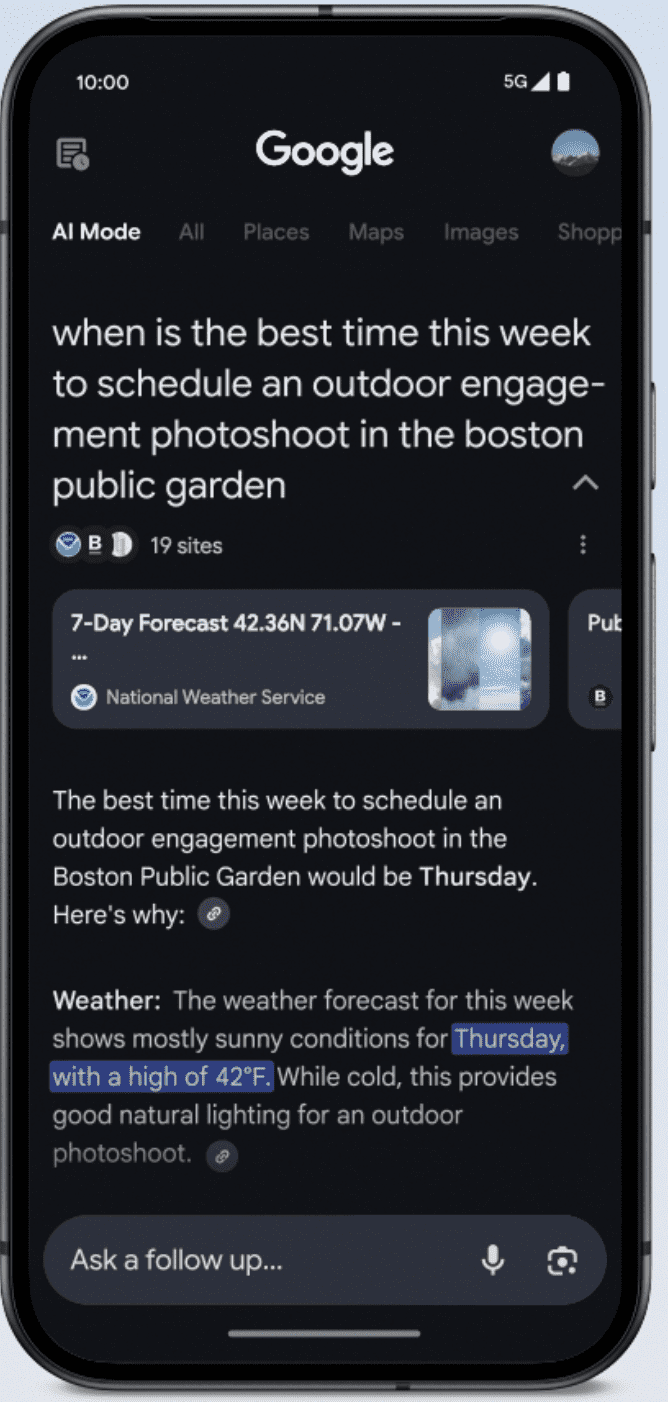
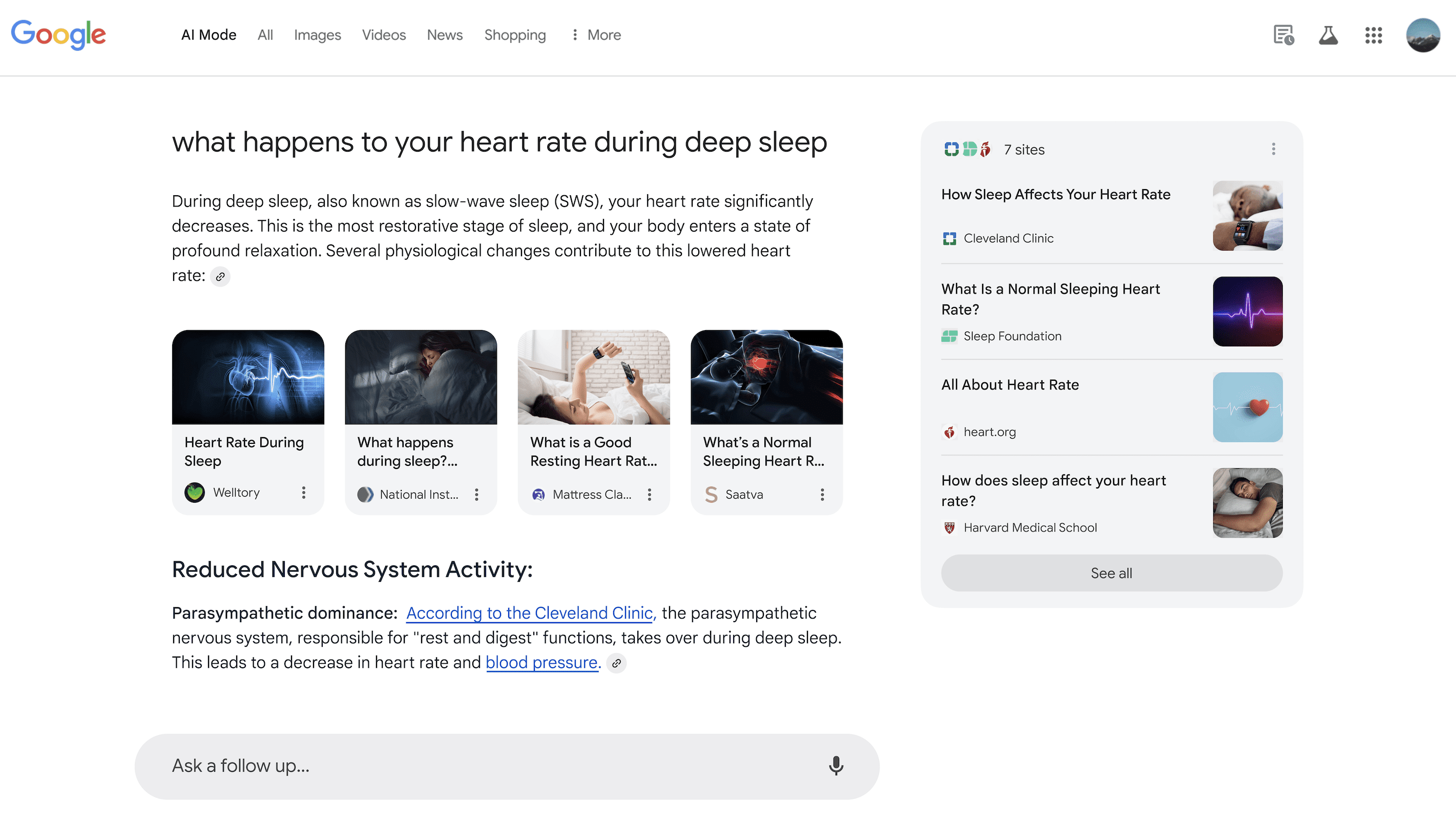
A new trend in Silicon Valley, Vibe Coding, is driving an exponential acceleration in how quickly engineers can develop products and algorithms. This approach aligns with principles outlined by Google co-founder Sergey Brin in a recent email to DeepMind engineers.
Top Silicon Valley insiders call Vibe Coding the “dominant way to code,” and Brin’s message suggests that Google will embrace it to dramatically speed up AI development. Given its potential, this approach may also extend to Google’s search algorithms, leading to more changes to how search results are ranked.
Vibe Coding Is Here To Stay
The four Y Combinator executives agreed that vibe coding is a very big deal but were surprised at how fast it has overtaken the industry. Jarede Friedman observed that it’s like something out of the fairy tale Jack and the Beanstalk, where the world-changing magic beans sprout into gigantic beanstalks over night.
Garry Tan agreed, saying:
“I think our sense right now is this isn’t a fad. This isn’t going away. This is actually the dominant way to code, and if you’re not doing it, you might be left behind. This is here to stay.”
What Is Vibe Coding?
Vibe coding is software engineering with AI:
- Software engineers use AI to generate code rather than writing it manually.
- Rely on natural language prompts to guide software development.
- Prioritize speed and iteration.
- Time isn’t spent on debugging as code is simply regenerated until it works.
- Vibe coding shifts software engineering focus from writing code to choosing what kinds of problems to solve.
- Leverage AI for rapid code regeneration instead of traditional debugging.
- It is exponentially speeding up coding.
Vibe coding is a way creating code with AI with an emphasis on speed. That means it’s increasingly less necessary to debug code because an engineer can simply re-roll the code generations multiple times until the AI gets it right.
A recent tweet by Andrej Karpathy kicked off a wave of excitement in Silicon Valley. Karpathy, a prominent AI researcher and former director of AI at Tesla, described what Vibe Coding is and explained why it’s the fastest way to code with AI. It’s so reliable that he doesn’t even check the modifications the AI makes (referred to as “diffs”).
Karpathy tweeted:
“There’s a new kind of coding I call “vibe coding”, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It’s possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good.
Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like “decrease the padding on the sidebar by half” because I’m too lazy to find it. I “Accept All” always, I don’t read the diffs anymore.
When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I’d have to really read through it for a while.
Sometimes the LLMs can’t fix a bug so I just work around it or ask for random changes until it goes away. It’s not too bad for throwaway weekend projects, but still quite amusing.
I’m building a project or webapp, but it’s not really coding – I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.”
Sergey Brin Emphasizes Vibe Coding Principles
A recent email from Google co-founder Sergey Brin to DeepMind engineers emphasized the need to integrate AI into their workflow to reduce time spent on coding. The email states that code matters most and that AI will improve itself, advising that if it’s simpler to prompt an AI for a solution, then that’s preferable to training an entirely new model. Brin describes this as highly important for becoming efficient coders. These principles align with Vibe Coding, which prioritizes speed, simplicity, and AI-driven development.
Brin also recommends using first-party code (code developed by Google) instead of relying on open-source or third-party software. This strongly suggests that Google intends to keep its AI advancements proprietary rather than open-source. That may mean any advancements created by Google will not be open-sourced and may not show up in research papers but instead may be discoverable through patent filings.
Brin’s message de-emphasizes the use of LoRA, a machine learning technique used to fine-tune AI models efficiently. This implies that he wants DeepMind engineers to prioritize efficient workflows rather than spending excessive time fine-tuning models. This also suggests that Google is shifting focus toward simpler, more scalable approaches like vibe coding which rely on prompt engineering.
Sergey Brin wrote:
“Code matters most — AGI will happen with takeoff, when the Al improves itself. Probably initially it will be with a lot of human help so the most important is our code performance. Furthermore this needs to work on our own 1p code. We have to be the most efficient coder and Al scientists in the world by using our own Al.
Simplicity — Lets use simple solutions where we can. Eg if prompting works, just do that, don’t posttrain a separate model. No unnecessary technical complexities (such as lora). Ideally we will truly have one recipe and one model which can simply be prompted for different uses.
Speed — we need our products, models, internal tools to be fast. Can’t wait 20 minutes to run a bit of python on borg.”
Those statements align with the principles of vibe coding so it’s important to understand what it is and how it may affect how Google develops search algorithms and AI which may be used for the purposes of ranking websites.
Software Engineers Transitioning To Product Engineers
A recent podcast by Y Combinator, a Silicon Valley startup accelerator company, discussed how vibe coding is changing what it means to be a software engineer and how it will affect hiring practices.
The podcast hosts quoted multiple people:
Leo Paz, Founder of Outlit observed:
“I think the role of Software Engineer will transition to Product Engineer. Human taste is now more important than ever as codegen tools make everyone a 10x engineer.”
Abhi Aiyer of Mastra shared how their coding practices changed:
“I don’t write code much. I just think and review.”
One of the podcast hosts, Jarede Friedman, Managing Partner, Y Combinator said:
“This is a super technical founder who’s last company was also a dev tool. He’s extremely able to code and so it’s fascinating to have people like that saying things like this.
They next quoted Abhi Balijepalli of Copycat:
“I am far less attached to my code now, so my decisions on whether we decide to scrap or refactor code are less biased. Since I can code 3 times as fast, it’s easy for me to scrap and rewrite if I need to.”
Garry Tan, President & CEO, Y Combinator commented:
“I guess the really cool thing about this stuff is it actually parallelizes really well.”
He quoted Yoav Tamir of Casixty:
“I write everything with Cursor. Sometimes I even have two windows of Cursor open in parallel and I prompt them on two different features.”
Tan commented on how much sense that makes and why not have three instances of Cursor open in order to accomplish even more.
The panelists on the podcast then cited Jackson Stokes of Trainloop who explains the exponential scale of how fast coding has become:
“How coding has changed six to one months ago: 10X speedup. One month ago to now: 100X speedup. Exponential acceleration. I’m no longer an engineer, I’m a product person.”
Garry Tan commented:
“I think that might be something that’s happening broadly. You know, it really ends up being two different roles you need. It actually maps to how engineers sort of self assign today, in that either you’re front-end or backend. And then backend ends up being about actually infrastructure and then front-end is so much more actually being a PM (product manager)…”
Harj Taggar, Managing Partner, Y Combinator observed that the LLMs are going to push people to the role of making choices, that the actual writing of the code will become less important.
Why Debugging With AI Is Unnecessary
An interesting wrinkle in Code Vibing is that one of the ways it speeds up development is that software engineers no longer have to spend long hours debugging. In fact, they don’t have to debug anymore. This means that they are able to push code out the door faster than ever before.
Tan commented on how poor AI is at debugging:
“…one thing the survey did indicate is that this stuff is terrible at debugging. And so… the humans have to do the debugging still. They have to figure out well, what is the code actually doing?
There doesn’t seem to be a way to just tell it, debug. You were saying that you have to be very explicit, like as if giving instructions to a first time software engineer.”
Jarede offered his observation on AI’s ability to debug:
“I have to really spoon feed it the instructions to get it to debug stuff. Or you can kind of embrace the vibes. I’d say Andrej Karpathy style, sort of re-roll, just like tell it to try again from scratch.
It’s wild how your coding style changes when actually writing the code becomes a 1000x cheaper. Like, as a human you would never just like blow away something that you’d worked on for a very long time and rewrite from scratch because you had a bug. You’d always fix the bug. But for the LLM, if you can just rewrite a thousand lines of code in just six seconds, like why not?”
Tan observed that it’s like how people use AI image generators where if there’s something they don’t like they just reiterate without even changing the prompt, they just simply click re-roll five times and then at the fifth time it works.
Vibe Coding And Google’s Search Algorithms
While Sergey Brin’s email does not explicitly mention search algorithms, it advocates AI-driven, prompt-based development at scale and high speed. Since Vibe Coding is now the dominant way to code, it is likely that Google will adopt this methodology across its projects, including the development of future search algorithms.
Watch the Y Combinator Video Roundtable
Vibe Coding Is The Future
Featured Image by Shutterstock/bluestork