Google doesn’t always spider every page on a site instantly. Sometimes, it can take weeks. This might get in the way of your SEO efforts. Your newly optimized landing page might not get indexed. At that point, it’s time to optimize your crawl budget. In this article, we’ll discuss what a ‘crawl budget’ is and what you can do to optimize it.
What is a crawl budget?
Crawl budget is the number of pages Google will crawl on your site on any given day. This number varies slightly daily, but overall, it’s relatively stable. Google might crawl six pages on your site each day; it might crawl 5,000 pages; it might even crawl 4,000,000 pages every single day. The number of pages Google crawls, your ‘budget,’ is generally determined by the size of your site, the ‘health’ of your site (how many errors Google encounters), and the number of links to your site. Some of these factors are things you can influence; we’ll get to that in a bit.
How does a crawler work?
A crawler like Googlebot gets a list of URLs to crawl on a site. It goes through that list systematically. It grabs your robots.txt file occasionally to ensure it’s still allowed to crawl each URL and then crawls the URLs individually. Once a spider has crawled a URL and parsed the contents, it adds new URLs found on that page that it has to crawl back on the to-do list.
Several events can make Google feel a URL has to be crawled. It might have found new links pointing at content, or someone has tweeted it, or it might have been updated in the XML sitemap, etc., etc… There’s no way to make a list of all the reasons why Google would crawl a URL, but when it determines it has to, it adds it to the to-do list.
Crawl budget is not a problem if Google has to crawl many URLs on your site and has allotted a lot of crawls. But, say your site has 250,000 pages, and Google crawls 2,500 pages on this particular site each day. It will crawl some (like the homepage) more than others. It could take up to 200 days before Google notices particular changes to your pages if you don’t act. Crawl budget is an issue now. On the other hand, if it crawls 50,000 a day, there’s no issue at all.
Follow the steps below to determine whether your site has a crawl budget issue. This does assume your site has a relatively small number of URLs that Google crawls but doesn’t index (for instance, because you added meta noindex).
Determine how many pages your site has; the number of URLs in your XML sitemaps might be a good start.
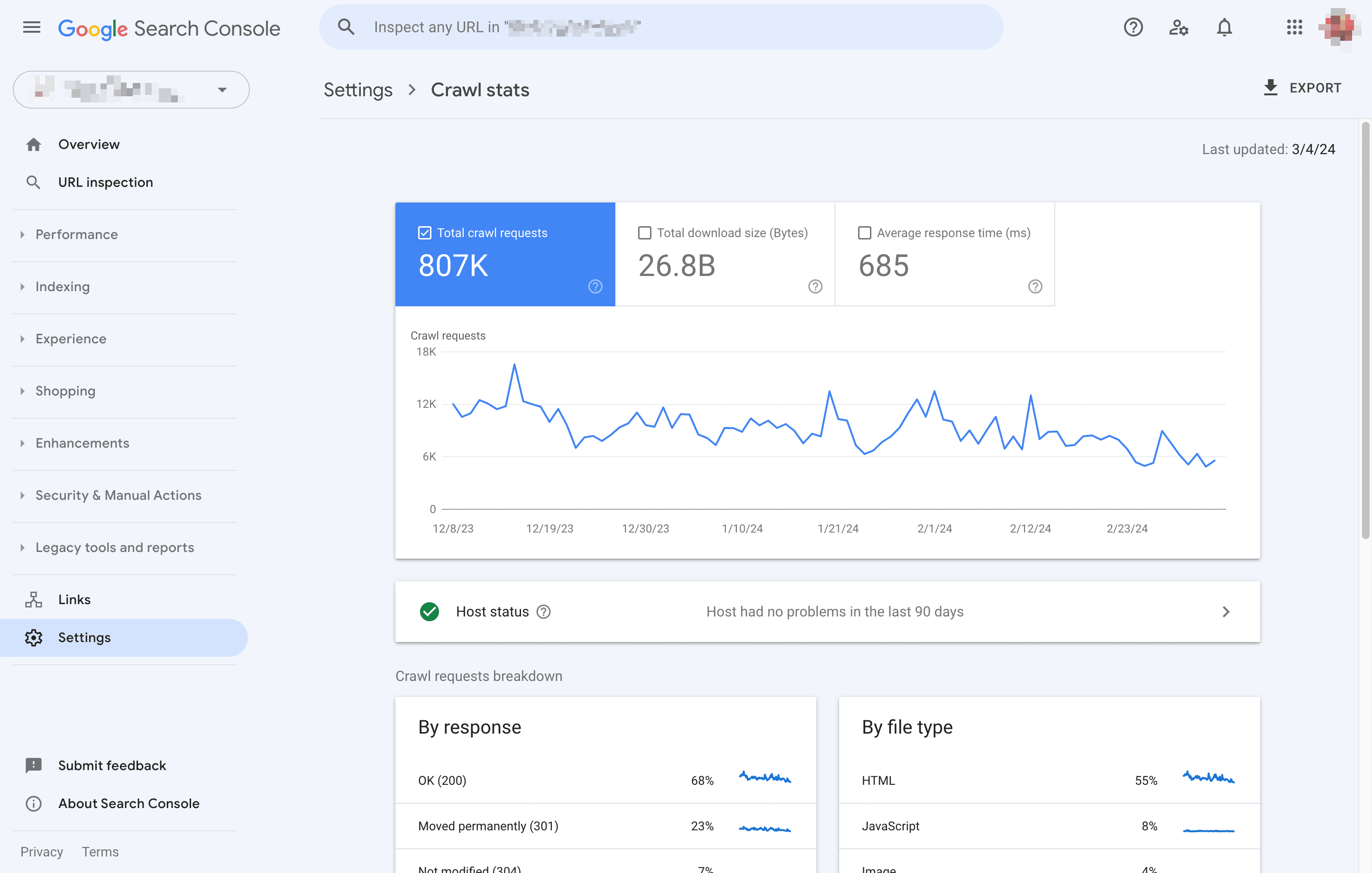
Go into Google Search Console.
Go to “Settings” -> “Crawl stats” and calculate the average pages crawled per day.
Divide the number of pages by the “Average crawled per day” number.
You should probably optimize your crawl budget if you end up with a number higher than ~10 (so you have 10x more pages than what Google crawls daily). You can read something else if you end up with a number lower than 3.
The ‘Crawl stats’ report Google Search Console
What URLs is Google crawling?
You really should know which URLs Google is crawling on your site. Your site’s server logs are the only ‘real’ way of knowing. For larger sites, you can use something like Logstash + Kibana. For smaller sites, the guys at Screaming Frog have released an SEO Log File Analyser tool.
Get your server logs and look at them
Depending on your type of hosting, you might not always be able to grab your log files. However, if you even think you need to work on crawl budget optimization because your site is big, you should get them. If your host doesn’t allow you to get them, it’s time to change hosts.
Fixing your site’s crawl budget is a lot like fixing a car. You can’t fix it by looking at the outside; you’ll have to open that engine. Looking at logs is going to be scary at first. You’ll quickly find that there is a lot of noise in logs. You’ll find many commonly occurring 404s that you think are nonsense. But you have to fix them. You must wade through the noise and ensure your site is not drowned in tons of old 404s.
Let’s look at the things that improve how many pages Google can crawl on your site.
Website maintenance: reduce errors
Step one in getting more pages crawled is making sure that the pages that are crawled return one of two possible return codes: 200 (for “OK”) or 301 (for “Go here instead”). All other return codes are not OK. To figure this out, look at your site’s server logs. Google Analytics and most other analytics packages will only track pages that served a 200. So you won’t find many errors on your site in there.
Once you’ve got your server logs, find and fix common errors. The most straightforward way is by grabbing all the URLs that didn’t return 200 or 301 and then ordering by how often they were accessed. Fixing an error might mean that you have to fix code. Or you might have to redirect a URL elsewhere. If you know what caused the error, you can also try to fix the source.
If you have sections of your site that don’t need to be in Google, block them using robots.txt. Only do this if you know what you’re doing, of course. One of the common problems we see on larger eCommerce sites is when they have a gazillion ways to filter products. Every filter might add new URLs for Google. In cases like these, you want to ensure that you’re letting Google spider only one or two of those filters and not all of them.
Reduce redirect chains
When you 301 redirect a URL, something weird happens. Google will see that new URL and add that URL to the to-do list. It doesn’t always follow it immediately; it adds it to its to-do list and goes on. When you chain redirects, for instance, when you redirect non-www to www, then http to https, you have two redirects everywhere, so everything takes longer to crawl.
Get more links
This is easy to say but hard to do. Getting more links is not just a matter of being awesome but also of making sure others know you’re awesome. It’s a matter of good PR and good engagement on social media. We’ve written extensively about link building; we’d suggest reading these three posts:
When you have an acute indexing problem, you should first look at your crawl errors, block parts of your site, and fix redirect chains. Link building is a very slow method to increase your crawl budget. On the other hand, link building must be part of your process if you intend to build a large site.
TL;DR: crawl budget optimization is hard
Crawl budget optimization is not for the faint of heart. If you’re doing your site’s maintenance well, or your site is relatively small, it’s probably not needed. If your site is medium-sized and well-maintained, it’s fairly easy to do based on the above tricks.
Assess your technical SEO fitness
Optimizing your crawl budget is part of your technical SEO. Are you curious how your site’s overall technical SEO fits? We’ve created a technical SEO fitness quiz that helps you figure out what you need to work on!
The robots.txt file is one of the main ways of telling a search engine where it can and can’t go on your website. All major search engines support its basic functionality, but some respond to additional rules, which can be helpful too. This guide covers all the ways to use robots.txt on your website.
Warning!
Any mistakes you make in your robots.txt can seriously harm your site, so read and understand this article before diving in.
Table of contents
What is a robots.txt file?
Crawl directives
The robots.txt file is one of a number of crawl directives. We have guides on all of them and you’ll find them here.
A robots.txt file is a plain text document located in a website’s root directory, serving as a set of instructions to search engine bots. Also called the Robots Exclusion Protocol, the robots.txt file results from a consensus among early search engine developers. It’s not an official standard set by any standards organization, although all major search engines adhere to it.
Robots.txt specifies which pages or sections should be crawled and indexed and which should be ignored. This file helps website owners control the behavior of search engine crawlers, allowing them to manage access, limit indexing to specific areas, and regulate crawling rate. While it’s a public document, compliance with its directives is voluntary, but it is a powerful tool for guiding search engine bots and influencing the indexing process.
A basic robots.txt file might look something like this:
Search engines typically cache the contents of the robots.txt so that they don’t need to keep downloading it, but will usually refresh it several times a day. That means that changes to instructions are typically reflected fairly quickly.
Search engines discover and index the web by crawling pages. As they crawl, they discover and follow links. This takes them from site A to site B to site C, and so on. But before a search engine visits any page on a domain it hasn’t encountered, it will open that domain’s robots.txt file. That lets them know which URLs on that site they’re allowed to visit (and which ones they’re not).
The robots.txt file should always be at the root of your domain. So if your domain is www.example.com, the crawler should find it at https://www.example.com/robots.txt.
It’s also essential that your robots.txt file is called robots.txt. The name is case-sensitive, so get that right, or it won’t work.
Yoast SEO and robots.txt
Our plugin has sensible defaults, but you can always change things as you see fit. Yoast SEO provides a user-friendly interface to edit the robots.txt file without needing to access it manually. With Yoast SEO, you can access and configure the robots.txt feature through the plugin’s settings. It allows you to include or exclude specific website areas from being crawled by search engines. When used in conjuncture with the crawl settings,
Pros and cons of using robots.txt
Pro: managing crawl budget
It’s generally understood that a search spider arrives at a website with a pre-determined “allowance” for how many pages it will crawl (or how much resource/time it’ll spend, based on a site’s authority/size/reputation, and how efficiently the server responds). SEOs call this the crawl budget.
If you think your website has problems with crawl budget, blocking search engines from ‘wasting’ energy on unimportant parts of your site might mean focusing instead on the sections that matter. Use the crawl cleanup settings in Yoast SEO to help Google crawls what matters.
It can sometimes be beneficial to block the search engines from crawling problematic sections of your site, especially on sites where a lot of SEO clean-up has to be done. Once you’ve tidied things up, you can let them back in.
A note on blocking query parameters
One situation where crawl budget is crucial is when your site uses a lot of query string parameters to filter or sort lists. Let’s say you have ten different query parameters, each with different values that can be used in any combination (like t-shirts in multiple colors and sizes). This leads to many possible valid URLs, all of which might get crawled. Blocking query parameters from being crawled will help ensure the search engine only spiders your site’s main URLs and won’t go into the enormous spider trap you’d otherwise create.
Con: not removing a page from search results
Even though you can use the robots.txt file to tell a crawler where it can’t go on your site, you can’t use it to say to a search engine which URLs not to show in the search results – in other words, blocking it won’t stop it from being indexed. If the search engine finds enough links to that URL, it will include it; it will just not know what’s on that page. So your result will look like this:
Use a meta robotsnoindex tag if you want to reliably block a page from appearing in the search results. That means that to find the noindex tag, the search engine has to be able to access that page, so don’t block it with robots.txt.
Noindex directives
It used to be possible to add ‘noindex’ directives in your robots.txt, to remove URLs from Google’s search results, and to avoid these ‘fragments’ showing up. This is no longer supported (and technically, never was).
Con: not spreading link value
If a search engine can’t crawl a page, it can’t spread the link value across the links on that page. It’s a dead-end when you’ve blocked a page in robots.txt. Any link value which might have flowed to (and through) that page is lost.
Robots.txt syntax
WordPress robots.txt
We have an article on how best to setup your robots.txt for WordPress. Don’t forget you can edit your site’s robots.txt file in the Yoast SEO Tools → File editor section.
A robots.txt file consists of one or more blocks of directives, each starting with a user-agent line. The “user-agent” is the name of the specific spider it addresses. You can have one block for all search engines, using a wildcard for the user-agent, or particular blocks for particular search engines. A search engine spider will always pick the block that best matches its name.
These blocks look like this (don’t be scared, we’ll explain below):
User-agent: * Disallow: /
User-agent: Googlebot Disallow:
User-agent: bingbot Disallow: /not-for-bing/
Directives like Allow and Disallow should not be case-sensitive, so it’s up to you to write them in lowercase or capitalize them. The values are case-sensitive, so /photo/ is not the same as /Photo/. We like capitalizing directives because it makes the file easier (for humans) to read.
The user-agent directive
The first bit of every block of directives is the user-agent, which identifies a specific spider. The user-agent field matches with that specific spider’s (usually longer) user-agent, so, for instance, the most common spider from Google has the following user-agent:
If you want to tell this crawler what to do, a relatively simple User-agent: Googlebot line will do the trick.
Most search engines have multiple spiders. They will use a specific spider for their normal index, ad programs, images, videos, etc.
Search engines always choose the most specific block of directives they can find. Say you have three sets of directives: one for *, one for Googlebot and one for Googlebot-News. If a bot comes by whose user-agent is Googlebot-Video, it will follow the Googlebot restrictions. A bot with the user-agent Googlebot-News would use more specific Googlebot-News directives.
The most common user agents for search engine spiders
Here’s a list of the user-agents you can use in your robots.txt file to match the most commonly used search engines:
Search engine
Field
User-agent
Baidu
General
baiduspider
Baidu
Images
baiduspider-image
Baidu
Mobile
baiduspider-mobile
Baidu
News
baiduspider-news
Baidu
Video
baiduspider-video
Bing
General
bingbot
Bing
General
msnbot
Bing
Images & Video
msnbot-media
Bing
Ads
adidxbot
Google
General
Googlebot
Google
Images
Googlebot-Image
Google
Mobile
Googlebot-Mobile
Google
News
Googlebot-News
Google
Video
Googlebot-Video
Google
Ecommerce
Storebot-Google
Google
AdSense
Mediapartners-Google
Google
AdWords
AdsBot-Google
Yahoo!
General
slurp
Yandex
General
yandex
The disallow directive
The second line in any block of directives is the Disallow line. You can have one or more of these lines, specifying which parts of the site the specified spider can’t access. An empty Disallow line means you’re not disallowing anything so that a spider can access all sections of your site.
The example below would block all search engines that “listen” to robots.txt from crawling your site.
User-agent: * Disallow: /
The example below would allow all search engines to crawl your site by dropping a single character.
User-agent: * Disallow:
The example below would block Google from crawling the Photo directory on your site – and everything in it.
User-agent: googlebot Disallow: /Photo
This means all the subdirectories of the /Photo directory would also not be spidered. It would not block Google from crawling the /photo directory, as these lines are case-sensitive.
This would also block Google from accessing URLs containing /Photo, such as /Photography/.
How to use wildcards/regular expressions
“Officially,” the robots.txt standard doesn’t support regular expressions or wildcards; however, all major search engines understand it. This means you can use lines like this to block groups of files:
In the example above, * is expanded to whatever filename it matches. Note that the rest of the line is still case-sensitive, so the second line above will not block a file called /copyrighted-images/example.JPG from being crawled.
Some search engines, like Google, allow for more complicated regular expressions but be aware that other search engines might not understand this logic. The most useful feature this adds is the $, which indicates the end of a URL. In the following example, you can see what this does:
Disallow: /*.php$
This means /index.php can’t be indexed, but /index.php?p=1could be. Of course, this is only useful in very specific circumstances and pretty dangerous: it’s easy to unblock things you didn’t want to.
Non-standard robots.txt crawl directives
In addition to the commonly used Disallow and User-agent directives, there are a few other crawl directives available for robots.txt files. However, it’s important to note that not all search engine crawlers support these directives, so it’s essential to understand their limitations and considerations before implementing them.
The allow directive
While not in the original “specification,” there was early talk of an allow directive. Most search engines seem to understand it, and it allows for simple and very readable directives like this:
The only other way of achieving the same result without an allow directive, would have been to specifically disallow every single file in the wp-admin folder.
The crawl-delay directive
Crawl-delay is an unofficial addition to the standard, and few search engines adhere to it. At least Google and Yandex don’t use it, with Bing being unclear. In theory, as crawlers can be pretty crawl-hungry, you could try the crawl-delay direction to slow them down.
A line like the one below would instruct those search engines to change how frequently they’ll request pages on your site.
crawl-delay: 10
Do take care when using the crawl-delay directive. By setting a crawl delay of ten seconds, you only allow these search engines to access 8,640 pages a day. This might seem plenty for a small site, but it isn’t much for large sites. On the other hand, if you get next to no traffic from these search engines, it might be a good way to save some bandwidth.
The sitemap directive for XML Sitemaps
Using the sitemap directive, you can tell search engines – Bing, Yandex, and Google – where to find your XML sitemap. You can, of course, submit your XML sitemaps to each search engine using their webmaster tools. We strongly recommend you do so because webmaster tools will give you a ton of information about your site. If you don’t want to do that, adding a sitemap line to your robots.txt is a quick alternative. Yoast SEO automatically adds a link to your sitemap if you let it generate a robots.txt file. On an existing robots.txt file, you can add the rule by hand via the file editor in the Tools section.
Sitemap: https://www.example.com/my-sitemap.xml
Don’t block CSS and JS files in robots.txt
Since 2015, Google Search Console has warned site owners not to block CSS and JS files. We’ve told you the same thing for ages: don’t block CSS and JS files in your robots.txt. Let us explain why you shouldn’t block these specific files from Googlebot.
By blocking CSS and JavaScript files, you’re preventing Google from checking if your website works correctly. If you block CSS and JavaScript files in yourrobots.txt file, Google can’t render your website as intended. Now, Google can’t understand your website, which might result in lower rankings. Moreover, even tools like Ahrefs render web pages and execute JavaScript. So, don’t block JavaScript if you want your favorite SEO tools to work.
This aligns perfectly with the general assumption that Google has become more “human.” Google wants to see your website like a human visitor would, so it can distinguish the main elements from the extras. Google wants to know if JavaScript enhances the user experience or ruins it.
Test and fix in Google Search Console
Google helps you find and fix issues with your robots.txt, for instance, in the Page Indexing section in Google Search Console. Select the Blocked by robots.txt option:
Check Search Console to see which URLs are blocked by your robots.txt
Unblocking blocked resources comes down to changing your robots.txt file. You need to set that file up so that it doesn’t disallow Google to access your site’s CSS and JavaScript files anymore. If you’re on WordPress and use Yoast SEO, you can do this directly with our Yoast SEO plugin.
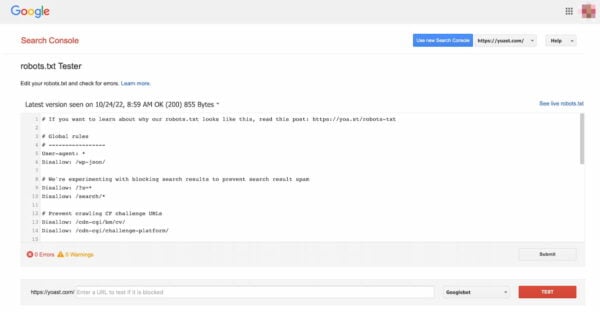
Validate your robots.txt
Various tools can help you validate your robots.txt, but we always prefer to go to the source when validating crawl directives. Google has a robots.txt testing tool in its Google Search Console (under the ‘Old version’ menu), and we’d highly recommend using that:
Testing a robots.txt file in Google Search Console
Be sure to test your changes thoroughly before you put them live! You wouldn’t be the first to accidentally use robots.txt to block your entire site and slip into search engine oblivion!
Behind the scenes of a robots.txt parser
In 2019, Google announced they were making their robots.txt parser open source. If you want to get into the nuts and bolts, you can see how their code works (and even use it yourself or propose modifications).
Joost de Valk
Joost de Valk is an internet entrepreneur and the founder of Yoast. After the sale of Yoast to Newfold Digital in 2021 he has stopped being active in 2023. Joost, together with his wife Marieke, actively invests in and advises several startups through their company Emilia Capital.
Bots have become an integral part of the digital space today. They help us order groceries, play music on our Slack channel, and pay our colleagues back for the delicious smoothies they bought us. Bots also populate the internet to carry out the functions they’re designed for. But what does this mean for website owners? And (perhaps more importantly) what does this mean for the environment? Read on to find out what you need to know about bot traffic and why you should care about it!
Table of contents
What is a bot?
Let’s start with the basics: A bot is a software application designed to perform automated tasks over the internet. Bots can imitate or even replace the behavior of a real user. They’re very good at executing repetitive and mundane tasks. They’re also swift and efficient, which makes them a perfect choice if you need to do something on a large scale.
What is bot traffic?
Bot traffic refers to any non-human traffic to a website or app. Which is a very normal thing on the internet. If you own a website, it’s very likely that you’ve been visited by a bot. As a matter of fact, bot traffic accounts for almost 30% of all internet traffic at the moment.
Is bot traffic bad?
You’ve probably heard that bot traffic is bad for your site. And in many cases, that’s true. But there are good and legitimate bots too. It depends on the purpose of the bots and the intention of their creators. Some bots are essential for operating digital services like search engines or personal assistants. However, some bots want to brute-force their way into your website and steal sensitive information. So, which bots are ‘good’ and which ones are ‘bad’? Let’s dive a bit deeper into this topic.
The ‘good’ bots
‘Good’ bots perform tasks that do not cause harm to your website or server. They announce themselves and let you know what they do on your website. The most popular ‘good’ bots are search engine crawlers. Without crawlers visiting your website to discover content, search engines have no way to serve you information when you’re searching for something. So when we talk about ‘good’ bot traffic, we’re talking about these bots.
Other than search engine crawlers, some other good internet bots include:
SEO crawlers: If you’re in the SEO space, you’ve probably used tools like Semrush or Ahrefs to do keyword research or gain insight into competitors. For those tools to serve you information, they also need to send out bots to crawl the web and gather data.
Commercial bots: Commercial companies send these bots to crawl the web to gather information. For instance, research companies use them to monitor news on the market; ad networks need them to monitor and optimize display ads; ‘coupon’ websites gather discount codes and sales programs to serve users on their websites.
Site-monitoring bots: They help you monitor your website’s uptime and other metrics. They periodically check and report data, such as your server status and uptime duration. This allows you to take action when something’s wrong with your site.
Feed/aggregator bots: They collect and combine newsworthy content to deliver to your site visitors or email subscribers.
The ‘bad’ bots
‘Bad’ bots are created with malicious intentions in mind. You’ve probably seen spam bots that spam your website with nonsense comments, irrelevant backlinks, and atrocious advertisements. And maybe you’ve also heard of bots that take people’s spots in online raffles, or bots that buy out the good seats in concerts.
It’s due to these malicious bots that bot traffic gets a bad reputation, and rightly so. Unfortunately, a significant amount of bad bots populate the internet nowadays.
Here are some bots you don’t want on your site:
Email scrapers: They harvest email addresses and send malicious emails to those contacts.
Comment spam bots: Spam your website with comments and links that redirect people to a malicious website. In many cases, they spam your website to advertise or to try to get backlinks to their sites.
Scrapers bots: These bots come to your website and download everything they can find. That can include your text, images, HTML files, and even videos. Bot operators will then re-use your content without permission.
Bots for credential stuffing or brute force attacks: These bots will try to gain access to your website to steal sensitive information. They do this by trying to log in like a real user.
Botnet, zombie computers: They are networks of infected devices used to perform DDoS attacks. DDoS stands for distributed denial-of-service. During a DDoS attack, the attacker uses such a network of devices to flood a website with bot traffic. This overwhelms your web server with requests, resulting in a slow or unusable website.
Inventory andticket bots: They go to websites to buy up tickets for entertainment events or to bulk purchase newly-released products. Brokers use them to resell tickets or products at a higher price to make profits.
Why you should care about bot traffic
Now that you’ve got some knowledge about bot traffic, let’s talk about why you should care.
For your website performance
Malicious bot traffic strains your web server and sometimes even overloads it. These bots take up your server bandwidth with their requests, making your website slow or utterly inaccessible in case of a DDoS attack. In the meantime, you might have lost traffic and sales to other competitors.
In addition, malicious bots disguise themselves as regular human traffic, so they might not be visible when you check your website statistics. The result? You might see random spikes in traffic but don’t understand why. Or, you might be confused as to why you receive traffic but no conversion. As you can imagine, this can potentially hurt your business decisions because you don’t have the correct data.
For your site security
Malicious bots are also bad for your site’s security. They will try to brute force their way into your website using various username/password combinations, or seek out weak entry points and report to their operators. If you have security vulnerabilities, these malicious players might even attempt to install viruses on your website and spread those to your users. And if you own an online store, you will have to manage sensitive information like credit card details that hackers would love to steal.
For the environment
Did you know that bot traffic affects the environment? When a bot visits your site, it makes an HTTP request to your server asking for information. Your server needs to respond, then return the necessary information. Whenever this happens, your server must spend a small amount of energy to complete the request. Now, consider how many bots there are on the internet. You can probably imagine that the amount of energy spent on bot traffic is enormous!
In this sense, it doesn’t matter if a good or bad bot visits your site. The process is still the same. Both use energy to perform their tasks, and both have consequences on the environment.
Even though search engines are an essential part of the internet, they’re guilty of being wasteful too. They can visit your site too many times, and not even pick up the right changes. We recommend checking your server log to see how many times crawlers and bots visit your site. Additionally, there’s a crawl stats report in Google Search Console that also tells you how many times Google crawls your site. You might be surprised by some numbers there.
A small case study from Yoast
Let’s take Yoast, for instance. On any given day, Google crawlers can visit our website 10,000 times. It might seem reasonable to visit us a lot, but they only crawl 4,500 unique URLs. That means energy was used on crawling the duplicate URLs over and over. Even though we regularly publish and update our website content, we probably don’t need all those crawls. These crawls aren’t just for pages; crawlers also go through our images, CSS, JavaScript, etc.
But that’s not all. Google bots aren’t the only ones visiting us. There are bots from other search engines, digital services, and even bad bots too. Such unnecessary bot traffic strains our website server and wastes energy that could otherwise be used for other valuable activities.
Statistic on the crawl behaviors of Google crawlers on Yoast.com in a day
What can you do against ‘bad’ bots?
You can try to detect bad bots and block them from entering your site. This will save you a lot of bandwidth and reduce strain on your server, which in turn helps to save energy. The most basic way to do this is to block an individual or an entire range of IP addresses. You should block an IP address if you identify irregular traffic from that source. This approach works, but it’s labor-intensive and time-consuming.
Alternatively, you can use a bot management solution from providers like Cloudflare. These companies have an extensive database of good and bad bots. They also use AI and machine learning to detect malicious bots, and block them before they can cause harm to your site.
Security plugins
Additionally, you should install a security plugin if you’re running a WordPress website. Some of the more popular security plugins (like Sucuri Security or Wordfence) are maintained by companies that employ security researchers who monitor and patch issues. Some security plugins automatically block specific ‘bad’ bots for you. Others let you see where unusual traffic comes from, then let you decide how to deal with that traffic.
What about the ‘good’ bots?
As we mentioned earlier, ‘good’ bots are good because they’re essential and transparent in what they do. But they can still consume a lot of energy. Not to mention, these bots might not even be helpful for you. Even though what they do is considered ‘good’, they could still be disadvantageous to your website and the environment. So, what can you do for the good bots?
1. Block them if they’re not useful
You have to decide whether or not you want these ‘good’ bots to crawl your site. Does them crawling your site benefit you? More specifically: Does them crawling your site benefit you more than the cost to your servers, their servers, and the environment?
Let’s take search engine bots, for instance. Google is not the only search engine out there. It’s most likely that crawlers from other search engines have visited you as well. What if a search engine has crawled your site 500 times today, while only bringing you ten visitors? Is that still useful? If this is the case, you should consider blocking them, since you don’t get much value from this search engine anyway.
2. Limit the crawl rate
If bots support the crawl-delay in robots.txt, you should try to limit their crawl rate. This way, they won’t come back every 20 seconds to crawl the same links over and over. Because let’s be honest, you probably don’t update your website’s content 100 times on any given day. Even if you have a larger website.
You should play with the crawl rate, and monitor its effect on your website. Start with a slight delay, then increase the number when you’re sure it doesn’t have negative consequences. Plus, you can assign a specific crawl delay rate for crawlers from different sources. Unfortunately, Google doesn’t support craw delay, so you can’t use this for Google bots.
3. Help them crawl more efficiently
There are a lot of places on your website where crawlers have no business coming. Your internal search results, for instance. That’s why you should block their access via robots.txt. This not only saves energy, but also helps to optimize your crawl budget.
Next, you can help bots crawl your site better by removing unnecessary links that your CMS and plugins automatically create. For instance, WordPress automatically creates an RSS feed for your website comments. This RSS feed has a link, but hardly anybody looks at it anyway, especially if you don’t have a lot of comments. Therefore, the existence of this RSS feed might not bring you any value. It just creates another link for crawlers to crawl repeatedly, wasting energy in the process.
Optimize your website crawl with Yoast SEO
Yoast SEO has a useful and sustainable new setting: the crawl optimization settings! With over 20 available toggles, you’ll be able to turn off the unnecessary things that WordPress automatically adds to your site. You can see the crawl settings as a way to easily clean up your site of unwanted overhead. For example, you have the option to clean up the internal site search of your site to prevent SEO spam attacks!
Even if you’ve only started using the crawl optimization settings today, you’re already helping the environment!
Do you want to outrank your competition? Then basic knowledge of technical SEO is a must. Of course, you also need to create great and relevant content for your site. Luckily, the Yoast SEO plugin takes care of (almost) everything on your WordPress site. Still, it’s good to understand one of the most important concepts of technical SEO: crawlability.
What is the crawler again?
A search engine like Google consists of three things: a crawler, an index, and an algorithm. A crawler follows the links on the web. It does this 24/7! Once a crawler comes to a website, it saves the HTML version in a gigantic database called the index. This index is updated every time the crawler comes around your website, and finds a new or revised version of it. Depending on how important Google deems your site and the number of changes you make on your website, the crawler comes around more or less often.
Fun fact: A crawler is also called a robot, a bot, or a spider! And Google’s crawler is sometimes referred to as Googlebot.
Crawlability has to do with the possibilities Google has to crawl your website. Luckily, you can block crawlers on your site. If your website or a page on your website is blocked, you’re saying to Google’s crawler: “Do not come here.” As a result, your site or the respective page won’t turn up in the search results. At least, in most cases.
So how do you block crawlers? There are a few things that could prevent Google from crawling (or indexing) your website:
If your robots.txt file blocks the crawler, Google will not come to your website or specific web page.
Before crawling your website, the crawler will take a look at the HTTP header of your page. This HTTP header contains a status code. If this status code says that a page doesn’t exist, Google won’t crawl your website. Want to know more? We’ll explain all about this HTTP header tip in the module of our Technical SEO training!
If the robots meta tag on a specific page blocks the search engine from indexing that page, Google will crawl that page, but won’t add it to its index.
How crawlers impact the environment
Yes, you read that right. Crawlers have a substantial impact on the environment. Here’s how: Crawlers can come to your site multiple times a day. Why? They want to discover new content, or check if there are any new updates. And every time they visit our site, they will crawleverything that looks like a URL to them. This means a URL is often crawled multiple times per day.
This is unnecessary, because you’re unlikely to make multiple changes on a URL on any given day. Not to mention, almost every CMS output URLs that don’t make sense that crawlers can safely skip. But instead of skipping these URLs, crawlers will crawl them, again and again, every time they come across one. All this unnecessary crawling takes up tons of energy resources which is harmful for our planet.
Improve your site’s crawlability with Yoast SEO Premium
To ensure you’re not wasting energy, it’s important to stay on top of your site’s crawlability settings. Luckily, you don’t have to do all the work yourself. Using tools such as Yoast SEO Premium will make it easier for you!
So how does it work? We have a crawl settings feature that removes unnecessary URLs, feeds, and assets from your website. This will make crawlers crawl your website more efficiently. Don’t worry, you’re still in control! Because the feature also allows you to decide per type of asset whether you want to actually remove the URL or not. If you want to know more, we’ll explain all about the crawl settings here.
Want to learn more about crawlability?
Although crawlability is a basic part of technical SEO (it has to do with all the things that enable Google to index your site), it’s already pretty advanced stuff for most people. Still, it’s important that you understand what crawlability is. You might be blocking – perhaps even without knowing! – crawlers from your site, which means you’ll never rank high in Google. So, if you’re serious about SEO, crawlability should matter to you.
An easy way to learn is by doing our technical SEO trainings. These SEO courses will teach you how to detect technical SEO issues and solve them (with our Yoast SEO plugin). We also have a training dedicated to crawlability and indexability! Good to know for Premium users: Yoast SEO Academy is already included at no extra cost in your Premium subscription!
Marieke is the head of strategy at Yoast and founder of Yoast SEO academy. She loves coming up with new ideas and products to make SEO attainable for everyone, and ensure a healthy growth for Yoast!
If you own a website or are thinking of creating one, you should be mindful about your ecological footprint. Because the tech industry plays a big role in the current climate crisis. With its data centers, large manufacturing operations, and huge amounts of e-waste, it’s accountable for nearly 4% of global CO2 emissions. Which, shockingly enough, is similar to the travel industry. And this number is only growing! So, what can you do to make your website greener?
Nowadays, everyone owns at least one digital device. Most of us own many. And the number continues to rise. According to Cisco’s Annual Internet Report, we will own 29.3 billion networked devices in 2023, which is a ridiculous amount of products that need to be manufactured.
And the factories needed to produce our devices don’t just negatively impact the environment because of their gas emissions. Factors such as land degradation, biodiversity loss, and water consumption also play a role. For example, the industry uses 12,760 liters of water (which is 3,190 gallons) to produce just one smartphone.
The rise of data centers
The story only gets bleaker when we look at data centers. Because the more digital devices we use, the higher our global data traffic will be. In order to keep up with this traffic, new data centers are being built and expanded every year. And though they currently only consume 1% of the world’s electricity, it’s expected that data centers will consume about 20% in 2025. Which isn’t all that strange, if you consider that there are currently 8000 data centers in the world.
It’s time to take action
Climate change is a serious threat. If we don’t want our world to become uninhabitable in a few years, we should take action. Luckily, there are multiple things you can do to improve your website’s carbon footprint. Before you get started, it’s good to check how green your website is now. You can use an online carbon footprint calculator, like Website Carbon Calculator.
Save energy by blocking bad bots
This is a big one. As we mentioned before, bots also spend energy as they crawl your site. And they crawl your site many times a day, and often when there is no need. So many, in fact, that bots make up around 30% of the daily internet traffic!
That’s why you should identify unnecessary bots and block them from your site, so when they request your server, your server won’t answer. You’ll be saving energy. You can block bad bots by blocking the individual or entire range of IPs where the unusual traffic comes from. Or you can use a bot management solution like Cloudflare.
Reduce bot traffic
What about the bots you don’t want to block? It is still useful to reduce their traffic. For example, on any given day, Google crawlers can visit the Yoast website 10,000 times. During these visits, they only crawl 4,500 unique URLs, meaning that a lot of energy gets wasted on crawling duplicate URLs.
And it’s not just Google bots that are visiting us. There are bots from other search engines, digital services, commercial bots, etc. And we don’t want to waste that much energy! That’s why we created the crawl optimization feature, which removes unnecessary URLs, feeds, and assets from your WordPress site. This helps bots crawl your site more efficiently and reduce their visits. In other words: You’re saving energy!
Green host, green website
You can also take control over your website’s carbon footprint by choosing the right hosting provider. Because 48% of the total energy that’s used by the internet (and your website) is used in a data center. So if you choose a hosting provider that actively purchases renewable energy for their data centers, you’ll have far lower carbon emissions.
Don’t be like GameSpot
With all these steps to make your website greener, it’s a surprise that many large companies still have ‘dirty’ sites. Take GameSpot for example, which is a news site about video games. GameSpot produced the most CO2 per visit last year. They also ranked second-to-last for the energy they produce per year, which is more than 550,000 grams of CO2. Meaning: It would take 26 trees an entire year to compensate for the carbon emitted by the GameSpot website.
GameSpot homepage
Example of a green site
Now that we’ve discussed the ‘dirtiest’ site, let’s look at the cleanest and greenest: Google. They only produce 5,480 grams per year. Which isn’t surprising when you consider their net-zero target in 2030. Google’s sustainability efforts range from machine learning to help cool data centers to smart thermostats that conserve home energy. And with their eco-routing in Google Maps, which gives users the route with the lowest carbon footprint, Google has reduced greenhouse gas emissions by more than 500,000 metric tons. Which is the equivalent of getting 100,000 fuel-burning cars off the road.
Google homepage
Final thoughts: Start now!
Our advice? Start now. Because the longer it takes to cut down on greenhouse gas emissions, the more damage we’re doing to our environment. That’s why Yoast introduced the crawl optimization feature. Because we also want to contribute to Google’s net-zero goal. So use our plugin to make your website greener, and do whatever else you can, no matter how small. Because small actionscan have a big impact.
Sam Alderson is a digital native with an analog heart, and a passion for all things marketing. They’ve a particular interest in social media. They believe it’s a fantastic way to communicate your brand’s story and values while having fun at the same time. And the more human you can make it, the more connections you’ll make.
Today, we’re very excited to be releasing Yoast SEO 20.4. With this release, we’re bringing our crawl optimization feature to Yoast SEO Free. With this feature, you can improve your SEO and reduce your carbon footprint with just a few clicks. This blog post will tell you about this feature and why we’ve brought it to Yoast SEO.
Before we explain this Yoast SEO feature, it’s good to start with a quick reminder of what crawling is. Search engines like Google or Bing use crawlers, also known as bots, to find your website, read it and save its content to their index. They go around the internet 24/7 to ensure the content saved in its index is as up-to-date as possible. Depending on the number of changes you make on your website and how important search engines deem your site, the crawler comes around more or less often.
That’s nice, but did you know crawlers do an incredible amount of unnecessary crawling?
Let’s reduce unnecessary crawling
As you can imagine, search engine crawlers don’t just visit your website but every single one they can find. The incredible number of websites out there keeps them quite busy. In fact, bots are responsible for around 30% of all web traffic. This uses lots of electricity, and a lot of that crawling isn’t necessary at all. This is where our crawl optimization feature comes in. With just a few simple changes, you can tell search engines like Google which pages or website elements they can skip — making it easier to visit the right pages on your website while reducing the energy wasted on unnecessary bot traffic.
You might be wondering why we want to help you reduce the energy consumption of your website. Does it make that much of a difference? The answer is yes! Regardless of the size of your website, the fact is that your website has a carbon footprint. Internet usage and digital technology are two massive players in pollution and energy consumption.
Every interaction on your website results in electricity being used. For instance, when someone visits your website, their browser needs to make an HTTP request to your server, and that server needs to return the necessary information. On the other side, the browser also needs the power to process data and present the page to the visitor. The energy needed to complete these requests might be small, but it adds up when you consider all the interactions on your website. Similar to when a visitor lands on your site, crawlers or bots also make these requests to your server that cost energy. Considering the amount of bot traffic (30% of web traffic), reducing the number of irrelevant pages and other resources crawled by search engines is worth it.
Take control of what’s being crawled
The crawl optimization feature in Yoast SEO lets you turn off crawling for certain types of URLs, scripts, and metadata that WordPress automatically adds. This makes it possible to improve your SEO and reduce your carbon footprint with just a few clicks.
Check out this fun animation to get an idea of what this feature can do for your website:
The crawl optimization feature was already part of Yoast SEO Premium, but today we’re also bringing it to the free version of our plugin. We do this to make as much of an impact as possible. There are over 13 million Yoast SEO users, so if everyone’s website crawling is optimized, we can have an enormous impact!
How to use the crawl optimization feature
How do you get started with crawl optimization for your website? Just go to Yoast SEO > Settings > Advanced > Crawl optimization. Here you will find an overview of all the types of metadata, content formats, etc., that you can tell search engines not to crawl. You can use the toggles on the right to enable crawl optimization.
Screenshot of the Crawl optimization section in Yoast SEO settings
The crawl optimization settings in Yoast SEO 20.4 allow you to:
Remove unwanted metadata: WordPress adds a lot of links and content to your site’s and HTTP headers. For most websites, you can safely disable these, making your site faster and more efficient.
Disable unwanted content formats: For every post, page, and category on your site, WordPress creates multiple types of feeds; content formats designed to be consumed by crawlers and machines. But most of these are outdated, and many websites won’t need to support them. Disable the formats you’re not actively using to improve your site’s efficiency.
Remove unused resources: WordPress loads countless resources, some of which your site might not need. Removing these can speed up your site and save energy if you’re not using them.
Internal site search cleanup: Your internal site search can create many confusing URLs for search engines and can even be used by SEO spammers to attack your site. This feature identifies some common spam patterns and stops them in their tracks. Most sites will benefit from experimenting with these optimizations, even if your theme doesn’t have a search feature.
Advanced: URL cleanup: Users and search engines may often request your URLs using query parameters, like ?color=red. These can help track, filter, and power advanced functionality – but they come at a performance and SEO ‘cost.’ Sites that don’t rely on URL parameters might benefit from these options. Important note: These are expert features, so ensure you know what you’re doing before removing the parameters.
That’s it for now. Make sure to update to Yoast SEO 20.4 and optimize your website’s crawling immediately! It’s not only better for your website, your site visitors, and search engines. It also has a positive impact on our environment. Especially when you realize how many we are, if all 13 million of us optimize the crawling on our website, we can reduce the amount of energy used by a ridiculous amount. So let’s start right now!
In this post, we’ll go into the basics of technical SEO. Now, discussing the basics of technical SEO might seem like a contradiction in terms. Nevertheless, some basic knowledge about the more technical side of SEO can mean the difference between a high-ranking site and a site that doesn’t rank at all. Technical SEO isn’t easy, but we’ll explain – in layman’s language – which aspects you should (ask your developer to) pay attention to when working on the technical foundation of your website.
What is technical SEO?
Technical SEO is all about improving the technical aspects of a website in order to increase the ranking of its pages in the search engines. Making a website faster, easier to crawl, and more understandable for search engines are the pillars of technical optimization. Technical SEO is part of on-page SEO, which focuses on improving elements on your website to get higher rankings. It’s the opposite of off-page SEO, which is about generating exposure for a website through other channels.
Why should you optimize your site technically?
Google and other search engines want to present their users with the best possible results for their queries. Therefore, Google’s robots crawl and evaluate web pages on a multitude of factors. Some factors are based on the user’s experience, like how fast a page loads. Other factors help search engine robots grasp what your pages are about. This is what, among others, structured data does. So, by improving technical aspects, you help search engines crawl and understand your site. If you do this well, you might be rewarded with higher rankings. Or even earn yourself some rich results!
It also works the other way around: if you make serious technical mistakes on your site, they can cost you. You wouldn’t be the first to block search engines entirely from crawling your site by accidentally adding a trailing slash in the wrong place in your robots.txt file.
But don’t think you should focus on the technical details of a website just to please search engines. A website should work well – be fast, clear, and easy to use – for your users in the first place. Fortunately, creating a strong technical foundation often coincides with a better experience for both users and search engines.
What are the characteristics of a technically optimized website?
A technically sound website is fast for users and easy to crawl for search engine robots. A proper technical setup helps search engines to understand what a site is about. It also prevents confusion caused by, for instance, duplicate content. Moreover, it doesn’t send visitors, nor search engines, to dead-ends caused by non-working links. Here, we’ll shortly go into some important characteristics of a technically optimized website.
1. It’s fast
Nowadays, web pages need to load fast. People are impatient and don’t want to wait for a page to open. In 2016 already, research showed that 53% of mobile website visitors will leave if a webpage doesn’t open within three seconds. And the trend hasn’t gone away – research from 2022 suggests ecommerce conversion rates drop by roughly 0.3% for every extra second it takes for a page to load. So if your website is slow, people get frustrated and move on to another website, and you’ll miss out on all that traffic.
Google knows slow web pages offer a less than optimal experience. Therefore they prefer web pages that load faster. So, a slow web page also ends up further down the search results than its faster equivalent, resulting in even less traffic. Since 2021, Page experience (how fast people experience a web page to be) has officially become a Google ranking factor. So having pages that load quickly enough is more important now than ever.
Search engines use robots to crawl, or spider, your website. The robots follow links to discover content on your site. A great internal linking structure will make sure that they’ll understand what the most important content on your site is.
But there are more ways to guide robots. You can, for instance, block them from crawling certain content if you don’t want them to go there. You can also let them crawl a page, but tell them not to show this page in the search results or not to follow the links on that page.
Robots.txt file
You can give robots directions on your site by using the robots.txt file. It’s a powerful tool, which should be handled carefully. As we mentioned in the beginning, a small mistake might prevent robots from crawling (important parts of) your site. Sometimes, people unintentionally block their site’s CSS and JS files in the robots.txt file. These files contain code that tells browsers what your site should look like and how it works. If those files are blocked, search engines can’t find out if your site works properly.
All in all, we recommend to really dive into robots.txt if you want to learn how it works. Or, perhaps even better, let a developer handle it for you!
The meta robots tag
The robots meta tag is a piece of code that you won’t see on the page as a visitor. It’s in the source code in the so-called head section of a page. Robots read this section when finding a page. In it, they’ll discover information about what they’ll find on the page or what they need to do with it.
If you want search engine robots to crawl a page, but to keep it out of the search results for some reason, you can tell them with the robots meta tag. With the robots meta tag, you can also instruct them to crawl a page, but not to follow the links on the page. With Yoast SEO it’s easy to noindex or nofollow a post or page. Learn for which pages you’d want to do that.
We’ve discussed that slow websites are frustrating. What might be even more annoying for visitors than a slow page, is landing on a page that doesn’t exist at all. If a link leads to a non-existing page on your site, people will encounter a 404 error page. There goes your carefully crafted user experience!
What’s more, search engines don’t like to find these error pages either. And, they tend to find even more dead links than visitors encounter because they follow every link they bump into, even if it’s hidden.
Unfortunately, most sites have (at least some) dead links, because a website is a continuous work in progress: people make things and break things. Fortunately, there are tools that can help you retrieve dead links on your site. Read about those tools and how to solve 404 errors.
To prevent unnecessary dead links, you should always redirect the URL of a page when you delete it or move it. Ideally, you’d redirect it to a page that replaces the old page. With Yoast SEO Premium, you can easily make redirects yourself. No need for a developer!
4. It doesn’t confuse search engines with duplicate content
If you have the same content on multiple pages of your site – or even on other sites – search engines might get confused. Because, if these pages show the same content, which one should they rank highest? As a result, they might give all pages with the same content a lower ranking.
Unfortunately, you might have duplicate content issues without even knowing it. Because of technical reasons, different URLs can show the same content. For a visitor, this doesn’t make any difference, but for a search engine it does; it’ll see the same content on a different URL.
Luckily, there’s a technical solution to this issue. With the so-called canonical link element, you can indicate what the original page – or the page you’d like to rank in the search engines – is. In Yoast SEO you can easily set a canonical URL for a page. And, to make it easy for you, Yoast SEO adds self-referencing canonical links to all your pages. This will help prevent duplicate content issues that you might not even be aware of.
5. It’s secure
A technically optimized website is a secure website. Making your website safe for users to guarantee their privacy is a basic requirement nowadays. There are many things you can do to make your (WordPress) website secure, and one of the most crucial things is implementing HTTPS.
HTTPS makes sure that nobody can intercept the data that’s sent over between the browser and the site. So, for instance, if people log in to your site, their credentials are safe. You’ll need something called an SSL certificate to implement HTTPS on your site. Google acknowledges the importance of security and therefore made HTTPS a ranking signal: secure websites rank higher than unsafe equivalents.
You can easily check if your website is HTTPS in most browsers. On the left-hand side of the search bar of your browser, you’ll see a lock if it’s safe. If you see the words “not secure” you (or your developer) have some work to do!
Structured data helps search engines better understand your website, content, or even your business. With structured data you can tell search engines what kind of product you sell, or which recipes you have on your site. Plus, it will give you the opportunity to provide all kinds of details about those products or recipes.
Implementing structured data can bring you more than just a better understanding by search engines. It also makes your content eligible for rich results; those shiny results with stars or details that stand out in the search results.
7. Plus: It has an XML sitemap
Simply put, an XML sitemap is a list of all pages of your site. It serves as a roadmap for search engines on your site. With it, you’ll make sure search engines won’t miss any important content on your site. The XML sitemap is often categorized in posts, pages, tags, or other custom post types, and includes the number of images and the last modified date for every page.
Ideally, a website doesn’t need an XML sitemap. If it has an internal linking structure that connects all content nicely, robots won’t need it. However, not all sites have a great structure, and having an XML sitemap won’t do any harm. So we’d always advise having an XML site map on your site.
8. Plus: International websites use hreflang
If your site targets more than one country or multiple countries where the same language is spoken, search engines need a little help to understand which countries or languages you’re trying to reach. If you help them, they can show people the right website for their area in the search results.
Hreflang tags help you do just that. You can use them to define which country and language each page is intended to serve. This also solves a possible duplicate content problem: even if your US and UK sites show the same content, Google will know they’re written for different regions.
Optimizing international websites is quite a specialism. If you’d like to learn how to make your international sites rank, we’d advise taking a look at our Multilingual SEO training.
Want to learn more about this?
So this is what technical SEO is, in a nutshell. It’s quite a lot already, while we’ve only scratched the surface here. There’s so much more to tell about the technical side of SEO!
Want to learn more? We have a great collection of SEO training courses in Yoast SEO academy, including Structured data for beginners. Plus we’ve just added a new Technical SEO training course covering Hosting and server configuration (for WordPress), and Crawlability and indexability.
Want to learn everything? Get Yoast SEO Premium and enjoy full access to all of our training courses!
There’s more! You can also take our technical SEO fitness quiz if you want to know how fit your site’s technical SEO is. This quiz helps you figure out what you need to work on and points you in the right direction to start improving your site.