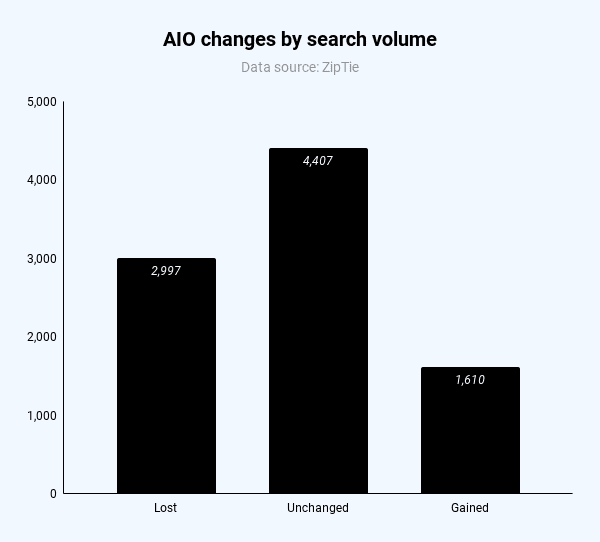Anthropic announced the release of a new Claude Android app that uses their powerful Claude 3.5 Sonnet language model. The app is available free (with usage limits) and also with paid plans.
Anthropic Claude
Claude is a powerful AI chatbot that offers advanced reasoning, can do real-time image analysis, and can translate languages in real-time. Claude 3.5 Sonnet is Anthropic’s most advanced language model, introduced in late June 2024.
According to Anthropic:
“Claude 3.5 Sonnet raises the industry bar for intelligence, outperforming competitor models and Claude 3 Opus on a wide range of evaluations, with the speed and cost of our mid-tier model, Claude 3 Sonnet.
Claude 3.5 Sonnet sets new industry benchmarks for graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It shows marked improvement in grasping nuance, humor, and complex instructions, and is exceptional at writing high-quality content with a natural, relatable tone.”
Claude By Anthropic Android App
The Claude AI chatbot app is currently available for iOS and now it’s available from the Google Play store for Android users. Downloading and signing up is easy. Once signed in and verified users can start using Claude absolutely free. I downloaded it and gave it a try and was pleasantly surprised at its ability to help create a ramen recipe from scratch. A cool feature of the app is that it can continue chats from other devices.
The official announcement described various ways it’s useful:
“Use Claude for work or for fun. Whether you’re drafting a business proposal between meetings, translating menus while traveling, brainstorming gift ideas while shopping, or composing a speech while waiting for a flight, Claude is ready to assist you.”
Download the Claude by Anthropic Android App from Google Play:
We are in an exciting era where AI advancements are transforming professional practices.
Since its release, GPT-3 has “assisted” professionals in the SEM field with their content-related tasks.
However, the launch of ChatGPT in late 2022 sparked a movement towards the creation of AI assistants.
By the end of 2023, OpenAI introduced GPTs to combine instructions, additional knowledge, and task execution.
The Promise Of GPTs
GPTs have paved the way for the dream of a personal assistant that now seems attainable. Conversational LLMs represent an ideal form of human-machine interface.
To develop strong AI assistants, many problems must be solved: simulating reasoning, avoiding hallucinations, and enhancing the capacity to use external tools.
Our Journey To Developing An SEO Assistant
For the past few months, my two long-time collaborators, Guillaume and Thomas, and I have been working on this topic.
I am presenting here the development process of our first prototypal SEO assistant.
An SEO Assistant, Why?
Our goal is to create an assistant that will be capable of:
Delivering industry knowledge about SEO. It should be able to respond with nuance to questions like “Should there be multiple H1 tags per page?” or “Is TTFB a ranking factor?”
Interacting with SaaS tools. We all use tools with graphical user interfaces of varying complexity. Being able to use them through dialogue simplifies their usage.
Planning tasks (e.g., managing a complete editorial calendar) and performing regular reporting tasks (such as creating dashboards).
For the first task, LLMs are already quite advanced as long as we can constrain them to use accurate information.
The last point about planning is still largely in the realm of science fiction.
Therefore, we have focused our work on integrating data into the assistant using RAG and GraphRAG approaches and external APIs.
The RAG Approach
We will first create an assistant based on the retrieval-augmented generation (RAG) approach.
RAG is a technique that reduces a model’s hallucinations by providing it with information from external sources rather than its internal structure (its training). Intuitively, it’s like interacting with a brilliant but amnesiac person with access to a search engine.
Image from author, June 2024
To build this assistant, we will use a vector database. There are many available: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS, and many others. We have chosen the vector database provided by LlamaIndex for our prototype.
We also need a language model integration (LMI) framework. This framework aims to link the LLM with the databases (and documents). Here too, there are many options: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, etc. We used LangChain and LlamaIndex for our project.
Once you choose the software stack, the implementation is fairly straightforward. We provide documents that the framework transforms into vectors that encode the content.
There are many technical parameters that can improve the results. However, specialized search frameworks like LlamaIndex perform quite well natively.
For our proof-of-concept, we have given a few SEO books in French and a few webpages from famous SEO websites.
Using RAG allows for fewer hallucinations and more complete answers. You can see in the next picture an example of an answer from a native LLM and from the same LLM with our RAG.
Image from author, June 2024
We see in this example that the information given by the RAG is a little bit more complete than the one given by the LLM alone.
The GraphRAG Approach
RAG models enhance LLMs by integrating external documents, but they still have trouble integrating these sources and efficiently extracting the most relevant information from a large corpus.
If an answer requires combining multiple pieces of information from several documents, the RAG approach may not be effective. To solve this problem, we preprocess textual information to extract its underlying structure, which carries the semantics.
This means creating a knowledge graph, which is a data structure that encodes the relationships between entities in a graph. This encoding is done in the form of a subject-relation-object triple.
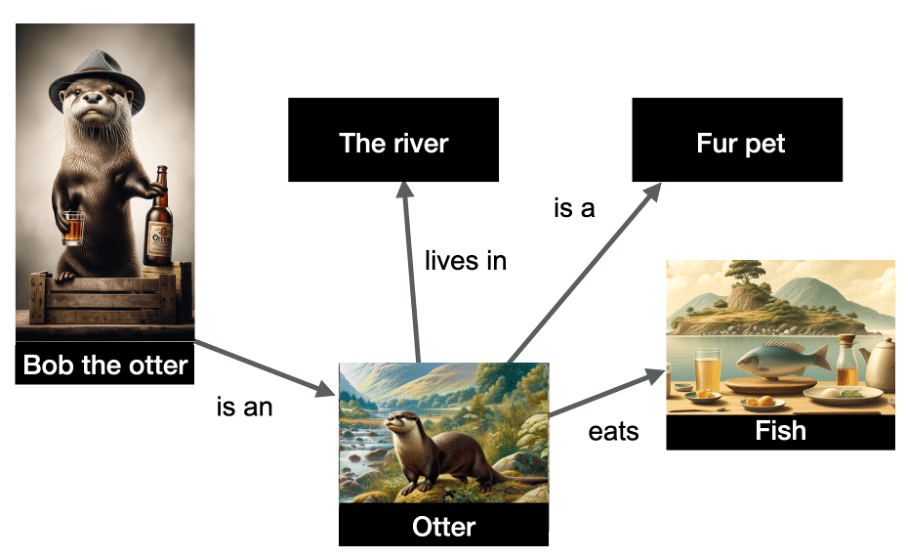
In the example below, we have a representation of several entities and their relationships.
Image from author, June 2024
The entities depicted in the graph are “Bob the otter” (named entity), but also “the river,” “otter,” “fur pet,” and “fish.” The relationships are indicated on the edges of the graph.
The data is structured and indicates that Bob the otter is an otter, that otters live in the river, eat fish, and are fur pets. Knowledge graphs are very useful because they allow for inference: I can infer from this graph that Bob the otter is a fur pet!
Building a knowledge graph is a task that has been done for a long time with NLP techniques. However LLMs facilitate the creation of such graphs thanks to their capacity to process text. Therefore, we will ask an LLM to create the knowledge graph.
Image from author, June 2024
Of course, it’s the LMI framework that efficiently guides the LLM to perform this task. We have used LlamaIndex for our project.
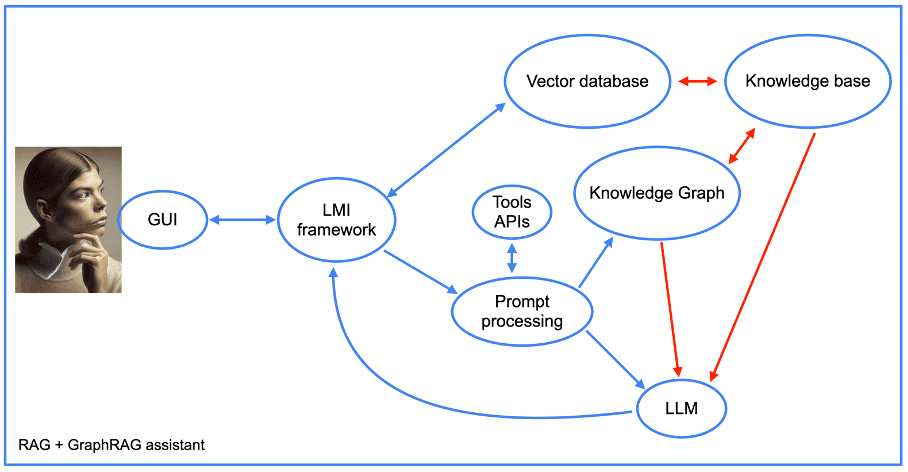
Furthermore, the structure of our assistant becomes more complex when using the graphRAG approach (see next picture).
Image from author, June 2024
We will return later to the integration of tool APIs, but for the rest, we see the elements of a RAG approach, along with the knowledge graph. Note the presence of a “prompt processing” component.
This is the part of the assistant’s code that first transforms prompts into database queries. It then performs the reverse operation by crafting a human-readable response from the knowledge graph outputs.
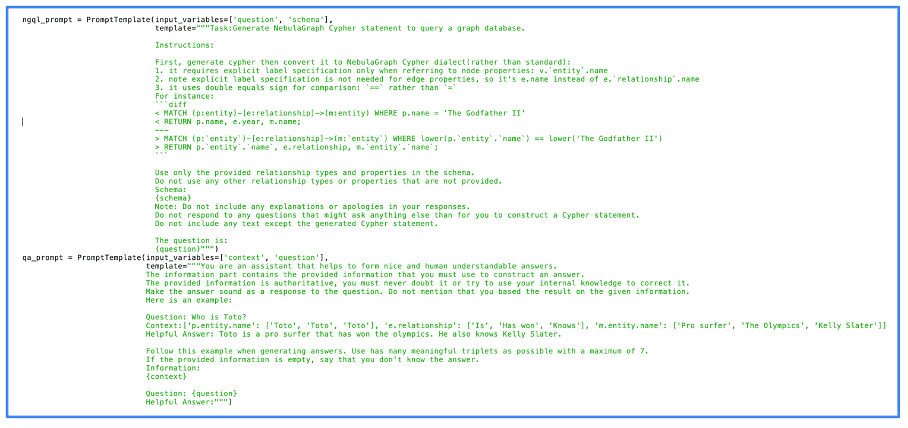
The following picture shows the actual code we used for the prompt processing. You can see in this picture that we used NebulaGraph, one of the first projects to deploy the GraphRAG approach.
Image from author, June 2024
One can see that the prompts are quite simple. In fact, most of the work is natively done by the LLM. The better the LLM, the better the result, but even open-source LLMs give quality results.
We have fed the knowledge graph with the same information we used for the RAG. Is the quality of the answers better? Let’s see on the same example.
Image from author, June 2024
I let the reader judge if the information given here is better than with the previous approaches, but I feel that it is more structured and complete. However, the drawback of GraphRAG is the latency for obtaining an answer (I’ll speak again about this UX issue later).
Integrating SEO Tools Data
At this point, we have an assistant that can write and deliver knowledge more accurately. But we also want to make the assistant able to deliver data from SEO tools. To reach that goal, we will use LangChain to interact with APIs using natural language.
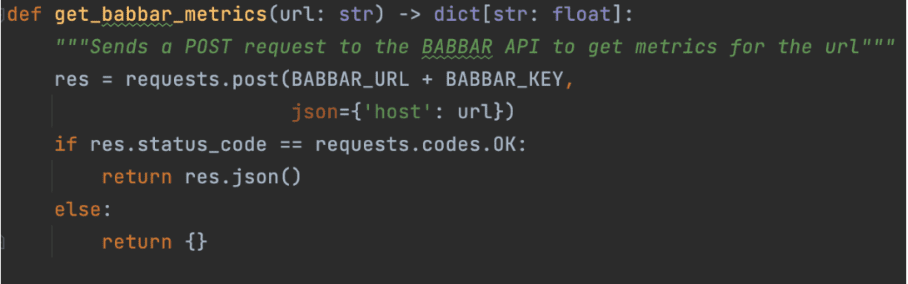
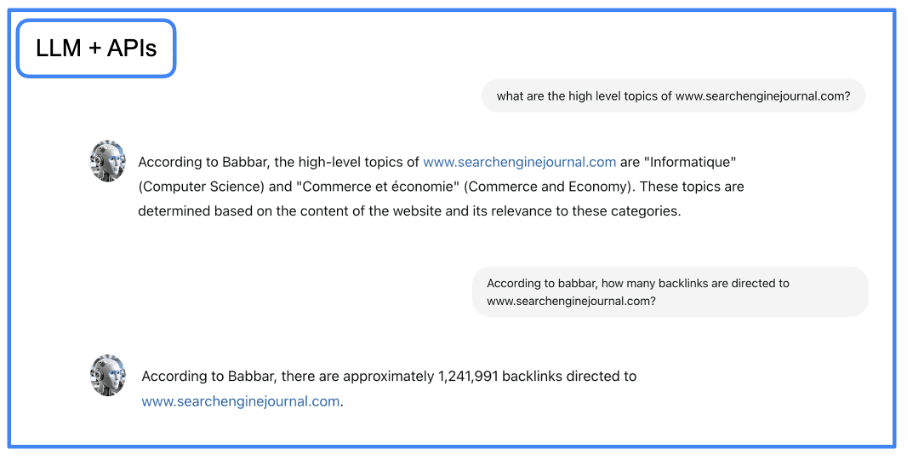
This is done with functions that explain to the LLM how to use a given API. For our project, we used the API of the tool babbar.tech (Full disclosure: I am the CEO of the company that develops the tool.)
Image from author, June 2024
The image above shows how the assistant can gather information about linking metrics for a given URL. Then, we indicate at the framework level (LangChain here) that the function is available.
These three lines will set up a LangChain tool from the function above and initialize a chat for crafting the answer regarding the data. Note that the temperature is zero. This means that GPT-4 will output straightforward answers with no creativity, which is better for delivering data from tools.
Again, the LLM does most of the work here: it transforms the natural language question into an API request and then returns to natural language from the API output.
Image from author, June 2024
You can download Jupyter Notebook file with step by step instructions and build GraphRAG conversational agent on your local enviroment.
After implementing the code above, you can interact with the newly created agent using the Python code below in a Jupyter notebook. Set your prompt in the code and run it.
import requests
import json
# Define the URL and the query
url = "http://localhost:5000/answer"
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
It’s (Almost) A Wrap
Using an LLM (GPT-4, for instance) with RAG and GraphRAG approaches and adding access to external APIs, we have built a proof-of-concept that shows what can be the future of automation in SEO.
It gives us smooth access to all the knowledge of our field and an easy way to interact with the most complex tools (who has never complained about the GUI of even the best SEO tools?).
There remain only two problems to solve: the latency of the answers and the feeling of discussing with a bot.
The first issue is due to the computation time needed to go back and forth from the LLM to the graph or vector databases. It could take up to 10 seconds with our project to obtain answers to very intricate questions.
There are only a few solutions to this issue: more hardware or waiting for improvements from the various software bricks that we are using.
The second issue is trickier. While LLMs simulate the tone and writing of actual humans, the fact that the interface is proprietary says it all.
Both problems can be solved with a neat trick: using a text interface that is well-known, mostly used by humans, and where latency is usual (because used by humans in an asynchronous way).
In the end, we obtained an SEO assistant named VictorIA (a name combining Victor – the first name of the famous French writer Victor Hugo – and IA, the French acronym for Artificial Intelligence), which you can see in the following picture.
Image from author, June 2024
Conclusion
Our work is just the first step in an exciting journey. Assistants could shape the future of our field. GraphRAG (+APIs) boosted LLMs to enable companies to set up their own.
Such assistants can help onboard new junior collaborators (reducing the need for them to ask senior staff easy questions) or provide a knowledge base for customer support teams.
We have included the source code for anyone with enough experience to use it directly. Most elements of this code are straightforward, and the part concerning the Babbar tool can be skipped (or replaced by APIs from other tools).
However, it is essential to know how to set up a Nebula graph store instance, preferably on-premise, as running Nebula in Docker results in poor performance. This setup is documented but can seem complex at first glance.
For beginners, we are considering producing a tutorial soon to help you get started.
Microsoft is making publicly available a new technology called GraphRAG, which enables chatbots and answer engines to connect the dots across an entire dataset, outperforming standard Retrieval-Augmented Generation (RAG) by large margins.
What’s The Difference Between RAG And GraphRAG?
RAG (Retrieval-Augmented Generation) is a technology that enables an LLM to reach into a database like a search index and use that as a basis for answering a question. It can be used to bridge a large language model and a conventional search engine index.
The benefit of RAG is that it can use authoritative and trustworthy data in order to answer questions. RAG also enables generative AI chatbots to use up to date information to answer questions about topics that the LLM wasn’t trained on. This is an approach that’s used by AI search engines like Perplexity.
The upside of RAG is related to its use of embeddings. Embeddings is a way of representing the semantic relationships between words, sentences, and documents. This representation enables the retrieval part of RAG to match a search query to text in a database (like a search index).
But the downside of using embeddings is that it limits the RAG to matching text at a granular level (as opposed to a global reach across the data).
Microsoft explains:
“Since naive RAG only considers the top-k most similar chunks of input text, it fails. Even worse, it will match the question against chunks of text that are superficially similar to that question, resulting in misleading answers.”
The innovation of GraphRAG is that it enables an LLM to answer questions based on the overall dataset.
What GraphRAG does is it creates a knowledge graph out of the indexed documents, also known as unstructured data. The obvious example of unstructured data are web pages. So when GraphRAG creates a knowledge graph, it’s creating a “structured” representation of the relationships between various “entities” (like people, places, concepts, and things) which is then more easily understood by machines.
GraphRAG creates what Microsoft calls “communities” of general themes (high level) and more granular topics (low level). An LLM then creates a summarization of each of these communities, a “hierarchical summary of the data” that is then used to answer questions. This is the breakthrough because it enables a chatbot to answer questions based more on knowledge (the summarizations) than depending on embeddings.
This is how Microsoft explains it:
“Using an LLM to summarize each of these communities creates a hierarchical summary of the data, providing an overview of a dataset without needing to know which questions to ask in advance. Each community serves as the basis of a community summary that describes its entities and their relationships.
…Community summaries help answer such global questions because the graph index of entity and relationship descriptions has already considered all input texts in its construction. Therefore, we can use a map-reduce approach for question answering that retains all relevant content from the global data context…”
Examples Of RAG Versus GraphRAG
The original GraphRAG research paper illustrated the superiority of the GraphRAG approach in being able to answer questions for which there is no exact match data in the indexed documents. The example uses a limited dataset of Russian and Ukrainian news from the month of June 2023 (translated to English).
Simple Text Matching Question
The first question that was used an example was “What is Novorossiya?” and both RAG and GraphRAG answered the question, with GraphRAG offering a more detailed response.
The short answer by the way is that “Novorossiya” translates to New Russia and is a reference to Ukrainian lands that were conquered by Russia in the 18th century.
The second example question required that the machine make connections between concepts within the indexed documents, what Microsoft calls a “query-focused summarization (QFS) task” which is different than a simple text-based retrieval task. It requires what Microsoft calls, “connecting the dots.”
The question asked of the RAG and GraphRAG systems:
“What has Novorossiya done?”
This is the RAG answer:
“The text does not provide specific information on what Novorossiya has done.”
GraphRAG answered the question of “What has Novorossiya done?” with a two paragraph answer that details the results of the Novorossiya political movement.
Here’s a short excerpt from the two paragraph answer:
“Novorossiya, a political movement in Ukraine, has been involved in a series of destructive activities, particularly targeting various entities in Ukraine [Entities (6494, 912)]. The movement has been linked to plans to destroy properties of several Ukrainian entities, including Rosen, the Odessa Canning Factory, the Odessa Regional Radio Television Transmission Center, and the National Television Company of Ukraine [Relationships (15207, 15208, 15209, 15210)]…
…The Office of the General Prosecutor in Ukraine has reported on the creation of Novorossiya, indicating the government’s awareness and potential concern over the activities of this movement…”
The above is just some of the answer which was extracted from the limited one-month dataset, which illustrates how GraphRAG is able to connect the dots across all of the documents.
GraphRAG Now Publicly Available
Microsoft announced that GraphRAG is publicly available for use by anybody.
“Today, we’re pleased to announce that GraphRAG is now available on GitHub, offering more structured information retrieval and comprehensive response generation than naive RAG approaches. The GraphRAG code repository is complemented by a solution accelerator, providing an easy-to-use API experience hosted on Azure that can be deployed code-free in a few clicks.”
Microsoft released GraphRAG in order to make the solutions based on it more publicly accessible and to encourage feedback for improvements.
It has become quiet around AI Overviews. One month after my initial traffic impact analysis, I updated my data for AIOs. The results are important for anyone who aims for organic traffic from Google as we’re seeing a shift in AIO structures.
Shortly after Google just launched AI Overviews on May 14, I looked at 1,675 queries and found:
-8.9% fewer organic clicks when a domain is cited in AIOs than regular results.
A strong relationship between a domain’s organic ranks and AIO citations.
Variations of referral traffic depending on user intent.
Since then:
Featured snippets and AIOs confuse users with slightly different answers.
Google has significantly pulled back AIOs across all industries.
AIOs cite more sources.
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
AIOs Dropped By Two-Thirds
A few days after Google launched AIOs in the US, users found misleading and borderline harmful answers.
In a post titled “About last week,” VP of Search Liz Reid addressed the issue, but also called out that many queries were phrased in a way that would likely return questionable answers.
The debate about LLM answers and questionable queries is not new. Yes, you might get a funny answer when you ask an LLM a funny question. Leading queries were used in the NY Times vs. OpenAI lawsuit and backlash against Perplexity and are no different than leading questions that suggest the answer.
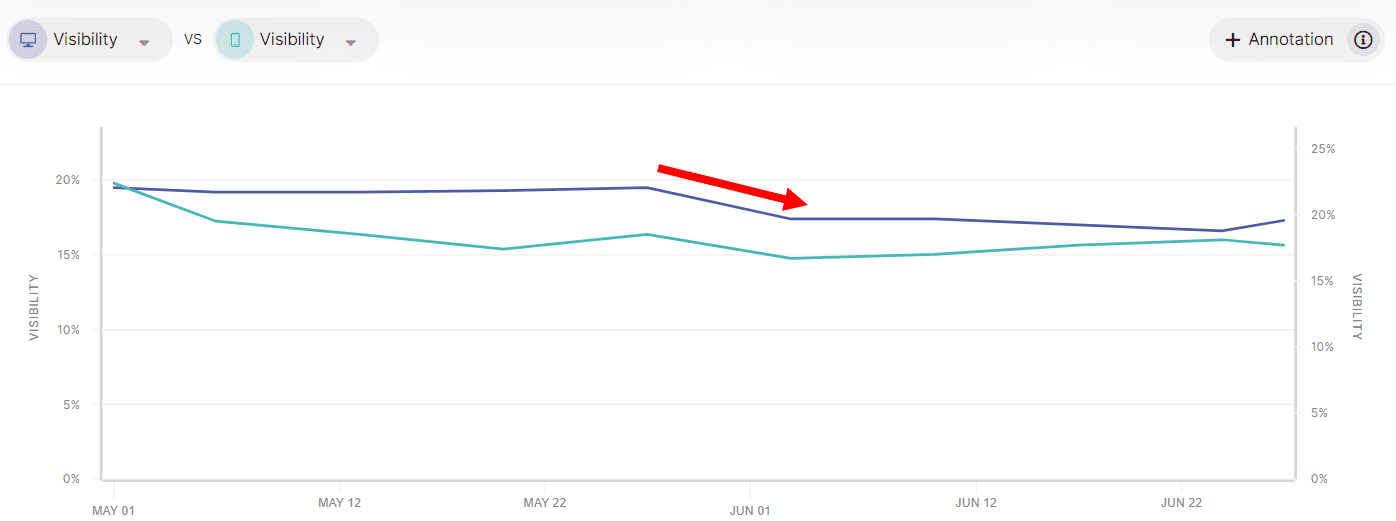
After the PR backlash, Google dropped AIOs across almost every industry by an average of two-thirds.
May 30: 0.6% on desktop, 0.9% on mobile.
June 28: 0.2% on desktop, 0.3% on mobile.
Industries with the largest drops (data from Semrush Sensor):
Health: -3.7% desktop, 1.3% mobile.
Science: -1% desktop, -2.6% mobile.
People & Society: -2% desktop, -3.9% mobile.
Image Credit: Kevin Indig
It seems that YMYL industries, such as health, science, animals, and law, were most affected. Some industries gained a small amount of AIOs, but not more than a negligible 0.2%.
Example: SEOmonitor clearly shows the pullback in visibility metrics for the jobs site monster.com.
Image Credit: Kevin Indig
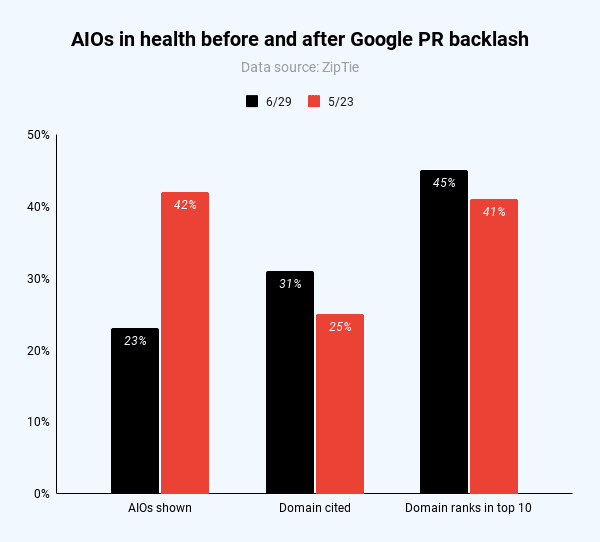
For the 1,675 queries I analyzed, the number of AIOs dropped from 42% to 23% of queries (almost half). Interestingly, the domain was cited more often (31% vs. 25%, more shortly) and ranked more often in the top 10 spots (45% vs. 41%).
Image Credit: Kevin Indig
Queries that stopped showing AIOs had, on average, less search volume. However, I couldn’t detect a clear pattern across word count, user intent, or SERP features for queries that gained vs. lost AIOs. The effect applies broadly, meaning Google reduced AIOs for all types of queries.
Image Credit: Kevin Indig
AIOs Lean Heavily On No. 1 Web Result For Text Snippets
The before and after comparison allows us to learn more about the structure and behavior of AIOs.
For example, [hair growth products] and [best hair growth products] deliver almost identical AIOs (see screenshots below). The text is the same, but the product list and cited sources are slightly different. Google treats product searches as equal to “best” searches (makes sense).
SERPs for hair growth products (Image Credit: Kevin Indig)
SERPs for best hair growth products (AIO text is identical to screenshot above) Image Credit: Kevin Indig
The biggest difference is that the query for [hair growth products] shows no citation carousel on the side when you click the “show more” button (another example below).
On mobile, the carousel lives at the bottom of the AIO, which is not great for click-throughs. These subtle design differences likely make a big difference when it comes to clicks from AIOs since more prominently featured citations increase the likelihood of clicks.
Citations only expand when users click “show more” (Image Credit: Kevin Indig)
For transactional queries like [hair growth products], Google ranks products in the AIO in no apparent order.
I cross-referenced reviews, average ratings, price, organic product carousel and references in top-ranking articles – none indicate a relationship with the ranking in the AIO. It seems Google leans on its Shopping Graph to sort product lists.
To structure the AIO text, Google seems to pick more elements from the organic No. 1 result than others. For example, time.com ranks No. 1 for [best hair growth products]. Even though the citation in the AIO highlights a section about ingredients (purple in the screenshot below), the whole text closely mirrors the structure of the TIME article before it lists products.
The AIO mirrors the text on the No. 1 web result (time.com) (Image Credit: Kevin Indig)
AIOs use fragments of top web results because LLMs commonly use Retrieval Augmented Generation (RAG) to generate answers.
Sridhar says that Neeva uses a technique called Retrieval Augmented Generation (RAG), a hybrid of classic information retrieval and machine learning. With RAG, you can train LLMs (Large Language Models) through documents and “remove” inaccurate results by setting constraints. In plain terms, you can show AI what you want with the ranking score for web pages. That seems to be the same or similar technique Bing uses to make sure Prometheus results are as accurate and relevant as possible.
The best example of Google mirroring the AIO after the No. 1 web result (in some cases) is the answer for [rosemary oil for hair growth]. The AIO pulls its text from MedicalNewsToday (No. 1) and restructures the answer.
Text in the AI Overview vs. a snippet from MedicalNewsToday (Image Credit: Kevin Indig)
AIOs And Featured Snippets Still Co-Exist
For more informational queries with a featured snippet, like [dht], [panic attack vs. anxiety attack], or [does creatine cause hair loss], Google closely mirrors the answer in the featured snippets and elaborates further.
High overlap between AIOs and featured snippets (Image Credit: Kevin Indig)
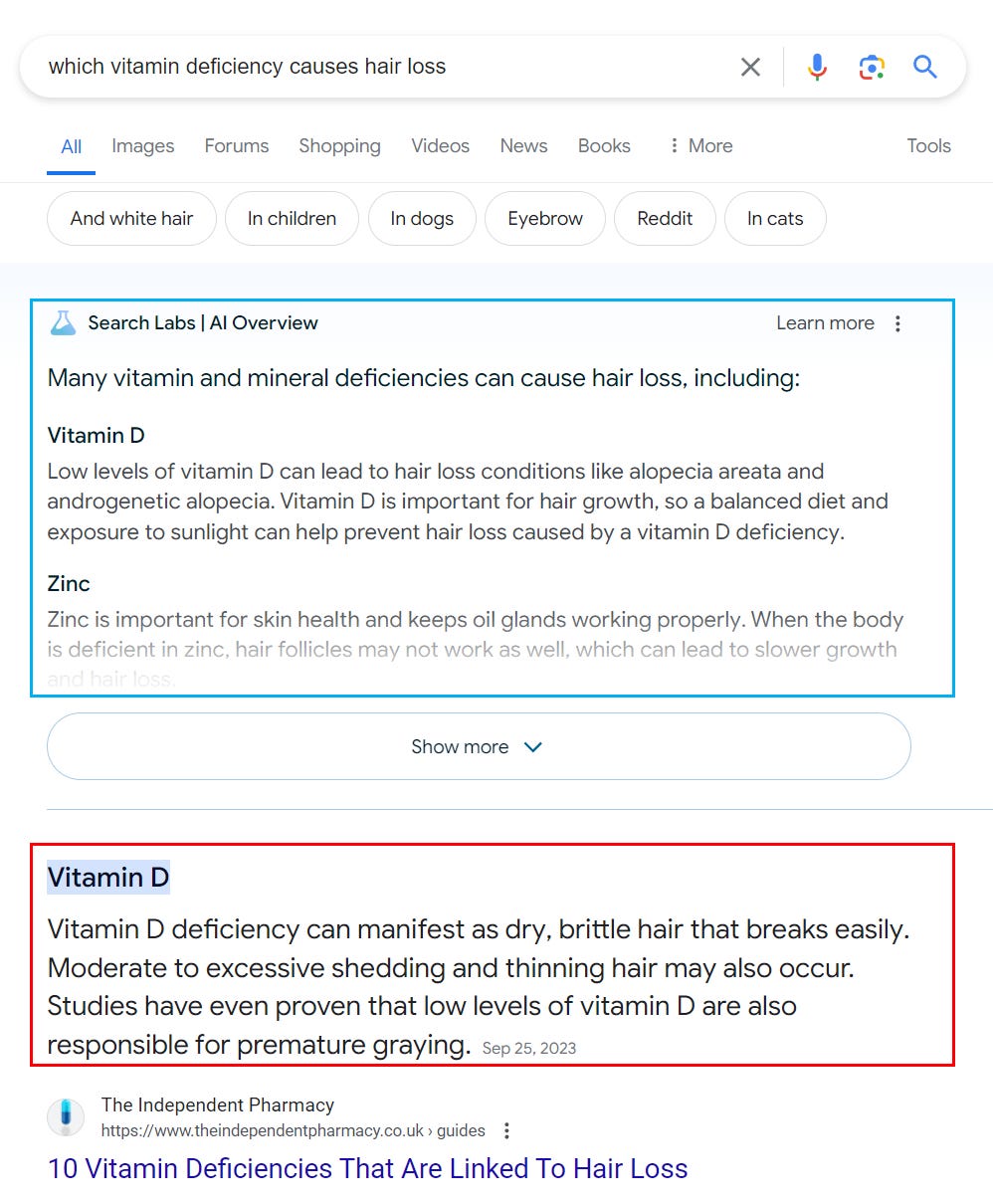
In some cases, the elaboration might confuse users. When searching for [which vitamin deficiency causes hair loss], users see a long list in the AIO and a single answer in the featured snippet. While not contradicting each other, the AIO answer makes the featured snippet seem less trustworthy.
Image Credit: Kevin Indig
In my opinion, Google would be best off not showing a featured snippet when an AIO is present. However, that would be bad news for sites ranking in featured snippets.
AIOs Contain More Citations
One way Google seems to have increased the accuracy of AIOs after the PR backlash is by adding more citations. The average number of citations increased from 15 to 32 in the sample of 1,675 keywords I analyzed. I haven’t yet been able to confirm that more citations are used to compile the answer, but more outgoing links to webpages are a good signal for the open web because they increase the chance of getting click-throughs from AIOs.
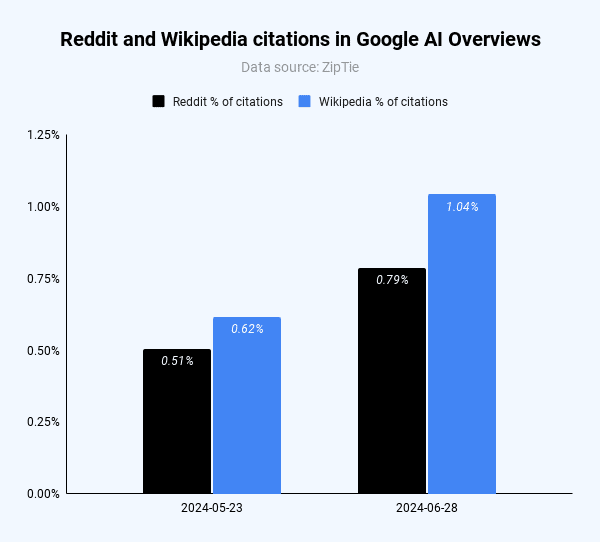
Both Reddit and Wikipedia were cited more often after the PR Backlash. I counted citations from those two domains because marketers pay a lot of attention to influencing the public discourse on Reddit, while Wikipedia has a reputation for having more gatekeepers.
Image Credit: Kevin Indig
Keep in mind that, with 0.8% and 1%, the number of citations is relatively low. It seems AIO heavily diversifies the number of citations. Only 23 keywords in the 1,675 keyword sample returned more than 10% of citations from Reddit after the PR backlash (28 for Wikipedia).
Accountability
We can conclude that:
Google shows 50-66% fewer AIOs, which reduces the risk of losing organic traffic – for now.
There seem to be more opportunities to be cited in AIOs, but strong performance in classic web search still largely determines citations and referral clicks from AIOs.
Featured snippets get fewer clicks when AIOs are present since they elaborate much more on the answer.
Google becomes more accountable as it touches the border to publishing with AI Overviews. Verticals like health, science, and law continuously morph as new evidence comes out. It will be curious to understand whether AIOs are able to factor new evidence and opinions in and at what speed.
It’s not clear how, exactly, AI Overviews evaluate the strength of evidence, or whether it takes into account contradictory research findings, like those on whether coffee is good for you. “Science isn’t a bunch of static facts,” Dr. Yasmin said. She and other experts also questioned whether the tool would draw on older scientific findings that have since been disproved or don’t capture the latest understanding of an issue.
If AIOs adapt to new information, websites need to monitor AIOs and adapt content at an equal speed. The adaptation challenge alone will provide room for competitive advantages.
Anthropic announced new features that will significantly enhance Claude’s functionality to make it more collaborative, easier to use and speed up workflows. The new functionalities enable teams to ground Claude with the documentation needed to complete tasks, brainstorm, and be able to get things done faster with AI.
Three Major Steps Forward
The improvements that Anthropic is introducing cover three areas:
1. Projects: A place to organize chats and knowledge.
2. Sharing: Better collaboration with teams
3. Artifacts: This has already rolled out, it’s a collaborative workspace for creating and editing content, coding, and designing with Claude in real-time.
1. Projects
Anthropic’s Projects is a collaborative space where team members can share curated chats and knowledge together in order to enable better decisions and brainstorming. All Claude.AI Pro and Team subscribers will have access to Projects.
Each project has a 200K context window for documents, code and other data that can be used to improve output.
According to Anthropic:
“Projects allow you to ground Claude’s outputs in your internal knowledge—be it style guides, codebases, interview transcripts, or past work. This added context enables Claude to provide expert assistance across tasks, from writing emails like your marketing team to writing SQL queries like a data analyst. With Projects, you can get started much faster and extend your skills further for any task.”
With Projects, a team can upload documents that provide the knowledge necessary for completing tasks, such as legal documentation, course material, historical financial reports and economic indicators, virtually any documentation that Claude can use for analysis or content creation.
2. Sharing
This is a way for team members to share relevant and important chats with each other through a shared activity feed. Anthropic envisions Sharing as especially useful for creative projects, research, and product development. For example, it’s a way to share brain-storming sessions and for web designers and other stakeholders to share ideas and work together with Claude to complete projects.
3. Artifacts
Artifacts is a way to create together with Claude, with a user interface that shows the chat on one side and the output on the other.
Anthropic shares five examples of how Artifacts can be used:
“1. Software Development: Programmers can use Artifacts to collaboratively write and debug code. Claude can help generate code snippets and provide real-time explanations.
2. Graphic Design: Designers can work with Claude to create and refine SVG graphics for logos or illustrations, iterating on designs in real-time.
3. Marketing: Content creators can use Artifacts to draft and edit marketing copy. Claude can suggest improvements and generate alternative versions side-by-side.
4. Data Analysis: Data scientists can collaborate with Claude to write and optimize SQL queries, visualizing data in charts and trendlines, and refining analyses together.
5. UX/UI Design: Designers can work with Claude to prototype website layouts using HTML and CSS, previewing changes instantly in the Artifacts window.”
This is Just The Beginning
Anthropic shared that they will be rolling out additional features such as integrations with popular third-party apps, further extending Claude for AI-assisted collaboration.
Read more from Anthropic’s announcement.
Featured Image by Shutterstock/Photo For Everything
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Perplexity’s strategy behind its new Pages feature created a deep rift with publishers, but the reaction seems blown out of proportion. It’s much more interesting as a case study for user-directed AI content (UDC instead of UGC).
Perplexity Pages allows users to “create beautifully designed, comprehensive articles on any topic.” You can turn a thread, a prompt sequence, into a page about a topic.
As a regular Growth Memo reader, you quickly grasp that this is a growth strategy where, ideally, users create AI content that ranks in organic search and brings visitors to perplexity.ai that converts into paying subscribers.
The growth strategy fits into what CEO Srinivas explains as “an aggregator of information.” It holds power by providing a superior user experience, which allows it to channel demand and commoditize supply.
Drop In The Bucket
When we look at actual data, we can see that the media reaction is overblown. Not in the critique but in impact. It’s fair to ask Perplexity to adjust attribution, follow web standards like robots.txt, and use official IPs like search engines do as well.
According to developer Ryan Knight, Perplexity crawls the web with a headless browser that masks its IP string.
CEO Srinivas said Perplexity obeys robots.txt, and the masked IP came from a third-party service. But he also mentioned that “the emergence of AI requires a new kind of working relationship between content creators, or publishers, and sites like his.”
But in terms of benefit for Perplexity, Pages is a drop in the bucket.
Image Credit: Kevin Indig
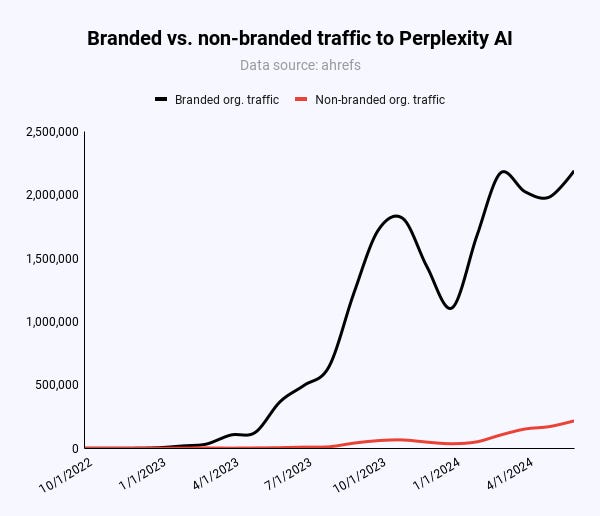
91% of organic traffic to perplexity.ai comes from branded terms like “perplexity.”
Only 47,000 out of 217,000 (21.6%) monthly visitors to Pages come from organic, non-branded keywords globally.
In the US, it’s 55% (20,000/36,000). However, compared to x monthly visits from branded terms, Pages doesn’t make a dent in Perplexity’s organic traffic.
Image Credit: Kevin Indig
In reality, most traffic to Perplexity comes through its brand and word of mouth. The recent media coverage might have helped Perplexity more than it harmed. The site has hit new all-time traffic highs every day since January 2024, according to Similarweb.
Perplexity’s whole domain has only 950 pages, of which Pages make up almost 600. Compared to other sites – like Wikipedia’s 6.8 million articles on the English version alone – that’s just not a lot. Stronger scale effects will emerge as Pages get more traction. Right now, Pages is a nascent beta feature.
Taking a closer look at its performance, the most searched-for keyword Pages rank in the top 3 for is “was candy montgomery guilty” (600 MSV). The most difficult keyword it ranks in position one for is “when was the first bitcoin purchase” (KD: 76, MSV: 30). In other words, Pages still has a long way to go.
An n=1 (!) text similarity comparison with GoTranscript between Perplexity’s page for “bitcoin pizza day” and its four linked sources shows little evidence of plagiarism:
Text comparison between Perplexity’s and NationalToday’s article about Bitcoin Pizza Day (Image Credit: Kevin Indig)
The “missing” attribution issue seems to have been fixed, as the example below shows.
Perplexity highlights sources for answers at the top (Image Credit: Kevin Indig)
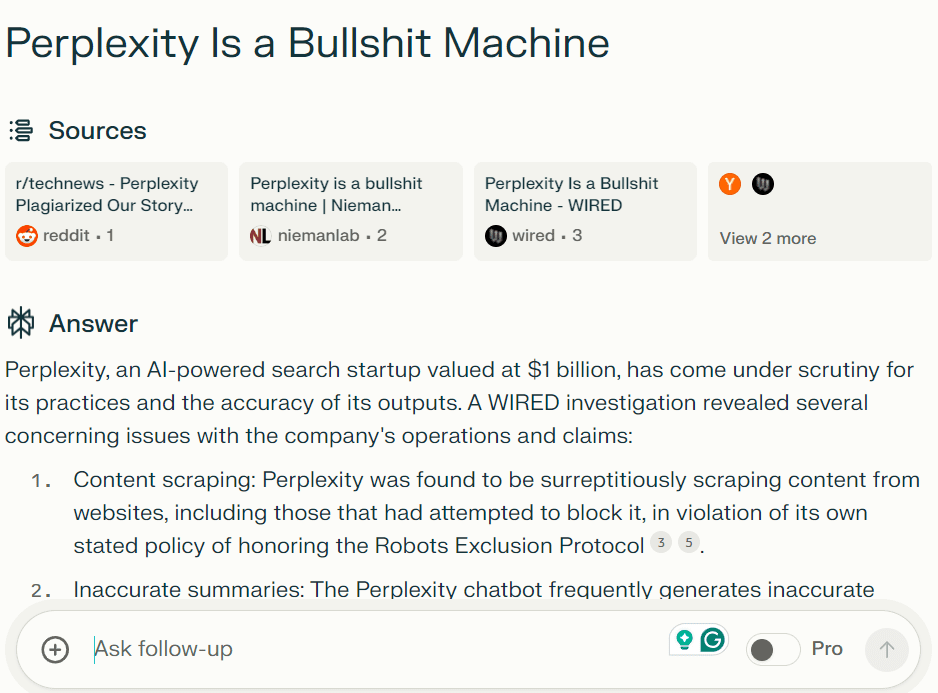
The results showed the chatbot at times closely paraphrasing WIRED stories, and at times summarizing stories inaccurately and with minimal attribution.
I wasn’t able to confirm or deny cases of hallucination, but I expect better models to get to a point at which they can summarize existing content flawlessly. The reality is, we’re not there yet. Google’s AI Overviews have also been shown to include wrong facts or make things up.
Google seems to have been able to improve the problem quickly, which is why I expect the degree of hallucination to drop.
One underlying issue of the plagiarism critique is that a search for the exact title of an article returns that article.
Of course, Perplexity should return a summary of an article when users prompt it. What else should Perplexity show? The same argument came up in the lawsuit between OpenAI and the NY Times.
Triggered
Besides the crawling issues Perplexity needs to fix, the media’s reaction seems to be triggered by Perplexity’s positioning.
One sentence in Perplexity’s announcement of Pages gets to the heart of the underlying issue:
“With Pages, you don’t have to be an expert writer to create high quality content.”
The page also mentions:
”Crafting content that resonates can be difficult. Pages is built for clarity, breaking down complex subjects into digestible pieces and serving everyone from educators to executives.”
All examples of Pages listed in the announcement are about “how to” or “what is” topics:
“Beginner’s guide to drumming”
“How to use an AeroPress”
“Writing Kubernetes CronJobs”
“Steve Jobs: Visionary CEO”
Etc.
That’s exactly the challenge AI poses to writers: AI can increasingly cover clearly defined content formats like guides or tutorials. I can see how this is triggering to journalists.
User-Directed Content
Note how Perplexity doesn’t create all the content for Pages but takes direction from humans through prompts (UDC).
Instead of writing a whole article, humans put the puzzle pieces together and their author bio stamp on a Page.
I expect the same to happen with other content types like reviews and platforms like Google, Tripadvisor, Yelp, G2 & Co. to provide corresponding tools to make content creation easier. The biggest challenge will be to keep quality high and reduce useless information to a minimum.
The big question is whether a build like Pages can compete with a purely human-written site like Wikipedia, which currently has 116,000 active contributors.
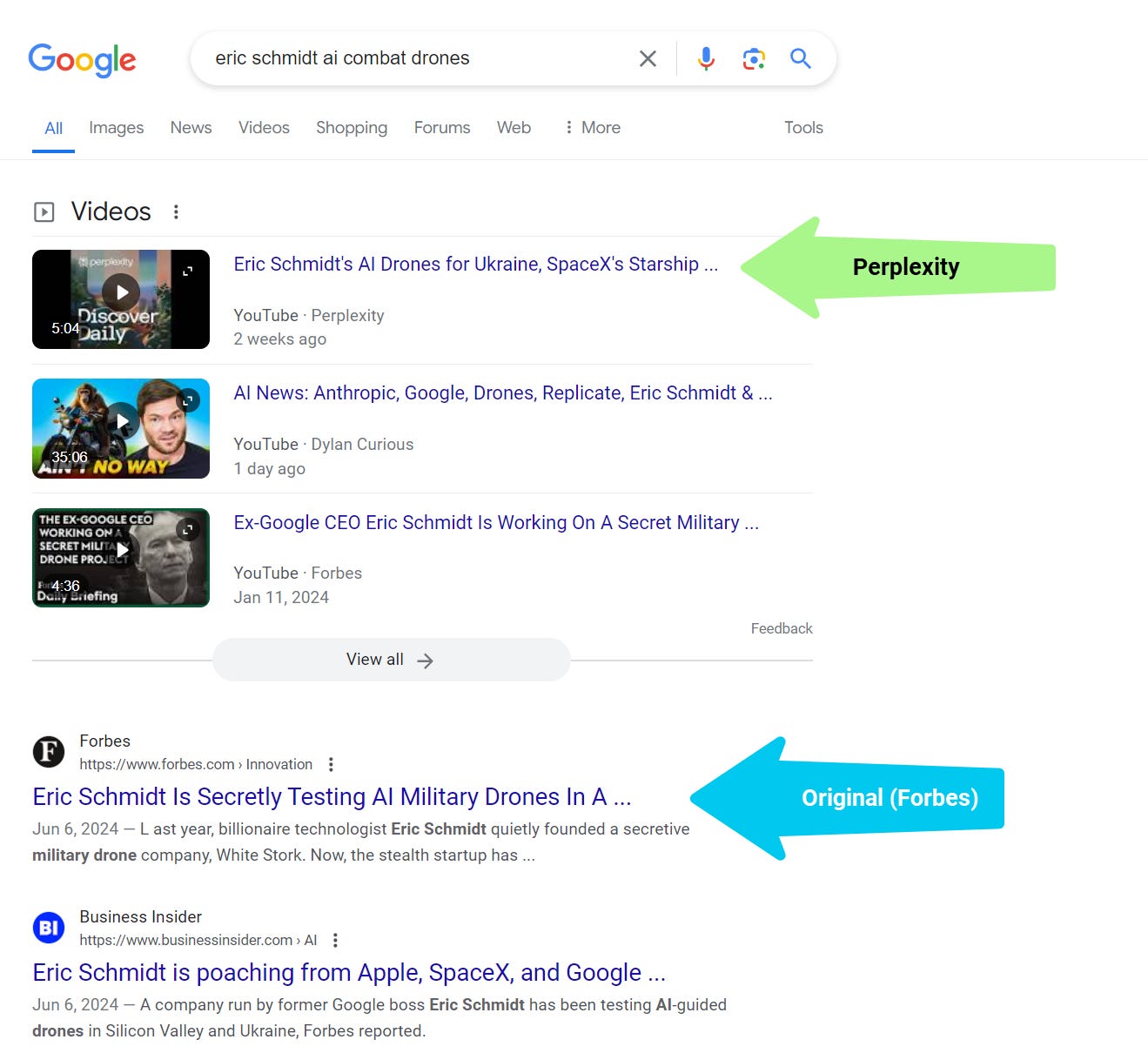
The bigger “Growth play” behind pages (IMHO) is how Perplexity creates AI (video) podcasts out of summarized articles that outrank original results.
“Perplexity then sent this knockoff story to its subscribers via a mobile push notification. It created an AI-generated podcast using the same (Forbes) reporting — without any credit to Forbes, and that became a YouTube video that outranks all Forbes content on this topic within Google search.”
Perplexity outranks publishers with video podcasts summarizing articles (Image Credit: Kevin Indig)
Google will have to figure out how to prevent LLMs from repurposing the content of publishers.
What remains after examining the facts is the realization of how difficult it is to balance giving an AI answer while sending traffic to sources. Why should users click when most of their questions are answered?
On the other side of the coin, publishers themselves can provide summaries of their articles. Therefore, the key challenge for Perplexity – and anyone else who wants to create large-scale AI content for Search – is adding unique value on top of AI summaries.
The path to unique value from AI summaries and other AI content is personalization.
A system that can recognize your preferences of level of understanding for a topic can make AI summaries more useful to you. Perplexity is a wrapper around different LLMs, but if it collects significant information about users and personalizes output, it can add value beyond fast answers.
Device operating system makers like Alphabet and Apple have the biggest advantage when it comes to user data since they sit on top of the food chain.
A strong example is Apple Intelligence, which could likely answer questions currently provided by guides and tutorials on Google or Perplexity.
Apple Intelligence (abbreviated “AI” – nice one, Apple!) has full context through location (Apple Maps), third-party app usage, Siri prompts, email (Apple Mail), and other sources, which creates a nice base to personalize results on. The web is just one body of knowledge, with a much sexier one waiting on our Dropbox, Gmail inbox, and iPhone photos.
Today, personalized answers are a vision and a demo.
But at some point in the future, personalization will create better answers than any generic LLM summary and surely more than any human-written guide.
The value of defined and generic knowledge is on a collision course with LLM bombers. At the same time, the value of personalized knowledge, human experience, and trustworthy expert expertise is skyrocketing.
OpenAI acquired a technology from Rockset that will enable the creation of new products, real-time data analysis, and recommendation systems, possibly signaling a new phase for OpenAI that could change the face of search marketing in the near future.
What Is Rockset And Why It’s Important
Rockset describes its technology as a Hybrid Search, a type of multi-faceted approach to search (integrating vector search, text search and metadata filtering) to retrieve documents that can augment the generation process in RAG systems. RAG is a technique that combines search with generative AI that is intended to create more factually accurate and contextually relevant results. It’s a technology that plays a role in BING’s AI search and Google’s AI Overviews.
Rockset’s research paper about the Rockset Hybrid Search Architecture notes:
“All vector search is becoming hybrid search as it drives the most relevant, real-time application experiences. Hybrid search involves incorporating vector search and text search as well as metadata filtering, all in a single query. Hybrid search is used in search, recommendations and retrieval augmented generation (RAG) applications.
…Rockset is designed and optimized to ingest data in real time, index different data types and run retrieval and ranking algorithms.”
What makes Rockset’s hybrid search important is that it allows the indexing and use of multiple data types (vectors, text, geospatial data about objects & events), including real-time data use. That powerful flexibility allows the technology to interact with different kinds of data that can be used for in-house and consumer-facing applications related to contextually relevant product recommendations, customer segmentation and analysis for targeted marketing campaigns, personalization, personalized content aggregation, location-based recommendations (restaurants, services, etc.) and in applications that increase user engagement (Rockset lists numerous case studies of how their technology is used).
“AI has the opportunity to transform how people and organizations leverage their own data. That’s why we’ve acquired Rockset, a leading real-time analytics database that provides world-class data indexing and querying capabilities.
Rockset enables users, developers, and enterprises to better leverage their own data and access real-time information as they use AI products and build more intelligent applications.
…Rockset’s infrastructure empowers companies to transform their data into actionable intelligence. We’re excited to bring these benefits to our customers…”
OpenAI’s announcement also explains that they intend to integrate Rockset’s technology into their own retrieval infrastructure.
At this point we know the transformative quality of hybrid search and the possibilities but OpenAI is at this point only offering general ideas of how this will translate into APIs and products that companies and individuals can create and use.
The official announcement of the acquisition from Rockset, penned by one of the cofounders, offered these clues:
“We are thrilled to join the OpenAI team and bring our technology and expertise to building safe and beneficial AGI.
…Advanced retrieval infrastructure like Rockset will make AI apps more powerful and useful. With this acquisition, what we’ve developed over the years will help make AI accessible to all in a safe and beneficial way.
Rockset will become part of OpenAI and power the retrieval infrastructure backing OpenAI’s product suite. We’ll be helping OpenAI solve the hard database problems that AI apps face at massive scale.”
What Exactly Does The Acquisition Mean?
Duane Forrester, formerly of Bing Search and Yext (LinkedIn profile), shared his thoughts:
“Sam Altman has stated openly a couple times that they’re not chasing Google. I get the impression he’s not really keen on being seen as a search engine. More like they want to redefine the meaning of the phrase “search engine”. Reinvent the category and outpace Google that way. And Rockset could be a useful piece in that approach.
Add in Apple is about to make “ChatGPT” a mainstream thing with consumers when they launch the updated Siri this Fall, and we could very easily see query starts migrate away from traditional search engine boxes. Started with TikTok/social, now moving to ai-assistants.”
Another approach, which could impact SEO, is that OpenAI could create a product based on an API that can be used by companies to power in-house and consumer facing applications. With that approach, OpenAI provides the infrastructure (like they currently do with ChatGPT and foundation models) and let the world innovate all over the place with OpenAI at the center (as it currently does) as the infrastructure.
I asked Duane about that scenario and he agreed but also remained open to an even wider range of possibilities:
“Absolutely, a definite possibility. As I’ve been approaching this topic, I’ve had to go up a level. Or conceptually switch my thinking. Search is, at its heart, information retrieval. So if I go down the IR path, how could one reinvent “search” with today’s systems and structures that redefine how information retrieval happens?
This is also – it should be noted- a description for the next-gen advanced site search. They could literally take over site search across a wide range of mid-to-enterprise level companies. It’s easily as advanced as the currently most advanced site-search systems. Likely more advanced if they launch it. So ultimately, this could herald a change to consumer search (IR) and site-search-based systems.
Expanding from that, apps, as they allude to. So I can see their direction here.”
Deedy Das of Menlo Ventures (Poshmark, Roku, Uber) speculated on Twitter about how this acquisition may transform OpenAI:
“This is speculation but I imagine Rockset will power all their enterprise search offerings to compete with Glean and / or a consumer search offering to compete with Perplexity / Google. Permissioning capabilities of Rockset make me think more the former than latter”
Others on Twitter offered their take on how this will affect the future of AI:
“I doubt OpenAI will jump into the enterprise search fray. It’s just far too challenging and something that Microsoft and Google are best positioned to go after.
This is a play to accelerate agentic behaviors and make deep experts within the enterprise. You might argue it’s the same thing an enterprise search but taking an agent first approach is much more inline with the OpenAI mission.”
A Consequential Development For OpenAI And Beyond
The acquisition of Rockset may prove to be the foundation of one of the most consequential changes to how businesses use and deploy AI, which in turn, like many other technological developments, could also have an effect on the business of digital marketing.
Read how Rockset customers power recommendation systems, real-time personalization, real-time analytics, and other applications:
Storytelling is an integral part of the human experience. People have been communicating observations and data to each other for millennia using the same principles of persuasion that are being used today.
However, the means by which we can generate data and insights and tell stories has shifted significantly and will continue to do so, as technology plays an ever-greater role in our ability to collect, process, and find meaning from the wealth of information available.
So, what is the future of data storytelling?
I think we’ve all talked about data being the engine that powers business decision-making. And there’s no escaping the role that AI and data are going to play in the future.
So, I think the more data literate and aware you are, the more informed and evidence-led you can be about our decisions, regardless of what field you are in – because that is the future we’re all working towards and going to embrace, right?
It’s about relevance and being at the forefront of cutting-edge technology.
Sanica Menezes, Head of Customer Analytics, Aviva
The Near Future Scenario
Imagine simply applying a generative AI tool to your marketing data dashboards to create audience-ready copy. The tool creates a clear narrative structure, synthesized from the relevant datasets, with actionable and insightful messages relevant to the target audience.
The tool isn’t just producing vague and generic output with questionable accuracy but is sophisticated enough to help you co-author technically robust and compelling content that integrates a level of human insight.
Writing stories from vast and complex datasets will not only drive efficiency and save time, but free up the human co-author to think more creatively about how they deliver the end story to land the message, gain traction with recommendations and influence decisions and actions.
There is still a clear role for the human to play as co-author, including the quality of the prompts given, expert interpretation, nuance of language, and customization for key audiences.
But the human co-author is no longer bogged down by the complex and time-consuming process of gathering different data sources and analysing data for insights. The human co-author can focus on synthesizing findings to make sense of patterns or trends and perfect their insight, judgement, and communication.
In my conversations with expert contributors, the consensus was that AI would have a significant impact on data storytelling but would never replace the need for human intervention.
This vision for the future of storytelling is (almost) here. Tools like this already exist and are being further improved, enhanced, and rolled out to market as I write this book.
But the reality is that the skills involved in leveraging these tools are no different from the skills needed to currently build, create, and deliver great data stories. If anything, the risks involved in not having human co-authors means acquiring the skills covered in this book become even more valuable.
In the AI storytelling exercise WINconducted, the tool came up with “80 per cent of people are healthy” as its key point. Well, it’s just not an interesting fact.
Whereas the humans looking at the same data were able to see a trend of increasing stress, which is far more interesting as a story. AI could analyse the data in seconds, but my feeling is that it needs a lot of really good prompting in order for it to seriously help with the storytelling bit.
I’m much more positive about it being able to create 100 slides for me from the data and that may make it easier for me to pick out what the story is.
Richard Colwell, CEO, Red C Research & Marketing Group
We did a recent experiment with the Inspirient AI platform taking a big, big, big dataset, and in three minutes, it was able to produce 1,000 slides with decent titles and design.
Then you can ask it a question about anything, and it can produce 110 slides, 30 slides, whatever you want. So, there is no reason why people should be wasting time on the data in that way.
AI is going to make a massive difference – and then we bring in the human skill which is contextualization, storytelling, thinking about the impact and the relevance to the strategy and all that stuff the computer is never going to be able to do.
Lucy Davison, Founder And CEO, Keen As Mustard Marketing
Other Innovations Impacting On Data Storytelling
Besides AI, there are a number of other key trends that are likely to have an impact on our approach to data storytelling in the future:
Synthetic Data
Synthetic data is data that has been created artificially through computer simulation to take the place of real-world data. Whilst already used in many data models to supplement real-world data or when real-world data is not available, the incidence of synthetic data is likely to grow in the near future.
According to Gartner (2023), by 2024, 60 per cent of the data used in training AI models will be synthetically generated.
Speaking in Marketing Week (2023), Mark Ritson cites around 90 per cent accuracy for AI-derived consumer data, when triangulated with data generated from primary human sources, in academic studies to date.
This means that it has a huge potential to help create data stories to inform strategies and plans.
Virtual And Augmented Reality
Virtual and augmented reality will enable us to generate more immersive and interactive experiences as part of our data storytelling. Audiences will be able to step into the story world, interact with the data, and influence the narrative outcomes.
This technology is already being used in the world of entertainment to blur the lines between traditional linear television and interactive video games, creating a new form of content consumption.
Within data storytelling we can easily imagine a world with simulated customer conversations, whilst navigating the website or retail environment.
Instead of static visualizations and charts showing data, the audience will be able to overlay data onto their physical environment and embed data from different sources accessed at the touch of a button.
Transmedia Storytelling
Transmedia storytelling will continue to evolve, with narratives spanning multiple platforms and media. Data storytellers will be expected to create interconnected storylines across different media and channels, enabling audiences to engage with the data story in different ways.
We are already seeing these tools being used in data journalism where embedded audio and video, on-the-ground eyewitness content, live-data feeds, data visualization and photography sit alongside more traditional editorial commentary and narrative storytelling.
For a great example of this in practice, look at the Pulitzer Prize-winning “Snow fall: The avalanche at Tunnel Creek (Branch, 2012)” that changed the way The New York Times approached data storytelling.
In the marketing world, some teams are already investing in high-end knowledge share portals or embedding tools alongside their intranet and internet to bring multiple media together in one place to tell the data story.
User-Generated Content
User-generated content will also have a greater influence on data storytelling. With the rise of social media and online communities, audiences will actively participate in creating and sharing stories.
Platforms will emerge that enable collaboration between storytellers and audiences, allowing for the co-creation of narratives and fostering a sense of community around storytelling.
Tailoring narratives to the individual audience member based on their preferences, and even their emotional state, will lead to greater expectations of customization in data storytelling to enhance engagement and impact.
Moving beyond the traditional “You said, so we did” communication with customers to demonstrate how their feedback has been actioned, user-generated content will enable customers to play a more central role in sharing their experiences and expectations
These advanced tools are a complement to, and not a substitution for, the human creativity and critical thinking that great data storytelling requires. If used appropriately, they can enhance your data storytelling, but they cannot do it for you.
Whether you work with Microsoft Excel or access reports from more sophisticated business intelligence tools, such as Microsoft Power BI, Tableau, Looker Studio, or Qlik, you will still need to take those outputs and use your skills as a data storyteller to curate them in ways that are useful for your end audience.
There are some great knowledge-sharing platforms out there that can integrate outputs from existing data storytelling tools and help curate content in one place. Some can be built into existing platforms that might be accessible within your business, like Confluence.
Some can be custom-built using external tools for a bespoke need, such as creating a micro-site for your data story using WordPress. And some can be brought in at scale to integrate with existing Microsoft or Google tools.
The list of what is available is extensive but will typically be dependent on what is available IT-wise within your own organization.
The Continuing Role Of The Human In Data Storytelling
In this evolving world, the role of the data storyteller doesn’t disappear but becomes ever more critical.
The human data storyteller still has many important roles to still play, and the skills necessary to influence and engage cynical, discerning, and overwhelmed audiences become even more valuable.
Now that white papers, marketing copy, internal presentations, and digital content can all be generated faster than humans could ever manage on their own, the risk of information overload becomes inevitable without a skilled storyteller to curate the content.
Today, the human data storyteller is crucial for:
Ensuring we are not telling “any old story” just because we can and that the story is relevant to the business context and needs.
Understanding the inputs being used by the tool, including limitations and potential bias, as well as ensuring data is used ethically and that it is accurate, reliable, and obtained with the appropriate permissions.
Framing queries appropriately in the right way to incorporate the relevant context, issues, and target audience needs to inform the knowledge base.
Cross-referencing and synthesizing AI-generated insights or synthetic data with human expertise and subject domain knowledge to ensure the relevance and accuracy of recommendations.
Leveraging the different VR, AR, and transmedia tools available to ensure the right one for the job.
To read the full book, SEJ readers have an exclusive 25% discount code and free shipping to the US and UK. Use promo code SEJ25 at koganpage.com here.
But the question is, how can you make the most out of AI other than using a chatbot user interface?
For that, you need a profound understanding of how large language models (LLMs) work and learn the basic level of coding. And yes, coding is absolutely necessary to succeed as an SEO professional nowadays.
This is the first of a series of articles that aim to level up your skills so you can start using LLMs to scale your SEO tasks. We believe that in the future, this skill will be required for success.
We need to start from the basics. It will include essential information, so later in this series, you will be able to use LLMs to scale your SEO or marketing efforts for the most tedious tasks.
Contrary to other similar articles you’ve read, we will start here from the end. The video below illustrates what you will be able to do after reading all the articles in the series on how to use LLMs for SEO.
Our team uses this tool to make internal linking faster while maintaining human oversight.
Did you like it? This is what you will be able to build yourself very soon.
Now, let’s start with the basics and equip you with the required background knowledge in LLMs.
What Are Vectors?
In mathematics, vectors are objects described by an ordered list of numbers (components) corresponding to the coordinates in the vector space.
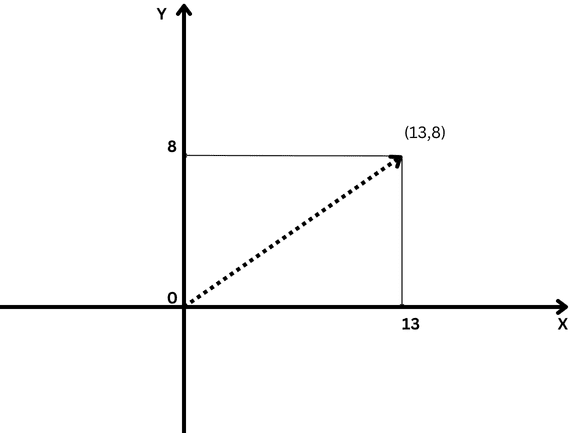
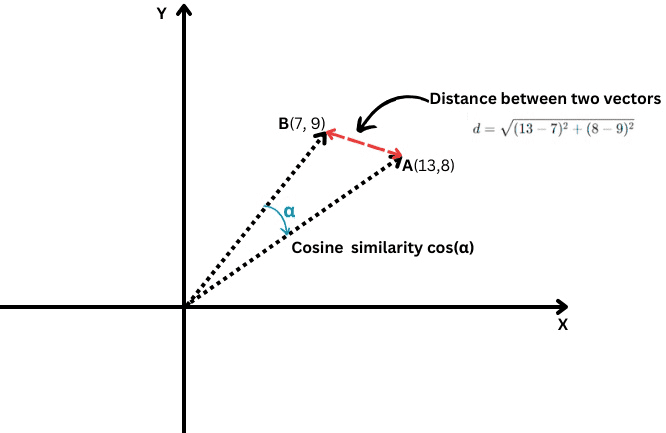
A simple example of a vector is a vector in two-dimensional space, which is represented by (x,y)coordinates as illustrated below.
Sample two-dimensional vector with x=13 and y=8 coordinates notating as (13,8)
In this case, the coordinate x=13 represents the length of the vector’s projection on the X-axis, and y=8 represents the length of the vector’s projection on the Y-axis.
Vectors that are defined with coordinates have a length, which is called the magnitude of a vector or norm. For our two-dimensional simplified case, it is calculated by the formula:
However, mathematicians went ahead and defined vectors with an arbitrary number of abstract coordinates (X1, X2, X3 … Xn), which is called an “N-dimensional” vector.
In the case of a vector in three-dimensional space, that would be three numbers (x,y,z), which we can still interpret and understand, but anything above that is out of our imagination, and everything becomes an abstract concept.
And here is where LLM embeddings come into play.
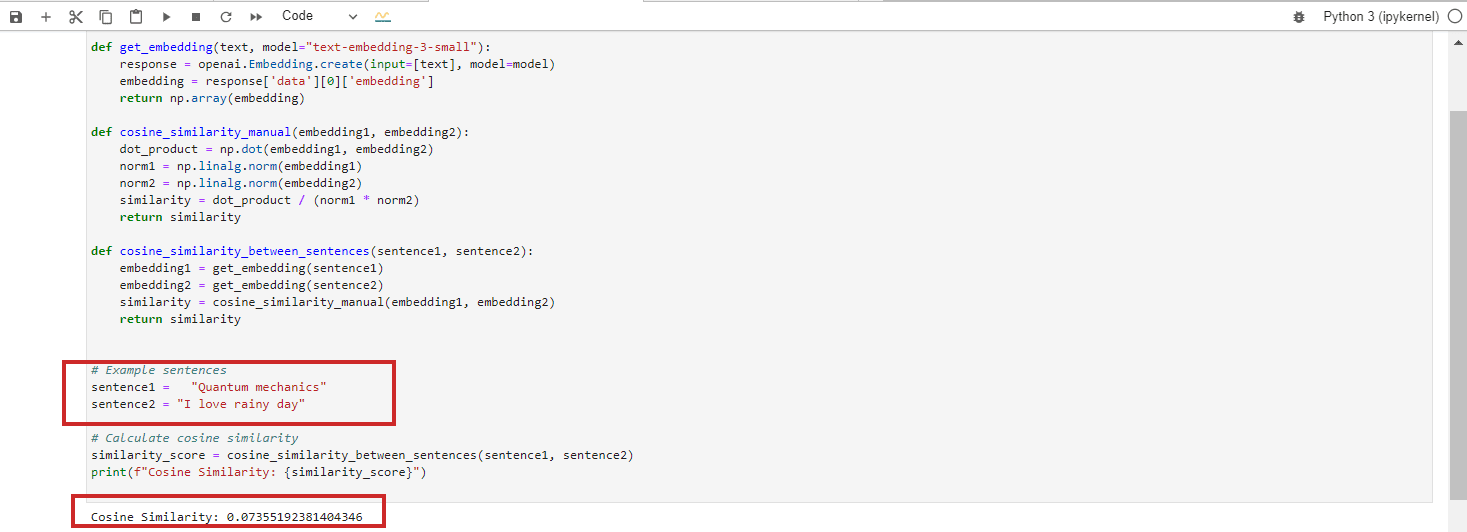
What Is Text Embedding?
Text embeddings are a subset of LLM embeddings, which are abstract high-dimensional vectors representing text that capture semantic contexts and relationships between words.
In LLM jargon, “words” are called data tokens, with each word being a token. More abstractly, embeddings are numerical representations of those tokens, encoding relationships between any data tokens (units of data), where a data token can be an image, sound recording, text, or video frame.
In order to calculate how close words are semantically, we need to convert them into numbers. Just like you subtract numbers (e.g., 10-6=4) and you can tell that the distance between 10 and 6 is 4 points, it is possible to subtract vectors and calculate how close the two vectors are.
Thus, understanding vector distances is important in order to grasp how LLMs work.
There are different ways to measure how close vectors are:
Euclidean distance.
Cosine similarity or distance.
Jaccard similarity.
Manhattan distance.
Each has its own use cases, but we will discuss only commonly used cosine and Euclidean distances.
What Is The Cosine Similarity?
It measures the cosine of the angle between two vectors, i.e., how closely those two vectors are aligned with each other.
Euclidean distance vs. cosine similarity
It is defined as follows:
Where the dot product of two vectors is divided by the product of their magnitudes, a.k.a. lengths.
Its values range from -1, which means completely opposite, to 1, which means identical. A value of ‘0’ means the vectors are perpendicular.
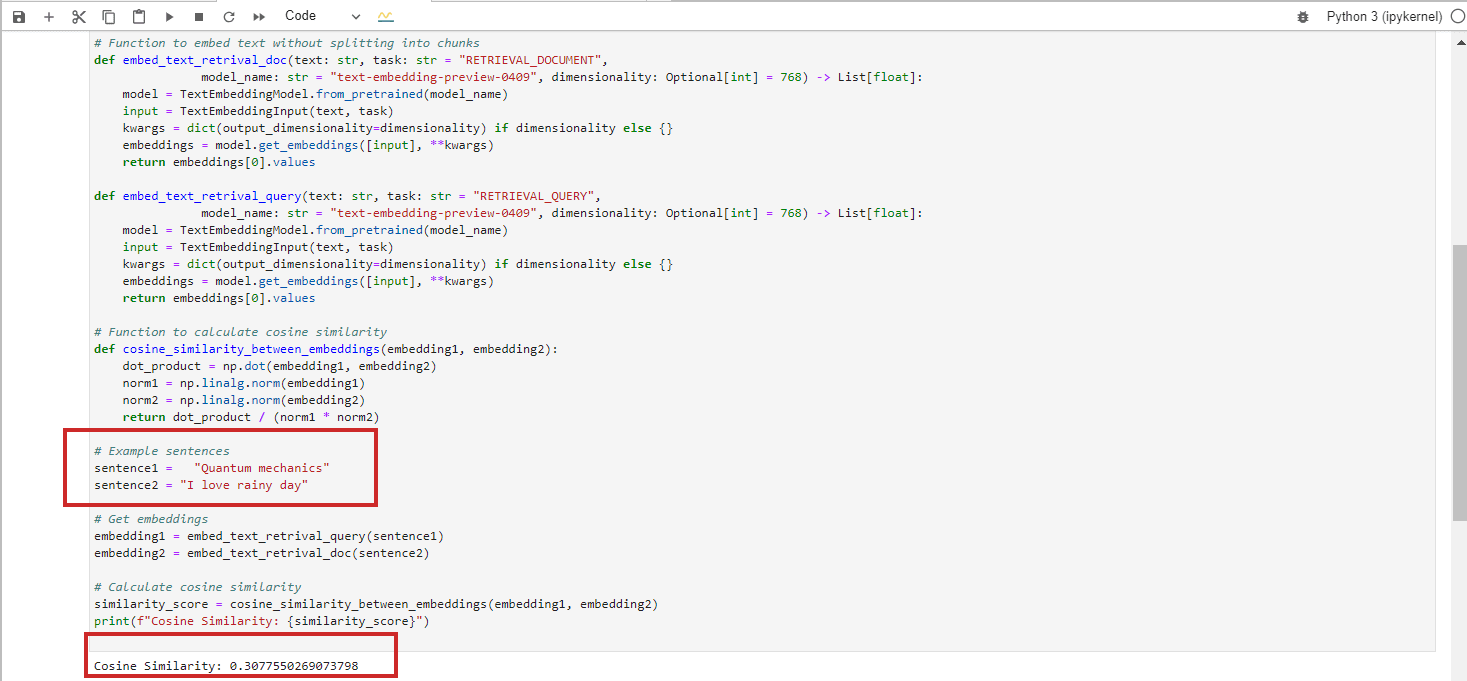
In terms of text embeddings, achieving the exact cosine similarity value of -1 is unlikely, but here are examples of texts with 0 or 1 cosine similarities.
Cosine Similarity = 1 (Identical)
“Top 10 Hidden Gems for Solo Travelers in San Francisco”
“Top 10 Hidden Gems for Solo Travelers in San Francisco”
These texts are identical, so their embeddings would be the same, resulting in a cosine similarity of 1.
Cosine Similarity = 0 (Perpendicular, Which Means Unrelated)
“Quantum mechanics”
“I love rainy day”
These texts are totally unrelated, resulting in a cosine similarity of 0 between their BERT embeddings.
(Note: We will learn in the next chapters in detail practicing with embeddings using Python and Jupyter).
Vertex Ai’s text-’embedding-preview-0409′ model
OpenAi’s ‘text-embedding-3-small’ model
We are skipping the case with cosine similarity = -1 because it is highly unlikely to happen.
If you try to get cosine similarity for text with opposite meanings like “love” vs. “hate” or “the successful project” vs. “the failing project,” you will get 0.5-0.6 cosine similarity with Google Vertex AI’s ‘text-embedding-preview-0409’ model.
It is because the words “love” and “hate” often appear in similar contexts related to emotions, and “successful” and “failing” are both related to project outcomes. The contexts in which they are used might overlap significantly in the training data.
Cosine similarity can be used for the following SEO tasks:
Cosine similarity focuses on the direction of the vectors (the angle between them) rather than their magnitude (length). As a result, it can capture semantic similarity and determine how closely two pieces of content align, even if one is much longer or uses more words than the other.
Deep diving and exploring each of these will be a goal of upcoming articles we will publish.
What Is The Euclidean Distance?
In case you have two vectors A(X1,Y1) and B(X2,Y2), the Euclidean distance is calculated by the following formula:
It is like using a ruler to measure the distance between two points (the red line in the chart above).
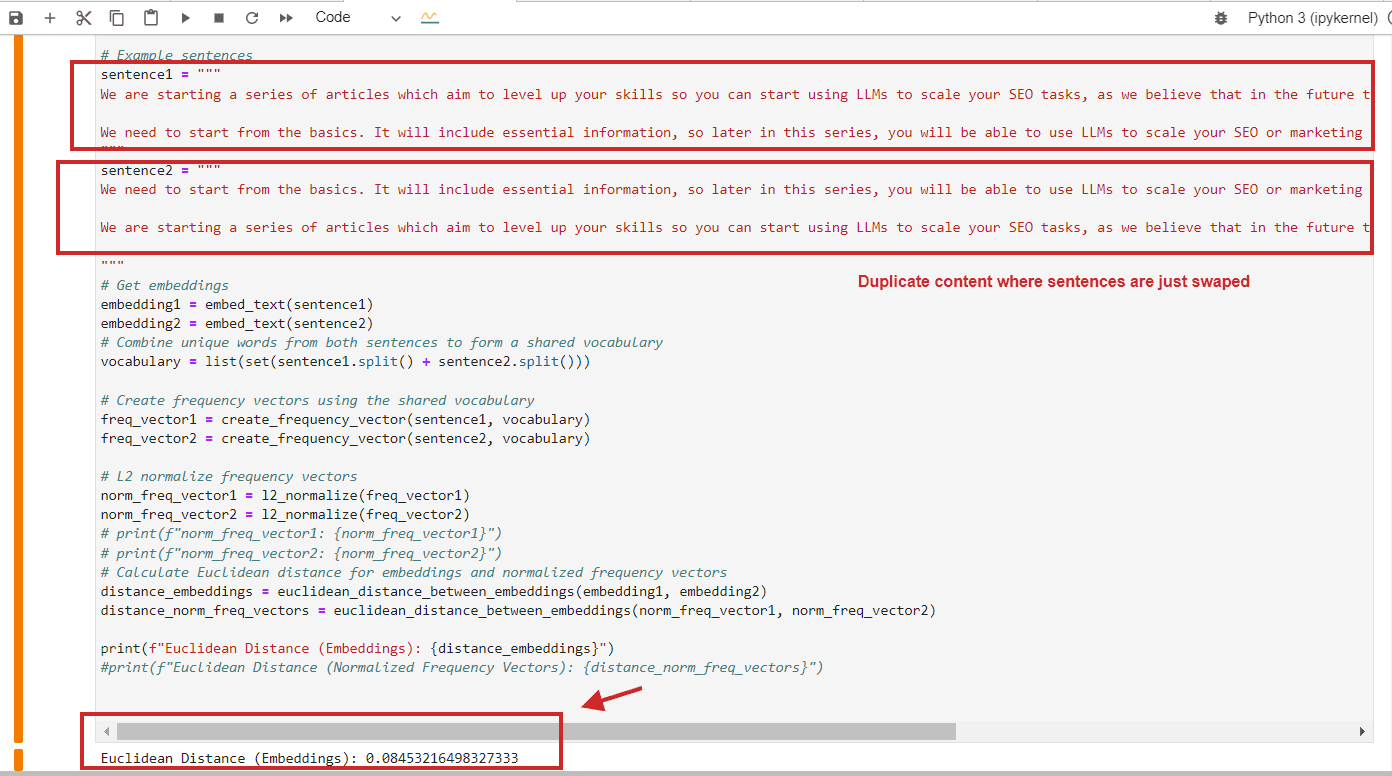
Euclidean distance can be used for the following SEO tasks:
Here is an example of Euclidean distance calculation with a value of 0.08, nearly close to 0, for duplicate content where paragraphs are just swapped – meaning the distance is 0, i.e., the content we compare is the same.
Euclidean distance calculation example of duplicate content
Of course, you can use cosine similarity, and it will detect duplicate content with cosine similarity 0.9 out of 1 (almost identical).
Here is a key point to remember: You should not merely rely on cosine similarity but use other methods, too, as Netflix’s research paper suggests that using cosine similarity can lead to meaningless “similarities.”
We show that cosine similarity of the learned embeddings can in fact yield arbitrary results. We find that the underlying reason is not cosine similarity itself, but the fact that the learned embeddings have a degree of freedom that can render arbitrary cosine-similarities.
As an SEO professional, you don’t need to be able to fully comprehend that paper, but remember that research shows that other distance methods, such as the Euclidean, should be considered based on the project needs and outcome you get to reduce false-positive results.
What Is L2 Normalization?
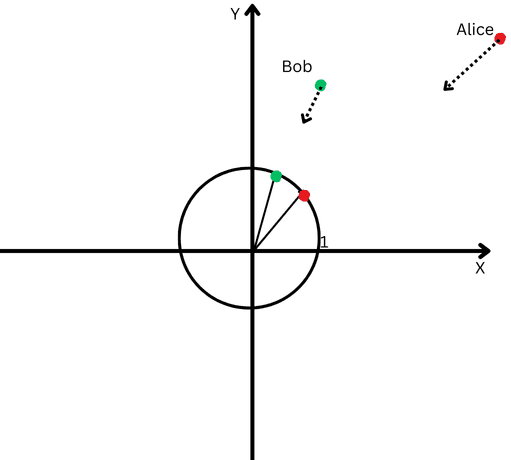
L2 normalization is a mathematical transformation applied to vectors to make them unit vectors with a length of 1.
To explain in simple terms, let’s say Bob and Alice walked a long distance. Now, we want to compare their directions. Did they follow similar paths, or did they go in completely different directions?
“Alice” is represented by a red dot in the upper right quadrant, and “Bob” is represented by a green dot.
However, since they are far from their origin, we will have difficulty measuring the angle between their paths because they have gone too far.
On the other hand, we can’t claim that if they are far from each other, it means their paths are different.
L2 normalization is like bringing both Alice and Bob back to the same closer distance from the starting point, say one foot from the origin, to make it easier to measure the angle between their paths.
Now, we see that even though they are far apart, their path directions are quite close.
A Cartesian plane with a circle centered at the origin.
This means that we’ve removed the effect of their different path lengths (a.k.a. vectors magnitude) and can focus purely on the direction of their movements.
In the context of text embeddings, this normalization helps us focus on the semantic similarity between texts (the direction of the vectors).
Most of the embedding models, such as OpeanAI’s ‘text-embedding-3-large’ or Google Vertex AI’s ‘text-embedding-preview-0409’ models, return pre-normalized embeddings, which means you don’t need to normalize.
But, for example, BERT model ‘bert-base-uncased’ embeddings are not pre-normalized.
Conclusion
This was the introductory chapter of our series of articles to familiarize you with the jargon of LLMs, which I hope made the information accessible without needing a PhD in mathematics.
If you still have trouble memorizing these, don’t worry. As we cover the next sections, we will refer to the definitions defined here, and you will be able to understand them through practice.
The next chapters will be even more interesting:
Introduction To OpenAI’s Text Embeddings With Examples.
Introduction To Google’s Vertex AI Text Embeddings With Examples.
Introduction To Vector Databases.
How To Use LLM Embeddings For Internal Linking.
How To Use LLM Embeddings For Implementing Redirects At Scale.
Putting It All Together: LLMs-Based WordPress Plugin For Internal Linking.
Many of you may say that there are tools you can buy that do these types of things automatically, but those tools will not be able to perform many specific tasks based on your project needs, which require a custom approach.
Using SEO tools is always great, but having skills is even better!
Bluehost launched an AI Website Creator that enables users to quickly create professional websites, an evolution of the click and build website builder that makes it easy for anyone to create a WordPress website and benefit from the power and freedom of the open source community.
The importance of what this means for businesses and agencies cannot be overstated because it allows agencies to scale WordPress site creation and puts the ability to create professional WordPress sites within reach of virtually everyone.
Point And Click Website Creation
Bluehost offers an easy website building experience that provides the ease of point and click site creation with the freedom of a the WordPress open source content management system. The heart of this system is called WonderSuite.
WonderSuite is comprised of multiple components, such as a user interface that walks a user through the site creation process with a series of questions that are used as part of the site creation process. There is also a library of patterns, templates, and an easy to configure shopping cart, essentially all the building blocks for creating a site and doing business online quickly and easily.
The new AI Website Creator functionality is the newest addition to the WonderSuite site builder.
AI Website Builder
An AI website builder is the natural evolution of the point and click site creation process. Rather than moving a cursor around on a screen the new way to build a website is with an AI that acts as a designer that responds to what a user’s website needs are.
The AI asks questions and starts building the website using open source WordPress components and plugins. Fonts, professional color schemes, and plugins are all installed as needed, completely automatically. Users can also save custom generated options for future use which should be helpful for agencies that need to scale client website creation.
Ed Jay, President of Newfold Digital, the parent company of Bluehost, commented:
“Efficiency and ease are what WordPress entrepreneurs and professionals need and our team at Bluehost is dedicated to deliver these essentials to all WordPress users across the globe. With AI Website Creator, any user can rely on the Bluehost AI engine to create their personalized website in just minutes. After answering a few simple questions, our AI algorithm leverages our industry leading WordPress experience, features and technology, including all aspects of WonderSuite, to anticipate the website’s needs and ensure high quality outcomes.
The AI Website Creator presents users with multiple fully functional, tailored and customizable website options that provide a powerful but flexible path forward. It even generates images and content aligned with the user’s brief input, expediting the website off the ground and ready for launch.”
Future Of Website Creation
Bluehost’s innovative AI site creator represents the future of how businesses get online and how entrepreneurs who service clients can streamline site creation and scale their business with WordPress.
Read more about Bluehost’s new AI Website Creator: