Alphabet Inc. reported its third-quarter earnings, with revenues reaching $88.3 billion, a 15% increase from last year.
The Google parent company’s operating margin expanded to 32% from 27.8% year-over-year, while net income rose 34% to $26.3 billion.
During the earnings call, the company highlighted the growing role of AI across its products and services.
Google Cloud revenue increased 35% to $11.4 billion, while YouTube surpassed $50 billion in combined advertising and subscription revenue over the past four quarters.
Several operational changes occurred during the quarter, including the reorganization of Google’s AI teams and the expansion of AI features across its products.
The company also reported improvements in AI infrastructure efficiency and increased deployment of AI-powered search capabilities.
Highlights
AI
CEO Sundar Pichai emphasized how AI transforms the search experience, telling investors that “new AI features are expanding what people can search for and how they search for it.”
Google’s AI infrastructure investments are yielding efficiency gains. According to Pichai, over a quarter of all new code at Google is now generated by AI and then reviewed by engineers, accelerating development cycles.
Google has reduced AI Overview query costs by 90% over 18 months while doubling the Gemini model size. These improvements extend across seven Google products, each serving over 2 billion monthly users.
Cloud
The Google Cloud division reported operating income of $1.95 billion, marking an increase from $266 million in the same quarter last year.
Company leadership attributed this growth to increased adoption of AI infrastructure and generative AI solutions among enterprise customers.
In an organizational move, Google announced it will transfer its Gemini consumer AI team to Google DeepMind, signaling a deeper integration of AI development across the company.
YouTube
YouTube achieved a notable milestone: its combined advertising and subscription revenues exceeded $50 billion over the past four quarters.
YouTube ads revenue grew to $8.9 billion in Q3, while the broader Google subscriptions, platforms, and devices segment reached $10.7 billion.
Financials
Net income increased 34% to $26.3 billion
Operating margin expanded to 32% from 27.8% last year
Earnings per share rose 37% to $2.12
Total Google Services revenue grew 13% to $76.5 billion
What This Means
Google’s Q3 results point to shifts in search that SEO professionals and businesses need to watch.
With AI Overviews now reaching over 1 billion monthly users, we’re seeing changes in search behavior.
According to CEO Sundar Pichai, users are submitting longer and more complex queries, exploring more websites, and increasing their search activity as they become familiar with AI features.
For publishers, the priorities are clear: create content that addresses complex queries and monitor how AI Overviews affect traffic patterns.
We can expect further advancements across services with Google’s heavy investment in AI. The key will be staying agile and continually testing new features as they roll out.
A British couple’s legal battle against Google’s search practices has concluded.
Europe’s highest court upheld a €2.4 billion fine against Google, marking a victory for small businesses in the digital marketplace.
Background
Shivaun and Adam Raff launched Foundem, a price comparison website, in June 2006.
On launch day, Google’s automated spam filters hit the site, pushing it deep into search results and cutting off its primary traffic source.
“Google essentially disappeared us from the internet,” says Shivaun Raff.
The search penalties remained in place despite Foundem later being recognized by Channel 5’s The Gadget Show as the UK’s best price comparison website.
From Complaint To Major Investigation
After two years of unanswered appeals to Google, the Raffs took their case to regulators.
Their complaint led to a European Commission investigation in 2010, which revealed similar issues affecting approximately 20 other comparison shopping services, including Kelkoo, Trivago, and Yelp.
The investigation concluded in 2017 with the Commission ruling that Google had illegally promoted its comparison shopping service while demoting competitors, resulting in the €2.4 billion fine.
Here’s a summary of what happened next.
Timeline: From Initial Fine to Final Ruling (2017-2024)
2017
European Commission issues €2.4 billion fine against Google
Google implements changes to its shopping search results
Google files initial appeal against the ruling
2021
General Court of the European Union upholds the fine
Google launches second appeal to the European Court of Justice
2024March
European Commission launches new investigation under Digital Markets Act
Probe examines whether Google continues to favor its services in search results
September
European Court of Justice rejects Google’s final appeal A fine of €2.4 billion is definitively upheld
Marks the end of main legal battle after 15 years
The seven-year legal process highlights the challenges small businesses face in seeking remedies for anti-competitive practices, despite having clear evidence.
Google’s Response
Google maintains its 2017 compliance changes resolved the issues.
A company spokesperson stated:
“The changes we made have worked successfully for more than seven years, generating billions of clicks for more than 800 comparison shopping services.”
What’s Next?
While the September 2024 ruling validates the Raffs’ claims, it comes too late for Foundem, which closed in 2016.
In March 2024, the European Commission launched a new investigation into Google’s current practices under the Digital Markets Act.
The Raffs are now pursuing a civil damages claim against Google, scheduled for 2026.
Why This Matters
This ruling confirms that Google’s search rankings can be subject to regulatory oversight and legal challenges.
The case has already influenced new digital marketplace regulations, including the EU’s Digital Markets Act.
Although Foundem’s story concluded with the company’s closure in 2016, the legal precedent it set will endure.
The official documentation for how Core Web Vitals are scored was recently updated with new insights into how Interaction to Next Paint (INP) scoring thresholds were chosen and offers a better understanding of Interaction To Next Paint.
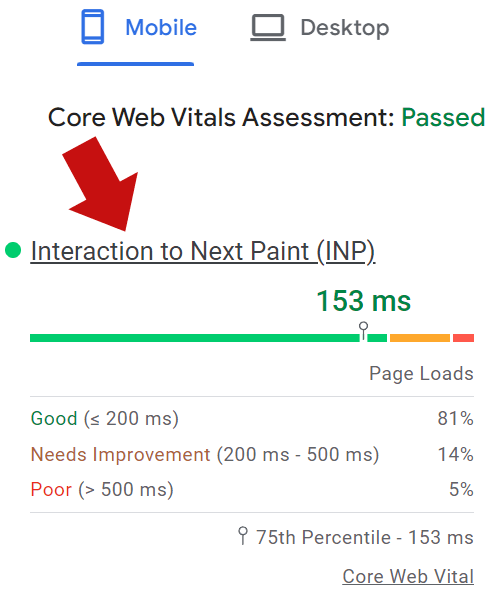
Interaction to Next Paint (INP)
Interaction to Next Paint (INP) is a relatively new metric, officially becoming a Core Web Vitals in the Spring of 2024. It’s a metric of how long it takes a site to respond to interactions like clicks, taps, and when users press on a keyboard (actual or onscreen).
“INP observes the latency of all interactions a user has made with the page, and reports a single value which all (or nearly all) interactions were beneath. A low INP means the page was consistently able to respond quickly to all—or the vast majority—of user interactions.”
INP measures the latency of all the interactions on the page, which is different than the now retired First Input Delay metric which only measured the delay of the first interaction. INP is considered a better measurement than INP because it provides a more accurate idea of the actual user experience is.
INP Core Web Vitals Score Thresholds
The main change to the documentation is to provide an explanation for the speed performance thresholds that show poor, needs improvement and good.
One of the choices made for deciding the scoring was how to handle scoring because it’s easier to achieve high INP scores on a desktop versus a mobile device because external factors like network speed and device capabilities heavily favor desktop environments.
But the user experience is not device dependent so rather that create different thresholds for different kinds of devices they settled on one metric that is based on mobile devices.
The new documentation explains:
“Mobile and desktop usage typically have very different characteristics as to device capabilities and network reliability. This heavily impacts the “achievability” criteria and so suggests we should consider separate thresholds for each.
However, users’ expectations of a good or poor experience is not dependent on device, even if the achievability criteria is. For this reason the Core Web Vitals recommended thresholds are not segregated by device and the same threshold is used for both. This also has the added benefit of making the thresholds simpler to understand. Additionally, devices don’t always fit nicely into one category. Should this be based on device form factor, processing power, or network conditions? Having the same thresholds has the side benefit of avoiding that complexity.
The more constrained nature of mobile devices means that most of the thresholds are therefore set based on mobile achievability. They more likely represent mobile thresholds—rather than a true joint threshold across all device types. However, given that mobile is often the majority of traffic for most sites, this is less of a concern.”
These are scores Chrome settled on:
Scores of under 200 ms (milliseconds) were chosen to represent a “good” score.
Scores between 200 ms – 500 ms represent a “needs improvement” score.
Performance of over 500 ms represent a “poor” score.
Screenshot Of An Interaction To Next Paint Score
Lower End Devices Were Considered
Chrome was focused on choosing achievable metrics. That’s why the thresholds for INP had to be realistic for lower end mobile devices because so many of them are used to access the Internet.
They explained:
“We also spent extra attention looking at achievability of passing INP for lower-end mobile devices, where those formed a high proportion of visits to sites. This further confirmed the suitability of a 200 ms threshold.
Taking into consideration the 100 ms threshold supported by research into the quality of experience and the achievability criteria, we conclude that 200 ms is a reasonable threshold for good experiences”
Most Popular Sites Influenced INP Thresholds
Another interesting insight in the new documentation is that achievability of the scores in the real world were another consideration for the INP scoring metrics, measured in milliseconds (ms). They examined the performance of the top 10,000 websites because they made up the vast majority of website visits in order to dial in the right threshold for poor scores.
What they discovered is that the top 10,000 websites struggled to achieve performance scores of 300 ms. The CrUX data that reports real-world user experience showed that 55% of visits to the most popular sites were at the 300 ms threshold. That meant that the Chrome team had to choose a higher millisecond score that was achieveable by the most popular sites.
The new documentation explains:
“When we look at the top 10,000 sites—which form the vast majority of internet browsing—we see a more complex picture emerge…
On mobile, a 300 ms “poor” threshold would classify the majority of popular sites as “poor” stretching our achievability criteria, while 500 ms fits better in the range of 10-30% of sites. It should also be noted that the 200 ms “good” threshold is also tougher for these sites, but with 23% of sites still passing this on mobile this still passes our 10% minimum pass rate criteria.
For this reason we conclude a 200 ms is a reasonable “good” threshold for most sites, and greater than 500 ms is a reasonable “poor” threshold.”
Barry Pollard, a Web Performance Developer Advocate on Google Chrome who is a co-author of the documentation, added a comment to a discussion on LinkedIn that offers more background information:
“We’ve made amazing strides on INP in the last year. Much more than we could have hoped for. But less than 200ms is going to be very tough on low-end mobile devices for some time. While high-end mobile devices are absolute power horses now, the low-end is not increasing at anywhere near that rate…”
A Deeper Understanding Of INP Scores
The new documentation offers a better understanding of how Chrome chooses achievable metrics and takes some of the mystery out of the relatively new INP Core Web Vital metric.
Google published a proposal in the Schema.org Project GitHub instance that proposes proposing an update at Schema.org to expand the shopping structured data so that merchants can provide more shipping information that will likely show up in Google Search and other systems.
Shipping Schema.org Structured Data
The proposed new structured data Type can be used by merchants to provide more shipping details. It also suggests adding the flexibility of using a sitewide shipping structured data that can then be nested with the Organization structured data, thereby avoiding having to repeat the same information thousands of times across a website.
The initial proposal states:
“This is a proposal from Google to support a richer representation of shipping details (such as delivery cost and speed) and make this kind of data explicit. If adopted by schema.org and publishers, we consider it likely that search experiences and other consuming systems could be improved by making use of such markup.
This change introduces a new type, ShippingService, that groups shipping constraints (delivery locations, time, weight and size limits and shipping rate). Redundant fields from ShippingRateSettings are therefore been deprecated in this proposal.
As a consequence, the following changes are also proposed:
some fields in OfferShippingDetails have moved to ShippingService; ShippingRateSettings has more ways to specify the shipping rate, proportional to the order price or shipping weight; linking from the Offer should now be done with standard Semantic Web URI linking.”
The proposal is open for discussion and many stakeholders are offering opinions on how the updated and new structured data would work.
For example, one person involved in the discussion asked how a sitewide structured data type placed in the Organization level could be superseded by individual products had different information and someone else provided an answer.
A participant in the GitHub discussion named Tiggerito posted:
“I re-read the document and what you said makes sense. The Organization is a place where shared ShippingConditions can be stored. But the ShippingDetails is always at the ProductGroup or Product level.
This is how I currently deal with Shipping Details:
In the back end the owner can define a global set of shipping details. Each contains the fields Google currently support, like location and times, but not specifics about dimensions. Each entry also has conditions for what product the entry can apply to. This can include a price range and a weight range.
When I’m generating the structured data for a page I include the entries where the product matches the conditions.
This change looks like it will let me change from filtering out the conditions on the server, to including them in the Structured Data on the product page.
Then the consumers of the data can calculate which ShippingConditions are a match and therefore what rates are available when ordering a specific number of the product. Currently, you can only provide prices for shipping one.
The split also means it’s easier to provide product specific information as well as shared shipping information without the need for repetition.
Your example in the document at the end for using Organization. It looks like you are referencing ShippingConditions for a product that are on a shipping page. This cross-referencing between pages could greatly reduce the bloat this has on the product page, if supported by Google.”
The Googler responded to Tiggerito:
“@Tiggerito
The Organization is a place where shared ShippingConditions can be stored. But the ShippingDetails is always at the ProductGroup or Product level.
Indeed, and this is already the case. This change also separates the two meanings of eg. width, height, weight as description of the product (in ShippingDetails) and as constraints in the ShippingConditions where they can be expressed as a range (QuantitativeValue has min and max).
In the back end the owner can define a global set of shipping details. Each contains the fields Google currently support, like location and times, but not specifics about dimensions. Each entry also has conditions for what product the entry can apply to. This can include a price range and a weight range.
When I’m generating the structured data for a page I include the entries where the product matches the conditions.
This change looks like it will let me change from filtering out the conditions on the server, to including them in the Structured Data on the product page.
Then the consumers of the data can calculate which ShippingConditions are a match and therefore what rates are available when ordering a specific number of the product. Currently, you can only provide prices for shipping one.
Some shipping constraints are not available at the time the product is listed or even rendered on a page (eg. shipping destination, number of items, wanted delivery speed or customer tier if the user is not logged in). The ShippingDetails attached to a product should contain information about the product itself only, the rest gets moved to the new ShippingConditions in this proposal. Note that schema.org does not specify a cardinality, so that we could specify multiple ShippingConditions links so that the appropriate one gets selected at the consumer side.
The split also means it’s easier to provide product specific information as well as shared shipping information without the need for repetition.
Your example in the document at the end for using Organization. It looks like you are referencing ShippingConditions for a product that are on a shipping page. This cross-referencing between pages could greatly reduce the bloat this has on the product page, if supported by Google.
Indeed. This is where we are trying to get at.”
Discussion On LinkedIn
LinkedIn member Irina Tuduce (LinkedIn profile), software engineer at Google Shopping, initiated a discussion that received multiple responses that demonstrating interest for the proposal.
Andrea Volpini (LinkedIn profile), CEO and Co-founder of WordLift, expressed his enthusiasm for the proposal in his response:
“Like this Irina Tuduce it would streamline the modeling of delivery speed, locations, and cost for large organizations
“I already gave my feedback on the naming conventions to schema.org which they implemented. My concern for Google is how exactly merchants will get this data into the markup. It’s nearly impossible to get exact shipping rates in the SD if they fluctuate. Merchants can enter a flat rate that is approximate, but they often wonder if that’s acceptable. Are there consequences to them if the shipping rates are an approximation (e.g. a price mismatch in GMC disapproves a product)?”
Inside Look At Development Of New Structured Data
The ongoing LinkedIn discussion offers a peek at how stakeholders in the new structured data feel about the proposal. The official Schema.org GitHub discussion not only provides a view of how the proposal is progressing, it offers stakeholders an opportunity to provide feedback for shaping what it will ultimately look like.
Google’s John Mueller answered a question on LinkedIn about how Google chooses canonicals, offering advice about what SEOs and publishers can do to encourage Google how to pick the right URL.
What Is A Canonical URL?
In the situation where multiple URLs (the addresses for multiple web pages) have the same content, Google will choose one URL that will be representative for all of the pages. The chosen page is referred to as the canonical URL.
Google Search Central has published documentation that explains how SEOs and publishes can communicate their preference of which URL to use. None of these methods force Google to choose the preferred URL, they mainly serve as a strong hint.
There are three ways to indicate the canonical URL:
Redirecting duplicate pages to the preferred URL (a strong signal)
Use the rel=canonical link attribute to specify the preferred URL (a strong signal)
List the preferred URL in the sitemap (a weak signal)
Some of Google’s canonicalization documentation incorrectly refers to the rel=canonical as a link element. The link tag, , is the element. The rel=canonical is an attribute of the link element. Google also calls rel=canonical an annotation, which might be an internal way Google refers to it but it’s not the proper way to refer to rel=canonical (it’s an HTML attribute of the link element).
There are two important things you need to know about HTML elements and attributes:
HTML elements are the building blocks for creating a web page.
An HTML attribute is something that adds more information about that building block (the HTML element).
The Mozilla Developer Network HTML documentation (an authoritative source for HTML specifications) notes that “link” is an HTML element and that “rel=” is an attribute of the link element.
Person Read The Manual But Still Has Questions
The person reading Google’s documentation which lists the above three ways to specify a canonical still had questions so he asked it on LinkedIn.
He referred to the documentation as “doc” in his question:
“The mentioned doc suggests several ways to specify a canonical URL.
1. Adding tag in
section of the page, and another, 2. Through sitemap, etc.
So, if we consider only point 2 of the above.
Which means the sitemap—Technically it contains all the canonical links of a website.
Then why in some cases, a couple of the URLs in the sitemap throws: “Duplicate without user-selected canonical.” ?”
As I pointed out above, Google’s documentation says that the sitemap is a weak signal.
Google Uses More Signals For Canonicalization
John Mueller’s answer reveals that Google uses more factors or signals than what is officially documented.
He explained:
“If Google’s systems can tell that pages are similar enough that one of them could be focused on, then we use the factors listed in that document (and more) to try to determine which one to focus on.”
Internal Linking Is A Canonical Factor
Mueller next explained that internal links can be used to give Google a strong signal of which URL is the preferred one.
This is how Mueller answered:
“If you have a strong preference, it’s best to make that preference very obvious, by making sure everything on your site expresses that preference – including the link-rel-canonical in the head, sitemaps, internal links, etc. “
He then followed up with:
“When it comes to search, which one of the pages Google’s systems focus on doesn’t matter so much, they’d all be shown similarly in search. The exact URL shown is mostly just a matter for the user (who might see it) and for the site-owner (who might want to monitor & track that URL).”
Takeaways
In my experience it’s not uncommon that a large website contains old internal links that point to the wrong URL. Sometimes it’s not old internal links that are the cause, it’s 301 redirects from an old page to another URL that is not the preferred canonical. That can also lead to Google choosing a URL that is not preferred by the publisher.
If Google is choosing the wrong URL then it may be useful to crawl the entire site (like with Screaming Frog) and then look at the internal linking patterns as well as redirects because it may very well be that forgotten internal links hidden deep within the website or chained redirects to the wrong URL are causing Google to choose the wrong URL.
Google’s documentation also notes that external links to the wrong page could influence which page Google chooses as the canonical, so that’s one more thing that needs to be checked for debugging why the wrong URL is being ranked.
The important takeaway here is that if the standard ways of specifying the canonical are not working then it’s possible that there is an external links, or unintentional internal linking, or a forgotten redirect that is causing Google to choose the wrong URL. Or, as John Mueller suggested, increasing the amount of internal links to the preferred URL may help Google to choose the preferred URL.
The concept of Compressibility as a quality signal is not widely known, but SEOs should be aware of it. Search engines can use web page compressibility to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords, making it useful knowledge for SEO.
Although the following research paper demonstrates a successful use of on-page features for detecting spam, the deliberate lack of transparency by search engines makes it difficult to say with certainty if search engines are applying this or similar techniques.
What Is Compressibility?
In computing, compressibility refers to how much a file (data) can be reduced in size while retaining essential information, typically to maximize storage space or to allow more data to be transmitted over the Internet.
TL/DR Of Compression
Compression replaces repeated words and phrases with shorter references, reducing the file size by significant margins. Search engines typically compress indexed web pages to maximize storage space, reduce bandwidth, and improve retrieval speed, among other reasons.
This is a simplified explanation of how compression works:
Identify Patterns: A compression algorithm scans the text to find repeated words, patterns and phrases
Shorter Codes Take Up Less Space: The codes and symbols use less storage space then the original words and phrases, which results in a smaller file size.
Shorter References Use Less Bits: The “code” that essentially symbolizes the replaced words and phrases uses less data than the originals.
A bonus effect of using compression is that it can also be used to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords.
Research Paper About Detecting Spam
This research paper is significant because it was authored by distinguished computer scientists known for breakthroughs in AI, distributed computing, information retrieval, and other fields.
Another of the co-authors is Dennis Fetterly, currently a software engineer at Google. He is listed as a co-inventor in a patent for a ranking algorithm that uses links, and is known for his research in distributed computing and information retrieval.
Those are just two of the distinguished researchers listed as co-authors of the 2006 Microsoft research paper about identifying spam through on-page content features. Among the several on-page content features the research paper analyzes is compressibility, which they discovered can be used as a classifier for indicating that a web page is spammy.
Detecting Spam Web Pages Through Content Analysis
Although the research paper was authored in 2006, its findings remain relevant to today.
Then, as now, people attempted to rank hundreds or thousands of location-based web pages that were essentially duplicate content aside from city, region, or state names. Then, as now, SEOs often created web pages for search engines by excessively repeating keywords within titles, meta descriptions, headings, internal anchor text, and within the content to improve rankings.
Section 4.6 of the research paper explains:
“Some search engines give higher weight to pages containing the query keywords several times. For example, for a given query term, a page that contains it ten times may be higher ranked than a page that contains it only once. To take advantage of such engines, some spam pages replicate their content several times in an attempt to rank higher.”
The research paper explains that search engines compress web pages and use the compressed version to reference the original web page. They note that excessive amounts of redundant words results in a higher level of compressibility. So they set about testing if there’s a correlation between a high level of compressibility and spam.
They write:
“Our approach in this section to locating redundant content within a page is to compress the page; to save space and disk time, search engines often compress web pages after indexing them, but before adding them to a page cache.
…We measure the redundancy of web pages by the compression ratio, the size of the uncompressed page divided by the size of the compressed page. We used GZIP …to compress pages, a fast and effective compression algorithm.”
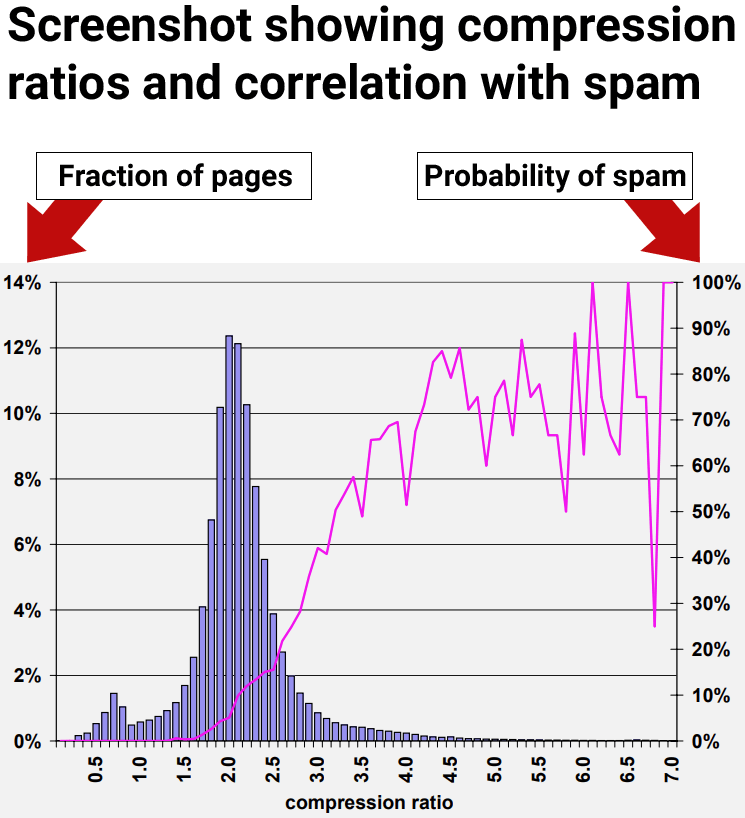
High Compressibility Correlates To Spam
The results of the research showed that web pages with at least a compression ratio of 4.0 tended to be low quality web pages, spam. However, the highest rates of compressibility became less consistent because there were fewer data points, making it harder to interpret.
Figure 9: Prevalence of spam relative to compressibility of page.
The researchers concluded:
“70% of all sampled pages with a compression ratio of at least 4.0 were judged to be spam.”
But they also discovered that using the compression ratio by itself still resulted in false positives, where non-spam pages were incorrectly identified as spam:
“The compression ratio heuristic described in Section 4.6 fared best, correctly identifying 660 (27.9%) of the spam pages in our collection, while misidentifying 2, 068 (12.0%) of all judged pages.
Using all of the aforementioned features, the classification accuracy after the ten-fold cross validation process is encouraging:
95.4% of our judged pages were classified correctly, while 4.6% were classified incorrectly.
More specifically, for the spam class 1, 940 out of the 2, 364 pages, were classified correctly. For the non-spam class, 14, 440 out of the 14,804 pages were classified correctly. Consequently, 788 pages were classified incorrectly.”
The next section describes an interesting discovery about how to increase the accuracy of using on-page signals for identifying spam.
Insight Into Quality Rankings
The research paper examined multiple on-page signals, including compressibility. They discovered that each individual signal (classifier) was able to find some spam but that relying on any one signal on its own resulted in flagging non-spam pages for spam, which are commonly referred to as false positive.
The researchers made an important discovery that everyone interested in SEO should know, which is that using multiple classifiers increased the accuracy of detecting spam and decreased the likelihood of false positives. Just as important, the compressibility signal only identifies one kind of spam but not the full range of spam.
The takeaway is that compressibility is a good way to identify one kind of spam but there are other kinds of spam that aren’t caught with this one signal. Other kinds of spam were not caught with the compressibility signal.
This is the part that every SEO and publisher should be aware of:
“In the previous section, we presented a number of heuristics for assaying spam web pages. That is, we measured several characteristics of web pages, and found ranges of those characteristics which correlated with a page being spam. Nevertheless, when used individually, no technique uncovers most of the spam in our data set without flagging many non-spam pages as spam.
For example, considering the compression ratio heuristic described in Section 4.6, one of our most promising methods, the average probability of spam for ratios of 4.2 and higher is 72%. But only about 1.5% of all pages fall in this range. This number is far below the 13.8% of spam pages that we identified in our data set.”
So, even though compressibility was one of the better signals for identifying spam, it still was unable to uncover the full range of spam within the dataset the researchers used to test the signals.
Combining Multiple Signals
The above results indicated that individual signals of low quality are less accurate. So they tested using multiple signals. What they discovered was that combining multiple on-page signals for detecting spam resulted in a better accuracy rate with less pages misclassified as spam.
The researchers explained that they tested the use of multiple signals:
“One way of combining our heuristic methods is to view the spam detection problem as a classification problem. In this case, we want to create a classification model (or classifier) which, given a web page, will use the page’s features jointly in order to (correctly, we hope) classify it in one of two classes: spam and non-spam.”
These are their conclusions about using multiple signals:
“We have studied various aspects of content-based spam on the web using a real-world data set from the MSNSearch crawler. We have presented a number of heuristic methods for detecting content based spam. Some of our spam detection methods are more effective than others, however when used in isolation our methods may not identify all of the spam pages. For this reason, we combined our spam-detection methods to create a highly accurate C4.5 classifier. Our classifier can correctly identify 86.2% of all spam pages, while flagging very few legitimate pages as spam.”
Key Insight:
Misidentifying “very few legitimate pages as spam” was a significant breakthrough. The important insight that everyone involved with SEO should take away from this is that one signal by itself can result in false positives. Using multiple signals increases the accuracy.
What this means is that SEO tests of isolated ranking or quality signals will not yield reliable results that can be trusted for making strategy or business decisions.
Takeaways
We don’t know for certain if compressibility is used at the search engines but it’s an easy to use signal that combined with others could be used to catch simple kinds of spam like thousands of city name doorway pages with similar content. Yet even if the search engines don’t use this signal, it does show how easy it is to catch that kind of search engine manipulation and that it’s something search engines are well able to handle today.
Here are the key points of this article to keep in mind:
Doorway pages with duplicate content is easy to catch because they compress at a higher ratio than normal web pages.
Groups of web pages with a compression ratio above 4.0 were predominantly spam.
Negative quality signals used by themselves to catch spam can lead to false positives.
In this particular test, they discovered that on-page negative quality signals only catch specific types of spam.
When used alone, the compressibility signal only catches redundancy-type spam, fails to detect other forms of spam, and leads to false positives.
Google Search Central published new documentation on Google Trends, explaining how to use it for search marketing. This guide serves as an easy to understand introduction for newcomers and a helpful refresher for experienced search marketers and publishers.
The new guide has six sections:
About Google Trends
Tutorial on monitoring trends
How to do keyword research with the tool
How to prioritize content with Trends data
How to use Google Trends for competitor research
How to use Google Trends for analyzing brand awareness and sentiment
The section about monitoring trends advises there are two kinds of rising trends, general and specific trends, which can be useful for developing content to publish on a site.
Using the Explore tool, you can leave the search box empty and view the current rising trends worldwide or use a drop down menu to focus on trends in a specific country. Users can further filter rising trends by time periods, categories and the type of search. The results show rising trends by topic and by keywords.
To search for specific trends users just need to enter the specific queries and then filter them by country, time, categories and type of search.
The section called Content Calendar describes how to use Google Trends to understand which content topics to prioritize.
Google explains:
“Google Trends can be helpful not only to get ideas on what to write, but also to prioritize when to publish it. To help you better prioritize which topics to focus on, try to find seasonal trends in the data. With that information, you can plan ahead to have high quality content available on your site a little before people are searching for it, so that when they do, your content is ready for them.”