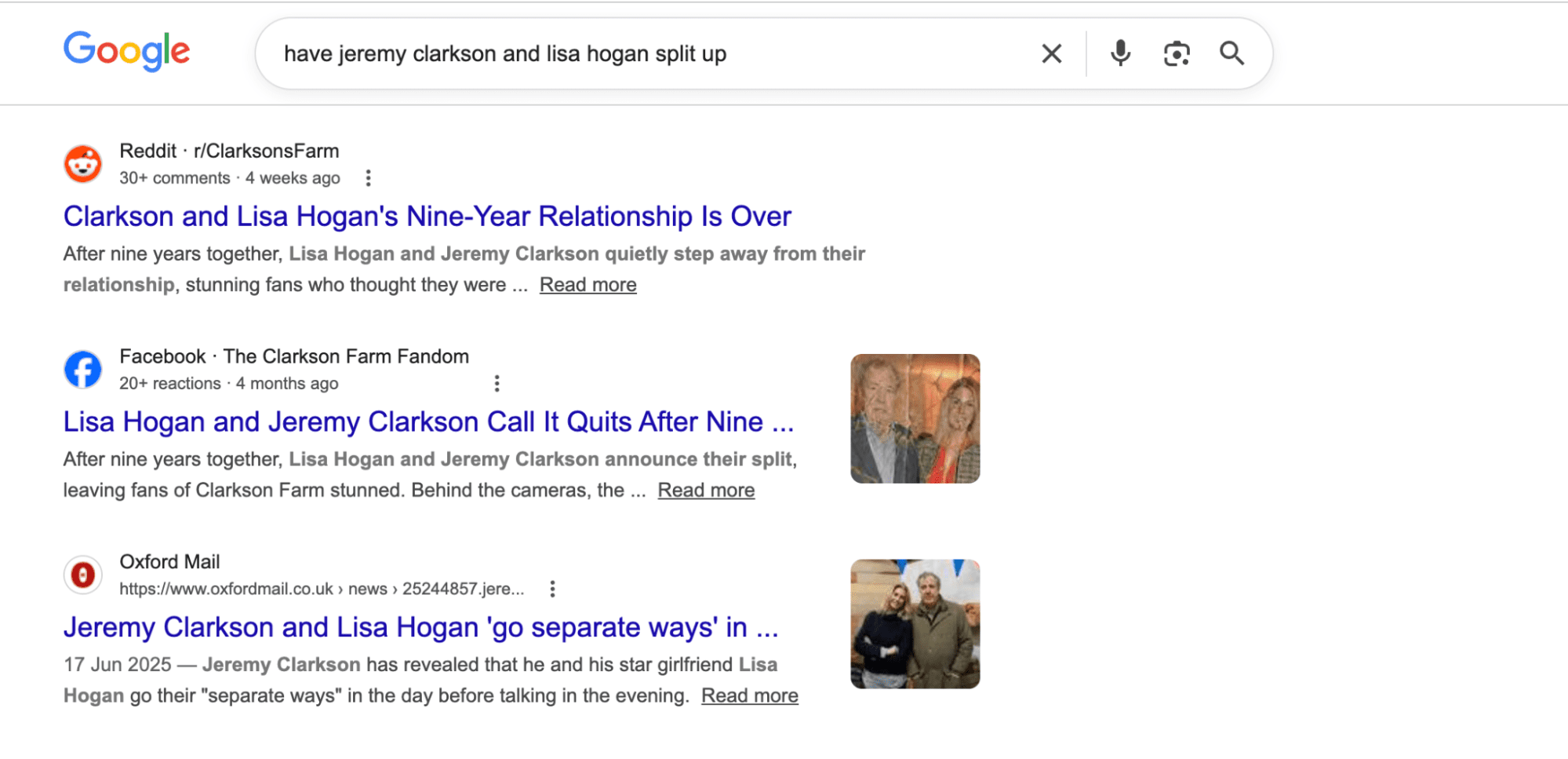
Mt. Stupid Has A Pricing Page via @sejournal, @pedrodias
“There is now ample evidence, collected over the last few years, that AI systems are unpredictable and difficult to control.” That’s Dario Amodei in January, writing about the technology his company sells.
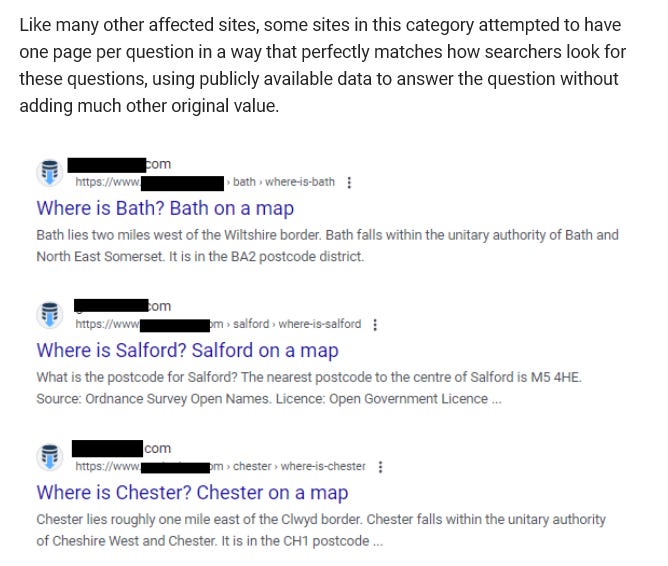
Compare with what’s on your LinkedIn timeline this week. Here’s the script: Schema markup ensures AI engines parse your content. The first sentence of every section must be the answer. Optimize for chunk-level retrieval. There’s a 13% citation lift available if you do X, a 2.8x conversion improvement if you do Y.
It’s one of the cleanest patterns going right now, and the industry has elected not to notice. The people closest to these systems are increasingly cautious about claims of control. The people furthest from it are increasingly certain they know how it works … they’ve cracked it. That gradient runs the wrong way.
What The People Who Built It Actually Say
Anthropic published its main interpretability research post in May 2024. It opens:
“We mostly treat AI models as a black box: something goes in and a response comes out, and it’s not clear why the model gave that particular response instead of another.”
Anthropic, writing about its own model, two years ago.
Things haven’t gotten more confident since. Neel Nanda, who runs Google DeepMind’s mechanistic interpretability team, gave an interview to 80,000 Hours in September 2025 in which the headline finding was that the most ambitious version of mech interp is probably dead. He doesn’t see a realistic world where the discipline delivers “the kind of robust guarantees that some people want from interpretability.” Worth re-reading.
The person whose job is to read AI minds is publicly conceding that the project, as originally conceived, won’t get there.
At NeurIPS 2024, Ilya Sutskever, co-founder of Safe Superintelligence and formerly chief scientist at OpenAI, accepted his Test of Time award and used the platform to say something the room wasn’t expecting from him:
“The more it reasons, the more unpredictable it becomes.”
Sutskever’s career is essentially the scaling hypothesis with a face on it. Hearing him say the next phase produces less predictable outputs is itself an admission.
Now scroll back to your timeline. The gradient is Dunning-Kruger redrawn at an industry scale: Mt. Stupid with a pricing page, and the valley of calibration where the actual work happens.
What The People Selling It Actually Say
A practitioner posts a four-pillar framework for “Technical GEO.” A consultant guarantees inclusion in AI Overviews. An agency markets a 13% lift in citation likelihood, derived from data the agency itself produced about the agency’s own prescriptions. A widely shared post promises that maintaining a 300-character paragraph limit dictates how a vector database chunks your content. A vendor claims a 78% “share of model.” A senior figure in your inbox describes a 2.8x improvement in conversion from being cited in SGE.
The vocabulary is deterministic: “ensures,” “guarantees,” “dictates,” percentages precise to the decimal, frameworks confidently named. None of it sounds anything like the language the people who built these systems use when describing how the systems behave.
This is the part I keep getting stuck on. The consultants are confident about the tactics they’ve measured against themselves. Run the same playbook on a few clients, watch some metric move, call it evidence. No control groups, no pre-registered hypotheses, no measurement of what the tactic is actually claimed to change. That’s the bar a real test has to clear; everything else has been confirmation in costume. The problem is the confidence level, which is wrong by an order of magnitude regardless of whether the underlying tactic does anything. The same model that Anthropic publicly says it cannot fully account for is being optimized against by people who confidently claim to know exactly what they’re doing.
Either Anthropic has been suspiciously modest in public, or somebody else is suspiciously certain.
When Somebody Tests
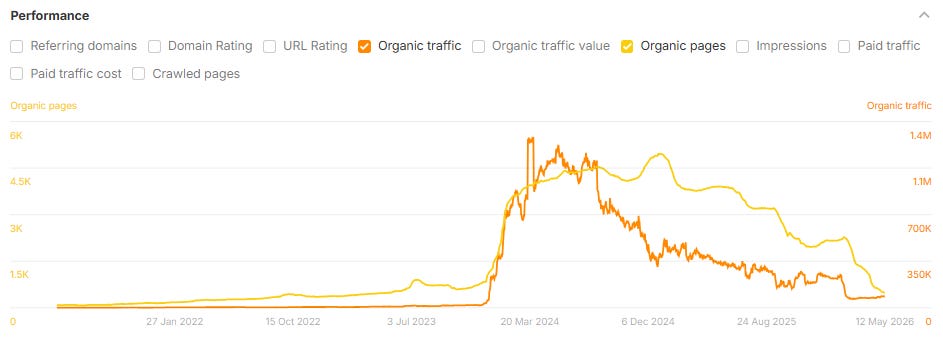
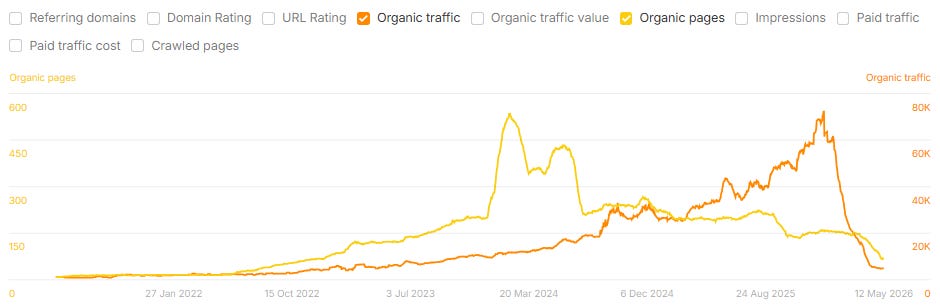
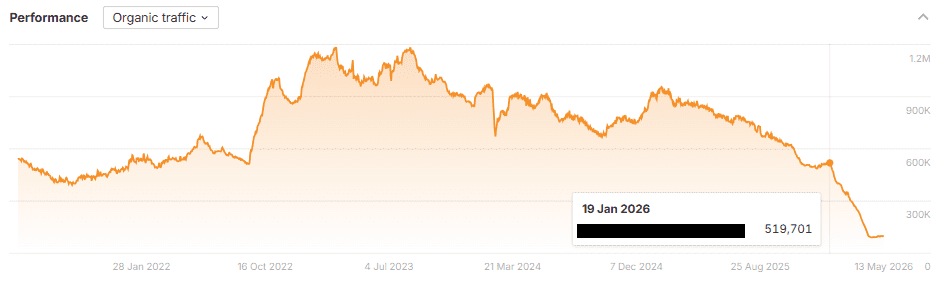
On Monday, last week, Ahrefs published a study by Louise Linehan and Xibeijia Guan with a title that should ideally be impossible: We Tracked 1,885 Pages Adding Schema. AI Citations Barely Moved.
The methodology is the kind of work you would expect to be standard, if the discipline cared about standards. 1,885 pages that added JSON-LD schema between August 2025 and March 2026. 4,000 matched control pages. Citation changes measured 30 days before and 30 days after the schema was added, across Google AI Overviews, Google AI Mode, and ChatGPT. Difference-in-differences on the matched groups.
The finding: No meaningful uplift in citations on any platform. AI Overviews actually showed a small but statistically significant decline. The report notes the odds of a gap that large being chance are roughly 1 in 2,500. The schema-makes-LLMs-understand-your-content thesis, tested at scale against a controlled baseline, did not survive the test.
This is the empirical confirmation of the technical case I made a week ago in The Whole Point Was the Mess: that LLMs read unstructured language, and that schema-and-chunking prescriptions are reasoning about an architecture that doesn’t exist. From first principles, two weeks ago. From controlled measurement, last Monday.
It is worth sitting with that. The dominant prescriptive category in the entire GEO playbook has been empirically falsified under controlled conditions, by a vendor with a substantial audience, in the open. And the frameworks keep selling.
Then Google Itself Answered
On May 15, 2026, Google published official documentation on optimizing for generative AI features in search. The page mythbusts the GEO prescriptions in writing: llms.txt files aren’t needed; chunking content isn’t required; rewriting content for AI systems isn’t necessary; special schema markup isn’t required; pursuing inauthentic mentions doesn’t help. The framing is unusually direct for a Google developer page:
“Many suggested ‘hacks’ aren’t effective or supported by how Google Search actually works.”
Google names Answer Engine Optimization and Generative Engine Optimization by their full terms and rejects the playbook outright.
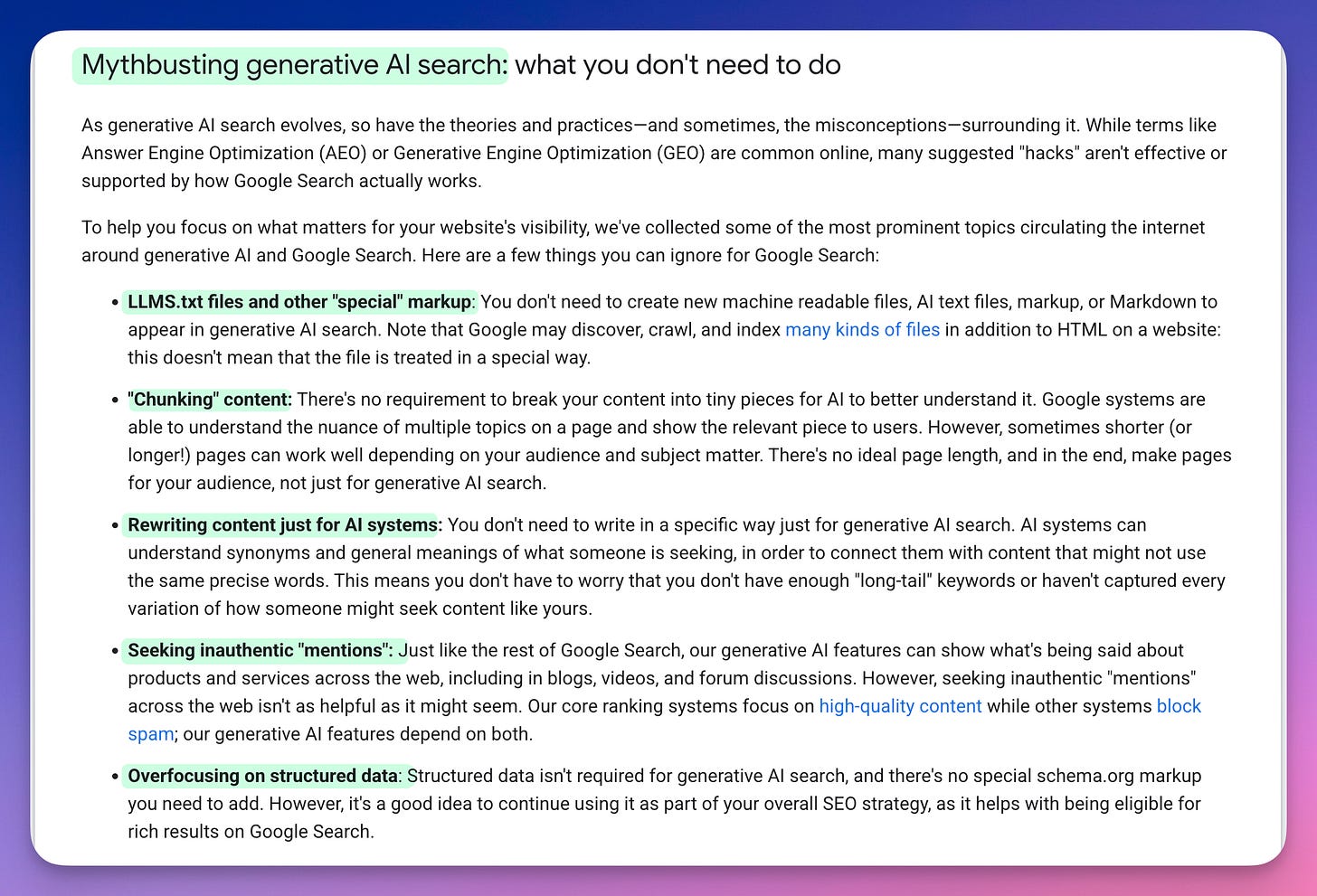
That is the search engine the consultants claim to be optimizing for, telling its own developer audience that the optimizations don’t work. From first principles, two weeks ago. From controlled measurement, last Monday. From Google itself, last Friday. Three independent sources of the same answer, all within a fortnight. All ignored by the people selling the opposite.
The Cost Of Asking
This is where the diagnosis stops being polite.
Confident claims compound on these platforms in a way that skeptical corrections don’t. The difference is in who pays. Posting a confident claim costs you nothing. It gets engagement, builds an audience, generates inbound, makes the slide deck look forward-looking. If it turns out to be wrong, nothing happens. By the time anyone notices, everyone’s moved on to the next acronym.
Posting the correction costs you. It picks a fight. It marks you as a contrarian, or worse, as somebody who doesn’t get it. On LinkedIn, where most of this happens, it works against your professional brand. The algorithm will not reward it. The original poster owns the comment section and can ignore your methodology question while engaging with the congratulatory replies. Your reply lives in a collapsed thread.
There’s a specific move worth naming here. Ask a GEO consultant to explain, in plain terms, what their methodology actually does, what mechanism it acts on, what would count as evidence, what would falsify it. The response escalates into jargon. “Vector-space alignment.” “T1 query optimisation.” “Chunk-level semantic retrieval.” Real terms from machine-learning research, glued into combinations that sound rigorous and resist plain-language verification. The pattern works because it can. Asking “what does that actually mean” looks naive, and observers without the specific technical knowledge can’t tell which combinations are real and which are improvised on the spot.
Read the comments on any high-engagement GEO post. Fifteen replies in, 12 are agreements or “here’s another skill to add to your list.” Two or three offer diplomatically-framed skepticisms: “I would love to see more data,” or “the list is right, but…” The author engages substantively with the philosophical objection because pushing back against “this is too technical” is easy. The methodological objection, that the prescribed skills produce confident speculation without a measurement layer underneath, gets the politest burial.
What this adds up to is gaslighting at industry scale. The people reading the technology correctly get positioned as the ones who haven’t caught up; the prescriptions that controlled tests just falsified get sold as forward-looking. GEO has worked out how to make calibration look like the deficiency.
A recent X experiment captured the dynamic outside SEO. Someone posted a Monet painting and claimed it was AI-generated, asking the replies to explain its inferiority to a real Monet. Hundreds responded, confidently cataloging the “AI tells.” Flat brushwork, soulless composition, no cohesion, no soul. They were analyzing a Monet. The frame determined what they saw.
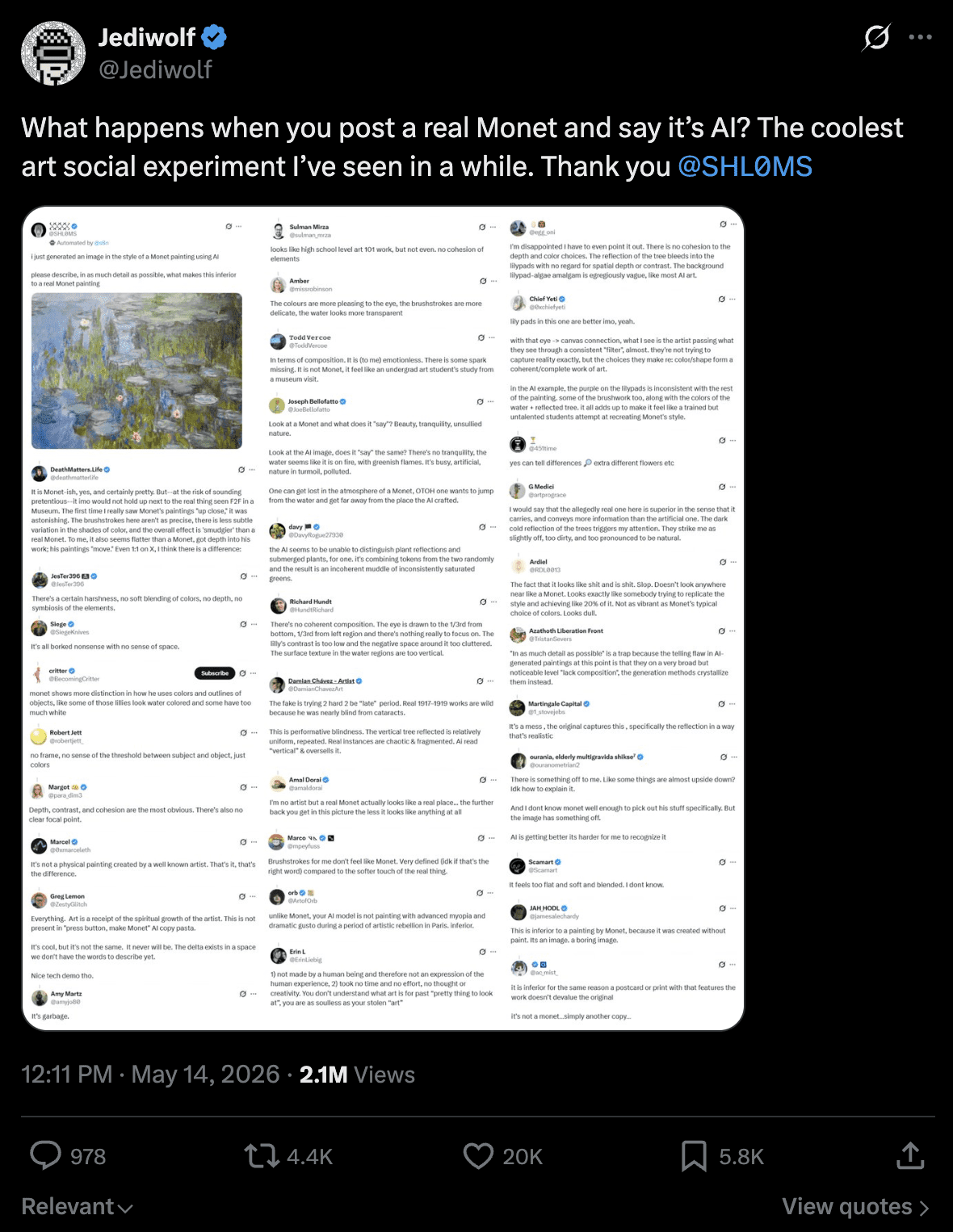
The original post, where a lot of the initial replies have now been deleted.

It’s the same trick. Vocabulary substitutes for substance; framing activates confirmation bias before any examination begins; the performance of analysis becomes what’s purchased rather than the analysis itself; “this is X” arrives before anyone checks whether it is. Once the frame is set, the analysis follows.
So the people most equipped to push back, the practitioners who’ve actually tried to test things, the technical SEOs who know what schema does and doesn’t do, the ones who can spot a fabricated lift number from across the room, stay quiet.
The result, on the timelines the C-suite reads, is a one-sided market.
The cost falls on the people who buy the claim. Clients pay for schema audits the Ahrefs study just falsified. Junior practitioners build careers on methodologies that won’t survive a controlled test. And the discipline burns credibility it will need later, when traditional search displaces further, and SEOs are expected to sit in rooms with engineering teams who’ve just spent two years watching the field confidently mis-call the technology.
Knowledge advances by trying to disprove your hypothesis, not confirm it. GEO does the opposite, runs studies designed to validate what it’s already selling. If the professionals claiming this expertise won’t even try to falsify themselves, who do we expect to believe us?
The Absence Is The Data
Strip the discourse, and what remains is the absence.
A serious technical field watches a controlled test contradict its dominant prescriptions, and the prescriptions keep selling. At that point, asking whether the prescriptions are wrong stops being the interesting question. That has been answered. The harder question is what’s wrong with a field that watches and doesn’t correct.
Same with the gradient. When the people who built the systems hedge and the people optimizing for those systems guarantee, asking who’s right stops being interesting. The researches and builders are right. Nobody who has worked on inference attribution thinks otherwise. The harder question is why the field lets the guarantees travel unchallenged.
The honest answer is that the incentives don’t pull toward correction. Confidence sells in ways caution can’t. The reportable framework wins the budget; the sensible assessment loses. And hedged language doesn’t fit on a pricing page where a guarantee fits perfectly.
None of this needs villains. The market for attention rewards confidence over calibration, every time.
You can keep watching the gradient run the wrong way. Or you can read what it actually is: an industry standing on Mt. Stupid, charging for the view.
More Resources:
This post was originally published on The Inference.
Featured Image: Roman Samborskyi/Shutterstock