A company founder shared their experience with programmatic SEO, which they credited for initial success until it was deindexed by Google, calling it a big mistake they won’t repeat. The post, shared on LinkedIn, received scores of supportive comments.
The website didn’t receive a manual action, Google deindexed the web pages due to poor content quality.
Programmatic SEO (pSEO)
Programmatic SEO (aka pSEO) is a phrase that encompasses a wide range of tactics that have automation at the heart of it. Some of it can be very useful, like automating sitewide meta descriptions, titles, and alt text for images.
pSEO is also the practice of using AI automation to scale content creation sitewide, which is what the person did. They created fifty thousand pages targeting long tail phrases, phrases that are not commonly queried. The site initially received hundreds of clicks and millions of impressions but the success was not long-lived.
We learned the hard way that shortcuts don’t scale sustainably.
It was a huge mistake, but also a great lesson.
And it’s one of the reasons we rebranded to Tailride.”
Thin AI Content Was The Culprit
A follow-up post explained that they believe the AI generated content backfired was because it was thin content, which makes sense. Thin content, regardless of how it was authored, can be problematic.
One of the posts by Palet explained:
“We’re not sure, but probably not because AI. It was thin content and probably duplicated.”
Rasmus Sørensen (LinkedIn profile), an experienced digital marketer shared his opinion that he’s seen some marketers pushing shady practices under the banner of pSEO:
“Thanks for sharing and putting some real live experiences forward. Programmatic SEO had been touted as the next best thing in SEO. It’s not and I’ve seen soo much garbage published the last few months and agencies claiming that their pSEO is the silver bullet. It very rarely is.”
Joe Youngblood (LinkedIn profile) shared that SEO trends can be abused and implied that it is a viable strategy if done correctly:
“I would always do something like pSEO under the supervision of a seasoned SEO consultant. This tale happens all too frequently with an SEO trend…”
What They Did To Fix The site
The company founder shared that they rebranded the website to a new domain, redirecting the old domain to the new one, and focused their site on higher quality content that’s relevant to users.
They explained:
“Less pages + more quality”
A site: search for their domain shows that Google is now indexing their content, indicating that they are back on track.
Takeaways
Programmatic SEO can be useful if approached with an understanding of where the line is between good quality and “not-quality” content.
A new SEO plugin called SureRank, by Brainstorm Force, makers of the popular Astra theme, is rapidly growing in popularity. In beta for a few months, it was announced in July and has amassed over twenty thousand installations. That’s a pretty good start for an SEO plugin that has only been out of beta for a few weeks.
One possible reason that SureRank is quickly becoming popular is that it’s created by a trusted brand, much loved for its Astra WordPress theme.
SureRank By Brainstorm Force
SureRank is the creation of the publishers of many highly popular plugins and themes installed in many millions of websites, such as Astra theme, Ultimate Addons for Elementor, Spectra Gutenberg Blocks – Website Builder for the Block Editor, and Starter Templates – AI-Powered Templates for Elementor & Gutenberg, to name a few.
Why Another SEO Plugin?
The goal of SureRank is to provide an easy-to-use SEO solution that includes only the necessary features every site needs in order to avoid feature bloat. It positions itself as an SEO assistant that guides the user with an intuitive user interface.
What Does SureRank Do?
SureRank has an onboarding process that walks a user through the initial optimizations and setup. It then performs an analysis and offers suggestions for site-level improvements.
It currently enables users to handle the basics like:
Edit titles and meta descriptions
Custom write social media titles, descriptions, and featured images,
Tweak home page and, archive page meta data
Meta robot directives, canonicals, and sitemaps
Schema structured data
Site and page level SEO analysis
Automatic image alt text generation
Google Search Console integration
WooCommerce integration
SureRank also provides a built-in tool for migrating settings from other popular SEO plugins like Rank Math, Yoast, and AIOSEO.
Check out the SureRank SEO plugin at the official WordPress.org repository:
As SEO evolves with AI optimization, generative engine optimization, and answer engine optimization, brands and marketers must rethink their SEO strategies to stay competitive.
Instead of focusing solely on traditional SEO strategies and tactics, you need to be visible in AI-powered search and answer engines.
Showing the value of SEO in this new world means showcasing how optimized, structured, and intent-driven content can maximize visibility across generative platforms.
It can also enhance user trust and drive qualified engagement in a world where AI chatbots and platforms interpret a user’s intent, retrieve relevant information, and generate clear and concise answers.
In today’s competitive AI-powered results, it can be difficult to maximize your visibility.
With SEO becoming more challenging and the search engine results constantly changing to incorporate AI results, what metrics do you need to track, and how can you show the value of SEO in today’s AI-powered search results?
Let’s explore.
Proving The Value Of SEO
Proving SEO value depends on your client or prospective client’s goals and what will move the needle for them to get visibility in the search engine results pages (SERPs) and in AI chatbots and platforms.
This could include local search, app store optimization, content marketing, technical optimization, AI Overviews, etc.
That said, you must show performance improvements and drive revenue to secure more funding and make your client successful.
In my experience, here are some of the best metrics to track and measure to prove the SEO value in an AI world:
1. Monitor AI Results
With AI Overviews and generative AI changing SEO, it is important to track visibility as we move from ranking to relevance.
AI Overviews are not expected to go anywhere. During I/O 2025, Google announced that AI Overviews were expanding to over 200 countries and more than 40 languages.
AI Mode is now available to all users in the United States without the need to opt in via Search Labs.
To track AI Overviews:
Identify Which Queries Trigger AI Overviews
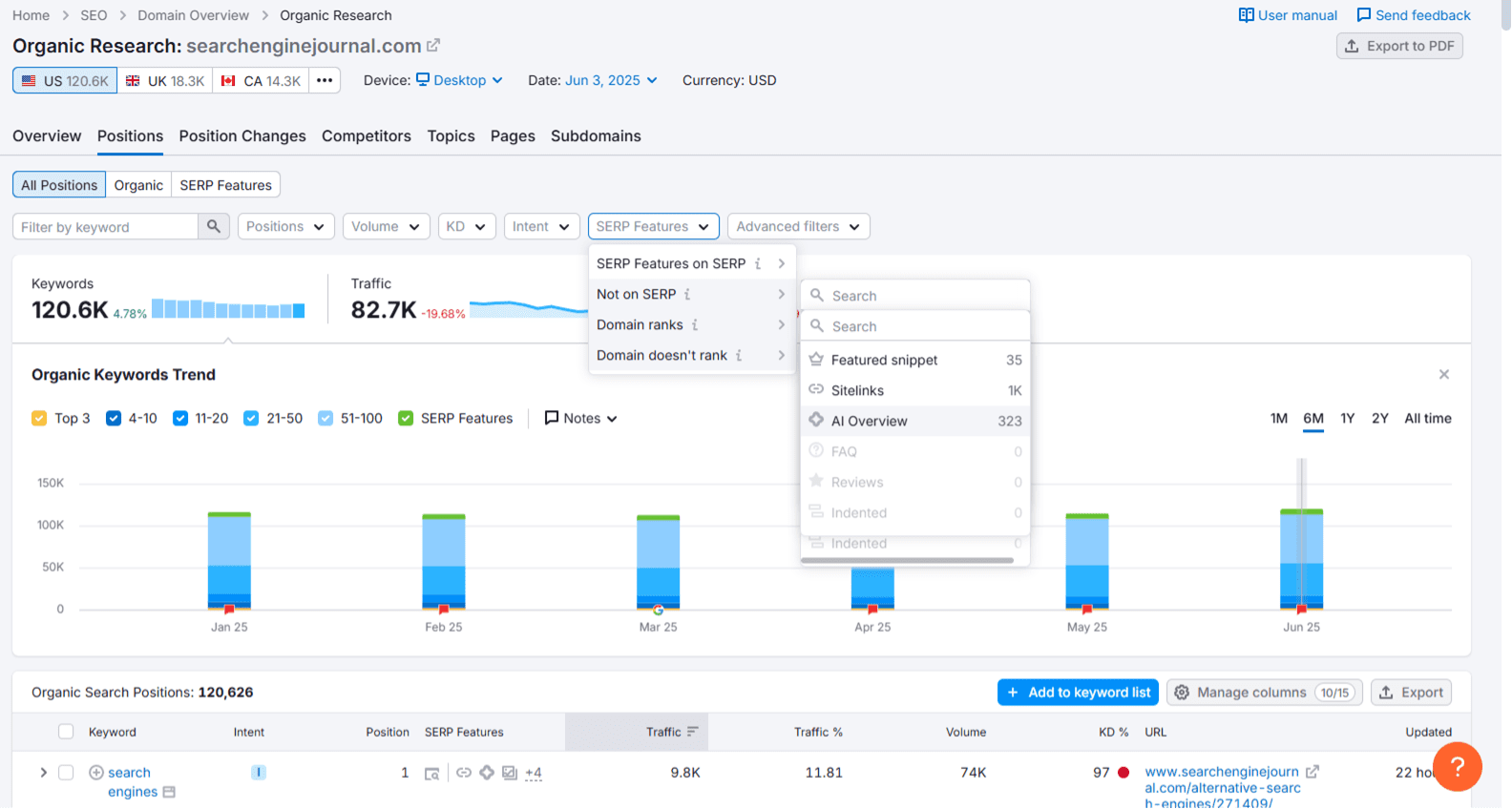
You can use tools like ZipTie.dev or Semrush to track which of your top-performing queries show AI Overviews and whether your site is included in those summaries.
Screenshot from Semrush, June 2025
Track AI Overview Queries
Once you have a list of queries that your site does or doesn’t appear in for an AI Overview, you should track those queries using keyword tracking tools and compare your traffic pre- and post-AI rollouts.
Strategize To Optimize Your Content For AI Overviews
Segment your traffic based on content type, as many informational queries are experiencing a decline in traffic due to users obtaining answers directly from AI Overviews.
This will help you identify which areas are most impacted and plan your strategy to optimize queries that have the potential to show AI Overviews.
Consider server-side analytics solutions (e.g., Writesonic’s AI Traffic Analytics) to track AI crawler visits, see which pages are accessed, and monitor trends over time.
2. Track AI Brand Mentions
Since AI platforms process information differently than traditional search engines, getting mentioned in ChatGPT, Perplexity, Claude, or Google’s AI Mode for relevant queries is a must.
AI platforms like ChatGPT and Google’s AI Overview generate answers from a mix of training data and some real-time retrieval, depending on the platform and setup.
In my experience, brands that are frequently mentioned across various platforms, including PR, blogs, social media, news coverage, YouTube forums (such as Reddit and Quora), and authoritative sites, tend to be mentioned by AI.
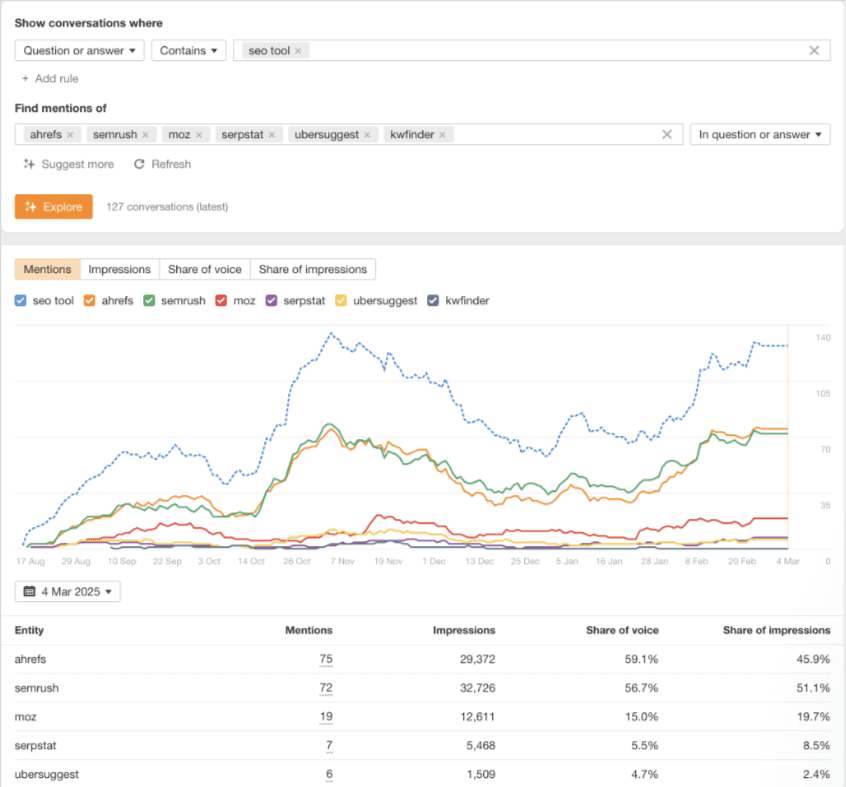
To track AI mentions, several tools like Brand24, Brand Radar from Ahrefs, and Mention.com use AI to monitor online conversations across various platforms, leveraging large datasets to provide insights into your brand’s perception and those of your competitors.
It’s imperative that you find out if your brand is mentioned, what people are saying about your brand (both positive and negative), what queries are used to describe it, and which websites mention your brand.
Screenshot from Brand Radar, Ahrefs, June 2025
3. Track AI Citations/References
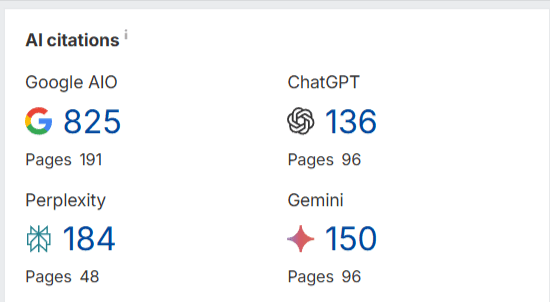
Checking to see if your website is cited by large language models (LLMs) can help brands and marketers understand how their content is being used by AI and assess their brand’s authority and visibility.
Ahrefs now offers a free tool that tracks when your website is cited in the answers generated by AI-powered search tools like Google AIO, ChatGPT, and Perplexity. AI citations count how often a domain was linked in AI results.
Pages show how many unique URLs from this domain were linked.
Screenshot from Ahrefs, June 2025
This is one of my favorite audit tools to look to see if there are any citations in any brand that we’re reviewing.
If Ahrefs adds trend analysis to track whether you’re gaining more citations in Google AIO, ChatGPT, and other platforms over time, it would be a valuable way to assess whether your strategies are working.
4. Tracking Branded Searches
It’s extremely important to track your branded searches in this new SEO AI era. AI-powered search results are personalized, and LLMs like Gemini and ChatGPT, to name a few, heavily consider user intent and context.
Having strong brand signals could improve entity recognition, which can improve your visibility for related queries.
Tracking how AI-generated answers (e.g., featured snippets or AI Overviews) treat your brand helps you optimize for entity-driven SEO.
In the AI SEO era, where search engines prioritize context, trust, and relevance, tracking branded searches could inform you to refine strategies that help defend your SERP presence and maximize conversions.
Here are some tips to help enhance branded visibility:
Create unique, authoritative, and factual, conversational content because AI models prioritize reliable and accurate information. Focus on content that demonstrates expertise and includes verifiable data.
Structure content for AI readability by using clear headings (H1, H2, H3), bullet lists, numbered lists, and data tables. Also, create concise paragraphs that directly answer questions.
Leverage schema markup like Organization, Product, Service, FAQPage, and Review to provide structured data that AI models can easily understand and reference.
Build brand authority and expertise by getting consistent citations, mentions on authoritative third-party sites, and positive reviews, to contribute to AI’s perception of your brand’s credibility.
Optimize conversational queries by creating content that directly answers “who, what, why, and how” in your niche.
Be active on platforms like Reddit and Quora, where AI models often pull information. SEO becomes “Search Engine Everywhere.”
Regularly review your AI visibility data, identify gaps, and adjust your content and SEO strategies based on insights.
AI Mode groups the user’s question into subtopics and searches for each one simultaneously, and users can go deeper.
If a user asks a follow-up question within AI Mode, they are essentially performing a new query. All impression, position, and click data in the new response are counted as coming from this new user query.
AI Traffic In GA4
While Google Analytics 4 doesn’t explicitly label AI traffic, you can look for patterns. Create custom reports with “Session source/medium” and apply regex filters for known AI domains (e.g., .*ChatGPT.*|.*perplexity.*|.*openai.*|.*bard.*).
For specific content you hope AI will cite, create unique URLs with UTM parameters (e.g., utm_source=chatgpt, utm_medium=ai). This can help attribute some traffic directly.
If you can get more conversions from AI Overviews, like Ahrefs did, when it found that AI search visitors converted at a rate 23 times higher than traditional organic search traffic, despite representing only 0.5% of total website visits, then you will have discovered a conversion goldmine that makes AI optimization not just worthwhile, but essential for staying competitive.
Final Thoughts
The SEO landscape has shifted from optimizing search engines and traditional search to optimizing for AI-powered chatbots and solutions, such as ChatGPT, Perplexity, Claude, Google’s AI Overviews, and potentially OpenAI’s web browser “in the coming weeks,” according to Reuters.
OpenAI has 500 million weekly active users of ChatGPT and could disrupt a key component of rival Google’s ad-money source.
SEO is no longer about ranking on the first page of Google.
It’s about being relevant and visible across multiple AI platforms, getting mentioned in generative responses, and demonstrating value through AI-focused metrics outside of the traditional metrics like rankings and traffic.
Brands and marketers that prove the SEO value in this new era can deliver immediate, measurable value while building momentum for larger investments in the future.
Day three picked up from there, diving into how Google actually returns search results.
The serving infrastructure encompasses query understanding, result retrieval, index selection, ranking, and feature application, including rich results, before presenting them to the user.
Image from author, July 2025
Making Sense Of User Queries
Cherry Prommawin provided a detailed explanation of how Google interprets users’ queries.
Not all queries are straightforward.
In languages like Chinese or Japanese, there are no spaces between words, so Google has to learn where words start and end by looking at past queries and documents. This is known as segmenting, and not all languages require this.
After that, it removes stopwords unless they’re part of a meaningful phrase or entity, like “The Lord of the Rings.”
Then, it expands the query to include synonyms across all languages to better match what the user is actually looking for (see image above).
Context plays a significant role in how Google understands and responds to queries. A crucial aspect of this is the utilization of contextual synonyms.
Image from author, July 2025
These aren’t like the typical synonyms you’d find in an English dictionary. Instead, they’re created to help return better search results, based on how words are used in real-world searches and content.
Google might learn that people searching for “car hire” often click on pages that say “rental car,” so it treats the two terms as similar in the right context. This is what Google refers to as “siblings.”
These relationships are mostly invisible to users, but they help connect queries to the most relevant information, even when the exact words don’t match.
Image from author, July 2025
How Google Understands Quality
Alfin Hotario Ho provided a clear explanation of how Google evaluates quality in search results.
Over the years, Google has attempted to define what “quality” means, and it consistently returns to five key points:
Focus on people-first content.
Expertise.
Content and quality.
Presentation and production.
Avoid creating search engine-first content.
Image from author, July 2025
Ho highlighted the Quality Rater Guidelines as a useful resource. These guidelines don’t directly influence ranking, but they help explain how Google measures whether its systems are performing well.
When the guidelines change, they reflect updates in Google’s thinking about what constitutes good content.
There are four main pillars of quality in the guidelines:
Effort: Content should be made for people, not search engines. It should clearly show time, skill, and first-hand knowledge.
Originality: The content should offer something new – original research, fresh analysis, or reporting that goes beyond what’s already out there.
Talent or Skill: It should be well-written or produced free from obvious errors, and show a strong level of craft. You also don’t need to be an expert in something, as long as you can demonstrate verifiable first-hand experience.
Accuracy: It must be factually correct, supported by evidence, and consistent with expert or public consensus when possible.
Other key takeaways from Ho’s session include:
From E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness), it is clear that trust matters most.
Even if a topic isn’t about health, money, or safety (Your Money or Your Life), Google still prioritizes trustworthy content.
If a page strongly disagrees with general expert opinion, it may be seen as less reliable overall.
Lots of 404 or noindex pages on a website are not a quality issue. 404 is a technical issue, as is the “noindex” tag.
Image from author, July 2025
What Are Quality Updates?
Google updates its search systems for three primary reasons: to support new content formats, to enhance content quality, or to combat spam.
These updates help ensure that people receive useful and relevant results when they search.Supporting New Content Formats
As new content types become more popular, such as short videos or interactive visuals, users start to expect to find them in search results.
If enough people show interest, Google may launch new features to match that demand.
This could include new filters or information views in the results. These updates help keep Search useful and aligned with how people want to explore information.
Improving Content Breadth And Relevance
The internet is constantly growing, and many topics become saturated. That makes it harder to find the best content.
To improve this, Google rolls out core updates. These updates don’t target specific websites or pages.
Instead, they improve how Google ranks content across the web with the overarching goal of surfacing higher-quality results overall.
Combating Low-Quality And Spam Content
Some people try to game the system with low-effort content. Google isn’t perfect, and spammers look for gaps to exploit.
In response, Google launches targeted updates that adjust how its systems detect spam or low-quality signals. These changes aim to remove poor content from search results.
Recovering From Google Updates
Core Updates
You’re technically not penalized, so technically there’s no recovery like with spam updates.
Google recommends that you should:
Continue doing a great job, look at what your competitors are doing better, and learn from sites that are doing better than you.
Spam Updates
Remove the type of spam that Google has mentioned in its blog communications.
Caveats On Structured Data Usage
Google addressed some common myths surrounding structured data, particularly its connection to serving and ranking.
None of these are new, but the reiteration has been based on continued questions around the impact and value of adding structured data.
Not A Direct Ranking Factor
Adding structured data to your site won’t directly improve your rankings. But, it can make your listings more attractive in search results, which might lead to more clicks.
That added engagement could help your site over time.
No Guarantees
Just because you’ve added structured data doesn’t mean Google will show rich results. The algorithms decide when and where it makes sense to display them.
Google Can Add Rich Results On Its Own
Even without structured data, Google may still display enhanced results, such as your site name or breadcrumbs, if it can infer that information from your page content.
It Needs Ongoing Maintenance
Structured data isn’t a one-time task. You should check it regularly to ensure it remains accurate and error-free.
Keeping it up to date helps you stay eligible for enhanced search features.
That’s all from Google Search Central Live in Thailand. There have been a lot of insights and a big announcement over the last three days.
I recommend that SEOs review the last three articles and digest what Google has said. Then, consider how they can apply that to their strategies for 2025.
Aleyda Solís conducted an experiment to test how fast ChatGPT indexes a web page and unexpectedly discovered that ChatGPT appears to use Google’s search results as a fallback for web pages that it cannot access or that are not yet indexed on Bing.
According to Aleyda:
I’ve run a simple but straightforward to follow test that confirms the reliance of ChatGPT on Google SERPs snippets for its answers.
Created A New Web Page, Not Yet Indexed
Aleyda created a brand new page (titled “LLMs.txt Generators”) on her website, LearningAISearch.com. She immediately tested ChatGPT (with web search enabled) to see if it could access or locate the page but ChatGPT failed to find it. ChatGPT responded with the suggestion that the URL was not publicly indexed or possibly outdated.
She then asked Google Gemini about the web page, which successfully fetched and summarized the live page content.
Submitted Web Page For Indexing
She next submitted the web page for indexing via Google Search Console and Bing Webmaster Tools. Google successfully indexed the web page but Bing had problems with it.
After several hours elapsed Google started showing results for the page with the site: operator and with a direct search for the URL. But Bing continued to have trouble indexing the web page.
Checked ChatGPT Until It Used Google Search Snippet
Aleyda went back to ChatGPT and after several tries it gave her an incomplete summary of the page content, mentioning just one tool that was listed on it. When she asked ChatGPT for the origin of that incomplete snippet it responded that it was using a “cached snippet via web search””, likely from “search engine indexing.”
She confirmed that the snippet shown by ChatGPT matched Google’s search result snippet, not Bing’s (which still hadn’t indexed it).
Aleyda explained:
“A snippet from where?
When I followed up asking where was that snippet they grabbed the information being shown, the answer was that it had “located a cached snippet via web search that previews the page content – likely from search engine indexing.”
But I knew the page wasn’t indexed yet in Bing, so it had to be … Google search results? I went to check.
When I compared the text snippet provided by ChatGPT vs the one shown in Google Search Results for the specific Learning AI Search LLMs.txt Generators page, I could confirm it was the same information…”
Proof That Traditional SEO Remains Relevant For AI Search
Aleyda also documented what happened on a LinkedIn post where Kyle Atwater Morley shared his observation:
“So ChatGPT is basically piggybacking off Google snippets to generate answers?
What a wake-up call for anyone thinking traditional SEO is dead.”
Stéphane Bureau shared his opinion on what’s going on:
“If Bing’s results are insufficient, it appears to fall back to scraping Google SERP snippets.”
He elaborated on his post with more details later on in the discussion:
“Based on current evidence, here’s my refined theory:
When browsing is enabled, ChatGPT sends search requests via Bing first (as seen in DevTools logs).
However, if Bing’s results are insufficient or outdated, it appears to fall back to scraping Google SERP snippets—likely via an undocumented proxy or secondary API.
This explains why some replies contain verbatim Google snippets that never appear in Bing API responses.
I’ve seen multiple instances that align with this dual-source behavior.”
Takeaway
ChatGPT was initially unable to access the page directly, and it was only after the page began to appear in Google’s search results that it was able to respond to questions about the page. Once the snippet appeared in Google’s search results, ChatGPT began referencing it, revealing a reliance on publicly visible Google Search snippets as a fallback when the same data is unavailable in Bing.
What would be interesting to see is whether the server logs held a clue as to whether ChatGPT attempted to crawl the page and, if so, what error code was returned in response to the failure to retrieve the data. It’s curious that ChatGPT was unable to retrieve the page, and though it probably doesn’t have any bearing on the conclusions, it would still contribute to making the conclusions feel more complete to have that last bit of information crossed off.
Nevertheless, it appears that this is yet more proof that standard SEO is still applicable for AI-powered search, including for ChatGPT Search. This adds to recent comments by Gary Illyes that confirms that there is no need for specialized GEO or AEO in order to rank well in Google AI Overviews and AI Mode.
Questions about the methodology used by the Pew Research Center suggest that its conclusions about Google’s AI summaries may be flawed. Facts about how AI summaries are created, the sample size, and statistical reliability challenge the validity of the results.
Google’s Official Statement
A spokesperson for Google reached out with an official statement and a discussion about why the Pew research findings do not reflect actual user interaction patterns related to AI summaries and standard search.
The main points of Google’s rebuttal are:
Users are increasingly seeking out AI features
They’re asking more questions
AI usage trends are increasing visibility for content creators.
The Pew research used flawed methodology.
Google shared:
“People are gravitating to AI-powered experiences, and AI features in Search enable people to ask even more questions, creating new opportunities for people to connect with websites.
This study uses a flawed methodology and skewed queryset that is not representative of Search traffic. We consistently direct billions of clicks to websites daily and have not observed significant drops in aggregate web traffic as is being suggested.”
Sample Size Is Too Low
I discussed the Pew Research with Duane Forrester (formerly of Bing, LinkedIn profile) and he suggested that the sampling size of the research was too low to be meaningful (900+ adults and 66,000 search queries). Duane shared the following opinion:
“Out of almost 500 billion queries per month on Google and they’re extracting insights based on 0.0000134% sample size (66,000+ queries), that’s a very small sample.
Not suggesting that 66,000 of something is inconsequential, but taken in the context of the volume of queries happening on any given month, day, hour or minute, it’s very technically not a rounding error and were it my study, I’d have to call out how exceedingly low the sample size is and that it may not realistically represent the real world.”
How Reliable Are Pew Center Statistics?
The Methodology page for the statistics used list how reliable the statistics are for the following age groups:
Ages 18-29 were ranked at plus/minus 13.7 percentage points. That ranks as a low level of reliability.
Ages 30–49 were ranked at plus/minus 7.9 percentage points. That ranks in the moderate, somewhat reliable, but still a fairly wide range.
Ages 50–64 were ranked at plus/minus 8.9 percentage points. That ranks as a moderate to low level of reliability.
Age 65+ were ranked at at plus/minus 10.2 percentage points, which is firmly in the low range of reliability.
The above reliability scores are from Pew Research’s Methodology page. Overall, all of these results have a high margin of error, making them statistically unreliable. At best, they should be seen as rough estimates, although as Duane says, the sample size is so low that it’s hard to justify it as reflecting real-world results.
Pew Research Results Compare Results In Different Months
After thinking about it overnight and reviewing the methodology, an aspect of the Pew Research methodology that stood out is that they compared the actual search queries from users during the month of March with the same queries the researchers conducted in one week in April.
That’s problematic because Google’s AI summaries change from month to month. For example, the kinds of queries that trigger an AI Overview changes, with AIOs becoming more prominent for certain niches and less so for other topics. Additionally user trends may impact what gets searched on which itself could trigger a temporary freshness update to the search algorithms that prioritize videos and news.
The takeaway is that comparing search results from different months is problematic for both standard search and AI summaries.
Pew Research Ignores That AI Search Results Are Dynamic
With respect to AI overviews and summaries, these are even more dynamic, subject to change not just for every user but to the same user.
Searching for a query in AI Overviews then repeating the query in an entirely different browser will result in a different AI summary and completely different set of links.
The point is that the Pew Research Center’s methodology where they compare user queries with scraped queries a month later are flawed because the two sets of queries and results cannot be compared, they are each inherently different because of time, updates, and the dynamic nature of AI summaries.
The following screenshots are the links shown for the query, What is the RLHF training in OpenAI?
Google AIO Via Vivaldi Browser
Google AIO Via Chrome Canary Browser
Not only are the links on the right hand side different, AI summary content and the links embedded within that content are also different.
Could This Be Why Publishers See Inconsistent Traffic?
Publishers and SEOs are used to static ranking positions in search results for a given search query. But Google’s AI Overviews and AI Mode show dynamic search results. The content in the search results and the links that are shown are dynamic, showing a wide range of sites in the top three positions for the exact same queries. SEOs and publishers have asked Google to show a broader range of websites and that, apparently, is what Google’s AI features are doing. Is this a case of be careful of what you wish for?
The second day of the Google Search Central Live APAC 2025 kicked off with a brief tie‑in to the previous day’s deep dive into crawling, before moving squarely into indexing.
Cherry Prommawin opened by walking us through how Google parses HTML and highlights the key stages in indexing:
HTML parsing.
Rendering and JavaScript execution.
Deduplication.
Feature extraction.
Signal extraction.
This set the theme for the rest of the day.
Cherry noted that Google first normalizes the raw HTML into a DOM, then looks for header and navigation elements, and determines which section holds the main content. During this process, it also extracts elements such as rel=canonical, hreflang, links and anchors, and meta-robots tags.
“There is no preference between responsive websites versus dynamic/adaptive websites. Google doesn’t try to detect this and doesn’t have a preferential weighting.” – Cherry Prommawin
Links remain central to the web’s structure, both for discovery and for ranking:
“Links are still an important part of the internet and used to discover new pages, and to determine site structure, and we use them for ranking.” – Cherry Prommawin
Controlling Indexing With Robots Rules
Gary Illyes clarified where robots.txt and robots‑meta tags fit into the flow:
Robots.txt controls what crawlers can fetch.
Meta robot tags control how that fetched data is used downstream.
He highlighted several lesser‑known directives:
none: Equivalent to noindex,nofollow combined into a single rule. Is there a benefit to this? While functionally identical, using one directive instead of two may simplify tag management.
notranslate: If set, Chrome will no longer offer to translate the page.
noimageindex: Also applies to video assets.
Unavailable after: Despite being introduced by engineers who have since moved on, it still works. This could be useful for deprecating time‑sensitive blog posts, such as limited‑time deals and promotions, so they don’t persist in Google’s AI features and risk misleading users or harming brand perception.
Understanding What’s On A Page
Gary Illyes emphasized that the main content, as defined by Google’s Quality Rater Guidelines, is the most critical element in crawling and indexing. It might be text, images, videos, or rich features like calculators.
He showed how shifting a topic into the main content area can boost rankings.
In one example, moving references to “Hugo 7” from a sidebar into the central (main) content led to a measurable increase in visibility.
“If you want to rank for certain things, put those words and topics in important places (on the page).” – Gary Illyes
Tokenization For Search
You can’t dump raw HTML into a searchable index at scale. Google breaks it into “tokens,” individual words or phrases, and stores those in its index.
The first HTML segmentation system dates back to Google’s 2001 Tokyo engineering office, and the same tokenization methods power its AI products, since “why reinvent the wheel.”
When the main content is thin or low value, what Google labels as a “soft 404,” it’s flagged with a centerpiece annotation to show that this deficiency is at the heart of the page, not just in a peripheral section.
Handling Web Duplication
Image from author, July 2025
Cherry Prommawin explained deduplication in three focus areas:
Clustering: Using redirects, content similarity, and rel=canonical to group duplicate pages.
Content checks: Checksums that ignore boilerplate and catch many soft‑error pages. Note that soft errors can bring down an entire cluster.
Localization: When pages differ only by locale (for example via geo‑redirects), hreflang bridges them without penalty.
She contrasted permanent versus temporary redirects: Both play a role in crawling and clustering, but only permanent redirects influence which URL is chosen as the cluster’s canonical.
Google prioritizes hijacking risk first, user experience second, and site-owner signals (such as your rel=canonical) third when selecting the representative URL.
Geotargeting
Geotargeting allows you to signal to Google which country or region your content is most relevant for, and it works differently from simple language targeting.
Prommawin emphasized that you don’t need to hide duplicate content across two country‑specific sites; hreflang will handle those alternates for you.
Image from author, July 2025
If you serve the duplicate content on multiple regional URLs without localization, you risk confusing both crawlers and users.
To geotarget effectively, ensure that each version has unique, localized content tailored to its specific audience.
The primary geotargeting signals Google uses are:
Country‑code top‑level domain (ccTLD): Domains like .sg or .au indicate the target country.
Hreflang annotations: Use tags, HTTP headers, or sitemap entries to declare language and regional alternates.
Server location: The IP address or hosting location of your server can act as a geographic hint.
Additional local signals, such as language and currency on the page, links from other regional websites, and signals from your local Business Profile, all reinforce your target region.
By combining these signals with genuinely localized content, you help Google serve the right version of your site to the right users, and avoid the pitfalls of unintended duplicate‑content clusters.
Structured Data & Media
Gary Illyes introduced the feature extraction phase, which runs after deduplication and is computationally expensive. It starts with HTML, then kicks off separate, asynchronous media indexing for images and videos.
If your HTML is in the index but your media isn’t, it simply means the media pipeline is still working.
Sessions in this track included:
Structured Data with William Prabowo.
Using Images with Ian Huang.
Engaging Users with Video with William Prabowo.
Q&A Takeaway On Schema
Schema markup can help Google understand the relationships between entities and enable LLM-driven features.
But, excessive or redundant schema only adds page bloat and has no additional ranking benefits. And Schema is not used as part of the ranking process.
Calculating Signals
During signal extraction, also part of indexing, Google computes a mix of:
Indirect signals (links, mentions by other pages).
Direct signals (on‑page words and placements).
Image from author, July 2025
Illyes confirmed that Google still uses PageRank internally. It is not the exact algorithm from the 1996 White Paper, but it bears the same name.
Handling Spam
Google’s systems identify around 40 billion spam pages each day, powered by their LLM‑based “SpamBrain.”
Image from author, July 2025
Additionally, Illyes emphasized that E-E-A-T is not an indexing or ranking signal. It’s an explanatory principle, not a computed metric.
Deciding What Gets Indexed
Index selection boils down to quality, defined as a combination of trustworthiness and utility for end users. Pages are dropped from the index for clear negative signals:
noindex directives.
Expired or time‑limited content.
Soft 404s and slipped‑through duplicates.
Pure spam or policy violations.
If a page has been crawled but not indexed, the remedy is to improve the content quality.
Internal linking can help, but only insofar as it makes the page genuinely more useful. Google’s goal is to reward user‑focused improvements, not signal manipulation.
Google Doesn’t Care If Your Images Are AI-Generated
AI-generated images have become common in marketing, education, and design workflows. These visuals are produced by deep learning models trained on massive picture collections.
During the session, Huang outlined that Google doesn’t care whether your images are generated by AI or humans, as long as they accurately and effectively convey the information or tell the story you intend.
As long as images are understandable, their AI origins are irrelevant. The primary goal is effective communication with your audience.
Huang highlighted an example of an AI image used by the Google team during the first day of the conference that, on close inspection, does have some visual errors, but as a “prop,” its job was to represent a timeline and was not the main content of the slide, so these errors do not matter.
Image from author, July 2025
We can adopt a similar approach to our use of AI-generated imagery. If the image conveys the message and isn’t the main content of the page, minor issues won’t lead to penalization, nor will using AI-generated imagery in general.
Images should undergo a quick human review to identify obvious mistakes, which can prevent production errors.
Ongoing oversight remains essential to maintain trust in your visuals and protect your brand’s integrity.
Google Trends API Announced
Finally, Daniel Waisberg and Hadas Jacobi unveiled the new Google Trends API (Alpha). Key features of the new API will include:
Consistently scaled search interest data that does not recalibrate when you change queries.
A five‑year rolling window, updated up to 48 hours ago, for seasonal and historical comparisons.
Flexible time aggregation (weekly, monthly, yearly).
Region and sub‑region breakdowns.
This opens up a world of programmatic trend analysis with reliable, comparable metrics over time.
That wraps up day two. Tomorrow, we have coverage of the final day three at Google Search Central Live, with more breaking news and insights.
If you spend time in SEO circles lately, you’ve probably heard query fan-out used in the same breath as semantic SEO, AI content, and vector-based retrieval.
It sounds new, but it’s really an evolution of an old idea: a structured way to expand a root topic into the many angles your audience (and an AI) might explore.
If this all sounds familiar, it should. Marketers have been digging for this depth since “search intent” became a thing years ago. The concept isn’t new; it just has fresh buzz, thanks to GenAI.
Like many SEO concepts, fan-out has picked up hype along the way. Some people pitch it as a magic arrow for modern search (it’s not).
Others call it just another keyword clustering trick dressed up for the GenAI era.
The truth, as usual, sits in the middle: Query fan-out is genuinely useful when used wisely, but it doesn’t magically solve the deeper layers of today’s AI-driven retrieval stack.
This guide sharpens that line. We’ll break down what query fan-out actually does, when it works best, where its value runs out, and which extra steps (and tools) fill in the critical gaps.
If you want a full workflow from idea to real-world retrieval, this is your map.
What Query Fan-Out Really Is
Most marketers already do some version of this.
You start with a core question like “How do you train for a marathon?” and break it into logical follow-ups: “How long should a training plan be?”, “What gear do I need?”, “How do I taper?” and so on.
In its simplest form, that’s fan-out. A structured expansion from root to branches.
Where today’s fan-out tools step in is the scale and speed; they automate the mapping of related sub-questions, synonyms, adjacent angles, and related intents. Some visualize this as a tree or cluster. Others layer on search volumes or semantic relationships.
Think of it as the next step after the keyword list and the topic cluster. It helps you make sure you’re covering the terrain your audience, and the AI summarizing your content, expects to find.
Why Fan-Out Matters For GenAI SEO
This piece matters now because AI search and agent answers don’t pull entire pages the way a blue link used to work.
Instead, they break your page into chunks: small, context-rich passages that answer precise questions.
This is where fan-out earns its keep. Each branch on your fan-out map can be a stand-alone chunk. The more relevant branches you cover, the deeper your semantic density, which can help with:
1. Strengthening Semantic Density
A page that touches only the surface of a topic often gets ignored by an LLM.
If you cover multiple related angles clearly and tightly, your chunk looks stronger semantically. More signals tell the AI that this passage is likely to answer the prompt.
2. Improving Chunk Retrieval Frequency
The more distinct, relevant sections you write, the more chances you create for an AI to pull your work. Fan-out naturally structures your content for retrieval.
3. Boosting Retrieval Confidence
If your content aligns with more ways people phrase their queries, it gives an AI more reason to trust your chunk when summarizing. This doesn’t guarantee retrieval, but it helps with alignment.
4. Adding Depth For Trust Signals
Covering a topic well shows authority. That can help your site earn trust, which nudges retrieval and citation in your favor.
Fan-Out Tools: Where To Start Your Expansion
Query fan-out is practical work, not just theory.
You need tools that take a root question and break it into every related sub-question, synonym, and niche angle your audience (or an AI) might care about.
A solid fan-out tool doesn’t just spit out keywords; it shows connections and context, so you know where to build depth.
Below are reliable, easy-to-access tools you can plug straight into your topic research workflow:
AnswerThePublic: The classic question cloud. Visualizes what, how, and why people ask around your seed topic.
AlsoAsked: Builds clean question trees from live Google People Also Ask data.
Frase: Topic research module clusters root queries into sub-questions and outlines.
Keyword Insights: Groups keywords and questions by semantic similarity, great for mapping searcher intent.
Semrush Topic Research: Big-picture tool for surfacing related subtopics, headlines, and question ideas.
Answer Socrates: Fast People Also Ask scraper, cleanly organized by question type.
LowFruits: Pinpoints long-tail, low-competition variations to expand your coverage deeper.
WriterZen: Topic discovery clusters keywords and builds related question sets in an easy-to-map layout.
If you’re short on time, start with AlsoAsked for quick trees or Keyword Insights for deeper clusters. Both deliver instant ways to spot missing angles.
Now, having a clear fan-out tree is only step one. Next comes the real test: proving that your chunks actually show up where AI agents look.
Where Fan-Out Stops Working Alone
So, fan-out is helpful. But it’s only the first step. Some people stop here, assuming a complete query tree means they’ve future-proofed their work for GenAI. That’s where the trouble starts.
Fan-out does not verify if your content is actually getting retrieved, indexed, or cited. It doesn’t run real tests with live models. It doesn’t check if a vector database knows your chunks exist. It doesn’t solve crawl or schema problems either.
Put plainly: Fan-out expands the map. But, a big map is worthless if you don’t check the roads, the traffic, or whether your destination is even open.
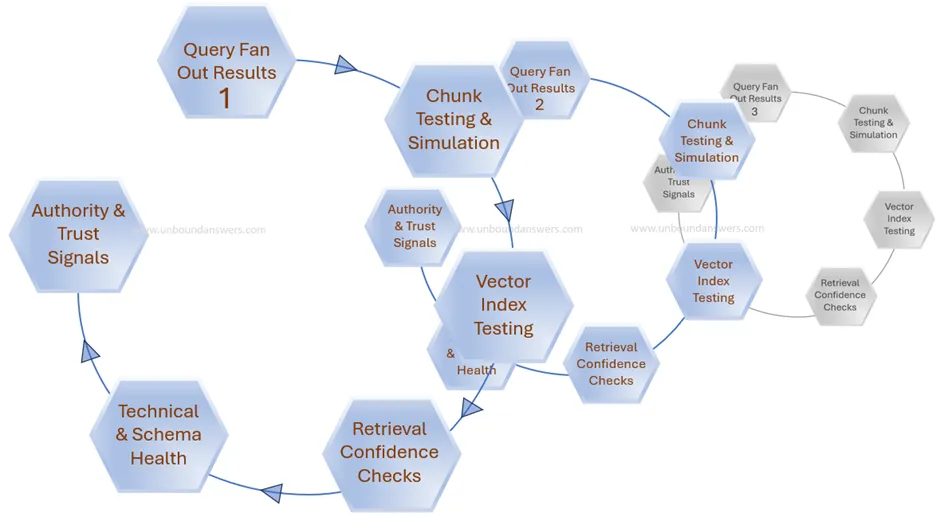
The Practical Next Steps: Closing The Gaps
Once you’ve built a great fan-out tree and created solid chunks, you still need to make sure they work. This is where modern GenAI SEO moves beyond traditional topic planning.
The key is to verify, test, and monitor how your chunks behave in real conditions.
Image Credit: Duane Forrester
Below is a practical list of the extra work that brings fan-out to life, with real tools you can try for each piece.
1. Chunk Testing & Simulation
You want to know: “Does an LLM actually pull my chunk when someone asks a question?” Prompt testing and retrieval simulation give you that window.
Tools you can try:
LlamaIndex: Popular open-source framework for building and testing RAG pipelines. Helps you see how your chunked content flows through embeddings, vector storage, and prompt retrieval.
Otterly: Practical, non-dev tool for running live prompt tests on your actual pages. Shows which sections get surfaced and how well they match the query.
Perplexity Pages: Not a testing tool in the strict sense, but useful for seeing how a real AI assistant surfaces or summarizes your live pages in response to user prompts.
2. Vector Index Presence
Your chunk must live somewhere an AI can access. In practice, that means storing it in a vector database.
Running your own vector index is how you test that your content can be cleanly chunked, embedded, and retrieved using the same similarity search methods that larger GenAI systems rely on behind the scenes.
You can’t see inside another company’s vector store, but you can confirm your pages are structured to work the same way.
Tools to help:
Weaviate: Open-source vector DB for experimenting with chunk storage and similarity search.
Pinecone: Fully managed vector storage for larger-scale indexing tests.
Qdrant: Good option for teams building custom retrieval flows.
3. Retrieval Confidence Checks
How likely is your chunk to win out against others?
This is where prompt-based testing and retrieval scoring frameworks come in.
They help you see whether your content is actually retrieved when an LLM runs a real-world query, and how confidently it matches the intent.
Tools worth looking at:
Ragas: Open-source framework for scoring retrieval quality. Helps test if your chunks return accurate answers and how well they align with the query.
Haystack: Developer-friendly RAG framework for building and testing chunk pipelines. Includes tools for prompt simulation and retrieval analysis.
Otterly: Non-dev tool for live prompt testing on your actual pages. Shows which chunks get surfaced and how well they match the prompt.
4. Technical & Schema Health
No matter how strong your chunks are, they’re worthless if search engines and LLMs can’t crawl, parse, and understand them.
Ryte: Detailed crawl reports, structural audits, and deep schema validation; excellent for finding markup or rendering gaps.
Screaming Frog: Classic SEO crawler for checking headings, word counts, duplicate sections, and link structure: all cues that affect how chunks are parsed.
Sitebulb: Comprehensive technical SEO crawler with robust structured data validation, clear crawl maps, and helpful visuals for spotting page-level structure problems.
5. Authority & Trust Signals
Even if your chunk is technically solid, an LLM still needs a reason to trust it enough to cite or summarize it.
That trust comes from clear authorship, brand reputation, and external signals that prove your content is credible and well-cited. These trust cues must be easy for both search engines and AI agents to verify.
Tools to back this up:
Authory: Tracks your authorship, keeps a verified portfolio, and monitors where your articles appear.
SparkToro: Helps you find where your audience spends time and who influences them, so you can grow relevant citations and mentions.
Perplexity Pro: Lets you check whether your brand or site appears in AI answers, so you can spot gaps or new opportunities.
Query fan-out expands the plan. Retrieval testing proves it works.
Putting It All Together: A Smarter Workflow
When someone asks, “Does query fan-out really matter?” the answer is yes, but only as a first step.
Use it to design a strong content plan and to spot angles you might miss. But always connect it to chunk creation, vector storage, live retrieval testing, and trust-building.
Here’s how that looks in order:
Expand: Use fan-out tools like AlsoAsked or AnswerThePublic.
Draft: Turn each branch into a clear, stand-alone chunk.
Check: Run crawls and fix schema issues.
Store: Push your chunks to a vector DB.
Test: Use prompt tests and RAG pipelines.
Monitor: See if you get cited or retrieved in real AI answers.
Refine: Adjust coverage or depth as gaps appear.
The Bottom Line
Query fan-out is a valuable input, but it’s never been the whole solution. It helps you figure out what to cover, but it does not prove what gets retrieved, read, or cited.
As GenAI-powered discovery keeps growing, smart marketers will build that bridge from idea to index to verified retrieval. They’ll map the road, pave it, watch the traffic, and adjust the route in real time.
So, next time you hear fan-out pitched as a silver bullet, you don’t have to argue. Just remind people of the bigger picture: The real win is moving from possible coverage to provable presence.
If you do that work (with the right checks, tests, and tools), your fan-out map actually leads somewhere useful.
The API will provide consistently scaled search interest figures. These figures align more predictably than the current website numbers.
Announced by Daniel Waisberg and Hadas Jacobi, the Alpha will be opening up from today, and they are looking for testers who will use the Alpha throughout 2025.
The API will not include Trending Now.
Image from author, July 2025
Key Features
Consistently Scaled Search Interest
The standout feature in this Alpha release is consistent scaling.
Unlike the web interface, where search interest values shift depending on your query mix, the API returns values that remain stable across requests.
These won’t be complete search volumes, but in the sample response shown, we can see an indicative search volume presented alongside the scaled number for comparison in the Google Trends website interface.
Five-Year Rolling Window
The API surfaces data across a five-year rolling window.
Data is available up to 48 hours ago to preserve temporal patterns, such as annual events or weekly cycles.
This longer context helps you contrast today’s search spikes with those of previous years. It’s ideal for spotting trends tied to seasonal events and recurring news cycles.
Flexible Aggregations And Geographic Breakdown
You choose how to aggregate data: weekly, monthly, or annually.
This flexibility allows you to zoom in for fine-grained analysis or step back for long-term trends.
Regional and sub-regional breakdowns are also exposed via the API. You can pinpoint interest in countries, states, or even cities without extra work.
Sample API Request & Response
Hadas shared an example request prompt using Python, as well as a sample response.
Google’s Gary Illyes confirmed that AI Search does not require specialized optimization, saying that “AI SEO” is not necessary and that standard SEO is all that is needed for both AI Overviews and AI Mode.
AI Search Is Everywhere
Standard search, in the way it used to be with link algorithms playing a strong role, no longer exists. AI is embedded within every step of the organic search results, from crawling to indexing and ranking. AI has been a part of Google Search for ten years, beginning with RankBrain and expanding from there.
Google’s Gary Illyes made it clear that AI is embedded within every step of today’s search ranking process.
Kenichi Suzuki (LinkedIn Profile) posted a detailed summary of what Illyes discussed, covering four main points:
AI Search features use the same infrastructure as traditional search
AI Search Optimization = SEO
Google’s focus is on content quality and is agnostic as to how it was created
AI is deeply embedded into every stage of search
Generative AI has unique features to ensure reliability
There’s No Need For AEO Or GEO
The SEO community has tried to wrap their minds around AI search, with some insisting that ranking in AI search requires an approach to optimization so distinct from SEO that it warrants its own acronym. Other SEOs, including an SEO rockstar, have insisted that optimizing for AI search is fundamentally the same as standard search. I’m not saying that one group of SEOs is right and another is wrong. The SEO community collectively discussing a topic and reaching different conclusions is one of the few things that doesn’t change in search marketing.
According to Google, ranking in AI Overviews and AI Mode requires only standard SEO practices.
Suzuki shared why AI search doesn’t require different optimization strategies:
“Their core message is that new AI-powered features like AI Overviews and AI Mode are built upon the same fundamental processes as traditional search. They utilize the same crawler (Googlebot), the same core index, and are influenced by the same ranking systems.
They repeatedly emphasized this with the phrase “same as above” to signal that a separate, distinct strategy for “AI SEO” is unnecessary. The foundation of creating high-quality, helpful content remains the primary focus.”
Content Quality Is Not About How It’s Created
The second point that Google made was that their systems are tuned to identify content quality and that identifying whether the content was created by a human or AI is not part of that quality assessment.
Gary Illyes is quoted as saying:
“We are not trying” to differentiate based on origin.”
According to Kenichi, the objective is to:
“…identify and reward high-quality, helpful, and reliable content, regardless of whether it was created by a human or with the assistance of AI.”
AI Is Embedded Within Every Stage Of Search
The third point that Google emphasized is that AI plays a role at every stage of search: crawling, indexing, and ranking.
Regarding the ranking part, Suzuki wrote:
“RankBrain helps interpret novel queries, while the Multitask Unified Model (MUM) understands information across various formats (text, images, video) and 75 different languages.”
Unique Processes Of Generative AI Features
The fourth point that Google emphasized is to acknowledge that AI Overviews does two different things at the ranking stage:
Query Fan-Out Generates multiple queries in order to provide deeper answers to queries, using the query fan-out technique.
Grounding AI Overviews checks the generated answers against online sources to make sure that they are factually accurate, a process called grounding.
Suzuki explains:
“It then uses a process called “grounding” to check the generated text against the information in its search index, a crucial step designed to verify facts and reduce the risk of AI ‘hallucinations.’”
Takeaways:
AI SEO vs. Traditional SEO
Google explicitly states that specialized “AI SEO” is not necessary.
Standard SEO practices remain sufficient to rank in AI-driven search experiences.
Integration of AI in Google Search
AI technology is deeply embedded across every stage of Google’s organic search: crawling, indexing, and ranking.
Technologies like RankBrain and the Multitask Unified Model (MUM) are foundational to Google’s current search ranking system.
Google’s Emphasis on Content Quality
Content quality assessment by Google is neutral regarding whether humans or AI produce the content.
The primary goal remains identifying high-quality, helpful, and reliable content.
Generative AI-Specific Techniques
Google’s AI Overviews employ specialized processes like “query fan-out” to answer queries thoroughly.
A technique called “grounding” is used to ensure factual accuracy by cross-checking generated content against indexed information.
Google clarified that there’s no need for AEO/GEO for Google AI Overviews and AI Mode. Standard search engine optimization is all that’s needed to rank across both standard and AI-based search. Content quality remains an important part of Google’s algorithms, and they made a point to emphasize that they don’t check whether content is created by a human or AI.