Wordfence issued an advisory on a vulnerability patched in the popular Happy Addons for Elementor plugin, installed on over 400,000 websites. The security flaw could allow attackers to upload malicious scripts that execute when browsers visit affected pages.
Happy Addons for Elementor
The Happy Addons for Elementor plugin extends the Elementor page builder with dozens of free widgets and features like image grids, a user feedback and reviews function, and custom navigation menus. A paid version of the plugin offers even more design functionalities that make it easy to create functional and attractive WordPress websites.
Stored Cross-Site Scripting (Stored XSS)
Stored XSS is a vulnerability typically occur when a theme or plugin doesn’t properly filter user inputs (called sanitization), allowing malicious scripts to be uploaded to the database and stored on the server itself. When a user visits the website the script downloads to the browser and executes actions like stealing browser cookies or redirecting the user to a malicious website.
The stored XSS vulnerability affecting the Happy Addons for Elementor plugin requires a hacker acquiring Contributor-level permissions (authentication), making it harder to take advantage of the vulnerability.
WordPress security company Wordfence rated the vulnerability 6.4 on a scale of 1 – 10, a medium threat level.
According Wordfence:
“The Happy Addons for Elementor plugin for WordPress is vulnerable to Stored Cross-Site Scripting via the before_label parameter in the Image Comparison widget in all versions up to, and including, 3.12.5 due to insufficient input sanitization and output escaping. This makes it possible for authenticated attackers, with Contributor-level access and above, to inject arbitrary web scripts in pages that will execute whenever a user accesses an injected page.”
Plugin users should consider updating to the latest version, currently 3.12.6, which contains a security patch for the vulnerability.
Google has released its latest broad core algorithm update for November 2024. This update continues Google’s refinement of search systems to enhance the quality of results.
On X, Google states:
“Today we released the November 2024 core update. We’ll add it to our ranking release history page in the near future and update when the rollout is complete.”
Today we released the November 2024 core update. We’ll add it to our ranking release history page in the near future and update when the rollout is complete. For more on core updates: https://t.co/43pVoYH8k7
These algorithmic changes, which Google implements several times annually, are designed to improve the overall search experience by reassessing how content is evaluated and ranked.
Unlike targeted updates, core updates affect search results globally across all regions and languages.
What You Should Know
According to Google’s documentation, most websites may not notice significant changes from core updates.
However, some sites might experience notable shifts in search rankings and traffic.
Google recommends that site owners who observe ranking changes should:
Wait until the update is completed before analyzing the impact
Compare traffic data from before and after the update in Search Console
Pay special attention to pages experiencing major position drops (particularly those falling more than 20+ positions)
Evaluate content quality using Google’s self-assessment guidelines
Focus on sustainable improvements rather than quick fixes
Recovery & Response
For sites affected by the update, Google emphasizes that recovery may take time—potentially several months—as its systems learn and validate improvements.
Specific changes aren’t guaranteed to result in ranking recoveries. Google emphasizes that search results are dynamic due to evolving user expectations and continuous web content updates.
Site owners can monitor the rollout’s completion status through Google’s Search Status Dashboard.
As with previous core updates, Google is expected to announce when the rollout, which typically takes about two weeks, has finished.
Looking Ahead
This marks Google’s final confirmed core update for 2024, following previous algorithmic changes throughout the year.
We will closely assess the impact as the update rolls out across Google’s search results.
New standards are being developed to extend the Robots Exclusion Protocol and Meta Robots tags, allowing them to block all AI crawlers from using publicly available web content for training purposes. The proposal, drafted by Krishna Madhavan, Principal Product Manager at Microsoft AI, and Fabrice Canel, Principal Product Manager at Microsoft Bing, will make it easy to block all mainstream AI Training crawlers with one simple rule.
Virtually all legitimate crawlers obey the Robots.txt and Meta Robots tags which makes this proposal a dream come true for publishers who don’t want their content used for AI training purposes.
Internet Engineering Task Force (IETF)
The Internet Engineering Task Force (IETF) is an international Internet standards making group founded in 1986 that coordinates the development and codification of standards that everyone can voluntarily agree one. For example, the Robots Exclusion Protocol was independently created in 1994 and in 2019 Google proposed that the IETF adopt it as an official standards with agreed upon definitions. In 2022 the IETF published an official Robots Exclusion Protocol that defines what it is and extends the original protocol.
Robots.Txt For Blocking AI Robots
The draft proposal seeks to create additional rules that will extend the Robots Exclusion Protocol (Robots.txt) to extend to AI Training Robots. This will bring about some order and give publishers choice in what robots are allowed to crawl their websites.
Adherance to the Robots.txt protocol is voluntary but all legitimate crawlers tend to obey it.
The draft explains the purpose of the new Robots.txt rules:
“While the Robots Exclusion Protocol enables service owners to control how, if at all, automated clients known as crawlers may access the URIs on their services as defined by [RFC8288], the protocol doesn’t provide controls on how the data returned by their service may be used in training generative AI foundation models.
Application developers are requested to honor these tags. The tags are not a form of access authorization however.”
An important quality of the new robots.txt rules and the meta robots HTML elements is that they don’t require naming specific crawlers. One rule covers all bots that are crawling for AI training data and that voluntarily agree to follow these protocols, which is something that all legitimate bots do. This will simplify bot blocking for publishers.
The following are the proposed Robots.txt rules:
DisallowAITraining – instructs the parser to not use the data for AI training language model.
AllowAITraining -instructs the parser that the data can be used for AI training language model.
The following are the proposed meta robots directives:
Provides Greater Control
AI companies have been unsuccessfully sued in court for using publicly available data. AI companies have asserted that it’s fair use to crawl publicly available websites, just as search engines have done for decades.
These new protocols give web publishers control over crawlers whose purpose is for consuming training data, bringing those crawlers into alignment with search crawlers.
In an ironic twist to the ongoing dispute between Automattic and WP Engine, a newly published website on WPEngineTracker.com is displaying a protest message against CEO Matt Mullenweg.
Copycat Domain Name Registered
Someone registered the domain name WPEngineTracker.com using the words that Automattic’s WordPressEngineTracker.com domain uses to describe itself (WP Engine Tracker) . If people who are looking for Automattic’s WP Engine Tracker domain navigate to WPEngine.com they will land on the variant website which is currently publishing a protest message against Matt Mullenweg.
Screenshot of Typosquat Domain
The above domain name was only registered a few days ago on November 7th. The Internet being what it is, it was arguable inevitable that someone would register the typosquat domain name variant.
Registration Of Domain Announced On GitHub
Someone posted a comment in the official WordPressEngineTracker.com GitHub repository to announce that they registered the domain name variant. The post was met with approval as evidenced by the 15 likes and 18 laughing emojis it received.
Screenshot Of Announcement In GitHub Repository
Domain Registration Announced On Reddit
The person who made the announcement on GitHub appears to have posted a discussion on the WordPress subreddit announcing that they have registered the domain name variant. The Reddit member who made the announcement is a 16 year member.
“I found it odd that Matt registered wordpressenginetracker.com when the thingamajig isn’t called “WordPress Engine Tracker” – it’s “WP Engine Tracker” Thought I should try to be helpful so I bought https://wpenginetracker.com”
That post was also met with positive reactions, receiving 138 upvotes three days later.
Matt Mullenweg’s Dispute With WPEngine
Disputes can appear different depending on who is telling the story. Automattic’s recent motion to dismiss WP Engine’s lawsuit offers details from its side, providing insight into the situation. Despite multiple opportunities to share its perspective, Automattic has received limited approval from WordPress users on social media. The registration of the WP Engine Tracker domain name variant could be said to be a manifestation of that negative sentiment toward Automattic and Mullenweg.
Automattic’s WP Engine Tracker website was temporarily blocked by Cloudflare over the weekend as a suspected phishing site, sparking cheers from members of the WordPress subreddit. Meanwhile, someone registered the typosquatting domain WPEngineTracker.com to protest against Matt Mullenweg.
Automattic, presumably under the direction of Matt Mullenweg, recently created a website called WP Engine Tracker on the WordPressEngineTracker.com domain name that lists how many WordPress sites have moved away from managed web host WP Engine. It also recommends web hosts that current customers can move to and offers a download of all domains that are hosted on WP Engine.
An Automattic emailed Search Engine Journal offered background information about the WP Engine Tracker website:
“The beauty of open source software is that everyone is able to access data on a granular level, because it’s all publicly available information. That public data has shown that ever since WP Engine filed its lawsuit – making it clear that they do not have an official association with WordPress and attracting greater attention to the company’s poor service, modifications to the WordPress core software, increasing and convoluted pricing structure, and repeated down times – their customers have left their platform for other hosting providers. WP Engine can and always has been able to access the WordPress software and plugins available on WordPress.org, as can anyone.”
Cloudflare Blocks WP Engine Tracker Website
Sometime on November 9th Cloudflare blocked access to Automattic’s WP Engine Tracker website with a message alerting Internet users that the website has been reported for phishing attempts.
The Cloudflare warning said:
“Warning
Suspected Phishing
This website has been reported for potential phishing.
Phishing is when a site attempts to steal sensitive information by falsely presenting as a safe source.”
WordPress Subreddit Cheers The Blocking
A Reddit discussion appeared soon after the site was blocked with the headline: Cloudflare is showing a phishing warning on wordpressenginetracker.com
Typical comments:
“Wow I’ve actually never seen that screen before. That’s hilarious.”
“As it should. Chrome should give it the red screen of death”
“It’s an interesting development, which made me wonder: Are people reporting phishing to Cloudflare just to mess with Mr. Mullenweg or is there something the site does that can actually be considered phishing?
Cloudflare’s report form has another type of abuse to select, which, in this case, is as obvious as the sun on the sunniest day: Trademark infringement. Why are people reporting phishing?”
One commenter noted the website was displaying a “403 Forbidden” error message if a site visitor ignored the warning and clicked through to the site. A 403 server response means that the server acknowledges the browser request but is denying access to the website.
Screenshot Of Blocked Website
Typosquatting Domain Name Registered
Typosquatting is when someone registers a domain name that is similar to a brand name and that users may type to visit. In this case, someone registered the domain name WPEngineTracker.com to take advantage of the fact that Automattic had registered the domain name WordPressEngineTracker.com but was calling it WP Engine Tracker. When people try to reach the Automattic site by typing in the name of the site as the domain they then arrive at the typosquat domain.
Screenshot of Typosquat Domain
The above domain name was only registered a few days ago on November 7th. The Internet being what it is, it was inevitable that someone would register the typosquat domain name variant.
WordPressEngineTracker.com Is Back Online
After a few hours of downtime Cloudflare removed the phishing block and the Automattic WordPress Engine Tracker website was restored.
Google continues updating AIO rankings, increasing the presence of larger shopping-related panels and ads that push organic search results lower on the page. The good news for search marketers is that AIO volatility in shopping queries is stabilizing, with AIO rankings increasingly matching sites typically ranked in organic search.
Arguably the most important change is the addition of advertising in AI Overviews, which has the effect of pushing organic search results lower down the page.
Citations to websites within AIO for general queries rose by over 300% since August, with the biggest growth (200%) experienced in September.
Since November 1, 2023, BrightEdge has been tracking a consistent set of search queries representing billions of searches across nine industries. The key point is that they are tracking the same queries every month using their unique technology, the BrightEdge Generative Parser (TM). The BrightEdge Generative Parser detects and tracks AIO formats, analyzes AIO search results, and provides insights into daily trends.
AIO & Top Ranked Organic Increasingly Match Since September
BrightEdge noticed a trend beginning in September where AI Overviews increasingly showed links to websites that matched the organic search results. This means that traditional ranking factors that put a website in the top of the organic search results should pay off in citations in AIO.
AIO Stability Continues To Improve
The BrightEdge data showed an 8% improvement in day-to-day stability and a less than 1% fluctuation the pixel size of AIO Panels. That means that AIO search results were less volatile and more dependable. Volatility in shopping-related search queries decreased 37% (from early August) to 26% (as of late September). The lower volatility indicates that rankings should be more consistent, a trend that hopefully will carry over into the holiday shopping season that begins in November.
More Precise AI Overview Results
That stability was accompanied by a 15% reduction in keywords with an AIO, demonstrating an increase in how precise search queries are to web page topics and perhaps may reflect a greater use of natural language in queries.
Bright Edge noted:
“As ads deploy, Google is more precise about where AIOs are most helpful.”
That trend toward more precise and concise AIOs began in August and continued through September, by which time Google AIO was collapsing unordered lists by an additional 14.6% over the previous month. Collapsed unordered lists show a concise answer in the visible part and reveal additional information if users click to see more. That trend continued in October, with the percentage of collapsed unordered growing by an additional 20%.
While that sounds like a lot, perhaps the most dramatic change was with the amount of times the AIO Product Carousel is triggered, experiencing a 300% increase since it initially was rolled out.
The trend of bigger AIO features suggests that shopping related AIO results with ads in them may increasingly displace organic content.
According to BrightEdge:
“As Google injects ads into AIOs in October, two features have experienced significant increases. Particularly with product carousels, there are direct opportunities for advertisers. As these are not taking up more space, it suggests those ads will likely displace an organic listing if this trend continues. All these trends point to a holiday shopping season where AI will play a bigger role than ever, but maybe not in the way we originally expected.”
YouTube Citations Increased In AIO
E-commerce-related YouTube citations within AIO increased by 121% through September, which may reflect that users prefer to watch videos while researching products This calls attention to the importance of video influencers as well considering multimodal strategies that incorporate video content for shopping-related topics (where the intent makes sense).
AIO for shopping wasn’t all growth in September, as queries related to certain topics triggered less AI Overviews.
The following topics showed less AIO results:
“Queries for Specific Products: -7.2%
Furniture and Home Décor: -2.7%
Clothing and Fashion: – 2.2%
Searches for ‘best’: – 1.7%
How-to and Instructional Shopping Searches: -1.6%”
Early Stage Research Intent
Another AIO trend discovered for October was an increase in research-phase search queries and intent. Publishers relying on search should be on the lookout for any traffic drops that may be correlated to an increase in AIO search results related to research-phase queries.
October Ecommerce AIO Trends
“81.1% deliver broad knowledge sharing
Only 1.4% provide step-by-step guidance
AIOs prioritize educational content over how-to directions
Early-Journey Content Structure 39.8% use list structures for easy scanning
Strong preference for broad explanations
Content organized for information gathering
Emphasis on comprehensive understanding”
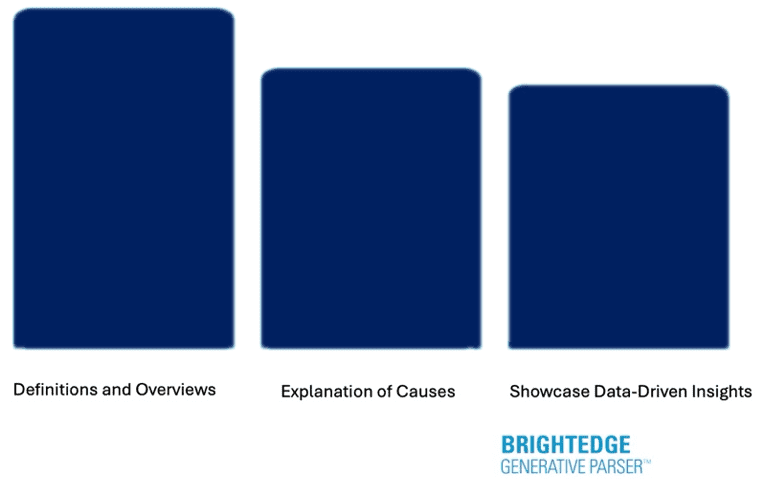
Kinds Of Answers Shown In AI Overviews
The BrightEdge data shows that in October discovery and research types of queries triggered the most AI Overviews.
The top 3 kinds of answers show in AI Overviews were:
Definitions and overviews
Explanation of causes
Data points
BrightEdge explains what it all means:
“The data clearly shows that AIOs are optimized for early-stage research and discovery.
Educational content with expert guidance on what’s trending or critical data points is more helpful to cite than specific how-to instructions.
Success means aligning your content with this top-of-funnel focus – comprehensive, educational content wins over transactional guidance that could be replaced with ads.”
Most Common Type Of Answer In AI Overviews
Takeaways
BrightEdge’s research offers many insights on the kinds of content Google’s AI Overviews is prioritizing and how it’s ramping up for the holiday shopping season which begins with Black Friday. If traffic patterns are changing then it may be due to the updates to the kinds of queries are triggering AIO and an increase in advertising which, combined with larger sizes of AIO panels, could be pushing organic results lower.
It must be emphasized that organic results have not been the norm for well over ten years and at this point it’s anachronistic to still be thinking in terms of ten blue links. This is why the BrightEdge data is important because it’s showing what’s going on in the search results.
Key Insights
Ads are now featuring in AI Overviews
Volatility in shopping-related queries is stabilizing, creating a more predictability
Google is becoming more precise about what triggers AIOs
Product carousels increased by 300% in October
Collapsed unordered lists that requires users to click to see more information increased by 20%
Queries for specific products are less likely to trigger AIOs
Research-phase queries and intents are increasingly the top triggers for AIO
LinkedIn’s push into video content is showing results, according to new research by marketing expert Caroline Giegerich.
Her analysis, published in Adweek, tests LinkedIn’s claim that video gets five times the engagement of text posts.
She writes:
“Curious to test LinkedIn’s claim that videos receive five times more engagement, I wanted to see if the hype held up. Additionally, with a staggering 84% of marketers utilizing video in their content strategies, I wanted to go deep and understand the real value of the format.”
Key Findings
Giegerich’s 90-day analysis revealed video posts consistently achieved higher reach than written content:
Her lowest-performing video posts garnered nearly triple the impressions of top-performing written posts
Her most successful video reached 774,000 impressions
Her video posts averaged around 250,000 views
Giegerich found the most success with:
Videos under 5 minutes
Direct-to-camera approach
Morning posts between 9-11 AM EST
Additionally, she notes adding personal flair to videos may have aided their performance:
“In terms of the content itself, I keep my videos under 5 minutes and speak directly to the camera about technology in terms everyone can understand to make it accessible.
I also post in the morning between 9 – 11 AM EST. If Gossip Girl covered tech, she’d be me. Over time, I added fun sound effects and captions with Capcut.”
When To Use Text Posts
Giegerich says that video works best to create awareness at the top of the sales funnel. Once people are aware, text posts are more valuable.
She states:
“My written posts dominate the top three spots for engagement, even though my video posts drive significantly more awareness. For example, my top-written post by engagement drove 68 times fewer impressions than my lowest-performing video post.”
Based on her testing, text posts received more targeted distribution to her connections, while videos were recommended to people outside her network.
Giegerich adds:
“One format is more targeted to my network and the other is being heavily fanned by the LinkedIn algorithm to an audience outside of my immediate network.”
Limited Monetization Opportunities
The study highlights LinkedIn’s limited monetization options compared to its competitors:
The current program offers sponsored posts and consulting opportunities.
The creator accelerator program is restricted to only 100 participants, selected in 2022.
The platform lags behind TikTok and Instagram when providing incentives for creators.
What This Means
LinkedIn’s algorithm tends to favor video, but Giegerich’s research highlights that video and text serve different roles.
Video posts excel at broad awareness and can achieve higher impression counts, though their performance is often unpredictable.
In contrast, written posts foster stronger engagement within established networks.
For marketers, Giegerich suggests a balanced approach: use video for visibility and maintain written posts for engagement.
YouTube has updated its video linking system, giving creators in the YouTube Partner Program (YPP) more control over advertising partnerships.
This addresses several long-standing issues in collaborations between creators and brands.
Previously, creators lacked a direct way to start advertising relationships. They had to wait for advertisers to reach out.
The new system allows creators to take a more active approach to monetization. Channels can now reach out to advertisers aligned with their audience.
This update is available to channels in the YouTube Partner Program that run ads on Shorts.
In an announcement, a YouTube representative states:
“We’re launching the ability for creators in YPP with more than 4,000 subscribers to send video linking requests for shorts to advertisers via YouTube Studio.
YouTube will recommend creator-initiated tagged content to brands if they choose to run ads.”
Key Features For Marketers
Performance Data
For creators, having their videos linked to advertisers’ accounts clarifies how their content performs and resonates with audiences.
This information can inform future content strategies and help creators refine their approach to brand collaborations.
Once a video linking request is approved, advertisers can access information through their Google Ads accounts.
This data includes organic video performance metrics such as view counts, engagement rates, and audience demographics.
Rights Management
Creators can restrict their content usage to only linked Google Ads accounts.
This feature, accessible through YouTube Studio’s Advanced Settings, helps prevent brands from using a creator’s videos without permission.
By linking videos to advertisers’ accounts, creators grant permission for their content to be used in ad campaigns.
A YouTube representative confirms creator-initiated video linking requests work the same way:
“These creator-initiated links will act in the same way as advertiser-initiated links, which confirm rights between brands and creators, and gives advertisers the ability to view organic video performance in Google ads.”
Up to 300 Google Ads accounts can be linked per channel
Looking Ahead
With the introduction of creator-initiated video linking, channels have more freedom to choose the brands they work with.
This can potentially lead to more authentic and engaging advertising opportunities.
Automattic appears to have created a site that draws attention to the number of customers that have left WP Engine for another web host. The site includes a searchable database of websites hosted on WP Engine that can also be downloaded as a CSV spreadsheet.
The name of the website is WP Engine Tracker, it features a prominent Automattic logo and a link to an associated GitHub repository that shows an Automattic employee is the developer of the website.
Ongoing Dispute Between Automattic And WP Engine
The website is the latest escalation in a dispute initiated by Matt Mullenweg, WordPress co-founder and CEO of Automattic, who argues that WP Engine’s contributions to WordPress development fall short. WordPress relies on contributions and sponsorships from volunteers, businesses, and individuals who benefit from the platform. The underlying principle is that the more everyone contributes the more the entire community benefits, strengthening WordPress’s position as the world’s most popular content management system.
The text of the website features a number representing the websites that have left WP Engine and an explanation:
“This is the number of websites that have left WP Engine and found a new home since Sep 21, 2024.
Search below to see if a site is still hosted by WP Engine”
Comments Left On WP Engine Tracker GitHub Repository
The website links to a GitHub repository that lists the author of the WP Engine Tracker website as being someone who works for Automattic.
Screenshot Of Author Listed On GitHub Repository
The Issues tab of the official GitHub repository contains critiques of the project and some criticism.
The first comment notes that the counter is incorrect because it claims to count websites that have left WP Engine but that it should be saying how many domains have left. The reason is because of the “websites” listed redirect to one domain, which means that the count is inflated.
Another person commented:
“It’s possible some folks have left WordPress as well, so saying sites have left WP Engine doesn’t necessarily mean they’ve gone to another web host that supports WordPress. This is a really tacky endeavor. I am not impressed at all.”
The latest comment calls the website “amateurish”:
“Also the check, if a domain is hosted by WPE, is quite amateurish.
missing dot at beginning for some only checks subdomains I’m not sure what the goal of this website is and what Matt tries to achieve. But the community is getting increasingly annoyed of such unprofessional behavior of Matt and in the security community some also think about dropping 0days for WordPress and related plugins / themes due to this whole situation.
The feedback under the tweet from the official WordPress account and in the reddit community shows, what most of us think.
The whole situation hurts everyone more than needed.”
Screenshot Of GitHub Repository For WP Engine Tracker
What Is The Point Of The Website?
It’s unclear what the purpose of the WP Engine Tracker website is other than the stated purpose of tracking sites that have left WP Engine.
The website draws attention to the specific domains of websites that have moved away from WP Engine but what purpose does that serve? Is the purpose is to draw attention to sites that could be solicited to move away from WP Engine? If so, there’s nothing on the website that encourages that use of the information. The WP Engine Tracker website is silent about what site visitors should do with the data.