Google has introduced a feature in Search Console that allows merchants to track their product listings in the Google Search Image tab.
This expanded functionality can help businesses better understand their visibility across Google’s shopping experiences.
New to Search Console Performance report 📢 you can now see merchant listings performance in the Google Search Image tab. Learn more about Shopping reports and tools at https://t.co/W7UdFeFG4ppic.twitter.com/3xc9tZNkZr
— Google Search Central (@googlesearchc) June 10, 2024
Where To Find ‘Merchant Listings Performance’ In Search Console
The new data is accessible through the “Performance” report under the “Google Search Image” tab.
From there, you can monitor the performance of your listings across various Google surfaces.
This includes information on impressions, clicks, and other key metrics related to your product showcases.
By integrating merchant listing performance into Search Console, businesses get a more comprehensive view of their product visibility to optimize their strategies accordingly.
Eligibility & Shopping Section In Search Console
To qualify for merchant listing reports, a website must be identified by Google as an online merchant primarily selling physical goods or services directly to consumers.
Affiliate sites or those that redirect users to other platforms for purchase completion are not considered eligible.
Once recognized as an online merchant, the Search Console will display a “Shopping” section in its navigation bar.
This dedicated area houses tools and reports tailored to shopping experiences, including:
Product Snippet Rich Report: Providing insights into product snippet structured data on the site, enabling enhanced search result displays with visual elements like ratings and prices.
Merchant Listing Rich Report: Offering analytics on merchant listing structured data enables more comprehensive search results, often appearing in carousels or knowledge panels.
Shopping Tab Listings: Information and guidance on enabling products to appear in the dedicated Shopping tab within Google Search results.
Google’s automated systems determine a site’s eligibility as an online merchant based on the presence of structured data and other factors.
In Summary
This new feature in Google’s Search Console provides valuable information about the visibility of your product listings in search results.
You can use these insights to make changes and improve your products’ visibility so that more potential customers can find them.
Many advertisers have a tight budget for pay-per-click (PPC) advertising, making it challenging to maximize results.
One of the first questions that often looms large is, “How much should we spend?” It’s a pivotal question, one that sets the stage for the entire PPC strategy.
Read on for tips to get started or further optimize budgets for your PPC program to maximize every dollar spent.
1. Set Expectations For The Account
With a smaller budget, managing expectations for the size and scope of the account will allow you to keep focus.
A very common question is: How much should our company spend on PPC?
To start, you must balance your company’s PPC budget with the cost, volume, and competition of keyword searches in your industry.
You’ll also want to implement a well-balanced PPC strategy with display and video formats to engage consumers.
First, determine your daily budget. For example, if the monthly budget is $2,000, the daily budget would be set at $66 per day for the entire account.
The daily budget will also determine how many campaigns you can run at the same time in the account because that $66 will be divided up among all campaigns.
Be aware that Google Ads and Microsoft Ads may occasionally exceed the daily budget to maximize results. The overall monthly budget, however, should not exceed the Daily x Number of Days in the Month.
Now that we know our daily budget, we can focus on prioritizing our goals.
2. Prioritize Goals
Advertisers often have multiple goals per account. A limited budget will also limit the number of campaigns – and the number of goals – you should focus on.
Some common goals include:
Brand awareness.
Leads.
Sales.
Repeat sales.
In the example below, the advertiser uses a small budget to promote a scholarship program.
They are using a combination of leads (search campaign) and awareness (display campaign) to divide up a daily budget of $82.
Screenshot from author, May 2024
The next several features can help you laser-focus campaigns to allocate your budget to where you need it most.
Remember, these settings will restrict traffic to the campaign. If you aren’t getting enough traffic, loosen up/expand the settings.
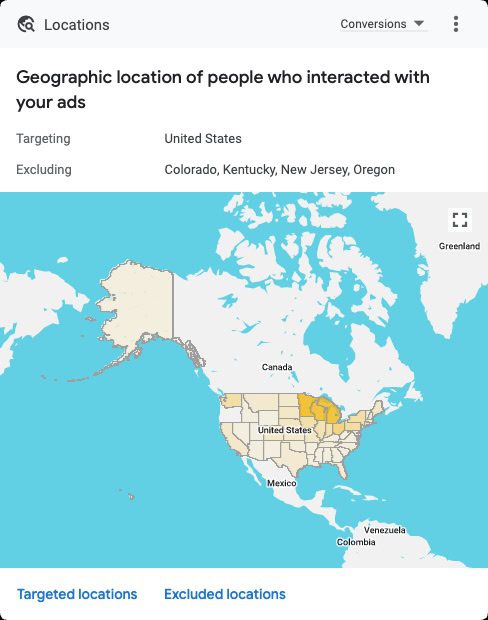
3. Location Targeting
Location targeting is a core consideration in reaching the right audience and helps manage a small ad budget.
To maximize a limited budget, you should focus on only the essential target locations where your customers are located.
While that seems obvious, you should also consider how to refine that to direct the limited budget to core locations. For example:
You can refine location targeting by states, cities, ZIP codes, or even a radius around your business.
Choosing locations to target should be focused on results.
The smaller the geographic area, the less traffic you will get, so balance relevance with budget.
Consider adding negative locations where you do not do business to prevent irrelevant clicks that use up precious budget.
If the reporting reveals targeted locations where campaigns are ineffective, consider removing targeting to those areas. You can also try a location bid modifier to reduce ad serving in those areas.
Screenshot by author from Google Ads, May 2024
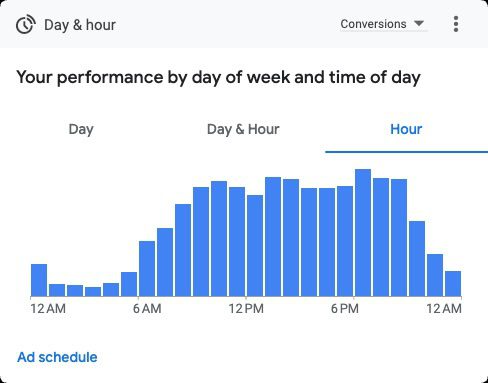
4. Ad Scheduling
Ad scheduling also helps to control budget by only running ads on certain days and at certain hours of the day.
With a smaller budget, it can help to limit ads to serve only during hours of business operation. You can choose to expand that a bit to accommodate time zones and for searchers doing research outside of business hours.
If you sell online, you are always open, but review reporting for hourly results over time to determine if there are hours of the day with a negative return on investment (ROI).
Limit running PPC ads if the reporting reveals hours of the day when campaigns are ineffective.
The purpose is to prevent your ad from showing on keyword searches and websites that are not a good match for your business.
Generate negative keywords proactively by brainstorming keyword concepts that may trigger ads erroneously.
Review query reports to find irrelevant searches that have already led to clicks.
Create lists and apply to the campaign.
Repeat on a regular basis because ad trends are always evolving!
6. Smart Bidding
Smart Bidding is a game-changer for efficient ad campaigns. Powered by Google AI, it automatically adjusts bids to serve ads to the right audience within budget.
The AI optimizes the bid for each auction, ideally maximizing conversions while staying within your budget constraints.
Smart bidding strategies available include:
Maximize Conversions: Automatically adjust bids to generate as many conversions as possible for the budget.
Target Return on Ad Spend (ROAS): This method predicts the value of potential conversions and adjusts bids in real time to maximize return.
Target Cost Per Action (CPA): Advertisers set a target cost-per-action (CPA), and Google optimizes bids to get the most conversions within budget and the desired cost per action.
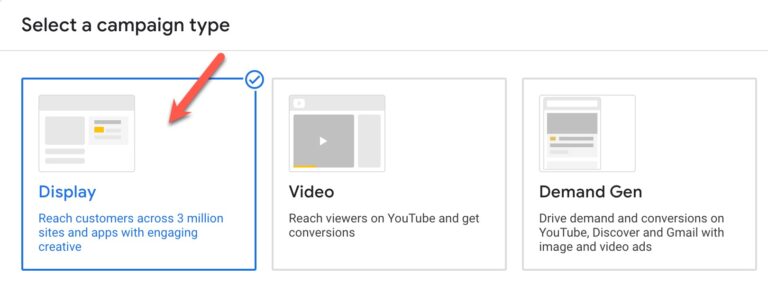
7. Try Display Only Campaigns
Screenshot by author from Google Ads, May 2024
For branding and awareness, a display campaign can expand your reach to a wider audience affordably.
Audience targeting is an art in itself, so review the best options for your budget, including topics, placements, demographics, and more.
Remarketing to your website visitors is a smart targeting strategy to include in your display campaigns to re-engage your audience based on their behavior on your website.
Let your ad performance reporting by placements, audiences, and more guide your optimizations toward the best fit for your business.
Screenshot by Lisa Raehsler from Google Ads, May 2024
In short, automation is used to maximize conversion results by serving ads across channels and with automated ad formats.
This campaign type can be useful for limited budgets in that it uses AI to create assets, select channels, and audiences in a single campaign rather than you dividing the budget among multiple campaign types.
Since the success of the PMax campaign depends on the use of conversion data, that data will need to be available and reliable.
9. Target Less Competitive Keywords
Some keywords can have very high cost-per-click (CPC) in a competitive market. Research keywords to compete effectively on a smaller budget.
Use your analytics account to discover organic searches leading to your website, Google autocomplete, and tools like Google Keyword Planner in the Google Ads account to compare and get estimates.
In this example, a keyword such as “business accounting software” potentially has a lower CPC but also lower volume.
Ideally, you would test both keywords to see how they perform in a live campaign scenario.
Screenshot by author from Google Ads, May 2024
10. Manage Costly Keywords
High volume and competitive keywords can get expensive and put a real dent in the budget.
In addition to the tip above, if the keyword is a high volume/high cost, consider restructuring these keywords into their own campaign to monitor and possibly set more restrictive targeting and budget.
Levers that can impact costs on this include experimenting with match types and any of the tips in this article. Explore the opportunity to write more relevant ad copy to these costly keywords to improve quality.
Every Click Counts
As you navigate these strategies, you will see that managing a PPC account with a limited budget isn’t just about monetary constraints.
Rocking your small PPC budgets involves strategic campaign management, data-driven decisions, and ongoing optimizations.
In the dynamic landscape of paid search advertising, every click counts, and with the right approach, every click can translate into meaningful results.
Google’s John Mueller responded to a question about whether it’s okay to stop optimizing a desktop version of a website now that Google is switching over to exclusively indexing mobile versions of websites.
The question asked is related to an announcement they made a week ago:
“…the small set of sites we’ve still been crawling with desktop Googlebot will be crawled with mobile Googlebot after July 5, 2024. … After July 5, 2024, we’ll crawl and index these sites with only Googlebot Smartphone. If your site’s content is not accessible at all with a mobile device, it will no longer be indexable.”
Stop Optimizing Desktop Version Of A Site?
The person asking the question wanted to know if it’s okay to abandon optimizing a purely desktop version of a site and just focus on the mobile friendly version. The person is asking because they’re new to a company and the developers are far into the process of developing a mobile-only version of a site.
This is the question:
“I am currently in a discussion at my new company, because they are implementing a different mobile site via dynamic serving instead of just going responsive. Next to requirements like http vary header my reasoning is that by having two code bases we need to crawl, analyze and optimize two websites instead of one. However, this got shut down because “due to mobile first indexing we no longer need to optimize the desktop website for SEO”. I read up on all the google docs etc. but I couldn’t find any reasons as to why I would need to keep improving the desktop website for SEO, meaning crawlability, indexability, using correct HTML etc. etc. What reasons are there, can you help me?”
Mobile-Only Versus Responsive Website
Google’s John Mueller expressed the benefits of one version of a website that’s responsive. This eliminates the necessity of maintaining two websites plus it’s desktop-friendly to site visitors who are visiting a site with a desktop browser.
He answered:
“First off, not making a responsive site in this day & age seems foreign to me. I realize sometimes things just haven’t been updated in a long time and you might need to maintain it for a while, but if you’re making a new site”
Maintaining A Desktop-Friendly Site Is A Good Idea
Mueller next offered reasons why it’s a good idea to maintain a functional desktop version of a website, such as other search engines, crawlers and site visitors who actually are on desktop devices. Most SEOs understand that conversions, generating income with a website, depends on being accessible to all site visitors, that’s the big picture. Optimizing a site for Google is only a part of that picture, it’s not the entire thing itself.
Mueller explained:
“With mobile indexing, it’s true that Google focuses on the mobile version for web search indexing. However, there are other search engines & crawlers / requestors, and there are other requests that use a desktop user-agent (I mentioned some in the recent blog post, there are also the non-search user-agents on the user-agent documentation page).”
He then said that websites exist for more than just getting crawled and ranked by Google.
“All in all, I don’t think it’s the case that you can completely disregard what’s served on desktop in terms of SEO & related. If you had to pick one and the only reason you’re running the site is for Google SEO, I’d probably pick mobile now, but it’s an artificial decision, sites don’t live in isolation like that, businesses do more than just Google SEO (and TBH I hope you do: a healthy mix of traffic sources is good for peace of mind). And also, if you don’t want to have to make this decision: go responsive.”
After the person asking the question explained that the decision had already been made to focus on mobile, Mueller responded that this is a case of choosing your battles.
“If this is an ongoing project, then shifting to dynamic serving is already a pretty big step forwards. Pick your battles :). Depending on the existing site, sometimes launching with a sub-optimal better version earlier is better than waiting for the ideal version to be completed. I’d just keep the fact that it’s dynamic-serving in mind when you work on it, with any tools that you use for diagnosing, monitoring, and tracking. It’s more work, but it’s not impossible. Just make sure the desktop version isn’t ignored completely :). Maybe there’s also room to grow what the team (developers + leads) is comfortable with – perhaps some smaller part of the site that folks could work on making responsive. Good luck!”
Choose Your Battles Or Stand Your Ground?
John Mueller’s right that there are times where it’s better to choose your battles rather than dig in and compromise. But just make sure that your recommendations are on record and that those pushing back are on record. That way if things go wrong the blame will find it’s way back to the ones who are responsible.
When Google launched its Privacy Sandbox, the news rang alarm bells for B2B marketers and advertisers. This signaled an end to third-party cookies on Google Chrome, which has over 65% of the browser market share.
The Privacy Sandbox, however, was only the final nail in the coffin for evolving legislation across the world to improve privacy compliance – particularly the GDPR in the European Union and the CCPA in the U.S. (and various other state regulations since following).
Despite setbacks announced by Google to eliminate third-party cookies (three times now in June 2024, with the last delay announced in April of the same year), preemptively building your first-party database is paramount for being prepared when these cookies are truly phased out.
Investing in this now presents a competitive advantage as many organizations have deprioritized their strategies to navigate the phase-out, which will likely lead to significant disruption when the Privacy Sandbox comes into effect.
Indeed, 75% of marketing and client experience users relied heavily on third-party cookies in 2023, and 45% of leaders are spending over half of their marketing budgets on cookie-based activations.
In this guide, I present a simple, three-step process to futureproof your data strategy.
The idea is to start with a demand generation program to collect your initial batch of first-party data and continue to enhance it in future iterations while phasing out third-party sources.
1. Survey Clients To Build Up Your First-Party Data
Surveying clients is the first step to building up your first-party database because they can comment on your buyer experience, as well as the quality of service.
The focus of this survey is to gain rich first-party data to inform updates to your buyer personas and Ideal Customer Profiles (ICPs) in line with your loyal clients to guide your demand generation strategy.
Therefore, determining precise questions that enable you to field actionable insights is key for this survey.
Below are four examples of questions to encourage clients to share valuable, first-party data:
Net Promoter Score (NPS): From 0 to 10, how likely is it that you would refer [Organization X] to your colleagues?
Pain points: What challenges made you consider purchasing a solution from [Organization X]?
Unique Value Proposition (UVP): What 3 unique features of [Organization X] do you like the most?
Market positioning: On a scale from 0 to 10, how much do you prefer [Organization X] over [Competitor Y]?
These are just a few of the many questions we ask loyal clients at INFUSE. Since buyer personas and ICPs are fictional representations, it is key to continuously inform them with rich first-party data to maintain their accuracy and relevance.
Recommendations
2. Conduct A Demand Program To Gain Audience First-Party Data
Once you have first-party data from surveys, you should develop and launch a trial demand generation program to refine your data.
The idea is to gain insights from key buyers to enrich your buyer personas and bolster overall go-to-market (GTM) and demand strategies.
Below is a process to launch your first trial demand generation program and refine your first-party database:
Start With Owned Media And Social Selling
Kickstarting your trial demand program by activating your owned media with your sales teams is a great first step that allows you to fully control your approach to engaging your audience and fielding first-party data.
Leveraging a content marketing strategy is an effective way to collect first-party data. Start small, but think of a high-value gated asset for this trial that will generate demand and encourage contact form fills (lead generation), such as a whitepaper, report, or learning course.
Then, you must build a demand strategy around this high-value asset to establish rapport with your audience and encourage continued engagement.
For example, if you opt for a whitepaper, support this with initiatives across your other channels, such as publishing curated insights on social media and crafting slides for your sales team to share with prospects.
The idea is to build a content marketing suite to support your demand program across the channels your audience frequents, creating a stronger basis of brand-to-demand and richer data insights as a result.
Recommendations
Nurture prospects with personalized email cadences to keep your brand top of mind and collect further first-party data (such as engagement with certain topics).
Develop materials to enable your sales team to share high-value assets and build interest.
Create snackable content, such as 30-second social media videos, that highlight the value of your content and encourage conversions.
Find A Content Distribution Partner
The right content distribution partner can greatly increase the reach of your demand program and engage audiences beyond your owned channels.
However, data quality is key when seeking partners. Since the goal is to obtain first-party data and select partners based on their ability to provide this data, as well as its quality – it should complement your existing dataset rather than offer redundant insights.
Focus on content distribution partners with an opt-in audience and managed ecosystems that certify that prospects have engaged with the right content.
This allows prospects to be identified and matched with your buyer personas and then routed to your organization for further engagement.
Content distribution partners commonly have databases with prospects and their market segmentation criteria. This ensures high-value assets are distributed to prospective buyers who are a good fit for your organization and its offerings.
Recommendations
Audit the content distribution partner and ask questions about how they segment their audience and ensure data privacy compliance.
Create a follow-up structure at your organization for receiving prospects from the partner, such as an email cadence that provides more context to the high-value asset.
Refine your outreach targeting with market segmentation information collected by the partner.
Combining first-party data from your owned media and content distribution partner, you are ready to conduct the demand program until its completion. This should ideally take at least a quarter to glean substantial insights and a broader overview of prospect interactions (and may need to be longer, depending on your sales cycle).
3. Analyze And Optimize First-Party Data Acquired From Your Demand Program
Once the demand program has been finalized, it is now time to analyze and optimize your first-party database.
This is the start of a continuous cycle of improvement and data enrichment, which will be enabled by actioning optimizations to your owned media and partner content distribution.
Below are four questions to guide your analysis when reviewing program results and the quality of your first-party database.
Are The Datasets Relevant And Actionable?
Since the principal goal of first-party data is to inform future strategies and target prospects with precision, its accuracy and role in achieving this should be the primary assessment criteria.
Recommendations
A/B test different contact form fields to glean relevant information (such as technographic data).
Train sales teams to qualify prospects by leveraging your high-value content assets.
Utilize lead nurturing cadences to clarify specific information, such as key buyer challenges, available budgets, and members of the prospect’s buying committee.
Interactive touchpoints, such as quizzes, can glean this information in a user-friendly manner.
Are Your Buyer Personas And ICPs Still Relevant?
It is quite common for trial programs to highlight misalignments between the audience that engaged with your assets and your buyer personas and ICPs.
Trials can also identify how the key pain points of your personas have evolved or become outdated, indicating necessary updates needed to ensure the relevancy of your messaging across all channels.
Independent of the findings you acquired, regularly examining and updating these profiles is beneficial.
Recommendations
Analyze the prospects from the trial with an “open mind,” ensuring that your new profiles truly reflect their pain points and aspirations – rather than fit them into an existing model.
Discuss your findings with client-facing teams, particularly sales, to determine their relevance and enrich them with further personal insights.
Is Your Unique Value Proposition (UVP) Still Relevant?
Similarly to your ICPs and personas, your UVP might require a refresh to ensure its relevance.
Due to its strategic nature, ensuring that your UVP is relevant informs all your organizational processes and communications, as well as steering how your brand is perceived by your audience.
The importance of your UVP also means that trialing new versions is key to ensuring its effectiveness before cementing it in the market.
Recommendations
A/B test your new UVP and complement this test with other methods (if available), such as focus groups, email nurturing, and surveys.
Identify common keywords and expressions used by prospects when discussing their pain points.
Analyze the benefits of your products and how well they align with the objectives of the prospects that were identified during your demand program.
Are Your Client-Facing Teams Following Outdated Playbooks?
Client-facing teams often have style guides, GTM playbooks, cheat sheets, and other materials to inform their daily activities. These assets can become rapidly outdated if they are not routinely audited.
Therefore, it is essential to revisit these assets, leveraging findings from your first-party database to ensure their relevance, considering the changes to your buyer personas, ICPs, and UVP.
Recommendations
Prioritize strategic assets used daily by teams, such as process documents and style guides.
Analyze marketing and sales outreach to assess if their approach regarding pain points is still relevant.
Book a session sharing tactics and key takeaways from the new first-party database to inform playbook optimizations.
These are only a few of the many optimizations you can perform after analyzing first-party data from your demand program.
When determining where to start your optimizations, look for low-effort, high-reward projects, specifically client-facing activities. The key is prioritizing the highest value for your organization and ensuring your first-party database empowers you to achieve your goals.
The demand program showcased in this article can serve as a foundation for future iterations to continuously enrich your first-party database.
Key Takeaways
When launching your demand programs and building your first-party database, keep these considerations top of mind to ensure the longevity of your strategies:
Begin with owned media: It is essential to optimize and enrich your owned media channels to start collecting first-party data. Kick-off this strategy with one gated asset in a trial demand program to gain insights.
Find a content distribution partner: Broaden your scope and engage pre-qualified prospects via a trustworthy partner that can enrich your first-party database with insights from new or expanded audiences.
Analyze results and optimize: Scrutinize the findings, summarize them, and determine priority updates to strategic areas and assets, such as your UVP, personas, and playbooks.
Email ads are cookie-proof. They do not depend on third-party tracking cookies for targeting. The end of tracking cookies in web browsers (as soon as 2025) has publishers and advertisers searching for new channels.
Email’s targeting capability could be the primary reason GAM is adding support.
Email Ads
Email ads typically fall into three categories:
Sponsorships: flat rate.
Context-based: priced per action.
Subscriber-targeted programmatic: priced per action.
In a technical sense, GAM is adding support for all of these. But functionally, the beta will best support programmatic ad slots. Let’s consider each type and then look at ad formats.
Sponsorships
Newsletter sponsorships are often personal endorsements of the sender. In the example below, the photograph may be the newsletter author using the product on a fishing trip. The ad is the author’s recommendation.
A newsletter sponsorship is often a personal endorsement from the sender.
In this case, the fishing gear promotion resembles an old-style print or television ad. It’s mass media on a small scale. A newsletter publisher with an audience of fly fishermen sells a sponsorship to a fishing gear company that goes to everyone on the list.
Sponsorships can transfer trust from the newsletter to the advertiser and produce strong sales.
Pricing for sponsorships is typically a flat rate.
Context-based
Context-based ads focus on the email’s subject matter and are similar to sponsorships with one advertiser per deployment (sometimes in multiple locations), sent to all subscribers.
Context-based performance advertisers compose the ads and target an email’s context.
Context-based performance ads most often feature advertiser-written copy. There is no personal endorsement.
The pricing is usually action-based, such as cost-per-impression, cost-per-click, or cost-per-sale.
Programmatic
Subscriber-targeted programmatic ads are the email equivalent of pay-per-click ads on Google search or social media. This ad unit is a linked image.
This ad unit is essentially a digital display advertisement.
Importantly, the ad is based on the recipient, not solely on the content. So, someone reading about rods and reels might see a retargeting ad for laundry detergent.
In theory, a fly fishing newsletter with 100,000 subscribers might show 100,000 different ads.
Pricing for programmatic ads is performance-based.
Ad Formats
Inserting sponsorship or context-based ads requires little setup since every subscriber sees the same headline, ad copy, and call-to-action. Publishers can use HTML or drag-and-drop tools for those items, depending on the email platform. It is a native ad, meaning its format is identical to the newsletter’s format, i.e., native HTML.
Programmatic ads from Google Ad Manager and all other providers use a linked HTML image tag that includes a unique identifier for each subscriber, but not ad components such as a headline.
When a subscriber opens the newsletter, the email client — Gmail or Apple Mail, for example — requests the image from the ad’s server. The server reads the subscriber’s unique ID and returns an ad image targeted at that person.
The image will include all ad components: headline, copy, CTA.
First, the src image-tag property will start with a path to the ad server.
https://securepubads.g.doubleclick.net/gampad/ad
The newsletter publisher will then append parameters to this base URL.
ptt
Identifies the ad as a newsletter and must have the value “21.”
iu
Specifies the Ad Manager ad unit to display.
sz
An HTML-encoded list of acceptable ad sizes where 216×36|300×50|320×50 would be 216×36%7c300x50%7c320x50.
clkk
The unique subscriber identifier.
clkp
Specifies the ad slot in the newsletter, i.e., “top” or “middle”.
url
The “view in browser” URL for the current newsletter.
t
An optional key-value pair for reporting or performance tracking.
The most critical parameter is the clkk. It combines a unique subscriber identifier, a campaign identifier, and the date in a day-month-year format.
*|UNIQID|*_*|CAMPAIGN_UID|*_*|DATE:d/m/y|*
GAM prohibits publishers from passing personally identifiable information in the unique subscriber identifier. So send a hashed email address, not the plain text version.
Unit Performance
The GAM tag functions for sponsorships, context-based, or programmatic ads, but it delivers image ads only. Subscribers with images turned off won’t see the message. Moreover, GAM’s image tags link to Doubleclick.net, a prominent ad server. Every ad blocker will remove it.
Thus GAM email tags are best suited for programmatic, as publishers can insert sponsorships and context-based ads without an ad management platform.
Google’s John Mueller answered a question about sitewide impacts on a site with ten pages that lost rankings in the March/April 2024 Core Update then subsequently experienced a sitewide collapse in May.
Can 10 Pages Trigger A Sitewide Penalty?
The person asking the question on Reddit explained that they had ten pages (out of 20,000 pages) that were hit by the Helpful Content Update (HCU) in September 2023. They subsequently updated the pages which eventually recovered their rankings and traffic. Things were fine until the the same ten pages got slammed by the March/April core update. The precise date of the second ranking drop event was April 20th.
Up to that point the rest of the site was fine. Only the same ten pages were affected. That changed on May 7th when the site experienced a sitewide drop in rankings across all 20,000 pages of the website.
Their question was if the ten problematic pages triggered a sitewide impact or whether the May 7th collapse was due to the Site Reputation Abuse penalties that were announced on May 6th.
A Note About Diagnosing Ranking Drops
I’m not commenting specifically about the person who asked the question but… the question has the appearance of correlating ranking drops with specific parts of announced algorithm updates.
Here is the exact wording:
“Our website has about 20K pages, and we found that around 10 pages were hit by HCU in September. We updated those articles and saw a recovery in traffic, but after the March core update around April 20, the same pages were hit again, likely due to HCU. On May 7th, we saw a sharp drop in rankings across the board, and suspect that a sitewide classifier may have been applied.
Question: Can an HCU hit on 10 pages cause a sitewide classifier for 20K pages? Or on May 7th reputation abuse update may had an impact?”
In general it’s reasonable to assume that a ranking drop is connected to a recently announced Google update when the dates of both events match. However, it bears pointing out that a core algorithm update can affect multiple things (for example query-content relevance) and it should be understood that the HCU is no longer a single system.
The person asking the question is following a pattern that I often see which is that they’re assuming that ranking drops are due to something wrong with their site but that’s not always the case, it could be changes in how Google interprets a search query (among many other potential reasons).
The other potential mistake is assuming that the problem is related to a specific algorithm. The person asking the question assumes they were hit by the HCU system, which is something that no longer exists. All the elements of the HCU were subsumed into the core ranking algorithm as signals.
“Is there a single “helpful content system” that Google Search uses for ranking? Our work to improve the helpfulness of content in search results began with what we called our “helpful content system” that was launched in 2022. Our processes have evolved since. There is no one system used for identifying helpful content. Instead, our core ranking systems use a variety of signals and systems.”
While Google is still looking for helpfulness in content there is no longer a helpful content system that’s de-ranking pages on specific dates.
The other potential evidence of faulty correlation is when the Redditor asked if their May 7th sitewide collapse was due to the site reputation abuse penalties. The site reputation abuse penalties weren’t actually in effect by May 7th. On May 6th it was announced that site reputation abuse manual actions would begin at some point in the near future.
Those are two examples of how it can be misleading to correlate site ranking anomalies with announced updates. There is more to diagnosing updates than correlating traffic patterns to announced updates. Site owners and SEOs who diagnose problems in this manner risk approaching the solution like someone who’s focusing on the map instead of looking at the road.
Properly diagnosing issues requires understanding the full range of technical issues that can impact a site and algorithmic changes that can happen on Google’s side (especially unannounced changes). I have over 20 years experience and know enough to be able to identify anomalies in the SERPs that indicate changes to how Google is approaching relevance.
Complicating the diagnosis is that sometimes it’s not something that needs “fixing” but rather it’s more about the competition is doing something more right than the sites that lost rankings. More right can be a wide range of things.
Ten Pages Caused Sitewide “Penalty”?
John Mueller responded by first addressing the specific issue of sitewide ranking collapse, remarking that he doesn’t think it’s likely that ten pages would cause 20,000 other pages to lose rankings.
John wrote:
“The issues more folks post about with regards to core updates tend to be site-wide, and not limited to a tiny subset of a site. The last core update was March/April, so any changes you’d be seeing from May would be unrelated. I’m not sure how that helps you now though :-), but I wouldn’t see those 10 pages as being indicative of something you need to change across 20k other pages.”
Sometimes It’s More Than Announced Updates
John Mueller didn’t offer a diagnosis of what is wrong with the site, that’s impossible to say without actually seeing the site. SEOs on YouTube, Reddit and Facebook routinely correlate ranking drops with recently announced updates but as I wrote earlier in this article, that could be a mistake.
When diagnosing a drop in rankings it’s important to look at the site, the competition and the SERPs.
Do:
Inspect the website
Review a range of keywords and respective changes in the SERPs
Inspect the top ranked sites
Don’t:
Assume that a ranking drop is associated with a recent update and stop your investigation right there.
Google’s John Mueller alludes to the complexity of diagnosing ranking drops by mentioning that sometimes it’s not even about SEO, which is 100% correct.
John explained:
“Based on the information you posted, it’s also impossible to say whether you need to improve / fix something on those 20k pages, or if the world has just moved on (in terms of their interests, their expectations & your site’s relevance).
It sounds like you did find things to make more “helpful” on those 10 pages, maybe there’s a pattern? That’s something for you to work out – you know your site, its content, its users best. This isn’t an easy part of SEO, sometimes it’s not even about SEO.”
Look At The Road Ahead
It’s been a trend now that site owners focus on recent announcements by Google as clues to what is going on with their sites. It’s a reasonable thing to do and people should 100% keep doing that. But don’t make that the limit of your gaze because there is always the possibility that there is something else going on.
Google resolved a site names issue that had been ongoing since September 2023 that prevented a website’s site name from properly appearing when an inner page was ranked in the search results.
Site Names In The Search Results
A site name is exactly what it sounds like, the name of a website that’s displayed in the search engine results pages (SERPs). This is a feature that allows users to identify the name of the site that’s in the search engine results pages (SERPs).
If your site name is Acme Anvil Company, and that’s how the company is known, then Google wants to display Acme Anvil Company in the search results. If Acme Anvil Company is better known as the AAC and that’s what the company wants to show in the SERPs, then that’s what Google wants to show.
Google allows site owners to use the “WebSite” structured data on the home page to specify the correct site name that Google should use.
Problem Propagating Site Names
Back in September 7, 2023, Google published a warning in their site name documentation that acknowledged they were having problems propagating the site name to the inner pages of a site when those inner pages were shown in the SERPs.
This is the warning that was published:
“Known issue: site name isn’t appearing for internal pages In some cases, a site name shown for a home page may not have propagated to appear for other pages on that site. For example, example.com might be showing a site name that’s different from example.com/internal-page.html.
We’re actively working to address this. We will update this help page when this issue is resolved. In the meantime, if your home page is showing the site name you prefer, understand that it should also appear for your internal pages eventually.”
Google Fixes Site Name Problem
The documentation for the site name problem was recently removed. A changelog for Google documentation noted this:
“Resolving the issue with site names and internal pages What: Removed the warning about the issue that was preventing new site names from propagating to internal pages.
Why: The issue has been resolved. Keep in mind that it takes time for Google to recrawl and process the new information, including recrawling your internal pages.”
There’s no word on what caused the site name propagation problem but it is interesting that it was finally fixed after all this time because one has to wonder if it took so long because it was low priority or if something on the backend of Google’s systems changed that allowed them to finally fix the issue.
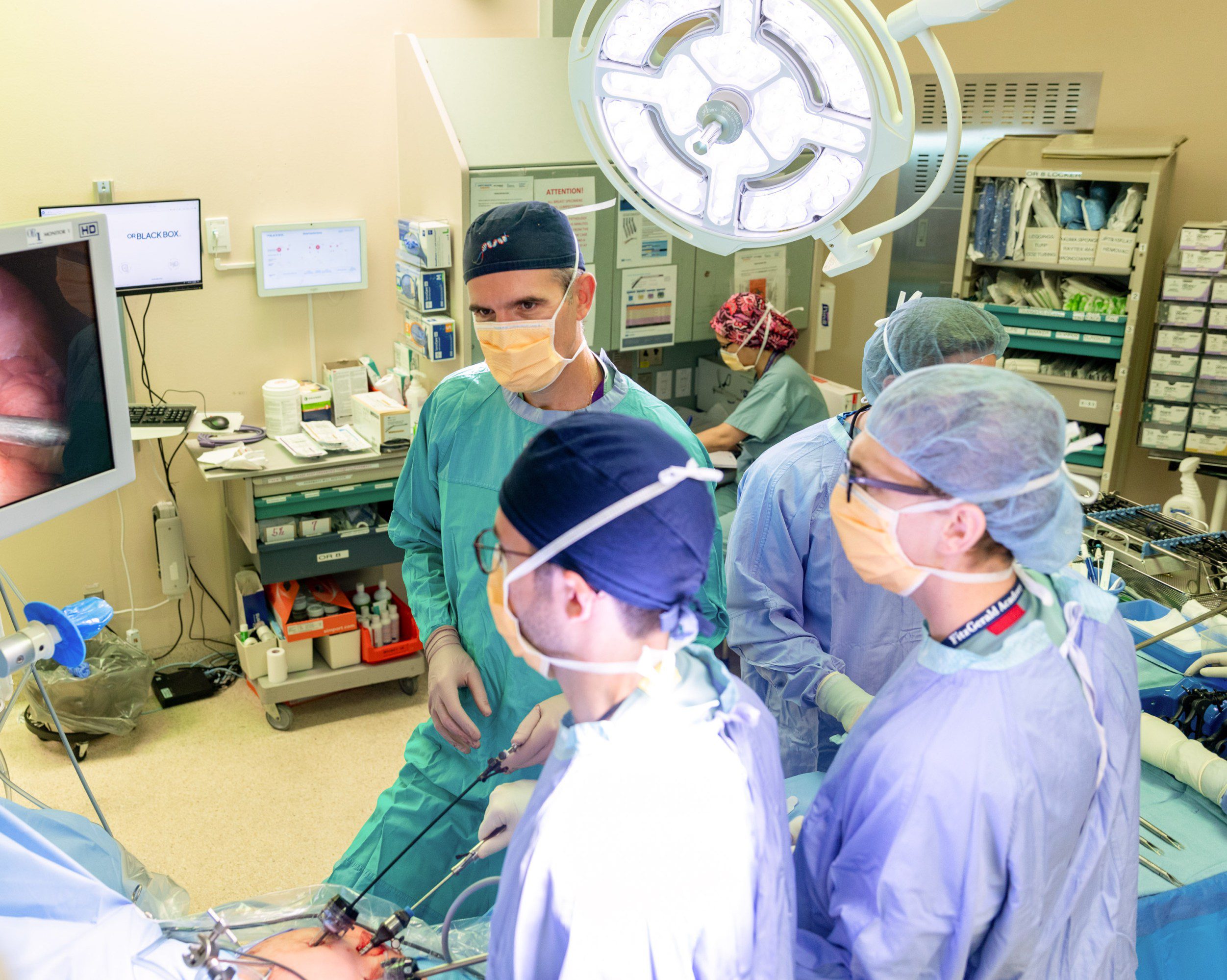
The first time Teodor Grantcharov sat down to watch himself perform surgery, he wanted to throw the VHS tape out the window.
“My perception was that my performance was spectacular,” Grantcharov says, and then pauses—“until the moment I saw the video.” Reflecting on this operation from 25 years ago, he remembers the roughness of his dissection, the wrong instruments used, the inefficiencies that transformed a 30-minute operation into a 90-minute one. “I didn’t want anyone to see it.”
This reaction wasn’t exactly unique. The operating room has long been defined by its hush-hush nature—what happens in the OR stays in the OR—because surgeons are notoriously bad at acknowledging their own mistakes. Grantcharov jokes that when you ask “Who are the top three surgeons in the world?” a typical surgeon “always has a challenge identifying who the other two are.”
But after the initial humiliation over watching himself work, Grantcharov started to see the value in recording his operations. “There are so many small details that normally take years and years of practice to realize—that some surgeons never get to that point,” he says. “Suddenly, I could see all these insights and opportunities overnight.”
There was a big problem, though: it was the ’90s, and spending hours playing back grainy VHS recordings wasn’t a realistic quality improvement strategy. It would have been nearly impossible to determine how often his relatively mundane slipups happened at scale—not to mention more serious medical errors like those that kill some 22,000 Americans each year. Many of these errors happen on the operating table, from leaving surgical sponges inside patients’ bodies to performing the wrong procedure altogether.
While the patient safety movement has pushed for uniform checklists and other manual fail-safes to prevent such mistakes, Grantcharov believes that “as long as the only barrier between success and failure is a human, there will be errors.” Improving safety and surgical efficiency became something of a personal obsession. He wanted to make it challenging to make mistakes, and he thought developing the right system to create and analyze recordings could be the key.
It’s taken many years, but Grantcharov, now a professor of surgery at Stanford, believes he’s finally developed the technology to make this dream possible: the operating room equivalent of an airplane’s black box. It records everything in the OR via panoramic cameras, microphones, and anesthesia monitors before using artificial intelligence to help surgeons make sense of the data.
Grantcharov’s company, Surgical Safety Technologies, is not the only one deploying AI to analyze surgeries. Many medical device companies are already in the space—including Medtronic with its Touch Surgery platform, Johnson & Johnson with C-SATS, and Intuitive Surgical with Case Insights.
But most of these are focused solely on what’s happening inside patients’ bodies, capturing intraoperative video alone. Grantcharov wants to capture the OR as a whole, from the number of times the door is opened to how many non-case-related conversations occur during an operation. “People have simplified surgery to technical skills only,” he says. “You need to study the OR environment holistically.”
Teodor Grantcharov in a procedure that is being recorded by Surgical Safety Technologies’ AI-powered black-box system.
COURTESY OF SURGICAL SAFETY TECHNOLOGIES
Success, however, isn’t as simple as just having the right technology. The idea of recording everything presents a slew of tricky questions around privacy and could raise the threat of disciplinary action and legal exposure. Because of these concerns, some surgeons have refused to operate when the black boxes are in place, and some of the systems have even been sabotaged. Aside from those problems, some hospitals don’t know what to do with all this new data or how to avoid drowning in a deluge of statistics.
Grantcharov nevertheless predicts that his system can do for the OR what black boxes did for aviation. In 1970, the industry was plagued by 6.5 fatal accidents for every million flights; today, that’s down to less than 0.5. “The aviation industry made the transition from reactive to proactive thanks to data,” he says—“from safe to ultra-safe.”
Grantcharov’s black boxes are now deployed at almost 40 institutions in the US, Canada, and Western Europe, from Mount Sinai to Duke to the Mayo Clinic. But are hospitals on the cusp of a new era of safety—or creating an environment of confusion and paranoia?
Shaking off the secrecy
The operating room is probably the most measured place in the hospital but also one of the most poorly captured. From team performance to instrument handling, there is “crazy big data that we’re not even recording,” says Alexander Langerman, an ethicist and head and neck surgeon at Vanderbilt University Medical Center. “Instead, we have post hoc recollection by a surgeon.”
Indeed, when things go wrong, surgeons are supposed to review the case at the hospital’s weekly morbidity and mortality conferences, but these errors are notoriously underreported. And even when surgeons enter the required notes into patients’ electronic medical records, “it’s undoubtedly—and I mean this in the least malicious way possible—dictated toward their best interests,” says Langerman. “It makes them look good.”
The operating room wasn’t always so secretive.
In the 19th century, operations often took place in large amphitheaters—they were public spectacles with a general price of admission. “Every seat even of the top gallery was occupied,” recounted the abdominal surgeon Lawson Tait about an operation in the 1860s. “There were probably seven or eight hundred spectators.”
However, around the 1900s, operating rooms became increasingly smaller and less accessible to the public—and its germs. “Immediately, there was a feeling that something was missing, that the public surveillance was missing. You couldn’t know what happened in the smaller rooms,” says Thomas Schlich, a historian of medicine at McGill University.
And it was nearly impossible to go back. In the 1910s a Boston surgeon, Ernest Codman, suggested a form of surveillance known as the end-result system, documenting every operation (including failures, problems, and errors) and tracking patient outcomes. Massachusetts General Hospital didn’t accept it, says Schlich, and Codman resigned in frustration.
Students watch a surgery performed at the former Philadelphia General Hospital around the turn of the century.
PUBLIC DOMAIN VIA WIKIPEDIA
Such opacity was part of a larger shift toward medicine’s professionalization in the 20th century, characterized by technological advancements, the decline of generalists, and the bureaucratization of health-care institutions. All of this put distance between patients and their physicians. Around the same time, and particularly from the 1960s onward, the medical field began to see a rise in malpractice lawsuits—at least partially driven by patients trying to find answers when things went wrong.
This battle over transparency could theoretically be addressed by surgical recordings. But Grantcharov realized very quickly that the only way to get surgeons to use the black box was to make them feel protected. To that end, he has designed the system to record the action but hide the identity of both patients and staff, even deleting all recordings within 30 days. His idea is that no individual should be punished for making a mistake. “We want to know what happened, and how we can build a system that makes it difficult for this to happen,” Grantcharov says. Errors don’t occur because “the surgeon wakes up in the morning and thinks, ‘I’m gonna make some catastrophic event happen,’” he adds. “This is a system issue.”
AI that sees everything
Grantcharov’s OR black box is not actually a box at all, but a tablet, one or two ceiling microphones, and up to four wall-mounted dome cameras that can reportedly analyze more than half a million data points per day per OR. “In three days, we go through the entire Netflix catalogue in terms of video processing,” he says.
The black-box platform utilizes a handful of computer vision models and ultimately spits out a series of short video clips and a dashboard of statistics—like how much blood was lost, which instruments were used, and how many auditory disruptions occurred. The system also identifies and breaks out key segments of the procedure (dissection, resection, and closure) so that instead of having to watch a whole three- or four-hour recording, surgeons can jump to the part of the operation where, for instance, there was major bleeding or a surgical stapler misfired.
Critically, each person in the recording is rendered anonymous; an algorithm distorts people’s voices and blurs out their faces, transforming them into shadowy, noir-like figures. “For something like this, privacy and confidentiality are critical,” says Grantcharov, who claims the anonymization process is irreversible. “Even though you know what happened, you can’t really use it against an individual.”
Another AI model works to evaluate performance. For now, this is done primarily by measuring compliance with the surgical safety checklist—a questionnaire that is supposed to be verbally ticked off during every type of surgical operation. (This checklist has long been associated with reductions in both surgical infections and overall mortality.) Grantcharov’s team is currently working to train more complex algorithms to detect errors during laparoscopic surgery, such as using excessive instrument force, holding the instruments in the wrong way, or failing to maintain a clear view of the surgical area. However, assessing these performance metrics has proved more difficult than measuring checklist compliance. “There are some things that are quantifiable, and some things require judgment,” Grantcharov says.
Each model has taken up to six months to train, through a labor-intensive process relying on a team of 12 analysts in Toronto, where the company was started. While many general AI models can be trained by a gig worker who labels everyday items (like, say, chairs), the surgical models need data annotated by people who know what they’re seeing—either surgeons, in specialized cases, or other labelers who have been properly trained. They have reviewed hundreds, sometimes thousands, of hours of OR videos and manually noted which liquid is blood, for instance, or which tool is a scalpel. Over time, the model can “learn” to identify bleeding or particular instruments on its own, says Peter Grantcharov, Surgical Safety Technologies’ vice president of engineering, who is Teodor Grantcharov’s son.
For the upcoming laparoscopic surgery model, surgeon annotators have also started to label whether certain maneuvers were correct or mistaken, as defined by the Generic Error Rating Tool—a standardized way to measure technical errors.
While most algorithms operate near perfectly on their own, Peter Grantcharov explains that the OR black box is still not fully autonomous. For example, it’s difficult to capture audio through ceiling mikes and thus get a reliable transcript to document whether every element of the surgical safety checklist was completed; he estimates that this algorithm has a 15% error rate. So before the output from each procedure is finalized, one of the Toronto analysts manually verifies adherence to the questionnaire. “It will require a human in the loop,” Peter Grantcharov says, but he gauges that the AI model has made the process of confirming checklist compliance 80% to 90% more efficient. He also emphasizes that the models are constantly being improved.
In all, the OR black box can cost about $100,000 to install, and analytics expenses run $25,000 annually, according to Janet Donovan, an OR nurse who shared with MIT Technology Review an estimate given to staff at Brigham and Women’s Faulkner Hospital in Massachusetts. (Peter Grantcharov declined to comment on these numbers, writing in an email: “We don’t share specific pricing; however, we can say that it’s based on the product mix and the total number of rooms, with inherent volume-based discounting built into our pricing models.”)
“Big brother is watching”
Long Island Jewish Medical Center in New York, part of the Northwell Health system, was the first hospital to pilot OR black boxes, back in February 2019. The rollout was far from seamless, though not necessarily because of the tech.
“In the colorectal room, the cameras were sabotaged,” recalls Northwell’s chair of urology, Louis Kavoussi—they were turned around and deliberately unplugged. In his own OR, the staff fell silent while working, worried they’d say the wrong thing. “Unless you’re taking a golf or tennis lesson, you don’t want someone staring there watching everything you do,” says Kavoussi, who has since joined the scientific advisory board for Surgical Safety Technologies.
Grantcharov’s promises about not using the system to punish individuals have offered little comfort to some OR staff. When two black boxes were installed at Faulkner Hospital in November 2023, they threw the department of surgery into crisis. “Everybody was pretty freaked out about it,” says one surgical tech who asked not to be identified by name since she wasn’t authorized to speak publicly. “We were being watched, and we felt like if we did something wrong, our jobs were going to be on the line.”
It wasn’t that she was doing anything illegal or spewing hate speech; she just wanted to joke with her friends, complain about the boss, and be herself without the fear of administrators peeking over her shoulder. “You’re very aware that you’re being watched; it’s not subtle at all,” she says. The early days were particularly challenging, with surgeons refusing to work in the black-box-equipped rooms and OR staff boycotting those operations: “It was definitely a fight every morning.”
“In the colorectal room, the cameras were sabotaged,” recalls Louis Kavoussi. “Unless you’re taking a golf or tennis lesson, you don’t want someone staring there watching everything you do.”
At some level, the identity protections are only half measures. Before 30-day-old recordings are automatically deleted, Grantcharov acknowledges, hospital administrators can still see the OR number, the time of operation, and the patient’s medical record number, so even if OR personnel are technically de-identified, they aren’t truly anonymous. The result is a sense that “Big Brother is watching,” says Christopher Mantyh, vice chair of clinical operations at Duke University Hospital, which has black boxes in seven ORs. He will draw on aggregate data to talk generally about quality improvement at departmental meetings, but when specific issues arise, like breaks in sterility or a cluster of infections, he will look to the recordings and “go to the surgeons directly.”
In many ways, that’s what worries Donovan, the Faulkner Hospital nurse. She’s not convinced the hospital will protect staff members’ identities and is worried that these recordings will be used against them—whether through internal disciplinary actions or in a patient’s malpractice suit. In February 2023, she and almost 60 others sent a letter to the hospital’s chief of surgery objecting to the black box. She’s since filed a grievance with the state, with arbitration proceedings scheduled for October.
The legal concerns in particular loom large because, already, over 75% of surgeons report having been sued at least once, according to a 2021 survey by Medscape, an online resource hub for health-care professionals. To the layperson, any surgical video “looks like a horror show,” says Vanderbilt’s Langerman. “Some plaintiff’s attorney is going to get ahold of this, and then some jury is going to see a whole bunch of blood, and then they’re not going to know what they’re seeing.” That prospect turns every recording into a potential legal battle.
From a purely logistical perspective, however, the 30-day deletion policy will likely insulate these recordings from malpractice lawsuits, according to Teneille Brown, a law professor at the University of Utah. She notes that within that time frame, it would be nearly impossible for a patient to find legal representation, go through the requisite conflict-of-interest checks, and then file a discovery request for the black-box data. While deleting data to bypass the judicial system could provoke criticism, Brown sees the wisdom of Surgical Safety Technologies’ approach. “If I were their lawyer, I would tell them to just have a policy of deleting it because then they’re deleting the good and the bad,” she says. “What it does is orient the focus to say, ‘This is not about a public-facing audience. The audience for these videos is completely internal.’”
A data deluge
When it comes to improving quality, there are “the problem-first people, and then there are the data-first people,” says Justin Dimick, chair of the department of surgery at the University of Michigan. The latter, he says, push “massive data collection” without first identifying “a question of ‘What am I trying to fix?’” He says that’s why he currently has no plans to use the OR black boxes in his hospital.
Mount Sinai’s chief of general surgery, Celia Divino, echoes this sentiment, emphasizing that too much data can be paralyzing. “How do you interpret it? What do you do with it?” she asks. “This is always a disease.”
At Northwell, even Kavoussi admits that five years of data from OR black boxes hasn’t been used to change much, if anything. He says that hospital leadership is finally beginning to think about how to use the recordings, but a hard question remains: OR black boxes can collect boatloads of data, but what does it matter if nobody knows what to do with it?
Grantcharov acknowledges that the information can be overwhelming. “In the early days, we let the hospitals figure out how to use the data,” he says. “That led to a big variation in how the data was operationalized. Some hospitals did amazing things; others underutilized it.” Now the company has a dedicated “customer success” team to help hospitals make sense of the data, and it offers a consulting-type service to work through surgical errors. But ultimately, even the most practical insights are meaningless without buy-in from hospital leadership, Grantcharov suggests.
Getting that buy-in has proved difficult in some centers, at least partly because there haven’t yet been any large, peer-reviewed studies showing how OR black boxes actually help to reduce patient complications and save lives. “If there’s some evidence that a comprehensive data collection system—like a black box—is useful, then we’ll do it,” says Dimick. “But I haven’t seen that evidence yet.”
A screenshot of the analytics produced by the black box.
COURTESY OF SURGICAL SAFETY TECHNOLOGIES
The best hard data thus far is from a 2022 study published in the Annals of Surgery, in which Grantcharov and his team used OR black boxes to show that the surgical checklist had not been followed in a fifth of operations, likely contributing to excess infections. He also says that an upcoming study, scheduled to be published this fall, will show that the OR black box led to an improvement in checklist compliance and reduced ICU stays, reoperations, hospital readmissions, and mortality.
On a smaller scale, Grantcharov insists that he has built a steady stream of evidence showing the power of his platform. For example, he says, it’s revealed that auditory disruptions—doors opening, machine alarms and personal pagers going off—happen every minute in gynecology ORs, that a median 20 intraoperative errors are made in each laparoscopic surgery case, and that surgeons are great at situational awareness and leadership while nurses excel at task management.
Meanwhile, some hospitals have reported small improvements based on black-box data. Duke’s Mantyh says he’s used the data to check how often antibiotics are given on time. Duke and other hospitals also report turning to this data to help decrease the amount of time ORs sit empty between cases. By flagging when “idle” times are unexpectedly long and having the Toronto analysts review recordings to explain why, they’ve turned up issues ranging from inefficient communication to excessive time spent bringing in new equipment.
That can make a bigger difference than one might think, explains Ra’gan Laventon, clinical director of perioperative services at Texas’s Memorial Hermann Sugar Land Hospital: “We have multiple patients who are depending on us to get to their care today. And so the more time that’s added in some of these operational efficiencies, the more impactful it is to the patient.”
The real world
At Northwell, where some of the cameras were initially sabotaged, it took a couple of weeks for Kavoussi’s urology team to get used to the black boxes, and about six months for his colorectal colleagues. Much of the solution came down to one-on-one conversations in which Kavoussi explained how the data was automatically de-identified and deleted.
During his operations, Kavoussi would also try to defuse the tension, telling the OR black box “Good morning, Toronto,” or jokingly asking, “How’s the weather up there?” In the end, “since nothing bad has happened, it has become part of the normal flow,” he says.
The reality is that no surgeon wants to be an average operator, “but statistically, we’re mostly average surgeons, and that’s okay,” says Vanderbilt’s Langerman. “I’d hate to be a below-average surgeon, but if I was, I’d really want to know about it.” Like athletes watching game film to prepare for their next match, surgeons might one day review their recordings, assessing their mistakes and thinking about the best ways to avoid them—but only if they feel safe enough to do so.
“Until we know where the guardrails are around this, there’s such a risk—an uncertain risk—that no one’s gonna let anyone turn on the camera,” Langerman says. “We live in a real world, not a perfect world.”
Simar Bajaj is an award-winning science journalist and 2024 Marshall Scholar. He has previously written for the Washington Post, Time magazine, the Guardian, NPR, and the Atlantic, as well as the New England Journal of Medicine, Nature Medicine, and The Lancet. He won Science Story of the Year from the Foreign Press Association in 2022 and the top prize for excellence in science communications from the National Academies of Science, Engineering, and Medicine in 2023. Follow him on X at @SimarSBajaj.
At the end of May, OpenAI marked a new “first” in its corporate history. It wasn’t an even more powerful language model or a new data partnership, but a report disclosing that bad actors had misused their products to run influence operations. The company had caught five networks of covert propagandists—including players from Russia, China, Iran, and Israel—using their generative AI tools for deceptive tactics that ranged from creating large volumes of social media comments in multiple languages to turning news articles into Facebook posts. The use of these tools, OpenAI noted, seemed intended to improve the quality and quantity of output. AI gives propagandists a productivity boost too.
First and foremost, OpenAI should be commended for this report and the precedent it hopefully sets. Researchers have long expected adversarial actors to adopt generative AI technology, particularly large language models, to cheaply increase the scale and caliber of their efforts. The transparent disclosure that this has begun to happen—and that OpenAI has prioritized detecting it and shutting down accounts to mitigate its impact—shows that at least one large AI company has learned something from the struggles of social media platforms in the years following Russia’s interference in the 2016 US election. When that misuse was discovered, Facebook, YouTube, and Twitter (now X) created integrity teams and began making regular disclosures about influence operations on their platforms. (X halted this activity after Elon Musk’s purchase of the company.)
OpenAI’s disclosure, in fact, was evocative of precisely such a report from Meta, released a mere day earlier. The Meta transparency report for the first quarter of 2024 disclosed the takedown of six covert operations on its platform. It, too, found networks tied to China, Iran, and Israel and noted the use of AI-generated content. Propagandists from China shared what seem to be AI-generated poster-type images for a “fictitious pro-Sikh activist movement.” An Israel-based political marketing firm posted what were likely AI-generated comments. Meta’s report also noted that one very persistent Russian threat actor was still quite active, and that its strategies were evolving. Perhaps most important, Meta included a direct set of “recommendations for stronger industry response” that called for governments, researchers, and other technology companies to collaboratively share threat intelligence to help disrupt the ongoing Russian campaign.
We are two such researchers, and we have studied online influence operations for years. We have published investigations of coordinated activity—sometimes in collaboration with platforms—and analyzed how AI tools could affect the way propaganda campaigns are waged. Our teams’ peer-reviewed research has found that language models can produce text that is nearly as persuasive as propaganda from human-written campaigns. We have seen influence operations continue to proliferate, on every social platform and focused on every region of the world; they are table stakes in the propaganda game at this point. State adversaries and mercenary public relations firms are drawn to social media platforms and the reach they offer. For authoritarian regimes in particular, there is little downside to running such a campaign, particularly in a critical global election year. And now, adversaries are demonstrably using AI technologies that may make this activity harder to detect. Media is writing about the “AI election,” and many regulators are panicked.
It’s important to put this in perspective, though. Most of the influence campaigns that OpenAI and Meta announced did not have much impact, something the companies took pains to highlight. It’s critical to reiterate that effort isn’t the same thing as engagement: the mere existence of fake accounts or pages doesn’t mean that real people are paying attention to them. Similarly, just because a campaign uses AI does not mean it will sway public opinion. Generative AI reduces the cost of running propaganda campaigns, making it significantly cheaper to produce content and run interactive automated accounts. But it is not a magic bullet, and in the case of the operations that OpenAI disclosed, what was generated sometimes seemed to be rather spammy. Audiences didn’t bite.
Producing content, after all, is only the first step in a propaganda campaign; even the most convincing AI-generated posts, images, or audio still need to be distributed. Campaigns without algorithmic amplification or influencer pickup are often just tweeting into the void. Indeed, it is consistently authentic influencers—people who have the attention of large audiences enthusiastically resharing their posts—that receive engagement and drive the public conversation, helping content and narratives to go viral. This is why some of the more well-resourced adversaries, like China, simply surreptitiously hire those voices. At this point, influential real accounts have far more potential for impact than AI-powered fakes.
Nonetheless, there is a lot of concern that AI could disrupt American politics and become a national security threat. It’s important to “rightsize” that threat, particularly in an election year. Hyping the impact of disinformation campaigns can undermine trust in elections and faith in democracy by making the electorate believe that there are trolls behind every post, or that the mere targeting of a candidate by a malign actor, even with a very poorly executed campaign, “caused” their loss.
By putting an assessment of impact front and center in its first report, OpenAI is clearly taking the risk of exaggerating the threat seriously. And yet, diminishing the threat or not fielding integrity teams—letting trolls simply continue to grow their followings and improve their distribution capability—would also be a bad approach. Indeed, the Meta report noted that one network it disrupted, seemingly connected to a political party in Bangladesh and targeting the Bangladeshi public, had amassed 3.4 million followers across 98 pages. Since that network was not run by an adversary of interest to Americans, it will likely get little attention. Still, this example highlights the fact that the threat is global, and vigilance is key. Platforms must continue to prioritize threat detection.
So what should we do about this? The Meta report’s call for threat sharing and collaboration, although specific to a Russian adversary, highlights a broader path forward for social media platforms, AI companies, and academic researchers alike.
Transparency is paramount. As outside researchers, we can learn only so much from a social media company’s description of an operation it has taken down. This is true for the public and policymakers as well, and incredibly powerful platforms shouldn’t just be taken at their word. Ensuring researcher access to data about coordinated inauthentic networks offers an opportunity for outside validation (or refutation!) of a tech company’s claims. Before Musk’s takeover of Twitter, the company regularly released data sets of posts from inauthentic state-linked accounts to researchers, and even to the public. Meta shared data with external partners before it removed a network and, more recently, moved to a model of sharing content from already-removed networks through Meta’s Influence Operations Research Archive. While researchers should continue to push for more data, these efforts have allowed for a richer understanding of adversarial narratives and behaviors beyond what the platform’s own transparency report summaries provided.
OpenAI’s adversarial threat report should be a prelude to more robust data sharing moving forward. Where AI is concerned, independent researchers have begun to assemble databases of misuse—like the AI Incident Database and the Political Deepfakes Incident Database—to allow researchers to compare different types of misuse and track how misuse changes over time. But it is often hard to detect misuse from the outside. As AI tools become more capable and pervasive, it’s important that policymakers considering regulation understand how they are being used and abused. While OpenAI’s first report offered high-level summaries and select examples, expanding data-sharing relationships with researchers that provide more visibility into adversarial content or behaviors is an important next step.
When it comes to combating influence operations and misuse of AI, online users also have a role to play. After all, this content has an impact only if people see it, believe it, and participate in sharing it further. In one of the cases OpenAI disclosed, online users called out fake accounts that used AI-generated text.
In our own research, we’ve seen communities of Facebook users proactively call out AI-generated image content created by spammers and scammers, helping those who are less aware of the technology avoid falling prey to deception. A healthy dose of skepticism is increasingly useful: pausing to check whether content is real and people are who they claim to be, and helping friends and family members become more aware of the growing prevalence of generated content, can help social media users resist deception from propagandists and scammers alike.
OpenAI’s blog post announcing the takedown report put it succinctly: “Threat actors work across the internet.” So must we. As we move into an new era of AI-driven influence operations, we must address shared challenges via transparency, data sharing, and collaborative vigilance if we hope to develop a more resilient digital ecosystem.
Josh A. Goldstein is a research fellow at Georgetown University’s Center for Security and Emerging Technology (CSET), where he works on the CyberAI Project. Renée DiResta is the research manager of the Stanford Internet Observatory and the author of Invisible Rulers: The People Who Turn Lies into Reality.
Google’s latest Search Off The Record podcast discussed examples of disruptive incidents that can affect crawling and indexing and discuss the criteria for deciding whether or not to disclose the details of what happened.
Complicating the issue of making a statement is that there are times when SEOs and publishers report that Search is broken when from Google’s point of view they’re working the way they’re supposed to.
Google Search Has A High Uptime
The interesting part of the podcast began with the observation that Google Search (the home page with the search box) itself has an “extremely” high uptime and rarely ever goes down and become unreachable. Most of the reported issues were due to network routing issues from the Internet itself than a failure from within Google’s infrastructure.
Gary Illyes commented:
“Yeah. The service that hosts the homepage is the same thing that hosts the status dashboard, the Google Search Status Dashboard, and it has like an insane uptime number. …the number is like 99.999 whatever.”
John Mueller jokingly responded with the word “nein” (pronounced like the number nine), which means “no” in German:
“Nein. It’s never down. Nein.”
The Googlers admit that the rest of Google Search on the backend does experience outages and they explain how that’s dealt with.
Crawling & Indexing Incidents At Google
Google’s ability to crawl and index web pages is critical for SEO and earnings. Disruption can lead to catastrophic consequences particularly for time-sensitive content like announcements, news and sales events (to name a few).
Gary Illyes explained that there’s a team within Google called Site Reliability Engineering (SRE) that’s responsible for making sure that the public-facing systems are running smoothly. There’s an entire Google subdomain devoted to the site reliability where they explain that they approach the task of keeping systems operational similar to how software issues are. They watch over services like Google Search, Ads, Gmail, and YouTube.
The SRE page explains the complexity of their mission as being very granular (fixing individual things) to fixing larger scale problems that affect “continental-level service capacity” for users that measure in the billions.
Gary Ilyes explains (at the 3:18 minute mark):
“Site Reliability Engineering org publishes their playbook on how they manage incidents. And a lot of the incidents are caught by incidents being issues with whatever systems. They catch them with automated processes, meaning that there are probers, for example, or there are certain rules that are set on monitoring software that looks at numbers.
And then, if the number exceeds whatever value, then it triggers an alert that is then captured by a software like an incident management software.”
February 2024 Indexing Problem
Gary next explains how the February 2024 indexing problem is an example of how Google monitors and responds to incidents that could impact users in search. Part of the response is figuring out if it’s an actual problem or a false positive.
He explains:
“That’s what happened on February 1st as well. Basically some number went haywire, and then that opened an incident automatically internally. Then we have to decide whether that’s a false positive or it’s something that we need to actually look into, as in like we, the SRE folk.
And, in this case, they decided that, yeah, this is a valid thing. And then they raised the priority of the incident to one step higher from whatever it was.
I think it was a minor incident initially and then they raised it to medium. And then, when it becomes medium, then it ends up in our inbox. So we have a threshold for medium or higher. Yeah.”
Minor Incidents Aren’t Publicly Announced
Gary Ilyes next explained that they don’t communicate every little incident that happens because most of the times it won’t even be noticed by users. The most important consideration is whether the incident affects users, which will automatically receive an upgraded priority level.
An interesting fact about how Google decides what’s important is that problems that affect users are automatically boosted to a higher priority level. Gary said he didn’t work in SRE so he was unable to comment on the exact number of users that need to be affected before Google decides to make a public announcement.
Gary explained:
“SRE would investigate everything. If they get a prober alert, for example, or an alert based on whatever numbers, they will look into it and will try to explain that to themselves.
And, if it’s something that is affecting users, then it almost automatically means that they need to raise the priority because users are actually affected.”
Incident With Images Disappearing
Gary shared another example of an incident, this time it was about images that weren’t showing up for users. It was decided that although the user experience was affected it was not affected to the point that it was keeping users from finding what they were searching for, the user experience was degraded but not to the point where Google became unusable. Thus, it’s not just whether users are affected by an incident that will cause an escalation in priority but also how badly the user experience is affected.
The case of the images not displaying was a situation in which they decided to not make a public statement because users could still be able to find the information they needed. Although Gary didn’t mention it, it does sound like an issue that recipe bloggers have encountered in the past where images stopped showing.
He explained:
“Like, for example, recently there was an incident where some images were missing. If I remember correctly, then I stepped in and I said like, “This is stupid, and we should not externalize it because the user impact is actually not bad,” right? Users will literally just not get the images. It’s not like something is broken. They will just not see certain images on the search result pages.
And, to me, that’s just, well, back to 1990 or back to 2008 or something. It’s like it’s still usable and still everything is dandy except some images.”
Are Publishers & SEOs Considered?
Google’s John Mueller asked Gary if the threshold for making a public announcement was if the user’s experience was degraded or if it was the case that the experience of publishers and SEOs were also considered.
Gary answered (at about the 8 minute mark):
“So it’s Search Relations, not Site Owners Relations, from Search perspective.
But by extension, like the site owners, they would also care about their users. So, if we care about their users, it’s the same group of people, right? Or is that too positive?”
Gary apparently sees his role as primarily as Search Relations in a general sense of their users. That may come as a surprise to many in the SEO community because Google’s own documentation for their Search Off The Record podcast explains the role of the Search Relations team differently:
“As the Search Relations team at Google, we’re here to help site owners be successful with their websites in Google Search.”
Listening to the entire podcast, it’s clear that Googlers John Mueller and Lizzi Sassman are strongly focused on engaging with the search community. So maybe there’s a language issue that’s causing his remark to be interpretable differently than he intended?
What Does Search Relations Mean?
Google explained that they have a process for deciding what to disclose about disruptions in search and it is a 100% sensible approach. But something to consider is that the definition of “relations” is that it’s about a connection between two or more people.
Search is a relation(ship). It is an ecosystem where two partners, the creators (SEOs and site owners) create content and Google makes it available to their users.