Google has updated its Business Profile rules for service-area businesses that sell age-restricted products.
Now, businesses selling alcohol, cannabis, weapons, and similar items must have a physical storefront to maintain their Google Business Profile.
We were alerted to this update by Stefan Somborac on X:
Google actually uses the phrase “Businesses associated with…” not “Businesses selling…”, which significantly broadens how this new change can be applied.
“Businesses associated with products or services that require the customer to be a certain minimum age, like alcohol, cannabis, or weapons, aren’t permitted as service-area businesses without a storefront.”
This is a notable change in how Google handles business listings for delivery and mobile services.
The policy outlines two main types of businesses:
Service-area businesses: These companies deliver to customers but do not have a physical business location.
Hybrid businesses: These operations have a physical location and offer delivery or mobile services.
Service Area Limitations
Google maintains its existing restrictions on service areas, including:
A maximum of 20 service areas per business
Service boundaries limited to approximately 2 hours of driving time from the business base
Service areas must be defined by city, postal code, or specific geographic region rather than radius
Impact On Businesses
This update affects certain types of businesses:
Mobile alcohol delivery services
Cannabis delivery services
Weapons dealers without a physical store
Vendors of age-restricted products that only deliver
The new rules require these businesses to have a physical storefront to keep their Google Business Profiles.
This change aims to ensure proper age checks and compliance with sensitive product and service regulations.
What This Means
The policy update addresses concerns about selling age-restricted products through delivery-only businesses.
This change mainly impacts new delivery services for cannabis and alcohol, which have grown in some cities.
Google Search’s market share in the UK weakened this year, with user reach dropping to 83% from 86%, according to Ofcom’s Online Nation report.
This decline comes as concerns grow over AI-powered search results, with only 18% of users confident in their accuracy.
The Rise & Fall of AI Search Adoption
Microsoft’s Bing gained popularity after adding ChatGPT in February 2023, peaking at 46% reach in the UK in April.
By May 2024, it settled at 39%, still above pre-AI levels.
This suggests the initial excitement about AI search tools is fading, and users are now more cautious with AI-generated results.
Trust Gap Emerges
Despite the widespread adoption of AI search features, trust remains a concern:
Only 18% of UK users believe AI search results are reliable
Younger users (ages 16-24) show marginally higher trust at 21%
A third of users express neutral confidence in AI-generated results
Men show higher confidence in AI search results than women
Demographics & Device Usage
The report reveals variations in search behavior across age groups and devices:
Google maintains 83% reach across smartphones, tablets, and computers
Google maintains 49% daily active users
Bing sees 39% reach, primarily driven by desktop users
Alternative search engines like DuckDuckGo show modest growth (3% reach)
Bing shows stronger performance among older users (43% of 65+ vs. 36% of 25-34-year-olds)
Mobile search dominates, with Google capturing 84% of mobile searches
Desktop usage remains stronger for traditional search engines like Bing and Yahoo
69% of UK online adults visit at least one search engine daily.
What This Means
As we approach 2025, search is changing with AI integration, but user trust remains essential.
Key points for search marketers and content creators include:
Many users still prefer traditional search methods despite the rise of AI.
Trust issues create both challenges and opportunities for content improvement.
Different age groups affect how people accept and use AI in search.
A successful strategy blends AI tools with established methods.
View AI search as an added layer rather than a replacement for current practices.
Focus on quality content and reliable information, optimizing for AI wisely where it adds value.
Methodology
The Online Nation 2024 report combines two main data sources:
Online Experiences Tracker:
7,280 UK internet users aged 13-84
Fielded May-June 2024 via YouGov panel
Standard demographic weighting applied
Ipsos iris Panel Data:
Passive tracking of 10,700 UK adults
Monitors actual device usage across mobile, tablet, and desktop
Continuous measurement through May 2024
Covers in-home and out-of-home usage
Worth noting: Some year-over-year comparisons, particularly around time spent metrics, may be affected by methodology updates. Apple News tracking began in October 2023, which impacts certain platform comparisons.
The data focuses on UK users, so global markets may show different patterns. All population estimates have standard margins of error.
YouTube is enhancing its Inspiration Tab, a tool for creators to understand their audience and improve content.
In a video demonstration, the company previewed new AI features that will launch in the coming months.
Initially a research tool, the Inspiration Tab now helps creators identify audience interests and content gaps.
The new AI features are designed to boost creativity and streamline content creation.
Personalized Ideas and Audience Insights
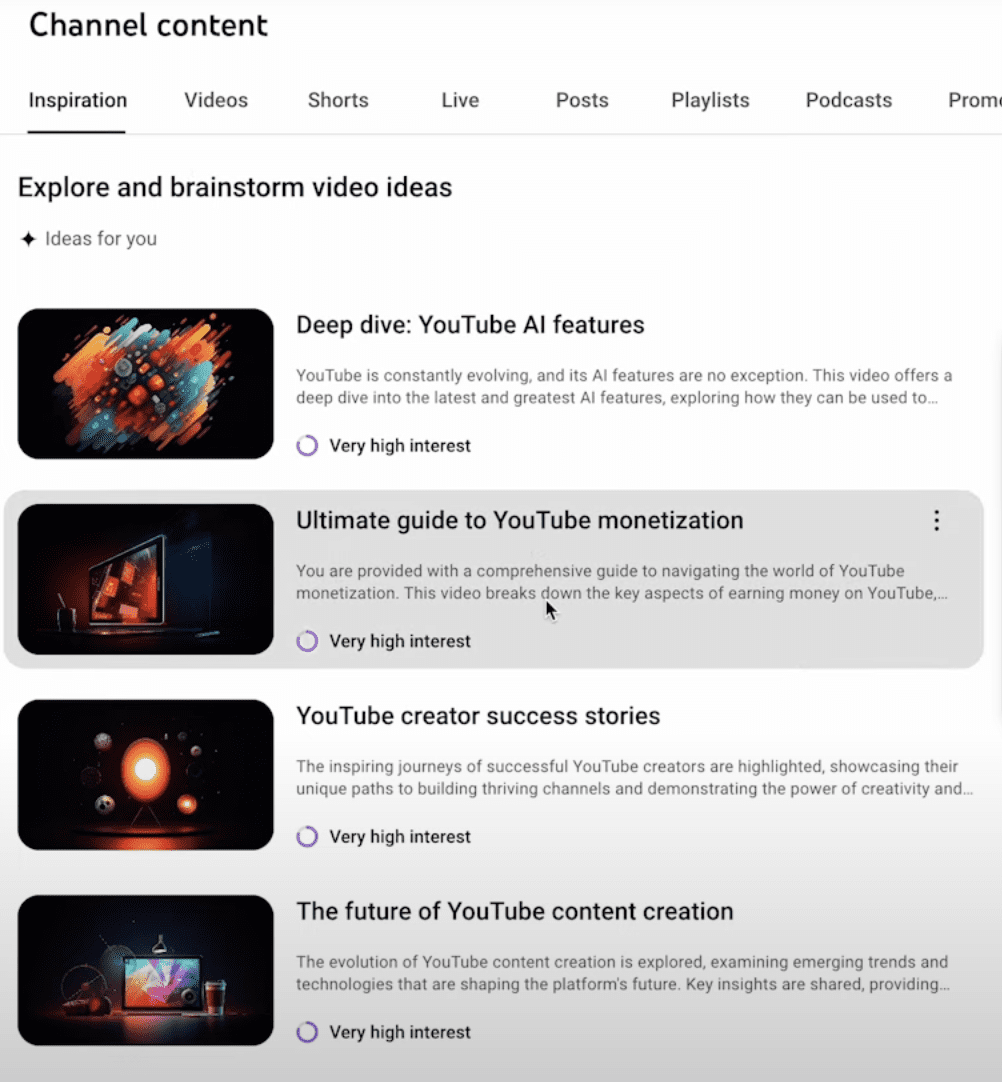
You’ll find five tailored ideas for your channel in the updated Inspiration Tab.
Screenshot from: YouTube.com/CreatorInsider, Nov 2024.
Each idea includes a thumbnail, title, summary, and audience interest insights, helping you see how well it fits your audience.
You can also input any topic as a text prompt, and the AI will generate ideas based on your request.
Screenshot from: YouTube.com/CreatorInsider, Nov 2024.
In the Idea Playground, you can personalize your idea by exploring different angles.
Choose from suggested angles or enter your own prompt.
The Playground also offers undo and redo options, so you don’t lose your work.
Screenshot from: YouTube.com/CreatorInsider, Nov 2024.
Screenshot from: YouTube.com/CreatorInsider, Nov 2024.
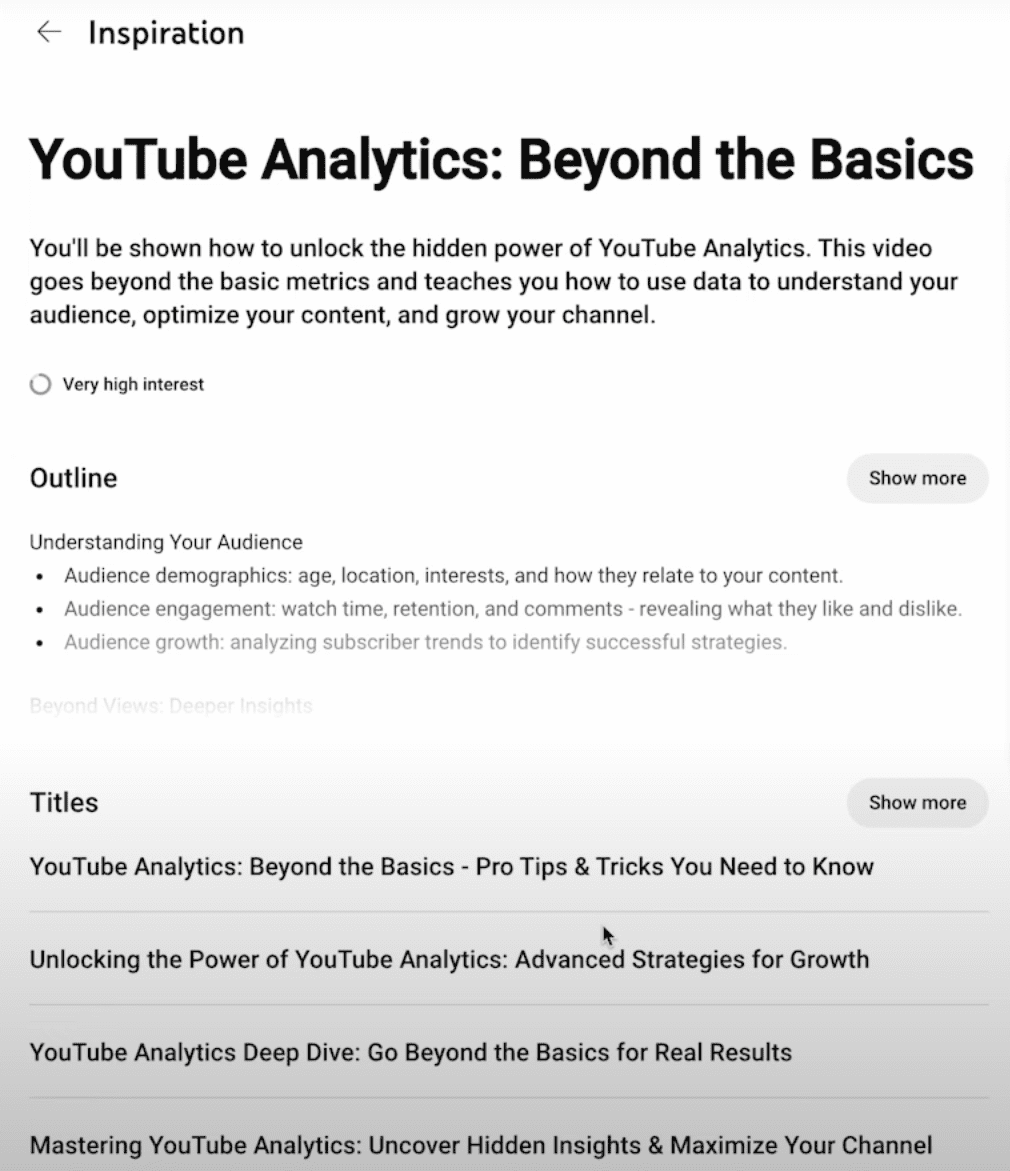
You can access outlines and thumbnails in the Playground. The AI will suggest ways to adjust your talking points. You can modify the entire outline or focus on specific sections.
Similar options are available for titles and thumbnails. You can download images for use as backgrounds or modify them to visualize before uploading.
Screenshot from: YouTube.com/CreatorInsider, Nov 2024.
Availability
The Inspiration Tab is the updated Trends Tab, formerly the Research Tab. It will be a central hub where you can use AI to brainstorm ideas, outlines, titles, thumbnails, and concepts.
YouTube plans to roll out these features over the next few months. Note that these features are not widely available yet, as YouTube is previewing them to gather creator feedback.
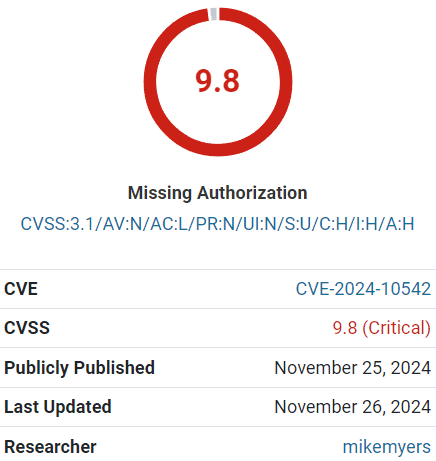
A flaw in a WordPress anti-spam plugin with over 200,000 installations allows rogue plugins to be installed on affected websites. Security researchers rated the vulnerability 9.8 out of 10, reflecting the high level of severity determined by security researchers.
Screenshot Of CleanTalk Vulnerability Severity Rating
A highly rated anti-spam firewall with over 200,000 installations was found to have an authentication bypass vulnerability that enables attackers to gain full access to websites without providing a username or password. The flaw lets attackers upload and install any plugin, including malware, granting them full control of the site.
The flaw in the Spam protection, Anti-Spam, FireWall by CleanTalk plugin, was pinpointed by security researchers at Wordfence as caused by reverse DNS spoofing. DNS is the system that turns an IP address to a domain name. Reverse DNS spoofing is where an attacker manipulates the system to show that it’s coming from a different IP address or domain name. In this case the attackers can trick the Ant-Spam plugin that the malicious request is coming from the website itself and because that plugin doesn’t have a check for that the attackers gain unauthorized access.
This vulnerability is categorized as: Missing Authorization. The Common Weakness Enumeration (CWE) website defines that as:
“The product does not perform an authorization check when an actor attempts to access a resource or perform an action.”
Wordfence explains it like this:
“The Spam protection, Anti-Spam, FireWall by CleanTalk plugin for WordPress is vulnerable to unauthorized Arbitrary Plugin Installation due to an authorization bypass via reverse DNS spoofing on the checkWithoutToken function in all versions up to, and including, 6.43.2. This makes it possible for unauthenticated attackers to install and activate arbitrary plugins which can be leveraged to achieve remote code execution if another vulnerable plugin is installed and activated.”
Recommendation
Wordfence recommends users of the affected plugin to update to version 6.44 or higher.
YouTube’s latest weekly update highlights new creator features, including expanding longer Shorts, launching images on Quiz posts for Android, and broader access to the Brand Connect tab in YouTube Studio.
Longer Shorts Update
YouTube has finished rolling out updates allowing Shorts videos ranging from 1 to 3 minutes to be displayed accordingly in the subscriptions tab, on channel pages, and in YouTube Studio.
These videos have been organized into the Shorts shelf on the subscriptions page and the Shorts tab on both the channel page and YouTube Studio.
Creators wishing their uploads to be classified as long-form videos can do so by uploading in a wider aspect ratio, such as 16:9.
Revamped Video Sharing From Other Apps
YouTube is updating how you share and publish videos from other apps on Android and iOS.
When sharing a video to YouTube from another app, you will now have direct access to Shorts creation tools.
This allows you to trim the video, add details such as captions, set visibility and location, and enhance your video before publishing.
Images On Quiz Posts
YouTube has announced an improvement following the launch of text-based Quiz posts.
You can now optionally add images to the multiple-choice answers in your quizzes.
This feature will initially be available on Android devices, but the image quizzes you create will be accessible to viewers on all devices where Community posts are available.
‘Transform’ and ‘DreamScreen’ For Posts
YouTube is launching two new tools designed to help you improve text input and generate images for posts.
The “Transform” tool allows you to rephrase and customize text while composing a post. The “DreamScreen” tool can help you generate new images based on a prompt.
Initially, these features will only be available in English and will support prompts in English.
Brand Connect Expansion
YouTube’s self-service platform, Brand Connect, is now available to all eligible creators. You can find the Brand Connect tab under the “Earn” section in YouTube Studio.
This tab allows you to sign up and access Brand Connect features. The platform helps you manage accepted brand deals and provides a customizable Media Kit with audience insights.
Open Call Pilot Program
YouTube is testing a new program called “Open Call” until December. This program allows advertisers to ask for custom ads from eligible creators.
Creators can review these requests and submit their content if they want. The goal of this pilot is to make it easier for brands and creators to work together on ad content.
C2PA Disclosure For Camera-Captured Content
YouTube is launching a new feature to help creators show where their content comes from and how authentic it is.
A label that says “Captured with a camera” will appear in the description box when a video is filmed using special technology.
This technology works with cameras that support C2PA version 2.1 or higher, allowing creators to verify their videos.
Looking Ahead
Many of these new features will be global, but some, like AI tools and BrandConnect, are region-specific.
Monitor your YouTube Studio dashboard and official messages for updates on features and rollout.
Google is beginning a test that will change hotel search results for users in Germany, Belgium, and Estonia.
This test will remove features like the map and hotel listings, replacing them with regular blue links to hotel websites and comparison sites.
The experiment will only affect users in these three countries, whether searching locally or internationally.
It won’t impact users outside these countries or when searching for a specific hotel.
Compliance With The Digital Markets Act (DMA)
Google is testing these changes to follow new rules in Europe called the Digital Markets Act (DMA).
In the past year, Google has made over 20 updates. These updates include new sections and formats to make comparison sites for flights, hotels, and shopping more visible.
The results of these changes have been mixed.
Major travel aggregators and comparison sites have gained visibility. However, other businesses, like airlines, hotel operators, and small retailers, have seen a drop in free direct booking clicks by as much as 30%.
Purpose Of The Test
Google will run this test in Germany, Belgium, and Estonia to see how proposed changes affect user experience and website traffic.
Google is hesitant about this decision. The company maintains that reverting to a “ten blue links” format would disadvantage both users and businesses.
Gary Illyes, Analyst at Google, emphasized that the test is temporary and websites need not take any action during the experimental period.
Looking Ahead
The results of this test results could influence future decisions about how search engines operate in Europe and potentially shape regulations worldwide.
Google says normal search functionality will resume after the test concludes, although the timing of the conclusion is unclear.
Automattic cloned WP Engine’s paid ACF Premium plugin and is distributing it for free. Many in the WordPress community disapprove of this action, expressing concerns that it undermines the plugin and theme ecosystem.
Advanced Custom Fields Plugin
Advanced Custom Fields (ACF) is a WordPress plugin that’s popular with WordPress website developers because it enables them to create custom fields that WordPress publishers and authors can use.
Custom fields allows developers to take full control of the editing screens to add things like a form for building structured data specific for a kind of WordPress page like Schema.org markup for ecommerce, news, legal or medical context. A custom field can be used to give article authors a place to enter the author name or a featured quote.
Website developers and use ACF to enable authors to add author bios, featured quotes, or article metadata like publication date, modification data or links to sources. For example, a field for a featured quote can be used so that authors can input what the featured quote says and it’ll appear in the article using all the predefined styling. All the author needs to do is fill in the form and hit the submit button.
ACF was developed by a company named Delicious Brains which was acquired by WP Engine in 2022 which assumed responsibility for developing and updating the free and premium versions.
WordPress Freemium Ecosystem
ACF is popular because it built trust and authoritativeness as a solid plugin through the use of the freemium WordPress business model. Plugin and theme developers use the freemium business model to offer a free version of their software and a premium version that offers additional functionality. Offering a highly functional and useful free version increases the popularity and goodwill of a plugin or theme with basic users and the more advanced users are able to try the functionality of the free version then choose the premium version for the additional features. It can take years to build that goodwill, trust and authoritativeness with users.
The developers of plugins like Yoast and Wordfence spend thousands of hours developing and promoting their free plugins, which are then installed on millions of websites. They put all that effort into the free versions to upsell their premium products.
Timeline: Automattic Forks ACF
In the context of WordPress plugins and themes, the term “forking” refers to the creation of an independent version of an existing WordPress plugin or theme using the source code of the original version to create a different version. Forking is made possible with open source licenses. All plugins and themes that are derivatives of WordPress must be developed with an open source license.
Forking of a theme or plugin sometimes happens when a developer abandons their project and an interested party decides to continue developing their version of the software, a “forked” version of the original.
October 3, 2024 Automattic Releases Independent Updates
Automattic locked ACF plugin out of the WordPress.org servers, preventing ACF customers from updating their versions of the plugin directly from WordPress.org servers, forcing WP Engine to create a workaround on October 3rd.
WP Engine announced:
“On October 3, we released new versions of our widely used plugins, featuring independent update capabilities and updates delivered directly from WP Engine.
While WP Engine and Flywheel customers are already protected by the WP Engine update system and don’t need to take any action, community members are encouraged to download these versions of our free, open-source plugins and updates directly from the ACF and NitroPack websites to ensure they receive updates directly from us.
If you’re running v6.3.2 or earlier of ACF, or have been forcibly switched to “Secure Custom Fields” without your consent, you can install ACF 6.3.8 directly from the ACF website, or follow these instructions to fix the issue.
These efforts support our customers and plugin users and seek to protect the community at large.”
Screenshot Of ACF Plugin Changelog Showing Lockout Workaround
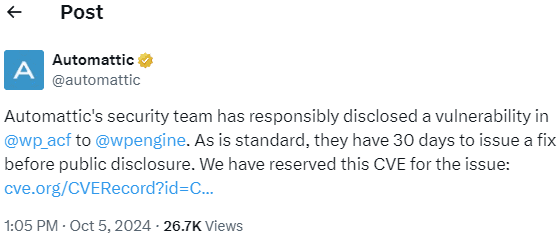
On October 5th Automattic notified WP Engine of a vulnerability in the ACF plugin and announced it on a now deleted post on X (formerly Twitter).
Screenshot Of Post On X By Automattic
October 7th: WP Engine Fixes ACF Vulnerability
On October 7th, WP Engine fixed the plugin vulnerability, as noted in their changelog.
Screenshot Of ACF Changelog About Security Patch
October 12, 2024: Automattic Forks ACF
But then, on October 12th, Automattic forked WP Engine’s ACF plugin, renaming it Secure Custom Forms (SCF) and replaced the ACF plugin in the official WordPress plugin respository with their fork, using the same URL formerly used by the ACF plugin. Matt Mullenweg posted an announcement on WordPress.org citing security concerns as the reason for forking ACF but later in the announcement also citing WP Engine’s lawsuit seeking relief from Mullenweg’s actions.
“On behalf of the WordPress security team, I am announcing that we are invoking point 18 of the plugin directory guidelines and are forking Advanced Custom Fields (ACF) into a new plugin, Secure Custom Fields. SCF has been updated to remove commercial upsells and fix a security problem.
…This is a rare and unusual situation brought on by WP Engine’s legal attacks, we do not anticipate this happening for other plugins.”
Automattic Forks Premium Version Of ACF
Social media was buzzing over the weekend because it was noticed that a new version of ACF was published on WordPress.org using a new URL (/secure-custom-fields/), marked as a beta version. David McCan of WebTNG downloaded the plugin, took a look at the code and confirmed that the new version is a fork of the paid version of ACF. He notes that the WP Engine copyright information was removed, remarking that may be a problem. He also noted that the code that checks for whether the software is paid for and licensed has also been removed.
Viewing the code, he says:
“We go to the version for secure custom fields. You see the file name is still the same ACF dot PHP, But this one. The header information says secure custom fields. It says the author is wordpress.org. There is no copyright notice in here of WP engines code, which is probably a problem.
So by removing the license check and update from WP engine, this seems like a classic case of an old plugin which is now being hosted in the WordPress plugin directory. So I’m wondering if this is even a legal fork. I’m not an expert in software licensing law, but my understanding is you need to preserve the original copyright notices when you fork a plug in. It’s one of the requirements.”
Developer Response In Facebook Group
Whether or not whether making the pro version of the plugin freely available for download is legal is something for the courts to decide. What Automattic may not have considered is that there is an impact to competitors like Meta Box Pro, who offer a similar functionality to ACF. Current users of Meta Box Pro may be incentivized to not renew their current license because they can now get similar premium features for free from WordPress.org.
Someone posted this concern in the private Dynamic WordPress group (posted here, group membership required to view), writing that they had purchased a lifetime license ($699) for Meta Box prior to Mullenweg’s dispute with WP Engine. They wrote that they feel like they made a mistake for purchasing a license for Meta Box, noting that they don’t agree with “stealing” ACF and expressed that this will cause Meta Box to lose users. A yearly subscription to Meta Box starts at $149/year.
One of the Facebook group members remarked that no, they didn’t make a bad decision by purchasing a license for Meta Box, saying that Matt Mullenweg was the one that made the poor decision. Another group member expressed that he regarded Mullenweg as an unreliable steward of the ACF fork and wouldn’t trust his fork, ACF, on any of the websites he develops.
Other developers agreed that SCF is not trustworthy enough for use on a live website, noting that many sites are having issues with the Secure Custom Fields. Someone else noted that this may end poorly for Meta Box within a year from now as SCF becomes more stable. Some members said they’re glad to have Meta Box and are glad to be uninvolved with the WordPress versus WP Engine drama.
Response On WordPress Subreddit
The response from the WordPress community on Reddit was similarly disapproving.
Members of the WordPress subreddit expressed disapproval, nobody was celebrating Mullenweg’s move.
“It’s crazy because they literally are suing someone else for hosting nulled plugins, and that guy had his bank accounts frozen. They are doing the same thing now over at WordPress.”
“Oh wow, so this is actually Matt putting the premium/pro version of ACF with all of it’s features that are normally behind their paywall, up for people to download and use for free on wordpress.org while calling it Secure Custom Forms Pro or whatever, completely out of spite?
This is worse than I thought it was from just seeing the title of this thread, much worse.”
Another post that’s representative of how people feel about WordPress.org distributing a premium plugin for free:
“If he wanted to shoot WordPress in the other foot, this was the perfect move.”
Whether this move will impact ACF’s competitors and the greater premium WordPress ecosystem remains to be seen. One thing is certain: most people on social media appear to disapprove of Matt Mullenweg forking a premium WordPress plugin, and, legal or not, it’s perceived as crossing a line typically associated with software piracy.
The Department of Justice (DOJ) and Google gave their final arguments on Monday in an antitrust case regarding Google’s digital advertising technology.
U.S. District Judge Leonie Brinkema is expected to make a decision by the end of the year.
DOJ’s Argument
The DOJ claims that Google has built and kept a monopoly in open-web display advertising through products like DoubleClick, Google Ads, and AdExchange.
They say Google holds about 91% of the market for publisher ad servers and 87% for advertiser ad networks.
The case against Google is supported by a 2009 email from former Google executive David Rosenblatt. He mentioned the company’s goal to “do to display what Google did to search.”
Prosecutors argue that this shows Google’s plan to control the digital advertising market.
Another important part of the trial is Google deleting internal chat messages. Google claims most of these were casual chats but admitted that some included business discussions.
Google’s Response
Google is challenging the DOJ’s definition of the advertising market.
Google believes digital advertising has three separate markets, while the DOJ sees it as one two-sided market.
Google argues it competes with several platforms, including:
Social media platforms like Meta and TikTok
Streaming services
Mobile app advertising
When considering these competitors, Google claims its market share is only about 10%. The company also states that this share is shrinking due to increased competition.
Additionally, Google points out that it has spent billions developing ad-matching technology. It argues that it shouldn’t have to share this competitive advantage with other companies.
Potential Consequences
If Judge Brinkema finds Google guilty of unfair business practices, the case will move to the next phase focused on solutions.
The DOJ and the states involved may try to make Google sell some parts of its ad tech business, earning tens of billions of dollars yearly.
This case is happening alongside another antitrust case targeting Google’s search business. In that case, Google might also have to sell its Chrome browser and face other penalties.
Publisher & Advertiser Impact
The case highlights tensions between Google and its customers:
Publishers say they must use Google’s full ad stack to earn more.
Advertisers feel they have few options to reach large audiences.
Small businesses worry about rising advertising costs.
The government claims Google’s dominance prevents fair revenue for publishers, stating the company takes up to 36% in commission.
Google argues its “take rate” is now 31% and falling and is lower than competitors’.
Looking Ahead
Judge Brinkema is expected to issue a written ruling on the case by the end of the year.
The outcome could set important precedents for how antitrust law applies to digital markets.