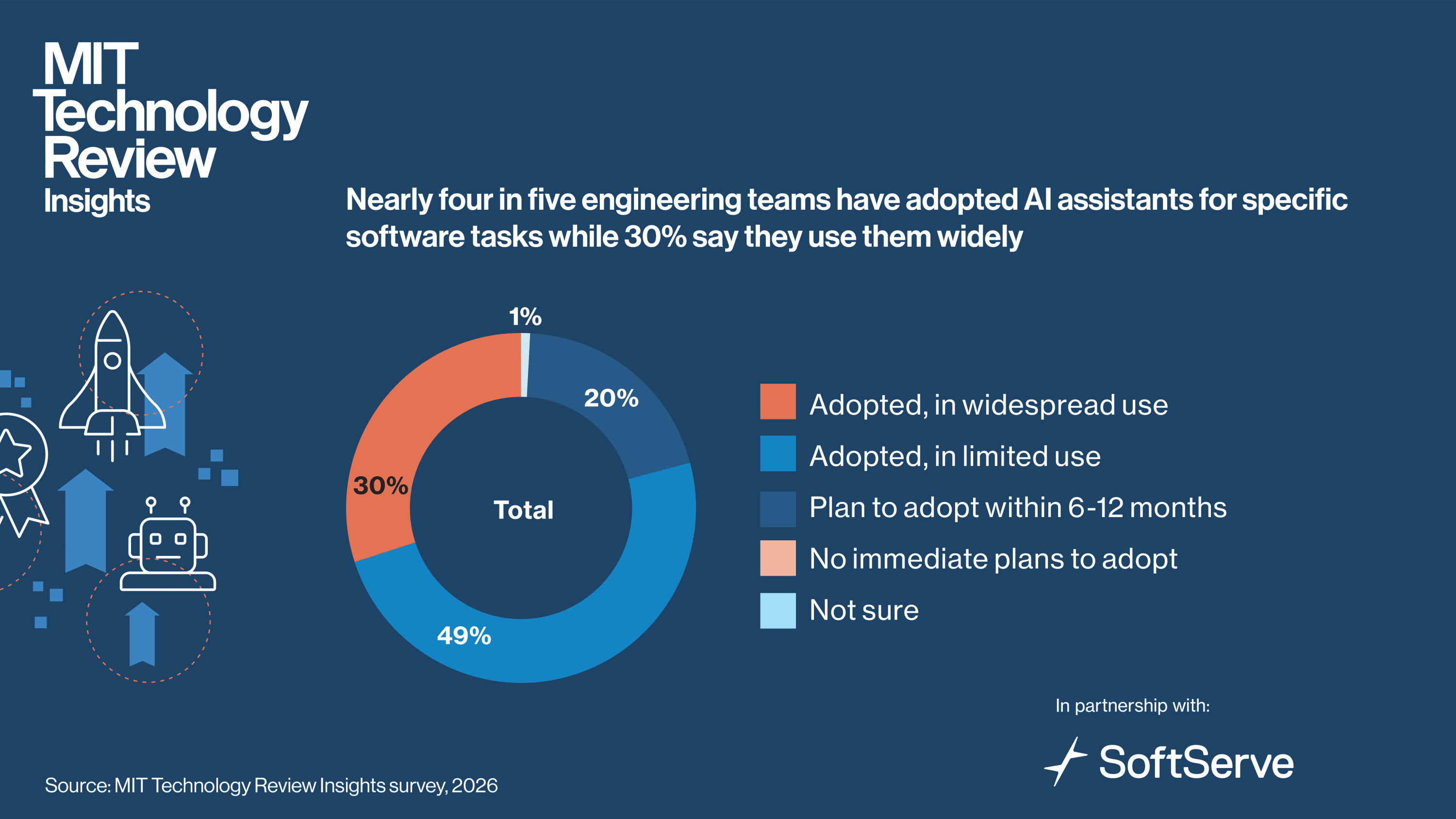Software engineering has experienced two seismic shifts this century. First was the rise of the open source movement, which gradually made code accessible to developers and engineers everywhere. Second, the adoption of development operations (DevOps) and agile methodologies took software from siloed to collaborative development and from batch to continuous delivery. Now, a third such shift looks to be taking shape with the adoption of agentic AI in software engineering.
Thus far, engineering teams have mainly used AI to assist with coding, testing, and other individual tasks, within tightly designed parameters. But with agentic capabilities, AI agents become reasoning, self-directing entities that can manage not just discrete tasks but entire software projects—and do so largely autonomously. If adopted and fully embraced by engineering teams, agentic AI will usher in end-to-end software process automation and, ultimately, agent-managed development and product lifecycle automation.
This report, which is based on a survey of 300 engineering and technology executives, finds that software engineering teams are seeing the potential in agentic AI and are beginning to put it to use, but so far in a mainly limited fashion. Their ambitions for it are high, but most realize it will take time and effort to reduce the barriers to its full diffusion in software operations. As with DevOps and agile, reaping the full benefits of agentic AI in engineering will require sometimes difficult organizational and process change to accompany technology adoption. But the gains to be won in speed, efficiency, and quality promise to make any such pain well worthwhile.
Key findings include the following:
Adoption momentum is building. While half of organizations deem agentic AI a top investment priority for software engineering today, it will be a leading investment for over four-fifths in two years. That spending is driving accelerated adoption. Agentic AI is in (mostly limited) use by 51% of software teams today, and 45% have plans to adopt it within the next 12 months.
Early gains will be incremental. It will take time for software teams’ investments in agentic AI to start bearing fruit. Over the next two years, most expect the improvements from agent use to be slight (14%) or at best moderate (52%). But around one-third (32%) have higher expectations, and 9% think the improvements will be game changing.
Agents will accelerate time-to-market. The chief gains from agentic AI use over that two-year time frame will come from greater speed. Nearly all respondents (98%) expect their teams’ delivery of software projects from pilot to production to accelerate, with the anticipated increase in speed averaging 37% across the group.
The goal for most is full agentic lifecycle management. Teams’ ambitions for scaling agentic AI are high. Most aim for AI agents to be managing the product development and software development lifecycles (PDLC and SDLC) end to end relatively quickly. At 41% of organizations, teams aim to achieve this for most or all products in 18 months. That figure will rise to 72% two years from now, if expectations are met.
Compute costs and integration pose key early challenges. For all survey respondents—but especially in early-adopter verticals such as media and entertainment and technology hardware—integrating agents with existing applications and the cost of computing resources are the main challenges they face with agentic AI in software engineering. The experts we interviewed, meanwhile, emphasize the bigger change management difficulties teams will face in changing workflows.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
The US-China AI race is closer than you think: Chinese models from DeepSeek and Alibaba now trail American ones by razor-thin margins. Meanwhile, the US has more data centers and capital, while China leads in research publications and robotics.
AI benchmarks are badly broken: One popular math benchmark has a 42% error rate, and models can game tests by training on the answers. Strong test scores increasingly fail to predict how AI actually performs in the real world.
Jobs and anxiety are both rising: Software developer employment for workers aged 22–25 has dropped nearly 20% since 2022, with AI likely a factor. Globally, 59% of people think AI will do more good than harm—but 52% say it still makes them nervous.
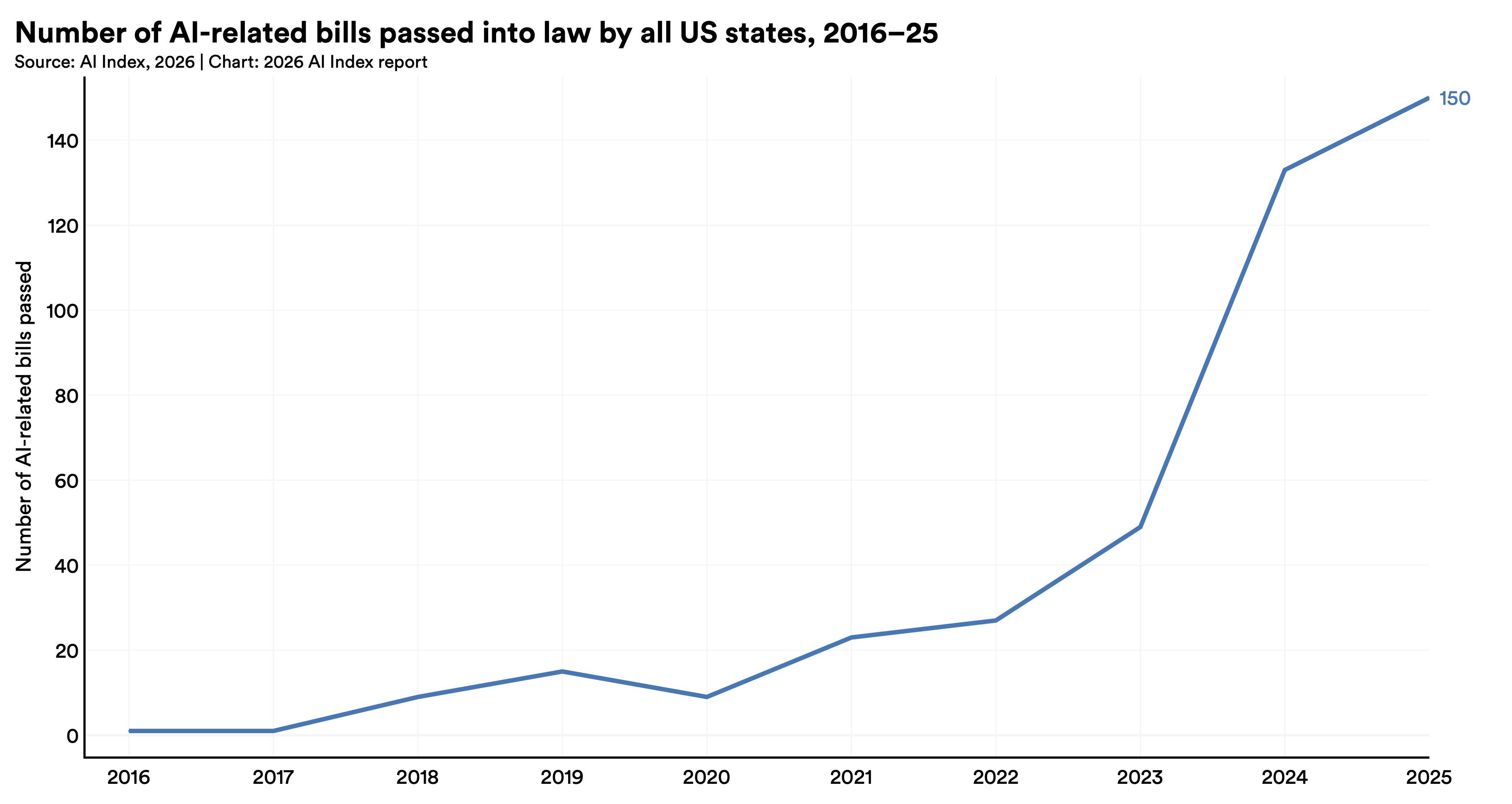
Regulation is losing the race: The EU banned predictive policing AI, and US states passed a record 150 AI-related bills, but experts say lawmakers don’t yet understand the technology well enough to govern it effectively.
If you’re following AI news, you’re probably getting whiplash. AI is a gold rush. AI is a bubble. AI is taking your job. AI can’t even read a clock. The 2026 AI Index from Stanford University’s Institute for Human-Centered Artificial Intelligence, AI’s annual report card, comes out today and cuts through some of that noise.
Despite predictions that AI development may hit a wall, the report says that the top models just keep getting better. People are adopting AI faster than they picked up the personal computer or the internet. AI companies are generating revenue faster than companies in any previous technology boom, but they’re also spending hundreds of billions of dollars on data centers and chips. The benchmarks designed to measure AI, the policies meant to govern it, and the job market are struggling to keep up. AI is sprinting, and the rest of us are trying to find our shoes.
All that speed comes at a cost. AI data centers around the world can now draw 29.6 gigawatts of power, enough to run the entire state of New York at peak demand. Annual water use from running OpenAI’s GPT-4o alone may exceed the drinking water needs of 12 million people. At the same time, the supply chain for chips is alarmingly fragile. The US hosts most of the world’s AI data centers, and one company in Taiwan, TSMC, fabricates almost every leading AI chip.
The data reveals a technology evolving faster than we can manage. Here’s a look at some of the key points from this year’s report.
The US and China are nearly tied
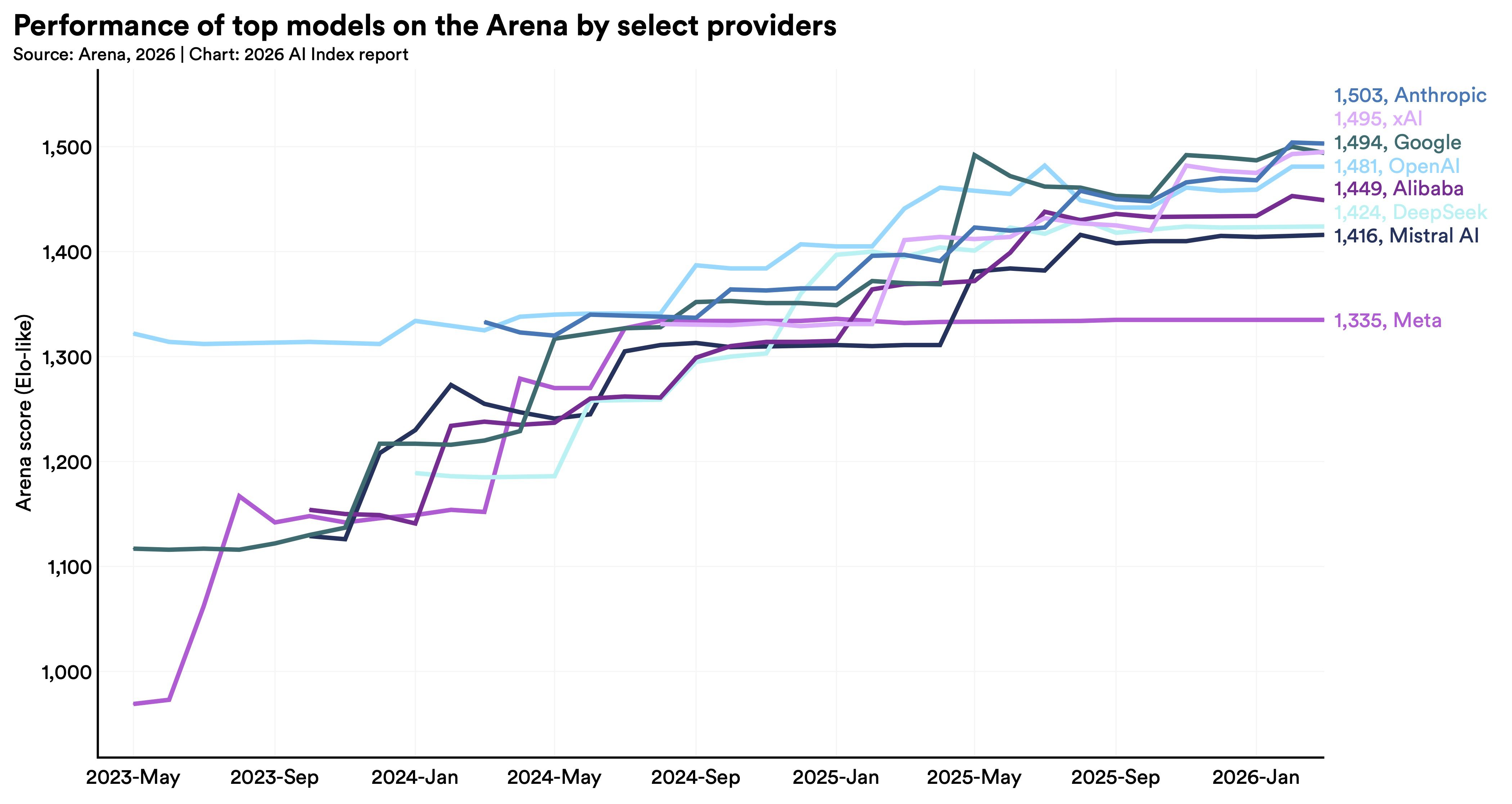
In a long, heated race with immense geopolitical stakes, the US and China are almost neck and neck on AI model performance, according to Arena, a community-driven ranking platform that allows users to compare the outputs of large language models on identical prompts. In early 2023, OpenAI had a lead with ChatGPT, but this gap narrowed in 2024 as Google and Anthropic released their own models. In February 2025, R1, an AI model built by the Chinese lab DeepSeek, briefly matched the top US model, ChatGPT. As of March 2026, Anthropic leads, trailed closely by xAI, Google, and OpenAI. Chinese models like DeepSeek and Alibaba lag only modestly. With the best AI models separated in the rankings by razor-thin margins, they’re now competing on cost, reliability, and real-world usefulness.
The index notes that the US and China have different AI advantages. While the US has more powerful AI models, more capital, and an estimated 5,427 data centers (more than 10 times as many as any other country), China leads in AI research publications, patents, and robotics.
As competition intensifies, companies like OpenAI, Anthropic, and Google no longer disclose their training code, parameter counts, or data-set sizes. “We don’t know a lot of things about predicting model behaviors,” says Yolanda Gil, a computer scientist at the University of Southern California who coauthored the report. This lack of transparency makes it difficult for independent researchers to study how to make AI models safer, she says.
AI models are advancing super fast
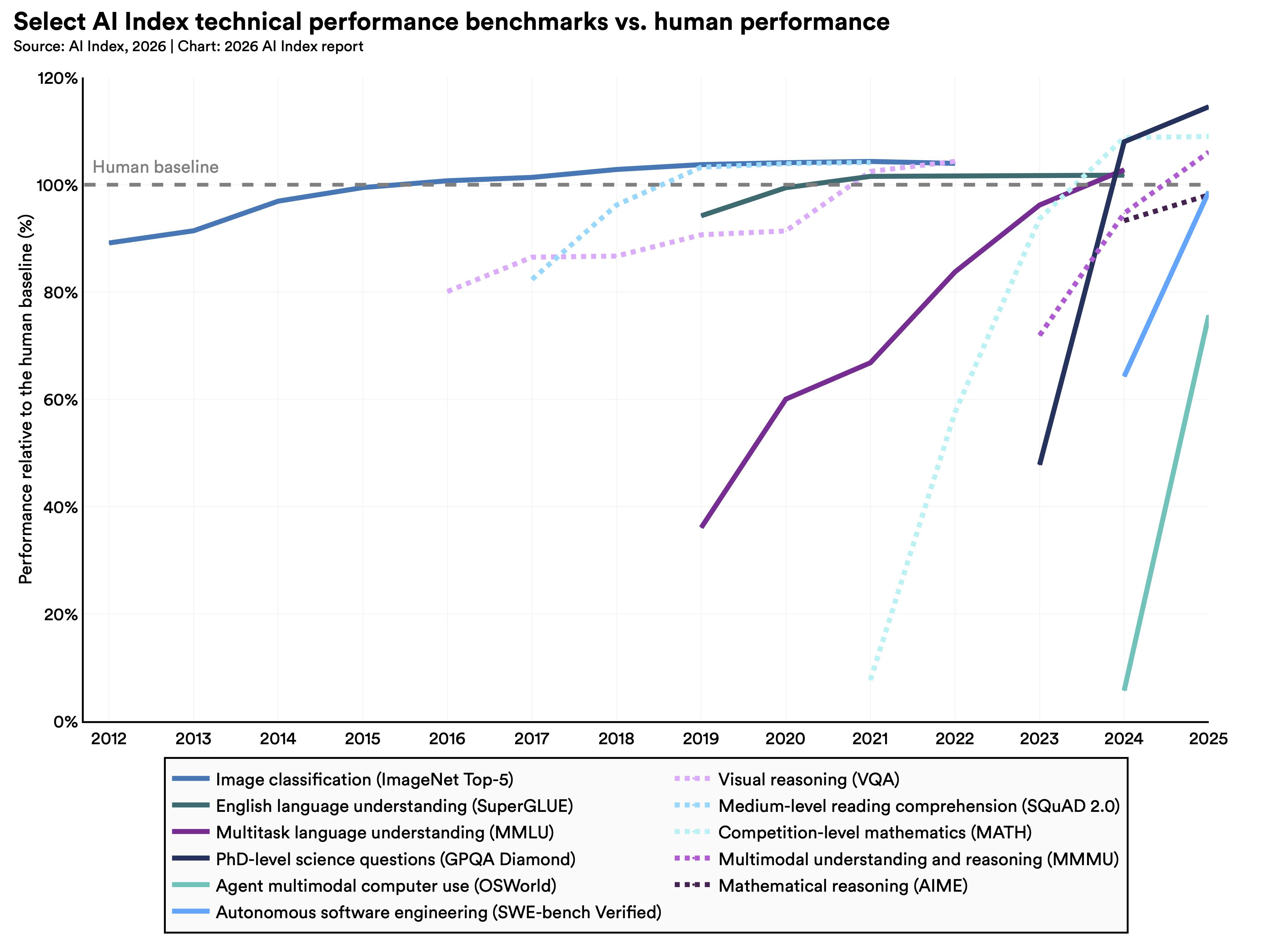
Despite predictions that development will plateau, AI models keep getting better and better. By some measures, they now meet or exceed the performance of human experts on tests that aim to measure PhD-level science, math, and language understanding. SWE-bench Verified, a software engineering benchmark for AI models, saw top scores jump from around 60% in 2024 to almost 100% in 2025. In 2025, an AI system produced a weather forecast on its own.
“I am stunned that this technology continues to improve, and it’s just not plateauing in any way,” says Gil.
However, AI still struggles in plenty of other areas. Because the models learn by processing enormous amounts of text and images rather than by experiencing the physical world, AI exhibits “jagged intelligence.” Robots are still in their early days and succeed in only 12% of household tasks. Self-driving cars are farther along: Waymos are now roaming across five US cities, and Baidu’s Apollo Go vehicles are shuttling riders around in China. AI is also expanding into professional domains like law and finance, but no model dominates the field yet.
But the way we test AI is broken
These reports of progress should be taken with a grain of salt. The benchmarks designed to track AI progress are struggling to keep up as models quickly blow past their ceilings, the Stanford report says. Some are poorly constructed—a popular benchmark that tests a model’s math abilities has a 42% error rate. Others can be gamed: when models are trained on benchmark test data, for example, they can learn to score well without getting smarter.
Because AI is rarely used the same way it’s tested, strong benchmark performance doesn’t always translate to real-world performance. And for complex, interactive technologies such as AI agents and robots, benchmarks barely exist yet.
AI companies are also sharing less about how their models are trained, and independent testing sometimes tells a different story from what they report. “A lot of companies are not releasing how their models do in certain benchmarks, particularly the responsible-AI benchmarks,” says Gil. “The absence of how your model is doing on a benchmark maybe says something.”
AI is starting to affect jobs
Within three years of going mainstream, AI is now used by more than half of people around the world, a rate of adoption faster than the personal computer or the internet. An estimated 88% of organizations now use AI, and four in five university students use it.
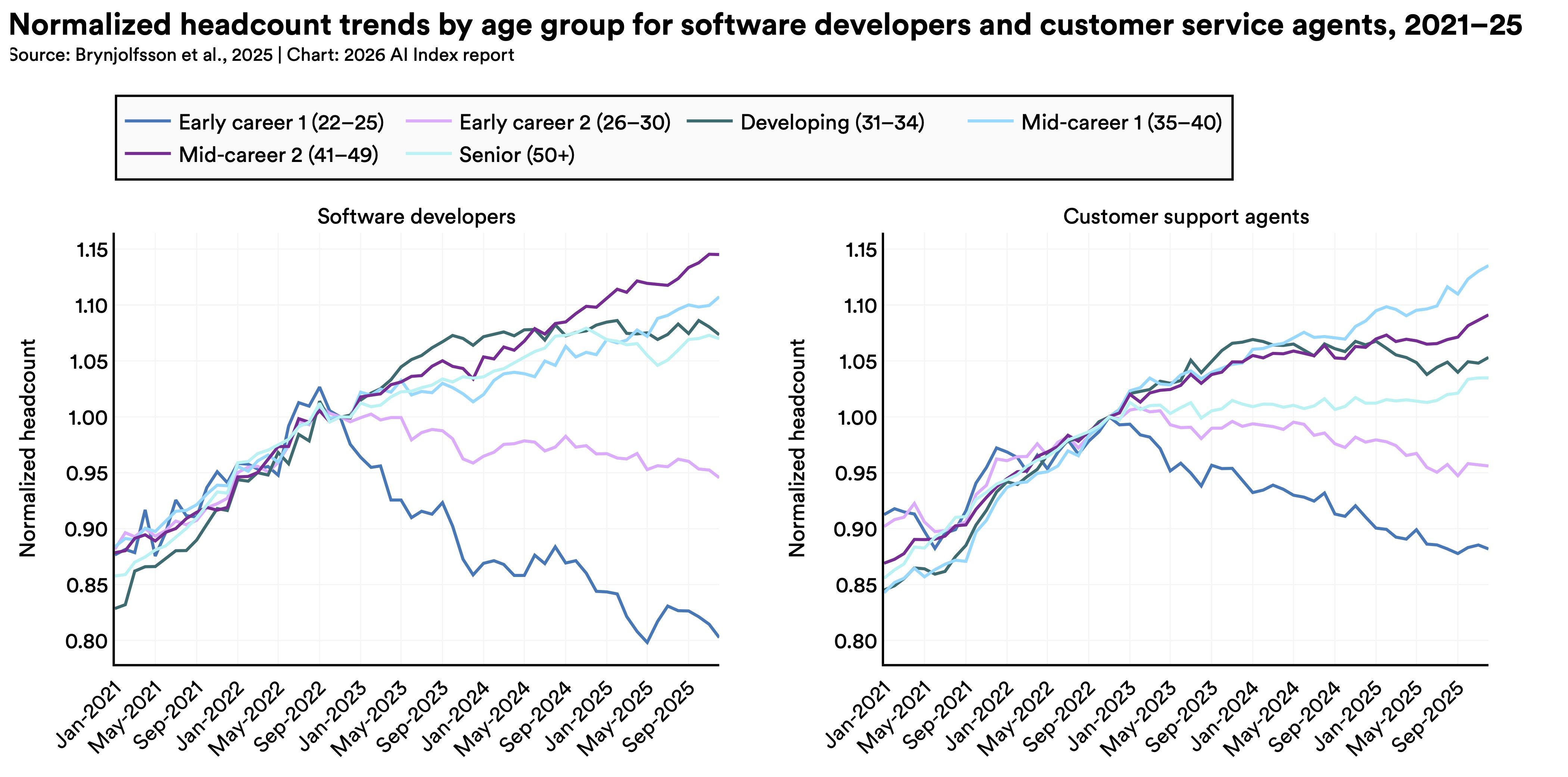
It’s early days for deployment, and AI’s impact on jobs is hard to measure. Still, some studies suggest AI is beginning to affect young workers in certain professions. According to a 2025 study by economists at Stanford, employment for software developers aged 22 to 25 has fallen nearly 20% since 2022. The decline might not be pinned on AI alone, as broader macroeconomic conditions could be to blame, but AI appears to be playing a part.
Employers say that hiring may continue to tighten. According to a 2025 survey conducted by McKinsey & Company, a third of organizations expect AI to shrink their workforce in the coming year, particularly in service and supply chain operations and software engineering. AI is boosting productivity by 14% in customer service and 26% in software development, according to research cited by the index, but such gains are not seen in tasks requiring more judgment. Overall, it’s still too early to understand the bigger economic impact of AI.
People have complicated feelings about AI
Around the world, people feel both optimistic and anxious about AI: 59% of people think that it will provide more benefits than drawbacks, while 52% say that it makes them nervous, according to an Ipsos survey cited in the index.
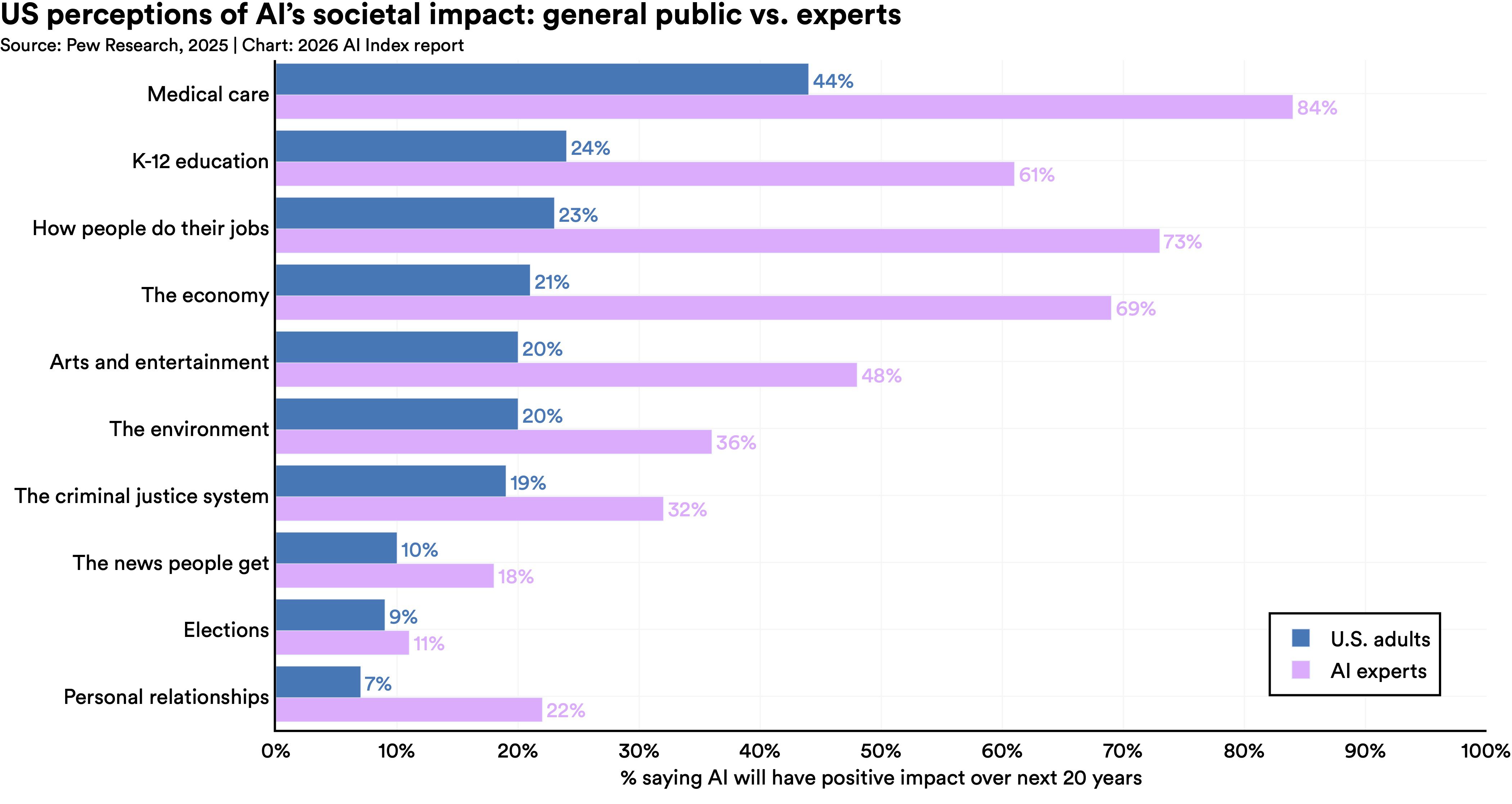
Notably, experts and the public see the future of AI very differently, according to a Pew survey. The biggest gap is around the future of work: While 73% of experts think that AI will have a positive impact on how people do their jobs, only 23% of the American public thinks so. Experts are also more optimistic than the public about AI’s impact on education and medical care, but they agree that AI will hurt elections and personal relationships.
Among all countries surveyed, Americans trust their government least to regulate AI appropriately, according to another Ipsos survey. More Americans worry federal AI regulation won’t go far enough than worry it will go too far.
Governments are struggling to regulate AI
Governments around the world are struggling to regulate AI, but there were some minor successes last year. The EU AI Act’s first prohibitions, which ban the use of AI in predictive policing and emotion recognition, took effect. Japan, South Korea, and Italy also passed national AI laws. Meanwhile, the US federal government moved toward deregulation, with President Trump issuing an executive order seeking to handcuff states from regulating AI.
Despite this federal action, state legislatures in the US passed a record 150 AI-related bills. California enacted landmark legislation, including SB 53, which mandates safety disclosures and whistleblower protections for developers of AI models. New York passed the RAISE Act, requiring AI companies to publish safety protocols and report critical safety incidents.
But for all the legislative activity, Gil says, regulation is running behind the technology because we don’t really understand how it works. “Governments are cautious to regulate AI because … we don’t understand many things very well,” she says. “We don’t have a good handle on those systems.”
This year’s report, which dropped today, is full of striking stats. A lot of the value comes from having numbers to back up gut feelings you might already have, such as the sense that the US is gunning harder for AI than everyone else: It hosts 5,427 data centers (and counting). That’s more than 10 times as many as any other country.
There’s also a reminder that the hardware supply chain the AI industry relies on has some major choke points. Here’s perhaps the most remarkable fact: “A single company, TSMC, fabricates almost every leading AI chip, making the global AI hardware supply chain dependent on one foundry in Taiwan.” One foundry! That’s just wild.
But the main takeaway I have from the 2026 AI Index is that the state of AI right now is shot through with inconsistencies. As my colleague Michelle Kim put it today in her piece about the report: “If you’re following AI news, you’re probably getting whiplash. AI is a gold rush. AI is a bubble. AI is taking your job. AI can’t even read a clock.” (The Stanford report notes that Google DeepMind’s top reasoning model, Gemini Deep Think, scored a gold medal in the International Math Olympiad but is unable to read analog clocks half the time.)
Michelle does a great job covering the report’s highlights. But I wanted to dwell on a question that I can’t shake. Why is it so hard to know exactly what’s going on in AI right now?
The widest gap seems to be between experts and non-experts. “AI experts and the general public view the technology’s trajectory very differently,” the authors of the AI Index write. “Assessing AI’s impact on jobs, 73% of U.S. experts are positive, compared with only 23% of the public, a 50 percentage point gap. Similar divides emerge with respect to the economy and medical care.”
That’s a huge gap. What’s going on? What do experts know that the public doesn’t? (“Experts” here means US-based researchers who took part in AI conferences in 2023 and 2024.)
I suspect part of what’s going on is that experts and non-experts base their views on very different experiences. “The degree to which you are awed by AI is perfectly correlated with how much you use AI to code,” a software developer posted on X the other day. Maybe that’s tongue-in-cheek, but there’s definitely something to it.
The latest models from the top labs are now better than ever at producing code. Because technical tasks like coding have right or wrong results, it is easier to train models to do them, compared with tasks that are more open-ended. What’s more, models that can code are proving to be profitable, so model makers are throwing resources at improving them.
This means that people who use those tools for coding or other technical work are experiencing this technology at its best. Outside of those use cases, you get more of a mixed bag. LLMs still make dumb mistakes. This phenomenon has become known as the “jagged frontier”: Models are very good at doing some things and less good at others.
The influential AI researcher Andrej Karpathy also had some thoughts. “Judging by my [timeline] there is a growing gap in understanding of AI capability,” he wrote in reply to that X post. He noted that power users (read: people who use LLMs for coding, math, or research) not only keep up to date with the latest models but will often pay $200 a month for the best versions. “The recent improvements in these domains as of this year have been nothing short of staggering,” he continued.
Because LLMs are still improving fast, someone who pays to use Claude Code will in effect be using a different technology from someone who tried using the free version of Claude to plan a wedding six months ago. Those two groups are speaking past each other.
Where does that leave us? I think there are two realities. Yes, AI is far better than a lot of people realize. And yes, it is still pretty bad at a lot of stuff that a lot of people care about (and it may stay that way). Anyone making bets about the future on either side should bear that in mind.
We evolved for a linear world. If you walk for an hour, you cover a certain distance. Walk for two hours and you cover double that distance. This intuition served us well on the savannah. But it catastrophically fails when confronting AI and the core exponential trends at its heart.
From the time I began work on AI in 2010 to now, the amount of training data that goes into frontier AI models has grown by a staggering 1 trillion times—from roughly 10¹⁴ flops (floating-point operations‚ the core unit of computation) for early systems to over 10²⁶ flops for today’s largest models. This is an explosion. Everything else in AI follows from this fact.
The skeptics keep predicting walls. And they keep being wrong in the face of this epic generational compute ramp. Often, they point out that Moore’s Law is slowing. They also mention a lack of data, or they cite limitations on energy.
But when you look at the combined forces driving this revolution, the exponential trend seems quite predictable. To understand why, it’s worth looking at the complex and fast-moving reality beneath the headlines.
Think of AI training as a room full of people working calculators. For years, adding computational power meant adding more people with calculators to that room. Much of the time those workers sat idle, drumming their fingers on desks, waiting for the numbers to come through for their next calculation. Every pause was wasted potential. Today’s revolution goes beyond more and better calculators (although it delivers those); it is actually about ensuring that all those calculators never stop, and that they work together as one.
Three advances are now converging to enable this. First, the basic calculators got faster. Nvidia’s chips have delivered an over sevenfold increase in raw performance in just six years, from312 teraflops in 2020 to2,250 teraflops today. Our ownMaia 200 chip, launched this January, delivers 30% better performance per dollar than any other hardware in our fleet. Second, the numbers arrive faster thanks to a technology called HBM, or high bandwidth memory, which stacks chips vertically like tiny skyscrapers; the latest generation, HBM3, triples the bandwidth of its predecessor, feeding data to processors fast enough to keep them busy all the time. Third, the room of people with calculators became an office and then a whole campus or city. Technologies likeNVLink andInfiniBand connect hundreds of thousands of GPUs into warehouse-size supercomputers that function as single cognitive entities. A few years ago this was impossible.
These gains all come together to deliver dramatically more compute. Where training a language model took 167 minutes on eight GPUs in 2020, it now takes under four minutes on equivalent modern hardware. To put this in perspective: Moore’s Law would predict only about a 5x improvement over this period. We saw 50x. We’ve gone from two GPUs training AlexNet, the image recognition model that kicked off the modern boom in deep learning in 2012, to over 100,000 GPUs in today’s largest clusters, each one individually far more powerful than its predecessors.
Then there’s the revolution in software. Research fromEpoch AI suggests that the compute required to reach a fixed performance level halves approximately every eight months, much faster than the traditional 18-to-24-month doubling of Moore’s Law. The costs of serving some recent models have collapsed by a factor of up to 900 on an annualized basis. AI is becoming radically cheaper to deploy.
The numbers for the near future are just as staggering. Consider that leading labs are growing capacity at nearly 4x annually. Since 2020, the compute used to train frontier models has grown5x every year. Global AI-relevant compute is forecast to hit 100 million H100-equivalents by 2027, a tenfold increase in three years. Put all this together and we’re looking at something like another 1,000x in effective compute by the end of 2028. It’s plausible that by 2030 we’ll bring an additional200 gigawatts of compute online every year—akin to the peak energy use of the UK, France, Germany, and Italy put together.
What does all this get us? I believe it will drive the transition from chatbots to nearly human-level agents—semiautonomous systems capable of writing code for days, carrying out weeks- and months-long projects, making calls, negotiating contracts, managing logistics. Forget basic assistants that answer questions. Think teams of AI workers that deliberate, collaborate, and execute. Right now we’re only in the foothills of this transition, and the implications stretch far beyond tech. Every industry built on cognitive work will be transformed.
The obvious constraint here is energy. A single refrigerator-size AI rack consumes 120 kilowatts, equivalent to 100 homes. But this hunger collides with another exponential: Solar costs have fallen by a factor of nearly 100 over 50 years;battery prices have dropped 97% over three decades. There is a pathway to clean scaling coming into view.
The capital is deployed. The engineering is delivering. The $100 billion clusters, the 10-gigawatt power draws, the warehouse-scale supercomputers … these are no longer science fiction. Ground is being broken for these projects now across the US and the world. As a result, we are heading toward true cognitive abundance. At Microsoft AI, this is the world our superintelligence lab is planning for and building.
Skeptics accustomed to a linear world will continue predicting diminishing returns. They will continue being surprised. The compute explosion is the technological story of our time, full stop. And it is still only just beginning.
Unlike static, rules-based systems, AI agents can learn, adapt, and optimize processes dynamically. As they interact with data, systems, people, and other agents in real time, AI agents can execute entire workflows autonomously.
But unlocking their potential requires redesigning processes around agents rather than bolting them onto fragmented legacy workflows using traditional optimization methods. Companies must become agent first.
In an agent-first enterprise, AI systems operate processes while humans set goals, define policy constraints, and handle exceptions.
“You need to shift the operating model to humans as governors and agents as operators,” says Scott Rodgers, global chief architect and U.S. CTO of the Deloitte Microsoft Technology Practice.
The agent-first imperative
With technology budgets for AI expected to increase more than 70% over the next two years, AI agents, powered by generative AI, are poised to fundamentally transform organizations and achieve results beyond traditional automation. These initiatives have the potential to produce significant performance gains, while shifting humans toward higher value work.
AI is advancing so quickly that static approaches to task automation will likely only produce incremental gains. Because legacy processes aren’t built for autonomous systems, AI agents require machine-readable process definitions, explicit policy constraints, and structured data flows, according to Rodgers.
Further complicating matters, many organizations don’t understand the full economic drivers of their business, such as cost to serve and per-transaction costs. As a result, they have trouble prioritizing agents that can create the most value and instead focus on flashy pilots. To achieve structural change, executives should think differently.
Companies must instead orchestrate outcomes faster than competitors. “The real risk isn’t that AI won’t work—it’s that competitors will redesign their operating models while you’re still piloting agents and copilots,” says Rodgers. “Nonlinear gains come when companies create agent-centric workflows with human governance and adaptive orchestration.”
Routine and repetitive tasks are increasingly handled automatically, freeing employees to focus on higher value, creative, and strategic work. This shift improves operational efficiency, fosters stronger collaboration, and generates faster decision-making—helping organizations modernize the workplace without sacrificing enterprise security.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
For years Mike McClary sold the Guardian LTE Flashlight, a heavy-duty black model, online through his small outdoor brand. The product, designed for brightness and durability, became one of his most popular items ever. Even after he stopped offering it around 2017, customers kept sending him emails asking where they could buy it.
When McClary decided to revisit the Guardian flashlight in 2025, he didn’t begin the way he might have in the past, by combing through supplier listings and sending inquiries to factories. Instead, he opened Accio, an AI sourcing and researching tool on Alibaba.com.
For small entrepreneurs in the US, deciding what to sell and where to make it has traditionally been a slow, labor-intensive process that can take months. Now that work is increasingly being done by AI tools like Accio, which help connect businesses with manufacturers in countries including China and India. Business owners and e-commerce experts told MIT Technology Review that these AI tools are making sourcing more accessible and significantly shortening the time it takes to go from product idea to launch.
McClary, 51, who runs his business from his Illinois living room, has sold products ranging from leather conditioner to camping lights, including one rechargeable lantern that brought in half a million dollars. Like many small online merchants, he built his business by being extremely scrappy—spotting demand for a product, tweaking existing designs, finding a factory, doing modest marketing, and getting the goods in front of customers fast.
This time, though, he began by telling Accio about the flashlight’s original design, production cost, and profit margin. Then Accio suggested several changes, making it smaller and slightly less bright and switching its charging method to battery power. It also identified a manufacturer in Ningbo, China, that McClary said could cut the manufacturing cost from $17 to about $2.50 per unit.
McClary took the process from there, contacting the supplier himself to discuss the revised design. Within a month, the new version of the Guardian flashlight was back up for sale on Amazon and on his brand’s website.
The new factory hunt
Although Alibaba is better known for owning Taobao, the biggest shopping site in China, its first business was Alibaba.com, the primary website that lists Chinese factories open for bulk orders. Placing an order with a manufacturer usually requires far more than clicking “Buy.” Sellers often spend days or weeks browsing listings, comparing suppliers’ reviews and manufacturing capacities, asking about minimum order quantities, requesting samples, and negotiating timelines and customization options.
But Accio has gained significant momentum by changing how that sourcing gets done. Launched in 2024, Accio exceeded 10 million monthly active users in March 2026, according to the company. That means about one in five Alibaba users consults with AI about product sourcing.
Accio’s interface looks a lot like ChatGPT or Claude: Users type a question into an empty box and choose between “fast” and “thinking” modes. But when asked about products, the tool returns more than text, offering charts, links, and visuals and asking follow-up questions to clarify the buyer’s needs. It then narrows the field to one or a handful of suppliers that appear capable of delivering. After that, the human work begins: Users still have to reach out to suppliers themselves and negotiate the details.
Zhang Kuo, the president of Alibaba.com, told MIT Technology Review that the tool is built on multiple frontier models, including the company’s own Qwen series, a popular family of open-source large language models. The system is able to pull from the site’s millions of supplier profiles and is trained on 26 years of proprietary transaction data.
For tasks like product research and sourcing analysis, the tool “blows it away” compared with general AI tools like ChatGPT, says Richard Kostick, CEO of the beauty brand 100% Pure.
Many websites have tried using AI to assist shopping, but Alibaba has been one of the most aggressive. In March, Eddie Wu, CEO of the site’s parent company Alibaba Group, told managers that integrating the company’s core services with Qwen’s AI capabilities is a top priority. During a Chinese New Year promotion of Qwen’s personal shopping AI agent, where the company gave away cash, customers placed 200 million orders, the firm says.
Vincenzo Toscano, an e-commerce seller and consultant, recommended Accio to his clients before deciding to try it himself for a new sunglasses brand. He came in with a rough vision: a brand shaped by his Italian heritage, his personal style, and a boutique aesthetic. He says the AI helped turn that concept into something more concrete, suggesting materials, refining the look, and pointing to design ideas that felt current.
But the tool has clear limits. McClary, who uses AI tools regularly, says Accio is strongest when it comes to product ideation, but less helpful on marketing questions such as advertising and social media outreach. To use it well, he says, buyers still need to challenge its recommendations, since some can be generic.
The rest of the business
As platforms become more AI-driven, manufacturers are adjusting too. Sally Li, a representative at a makeup packaging company in Wuhan, China, says her firm has started writing more detailed product descriptions and adding information about its equipment and manufacturing experience on Alibaba.com because it suspects those details make its listings more likely to be surfaced by AI.
Yan says manufacturers cannot tell whether an inquiry from a customer was generated or guided by AI, and that her firm is not using AI to negotiate pricing or product details.
“AI agents are increasingly used by people to assist purchase decisions and even directly making transactions, and with clear guardrails, they can become extremely useful,” says Jiaxin Pei, a research scientist at the Stanford Institute for Human-Centered AI, “but agents need to act transparently, securely, and in the customer’s best interest.” Pei says developers of these tools should disclose the data they collect and the incentives built into them to ensure that the marketplace remains fair.
Zhang, of Alibaba.com, says Accio currently does not include advertising. Suppliers can pay for higher placement in Alibaba.com’s regular search results, but Zhang says Accio is “not integrated” with that system. “We haven’t had a clear answer in terms of how to monetize this tool,” he says. For now, users can pay for additional tokens to continue chatting with the agent after their free queries run out.
Sellers say that while AI tools have made it easier to come up with ideas and get a business off the ground, they do not replace the core skills that make someone good at e-commerce. McClary believes that even when sellers have access to the same market information, some are still better at making decisions, acting quickly, and actually delivering on orders. Those differences, he says, still go a long way.
Toscano, the brand founder and e-commerce consultant, feels good about officially launching his new brand of sunglasses in just a few months: “We [small business owners] always have to bootstrap a lot of decisions. Deciding what to sell often comes down to an educated guess,” he says, “And we’re now in an era when making those decisions is easier than ever.”
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. The mood is so grim that a societal impacts researcher at Anthropic, responding Wednesday to a call for more optimistic visions of AI’s future, said there might be a recession in the near term and a “breakdown of the early-career ladder.” Her less-measured colleague Dario Amodei, the company’s CEO, has called AI “a general labor substitute for humans” that could do all jobs in less than five years. And those ideas are not just coming from Anthropic, of course.
These conversations have unsurprisingly left many workers in a panic (and are probably contributing to support for efforts to entirely pause the construction of data centers, some of which gained steam last week). The panic isn’t being helped by lawmakers, none of whom have articulated a coherent plan for what comes next.
Even economists who have cautioned that AI has not yet cut jobs and may not result in a cliff ahead are coming around to the idea that it could have a unique and unprecedented impact on how we work.
Alex Imas, based at the University of Chicago, is one of those economists. He shared two things with me when we spoke on Friday morning: a blunt assessment that our tools for predicting what this will look like are pretty abysmal, and a “call to arms” for economists to start collecting the one type of data that could make a plan to address AI in the workforce possible at all.
On our abysmal tools: consider the fact that any job is made up of individual tasks. One part of a real estate agent’s job, for example, is to ask clients what sort of property they want to buy. The US government chronicled thousands of these tasks in a massive catalogue first launched in 1998 and updated regularly since then. This was the data that researchers at OpenAI used in December to judge how “exposed” a job is to AI (they found a real estate agent to be 28% exposed, for example). Then in February, Anthropic used this data in its analysis of millions of Claude conversations to see which tasks people are actually using its AI to complete and where the two lists overlapped.
But knowing the AI exposure of tasks leads to an illusory understanding of how much a given job is at risk, Imas says. “Exposure alone is a completely meaningless tool for predicting displacement,” he told me.
Sure, it is illustrative in the gloomiest case—for a job in which literally every task could be done by AI with no human direction. If it costs less for an AI model to do all those tasks than what you’re paid—which is not a given, since reasoning models and agentic AI can rack up quite a bill—and it can do them well, the job likely disappears, Imas says. This is the oft-mentioned case of the elevator operator from decades ago; maybe today’s parallel is a customer service agent solely doing phone call triage.
But for the vast majority of jobs, the case is not so simple. And the specifics matter, too: Some jobs are likely to have dark days ahead, but knowing how and when this will play out is hard to answer when only looking at exposure.
Take writing code, for example. Someone who builds premium dating apps, let’s say, might use AI coding tools to create in one day what used to take three days. That means the worker is more productive. The worker’s employer, spending the same amount of money, can now get more output. So then will the employer want more employees or fewer?
This is the question that Imas says should keep any policymaker up at night, because the answer will change depending on the industry. And we are operating in the dark.
In this coder’s case, these efficiencies make it possible for dating apps to lower prices. (A skeptic might expect companies to simply pocket the gains, but in a competitive market, they risk being undercut if they do.) These lower prices will always drive some increase in demand for the apps. But how much? If millions more people want it, the company might grow and ultimately hire more engineers to meet this demand. But if demand barely ticks up—maybe the people who don’t use premium dating apps still won’t want them even at a lower price—fewer coders are needed, and layoffs will happen.
Repeat this hypothetical across every job with tasks that AI can do, and you have the most pressing economic question of our time: the specifics of price elasticity, or how much demand for something changes when its price changes. And this is the second part of what Imas emphasized last week: We don’t currently have this data across the economy. But we could.
We do have the numbers for grocery items like cereal and milk, Imas says, because the University of Chicago partners with supermarkets to get data from their price scanners. But we don’t have such figures for tutors or web developers or dietitians (all jobs found to have “exposure” to AI, by the way). Or at least not in a way that’s been widely compiled or made accessible to researchers; sometimes it’s scattered across private companies or consultancies.
“We need, like, a Manhattan Project to collect this,” Imas says. And we don’t need it just for jobs that could obviously be affected by AI now: “Fields that are not exposed now will become exposed in the future, so you just want to track these statistics across the entire economy.”
Getting all this information would take time and money, but Imas makes the case that it’s worth it; it would give economists the first realistic look at how our AI-enabled future could unfold and give policymakers a shot at making a plan for it.
When Zeus, a medical student living in a hilltop city in central Nigeria, returns to his studio apartment from a long day at the hospital, he turns on his ring light, straps his iPhone to his forehead, and starts recording himself. He raises his hands in front of him like a sleepwalker and puts a sheet on his bed. He moves slowly and carefully to make sure his hands stay within the camera frame.
Zeus is a data recorder for Micro1, a US company based in Palo Alto, California that collects real-world data to sell to robotics companies. As companies like Tesla, Figure AI, and Agility Robotics race to build humanoids—robots designed to resemble and move like humans in factories and homes—videos recorded by gig workers like Zeus are becoming the hottest new way to train them.
Micro1 has hired thousands of contract workers in more than 50 countries, including India, Nigeria, and Argentina, where swathes of tech-savvy young people are looking for jobs. They’re mounting iPhones on their heads and recording themselves folding laundry, washing dishes, and cooking. The job pays well by local standards and is boosting local economies, but it raises thorny questions around privacy and informed consent. And the work can be challenging at times—and weird.
Zeus found the job in November, when people started talking about it everywhere on LinkedIn and YouTube. “This would be a real nice opportunity to set a mark and give data that will be used to train robots in the future,” he thought.
Zeus is paid $15 an hour, which is good income in Nigeria’s strained economy with high unemployment rates. But as a bright-eyed student dreaming of becoming a doctor, he finds ironing his clothes for hours every day boring.
“I really [do] not like it so much,” he says. “I’m the kind of person that requires … a technical job that requires me to think.”
Zeus, and all the workers interviewed by MIT Technology Review, asked to be referred to only by pseudonyms because they were not authorized to talk about their work.
Humanoid robots are notoriously hard to build because manipulating physical objects is a difficult skill to master. But the rise of large language models underlying chatbots like ChatGPT has inspired a paradigm shift in robotics. Just as large language models learned to generate words by being trained on vast troves of text scraped from the internet, many researchers believe that humanoid robots can learn to interact with the world by being trained on massive amounts of movement data.
Editor’s note: In a recent poll, MIT Technology Review readers selected humanoid robots as the 11th breakthrough for our 2026 list of 10 Breakthrough Technologies.
Robotics requires far more complex data about the physical world, though, and that is much harder to find. Virtual simulations can train robots to perform acrobatics, but not how to grasp and move objects, because simulations struggle to model physics with perfect accuracy. For robots to work in factories and serve as housekeepers, real-world data, however time-consuming and expensive to collect, may be what we need.
Investors are pouring money feverishly into solving this challenge, spending over $6 billion on humanoid robots in 2025. And at-home data recording is becoming a booming gig economy around the world. Data companies like Scale AI and Encord are recruiting their own armies of data recorders, while DoorDash pays delivery drivers to film themselves doing chores. And in China, workers in dozens of state-owned robot training centers wear virtual-reality headsets and exoskeletons to teach humanoid robots how to open a microwave and wipe down the table.
“There is a lot of demand, and it’s increasing really fast,” says Ali Ansari, CEO of Micro1. He estimates that robotics companies are now spending more than $100 million each year to buy real-world data from his company and others like it.
A day in the life
Workers at Micro1 are vetted by an AI agent named Zara that conducts interviews and reviews samples of chore videos. Every week, they submit videos of themselves doing chores around their homes, following a list of instructions about things like keeping their hands visible and moving at natural speed. The videos are reviewed by both AI and a human and are either accepted or rejected. They’re then annotated by AI and a team of hundreds of humans who label the actions in the footage.
“There is a lot of demand, and it’s increasing really fast.”
Ali Ansari, CEO of Micro1
Because this approach to training robots is in its infancy, it’s not clear yet what makes good training data. Still, “you need to give lots and lots of variations for the robot to generalize well for basic navigation and manipulation of the world,” says Ansari.
But many workers say that creating a variety of “chore content” in their tiny homes is a challenge. Zeus, a scrappy student living in a humble studio, struggles to record anything beyond ironing his clothes every day. Arjun, a tutor in Delhi, India, takes an hour to make a 15-minute video because he spends so much time brainstorming new chores.
“How much content [can be made] in the home? How much content?” he says.
There’s also the sticky question of privacy. Micro1 asks workers not to show their faces to the camera or reveal personal information such as names, phone numbers, and birth dates. Then it uses AI and human reviewers to remove anything that slips through.
But even without faces, the videos capture an intimate slice of workers’ lives: the interiors of their homes, their possessions, their routines. And understanding what kind of personal information they might be recording while they’re busy doing chores on camera can be tricky. Reviews of such footage might not filter out sensitive information beyond the most obvious identifiers.
For workers with families, keeping private life off camera is a constant negotiation. Arjun, a father of two daughters, has to wrangle his chaotic two-year-old out of frame. “Sometimes it’s very difficult to work because my daughter is small,” he says.
Sasha, a banker turned data recorder in Nigeria, tiptoes around when she hangs her laundry outside in a shared residential compound so she won’t record her neighbors, who watch her in bewilderment.
“It’s going to take longer than people think.”
Ken Goldberg, UC Berkeley
While the workers interviewed by MIT Technology Review understand that their data is being used to train robots, none of them know how exactly their data will be used, stored, and shared with third parties, including the robotics companies that Micro1 is selling the data to. For confidentiality reasons, says Ansari, Micro1 doesn’t name its clients or disclose to workers the specific nature of the projects they are contributing to.
“It is important that if workers are engaging in this, that they are informed by the companies themselves of the intention … where this kind of technology might go and how that might affect them longer term,” says Yasmine Kotturi, a professor of human-centered computing at the University of Maryland.
Occasionally, some workers say, they’ve seen other workers asking on the company Slack channel if the company could delete their data. Micro1 declined to comment on whether such data is deleted.
“People are opting into doing this,” says Ansari. “They could stop the work at any time.”
Hungry for data
With thousands of workers doing their chores differently in different homes, some roboticists wonder if the data collected from them is reliable enough to train robots safely.
“How we conduct our lives in our homes is not always right from a safety point of view,” says Aaron Prather, a roboticist at ASTM International. “If those folks are teaching those bad habits that could lead to an incident, then that’s not good data.” And the sheer volume of data being collected makes reviewing it for quality control challenging. But Ansari says the company rejects videos showing unsafe ways of performing a task, while clumsy movements can be useful to teach robots what not to do.
Then there’s the question of how much of this data we need. Micro1 says it has tens of thousands of hours of footage, while Scale AI announced it had gathered more than 100,000 hours.
“It’s going to take a long time to get there,” says Ken Goldberg, a roboticist at the University of California, Berkeley. Large language models were trained on text and images that would take a human 100,000 years to read, and humanoid robots may need even more data, because controlling robotic joints is even more complicated than generating text. “It’s going to take longer than people think,” he says.
When Dattu, an engineering student living in a bustling tech hub in India, comes home after a full day of classes at his university, he skips dinner and dashes to his tiny balcony, cramped with potted plants and dumbbells. He straps his iPhone to his forehead and records himself folding the same set of clothes over and over again.
His family stares at him quizzically. “It’s like some space technology for them,” he says. When he tells his friends about his job, “they just get astounded by the idea that they can get paid by recording chores.”
Juggling his university studies with data recording, as well as other data annotation gigs, takes a toll on him. Still, “it feels like you’re doing something different than the whole world,” he says.
For decades, artificial intelligence has been evaluated through the question of whether machines outperform humans. From chess to advanced math, from coding to essay writing, the performance of AI models and applications is tested against that of individual humans completing tasks.
This framing is seductive: An AI vs. human comparison on isolated problems with clear right or wrong answers is easy to standardize, compare, and optimize. It generates rankings and headlines.
But there’s a problem: AI is almost never used in the way it is benchmarked. Although researchers and industry have started to improve benchmarking by moving beyond static tests to more dynamic evaluation methods, these innovations resolve only part of the issue. That’s because they still evaluate AI’s performance outside the human teams and organizational workflows where its real-world performance ultimately unfolds.
While AI is evaluated at the task level in a vacuum, it is used in messy, complex environments where it usually interacts with more than one person. Its performance (or lack thereof) emerges only over extended periods of use. This misalignment leaves us misunderstanding AI’s capabilities, overlooking systemic risks, and misjudging its economic and social consequences.
To mitigate this, it’s time to shift from narrow methods to benchmarks that assess how AI systems perform over longer time horizons within human teams, workflows, and organizations. I have studied real-world AI deployment since 2022 in small businesses and health, humanitarian, nonprofit, and higher-education organizations in the UK, the United States, and Asia, as well as within leading AI design ecosystems in London and Silicon Valley. I propose a different approach, which I call HAIC benchmarks—Human–AI, Context-Specific Evaluation.
What happens when AI fails
For governments and businesses, AI benchmark scores appear more objective than vendor claims. They’re a critical part of determining whether an AI model or application is “good enough” for real-world deployment. Imagine an AI model that achieves impressive technical scores on the most cutting-edge benchmarks—98% accuracy, groundbreaking speed, compelling outputs. On the strength of these results, organizations may decide to adopt the model, committing sizable financial and technical resources to purchasing and integrating it.
But then, once it’s adopted, the gap between benchmark and real-world performance quickly becomes visible. For example, take the swathe of FDA-approved AI models that can read medical scans faster and more accurately than an expert radiologist. In the radiology units of hospitals from the heart of California to the outskirts of London, I witnessed staff using highly ranked radiology AI applications. Repeatedly, it took them extra time to interpret AI’s outputs alongside hospital-specific reporting standards and nation-specific regulatory requirements. What appeared as a productivity-enhancing AI tool when tested in a vacuum introduced delays in practice.
It soon became clear that the benchmark tests on which medical AI models are assessed do not capture how medical decisions are actually made. Hospitals rely on multidisciplinary teams—radiologists, oncologists, physicists, nurses—who jointly review patients. Treatment planning rarely hinges on a static decision; it evolves as new information emerges over days or weeks. Decisions often arise through constructive debate and trade-offs between professional standards, patient preferences, and the shared goal of long-term patient well-being. No wonder even highly scored AI models struggle to deliver the promised performance once they encounter the complex, collaborative processes of real clinical care.
The same pattern emerges in my research across other sectors: When embedded within real-world work environments, even AI models that perform brilliantly on standardized tests don’t perform as promised.
When high benchmark scores fail to translate into real-world performance, even the most highly scored AI is soon abandoned to what I call the “AI graveyard.”The costs are significant: Time, effort and money end up being wasted. And over time, repeated experiences like this erode organizational confidence in AI and—in critical settings such as health—may erode broader public trust in the technology as well.
When current benchmarks provide only a partial and potentially misleading signal of an AI model’s readiness for real-world use, this creates regulatory blind spots: Oversight is shaped by metrics that do not reflect reality. It also leaves organizations and governments to shoulder the risks of testing AI in sensitive real-world settings, often with limited resources and support.
How to build better tests
To close the gap between benchmark and real-world performance, we must pay attention to the actual conditions in which AI models will be used. The critical questions: Can AI function as a productive participant within human teams? And can it generate sustained, collective value?
Through my research on AI deployment across multiple sectors, I have seen a number of organizations already moving—deliberately and experimentally—toward the HAIC benchmarks I favor.
HAIC benchmarks reframe current benchmarking in four ways:
1. From individual and single-task performance to team and workflow performance (shifting the unit of analysis)
2. From one-off testing with right/wrong answers to long-term impacts (expanding the time horizon)
3. From correctness and speed to organizational outcomes, coordination quality, and error detectability (expanding outcome measures)
4. From isolated outputs to upstream and downstream consequences (system effects)
Across the organizations where this approach has emerged and started to be applied, the first step is shifting the unit of analysis.
For example, in one UK hospital system in the period 2021–2024, the question expanded from whether a medical AI application improves diagnostic accuracy to how the presence of AI within the hospital’s multidisciplinary teams affects not only accuracy but also coordination and deliberation. The hospital specifically assessed coordination and deliberation in human teams using and not using AI. Multiple stakeholders (within and outside the hospital) decided on metrics like how AI influences collective reasoning, whether it surfaces overlooked considerations, whether it strengthens or weakens coordination, and whether it changes established risk and compliance practices.
This shift is fundamental. It matters a lot in high-stakes contexts where system-level effects matter more than task-level accuracy. It also matters for the economy. It may help recalibrate inflated expectations of sweeping productivity gains that are so far predicated largely on the promise of improving individual task performance.
Once that foundation is set, HAIC benchmarking can begin to take on the element of time.
Today’s benchmarks resemble school exams—one-off, standardized tests of accuracy. But real professional competence is assessed differently. Junior doctors and lawyers are evaluated continuously inside real workflows, under supervision, with feedback loops and accountability structures. Performance is judged over time and in a specific context, because competence is relational. If AI systems are meant to operate alongside professionals, their impact should be judged longitudinally, reflecting how performance unfolds over repeated interactions.
I saw this aspect of HAIC applied in one of my humanitarian-sector case studies. Over 18 months, an AI system was evaluated within real workflows, with particular attention to how detectable its errors were—that is, how easily human teams could identify and correct them. This long-term “record of error detectability” meant the organizations involved could design and test context-specific guardrails to promote trust in the system, despite the inevitability of occasional AI mistakes.
A longer time horizon also makes visible the system-level consequences that short-term benchmarks miss. An AI application may outperform a single doctor on a narrow diagnostic task yet fail to improve multidisciplinary decision-making. Worse, it may introduce systemic distortions: anchoring teams too early in plausible but incomplete answers, adding to people’s cognitive workloads, or generating downstream inefficiencies that offset any speed or efficiency gains at the point of the AI’s use. These knock-on effects—often invisible to current benchmarks—are central to understanding real impact.
The HAIC approach, admittedly promises to make benchmarking more complex, resource-intensive, and harder to standardize. But continuing to evaluate AI in sanitized conditions detached from the world of work will leave us misunderstanding what it truly can and cannot do for us. To deploy AI responsibly in real-world settings, we must measure what actually matters: not just what a model can do alone, but what it enables—or undermines—when humans and teams in the real world work with it.
Angela Aristidou is a professor at University College London and a faculty fellow at the Stanford Digital Economy Lab and the Stanford Human-Centered AI Institute. She speaks, writes, and advises about the real-life deployment of artificial-intelligence tools for public good.
In the early days of large language models (LLMs), we grew accustomed to massive 10x jumps in reasoning and coding capability with every new model iteration. Today, those jumps have flattened into incremental gains. The exception is domain-specialized intelligence, where true step-function improvements are still the norm.
When a model is fused with an organization’s proprietary data and internal logic, it encodes the company’s history into its future workflows. This alignment creates a compounding advantage: a competitive moat built on a model that understands the business intimately. This is more than fine-tuning; it is the institutionalization of expertise into an AI system. This is the power of customization.
Intelligence tuned to context
Every sector operates within its own specific lexicon. In automotive engineering, the “language” of the firm revolves around tolerance stacks, validation cycles, and revision control. In capital markets, reasoning is dictated by risk-weighted assets and liquidity buffers. In security operations, patterns are extracted from the noise of telemetry signals and identity anomalies.
Custom-adapted models internalize the nuances of the field. They recognize which variables dictate a “go/no-go” decision, and they think in the language of the industry.
Domain expertise in action
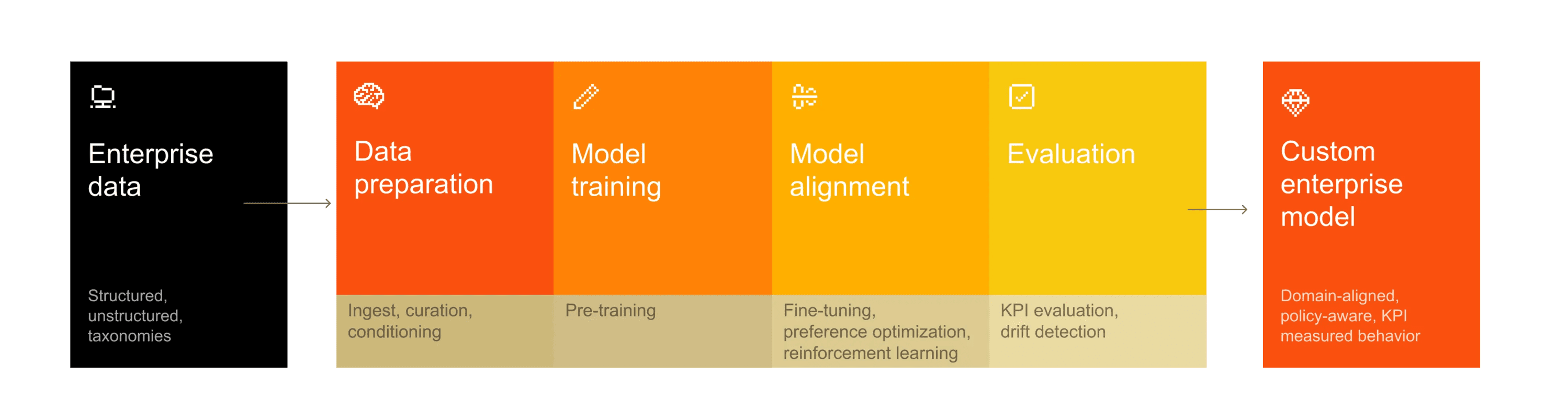
The transition from general-purpose to tailored AI centers on one goal: encoding an organization’s unique logic directly into a model’s weights.
Mistral AI partners with organizations to incorporate domain expertise into their training ecosystems. A few use cases illustrate customized implementations in practice:
Software engineering and assisting at scale: A network hardware company with proprietary languages and specialized codebases found that out-of-the-box models could not grasp their internal stack. By training a custom model on their own development patterns, they achieved a step function in fluency. Integrated into Mistral’s software development scaffolding, this customized model now supports the entire lifecycle—from maintaining legacy systems to autonomous code modernization via reinforcement learning. This turns once-opaque, niche code into a space where AI reliably assists at scale.
Automotive and the engineering copilot: A leading automotive company uses customization to revolutionize crash test simulations. Previously, specialists spent entire days manually comparing digital simulations with physical results to find divergences. By training a model on proprietary simulation data and internal analyses, they automated this visual inspection, flagging deformations in real time. Moving beyond detection, the model now acts as a copilot, proposing design adjustments to bring simulations closer to real-world behavior and radically accelerating the R&D loop.
Public sector and sovereign AI: In Southeast Asia, a government agency is building a sovereign AI layer to move beyond Western-centric models. By commissioning a foundation model tailored to regional languages, local idioms, and cultural contexts, they created a strategic infrastructure asset. This ensures sensitive data remains under local governance while powering inclusive citizen services and regulatory assistants. Here, customization is the key to deploying AI that is both technically effective and genuinely sovereign.
The blueprint for strategic customization
Moving from a general-purpose AI strategy to a domain-specific advantage requires a structural rethinking of the model’s role within the enterprise. Success is defined by three shifts in organizational logic.
1. Treat AI as infrastructure, not an experiment. Historically, enterprises have treated model customization as an ad hoc experiment—a single fine-tuning run for a niche use case or a localized pilot. While these bespoke silos often yield promising results, they are rarely built to scale. They produce brittle pipelines, improvised governance, and limited portability. When the underlying base models evolve, the adaptation work must often be discarded and rebuilt from scratch.
In contrast, a durable strategy treats customization as foundational infrastructure. In this model, adaptation workflows are reproducible, version-controlled, and engineered for production. Success is measured against deterministic business outcomes. By decoupling the customization logic from the underlying model, firms ensure that their “digital nervous system” remains resilient, even as the frontier of base models shifts.
2. Retain control of your own data and models. As AI migrates from the periphery to core operations, the question of control becomes existential. Reliance on a single cloud provider or vendor for model alignment creates a dangerous asymmetry of power regarding data residency, pricing, and architectural updates.
Enterprises that retain control of their training pipelines and deployment environments preserve their strategic agency. By adapting models within controlled environments, organizations can enforce their own data residency requirements and dictate their own update cycles. This approach transforms AI from a service consumed into an asset governed, reducing structural dependency and allowing for cost and energy optimizations aligned with internal priorities rather than vendor roadmaps.
3. Design for continuous adaptation. The enterprise environment is never static: regulations shift, taxonomies evolve, and market conditions fluctuate. A common failure is treating a customized model as a finished artifact. In reality, a domain-aligned model is a living asset subject to model decay if left unmanaged.
Designing for continuous adaptation requires a disciplined approach to ModelOps. This includes automated drift detection, event-driven retraining, and incremental updates. By building the capacity for constant recalibration, the organization ensures that its AI does not just reflect its history, but it evolves in lockstep with its future. This is the stage where the competitive moat begins to compound: the model’s utility grows as it internalizes the organization’s ongoing response to change.
Control is the new leverage
We have entered an era where generic intelligence is a commodity, but contextual intelligence is a scarcity. While raw model power is now a baseline requirement, the true differentiator is alignment—AI calibrated to an organization’s unique data, mandates, and decision logic.
In the next decade, the most valuable AI won’t be the one that knows everything about the world; it will be the one that knows everything about you. The firms that own the model weights of that intelligence will own the market.
This content was produced by Mistral AI. It was not written by MIT Technology Review’s editorial staff.