On a table in his lab at the University of Pennsylvania, physicist Sam Dillavou has connected an array of breadboards via a web of brightly colored wires. The setup looks like a DIY home electronics project—and not a particularly elegant one. But this unassuming assembly, which contains 32 variable resistors, can learn to sort data like a machine-learning model.
While its current capability is rudimentary, the hope is that the prototype will offer a low-power alternative to the energy-guzzling graphical processing unit (GPU) chips widely used in machine learning.
“Each resistor is simple and kind of meaningless on its own,” says Dillavou. “But when you put them in a network, you can train them to do a variety of things.”
Sam Dillavou’s laboratory at the University of Pennsylvania is using circuits composed of resistors to perform simple machine learning classification tasks.
FELICE MACERA
A task the circuit has performed: classifying flowers by properties such as petal length and width. When given these flower measurements, the circuit could sort them into three species of iris. This kind of activity is known as a “linear” classification problem, because when the iris information is plotted on a graph, the data can be cleanly divided into the correct categories using straight lines. In practice, the researchers represented the flower measurements as voltages, which they fed as input into the circuit. The circuit then produced an output voltage, which corresponded to one of the three species.
This is a fundamentally different way of encoding data from the approach used in GPUs, which represent information as binary 1s and 0s. In this circuit, information can take on a maximum or minimum voltage or anything in between. The circuit classified 120 irises with 95% accuracy.
Now the team has managed to make the circuit perform a more complex problem. In a preprint currently under review, the researchers have shown that it can perform a logic operation known as XOR, in which the circuit takes in two binary numbers and determines whether the inputs are the same. This is a “nonlinear” classification task, says Dillavou, and “nonlinearities are the secret sauce behind all machine learning.”
Their demonstrations are a walk in the park for the devices you use every day. But that’s not the point: Dillavou and his colleagues built this circuit as an exploratory effort to find better computing designs. The computing industry faces an existential challenge as it strives to deliver ever more powerful machines. Between 2012 and 2018, the computing power required for cutting-edge AI models increased 300,000-fold. Now, training a large language model takes the same amount of energy as the annual consumption of more than a hundred US homes. Dillavou hopes that his design offers an alternative, more energy-efficient approach to building faster AI.
Training in pairs
To perform its various tasks correctly, the circuitry requires training, just like contemporary machine-learning models that run on conventional computing chips. ChatGPT, for example, learned to generate human-sounding text after being shown many instances of real human text; the circuit learned to predict which measurements corresponded to which type of iris after being shown flower measurements labeled with their species.
Training the device involves using a second, identical circuit to “instruct” the first device. Both circuits start with the same resistance values for each of their 32 variable resistors. Dillavou feeds both circuits the same inputs—a voltage corresponding to, say, petal width—and adjusts the output voltage of the second circuit to correspond to the correct species. The first circuit receives feedback from that second circuit, and both circuits adjust their resistances so they converge on the same values. The cycle starts again with a new input, until the circuits have settled on a set of resistance levels that produce the correct output for the training examples. In essence, the team trains the device via a method known as supervised learning, where an AI model learns from labeled data to predict the labels for new examples.
It can help, Dillavou says, to think of the electric current in the circuit as water flowing through a network of pipes. The equations governing fluid flow are analogous to those governing electron flow and voltage. Voltage corresponds to fluid pressure, while electrical resistance corresponds to the pipe diameter. During training, the different “pipes” in the network adjust their diameter in various parts of the network in order to achieve the desired output pressure. In fact, early on, the team considered building the circuit out of water pipes rather than electronics.
For Dillavou, one fascinating aspect of the circuit is what he calls its “emergent learning.” In a human, “every neuron is doing its own thing,” he says. “And then as an emergent phenomenon, you learn. You have behaviors. You ride a bike.” It’s similar in the circuit. Each resistor adjusts itself according to a simple rule, but collectively they “find” the answer to a more complicated question without any explicit instructions.
A potential energy advantage
Dillavou’s prototype qualifies as a type of analog computer—one that encodes information along a continuum of values instead of the discrete 1s and 0s used in digital circuitry. The first computers were analog, but their digital counterparts superseded them after engineers developed fabrication techniques to squeeze more transistors onto digital chips to boost their speed. Still, experts have long known that as they increase in computational power, analog computers offer better energy efficiency than digital computers, says Aatmesh Shrivastava, an electrical engineer at Northeastern University. “The power efficiency benefits are not up for debate,” he says. However, he adds, analog signals are much noisier than digital ones, which make them ill suited for any computing tasks that require high precision.
In practice, Dillavou’s circuit hasn’t yet surpassed digital chips in energy efficiency. His team estimates that their design uses about 5 to 20 picojoules per resistor to generate a single output, where each resistor represents a single parameter in a neural network. Dillavou says this is about a tenth as efficient as state-of-the-art AI chips. But he says that the promise of the analog approach lies in scaling the circuit up, to increase its number of resistors and thus its computing power.
He explains the potential energy savings this way: Digital chips like GPUs expend energy per operation, so making a chip that can perform more operations per second just means a chip that uses more energy per second. In contrast, the energy usage of his analog computer is based on how long it is on. Should they make their computer twice as fast, it would also become twice as energy efficient.
Dillavou’s circuit is also a type of neuromorphic computer, meaning one inspired by the brain. Like other neuromorphic schemes, the researchers’ circuitry doesn’t operate according to top-down instruction the way a conventional computer does. Instead, the resistors adjust their values in response to external feedback in a bottom-up approach, similar to how neurons respond to stimuli. In addition, the device does not have a dedicated component for memory. This could offer another energy efficiency advantage, since a conventional computer expends a significant amount of energy shuttling data between processor and memory.
While researchers have already built a variety of neuromorphic machines based on different materials and designs, the most technologically mature designs are built on semiconducting chips. One example is Intel’s neuromorphic computer Loihi 2, to which the company began providing access for government, academic, and industry researchers in 2021. DeepSouth, a chip-based neuromorphic machine at Western Sydney University that is designed to be able to simulate the synapses of the human brain at scale, is scheduled to come online this year.
The machine-learning industry has shown interest in chip-based neuromorphic computing as well, with a San Francisco–based startup called Rain Neuromorphics raising $25 million in February. However, researchers still haven’t found a commercial application where neuromorphic computing definitively demonstrates an advantage over conventional computers. In the meantime, researchers like Dillavou’s team are putting forth new schemes to push the field forward. A few people in industry have expressed interest in his circuit. “People are most interested in the energy efficiency angle,” says Dillavou.
But their design is still a prototype, with its energy savings unconfirmed. For their demonstrations, the team kept the circuit on breadboards because it’s “the easiest to work with and the quickest to change things,” says Dillavou, but the format suffers from all sorts of inefficiencies. They are testing their device on printed circuit boards to improve its energy efficiency, and they plan to scale up the design so it can perform more complicated tasks. It remains to be seen whether their clever idea can take hold out of the lab.
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
Have you ever thought about the miraculous fact that despite the myriad differences between languages, virtually everyone uses the same QWERTY keyboards? Many languages have more or fewer than 26 letters in their alphabet—or no “alphabet” at all, like Chinese, which has tens of thousands of characters. Yet somehow everyone uses the same keyboard to communicate.
Last week, MIT Technology Review published an excerpt from a new book, The Chinese Computer, which talks about how this problem was solved in China. After generations of work to sort Chinese characters, modify computer parts, and create keyboard apps that automatically predict the next character, it is finally possible for any Chinese speaker to use a QWERTY keyboard.
But the book doesn’t stop there. It ends with a bigger question about what this all means: Why is it necessary for speakers of non-Latin languages to adapt modern technologies for their uses, and what do their efforts contribute to computing technologies?
I talked to the book’s author, Tom Mullaney, a professor of history at Stanford University. We ended up geeking out over keyboards, computers, the English-centric design that underlies everything about computing, and even how keyboards affect emerging technologies like virtual reality. Here are some of his most fascinating answers, lightly edited for clarity and brevity.
Mullaney’s book covers many experiments across multiple decades that ultimately made typing Chinese possible and efficient on a QWERTY keyboard, but a similar process has played out all around the world. Many countries with non-Latin languages had to work out how they could use a Western computer to input and process their own languages.
Mullaney: In the Chinese case—but also in Japanese, Korean, and many other non-Western writing systems—this wasn’t done for fun. It was done out of brute necessity because the dominant model of keyboard-based computing, born and raised in the English-speaking world, is not compatible with Chinese. It doesn’t work because the keyboard doesn’t have the necessary real estate. And the question became: I have a few dozen keys but 100,000 characters. How do I map one onto the other?
Simply put, half of the population on Earth uses the QWERTY keyboard in ways the QWERTY keyboard was never intended to be used, creating a radically different way of interacting with computers.
The root of all of these problems is that computers were designed with English as the default language. So the way English works is just the way computers work today.
M: Every writing system on the planet throughout history is modular, meaning it’s built out of smaller pieces. But computing carefully, brilliantly, and understandably worked on one very specific kind of modularity: modularity as it functions in English.
And then everybody else had to fit themselves into that modularity. Arabic letters connect, so you have to fix [the computer for it]; In South Asian scripts, the combination of a consonant and a vowel changes the shape of the letter overall—that’s not how modularity works in English.
The English modularity is so fundamental in computing that non-Latin speakers are still grappling with the impacts today despite decades of hard work to change things.
Mullaney shared a complaint that Arabic speakers made in 2022 about Adobe InDesign, the most popular publishing design software. As recently as two years ago, pasting a string of Arabic text into the software could cause the text to become messed up, misplacing its diacritic marks, which are crucial for indicating phonetic features of the text. It turns out you need to install a Middle East version of the software and apply some deliberate workarounds to avoid the problem.
M: Latin alphabetic dominance is still alive and well; it has not been overthrown. And there’s a troubling question as to whether it can ever be overthrown. Some turn was made, some path taken that advantaged certain writing systems at a deep structural level and disadvantaged others.
That deeply rooted English-centric design is why mainstream input methods never deviate too far from the keyboards that we all know and love/hate. In the English-speaking world, there have been numerous attempts to reimagine the way text input works. Technologies such as the T9 phone keyboard or the Palm Pilot handwriting alphabet briefly achieved some adoption. But they never stick for long because most developers snap back to QWERTY keyboards at the first opportunity.
M: T9 was born in the context of disability technology and was incorporated into the first mobile phones because button real estate was a major problem (prior to the BlackBerry reintroducing the QWERTY keyboard). It was a necessity; [developers] actually needed to think in a different way. But give me enough space, give me 12 inches by 14 inches, and I’ll default to a QWERTY keyboard.
Every 10 years or so, some Western tech company or inventor announces: “Everybody! I have finally figured out a more advanced way of inputting English at much higher speeds than the QWERTY keyboard.” And time and time again there is zero market appetite.
Will the QWERTY keyboard stick around forever? After this conversation, I’m secretly hoping it won’t. Maybe it’s time for a change. With new technologies like VR headsets, and other gadgets on the horizon, there may come a time when QWERTY keyboards are not the first preference, and non-Latin languages may finally have a chance in shaping the new norm of human-computer interactions.
M: It’s funny, because now as you go into augmented and virtual reality, Silicon Valley companies are like, “How do we overcome the interface problem?” Because you can shrink everything except the QWERTY keyboard. And what Western engineers fail to understand is that it’s not a tech problem—it’s a technological cultural problem. And they just don’t get it. They think that if they just invent the tech, it is going to take off. And thus far, it never has.
If I were a software or hardware developer, I would be hanging out in online role-playing games, just in the chat feature; I would be watching people use their TV remote controls to find the title of the film they’re looking for; I would look at how Roblox players chat with each other. It’s going to come from some arena outside the mainstream, because the mainstream is dominated by QWERTY.
What are other signs of the dominance of English in modern computing? I’d love to hear about the geeky details you’ve noticed. Send them to zeyi@technologyreview.com.
Now read the rest of China Report
Catch up with China
1. Today marks the 35th anniversary of the student protests and subsequent massacre in Tiananmen Square in Beijing.
For decades, Hong Kong was the hub for Tiananmen memorial events. That’s no longer the case, due to Beijing’s growing control over the city’s politics after the 2019 protests. (New Yorker $)
To preserve the legacy of the student protesters at Tiananmen, it’s also important to address ethical questions about how American universities and law enforcement have been treating college protesters this year. (The Nation)
2. A Chinese company that makes laser sensors was labeled by the US government as a security concern. A few months later, it discreetly rebranded as a Michigan-registered company called “American Lidar.” (Wall Street Journal $)
3. It’s a tough time to be a celebrity in China. An influencer dubbed “China’s Kim Kardashian” for his extravagant displays of wealth has just been banned by multiple social media platforms after the internet regulator announced an effort to clear out “ostentatious personas.” (Financial Times $)
Meanwhile, Taiwanese celebrities who also have large followings in China are increasingly finding themselves caught in political crossfires. (CNN)
4. Cases of Chinese students being rejected entry into the US reveals divisions within the Biden administration. Customs agents, who work for the Department of Homeland Security, have canceled an increasing number of student visas that had already been approved by the State Department. (Bloomberg $)
5. Palau, a small Pacific island nation that’s one of the few countries in the world that recognizes Taiwan as a sovereign country, says it is under cyberattack by China. (New York Times $)
6. After being the first space mission to collect samples from the moon’s far side, China’s Chang’e-6 lunar probe has begun its journey back to Earth. (BBC)
7. The Chinese government just set up the third and largest phase of its semiconductor investment fund to prop up its domestic chip industry. This one’s worth $47.5 billion. (Bloomberg $)
The Chinese generative AI community has been stirred up by the first discovery of a Western large language model plagiarizing a Chinese one, according to the Chinese publication PingWest.
Last week, two undergraduate computer science students at Stanford University released an open-source model called Llama 3-V that they claimed is more powerful than LLMs made by OpenAI and Google, while costing less. But Chinese AI researchers soon found out that Llama 3-V had copied the structure, configuration files, and code from MiniCPM-Llama3-V 2.5, another open-source LLM developed by China’s Tsinghua University and ModelBest Inc, a Chinese startup.
What proved the plagiarism was the fact that the Chinese team secretly trained the model on a collection of Chinese writings on bamboo slips from 2000 years ago, and no other LLMs can recognize the Chinese characters in this ancient writing style accurately. But Llama 3-V could recognize these characters as well as MiniCPM, while making the exact same mistakes as the Chinese model. The students who released Llama 3-V have removed the model and apologized to the Chinese team, but the incident is seen as proof of the rapidly improving capabilities of homegrown LLMs by the Chinese AI community.
One more thing
Hand-crafted squishy toys (or pressure balls) in the shape of cute animals or desserts have become the latest viral products on Chinese social media. Made in small quantities and sold in limited batches, some of them go for up to $200 per toy on secondhand marketplaces. I mean, they are cute for sure, but I’m afraid the idea of spending $200 on a pressure ball only increases my anxiety.
In the early 2010s, electricity seemed poised for a hostile takeover of your doctor’s office. Research into how the nervous system controls the immune response was gaining traction. And that had opened the door to the possibility of hacking into the body’s circuitry and thereby controlling a host of chronic diseases, including rheumatoid arthritis, asthma, and diabetes, as if the immune system were as reprogrammable as a computer.
To do that you’d need a new class of implant: an “electroceutical,” formally introduced in an article in Naturein 2013. “What we are doing is developing devices to replace drugs,” coauthor and neurosurgeon Kevin Tracey told Wired UK. These would become a “mainstay of medical treatment.” No more messy side effects. And no more guessing whether a drug would work differently for you and someone else.
There was money behind this vision: the British pharmaceutical giant GlaxoSmithKline announced a $1 million research prize, a $50 million venture fund, and an ambitious program to fund 40 researchers who would identify neural pathways that could control specific diseases. And the company had an aggressive timeline in mind. As one GlaxoSmithKline executive put it, the goal was to have “the first medicine that speaks the electrical language of our body ready for approval by the end of this decade.”
In the 10 years or so since, around a billion dollars has accreted around the effort by way of direct and indirect funding. Some implants developed in that electroceutical push have trickled into clinical trials, and two companies affiliated with GlaxoSmithKline and Tracey are ramping up for splashy announcements later this year. We don’t know much yet about how successful the trials now underway have been. But widespread regulatory approval of the sorts of devices envisioned in 2013—devices that could be applied to a broad range of chronic diseases—is not imminent. Electroceuticals are a long way from fomenting a revolution in medical care.
At the same time, a new area of science has begun to cohere around another way of using electricity to intervene in the body. Instead of focusing only on the nervous system—the highway that carries electrical messages between the brain and the body—a growing number of researchers are finding clever ways to electrically manipulate cells elsewhere in the body, such as skin and kidney cells, more directly than ever before. Their work suggests that this approach could match the early promise of electroceuticals, yielding fast-healing bioelectric bandages, novel approaches to treating autoimmune disorders, new ways of repairing nerve damage, and even better treatments for cancer. However, such ventures have not benefited from investment largesse. Investors tend to understand the relationship between biology and electricity only in the context of the nervous system. “These assumptions come from biases and blind spots that were baked in during 100 years of neuroscience,” says Michael Levin, a bioelectricity researcher at Tufts University.
Electrical implants have already had success in targeting specific problems like epilepsy, sleep apnea, and catastrophic bowel dysfunction. But the broader vision of replacing drugs with nerve-zapping devices, especially ones that alter the immune system, has been slower to materialize. In some cases, perhaps the nervous system is not the best way in. Looking beyond this singular locus of control might open the way for a wider suite of electromedical interventions—especially if the nervous system proves less amenable to hacking than originally advertised.
How it started
GSK’s ambitious electroceutical venture was a response to an increasingly onerous problem: 90% of drugs fall down during the obstacle race through clinical trials. A new drug that does squeak by can cost $2 billion or $3 billion and take 10 to 15 years to bring to market, a galling return on investment. The flaw is in the delivery system. The way we administer healing chemicals hasn’t had much of a conceptual overhaul since the Renaissance physician Paracelsus: ingest or inject. Both approaches have built-in inefficiencies: it takes a long time for the drugs to build up in your system, and they can disperse widely before arriving in diluted form at their target, which may make them useless where they are needed and toxic elsewhere. Tracey and Kristoffer Famm, a coauthor on the Nature article who was then a VP at GlaxoSmithKline, explained on the publicity circuit that electroceuticals would solve these problems—acting more quickly and working only in the precise spot where the intervention was needed. After 500 years, finally, here was a new idea.
Well … new-ish.Electrically stimulating the nervous system had racked up promising successes since the mid-20th century. For example, the symptoms of Parkinson’s disease had been treated via deep brain stimulation, and intractable pain via spinal stimulation. However, these interventions could not be undertaken lightly; the implants needed to be placed in the spine or the brain, a daunting prospect to entertain. In other words, this idea would never be a money spinner.
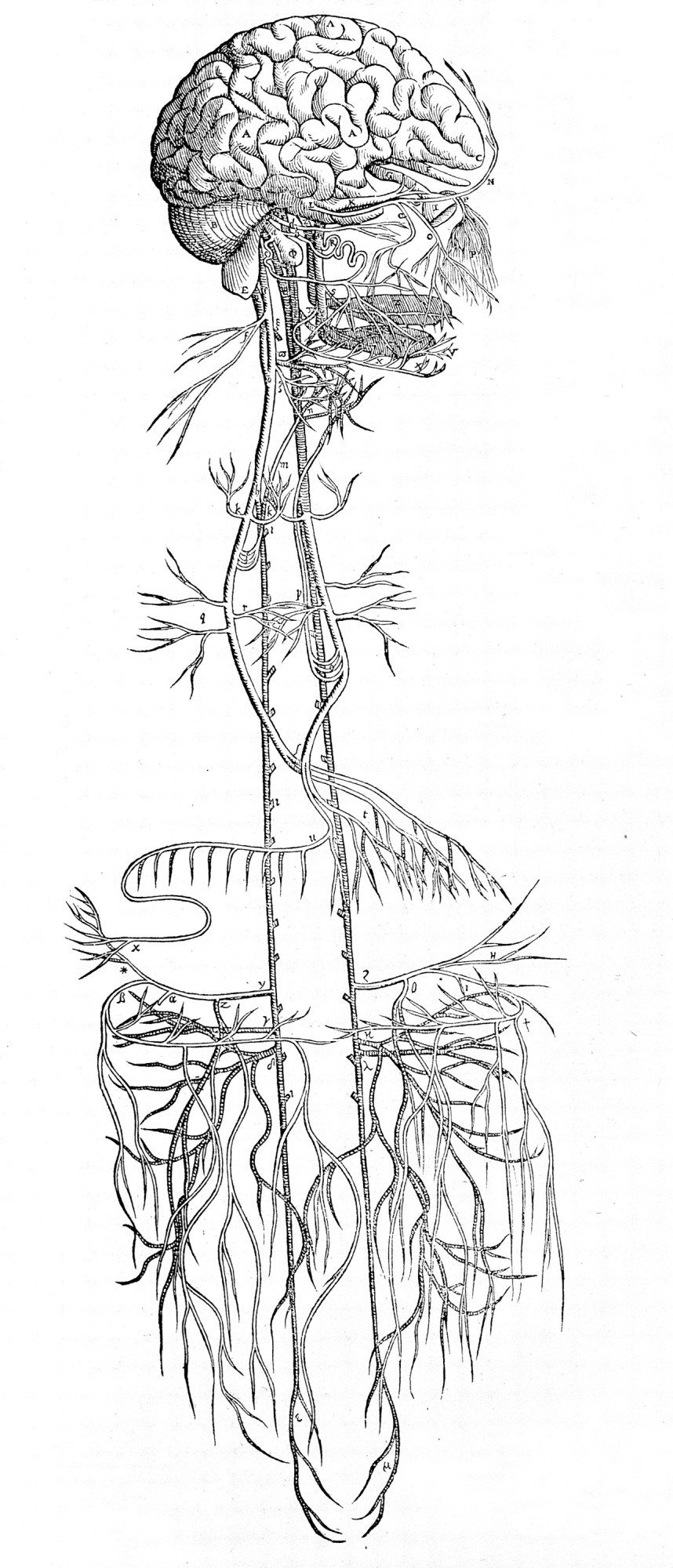
The vagus nerve runs from the brain through the body
WELLCOME COLLECTION
What got GSK excited was recent evidence that health could be more broadly controlled, and by nerves that were easier to access. By the dawn of the 21st century it had become clear you could tap the nervous system in a way that carried fewer risks and more rewards. That was because of findings suggesting that the peripheral nervous system—essentially, everything but the brain and spine—had much wider influence than previously believed.
The prevailing wisdom had long been that the peripheral nervous system had only one job: sensory awareness of the outside world. This information is ferried to the brain along many little neural tributaries that emerge from the extremities and organs, most of which converge into a single main avenue at the torso: the vagus nerve.
Starting in the 1990s, research by Linda Watkins, a neuroscientist leading a team at the University of Colorado, Boulder, suggested that this main superhighway of the peripheral nervous system was not a one-way street after all. Instead it seemed to carry message traffic in both directions, not just into the brain but from the brain back into all those organs. Furthermore, it appeared that this comms link allows the brain to exert some control over the immune system—for example, stoking a fever in response to an infection.
And unlike the brain or spinal cord, the vagus nerve is comparatively easy to access: its path to and from the brain stem runs close to the surface of the neck, along a big cable on either side. You could just pop an electrode on it—typically on the left branch—and get zapping.
Meddling with the flow of traffic up the vagus nerve in this wayhad successfully treated issues in the brain, specifically epilepsy and treatment-resistant depression (and electrical implants for those applications were approved by the FDA around the turn of the millennium). But the insights from Watkins’s team put the down direction in play.
It was Kevin Tracey who joined all these dots, after which it did not take long for him to become the public face of research on vagus nerve stimulation. During the 2000s, he showed that electrically stimulating the nerve calmed inflammation in animals. This “inflammatory reflex,” as he came to call it, implied that the vagus nerve could act as a switch capable of turning off a wide range of diseases, essentially hacking the immune system. In 2007, while based at what is now called the Feinstein Institutes for Medical Research, in New York, he spun his insights off into a Boston startup called SetPoint Medical. Its aim was to develop devices to flip this switch and bring relief, starting with inflammatory bowel disease and rheumatoid arthritis.
By 2012, a coordinated relationship had developed between GSK, Tracey, and US government agencies. Tracey says that Famm and others contacted him “to help them on that Nature article.” A year later the electroceuticals road map was ready to be presented to the public.
The story the researchers told about the future was elegant and simple. It was illustrated by a tale Tracey recounted frequently on the publicity circuit, of a first-in-human case study SetPoint had coordinated at the University of Amsterdam’s Academic Medical Center. That team had implanted a vagus nerve stimulator in a man suffering from rheumatoid arthritis. The stimulation triggered his spleen to release a chemical called acetylcholine. This in turn told the cells in the spleen to switch off production of inflammatory molecules called cytokines. For this man, the approach worked well enough to let him resume his job, play with his kids, and even take up his old hobbies. In fact, his overenthusiastic resumption of his former activities resulted in a sports injury, as Tracey delighted in recounting for reporters and conferences.
Such case studies opened the money spigot. The combination of a wider range of disease targets and less risky surgical targets was an investor’s love language. Where deep brain stimulation and other invasive implants had been limited to rare, obscure, and catastrophic problems, this new interface with the body promised many more customers: the chronic diseases now on the table are much more prevalent, including not only rheumatoid arthritis but diabetes, asthma, irritable bowel syndrome, lupus, and many other autoimmune disorders. GSK launched an investment arm it dubbed Action Potential Venture Capital Limited, with $50 million in the coffers to invest in the technologies and companies that would turn the futuristic vision of electroceuticals into reality. Its inaugural investment was a $5 million stake in SetPoint.
If you were superstitious, what happened next might have looked like an omen. The word “electroceutical” already belonged to someone else—a company called Ivivi Technologies had trademarked it in 2008. “I am fairly certain we sent them a letter soon after they started that campaign, to alert them of our trademark,” says Sean Hagberg, a cofounder and then chief science officer at the company. Today neither GSK nor SetPoint can officially call its tech “electroceuticals,” and both refer to the implants they are developing as “bioelectronic medicine.” However, this umbrella term encompasses a wide range of other interventions, some quite well established, including brain implants, spine implants, hypoglossal nerve stimulation for sleep apnea (which targets a motor nerve running through the vagus), and other peripheral-nervous-system implants, including those for people with severe gastric disorders.
Kevin Tracey has been one of the leading proponents of using electrical stimulation to target inflammation in the body.
MIKE DENORA VIA WIKIPEDIA
The next problem appeared in short order: how to target the correct nerve. The vagus nerve has roughly 100,000 fibers packed tightly within it, says Kip Ludwig, who was then with the US National Institutes of Health and now co-directs the Wisconsin Institute for Translational Neuroengineering at the University of Wisconsin, Madison. These myriad fibers connect to many different organs, including the larynx and lower airways, and electrical fields are not precise enough to hit a single one without hitting many of its neighbors (as Ludwig puts it, “electric fields [are] really promiscuous”).
This explains why a wholesale zap of the entire bundle had long been associated with unpredictable “on-target effects” and unpleasant “off-target effects,” which is another way of saying it didn’t always work and could carry side effects that ranged from the irritating, like a chronic cough, to the life-altering, including headaches and a shortness of breath that is better described as air hunger. Singling out the fibers that led to the particular organ you were after was hard for another reason, too: the existing maps of the human peripheral nervous system were old and quite limited. Such a low-resolution road map wouldn’t be sufficient to get a signal from the highway all the way to a destination.
In 2014, to remedy this and generally advance the field of peripheral nerve stimulation, the NIH announced a research initiative known as SPARC—Stimulating Peripheral Activity to Relieve Conditions—with the aim of pouring $248 million into research on new ways to exploit the nervous system’s electrical pathways for medicine. “My job,” says Gene Civillico, who managed the program until 2021, “was to do a program related to electroceuticals that used the NIH policy options that were available to us to try to make something catalytic happen.” The idea was to make neural anatomical maps and sort out the consequences of following various paths. After the organs were mapped, Civillico says, the next step was to figure out which nerve circuit would stimulate them, and settle on an access point—“And the access point should be the vagus nerve, because that’s where the most interest is.”
Two years later, as SPARC began to distribute its funds, companies moved forward with plans for the first generation of implants. GSK teamed up with Verily (formerly Google Life Sciences) on a $715 million research initiative they called Galvani Bioelectronics, with Famm at its helm as president. SetPoint, which had relocated to Valencia, California, moved to an expanded location, a campus that had once housed a secret Lockheed R&D facility.
How it’s going
Ten years after electroceuticals entered (and then quickly departed) the lexicon, the SPARC program has yielded important information about the electrical particulars of the peripheral nervous system. Its maps have illuminated nodes that are both surgically attractive and medically relevant. It has funded a global constellation of academic researchers. But its insights will be useful for the next generation of implants, not those in trials today.
Today’s implants, from SetPoint and Galvani, will be in the news later this year. Though SetPoint estimates that an extended study of its phase III clinical trial will conclude in 2027, the primary outcomes will be released this summer, says Ankit Shah, a marketing VP at SetPoint. And while Galvani’s trial will conclude in 2029, Famm says, the company is “coming to an exciting point” and will publish patient data later in 2024.
The results could be interpreted as a referendum on the two companies’ different approaches. Both devices treat rheumatoid arthritis, and both target the immune system via the peripheral nervous system, but that’s where the similarities end. SetPoint’s device uses a clamshell design that cuffs around the vagus nerve at the neck. It stimulates for just one minute, once per day. SetPoint representatives say they have never seen the sorts of side effects that have resulted from using such stimulators to treat epilepsy. But if anyone did experience those described by other researchers—even vomiting and headaches—they might be tolerable if they only lasted a minute.
But why not avoid the vagus nerve entirely? Galvani is using a more precise implant that targets the “end organ” of the spleen. If the vagus nerve can be considered the main highway of the peripheral nervous system, an end organ is essentially a particular organ’s “driveway.” Galvani’s target is the point where the splenic nerve (having split off from a system connected to the vagus highway) meets the spleen.
To zero in on such a specific target, the company has sacrificed ease of access. Its implant, which is about the size of a house key, is laparoscopically injected into the body through the belly button. Famm says if this approach works for rheumatoid arthritis, then it will likely translate for all autoimmune disorders. Highlighting this clinical trial in 2022, he told Nature Reviews: “This is what makes the next 10 years exciting.”
The Galvani device and system targets the splenic nerve.
GALVANI VIA BUSINESSWIRE
Perhaps more so for researchers than for patients, however. Even as Galvani and SetPoint prepare talking points, other SPARC-funded groups are still pondering the sorts of research questions suggesting that the best technological interface with the immune system is still up for debate. At the moment, electroceuticals are in the spotlight, but they have a long way to go, says Vaughan Macefield, a neurophysiologist at Monash University in Australia, whose work is funded by a more recent $21 million SPARC grant: “It’s an elegant idea, [but] there are conflicting views.”
Macefield doesn’t think zapping the entire bundle is a good idea. Many researchers are working on ways to get more selective about which particular fibers of the vagus nerve they stimulate. Some are designing novel electrodes that will penetrate specific fibers rather than clamping around all of them. Others are trying to hit the vagus at deeper points in the abdomen. Indeed, some aren’t sure either electricity or an implant is a necessary ingredient of the “electroceutical.” Instead, they are pivoting from electrical stimulation to ultrasound.
The sheer range of these approaches makes it pretty clear that the electroceutical’s final form is still an open research question. Macefield says we still don’t know the nitty-gritty of how vagus nerve stimulation works.
However, Tracey thinks the variety of approaches being developed doesn’t contravene the merits of the basic idea. How tech companies will make this work in the clinic, he says, is a separate business and IP question: “Can you do it with focused ultrasound? Can you do it with a device implanted with abdominal surgery? Can you do it with a device implanted in the neck? Can you do it with a device implanted in the brain, even? All of these strategies are enabled by the idea of the inflammatory reflex.” Until clinical trial data is in, he says, there’s no point arguing about the best way to manipulate the mechanism—and if one approach fails to work, that is not a referendum on the validity of the inflammatory reflex.
After stepping down from SetPoint’s board to resume a purely consulting role in 2011, Tracey focused on his lab work at the Feinstein Institutes, which he directs, to deepen understanding of this pathway. The research there is wide-ranging. Several researchers under his remit are exploring a type of noninvasive, indirect manipulation called transcutaneous auricular vagus nerve stimulation, which stimulates the skin of the ear with a wearable device. Tracey says it’s a “malapropism” to call this approach vagus nerve stimulation. “It’s just an ear buzzer,” he says. It may stimulate a sensory branch of the vagus nerve, which may engage the inflammatory reflex. “But nobody knows,” he says. Nonetheless, several clinical trials are underway.
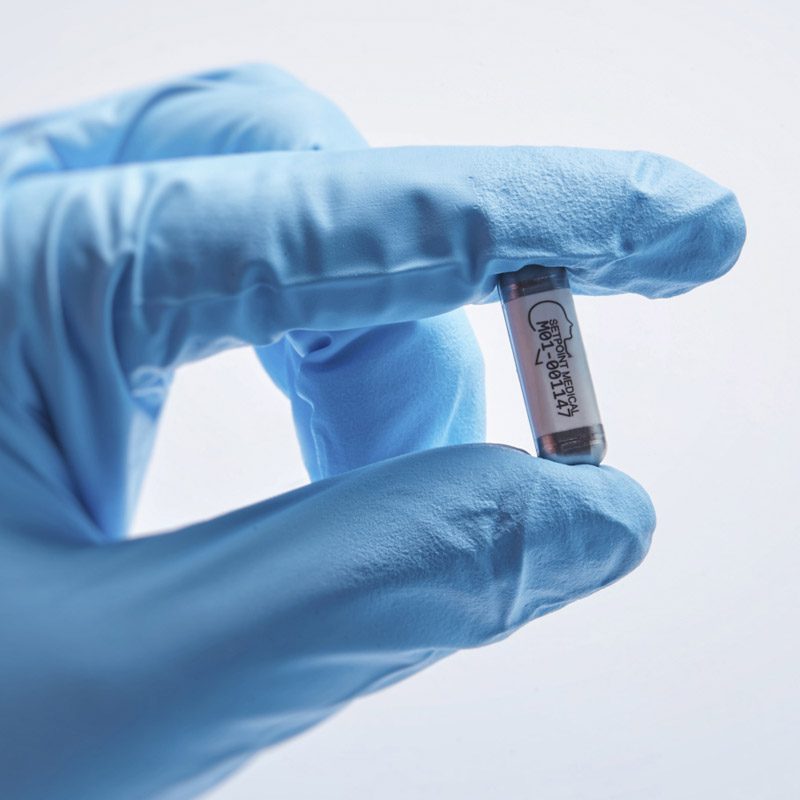
SetPoint’s device is cuffed around the vagus nerve within the neck of a patient.
SETPOINT MEDICAL
“These things take time,” Tracey says. “It is extremely difficult to invent and develop a completely revolutionary new thing in medicine. In the history of medicine, anything that was truly new and revolutionary takes between 20 and 40 years from the time it’s invented to the time it’s widely adopted.”
“As the discoverer of this pathway,” he says, “what I want to see is multiple therapies, helping millions of people.” This vision will hinge on bigger trials conducted over many more years. These tend to be about as hard for devices as they are for drugs. Many results that look compelling in early trials disappoint in later rounds—just as for drugs. It will be possible, says Ludwig, “for them to pass a short-duration FDA trial yet still really not be a major improvement over the drug solutions.” Even after FDA approval, should it come, yet more studies will be needed to determine whether the implants are subject to the same issues that plague drugs, including habituation.
This vision of electroceuticals seems to have placed about a billion eggs into the single basket of the peripheral nervous system. In some ways, this makes sense. After all, the received wisdom has it that these nervous signals are the only way to exert electrical control of the other cells in the body. Those other trillions—the skin cells, the immune cells, the stem cells—are beyond the reach of direct electrical intervention.
Except in the past 20 years it’s become abundantly clear thatthey are not.
Other cells speak electricity
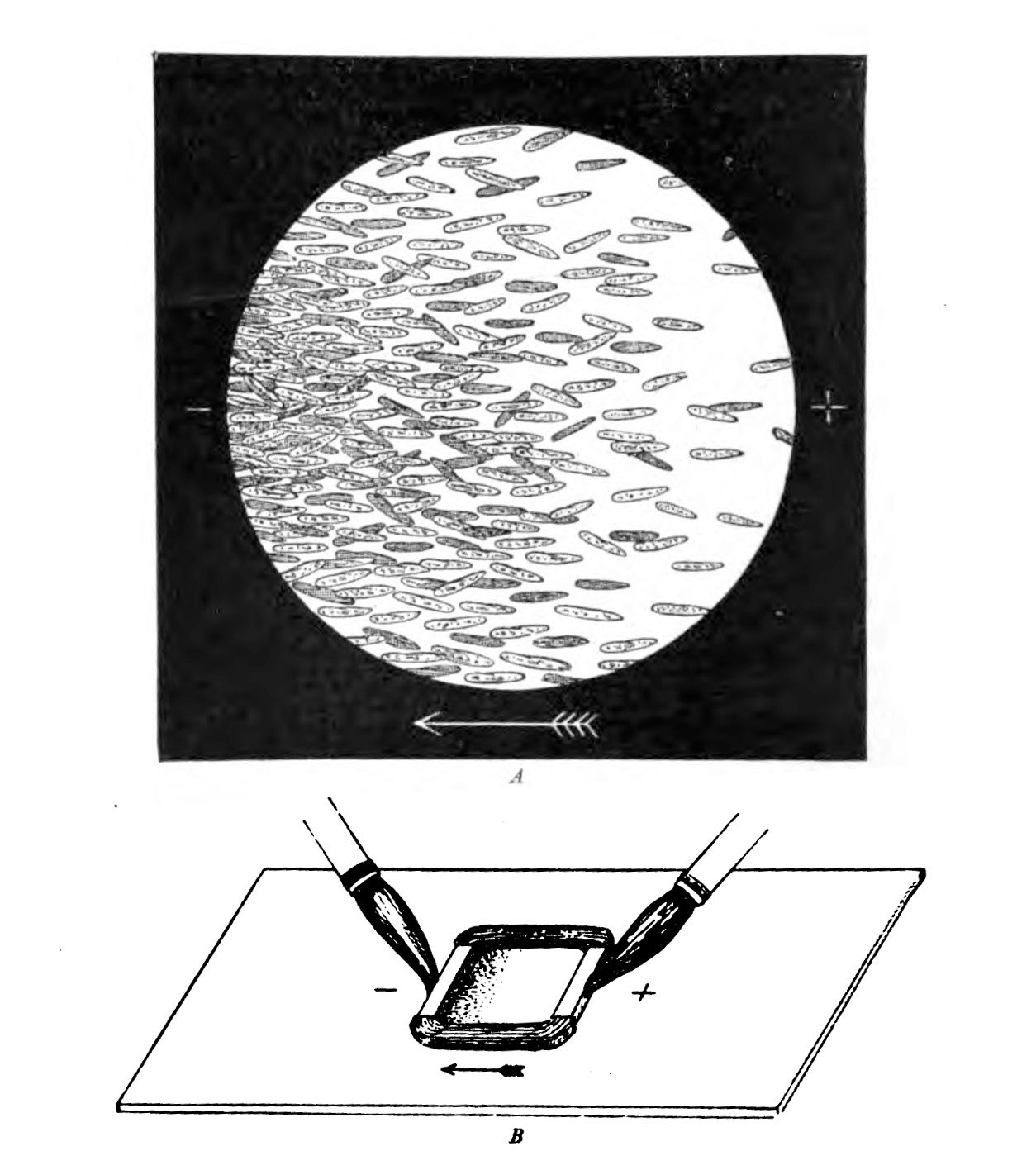
At the end of the 19th century, the German physiologist Max Verworn watched as a single-celled marine creature was drawn across the surface of his slide as if captured by a tractor beam. It had been, in a way: under the influence of an electric field, it squidged over to the cathode (the pole that attracts positive charge). Many other types of cells could be coaxed to obey the directional wiles of an electric field, a phenomenon known as galvanotaxis.
But this was too weird for biology, and charlatans already occupied too much of the space in the Venn diagram where electricity met medicine. (The association was formalized in 1910 in the Flexner Report, commissioned to improve the dismal state of American medical schools, which sent electrical medicine into exile along with the likes of homeopathy.) Everyone politely forgot about galvanotaxis until the 1970s and ’80s, when the peculiar behavior resurfaced. Yeast, fungi, bacteria, you name it—they all liked a cathode. “We were pulling every kind of cell along on petri dishes with an electric field,” says Ann Rajnicek of the University of Aberdeen in Scotland, who was among the first group of researchers who tried to discover the mechanism when scientific interest reawakened.
Galvanotaxis would have raised few eyebrows if the behavior had been confined to neurons. Those cells have evolved receptors that sense electric fields; they are a fundamental aspect of the mechanism the nervous system uses to send its information. Indeed, the reason neurons are so amenable to electrical manipulation in the first place is that electric implants hijack a relatively predictable mechanism. Zap a nerve or a muscle and you are forcing it to “speak” a language in which it is already fluent.
Non-excitable cells such as those found in skin and bone don’t share these receptors, but it keeps getting more obvious that they somehow still sense and respond to electric fields.
Why? We keep finding more reasons. Galvanotaxis, for example, is increasingly understood to play a crucial role in wound healing. In every species studied, injury to the skin produces an instant, internally generated electric field, and there’s overwhelming evidence that it guides patch-up cells to the center of the wound to start the rebuilding process. But galvanotaxis is not the only way these cells are led by electricity. During development, immature cells seem to sense the electric properties of their neighbors, which plays a role in their future identity—whether they become neurons, skin cells, fat cells, or bone cells.
Early experiments showed that paramecia on a wet plate will orient themselves in the direction of a cathode.
PUBLIC DOMAIN
Intriguing as this all was, no one had much luck turning such insights into medicine. Even attempts to go after the lowest-hanging fruit—by exploiting galvanotaxis for novel bandages—were for many years at best hit or miss. “When we’ve come upon wounds that are intractable, resistant, and will not heal, and we apply an electric field, only 50% or so of the cases actually show any effect,” says Anthony Guiseppi-Elie, a senior fellow with the American International Institute for Medical Sciences, Engineering, and Innovation.
However, in the past few years, researchers have found ways to make electrical stimulation outside the nervous system less of a coin toss.
That’s down to steady progress in our understanding of how exactly non-neural cells pick up on electric fields, which has helped calm anxieties around the mysticism and the Frankenstein associations that have attended biological responses to electricity.
The first big win came in 2006, with the identification of specific genes in skin cells that get turned on and off by electric fields. When skin is injured, the body’s native electric field orients cells toward the center of the wound, and the physiologist Min Zhao and his colleagues found important signaling pathways that are turned on by this field and mobilized to move cells toward this natural cathode. He also found associated receptors, and other scientists added to the catalogue of changes to genes and gene regulatory networks that get switched on and off under an electric field.
What has become clear since then is that there is no simple mechanism waiting at the end of the rainbow. “There isn’t one single master protein, as far as anybody knows, that regulates responses [to an electric field],” says Daniel Cohen, a bioengineer at Princeton University. “Every cell type has a different cocktail of stuff sticking out of it.”
But recent years have brought good news, in both experimental and applied science. First, the experimental platforms to investigate gene expression are in the middle of a transformation. One advance was unveiled last year by Sara Abasi, Guiseppi-Elie, and their colleagues at Texas A&M and the Houston Methodist Research Institute: their carefully designed research platform kept track of pertinent cellular gene expression profiles and how they change under electric fields—specifically, ones tuned to closely mimic what you find in biology. They found evidence for the activation of two proteins involved in tissue growth along with increased expression of a protein called CD-144, a specific version of what’s known as a cadherin. Cadherins are important physical structures that enable cells to stick to each other, acting like little handshakes between cells. They are crucial to the cells’ ability to act en masse instead of individually.
The other big improvement is in tools that can reveal just how cells work together in the presence of electric fields.
A different kind of electroceutical
A major limit on past experiments was that they tended to test the effects of electrical fields either on single cells or on whole animals. Neither is quite the right scale to offer useful insights, explains Cohen: measuring these dynamics in animals is too “messy,” but in single cells, the dynamics are too artificial to tell you much about how cells behave collectively as they heal a wound. That behavior emerges only at relevant scales, like bird flocks, schools of fish, or road traffic. “The math is identical to describe these types of collective dynamics,” he says.
In 2020, Cohen and his team came up with a solution: an experimental setup that strikes the balance between single cell (tells you next to nothing) and animal (tells you too many things at once). The device, called SCHEEPDOG, can reveal what is going on at the tissue level, which is the relevant scale for investigating wound healing.
It uses two sets of electrodes—a bit the way you might twiddle the dials on an Etch A Sketch—placed in a closed bioreactor, which better approximates how electric fields operate in biology. With this setup, Cohen and his colleagues can precisely tune the electrical environment of tens of thousands of cells at a time to influence their behavior.
In this time-lapse, SCHEEPDOG maneuvers epithelial cells with electric fields.
COHEN ET AL
Their subsequent “healing-on-a-chip” platform yielded an interesting discovery: skin cells’ response to an electric field depends on their maturity. The less mature, the easier they were to control.
The culprit? Those cadherins that Abasi and Guiseppi-Elie had also observed changing under electric fields. In mature cells, these little handshakes had become so strong that a competing electric field, instead of gently guiding the cells, caused them to rip apart. The immature skin cells followed the electric field’s directions without complaint.
After they found a way to dial down the cadherins with an antibody drug, all the cells synchronized. For Cohen, the lesson was that it’s more important to look at the system, and the collective dynamics that govern a behavior like wound healing, than at what is happening in any single cell. “This is really important because many clinical attempts at using electrical stimulation to accelerate wound healing have failed,” says Guiseppi-Elie, and it had never become clear why some worked and others some didn’t.
Cohen’s team is now working to translate these findings into next-generation bioelectric plasters. They are far from alone, and the payoff is more than skin deep. A lot of work is going on, some of it open and some behind closed doors with patents being closely guarded, says Cohen.
At Stanford, the University of Arizona, and Northwestern, researchers are creating smart electric bandages that can be implanted under the skin. They can also monitor the state of the wound in real time, increasing the stimulation if healing is too slow. More challenging, says Rajnicek, are ways to interface with less accessible areas of the body. However, here too new tools are revealing intriguing creative solutions.
Electric fields don’t have to directly changecells’ gene expression to be useful. There is another way their application can be turned to medical benefit. Electric fields evoke reactive oxygen species (ROS) in biological cells. Normally, these charged molecules are a by-product of a cell’s everyday metabolic activities. If you induce them purposefully using an external DC current, however, they can be hijacked to do your bidding.
Starting in 2020, theSwiss bioengineer Martin Fussenegger and an international team of collaborators began to publish investigations into this mechanism to power gene expression. He and his team engineered human kidney cells to be hypersensitive to the induced ROSs in quantities that normal cells couldn’t sense. But when these were generated by DC electrodes, the kidney cells could sense the minute quantities just fine.
Using this instrument, in 2023 they were able to create a tiny, wearable insulin factory. The designer kidney cells were created with a synthetic promoter—an engineered sequence of DNA that can drive expression of a target gene—that reacted to those faint inducedROSs by activating a cascade of genetic changes that opened a tap for insulin production on demand.
Then they packaged this electrogenetic contraption into a wearable device that worked for a month in a living mouse, which had been engineered to be diabetic (Fussenegger says that “others have shown that implanted designer cells can generally be active for over a year”). The designer cells in the wearable are kept alive by algae gelatine but are fed by the mouse’s own vascular system, permitting the exchange of nutrients and protein. The cells can’t get out, but the insulin they secrete can, seeping straight into the mouse’s bloodstream. Ten seconds a day of electrical stimulation delivered via needles connected to three AAA batteries was enough to make the implant perform like a pancreas, returning the mouse’s blood sugar to nondiabetic levels. Given how easy it would be to generalize the mechanism, Fussenegger says, there’s no reason insulin should be the only drug such a device can generate. He is quick to stress that this wearable device is very much in the proof-of-concept stage, but others outside the team are excited about its potential. It could provide a more direct electrical alternative to the solution electroceuticals promised for diabetes.
Escaping neurochauvinism
Before the concerted push around branding electroceuticals, efforts to tap the peripheral nervous system were fragmented and did not share much data. Today, thanks to SPARC, which is winding down, data-sharing resources have been centralized. And money, both direct and indirect, for the electroceuticals project has been lavish. Therapies—especially vagus nerve stimulation—have been the subject of “a steady increase in funding and interest,” says Imran Eba, a partner at GSK’s bioelectronics investment arm Action Potential Venture Capital. Eba estimates that the initial GSK seed of $50 million at Action Potential has grown to about $200 million in assets under management.
Whether you call it bioelectronic medicine or electroceuticals, some researchers would like to see the definition take on a broader remit. “It’s been an extremely neurocentric approach,” says Daniel Cohen.
Neurostimulation has not yet shown success against cancer. Other forms of electrical stimulation, however, have proved surprisingly effective. In one study on glioblastoma, tumor-treating fields offered an electrical version of chemotherapy: an electric field blasts a brain tumor, preferentially killing only cells whose electrical identity marks them as dividing (which cancer cells do, pathologically—but neurons, being fully differentiated, do not). A study recently published in The Lancet Oncology suggests that these fields could also work in lung cancer to boost existing drugs and extend survival.
All of this points to more sophisticated interventions than a zap to a nerve. “The complex things that we need to do in medicine will be about communicating with the collective decision-making and problem-solving of the cells,” says Michael Levin. He has been working to repurpose already-approved drugs so they can be used to target the electrical communication between cells. In a funny twist, he has taken to calling these drugs electroceuticals, which has ruffled some feathers. But he would certainly find support from researchers like Cohen. “I would describe electroceuticals much more broadly as anything that manipulates cellular electrophysiology,” Cohen says.
Even interventions with the nervous system could be helped by expanding our understanding of the ways nerve cells react to electricity beyond action potentials. Kim Gokoffski, a professor of clinical ophthalmology at the University of Southern California, is working with galvanotaxis as a possible means of repairing damage to the optic nerve. In prior experiments that involve regrowing axons—the cables that carry messages out of neurons—these new nerve fibers tend to miss the target they’re meant to rejoin. Existing approaches “are all pushing the gas pedal,” she says, “but no one is controlling the steering wheel.” So her group uses electric fields to guide the regenerating axons into position. In rodent trials, this has worked well enough to partially restore sight.
And yet, Cohen says, “there’s massive social stigma around this that is significantly hampering the entire field.” That stigma has dramatically shaped research direction and funding. For Gokoffski, it has led to difficulties with publishing. She also recounts hearing a senior NIH official refer to her lab’s work on reconnecting optic nerves as “New Age–y.” It was a nasty surprise: “New Age–y has a very bad connotation.”
However, there are signs of more support for work outside the neurocentric model of bioelectric medicine. The US Defense Department funds projects in electrical wound healing (including Gokoffski’s). Action Potential’s original remit—confined to targeting peripheral nerves with electrical stimulation—has expanded. “We have a broader approach now, where energy (in any form, be it electric, electromagnetic, or acoustic) can be directed to regulate neuronal or other cellular activities in the body,” Eba wrote in an email. Three of the companies now in their portfolio focus on areas outside neurostimulation. “While we don’t have any investments targeting wound healing or regenerative medicine specifically, there is no explicit exclusion here for us,” he says.
This suggests that the “social stigma” Cohen described around electrical medicine outside the nervous system is slowly beginning to abate. But if such projects are to really flourish, the field needs to be supported, not just tolerated—perhaps with its own road map and dedicated NIH program. Whether or not bioelectric medicine ends up following anything like the original electroceuticals road map, SPARC ensured a flourishing research community, one that is in hot pursuit of promising alternatives.
The use of electricity outside the nervous system needs a SPARC program of its own. But if history is any guide, first it needs a catchy name. It can’t be “electroceuticals.” And the researchers should definitely check the trademark listings before rolling it out.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
SUVs are taking over the world—larger vehicle models made up nearly half of new car sales globally in 2023, a new record for the segment.
There are a lot of reasons to be nervous about the ever-expanding footprint of vehicles, from pedestrian safety and road maintenance concerns to higher greenhouse-gas emissions. But in a way, SUVs also represent a massive opportunity for climate action, since pulling the worst gas-guzzlers off the roads and replacing them with electric versions could be a big step in cutting pollution.
It’s clear that we’re heading toward a future with bigger cars. Here’s what it might mean for the climate, and for our future on the road.
SUVs accounted for 48% of global car sales in 2023, according to a new analysis from the International Energy Agency. This is a continuation of a trend toward bigger cars—just a decade ago, SUVs only made up about 20% of new vehicle sales.
Big vehicles mean big emissions numbers. Last year there were more than 360 million SUVs on the roads, and they produced a billion metric tons of carbon dioxide. If SUVs were a country, they’d have the fifth-highest emissions of any nation on the planet—more than Japan. Of all the energy-related emissions growth last year, over 20% can be attributed to SUVs.
There are several factors driving the world’s move toward larger vehicles. Larger cars tend to have higher profit margins, so companies may be more likely to make and push those models. And drivers are willing to jump on the bandwagon. I understand the appeal—I learned to drive in a huge SUV, and being able to stretch out my legs and float several feet above traffic has its perks.
Electric vehicles are very much following the trend, with several companies unveiling larger models in the past few years. Some of these newly released electric SUVs are seeing massive success. The Tesla Model Y, released in 2020, was far and away the most popular EV last year, with over 1.2 million units sold in 2023. The BYD Song (also an SUV) took second place with 630,000 sold.
Globally, SUVs made up nearly 50% of new EV sales in 2023, compared to just under 20% in 2018, according to the IEA’s Global EV Outlook 2024. There’s also been a shift away from small cars (think the size of the Fiat 500) and toward large ones (similar to the BMW 7-series).
And big-car obsession is a global phenomenon. The US is the land of the free and the home of the massive vehicles—SUVs made up 65% of new electric-vehicle sales in the country in 2023. But other major markets aren’t all that far behind: in Europe, the share was 52%, and in China, it was 36%. (You can see the above chart broken down by region from the IEA here.)
So it’s clear that we’re clamoring for bigger cars. Now what?
One way of looking at this whole thing is that SUVs offer up an incredible opportunity for climate action. EVs will reduce emissions over their life span relative to gas-powered versions of the same model, so electrifying the biggest emitters on the roads would have an outsize impact. If all gas-powered and hybrid SUVs sold in 2023 were instead electric vehicles, about 770 million metric tons of carbon dioxide would be avoided over the lifetime of those vehicles, according to the IEA report. That’s equivalent to all of China’s road emissions last year.
I previously wrote a somewhat hesitant defense of large EVs for this reason—electric SUVs aren’t perfect, but they could still help us address climate change. If some drivers are willing to buy an EV but aren’t willing to downsize their cars, then having larger electric options available could be a huge lever for climate action.
But there are several very legitimate reasons why not everyone is welcoming the future of massive cars (even electric ones) with open arms. Larger vehicles are harder on roads, making upkeep more expensive. SUVs and other big vehicles are way more dangerous for pedestrians, too. Vehicles with higher front ends and blunter profiles are 45% more likely to cause fatalities in crashes with pedestrians.
Bigger EVs could also have a huge effect on the amount of mining we’ll need to do to meet demand for metals like lithium, nickel, and cobalt. One 2023 study found that larger vehicles could increase the amount of mining needed more than 50% by 2050, relative to the amount that would be necessary if people drove smaller vehicles. Given that mining is energy intensive and can come with significant environmental harms, it’s not an unreasonable worry.
New technologies could help reduce the mining we need to do for some materials: LFP batteries that don’t contain nickel or cobalt are quickly growing in market share, especially in China, and they could help reduce demand for those metals.
Another potential solution is reducing the demand for bigger cars in the first place. Policies have historically had a hand in pushing people toward larger cars and could help us make a U-turn on car bloat. Some countries, including Norway and France, now charge more in taxes or registration for larger vehicles. Paris recently jacked up parking rates for SUVs.
For now, our vehicles are growing, and if we’re going to have SUVs on the roads, then we should have electric options. But bigger isn’t always better.
Now read the rest of The Spark
Related reading
I’ve defended big EVs in the past—SUVs come with challenges, but electric ones are hands-down better for emissions than gas-guzzlers. Read this 2023 newsletter for more.
The average size of batteries in EVs has steadily ticked up in recent years, as I touched on in this newsletter from last year.
Electric cars are still cars, and smaller, safer EVs, along with more transit options, will be key to hitting our climate goals, Paris Marx argued in this 2022 op-ed.
Keeping up with climate
We might be underestimating how much power transmission lines can carry. Sensors can give grid operators a better sense of capacity based on factors like temperature and wind speed, and it could help projects hook up to the grid faster. (Canary Media)
North America could be in for an active fire season, though it’s likely not going to rise to the level of 2023. (New Scientist)
Climate change is making some types of turbulence more common, and that could spell trouble for flying. Studying how birds move might provide clues about dangerous spots. (BBC)
The perceived slowdown for EVs in the US is looking more like a temporary blip than an ongoing catastrophe. Tesla is something of an outlier with its recent slump—most automakers saw greater than 50% growth in the first quarter of this year. (Bloomberg)
This visualization shows just how dominant China is in the EV supply chain, from mining materials like graphite to manufacturing battery cells. (Cipher News)
Climate change is coming for our summer oysters. The variety that have been bred to be eaten year round are sensitive to extreme heat, making their future rocky. (The Atlantic)
The US has new federal guidelines for carbon offsets. It’s an effort to fix up an industry that studies and reports have consistently shown doesn’t work very well. (New York Times)
The most stubborn myth about heat pumps is that they don’t work in cold weather. Heat pumps are actually more efficient than gas furnaces in cold conditions. (Wired)
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Here in the US, bird flu has now infected cows in nine states, millions of chickens, and—as of last week—a second dairy worker. There’s no indication that the virus has acquired the mutations it would need to jump between humans, but the possibility of another pandemic has health officials on high alert. Last week, they said they are working to get 4.8 million doses of H5N1 bird flu vaccine packaged into vials as a precautionary measure.
The good news is that we’re far more prepared for a bird flu outbreak than we were for covid. We know so much more about influenza than we did about coronaviruses. And we already have hundreds of thousands of doses of a bird flu vaccine sitting in the nation’s stockpile.
The bad news is we would need more than 600 million doses to cover everyone in the US, at two shots per person. And the process we typically use to produce flu vaccines takes months and relies on massive quantities of chicken eggs. Yes, chickens. One of the birds that’s susceptible to avian flu. (Talk about putting all our eggs in one basket. #sorrynotsorry)
This week in The Checkup, let’s look at why we still use a cumbersome, 80-year-old vaccine production process to make flu vaccines—and how we can speed it up.
The idea to grow flu virus in fertilized chicken eggs originated with Frank Macfarlane Burnet, an Australian virologist. In 1936, he discovered that if he bored a tiny hole in the shell of a chicken egg and injected flu virus between the shell and the inner membrane, he could get the virus to replicate.
Even now, we still grow flu virus in much the same way. “I think a lot of it has to do with the infrastructure that’s already there,” says Scott Hensley, an immunologist at the University of Pennsylvania’s Perelman School of Medicine. It’s difficult for companies to pivot.
The process works like this:Health officials provide vaccine manufacturers with a candidate vaccine virus that matches circulating flu strains. That virus is injected into fertilized chicken eggs, where it replicates for several days. The virus is then harvested, killed (for most use cases), purified, and packaged.
Making flu vaccine in eggs has a couple of major drawbacks. For a start, the virus doesn’t always grow well in eggs. So the first step in vaccine development is creating a virus that does. That happens through an adaptation process that can take weeks or even months. This process is particularly tricky for bird flu: Viruses like H5N1 are deadly to birds, so the virus might end up killing the embryo before the egg can produce much virus. To avoid this, scientists have to develop a weakened version of the virus by combining genes from the bird flu virus with genes typically used to produce seasonal flu virus vaccines.
And then there’s the problem of securing enough chickens and eggs. Right now, many egg-based production lines are focused on producing vaccines for seasonal flu. They could switch over to bird flu, but “we don’t have the capacity to do both,” Amesh Adalja, an infectious disease specialist at Johns Hopkins University, told KFF Health News. The US government is so worried about its egg supply that it keeps secret, heavily guarded flocks of chickens peppered throughout the country.
Most of the flu virus used in vaccines is grown in eggs, but there are alternatives. The seasonal flu vaccine Flucelvax, produced by CSL Seqirus, is grown in a cell line derived in the 1950s from the kidney of a cocker spaniel. The virus used in the seasonal flu vaccine FluBlok, made by Protein Sciences, isn’t grown; it’s synthesized. Scientists engineer an insect virus to carry the gene for hemagglutinin, a key component of the flu virus that triggers the human immune system to create antibodies against it. That engineered virus turns insect cells into tiny hemagglutinin production plants.
And then we have mRNA vaccines, which wouldn’t require vaccine manufacturers to grow any virus at all. There aren’t yet any approved mRNA vaccines for influenza, but many companies are fervently working on them, including Pfizer, Moderna, Sanofi, and GSK. “With the covid vaccines and the infrastructure that’s been built for covid, we now have the capacity to ramp up production of mRNA vaccines very quickly,” says Hensley. This week, the Financial Timesreported that the US government will soon close a deal with Moderna to provide tens of millions of dollars to fund a large clinical trial of a bird flu vaccine the company is developing.
There are hints that egg-free vaccines might work better than egg-based vaccines.A CDC study published in January showed that people who received Flucelvax or FluBlok had more robust antibody responses than those who received egg-based flu vaccines. That may be because viruses grown in eggs sometimes acquire mutations that help them grow better in eggs. Those mutations can change the virus so much that the immune response generated by the vaccine doesn’t work as well against the actual flu virus that’s circulating in the population.
Hensley and his colleagues are developing an mRNA vaccine against bird flu. So far they’ve only tested it in animals, but the shot performed well, he claims. “All of our preclinical studies in animals show that these vaccines elicit a much stronger antibody response compared with conventional flu vaccines.”
No one can predict when we might need a pandemic flu vaccine. But just because bird flu hasn’t made the jump to a pandemic doesn’t mean it won’t. “The cattle situation makes me worried,” Hensley says. Humans are in constant contact with cows, he explains. While there have only been a couple of human cases so far, “the fear is that some of those exposures will spark a fire.” Let’s make sure we can extinguish it quickly.
I don’t have to tell you that mRNA vaccines are a big deal. In 2021, MIT Technology Review highlighted them as one of the year’s 10 breakthrough technologies. Antonio Regalado explored their massive potential to transform medicine. Jessica Hamzelou wrote about the other diseases researchers are hoping to tackle.I followed up with a story after two mRNA researchers won a Nobel Prize. And earlier this year I wrote about a new kind of mRNA vaccine that’s self-amplifying, meaning it not only works at lower doses, but also sticks around for longer in the body.
From around the web
Researchers installed a literal window into the brain, allowing for ultrasound imaging that they hope will be a step toward less invasive brain-computer interfaces. (Stat)
People who carry antibodies against the common viruses used to deliver gene therapies can mount a dangerous immune response if they’re re-exposed. That means many people are ineligible for these therapies and others can’t get a second dose. Now researchers are hunting for a solution. (Nature)
More good news about Ozempic. A new study shows that the drug can cut the risk of kidney complications, including death in people with diabetes and chronic kidney disease. (NYT)
Must read: This story, the second in series on the denial of reproductive autonomy for people with sickle-cell disease, examines how the US medical system undermines a woman’s right to choose. (Stat)
When Google announced it was rolling out its artificial-intelligence-powered search feature earlier this month, the company promised that “Google will do the googling for you.” The new feature, called AI Overviews, provides brief, AI-generated summaries highlighting key information and links on top of search results.
Unfortunately, AI systems are inherently unreliable. Within days of AI Overviews’ release in the US, users were sharing examples of responses that were strange at best. It suggested that users add glue to pizza or eat at least one small rock a day, and that former US president Andrew Johnson earned university degrees between 1947 and 2012, despite dying in 1875.
On Thursday, Liz Reid, head of Google Search, announced that the company has been making technical improvements to the system to make it less likely to generate incorrect answers, including better detection mechanisms for nonsensical queries. It is also limiting the inclusion of satirical, humorous, and user-generated content in responses, since such material could result in misleading advice.
But why is AI Overviews returning unreliable, potentially dangerous information? And what, if anything, can be done to fix it?
How does AI Overviews work?
In order to understand why AI-powered search engines get things wrong, we need to look at how they’ve been optimized to work. We know that AI Overviews uses a new generative AI model in Gemini, Google’s family of large language models (LLMs), that’s been customized for Google Search. That model has been integrated with Google’s core web ranking systems and designed to pull out relevant results from its index of websites.
Most LLMs simply predict the next word (or token) in a sequence, which makes them appear fluent but also leaves them prone to making things up. They have no ground truth to rely on, but instead choose each word purely on the basis of a statistical calculation. That leads to hallucinations. It’s likely that the Gemini model in AI Overviews gets around this by using an AI technique called retrieval-augmented generation (RAG), which allows an LLM to check specific sources outside of the data it’s been trained on, such as certain web pages, says Chirag Shah, a professor at the University of Washington who specializes in online search.
Once a user enters a query, it’s checked against the documents that make up the system’s information sources, and a response is generated. Because the system is able to match the original query to specific parts of web pages, it’s able to cite where it drew its answer from—something normal LLMs cannot do.
One major upside of RAG is that the responses it generates to a user’s queries should be more up to date, more factually accurate, and more relevant than those from a typical model that just generates an answer based on its training data. The technique is often used to try to prevent LLMs from hallucinating. (A Google spokesperson would not confirm whether AI Overviews uses RAG.)
So why does it return bad answers?
But RAG is far from foolproof. In order for an LLM using RAG to come up with a good answer, it has to both retrieve the information correctly and generate the response correctly. A bad answer results when one or both parts of the process fail.
In the case of AI Overviews’ recommendation of a pizza recipe that contains glue—drawing from a joke post on Reddit—it’s likely that the post appeared relevant to the user’s original query about cheese not sticking to pizza, but something went wrong in the retrieval process, says Shah. “Just because it’s relevant doesn’t mean it’s right, and the generation part of the process doesn’t question that,” he says.
Similarly, if a RAG system comes across conflicting information, like a policy handbook and an updated version of the same handbook, it’s unable to work out which version to draw its response from. Instead, it may combine information from both to create a potentially misleading answer.
“The large language model generates fluent language based on the provided sources, but fluent language is not the same as correct information,” says Suzan Verberne, a professor at Leiden University who specializes in natural-language processing.
The more specific a topic is, the higher the chance of misinformation in a large language model’s output, she says, adding: “This is a problem in the medical domain, but also education and science.”
According to the Google spokesperson, in many cases when AI Overviews returns incorrect answers it’s because there’s not a lot of high-quality information available on the web to show for the query—or because the query most closely matches satirical sites or joke posts.
The spokesperson says the vast majority of AI Overviews provide high-quality information and that many of the examples of bad answers were in response to uncommon queries, adding that AI Overviews containing potentially harmful, obscene, or otherwise unacceptable content came up in response to less than one in every 7 million unique queries. Google is continuing to remove AI Overviews on certain queries in accordance with its content policies.
It’s not just about bad training data
Although the pizza glue blunder is a good example of a case where AI Overviews pointed to an unreliable source, the system can also generate misinformation from factually correct sources. Melanie Mitchell, an artificial-intelligence researcher at the Santa Fe Institute in New Mexico, googled “How many Muslim presidents has the US had?’” AI Overviews responded: “The United States has had one Muslim president, Barack Hussein Obama.”
While Barack Obama is not Muslim, making AI Overviews’ response wrong, it drew its information from a chapter in an academic book titled Barack Hussein Obama: America’s First Muslim President?So not only did the AI system miss the entire point of the essay, it interpreted it in the exact opposite of the intended way, says Mitchell. “There’s a few problems here for the AI; one is finding a good source that’s not a joke, but another is interpreting what the source is saying correctly,” she adds. “This is something that AI systems have trouble doing, and it’s important to note that even when it does get a good source, it can still make errors.”
Can the problem be fixed?
Ultimately, we know that AI systems are unreliable, and so long as they are using probability to generate text word by word, hallucination is always going to be a risk. And while AI Overviews is likely to improve as Google tweaks it behind the scenes, we can never be certain it’ll be 100% accurate.
Google has said that it’s adding triggering restrictions for queries where AI Overviews were not proving to be especially helpful and has added additional “triggering refinements” for queries related to health. The company could add a step to the information retrieval process designed to flag a risky query and have the system refuse to generate an answer in these instances, says Verberne. Google doesn’t aim to show AI Overviews for explicit or dangerous topics, or for queries that indicate a vulnerable situation, the company spokesperson says.
Techniques like reinforcement learning from human feedback, which incorporates such feedback into an LLM’s training, can also help improve the quality of its answers.
Similarly, LLMs could be trained specifically for the task of identifying when a question cannot be answered, and it could also be useful to instruct them to carefully assess the quality of a retrieved document before generating an answer, Verbene says: “Proper instruction helps a lot!”
Although Google has added a label to AI Overviews answers reading “Generative AI is experimental,” it should consider making it much clearer that the feature is in beta and emphasizing that it is not ready to provide fully reliable answers, says Shah. “Until it’s no longer beta—which it currently definitely is, and will be for some time— it should be completely optional. It should not be forced on us as part of core search.”
If a hiker gets lost in the rugged Scottish Highlands, rescue teams sometimes send up a drone to search for clues of the individual’s route—trampled vegetation, dropped clothing, food wrappers. But with vast terrain to cover and limited battery life, picking the right area to search is critical.
Traditionally, expert drone pilots use a combination of intuition and statistical “search theory”—a strategy with roots in World War II–era hunting of German submarines—to prioritize certain search locations over others. Jan-Hendrik Ewers and a team from the University of Glasgow recently set out to see if a machine-learning system could do better.
Ewers grew up skiing and hiking in the Highlands, giving him a clear idea of the complicated challenges involved in rescue operations there. “There wasn’t much to do growing up, other than spending time outdoors or sitting in front of my computer,” he says. “I ended up doing a lot of both.”
To start, Ewers took data sets of search-and-rescue cases from around the world, which include details such as an individual’s age, whether they were hunting, horseback riding, or hiking, and if they suffered from dementia, along with information about the location where the person was eventually found—by water, buildings, open ground, trees, or roads. He trained an AI model with this data, in addition to geographical data from Scotland. The model runs millions of simulations to reveal the routes a missing person would be most likely to take under the specific circumstances. The result is a probability distribution—a heat map of sorts—indicating the priority search areas.
With this kind of probability map, the team showed that deep learning could be used to design more efficient search paths for drones. In research published last week on arXiv, which has not yet been peer reviewed, the team tested its algorithm against two common search patterns: the “lawn mower,” in which a drone would fly over a target area in a series of simple stripes, and an algorithm similar to Ewers’s but less adept at working with probability distribution maps.
In virtual testing, Ewers’s algorithm beat both of those approaches on two key measures: the distance a drone would have to fly to locate the missing person, and the likelihood that the person was found. While the lawn mower and the existing algorithmic approach found the person 8% of the time and 12% of the time, respectively, Ewers’s approach found them 19% of the time. If it proves successful in real rescue situations, the new system could speed up response times, and save more lives, in scenarios where every minute counts.
“The search-and-rescue domain in Scotland is extremely varied, and also quite dangerous,” Ewers says. Emergencies can arise in thick forests on the Isle of Arran, the steep mountains and slopes around the Cairngorm Plateau, or the faces of Ben Nevis, one of the most revered but dangerous rock climbing destinations in Scotland. “Being able to send up a drone and efficiently search with it could potentially save lives,” he adds.
Search-and-rescue experts say that using deep learning to design more efficient drone routes could help locate missing persons faster in a variety of wilderness areas, depending on how well suited the environment is for drone exploration (it’s harder for drones to explore dense canopy than open brush, for example).
“That approach in the Scottish Highlands certainly sounds like a viable one, particularly in the early stages of search when you’re waiting for other people to show up,” says David Kovar, a director at the US National Association for Search and Rescue in Williamsburg, Virginia, who has used drones for everything from disaster response in California to wilderness search missions in New Hampshire’s White Mountains.
But there are caveats. The success of such a planning algorithm will hinge on how accurate the probability maps are. Overreliance on these maps could mean that drone operators spend too much time searching the wrong areas.
Ewers says a key next step to making the probability maps as accurate as possible will be obtaining more training data. To do that, he hopes to use GPS data from more recent rescue operations to run simulations, essentially helping his model to understand the connections between the location where someone was last seen and where they were ultimately found.
Not all rescue operations contain rich enough data for him to work with, however. “We have this problem in search and rescue where the training data is extremely sparse, and we know from machine learning that we want a lot of high-quality data,” Ewers says. “If an algorithm doesn’t perform better than a human, you are potentially risking someone’s life.”
In the US, for example, drone pilots are required to have a constant line of sight between them and their drone. In Scotland, meanwhile, operators aren’t permitted to be more than 500 meters away from their drone. These rules are meant to prevent accidents, such as a drone falling and endangering people, but in rescue settings such rules severely curtail ground rescuers’ ability to survey for clues.
“Oftentimes we’re facing a regulatory problem rather than a technical problem,” Kovar says. “Drones are capable of doing far more than we’re allowed to use them for.”
Ewers hopes that models like his might one day expand the capabilities of drones even more. For now, he is in conversation with the Police Scotland Air Support Unit to see what it would take to test and deploy his system in real-world settings.
This is an excerpt from The Chinese Computer: A Global History of the Information Age by Thomas S. Mullaney, published on May 28 by The MIT Press. It has been lightly edited.
ymiw2
klt4
pwyy1
wdy6
o1
dfb2
wdv2
fypw3
uet5
dm2
dlu1 …
A young Chinese man sat down at his QWERTY keyboard and rattled off an enigmatic string of letters and numbers.
Was it code? Child’s play? Confusion? It was Chinese.
The beginning of Chinese, at least. These forty-four keystrokes marked the first steps in a process known as “input” or shuru: the act of getting Chinese characters to appear on a computer monitor or other digital device using a QWERTY keyboard or trackpad.
Stills taken from a 2013 Chinese input competition screencast.
COURTESY OF MIT PRESS
Across all computational and digital media, Chinese text entry relies on software programs known as “Input Method Editors”—better known as “IMEs” or simply “input methods” (shurufa). IMEs are a form of “middleware,” so-named because they operate in between the hardware of the user’s device and the software of its program or application. Whether a person is composing a Chinese document in Microsoft Word, searching the web, sending text messages, or otherwise, an IME is always at work, intercepting all of the user’s keystrokes and trying to figure out which Chinese characters the user wants to produce. Input, simply put, is the way ymiw2klt4pwyy … becomes a string of Chinese characters.
IMEs are restless creatures. From the moment a key is depressed, or a stroke swiped, they set off on a dynamic, iterative process, snatching up user-inputted data and searching computer memory for potential Chinese character matches. The most popular IMEs these days are based on Chinese phonetics—that is, they use the letters of the Latin alphabet to describe the sound of Chinese characters, with mainland Chinese operators using the country’s official Romanization system, Hanyu pinyin.
Example of Chinese Input Method Editor pop-up menu (抄袭 / “plagiarism”)
COURTESY OF MIT PRESS
This young man’s name was Huang Zhenyu (also known by his nom de guerre, Yu Shi). He was one of around sixty contestants that day, each wearing a bright red shoulder sash—like a tickertape parade of old, or a beauty pageant. “Love Chinese Characters” (Ai Hanzi) was emblazoned in vivid, golden yellow on a poster at the front of the hall. The contestants’ task was to transcribe a speech by outgoing Chinese president Hu Jintao, as quickly and as accurately as they could. “Hold High the Great Banner of Socialism with Chinese Characteristics,” it began, or in the original: 高举中国特色社会主义伟大旗帜为夺取全面建设小康社会新胜利而奋斗. Huang’s QWERTY keyboard did not permit him to enter these characters directly, however, and so he entered the quasi-gibberish string of letters and numbers instead: ymiw2klt4pwyy1wdy6…
With these four-dozen keystrokes, Huang was well on his way, not only to winning the 2013 National Chinese Characters Typing Competition, but also to clock one of the fastest typing speeds ever recorded, anywhere in the world.
ymiw2klt4pwyy1wdy6 … is not the same as 高举中国特色社会主义 … the keys that Huang actually depressed on his QWERTY keyboard—his “primary transcript,” as we could call it—were completely different than the symbols that ultimately appeared on his computer screen, namely the “secondary transcript” of Hu Jintao’s speech. This is true for every one of the world’s billion-plus Sinophone computer users. In Chinese computing, what you type is never what you get.
For readers accustomed to English-language word processing and computing, this should come as a surprise. For example, were you to compare the paragraph you’re reading right now against a key log showing exactly which buttons I depressed to produce it, the exercise would be unenlightening (to put it mildly). “F-o-r-_-r-e-a-d-e-r-s-_-a-c-c-u-s-t-o-m-e-d-_t-o-_-E-n-g-l-i-s-h … ” it would read (forgiving any typos or edits). In English-language typewriting and computer input, a typist’s primary and secondary transcripts are, in principle, identical. The symbols on the keys and the symbols on the screen are the same.
Not so for Chinese computing. When inputting Chinese, the symbols a person sees on their QWERTY keyboard are always different from the symbols that ultimately appear on the monitor or on paper. Every single computer and new media user in the Sinophone world—no matter if they are blazing-fast or molasses-slow—uses their device in exactly the same way as Huang Zhenyu, constantly engaged in this iterative process of criteria-candidacy-confirmation, using one IME or another. Not some Chinese-speaking users, mind you, but all. This is the first and most basic feature of Chinese computing: Chinese human-computer interaction (HCI) requires users to operate entirely in code all the time.
If Huang Zhenyu’s mastery of a complex alphanumeric code weren’t impressive enough, consider the staggering speed of his performance. He transcribed the first 31 Chinese characters of Hu Jintao’s speech in roughly 5 seconds, for an extrapolated speed of 372 Chinese characters per minute. By the close of the grueling 20-minute contest, one extending over thousands of characters, he crossed the finish line with an almost unbelievable speed of 221.9 characters per minute.
That’s 3.7 Chinese characters every second.
In the context of English, Huang’s opening 5 seconds would have been the equivalent of around 375 English words-per-minute, with his overall competition speed easily surpassing 200 WPM—a blistering pace unmatched by anyone in the Anglophone world (using QWERTY, at least). In 1985, Barbara Blackburn achieved a Guinness Book of World Records–verified performance of 170 English words-per-minute (on a typewriter, no less). Speed demon Sean Wrona later bested Blackburn’s score with a performance of 174 WPM (on a computer keyboard, it should be noted). As impressive as these milestones are, the fact remains: had Huang’s performance taken place in the Anglophone world, it would be his name enshrined in the Guinness Book of World Records as the new benchmark to beat.
Huang’s speed carried special historical significance as well.
For a person living between the years 1850 and 1950—the period examined in the book The Chinese Typewriter—the idea of producing Chinese by mechanical means at a rate of over two hundred characters per minute would have been virtually unimaginable. Throughout the history of Chinese telegraphy, dating back to the 1870s, operators maxed out at perhaps a few dozen characters per minute. In the heyday of mechanical Chinese typewriting, from the 1920s to the 1970s, the fastest speeds on record were just shy of eighty characters per minute (with the majority of typists operating at far slower rates). When it came to modern information technologies, that is to say, Chinese was consistently one of the slowest writing systems in the world.
What changed? How did a script so long disparaged as cumbersome and helplessly complex suddenly rival—exceed, even—computational typing speeds clocked in other parts of the world? Even if we accept that Chinese computer users are somehow able to engage in “real time” coding, shouldn’t Chinese IMEs result in a lower overall “ceiling” for Chinese text processing as compared to English? Chinese computer users have to jump through so many more hoops, after all, over the course of a cumbersome, multistep process: the IME has to intercept a user’s keystrokes, search in memory for a match, present potential candidates, and wait for the user’s confirmation. Meanwhile, English-language computer users need only depress whichever key they wish to see printed on screen. What could be simpler than the “immediacy” of “Q equals Q,” “W equals W,” and so on?
COURTESY OF TOM MULLANEY
To unravel this seeming paradox, we will examine the first Chinese computer ever designed: the Sinotype, also known as the Ideographic Composing Machine. Debuted in 1959 by MIT professor Samuel Hawks Caldwell and the Graphic Arts Research Foundation, this machine featured a QWERTY keyboard, which the operator used to input—not the phonetic values of Chinese characters—but the brushstrokes out of which Chinese characters are composed. The objective of Sinotype was not to “build up” Chinese characters on the page, though, the way a user builds up English words through the successive addition of letters. Instead, each stroke “spelling” served as an electronic address that Sinotype’s logical circuit used to retrieve a Chinese character from memory. In other words, the first Chinese computer in history was premised on the same kind of “additional steps” as seen in Huang Zhenyu’s prizewinning 2013 performance.
During Caldwell’s research, he discovered unexpected benefits of all these additional steps—benefits entirely unheard of in the context of Anglophone human-machine interaction at that time. The Sinotype, he found, needed far fewer keystrokes to find a Chinese character in memory than to compose one through conventional means of inscription. By way of analogy, to “spell” a nine-letter word like “crocodile” (c-r-o-c-o-d-i-l-e) took far more time than to retrieve that same word from memory (“c-r-o-c-o-d” would be enough for a computer to make an unambiguous match, after all, given the absence of other words with similar or identical spellings). Caldwell called his discovery “minimum spelling,” making it a core part of the first Chinese computer ever built.
Today, we know this technique by a different name: “autocompletion,” a strategy of human-computer interaction in which additional layers of mediation result in faster textual input than the “unmediated” act of typing. Decades before its rediscovery in the Anglophone world, then, autocompletion was first invented in the arena of Chinese computing.
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
Last week’s release of GPT-4o, a new AI “omnimodel” that you can interact with using voice, text, or video, was supposed to be a big moment for OpenAI. But just days later, it feels as if the company is in big trouble. From the resignation of most of its safety team to Scarlett Johansson’s accusation that it replicated her voice for the model against her consent, it’s now in damage-control mode.
Add to that another thing OpenAI fumbled with GPT-4o: the data it used to train its tokenizer—a tool that helps the model parse and process text more efficiently—is polluted by Chinese spam websites. As a result, the model’s Chinese token library is full of phrases related to pornography and gambling. This could worsen some problems that are common with AI models: hallucinations, poor performance, and misuse.
I wrote about it on Friday after several researchers and AI industry insiders flagged the problem. They took a look at GPT-4o’s public token library, which has been significantly updated with the new model to improve support of non-English languages, and saw that more than 90 of the 100 longest Chinese tokens in the model are from spam websites. These are phrases like “_free Japanese porn video to watch,” “Beijing race car betting,” and “China welfare lottery every day.”
Anyone who reads Chinese could spot the problem with this list of tokens right away. Some such phrases inevitably slip into training data sets because of how popular adult content is online, but for them to account for 90% of the Chinese language used to train the model? That’s alarming.
“It’s an embarrassing thing to see as a Chinese person. Is that just how the quality of the [Chinese] data is? Is it because of insufficient data cleaning or is the language just like that?” says Zhengyang Geng, a PhD student in computer science at Carnegie Mellon University.
It could be tempting to draw a conclusion about a language or a culture from the tokens OpenAI chose for GPT-4o. After all, these are selected as commonly seen and significant phrases from the respective languages. There’s an interesting blog post by a Hong Kong–based researcher named Henry Luo, who queried the longest GPT-4o tokens in various different languages and found that they seem to have different themes. While the tokens in Russian reflect language about the government and public institutions, the tokens in Japanese have a lot of different ways to say “thank you.”
But rather than reflecting the differences between cultures or countries, I think this explains more about what kind of training data is readily available online, and the websites OpenAI crawled to feed into GPT-4o.
After I published the story, Victor Shih, a political science professor at the University of California, San Diego, commented on it on X: “When you try not [to] train on Chinese state media content, this is what you get.”
It’s half a joke, and half a serious point about the two biggest problems in training large language models to speak Chinese: the readily available data online reflects either the “official,” sanctioned way of talking about China or the omnipresent spam content that drowns out real conversations.
In fact, among the few long Chinese tokens in GPT-4o that aren’t either pornography or gambling nonsense, two are “socialism with Chinese characteristics” and “People’s Republic of China.” The presence of these phrases suggests that a significant part of the training data actually is from Chinese state media writings, where formal, long expressions are extremely common.
OpenAI has historically been very tight-lipped about the data it uses to train its models, and it probably will never tell us how much of its Chinese training database is state media and how much is spam. (OpenAI didn’t respond to MIT Technology Review’s detailed questions sent on Friday.)
But it is not the only company struggling with this problem. People inside China who work in its AI industry agree there’s a lack of quality Chinese text data sets for training LLMs. One reason is that the Chinese internet used to be, and largely remains, divided up by big companies like Tencent and ByteDance. They own most of the social platforms and aren’t going to share their data with competitors or third parties to train LLMs.
In fact, this is also why search engines, including Google, kinda suck when it comes to searching in Chinese. Since WeChat content can only be searched on WeChat, and content on Douyin (the Chinese TikTok) can only be searched on Douyin, this data is not accessible to a third-party search engine, let alone an LLM. But these are the platforms where actual human conversations are happening, instead of some spam website that keeps trying to draw you into online gambling.
The lack of quality training data is a much bigger problem than the failure to filter out the porn and general nonsense in GPT-4o’s token-training data. If there isn’t an existing data set, AI companies have to put in significant work to identify, source, and curate their own data sets and filter out inappropriate or biased content.
It doesn’t seem OpenAI did that, which in fairness makes some sense, given that people in China can’t use its AI models anyway.
Still, there are many people living outside China who want to use AI services in Chinese. And they deserve a product that works properly as much as speakers of any other language do.
How can we solve the problem of the lack of good Chinese LLM training data? Tell me your idea at zeyi@technologyreview.com.
Now read the rest of China Report
Catch up with China
1. China launched an anti-dumping investigation into imports of polyoxymethylene copolymer—a widely used plastic in electronics and cars—from the US, the EU, Taiwan, and Japan. It’s widely seen as a response to the new US tariff announced on Chinese EVs. (BBC)
Meanwhile, Latin American countries, including Mexico, Chile, and Brazil, have increased tariffs on Chinese-imported steel, testing China’s relationship with the region. (Bloomberg $)
2. China’s solar-industry boom is incentivizing farmers to install solar panels and make some extra cash by selling the electricity they generate. (Associated Press)
3. Hedging against the potential devaluation of the RMB, Chinese buyers are pushing the price of gold to all-time highs. (Financial Times $)
4. The Shanghai government set up a pilot project that allows data to be transferred out of China without going through the much-dreaded security assessments, a move that has been sought by companies like Tesla. (Reuters $)
5. China’s central bank fined seven businesses—including a KFC and branches of state-owned corporations—for rejecting cash payments. The popularization of mobile payment has been a good thing, but the dwindling support for cash is also making life harder for people like the elderly and foreign tourists. (Business Insider $)
6. Alibaba and Baidu are waging an LLM price war in China to attract more users. (Bloomberg $)
7. The Chinese government has sanctioned Mike Gallagher, a former Republican congressman who chaired the Select Committee on China and remains a fierce critic of Beijing. (NBC News)
Lost in translation
China’s National Health Commission is exploring the relaxation of stringent rules around human genetic data to boost the biotech industry, according to the Chinese publication Caixin. A regulation enacted in 1998 required any research that involves the use of this data to clear an approval process. And there’s even more scrutiny if the research involves foreign institutions.
In the early years of human genetic research, the regulation helped prevent the nonconsensual collection of DNA. But as the use of genetic data becomes increasingly important in discovering new treatments, the industry has been complaining about the bureaucracy, which can add an extra two to four months to research projects. Now the government is holding discussions on how to revise the regulation, potentially lifting the approval process for smaller-scale research and more foreign entities, as part of a bid to accelerate the growth of biotech research in China.
One more thing
Did you know that the Beijing Capital International Airport has been employing birds of prey to chase away other birds since 2019? This month, the second generation of Beijing’s birdy employees started their work driving away the migratory birds that could endanger aircraft. The airport even has different kinds of raptors—Eurasian hobbies, Eurasian goshawks, and Eurasian sparrowhawks—to deal with the different bird species that migrate to Beijing at different times.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
Tech companies keep finding new ways to bring AI into every facet of our lives. AI has taken over my search engine results, and new virtual assistants from Google and OpenAI announced last week are bringing the world eerily close to the 2013 film Her (in more ways than one).
So how worried should we be about AI’s electricity demands? Well, it’s complicated.
Using AI for certain tasks can come with a significant energy price tag. With some powerful AI models, generating an image can require as much energy as charging up your phone, as my colleague Melissa Heikkilä explained in a story from December. Create 1,000 images with a model like Stable Diffusion XL, and you’ve produced as much carbon dioxide as driving just over four miles in a gas-powered car, according to the researchers Melissa spoke to.
But while generated images are splashy, there are plenty of AI tasks that don’t use as much energy. For example, creating images is thousands of times more energy-intensive than generating text. And using a smaller model that’s tailored to a specific task, rather than a massive, all-purpose generative model, can be dozens of times more efficient. In any case, generative AI models require energy, and we’re using them a lot.
Electricity consumption from data centers, AI, and cryptocurrency could reach double 2022 levels by 2026, according to projections from the International Energy Agency. Those technologies together made up roughly 2% of global electricity demand in 2022. Note that these numbers aren’t just for AI—it’s tricky to nail down AI’s specific contribution, so keep that in mind when you see predictions about electricity demand from data centers.
There’s a wide range of uncertainty in the IEA’s projections, depending on factors like how quickly deployment increases and how efficient computing processes get. On the low end, the sector could require about 160 terawatt-hours of additional electricity by 2026. On the higher end, that number might be 590 TWh. As the report puts it, AI, data centers, and cryptocurrency together are likely adding “at least one Sweden or at most one Germany” to global electricity demand.
In total, the IEA projects, the world will add about 3,500 TWh of electricity demand over that same period—so while computing is certainly part of the demand crunch, it’s far from the whole story. Electric vehicles and the industrial sector will both be bigger sources of growth in electricity demand than data centers in the European Union, for example.
Still, some big tech companies are suggesting that AI could get in the way of their climate goals. Microsoft pledged four years ago to bring its greenhouse-gas emissions to zero (or even lower) by the end of the decade. But the company’s recent sustainability report shows that instead, emissions are still ticking up, and some executives point to AI as a reason. “In 2020, we unveiled what we called our carbon moonshot. That was before the explosion in artificial intelligence,” Brad Smith, Microsoft’s president, told Bloomberg Green.
What I found interesting, though, is that it’s not AI’s electricity demand that’s contributing to Microsoft’s rising emissions, at least on paper. The company has agreements in place and buys renewable-energy credits so that electricity needs for all its functions (including AI) are met with renewables. (How much these credits actually help is questionable, but that’s a story for another day.)
Instead, infrastructure growth could be adding to the uptick in emissions. Microsoft plans to spend $50 billion between July 2023 and June 2024 on expanding data centers to meet demand for AI products, according to the Bloomberg story. Building those data centers requires materials that can be carbon intensive, like steel, cement, and of course chips.
Meyer points to estimates from 1999 that information technologies were already accounting for up to 13% of US power demand, and that personal computers and the internet could eat up half the grid’s capacity within the decade. That didn’t end up happening, and even at the time, computing was actually accounting for something like 3% of electricity demand.
We’ll have to wait and see if doomsday predictions about AI’s energy demand play out. The way I see it, though, AI is probably going to be a small piece of a much bigger story. Ultimately, rising electricity demand from AI is in some ways no different from rising demand from EVs, heat pumps, or factory growth. It’s really how we meet that demand that matters.
If we build more fossil-fuel plants to meet our growing electricity demand, it’ll come with negative consequences for the climate. But if we use rising electricity demand as a catalyst to lean harder into renewable energy and other low-carbon power sources, and push AI to get more efficient, doing more with less energy, then we can continue to slowly clean up the grid, even as AI continues to expand its reach in our lives.
Now read the rest of The Spark
Related reading
Check out my colleague Melissa’s story on the carbon footprint of AI from December here.
For a closer look at Microsoft’s new sustainability report and the effects of AI, give this Bloomberg Greenstory from reporters Akshat Rathi and Dina Bass a read.
Robinson Meyer at Heatmap dug into the context around the AI energy demand in this April piece.
Another thing
Missed our event last week on thermal batteries? Good news—the recording is now available for subscribers!
For the latest in our Roundtables series, I spoke with Amy Nordrum, MIT Technology Review executive editor, about how the technology works, who the crucial players are, and what I’m watching for next. Check it out here.
Keeping up with climate
Changing how we generate heat in industry will be crucial to cleaning up that sector in China, according to a new report. Thermal batteries and heat pumps could meet most of the demand. (Axios)
Form Energy is known for its iron-air batteries, which could help unlock cheap energy storage on the grid. Now, the company is working on research to produce green iron. (Canary Media)
The NET Power pilot in Texas is working to generate electricity with natural gas while capturing the vast majority of emissions. But carbon capture technology in power plants is far from proven. (Cipher News)
MIT spinoff Electrified Thermal Solutions is working to bring its thermal battery technology to commercial use. The company’s product is roughly the size of an elevator and can reach temperatures up to 1,800 °C. (Inside Climate News)
Mexico City has seen constant struggles over water. Now groundwater is drying up, and a system of dams and canals may soon be unable to provide water to the city. (New York Times)
Sodium-ion batteries could offer cheap energy storage while avoiding material crunches for metals like lithium, nickel, and cobalt. China has a massive head start, leaving other countries scrambling to catch up. (Latitude Media)
→ Here’s how this abundant material could unlock cheaper energy storage. (MIT Technology Review)
Biochar is made by heating up biomass like wood and plants in low-oxygen environments. It’s a simple approach to carbon removal, but it doesn’t always get as much attention as other carbon removal technologies. (Heatmap)
This startup wants ships to capture their own emissions by bubbling exhaust through seawater and limestone and dumping it into the ocean. Experts caution that some components of the exhaust could harm sea life if they’re not handled properly. (New Scientist)