she now has to describe scenes with far greater visual specificity, effectively taking on responsibilities once handled by cinematographers or visual effects teams.
“Before AI, writing ‘He gave her a cold stare’ might have been enough,” Zhu says. “Now I might need to write, ‘Cold beams of light shot out from his eyes.’”
Fang of Kunlun Tech believes the future quality of AI-generated short dramas is ultimately a numbers game. “Good ideas and good writing still stand out,” Fang says. “The quality [of AI short drama] will improve simply because more people with strong ideas will be able to make their shows.”
In the final week of the Musk v. Altman trial, lawyers traded blows over Elon Musk’s and OpenAI CEO Sam Altman’s credibility. Altman was grilled on his alleged history of lying and self-dealing involving companies that do business with OpenAI. But he fired back, painting Musk as a power-seeker who wanted to control the development of artificial general intelligence (AGI)—powerful AI that can compete with humans on most cognitive tasks.
As evidence of their commitment to AI safety, OpenAI brought out a golden trophy of a donkey’s ass that was gifted to an employee after he was called a “jackass” for standing up to Musk’s plans to race toward AGI.
Lawyers for both sides also presented their closing arguments, floating unflattering mugshot-style photos of Musk and Altman next to each other on a giant screen. Musk’s lawyer Steven Molo argued that Altman and OpenAI president Greg Brockman broke their promise to use money Musk donated to maintain OpenAI as a nonprofit that develops AI for the benefit of humanity. Instead, they created a for-profit subsidiary that made them extraordinarily wealthy.
OpenAI’s lawyer Sarah Eddy argued that Altman and Brockman never promised to keep OpenAI a nonprofit. She added that even though it’s been restructured, OpenAI remains a nonprofit dedicated to developing AI safely.
She claimed that Musk sued too late—and that his real motive is to sabotage a competitor to his own AI company, xAI, which he launched in 2023.
Musk is asking the court to unwind the 2025 restructuring that converted OpenAI’s for-profit subsidiary into a public benefit corporation and to remove Altman and Brockman from their roles. He is also seeking as much as $134 billion in damages from OpenAI and Microsoft, to be awarded to OpenAI’s nonprofit.
The jury will begin deliberating on Monday and deliver an advisory verdict as soon as next week. The jury verdict is not binding on the judge, who will decide the case.
If the judge rules in Musk’s favor, it could upend OpenAI’s race toward an IPO at a valuation approaching $1 trillion. Meanwhile, xAI is expected to go public as a part of Musk’s rocket company SpaceX as early as June, at a target valuation of $1.75 trillion.
Musk the power-seeker, Altman the liar.
In the first week of the trial, Musk said he was suing to save OpenAI’s mission to build AI safely for the benefit of humanity. This week, Altman denied Musk was a paladin of AI safety and painted him as a power-seeker who wanted to control OpenAI.
Altman told the jury that in 2017, when Musk and other cofounders were discussing creating a for-profit arm, they asked Musk what would happen to his control over such an entity if he died. “Maybe the control of OpenAI should pass to my children,” Musk said, according to Altman.
Musk’s lawyer shot back, grilling Altman on his alleged history of lying. He pointed out that OpenAI’s former executives Ilya Sutskever and Mira Murati, and former board members Helen Toner and Tasha McCauley, all testified that Altman had lied to them. In 2023, Altman was briefly fired as CEO over the alleged behavior.
Molo also pressed Altman about his personal investments in startups that do business with OpenAI. Altman testified that he tried to steer OpenAI to buying power from the nuclear energy company Helion Energy, a third of which he owns.
(Last Friday, the US House oversight committee launched an investigation into Altman’s potential conflicts of interest. Attorneys general from more than a half-dozen states called for the Securities and Exchange Commission to review them.)
During his closing statement, Molo put Altman’s credibility on the stand again. “Imagine that you’re on a hike, and you come upon one of those wooden bridges that you see on a trail, and it’s over a gorge,” he said. “A woman standing by the entry to the bridge says, ‘Don’t worry—the bridge is built on Sam Altman’s version of the truth.’ Would you walk across that bridge?”
Altman, who sat behind his lawyers, looked up uneasily every time his name was mentioned.
During her closing argument, Eddy fired back. Musk “never cared about the nonprofit structure,” she said. “What he cared about was winning.”
Musk, though, was absent. Despite the judge’s order that he remain available, he flew to China with President Trump.
Did Altman promise to keep OpenAI a nonprofit?
During her closing argument, Eddy argued that no testimony or evidence showed any conditions on Musk’s donations, or any promises made by Altman and Brockman to keep the company a nonprofit. “No commitments or promises were made. No restrictions were placed on Mr. Musk’s donations,” she said.
Eddy added that it was evident Musk wasn’t truly committed to keeping OpenAI a nonprofit. She noted that in 2017, he tried to create a for-profit subsidiary and fought a bitter battle with Altman and Brockman to have control over it.
“I was not opposed to there being a small for-profit that provides funding to the nonprofit,” Musk told the jury earlier in the trial, “as long as the tail didn’t wag the dog.”
Eddy then argued that Musk sued too late, filing in 2024 after the statutes of limitations on his claims ran out. In 2019, OpenAI created a for-profit subsidiary, under which employees and investors received a capped return on their investment.
But Musk testified that he discovered OpenAI had abandoned its nonprofit mission only in 2022, when Microsoft was preparing to invest $10 billion in OpenAI—a deal that closed in 2023. “I was disturbed to see OpenAI with a $20B valuation,” he texted Altman after reading the news. “This is a bait and switch.”
Musk told the jury that the $20 billion valuation made him realize “the for-profit is the tail wagging the dog.”
“The 2023 deal was different,” Molo hammered home during his closing argument.
Is OpenAI still a nonprofit committed to its mission?
A central question raised in the last week of trial was whether OpenAI remains a nonprofit committed to developing AGI safely for the benefit of humanity. Eddy, the OpenAI lawyer, argued that the nonprofit still controls the for-profit and seeks to “help AGI turn out well for humanity.” “The OpenAI nonprofit is the best-resourced nonprofit in the world,” thanks to the for-profit, she added.
Molo countered that while the OpenAI’s nonprofit nominally controls the company, it does not do so in practice. OpenAI’s nonprofit and for-profit are controlled by the same people—seven of the nonprofit’s eight board members are on the for-profit’s board. The nonprofit hired employees only a month before the trial started and does work only in grant-making rather than AI research.
Molo played a video interview of Altman saying that the nonprofit board’s failure to fire him in 2023 was “its own kind of governance failure.”
“We’re left with this nonprofit that doesn’t have any voice,” Jill Horwitz, a law professor at Northwestern University who studies nonprofits, told MIT Technology Review. “It doesn’t have much money, and OpenAI doesn’t think it has any obligation to fund it. It barely has a staff,” she says. “It’s unclear how on earth the nonprofit is supposed to exercise its duties and control the entire company.”
Civil society groups and policymakers have spoken out against OpenAI’s restructuring over the years. So has Musk, although his own stake in the AI race makes him a dubious champion for the public interest.
“The public interest in the nonprofit loses, no matter who wins or loses this trial,” says Horwitz.
Jackass for AI safety
Despite US District Judge Yvonne Gonzalez Rogers’s warning during the first week that this trial was not about AI safety, the issue stole the show again. Throughout the trial, the lawyers from both sides traded barbs over the safety track records of ChatGPT (which has allegedly caused teen suicides) and Grok (which has flooded X with porn).
On the last day of testimony, OpenAI’s lawyer Bradley Wilson handed the judge a small golden trophy of a donkey’s ass, inscribed: “Never stop being a jackass for safety.”
The trophy belonged to Joshua Achiam, OpenAI’s chief futurist. He testified that he’d warned, when Musk announced in 2018 that he was leaving OpenAI to race toward building AGI, that speed could compromise safety. Musk snapped and called him a “jackass,” said Achiam. His colleagues, including Dario Amodei, now CEO of Anthropic, gave him the trophy to enshrine the diss.
“I don’t want it,” said the judge. The shenanigans spilled out into the street too. In front of the Oakland courthouse, a protester paraded around wearing a costume of Musk holding a bag of ketamine and driving a Cybertruck. Another held a photo of Sam Altman and a poster reading, “Stop AGI or we’re all gonna die.”
When Jennifer got a job doing research for a nonprofit in 2023, she ran her new professional headshot through a facial recognition program. She wanted to see if the tech would pull up the porn videos she’d made more than 10 years before, when she was in her early 20s. It did in fact return some of that content, and also something alarming that she’d never seen before: one of her old videos, but with someone else’s face on her body.
“At first, I thought it was just a different person,” says Jennifer, who is being identified by a pseudonym to protect her privacy.
But then she recognized a distinctly garish background from a video she’d shot around 2013, and she realized: “Somebody used me in a deepfake.”
Eerily, the facial recognition tech had identified her because the image still contained some of Jennifer’s features—her cheekbones, her brow, the shape of her chin. “It’s like I’m wearing somebody else’s face like a mask,” she says.
“It’s like I’m wearing somebody else’s face like a mask.”
Conversations about sexualized deepfakes—which fall under the umbrella of nonconsensual intimate imagery, or NCII—most often center on the people whose faces are featured doing something they didn’t really do or on bodies that aren’t really theirs. These are often popular celebrities, though over the past few years more people (mostly women and sometimes youths) have been targeted, sparking alarm, fear, and even legislation. But these discussions and societal responses usually are not concerned with the bodies the faces are attached to in these images and videos.
As Jennifer, now 37 and a psychotherapist working in New York City, says: “There’s never any discussion about Whose body is this?”
For years, the answerhas generally been adult content creators. Deepfakes in fact earned their name back in November 2017, when someone with the Reddit username “deepfakes” uploaded videos showing faces of stars like Scarlett Johansson and Gal Gadot pasted onto porn actors’ bodies. The nonconsensual use of their bodies “happens all the time” in deepfakes, says Corey Silverstein, an attorney specializing in the adult industry.
But more recently, as generative AI has improved, and as “nudify” apps have begun to proliferate, the issue has grown far more complicated—and, arguably, more dangerous for creators’ futures.
Porn actors’ bodies aren’t necessarily being taken directly from sexual images and videos anymore, or at least not in an identifiable way. Instead, they are inevitably being used as training data to inform how new AI-generated bodies look, move, and perform. This threatens the livelihood and rights of porn actors as their work is used to train AI nudes that in turn could take away their business. And that’s not all: Advancements in AI have also made it possible for people to wholly re-create these performers’ likenesses without their consent, and the AI copycats may do things the performers wouldn’t do in real life. This could mean their digital doubles are participating in certain sex acts that they haven’t agreed to do, or even perpetrating scams against fans.
Adult content creators are already marginalized by a society that largely fails to protect their safety and rights, and these developments put them in an even more vulnerable position. After Jennifer found the deepfake featuring her body, she posted on social media about the psychological effects: “I’ve never seen anyone ask whether that might be traumatic for the person whose body was used without consent too. IT IS!” Several other creators I spoke with shared the mental toll that comes with knowing their bodies have been used nonconsensually, as well as the fear that they’ll suffer financially as other people pirate their work. Silverstein says he hears from adult actors every day who “are concerned that their content is being exploited via AI, and they’re trying to figure out how to protect it.”
One law professor and expert in violence against women calls these creators the “forgotten victims” of NCII deepfakes. And several of the people I spoke with worry that as the US develops a legal framework to combat nonconsensual sexual content online, adult actors are only at risk of further injury; instead of helping them, the crackdown on deepfakes may provide a loophole through which their content and careers could be stripped from the internet altogether.
How deepfakes cause “embodied harms”
During his preteen years in the 1970s, Spike Irons, now a porn actor and president of the adult content platform XChatFans, was “in love” with Farrah Fawcett. Though Fawcett did not pose nude, Jones managed to get his hands on what looked like pictures of her naked. “People were cutting out faces and pasting them on bodies,” Irons says. “Deepfakes, before AI, had been going around for quite a while. They just weren’t as prolific.”
The early public internet was rife with websites capitalizing on the idea that you could use technology to “see” celebrities naked. “People would just use Microsoft Paint,” says Silverstein, the attorney. It was a simple way to mash up celebrities’ faces with porn.
People later used software like Adobe After Effects or FakeApp, which was designed to swap two individuals’ faces in images or videos. None of these programs required serious expertise to alter content, so there was a low barrier to entry. That, plus the wealth of porn performers’ videos online, helped make face-swap deepfakes that used real bodies prevalent by the 2010s. When, later in the decade, deepfakes of Gal Gadot and Emma Watson caused something of a broader panic, their faces were allegedly swapped onto the bodies of the porn actors Pepper XO and Mary Moody, respectively.
But it wasn’t just high-profile actors like them whose bodies were being used. Jennifer was “a very minor performer,” she says. “If it happened to me, I feel like it could happen to anybody who’s shot porn.” Since he started his practice in 2006, Silverstein says, “numerous clients” have reached out to report “This is my body on so-and-so.”
Both people whose faces appear in NCII deepfakes and those whose bodies are used this way can feel serious distress. Experts call this type of damage “embodied harms,” says Anne Craanen, who researches gender-based violence at the UK’s Institute for Strategic Dialogue, an organization that analyzes extremist content, disinformation, and online threats.
The term reflects the fact that even though the content exists in the virtual realm, it can cause physiological effects, including body dysmorphia. The face-swapped entity occupies the uncanny valley, distorting self-perception. After discovering their faces in sexual deepfakes, many people feel silenced, experts told me; they may “self-censor,” as Craanen puts it, and step back from public-facing life. Allison Mahoney, an attorney who works with abuse survivors, says that people whose faces appear in NCII can experience depression, anxiety, and suicidal ideation: “I’ve had multiple clients tell me that they don’t sleep at night, that they’re losing their hair.”
Independent creators aren’t just “having sex on camera.” For someone to rip off their work “for their own entertainment or financial gain fucking sucks.”
Though the impact on people whose bodies are used hasn’t been discussed or studied as often, Jennifer says that “it’s just a really terrible feeling, knowing that you are part of somebody else’s abuse.” She sees it as akin to “a new form of sexual violence.”
The uncertainty that comes with not being aware of what your body is doing online can be highly unsettling. Like Jennifer, many adult actors don’t really know what’s out there. But some devoted followers know the actors’ bodies well—often recognizing tattoos, scars, or birthmarks—and “very quickly they bring [deepfakes] to the adult performer’s attention,” says Silverstein. Or performers will stumble upon the content by chance; some 20 years ago, for instance, the first such client to tell Silverstein her body was being used in a deepfake happened to be searching Nicole Kidman online when she found that one of the results showed Kidman’s face on her porn. “She was devastated, obviously, because they took her body,” he says, “and they were monetizing it.”
Otherwise, this imagery may be found by an organization like Takedown Piracy, one of several copyright enforcement companies serving adult content creators. US copyright violations can be challenging to prove if someone’s body lacks distinguishing features, says Reba Rocket, Takedown Piracy’s chief operating and marketing officer. But Rocket says her team has added digital fingerprinting technology to clients’ material to help flag and remove problematic videos, often finding them before clients realize they’re online.
By capturing “tens of thousands of tiny little visual data points” from videos, digital fingerprinting creates unique corresponding files that can be used to identify them, Rocket says—kind of like an invisible watermark. The prints remain even if pirates alter the videos or replace performers’ faces. Takedown Piracy has digitally fingerprinted more than half a billion videos and the organization has gotten 130 million copyrighted videos taken down from Google alone (though, of those videos, Rocket hasn’t tracked how many of these specifically include someone else’s face on a performer’s body).
Besides copyright, a range of legal tools can be used to try to combat NCII, says Eric Goldman, a law professor at Santa Clara University. For example, victims can claim invasion of privacy. But using these tools isn’t particularly straightforward, and they may not even apply when it comes to someone’s body. If there aren’t, for instance, unique markers indicating that a body in a deepfake belongs to the person who says it does, US law “doesn’t really treat [this content] as invasion of privacy,” Goldman says, “because we don’t know who to attribute it to.”
In a 2018 study that reviewed “judicial resolution” of cases involving NCII, Goldman found that one successful way plaintiffs were able to win cases was to assert “intentional affliction of emotional distress.” But again, that hinges on the ability to clearly identify the person in the content. Relevant statutes, he adds, might also require “intent to harm the individual,” which may be hard to show for people whose bodies alone are featured.
“AI girls will do whatever you want”
In the last few years, Silverstein says, it’s become less and less common to see the bodies of real adult content creators in deepfakes, at least in a way that makes them clearly identifiable.
Sometimes the bodies have been manipulated using AI or simpler editing tools. This can be as basic as erasing a birthmark or changing the size of a body part—minor edits that make it impossible to identify someone’s image beyond a reasonable doubt, so even porn actors who can tell that an altered image used their body as a base won’t get very far in the legal realm. “A lot of people are like, That looks like my body,” says Silverstein, but when he asks them how, they’ll reply, It just does.
At the same time, other users are now creating NCII with wholly AI-generated bodies. In “nudify” apps, anyone with a minimal grasp of technology can upload a photo of someone’s clothed body and have it replaced with a fake naked one. “So [much] of this content being created is just someone’s face on an AI body,” Silverstein says.
Such apps have drawn a ton of attention recently, in incidents from Grok’s “nudifying” minors to Meta’s running ads for—and then suing—the nudify app Crushmate. But there’s been relatively little attention paid to the content being used to train them. They almost certainly draw on the more than 10,000 terabytes of online porn, and performers have virtually zero recourse.
One reason is that creators aren’t able to demonstrate with any certainty that their content is being used to train AI models like those used by nudify apps. “These things are all a black box,” says Hany Farid, a professor at the University of California, Berkeley, who specializes in digital forensics. But “given the ubiquity” of adult content, he adds, it’s a “reasonable assumption” that online porn is being used in AI training.
“It’s just not at all difficult to come up with pornographic data sets on the internet,” says Stephen Casper, a computer science PhD student at MIT who researches deepfakes. What’s more, he says, plenty of shadowy online communities provide “user guides” on how to use this data to train AI, and in particular programs that generate nudes.
It’s not certain whether this activity falls within the US legal definition of “fair use”—an issue that’s currently being litigated in several lawsuits from other types of content creators—but Casper argues that even if it does, it’s ethically murky for porn created by consenting adults 10 years ago to wind up in those training data sets. When people “have their stuff used in a way that doesn’t respect or reflect reasonable expectations that they had at that time about what they were creating and how it would be used,” he says, there’s “a legitimate sense in which it’s kind of … nonconsensual.”
Adult performers who started working years ago couldn’t possibly have consented to AI anything; Jennifer calls AI-related risks “retroactively placed.” Contracts that porn actors signed before AI, adds Silverstein, might provide that “the publisher could do anything with the content using technology that now exists or here and after will be discovered.” That felt more innocuous when producers were talking about the shift from VHS to DVD, because that didn’t change the content itself, just the way it was conveyed. It’s a far different prospect for someone to use your content to train a program to create new content … content that could replace your work altogether.
Of course, this all affects creators’ bottom line—not unlike the way Google’s AI overviews affect revenue for online publishers who’ve stopped getting clicks when people are content with just reading AI-generated summaries. Performers’ “concern is … it’s another way to pirate [their] content,” says Rocket.
After all, independent creators aren’t just “having sex on camera,” as the adult content creator Allie Eve Knox puts it. They’re paying for filming equipment and location rentals, and then spending hours editing and marketing. For someone to then rip off and distort that content “for their own entertainment or financial gain,” she says, “fucking sucks.”
KIM HOECKELE
Tanya Tate, a longtime adult content creator, tells me about another highly unsettling AI-created situation: She was recently chatting with a fan on Mynx, a sexting app, when he asked her if she knew him. She told him no, and “his eyes just started watering,” Tate says. He was upset because he thought she did know him. Turns out he’d sent $20,000 to a scammer who’d used an AI-generated deepfake of Tate to seduce him.
Several men, Tate subsequently learned, had been scammed by an AI version of her, and some of them began blaming her for their losses and posting false statements about her online. When she reported one particularly aggressive harasser to the police, they told her he was exercising his “freedom of speech,” she says. Rocket, too, is familiar with situations where AI is used to take advantage of fans. “The actual content creator will get nasty emails from these people who’ve been scammed,” she says.
Other porn actors say they fear that their likenesses have been used without consent to do other things they wouldn’t do. One, Octavia Red, tells me she doesn’t do anal scenes, “but I’m sure there’s tons of deepfake anal videos of me that I didn’t consent to.” That could cost her, she fears, if viewers choose to watch those videos instead of subscribing to her websites. And it could cause fans to develop false expectations about what kind of porn she’ll create.
“I saw one AI creator saying, ‘Well, AI girls will do whatever you want. They don’t say no,’” says Rocket. “That horrifies me … especially if they’re training those AI models on real people. I don’t think they understand the damage to mental health or reputation that that can create. And once it’s on the internet, it’s there forever.”
Efforts to “scrub adult content from the internet”
As AI technology improves, it’s increasingly difficult for people to discern any type of real video from the best AI-generated ones on their own. In one 2025 study, UC Berkeley’s Farid found that participants correctly identified AI-generated voices about 60% of the time (not much better than random chance), while advances like false heartbeats make AI-generated humans tougher than ever to spot.
Nevertheless, most lawyers and legal experts I spoke with said copyright laws are still adult performers’ best bet in the US legal system, at least for getting their face-swapped content taken down. For his clients, Silverstein says, he tries to figure out the content’s origins and then issue takedown requests under the Digital Millennium Copyright Act, a 1998 law that adapted copyright law for the internet era. “Even recently, I had a performer who has an insanely well-known tattoo,” he says, and with a DMCA subpoena he managed to identify the poster of the content, who voluntarily removed it.
But this way of working is becoming increasingly rare.
These days it’s nearly “impossible,” Silverstein says, to determine who produced a deepfake, because many platforms that host pirated content operate facelessly. They’re also often based in places that “don’t really care about US law when it comes to copyrights,” says Rocket—places like Russia, the Seychelles, and the Netherlands.
While governments in the EU, the UK, and Australia have said they will ban or restrict access to nudify apps, it’s not an easily executed proposition. As Craanen notes, when app stores remove these services, they often simply reappear under different names, providing the same services. And social platforms where people share NCII deepfakes, argues Rocket, are slacking in getting them removed. “It’s endless, and it’s ridiculous, because places like Twitter and Facebook have the same technology we do,” Rocket says. “They can identify something as an infringement instantly, but they choose not to.”
(An Apple spokesperson, Adam Dema, said in an email that “’nudification’ apps are against our guidelines” in the app store, and it has “proactively rejected many of these apps and removed many others,” flagging a reporting portal for users. A Google spokesperson emailed, “Google Play does not allow apps that contain sexual content,” noting that the company takes “proactive steps to detect and remove apps with harmful content” and has suspended hundreds of apps for violating its policy. A Meta spokesperson shared a blog post about actions that company has taken against nudify apps but did not respond to follow-up questions about copyrighted material. X did not respond to a request for comment.)
As porn performers are forced to navigate AI-related threats, the only current federal law to address deepfakes may not help them much—and could even make matters worse. The Take It Down Act, which became US law last year, criminalizes publishing NCII and requires websites to remove it within 48 hours. But, as Farid notes, people could weaponize the measure by reporting porn that was made legally and with consent and claiming that it’s NCII. This could result in the content’s removal, which would hurt the performers who made it. Santa Clara’s Goldman points to Project 2025, the Heritage Foundation’s policy blueprint for the second Trump administration, which aims to wipe porn from the web. The Take It Down Act, he argues, “allows for the coordinated effort to scrub adult content from the internet.”
US lawmakers have a history of hurting sex workers in their attempts to regulate explicit content online. State-level age verification laws are an example; visitors can pretty easily get around these measures, but they can still result in reduced revenue for adult performers (because of lower traffic to those sites and the high price of age-checking services they have to purchase).
“They’re always doing something to fuck with the porn industry, but not in a way that actually helps sex workers,” says Jennifer. “If they do something, they’re taking away your income again—as opposed to something like giving you more rights to your image, [which] would be tremendously helpful.”
But as generative AI plays an increasingly large role in NCII deepfakes, the types of images to which adult performers have rights moves deeper into a gray area. Can actors lay claim to AI images likely trained on their bodies? How about AI-generated videos that impersonate them, like the one that tricked Tanya Tate’s fan?
The biggest challenge will be creating “legitimate, effective laws that will absolutely protect content creators from abusing their likeness to train and create AI,” Rocket says. “Absent that, we’re just going to have to keep pulling content down from the internet that’s fake.”
In the meantime, a few porn actors tell me, they’re trying to take advantage of copyright laws that weren’t really made for them; they’ve signed with platforms that host their AI-generated duplicates, with whom fans pay to chat, in part so they’ll have contracts that protect ownership of their AI likenesses. When I spoke with the actor Kiki Daire in September 2025 for a story on adult creators’ “AI twins,” she said she “own[ed] her AI” because she’d signed a contract with Spicey AI, a site that hosted AI duplicates of adult performers. If another company or person created her AI-generated likeness, she added, “I have a leg to stand on, as far as being able to shut that down.”
Even this, though, is not a sure thing; Spicey AI, for instance, shut down several months after I spoke with Daire, so it’s unlikely that her contract would hold. And when I spoke in October with Rachael Cavalli, another adult actor who had signed with an AI duplicate site in hopes it’d help protect her AI image, she admitted, “I don’t have time to sit around and look for companies that have used my image or turned something into a video that I didn’t actually do … it’s a lot of work.” In other words, having rights to your AI image on paper doesn’t make it easier to track down all the potentially infinite breaches of those rights online.
If she’d known what she knows about technology today, Jennifer says, she doesn’t think she would have done porn. The risks have increased too much, and too unpredictably. She now does in-person sex work; it’s “not necessarily safer,” she says, “but it’s a different risk profile that I feel more equipped to manage.”
Plus, she figures AI is unlikely to replace in-person sex workers the way it could porn actors: “I don’t think there’s going to be stripper robots.”
Jessica Klein is a Philadelphia-based freelance journalist covering intimate partner violence, cryptocurrency, and other topics.
The Tesla Semi has officially arrived. The company recently released a photo of the first vehicle rolling off its new full-scale production line.
This moment has been nearly a decade in the making: The company first announced the truck in late 2017. And now we’ve got final battery specs, official prices, and big news about big orders.
The Semi is a relatively affordable electric semitruck with pretty impressive performance. It also comes at a moment when Tesla has lost its grip on the global electric-vehicle market. Let’s talk about what’s new with the Tesla Semi and why this could be a breakout moment for electric trucking.
Medium- and heavy-duty vehicles, like buses and semitrucks, make up a small fraction of vehicles on the road but contribute an outsize fraction of pollution, including both carbon dioxide emissions and other pollutants like nitrogen oxides (NOx) and small particles. Globally, trucks and buses represent about 8% of total vehicles on the road, but they create 35% of carbon dioxide emissions from road transport.
Tesla’s latest addition to its vehicle lineup, the Class 8 Semi, could be part of the solution to cleaning up this polluting sector. (I’ll note here that I briefly interned at Tesla in 2016. I don’t have any ties to or financial interest in the company today.)
In November 2017, Elon Musk took to the stage at a lavish event in LA to announce the Semi. At that event, Musk promised a truck that could go from zero to 60 miles per hour in five seconds, could achieve a range of 500 miles, and would come with thermonuclear-explosion-proof glass. (Remember the era before the Twitter takeover and DOGE, when this was what Musk was known for? A simpler time.)
Soon after the unveiling, major corporations including Walmart put in early orders for Tesla Semis. Deliveries were expected in 2019.
That deadline obviously didn’t work out. The date was pushed back several times, and Tesla did start delivering a small number of pilot trucks, beginning in 2022. But this year, things got more serious, with the company releasing its final production specifications in February and rolling its first Semi off its high-volume production line in late April.
And last week, WattEV announced an order of 370 Tesla Semis. WattEV offers electric freight operations, essentially providing trucks as a service to companies so they don’t have to purchase their own or supply their own charging infrastructure. The company will pay over $100 million for the new trucks, and the first 50 should be delivered this year, with the full fleet expected by the end of 2027. Those trucks will be supported by megawatt-charging systems located in Oakland, Fresno, Stockton, and Sacramento.
With the factory up and running and a huge order on the books, it feels as if the Tesla Semi has truly arrived. And some of Musk’s claims from 2017 ring true: The base model has a range of about 320 miles, and the long-range version about 480 miles (quite close to his 500-mile claim).
Delivering this much range for this big truck means a whopping battery. The base model Tesla Semi battery pack has a usable capacity of 548 kilowatt-hours, according to a document filed with the California Air Resources Board (CARB). But the battery is even more massive in the long-range version, which boasts a whopping 822 kilowatt-hour battery. Compare these to the Tesla Model 3, which typically comes with a 64 kilowatt-hour pack.
I reached out to Tesla to confirm the battery size and ask other questions for this article; the company didn’t respond.
These trucks cost quite a bit more than they were expected to in 2017. At that time, the expected price was $150,000 for the base model and $180,000 for the long-range. Today, Tesla is pricing the trucks at $260,000 and $300,000, respectively, according to documentation filed with CARB.
That’s considerably more expensive than the median diesel truck being sold today, which rang in at $172,500 for the 2025 model year, according to research from the International Council on Clean Transportation. But it’s much cheaper than similar battery-electric trucks available today, where the median is about $411,000.
And in California, where companies can get vouchers that cover $120,000 towards the purchase price of an electric truck, the Tesla Semi is competitive right away, especially since electric trucks tend to be much cheaper to run and maintain than diesel ones.
Over the years, it wasn’t always clear that the Tesla Semi would ever actually hit the roads. (At that same 2017 event, Musk announced a new Roadster sports car, and that’s nowhere to be seen.) So it’s encouraging to see the factory starting up, and a large order that looks like it could lend this project some commercial momentum.
Tesla had a massive impact on the electric vehicle market, and if it can scale production and support charging infrastructure, it could help do the same for trucking.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
A big deal: Varda Space Industries says it has signed a pharmaceutical company as a commercial customer, marking what could be a landmark moment for in-orbit manufacturing.
Space as a lab: The bet is that microgravity causes drug molecules to crystallize into atomic arrangements impossible on Earth, potentially unlocking new versions of existing medicines.
Economics favor drugs: At $7,000 per kilogram to reach orbit, space manufacturing is impractical for most industries — but blockbuster drugs can be worth over $100 million per kilogram, making them a rare exception to the brutal math of rocket launches.
Still more experiment than factory: Despite the excitement, no product has ever been manufactured in space, brought back, and sold on Earth.
Varda Space Industries, a startup that’s been pitching its ability to perform drug experiments in space, says it has signed up the pharmaceutical company United Therapeutics in what may be remembered as a notable step toward in-orbit manufacturing.
The idea of building things in outer space for use on Earth has so far been explored mostly on board the International Space Station, and only in small-scale experiments backed by governments.
But Varda, based in El Segundo, California, is now telling drug companies it has a practical, and repeatable, way to produce novel molecules in microgravity.
“This is the first commercial path to products made in space,” says Michael Reilly, Varda’s chief strategy officer.
The scientific idea is that chemical mixtures have different properties under weightless conditions. For instance, water will hang together in a wiggly sphere, since without gravity, surface tension is the strongest force present.
The plan is to launch versions of United Therapeutics’ drugs into orbit, where they can be allowed to form solid crystals. The hope is that in microgravity, they’ll take on atomic arrangements not seen on Earth, possibly leading to new versions with improved stability or other valuable properties.
United is led by CEO Martine Rothblatt, who worked on early telecommunications satellites. Since then, she’s built a multibillion-dollar health franchise with a succession of drugs to treat a lung disease called pulmonary arterial hypertension, which her daughter suffers from, and a subsidiary developing genetically modified pigs as a source of organs for transplantation.
Rothblatt says space could be the next step if orbital conditions permit United to identify “even more amazing” versions of its drugs.
Space to reformulate
Pharmaceutical companies often try to keep their blockbuster franchises alive by creating improved versions of drugs or reformulating them—for example, making the switch from a pill to an inhaled version, as United has done with some of its products. Doing so can keep imitators at bay and create extra decades of patent protection.
Assisting drugmakers are specialist companies, such as Halozyme and MannKind, that earn profits by helping to reformulate other companies’ drugs, often taking a royalty on future sales.
That’s the business Varda has been trying to break into—by using excursions into space instead of nebulizers, patches, or nanoparticles. The company was formed in 2021 by Delian Asparouhov, a partner at Peter Thiel’s Founders Fund, along with Will Bruey, a former avionics engineer with Elon Musk’s SpaceX who is now Varda’s CEO.
The pair’s bet is that space manufacturing will become viable once rocket launches become frequent enough—and cheap enough—to support a business model in which raw materials are sent into orbit, processed, and then returned to Earth in a new form.
And that’s starting to happen. To get into space, Varda has been purchasing rides from SpaceX—which now launches a rocket every two or three days, usually a reusable Falcon 9.
Those rockets have a nose cone, or payload fairing, about the size of a moving truck that gets filled with satellites or instruments, which are then released into orbit.
Starting in 2023, Varda began sending up small satellites that have a boulder-size capsule attached. The capsule contains equipment to carry out experiments, and it can detach and fall back to Earth, entering the atmosphere at a speed of around Mach 25 before slowing via air resistance and eventually drifting to land with a parachute. (Varda lands its craft in the Australian outback.)
That speedy reentry has also drawn interest from the US military, including the Air Force, which has paid Varda to fly instruments and take measurements relevant to hypersonic missile technology. Of the six craft Varda has paid to put into orbit so far, half have been dedicated to military research and half carried drug-related demonstrations.
At Varda, such “dual use” of technology is accepted as part of being in the space business, which remains reliant on government support. The company’s founders say Varda may be the only company that employs hypersonic engineers and pharmaceutical chemists under the same roof.
At Varda’s headquarters, drug samples are loaded into a spinning arm that creates extra-high g-forces. While that’s the opposite of microgravity, increased weight can provide clues into whether a drug will act differently under new conditions.
COURTESY VARDA
Launching industries
Actual space manufacturing still remains mostly an aspirational project. In 2021, Jeff Bezos, after his first trip aloft in a rocket, suggested that polluting industries should be moved beyond the atmosphere. “We need to take all heavy industry, all polluting industry, and move it into space. And keep Earth as this beautiful gem of a planet that it is,” he told MSNBC.
Weight is the big obstacle to such dreams. It still costs around $7,000 to launch a single kilogram of payload into orbit, which makes it impractical to, say, send cotton into space to be dyed there, or even to launch the acids and solvents needed to make a semiconductor chip.
But drugs may be among the few exceptions to this economic rule, since pound for pound, they can be as valuable as rare radioactive isotopes and fine-cut diamonds.
For instance, just one kilogram of the weight-loss drug Ozempic is worth more than $100 million at retail. (The reason your Ozempic bill is only $1,000 a month is that minute quantities of the active ingredient are present in the shots.)
That’s why Varda thinks it may eventually be able to manufacture drugs in orbit. However, its effort with United is more of a flying experiment to learn whether the company’s lung medicines will crystallize differently in microgravity.
The terms of the deal between Varda and United aren’t public, and the companies haven’t said which specific drugs the collaboration will study. But Rothblatt did confirm that United is paying Varda to help it identify new crystal forms of its drugs (also called polymorphs), which it hopes could have improved properties.
“One has to do the experiment to find out if that is so. The first part of the experiment is to see what polymorphs of these molecules can be made without the influence of gravity,” she says. “Then, once we have those polymorphs, we will test them.”
There is good evidence that crystals form differently in space. For instance, in 2017 the pharmaceutical giant Merck sent samples of its cancer immunotherapy drug Keytruda to the International Space Station, where it was found to form crystals of a single size. On Earth, the drug tended to form two different sizes at once.
That experiment offered clues for how to formulate the drug as a shot instead of administering it intravenously. Still, when Merck introduced a Keytruda injection last year, it ended up using a different approach. That means there’s still no straight-line connection between orbital discoveries and any drug here on Earth. Actual space factories are another step further from reality.
“We’ve been learning from space for years, but I can’t name anything manufactured in space, brought down to Earth, and sold,” says Reilly. “So that is a first—or it will be a first.”
Reilly says that Varda anticipates launching United Therapeutics’ drugs into orbit sometime early next year.