I remember seeing those “God is my co-pilot” bumper stickers since I was old enough to read them.
I was a precocious little agnostic, so they always struck me as weird. God can’t be your co-pilot because God isn’t a physical manifestation of someone who can help you drive a car.
I eventually figured out that “God is my co-pilot” was less a literal statement and more a declaration of faith that there is an omniscient presence available to help you navigate life’s construction zones (if you believe, anyway).
So, fast forward to 2025, and marketers have a new omniscient presence that they can put their faith in. Something that seems equally all-knowing but perhaps a little more … unpredictable.
AI.
Large language models (LLMs) – like ChatGPT, Claude, Gemini – feel delightfully divine when you first try them. They answer instantly, confidently, and often with an authority that makes you wonder if they do know everything.
But, spend enough time with these tools, and you discover something unsettling: AI isn’t just your god-like guide. It can also act like the devil, gleefully granting your wishes exactly as asked – and letting you suffer the consequences.
This is why the healthiest way to think of AI in your SEO and content workflows is as a co-pilot. Not God. Not Lucifer. But, a powerful partner that can elevate your work, if you exercise your free will (and make good choices).
The God-Like Qualities Of AI
There’s a reason AI feels god-like in a marketing context:
- It seems omnipresent, embedded in your search results, your content management system (CMS), your analytics.
- It delivers answers instantly, with confidence and authority.
- It processes far more data than any human ever could, instantly finding patterns we mere mortals miss on the first (or third) pass.
Ask it to draft a content brief, summarize competitive search engine results pages (SERPs), generate topic clusters, or even shape a brand narrative – and it performs in seconds what would have taken you hours.
That kind of power can feel miraculous.
But, just as theologians remind us that God’s will is mysterious and not always aligned with ours, LLMs work on their own unknowable internal logic.
The outputs may not match your intent. The answer may not come in the form you wanted. And you may not even fully grasp why it chose the answer it did.
The Devilish Side Of AI
On the flip side, AI can also be a trickster: seductive, transactional, and literal. It will grant you exactly what you wish for – and sometimes that’s the worst thing possible.
When you prompt an LLM poorly, you’re effectively making a deal with the devil. The model will fulfill your request to the letter, even if what you asked was misguided, incomplete, or poorly articulated.
The result? Content that’s technically correct but off-brand, off-tone, or even factually wrong – yet delivered with such confidence it lulls you into publishing it.
The moral: Be careful what you ask for. The clarity of your prompt determines the quality of your output.
What AI Is Good At
When treated as a co-pilot, not as a god, AI can supercharge your workflow:
Research & Insights
- Competitive landscape analyses.
- SERP gap identification.
- Tracking how competitors frame their unique value propositions.
- Summarizing multiple opinion pieces or reviews into one clear insight.
- Identifying overlooked audience segments based on forums and social media discussions.
Content Ideation & Briefing
- Generating alternative angles on stale topics: e.g., turning “best practices” into “common mistakes” or “myths to avoid.”
- Rewriting existing briefs to prioritize experience, expertise, authoritativeness, and trustworthiness (E-E-A-T) signals
- Drafting Q&A content by scanning customer service transcripts or Reddit threads.
- Suggesting specific examples or metaphors to make dry topics more engaging.
Narrative Shaping & Messaging
- Reworking messaging for different formats: a LinkedIn post, an email subject line, and a webinar title – all aligned.
- Auditing your current messaging to highlight jargon and suggest plain-language alternatives.
- Helping articulate your brand’s point of view in ways that differentiate it from competitors.
- Stress-testing your messaging by generating “devil’s advocate” objections you can preemptively address.
Workflow Enhancements
- Drafting a competitive heat map: strengths, weaknesses, opportunities, threats – with citations.
- Organizing customer testimonials into themed categories and crafting pull quotes.
- Generating follow-up email sequences based on webinar transcripts or meeting notes.
- Converting white papers into tweet threads, infographic outlines, and video scripts.
It’s like an intern with infinite energy and decent taste – incredibly helpful, but still in need of supervision.
What AI Is Not Good At
Don’t confuse the fluency of AI with wisdom. Here’s where it stumbles:
Judgment & Nuance
It doesn’t understand your brand’s unique sensibility, your audience’s emotional context, or when not to say something. You have to give it that context and direction. You cannot assume it will figure it out.
Accuracy & Truth
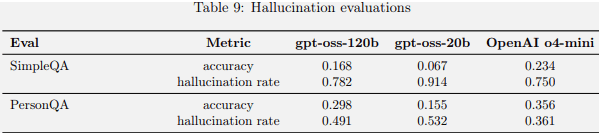
It is still prone to “hallucinations” – confidently wrong statements presented as fact.
We have limited understanding of why this happens, but it is so frequent that you almost have to assume there are at least a few hallucinations in the output somewhere.
Accountability
It cannot make decisions, nor does it bear the consequences of your choices. That’s on you.
In short, AI lacks your free will. And free will is what allows you to question, interpret, and choose what to do with its suggestions.
The Co-Pilot Mindset: Free Will Wins
To work effectively with your AI co-pilot, you need to strike the right balance between trust and control.
Here’s how:
Stay In The Pilot’s Seat
Never hand over full control. You’re still ultimately responsible for the vehicle.
Treat AI as a partner – or maybe not even a full partner, more like an exceptionally bright and quick research assistant – but never a replacement for you in any equation.
Be Precise In Your Prompts
Don’t assume it “knows what you mean.” Giving the AI instructions is like giving instructions to a particularly clever child who enjoys maliciously complying with your orders, except the AI doesn’t actually experience the joy.
You need to articulate your expectations clearly: format, tone, audience, and purpose. Add as much context and as many constraints as you can. The more data points and context you can provide, the better the outputs will be.
Use It To Accelerate, Not Replace
AI can speed up research, help shape narratives, and generate ideas, but it can’t replace your expertise or final judgment.
Review & Revise
Never, never, never, never publish output unedited. Always apply your brand’s perspective, always fact-check, and always ensure alignment with your goals.
Read everything you’re about to publish carefully. It’s okay to trust, but always verify.
Here’s an example of how that looks in practice:
I recently took a client’s complete keyword ranking report – not just the terms they were tracking, but every single ranking URL and query – and filtered out any URL already on page 1.
Then, I narrowed the data to just rankings in positions 11-20 (to keep it manageable) and fed that into an LLM.
I asked it to estimate the potential lift in organic traffic if each term improved to position 1 and to rank the list by estimated lift, highest to lowest.
But, I also gave the LLM context about the client’s business, explaining what kinds of customers and services were most valuable to them.
Then, I asked the model to highlight the keywords that made the most business sense for this client, because not every keyword you rank for is one you actually want to rank for.
With that context, the LLM was able to match keyword intent to the client’s goals and call out the terms that aligned with their business priorities.
In just minutes, I had a prioritized roadmap of high-impact, high-fit opportunities – something that would have taken hours to produce manually.
Practical Ways To Work With AI
Here are some more actionable ways you can incorporate AI into your workflow effectively:
Research Smarter And Faster
- Create a competitive matrix with links and pros/cons.
- Summarize customer sentiment across reviews, highlighting recurring pain points.
- Surface conflicting expert opinions to inform balanced thought leadership pieces.
- Forecast upcoming trends based on chatter in niche forums and early adopters.
Build Better Briefs
- Include competitive positioning suggestions in briefs, not just keywords.
- Add tone-of-voice examples aligned to audience segments.
- Incorporate real data sources and reference points to help writers anchor their copy.
- Generate sample social captions to support a campaign.
Strengthen Your Messaging
- Stress-test a headline by generating objections and counterpoints.
- Rewrite complex product descriptions into benefit-driven language for different audiences.
- Propose alternate positioning statements for product launches or rebrands.
- Audit your FAQ section to make it more conversational and AI-friendly.
Repurpose And Expand Content
- Turn webinar transcripts into ebooks, blog series, and email drips.
- Extract key insights from research reports to create shareable social graphics.
- Draft SEO-friendly meta descriptions and titles for old content.
- Identify missed opportunities in evergreen content for updates or expansion.
AI can do so much more than just “help you ideate.” It can help you uncover blind spots, repurpose assets, and deepen your strategic thinking, but only when you stay in the driver’s seat to guide and refine the outputs.
Final Thought: You, And Only You, Are The Pilot
I think we tend to treat our collective relationship with AI the same way we look at religion – you’re either a believer or an atheist.
Some have complete faith and trust it without question, while others reject it entirely and are convinced there is nothing there to believe in. The truth is somewhere in the middle (as it often is).
AI can be a powerful, tireless, but imperfect partner. It can help carry and manage heavy mental loads, work with you to map out routes and decide on destinations, but it can not take responsibility for driving the car. That’s got to be on you.
Your free will – your ability to keep your hands on the wheel – is what ensures the journey ends where you intended. If you actually let go, you’re certainly going to crash. You’re asking for assistance, not a magical autopilot.
So, go ahead: Let AI ride shotgun and keep your hands at 10 and two, where they belong.
More Resources:
Featured Image: Rawpixel.com/Shutterstock