This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Fuel prices are soaring. Plastic could be next.
As the war in Iran continues, one of the most visible global economic ripple effects has been fossil-fuel prices. But looking ahead, further consequences could be looming for plastics.
Plastics are made from petrochemicals, and the supply chain impacts from the conflict are starting to build up. Americans will likely feel the ripples.
This story is from The Spark, our weekly climate newsletter. Sign up to get it in your inbox every Wednesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 SpaceX has filed for an IPO It’s set to be the largest ever, targeting a $1.75 trillion valuation. (NYT $) + Which would make Elon Musk the world’s first trillionaire. (Al Jazeera) + But the IPO could hinge on the success of Moon missions. (LA Times $) + And the conflicts of interest are staggering. (The Next Web) + Meanwhile, rivals are rising to challenge SpaceX. (MIT Technology Review)
2 Artemis II is on its way to the Moon NASA successfully launched the four astronauts on its rocket yesterday. (Axios) + The lunar plans could violate international law. (The Verge) + But the potential scientific advances are tremendous. (Nature) + Check out our roundtable on the next era of space exploration. (MIT Technology Review)
3 Iran has struck Amazon’s cloud business in Bahrain again It promised to hit US companies only yesterday. (FT $) + Other targets include Google, Microsoft, Apple, and Nvidia. (CNBC) + AWS data centers in Bahrain were also hit last month. (Reuters $)
4 OpenAI was secretly behind a child safety campaign group It pushed for age verification requirements for AI. (The San Francisco Standard $) + OpenAI had backed the legislation as a compromise measure. (WSJ $) + Coincidentally, Sam Altman heads a company providing age verification. (Engadget)
5 Anthropic is scrambling to limit the Claude Code leak It’s trying to remove 8,000 copies of the exposed code from GitHub. (Gizmodo) + An executive blamed the leak on “process errors.” (Bloomberg $) + Here’s what it reveals about Anthropic’s plans. (Ars Technica) + AI is making online crimes easier—and it could get much worse. (MIT Technology Review)
6 A new Russian “super-app” aims to emulate China’s WeChat And give the Kremlin new surveillance powers. (WSJ $)
7 America’s AI boom is leaving the rest of the world behind And it’s concentrating power and wealth in a handful of companies. (Rest of World)
8 Chinese chipmakers have claimed nearly half the country’s market Nvidia’s lead is shrinking rapidly. (Reuters $)
9 The first quantum computer to break encryption is imminent New research reveals how it could happen. (New Scientist)
10 The world’s oldest tortoise has been embroiled in a crypto scam Reports that Jonathan died at just 194 years old are thankfully false. (Guardian)
Quote of the day
“Starlink is the only reason this valuation is defensible.”
—Shay Boloor, chief market strategist at Futurum Equities, tells Reuters why SpaceX has such high hopes for its IPO.
One More Thing
These companies are creating food out of thin air
Dried cells—it’s what’s for dinner. At least that’s what a new crop of biotech startups, armed with carbon-guzzling bacteria and plenty of capital, are hoping to convince us.
Their claims sound too good to be true: they say they can make food out of thin air. But that’s exactly how certain soil-dwelling bacteria work.
Startups are replicating the process to turn abundant carbon dioxide into nutritious “air protein.” They believe it could dramatically lower farming emissions—and even disrupt agriculture altogether. Read the full story.
—Claire L. Evans
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ Need more Artemis II in your life? This site takes you inside the flight. + Here’s a fascinating look at the recording errors that improved songs. + Good news: the elusive Nightjar bird is making a comeback. + Finally, a master chef has baked clam chowder donuts.
AI-powered shopping is winning over American consumers when it saves time or makes buying decisions easy, but a slew of recent surveys show shoppers are not ready for autonomous purchase agents.
For example, in January 2026 email platform Omnisend commissioned a survey of 4,000 shoppers across the U.S., Canada, and Australia as to their use of AI for shopping in the previous six months.
Of the 1,072 U.S. shoppers surveyed, only 8.29% were “fully comfortable” with AI completing online purchases. Nearly three-quarters of respondents wanted some form of transactional restriction, and 20.28% were “not comfortable at all” with “handing over transactions to AI tools.”
Shopping Effort
Yet shoppers are using AI in the buying journey. Omnisend’s survey found that 47% of U.S. respondents use AI for product research and comparisons, 40.9% for finding deals or coupons, and 38.6% for summarizing reviews.
Separately, eMarketer, citing a Q3 2025 IBM survey of 18,000 global consumers, reported last month that shoppers most often use AI for general help, product research, and reviewing options. And McKinsey’s February 2026 survey of roughly 4,000 U.S. consumers found that 68% had used AI tools in the previous three months, mostly to support decision-making.
Collectively, the data indicate that shoppers value AI when it makes shopping easier.
In Omnisend’s data, 47.2% of U.S. respondents said AI saves time. Another 40.1% said it simplifies the process, and 38.6% said it helps discover products they might not have found otherwise.
Generally, saving time, simplifying, and identifying all reduce cognitive load or effort. Instead of sorting through dozens of product pages or reviews, shoppers can compress that work into a few prompts or queries.
This distinction is significant. Prompt-based shopping shifts how consumers decide what to buy. AI narrows the selection before a shopper reaches an ecommerce product page.
Purchase Control
Despite the ease of use, survey respondents are less comfortable giving up purchase control. Again, only 8.29% of Omnisend’s U.S. respondents said they are fully comfortable with AI completing a transaction.
Thus shoppers remain cautious. Some 56.4% of Omnisend respondents said they always or usually double-check AI-generated recommendations before buying.
Moreover, a February 2026 survey of 1,500 U.S. adults from Ipsos, the research firm, found that just 27% of Gen Z respondents (born 1997-2012) said they would allow an AI agent to choose and buy a product without approval, while just 4% of Gen X (1965-1980) and younger Boomers (1946-1964) would do the same.
Ipsos found consumers tend to prefer automation over agent autonomy. AI agents could make purchases based on prior behavior, such as selecting familiar brands or working from a predefined list, but not from new, autonomous selections.
Ecommerce Implications
Hence survey data suggests consumers use AI for product discovery, but not yet for agentic buying. That distinction should inform ecommerce businesses where to prioritize efforts.
For example, ensuring that product data is structured and feed-ready is key. AI chat tools use that structured information to summarize, compare, and surface product recommendations. The mundane task of cleaning data is more important than launching a co-shopping agent.
Similarly, content marketing is a priority over cutting-edge AI widgets. GenAI-optimized product comparisons, buying guides, instructions, and even reviews feed discovery.
While merchants should monitor how AI platforms evolve, the shopping journey is the near-term opportunity. AI is helping consumers decide what to buy, but not yet buying for them.
Artificial intelligence led all employer-cited reasons for U.S. job cuts in March, accounting for 15,341 of the month’s 60,620 announced layoffs, according to outplacement firm Challenger, Gray & Christmas.
That’s 25% of all cuts for the month, up from roughly 10% in February.
Since Challenger began tracking AI as a reason in 2023, employers have now cited it in 99,470 layoff announcements, or 3.5% of all cuts during that period.
What The Numbers Show
Total U.S. job cuts rose 25% from February to March but are down 78% from March 2025, when a wave of federal layoffs pushed that month’s total to 275,240.
For the first quarter overall, employers announced 217,362 cuts. That’s the lowest Q1 total since 2022.
AI ranks fifth among all cited reasons year-to-date, behind market and economic conditions, restructuring, closings, and contract loss. But its share is growing. In all of 2025, AI accounted for 5% of cited cuts. Through Q1 2026, it’s at 13%.
These are employer-stated reasons, not independently verified causes. Companies may cite AI when cuts involve broader cost restructuring.
Technology Sector Hit Hardest
Technology companies announced 18,720 cuts in March alone, bringing the 2026 total to 52,050. That’s up 40% from the 37,097 tech cuts announced in the same period last year. It’s the highest year-to-date total for the sector since 2023.
Andy Challenger, the firm’s chief revenue officer, said the pattern goes beyond traditional cost-cutting.
“Companies are shifting budgets toward AI investments at the expense of jobs. The actual replacing of roles can be seen in Technology companies, where AI can replace coding functions. Other industries are testing the limits of this new technology, and while it can’t replace jobs completely, it is costing jobs.”
Dell accounted for a large portion of March’s tech cuts based on its latest annual filing, according to the report. Oracle reportedly began layoffs late last month but has not released a total. Meta is also cutting roles in its Reality Labs division as it redirects resources toward AI.
Other Industries
Transportation companies announced the second-most cuts year-to-date with 32,241, up 703% from the same period in 2025. It’s the highest Q1 total for the sector on record.
Healthcare announced 23,520 cuts in Q1, also a record for the sector.
The news industry, tracked as a subset of media, announced 639 cuts through Q1 2026, up 12% from 573 in the same period last year.
Why This Matters
The Challenger data puts company-level numbers behind what workforce projections have estimated.
SEJ recently covered the Tufts American AI Jobs Risk Index, which ranked computer programmers at 55% vulnerability and web developers at 46%.
Challenger’s report separately shows tech sector cuts at their highest since 2023 and AI as the top employer-cited reason for March layoffs overall. The two datasets measure different things, but they point in the same direction.
For people working in search, content, and digital marketing, Challenger’s data adds another reference point to track alongside academic projections and company earnings calls.
Looking Ahead
Challenger said he expects more tech layoffs in 2026 as companies continue redirecting budgets toward AI.
“One thing that is clear is that AI is changing work and the workforce. Workers will need to be more strategic as they lead AI-powered agents that handle increasingly complex tasks.”
Challenger, Gray & Christmas publishes updated cut data monthly.
The conversation around llms.txt is real and worth continuing. I covered it in a previous article, and the core instinct behind the proposal is correct: AI systems need clean, structured, authoritative access to your brand’s information, and your current website architecture was not built with that in mind. Where I want to push further is on the architecture itself. llms.txt is, at its core, a table of contents pointing to Markdown files. That is a starting point, not a destination, and the evidence suggests the destination needs to be considerably more sophisticated.
Before we get into architecture, I want to be clear about something: I am not arguing that every brand should sprint to build everything described in this article by next quarter. The standards landscape is still forming. No major AI platform has formally committed to consuming llms.txt, and an audit of CDN logs across 1,000 Adobe Experience Manager domains found that LLM-specific bots were essentially absent from llms.txt requests, while Google’s own crawler accounted for the vast majority of file fetches. What I am arguing is that the question itself, specifically how AI systems gain structured, authoritative access to brand information, deserves serious architectural thinking right now, because the teams that think it through early will define the patterns that become standards. That is not a hype argument. That is just how this industry has worked every other time a new retrieval paradigm arrived.
Where Llms.txt Runs Out Of Road
The proposal’s honest value is legibility: it gives AI agents a clean, low-noise path into your most important content by flattening it into Markdown and organizing it in a single directory. For developer documentation, API references, and technical content where prose and code are already relatively structured, this has real utility. For enterprise brands with complex product sets, relationship-heavy content, and facts that change on a rolling basis, it is a different story.
The structural problem is that llms.txt has no relationship model. It tells an AI system “here is a list of things we publish,” but it cannot express that Product A belongs to Product Family B, that Feature X was deprecated in Version 3.2 and replaced by Feature Y, or that Person Z is the authoritative spokesperson for Topic Q. It is a flat list with no graph. When an AI agent is doing a comparison query, weighting multiple sources against each other, and trying to resolve contradictions, a flat list with no provenance metadata is exactly the kind of input that produces confident-sounding but inaccurate outputs. Your brand pays the reputational cost of that hallucination.
There is also a maintenance burden question that the proposal does not fully address. One of the strongest practical objections to llms.txt is the ongoing upkeep it demands: every strategic change, pricing update, new case study, or product refresh requires updating both the live site and the file. For a small developer tool, that is manageable. For an enterprise with hundreds of product pages and a distributed content team, it is an operational liability. The better approach is an architecture that draws from your authoritative data sources programmatically rather than creating a second content layer to maintain manually.
The Machine-Readable Content Stack
Think of what I am proposing not as an alternative to llms.txt, but as what comes after it, just as XML sitemaps and structured data came after robots.txt. There are four distinct layers, and you do not have to build all of them at once.
Layer two is entity relationship mapping. This is where you express the graph, not just the nodes. Your products relate to your categories, your categories map to your industry solutions, your solutions connect to the use cases you support, and all of it links back to the authoritative source. This can be implemented as a lightweight JSON-LD graph extension or as a dedicated endpoint in a headless CMS, but the point is that a consuming AI system should be able to traverse your content architecture the way a human analyst would review a well-organized product catalog, with relationship context preserved at every step.
Layer three is content API endpoints, programmatic and versioned access to your FAQs, documentation, case studies, and product specifications. This is where the architecture moves beyond passive markup and into active infrastructure. An endpoint at /api/brand/faqs?topic=pricing&format=json that returns structured, timestamped, attributed responses is a categorically different signal to an AI agent than a Markdown file that may or may not reflect current pricing. The Model Context Protocol, introduced by Anthropic in late 2024 and subsequently adopted by OpenAI, Google DeepMind, and the Linux Foundation, provides exactly this kind of standardized framework for integrating AI systems with external data sources. You do not need to implement MCP today, but the trajectory of where AI-to-brand data exchange is heading is clearly toward structured, authenticated, real-time interfaces, and your architecture should be building toward that direction. I have been saying this for years now – that we are moving toward plugged-in systems for the real-time exchange and understanding of a business’s data. This is what ends crawling, and the cost to platforms, associated with it.
Layer four is verification and provenance metadata, timestamps, authorship, update history, and source chains attached to every fact you expose. This is the layer that transforms your content from “something the AI read somewhere” into “something the AI can verify and cite with confidence.” When a RAG system is deciding which of several conflicting facts to surface in a response, provenance metadata is the tiebreaker. A fact with a clear update timestamp, an attributed author, and a traceable source chain will outperform an undated, unattributed claim every single time, because the retrieval system is trained to prefer it.
What This Looks Like In Practice
Take a mid-market SaaS company, a project management platform doing around $50 million ARR and selling to both SMBs and enterprise accounts. They have three product tiers, an integration marketplace with 150 connectors, and a sales cycle where competitive comparisons happen in AI-assisted research before a human sales rep ever enters the picture.
Right now, their website is excellent for human buyers but opaque to AI agents. Their pricing page is dynamically rendered JavaScript. Their feature comparison table lives in a PDF that the AI cannot parse reliably. Their case studies are long-form HTML with no structured attribution. When an AI agent evaluates them against a competitor for a procurement comparison, it is working from whatever it can infer from crawled text, which means it is probably wrong on pricing, probably wrong on enterprise feature availability, and almost certainly unable to surface the specific integration the prospect needs.
A machine-readable content architecture changes this. At the fact-sheet layer, they publish JSON-LD Organization and Product schemas that accurately describe each pricing tier, its feature set, and its target use case, updated programmatically from the same source of truth that drives their pricing page. At the entity relationship layer, they define how their integrations cluster into solution categories, so an AI agent can accurately answer a compound capability question without having to parse 150 separate integration pages. At the content API layer, they expose a structured, versioned comparison endpoint, something a sales engineer currently produces manually on request. At the provenance layer, every fact carries a timestamp, a data owner, and a version number.
When an AI agent now processes a product comparison query, the retrieval system finds structured, attributed, current facts rather than inferred text. The AI does not hallucinate their pricing. It correctly represents their enterprise features. It surfaces the right integrations because the entity graph connected them to the correct solution categories. The marketing VP who reads a competitive loss report six months later does not find “AI cited incorrect pricing” as the root cause.
This Is The Infrastructure Behind Verified Source Packs
In the previous article on Verified Source Packs, I described how brands can position themselves as preferred sources in AI-assisted research. The machine-readable content API is the technical architecture that makes VSPs viable at scale. A VSP without this infrastructure is a positioning statement. A VSP with it is a machine-validated fact layer that AI systems can cite with confidence. The VSP is the output visible to your audience; the content API is the plumbing that makes the output trustworthy. Clean structured data also directly improves your vector index hygiene, the discipline I introduced in an earlier article, because a RAG system building representations from well-structured, relationship-mapped, timestamped content produces sharper embeddings than one working from undifferentiated prose.
History, however, suggests the objection cuts the other way. The brands that implemented Schema.org structured data in 2012, when Google had just launched it, and nobody was sure how broadly it would be used, shaped how Google consumed structured data across the next decade. They did not wait for a guarantee; they built to the principle and let the standard form around their use case. The specific mechanism matters less than the underlying principle: content must be structured for machine understanding while remaining valuable for humans. That will be true regardless of which protocol wins.
The minimum viable implementation, one you can ship this quarter without betting the architecture on a standard that may shift, is three things. First, a JSON-LD audit and upgrade of your core commercial pages, Organization, Product, Service, and FAQPage schemas, properly interlinked using the @id graph pattern, so your fact layer is accurate and machine-readable today. Second, a single structured content endpoint for your most frequently compared information, which, for most brands, is pricing and core features, generated programmatically from your CMS so it stays current without manual maintenance. Third, provenance metadata on every public-facing fact you care about: a timestamp, an attributed author or team, and a version reference.
That is not an llms.txt. It is not a Markdown copy of your website. It is durable infrastructure that serves both current AI retrieval systems and whatever standard formalizes next, because it is built on the principle that machines need clean, attributed, relationship-mapped facts. The brands asking “should we build this?” are already behind the ones asking “how do we scale it.” Start with the minimum. Ship something this quarter that you can measure. The architecture will tell you where to go next.
Duane Forrester has nearly 30 years of digital marketing and SEO experience, including a decade at Microsoft running SEO for MSN, building Bing Webmaster Tools, and launching Schema.org. His new book about staying trusted and relevant in the AI era (The Machine Layer) is available now on Amazon.
Cloudflare announced a new content management system called EmDash that it says is the “spiritual successor to WordPress.” Could EmDash be your next content management system? Here are six reasons why EmDash may be the content management system of tomorrow… but not today.
1. EmDash Is Not User Focused
Cloudflare’s biggest selling point for its new CMS, as stated in the title of the announcement, is that it solves the WordPress security problem. Over 25% of the announcement focuses on discussing plugin security.
The remaining 73% of the announcement is dedicated to:
Background information about the evolution of web development.
Putting WordPress within the context of the history of web development.
The technical architecture.
Security and authentication.
Readiness for the x402 standard, which enables users to monetize agentic website traffic.
There are over 2,700 words in that announcement, and the only part that arguably has direct importance to actual users like bloggers, businesses, and other publishers is the part about plugin security. The rest of the content is developer- and coder-focused and not user-focused at all.
There are many reasons to choose a CMS, and while security is important to businesses and online publishers, there are other reasons that are far more important.
2. The Case For Plugin Security
Cloudflare explains that WordPress plugin security is compromised because plugins are granted full access to a website’s internal files and database. This lack of boundaries means that if a single plugin has a flaw or malicious intent, it can compromise the entire site. The announcement explains that the vast majority of security vulnerabilities (96%) originate from third-party plugins.
What the announcement doesn’t say is that the vast majority of WordPress plugin vulnerabilities are not likely to be exploitable at scale. Only 17% of plugins are high severity, and of those, many of them are not installed on many websites.
“1,966 (17%) vulnerabilities had a high severity score, meaning they were likely to be exploited in automated mass-scale attacks.
…Furthermore, our Zero Day program found 33 highly critical vulnerabilities in Premium components, compared to only 12 in free components.”
There are many WordPress vulnerabilities discovered every day, but most of them are low risk and are found on plugins that are not widely used. If plugin security is EmDash’s main selling point, it’s not much of a selling point in the real world.
Cloudflare’s solution for improving plugin security is solid and well designed. However, a reasonable argument could be made that Cloudflare’s case for plugin security is overstating its importance in the overall scheme of what users actually need.
3. EmDash Is Built To Solve Infrastructure Problems
In a post on X, Jamie Marsland of Automattic acknowledged that EmDash offers innovative solutions but argues that its focus is on solving infrastructure issues and is not focused on the daily problems that an actual CMS user (like a restaurant owner or a recipe blogger) would be interested in.
Marsland makes the point that developers may care about “cleaner abstractions” and “isolate runtimes,” but small business owners care about things like bookings, SEO, and customer acquisition. He uses the analogy of EmDash being a “tidy desk” for people who aren’t actually looking to tidy their desks but rather are focused on using a CMS that helps them run a business.
“…when very smart people rebuild something from scratch, they tend to fix the problems they can see most clearly. And the problems Cloudflare sees are very real:
Plugin security (sandboxing, isolation)
Serverless scaling
Modern developer experience
AI-native programmability
All of which make perfect sense… If you are looking at the world from inside an infrastructure company.
…If you are a developer, this feels like someone has finally tidied your desk. The problem is that most people are not trying to tidy their desk.
They are trying to run a business from it while:
replying to emails
posting on social
updating their website
wondering why traffic dropped”
4. EmDash May Not Be User Friendly
EmDash is built on Astro, which technically is not a CMS; it’s a web framework. EmDash wraps Astro around a graphical user interface (GUI) for content management that may feel familiar to anyone who has used WordPress. But setting it all up is not as easy as WordPress’s famous five minute setup because it can involve connecting to a GitHub repository and configuring database settings. The same is true for getting the site to look how a user wants it to look.
It has a GUI for managing content, but it does not (yet) have a point-and-click website builder the way most modern content management systems like WordPress and Wix do.
5. Command Line Interface
I’m old enough to remember what using a desktop computer in 1980 was like. The interface was essentially a command line interface, with a cursor impatiently blinking at the user, waiting for cryptic commands to make it do something. It was not until 1983 that Apple introduced a graphical user interface (GUI) that made interacting with a computer easy for everyday users.
Image by Shutterstock/AG_Design_stocks
If you like typing cryptic commands to make a computer function, then EmDash’s command line interface is for you. At this point, users won’t be able to get away from it because users currently cannot set up an EmDash site from scratch without resorting to a CLI. Even the “one-click” deployment options in the Cloudflare Dashboard eventually require technical configuration that is usually handled via the terminal.
6. EmDash Is Not Ready For Most Users
I was quite excited to read Cloudflare’s announcement about a “spiritual successor” to WordPress, but the more I read, the more it became apparent that EmDash is not the solution I am looking for. Yes, I want a fast-performing website. Yes, I want a site that is secure and won’t surprise me one day with Japanese text.
But I don’t want to deal with a CLI, and I do want an easy-to-use interface for setting up and building an attractive website for myself. EmDash is not ready for general use. It’s still in early developer beta. The version number on it is 0.1.0, so at this point it’s literally not for the average user.
Hopefully, some day it will be a viable competitor to WordPress, but EmDash is not that right now.
This week’s Ask a PPC addresses one of advertisers’ most frustrating fears:
“I suspect my account has click fraud. What checks can I do to confirm this, and what can I do about it?”
Click fraud is easily one of the most frustrating pitfalls in managing a paid media account. Whether it shows up as bots on low‑quality apps, suspicious display placements, or highly sophisticated schemes that mimic real search behavior, click fraud is real.
That said, not every odd click pattern, low cost-per-click, or disappointing conversion rate is the result of fraud. In many cases, what looks like click fraud is actually the outcome of campaign settings, targeting choices, or creative mismatches.
In this article, we will cover:
How to distinguish click fraud from human‑driven performance issues.
What ad platforms proactively do to protect advertisers.
What you can do when click fraud is genuinely present.
A quick note on perspective: I am a Microsoft Ads employee. This article is platform‑agnostic, and the guidance shared here applies broadly across paid media platforms.
1. Distinguishing Click Fraud From Human Error
Before assuming malicious intent, it is critical to audit whether your own campaign setup could be creating performance patterns that resemble click fraud.
There are several common scenarios where human behavior can look suspicious at first glance.
Start With Where Your Budget Is Going
The first question to ask is simple: Is the majority of my spend going to placements I intentionally targeted?
If the answer is no, that is your first red flag.
Review placement and domain reports carefully.
Identify whether spend is flowing to sites, apps, or partner placements you do not recognize.
If you see unfamiliar placements, open those URLs on a device or browser where you are comfortable evaluating risk.
If a placement feels spammy, low‑quality, or clearly misaligned with your brand, exclude it immediately. If the placement appears legitimate but you cannot realistically see how a user would engage with the ad, that may indicate fraudulent behavior.
In either case, exclusion is the right move, followed by a conversation with platform support. Ad platforms have a vested interest in removing low‑quality or fraudulent inventory.
Review Location Targeting Settings Closely
Location targeting is one of the most common sources of perceived click fraud.
When advertisers enable “People who show interest in your target locations,” they are effectively allowing global eligibility. This can lead to traffic from regions with higher bot activity or from users who appear suspicious simply because they are unlikely to convert.
If you choose to use “showing interest in,” consider adding an additional layer of geographic exclusions to ensure your ads only serve where you truly intend.
Evaluate Creative For Accidental Click Risk
Ad creative can also create misleading signals.
Display ads with prominent buttons can invite accidental clicks.
Creative that does not clearly communicate value may generate curiosity clicks without intent.
Small screens increase the risk of fat‑finger clicks.
In these cases, the issue is not fraud. It is design. Adjusting creative can often resolve the problem.
2. What Ad Platforms Proactively Do To Prevent Click Fraud
While I cannot speak for every ad platform, there are shared principles across the industry.
Platforms Are Incentivized To Protect Inventory Quality
If inventory performs poorly, advertisers stop investing. That creates a strong incentive for platforms to maintain secure, valuable placements.
One example from Microsoft Ads is a policy requiring Search Partner publishers to implement Microsoft Clarity. This allows deeper insight into user behavior and helps identify invalid or fraudulent activity before advertisers are exposed to it.
Other platforms have similar verification and monitoring systems in place, even if the tools differ.
Advertisers Are Not Charged For Invalid Clicks
Another core principle is that advertisers should not pay for fraudulent activity.
Most platforms continuously review clicks. When invalid or fraudulent clicks are detected, those costs are credited back to the advertiser. These credits may not appear immediately, as click validation takes time, but they are visible in platform reporting.
If you believe a significant spike in fraudulent clicks was missed, you should contact support. Platforms expect and encourage those conversations.
3. What You Can Do When Click Fraud Is Real
Once you have ruled out configuration and creative issues, and click fraud still appears present, there are concrete actions you can take.
Consider Click Fraud Mitigation Tools
If fraudulent clicks represent 40% or more of your traffic, I would recommend investing in a third‑party solution.
These tools typically focus on:
IP‑based blocking for simpler threats.
Behavioral pattern detection for advanced schemes.
Be aware that consent requirements can complicate implementation in certain regions, particularly where third‑party cookie consent is required. In markets with fewer restrictions, these tools are easier to deploy.
Use AI And Automation Where Possible
Some advertisers choose to build their own systems using AI to identify patterns and automatically exclude malicious IPs. This can be effective when done carefully and within privacy and consent guidelines.
Set Expectations Around Risky Placements And Markets
Certain placements and regions carry higher click fraud risk. If you choose to invest in them, transparency matters.
A practical approach is to communicate a 10% variance buffer to clients or stakeholders. This acknowledges that temporary spikes may occur before credits are issued.
You should not ultimately pay for click fraud, but there may be short periods where spend looks inflated before reconciliation. Monitoring credit card billing closely is important to avoid overcharging during those windows.
Remember That Fraud Is Not Limited To Clicks
Some of the most damaging fraud never happens at the click level.
Account takeovers, My Client Center (MCC) compromises, and phishing attempts are real threats. Protect yourself by:
Only opening emails from trusted senders.
Verifying suspicious messages with peers or platform support.
Avoiding login links unless you are certain of their legitimacy.
A well‑run account can unravel quickly if access is compromised.
Final Thoughts
Click fraud is frustrating, but it is manageable. The key is separating perception from reality, understanding how platforms protect advertisers, and knowing when to take action.
If you found this helpful, I would love to hear from you. And as always, stay tuned for next month’s Ask the PPC.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
When Zeus, a medical student living in a hilltop city in central Nigeria, returns to his studio apartment from a long day at the hospital, he turns on his ring light, straps his iPhone to his forehead, and starts recording himself. He raises his hands in front of him like a sleepwalker and puts a sheet on his bed. He moves slowly and carefully to make sure his hands stay within the camera frame.
Zeus is a data recorder for Micro1, a US company based in Palo Alto, California that collects real-world data to sell to robotics companies. As companies like Tesla, Figure AI, and Agility Robotics race to build humanoids—robots designed to resemble and move like humans in factories and homes—videos recorded by gig workers like Zeus are becoming the hottest new way to train them.
Micro1 has hired thousands of contract workers in more than 50 countries, including India, Nigeria, and Argentina, where swathes of tech-savvy young people are looking for jobs. They’re mounting iPhones on their heads and recording themselves folding laundry, washing dishes, and cooking. The job pays well by local standards and is boosting local economies, but it raises thorny questions around privacy and informed consent. And the work can be challenging at times—and weird.
Zeus found the job in November, when people started talking about it everywhere on LinkedIn and YouTube. “This would be a real nice opportunity to set a mark and give data that will be used to train robots in the future,” he thought.
Zeus is paid $15 an hour, which is good income in Nigeria’s strained economy with high unemployment rates. But as a bright-eyed student dreaming of becoming a doctor, he finds ironing his clothes for hours every day boring.
“I really [do] not like it so much,” he says. “I’m the kind of person that requires … a technical job that requires me to think.”
Zeus, and all the workers interviewed by MIT Technology Review, asked to be referred to only by pseudonyms because they were not authorized to talk about their work.
Humanoid robots are notoriously hard to build because manipulating physical objects is a difficult skill to master. But the rise of large language models underlying chatbots like ChatGPT has inspired a paradigm shift in robotics. Just as large language models learned to generate words by being trained on vast troves of text scraped from the internet, many researchers believe that humanoid robots can learn to interact with the world by being trained on massive amounts of movement data.
Editor’s note: In a recent poll, MIT Technology Review readers selected humanoid robots as the 11th breakthrough for our 2026 list of 10 Breakthrough Technologies.
Robotics requires far more complex data about the physical world, though, and that is much harder to find. Virtual simulations can train robots to perform acrobatics, but not how to grasp and move objects, because simulations struggle to model physics with perfect accuracy. For robots to work in factories and serve as housekeepers, real-world data, however time-consuming and expensive to collect, may be what we need.
Investors are pouring money feverishly into solving this challenge, spending over $6 billion on humanoid robots in 2025. And at-home data recording is becoming a booming gig economy around the world. Data companies like Scale AI and Encord are recruiting their own armies of data recorders, while DoorDash pays delivery drivers to film themselves doing chores. And in China, workers in dozens of state-owned robot training centers wear virtual-reality headsets and exoskeletons to teach humanoid robots how to open a microwave and wipe down the table.
“There is a lot of demand, and it’s increasing really fast,” says Ali Ansari, CEO of Micro1. He estimates that robotics companies are now spending more than $100 million each year to buy real-world data from his company and others like it.
A day in the life
Workers at Micro1 are vetted by an AI agent named Zara that conducts interviews and reviews samples of chore videos. Every week, they submit videos of themselves doing chores around their homes, following a list of instructions about things like keeping their hands visible and moving at natural speed. The videos are reviewed by both AI and a human and are either accepted or rejected. They’re then annotated by AI and a team of hundreds of humans who label the actions in the footage.
“There is a lot of demand, and it’s increasing really fast.”
Ali Ansari, CEO of Micro1
Because this approach to training robots is in its infancy, it’s not clear yet what makes good training data. Still, “you need to give lots and lots of variations for the robot to generalize well for basic navigation and manipulation of the world,” says Ansari.
But many workers say that creating a variety of “chore content” in their tiny homes is a challenge. Zeus, a scrappy student living in a humble studio, struggles to record anything beyond ironing his clothes every day. Arjun, a tutor in Delhi, India, takes an hour to make a 15-minute video because he spends so much time brainstorming new chores.
“How much content [can be made] in the home? How much content?” he says.
There’s also the sticky question of privacy. Micro1 asks workers not to show their faces to the camera or reveal personal information such as names, phone numbers, and birth dates. Then it uses AI and human reviewers to remove anything that slips through.
But even without faces, the videos capture an intimate slice of workers’ lives: the interiors of their homes, their possessions, their routines. And understanding what kind of personal information they might be recording while they’re busy doing chores on camera can be tricky. Reviews of such footage might not filter out sensitive information beyond the most obvious identifiers.
For workers with families, keeping private life off camera is a constant negotiation. Arjun, a father of two daughters, has to wrangle his chaotic two-year-old out of frame. “Sometimes it’s very difficult to work because my daughter is small,” he says.
Sasha, a banker turned data recorder in Nigeria, tiptoes around when she hangs her laundry outside in a shared residential compound so she won’t record her neighbors, who watch her in bewilderment.
“It’s going to take longer than people think.”
Ken Goldberg, UC Berkeley
While the workers interviewed by MIT Technology Review understand that their data is being used to train robots, none of them know how exactly their data will be used, stored, and shared with third parties, including the robotics companies that Micro1 is selling the data to. For confidentiality reasons, says Ansari, Micro1 doesn’t name its clients or disclose to workers the specific nature of the projects they are contributing to.
“It is important that if workers are engaging in this, that they are informed by the companies themselves of the intention … where this kind of technology might go and how that might affect them longer term,” says Yasmine Kotturi, a professor of human-centered computing at the University of Maryland.
Occasionally, some workers say, they’ve seen other workers asking on the company Slack channel if the company could delete their data. Micro1 declined to comment on whether such data is deleted.
“People are opting into doing this,” says Ansari. “They could stop the work at any time.”
Hungry for data
With thousands of workers doing their chores differently in different homes, some roboticists wonder if the data collected from them is reliable enough to train robots safely.
“How we conduct our lives in our homes is not always right from a safety point of view,” says Aaron Prather, a roboticist at ASTM International. “If those folks are teaching those bad habits that could lead to an incident, then that’s not good data.” And the sheer volume of data being collected makes reviewing it for quality control challenging. But Ansari says the company rejects videos showing unsafe ways of performing a task, while clumsy movements can be useful to teach robots what not to do.
Then there’s the question of how much of this data we need. Micro1 says it has tens of thousands of hours of footage, while Scale AI announced it had gathered more than 100,000 hours.
“It’s going to take a long time to get there,” says Ken Goldberg, a roboticist at the University of California, Berkeley. Large language models were trained on text and images that would take a human 100,000 years to read, and humanoid robots may need even more data, because controlling robotic joints is even more complicated than generating text. “It’s going to take longer than people think,” he says.
When Dattu, an engineering student living in a bustling tech hub in India, comes home after a full day of classes at his university, he skips dinner and dashes to his tiny balcony, cramped with potted plants and dumbbells. He straps his iPhone to his forehead and records himself folding the same set of clothes over and over again.
His family stares at him quizzically. “It’s like some space technology for them,” he says. When he tells his friends about his job, “they just get astounded by the idea that they can get paid by recording chores.”
Juggling his university studies with data recording, as well as other data annotation gigs, takes a toll on him. Still, “it feels like you’re doing something different than the whole world,” he says.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The gig workers who are training humanoid robots at home
When Zeus, a medical student in Nigeria, returns to his apartment from a long day at the hospital, he straps his iPhone to his forehead and records himself doing chores.
Zeus is a data recorder for Micro1, which sells the data he collects to robotics firms. As these companies race to build humanoids, videos from workers like Zeus have become the hottest new way to train them.
Micro1 has hired thousands of them in more than 50 countries, including India, Nigeria, and Argentina. The jobs pay well locally, but raise thorny questions around privacy and informed consent. The work can be challenging—and weird. Read the full story.
AI benchmarks are broken. Here’s what we need instead.
For decades, AI has been evaluated based on whether it can outperform humans on isolated problems. But it’s seldom used this way in the real world.
While AI is assessed in a vacuum, it operates in messy, complex, multi-person environments over time. This misalignment leads us to misunderstand its capabilities, risks, and impacts.
We need new benchmarks that assess AI’s performance over longer horizons within human teams, workflows, and organizations. Here’s a proposal for one such approach: Human–AI, Context-Specific Evaluation.
—Angela Aristidou, professor at University College London and faculty fellow at the Stanford Digital Economy Lab and the Stanford Human-Centered AI Institute.
MIT Technology Review Narrated: can quantum computers now solve health care problems? We’ll soon find out.
In a laboratory on the outskirts of Oxford, a quantum computer built from atoms and light awaits its moment. The device is small but powerful—and also very valuable. Infleqtion, the company that owns it, is hoping its abilities will win $5 million at a competition.
The prize will go to the quantum computer that can solve real health care problems that “classical” computers cannot. But there can be only one big winner—if there is a winner at all.
—Michael Brooks
This is our latest story to be turned into an MIT Technology Review Narrated podcast, which we’re publishing each week on Spotify and Apple Podcasts. Just navigate to MIT Technology Review Narrated on either platform, and follow us to get all our new content as it’s released.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 OpenAI just closed the biggest funding round in Silicon Valley history It raised $122 billion ahead of its blockbuster IPO, which is expected later this year. (WSJ $) + It’s also prepping a push to “rethink the social contract.” (Vanity Fair $) + Campaigners are urging people to quit ChatGPT. (MIT Technology Review)
2 Iran has threatened to attack 18 US tech companies It’s eyeing their operations in the Middle East. (Politico) + Targets include Nvidia, Apple, Microsoft, and Google. (Engadget) + Iran struck AWS data centers earlier this month. (Reuters $)
3 Artemis II is about to fly humans to the Moon. Here’s the science they’ll do Their experiments will set the stage for future explorers. (Nature) + You can watch the launch attempt today. (Engadget)
4 Putin is trying to take full control of Russia’s internet New outages and blockages are cutting the country off from the world. (NYT $) + Can we repair the internet? (MIT Technology Review)
5 A robotaxi outage in China left passengers stranded on highways Baidu vehicles froze on the streets of Wuhan. (Bloomberg $) + Police are blaming a “system failure.” (Reuters $)
6 US government requests for social media user data are soaring They’ve skyrocketed by 770% in the past decade. (Bloomberg $) + Is the Pentagon allowed to surveil Americans with AI? (MIT Technology Review)
7 Tesla has admitted that humans sometimes drive its robotaxis Remote drivers occasionally control them completely. (Wired $)
8 A satellite-smashing chain reaction could spiral out of control This data visualization captures the dangers of space collisions. (Guardian) + Here’s all the stuff we’ve put into space. (MIT Technology Review)
9 Meta’s smartglasses can turn you into a creep According to one journalist who wore them for a month. (Guardian)
10 A Claude Code leak has exposed plans for a virtual pet We could be getting a Tamagotchi for the GenAI era. (The Verge)
Quote of the day
“From now on, for every assassination, an American company will be destroyed.”
—Iran’s Islamic Revolutionary Guard Corps (IRGC) threatens US tech firms in an affiliated Telegram, per CNBC.
One More Thing
ACKERMAN + GRUBER
How one mine could unlock billions in EV subsidies
In a pine farm north of the tiny town of Tamarack, Minnesota, Talon Metals has uncovered one of America’s densest nickel deposits. Now it wants to begin mining the ore.
Products made from the nickel could net more than $26 billion in subsidies through the Inflation Reduction Act (IRA), which is starting to transform the US economy. To understand how, we tallied up the potential tax credits available. Read the full story to find out what we discovered.
—James Temple
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
Every week we publish a rundown of new services for ecommerce merchants. This installment includes updates on product images, syndicated reviews, box-free returns, installment payments, marketplace integrations, agentic commerce, shipping intelligence, cross-border ecommerce, and affiliate partnerships.
Got an ecommerce product release? Email updates@practicalecommerce.com.
New Tools for Merchants
Designkit launches platform to streamline product visuals.Designkit has launched its product image platform. The AI-powered tool enables sellers to generate a full listing image set from a single prompt, including white-background shots, lifestyle scenes, and in-use visuals. It supports high-volume batch processing and localization across five languages. The AI Photo Editor Suite delivers refinement through five core tools: Background Remover, Background Generation, Object Remover, Image Enhancer, and Text & Element Integration.
Designkit
Ordoro and SPS Commerce partner to support brands on Amazon and Walmart.Ordoro, an ecommerce operations platform, has partnered with SPS Commerce, an intelligent supply chain network, to support scaling brands across retail and marketplace channels, including Amazon and Walmart. SPS Commerce helps brands recover revenue tied to retailer deductions, compliance fines, and marketplace reimbursement opportunities. Ordoro equips brands with the tools to manage inventory, shipping, and order workflows. Combined, the companies state they provide guidance for brands transitioning from early traction to operational maturity.
Shopware and Balance partner on B2B payments.Shopware, an open-source ecommerce platform, and Balance, an AI-powered financial infrastructure for B2B brands, have partnered to bring advanced B2B payment options to merchants in the Shopware ecosystem. Through the partnership, Shopware merchants can integrate Balance into checkout and buyer portals to offer and manage their pay-by-invoice and buy-now-pay-later programs. Balance automates the invoice-to-cash lifecycle with built-in fraud detection, credit management, and collection and reconciliation.
VisiGEO launches to make brands visible to AI. Focus Technology Co. has launched VisiGEO, a generative engine optimization platform. VisiGEO’s AI Visibility Analysis details mentions of your brand and competitors, along with the sentiment. VisiGEO’s Website GEO Audit corrects technical barriers blocking AI crawlers, from robots.txt misconfigurations to missing Schema.org markup. VisiGEO helps brands generate content and then provides publishing guidance to maximize AI impact.
Jliveo introduces AI-driven platform for B2B cross-border ecommerce.Jliveo, a B2B ecommerce solutions provider, has launched its AI-driven platform to support global wholesale and cross-border operations. The platform integrates sourcing, dropshipping, and fulfillment management into a single system — both wholesale purchasing and on-demand order fulfillment. Jliveo also incorporates automated content workflows and multilingual communication.
Jliveo
Shopify introduces Tinker app for AI tools.Shopify has debuted Tinker, a free mobile app that combines 100 specialized AI tools for creating images, videos, logos, and more. Tinker organizes tools by outcome, such as product photography, logo creation, social media videos, 360-degree views, and more. Each tool shows examples of what it creates and how to use it. Tinker brings models from providers such as OpenAI, Google, Anthropic, and others into a single app.
Amazon lets external websites offer Prime shipping without an Amazon login.Amazon is testing a program that lets shoppers access Prime shipping benefits on other websites without logging in to an Amazon account. The initiative includes a small group of test merchants who use Amazon’s multichannel fulfillment services to pick, pack, and deliver orders from their online store or other marketplaces and may have resisted deeper integration with Amazon’s ecosystem.
FedEx Office joins Amazon’s return network. Over 1,500 FedEx Office locations across the U.S. now offer Amazon’s free, label-free, box-free return option for eligible items. Customers begin the return process in their Amazon account, choose a nearby drop-off location, and receive a QR code. They can then bring their unpackaged item and its QR code to the selected location, where it is scanned and prepared for shipping — no shipping box or label required.
Meta expands Facebook affiliate partnerships.Meta is expanding Facebook affiliate partnerships to more test partners, including Amazon, eBay, and Temu in the U.S., Mercado Libre in Latin America, and Shopee in Asia. With affiliate partnerships, creators tag products from merchants in their Facebook posts to help their communities find and buy. Merchant partners choose which products to feature and set the commission for sales. Meta says it also plans to test similar affiliate experiences on Instagram.
Firmly launches Connect agentic marketing tool.Firmly, an agentic commerce platform, has introduced Connect, a no-code onboarding tool that autonomously integrates with merchants’ websites and commerce infrastructure to sell through agentic marketing channels. Firmly Connect allows merchants to quickly activate agentic commerce by verifying their business credentials, selecting where they want to sell, and publishing their product catalog while maintaining full control over pricing, inventory, and distribution.
Firmly
ShipperHQ launches AI-powered shipping intelligence platform.ShipperHQ, a shipping and checkout experience platform, has launched ShipperHQ.ai, a feature to give ecommerce merchants full visibility into their shipping operations. ShipperHQ.ai introduces an intelligence layer that combines real-time analytics with AI agents that analyze, test, and optimize shipping and checkout performance. Built on shipping logic refined across merchants, carrier integrations, and rate calculations, ShipperHQ.ai connects directly to an ecommerce store’s live shipping configuration and checkout data.
Thryv launches AI-powered sales automation for small businesses.Thryv, a provider of small-business marketing and sales software, launched AI Lead Flow. According to Thryv, the new tool connects online visibility, intelligent lead management, and automated sales follow-ups into a single experience. AI Lead Flow combines Thryv’s Marketing Center’s online visibility tools with its Keap sales automation engine to create a continuous, automated pipeline from the first online impression to the closed deal, eliminating the most common lead management failures for small businesses.
Shopify merchant brands are now available in ChatGPT.Shopify merchants can now sell to ChatGPT users via Shopify’s Agentic Storefronts, which provide access to genAI platforms such as ChatGPT, Microsoft Copilot, AI Mode in Google Search, and the Gemini app — all managed centrally from the Shopify admin. Brands not using Shopify for ecommerce can add products to the Shopify Catalog to reach shoppers and sell across these same AI channels.
Fair to say the majority of evergreen content will not drive the value it did five years ago. Hell, even one or two years ago. What we have done for the last decade will not be as profitable.
AIOs have eroded clicks. Answer engines have given people options. And to be fair, people are bored of the +2,000-word article answering “What time does X start?” Or recipes where the ingredient list is hidden below 1,500 words about why daddy didn’t like me.
So, you’ve got to be smart. This has to be framed as a commercial decision. Content needs to drive real business value. You’ve got to be confident in it delivering.
That doesn’t mean every article, video, or podcast has to drive a subscription or direct conversion. But it needs to play a clear part in the user’s journey. You need to be able to argue for its inclusion:
Is it a jumping-off point?
Will it drive a registration?
Or a free subscriber, save or follow on social
More commonly known as micro-conversions, these things really matter when it comes to cultivating and retaining an audience. People don’t want more bland, banal nonsense. They want something better.
The antithesis to AI slop will help your business be profitable.
Inherently, nothing. It’s a foundational part of the content pyramid.
In most cases, it’s been done to death, and AI is very effective at summarizing a lot of this bread-and-butter content.
The epitome of quantity over quality; it worked and made a fortune.
But I digress.
An authoritative enough site has been able to drive clicks and follow-up value with sub-par content for decades. That is, slowly diminishing. Rightly or wrongly.
And not because of the Helpful Content stuff. Google nerfed all the small sites long before the goliaths. Now they’ve gone after the big fish.
We have to make commercial decisions that help businesses make the right choice. Concepts like E-E-A-T have had an impact on the quality of content (a good thing). It’s also had an impact on the cost of creating quality content.
Working with experts.
Unique imagery.
Video.
Product and development costs.
Data.
This isn’t cheap. Once upon a time, we could generate value from authorless content full of stock images and no unique value. Unless you’re willing to bend the rules (which isn’t an option for most of us), you need an updated plan.
It depends.
You need to establish how much your content now costs to produce and the value it brings. Not everything is going to drive a significant conversion. That doesn’t mean you shouldn’t do it. It means you need to have a very clear reason for what you’re creating and why.
If particular topics are essential to your audience, service, and/or product, then they should at least be investigated.
One of the joys of creating evergreen content has always been that it adds value throughout the year(s). A couple of annual updates, even relatively light touch, could yield big results.
Commissioning something of quality in this space is likely more expensive. It needs to be worth it; it has to form part of your multi-channel experience to make it so.
Unique data and visuals that can be shared on socials.
Building campaigns around it (or it’s part of a campaign).
You can even build authors and your brand around it.
And if it resonates, you can rinse and repeat year after year.
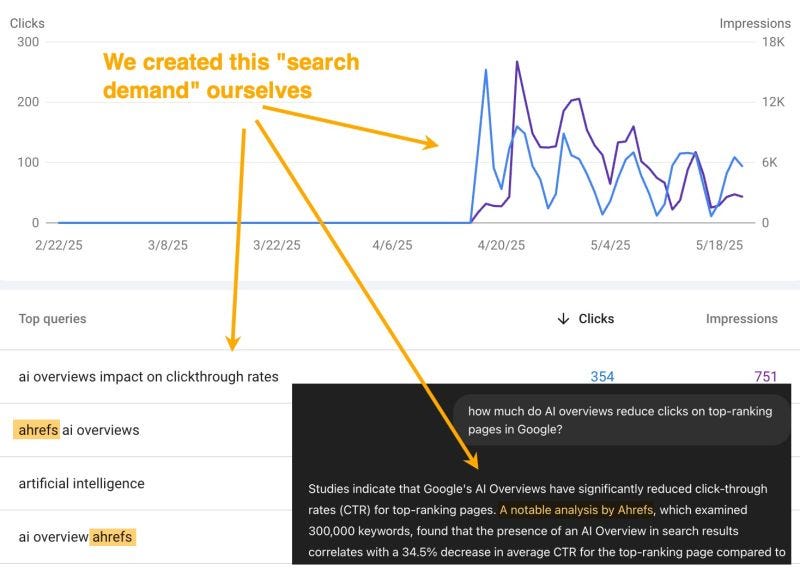
Ahrefs created demand for their brand + an evergreen topic – AIOs (Image Credit: Harry Clarkson-Bennett)
And this type of content or campaign can increase demand for a topic. You can become a thought leader by shifting the tide of public opinion.
For publishers and content creators, that is foundational.
I don’t – on both counts. We should want to be targeted on driving real value for the business.
Something like:
Tier 1: Value – core, revenue, and value-driving conversions.
Tier 2: Registrations (and things that help you build your owned properties), links, shares, and comments.
Tier 3: Page views, returning visits, and engagement metrics.
Micro-conversions over clicks. We’re focusing on registrations, free or lower-value subscriptions. Whatever gets the user into the ecosystem and one step closer to a genuinely valuable conversion.
The messy middle has changed, and it is largely unattributable (Image Credit: Harry Clarkson-Bennett)
Now, could a click be a micro-conversion? If you know that someone who reads a secondary article (by clicking a follow-up link) is 10x more likely to register, that follow-up click could be a sensible micro-conversion.
This type of conversion may not directly drive your bottom line. But it forces you and your team to focus on behaviors that are more likely to lead to a valuable conversion.
That is the point of a micro-conversion. It changes behaviors.
You can tweak the above tiers to better suit your content offering. Not all content is going to drive direct tier one or even two value. You just need to have a very clear idea of its purpose in the customer journey.
If what you’re creating already exists, you’d better make sure you add something extra. You’ve got to force your way into the conversation, and unless you can offer something unique, you’re (almost certainly) wasting your time IMO.
I’ll break all of these down, but I think (in order of importance):
Writing content for people.
Information gain.
Getting it found.
Creating it at the right time.
Structuring it for bots.
Everyone is obsessed with getting cited or being visible in AI.
I think this is completely the wrong way of framing this new era. Getting cited there, or being visible, is a happy byproduct of building a quality brand with an efficient, joined-up approach to marketing.
The more you understand your audience, the more likely you will be to create high-quality, relevant content that gets cited.
If you know your audience really cares about a topic, that’s step one taken care of. If you know where they spend time and how they’re influenced, that’s step two. And if you know how to cut through the noise, that’s step three.
Really, this is an evolution in SEO and the internet at large.
Invest in and create content that will resonate with your audience.
Create a cross-channel marketing strategy that will genuinely reach and influence them.
Share, share, share. Be impactful. Get out there.
Make sure it’s easy to read, share, and consume.
Your content still needs to reach and be remembered by the right people. Do that better than anybody else, and wider visibility will come.
In SEO, we have a different definition of information gain than more traditional information retrieval mechanics. I don’t know if that’s because we’re wrong (probably), or that we have a valid reason…
Maybe someone can enlighten me?
In more traditional machine learning, information gain measures how much uncertainty is reduced after observing new data. That uncertainty is captured by entropy, which is a way of quantifying how unpredictable a variable is based on its probability distribution.
Events with low probability are more surprising and therefore carry more information. High probability events are less surprising and novel. Therefore, entropy reflects the overall level of disorder and unpredictability across all possible outcomes.
Information gain, then, tells us how much that unpredictability drops when we split or segment the data. A higher information gain means the data has become more ordered and less uncertain – in other words, we’ve learned something useful.
To us in SEO, information gain means the addition of new, relevant information. Beyond what is already out there in the wider corpus.
A representative workflow of Google’s Contextual estimation of link information gain patent (Image Credit: Harry Clarkson-Bennett)
Google wants to reduce uncertainty. Reduce ambiguity. Content with a higher level of information gain isn’t only different, it elevates a user’s understanding. It raises the bar by answering the question(s) and topic more effectively than anyone else.
So, try something different, novel even, and watch Google test your content higher up in the SERPs to see if it satisfies a user.
This is such an important concept for evergreen content because so many of these queries have well-established answers. If you’re just parroting these answers because your competitors do it, you’re not forcing Google’s hand.
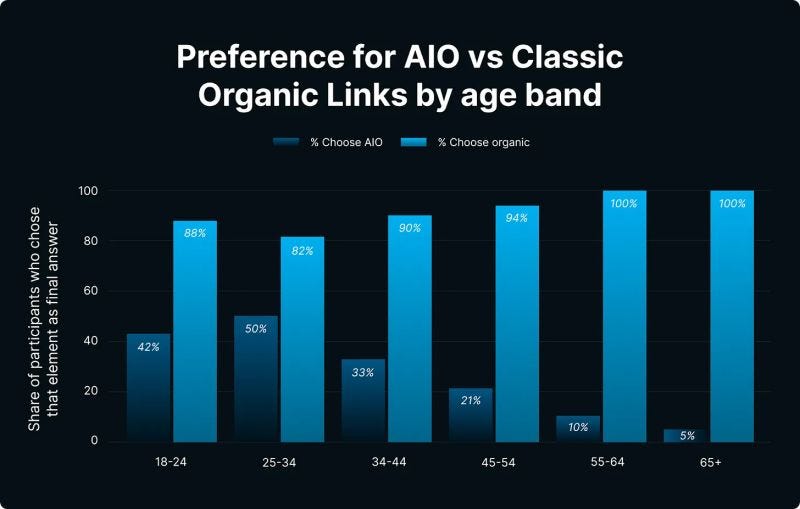
Particularly if you’re still just copying headers and FAQs from the top three results. Audiences are not arriving at publisher destinations through direct navigation at the same scale. They encounter journalism incidentally, through social feeds, not through habitual site visits.
Younger audiences spend less time on news sites and more time on social every year (Image Credit: Harry Clarkson-Bennett)
You’ve got to meet them there and force their hand.
According to this patent – contextual estimation of link information gain – Google scores documents based on the additional information they offer to a user, considering what the user has already seen.
“Based on the information gain scores of a set of documents, the documents can be provided to the user in a manner that reflects the likely information gain that can be attained by the user if the user were to view the documents.”
Bots, like people, need structure to properly “understand” content.
Elements like headings (h1 – h6), semantic HTML, and linking effectively between articles help search engines (and other forms of information retrieval) understand what content you deem important.
While the majority of semi-literates “understand” content, bots don’t. They fake it. They use engagement signals, NLP, and the vector model space to map your document against others.
They can only do this effectively if you understand how to structure a page.
Frontloading key information.
Effectively targeting highly relevant queries.
Using structured data formats like lists and tables, where appropriate (these are more cost-effective forms of tokenization).
The more clearly a page communicates its topic, subtopics, and relationships, the more likely it is to be consistently retrieved and reused across search and AI surfaces. This has a compounding effect.
Rank more effectively (great for RAG, obviously) – feature more heavily in versions of the internet – force your way into model training data.
If you need to get development work put through, frame it through the lens of assistive technology. Can people with specific needs fully access your pages?
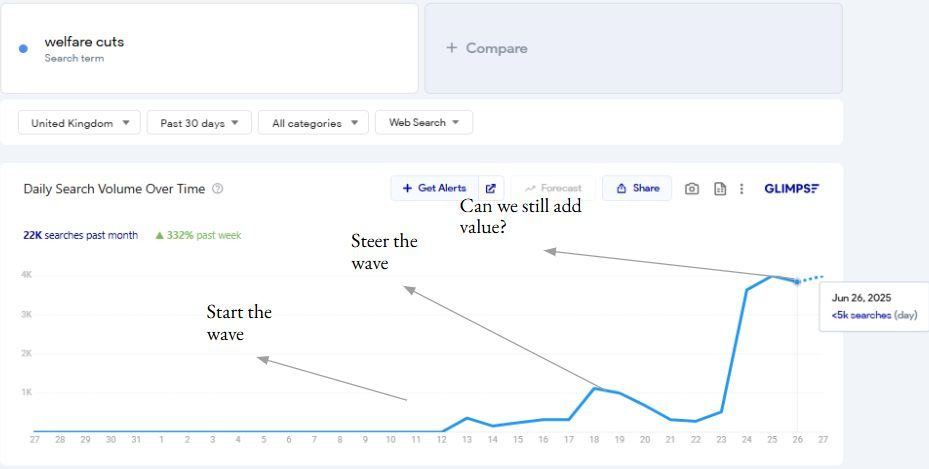
Track and pay very close attention to spikes in demand (Google Trends API being a very obvious option here).
Make sure you’re adding something of value to the wider corpus.
If quality content is already out there and you have nothing extra to add, consider whether it’s worth spending money on (SEO is not free).
Create and update timely evergreen content (Image Credit: Harry Clarkson-Bennett)
While this is primarily for news, you can apply a similar logic to evergreen content if you zoom out and follow macro trends.
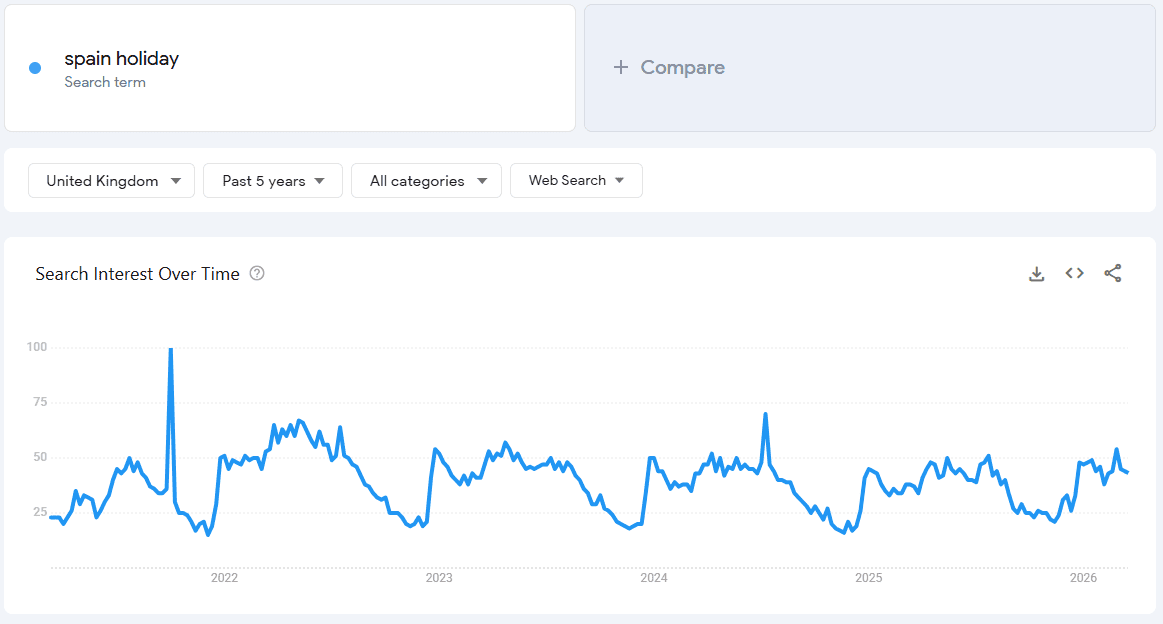
Evergreen content still spikes at different times throughout the year. Take Spain as an example. There’s much more limited interest in going to Spain in the Winter months from the UK. But January (holiday planning or weekend breaks) and summer (more immediate holiday-ing with the kids) provide better opportunities to generate traffic.
You’re capturing the spike in demand by updating content at the right time. Particularly if you understand the difference in user needs when this spike in demand happens.
In January, get your holiday planning content ready.
In the summer, get your family-friendly and last-minute holiday content up and running.
Image Credit: Harry Clarkson-Bennett
Demand for evergreen topics can be cyclical. In this example, you would want to capture the spike(s) with carefully planned updates, so you have up-to-date content when a user is really searching for that product, service, or information.
Well, what matters to your brand and your users? Have you asked them?
By the very nature of new and evolving topics and concepts, not everything “evergreen” has been done.
New topics rise. Old ones fall. Some are cyclical.
My rule(s) of thumb would be to establish:
Is the topic foundational to your product and service?
Does your current (and potential) audience demand it?
Do you have something new to add to the wider corpus of information?
If the answer to those three is a broad variation of yes, it’s almost certainly a good bet. Then, I would consider topic search volume, cross-platform demand, and whether the topic is trending up or down in popularity.
There are some things you should be doing “just for SEO.” Content isn’t one of them. You can yell topical authority until you’re blue in the face. If you’re creating stuff just for SEO – kill it.
IMO, these plays have been dead or dying for some time. The modern-day version of the internet (in particular search) demands disambiguation. It demands accuracy. Verification that you are an expert. Otherwise, you’re competing with those who have a level of legitimacy that you do not.
Social profiles, newsletters, real people sharing stories. You’re competing with people who aren’t polishing turds.
If all you’re thinking about is search volume or clicks, I don’t think it’s worth it.
And this brings me nicely onto rented land. Platforms you don’t own.
We’ve spent years creating assets (your websites) to deliver value in search. Owning all of your assets and prioritizing your site above all else. But that is changing. In many cases, people don’t reach your website until they’ve already made a purchasing decision.
I think Rand has managed this transition better than anybody (Image Credit: Harry Clarkson-Bennett)
So, you have to get your stuff out there. Create large, unique studies. Cut them into snippets and short-form videos. Use your individual platform to boost your profile and the content’s chances of soaring.
This is, IMO, particularly prescient for publishers. You’ve got to get out there. You’ve got to share and reuse your content. To make the most of what you’ve created.
Sweat your assets. Even if senior figures aren’t comfortable with this, you need to make it happen.
People have been espousing how important it is to feature as part of the answer. And that may be true. But you’re going to have to be good at selling your projects in if there’s no clear attribution or value.
It might not have the spikes of news, but evergreen interest still spikes at certain times in the year.
Get people – real people – to share it. To have their spin on it.
Outperform the expected early stage engagement and maximize your chance of appearing in platforms like Discover with wider platform engagement.
You have to work harder than before.
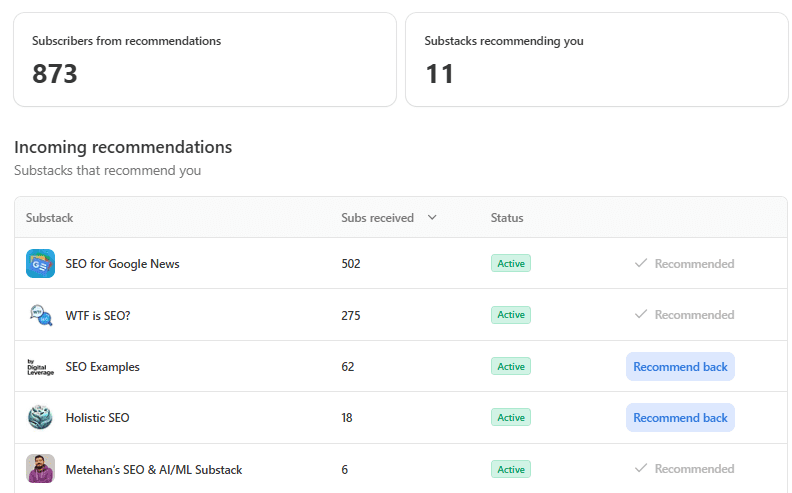
I shared an example of this around a year ago, but to revisit it, I now have 11 recommendations from other Substacks.
You can’t do this alone (Image Credit: Harry Clarkson-Bennett)
They have accounted for over 40% of my total subscribers. Admittedly, mainly from Barry, Shelby, and Jessie. But they are, if I may be so bold, superhumans.
And when our main driver of evergreen traffic to the site (Google) has really leaned into the evil that surrounds big tech, we’ve got to be cannier. We have to find ways to get people to share our content.
Even evergreen content.
If we’re being honest, a lot of SEO content has been rubbish. Churned out muck.
People are still churning out muck at an incredible rate. When what you’ve got is crap, more crap isn’t the answer. I think people are turned off. They’re tuning out of things at an alarming rate, especially young people.
It is all about getting the right people into the system. Evergreen content is still foundational here. You just have to make it work harder. Be more interesting. Be shareable.
Hopefully, this makes decisions over what we should and shouldn’t create easier.