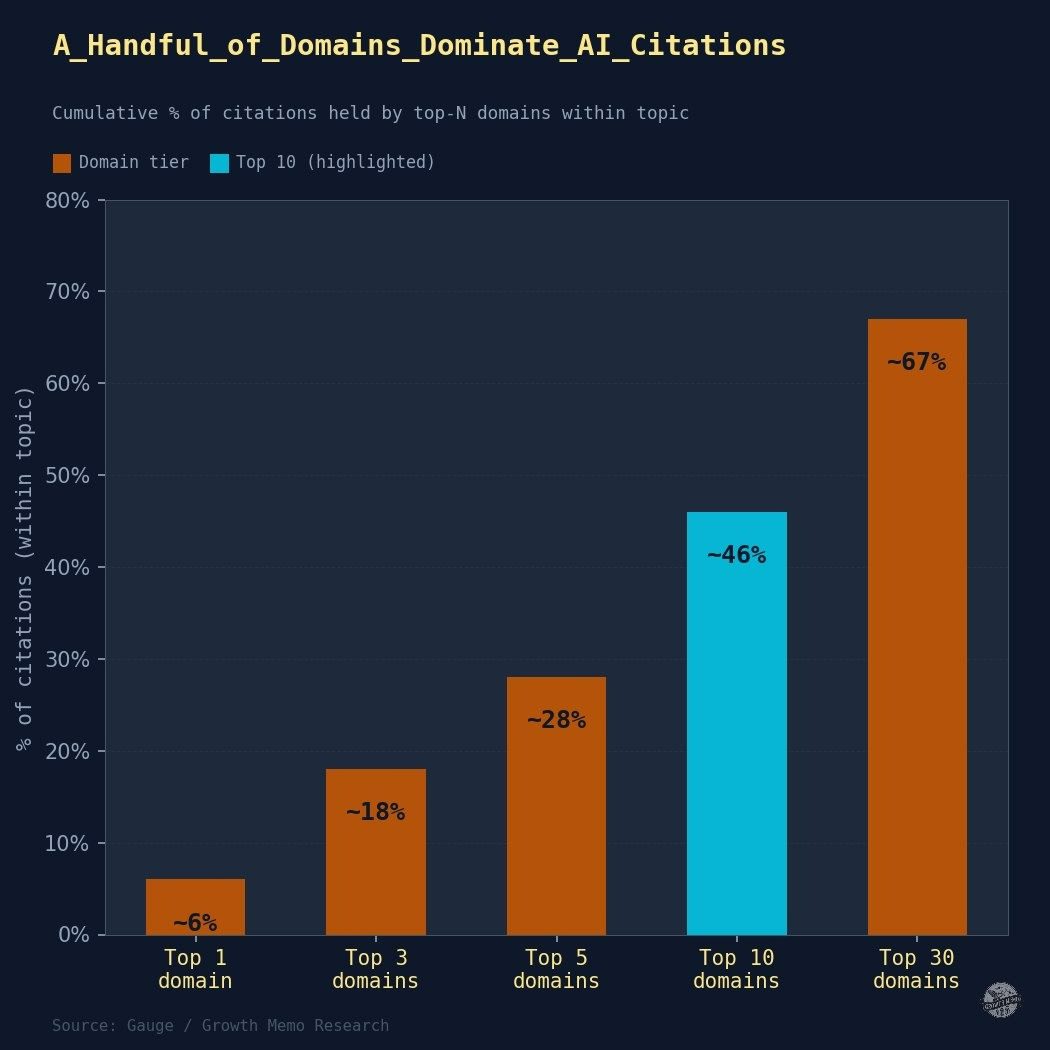
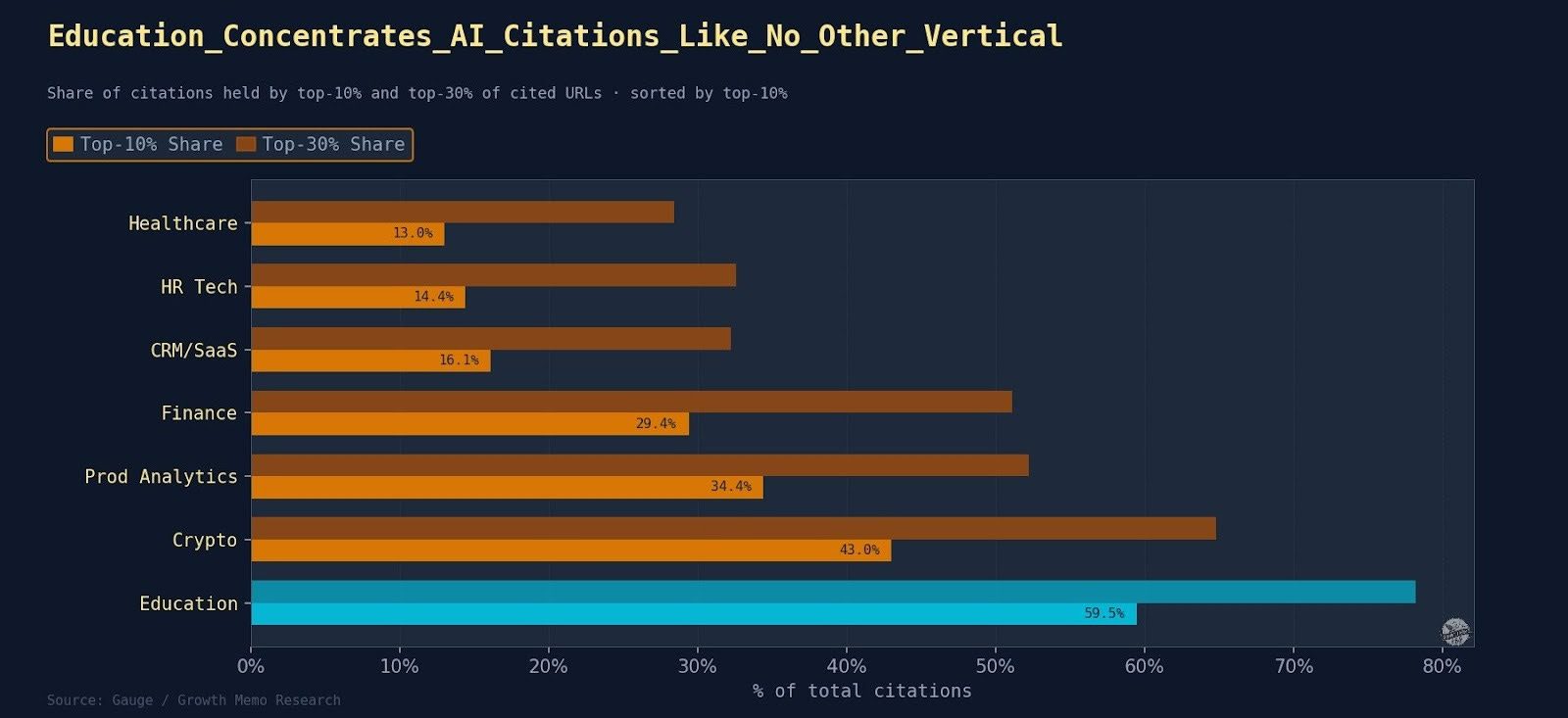
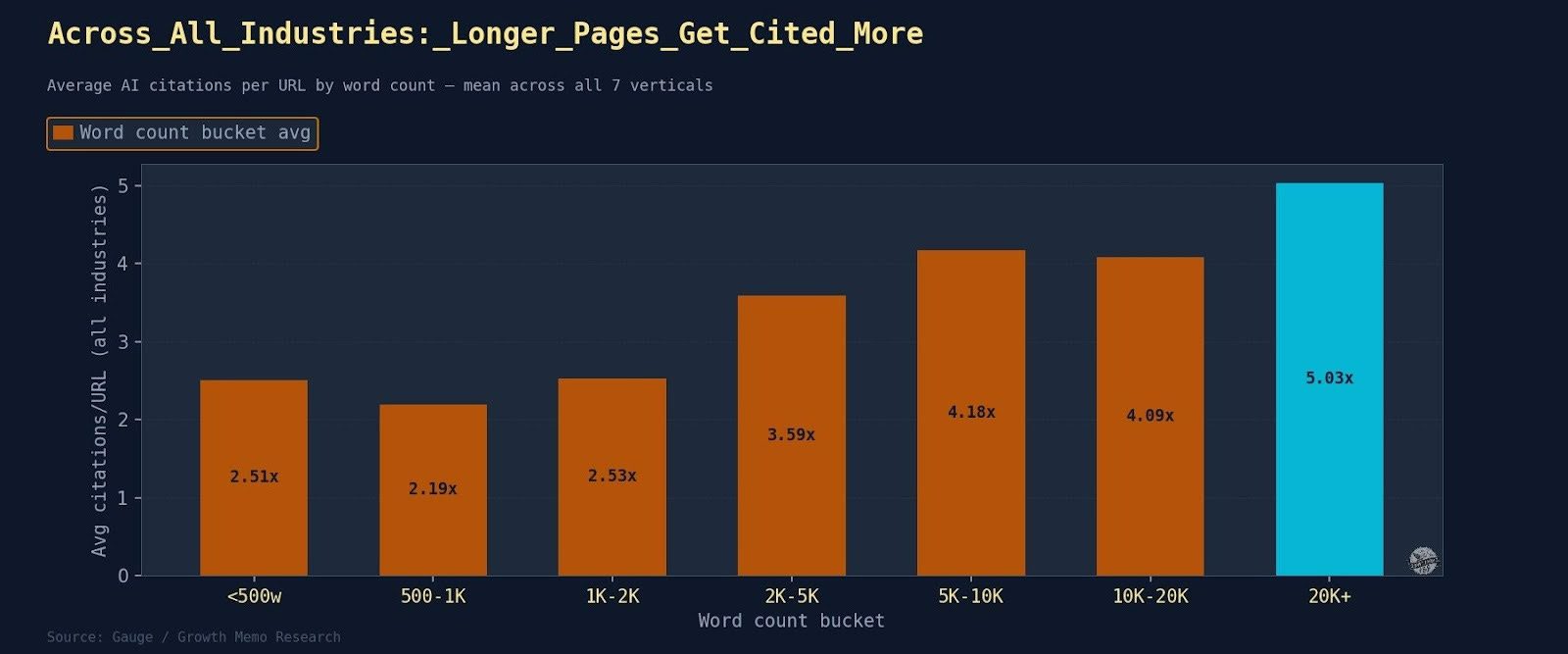
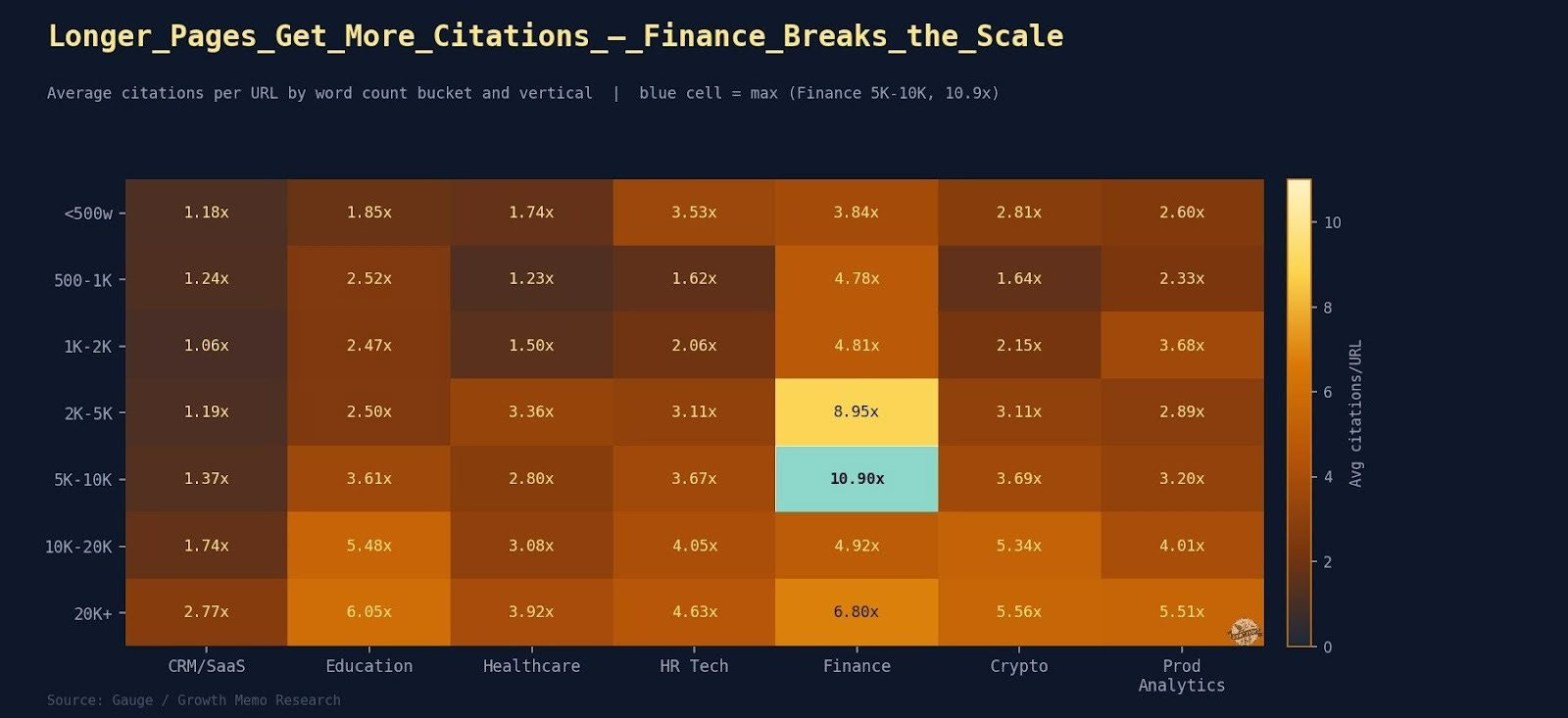
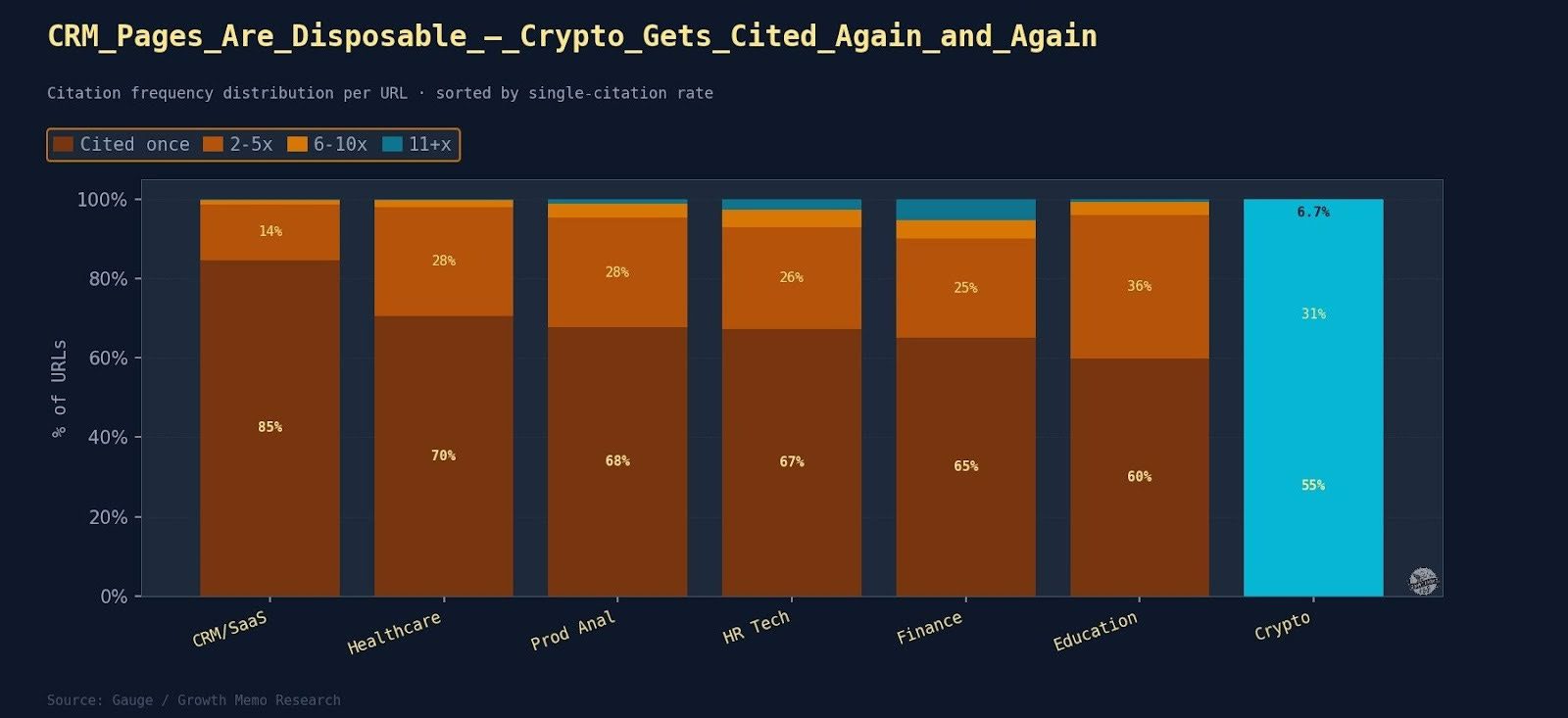
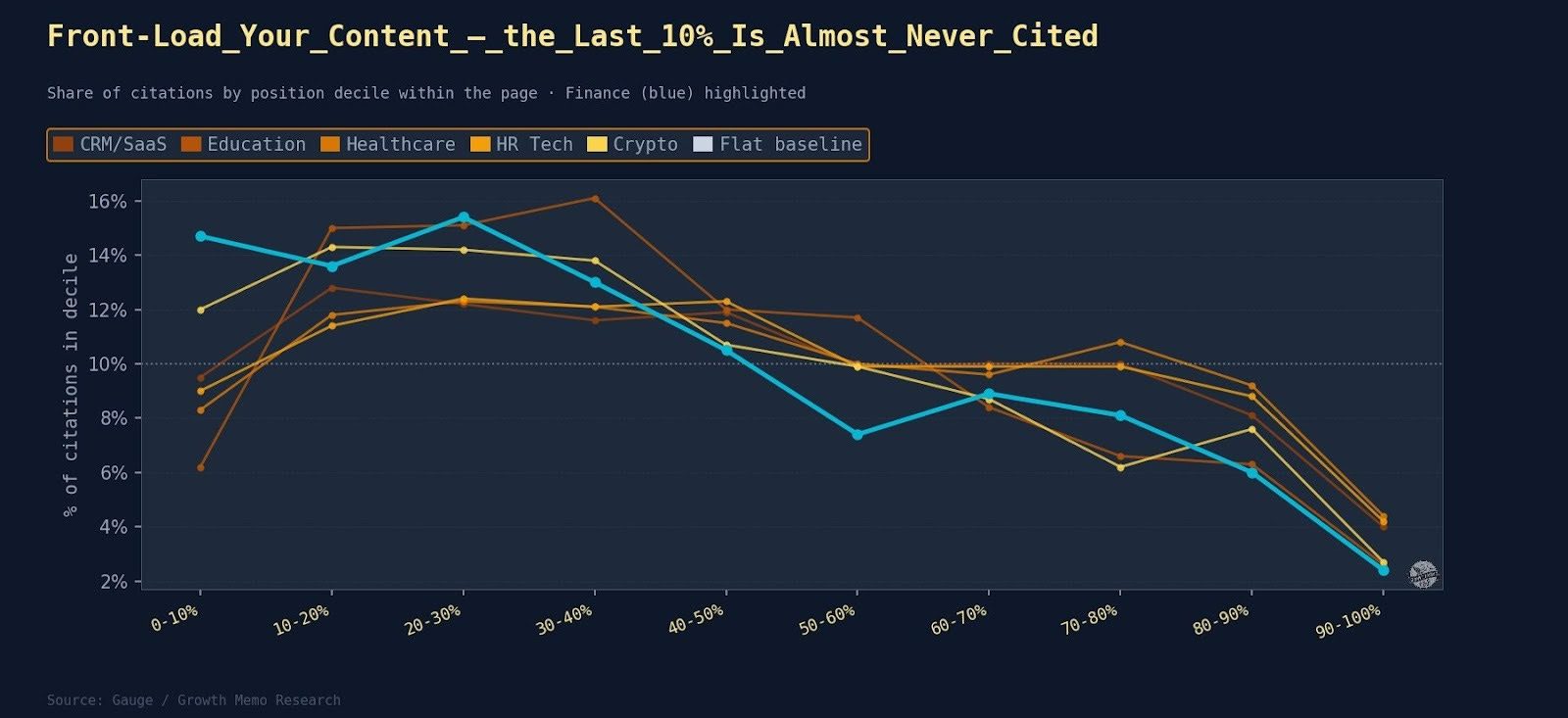
Search is moving from queries typed into a box to conversations held with systems that understand intent, context, and outcomes. People no longer look for pages. They look for solutions, guidance, and confidence that they are making the right choice.
Agentic AI pushes this shift further. Instead of waiting for instructions, agents act on goals. They discover information, compare options, trigger workflows, and adjust based on feedback. For digital leaders, this means visibility is no longer only a ranking problem. It becomes a problem of influence inside AI systems.
SEO now touches product, data, knowledge management, and experience design. This playbook explains how to prepare for that shift, build capability, and lead change.
Search Is Becoming AI-Mediated
AI systems have become the layer between users and the web. They read content on behalf of users, make selections instead of requiring users to browse, and influence decisions in ways that search pages once did.
This shift changes how people interact with information. Users now ask broader, more complex questions, expecting systems to understand nuance and intent. The traditional act of navigating through links is giving way to direct answers and immediate actions.
Content can no longer be designed solely for human readers. It must also be structured in ways that AI systems can interpret accurately and confidently. In this environment, trust and evidence carry more weight than keywords or search optimization tactics.
Winning in search today means becoming part of the models that shape decisions, not just appearing in the results.
What Agentic AI Means For SEO And Digital
Agentic AI is changing how people discover and choose brands. Discovery now depends on how well models learn from your content, the paths users take on your site, and the external signals that establish credibility. These systems decide when your brand is relevant, based on what they understand and trust.
During evaluation, AI compares your product, price, quality, reviews, and suitability for a given user against other options. It looks for proof, tests claims, and weighs real signals over marketing language.
When supporting decisions, AI doesn’t just provide information. It actively guides users toward what it considers the best fit. Your brand might be brought forward or quietly passed over, depending on how well it matches user needs.
In this landscape, SEO is no longer just about publishing content. It’s about shaping how AI systems perceive your brand and when they choose to recommend it.
New Operating Model For SEO
The future of search brings marketing, product, and data teams into a shared effort. Success depends on how well these areas work together to shape how AI systems perceive and present your brand.
The key is building structured knowledge that AI can easily process and apply. Instead of designing for clicks and views, focus on creating journeys that help users complete tasks through the systems guiding them. It’s also critical to train these systems with the right brand messages, supported by clear evidence and consistent proof points.
Ongoing visibility requires monitoring how models reference your brand, how they rank it, and how they reason about its relevance. This means continuously refining the signals you send, improving your content, updating product data, and reinforcing trust in every interaction.
The goal remains clear and hasn’t really changed from our technical goals for SEO. Make it easy for AI agents to understand, trust, and ultimately recommend your brand.
Maturity Model
| Level |
Name |
Description |
Key indicators |
| 0 |
Manual SEO |
Basic optimization and manual workflows |
Keyword focus, isolated content execution, minimal data alignment |
| 1 |
Assisted SEO |
AI supports research and content creation |
AI‑assisted briefs, content suggestions, faster execution, manual oversight |
| 2 |
Integrated AI workflows |
Core SEO tasks automated and structured |
Content pipelines, structured data adoption, automated QA, analytics integration |
| 3 |
Agent‑driven operations |
Agents monitor, trigger, and refine SEO |
Automated reporting, performance triggers, self‑adjusting content modules |
| 4 |
Autonomous acquisition systems |
Self‑improving systems tied to revenue |
Continuous testing, adaptive journeys, revenue‑linked triggers, real‑time optimization |
The goal is not automation alone. It is intelligence and improvement at scale.
Technical And Data Foundations
To prepare for agentic SEO, organizations need more than traditional content systems built for publishing. They need strong foundations that help AI systems understand, evaluate, and act with confidence.
This starts with clarity, which means crafting messaging that is consistent, accurate, and easy for machines to interpret. Structure is also essential, requiring content, data, and signals to be organized in ways that align with how AI systems process and reason through information.
Key components of this are:
- Structured data that turns content into machine‑readable knowledge.
- Knowledge graphs that explain relationships between products, categories, and needs.
- Taxonomy and naming standards to ensure consistency across pages, feeds, and assets.
- APIs and automation for publishing and optimization, so agents can trigger updates.
- Clean product and service data, including specifications, pricing, and availability.
- Evaluation systems to audit AI outputs and detect hallucinations or misalignment.
- Identity and trust signals, including reviews, authority, certifications, and product proof.
This calls for a shift from simply building web pages to creating a well-organized information architecture. The goal is to structure information in a way that AI systems can easily navigate, understand, and apply.
In practice, this means bringing together product data, content metadata, and customer intent into a single, connected system. It involves defining the key entities your business represents, such as products or services, and mapping how they relate to what users are trying to accomplish. Content feeds and structured data should reflect the actual state of the business rather than just marketing language.
Equally important is creating feedback loops that show how AI systems interpret and reference your brand. These insights help you see where your content is being used, how it is being understood, and whether it is guiding users toward your brand. With this information, you can keep refining what you share to improve how systems recognize and recommend you.
Instead of asking, “How do we rank for this query?” leaders will ask, “How do systems understand us, trust us, and act on our information?”
KPI And Measurement Model
Traditional key performance indicators still hold value, but they no longer capture the full picture. Rankings and session metrics continue to provide insight, yet they now exist within a broader framework shaped by how AI systems retrieve, interpret, and act on information. Ranking reports will sit alongside AI retrieval dashboards, and session counts will be evaluated alongside metrics focused on task completion and user outcomes.
In my opinion, you should also be looking to monitor:
- Share of voice in AI assistants.
- Retrieval and inclusion rate in AI answers.
- Brand alignment and brand safety in model outputs.
- Presence in multi‑step reasoning chains.
- Task completion and conversion paths from AI systems.
- Cost per automated workflow and cost per agent‑driven action.
- Model education, data freshness, and trust scores.
As measurement evolves, the focus moves from tracking visitor numbers to understanding how AI systems shape decisions. To navigate this shift, leaders should design metrics that reflect influence within these systems. Visibility will measure whether the brand is appearing in AI-generated responses and assistant-led interactions.
Accuracy will assess whether the brand is being represented correctly and safely across touchpoints. Trust will reflect whether AI systems choose your content and signals over others when making recommendations. Action will capture whether AI-driven experiences result in tangible outcomes like leads, bookings, or purchases. Efficiency will show whether AI agents are reducing manual effort, improving speed, and delivering better user experiences.
Success will no longer be defined by visibility alone but by a brand’s ability to perform across discovery, decision support, and operational impact.
Talent And Capability Model
Agentic SEO is not a standalone skill set, it draws from a mix of disciplines that span marketing, data, and product. Success in this space requires a collaborative approach, where expertise is integrated rather than siloed.
Future-facing teams bring together SEO and content strategy, data and automation engineering, product and user experience thinking, as well as governance and prompt development. Legal and compliance awareness also play a critical role, ensuring that outputs remain responsible and aligned with brand and regulatory standards.
These teams operate in cross-functional pods, organized around delivering customer outcomes rather than managing individual channels. This structure allows them to move faster, adapt to change, and create more cohesive experiences across AI-driven platforms.
Modern SEO teams include several key roles. The SEO strategist focuses on how AI systems search, retrieve, and rank content. The data engineer manages the integrity of structured content, metadata, and live data feeds. The automation specialist builds the workflows and agents that connect information to user actions. The AI evaluator audits model outputs to ensure accuracy, brand alignment, and safety. The product partner bridges SEO efforts with real user journeys, making sure that discovery leads to meaningful interaction and conversion.
As this approach matures, teams will spend less time producing content manually and more time designing the systems, signals, and experiences that guide AI behavior and improve how users discover and engage with the brand.
The First 90 days
Days 1 To 30: Foundation And Alignment
- Audit content, data, and search performance.
- Map where AI already touches customer journeys.
- Identify gaps in structure, trust signals, and data quality.
- Set goals for AI visibility and agent‑driven workflows.
Days 31 To 60: Build And Test Pilots
- Launch structured data and knowledge base improvements.
- Test AI‑assisted content and QA pipelines.
- Introduce early agent monitoring for SEO signals.
- Create evaluation benchmarks for AI accuracy and brand safety.
Days 61 To 90: Scale And Govern
- Deploy automation in high‑impact workflows.
- Formalize model governance and feedback loops.
- Train cross‑functional teams on AI‑ready processes.
- Build dashboards for AI visibility, trust, and conversion.
Future Outlook
Search will not disappear. It will merge into tasks, journeys, and decisions across devices and interfaces. Brands that train AI systems, structure knowledge, and build agent‑ready operations will lead.
The winners will not be those who automate content. They will be those who help users and systems make better decisions at speed and scale.
More Resources:
Featured Image: Collagery/Shutterstock