Circle, highlight, or tap anything you want to search.
You can identify objects, translate text, or learn about locations. The results appear right above the video. When you’re finished, just swipe down to continue watching.
Here’s an example of the interface:
Screenshot from: YouTube.com/CreatorInsider, May 2025.
The feature works with products, plants, animals, landmarks, and text. You can even translate captions in real-time. Some searches include AI Overviews that provide more detailed information about what you’re looking for.
Google shared an example in its announcement:
“If you’re watching a short filmed in a location that you want to visit, you can select a landmark to identify it and learn more about the destination’s culture and history.”
See a demonstration in the video below:
Important Limitations
There are some key restrictions. Google Lens won’t work on Shorts with YouTube Shopping affiliate tags or paid product promotions.
“Tagging a product via YouTube Shopping will disable the lens search.”
Search results only show organic content, meaning no ads will appear when you use Lens. Google also states that it doesn’t use facial recognition technology, although the system may display results for famous people when relevant.
The feature is only compatible with mobile devices (iOS and Android). Google says the beta is “starting to roll out to all viewers this week,” though it hasn’t shared specific dates for different regions.
What This Means For Marketers
This update presents several opportunities for content creators and marketers:
Visual elements in your Shorts can now boost engagement.
Travel and hospitality businesses receive free visibility when their locations feature in videos. Educational creators can benefit as viewers explore the topics presented in their content.
The ban on affiliate content poses a challenge. Creators who rely on YouTube Shopping must carefully consider their monetization strategies. They will need to find a balance between discoverable content and their revenue goals.
Looking Ahead
Google Lens in YouTube Shorts signals a shift in how people interact with video content. You can now search within videos, not just for them.
For marketers, this means visual elements matter more than ever. The objects, locations, and text in your videos are now searchable entry points.
The exclusion of monetized content also sets up an interesting dynamic. Creators must choose between affiliate revenue and visibility in visual search.
Start planning your Shorts with searchable moments in mind. Your viewers are about to become visual searchers.
Google has confirmed that most websites still don’t need to worry about crawl budget unless they have over one million pages. However, there’s a twist.
Google Search Relations team member Gary Illyes revealed on a recent podcast that how quickly your database operates matters more than the number of pages you have.
This update comes five years after Google shared similar guidance on crawl budgets. Despite significant changes in web technology, Google’s advice remains unchanged.
The Million-Page Rule Stays The Same
During the Search Off the Record podcast, Illyes maintained Google’s long-held position when co-host Martin Splitt inquired about crawl budget thresholds.
Illyes stated:
“I would say 1 million is okay probably.”
This implies that sites with fewer than a million pages can stop worrying about their crawl budget.
What’s surprising is that this number has remained unchanged since 2020. The web has grown significantly, with an increase in JavaScript, dynamic content, and more complex websites. Yet, Google’s threshold has remained the same.
Your Database Speed Is What Matters
Here’s the big news: Illyes revealed that slow databases hinder crawling more than having a large number of pages.
Illyes explained:
“If you are making expensive database calls, that’s going to cost the server a lot.”
A site with 500,000 pages but slow database queries might face more crawl issues than a site with 2 million fast-loading static pages.
What does this mean? You need to evaluate your database performance, not just count the number of pages. Sites with dynamic content, complex queries, or real-time data must prioritize speed and performance.
The Real Resource Hog: Indexing, Not Crawling
Illyes shared a sentiment that contradicts what many SEOs believe.
He said:
“It’s not crawling that is eating up the resources, it’s indexing and potentially serving or what you are doing with the data when you are processing that data.”
Consider what this means. If crawling doesn’t consume many resources, then blocking Googlebot may not be helpful. Instead, focus on making your content easier for Google to process after it has been crawled.
How We Got Here
The podcast provided some context about scale. In 1994, the World Wide Web Worm indexed only 110,000 pages, while WebCrawler indexed 2 million. Illyes called these numbers “cute” compared to today.
This helps explain why the one-million-page mark has remained unchanged. What once seemed huge in the early web is now just a medium-sized site. Google’s systems have expanded to manage this without altering the threshold.
Why The Threshold Remains Stable
Google has been striving to reduce its crawling footprint. Illyes revealed why that’s a challenge.
He explained:
“You saved seven bytes from each request that you make and then this new product will add back eight.”
This push-and-pull between efficiency improvements and new features helps explain why the crawl budget threshold remains consistent. While Google’s infrastructure evolves, the basic math regarding when crawl budget matters stays unchanged.
What You Should Do Now
Based on these insights, here’s what you should focus on:
Sites Under 1 Million Pages: Continue with your current strategy. Prioritize excellent content and user experience. Crawl budget isn’t a concern for you.
Larger Sites: Enhance database efficiency as your new priority. Review:
Query execution time
Caching effectiveness
Speed of dynamic content generation
All Sites: Redirect focus from crawl prevention to indexing optimization. Since crawling isn’t the resource issue, assist Google in processing your content more efficiently.
However, the insight regarding database efficiency shifts the conversation for larger sites. It’s not just about the number of pages you have; it’s about how efficiently you serve them.
For SEO professionals, this means incorporating database performance into your technical SEO audits. For developers, it underscores the significance of query optimization and caching strategies.
Five years from now, the million-page threshold might still exist. But sites that optimize their database performance today will be prepared for whatever comes next.
A Google engineer has warned that AI agents and automated bots will soon flood the internet with traffic.
Gary Illyes, who works on Google’s Search Relations team, said “everyone and my grandmother is launching a crawler” during a recent podcast.
The warning comes from Google’s latest Search Off the Record podcast episode.
AI Agents Will Strain Websites
During his conversation with fellow Search Relations team member Martin Splitt, Illyes warned that AI agents and “AI shenanigans” will be significant sources of new web traffic.
Illyes said:
“The web is getting congested… It’s not something that the web cannot handle… the web is designed to be able to handle all that traffic even if it’s automatic.”
This surge occurs as businesses deploy AI tools for content creation, competitor research, market analysis, and data gathering. Each tool requires crawling websites to function, and with the rapid growth of AI adoption, this traffic is expected to increase.
How Google’s Crawler System Works
The podcast provides a detailed discussion of Google’s crawling setup. Rather than employing different crawlers for each product, Google has developed one unified system.
Google Search, AdSense, Gmail, and other products utilize the same crawler infrastructure. Each one identifies itself with a different user agent name, but all adhere to the same protocols for robots.txt and server health.
Illyes explained:
“You can fetch with it from the internet but you have to specify your own user agent string.”
This unified approach ensures that all Google crawlers adhere to the same protocols and scale back when websites encounter difficulties.
The Real Resource Hog? It’s Not Crawling
Illyes challenged conventional SEO wisdom with a potentially controversial claim: crawling doesn’t consume significant resources.
Illyes stated:
“It’s not crawling that is eating up the resources, it’s indexing and potentially serving or what you are doing with the data.”
He even joked he would “get yelled at on the internet” for saying this.
This perspective suggests that fetching pages uses minimal resources compared to processing and storing the data. For those concerned about crawl budget, this could change optimization priorities.
From Thousands to Trillions: The Web’s Growth
The Googlers provided historical context. In 1994, the World Wide Web Worm search engine indexed only 110,000 pages, whereas WebCrawler managed to index 2 million. Today, individual websites can exceed millions of pages.
This rapid growth necessitated technological evolution. Crawlers progressed from basic HTTP 1.1 protocols to modern HTTP/2 for faster connections, with HTTP/3 support on the horizon.
“You saved seven bytes from each request that you make and then this new product will add back eight.”
Every efficiency gain is offset by new AI products requiring more data. This is a cycle that shows no signs of stopping.
What Website Owners Should Do
The upcoming traffic surge necessitates action in several areas:
Infrastructure: Current hosting may not support the expected load. Assess server capacity, CDN options, and response times before the influx occurs.
Access Control: Review robots.txt rules to control which AI crawlers can access your site. Block unnecessary bots while allowing legitimate ones to function properly.
Database Performance: Illyes specifically pointed out “expensive database calls” as problematic. Optimize queries and implement caching to alleviate server strain.
Monitoring: Differentiate between legitimate crawlers, AI agents, and malicious bots through thorough log analysis and performance tracking.
The Path Forward
Illyes pointed to Common Crawl as a potential model, which crawls once and shares data publicly, reducing redundant traffic. Similar collaborative solutions may emerge as the web adapts.
While Illyes expressed confidence in the web’s ability to manage increased traffic, the message is clear: AI agents are arriving in massive numbers.
Websites that strengthen their infrastructure now will be better equipped to weather the storm. Those who wait may find themselves overwhelmed when the full force of the wave hits.
A patent that Google filed in December 2024 presents a close match to the Query Fan-Out technique that Google’s AI Mode uses. The patent, called Thematic Search, offers an idea of how AI Mode answers are generated and suggests new ways to think about content strategy.
The patent describes a system that organizes related search results to a search query into categories, what it calls themes, and provides a short summary for each theme so that users can understand the answers to their questions without having to click a link to all of the different sites.
The patent describes a system for deep research, for questions that are broad or complex. What’s new about the invention is how it automatically identifies themes from the traditional search results and uses an AI to generate an informative summary for each one using both the content and context from within those results.
Thematic Search Engine
Themes is a concept that goes back to the early days of search engines, which is why this patent caught my eye a few months ago and caused me to bookmark it.
Here’s the TL/DR of what it does:
The patent references its use within the context of a large language model and a summary generator.
It also references a thematic search engine that receives a search query and then passes that along to a search engine.
The thematic search engine takes the search engine results and organizes them into themes.
The patent describes a system that interfaces with a traditional search engine and uses a large language model for generating summaries of thematically grouped search results.
The patent describes that a single query can result in multiple queries that are based on “sub-themes”
Comparison Of Query Fan-Out And Thematic Search
The system described in the parent mirrors what Google’s documentation says about the Query Fan-Out technique.
Here’s what the patent says about generating additional queries based on sub-themes:
“In some examples, in response to the search query 142-2 being generated, the thematic search engine 120 may generate thematic data 138-2 from at least a portion of the search results 118-2. For example, the thematic search engine 120 may obtain the search results 118-2 and may generate narrower themes 130 (e.g., sub-themes) (e.g., “neighborhood A”, “neighborhood B”, “neighborhood C”) from the responsive documents 126 of the search results 118-2. The search results page 160 may display the sub-themes of theme 130a and/or the thematic search results 119 for the search query 142-2. The process may continue, where selection of a sub-theme of theme 130a may cause the thematic search engine 120 to obtain another set of search results 118 from the search engine 104 and may generate narrower themes 130 (e.g., sub-sub-themes of theme 130a) from the search results 118 and so forth.”
Here’s what Google’s documentation says about the Query Fan-Out Technique:
“It uses a “query fan-out” technique, issuing multiple related searches concurrently across subtopics and multiple data sources and then brings those results together to provide an easy-to-understand response. This approach helps you access more breadth and depth of information than a traditional search on Google.”
The system described in the patent resembles what Google’s documentation says about the Query Fan-Out technique, particularly in how it explores subtopics by generating new queries based on themes.
Summary Generator
The summary generator is a component of the thematic search system. It’s designed to generate textual summaries for each theme generated from search results.
This is how it works:
The summary generator is sometimes implemented as a large language model trained to create original text.
The summary generator uses one or more passages from search results grouped under a particular theme.
It may also use contextual information from titles, metadata, surrounding related passages to improve summary quality.
The summary generator can be triggered when a user submits a search query or when the thematic search engine is initialized.
The patent doesn’t define what ‘initialization’ of the thematic search engine means, maybe because it’s taken for granted that it means the thematic search engine starts up in anticipation of handling a query.
Query Results Are Clustered By Theme Instead Of Traditional Ranking
The traditional search results, in some examples shared in the patent, are replaced by grouped themes and generated summaries. Thematic search changes what content is shown and linked to users. For example, a typical query that a publisher or SEO is optimizing for may now be the starting point for a user’s information journey. The thematic search results leads a user down a path of discovering sub-themes of the original query and the site that ultimately wins the click might not be the one that ranks number one for the initial search query but rather it may be another web page that is relevant for an adjacent query.
The patent describes multiple ways that the thematic search engine can work (I added bullet points to make it easier to understand):
“The themes are displayed on a search results page, and, in some examples, the search results (or a portion thereof) are arranged (e.g., organized, sorted) according to the plurality of themes. Displaying a theme may include displaying the phrase of the theme.
In some examples, the thematic search engine may rank the themes based on prominence and/or relevance to the search query.
The search results page may organize the search results (or a portion thereof) according to the themes (e.g., under the theme of ‘cost of living”, identifying those search results that relate to the theme of ‘cost of living”).
The themes and/or search results organized by theme by the thematic search engine may be rendered in the search results page according to a variety of different ways, e.g., lists, user interface (UI) cards or objects, horizontal carousel, vertical carousel, etc.
The search results organized by theme may be referred to as thematic search results. In some examples, the themes and/or search results organized by theme are displayed in the search results page along with the search results (e.g., normal search results) from the search engine.
In some examples, the themes and/or theme-organized search results are displayed in a portion of the search results page that is separate from the search results obtained by the search engine.”
Content From Multiple Sources Are Combined
The AI-generated summaries are created from multiple websites and grouped under a theme. This makes link attribution, visibility, and traffic difficult to predict.
In the following citation from the patent, the reference to “unstructured data” means content that’s on a web page.
According to the patent:
“For example, the thematic search engine may generate themes from unstructured data by analyzing the content of the responsive documents themselves and may thematically organize the search results according to the themes.
….In response to a search query (“moving to Denver”), a search engine may obtain search results (e.g., responsive documents) responsive to that search query.
The thematic search engine may select a set of responsive documents (e.g., top X number of search results) from the search results obtained by the search engine, and generate a plurality of themes (e.g., “neighborhoods”, “cost of living”, “things to do”, “pros and cons”, etc.) from the content of the responsive documents.
A theme may include a phrase, generated by a language model, that describes a theme included in the responsive documents. In some examples, the thematic search engine may map semantic keywords from each responsive document (e.g., from the search results) and connect the semantic keywords to similar semantic keywords from other responsive documents to generate themes.”
Content From Source Pages Are Linked
The documentation states that the thematic search engine links to the URLs of the source pages. It also states that the thematic search result could include the web page’s title or other metadata. But the part that’s important for SEOs and publishers is the part about attribution, links.
“…a thematic search result 119 may include a title 146 of the responsive document 126, a passage 145 from the responsive document 126, and a source 144 of the responsive document. The source 144 may be a resource locator (e.g., uniform resource location (URL)) of the responsive document 126.
The passage 145 may be a description (e.g., a snippet obtained from the metadata or content of the responsive document 126). In some examples, the passage 145 includes a portion of the responsive document 126 that mentions the respective theme 130. In some examples, the passage 145 included in the thematic search result 119 is associated with a summary description 166 generated by the language model 128 and included in a cluster group 172.”
User Interaction Influences Presentation
As previously mentioned, the thematic search engine is not a ranked list of documents for a search query. It’s a collection of information across themes that are related to the initial search query. User interaction with those AI generated summaries influences which sites are going to receive traffic.
Automatically generated sub-themes can present alternative paths on the user’s information journey that begins with the initial search query.
Summarization Uses Publisher Metadata
The summary generator uses document titles, metadata, and surrounding textual content. That may mean that well-structured content may influence how summaries are constructed.
The following is what the patent says, I added bullet points to make it easier to understand:
“The summary generator 164 may receive a passage 145 as an input and outputs a summary description 166 for the inputted passage 145.
In some examples, the summary generator 164 receives a passage 145 and contextual information as inputs and outputs a summary description 166 for the passage 145.
In some examples, the contextual information may include the title of the responsive document 126 and/or metadata associated with the responsive document 126.
In some examples, the contextual information may include one or more neighboring passages 145 (e.g., adjacent passages).
In some examples, the contextual information may include a summary description 166 for one or more neighboring passages 145 (e.g., adjacent passages).
In some examples, the contextual information may include all the other passages 145 on the same responsive document 126. For example, the summary generator may receive a passage 145 and the other passages 145 (e.g., all other passages 145) on the same responsive document 126 (and, in some examples, other contextual information) as inputs and may output a summary description 166 for the passage 145.”
Thematic Search: Implications For Content & SEO
There are two way that AI Mode ends for a publisher:
Since users may get their answers from theme summaries or dropdowns, zero-click behavior is likely to increase, reducing traffic from traditional links.
Or, it could be that the web page that provides the end of the user’s information journey for a given query is the one that receives the click.
I think this means that we really need to re-think the paradigm of ranking for keywords and maybe consider what the question is that’s being answered by a web page, and then identify follow-up questions that may be related to that initial query and either include that in the web page or create another web page that answers what may be the end of the information journey for a given search query.
Google has fixed a bug that caused AI Mode search traffic to be reported as “direct traffic” instead of “organic traffic” in Google Analytics.
The problem started last week. Google was adding a special code (rel=”noopener noreferrer”) to links in its AI Mode search results. This code caused Google Analytics to incorrectly attribute traffic to websites, rather than from Google search.
Reports from Aleyda Solis, Founder at Orainti, and others in the SEO community confirm the issue is resolved.
Discovery of the Attribution Problem
Maga Sikora, an SEO director specializing in AI search, first identified the issue. She warned other marketers:
“Traffic from Google’s AI Mode is being tagged as direct in GA — not organic, as Google adds a rel=’noopener noreferrer’ to those links. Keep this in mind when reviewing your reports.”
The noreferrer code is typically used for security purposes. However, in this case, it was blocking Google Analytics from tracking the actual source of the traffic.
Google Acknowledges the Bug
John Mueller, Search Advocate at Google, quickly responded. He suggested it was a mistake on Google’s end, stating:
“My assumption is that this will be fixed; it looks like a bug on our side.”
Mueller also explained that Search Console doesn’t currently display AI Mode data, but it will be available soon.
He added:
“We’re updating the documentation to reflect this will be showing soon as part of the AI Mode rollout.”
“I don’t see the ‘noreferrer’ in Google’s AI Mode links anymore.”
She’s now seeing AI Mode data in her analytics and is verifying that traffic is correctly labeled as “organic” instead of “direct.”
Impact on SEO Reporting
The bug may have affected your traffic data for several days. If your site received AI Mode traffic during this period, some of your “direct” traffic may have been organic search traffic.
This misclassification could have:
Skewed conversion tracking
Affected budget decisions
Made SEO performance look worse than it was
Hidden the true impact of AI Mode on your site
What To Do Now
Here’s your action plan:
Audit recent traffic data – Check for unusual spikes in direct traffic from the past week
Document the issue – Note the affected dates for future reference
Adjust reporting – Consider adding notes to client reports about the temporary bug
Prepare for AI Mode tracking – Start planning how to measure this new traffic source
Google’s prompt response shows it understands the importance of accurate data for marketers.
New research analyzing 25,000 user searches found that websites ranked #1 on Google appear in AI search answers 25% of the time.
This data demonstrates that traditional SEO remains relevant, despite claims that AI has rendered it obsolete.
Tomasz Rudzki, co-founder of ZipTie, studied real searches across ChatGPT, Perplexity, and Google’s AI Overviews. His findings challenge the widespread belief that AI makes traditional SEO pointless.
Top Rankings Translate To AI Visibility
The data shows a clear pattern: if you rank #1 on Google, you have a 1-in-4 chance of appearing in AI search results. Lower rankings result in lower chances.
Rudzki stated:
“The higher you rank in Google’s top 10, the more likely you are to appear in AI search results across platforms. This isn’t speculation – it’s based on real queries from real users.”
The pattern holds across all major AI search platforms, suggesting that they all rely on traditional rankings when selecting sources.
How AI Search Engines Select Sources
The study detailed how AI search operates, using information from Google’s antitrust trial. The process involves three main steps:
Step 1: Pre-selection AI systems identify the best documents for each query, favoring pages with higher Google rankings.
Step 2: Content Extraction The AI extracts relevant information from these top-ranking pages, prioritizing content that directly answers the user’s question.
Step 3: AI Synthesis The AI synthesizes this information into one clear answer, utilizing Google’s Gemini model for this step.
Google’s internal documents from the trial confirmed a critical fact: using top-ranking content enhances the accuracy of AI responses, which explains why traditional rankings continue to be so significant.
The Query Fan-Out Effect Explained
Sometimes, you’ll come across sources that don’t make it into the top 10. Research identified two reasons why:
Reason 1: Personalization
Search results differ by user. A page might rank high for one user but not for another.
Reason 2: Query Fan-Out
This is the more significant factor. According to Google’s documentation:
“Both AI Overviews and AI Mode may use a ‘query fan-out’ technique — issuing multiple related searches across subtopics and data sources — to develop a response.”
Here’s what that means in simple terms:
When you search for “SEO vs SEM,” the AI discreetly runs multiple searches:
“What is SEO?”
“SEO explained”
“What is PP?C”
Plus several other related searches
Pages that perform well for these additional searches can appear in results even if they don’t rank for your primary search.
The research shows we need to think differently about content.
Traditional SEO focused on creating the “best page.” This meant comprehensive guides covering everything about a topic.
AI search wants the “best answer.” This means specific, focused responses to exact questions.
The analysis notes:
“When someone asks specifically about iPhone 15 battery life, you may rank top 1 in Google, but AI doesn’t care about it if you don’t provide a precise, relevant answer to that exact question.”
This research comes at the perfect time. AI search is growing rapidly. Understanding how it connects to traditional rankings gives you an edge.
Consider this: Only 25% of #1-ranked content appears in AI results. That means 75% is missing out. This suggests an opportunity for marketers who adapt.
Rudzki concludes:
“Instead of asking ‘How do I rank higher?’ start asking ‘How do I better serve users who have specific questions?’ That mindset shift is the key to thriving in the AI search era.”
For an industry experiencing rapid adoption of AI, these findings provide a strong foundation for informed strategic decisions. Instead of abandoning SEO practices, the evidence suggests building on what already works.
Google’s Sundar Pichai said in an interview that AI Overviews sends more traffic to a wider set of websites, insisting that Google cares about the web ecosystem and that he expects AI Mode to continue to send more traffic to websites, a claim that the interviewer challenged.
AI Agents Remove Customer Relationship Opportunities
There is a revolutionary change in how ecommerce that’s coming soon, where AI agents research and make purchase decisions on behalf of consumers. The interviewer brought up that some merchants have expressed concern that this will erode their ability to upsell or develop a customer relationship.
A customer relationship can be things like getting them to subscribe to an email or to receive text messages about sales, offer a coupon for a future purchase or to get them to come back and leave product reviews, all the ways that a human consumer interacts with a brand that an AI agent does not.
Sundar Pichai responded that AI agents present a good user experience and compared the AI agent in the middle between a customer and a merchant to a credit card company that sits in between the merchant and a customer, it’s a price that a merchant is willing to pay to increase business.
Pichai explained:
“I can literally see, envision 20 different ways this could work. Consumers could pay a subscription for agents, and their agents could rev share back. So you know, so that that is the CIO use case you’re talking about. That’s possible. We can’t rule that out. I don’t think we should underestimate, people may actually see more value participating in it.
I think this is, you know, it’s tough to predict, but I do think over time like you know like if you’re removing friction and improving user experience, it’s tough to bet against those in the long run, right? And so I think, in general if you’re lowering friction for it, you know, and and people are enjoying using it, somebody’s going to want to participate in it and grow their business.
And like would brands want to be in retailers? Why don’t they sell directly today? Why don’t they sell directly today? Why won’t they do that? Because retailers provide value in the middle.
Why do merchants take credit cards? There are many parts like and you find equilibrium because merchants take credit cards because they see more business as part of taking credit cards than not, right. And which justifies the increased cost of taking credit cards and may not be the perfect analogy. But I think there are all these kinds of effects going around.”
Pichai Claims That Web Ecosystem Is Growing
The interviewer began talking about the web ecosystem, calling attention to the the “downstream” effect of AI Search and AI search agents on information providers and other sites on the web.
Pichai started his answer by doing something he did in another interview about this same question where he deflected the question about web content by talking about video content.
He also made the claim that Google isn’t killing the web ecosystem and cited that the number of web pages in Google’s index has grown by 45% over the past two years, claiming it’s not AI generated content.
He said:
“I do think people are consuming a lot more information and the web is one specific format. So we should talk about the web, but zooming back out, …there are new platforms like YouTube and others too. So I think people are just consuming a lot more information, right? So it feels like like an expansionary moment. I think there are more creators. People are putting out more content, you know, and so people are generally doing a lot more. Maybe people have a little extra time in their hands. And so it’s a combination of all that.
On the web, look things have been interesting and you know we’ve had these conversations for a while, you know, obviously in 2015 there was this famous, the web is dead. You know, I always have it somewhere around, you know, which I look at it once in a while. Predictions, it’s existed for a while.
I think web is evolving pretty profoundly. When we crawl, when we look at the number of pages available to us, that number has gone up by 45% in the last two years alone. So that’s a staggering thing to think about.”
The interviewer challenged Pichai’s claim by asking if Google is detecting whether that increase in web pages is because they’re AI generated.
Pichai was caught by surprise by that question and struggled to find the answer and then finally responded that Google has many techniques for understanding the quality of web pages, including whether it was machine generated.
He doubled down on his statement that the web ecosystem is growing and then he started drifting off-topic, then he returned to the topic.
He continued:
“That doesn’t explain the trend we are seeing. So, generally there are more web pages. At an underlying level, so I think that’s an interesting phenomenom. I think everybody as a creator, like you do at The Verge, I think today if you’re doing stuff you have to do it in a cross-platform, cross-format way. So I think things are becoming more dynamic cross-format.
I think another thing people are underestimating with AI is AI will make it zero-friction to move from one format to another, because our models are multi-modal.
So I think this notion, the static moment of, you produce content by format, whereas I think machines can help translate it from, almost like different languages and they can go seamlessly between. I think it’s one of the incredible opportunities to be unlocked.
I think people are producing a lot of content, and I see consumers consuming a lot of content. We see it in our products. Others are seeing it too. So that’s probably how I would answer at the highest level.”
The interviewer asked Pichai what his response is to people who say that AI Overviews is crushing their business.
Pichai answered:
“AI mode is going to have sources and you know, we’re very committed as a direction, as a product direction, part of why people come to Google is to experience that breadth of the web and and go in the direction they want to, right?
So I view us as giving more context. Yes, there are certain questions which may get answers, but overall that’s the pattern we see today. And if anything over the last year, it’s clear to us the breadth of where we are sending people to is increasing. And, so I expect that to be true with AI Mode as well.”
The interviewer immediately responded by noting that if everything Pichai said was true, people would be less angry with him.
Pichai dismissed the question, saying:
“You’re always going to have areas where people are robustly debating value exchanges, etc. … No one sends traffic to the web the way we do.”
Google claims that search results with AI Overviews generate the same amount of advertising revenue as traditional search results.
This claim was made during Google Marketing Live when the company revealed plans to expand AI Overview ads to desktop users and more English-speaking markets.
If true, this could reshape how marketers perceive Google’s AI-powered future. However, the claim raises questions about how Google measures success and what it means for your campaigns.
Marketers need to understand what lies behind these claims and what they indicate for the future of search advertising.
AI Overviews Reaches Massive Scale
Google launched AI Overviews on mobile in the US last year. Since then, the company has quickly expanded the feature worldwide. It now processes AI-generated responses for users in more than 200 countries.
Shashi Thakur, Google’s VP/GM of Advertising, stated during the press session:
“We started rolling out AI overviews in search on US mobile last year. At this point, we are reaching a billion and a half users using it every month.”
Thakur oversees advertising across Google’s search products. This includes Google.com, Discover, Image Search, Lens, and Maps. He noted that users are happy with the feature.
The expansion shows Google’s confidence in both user adoption and commercial success. The company announced the desktop expansion that morning at the event, representing the latest phase of their rapid global rollout.
Thakur explained the growth impact:
“The consequence of us building AI overviews is that people are seeing growth. People are asking more of those questions… So we are seeing growth. So people are asking more questions. Many of those questions are even commercial. So we are seeing a growth even in commercial.”
Google’s Broader Vision For Search Evolution
Google’s approach to AI Overviews reflects a fundamental shift in how the company thinks about search capabilities. Thakur outlined this vision:
“At its core, we think about search as expanding the kinds of curiosities you can express. Humans have innumerable number of curiosities. There’s only a fraction of those that gets expressed to search. The more we advance the technology, the more we advance the product, users can bring more of their curiosities to search.”
This philosophy drives Google’s push toward AI-powered responses that can handle more complex and nuanced queries than traditional keyword-based searches.
How Google Measures AI Overview Monetization
Google’s revenue claims are based on controlled experiments. The company compares identical search queries with and without AI Overviews. They use standard A/B testing methods.
This means showing the AI feature to some users while holding it back from others. Then they measure the revenue difference.
Thakur explained to reporters:
“When we say AI overviews monetizes at the same rate, if you had taken the exact same set of queries and not shown AI overviews, it would have monetized at some rate. This continues to monetize at the same rate.”
The testing focuses on overall business value and revenue. It doesn’t examine individual metrics, such as click-through rates. Google emphasized this represents performance across many queries, not individual searches.
For advertisers, this suggests AI Overviews don’t hurt existing search advertising effectiveness. However, the long-term effects of changing user behavior patterns remain unclear.
Shashi Thakur speaks to press at Google Marketing Live. Photo: Matt G. Southern/Search Engine Journal.
Strategic Approach To AI Overview Advertising
Google states that ads within AI Overviews adhere to the same quality guidelines as traditional search ads. The company requires that ads be of high quality and fit well with the user experience. All ads must be marked as sponsored content.
Advertisers have three placement options for AI Overview ads: above the AI response, below the response, or integrated within the AI answer itself. This gives marketers flexibility in how they appear alongside AI-generated content.
The complexity of modern user behavior drives Google’s advertising strategy. Thakur noted:
“I think the main thing to take away from those conversations is user journeys are complicated. And users get inspiration to get into their commercial journeys at innumerable points in their journeys.”
The integration focuses on identifying commercial intent within complex queries through what Google refers to as “faceted” searches. These are complex questions that contain multiple sub-questions, some of which have commercial intent.
Thakur gave an example of a user asking about airline rules for traveling with pets. That person might then need pet carriers or travel accessories, creating natural opportunities for advertising. The AI system can identify these layered commercial needs within a single complex query.
Google uses various classifiers to identify commercial intent, including shopping queries, travel queries, and insurance queries. This automated classification system helps match ads to relevant user needs.
Thakur stated:
“Ads need to be high quality, and they need to be cohesive with the experience. Ads of this nature extend how good the answer is for certain users.”
Google reports positive user feedback about ads shown with AI Overviews. This suggests the integration doesn’t significantly hurt user satisfaction.
This user acceptance seems crucial to Google’s strategy. The company plans to expand AI Overview advertising to more platforms and markets.
Shashi Thakur speaks to press at Google Marketing Live. Photo: Matt G. Southern/Search Engine Journal.
Implications For Digital Marketers
The revenue parity claim addresses advertiser concerns about AI’s impact on search advertising effectiveness.
Thakur acknowledged the fundamental question marketers are asking:
“So now, the question we often get from our advertisers, and it’s a natural question, which is, this is great. Search is evolving in lots of exciting directions. How do we participate? And how do we connect with our customers in the context of this evolving experience?”
Thakur noted that over 80% of Google advertisers already use some form of AI-driven advertising technology. This suggests the industry is ready for more AI integration.
However, the shift toward AI-powered search responses may require advertisers to adapt their strategies. Users are asking increasingly complex, longer queries. Traditional keyword targeting may not be effective in addressing these.
Google’s solution involves increased automation through tools like the newly announced “AI Max for search” feature. Early beta testing of AI Max has shown promising results, with advertisers experiencing an average 27% increase in conversions while maintaining similar return on investment (ROI) targets.
Thakur explained the motivation behind AI Max:
“So the motivation for this, essentially, was this changing user behavior. That’s number one. As we heard from our advertisers, we got the feedback very clearly that transparency and control of the form, they were already used on search campaigns. That continues to be super important in addition to the automation.”
The tool maintains the transparency and control features that advertisers expect from traditional search campaigns, including keyword performance reporting and campaign controls. This addresses concerns about losing visibility when embracing automation.
The company’s emphasis on automation reflects a challenge. It’s hard to match ads to sophisticated, conversational queries that can contain multiple commercial intents.
Manual keyword strategies may become less effective over time. This is especially true as search behavior evolves toward natural language interactions.
AI Mode Expansion Creates New Opportunities
Beyond AI Overviews, Google is testing ads within its new AI Mode, which enables fully conversational search experiences. Early data indicates that users in AI mode ask questions that are up to twice as long as regular search queries.
These longer, more conversational queries create additional opportunities for identifying commercial intent within complex questions. The extended query length often means users are providing more context about their needs, potentially making ad targeting more precise.
Google is applying lessons learned from AI Overviews to ensure ads in AI mode maintain the same quality and user experience standards.
Looking Ahead
Thakur emphasized that Google’s approach remains focused on delivering a high-quality user experience while providing business value to advertisers.
The actual test of Google’s revenue claims will come as AI Overviews mature. User behavior patterns need time to solidify.
As Google continues expanding AI Overview advertising globally, digital marketers face a balancing act. They must embrace new automated tools while maintaining the control and transparency that drive successful campaign performance.
Google co-founder Sergey Brin says AI is transforming search from a process of retrieving links to one of synthesizing answers by analyzing thousands of results and conducting follow-up research. He explains that this shift enables AI to perform research tasks that would take a human days or weeks, changing how people interact with information online.
Machine Learning Models Are Converging
For those who are interested in how search works, another interesting insight he shared was that algorithms are converging into a single model. In the past, Googlers have described a search engine as multiple engines, multiple algorithms, thousands of little machines working together on different parts of search.
What Brin shared is that machine learning algorithms are converging into models that can do it all, where the learnings from specialist models are integrated into the more general model.
Brin explained:
“You know, things have been more converging. And, this is sort of broadly through across machine learning. I mean, you used to have all kinds of different kinds of models and whatever, convolutional networks for vision things. And you know, you had… RNN’s for text and speech and stuff. And, you know, all of this has shifted to Transformers basically.
And increasingly, it’s also just becoming one model.”
Google Integrates Specialized Model Learnings Into General Models
His answer continued, shifting to explaining how it’s the usual thing that Google does, integrating learnings from specialized models into more general ones.
Brin continued his answer:
“Now we do get a lot of oomph occasionally, we do specialized models. And it’s it’s definitely scientifically a good way to iterate when you have a particular target, you don’t have to, like, do everything in every language, handle whatever both images and video and audio in one go. But we are generally able to. After we do that, take those learnings and basically put that capability into a general model.”
Future Interfaces: Multimodal Interaction
Google has recently filed multiple patents around a new kind of visual and audio interface where Google’s AI can take what a user is seeing as input and provide answers about it. Brin admitted that their first attempt at doing that with Google Glasses was premature, that the technology for supporting that wasn’t mature. He says that they’ve made progress with that kind of searching but that they’re still working on battery life.
Brin shared:
“Yeah, I kind of messed that up. I’ll be honest. Got the timing totally wrong on that.
There are a bunch of things I wish I’d done differently, but honestly, it was just like the technology wasn’t ready for Google Glass.
But nowadays these things I think are more sensible. I mean, there’s still battery life issues, I think, that you know we and others need to overcome, but I think that’s a cool form factor.”
Predicting The Future Of AI Is Difficult
Sergey Brin declined to predict what the future will be like because technology is moving so fast.
He explained:
“I mean when you say 10 years though, you know a lot of people are saying, hey, the singularity is like, right, five years away. So your ability to see through that into the future, I mean, it’s very hard”
Improved Response Time and Voice Input Are Changing Habits
He agreed with the interviewers that improved response time to voice input are changing user habits, making real-time verbal interaction more viable. But he also said that voice mode isn’t always the best way to interface with AI and used the example of a person talking to a computer at work as a socially awkward application of voice input. This is interesting because we think of the Star Trek Computer voice method of interacting with a computer but what it would get quite loud and distracting if everyone in an office were interacting audibly with an AI.
He shared:
“Everything is getting better and faster and so for you know, smaller models are more capable. There are better ways to do inference on them that are faster.
We have the big open shared offices. So during work I can’t really use voice mode too much. I usually use it on the drive.
I don’t feel like I could, I mean, I would get its output in my headphones, but if I want to speak to it, then everybody’s listening to me. So I just think that would be socially awkward. …I do chat to the AI, but then it’s like audio in and audio out. Yeah, but I feel like I honestly, maybe it’s a good argument for a private office.”
AI Deep Research Can Synthesize Top 1,000 Search Results
Brin explained how AI’s ability to conduct deep research, such as analyzing massive amounts of search results and conducting follow-up research changes what it means to do search. He described a shift in search that changes the fundamental nature of search from retrieval (here are some links, look at them) to generating insights from the data (here’s a summary of what it all means, I did the work for you).
Brin contrasted what he can do manually with regular search and what AI can do at scale.
He said:
“To me, the exciting thing about AI, especially these days, I mean, it’s not like quite AGI yet as people are seeking or it’s not superhuman intelligence, but it’s pretty damn smart and can definitely surprise you.
So I think of the superpower is when it can do things in the volume that I cannot. So you know by default when you use some of our AI systems, you know, it’ll suck down whatever top ten search results and kind of pull out what you need out of them, something like that. But I could do that myself, to be honest, you know, maybe take me a little bit more time.
But if it sucks down the top, you know thousand results and then does follow-on searches for each of those and reads them deeply, like that’s, you know, a week of work for me like I can’t do that.”
AI With Advertising
Sergey Brin expressed enthusiasm for advertising within the context of the free tier of AI but his answer skipped over that, giving the indication that this wasn’t something they were planning for. He instead promoted the concept of providing a previous generation model for free while reserving the latest generation model for the paid tiers.
Sergey explained:
“Well, OK, it’s free today without ads on the side. You just got a certain number of the Top Model. I think we likely are going to have always now like sort of top models that we can’t supply infinitely to everyone right off the bat. But you know, wait three months and then the next generation.
I’m all for, you know, really good AI advertising. I don’t think we’re going to like necessarily… our latest and greatest models, which are you, know, take a lot of computation, I don’t think, we’re going to just be free to everybody right off the bat, but as we go to the next generation, you know, it’s like every time we’ve gone forward a generation, then the sort of the new free tier is usually as good as the previous pro tier and sometimes better.”
Watch the interview here:
Sergey Brin, Google Co-Founder | All-In Live from Miami
Google’s latest AI tools promise to manage campaigns automatically. But advertisers are asking whether these new features give up too much human control.
At Google Marketing Live, the company showcased three new AI agents. These tools can handle everything from creating campaigns to managing tasks across multiple platforms.
However, the announcement raised questions from attendees about accountability and transparency.
The reaction highlights growing tension in the industry. Platforms want more automation, while marketers worry about losing control of their accounts.
What Google Introduced
1. Google Ads Agentic Expert
This system makes changes to your campaigns without first asking for permission. It can:
Create multiple ad groups with matching creative assets
Add keywords and implement creative suggestions
Fix policy issues and submit appeals
Generate reports and answer campaign questions
2. Google Analytics Data Expert
This tool finds insights and trends automatically. It also makes data exploration easier through simple visuals.
The goal is to help marketers spot performance patterns without deep Analytics knowledge.
3. Marketing Advisor Chrome Extension
This browser extension launches later this year. It manages tasks across multiple platforms, including:
Automated tagging and tag installation
Seasonal trend analysis
Problem diagnosis across different sites
Marketing Advisor works across Google properties like Google Ads and Analytics. It also works on external websites and content management systems.
Here’s a promotional video demonstrating these tools’ capabilities:
Where Advertisers Push Back
During a press session led by Melissa Hsieh Nikolic, Director of Product Management for YouTube Ads, and Pallavi Naresh, Director of Product Management for Google Ads, executives addressed concerns from industry professionals.
Control and Change Tracking Issues
Advertisers asked how AI-made changes would appear in Google Ads’ change history, but executives couldn’t give clear answers.
Naresh responded:
“That’s a great question. I don’t know if it’ll show up with your username or like you and the agent’s username.”
This uncertainty worries agencies and brands. They need detailed records of campaign changes for client reports and internal approvals.
One attendee directly questioned the automation direction, stating:
“We’ve seen the ‘googlification’ of the Google help desk. Getting to a human is hard. This seems like it’s going down the path of replacing that.”
Google reps promised human support would stay available, responding:
“That’s not the intention. You will still be able to access support in the ways you can today.”
Transparency and Content Labeling Gaps
The new AI creative tools raised questions about content authenticity.
Google introduced image-to-video creation and “outpainting” technology. Outpainting expands video content for different screen sizes. However, Google’s approach to AI content labeling differs from other platforms.
Hsieh Nikolic explained:
“All of our images are watermarked with metadata and SynthID so generated content can be identified. At this time, we’re not labeling ads with any sort of identification.”
This approach is different from other platforms that use visible AI content labels.
Performance Claims & Industry Context
Google shared performance data for its AI-enhanced tools. Products with AI-generated images saw a “remarkable 20% increase on return on ad spend” compared to standard listings.
The company also said “advertiser adoption of Google AI for generating creative increased by 2500%” in the past year. But this growth comes with the control concerns mentioned above.
Google revealed it’s “actively working on a generative creative API.” This could impact third-party tools and agency workflows.
The timing makes sense given industry pressures. Google says marketers spend “10 hours or more every week creating visual content.” These tools directly address that pain point.
What This Means for Digital Marketing
The three-agent system is Google’s biggest push into hands-off advertising management yet. It moves beyond creative help to full campaign control.
Digital marketing has always been about precise budget and targeting control. This shift toward AI decision-making changes how advertisers and platforms work together.
The pushback from advertisers suggests more resistance than Google expected. This is especially true around accountability and transparency, which agencies and brands need for client relationships.
The Marketing Advisor Chrome extension is particularly ambitious. It extends Google’s reach beyond its platforms into general marketing workflow management, which could reshape how digital marketing teams work across the industry.
What Marketers Should Do
Set Up AI Change Protocols
As these features roll out, advertisers should:
Create clear rules for AI-driven campaign changes
Make sure approval processes can handle automated changes
Develop documentation requirements for AI modifications
Demand Clear Tracking
The change history question is still unresolved. It’s critical for agencies and brands that need detailed campaign records. Marketers should:
Ask for specific details about change tracking before using agentic features
Create backup documentation processes for AI modifications
Clarify how automated changes will show in client reports
Prepare for API Changes
Google is developing a generative creative API. Marketing teams should think about how this might impact:
Existing third-party tool connections
Agency workflow automation
Custom reporting systems
Closing Thoughts
Google’s three-agent system shows the company’s confidence in AI-driven advertising management. It builds on the success of over 500,000 advertisers using conversational AI features.
However, industry practitioners’ concerns highlight real challenges around control, transparency, and technical readiness. As these tools become standard practice, these issues need solutions.

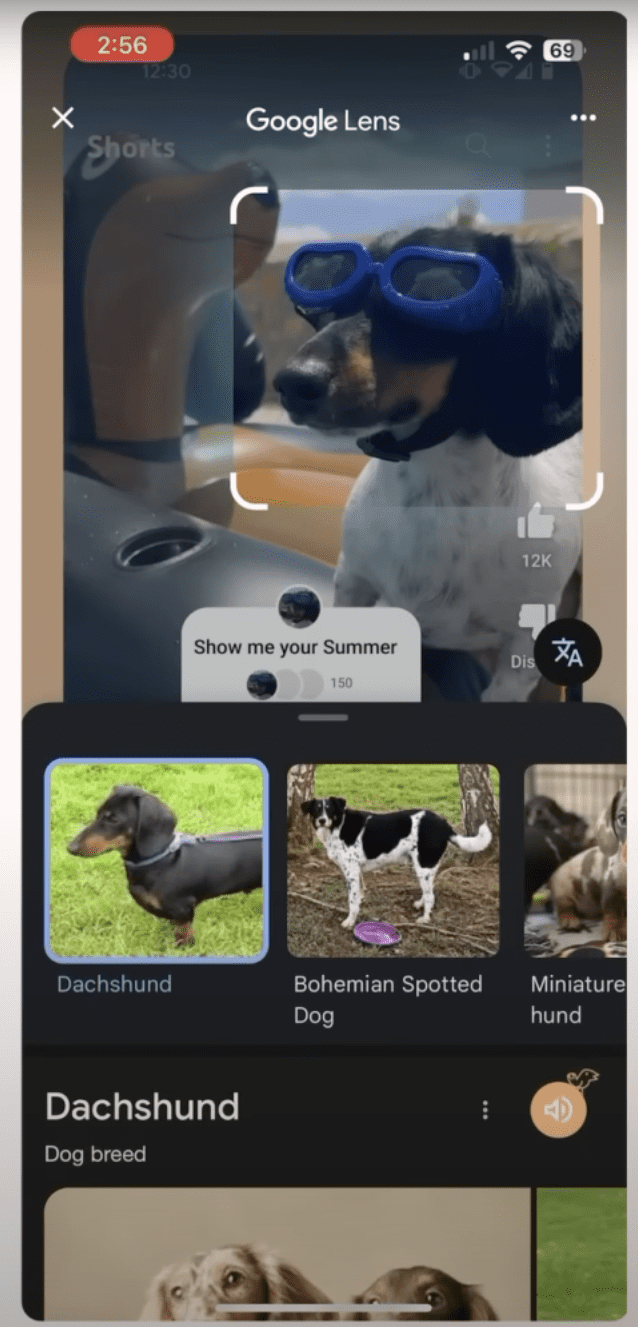 Screenshot from: YouTube.com/CreatorInsider, May 2025.
Screenshot from: YouTube.com/CreatorInsider, May 2025.