22 SEO Experts Offer Their Predictions For 2025 via @sejournal, @theshelleywalsh

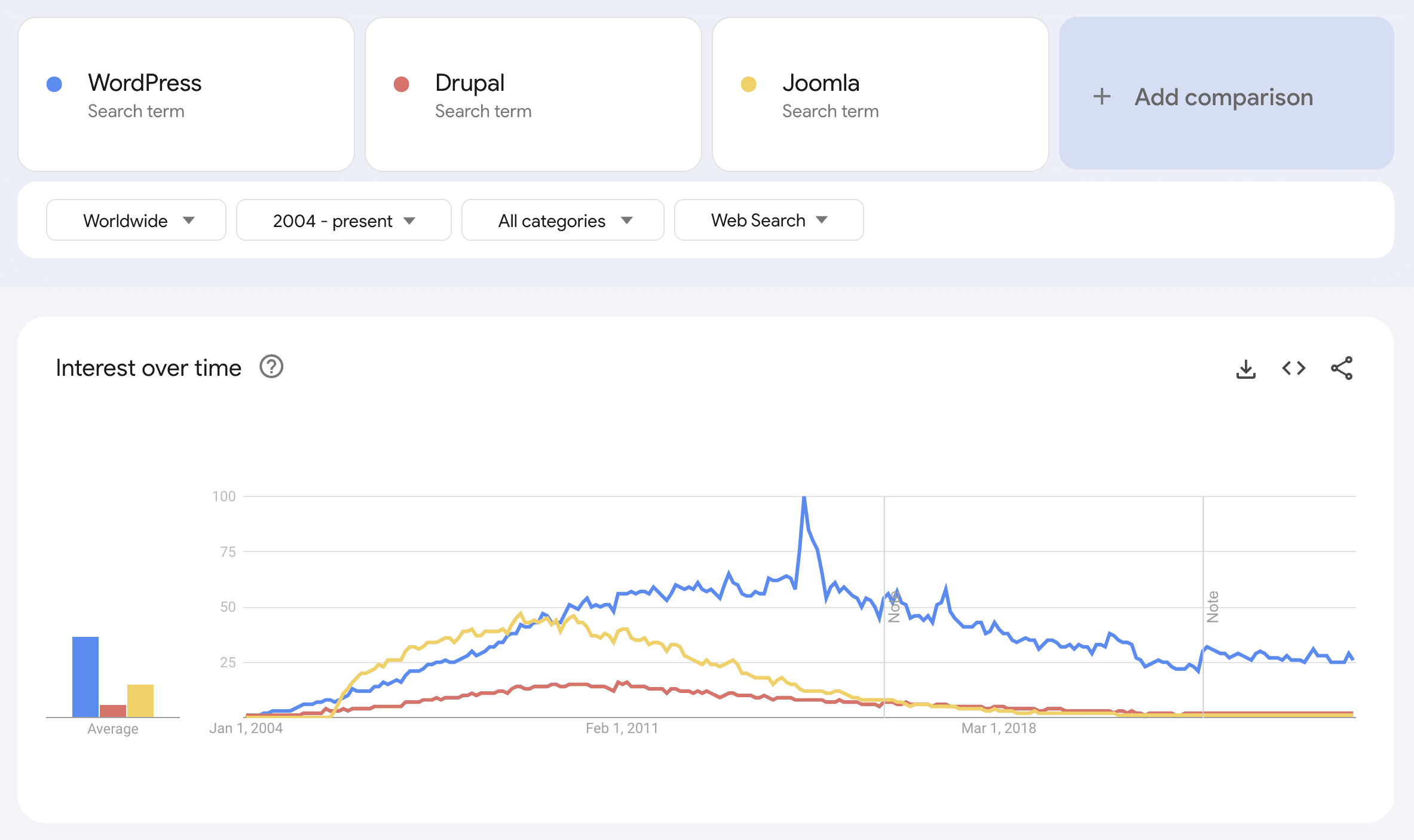
This year continued with the same theme as the year before – a bombardment of updates and rapid developments in AI.
AI Overviews were introduced in May, which then saw a drop in organic traffic alongside major drops from Google updates.
It’s not been an easy year in SEO.
Whereas last year was considering how AI tools could be leveraged to augment our work, this year has been the acceptance that Google SERPs are changing and not delivering the same levels of organic traffic as before.
This introduction of AIO and the uncertainty of Google organic traffic has accelerated the move towards SEO becoming “marketing.”
Moving forward, SEO is now as much about branding and marketing as it is about what we used to know about SEO.
To make this transition, everything that you were doing in SEO needs to be reconsidered. The future of online marketing will involve being found in generative AI apps, AI-powered search engines, social media, forums, and communities.
The bottom line is that SEO is now marketing, and that could be challenging for anyone who holds on to a one-dimensional SEO mindset.
As is our tradition this time of year, we turned to some of the best minds in the industry to get their thoughts on where the industry is going and what might happen next.
We asked 22 of the best practicing SEO professionals: In your expert opinion, what should SEO pros focus on in 2025 to maintain visibility and get results?
1. Focus On The Fundamentals
Jono Alderson, Consultant at Jono Alderson
Make 2025 the year you actually optimize your website. Forget shiny new toys and focus on the fundamentals.
Fix your errors. Make it faster. Make it more accessible. Improve the UX. Correct the typos. Redirect the broken links. Clean up the mess.
And while you’re at it, trim the fat. Remove the zombie pages that nobody visits. Prune your bloated navigation. Consolidate duplicate content.
Fix those annoying forms that never seem to work. Make your images smaller. Stop auto-playing videos. Test your site on a cheap phone on bad Wi-Fi and see how frustrating it is. Then fix that, too.
SEO professionals are so busy chasing trends, tweaking metadata, and begging for backlinks that we’ve lost sight of what really matters: creating a website that works beautifully for users.
A faster, simpler, cleaner site isn’t just better for people – it’s better for search engines, too. Do the unglamorous work. Google notices, and so does the market.
2. Focus More On UX
Arnout Hellemans, Consultant at Online Market Think
Here are a few tips for SEO pros to focus on in 2025:
Stop focussing on keywords and shift to user intent. Look at SERPs into all the questions users have.
Check the People Also Ask (PAA) features and check if your article satisfies that intent on the page.
Focus more on the UX (usability, site speed).
If you want to get traffic from other AI discovery engines, check your website without JavaScript. You can use SSR or pre-render your webpages, so that other crawlers can consume your content too.
3. Start Considering Awareness And Upper Funnel Metrics
Ryan Jones, Senior Vice President at Razorfish
2025 will be the year when we finally treat SEO like full-funnel marketing.
SEO pros will have to move beyond just measuring clicks and start considering awareness and upper funnel metrics as users less frequently desire websites in favor of AI, instant answers, and other search features.
SEO pros will still be needed to help influence these features and ensure brands show up, but we’ll have to focus on user intents – the queries where users want to do or accomplish something – over high search volumes.
4. Start With Video-First Content
Mark Williams-Cook, Digital Marketing Director at Candour
Over the past 20 years, we’ve consistently seen Google take steps to keep users on their SERP, as it’s more profitable for them.
In its Q3 announcement, it revealed a 90% reduction in the cost of generating AIOs, signaling even more aggressive deployment of these and AI-organized results in ecommerce.
This likely means a decline in traffic to “solved” knowledge and informational spaces – though that’s not necessarily a bad thing for the web (how many lasagna recipes does humanity really need?).
On the other hand, we can expect increased traffic from sources like Google Discover and Lens, particularly for non-text content such as video.
I believe those who rely solely on GenAI to generate content directly from LLMs will struggle.
However, those leveraging LLMs to enhance original material – such as generating transcriptions from video—are positioned to benefit, as this top-down approach now feels even more strategically aligned with current trends.
In 2025, I am going to be encouraging clients to start with video-first content and work backwards, with a special focus on Discover and Lens search, which has now been integrated.
5. Diversify Where Your Community Might Be Spending Time Online
Miriam Ellis, Consultant at Miriam Ellis Consulting
A trend to pay particular interest to in 2025 is the diversity of digital platforms to which your potential customers may be going for local business information and recommendations.
2024 has seen many developments that may not be increasing searcher satisfaction, such as the rise of AI Overviews, which can’t be relied on for factual information, and a growing sense that Google search has become less skilled at intent matching.
I’ve fielded sentiment from a range of users encompassing some of the best SEO pros in the world to everyday searchers stating that it’s simply harder than it used to be for them to find what they’re looking for in Google.
While all the traditional SEO and local SEO skills and work remain relevant, diversifying your picture of where your community might be spending time online will be smart work for the year ahead.
In the U.S., we’ve reached a state in which half our counties no longer have access to local news, so people looking for trustworthy, authentic communications about their community will have to look elsewhere. This could include the big social media platforms like Facebook, Instagram, and TikTok, but don’t stop there.
I recommend taking a very good look at Discord to see if it has become a community hub, or if you could turn it into one to increase your neighbors’ awareness of your brand taking an active role in your town or city. YouTube, Reddit, and hyperlocal podcasts are also very strong candidates for contributing to community life.
In summary, while normal SERP visibility will still be essential to your marketing strategy, be sure you’re studying consumers’ shifting behaviors so you can learn to be present wherever they feel information can be trusted.
6. Organize And Structure The Content Hierarchy
Motoko Hunt, Founder & President at International SEO & SEM Consulting
Many SEO pros have been focusing so much on content generation in recent years, especially in 2024 with the help of AI.
It’s time to better organize generated content based on the target audience’s intent and business goals.
- Identify the purpose of each content/page on site.
- Identify the target audience’s intent and stage for each content.
- Group content by topics.
- Create a content tree within the group based on the searcher’s intent and stage.
By organizing and structuring the content hierarchy, you can touch searchers at each stage of their journey and influence their decision-making.
You should also update the content as needed. You want your content to stand out in the sea of similar content out there. Make sure that your content adds value.
With this, the content will not just generate traffic but will contribute to the business growth.
7. Build Author Authority And Explore Alternative Traffic Sources
John Shehata, CEO & Founder at NewzDash and Former Global VP of Audience Strategy at Conde Nast
I believe these key areas will be crucial for SEO success in 2025:
E-E-A-T Is King
Google’s emphasis on experience, expertise, authoritativeness, and trustworthiness will be even more critical.
SEO pros need to build Author Authority by showcasing expert credentials and first-hand experience, and digital and social footprint, especially in niches like health and finance (think doctor bios with links to publications).
Strong Domain Authority still relies on high-quality backlinks, but focus on those that drive traffic.
For Document Authority, create in-depth, entity-focused content that satisfies user intent better than competitors. Think comprehensive guides with clear attribution and original research.
AI Is Your Co-Pilot
AI is transforming search. Optimize for AI-generated answers by structuring content around topics and entities.
For example, instead of just targeting “best running shoes,” create content around “best running shoes for trail running” and “best running shoes for flat feet.”
Use AI tools to scale – not to write – content creation, but maintain a human touch for quality and originality. Think of AI as a research assistant and editor, not a replacement for your own expertise.
Diversify To Thrive
Expect fewer Google clicks with all the new SERP updates, and don’t put all your eggs in the Google basket.
Explore alternative traffic sources like Threads, Reddit, newsletters, and even push notifications.
A diversified approach makes you less vulnerable to algorithm updates and opens up new audience streams.
Adapt And Analyze
Stay informed about algorithm updates and adjust your strategies accordingly. Pay close attention to user behavior on your website to identify areas for improvement.
Tools like heatmaps and scroll maps can provide valuable insights.
8. Create More Q&A Content To Be Present In LLMs
Kevin Indig, Growth Advisor and publisher of The Growth Memo
In my opinion, the big question is, “What is the story of your brand in an LLM world?”
Track sales/revenue/leads from LLM referral traffic like ChatGPT, Perplexity, Gemini, etc. See if this could become meaningful when extrapolating the trend from the last six months out over the next two years.
If so, you want to invest in technical SEO to make crawling easier and create more structured content (like Q&A style content) to be more present in LLMs.
9. Index Licensing Will Become Increasingly Important
Jes Scholz, Marketing Consultant at JesScholz Consulting
The Bing index powers ChatGPT (and thus will be integrated into Siri), as well as Microsoft Copilot and many answers of Meta AI.
It’s also leveraged by smaller search engines, including Yahoo, DuckDuckGo, and Ecosia.
While other players, like Perplexity, aim to build their own index, it’s clear that index licensing will become increasingly important as the search landscape diversifies.
This means SEO marketers need to expand their focus beyond Google from an indexing perspective.
Now is the time to revisit Bing Webmaster Tools. Conduct a content audit using XML sitemaps for each page type to compare indexing rates on Bing versus Google.
If either search engine is missing valuable content, prioritize crawling and indexing optimization.
Because no matter the surface – whether it’s in traditional SERPs, AI-powered SERPs, chatbots, Google Discover, Google Shopping, or elsewhere – if your content isn’t indexed, you have no chance to earn visibility.
10. Build Relationships With Other Well-Ranking Sites In Relevant Industries
Glen Allsopp, Fonder at Gaps.com
One recommendation I have for 2025 is to actively study as many of the main search results you’re trying to rank in, see what Google is rewarding, and look to get involved in those sources.
Bear with me – it gets better.
Besides traditional service or shopping pages, there’s a good chance you’ll also see:
- Guides recommending products and services.
- YouTube videos.
- Similar but non-competing brands.
- Interviews.
- Tweets.
- Forum posts.
- Reddit posts.
While a simplified goal of SEO is to get more targeted search traffic to your own website, you shouldn’t ignore the possibility of getting more exposure via creating videos, being involved in relevant Reddit communities, and so on.
One of the most effective things I’ve done is build relationships with other well-ranking sites in relevant industries. Even better if you’re in the same space but don’t compete on the end product you’re selling.
You would be surprised how open people are to also cover your product, service, or content when they get to connect with a human who actually cares about what they’re working on.
It’s far from the most important or only thing you should be doing, of course, but it’s always good to expand your marketing horizons.
11. Building And Enriching Knowledge Graphs With Well-Defined Entities Is Key
Andrea Volpini, CEO and Co-Founder of Wordlift
SEO professionals and marketers should optimize for both human and AI audiences, particularly large language models (LLMs).
LLMs excel at processing structured, concise text but often struggle with complex, visually rich websites.
Providing clear, organized, and dense content – such as markdown files or LLM-specific resources like /llms.txt – helps LLMs better understand and represent your brand to users.
Structured data remains essential for search visibility and enhancing AI-driven customer experiences. It enables training models, improving content suggestions, and supporting advanced features like conversational search.
Understanding how LLMs function is equally critical. These models can be interpreted through monosemanticity – the ability to extract precise, entity-like features from their deep neural networks.
SEO pros should focus on creating clear, entity-rich content and evaluating how these entities align with openly distributed models.
Building and enriching Knowledge Graphs with well-defined entities is key. This approach ensures LLMs can effectively contextualize your content, unlocking new optimization opportunities and improving both AI and human experiences.
12. Sit And Sync With Comms
Mordy Oberstein, Founder of Unify Brand Marketing
Let’s define “maximum visibility” for a second. Do we mean as many eyeballs as possible as quickly as possible? If so, I have no tips for you.
On the other hand, if we mean being visible as much as possible in as meaningful a way as possible, then I have one tip for you: Sit and sync with comms.
Be aligned with and on board with your company’s or client’s comms or brand department. Understand where they want to go. Understand how they see the company’s identity, positioning, and the messaging they want to send.
Be a part of that process. Help them align and amplify that positioning and messaging. Help the brand become what it aims to be.
We’re entering a digital winter. There is so much volatility and so much dysfunction (hello, search and social algorithms).
Most of all, there is so much noise. It’s much harder for your audience to tune it all out and to allow themselves to be impacted by what you’re putting out there.
That’s a huge hurdle to overcome. We’ve become inundated and numbed to all of the digital content thrown at us. And we’re only getting more inundated and more numb.
There’s a huge need for resonance. Your content needs to be crafted in a way that can cut through all the noise and resonate.
There’s not a whole lot of point in grabbing as much traffic as possible if it’s not going to be “seen” by the audience.
That old model of garnering as much visibility as possible is outdated. It’s better to be purposeful more than anything. And to do that, SEO pros can no longer afford to be siloed.
Sitting with whoever is running the overall communications strategy is an absolute must. It leads to a healthier approach and better outcomes. It’s what will drive visibility that actually matters.
13. Know Who Your Customers Are, Create Resonant Messages, And Deliver Value
Ameet Khabra, Founder at Hop Skip Media
Fully embrace artificial intelligence (AI) and machine learning (ML) in every part of marketing.
This is about so much more than automating PPC campaigns, though that’s a huge part, especially since Google is retiring manual bid controls like eCPC.
The marketers who will succeed are the ones who can make the most of AI and automation while keeping that human touch to connect with customers.
Build strong first-party (1P) data sets, as third-party (3P) cookies will continue to fade away, and privacy rules will get stricter.
This is all about the information you gather directly from your customers – their website habits, how they interact with your brand, and what they’ve bought.
Those who invest heavily in tools and strategies to collect 1P data will be able to deliver compelling experiences at every point of the buyer’s journey.
You must also incorporate that data into creating experiences that catch your customer’s attention.
Create immersive, interactive experiences that capture attention and spark emotion, and look beyond the screen to voice interfaces, wearables, and wherever your customers engage.
It’s the brands that can create these amazing, human-centred experiences that are going to be the real differentiators.
Finally, create some organizational agility. This is not news, but things are moving fast for us in this industry, and we need to create a culture where ongoing learning and testing are part of the rhythm.
The fundamental rules of marketing remain constant. It is all about knowing who your customers are, creating resonant messages, and delivering value in every interaction.
14. Users And Search Engines Prioritize Trusted Brands
Montserrat Cano, Consultant at MC. International SEO & Digital Strategy
In 2025, understanding your audience and market is key to building brand authority, increasing visibility and driving online leads or sales.
Users and search engines prioritize trusted brands, so consistent branding and high-quality content are essential.
This is especially important in international markets, due to the unique cultural nuances and search behaviours.
Combine this with a solid website that focuses on user experience and accessibility for long-term growth.
15. Communities Can Have A Big Impact On Visibility
Jo Turnbull, Digital Marketing Consultant at Turn Global, Organizer of Search London, and Co-host of SEO Office-Hours
SEO professionals should focus on being part of communities, supporting them or creating ones where there is a gap in the market.
This is particularly important for small brands who do not have a lot of budget to make significant changes to their website.
Communities can have a big impact on visibility, helping to build brands and subsequently conversions.
Through communities, SEO pros can connect with and support one another in initiatives such as mentorship, writing for key sites, as well as attending virtual and/or in-person events.
16. Understand How Users Consume Information
Navah Hopkins, Brand Evangelist for Optymzr
Looking ahead to 2025 and beyond, it’s all about understanding how users consume information.
By focusing on non-login forums (Reddit, Quora, etc), and getting indexed on Bing for ChatGPT visibility, brands can bypass expensive and time intensive conventional Google SEO.
Forums often rank better on SERPs and offer a more authentic, human touch compared to traditional websites.
If you plan to promote yourself, make sure you’re honest about it – building an infrastructure for your customers and brand influencers to share on your behalf can serve better.
17. Gain A Foothold In New Trends And Topics Before Larger Competitors
Tory Gray, CEO at Gray Dot Company
There’s a fundamental shortcoming to traditional SEO keyword research that we maybe don’t talk about enough: It’s a lagging indicator.
So, when it comes to identifying new trends, topics, or questions for content, relying on traditional keyword research makes SEO professionals and content strategists late to the game.
That’s especially important for smaller, less authoritative domains. In established industries and verticals, many existing topics are dominated by high-authority competitors.
Gaining a foothold in new trends and topics before larger competitors is one of the few, strong tactics that can help close the gap.
Today, trends and topics take off on platforms like TikTok and Reddit before they make their way to search engines like Google.
In 2025, looking outside of traditional search data – and incorporating platforms where “newness” happens – is how we can tap into leading indicators that let us know which new and useful information our audience really wants.
18. Finding Truly Unique Angles For New Content Will Reward You
Alli Berry, Search Engine Optimization Consultant at Alli Berry Consulting, LLC
Less is more when it comes to your content strategy.
Google has been busy continuing to punish lower-quality pages, so it’s time to cut the robotic-like programmatic and low-quality AI-generated pages that may have given you some short-term gains.
I know everyone says they’d never do that, but the internet suggests otherwise.
I would also be cutting low-performing pages and thin pages because they may be harming the overall quality of your site from a search engine lens.
Finding truly unique angles for new content will reward you, especially if you can incorporate proprietary or 1st party research.
The Google documents leaked suggest that high-quality news links and links from new pages count for more, so anything you can do to drive new external links should reward you.
Also, if you’ve got all of your eggs in the affiliate revenue model basket, it’s time to diversify your business model. Google is coming hard for affiliate sites.
19. Mentions In LLMs Will Emerge As A Key Aspect Of SEO
Olga Zarr, SEO Consultant at SEOSLY
SEO professionals should broaden their focus beyond just Google to include Bing and LLMs, as visibility across all these platforms will likely become increasingly critical.
Mentions in LLMs will emerge as a key aspect of SEO, extending the discipline beyond traditional search engines.
Good rankings in Google will still matter, especially since they will influence mentions in AI Overviews. However, the dynamics shift when considering the leading LLM player, ChatGPT, which relies on Bing for search results in both ChatGPT and GPT-powered search.
This means that strong rankings in Bing will become significantly more valuable. SEO pros must familiarize themselves with Bing’s ranking criteria and closely study its documentation, as its algorithm and priorities differ from Google’s.
For other LLMs – regardless of their data sources – SEO marketers should ensure that the brand they aim to promote is consistently and clearly positioned online.
It’s crucial to communicate what the brand represents and offers, so it becomes a reliable source for LLMs to cite. Cohesive and authoritative branding will play a big role in improving visibility.
20. Do More With Less By Swapping The Fluff For Trustworthy Information
Jamie Indigo, Director of Technical SEO at Cox Automotive Inc.
Visibility in 2025 is all about understanding the context in which your site exists. More content will be created this year than 2010-2018 combined.
In the face of a rapidly expanding internet full of regurgitated AI, Google’s goal of crawling less makes sense. If your site is made of the same content as all the others using that particular AI tool, why bother?
AI-generated content is statistically probable rather than factually accurate. It may lack the depth, nuance, and originality that users seek.
Google’s emphasis on crawling less underscores the need for unique, high-quality content that provides genuine value to users.
This is why your website’s unique context is so important. Smaller sites should have different focuses than large sites.
If your site is greater than 100,000 pages … does it need to be? How much of that content do users actually engage with? This is your time to be intentional about the index.
If it doesn’t solve a real human problem, cut the cruft. Do more with less by swapping the fluff for trustworthy information.
This includes all the bells and whistles on your site to make it as shiny as possible. A feature no one uses is waste. Great content with a bad user experience is still bad content. Even great content is useless if it isn’t relevant to why the user came to the page.
SEO professionals should prioritize trustworthy experiences that fulfill user intent. If you’re answering questions and helping get things done, you’ll see growth.
21. Learn How To “Program Personas” Effectively
Michael Bonfils, Global Managing Director at SEM International
As you already know, SEO professionals who figure out how to combine data, creativity, and AI-driven innovation will be the ones who win.
An opportunity for SEO pros in 2025 will be learning how to “program personas” effectively.
This means taking tools like ChatGPT and other LLMs and feeding them the right inputs – like your target audience’s behaviors, their pain points, and the brand tone – to create AI-driven personas that are specific, strategic, and actionable.
Think of these personas as virtual assistants who can brainstorm and refine ideas with you tailored to your exact needs.
For example, you could program an AI persona to act like a Gen Z skateboarder or a busy CFO and have it generate ideas or strategies that would appeal directly to that group.
This goes beyond traditional keyword research; it’s about having AI provide insights you might not have considered, delivering fresh, relevant angles.
22. Businesses Should Invest In A Strong Internal SEO Product-Oriented Team
Pedro Dias, Founder and SEO Consultant at Visively
SEO professionals should step back and try to understand how their strategies impact the new rules of the game we’re currently playing in search.
There’s a lot of noise around promises of easy traffic at scale that are more designed to catch off-guard anyone not fully aware of what they should be doing, and make money from the less savvy.
That said, the important pillars of SEO remain:
Technical Excellence
Ensuring a site is crawlable and indexable by search engines is foundational – log file analysis, optimizing crawl paths, and resolving technical barriers (e.g., redirects, canonicalization, and URL structures).
Data-Driven Decision Making
Leveraging tools like Google BigQuery to analyze search and performance data — making SEO decisions based on solid data, such as understanding user behavior, identifying patterns in search intent, or assessing technical performance.
Scalability And Sustainability
Building scalable systems and processes that support SEO growth — preventative measures, automation, and frameworks (“Improvements, Prevention, Recovery” models) for a proactive approach over reactive fixes.
Collaboration With Product Teams (For Internal Teams)
Integrating SEO into product and development workflows, highlighting the importance of SEO as a core component rather than a marketing afterthought.
User-Centric Approach
Ensuring SEO efforts align with delivering value to users, as user satisfaction often drives ranking improvements.
I believe it’s more important than ever that businesses seriously invest in having a strong internal SEO product-oriented team.
This will be a game changer for the future as this will increasingly be a factor to differentiate sustained growth better catered when you have a deep knowledge of your product and vertical of operation, rather than the sole reliance on intermittent external collaborators.
SEO in 2025
In a continuation from last year, SEO is changing more rapidly than at any other time in the history of the industry.
As we said at the beginning, SEOs need to change their mindset away from the old way to a new holistic approach that seeks to find visibility where your audience is. Most likely across Google SERPs, Bing SERPs, ChatGPT Search, Perplexity, Gemini, TikTok, YouTube, all in varying degrees.
Most of the experts agree that focusing on brand and producing quality content that demonstrates expertise is an area of focus.
We also think, removing reliance on Google for organic traffic would be a smart investment to make right now.
More Resources:
Featured Image: jamaludinyusuppp/Shutterstock