Is a secure AI assistant possible?
<div data-chronoton-summary="
Risky business of AI assistants OpenClaw, a viral tool created by independent engineer Peter Steinberger, allows users to create personalized AI assistants. Security experts are alarmed by its vulnerabilities, with even the Chinese government issuing warnings about the risks.
The prompt injection threat Tools like OpenClaw have many vulnerabilities, but the one experts are most worried about its prompt injection. Unlike conventional hacking, prompt injection tricks an LLM by embedding malicious text in emails or websites the AI reads.
No silver bullet for security Researchers are exploring multiple defense strategies: training LLMs to ignore injections, using detector LLMs to screen inputs, and creating policies that restrict harmful outputs. The fundamental challenge remains balancing utility with security in AI assistants.
” data-chronoton-post-id=”1132768″ data-chronoton-expand-collapse=”1″ data-chronoton-analytics-enabled=”1″>
AI agents are a risky business. Even when stuck inside the chatbox window, LLMs will make mistakes and behave badly. Once they have tools that they can use to interact with the outside world, such as web browsers and email addresses, the consequences of those mistakes become far more serious.
That might explain why the first breakthrough LLM personal assistant came not from one of the major AI labs, which have to worry about reputation and liability, but from an independent software engineer, Peter Steinberger. In November of 2025, Steinberger uploaded his tool, now called OpenClaw, to GitHub, and in late January the project went viral.
OpenClaw harnesses existing LLMs to let users create their own bespoke assistants. For some users, this means handing over reams of personal data, from years of emails to the contents of their hard drive. That has security experts thoroughly freaked out. The risks posed by OpenClaw are so extensive that it would probably take someone the better part of a week to read all of the security blog posts on it that have cropped up in the past few weeks. The Chinese government took the step of issuing a public warning about OpenClaw’s security vulnerabilities.
In response to these concerns, Steinberger posted on X that nontechnical people should not use the software. (He did not respond to a request for comment for this article.) But there’s a clear appetite for what OpenClaw is offering, and it’s not limited to people who can run their own software security audits. Any AI companies that hope to get in on the personal assistant business will need to figure out how to build a system that will keep users’ data safe and secure. To do so, they’ll need to borrow approaches from the cutting edge of agent security research.
Risk management
OpenClaw is, in essence, a mecha suit for LLMs. Users can choose any LLM they like to act as the pilot; that LLM then gains access to improved memory capabilities and the ability to set itself tasks that it repeats on a regular cadence. Unlike the agentic offerings from the major AI companies, OpenClaw agents are meant to be on 24-7, and users can communicate with them using WhatsApp or other messaging apps. That means they can act like a superpowered personal assistant who wakes you each morning with a personalized to-do list, plans vacations while you work, and spins up new apps in its spare time.
But all that power has consequences. If you want your AI personal assistant to manage your inbox, then you need to give it access to your email—and all the sensitive information contained there. If you want it to make purchases on your behalf, you need to give it your credit card info. And if you want it to do tasks on your computer, such as writing code, it needs some access to your local files.
There are a few ways this can go wrong. The first is that the AI assistant might make a mistake, as when a user’s Google Antigravity coding agent reportedly wiped his entire hard drive. The second is that someone might gain access to the agent using conventional hacking tools and use it to either extract sensitive data or run malicious code. In the weeks since OpenClaw went viral, security researchers have demonstrated numerous such vulnerabilities that put security-naïve users at risk.
Both of these dangers can be managed: Some users are choosing to run their OpenClaw agents on separate computers or in the cloud, which protects data on their hard drives from being erased, and other vulnerabilities could be fixed using tried-and-true security approaches.
But the experts I spoke to for this article were focused on a much more insidious security risk known as prompt injection. Prompt injection is effectively LLM hijacking: Simply by posting malicious text or images on a website that an LLM might peruse, or sending them to an inbox that an LLM reads, attackers can bend it to their will.
And if that LLM has access to any of its user’s private information, the consequences could be dire. “Using something like OpenClaw is like giving your wallet to a stranger in the street,” says Nicolas Papernot, a professor of electrical and computer engineering at the University of Toronto. Whether or not the major AI companies can feel comfortable offering personal assistants may come down to the quality of the defenses that they can muster against such attacks.
It’s important to note here that prompt injection has not yet caused any catastrophes, or at least none that have been publicly reported. But now that there are likely hundreds of thousands of OpenClaw agents buzzing around the internet, prompt injection might start to look like a much more appealing strategy for cybercriminals. “Tools like this are incentivizing malicious actors to attack a much broader population,” Papernot says.
Building guardrails
The term “prompt injection” was coined by the popular LLM blogger Simon Willison in 2022, a couple of months before ChatGPT was released. Even back then, it was possible to discern that LLMs would introduce a completely new type of security vulnerability once they came into widespread use. LLMs can’t tell apart the instructions that they receive from users and the data that they use to carry out those instructions, such as emails and web search results—to an LLM, they’re all just text. So if an attacker embeds a few sentences in an email and the LLM mistakes them for an instruction from its user, the attacker can get the LLM to do anything it wants.
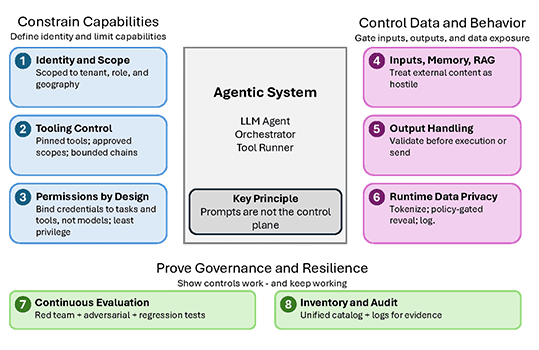
Prompt injection is a tough problem, and it doesn’t seem to be going away anytime soon. “We don’t really have a silver-bullet defense right now,” says Dawn Song, a professor of computer science at UC Berkeley. But there’s a robust academic community working on the problem, and they’ve come up with strategies that could eventually make AI personal assistants safe.
Technically speaking, it is possible to use OpenClaw today without risking prompt injection: Just don’t connect it to the internet. But restricting OpenClaw from reading your emails, managing your calendar, and doing online research defeats much of the purpose of using an AI assistant. The trick of protecting against prompt injection is to prevent the LLM from responding to hijacking attempts while still giving it room to do its job.
One strategy is to train the LLM to ignore prompt injections. A major part of the LLM development process, called post-training, involves taking a model that knows how to produce realistic text and turning it into a useful assistant by “rewarding” it for answering questions appropriately and “punishing” it when it fails to do so. These rewards and punishments are metaphorical, but the LLM learns from them as an animal would. Using this process, it’s possible to train an LLM not to respond to specific examples of prompt injection.
But there’s a balance: Train an LLM to reject injected commands too enthusiastically, and it might also start to reject legitimate requests from the user. And because there’s a fundamental element of randomness in LLM behavior, even an LLM that has been very effectively trained to resist prompt injection will likely still slip up every once in a while.
Another approach involves halting the prompt injection attack before it ever reaches the LLM. Typically, this involves using a specialized detector LLM to determine whether or not the data being sent to the original LLM contains any prompt injections. In a recent study, however, even the best-performing detector completely failed to pick up on certain categories of prompt injection attack.
The third strategy is more complicated. Rather than controlling the inputs to an LLM by detecting whether or not they contain a prompt injection, the goal is to formulate a policy that guides the LLM’s outputs—i.e., its behaviors—and prevents it from doing anything harmful. Some defenses in this vein are quite simple: If an LLM is allowed to email only a few pre-approved addresses, for example, then it definitely won’t send its user’s credit card information to an attacker. But such a policy would prevent the LLM from completing many useful tasks, such as researching and reaching out to potential professional contacts on behalf of its user.
“The challenge is how to accurately define those policies,” says Neil Gong, a professor of electrical and computer engineering at Duke University. “It’s a trade-off between utility and security.”
On a larger scale, the entire agentic world is wrestling with that trade-off: At what point will agents be secure enough to be useful? Experts disagree. Song, whose startup, Virtue AI, makes an agent security platform, says she thinks it’s possible to safely deploy an AI personal assistant now. But Gong says, “We’re not there yet.”
Even if AI agents can’t yet be entirely protected against prompt injection, there are certainly ways to mitigate the risks. And it’s possible that some of those techniques could be implemented in OpenClaw. Last week, at the inaugural ClawCon event in San Francisco, Steinberger announced that he’d brought a security person on board to work on the tool.
As of now, OpenClaw remains vulnerable, though that hasn’t dissuaded its multitude of enthusiastic users. George Pickett, a volunteer maintainer of the OpenGlaw GitHub repository and a fan of the tool, says he’s taken some security measures to keep himself safe while using it: He runs it in the cloud, so that he doesn’t have to worry about accidentally deleting his hard drive, and he’s put mechanisms in place to ensure that no one else can connect to his assistant.
But he hasn’t taken any specific actions to prevent prompt injection. He’s aware of the risk but says he hasn’t yet seen any reports of it happening with OpenClaw. “Maybe my perspective is a stupid way to look at it, but it’s unlikely that I’ll be the first one to be hacked,” he says.