Flowers play a key role in most landscapes, from urban to rural areas. There might be dandelions poking through the cracks in the pavement, wildflowers on the highway median, or poppies covering a hillside. We might notice the time of year they bloom and connect that to our changing climate. Perhaps we are familiar with their cycles: bud, bloom, wilt, seed. Yet flowers have much more to tell in their bright blooms: The very shape they take is formed by local and global climate conditions.
The form of a flower is a visual display of its climate, if you know what to look for. In a dry year, its petals’ pigmentation may change. In a warm year, the flower might grow bigger. The flower’s ultraviolet-absorbing pigment increases with higher ozone levels. As the climate changes in the future, how might flowers change?
Anthocyanins are red or indigo pigments that supply antioxidants and photoprotectants, which help a plant tolerate climate-related stresses such as droughts.
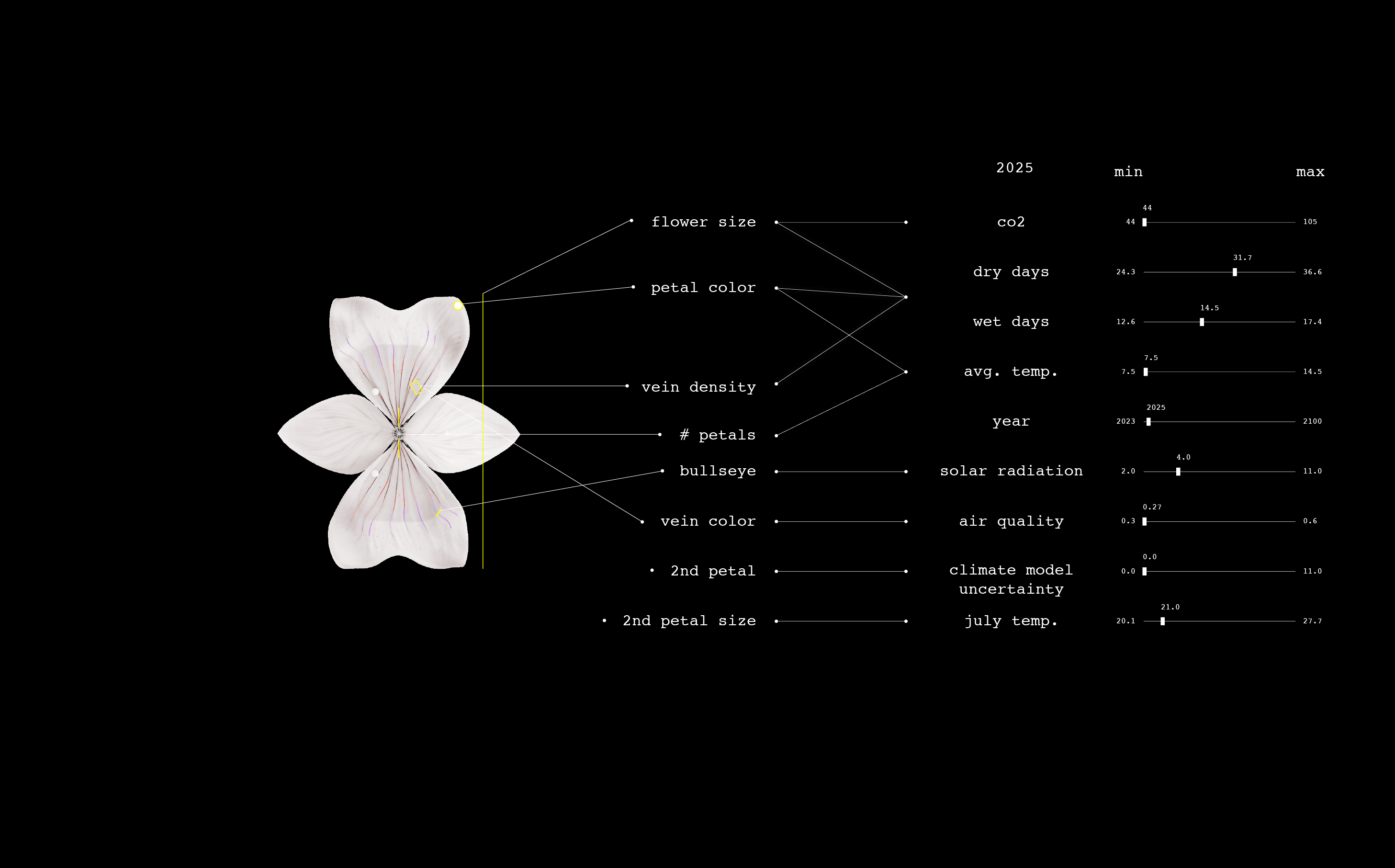
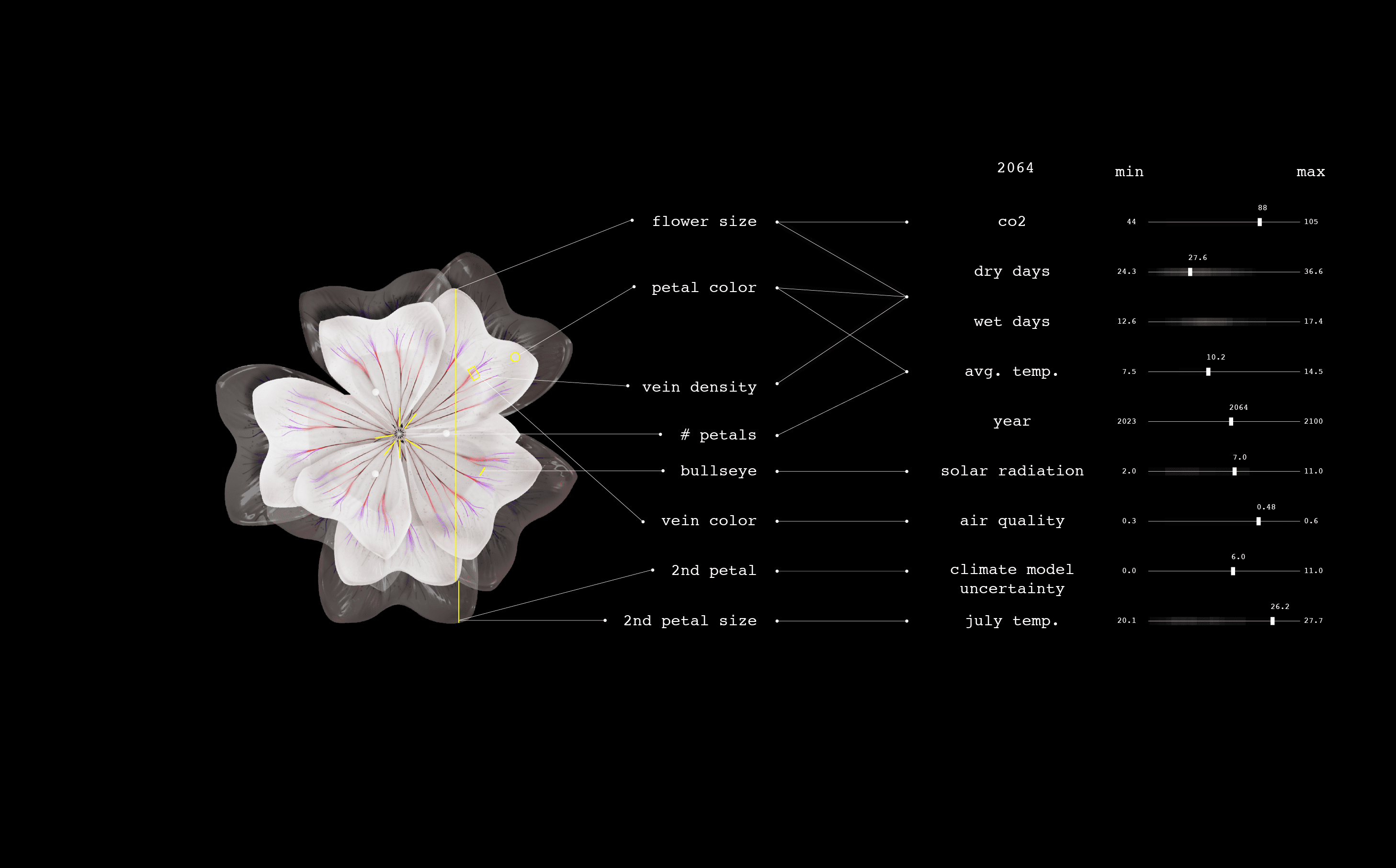
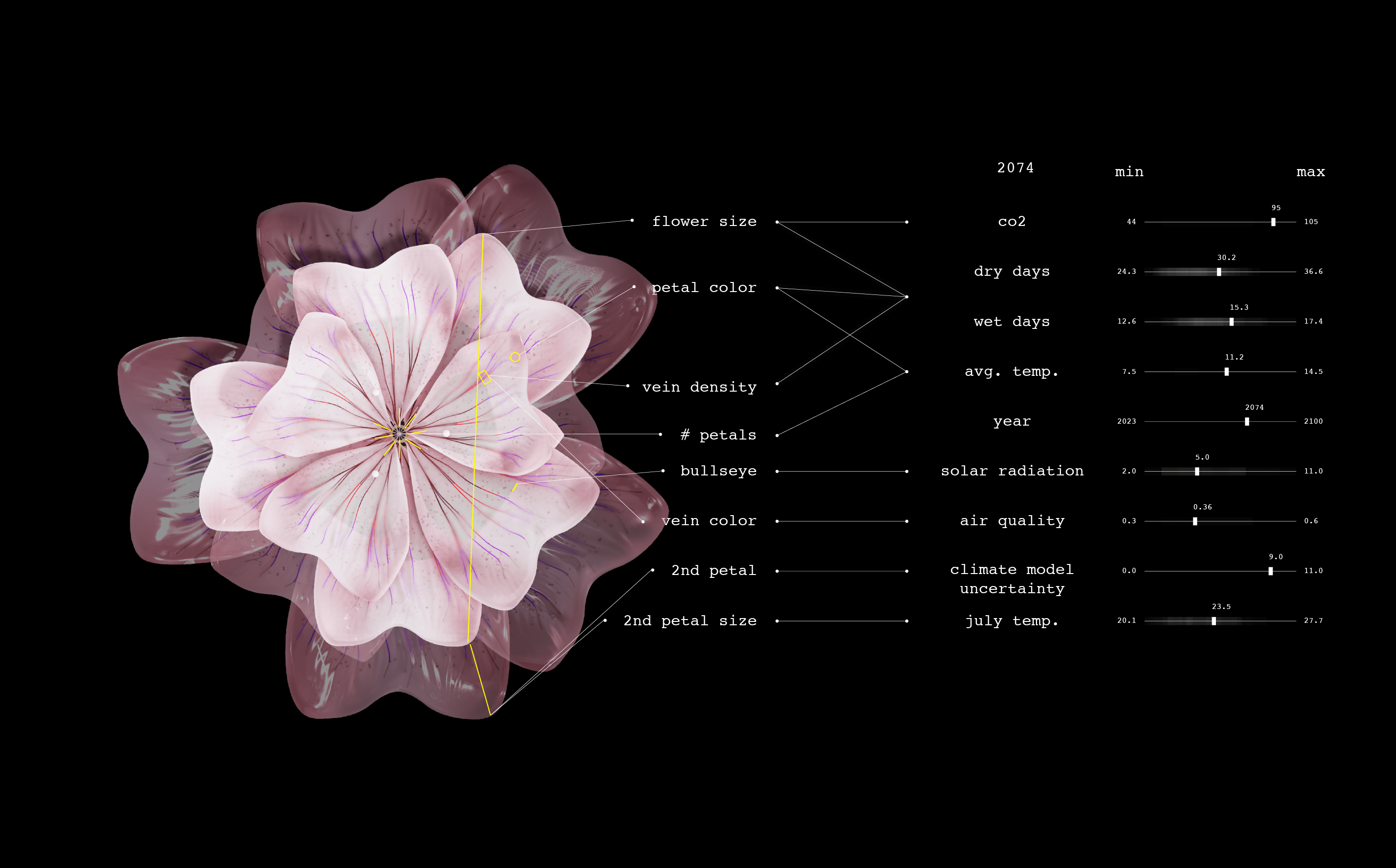
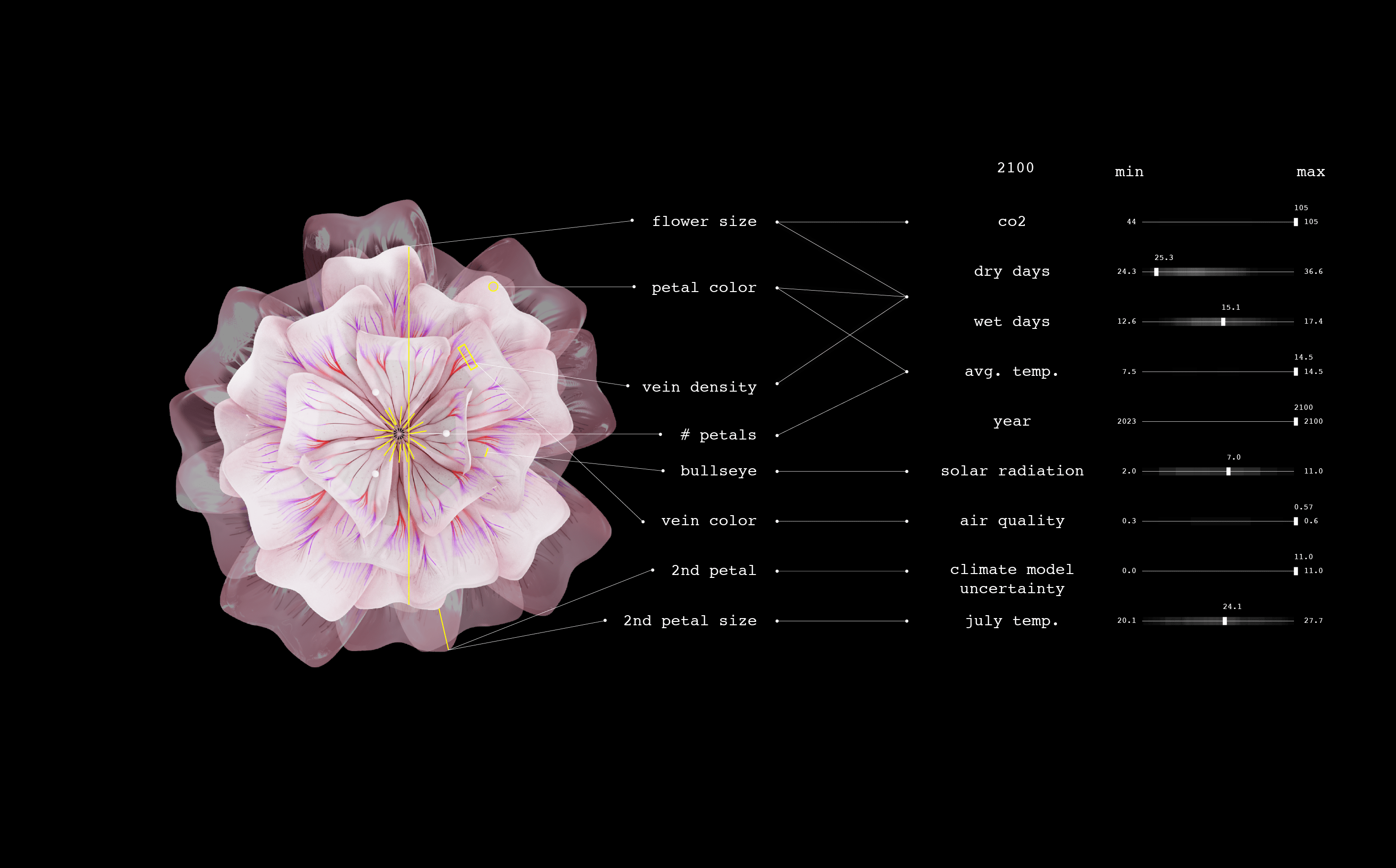
An artistic research project called Plant Futures imagines how a single species of flower might evolve in response to climate change between 2023 and 2100—and invites us to reflect on the complex, long-term impacts of our warming world. The project has created one flower for every year from 2023 to 2100. The form of each one is data-driven, based on climate projections and research into how climate influences flowers’ visual attributes.
More ultraviolet pigment protects flowers’ pollen against increasing ozone levels.
MARCO TODESCO
Under unpredictable weather conditions, the speculative flowers grow a second layer of petals. In botany, a second layer is called a “double bloom” and arises from random mutations.
COURTESY OF ANNELIE BERNER
Plant Futures began during an artist residency in Helsinki, where I worked closely with the biologist Aku Korhonen to understand how climate change affected the local ecosystem. While exploring the primeval Haltiala forest, I learned of the Circaea alpina, a tiny flower that was once rare in that area but has become more common as temperatures have risen in recent years. Yet its habitat is delicate: The plant requires shade and a moist environment, and the spruce population that provides those conditions is declining in the face of new forest pathogens. I wondered: What if the Circaea alpina could survive in spite of climate uncertainty? If the dark, shaded bogs turn into bright meadows and the wet ground dries out, how might the flower adapt in order to survive? This flower’s potential became the project’s grounding point.
The author studying historical Circaea samples in the Luomus Botanical Collections.
COURTESY OF ANNELIE BERNER
Outside the forest, I worked with botanical experts in the Luomus Botanical Collections. I studied samples of Circaea flowers from as far back as 1906, and I researched historical climate conditions in an attempt to understand how flower size and color related to a year’s temperature and precipitation patterns.
I researched how other flowering plants respond to changes to their climate conditions and wondered how the Circaea would need to adapt to thrive in a future world. If such changes happened, what would the Circaea look like in 2100?
We designed the future flowers through a combination of data-driven algorithmic mapping and artistic control. I worked with the data artist Marcin Ignac from Variable Studio to create 3D flowers whose appearance was connected to climate data. Using Nodes.io, we made a 3D model of the Circaea alpina based on its current morphology and then mapped how those physical parameters might shift as the climate changes. For example, as the temperature rises and precipitation decreases in the data set, the petal color shifts toward red, reflecting how flowers protect themselves with an increase in anthocyanins. Changes in temperature, carbon dioxide levels, and precipitation rates combine to affect the flowers’ size, density of veins, UV pigments, color, and tendency toward double bloom.2025: Circaea alpina is ever so slightly larger than usual owing to a warmer summer, but it is otherwise close to the typical Circaea flower in size, color, and other attributes.2064: We see a bigger flower with more petals, given an increase in carbon dioxide levels and temperature. The bull’s-eye pattern, composed of UV pigment, is bigger and messier because of an increase in ozone and solar radiation. A second tier of petals reflects uncertainty in the climate model.2074: The flower becomes pinker, an antioxidative response to the stress of consecutive dry days and higher temperatures. Its size increases, primarily because of higher levels of carbon dioxide. The double bloom of petals persists as the climate model’s projections increase in uncertainty.2100: The flower’s veins are densely packed, which could signal appropriation of a technique leaves use to improve water transport during droughts. It could also be part of a strategy to attract pollinators in the face of worsening air quality that degrades the transmission of scents.2023—2100: Each year, the speculative flower changes. Size, color, and form shift in accordance with the increased temperature and carbon dioxide levels and the changes in precipitation patterns.
In this 10-centimeter cube of plexiglass, the future flowers are “preserved,” allowing the viewer to see them in a comparative, layered view.
COURTESY OF ANNELIE BERNER
Based in Copenhagen, Annelie Berner is a designer, researcher, teacher, and artist specializing in data visualization.
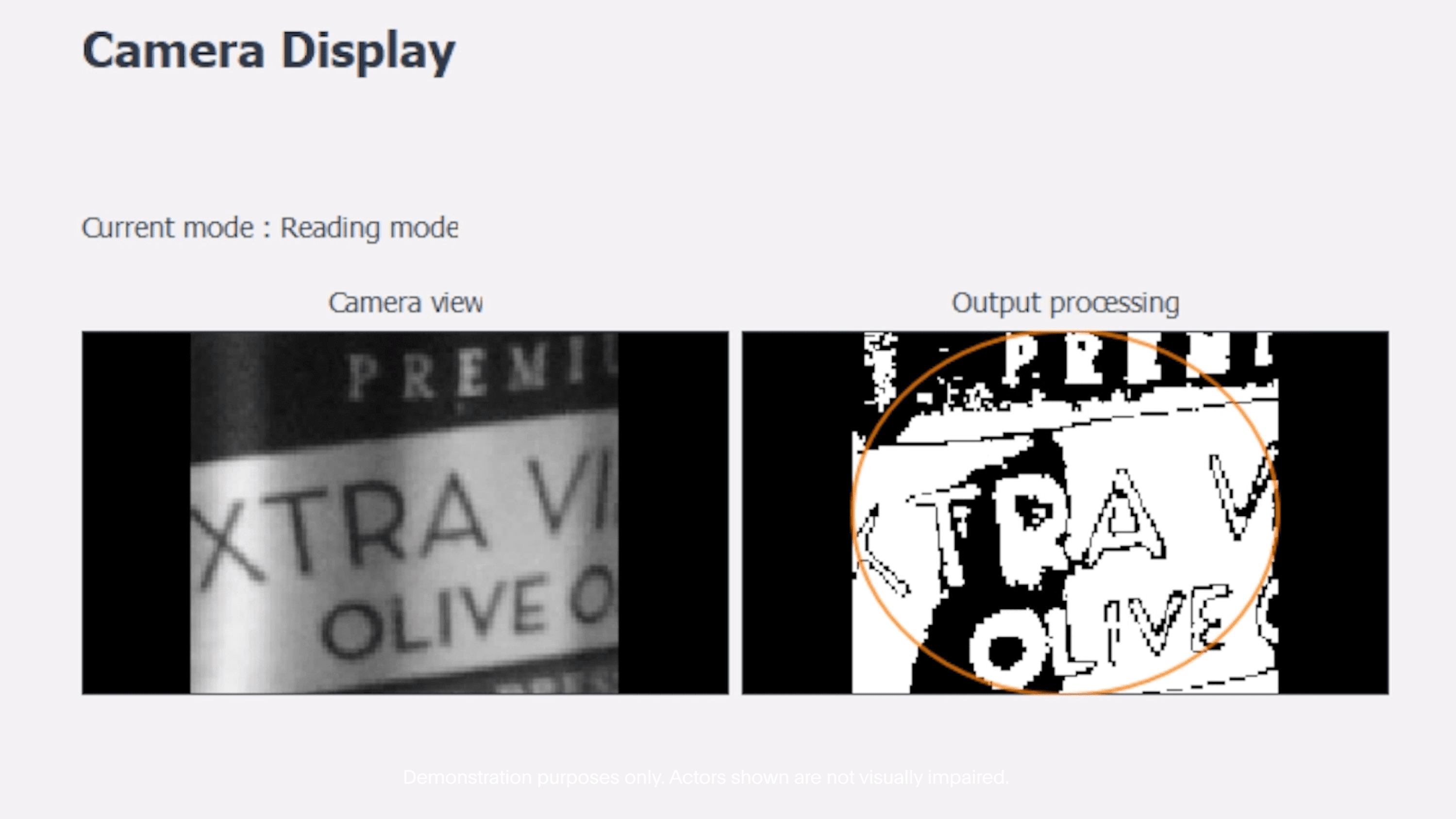
Science Corporation—a competitor to Neuralink founded by the former president of Elon Musk’s brain-interface venture—has leapfrogged its rival after acquiring, at a fire-sale price, a vision implant that’s in advanced testing,.
The implant is a microelectronic chip placed under the retina. Using signals from a camera mounted on a pair of glasses, the chip emits bursts of electricity in order to bypass photoreceptor cells damaged by macular degeneration, the leading cause of vision loss in elderly people.
“The magnitude of the effect is what’s notable,” says José-Alain Sahel, a University of Pittsburgh vision scientist who led testing of the system, which is called PRIMA. “There’s a patient in the UK and she is reading the pages of a regular book, which is unprecedented.”
Until last year, the device was being developed by Pixium Vision, a French startup cofounded by Sahel, which faced bankruptcy after it couldn’t raise more cash.
That’s when Science Corporation swept in to purchase the company’s assets for about €4 million ($4.7 million), according to court filings.
“Science was able to buy it for very cheap just when the study was coming out, so it was good timing for them,” says Sahel. “They could quickly access very advanced technology that’s closer to the market, which is good for a company to have.”
Science was founded in 2021 by Max Hodak, the first president of Neuralink, after his sudden departure from that company. Since its founding, Science has raised around $290 million, according to the venture capital database Pitchbook, and used the money to launch broad-ranging exploratory research on brain interfaces and new types of vision treatments.
“The ambition here is to build a big, standalone medical technology company that would fit in with an Apple, Samsung, or an Alphabet,” Hodak said in an interview at Science’s labs in Alameda, California in September. “The goal is to change the world in important ways … but we need to make money in order to invest in these programs.”
By acquiring the PRIMA implant program, Science effectively vaulted past years of development and testing. The company has requested approval to sell the eye chip in Europe and is in discussions with regulators in the US.
Unlike Neuralink’s implant, which records brain signals so paralyzed recipients can use their thoughts to move a computer mouse, the retina chip sends information into the brain to produce vision. Because the retina is an outgrowth of the brain, the chip qualifies as a type of brain-computer interface.
Artificial vision systems have been studied for years and one, called the Argus II, even reached the market and was installed in the eyes of about 400 people. But that product was later withdrawn after it proved to be a money-loser, according to Cortigent, the company that now owns that technology.
Thirty-eight patients in Europe received a PRIMA implant in one eye. On average, the study found, they were able to read five additional lines on a vision chart—the kind with rows of letters, each smaller than the last. Some of that improvement was due to what Sahel calls “various tricks” like using a zoom function, which allows patients to zero in on text they want to read.
The type of vision loss being treated with the new implant is called geographic atrophy, in which patients have peripheral vision but can’t make out objects directly in front of them, like words or faces. According to Prevent Blindness, an advocacy organization, this type of central vision loss affects around one in 10 people over 80.
The implant was originally designed starting 20 years ago by Daniel Palanker, a laser expert and now a professor at Stanford University, who says his breakthrough was realizing that light beams could supply both energy and information to a chip placed under the retina. Other implants, like Argus II, use a wire, which adds complexity.
“The chip has no brains at all. It just turns light into electrical current that flows into the tissue,” says Palanker. “Patients describe the color they see as yellowish blue or sun color.”
The system works using a wearable camera that records a scene and then blasts bright infrared light into the eye, using a wavelength humans can’t see. That light hits the chip, which is covered by “what are basically tiny solar panels,” says Palanker. “We just try to replace the photoreceptors with a photo-array.”
A diagram of how a visual scene could be represented by a retinal implant.
COURTESY SCIENCE CORPORATION
The current system produces about 400 spots of vision, which lets users make out the outlines of words and objects. Palanaker says a next-generation device will have five times as many “pixels” and should let people see more: “What we discovered in the trial is that even though you stimulate individual pixels, patients perceive it as continuous. The patient says ‘I see a line,’ “I see a letter.’”
Palanker says it will be important to keep improving the system because “the market size depends on the quality of the vision produced.”
When Pixium teetered on insolvency, Palanker says, he helped search for a buyer, meeting with Hodak. “It was a fire sale, not a celebration,” he says. “But for me it’s a very lucky outcome, because it means the product is going forward. And the purchase price doesn’t really matter, because there’s a big investment needed to bring it to market. It’s going to cost money.”
The PRIMA artificial vision system has a battery pack/controller and an eye-mounted camera.
COURTESY SCIENCE CORPORATION
During a visit to Science’s headquarters, Hodak described the company’s effort to redesign the system into something sleeker and more user-friendly. In the original design, in addition to the wearable camera, the patient has to carry around a bulky controller containing a battery and laser, as well as buttons to zoom in and out.
But Science has already prototyped a version in which those electronics are squeezed into what look like an extra-large pair of sunglasses.
“The implant is great, but we’ll have new glasses on patients fairly shortly,” Hodak says. “This will substantially improve their ability to have it with them all day.”
Other companies also want to treat blindness with brain-computer interfaces, but some think it might be better to send signals directly into the brain. This year, Neuralink has been touting plans for “Blindsight,” a project to send electrical signals directly into the brain’s visual cortex, bypassing the retina entirely. It has yet to test the approach in a person.
In this era of AI slop, the idea that generative AI tools like Midjourney and Runway could be used to make art can seem absurd: What possible artistic value is there to be found in the likes of Shrimp Jesus and Ballerina Cappuccina? But amid all the muck, there are people using AI tools with real consideration and intent. Some of them are finding notable success as AI artists: They are gaining huge online followings, selling their work at auction, and even having it exhibited in galleries and museums.
“Sometimes you need a camera, sometimes AI, and sometimes paint or pencil or any other medium,” says Jacob Adler, a musician and composer who won the top prize at the generative video company Runway’s third annual AI Film Festival for his work Total Pixel Space. “It’s just one tool that is added to the creator’s toolbox.”
One of the most conspicuous features of generative AI tools is their accessibility. With no training and in very little time, you can create an image of whatever you can imagine in whatever style you desire. That’s a key reason AI art has attracted so much criticism: It’s now trivially easy to clog sites like Instagram and TikTok with vapid nonsense, and companies can generate images and video themselves instead of hiring trained artists.
Henry Daubrez created these visuals for a bitcoin NFT titled The Order of Satoshi, which sold at Sotheby’s for $24,000.
COURTESY OF THE ARTIST
Henry Daubrez, an artist and designer who created the AI-generated visuals for a bitcoin NFT that sold for $24,000 at Sotheby’s and is now Google’s first filmmaker in residence, sees that accessibility as one of generative AI’s most positive attributes. People who had long since given up on creative expression, or who simply never had the time to master a medium, are now creating and sharing art, he says.
But that doesn’t mean the first AI-generated masterpiece could come from just anyone. “I don’t think [generative AI] is going to create an entire generation of geniuses,” says Daubrez, who has described himself as an “AI-assisted artist.” Prompting tools like DALL-E and Midjourney might not require technical finesse, but getting those tools to create something interesting, and then evaluating whether the results are any good, takes both imagination and artistic sensibility, he says: “I think we’re getting into a new generation which is going to be driven by taste.”
Kira Xonorika’s Trickster is the first piece to use generative AI in the Denver Art Museum’s permanent collection.
COURTESY OF THE ARTIST
Even for artists who do have experience with other media, AI can be more than just a shortcut. Beth Frey, a trained fine artist who shares her AI art on an Instagram account with over 100,000 followers, was drawn to early generative AI tools because of the uncanniness of their creations—she relished the deformed hands and haunting depictions of eating. Over time, the models’ errors have been ironed out, which is part of the reason she hasn’t posted an AI-generated piece on Instagram in over a year. “The better it gets, the less interesting it is for me,” she says. “You have to work harder to get the glitch now.”
Beth Frey’s Instagram account @sentientmuppetfactory features uncanny AI creations.
COURTESY OF THE ARTIST
Making art with AI can require relinquishing control—to the companies that update the tools, and to the tools themselves. For Kira Xonorika, a self-described “AI-collaborative artist” whose short film Trickster is the first generative AI piece in the Denver Art Museum’s permanent collection, that lack of control is part of the appeal. “[What] I really like about AI is the element of unpredictability,” says Xonorika, whose work explores themes such as indigeneity and nonhuman intelligence. “If you’re open to that, it really enhances and expands ideas that you might have.”
But the idea of AI as a co-creator—or even simply as an artistic medium—is still a long way from widespread acceptance. To many people, “AI art” and “AI slop” remain synonymous. And so, as grateful as Daubrez is for the recognition he has received so far, he’s found that pioneering a new form of art in the face of such strong opposition is an emotional mixed bag. “As long as it’s not really accepted that AI is just a tool like any other tool and people will do whatever they want with it—and some of it might be great, some might not be—it’s still going to be sweet [and] sour,” he says.
It is a yellow blob with no brain, yet some researchers believe a curious organism known as slime mold could help us build more resilient cities.
Humans have been building cities for 6,000 years, but slime mold has been around for 600 million. The team behind a new startup called Mireta wants to translate the organism’s biological superpowers into algorithms that might help improve transit times, alleviate congestion, and minimize climate-related disruptions in cities worldwide.
Mireta’s algorithm mimics how slime mold efficiently distributes resources through branching networks. The startup’s founders think this approach could help connect subway stations, design bike lanes, or optimize factory assembly lines. They claim its software can factor in flood zones, traffic patterns, budget constraints, and more.
“It’s very rational to think that some [natural] systems or organisms have actually come up with clever solutions to problems we share,” says Raphael Kay, Mireta’s cofounder and head of design, who has a background in architecture and mechanical engineering and is currently a PhD candidate in materials science and mechanical engineering at Harvard University.
As urbanization continues—about 60% of the global population will live in metropolises by 2030—cities must provide critical services while facing population growth, aging infrastructure, and extreme weather caused by climate change. Kay, who has also studied how microscopic sea creatures could help researchers design zero-energy buildings, believes nature’s time-tested solutions may offer a path toward more adaptive urban systems.
Officially known as Physarum polycephalum, slime mold is neither plant, animal, nor fungus but a single-celled organism older than dinosaurs. When searching for food, it extends tentacle-like projections in multiple directions simultaneously. It then doubles down on the most efficient paths that lead to food while abandoning less productive routes. This process creates optimized networks that balance efficiency with resilience—a sought-after quality in transportation and infrastructure systems.
The organism’s ability to find the shortest path between multiple points while maintaining backup connections has made it a favorite among researchers studying network design. Most famously, in 2010 researchers at Hokkaido University reported results from an experiment in which they dumped a blob of slime mold onto a detailed map of Tokyo’s railway system, marking major stations with oat flakes. At first the brainless organism engulfed the entire map. Days later, it had pruned itself back, leaving behind only the most efficient pathways. The result closely mirrored Tokyo’s actual rail network.
Since then, researchers worldwide have used slime mold to solve mazes and even map the dark matter holding the universe together. Experts across Mexico, Great Britain, and the Iberian peninsula have tasked the organism with redesigning their roadways—though few of these experiments have translated into real-world upgrades.
Historically, researchers working with the organism would print a physical map and add slime mold onto it. But Kay believes that Mireta’s approach, which replicates slime mold’s pathway-building without requiring actual organisms, could help solve more complex problems. Slime mold is visible to the naked eye, so Kay’s team studied how the blobs behave in the lab, focusing on the key behaviors that make these organisms so good at creating efficient networks. Then they translated these behaviors into a set of rules that became an algorithm.
Some experts aren’t convinced. According to Geoff Boeing, an associate professor at the University of Southern California’s Department of Urban Planning and Spatial Analysis, such algorithms don’t address “the messy realities of entering a room with a group of stakeholders and co-visioning a future for their community.” Modern urban planning problems, he says, aren’t solely technical issues: “It’s not that we don’t know how to make infrastructure networks efficient, resilient, connected—it’s that it’s politically challenging to do so.”
Michael Batty, a professor emeritus at University College London’s Centre for Advanced Spatial Analysis, finds the concept more promising. “There is certainly potential for exploration,” he says, noting that humans have long drawn parallels between biological systems and cities. For decades now, designers have looked to nature for ideas—think ventilation systems inspired by termite mounds or bullet trains modeled after the kingfisher’s beak.
Like Boeing, Batty worries that such algorithms could reinforce top-down planning when most cities grow from the bottom up. But for Kay, the algorithm’s beauty lies in how it mimics bottom-up biological growth—like the way slime mold starts from multiple points and connects organically rather than following predetermined paths.
Since launching earlier this year, Mireta, which is based in Cambridge, Massachusetts, has worked on about five projects. And slime mold is just the beginning. The team is also looking at algorithms inspired by ants, which leave chemical trails that strengthen with use and have their own decentralized solutions for network optimization. “Biology has solved just about every network problem you can imagine,” says Kay.
Elissaveta M. Brandon is an independent journalist interested in how design, culture, and technology shape the way we live.
You live in a house you designed and built yourself. You rely on the sun for power, heat your home with a woodstove, and farm your own fish and vegetables. The year is 2025.
This is the life of Marcin Jakubowski, the 53-year-old founder of Open Source Ecology, an open collaborative of engineers, producers, and builders developing what they call the Global Village Construction Set (GVCS). It’s a set of 50 machines—everything from a tractor to an oven to a circuit maker—that are capable of building civilization from scratch and can be reconfigured however you see fit.
Jakubowski immigrated to the US from Slupca, Poland, as a child. His first encounter with what he describes as the “prosperity of technology” was the vastness of the American grocery store. Seeing the sheer quantity and variety of perfectly ripe produce cemented his belief that abundant, sustainable living was within reach in the United States.
With a bachelor’s degree from Princeton and a doctorate in physics from the University of Wisconsin, Jakubowski had spent most of his life in school. While his peers kick-started their shiny new corporate careers, he followed a different path after he finished his degree in 2003: He bought a tractor to start a farm in Maysville, Missouri, eager to prove his ideas about abundance. “It was a clear decision to give up the office cubicle or high-level research job, which is so focused on tiny issues that one never gets to work on the big picture,” he says. But in just a short few months, his tractor broke down—and he soon went broke.
Every time his tractor malfunctioned, he had no choice but to pay John Deere for repairs—even if he knew how to fix the problem on his own. John Deere, the world’s largest manufacturer of agricultural equipment, continues to prohibit farmers from repairing their own tractors (except in Colorado, where farmers were granted a right to repair by state law in 2023). Fixing your own tractor voids any insurance or warranty, much like jailbreaking your iPhone.
Today, large agricultural manufacturers have centralized control over the market, and most commercial tractors are built with proprietary parts. Every year, farmers pay $1.2 billion in repair costs and lose an estimated $3 billion whenever their tractors break down, entirely because large agricultural manufacturers have lobbied against the right to repair since the ’90s. Currently there are class action lawsuits involving hundreds of farmers fighting for their right to do so.
“The machines own farmers. The farmers don’t own [the machines],” Jakubowski says. He grew certain that self-sufficiency relied on agricultural autonomy, which could be achieved only through free access to technology. So he set out to apply the principles of open-source software to hardware. He figured that if farmers could have access to the instructions and materials required to build their own tractors, not only would they be able to repair them, but they’d also be able to customize the vehicles for their needs. Life-changing technology should be available to all, he thought, not controlled by a select few. So, with an understanding of mechanical engineering, Jakubowski built his own tractor and put all his schematics online on his platform Open Source Ecology.
That tractor Jakubowski built is designed to be taken apart. It’s a critical part of the GVCS, a collection of plug-and-play machines that can “build a thriving economy anywhere in the world … from scratch.” The GVCS includes a 3D printer, a self-contained hydraulic power unit called the Power Cube, and more, each designed to be reconfigured for multiple purposes. There’s even a GVCS micro-home. You can use the Power Cube to power a brick press, a sawmill, a car, a CNC mill, or a bioplastic extruder, and you can build wind turbines with the frames that are used in the home.
Jakubowski compares the GVCS to Lego blocks and cites the Linux ecosystem as his inspiration. In the same way that Linux’s source code is free to inspect, modify, and redistribute, all the instructions you need to build and repurpose a GVCS machine are freely accessible online. Jakubowski envisions a future in which the GVCS parallels the Linux infrastructure, with custom tools built to optimize agriculture, construction, and material fabrication in localized contexts. “The [final form of the GVCS] must be proven to allow efficient production of food, shelter, consumer goods, cars, fuel, and other goods—except for exotic imports (coffee, bananas, advanced semiconductors),” he wrote on his Open Source Ecology wiki.
The ethos of GVCS is reminiscent of the Whole Earth Catalog, a countercultural publication that offered a combination of reviews, DIY manuals, and survival guides between 1968 and 1972. Founded by Stewart Brand, the publication had the slogan “Access to tools” and was famous for promoting self-sufficiency. It heavily featured the work of R. Buckminster Fuller, an American architect known for his geodesic domes (lightweight structures that can be built using recycled materials) and for coining the term “ephemeralization,” which refers to the ability of technology to let us do more with less material, energy, and effort.
The schematics for Marcin Jakubowski’s designs are all available online.
COURTESY OF OPEN SOURCE ECOLOGY
Jakubowski owns the publication’s entire printed output, but he offers a sharp critique of its legacy in our current culture of tech utopianism. “The first structures we built were domes. Good ideas. But the open-source part of that was not really there yet—Fuller patented his stuff,” he says. Fuller and the Whole Earth Catalog may have popularized an important philosophy of self-reliance, but to Jakubowski, their failure to advocate for open collaboration stopped the ultimate vision of sustainability from coming to fruition. “The failure of the techno-utopians to organize into a larger movement of collaborative, open, distributed production resulted in a miscarriage of techno-utopia,” he says.
With a background in physics and an understanding of mechanical engineering, Marcin Jakubowski built his own tractor.
COURTESY OF OPEN SOURCE ECOLOGY
Unlike software, hardware can’t be infinitely reproduced or instantly tested. It requires manufacturing infrastructure and specific materials, not to mention exhaustive documentation. There are physical constraints—different port standards, fluctuations in availability of materials, and more. And now that production chains are so globalized that manufacturing a hot tub can require parts from seven different countries and 14 states, how can we expect anything to be replicable in our backyard? The solution, according to Jakubowski, is to make technology “appropriate.”
Appropriate technology is technology that’s designed to be affordable and sustainable for a specific local context. The idea comes from Gandhi’s philosophy of swadeshi (self-reliance) and sarvodaya (upliftment of all) and was popularized by the economist Ernst Friedrich “Fritz” Schumacher’s book Small Is Beautiful, which discussed the concept of “intermediate technology”: “Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius—and a lot of courage—to move in the opposite direction.” Because different environments operate at different scales and with different resources, it only makes sense to tailor technology for those conditions. Solar lamps, bikes, hand-powered water pumps—anything that can be built using local materials and maintained by the local community—are among the most widely cited examples of appropriate technology.
This concept has historically been discussed in the context of facilitating economic growth in developing nations and adapting capital-intensive technology to their needs. But Jakubowski hopes to make it universal. He believes technology needs to be appropriate even in suburban and urban places with access to supermarkets, hardware stores, Amazon deliveries, and other forms of infrastructure. If technology is designed specifically for these contexts, he says, end-to-end reproduction will be possible, making more space for collaboration and innovation.
What makes Jakubowski’s technology “appropriate” is his use of reclaimed materials and off-the-shelf parts to build his machines. By using local materials and widely available components, he’s able to bypass the complex global supply chains that proprietary technology often requires. He also structures his schematics around concepts already familiar to most people who are interested in hardware, making his building instructions easier to follow.
Everything you need to build Jakubowski’s machines should be available around you, just as everything you need to know about how to repair or operate the machine is online—from blueprints to lists of materials to assembly instructions and testing protocols. “If you’ve got a wrench, you’ve got a tractor,” his manual reads.
This spirit dates back to the ’70s, when the idea of building things “moved out of the retired person’s garage and into the young person’s relationship with the Volkswagen,” says Brand. He references John Muir’s 1969 book How to Keep Your Volkswagen Alive: A Manual of Step-by-Step Procedures for the Compleat Idiot and fondly recalls how the Beetle’s simple design and easily swapped parts made it common for owners to rebody their cars, combining the chassis of one with the body of another. He also mentions the impact of the Ford Model T cars that, with a few extra parts, were made into tractors during the Great Depression.
For Brand, the focus on repairability is critical in the modern context. There was a time when John Deere tractors were “appropriate” in Jakubowski’s terms, Brand says: “A century earlier, John Deere took great care to make sure that his plowshares could be taken apart and bolted together, that you can undo and redo them, replace parts, and so on.” The company “attracted insanely loyal customers because they looked out for the farmers so much,” Brand says, but “they’ve really reversed the orientation.” Echoing Jakubowski’s initial motivation for starting OSE, Brand insists that technology is appropriate to the extent that it is repairable.
Even if you can find all the parts you need from Lowe’s, building your own tractor is still intimidating. But for some, the staggering price advantage is reason enough to take on the challenge: A GVCS tractor costs $12,000 to build, whereas a commercial tractor averages around $120,000 to buy, not including the individual repairs that might be necessary over its lifetime at a cost of $500 to $20,000 each. And gargantuan though it may seem, the task of building a GVCS tractor or other machine is doable: Just a few years after the project launched in 2008, more than 110 machines had been built by enthusiasts from Chile, Nicaragua, Guatemala, China, India, Italy, and Turkey, just to name a few places.
Of the many machines developed, what’s drawn the most interest from GVCS enthusiasts is the one nicknamed “The Liberator,” which presses local soil into compressed earth blocks, or CEBs—a type of cost- and energy-efficient brick that can withstand extreme weather conditions. It’s been especially popular among those looking to build their own homes: A man named Aurélien Bielsa replicated the brick press in a small village in the south of France to build a house for his family in 2018, and in 2020 a group of volunteers helped a member of the Open Source Ecology community build a tiny home using blocks from one of these presses in a fishing village near northern Belize.
The CEB press, nicknamed “The Liberator,” turns local soil into energy-efficient compressed earth blocks.
COURTESY OF OPEN SOURCE ECOLOGY
Jakubowski recalls receiving an email about one of the first complete reproductions of the CEB press, built by a Texan named James Slate, who ended up starting a business selling the bricks: “When [James] sent me a picture [of our brick press], I thought it was a Photoshopped copy of our machine, but it was his. He just downloaded the plans off the internet. I knew nothing about it.” Slate described having a very limited background in engineering before building the brick press. “I had taken some mechanics classes back in high school. I mostly come from an IT computer world,” he said in an interview with Open Source Ecology. “Pretty much anyone can build one, if they put in the effort.”
Andrew Spina, an early GVCS enthusiast, agrees. Spina spent five years building versions of the GVCS tractor and Power Cube, eager to create means of self-sufficiency at an individual scale. “I’m building my own tractor because I want to understand it and be able to maintain it,” he wrote in his blog, Machining Independence. Spina’s curiosity gestures toward the broader issue of technological literacy: The more we outsource to proprietary tech, the less we understand how things work—further entrenching our need for that proprietary tech. Transparency is critical to the open-source philosophy precisely because it helps us become self-sufficient.
Since starting Open Source Ecology, Jakubowski has been the main architect behind the dozens of machines available on his platform, testing and refining his designs on a plot of land he calls the Factor e Farm in Maysville. Most GVCS enthusiasts reproduce Jakubowski’s machines for personal use; only a few have contributed to the set themselves. Of those select few, many made dedicated visits to the farm for weeks at a time to learn how to build Jakubowski’s GVCS collection. James Wise, one of the earliest and longest-term GVCS contributors, recalls setting up tents and camping out in his car to attend sessions at Jakubowski’s workshop, where visiting enthusiasts would gather to iterate on designs: “We’d have a screen on the wall of our current best idea. Then we’d talk about it.” Wise doesn’t consider himself particularly experienced on the engineering front, but after working with other visiting participants, he felt more emboldened to contribute. “Most of [my] knowledge came from [my] peers,” he says.
Jakubowski’s goal of bolstering collaboration hinges on a degree of collective proficiency. Without a community skilled with hardware, the organic innovation that the open-source approach promises will struggle to bear fruit, even if Jakubowski’s designs are perfectly appropriate and thoroughly documented.
“That’s why we’re starting a school!” said Jakubowski, when asked about his plan to build hardware literacy. Earlier this year, he announced the Future Builders Academy, an apprenticeship program where participants will be taught all the necessary skills to develop and build the affordable, self-sustaining homes that are his newest venture. Seed Eco Homes, as Jakubowski calls them, are “human-sized, panelized” modular houses complete with a biodigester, a thermal battery, a geothermal cooling system, and solar electricity. Each house is entirely energy independent and can be built in five days, at a cost of around $40,000. Over eight of these houses have been built across the country, and Jakubowski himself lives in the earliest version of the design. Seed Eco Homes are the culmination of his work on the GVCS: The structure of each house combines parts from the collection and embodies its modular philosophy. The venture represents Jakubowski’s larger goal of making everyday technology accessible. “Housing [is the] single largest cost in one’s life—and a key to so much more,” he says.
The final goal of Open Source Ecology is a “zero marginal cost” society, where producing an additional unit of a good or service costs little to nothing. Jakubowski’s interpretation of the concept (popularized by the American economist and social theorist Jeremy Rifkin) assumes that by eradicating licensing fees, decentralizing manufacturing, and fostering collaboration through education, we can develop truly equitable technology that allows us to be self-sufficient. Open-source hardware isn’t just about helping farmers build their own tractors; in Jakubowski’s view, it’s a complete reorientation of our relationship to technology.
In the first issue of the Whole Earth Catalog, a key piece of inspiration for Jakubowski’s project, Brand wrote: “We are as gods and we might as well get good at it.” In 2007, in a book Brand wrote about the publication, he corrected himself: “We are as gods and have to get good at it.” Today, Jakubowski elaborates: “We’re becoming gods with technology. Yet technology has badly failed us. We’ve seen great progress with civilization. But how free are people today compared to other times?” Cautioning against our reliance on the proprietary technology we use daily, he offers a new approach: Progress should mean not just achieving technological breakthroughs but also making everyday technology equitable.
“We don’t need more technology,” he says. “We just need to collaborate with what we have now.”
Tiffany Ng is a freelance writer exploring the relationship between art, tech, and culture. She writes Cyber Celibate, a neo-Luddite newsletter on Substack.
Consider, if you will, the translucent blob in the eye of a microscope: a human blastocyst, the biological specimen that emerges just five days or so after a fateful encounter between egg and sperm. This bundle of cells, about the size of a grain of sand pulled from a powdery white Caribbean beach, contains the coiled potential of a future life: 46 chromosomes, thousands of genes, and roughly six billion base pairs of DNA—an instruction manual to assemble a one-of-a-kind human.
Now imagine a laser pulse snipping a hole in the blastocyst’s outermost shell so a handful of cells can be suctioned up by a microscopic pipette. This is the moment, thanks to advances in genetic sequencing technology, when it becomes possible to read virtually that entire instruction manual.
An emerging field of science seeks to use the analysis pulled from that procedure to predict what kind of a person that embryo might become. Some parents turn to these tests to avoid passing on devastating genetic disorders that run in their families. A much smaller group, driven by dreams of Ivy League diplomas or attractive, well-behaved offspring, are willing to pay tens of thousands of dollars to optimize for intelligence, appearance, and personality. Some of the most eager early boosters of this technology are members of the Silicon Valley elite, including tech billionaires like Elon Musk, Peter Thiel, and Coinbase CEO Brian Armstrong.
Embryo selection is less like a build-a-baby workshop and more akin to a store where parents can shop for their future children from several available models—complete with stat cards.
But customers of the companies emerging to provide it to the public may not be getting what they’re paying for. Genetics experts have been highlighting the potential deficiencies of this testing for years. A 2021 paper by members of the European Society of Human Genetics said, “No clinical research has been performed to assess its diagnostic effectiveness in embryos. Patients need to be properly informed on the limitations of this use.” And a paper published this May in the Journal of Clinical Medicine echoed this concern and expressed particular reservations about screening for psychiatric disorders and non-disease-related traits: “Unfortunately, no clinical research has to date been published comprehensively evaluating the effectiveness of this strategy [of predictive testing]. Patient awareness regarding the limitations of this procedure is paramount.”
Moreover, the assumptions underlying some of this work—that how a person turns out is the product not of privilege or circumstance but of innate biology—have made these companies a political lightning rod.
SELMAN DESIGN
As this niche technology begins to make its way toward the mainstream, scientists and ethicists are racing to confront the implications—for our social contract, for future generations, and for our very understanding of what it means to be human.
Preimplantation genetic testing (PGT), while still relatively rare, is not new. Since the 1990s, parents undergoing in vitro fertilization have been able to access a number of genetic tests before choosing which embryo to use. A type known as PGT-M can detect single-gene disorders like cystic fibrosis, sickle cell anemia, and Huntington’s disease. PGT-A can ascertain the sex of an embryo and identify chromosomal abnormalities that can lead to conditions like Down syndrome or reduce the chances that an embryo will implant successfully in the uterus. PGT-SR helps parents avoid embryos with issues such as duplicated or missing segments of the chromosome.
Those tests all identify clear-cut genetic problems that are relatively easy to detect, but most of the genetic instruction manual included in an embryo is written in far more nuanced code. In recent years, a fledgling market has sprung up around a new, more advanced version of the testing process called PGT-P: preimplantation genetic testing for polygenic disorders (and, some claim, traits)—that is, outcomes determined by the elaborate interaction of hundreds or thousands of genetic variants.
In 2020, the first baby selected using PGT-P was born. While the exact figure is unknown, estimates put the number of children who have now been born with the aid of this technology in the hundreds. As the technology is commercialized, that number is likely to grow.
Embryo selection is less like a build-a-baby workshop and more akin to a store where parents can shop for their future children from several available models—complete with stat cards indicating their predispositions.
A handful of startups, armed with tens of millions of dollars of Silicon Valley cash, have developed proprietary algorithms to compute these stats—analyzing vast numbers of genetic variants and producing a “polygenic risk score” that shows the probability of an embryo developing a variety of complex traits.
For the last five years or so, two companies—Genomic Prediction and Orchid—have dominated this small landscape, focusing their efforts on disease prevention. But more recently, two splashy new competitors have emerged: Nucleus Genomics and Herasight, which have rejected the more cautious approach of their predecessors and waded into the controversial territory of genetic testing for intelligence. (Nucleus also offers tests for a wide variety of other behavioral and appearance-related traits.)
The practical limitations of polygenic risk scores are substantial. For starters, there is still a lot we don’t understand about the complex gene interactions driving polygenic traits and disorders. And the biobank data sets they are based on tend to overwhelmingly represent individuals with Western European ancestry, making it more difficult to generate reliable scores for patients from other backgrounds. These scores also lack the full context of environment, lifestyle, and the myriad other factors that can influence a person’s characteristics. And while polygenic risk scores can be effective at detecting large, population-level trends, their predictive abilities drop significantly when the sample size is as tiny as a single batch of embryos that share much of the same DNA.
But beyond questions of whether evidence supports the technology’s effectiveness, critics of the companies selling it accuse them of reviving a disturbing ideology: eugenics, or the belief that selective breeding can be used to improve humanity. Indeed, some of the voices who have been most confident that these methods can successfully predict nondisease traits have made startling claims about natural genetic hierarchies and innate racial differences.
What everyone can agree on, though, is that this new wave of technology is helping to inflame a centuries-old debate over nature versus nurture.
The term “eugenics” was coined in 1883 by a British anthropologist and statistician named Sir Francis Galton, inspired in part by the work of his cousin Charles Darwin. He derived it from a Greek word meaning “good in stock, hereditarily endowed with noble qualities.”
Some of modern history’s darkest chapters have been built on Galton’s legacy, from the Holocaust to the forced sterilization laws that affected certain groups in the United States well into the 20th century. Modern science has demonstrated the many logical and empirical problems with Galton’s methodology. (For starters, he counted vague concepts like “eminence”—as well as infections like syphilis and tuberculosis—as heritable phenotypes, meaning characteristics that result from the interaction of genes and environment.)
Yet even today, Galton’s influence lives on in the field of behavioral genetics, which investigates the genetic roots of psychological traits. Starting in the 1960s, researchers in the US began to revisit one of Galton’s favorite methods: twin studies. Many of these studies, which analyzed pairs of identical and fraternal twins to try to determine which traits were heritable and which resulted from socialization, were funded by the US government. The most well-known of these, the Minnesota Twin Study, also accepted grants from the Pioneer Fund, a now defunct nonprofit that had promoted eugenics and “race betterment” since its founding in 1937.
The nature-versus-nurture debate hit a major inflection point in 2003, when the Human Genome Project was declared complete. After 13 years and at a cost of nearly $3 billion, an international consortium of thousands of researchers had sequenced 92% of the human genome for the first time.
Today, the cost of sequencing a genome can be as low as $600, and one company says it will soon drop even further. This dramatic reduction has made it possible to build massive DNA databases like the UK Biobank and the National Institutes of Health’s All of Us, each containing genetic data from more than half a million volunteers. Resources like these have enabled researchers to conduct genome-wide association studies, or GWASs, which identify correlations between genetic variants and human traits by analyzing single-nucleotide polymorphisms (SNPs)—the most common form of genetic variation between individuals. The findings from these studies serve as a reference point for developing polygenic risk scores.
Most GWASs have focused on disease prevention and personalized medicine. But in 2011, a group of medical researchers, social scientists, and economists launched the Social Science Genetic Association Consortium (SSGAC) to investigate the genetic basis of complex social and behavioral outcomes. One of the phenotypes they focused on was the level of education people reached.
“It was a bit of a phenotype of convenience,” explains Patrick Turley, an economist and member of the steering committee at SSGAC, given that educational attainment is routinely recorded in surveys when genetic data is collected. Still, it was “clear that genes play some role,” he says. “And trying to understand what that role is, I think, is really interesting.” He adds that social scientists can also use genetic data to try to better “understand the role that is due to nongenetic pathways.”
Many on the left are generally willing to allow that any number of traits, from addiction to obesity, are genetically influenced. Yet heritable cognitive ability seems to be “beyond the pale for us to integrate as a source of difference.”
The work immediately stirred feelings of discomfort—not least among the consortium’s own members, who feared that they might unintentionally help reinforce racism, inequality, and genetic determinism.
It’s also created quite a bit of discomfort in some political circles, says Kathryn Paige Harden, a psychologist and behavioral geneticist at the University of Texas in Austin, who says she has spent much of her career making the unpopular argument to fellow liberals that genes are relevant predictors of social outcomes.
Harden thinks a strength of those on the left is their ability to recognize “that bodies are different from each other in a way that matters.” Many are generally willing to allow that any number of traits, from addiction to obesity, are genetically influenced. Yet, she says, heritable cognitive ability seems to be “beyond the pale for us to integrate as a source of difference that impacts our life.”
Harden believes that genes matter for our understanding of traits like intelligence, and that this should help shape progressive policymaking. She gives the example of an education department seeking policy interventions to improve math scores in a given school district. If a polygenic risk score is “as strongly correlated with their school grades” as family income is, she says of the students in such a district, then “does deliberately not collecting that [genetic] information, or not knowing about it, make your research harder [and] your inferences worse?”
To Harden, persisting with this strategy of avoidance for fear of encouraging eugenicists is a mistake. If “insisting that IQ is a myth and genes have nothing to do with it was going to be successful at neutralizing eugenics,” she says, “it would’ve won by now.”
Part of the reason these ideas are so taboo in many circles is that today’s debate around genetic determinism is still deeply infused with Galton’s ideas—and has become a particular fixation among the online right.
SELMAN DESIGN
After Elon Musk took over Twitter (now X) in 2022 and loosened its restrictions on hate speech, a flood of accounts started sharing racist posts, some speculating about the genetic origins of inequality while arguing against immigration and racial integration. Musk himself frequently reposts and engages with accounts like Crémieux Recueil, the pen name of independent researcher Jordan Lasker, who has written about the “Black-White IQ gap,” and i/o, an anonymous account that once praised Musk for “acknowledging data on race and crime,” saying it “has done more to raise awareness of the disproportionalities observed in these data than anything I can remember.” (In response to allegations that his research encourages eugenics, Lasker wrote to MIT Technology Review, “The popular understanding of eugenics is about coercion and cutting people cast as ‘undesirable’ out of the breeding pool. This is nothing like that, so it doesn’t qualify as eugenics by that popular understanding of the term.” After going to print, i/o wrote in an email, “Just because differences in intelligence at the individual level are largely heritable, it does not mean that group differences in measured intelligence … are due to genetic differences between groups,” but that the latter is not “scientifically settled” and “an extremely important (and necessary) research area that should be funded rather than made taboo.” He added, “I’ve never made any argument against racial integration or intermarriage or whatever.”X and Musk did not respond to requests for comment.)
Harden, though, warns against discounting the work of an entire field because of a few noisy neoreactionaries. “I think there can be this idea that technology is giving rise to the terrible racism,” she says. The truth, she believes, is that “the racism has preexisted any of this technology.”
In 2019, a company called Genomic Prediction began to offer the first preimplantation polygenic testing that had ever been made commercially available. With its LifeView Embryo Health Score, prospective parents are able to assess their embryos’ predisposition to genetically complex health problems like cancer, diabetes, and heart disease. Pricing for the service starts at $3,500. Genomic Prediction uses a technique called an SNP array, which targets specific sites in the genome where common variants occur. The results are then cross-checked against GWASs that show correlations between genetic variants and certain diseases.
Four years later, a company named Orchid began offering a competing test. Orchid’s Whole Genome Embryo Report distinguished itself by claiming to sequence more than 99% of an embryo’s genome, allowing it to detect novel mutations and, the company says, diagnose rare diseases more accurately. For $2,500 per embryo, parents can access polygenic risk scores for 12 disorders, including schizophrenia, breast cancer, and hypothyroidism.
Orchid was founded by a woman named Noor Siddiqui. Before getting undergraduate and graduate degrees from Stanford, she was awarded the Thiel fellowship—a $200,000 grant given to young entrepreneurs willing to work on their ideas instead of going to college—back when she was a teenager, in 2012. This set her up to attract attention from members of the tech elite as both customers and financial backers. Her company has raised $16.5 million to date from investors like Ethereum founder Vitalik Buterin, former Coinbase CTO Balaji Srinivasan, and Armstrong, the Coinbase CEO.
In August Siddiqui made the controversial suggestion that parents who choose not to use genetic testing might be considered irresponsible. “Just be honest: you’re okay with your kid potentially suffering for life so you can feel morally superior …” she wrote on X.
Americans have varied opinions on the emerging technology. In 2024, a group of bioethicists surveyed 1,627 US adults to determine attitudes toward a variety of polygenic testing criteria. A large majority approved of testing for physical health conditions like cancer, heart disease, and diabetes. Screening for mental health disorders, like depression, OCD, and ADHD, drew a more mixed—but still positive—response. Appearance-related traits, like skin color, baldness, and height, received less approval as something to test for.
Intelligence was among the most contentious traits—unsurprising given the way it has been weaponized throughout history and the lack of cultural consensus on how it should even be defined. (In many countries, intelligence testing for embryos is heavily regulated; in the UK, the practice is banned outright.) In the 2024 survey, 36.9% of respondents approved of preimplantation genetic testing for intelligence, 40.5% disapproved, and 22.6% said they were uncertain.
Despite the disagreement, intelligence has been among the traits most talked about as targets for testing. From early on, Genomic Prediction says, it began receiving inquiries “from all over the world” about testing for intelligence, according to Diego Marin, the company’s head of global business development and scientific affairs.
At one time, the company offered a predictor for what it called “intellectual disability.” After some backlash questioning both the predictive capacity and the ethics of these scores, the company discontinued the feature. “Our mission and vision of this company is not to improve [a baby], but to reduce risk for disease,” Marin told me. “When it comes to traits about IQ or skin color or height or something that’s cosmetic and doesn’t really have a connotation of a disease, then we just don’t invest in it.”
Orchid, on the other hand, does test for genetic markers associated with intellectual disability and developmental delay. But that may not be all. According to one employee of the company, who spoke on the condition of anonymity, intelligence testing is also offered to “high-roller” clients. According to this employee, another source close to the company, and reporting in the Washington Post, Musk used Orchid’s services in the conception of at least one of the children he shares with the tech executive Shivon Zilis. (Orchid, Musk, and Zilis did not respond to requests for comment.)
I met Kian Sadeghi, the 25-year-old founder of New York–based Nucleus Genomics, on a sweltering July afternoon in his SoHo office. Slight and kinetic, Sadeghi spoke at a machine-gun pace, pausing only occasionally to ask if I was keeping up.
Sadeghi had modified his first organism—a sample of brewer’s yeast—at the age of 16. As a high schooler in 2016, he was taking a course on CRISPR-Cas9 at a Brooklyn laboratory when he fell in love with the “beautiful depth” of genetics. Just a few years later, he dropped out of college to build “a better 23andMe.”
His company targets what you might call the application layer of PGT-P, accepting data from IVF clinics—and even from the competitors mentioned in this story—and running its own computational analysis.
“Unlike a lot of the other testing companies, we’re software first, and we’re consumer first,” Sadeghi told me. “It’s not enough to give someone a polygenic score. What does that mean? How do you compare them? There’s so many really hard design problems.”
Like its competitors, Nucleus calculates its polygenic risk scores by comparing an individual’s genetic data with trait-associated variants identified in large GWASs, providing statistically informed predictions.
Nucleus provides two displays of a patient’s results: a Z-score, plotted from –4 to 4, which explains the risk of a certain trait relative to a population with similar genetic ancestry (for example, if Embryo #3 has a 2.1 Z-score for breast cancer, its risk is higher than average), and an absolute risk score, which includes relevant clinical factors (Embryo #3 has a minuscule actual risk of breast cancer, given that it is male).
The real difference between Nucleus and its competitors lies in the breadth of what it claims to offer clients. On its sleek website, prospective parents can sort through more than 2,000 possible diseases, as well as traits from eye color to IQ. Access to the Nucleus Embryo platform costs $8,999, while the company’s new IVF+ offering—which includes one IVF cycle with a partner clinic, embryo screening for up to 20 embryos, and concierge services throughout the process—starts at $24,999.
“Maybe you want your baby to have blue eyes versus green eyes,” Nucleus founder Kian Sadeghi said at a June event. “That is up to the liberty of the parents.”
Its promises are remarkably bold. The company claims to be able to forecast a propensity for anxiety, ADHD, insomnia, and other mental issues. It says you can see which of your embryos are more likely to have alcohol dependence, which are more likely to be left-handed, and which might end up with severe acne or seasonal allergies. (Nevertheless, at the time of writing, the embryo-screening platform provided this disclaimer: “DNA is not destiny. Genetics can be a helpful tool for choosing an embryo, but it’s not a guarantee. Genetic research is still in it’s [sic] infancy, and there’s still a lot we don’t know about how DNA shapes who we are.”)
To people accustomed to sleep trackers, biohacking supplements, and glucose monitoring, taking advantage of Nucleus’s options might seem like a no-brainer. To anyone who welcomes a bit of serendipity in their life, this level of perceived control may be disconcerting to say the least.
Sadeghi likes to frame his arguments in terms of personal choice. “Maybe you want your baby to have blue eyes versus green eyes,” he told a small audience at Nucleus Embryo’s June launch event. “That is up to the liberty of the parents.”
On the official launch day, Sadeghi spent hours gleefully sparring with X users who accused him of practicing eugenics. He rejects the term, favoring instead “genetic optimization”—though it seems he wasn’t too upset about the free viral marketing. “This week we got five million impressions on Twitter,” he told a crowd at the launch event, to a smattering of applause. (In an email to MIT Technology Review, Sadeghi wrote, “The history of eugenics is one of coercion and discrimination by states and institutions; what Nucleus does is the opposite—genetic forecasting that empowers individuals to make informed decisions.”)
Nucleus has raised more than $36 million from investors like Srinivasan, Alexis Ohanian’s venture capital firm Seven Seven Six, and Thiel’s Founders Fund. (Like Siddiqui, Sadeghi was a recipient of a Thiel fellowship when he dropped out of college; a representative for Thiel did not respond to a request for comment for this story.) Sadeghi has even poached Genomic Prediction’s cofounder Nathan Treff, who is now Nucleus’s chief clinical officer.
Sadeghi’s real goal is to build a one-stop shop for every possible application of genetic sequencing technology, from genealogy to precision medicine to genetic engineering. He names a handful of companies providing these services, with a combined market cap in the billions. “Nucleus is collapsing all five of these companies into one,” he says. “We are not an IVF testing company. We are a genetic stack.”
This spring, I elbowed my way into a packed hotel bar in the Flatiron district, where over a hundred people had gathered to hear a talk called “How to create SUPERBABIES.” The event was part of New York’s Deep Tech Week, so I expected to meet a smattering of biotech professionals and investors. Instead, I was surprised to encounter a diverse and curious group of creatives, software engineers, students, and prospective parents—many of whom had come with no previous knowledge of the subject.
The speaker that evening was Jonathan Anomaly, a soft-spoken political philosopher whose didactic tone betrays his years as a university professor.
Some of Anomaly’s academic work has focused on developing theories of rational behavior. At Duke and the University of Pennsylvania, he led introductory courses on game theory, ethics, and collective action problems as well as bioethics, digging into thorny questions about abortion, vaccines, and euthanasia. But perhaps no topic has interested him so much as the emerging field of genetic enhancement.
In 2018, in a bioethics journal, Anomaly published a paper with the intentionally provocative title “Defending Eugenics.” He sought to distinguish what he called “positive eugenics”—noncoercive methods aimed at increasing traits that “promote individual and social welfare”—from the so-called “negative eugenics” we know from our history books.
Anomaly likes to argue that embryo selection isn’t all that different from practices we already take for granted. Don’t believe two cousins should be allowed to have children? Perhaps you’re a eugenicist, he contends. Your friend who picked out a six-foot-two Harvard grad from a binder of potential sperm donors? Same logic.
His hiring at the University of Pennsylvania in 2019 caused outrage among some students, who accused him of “racial essentialism.” In 2020, Anomaly left academia, lamenting that “American universities had become an intellectual prison.”
A few years later, Anomaly joined a nascent PGT-P company named Herasight, which was promising to screen for IQ.
At the end of July, the company officially emerged from stealth mode. A representative told me that most of the money raised so far is from angel investors, including Srinivasan, who also invested in Orchid and Nucleus. According to the launch announcement on X, Herasight has screened “hundreds of embryos” for private customers and is beginning to offer its first publicly available consumer product, a polygenic assessment that claims to detect an embryo’s likelihood of developing 17 diseases.
Their marketing materials boast predictive abilities 122% better than Orchid’s and 193% better than Genomic Prediction’s for this set of diseases. (“Herasight is comparing their current predictor to models we published over five years ago,” Genomic Prediction responded in a statement. “Our team is confident our predictors are world-class and are not exceeded in quality by any other lab.”)
The company did not include comparisons with Nucleus, pointing to the “absence of published performance validations” by that company and claiming it represented a case where “marketing outpaces science.” (“Nucleus is known for world-class science and marketing, and we understand why that’s frustrating to our competitors,” a representative from the company responded in a comment.)
Herasight also emphasized new advances in “within-family validation” (making sure that the scores are not merely picking up shared environmental factors by comparing their performance between unrelated people to their performance between siblings) and “cross-ancestry accuracy” (improving the accuracy of scores for people outside the European ancestry groups where most of the biobank data is concentrated). The representative explained that pricing varies by customer and the number of embryos tested, but it can reach $50,000.
When it comes to traits that Jonathan Anomaly believes are genetically encoded, intelligence is just the tip of the iceberg. He has also spoken about the heritability of empathy, violence, religiosity, and political leanings.
Herasight tests for just one non-disease-related trait: intelligence. For a couple who produce 10 embryos, it claims it can detect an IQ spread of about 15 points, from the lowest-scoring embryo to the highest. The representative says the company plans to release a detailed white paper on its IQ predictor in the future.
The day of Herasight’s launch, Musk responded to the company announcement: “Cool.” Meanwhile, a Danish researcher named Emil Kirkegaard, whose research has largely focused on IQ differences between racial groups, boosted the company to his nearly 45,000 followers on X (as well as in a Substack blog), writing, “Proper embryo selection just landed.” Kirkegaard has in fact supported Anomaly’s work for years; he’s posted about him on X and recommended his 2020 book Creating Future People, which he called a “biotech eugenics advocacy book,” adding: “Naturally, I agree with this stuff!”
When it comes to traits that Anomaly believes are genetically encoded, intelligence—which he claimed in his talk is about 75% heritable—is just the tip of the iceberg. He has also spoken about the heritability of empathy, impulse control, violence, passivity, religiosity, and political leanings.
Anomaly concedes there are limitations to the kinds of relative predictions that can be made from a small batch of embryos. But he believes we’re only at the dawn of what he likes to call the “reproductive revolution.” At his talk, he pointed to a technology currently in development at a handful of startups: in vitro gametogenesis. IVG aims to create sperm or egg cells in a laboratory using adult stem cells, genetically reprogrammed from cells found in a sample of skin or blood. In theory, this process could allow a couple to quickly produce a practically unlimited number of embryos to analyze for preferred traits. Anomaly predicted this technology could be ready to use on humans within eight years.
SELMAN DESIGN
“I doubt the FDA will allow it immediately. That’s what places like Próspera are for,” he said, referring to the so-called “startup city” in Honduras, where scientists and entrepreneurs can conduct medicalexperiments free from the kinds of regulatory oversight they’d encounter in the US.
“You might have a moral intuition that this is wrong,” said Anomaly, “but when it’s discovered that elites are doing it privately … the dominoes are going to fall very, very quickly.” The coming “evolutionary arms race,” he claimed, will “change the moral landscape.”
He added that some of those elites are his own customers: “I could already name names, but I won’t do it.”
After Anomaly’s talk was over, I spoke with a young photographer who told me he was hoping to pursue a master’s degree in theology. He came to the event, he told me, to reckon with the ethical implications of playing God. “Technology is sending us toward an Old-to-New-Testament transition moment, where we have to decide what parts of religion still serve us,” he said soberly.
Criticisms of polygenic testing tend to fall into two camps: skepticism about the tests’ effectiveness and concerns about their ethics. “On one hand,” says Turley from the Social Science Genetic Association Consortium, “you have arguments saying ‘This isn’t going to work anyway, and the reason it’s bad is because we’re tricking parents, which would be a problem.’ And on the other hand, they say, ‘Oh, this is going to work so well that it’s going to lead to enormous inequalities in society.’ It’s just funny to see. Sometimes these arguments are being made by the same people.”
One of those people is Sasha Gusev, who runs a quantitative genetics lab at the Dana-Farber Cancer Institute. A vocal critic of PGT-P for embryo selection, he also often engages in online debates with the far-right accounts promoting race science on X.
Gusev is one of many professionals in his field who believe that because of numerous confounding socioeconomic factors—for example, childhood nutrition, geography, personal networks, and parenting styles—there isn’t much point in trying to trace outcomes like educational attainment back to genetics, particularly not as a way to prove that there’s a genetic basis for IQ.
He adds, “I think there’s a real risk in moving toward a society where you see genetics and ‘genetic endowments’ as the drivers of people’s behavior and as a ceiling on their outcomes and their capabilities.”
Gusev thinks there is real promise for this technology in clinical settings among specific adult populations. For adults identified as having high polygenic risk scores for cancer and cardiovascular disease, he argues, a combination of early screening and intervention could be lifesaving. But when it comes to the preimplantation testing currently on the market, he thinks there are significant limitations—and few regulatory measures or long-term validation methods to check the promises companies are making. He fears that giving these services too much attention could backfire.
“These reckless, overpromised, and oftentimes just straight-up manipulative embryo selection applications are a risk for the credibility and the utility of these clinical tools,” he says.
Many IVF patients have also had strong reactions to publicity around PGT-P. When the New York Timespublished an opinion piece about Orchid in the spring, angry parents took to Reddit to rant. One user posted, “For people who dont [sic] know why other types of testing are necessary or needed this just makes IVF people sound like we want to create ‘perfect’ babies, while we just want (our) healthy babies.”
Still, others defended the need for a conversation. “When could technologies like this change the mission from helping infertile people have healthy babies to eugenics?” one Redditor posted. “It’s a fine line to walk and an important discussion to have.”
Some PGT-P proponents, like Kirkegaard and Anomaly, have argued that policy decisions should more explicitly account for genetic differences. In a series of blog posts following the 2024 presidential election, under the header “Make science great again,” Kirkegaard called for ending affirmative action laws, legalizing race-based hiring discrimination, and removing restrictions on data sets like the NIH’s All of Us biobank that prevent researchers like him from using the data for race science. Anomaly has criticized social welfare policies for putting a finger on the scale to “punish the high-IQ people.”
Indeed, the notion of genetic determinism has gained some traction among loyalists to President Donald Trump.
In October 2024, Trump himself made a campaign stop on the conservative radio program The Hugh Hewitt Show. He began a rambling answer about immigration and homicide statistics. “A murderer, I believe this, it’s in their genes. And we got a lot of bad genes in our country right now,” he told the host.
Gusev believes that while embryo selection won’t have much impact on individual outcomes, the intellectual framework endorsed by many PGT-P advocates could have dire social consequences.
“If you just think of the differences that we observe in society as being cultural, then you help people out. You give them better schooling, you give them better nutrition and education, and they’re able to excel,” he says. “If you think of these differences as being strongly innate, then you can fool yourself into thinking that there’s nothing that can be done and people just are what they are at birth.”
For the time being, there are no plans for longitudinal studies to track actual outcomes for the humans these companies have helped bring into the world. Harden, the behavioral geneticist from UT Austin, suspects that 25 years down the line, adults who were once embryos selected on the basis of polygenic risk scores are “going to end up with the same question that we all have.” They will look at their life and wonder, “What would’ve had to change for it to be different?”
Julia Black is a Brooklyn-based features writer and a reporter in residence at Omidyar Network. She has previously worked for Business Insider, Vox, The Information, and Esquire.
Sucking carbon pollution out of the atmosphere is becoming a big business—companies are paying top dollar for technologies that can cancel out their own emissions.
Today, nearly 70% of announced carbon removal contracts are for one technology: bioenergy with carbon capture and storage (BECCS). Basically, the idea is to use trees or some other types of biomass for energy, and then capture the emissions when you burn it.
While corporations, including tech giants like Microsoft, are betting big on this technology, there are a few potential problems with BECCS, as my colleague James Temple laid out in a new story. And some of the concerns echo similar problems with other climate technologies we cover, like carbon offsets and alternative jet fuels.
Carbon math can be complicated.
To illustrate one of the biggest issues with BECCS, we need to run through the logic on its carbon accounting. (And while this tech can use many different forms of biomass, let’s assume we’re talking about trees.)
When trees grow, they suck up carbon dioxide from the atmosphere. Those trees can be harvested and used for some intended purpose, like making paper. The leftover material, which might otherwise be waste, is then processed and burned for energy.
This cycle is, in theory, carbon neutral. The emissions from burning the biomass are canceled out by what was removed from the atmosphere during plants’ growth. (Assuming those trees are replaced after they’re harvested.)
So now imagine that carbon-scrubbing equipment is added to the facility that burns the biomass, capturing emissions. If the cycle was logically carbon neutral before, now it’s carbon negative: On net, emissions are removed from the atmosphere. Sounds great, no notes.
There are a few problems with this math, though. For one, it leaves out the emissions that might be produced while harvesting, transporting, and processing wood. And if projects require clearing land to plant trees or grow crops, that transformation can wind up releasing emissions too.
Issues with carbon math might sound a little familiar if you’ve read any of James’s reporting on carbon offsets, programs where people pay for others to avoid emissions. In particular, his 2021 investigation with ProPublica’s Lisa Song laid out how this so-called solution was actually adding millions of tons of carbon dioxide into the atmosphere.
Carbon capture may entrench polluting facilities.
One of the big benefits of BECCS is that it can be added to existing facilities. There’s less building involved than there might be in something like a facility that vacuums carbon directly out of air. That helps keep costs down, so BECCS is currently much cheaper than direct air capture and other forms of carbon removal.
But keeping legacy equipment running might not be a great thing for emissions or local communities in the long run.
Carbon dioxide is far from the only pollutant spewing out of these facilities. Burning biomass or biofuels can release emissions that harm human health, like particulate matter, sulfur dioxide, and carbon monoxide. Carbon capture equipment might trap some of these pollutants, like sulfur dioxide, but not all.
Assuming that waste material wouldn’t be used for something else might not be right.
It sounds great to use waste, but there’s a major asterisk lurking here, as James lays out in the story:
But the critical question that emerges with waste is: Would it otherwise have been burned or allowed to decompose, or might some of it have been used in some other way that kept the carbon out of the atmosphere?
Biomass can be used for other things, like making plastic, building material, or even soil additives that can help crops get more nutrients. So the assumption that it’s BECCS or nothing is flawed.
Moreover, a weird thing happens when you start making waste valuable: There’s an incentive to produce more of it. Some experts are concerned that companies could wind up trimming more trees or clearing more forests than what’s needed to make more material for BECCS.
These waste issues remind me of conversations around sustainable aviation fuels. These alternative fuels can be made from a huge range of materials, including crop waste or even used cooking oil. But as demand for these clean fuels has ballooned, things have gotten a little wonky—there are even some reports of fraud, where scammers try to pass off newly made oil from crops as used cooking oil.
BECCS is a potentially useful technology, but like many things in climate tech, it can quickly get complicated.
James has been reporting on carbon offsets and carbon removal for years. As he put it to me this week when we were chatting about this story: “Just cut emissions and stop messing around.”
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
This week we had some terrifying news from the World Health Organization: Antibiotics are failing us. A growing number of bacterial infections aren’t responding to these medicines—including common ones that affect the blood, gut, and urinary tract. Get infected with one of these bugs, and there’s a fair chance antibiotics won’t help.
The scary truth is that a growing number of harmful bacteria and fungi are becoming resistant to drugs. Just a few weeks ago, the US Centers for Disease Control and Prevention published a report finding a sharp rise in infections caused by a dangerous type of bacteria that are resistant to some of the strongest antibiotics. Now, the WHO report shows that the problem is surging around the world.
In this week’s Checkup, we’re trying something a bit different—a little quiz. You’ve probably heard about antimicrobial resistance (AMR) before, but how much do you know about microbes, antibiotics, and the scale of the problem? Here’s our attempt to put the “fun” in “fundamental threat to modern medicine.” Test your knowledge below!
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
It’s the 25th of June and I’m shivering in my lab-issued underwear in Fort Worth, Texas. Libby Cowgill, an anthropologist in a furry parka, has wheeled me and my cot into a metal-walled room set to 40 °F. A loud fan pummels me from above and siphons the dregs of my body heat through the cot’s mesh from below. A large respirator fits snug over my nose and mouth. The device tracks carbon dioxide in my exhales—a proxy for how my metabolism speeds up or slows down throughout the experiment. Eventually Cowgill will remove my respirator to slip a wire-thin metal temperature probe several pointy inches into my nose.
Cowgill and a graduate student quietly observe me from the corner of their so-called “climate chamber.” Just a few hours earlier I’d sat beside them to observe as another volunteer, a 24-year-old personal trainer, endured the cold. Every few minutes, they measured his skin temperature with a thermal camera, his core temperature with a wireless pill, and his blood pressure and other metrics that hinted at how his body handles extreme cold. He lasted almost an hour without shivering; when my turn comes, I shiver aggressively on the cot for nearly an hour straight.
I’m visiting Texas to learn about this experiment on how different bodies respond to extreme climates. “What’s the record for fastest to shiver so far?” I jokingly ask Cowgill as she tapes biosensing devices to my chest and legs. After I exit the cold, she surprises me: “You, believe it or not, were not the worst person we’ve ever seen.”
Climate change forces us to reckon with the knotty science of how our bodies interact with the environment.
Cowgill is a 40-something anthropologist at the University of Missouri who powerlifts and teaches CrossFit in her spare time. She’s small and strong, with dark bangs and geometric tattoos. Since 2022, she’s spent the summers at the University of North Texas Health Science Center tending to these uncomfortable experiments. Her team hopes to revamp the science of thermoregulation.
While we know in broad strokes how people thermoregulate, the science of keeping warm or cool is mottled with blind spots. “We have the general picture. We don’t have a lot of the specifics for vulnerable groups,” says Kristie Ebi, an epidemiologist with the University of Washington who has studied heat and health for over 30 years. “How does thermoregulation work if you’ve got heart disease?”
“Epidemiologists have particular tools that they’re applying for this question,” Ebi continues. “But we do need more answers from other disciplines.”
Climate change is subjecting vulnerable people to temperatures that push their limits. In 2023, about 47,000 heat-related deaths are believed to have occurred in Europe. Researchers estimate that climate change could add an extra 2.3 million European heat deaths this century. That’s heightened the stakes for solving the mystery of just what happens to bodies in extreme conditions.
Extreme temperatures already threaten large stretches of the world. Populations across the Middle East, Asia, and sub-Saharan Africa regularly face highs beyond widely accepted levels of human heat tolerance. Swaths of the southern US, northern Europe, and Asia now also endure unprecedented lows: The 2021 Texas freeze killed at least 246 people, and a 2023 polar vortex sank temperatures in China’s northernmost city to a hypothermic record of –63.4 °F.
This change is here, and more is coming. Climate scientists predict that limiting emissions can prevent lethal extremes from encroaching elsewhere. But if emissions keep course, fierce heat and even cold will reach deeper into every continent. About 2.5 billion people in the world’s hottest places don’t have air-conditioning. When people do, it can make outdoor temperatures even worse, intensifying the heat island effect in dense cities. And neither AC nor radiators are much help when heat waves and cold snaps capsize the power grid.
COURTESY OF MAX G. LEVY
COURTESY OF MAX G. LEVY
COURTESY OF MAX G. LEVY
“You, believe it or not, were not the worst person we’ve ever seen,” the author was told after enduring Cowgill’s “climate chamber.”
Through experiments like Cowgill’s, researchers around the world are revising rules about when extremes veer from uncomfortable to deadly. Their findings change how we should think about the limits of hot and cold—and how to survive in a new world.
Embodied change
Archaeologists have known for some time that we once braved colder temperatures than anyone previously imagined. Humans pushed into Eurasia and North America well before the last glacial period ended about 11,700 years ago. We were the only hominins to make it out of this era. Neanderthals, Denisovans, and Homo floresiensis all went extinct. We don’t know for certain what killed those species. But we do know that humans survived thanks to protection from clothing, large social networks, and physiological flexibility. Human resilience to extreme temperature is baked into our bodies, behavior, and genetic code. We wouldn’t be here without it.
“Our bodies are constantly in communication with the environment,” says Cara Ocobock, an anthropologist at the University of Notre Dame who studies how we expend energy in extreme conditions. She has worked closely with Finnish reindeer herders and Wyoming mountaineers.
But the relationship between bodies and temperature is surprisingly still a mystery to scientists. In 1847, the anatomist Carl Bergmann observed that animal species grow larger in cold climates. The zoologist Joel Asaph Allen noted in 1877 that cold-dwellers had shorter appendages. Then there’s the nose thing: In the 1920s, the British anthropologist Arthur Thomson theorized that people in cold places have relatively long, narrow noses, the better to heat and humidify the air they take in. These theories stemmed from observations of animals like bears and foxes, and others that followed stemmed from studies comparing the bodies of cold-accustomed Indigenous populations with white male control groups. Some, like those having to do with optimization of surface area, do make sense: It seems reasonable that a tall, thin body increases the amount of skin available to dump excess heat. The problem is, scientists have never actually tested this stuff in humans.
“Our bodies are constantly in communication with the environment.”
Cara Ocobock, anthropologist, University of Notre Dame
Some of what we know about temperature tolerance thus far comes from century-old race science or assumptions that anatomy controls everything. But science has evolved. Biology has matured. Childhood experiences, lifestyles, fat cells, and wonky biochemical feedback loops can contribute to a picture of the body as more malleable than anything imagined before. And that’s prompting researchers to change how they study it.
“If you take someone who’s super long and lanky and lean and put them in a cold climate, are they gonna burn more calories to stay warm than somebody who’s short and broad?” Ocobock says. “No one’s looked at that.”
Ocobock and Cowgill teamed up with Scott Maddux and Elizabeth Cho at the Center for Anatomical Sciences at the University of North Texas Health Fort Worth. All four are biological anthropologists who have also puzzled over whether the rules Bergmann, Allen, and Thomson proposed are actually true.
For the past four years, the team has been studying how factors like metabolism, fat, sweat, blood flow, and personal history control thermoregulation.
Your native climate, for example, may influence how you handle temperature extremes. In a unique study of mortality statistics from 1980s Milan, Italians raised in warm southern Italy were more likely to survive heat waves in the northern part of the country.
Similar trends have appeared in cold climes. Researchers often measure cold tolerance by a person’s “brown adipose,” a type of fat that is specialized for generating heat (unlike white fat, which primarily stores energy). Brown fat is a cold adaptation because it delivers heat without the mechanism of shivering. Studies have linked it to living in cold climates, particularly at young ages. Wouter van Marken Lichtenbelt, the physiologist at Maastricht University who with colleagues discovered brown fat in adults, has shown that this tissue can further activate with cold exposure and even help regulate blood sugar and influence how the body burns other fat.
That adaptability served as an early clue for the Texas team. They want to know how a person’s response to hot and cold correlates with height, weight, and body shape. What is the difference, Maddux asks, between “a male who’s 6 foot 6 and weighs 240 pounds” and someone else in the same environment “who’s 4 foot 10 and weighs 89 pounds”? But the team also wondered if shape was only part of the story.
Their multi-year experiment uses tools that anthropologists couldn’t have imagined a century ago—devices that track metabolism in real time and analyze genetics. Each participant gets a CT scan (measuring body shape), a DEXA scan (estimating percentages of fat and muscle), high-resolution 3D scans, and DNA analysis from saliva to examine ancestry genetically.
Volunteers lie on a cot in underwear, as I did, for about 45 minutes in each climate condition, all on separate days. There’s dry cold, around 40 °F, akin to braving a walk-in refrigerator. Then dry heat and humid heat: 112 °F with 15% humidity and 98 °F with 85% humidity. They call it “going to Vegas” and “going to Houston,” says Cowgill. The chamber session is long enough to measure an effect, but short enough to be safe.
Before I traveled to Texas, Cowgill told me she suspected the old rules would fall. Studies linking temperature tolerance to race and ethnicity, for example, seemed tenuous because biological anthropologists today reject the concept of distinct races. It’s a false premise, she told me: “No one in biological anthropology would argue that human beings do not vary across the globe—that’s obvious to anyone with eyes. [But] you can’t draw sharp borders around populations.”
She added, “I think there’s a substantial possibility that we spend four years testing this and find out that really, limb length, body mass, surface area […] are not the primary things that are predicting how well you do in cold and heat.”
Adaptable to a degree
In July 1995, a week-long heat wave pushed Chicago above 100 °F, killing roughly 500 people. Thirty years later, Ollie Jay, a physiologist at the University of Sydney, can duplicate the conditions of that exceptionally humid heat wave in a climate chamber at his laboratory.
“We can simulate the Chicago heat wave of ’95. The Paris heat wave of 2003. The heat wave [in early July of this year] in Europe,” Jay says. “As long as we’ve got the temperature and humidity information, we can re-create those conditions.”
“Everybody has quite an intimate experience of feeling hot, so we’ve got 8 billion experts on how to keep cool,” he says. Yet our internal sense of when heat turns deadly is unreliable. Even professional athletes overseen by experienced medics have died after missing dangerous warning signs. And little research has been done to explore how vulnerable populations such as elderly people, those with heart disease, and low-income communities with limited access to cooling respond to extreme heat.
Jay’s team researches the most effective strategies for surviving it. He lambastes air-conditioning, saying it demands so much energy that it can aggravate climate change in “a vicious cycle.” Instead, he has monitored people’s vital signs while they use fans and skin mists to endure three hours in humid and dry heat. In results published last year, his research found that fans reduced cardiovascular strain by 86% for people with heart disease in the type of humid heat familiar in Chicago.
Dry heat was a different story. In that simulation, fans not only didn’t help but actually doubled the rate at which core temperatures rose in healthy older people.
Heat kills. But not without a fight. Your body must keep its internal temperature in a narrow window flanking 98 °F by less than two degrees. The simple fact that you’re alive means you are producing heat. Your body needs to export that heat without amassing much more. The nervous system relaxes narrow blood vessels along your skin. Your heart rate increases, propelling more warm blood to your extremities and away from your organs. You sweat. And when that sweat evaporates, it carries a torrent of body heat away with it.
This thermoregulatory response can be trained. Studies by van Marken Lichtenbelt have shown that exposure to mild heat increases sweat capacity, decreases blood pressure, and drops resting heart rate. Long-term studies based on Finnish saunas suggest similar correlations.
The body may adapt protectively to cold, too. In this case, body heat is your lifeline. Shivering and exercise help keep bodies warm. So can clothing. Cardiovascular deaths are thought to spike in cold weather. But people more adapted to cold seem better able to reroute their blood flow in ways that keep their organs warm without dropping their temperature too many degrees in their extremities.
Earlier this year, the biological anthropologist Stephanie B. Levy (no relation) reported that New Yorkers who experienced lower average temperatures had more productive brown fat, adding evidence for the idea that the inner workings of our bodies adjust to the climate throughout the year and perhaps even throughout our lives. “Do our bodies hold a biological memory of past seasons?” Levy wonders. “That’s still an open question. There’s some work in rodent models to suggest that that’s the case.”
Although people clearly acclimatize with enough strenuous exposures to either cold or heat, Jay says, “you reach a ceiling.” Consider sweat: Heat exposure can increase the amount you sweat only until your skin is completely saturated. It’s a nonnegotiable physical limit. Any additional sweat just means leaking water without carrying away any more heat. “I’ve heard people say we’ll just find a way of evolving out of this—we’ll biologically adapt,” Jay says. “Unless we’re completely changing our body shape, then that’s not going to happen.”
And body shape may not even sway thermoregulation as much as previously believed. The subject I observed, a personal trainer, appeared outwardly adapted for cold: his broad shoulders didn’t even fit in a single CT scan image. Cowgill supposed that this muscle mass insulated him. When he emerged from his session in the 40 °F environment, though, he had finally started shivering—intensely. The researchers covered him in a heated blanket. He continued shivering. Driving to lunch over an hour later in a hot car, he still mentioned feeling cold. An hour after that, a finger prick drew no blood, a sign that blood vessels in his extremities remained constricted. His body temperature fell about half a degree C in the cold session—a significant drop—and his wider build did not appear to shield him from the cold as well as my involuntary shivering protected me.
I asked Cowgill if perhaps there is no such thing as being uniquely predisposed to hot or cold. “Absolutely,” she said.
A hot mess
So if body shape doesn’t tell us much about how a person maintains body temperature, and acclimation also runs into limits, then how do we determine how hot is too hot?
In 2010 two climate change researchers, Steven Sherwood and Matthew Huber, argued that regions around the world become uninhabitable at wet-bulb temperatures of 35 °C, or 95 °F. (Wet-bulb measurements are a way to combine air temperature and relative humidity.) Above 35 °C, a person simply wouldn’t be able to dissipate heat quickly enough. But it turns out that their estimate was too optimistic.
Researchers “ran with” that number for a decade, says Daniel Vecellio, a bioclimatologist at the University of Nebraska, Omaha. “But the number had never been actually empirically tested.” In 2021 a Pennsylvania State University physiologist, W. Larry Kenney, worked with Vecellio and others to test wet-bulb limits in a climate chamber. Kenney’s lab investigates which combinations of temperature, humidity, and time push a person’s body over the edge.
Not long after, the researchers came up with their own wet-bulb limit of human tolerance: below 31 °C in warm, humid conditions for the youngest cohort, people in their thermoregulatory prime. Their research suggests that a day reaching 98 °F and 65% humidity, for example, poses danger in a matter of hours, even for healthy people.
JUSTIN CLEMONS
JUSTIN CLEMONS
JUSTIN CLEMONS
Cowgill and her colleagues Elizabeth Cho (top) and Scott Maddux prepare graduate student Joanna Bui for a “room-temperature test.”
In 2023, Vecellio and Huber teamed up, combining the growing arsenal of lab data with state-of-the-art climate simulations to predict where heat and humidity most threatened global populations: first the Middle East and South Asia, then sub-Saharan Africa and eastern China. And assuming that warming reaches 3 to 4 °C over preindustrial levels this century, as predicted, parts of North America, South America, and northern and central Australia will be next.
Last June, Vecellio, Huber, and Kenney co-published an article revising the limits that Huber had proposed in 2010. “Why not 35 °C?” explained why the human limits have turned out to be lower than expected. Those initial estimates overlooked the fact that our skin temperature can quickly jump above 101 °F in hot weather, for example, making it harder to dump internal heat.
The Penn State team has published deep dives on how heat tolerance changes with sex and age. Older participants’ wet-bulb limits wound up being even lower—between 27 and 28 °C in warm, humid conditions—and varied more from person to person than they did in young people. “The conditions that we experience now—especially here in North America and Europe, places like that—are well below the limits that we found in our research,” Vecellio says. “We know that heat kills now.”
What this fast-growing body of research suggests, Vecellio stresses, is that you can’t define heat risk by just one or two numbers. Last year, he and researchers at Arizona State University pulled up the hottest 10% of hours between 2005 and 2020 for each of 96 US cities. They wanted to compare recent heat-health research with historical weather data for a new perspective: How frequently is it so hot that people’s bodies can’t compensate for it? Over 88% of those “hot hours” met that criterion for people in full sun. In the shade, most of those heat waves became meaningfully less dangerous.
“There’s really almost no one who ‘needs’ to die in a heat wave,” says Ebi, the epidemiologist. “We have the tools. We have the understanding. Essentially all [those] deaths are preventable.”
More than a number
A year after visiting Texas, I called Cowgill to hear what she was thinking after four summers of chamber experiments. She told me that the only rule about hot and cold she currently stands behind is … well, none.
She recalled a recent participant—the smallest man in the study, weighing 114 pounds. “He shivered like a leaf on a tree,” Cowgill says. Normally, a strong shiverer warms up quickly. Core temperature may even climb a little. “This [guy] was just shivering and shivering and shivering and not getting any warmer,” she says. She doesn’t know why this happened. “Every time I think I get a picture of what’s going on in there, we’ll have one person come in and just kind of be a complete exception to the rule,” she says, adding that you can’t just gloss over how much human bodies vary inside and out.
The same messiness complicates physiology studies.
Jay looks to embrace bodily complexities by improving physiological simulations of heat and the human strain it causes. He’s piloted studies that input a person’s activity level and type of clothing to predict core temperature, dehydration, and cardiovascular strain based on the particular level of heat. One can then estimate the person’s risk on the basis of factors like age and health. He’s also working on physiological models to identify vulnerable groups, inform early-warning systems ahead of heat waves, and possibly advise cities on whether interventions like fans and mists can help protect residents. “Heat is an all-of-society issue,” Ebi says. Officials could better prepare the public for cold snaps this way too.
“Death is not the only thing we’re concerned about,” Jay adds. Extreme temperatures bring morbidity and sickness and strain hospital systems: “There’s all these community-level impacts that we’re just completely missing.”
Climate change forces us to reckon with the knotty science of how our bodies interact with the environment. Predicting the health effects is a big and messy matter.
The first wave of answers from Fort Worth will materialize next year. The researchers will analyze thermal images to crunch data on brown fat. They’ll resolve whether, as Cowgill suspects, your body shape may not sway temperature tolerance as much as previously assumed. “Human variation is the rule,” she says, “not the exception.”
Max G. Levy is an independent journalist who writes about chemistry, public health, and the environment.
For years at Orchard Care Homes, a 23‑facility dementia-care chain in northern England, Cheryl Baird watched nurses fill out the Abbey Pain Scale, an observational methodology used to evaluate pain in those who can’t communicate verbally. Baird, a former nurse who was then the facility’s director of quality, describes it as “a tick‑box exercise where people weren’t truly considering pain indicators.”
As a result, agitated residents were assumed to have behavioral issues, since the scale does not always differentiate well between pain and other forms of suffering or distress. They were often prescribed psychotropic sedatives, while the pain itself went untreated.
Then, in January 2021, Orchard Care Homes began a trial of PainChek, a smartphone app that scans a resident’s face for microscopic muscle movements and uses artificial intelligence to output an expected pain score. Within weeks, the pilot unit saw fewer prescriptions and had calmer corridors. “We immediately saw the benefits: ease of use, accuracy, and identifying pain that wouldn’t have been spotted using the old scale,” Baird recalls.
In nursing homes, neonatal units, and ICU wards, researchers are racing to turn pain into something a camera or sensor can score as reliably as blood pressure.
This kind of technology-assisted diagnosis hints at a bigger trend. In nursing homes, neonatal units, and ICU wards, researchers are racing to turn pain—medicine’s most subjective vital sign—into something a camera or sensor can score as reliably as blood pressure. The push has already produced PainChek, which has been cleared by regulators on three continents and has logged more than 10 million pain assessments. Other startups are beginning to make similar inroads in care settings.
The way we assess pain may finally be shifting, but when algorithms measure our suffering, does that change the way we understand and treat it?
Science already understands certain aspects of pain. We know that when you stub your toe, for example, microscopic alarm bells called nociceptors send electrical impulses toward your spinal cord on “express” wires, delivering the first stab of pain, while a slower convoy follows with the dull throb that lingers. At the spinal cord, the signal meets a microscopic switchboard scientists call the gate. Flood that gate with friendly touches—say, by rubbing the bruise—or let the brain return an instruction born of panic or calm, and the gate might muffle or magnify the message before you even become aware of it.
The gate can either let pain signals pass through or block them, depending on other nerve activity and instructions from your brain. Only the signals that succeed in getting past this gate travel up to your brain’s sensory map to help locate the damage, while others branch out to emotion centers that decide how bad it feels. Within milliseconds, those same hubs in the brain shoot fresh orders back down the line, releasing built-in painkillers or stoking the alarm. In other words, pain isn’t a straightforward translation of damage or sensation but a live negotiation between the body and the brain.
But much of how that negotiation plays out is still a mystery. For instance, scientists cannot predict what causes someone to slip from a routine injury into years-long hypersensitivity; the molecular shift from acute to chronic pain is still largely unknown. Phantom-limb pain remains equally puzzling: About two-thirds of amputees feel agony in a part of their body that no longer exists, yet competing theories—cortical remapping, peripheral neuromas, body-schema mismatch—do not explain why they suffer while the other third feel nothing.
The first serious attempt at a system for quantifying pain was introduced in 1921. Patients marked their degree of pain as a point on a blank 10‑centimeter line and clinicians scored the distance in millimeters, converting lived experience into a 0–100 ladder. By 1975, psychologist Ronald Melzack’s McGill Pain Questionnaire offered 78 adjectives like “burning,” “stabbing,” and “throbbing,” so that pain’s texture could join intensity in the chart. Over the past few decades, hospitals have ultimately settled on the 0–10 Numeric Rating Scale.
Yet pain is stubbornly subjective. Feedback from the brain in the form of your reaction can send instructions back down the spinal cord, meaning that expectation and emotion can change how much the same injury hurts. In one trial, volunteers who believed they had received a pain relief cream reported a stimulus as 22% less painful than those who knew the cream was inactive—and a functional magnetic resonance image of their brains showed that the drop corresponded with decreased activity in the parts of the brain that report pain, meaning they really did feel less hurt.
What’s more, pain can also be affected by a slew of external factors. In one study, experimenters applied the same calibrated electrical stimulus to volunteers from Italy, Sweden, and Saudi Arabia, and the ratings varied dramatically. Italian women recorded the highest scores on the 0–10 scale, while Swedish and Saudi participants judged the identical burn several points lower, implying that culture can amplify or dampen the felt intensity of the same experience.
Bias inside the clinic can drive different responses even to the same pain score. A 2024 analysis of discharge notes found that women’s scores were recorded 10% less often than men’s. At a large pediatric emergency department, Black children presenting with limb fractures were roughly 39% less likely to receive an opioid analgesic than their white non-Hispanic peers, even after the researchers controlled for pain score and other clinical factors. Together these studies make clear that an “8 out of 10” does not always result in the same reaction or treatment. And many patients cannot self-report their pain at all—for example, a review of bedside studies concludes that about 70% of intensive-care patients have pain that goes unrecognized or undertreated, a problem the authors link to their impaired communication due to sedation or intubation.
These issues have prompted a search for a better, more objective way to understand and assess pain. Progress in artificial intelligence has brought a new dimension to that hunt.
Research groups are pursuing two broad routes. The first listens underneath the skin. Electrophysiologists strap electrode nets to volunteers and look for neural signatures that rise and fall with administered stimuli. A 2024 machine-learning study reported that one such algorithm could tell with over 80% accuracy, using a few minutes of resting-state EEG, which subjects experienced chronic pain and which were pain-free control participants. Other researchers combine EEG with galvanic skin response and heart-rate variability, hoping a multisignal “pain fingerprint” will provide more robust measurements.
One example of this method is the PMD-200 patient monitor from Medasense, which uses AI-based tools to output pain scores. The device uses physiological patterns like heart rate, sweating, or peripheral temperature changes as the input and focuses on surgical patients, with the goal of helping anesthesiologists adjust doses during operations. In a 2022 study of 75 patients undergoing major abdominal surgery, use of the monitor resulted in lower self-reported pain scores after the operation—a median score of 3 out of 10, versus 5 out of 10 in controls—without an increase in opioid use. The device is authorized by the US Food and Drug Administration and is in use in the United States, the European Union, Canada, and elsewhere.
The second path is behavioral. A grimace, a guarded posture, or a sharp intake of breath correlates with various levels of pain. Computer-vision teams have fed high-speed video of patients’ changing expressions into neural networks trained on the Face Action Coding System (FACS), which was introduced in the late 1970s with the goal of creating an objective and universal system to analyze such expressions—it’s the Rosetta stone of 44 facial micro-movements. In lab tests, those models can flag frames indicating pain from the data set with over 90% accuracy, edging close to the consistency of expert human assessors. Similar approaches mine posture and even sentence fragments in clinical notes, using natural-language processing, to spot phrases like “curling knees to chest” that often correlate with high pain.
PainChek is one of these behavioral models, and it acts like a camera‑based thermometer, but for pain: A care worker opens the app and holds a phone 30 centimeters from a person’s face. For three seconds, a neural network looks for nine particular microscopic movements—upper‑lip raise, brow pinch, cheek tension, and so on—that research has linked most strongly to pain. Then the screen flashes a score of 0 to 42. “There’s a catalogue of ‘action‑unit codes’—facial expressions common to all humans. Nine of those are associated with pain,” explains Kreshnik Hoti, a senior research scientist with PainChek and a co-inventor of the device. This system is built directly on the foundation of FACS. After the scan, the app walks the user through a yes‑or‑no checklist of other signs, like groaning, “guarding,” and sleep disruption, and stores the result on a cloud dashboard that can show trends.
Linking the scan to a human‑filled checklist was, Hoti admits, a late design choice. “Initially, we thought AI should automate everything, but now we see [that] hybrid use—AI plus human input—is our major strength,” he says. Care aides, not nurses, complete most assessments, freeing clinicians to act on the data rather than gather it.
PainChek was cleared by Australia’s Therapeutic Goods Administration in 2017, and national rollout funding from Canberra helped embed it in hundreds of nursing homes in the country. The system has also won authorization in the UK—where expansion began just before covid-19 started spreading and resumed as lockdowns eased—and in Canada and New Zealand, which are running pilot programs. In the US, it’s currently awaiting an FDA decision. Company‑wide data show “about a 25% drop in antipsychotic use and, in Scotland, a 42% reduction in falls,” Hoti says.
PainChek is a mobile app that estimates pain scores by applying artificial intelligence to facial scans.
COURTESY OF PAINCHEK
Orchard Care Homes is one of its early adopters. Baird, then the facility’s director of quality, remembers the pre‑AI routine that was largely done “to prove compliance,” she says.
PainChek added an algorithm to that workflow, and the hybrid approach has paid off. Orchard’s internal study of four care homes tracked monthly pain scores, behavioral incidents, and prescriptions. Within weeks, psychotropic scripts fell and residents’ behavior calmed. The ripple effects went beyond pharmacy tallies. Residents who had skipped meals because of undetected dental pain “began eating again,” Baird notes, and “those who were isolated due to pain began socializing.”
Inside Orchard facilities, a cultural shift is underway. When Baird trained new staff, she likened pain “to measuring blood pressure or oxygen,” she says. “We wouldn’t guess those, so why guess pain?” The analogy lands, but getting people fully on board is still a slog. Some nurses insist their clinical judgment is enough; others balk at another login and audit trail. “The sector has been slow to adopt technology, but it’s changing,” Baird says. That’s helped by the fact that administering a full Abbey Pain Scale takes 20 minutes, while a PainChek scan and checklist take less than five.
Engineers at PainChek are now adapting the code for the very youngest patients. PainChek Infant targets babies under one year, whose grimaces flicker faster than adults’. The algorithm, retrained on neonatal faces, detects six validated facial action units based on the well-established Baby Facial Action Coding System. PainChek Infant is starting limited testing in Australia while the company pursues a separate regulatory pathway.
Skeptics raise familiar red flags about these devices. Facial‑analysis AI has a history of skin‑tone bias, for example. Facial analysis may also misread grimaces stemming from nausea or fear. The tool is only as good as the yes‑or‑no answers that follow the scan; sloppy data entry can skew results in either direction. Results lack the broader clinical and interpersonal context a caregiver is likely to have from interacting with individual patients regularly and understanding their medical history. It’s also possible that clinicians might defer too strongly to the algorithm, over-relying on outside judgment and eroding their own.
If PainChek is approved by the FDA this fall, it will be part of a broader effort to create a system of new pain measurement technology. Other startups are pitching EEG headbands for neuropathic pain, galvanic skin sensors that flag breakthrough cancer pain, and even language models that comb nursing notes for evidence of hidden distress. Still, quantifying pain with an external device could be rife with hidden issues, like bias or inaccuracies, that we will uncover only after significant use.
For Baird, the issue is fairly straightforward nonetheless. “I’ve lived with chronic pain and had a hard time getting people to believe me. [PainChek] would have made a huge difference,” she says. If artificial intelligence can give silent sufferers a numerical voice—and make clinicians listen—then adding one more line to the vital‑sign chart might be worth the screen time.
Deena Mousa is a researcher, grantmaker, and journalist focused on global health, economic development, and scientific and technological progress.
Mousa is employed as lead researcher by Open Philanthropy, a funder and adviser focused on high-impact causes, including global health and the potential risks posed by AI. The research team investigates new causes of focus and is not involved in work related to pain management. Mousa has not been involved with any grants related to pain management, although Open Philanthropy has funded research in this area in the past.