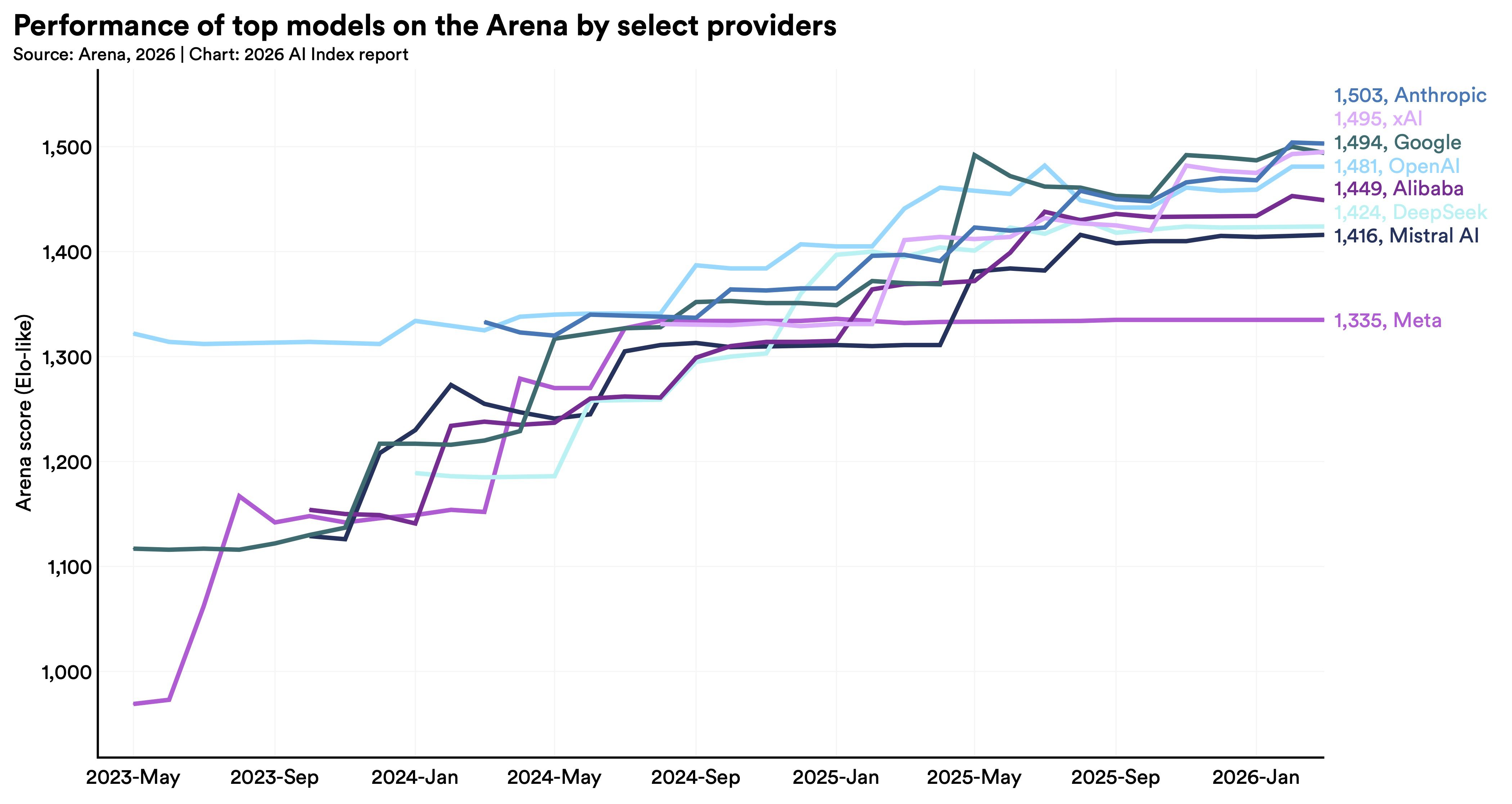
How To Break Through An Affiliate Site Plateau & Find New Growth – Ask An SEO via @sejournal, @rollerblader

This week’s Ask an SEO question is:
“I’ve been running an affiliate site for 2 years but hit a plateau. What advanced data analysis techniques can help me identify new growth opportunities that I might be missing?“
This is one of my favorite questions that come up at conferences and in the affiliate marketing programs we manage. Most of the time, the affiliate submits their site or niche, and I can give direct examples and opportunities. But for this, we want to keep everything anonymous, so I’ll share the processes and ideas so you and anyone else reading can implement, no matter what industry, type of content, etc., you produce.
Breaking The Plateaus
There are a few plateaus affiliates face more than others, including:
- Traffic stagnation.
- New products and services for recommendation.
- Revenue flat lines.
- Topics to talk about.
These are the most common with this question, so I’ll focus on them. If anyone reading this has hit a different one and is looking for ways to overcome them, send the question through my author bio page here. If I’ve worked through it, I’ll do my best to answer it in an upcoming column.
Traffic Stagnation
If you have a website and traffic has stagnated because you dominate for all the main queries and topics, look outside your own writing and knowledge base for help. Instead of hiring writers to help with more content based on what exists within your platform, try funneling new visitors in from other platforms (websites, podcasts, apps, etc.) or bringing people in to create unique content for you by featuring them and asking them to promote it.
To find new topics, ideas, and questions people have, adding a forum or community can help bring new traffic and ideas to your website or community. Some search engines like Google tend to reward this authentic user-generated content, but it does come with a decent amount of manual labor with monitoring and quality control. The benefit here is you build a community that creates content for you.
Pro-tip: Add a prompt on the main website pages like “question not answered, click here to ask the community,” where it goes to the forum, or have it go to an answer box where you collect it and create a new guide. Similar to how Search Engine Journal has a “Submit Questions” section for me and other “Ask an” columnists.
The UGC can begin showing up in Google as well as LLMs like ChatGPT, Perplexity, and Claude, and you can begin getting new traffic in and a new user base. This can all be monetized. But maybe you don’t want the hassle and risk of a UGC platform; there are more options.
Take your top guides and articles and begin turning them into videos. A long-form video can help with YouTube and bringing in traffic; it can be uploaded to Skool if you create a course. Skool and other platforms let you charge a fee for access, and each chapter in the video can become a long-form video or a short that works for YouTube, TikTok, and likely Instagram. With the exception of the shorts, affiliate links can be used on all of these platforms. The benefit of videos is a lot of the platforms like YouTube can be steady streams of traffic vs. IG or TikTok where it only lasts for a couple days to a week.
Now begin adding text versions to social media platforms in ways that fit. LinkedIn allows long-form and encourages users to ask questions, answer polls, and then you can link to your website. Bluesky and X are short-form but allow quick and easy links to your website or pages, although the traffic is in short bursts. Pinterest is short form, but image-heavy, and a pin that is done well and gets attention can be consistent traffic for a year and sometimes longer.
Some partners decide they want to start podcasting. Every topic on your website can become a theme or session, or combined into a really strong one that becomes a course you can monetize. Find other people with complementary knowledge and/or who have audiences and invite them to participate. You’ll be helping to grow each other’s traffic and sharing expertise. Sometimes your guest may spur new content ideas for you, too.
New Products And Services And Fixing Revenue Flatlines
When you run out of products and services to promote, or you’re hitting the highest AOVs available, revenue begins to flatline. While you cannot control what happens on the merchant or lead gen website’s funnel, you can control how you make money. This is an affiliate post so I won’t talk about driving higher EPCs and CPMs or getting pageviews to increase ad media, instead it is about using affiliate links and offers.
Here’s where to begin looking.
Survey Your Audience Or Use Your Analytics For Demographics
Having your audience’s demographics, including age, urban/rural/suburban, likes and interests, and anything else, can make you a ton of money. If it turns out the majority have dogs and are urban, but you run a cooking site, add in pet-friendly matching recipes or toys for dogs that get them exercise and stimulation when they cannot be outside more regularly to burn energy.
If the same demographics are local-based, like a group for parents in New England, create snow day resources where you review family-friendly tabletop games for snow days, lists of local restaurants across the area that offer kids eat free or family deals, and affordable snowbird family vacations.
If your audience has a large portion in rural areas, think about the ingredients that are hard to come by in rural areas due to smaller grocery stores, then share online resources to access them. This is a low-hanging fruit item I see as recipe sites will focus on the tools and products, but they can also monetize ingredients.
Learn What Else They’re Into
Once you know who your audience is and where they skew demographically, survey them to find their interests. If you can’t get them to take surveys, even with incentives like gift cards or prizes via a drawing (assuming it’s legal where you and your audience live), look up free research documents and use your marketing skills to find hobbies, stores, and associations that have similar audiences.
Maybe your audience is 50-year-old suburbanites that love bird watching. You’ve already maxed out sportswear and hiking equipment, same with books on birds and binoculars. Maybe it turns out they’re also into photography, so you can sell cameras, photo storage solutions, ways to print the photos and sell them, editing software, and guides to using the camera and setting up different types of shots.
It could also turn out they love to travel. Create guides of where to go that are friendly for people 50-60 years old, including the types of birds that they could see in each spot along the route, and what to pack based on the season, as weather can change. You can now use affiliate links for hotels and airfare, travel supplies, camera bags for different climates, and ebooks or physical books with trail maps, travel guides, and bird watching books to check off the ones they see.
You do need to watch adding too much content that is not the core topic of your channel, so you don’t accidentally uncategorize your platforms for SEO or alienate your core reader base. When you go off topic too often, you chase away current and new subscribers while also confusing algorithms. This is easy to resolve with tech SEO by using metarobots or robots.txt, and having an editorial calendar, but that is a different topic.
Now you have new products and services to promote, new merchants to work with, and this leads to more affiliate sales, increasing your revenue. Shopping guides, comparison grids, listicles, etc.
New Topics To Talk About
Above, I mentioned podcast guests, UGC, and a few ways that can spark new ideas for topics when you run out of things to talk about. So here are a few other ways I break writer’s block with the programs I work on for myself, for clients, and the affiliates in our programs.
- AlsoAsked.com: You plug in a topic like “running shoes,” and it spits out a ton of potential questions about them. From there, I go to Google or an LLM and type it in, then I look to see what shows up. To go a step further, I may ask, “What are similar questions to this one?” or “What are complementary but different questions to this one?” as a second query to see what I may be missing.
- Rank trackers: Take a URL for a blog or forum and plug it into a rank tracking tool. It’ll provide a list of keywords, questions, and phrases it shows up for.
- Comments: Read the comments on YouTube videos for channels that are directly related to your business. These are things people want to know about and can be a way to get new traffic while breaking writer’s block.
- AI and LLMs: Ask AI for a list of ideas that are related but not covered on your platform yet, and then have it double-verify. Not everything it recommends will be relevant, but it could spark ideas for you.
There are almost always solutions to preventing stagnation for affiliates, no matter if it is traffic, revenue, topics, or products and services to promote. You may need to expand your offerings to other types of products and services that match the same demographics or look to other platforms and competitors for content inspiration. I hope this helps, and thank you for asking.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal