During Black Friday in 2024, Stripe processed more than $31 billion in transactions, with processing rates peaking at 137,000 transactions per minute, the highest in the company’s history. The financial-services firm had to analyze every transaction in real timeto prevent nearly 21 million fraud attempts that could have siphoned more than $910 million from its merchant customers.
Yet, fraud protection is only one reason that Stripe embraced real-time data analytics. Evaluating trends in massive data flows is essential for the company’s services, such as allowing businesses to bill based on usage and monitor orders and inventory. In fact, many of Stripe’s services would not be possible without real-time analytics, says Avinash Bhat, head of data infrastructure at Stripe. “We have certain products that require real-time analytics, like usage-based billing and fraud detection,” he says. “Without our real-time analytics, we would not have a few of our products and that’s why it’s super important.”
Stripe is not alone. In today’s digital world, data analysis is increasingly delivered directly to business customers and individual users, allowing real-time, continuous insights to shape user experiences. Ride-hailing apps calculate prices and estimate times of arrival (ETAs) in near-real time. Financial platforms deliver real-time cash-flow analysis. Customers expect and reward data-driven services that reflect what is happening now.
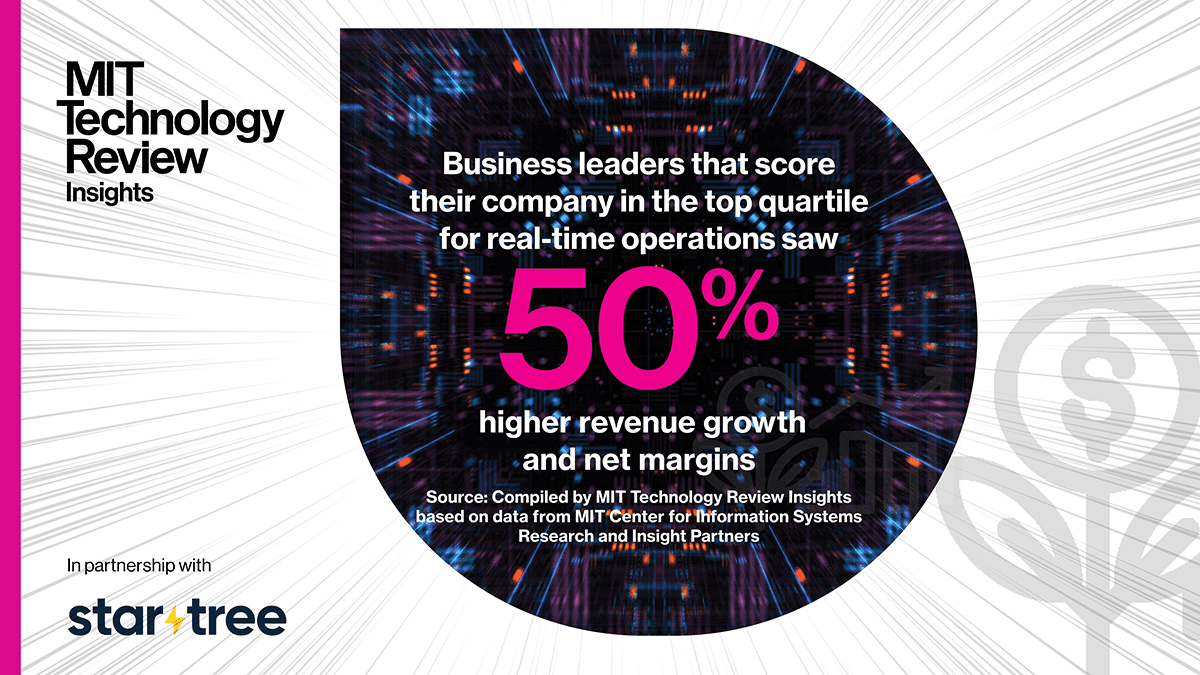
In fact, having the capability to collect and analyze data in real time correlates with companies’ ability to grow. Business leaders that scored company in the top quartile for real-time operations saw 50% higher revenue growth and net margins, compared to companies placed in the bottom quartile, according to a surveyconducted by the MIT Center for Information Systems Research (CISR) and Insight Partners. The top companies focused on automated processes and fast decision-making at all levels, relying on easily accessible data services updated in real time.
Companies that wait on data are putting themselves in a bind, says Kishore Gopalakrishna, co-founder and CEO of StarTree, a real-time data-analytics technology provider. “The basis of real-time analytics is—when the value of the data is very high—we want to capitalize on it instead of waiting and doing batch analytics,” he says. “Getting access to the data a day, or even hours, later is sometimes actually too late.”
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.It was researched, designed, and written entirely by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Synthesia’s AI clones are more expressive than ever. Soon they’ll be able to talk back.
—Rhiannon Williams
Earlier this summer, I visited the AI company Synthesia to give it what it needed to create a hyperrealistic AI-generated avatar of me. The company’s avatars are a decent barometer of just how dizzying progress has been in AI over the past few years, so I was curious just how accurately its latest AI model, introduced last month, could replicate me.
I found my avatar as unnerving as it is technically impressive. It’s slick enough to pass as a high-definition recording of a chirpy corporate speech, and if you didn’t know me, you’d probably think that’s exactly what it was.
My avatar shows how it’s becoming ever-harder to distinguish the artificial from the real. And before long, these avatars will even be able to talk back to us. But how much better can they get? And what might interacting with AI clones do to us? Read the full story.
How Trump is helping China extend its massive lead in clean energy
On a spring day in 1954, Bell Labs researchers showed off the first practical solar panels at a press conference in New Jersey, using sunlight to spin a toy Ferris wheel before a stunned crowd.
The solar future looked bright. But in the race to commercialize the technology it invented, the US would lose resoundingly. Last year, China exported $40 billion worth of solar panels and modules, while America shipped just $69 million, according to the New York Times. It was a stunning forfeit of a huge technological lead.
Now, thanks to its policies propping up aging fossil-fuel industries, the US seems determined to repeat the mistake. Read the full story.
—James Temple
This article is from The Spark, MIT Technology Review’s newsletter all about the latest in climate and energy tech. To receive it in your inbox every Wednesday, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 AI chatbots of celebrities sent risqué messages to teenagers Virtual versions of Timothée Chalamet and Chappell Roan discussed sex and drugs. (WP $) + An AI companion site is hosting sexually charged conversations with underage celebrity bots. (MIT Technology Review)
2 Trump can’t make up his mind about US tech giants While defending them against EU regulation, he’s also pushing to break them up. (FT $) + He’s hosting tech leaders at the White House later today. (Reuters) + Elon Musk doesn’t appear to have made the guest list. (CNBC)
3 Trump’s cuts have led to babies born with HIV Clinics in East Africa are closing, and people are being forced to skip vital drug doses. (The Guardian) + Artificial blood could save many lives. Why aren’t we using it? (Slate)
4Germany has already met its 2028 goal for reducing coal-fired power For the second year running, it won’t have to shut any more plants as a result. (Bloomberg $) + The UK is done with coal. How’s the rest of the world doing? (MIT Technology Review)
5 The risk of all-out nuclear war is growing But we’ve normalized nuclear competition so much, the risks aren’t always clear. (New Yorker $) + Maybe it’s time to start burying nuclear reactors’ cores. (Economist $)
6 xAI is hemorrhaging executives The CFO has left just months after joining. (WSJ $)
7 India’s chip industry is gaining momentum Years of investment are starting to pay off. But can it strike deals with overseas chip giants too? (Bloomberg $) + Meanwhile, Taiwan’s chip hub is home to a baby boom. (Rest of World) + Inside India’s scramble for AI independence. (MIT Technology Review)
8 Boston Dynamics’ Atlas robot only needs one AI model to work It’s all it requires to master humanlike movements successfully. (Wired $) + How ‘robot ballet’ could shake up factory production lines. (FT $) + Humanoid robots still aren’t living up to their lofty promises. (IEEE Spectrum) + Will we ever trust robots? (MIT Technology Review)
9 How studying astronauts could improve health on Earth There’s still a huge amount we don’t know about space’s effects on humans. (Vox) + Space travel is dangerous. Could genetic testing and gene editing make it safer? (MIT Technology Review)
10 The Caribbean island of Anguilla has hit upon an AI cash cow By selling its .ai domain. (Semafor) + How a tiny Pacific Island became the global capital of cybercrime. (MIT Technology Review)
Quote of the day
“If you are not being scammed yet, it’s because you haven’t encountered a scam designed just for you and only for you.”
—Jeff Kuo, chief executive of Taiwanese fraud prevention company Gogolook, warns the Financial Times about the endless possibilities generative AI presents to scammers.
One more thing
China built hundreds of AI data centers to catch the AI boom. Now many stand unused.
Last year, China’s boom in data center construction was at its height, fueled by both government and private investors. Renting out GPUs to companies that need them for training AI models was seen as a sure bet.
But with the rise of DeepSeek and a sudden change in the economics around AI, the industry is faltering. Prices for GPUs are falling and many newly built facilities are now sitting empty. Read the full story to find out why.
—Caiwei Chen
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ The trailer for the forthcoming Wuthering Heights film is here and it looks…interesting. + This fall’s crop of video games is outstanding. + Textured walls are a surefire way to make your home look dated. Here’s some other faux pas to avoid. +The dogs of this year’s US Open are too cute ($)
Agentic AI is coming of age. And with it comes new opportunities in the financial services sector. Banks are increasingly employing agentic AI to optimize processes, navigate complex systems, and sift through vast quantities of unstructured data to make decisions and take actions—with or without human involvement. “With the maturing of agentic AI, it is becoming a lot more technologically possible for large-scale process automation that was not possible with rules-based approaches like robotic process automation before,” says Sameer Gupta, Americas financial services AI leader at EY. “That moves the needle in terms of cost, efficiency, and customer experience impact.”
From responding to customer services requests, to automating loan approvals, adjusting bill payments to align with regular paychecks, or extracting key terms and conditions from financial agreements, agentic AI has the potential to transform the customer experience—and how financial institutions operate too.
Adapting to new and emerging technologies like agentic AI is essential for an organization’s survival, says Murli Buluswar, head of US personal banking analytics at Citi. “A company’s ability to adopt new technical capabilities and rearchitect how their firm operates is going to make the difference between the firms that succeed and those that get left behind,” says Buluswar. “Your people and your firm must recognize that how they go about their work is going to be meaningfully different.”
The emerging landscape
Agentic AI is already being rapidly adopted in the banking sector. A 2025 survey of 250 banking executives by MIT Technology Review Insights found that 70% of leaders say their firm uses agentic AI to some degree, either through existing deployments (16%) or pilot projects (52%). And it is already proving effective in a range of different functions. More than half of executives say agentic AI systems are highly capable of improving fraud detection (56%) and security (51%). Other strong use cases include reducing cost and increasing efficiency (41%) and improving the customer experience (41%).
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written entirely by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
Every week we publish a handpicked list of new products and services from vendors of ecommerce merchants. This installment includes updates on email marketing, marketplace automation, AI agents, multi-site commerce, D2C subscriptions, interactive messaging, and website builders.
Got an ecommerce product release? Email releases@practicalecommerce.com.
New Tools for Merchants
Getsitecontrol launches email deliverability tools.Getsitecontrol, an email marketing platform for ecommerce brands, has released features to help businesses monitor, understand, and improve email performance. Getsitecontrol provides live analytics for each campaign type. Users can now send email campaigns from their own domain instead of a shared one. Smart Sending mode uses AI to analyze each recipient’s behavior and deliver emails at the optimal time. Also, Getsitecontrol forms now support Google reCAPTCHA to verify subscribers.
Getsitecontrol
Amazon introduces Lens Live, an AI-powered visual search feature.Amazon Lens, a visual search tool in the company’s Shopping app, is adding Lens Live. When shoppers with Lens Live open Lens, the camera instantly scans products and displays matching items in a swipeable carousel. Shoppers can tap an item in the camera view to focus on a specific product, add items directly to their cart, and save to their wish lists. Lens Live also integrates with Rufus, Amazon’s AI shopping assistant.
Fortis expands embedded payments capabilities with Adobe Commerce extension.Fortis, a provider of embedded payments and commerce technology, has launched its FortisPay extension for Adobe Commerce, accepting e-checks, ACH, credit cards, Apple Pay, Google Pay, and more. Users of the Fortis extension can (i) securely store payment information and monitor for expired cards, (ii) get real-time order status updates embedded directly in the ecommerce platform, (iii) access Level 2 and Level 3 processing for B2B optimization, and (iv) embed workflows with NetSuite, Microsoft, Sage, Acumatica, and other leading systems.
eBay releases regulatory resource for sellers.eBay has launched a guide on the laws and regulations that may apply to sellers on the platform. The guide provides a central location for key regulatory information, a discovery tool to help identify relevant laws and regulations, and direct links to guidance on how to comply. Enter your location and shipping destination, and the discovery tool will highlight potential applicable laws and provide info on how to stay compliant.
ChannelEngine and Salsify partner on marketplace expansion.ChannelEngine, a marketplace integration and automation platform, has partnered with Salsify, a platform for product experience management and content syndication, to enable brands to expand reach, optimize performance, and scale across retail channels. Users can (i) enrich and localize product content through Salsify’s PXM platform, (ii) activate listings across 950 global marketplaces via ChannelEngine’s direct integrations, (iii) automate operations such as inventory syncing, pricing, order flows, and returns, and (iv) track performance and optimize growth with built-in reporting and insights.
Salsify
Alibaba launches AI agents to boost efficiency for global merchants.Alibaba International has launched Marco, an AI tool to enhance global ecommerce operations. Marco assists ecommerce merchants across Alibaba’s ecosystem, handling over 60 tasks across marketing, marketplace compliance, and customer service. The company has also introduced three specialized AI agents for complex cross-border ecommerce tasks: Intelligent Refund Agent, HS Code Agent to automate customs classifications, and Merchant Recruitment Agent to identify and pre-qualify potential sellers.
Run Payments launches Merchant for payments, reporting, dispute management.Run Payments, a payments orchestration platform, has launched Run Merchant, an application to orchestrate credit card and ACH payment data across multiple gateways and processors. Merchants can (i) manage all transactions in real-time across every location, sales channel, and processor, (ii) accept payments via virtual terminal, hosted payment pages, or API, (iii) track, respond, and resolve disputes without leaving the portal, and (iv) stay compliant with B2B transactions by accommodating Level 2 and Level 3 interchange optimization under Visa’s evolving Commercial Enhanced Data Program framework.
RunDTC unveils Unify Accelerator to power multi-site commerce on Shopify.RunDTC, a digital commerce agency, has launched Unify Accelerator, a quick-launch platform for enterprise retailers, developed with Contentstack, an adaptive digital experience platform. Designed for large-scale commerce organizations, Unify provides an interface powered by Contentstack’s DXP, enabling marketers and merchandisers to manage content across Shopify efficiently and at scale. From a single interface, merchants can access scheduling, preview and staging functionality, and control who can create, approve, and publish content.
Cleeng unveils free D2C subscription platform.Cleeng, a developer of subscriber retention management solutions, has unveiled Pro, a direct-to-consumer subscription management platform that can be launched quickly. Free for up to 10,000 subscribers, Cleeng Pro offers subscription management, identity and entitlement control, advanced analytics, support, and optional Merchant of Record and payment orchestration services. Cleeng Pro features no-code onboarding, best practice guides, and a partner network that includes JWPlayer, Applicaster, Videodock, Urban Zoo, Alpha Networks, and Sportradar.
Cleeng
Genstore launches AI-native store builder with a conversational interface.Genstore, an AI-native store builder, has launched its platform, which enables small and micro businesses to start, run, and scale a store, combining a simple conversational interface, instant AI store setup, autonomous growth tools, and multichannel integration. Genstore lets users upload a product image in the chat and instantly generates a product page with descriptions, templates, and visuals. Sellers can create a site, list products, answer questions, and run campaigns — all by chatting.
WEX partners with Trulioo for digital onboarding and fraud prevention.Trulioo, an identity platform for personal and business verification, has partnered with WEX, a payment processing and fleet management company. WEX provides processing for customers in the areas of corporate payments, employee benefits, and fleet services. Trulioo Document Verification combines advanced biometrics and machine learning to detect forgeries, deep fakes, and injection attacks.
Twilio introduces Rich Communication Services for branded interactive messaging.Twilio, a customer engagement platform for real-time, personalized experiences, has announced the global availability of Rich Communication Services messaging. Twilio’s RCS enables companies to send branded, verified messages with rich interactive features. RCS is available to all active customer accounts through Twilio’s Programmable Messaging and Verify APIs. Existing customers can upgrade, and new customers can implement both SMS and RCS through a single integration via the Twilio platform.
Miva launches Vexture, AI-powered search for ecommerce discovery. Ecommerce platform Miva has launched Vexture, a product discovery tool to help merchants deliver faster, more relevant search results based on real customer intent. Vexture combines local private AI embeddings from the merchant’s product catalog and other data, enabling it to interpret shopper language naturally and dynamically. Vexture leverages AI-driven natural language processing and store data to go beyond traditional keyword matching and understand what shoppers mean, not just what they type.
Google’s Search Relations team says generic login pages can confuse indexing and hurt rankings.
When many private URLs all show the same bare login form, Google may treat them as duplicates and show the login page in search.
In a recent “Search Off the Record” episode, John Mueller and Martin Splitt explained how this happens and what to do about it.
Why It Happens
If different private URLs all load the same login screen, Google sees those URLs as the same page.
Mueller said on the podcast:
“If you have a very generic login page, we will see all of these URLs that show that login page that redirect to that login page as being duplicates… We’ll fold them together as duplicates and we’ll focus on indexing the login page because that’s kind of what you give us to index.”
That means people searching for your brand may land on a login page instead of helpful information.
“We regularly see Google services getting this wrong,” Mueller admitted, noting that with many teams, “you invariably run across situations like that.”
Search Console fixed this by sending logged-out visitors to a marketing page with a clear sign-in link, which gave Google indexable context.
Don’t Rely On robots.txt To Hide Private URLs
Blocking sensitive areas in robots.txt can still let those URLs appear in search with no snippet. That’s risky if the URLs expose usernames or email addresses.
Mueller warned:
“If someone does something like a site query for your site… Google and other search engines might be like, oh, I know about all of these URLs. I don’t have any information on what’s on there, but feel free to try them out essentially.”
If it’s private, avoid leaking details in the URL, and use noindex or a login redirect instead of robots.txt.
What To Do Instead
If content must stay private, serve a noindex on private endpoints or redirect requests to a dedicated login or marketing page.
Don’t load private text into the page and then hide it with JavaScript. Screen readers and crawlers may still access it.
If you want restricted pages indexed, use the paywall structured data. It allows Google to fetch the full content while understanding that regular visitors will hit an access wall.
“It doesn’t have to be something that’s behind like a clear payment thing. It can just be something like a login or some other mechanism that basically limits the visibility of the content.”
Lastly, add context to login experiences. Include a short description of the product or the section someone is trying to reach.
As Mueller advised:
“Put some information about what your service is on that login page.”
A Quick Test
Open an incognito window. While logged out, search for your brand or service and click the top results.
If you land on bare login pages with no context, you likely need updates. You can also search for known URL patterns from account areas to see what shows up.
Looking Ahead
As more businesses use subscriptions and gated experiences, access design affects SEO.
Use clear patterns (noindex, proper redirects, and paywalled markup where needed) and make sure public entry points provide enough context to rank for the right queries.
Small changes to login pages and redirects can prevent duplicate grouping and improve how your site appears in search.
Product variations are more than just an ecommerce feature. They give your customers choices, whether it’s size, color, style, or material, while helping your store stand out in competitive search results. When optimized correctly, product variations do more than display available options. They improve the customer experience by making shopping easier. At the same time, they boost conversions by catering to diverse needs and support your SEO strategy by targeting more keywords.
This guide will explain the best practices for product variations and show you how to optimize them for search engines and customers so your ecommerce site can grow in traffic, rankings, and sales.
What are product variations in ecommerce?
Product variations or product variants are different versions of the same product designed to give customers options. These variations can be based on attributes like size, color, material, style, or capacity. Instead of creating multiple product listings, variations group all options under a single product, making it easier for customers to browse and purchase.
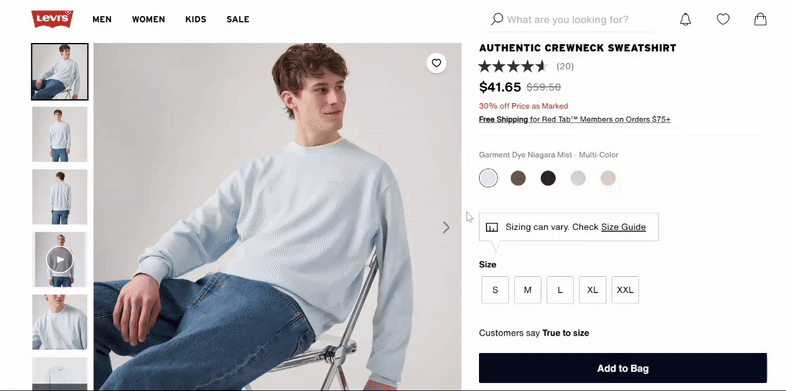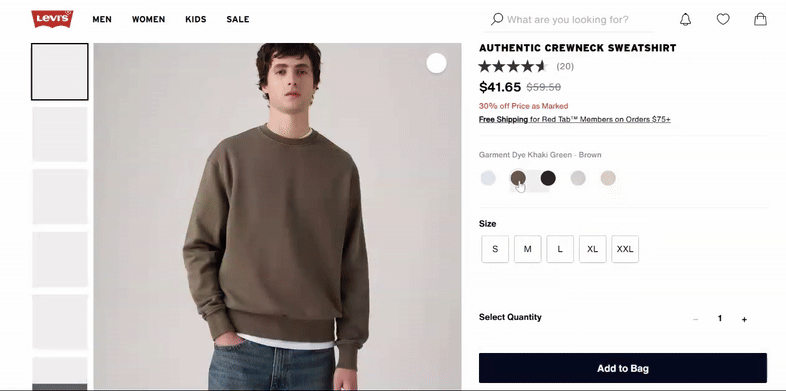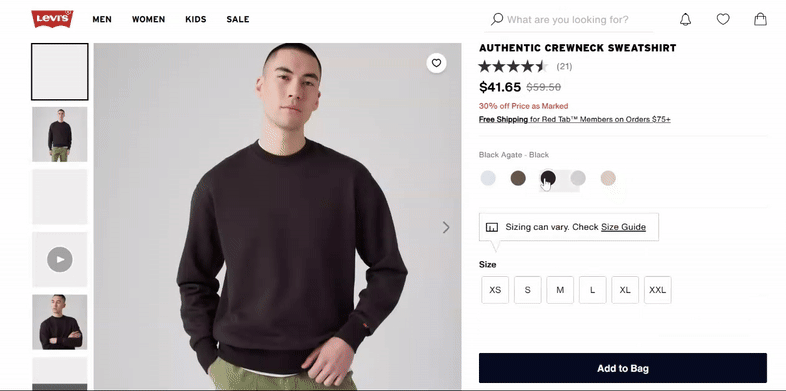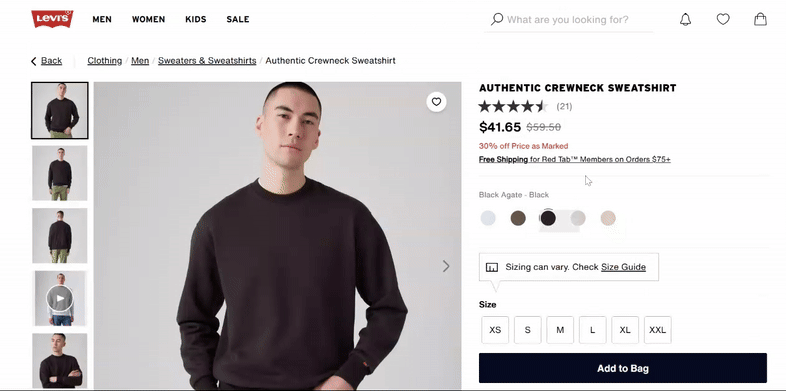
For example, when you search for an iPhone on Amazon, you’ll see options for different colors and storage capacities, all available on a single page. This setup lets customers explore multiple choices without leaving the main product page.
Example of product variants
Managing product variations depends on the platform you use:
In WooCommerce, product variations are created using attributes such as size or color, and then assigning values to those attributes. Store owners can upload unique images, set prices, and adjust stock for each variation
In Shopify, variations are managed under the ‘Variants’ section of a product. You can add options like size, color, or material, and then assign values. Each variant can have its own price, SKU, and image, making it simple to customize how the variations appear in your store
Okay, now let’s see why you need product variants and not upload each option as a completely separate product. Think of it this way: customers don’t want to scroll through endless listings just to compare a black t-shirt with a white one or a 64GB phone with a 128GB version. Variations keep everything in one place, making shopping smoother and more intuitive.
Here’s why product variations are so important for your customers:
Improved shopping experience: Variants reduce unnecessary clicks and allow customers to compare options side by side within a single product page. This saves time and makes decision-making easier
Higher conversions and lower bounce rates: When customers find their preferred size, color, or feature right away, they are more likely to complete a purchase instead of leaving your store
Reduced purchase anxiety: Variants ensure customers do not feel limited by stock. Seeing multiple choices available decreases the chance of cart abandonment
Personalization and satisfaction: Offering customers options empowers them to choose a product that feels tailor-made for them, improving overall satisfaction
Indirect SEO benefits: A better shopping experience often leads to longer session durations, fewer bounces, and more engagement. These signals may indirectly support stronger SEO performance, as they align with positive user experience metrics
How do product variations support your ecommerce SEO strategies?
Product variations are not just about creating a better shopping experience; they also bring direct ecommerce SEO benefits that can help your store attract more qualified traffic. When optimized correctly, variants can make your product pages richer, more discoverable, and more engaging.
Increase in keyword targeting
Variants allow you to target a wider range of long-tail keywords that reflect real customer search behavior. For example, instead of only competing for ‘men’s wallet,’ you can rank for ‘men’s black leather wallet’ or ‘slim men’s brown wallet.’ These specific keywords usually carry higher purchase intent and face less competition
Levi’s product page for jeans uses long-tail keywords in the product description for keyword targeting
Richer content for search engines and AI engines
Each variation allows you to add unique attributes, descriptions, and specifications. This creates a more detailed and content-rich product page that search engines and AI-driven engines (like ChatGPT or Google’s AI Overviews) value when surfacing answers and shaping brand perception.
ChatGPT showing product options for a t-shirt
Improved user engagement and longer sessions
A well-structured page that clearly displays variations keeps users from bouncing to competitor sites when they don’t immediately find their preferred option. Instead, they spend more time exploring, comparing, and interacting with your store, which indirectly supports SEO through stronger engagement signals.
Better structured data for enhanced search results
When product variants are properly marked up with structured data, search engines can display rich snippets that include price ranges, availability, color options, and reviews. This not only makes your listings stand out but also boosts click-through rates (CTRs) from search results.
Yoast SEO’s Structure data feature describes your product content as a single interconnected schema graph that search engines can easily understand. This helps them interpret your product variations more accurately and increases your chances of getting rich results, from product details to FAQs.
In short, optimized product variants make your product pages more keyword-diverse, content-rich, and engaging while also improving how your store is presented in search results and generative AI chat replies.
Blueprint for optimizing your product variations
Here’s the part you’ve been waiting for: how to optimize your product variations for SEO, conversions, and user experience. In this section, we’ll cover the right technical implementation, smart SEO tactics, and the common mistakes you’ll want to avoid.
Technical implementation of product variations
Getting the technical setup right is the foundation for optimizing your product variations for both ecommerce SEO and user experience. Poor implementation can lead to crawl inefficiencies, duplicate content, and a confusing buyer journey.
Here’s how to approach it effectively:
Handling variations in URLs
One of the biggest decisions you’ll make is how to structure URLs for your product variations:
Parameters (e.g., ?color=red&size=12): Good for filtering and faceted navigation, but they can create crawl bloat if not managed properly. Always define URL parameters in Google Search Console and use canonical tags to consolidate signals
Separate pages for each variation (e.g., /red-dress-size-12): This can be useful when specific variations have significant search demand (like ‘iPhone 15 Pro Max 512GB Blue’). However, it requires careful duplication management and unique, optimized content for each page
Single product page with dropdowns or swatches: The most common approach for ecommerce stores, as it consolidates SEO signals into one canonical page while providing users with all available variations in one place
Takeaway: Use a hybrid approach. Keep a single master product page, but only create dedicated variation URLs for high-demand search queries (with unique descriptions, images, and structured data).
Note: only create dedicated variation URLs if you can add unique value (content/images), otherwise, it risks duplication
Internal linking best practices
Internal linking is crucial in helping search engines understand the relationships between your main product page and its variations.
Always link back to the parent product page from any variation-specific pages
Ensure your category pages link to the main product page, not every single variation (to prevent diluting crawl equity)
Use descriptive anchor text when linking internally, e.g., ‘men’s black leather wallet’ rather than just ‘wallet’
The Internal linking suggestions feature in Yoast SEO Premium is a real time-saver. As you write, it recommends relevant pages and posts so you can easily connect variations, parent products, and related content. This not only strengthens your site structure and boosts SEO but also ensures visitors enjoy a seamless browsing experience.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
Takeaway: Build a clean hierarchy where category pages → main product pages → variations, ensuring both users and crawlers can navigate easily.
Managing faceted navigation and filters
Filters (like size, color, brand, or price) enhance user experience but can create SEO challenges if every filter combination generates a new crawlable URL.
Use or noindex for low-value filter pages (like ‘price under $20’ if it doesn’t add SEO value)
Block irrelevant filter parameters in robots.txt to prevent crawl bloat
For valuable filters (e.g., ‘red running shoes’), allow them to be indexed and optimize the content
Takeaway: Conduct a filter audit in Google Search Console. Identify which filtered URLs actually drive impressions and clicks, and only allow those to be indexable.
Media content optimization for ecommerce product variations
When it comes to product variations, visuals and supporting media play a critical role in both SEO and conversions. Shoppers often make purchase decisions based on how well they can visualize a specific variation. In fact, 75% of online shoppers rely on product images when making purchasing decisions.
Here’s how you can optimize media content for ecommerce product variations:
Use unique images for each variation
Avoid using the same generic image across all variations. Display each color, size, material, or feature with its own high-quality image set. For example, if you sell a t-shirt in six colors, show each color separately to help customers make confident choices.
Unique product images for each variant
Leverage 360° views and videos
Showcase variations with interactive media like 360° spins or short product videos. For example, a ‘black leather recliner’ video demonstrates texture and function more effectively than a static image, leading to higher engagement and conversions.
Use videos and 360-degree media to portray your products
Optimize alt text, file names, and metadata
Every image should have descriptive, keyword-rich alt text that specifies the variation. Instead of writing ‘red shoe,’ use ‘women’s red running shoe size 8.’ File names (e.g., womens-red-running-shoe-size8.webp) and captions should also reinforce the variation for better indexing.
Implement structured data for media
Use the Product schema to explicitly define images and videos for each variation. Including structured data ensures that Google and AI-driven engines like ChatGPT can clearly interpret your variation visuals and display them in rich results or AI summaries.
For instance, assigning images to specific SKUs (via image markup) makes it easier for search engines to show the correct variation in shopping results.
SEO tips for product variations
Optimizing product variations for SEO requires more than attractive visuals and solid descriptions. You need to apply some proven SEO techniques to ensure search engines correctly interpret your product pages and users get the best possible experience.
Here are a few key practices every ecommerce store owner should follow:
Use canonical tags to avoid duplicate content issues
Product variations often generate multiple URLs, which can cause duplicate content problems. Canonical tags help solve this by pointing to the primary version of a page, consolidating ranking signals, and avoiding internal competition.
Yoast simplifies this process by automatically inserting canonical URL tags on your product pages. This ensures search engines know which version to prioritize, prevents diluted link equity, and even consolidates social shares under the original page. For store owners, this means less technical overhead and stronger, cleaner rankings.
Apply global product identifiers (GTIN, MPN, ISBN) where relevant
Global product identifiers like GTINs, MPNs, and ISBNs act as unique fingerprints for your products. They help Google and other search engines correctly match your items in their vast index, which improves the accuracy of search listings and reduces confusion with similar products. They also add credibility, since customers can cross-check these identifiers before purchase.
With Yoast WooCommerce SEO, adding these identifiers becomes much easier. The plugin reminds you to fill in missing SKUs, GTINs, or EANs for each product variation and automatically outputs them in structured data. This not only helps your products qualify for rich results but also ensures that no variant is left incomplete from an SEO standpoint.
Buy WooCommerce SEO now!
Unlock powerful features and much more for your online store with Yoast WooCommerce SEO!
Regularly audit Google Search Console data to track performance
Google Search Console is a goldmine for understanding how product variations are performing. By monitoring which variant pages are driving impressions, clicks, and conversions, you can refine your SEO strategy.
For example, if certain variants attract little traffic but consume crawl budget, it might be better to consolidate them under canonical tags.
Regular audits also help you detect indexing issues, thin content problems, or underperforming structured data. This keeps your product catalogue lean, crawl-efficient, and focused on driving meaningful organic traffic.
Common product variation ecommerce errors to avoid
Even if you’ve implemented the right technical setup, added structured data, and optimized your media content, a few small mistakes can undo all that effort. To make sure your product variations support SEO and conversions instead of hurting them, here are some common pitfalls to avoid:
Duplicate content: Creating separate standalone pages for each variation (like size or color) without consolidation leads to content duplication. This confuses search engines and dilutes rankings across multiple weak pages
Poor user experience: If your variation options are hidden, unclear, or slow to load, users struggle to make choices. This friction reduces conversions and increases bounce rates
Incorrect structured data: Applying schema inaccurately can cause search engines to display the wrong product details in search results, damaging credibility and visibility
Thin content: Not providing unique descriptions, images, or metadata for each variation leaves the page with little value. Search engines tend to down-rank such content, reducing discoverability
Crawl bloat: Generating too many low-value variation URLs (like separate pages for every minor option) wastes crawl budget and prevents high-priority pages from being indexed efficiently. Additionally, it could dilute internal link equity
By keeping these errors in check, you’ll ensure your product variation strategy strengthens your SEO and user experience instead of working against them.
Ready to unfold all variations?
Product variations are not just small details hidden in your catalogue. They play a major role in how both search engines and shoppers experience your store. When done right, they prevent duplicate content issues, improve crawl efficiency, deliver richer search results, and create a seamless journey for your customers.
The key is to treat product variations as part of your overall SEO strategy, not as an afterthought. Every unique image, structured snippet, and clear variation option makes your store more visible, more reliable, and more profitable.
This is where Yoast SEO becomes a game-changer. With automatic structured data, smart handling of canonical URLs, and advanced content optimization tools, Yoast helps you get product variations right the first time.
Ahad Qureshi
I’m a Computer Science grad who accidentally stumbled into writing—and stayed because I fell in love with it. Over the past six years, I’ve been deep in the world of SEO and tech content, turning jargon into stories that actually make sense. When I’m not writing, you’ll probably find me lifting weights to balance my love for food (because yes, gym and biryani can coexist) or catching up with friends over a good cup of chai.
New research examining 16 million URLs aligns with Google’s predictions that hallucinated links will become an issue across AI platforms.
An Ahrefs study shows that AI assistants send users to broken web pages nearly three times more often than Google Search.
The data arrives six months after Google’s John Mueller raised awareness about this issue.
ChatGPT Leads In URL Hallucination Rates
ChatGPT creates the most fake URLs among all AI assistants tested. The study found that 1% of URLs people clicked led to 404 pages. Google’s rate is just 0.15%.
The problem gets worse when looking at all URLs ChatGPT mentions, not just clicked ones. Here, 2.38% lead to error pages. Compare this to Google’s top search results, where only 0.84% are broken links.
Claude came in second with 0.58% broken links for clicked URLs. Copilot had 0.34%, Perplexity 0.31%, and Gemini 0.21%. Mistral had the best rate at 0.12%, but it also sends the least traffic to websites.
Why Does This Happen?
The research found two main reasons why AI creates fake links.
First, some URLs used to exist but don’t anymore. When AI relies on old information instead of searching the web in real-time, it might suggest pages that have been deleted or moved.
Second, AI sometimes invents URLs that sound right but never existed.
Ryan Law from Ahrefs shared examples from their own site. AI assistants created fake URLs like “/blog/internal-links/” and “/blog/newsletter/” because these sound like pages Ahrefs might have. But they don’t actually exist.
Limited Impact on Overall Traffic
The problem may seem significant, but most websites won’t notice much impact. AI assistants only bring in about 0.25% of website traffic. Google, by comparison, drives 39.35% of traffic.
This means fake URLs affect a tiny portion of an already small traffic source. Still, the issue might grow as more people use AI for research and information.
The study also found that 74% of new web pages contain AI-generated content. When this content includes fake links, web crawlers might index them, spreading the problem further.
Mueller’s Prediction Proves Accurate
These findings match what Google’s John Mueller predicted in March. He forecasted a “slight uptick of these hallucinated links being clicked” over the next 6-12 months.
Mueller suggested focusing on better 404 pages rather than chasing accidental traffic.
His advice to collect data before making big changes looks smart now, given the small traffic impact Ahrefs found.
Mueller also predicted the problem would fade as AI services improve how they handle URLs. Time will tell if he’s right about this, too.
Looking Forward
For now, most websites should focus on two things. Create helpful 404 pages for users who hit broken links. Then, set up redirects only for fake URLs that get meaningful traffic.
This allows you to handle the problem without overreacting to what remains a minor issue for most sites.
Ask a question in ChatGPT, Perplexity, Gemini, or Copilot, and the answer appears in seconds. It feels effortless. But under the hood, there’s no magic. There’s a fight happening.
This is the part of the pipeline where your content is in a knife fight with every other candidate. Every passage in the index wants to be the one the model selects.
For SEOs, this is a new battleground. Traditional SEO was about ranking on a page of results. Now, the contest happens inside an answer selection system. And if you want visibility, you need to understand how that system works.
Image Credit: Duane Forrester
The Answer Selection Stage
This isn’t crawling, indexing, or embedding in a vector database. That part is done before the query ever happens. Answer selection kicks in after a user asks a question. The system already has content chunked, embedded, and stored. What it needs to do is find candidate passages, score them, and decide which ones to pass into the model for generation.
Every modern AI search pipeline uses the same three stages (across four steps): retrieval, re-ranking, and clarity checks. Each stage matters. Each carries weight. And while every platform has its own recipe (the weighting assigned at each step/stage), the research gives us enough visibility to sketch a realistic starting point. To basically build our own model to at least partially replicate what’s going on.
The Builder’s Baseline
If you were building your own LLM-based search system, you’d have to tell it how much each stage counts. That means assigning normalized weights that sum to one.
A defensible, research-informed starting stack might look like this:
Lexical retrieval (keywords, BM25): 0.4.
Semantic retrieval (embeddings, meaning): 0.4.
Re-ranking (cross-encoder scoring): 0.15.
Clarity and structural boosts: 0.05.
Every major AI system has its own proprietary blend, but they’re all essentially brewing from the same core ingredients. What I’m showing you here is the average starting point for an enterprise search system, not exactly what ChatGPT, Perplexity, Claude, Copilot, or Gemini operate with. We’ll never know those weights.
Hybrid defaults across the industry back this up. Weaviate’s hybrid search alpha parameter defaults to 0.5, an equal balance between keyword matching and embeddings. Pinecone teaches the same default in its hybrid overview.
Re-ranking gets 0.15 because it only applies to the short list. Yet its impact is proven: “Passage Re-Ranking with BERT” showed major accuracy gains when BERT was layered on BM25 retrieval.
Clarity gets 0.05. It’s small, but real. A passage that leads with the answer, is dense with facts, and can be lifted whole, is more likely to win. That matches the findings from my own piece on semantic overlap vs. density.
At first glance, this might sound like “just SEO with different math.” It isn’t. Traditional SEO has always been guesswork inside a black box. We never really had access to the algorithms in a format that was close to their production versions. With LLM systems, we finally have something search never really gave us: access to all the research they’re built on. The dense retrieval papers, the hybrid fusion methods, the re-ranking models, they’re all public. That doesn’t mean we know exactly how ChatGPT or Gemini dials their knobs, or tunes their weights, but it does mean we can sketch a model of how they likely work much more easily.
From Weights To Visibility
So, what does this mean if you’re not building the machine but competing inside it?
Overlap gets you into the room, density makes you credible, lexical keeps you from being filtered out, and clarity makes you the winner.
That’s the logic of the answer selection stack.
Lexical retrieval is still 40% of the fight. If your content doesn’t contain the words people actually use, you don’t even enter the pool.
Semantic retrieval is another 40%. This is where embeddings capture meaning. A paragraph that ties related concepts together maps better than one that is thin and isolated. This is how your content gets picked up when users phrase queries in ways you didn’t anticipate.
Re-ranking is 15%. It’s where clarity and structure matter most. Passages that look like direct answers rise. Passages that bury the conclusion drop.
Clarity and structure are the tie-breaker. 5% might not sound like much, but in close fights, it decides who wins.
Two Examples
Zapier’s Help Content
Zapier’s documentation is famously clean and answer-first. A query like “How to connect Google Sheets to Slack” returns a ChatGPT answer that begins with the exact steps outlined because the content from Zapier provides the exact data needed. When you click through a ChatGPT resource link, the page you land on is not a blog post; it’s probably not even a help article. It’s the actual page that lets you accomplish the task you asked for.
Lexical? Strong. The words “Google Sheets” and “Slack” are right there.
Semantic? Strong. The passage clusters related terms like “integration,” “workflow,” and “trigger.”
Re-ranking? Strong. The steps lead with the answer.
Clarity? Very strong. Scannable, answer-first formatting.
In a 0.4 / 0.4 / 0.15 / 0.05 system, Zapier’s chunk scores across all dials. This is why their content often shows up in AI answers.
A Marketing Blog Post
Contrast that with a typical long marketing blog post about “team productivity hacks.” The post mentions Slack, Google Sheets, and integrations, but only after 700 words of story.
Lexical? Present, but buried.
Semantic? Decent, but scattered.
Re-ranking? Weak. The answer to “How do I connect Sheets to Slack?” is hidden in a paragraph halfway down.
Clarity? Weak. No liftable answer-first chunk.
Even though the content technically covers the topic, it struggles in this weighting model. The Zapier passage wins because it aligns with how the answer selection layer actually works.
Traditional search still guides the user to read, evaluate, and decide if the page they land on answers their need. AI answers are different. They don’t ask you to parse results. They map your intent directly to the task or answer and move you straight into “get it done” mode. You ask, “How to connect Google Sheets to Slack,” and you end up with a list of steps or a link to the page where the work is completed. You don’t really get a blog post explaining how someone did this during their lunch break, and it only took five minutes.
Volatility Across Platforms
There’s another major difference from traditional SEO. Search engines, despite algorithm changes, converged over time. Ask Google and Bing the same question, and you’ll often see similar results.
LLM platforms don’t converge, or at least, aren’t so far. Ask the same question in Perplexity, Gemini, and ChatGPT, and you’ll often get three different answers. That volatility reflects how each system weights its dials. Gemini may emphasize citations. Perplexity may reward breadth of retrieval. ChatGPT may compress aggressively for conversational style. And we have data that shows that between a traditional engine, and an LLM-powered answer platform, there is a wide gulf between answers. Brightedge’s data (62% disagreement on brand recommendations) and ProFound’s data (…AI modules and answer engines differ dramatically from search engines, with just 8 – 12% overlap in results) showcase this clearly.
For SEOs, this means optimization isn’t one-size-fits-all anymore. Your content might perform well in one system and poorly in another. That fragmentation is new, and you’ll need to find ways to address it as consumer behavior around using these platforms for answers shifts.
Why This Matters
In the old model, hundreds of ranking factors blurred together into a consensus “best effort.” In the new model, it’s like you’re dealing with four big dials, and every platform tunes them differently. In fairness, the complexity behind those dials is still pretty vast.
Ignore lexical overlap, and you lose part of that 40% of the vote. Write semantically thin content, and you can lose another 40. Ramble or bury your answer, and you won’t win re-ranking. Pad with fluff and you miss the clarity boost.
The knife fight doesn’t happen on a SERP anymore. It happens inside the answer selection pipeline. And it’s highly unlikely those dials are static. You can bet they move in relation to many other factors, including each other’s relative positioning.
The Next Layer: Verification
Today, answer selection is the last gate before generation. But the next stage is already in view: verification.
Research shows how models can critique themselves and raise factuality. Self-RAG demonstrates retrieval, generation, and critique loops. SelfCheckGPT runs consistency checks across multiple generations. OpenAI is reported to be building a Universal Verifier for GPT-5. And, I wrote about this whole topic in a recent Substack article.
When verification layers mature, retrievability will only get you into the room. Verification will decide if you stay there.
Closing
This really isn’t regular SEO in disguise. It’s a shift. We can now more clearly see the gears turning because more of the research is public. We also see volatility because each platform spins those gears differently.
For SEOs, I think the takeaway is clear. Keep lexical overlap strong. Build semantic density into clusters. Lead with the answer. Make passages concise and liftable. And I do understand how much that sounds like traditional SEO guidance. I also understand how the platforms using the information differ so much from regular search engines. Those differences matter.
This is how you survive the knife fight inside AI. And soon, how you pass the verifier’s test once you’re there.
It is a wild job market right now, and if you’re applying for a PPC role, you’re probably feeling the pressure to stand out in interviews that are increasingly demanding and often unclear in their expectations.
Whether you’re interviewing for a specialist, manager, or hybrid media role, one thing is certain: You need to be ready to demonstrate platform expertise, strategic thinking, and the ability to connect performance with business outcomes.
One reader put it this way:
“I’m preparing for a performance marketing job, specifically in PPC, and I want to focus on Google and Meta ads. Have you any advice that would help me with interview preparation for these roles?”
This question is particularly timely because it doesn’t just ask about one platform. It is looking for dual fluency in Google and Meta, which represent paid search and paid social. That nuance matters.
Stopping there, however, is a mistake. Savvy employers will appreciate an applicant who can speak to Microsoft Ads, TikTok, LinkedIn, Pinterest, Reddit, and emerging platforms, even if those channels are not in scope right now. That breadth of perspective signals that you’re not just a button-pusher; you’re a strategist.
Below is a breakdown of the three core areas most interviewers will evaluate: Paid Search, Paid Social, and General Marketing and Culture Fit.
Modern paid search, especially within Google, demands more than keyword-level tactics. You need to understand how campaigns serve business objectives.
Expect strategy questions like, “X business has Y budget and Z goals – what kind of campaign would you run and why?” Strong candidates will be able to discuss budgeting frameworks, auction mechanics, audience segmentation, and creative message mapping.
You will likely be asked about reporting. Expect to reference tools like Looker Studio, Google Analytics 4, Power BI, Adobe, or Triple Whale. Even speaking confidently about one tool while showing awareness of others can be impressive.
Mention tools like Microsoft Clarity when discussing conversion rate optimization. Behavioral analytics insights reinforce that you understand the full user journey and do not treat campaigns as isolated events.
One frequently asked question involves account structure. You might be asked, “Why would you structure a campaign/account this way?” Never cite “best practices” or default methods as your rationale. Interviewers want reasoning rooted in context, goals, and a test-and-learn approach.
Stay current on innovations. Be ready to speak about features such as Performance Max, audience expansion tools, or any other platform updates that impact strategy. Share why you find them valuable and how you would explain their relevance to a client.
To stand out even further, draw comparisons between Google and Microsoft Ads, or highlight how Reddit and Amazon are bringing new energy to the paid search space.
Paid Social Interview Prep (Meta, TikTok, LinkedIn, Etc.)
Paid social requires creative fluency, audience empathy, and an understanding of privacy constraints. These platforms are less about exact keyword intent and more about relevance, scale, and emotional resonance.
Prepare to talk about platform-specific ad types and creative strategies. Discuss how you would use Facebook, Instagram, WhatsApp, and Threads, and how your tactics might differ on TikTok, LinkedIn, YouTube Shorts, or Reddit.
Understand how platforms organize their campaign hierarchies. For instance, Meta emphasizes the ad set level for budgeting and targeting, whereas Google does not. Create a reference sheet for yourself so you can confidently speak to the differences during interviews.
Expect questions around creative production and reporting. Interviewers may ask, “What would you do if the client is picky about creative but refuses to supply any?” or “How would you prove that your campaign delivered results if the client questions the attribution?” These are behavioral and strategic tests rolled into one.
Be prepared to explain your approach to budgeting. Paid social often involves very large or very small budgets, and employers want to hear how you allocate funds based on audience size, objective, and creative lifecycle.
Show an understanding of creative testing frameworks, including how you develop variations of hooks, visuals, or calls to action across placements and formats.
General Marketing And Culture Fit
Some parts of the interview will focus less on tactics and more on how you think and collaborate. These are just as important to prepare for.
Be ready to answer questions like, “Tell me about a campaign that worked – and one that didn’t.” Use those stories to demonstrate analytical thinking, cross-functional collaboration, and your ability to learn from both success and failure.
You will also likely get questions about how you communicate performance. You might be asked how you handle underperformance and how you keep stakeholders aligned and informed during those periods.
Come prepared with thoughtful questions of your own. Ask, “What’s behind hiring for this role?” This can give insight into whether the role is tied to growth, turnover, or team restructuring. It also helps you gauge whether expectations are realistic.
Another useful question is, “What does success look like in this role?” This will tell you whether the role is tied to long-term strategic goals or short-term revenue. Follow that up with, “How will I be measured in the first six months versus the next two years?” This demonstrates that you are serious about growth and longevity.
Culture questions are also important. Asking, “Do people tend to hang out or do their own thing?” invites a conversation about the team dynamic, without feeling overly formal or forced.
Preparation Support
You do not need to prepare alone. Use AI tools like ChatGPT, Copilot, or Gemini to help you simulate interviews, organize your thoughts, or analyze job descriptions. Ask the AI to role-play as an interviewer and challenge you with platform-specific or scenario-based questions.
Use those tools to map out which metrics, frameworks, and features align with each platform. You want your prep to feel structured so you can walk into the interview with clarity and confidence.
Ultimately, interviews are not just an audition. They are a dialogue. Prepare thoroughly, think critically, and lead with the mindset of a strategist. That is how you stand out in a sea of applicants, and that is how you set yourself up for success.
If you have a PPC question you want answered in a future edition of Ask the PPC, send it in. Whether you’re prepping for interviews, troubleshooting performance issues, or pitching channel expansion, we are here to help.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
A sharp-eyed search marketer discovered the reason why Google’s AI Overviews showed spammy web pages. The recent Memorandum Opinion in the Google antitrust case featured a passage that offers a clue as to why that happened and speculates how it reflects Google’s move away from links as a prominent ranking factor.
Ryan Jones, founder of SERPrecon (LinkedIn profile), called attention to a passage in the recent Memorandum Opinion that shows how Google grounds its Gemini models.
Grounding Generative AI Answers
The passage occurs in a section about grounding answers with search data. Ordinarily, it’s fair to assume that links play a role in ranking the web pages that an AI model retrieves from a search query to an internal search engine. So when someone asks Google’s AI Overviews a question, the system queries Google Search and then creates a summary from those search results.
But apparently, that’s not how it works at Google. Google has a separate algorithm that retrieves fewer web documents and does so at a faster rate.
The passage reads:
“To ground its Gemini models, Google uses a proprietary technology called FastSearch. Rem. Tr. at 3509:23–3511:4 (Reid). FastSearch is based on RankEmbed signals—a set of search ranking signals—and generates abbreviated, ranked web results that a model can use to produce a grounded response. Id. FastSearch delivers results more quickly than Search because it retrieves fewer documents, but the resulting quality is lower than Search’s fully ranked web results.”
“This is interesting and confirms both what many of us thought and what we were seeing in early tests. What does it mean? It means for grounding Google doesn’t use the same search algorithm. They need it to be faster but they also don’t care about as many signals. They just need text that backs up what they’re saying.
…There’s probably a bunch of spam and quality signals that don’t get computed for fastsearch either. That would explain how/why in early versions we saw some spammy sites and even penalized sites showing up in AI overviews.”
He goes on to share his opinion that links aren’t playing a role here because the grounding uses semantic relevance.
What Is FastSearch?
Elsewhere the Memorandum shares that FastSearch generates limited search results:
“FastSearch is a technology that rapidly generates limited organic search results for certain use cases, such as grounding of LLMs, and is derived primarily from the RankEmbed model.”
Now the question is, what’s the RankEmbed model?
The Memorandum explains that RankEmbed is a deep-learning model. In simple terms, a deep-learning model identifies patterns in massive datasets and can, for example, identify semantic meanings and relationships. It does not understand anything in the same way that a human does; it is essentially identifying patterns and correlations.
The Memorandum has a passage that explains:
“At the other end of the spectrum are innovative deep-learning models, which are machine-learning models that discern complex patterns in large datasets. …(Allan)
…Google has developed various “top-level” signals that are inputs to producing the final score for a web page. Id. at 2793:5–2794:9 (Allan) (discussing RDXD-20.018). Among Google’s top-level signals are those measuring a web page’s quality and popularity. Id.; RDX0041 at -001.
Signals developed through deep-learning models, like RankEmbed, also are among Google’s top-level signals.”
User-Side Data
RankEmbed uses “user-side” data. The Memorandum, in a section about the kind of data Google should provide to competitors, describes RankEmbed (which FastSearch is based on) in this manner:
“User-side Data used to train, build, or operate the RankEmbed model(s); “
Elsewhere it shares:
“RankEmbed and its later iteration RankEmbedBERT are ranking models that rely on two main sources of data: _____% of 70 days of search logs plus scores generated by human raters and used by Google to measure the quality of organic search results.”
Then:
“The RankEmbed model itself is an AI-based, deep-learning system that has strong natural-language understanding. This allows the model to more efficiently identify the best documents to retrieve, even if a query lacks certain terms. PXR0171 at -086 (“Embedding based retrieval is effective at semantic matching of docs and queries”);
…RankEmbed is trained on 1/100th of the data used to train earlier ranking models yet provides higher quality search results.
…RankEmbed particularly helped Google improve its answers to long-tail queries.
…Among the underlying training data is information about the query, including the salient terms that Google has derived from the query, and the resultant web pages.
…The data underlying RankEmbed models is a combination of click-and-query data and scoring of web pages by human raters.
…RankEmbedBERT needs to be retrained to reflect fresh data…”
A New Perspective On AI Search
Is it true that links do not play a role in selecting web pages for AI Overviews? Google’s FastSearch prioritizes speed. Ryan Jones theorizes that it could mean Google uses multiple indexes, with one specific to FastSearch made up of sites that tend to get visits. That may be a reflection of the RankEmbed part of FastSearch, which is said to be a combination of “click-and-query data” and human rater data.
Regarding human rater data, with billions or trillions of pages in an index, it would be impossible for raters to manually rate more than a tiny fraction. So it follows that the human rater data is used to provide quality-labeled examples for training. Labeled data are examples that a model is trained on so that the patterns inherent to identifying a high-quality page or low-quality page can become more apparent.