A major AI training data set contains millions of examples of personal data
Millions of images of passports, credit cards, birth certificates, and other documents containing personally identifiable information are likely included in one of the biggest open-source AI training sets, new research has found.
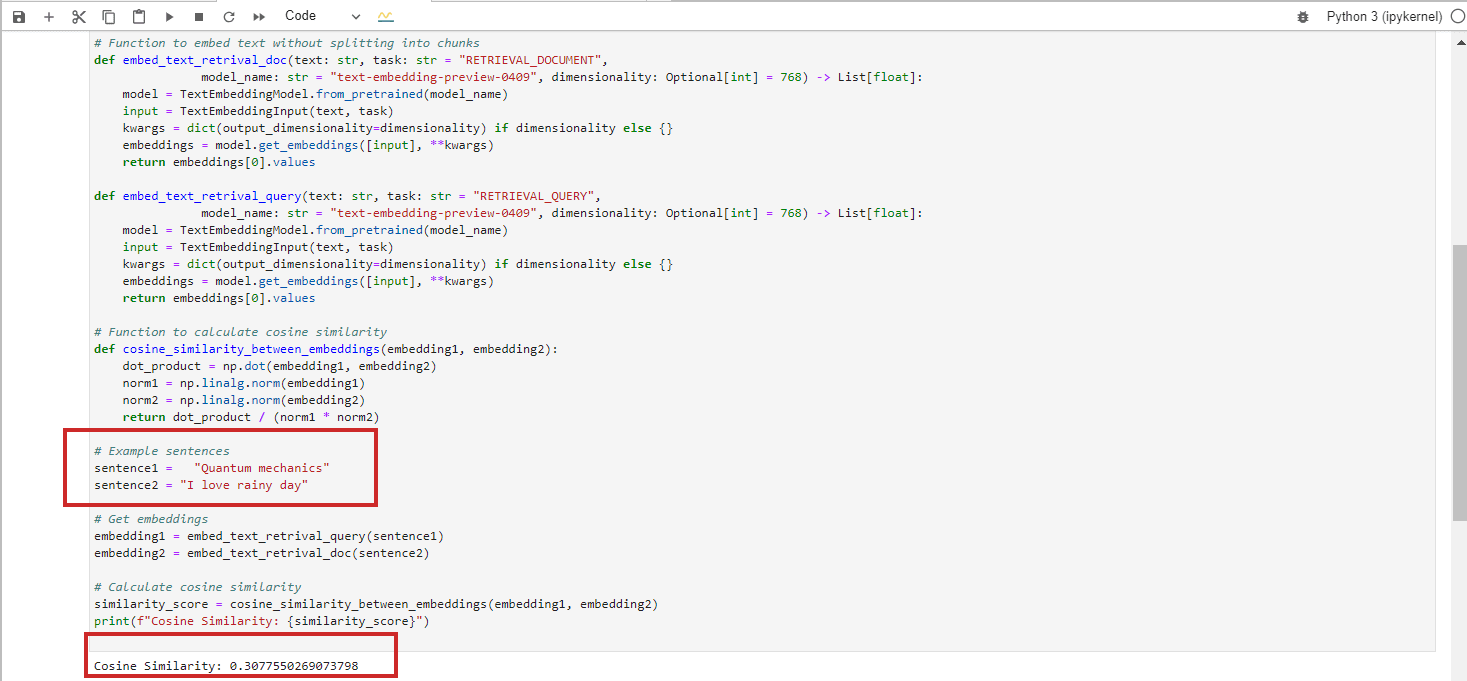
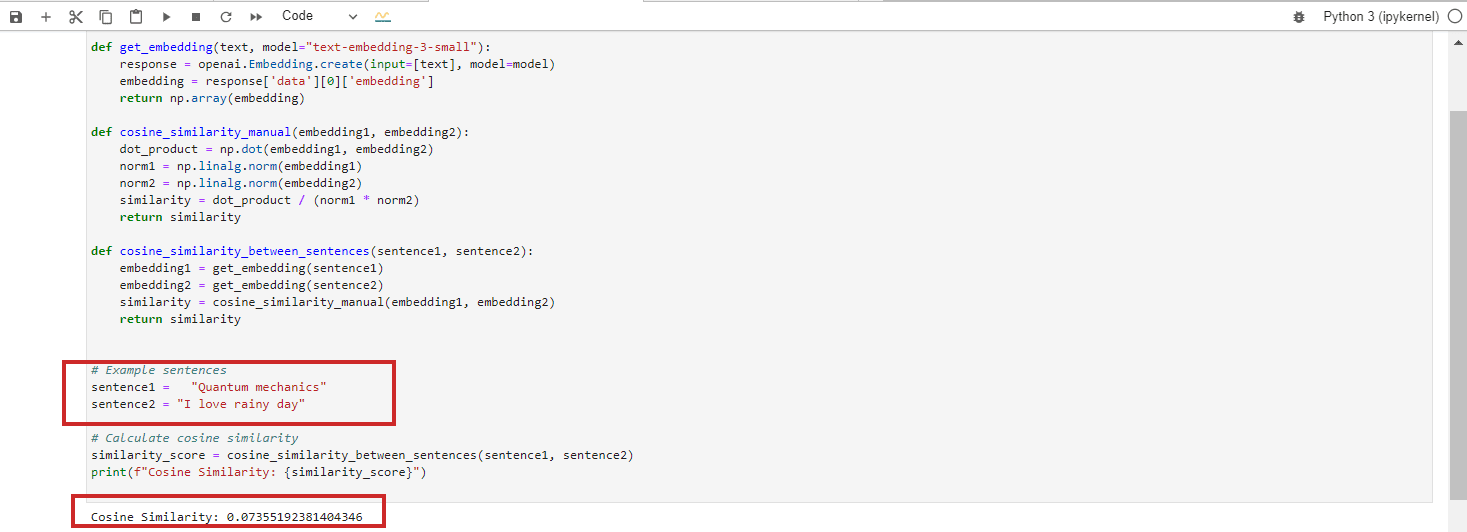
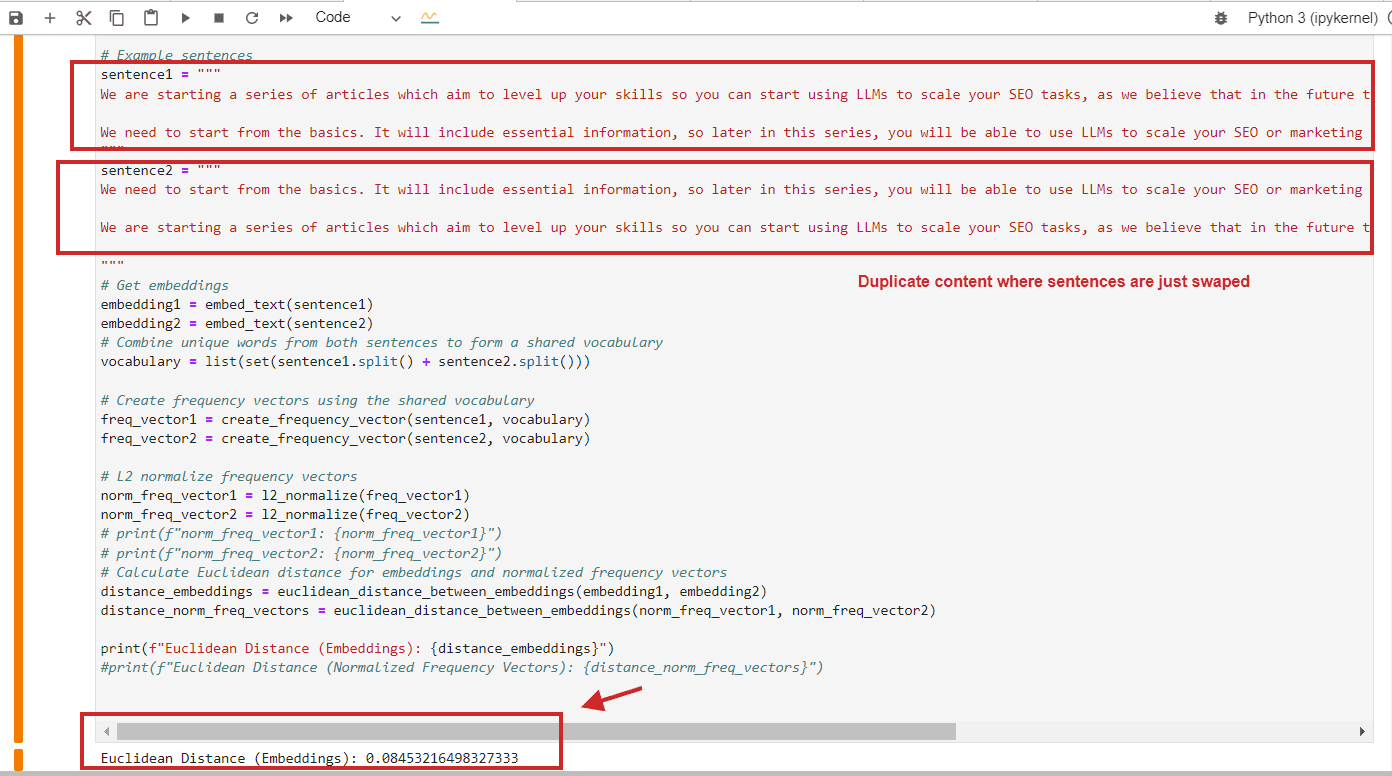
Thousands of images—including identifiable faces—were found in a small subset of DataComp CommonPool, a major AI training set for image generation scraped from the web. Because the researchers audited just 0.1% of CommonPool’s data, they estimate that the real number of images containing personally identifiable information, including faces and identity documents, is in the hundreds of millions. The study that details the breach was published on arXiv earlier this month.
The bottom line, says William Agnew, a postdoctoral fellow in AI ethics at Carnegie Mellon University and one of the coauthors, is that “anything you put online can [be] and probably has been scraped.”
The researchers found thousands of instances of validated identity documents—including images of credit cards, driver’s licenses, passports, and birth certificates—as well as over 800 validated job application documents (including résumés and cover letters), which were confirmed through LinkedIn and other web searches as being associated with real people. (In many more cases, the researchers did not have time to validate the documents or were unable to because of issues like image clarity.)
A number of the résumés disclosed sensitive information including disability status, the results of background checks, birth dates and birthplaces of dependents, and race. When résumés were linked to people with online presences, researchers also found contact information, government identifiers, sociodemographic information, face photographs, home addresses, and the contact information of other people (like references).
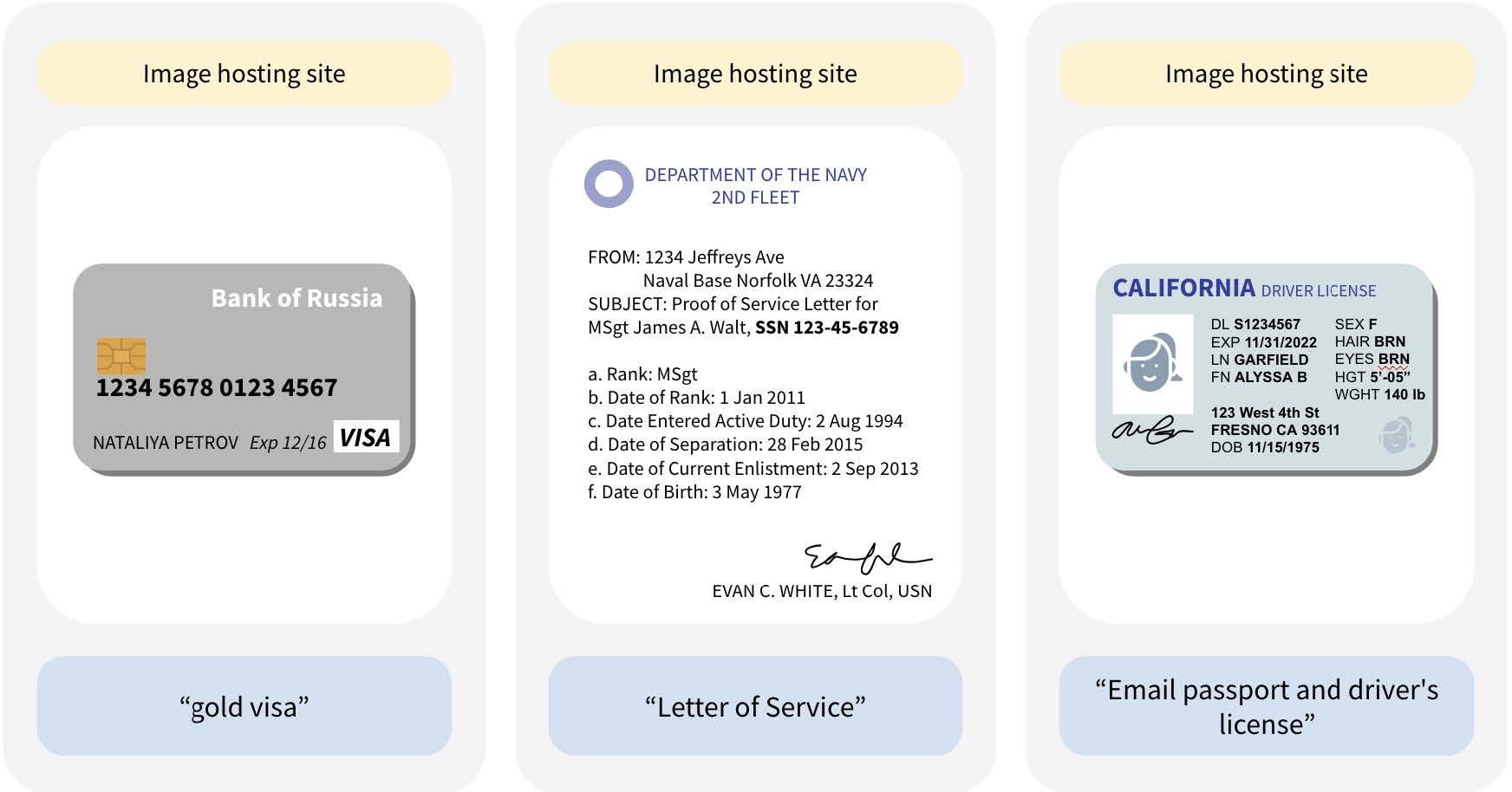
When it was released in 2023, DataComp CommonPool, with its 12.8 billion data samples, was the largest existing data set of publicly available image-text pairs, which are often used to train generative text-to-image models. While its curators said that CommonPool was intended for academic research, its license does not prohibit commercial use as well.
CommonPool was created as a follow-up to the LAION-5B data set, which was used to train models including Stable Diffusion and Midjourney. It draws on the same data source: web scraping done by the nonprofit Common Crawl between 2014 and 2022.
While commercial models often do not disclose what data sets they are trained on, the shared data sources of DataComp CommonPool and LAION-5B mean that the data sets are similar, and that the same personally identifiable information likely appears in LAION-5B, as well as in other downstream models trained on CommonPool data. CommonPool researchers did not respond to emailed questions.
And since DataComp CommonPool has been downloaded more than 2 million times over the past two years, it is likely that “there [are]many downstream models that are all trained on this exact data set,” says Rachel Hong, a PhD student in computer science at the University of Washington and the paper’s lead author. Those would duplicate similar privacy risks.
Good intentions are not enough
“You can assume that any large-scale web-scraped data always contains content that shouldn’t be there,” says Abeba Birhane, a cognitive scientist and tech ethicist who leads Trinity College Dublin’s AI Accountability Lab—whether it’s personally identifiable information (PII), child sexual abuse imagery, or hate speech (which Birhane’s own research into LAION-5B has found).
Indeed, the curators of DataComp CommonPool were themselves aware it was likely that PII would appear in the data set and did take some measures to preserve privacy, including automatically detecting and blurring faces. But in their limited data set, Hong’s team found and validated over 800 faces that the algorithm had missed, and they estimated that overall, the algorithm had missed 102 million faces in the entire data set. On the other hand, they did not apply filters that could have recognized known PII character strings, like emails or Social Security numbers.
“Filtering is extremely hard to do well,” says Agnew. “They would have had to make very significant advancements in PII detection and removal that they haven’t made public to be able to effectively filter this.”
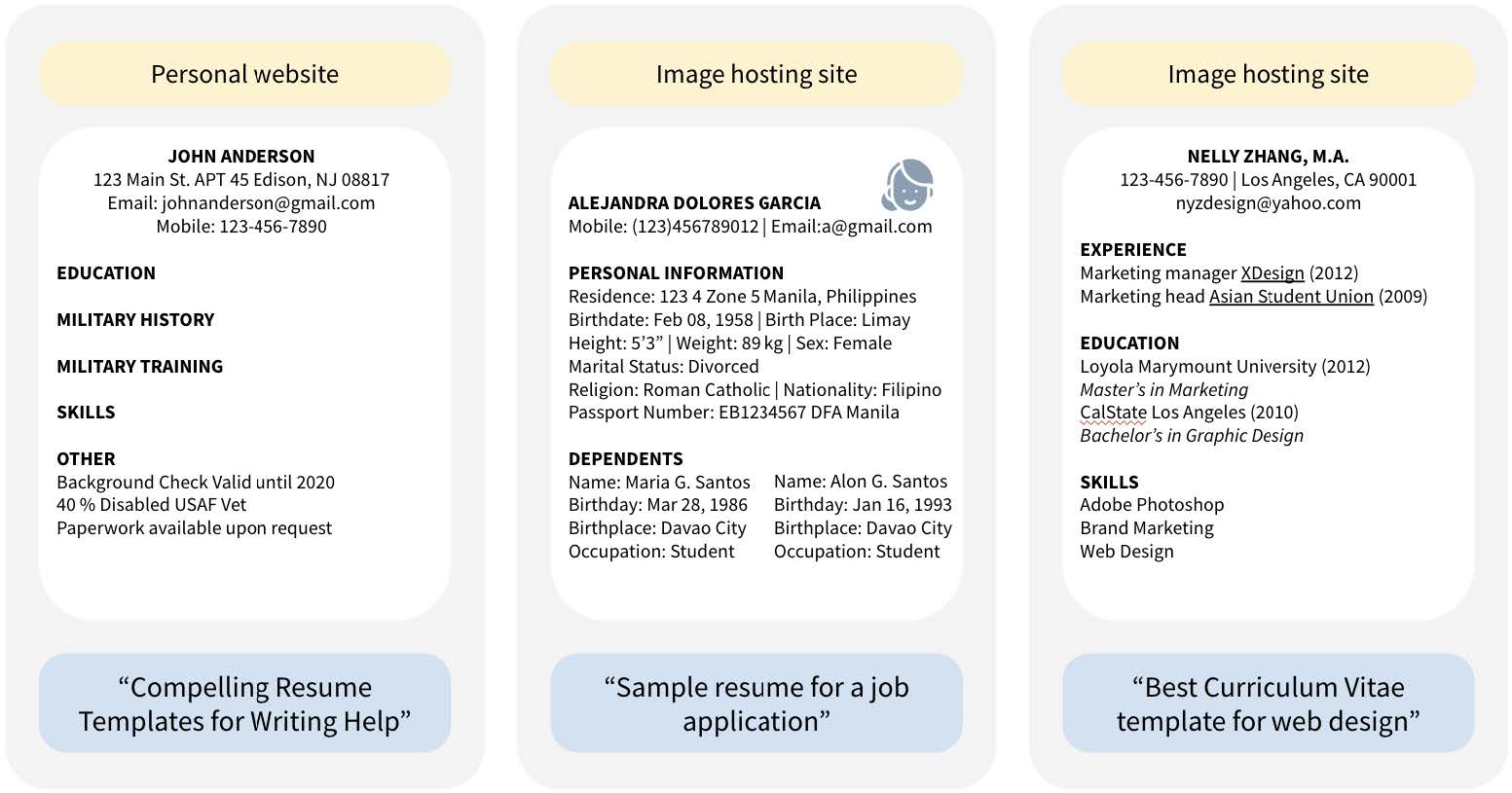
There are other privacy issues that the face blurring doesn’t address. While the blurring filter is automatically applied, it is optional and can be removed. Additionally, the captions that often accompany the photos, as well as the photos’ metadata, often contain even more personal information, such as names and exact locations.
Another privacy mitigation measure comes from Hugging Face, a platform that distributes training data sets and hosts CommonPool, which integrates with a tool that theoretically allows people to search for and remove their own information from a data set. But as the researchers note in their paper, this would require people to know that their data is there to start with. When asked for comment, Florent Daudens of Hugging Face said that “maximizing the privacy of data subjects across the AI ecosystem takes a multilayered approach, which includes but is not limited to the widget mentioned,” and that the platform is “working with our community of users to move the needle in a more privacy-grounded direction.”
In any case, just getting your data removed from one data set probably isn’t enough. “Even if someone finds out their data was used in a training data sets and … exercises their right to deletion, technically the law is unclear about what that means,” says Tiffany Li, an associate professor of law at the University of San Francisco School of Law. “If the organization only deletes data from the training data sets—but does not delete or retrain the already trained model—then the harm will nonetheless be done.”
The bottom line, says Agnew, is that “if you web-scrape, you’re going to have private data in there. Even if you filter, you’re still going to have private data in there, just because of the scale of this. And that’s something that we [machine-learning researchers], as a field, really need to grapple with.”
Reconsidering consent
CommonPool was built on web data scraped between 2014 and 2022, meaning that many of the images likely date to before 2020, when ChatGPT was released. So even if it’s theoretically possible that some people consented to having their information publicly available to anyone on the web, they could not have consented to having their data used to train large AI models that did not yet exist.
And with web scrapers often scraping data from each other, an image that was originally uploaded by the owner to one specific location would often find its way into other image repositories. “I might upload something onto the internet, and then … a year or so later, [I] want to take it down, but then that [removal] doesn’t necessarily do anything anymore,” says Agnew.
The researchers also found numerous examples of children’s personal information, including depictions of birth certificates, passports, and health status, but in contexts suggesting that they had been shared for limited purposes.
“It really illuminates the original sin of AI systems built off public data—it’s extractive, misleading, and dangerous to people who have been using the internet with one framework of risk, never assuming it would all be hoovered up by a group trying to create an image generator,” says Ben Winters, the director of AI and privacy at the Consumer Federation of America.
Finding a policy that fits
Ultimately, the paper calls for the machine-learning community to rethink the common practice of indiscriminate web scraping and also lays out the possible violations of current privacy laws represented by the existence of PII in massive machine-learning data sets, as well as the limitations of those laws’ ability to protect privacy.
“We have the GDPR in Europe, we have the CCPA in California, but there’s still no federal data protection law in America, which also means that different Americans have different rights protections,” says Marietje Schaake, a Dutch lawmaker turned tech policy expert who currently serves as a fellow at Stanford’s Cyber Policy Center.
Besides, these privacy laws apply to companies that meet certain criteria for size and other characteristics. They do not necessarily apply to researchers like those who were responsible for creating and curating DataComp CommonPool.
And even state laws that do address privacy, like California’s consumer privacy act, have carve-outs for “publicly available” information. Machine-learning researchers have long operated on the principle that if it’s available on the internet, then it is public and no longer private information, but Hong, Agnew, and their colleagues hope that their research challenges this assumption.
“What we found is that ‘publicly available’ includes a lot of stuff that a lot of people might consider private—résumés, photos, credit card numbers, various IDs, news stories from when you were a child, your family blog. These are probably not things people want to just be used anywhere, for anything,” says Hong.
Hopefully, Schaake says, this research “will raise alarm bells and create change.”
This article previously misstated Tiffany Li’s affiliation. This has been fixed.